

Abstract
We study estimation and model selection of semiparametric models of multivariate survival functions for censored data, which are characterized by possibly misspecified parametric copulas and nonparametric marginal survivals. We obtain the consistency and root-n asymptotic normality of a two-step copula estimator to the pseudo-true copula parameter value according to KLIC, and provide a simple consistent estimator of its asymptotic variance, allowing for a first-step nonparametric estimation of the marginal survivals. We establish the asymptotic distribution of the penalized pseudo-likelihood ratio statistic for comparing multiple semiparametric multivariate survival functions subject to copula misspecification and general censorship. An empirical application is provided.
Keywords: Multivariate survival models, Misspecified copulas, Penalized pseudo-likelihood ratio, Fixed or random censoring, Kaplan–Meier estimator
1. Introduction
Economic, financial, and medical multivariate survival data are typically non-normally distributed and exhibit nonlinear dependence among their component variables. A class of semiparametric multivariate survival models that has proven to be useful in modeling such data is the class of semiparametric copula-based multivariate survival functions in which the marginal survival functions are nonparametric, but the copula functions characterizing the dependence structure between the component variables are parameterized. More specifically, let X = (X1, …, Xd)′ be the survival variables of interest with a d-variate joint survival function: Fo(x1, …, xd) = P(X1 > x1, …, Xd > xd) and marginal survival functions . Assume that are continuous. A straightforward application of Sklar's (1959) theorem shows that there exists a unique d-variate copula function Co such that , where the copula Co(·) : [0, 1]d → [0, 1] is itself a multivariate probability distribution function; it captures the dependence structure among the component variables X1, …, Xd. This decomposition of the joint survival function leads naturally to the class of semiparametric multivariate survival functions in which the marginal survival functions are unspecified, but the copula function is parameterized: Co(u1, …, ud) = Co(u1, …, ud; αo) for some parametric copula function Co(u1, …, ud; α) and some value . As a multivariate survival function in this class depends on nonparametric functions of only one dimension, it achieves dimension reduction while maintaining a more flexible form than purely parametric survival functions. This class of semiparametric multivariate survival functions has been used widely in survival analysis, where modeling and estimating the dependence structure between survival variables is of importance. See Joe (1997), Nelsen (1999), Oakes (1989, 1994), Frees and Valdez (1998) and Li (2000) for examples of such applications.
A semiparametric copula-based multivariate survival model has two sets of unknown parameters: the unknown marginal survival functions , and the copula parameter αo of the parametric copula function Co(u1, …, ud; αo). For complete data (i.e., data without censoring or truncation), Oakes (1994) and Genest et al. (1995) propose a two-step estimation procedure: in first step the marginal distribution functions are estimated by the rescaled empirical distribution functions, in the second step the copula parameter αo is estimated by maximizing the estimated log-likelihood function. For randomly right censored data, Shih and Louis (1995) independently propose the same two-step procedure, except that the Kaplan–Meier estimators of marginal survival functions are used in the first step. For a random sample of size n, Genest et al. (1995) establish the root-n consistency and asymptotic normality of their two-step estimator of αo. For randomly right censored data, Shih and Louis (1995) derive similar large sample properties of their two-step estimator of αo under the assumption of bounded partial derivatives of score functions. Unfortunately, this assumption is violated by many commonly used copulas including the Gaussian copula, the Student's t copula, Clayton copula and Gumbel copula. In addition, Shih and Louis (1995) assume that the censoring scheme is i.i.d. random and the parametric copula function is correctly specified.
A closely related important issue in applying this class of semiparametric survival functions to a given data set is how to choose an appropriate parametric copula, as different parametric copulas lead to survival functions that may have very different dependence properties. A number of existing papers has attempted to address this issue. For complete data, we refer to Chen and Fan (2005, 2006a) for a detailed discussion of existing approaches and references. For bivariate censored data, existing work include Frees and Valdez (1998), Klugman and Parsa (1999), Wang and Wells (2000), Chen and Fan (2007), and Denuit et al. (2006). Frees and Valdez (1998) and Klugman and Parsa (1999) consider fully parametric models of bivariate distribution (or survival) functions, and they address model selection of parametric copulas and parametric marginals for insurance company data on losses and allocated loss adjustment expenses (ALAEs). The particular data set they use was collected by the US Insurance Services Office in which loss is censored by a fixed censoring mechanism and ALAE is not censored. Using various model selection techniques including AIC/BIC, Frees and Valdez (1998) select the Pareto marginal distributions and the Gumbel copula, while Klugman and Parsa (1999) select inverse paralogistic for loss marginal distribution, inverse Burr for ALAE marginal distribution and the Frank copula. Wang and Wells (2000), Denuit et al. (2006) and Chen and Fan (2007) consider model selection of semiparametric bivariate distribution (or survival) functions in which they do not specify marginals, but restrict the parametric copulas to be in the Archimedean family. In particular, Wang and Wells (2000) propose a model selection procedure for comparing copulas in the one-parameter Archimedean family, allowing for various censoring mechanisms, as long as a consistent nonparametric estimator for the bivariate joint distribution (or survival) function is available. Their selection procedure is based on comparing point estimates of the integrated squared difference between the true Archimedean copula and a parametric copula; the one with the smallest value of the integrated squared difference is chosen over the rest of the one-parameter Archimedean copulas. Denuit et al. (2006) apply Wang and Wells's (2000) procedure to copula model selection for the same Loss-ALAE data set studied in Frees and Valdez (1998). They use a nonparametric estimator of the bivariate distribution that takes into account the fixed censoring mechanism underlying the Loss-ALAE data. They examine four one-parameter Archimedean copulas (Gumbel, Clayton, Frank and Joe) and select Gumbel copula since it yields the smallest estimated integrated squared difference. Chen and Fan (2007) propose a model selection test for comparing multiple semiparametric bivariate survival functions by taking into account the randomness in the estimated integrated squared difference. However, their test is still only applicable to model selection of parametric copulas within the Archimedean family only. It is known that a one or two-parameter Archimedean copula family could be too restrictive to capture various dependence structures among multivariate variables. In addition, the semiparametric model selection procedures in Wang and Wells (2000), Denuit et al. (2006) and Chen and Fan (2007) require consistent nonparametric estimation of the joint distribution function and the limiting distributions are complicated. As a result, even for a parametric Archimedean copula family, these tests are difficult to implement for multivariate (higher than bivariate) data with general censorship.
In this paper we bridge the gap in existing work for estimating and selecting a semiparametric multivariate copula-based survival model by (i) allowing for data to be censored under various censoring mechanisms, (ii) using nonparametric estimation of marginal survival functions only, (iii) permitting any parametric copula specification, which may be misspecified, non-Archimedean, and its score function may have unbounded partial derivatives. For random samples without censoring, Chen and Fan (2005) already consider the Pseudo-likelihood estimation of copula parameters and Pseudo-likelihood ratio (PLR) model selection test for semiparametric multivariate copula-based distribution models, accounting for (ii) and (iii). In this paper, we extend their results to allow for general right censorship. In particular, we first establish the convergence of the two-step estimator of the copula parameter to the pseudo-true value defined as the value of the parameter that minimizes the Kullback-Leibler Information Criterion (KLIC) between the parametric copula induced multivariate density and the unknown true density. We then derive its root-n asymptotically normal distribution and provide a simple consistent asymptotic variance estimator by accounting for (i), (ii) and (iii). These results are used to establish the asymptotic distribution of the penalized PLR statistic for comparing multiple semiparametric multivariate survival functions subject to copula misspecification and general censorship. We also propose a standardized version of the test, whose limiting null distribution is easy to simulate. To illustrate the usefulness of our testing procedure, we apply it to copula model selection for the loss-ALAE data, taking into account the underlying censoring mechanism in the data and allowing parametric copulas to exhibit more flexible dependence structures than those in the Archimedean family. We find that the standardized test is generally more powerful than the non-standardized test.
The rest of this paper is organized as follows. Section 2 introduces the model selection criterion function and the two-step estimation of the copula dependence parameter. In Section 3, we study the large sample properties of the pseudo-likelihood estimator of the copula parameter allowing for independent but general right censorship and misspecified parametric copulas. In Section 4, we present the limiting null distributions of the (penalized) PLR test statistics for model selection among multiple semiparametric copula models for multivariate censored data. Section 5 provides an empirical application to the Loss-ALAE data set and Section 6 briefly concludes. All technical proofs are gathered into the Appendix.
2. Model selection criterion and parameter estimation
To simplify notation, we shall present our results for bivariate survival models only. Obviously, all these results have straightforward extensions to multivariate copula models for survival data with any finite dimension.
In the following we shall use (D1, D2) to denote the censoring variables. Thus under the right censorship, one observes (, ) = (X1 ^ D1, X2 ^ D2) and a pair of indicators, (δ1, δ2) = (I{X1 ≤ D1}, I{X2 ≤ D2}), where a ^ b = min(a, b) for real numbers a and b and I{·} is the indicator function. We assume that the censoring variables (D1, D2) are independent of the survival variables (X1, X2). Let denote the true but unknown marginal survival function of Xj for j = 1, 2. Suppose n independent (but possibly non-identically distributed) observations are available, where (, ) = (X1t ^ D1t, X2t ^ D2t) and (δ1t, δ2t) = (I{X1t ≤ D1t}, I{X2t ≤ D2t}). Denote .
2.1. Model selection criterion
Let be a class of parametric copulas with i = 1, 2, …, M. By Sklar's (1959) theorem, each parametric copula family i corresponds to a parametric likelihood , where
where is the density function of copula Ci(u1, u2; αi).
In this paper, we are interested in testing whether a benchmark model (say copula model 1) performs significantly better than the rest of the copula models according to the KLIC. Let E0 denote the expectation with respect to the true probability measure. Define
as the pseudo-true value that minimizes the KLIC between the i-th parametric copula family induced multivariate density and the unknown true density. To conclude that copula model 1 performs significantly better than the rest of the copula models calls for a formal statistical test, where the null hypothesis is:
meaning that none of the copula models 2, …, M is closer to the true model (according to KLIC) than model 1, and the alternative hypothesis is:
meaning that there exists a copula model from 2, …, M that is closer to the true model (according to KLIC) than model 1.
2.2. Two-step estimation
To construct a test statistic for the null hypothesis H0 against the alternative H1, we need estimates of and for i = 1, …, M.
For j = 1, 2, let be the Kaplan–Meier estimator of :
where are order statistics of for j = 1, 2, and are similarly defined. Then under independent censoring, is consistent for , j = 1, 2; see e.g., Lai and Ying (1991).
Given the definition of , a natural estimator for it is the pseudo-likelihood estimator :
Since this estimation procedure involves the first-step nonparametric estimation of the marginal survival functions , j = 1, 2, the estimator is also called the “two-step” estimator.
Note that no assumption is made on the censoring variables (D1t, D2t) other than their independence with the survival variables (X1t, X2t). As a result, various censoring mechanisms are allowed, including the simple random censoring, fixed censoring, and of course no censoring. If the censoring variables are fixed at Djt = +∞ for j = 1, 2, becomes the estimator proposed in Genest et al. (1995). If the censoring variables (D1t, D2t) are i.i.d. with a continuous joint survival function, becomes the estimator proposed in Shih and Louis (1995). Assuming that the parametric copula density ci(u1, u2; αi) is correctly specified and that log ci(u1, u2; αi) has bounded partial derivatives with respect to u1, u2, Shih and Louis (1995) establish the root-n asymptotic normality of and provide a consistent estimator of its asymptotic variance for i.i.d. randomly censored data.
The censoring mechanism for the loss-ALAE data is non-random; ALAE is not censored and Loss is censored by a constant which differs from each individual to another. Results in Shih and Louis (1995) may not be directly applicable to this data set even under a correct specification of the copula function. Moreover, for model selection, we need to establish the asymptotic properties of the two-step estimator under copula misspecification. This will be done in the next section for a general censoring mechanism.
2.3. Penalized pseudo-likelihood ratio criteria
To test the null hypothesis H0 against the alternative H1, we use the PLR statistic:
where
In most applications, several parametric copula families are compared which may have different numbers of parameters. To take this into account, we follow the approach in Sin and White (1996) by adopting a general penalization of model complexity. Let Pen(pi, n) denote a penalization term such that Pen(pi, n) increases with pi dim(), decreases with n, and Pen(pi, n)/n → 0. Then the penalized PLR statistic is
We note that Pen(pi, n) = pi corresponds to AIC, and Pen(pi, n) = 0.5pi log n corresponds to BIC criterion.
In many existing applications of copula models, AIC has been used to compare different families of parametric copula models. To be more specific, let
Then the values of AICi for i = 1, …, M are compared; copula model 1 will be selected if AIC1 = min{AICi : 1 ≤ i ≤ M} or equivalently if
| (2.1) |
Noting, however, that (such as AICi) is a random variable, the fact that for i = 2, …, M (or inequality (2.1) holds) for one sample may not imply that copula model 1 performs significantly better than the rest of the models; it may occur by chance. As we will show in the next section, for i = 2, …, M. To conclude that copula model 1 performs significantly better than the rest of the models we need to perform a formal statistical test for H0 against H1.
To test H0, we have to take into account the randomness of the (penalized) PLR statistic. More precisely, we need to derive the asymptotic distributions of and the test statistics under the null hypothesis. This will be accomplished in Sections 3 and 4 of this paper.
3. Asymptotic properties of the two-step estimator under copula misspecification
As mentioned in the previous section, asymptotic properties of the two-step estimator are established for randomly censored data in Shih and Louis (1995) under the assumptions that the parametric copula density correctly specifies the true copula density and that its score function has bounded partial derivatives. In this section, we will extend their results to a more general censoring mechanism and allow for misspecified parametric copulas whose score functions may have unbounded partial derivatives.
Recall that is the parameter space. For α, we use ∥α − α*∥ to denote the usual Euclidean metric. To simplify notation, we now let
where c(u1, u2; α) is the density of the parametric copula C(u1, u2; α). Then the pseudo-true copula parameter value is , and its two-step estimator is .
Finally we denote
3.1. Consistency
The following conditions are sufficient to ensure the convergence of the two-step estimator to the pseudo true value .
-
C1
-
(i)The sequence of survival variables, is an i.i.d. sample from an unknown survival function Fo(x1, x2) with continuous marginal survival functions ;
-
(ii)The sequence of censoring variables is an independent sample with joint survival functions and marginal survival functions ;
-
(iii)The censoring variables (D1t, D2t) are independent of survival variables (X1t, X2t) and there is no mass concentration at 0 in the sense that as η → 0.
-
(i)
-
C2Let be a compact subset of . For every ∊ > 0,
-
C3
The true (unknown) copula function Co(u1, u2) has continuous partial derivatives.
-
C4
-
(i)For any (u1, u2) ∈ (0, 1)2, ℓ(u1, u2; α) is a continuous function of
-
(ii)Let and Then,
-
(iii)For any η > 0, ∊ > 0, there is K > 0 such that for all and all uj ∈ [η, 1) such that
-
(i)
-
C5
If are subject to non-trivial censoring (i.e., Djt ≠ ∞), then is truncated at the tail in the sense that for some for all xj ≥ τj and lim inf n−1 .
Note that in contrast to the censoring mechanism in Shih and Louis (1995) Condition C1(ii) allows the censoring variables to be non-identically distributed. In addition, no assumption is made on the joint survival function Gt(x1, x2) of the censoring variables (D1t, D2t). Hence Condition C1(ii) includes the fixed censoring mechanism in which each survival variable (X1t, X2t) is censored at a pre-specified, fixed time (D1t, D2t) which may differ from one observation to another, in which case, the survival function Gt(x1, x2) is degenerate at (D1t, D2t). It also allows the variables X1t and X2t to have different censoring mechanisms, one random and the other fixed or one censored and the other uncensored. For example, the censoring mechanism for the Loss-ALAE data is such that Loss is censored by a fixed censoring mechanism and ALAE is uncensored. As a result, the observed variables may not be identically distributed and the identifiably unique maximizer defined in Condition C2 may depend on n. Condition C5 is imposed to handle the possible tail instability of the Kaplan–Meier estimator, especially for non-identically distributed censoring times. The truncation can be achieved by simply using Djt ∧ τj as the censoring variables. Thus, without loss of generality, we shall assume that Djt ∧ τj are the censoring variables so that . The simple truncation at τj can be changed to the more elaborate tail modification. We refer to Lai and Ying (1991) for the issue of tail instability and modification. Finally, because we allow the left tail of the copula to blow up as well, we shall set whenever for j = 1 or 2.
Proposition 3.1. Under conditions C1–C5, we have:
-
(1)
-
(2)
Proposition 3.1(1) states that the two-step estimator is a consistent estimator of the pseudo true value . If the censoring mechanism is random, then which does not depend on n. In addition, if the parametric copula correctly specifies the true copula, then , where αo is such that C(u1, u2; αo) = Co(u1, u2) for almost all (u1, u2) ∈ (0, 1)2.
3.2. Asymptotic normality
Recall that . For j = 1, 2, we denote
with the cumulative hazard function of Xj, and dNjt (u) = Njt (u) − Njt (u−), and .
Let Var0 denote the variance with respect to the true probability measure. The following conditions are sufficient to ensure the asymptotic normality of .
-
A1
-
(i)C2 holds with ∈ int(A*) for all n, where A* is a compact subset of ;
-
(ii)has all its eigenvalues bounded below and above by some finite positive constants;
-
(iii)has all its eigenvalues bounded below and above by some finite positive constants;
-
(iv)satisfies Lindeberg condition.
-
(i)
-
A2
Functions ℓαα(u1, u2; α) and ℓαj(u1, u2; α), j = 1, 2, are well-defined and continuous in .
-
A3
-
(i)for some q > 0 and aj ≥ 0 such that ;
-
(ii)for some bk, ak and j ≠ k such that for some ξj ∈ (0, 1/2).
-
(i)
-
A4
-
(i)Let and . Then,
-
(ii)For any η > 0 and any ∊ > 0, there is K > 0, such that for all and all uj ∈ [η, 1) such that , j = 1, 2.
-
(i)
Shih and Louis (1995) require bounded and for j = 1, 2, however, this requirement is not satisfied by many popular copula functions such as Gaussian copula, t-copula, Gumbel copula and Clayton copula. Conditions A3 and A4 relax the boundedness requirement, and allow the score function and its partial derivatives with respect to the first two arguments to blow up at the boundaries. Similar conditions have been verified for Gaussian, Frank and Clayton copulas in Chen and Fan (2006b).
Proposition 3.2. Under conditions C1–C5 and A1–A4, we have: in distribution, where Bn and Σn are defined A1.
Proposition 3.2 extends Theorem 2 in Shih and Louis (1995) in two directions: (i) it allows for more general censoring mechanisms than the simple random censoring in Shih and Louis (1995), and (ii) it allows for the possibility that the parametric copula may not specify the true copula correctly. As a result, there are several differences between Proposition 3.2 and Theorem 2 in Shih and Louis (1995): First, since the censoring variables may not be identically distributed, Bn and Σn may depend on n; Second, since the parametric copula may misspecify the true copula, the information matrix equality may not hold. Consequently, the asymptotic variance of , , can not be reduced to as in Shih and Louis (1995). For complete data, Proposition 3.2 reduces to that in Chen and Fan (2005).
To estimate the asymptotic variance of , we let
with
in which for j = 1, 2,
| (3.1) |
We note that an alternative expression for is:
where ,
in which is so-called Nelson's estimator. This is because
By the consistency of the Kaplan-Meier estimators and , and by applying the law of large numbers to independent observations, we can the following result, which provides a consistent variance estimator.
Proposition 3.3. Under conditions C1–C5 and A1–A4, the asymptotic variance of can be consistently estimated by , where is the generalized inverse of .
4. Pseudo-likelihood ratio test for model comparison
By applying Proposition 3.1(2) we immediately obtain the probability limit of the PLR statistic.
Proposition 4.1. Suppose for i = 1, …, M, the copula model i satisfies the conditions of Proposition 3.1. Then
where for j = 1, 2.
In the following, we adopt the convention that all the notations involving the copula function C(u1, u2; α) introduced in Section 3 are now indexed by a subscript i for i = 1, …, M to make explicit their dependence on the parametric copula model i. In addition, we define ,
where for i = 1, …, M and for j = 1, 2,
It is easy to see that has the same asymptotic distribution as a multivariate normal random variable with mean zero and variance Ωn, where
It is easy to compute a consistent estimator for Ωn:
| (4.1) |
where and for i = 2, …, M,
in which
for i = 1, …, M and j = 1, 2 with given in (3.1).
Before we present the test statistics, we recall the following definition from Chen and Fan (2005): For model i ∈ {2, …, M},
Models 1 and i are generalized non-nested if the set has positive Lebesgue measure;
Models 1 and i are generalized nested if for almost all (v1, v2) ∈ (0, 1)2.
Given the definition of the pseudo true value , the closest to the true copula c0 (according to KLIC) in a parametric class of copulas depends on the true (but unknown) copula. Hence it is not obvious a priori whether two parametric classes of copulas are generalized non-nested or generalized nested.
Remark 4.1. Define
It is obvious that if models 1 and i are generalized nested, then almost surely, eit = 0 almost surely, and . Following the proof of Proposition 3 in Chen and Fan (2005), we can show that if then models 1 and i are generalized nested, and σii = 0. Therefore it is easy to test whether the models 1 and i are generalized nested by testing , which may be done by using its consistent estimator:
See Chen and Fan (2005) for details.
The following proposition provides the basis for our tests. Note that we allow for some but not all of the candidate models i ∈ {2, …, M} to be generalized nested with the benchmark model 1.
Proposition 4.2. For i = 1, 2, …, M, assume that the copula model i satisfies conditions of Proposition 3.2 and that {eit : t = 1, …, n} satisfies Lindeberg condition. If is finite and its largest eigenvalue is positive uniformly in n, then:
-
(1)
-
(2)
Proposition 4.2 and the continuous mapping theorem imply
Define
Proposition 4.2 implies that under the Least Favorable Configuration (LFC), i.e.,
Tn → maxi=2,…,M Zi in distribution. This allows us to construct a test for H0. Suppose the largest eigenvalue of Ωn is positive uniformly in n, then we will reject H0 if Tn > Zα, where Zα is the upper α-percentile of the distribution of maxi=2,…,M Zi.
The asymptotic power properties of this test against fixed alternatives and Pitman local alternatives follow immediately from Proposition 4.2 and are summarized in the following proposition.
Proposition 4.3. Suppose all conditions of Proposition 4.2 are satisfied. Then the test based on Tn is consistent against fixed alternatives of the form H1 and has non-trivial power against local alternatives satisfying
Note that if the censoring mechanism is random, then the local alternatives in Proposition 4.3 can be written in the more familiar form:
for a positive constant K.
In general, the distribution of maxi=2,…,M Zi is unknown, since the asymptotic variance Ωn of (Z2, #x2026;, ZM) depends on . Following White (2000), one can use either “Monte-Carlo RC” p-value or “bootstrap RC” p-value to implement this test. As noted in Chen and Fan (2005), Hansen (2003), and Romano and Wolf (2005), the finite sample power of this test may be improved by standardization. In our empirical application, we have computed both “Monte-Carlo RC” p-value using
and “bootstrap RC” p-value based on
where is a consistent estimator of σii such as the one given in (4.1), b = bn → 0 as n → ∞, and Gb(·) is a is smoothed trimming which trims out small . The particular trimming function being used in our empirical study is
where gb(χ) = (b−1g(b−1 χ−1) and g(z) = B(a+1)−1za(1−z)a,z ∈ [0, 1] for some positive integer a ≥ 1, where B(a) = Γ(a)2/Γ(2a) is the beta function and Γ(a) is the Euler gamma function.
We note that the standardized tests TnS and TnI proposed here allow that some candidate models are generalized nested with the benchmark model, since the trimming in TnS and TnI removes the effect of generalized nested models (with the benchmark model) on its limiting distribution. By a minor modification of the proof of Theorem 7 in Chen and Fan (2005), we immediately obtain the following result:
Proposition 4.4. Suppose all conditions of Proposition 4.2 are satisfied. If b → 0 and nb → ∞, then under the null hypothesis H0, the limiting distribution of TnI is given by that of , where
Proposition 4.4 implies that the asymptotic null distribution of TnI depends on models that are generalized non-nested with the benchmark and satisfy
and hence is unknown. We propose the following bootstrap procedure to approximate the asymptotic null distribution of TnI:
-
Step1
Generate a bootstrap sample by random draws with replacement from a consistent nonparametric estimator of the unknown joint distribution of (X1t, X2t) that takes into account the censoring scheme. Denote (, , , ) as the bootstrap analogs of (, , , ).
-
Step2
Compute the bootstrap value of , i = 2, …, M, and define its recentered value as , where an → 0 is a small positive (possibly random) number such that .
-
Step3Compute the bootstrap value of TnI as
-
Step4
Repeat Steps 1–3 for a large number of times and use the empirical distribution function of the resulting values to approximate the null distribution of TnI.
We note that the above bootstrap procedure is very similar to that proposed in Chen and Fan (2005), except that in Step 1 we generate bootstrap samples from a consistent nonparametric estimator of the joint distribution that takes account of the censoring. For example, for bivariate random right censoring, we could sample from the bivariate Kaplan–Meier estimator; see Dabrowska (1989). See Davison and Hinkley (1997, page 85) for additional ways to generate bootstrap sample for censored data. The consistency of this standardized bootstrap RC test could be established by a minor modification of the proof of Theorem 8 in Chen and Fan (2005).
Remark 4.2. Recall that
If (which is automatically satisfied with AIC and BIC), then
Therefore, penalization could be incorporated in the tests. Define
and
| (4.2) |
Then we can conduct the test using (or or ) instead of Tn (or TnS or TnI).
5. An empirical application
In this section, we illustrate our testing procedure for the selection of multiple copula-based survival functions by using insurance company data on losses and ALAEs. The particular data set we use was collected by the US Insurance Services Office and has been analyzed in some detail in Frees and Valdez (1998), Klugman and Parsa (1999), and Denuit et al. (2006).
Two alternative approaches have been used in the literature to model multivariate survival data; that of the multivariate distribution function and that of the multivariate survival function. It is important to realize that in the context of semiparametric copula-based models, the copula in a semiparametric copula-based distribution function corresponds to its survival copula in the corresponding semiparametric survival function. To be specific, consider the bivariate case. Let (X1, X2) be the survival variables of interest with a joint survival function Fo(x1, x2) = Pr(X1 > x1, X2 > x2) and marginal survival functions , j = 1, 2. Let H(x1, x2) denote the corresponding joint cumulative distribution function (cdf) with marginal distributions Hj(·), j = 1, 2. Assume that and are continuous. By the Sklar's (1959 theorem, there exists a unique copula function Ch such that H(x1, x2) ≡ Ch(H1(x1), H2(x2)), which in turn implies that the representation
holds where
is itself a copula function, known as a survival copula. Hence the bivariate distribution function Ch(H1(x1), H2(x2)) and the bivariate survival function , where is the survival function of Hj(·) and Co is the survival copula of Ch represent the same model.
In Frees and Valdez (1998) and Klugman and Parsa (1999), fully parametric modeling of the joint distribution of the loss and ALAE has been examined; using various model selection techniques including AIC/BIC, Frees and Valdez (1998) select Pareto marginals and Gumbel copula, while Klugman and Parsa (1999) select inverse paralogistic for the loss, inverse Burr for ALAE and the Frank copula. Denuit et al. (2006) adopt a semiparametric distribution framework in which the marginal distributions of loss and ALAE are left unspecified, but their copula is modeled parametrically via a one-parameter Archimedean copula. Their model selection procedure is the same as that in Wang and Wells (2000) except that the joint distributions of loss and ALAE are estimated differently. They examined four one-parameter Archimedean copulas: Gumbel, Clayton, Frank and Joe, and select the same Gumbel copula as Frees and Valdez (1998). Compared with Denuit et al. (2006), we do not restrict the parametric copulas to be Archimedean. In addition, our test takes into account the randomness of the selection criterion. Chen and Fan (2005) have also studied this data set, but since their model selection test is applicable to uncensored data only, they restrict their analysis to the subset of 1466 complete data. We now apply our proposed test to the original censored data with 1500 data points.
The scatterplots for loss and ALAE presented in Frees and Valdez (1998) and Denuit et al. (2006) reveal positive right tail dependence between loss and ALAE: large losses tend to be associated with large ALAE's. This is because expensive claims generally need some time to be settled and induce considerable costs for the insurance company. Actuaries therefore expect positive dependence between large losses and large ALAE's. On the other hand, these plots do not reveal any visible left tail dependence between the two variables. As a result, it is not surprising that the Gumbel copula is chosen in Frees and Valdez (1998) and Denuit et al. (2006). To shed some light on the robustness of this result to the set of copula families being considered, we add three more copula families to the set considered in Denuit et al. (2006): Gaussian copula, survival Clayton, mixture of Clayton and Gumbel copulas; see Appendix B for expressions of these seven copulas and their partial derivatives. Survival Clayton has right tail dependence and the mixture of Clayton and Gumbel exhibits both left tail and right tail dependence unless the weights are degenerate. the Gaussian copula does not have tail dependence and is thus expected to fit poorly. They are included here in the set of copulas to see if the power of the test is adversely affected by the presence of poor copula candidates in the selection set.1
To facilitate comparison, we also apply our tests to the subset of 1466 complete data. The results of the “Monte Carlo RC” test (using the AIC penalization factor) for the original censored data are presented in Table 1 and those for the subset of 1466 complete data are presented in Table 2, with 500,000 Monte Carlo repetitions. For each copula, we estimated its parameter(s) by the two-step procedure and computed the value of the AIC. To apply our model selection test we need to choose a benchmark model. In view of the existing results, we first use the Gumbel copula as the benchmark. For the Gumbel benchmark, we found the p-value of the test to be 1 with or without taking into account censoring. This provides strong evidence that none of the other six copulas performs significantly better than the Gumbel copula for the loss-ALAE data. This is consistent with the selection result based on comparing the values of the AIC only; Gumbel followed by mixture of Clayton and Gumbel, then by survival Clayton and then by Joe. The parameter estimates for the mixture of Clayton and Gumbel provide additional evidence in favor of the Gumbel copula; the estimates of the weight on Clayton are only 0.0003 when censoring is taken into account and 0.0002 when censoring is not taken into account. In addition, the estimates of the parameter in the Gumbel copula obtained by fitting the mixture of Clayton and Gumbel are very close to the estimates obtained by fitting the Gumbel copula alone for both the subset of complete data and the original censored data. To see if the test is sensitive to the choice of the benchmark model, we also used each of the remaining six copulas as the benchmark.
Table 1.
Monte Carlo p-values of the test for the original dataset subject to censoring.
| Benchmark |
p-value of 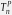
|
p-value of 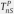
|
AIC | 2-step estimator |
|---|---|---|---|---|
| Gumbel | 1.0000 | 0.9980 | −0.1447 | 1.4428 |
| Clayton | 0.0015 | 0.0004 | −0.0000 | 0.5152 |
| Frank | 0.0688 | 0.0394 | −0.1009 | 0.0473 |
| Joe | 0.3968 | 0.2533 | −0.1263 | 1.6466 |
| Gaussian | 0.1692 | 0.0724 | −0.1125 | 0.4668 |
| Survival Clayton | 0.6295 | 0.4298 | −0.1380 | 0.7825 |
| Mix Clayton & Gumbel | 0.9469 | 0.9794 | −0.1420 | (0.1505, 1.4433, 0.0003) |
Table 2.
Monte Carlo p-values of the test for the subset without censoring.
| Benchmark |
p-value of 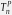
|
p-value of 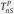
|
AIC | 2-step estimator |
|---|---|---|---|---|
| Gumbel | 1.0000 | 0.9940 | −0.2560 | 1.4254 |
| Clayton | 0.0037 | 0.0008 | −0.1203 | 0.5098 |
| Frank | 0.1197 | 0.0834 | −0.2160 | 0.0494 |
| Joe | 0.3530 | 0.1643 | −0.2384 | 1.6105 |
| Gaussian | 0.2499 | 0.1442 | −0.2286 | 0.4604 |
| Survival Clayton | 0.5570 | 0.3412 | −0.2472 | 0.7440 |
| Mix Clayton & Gumbel | 0.9382 | 0.9590 | −0.2530 | (0.1572, 1.4256, 0.0002) |
For each of the Tables 1 and 2, we present two versions of the Monte Carlo tests based on the non-standardized test, , and the standardized test, , as described in Remark 4.2.2 Comparing the first two columns in Tables 1 and 2, we see that both tests yield similar high p-values when the benchmark is either Gumbel or the mixture of Clayton and Gumbel; for all the other cases, the standardized test yields significantly lower p-values than those of . This indicates that the standardized version of the test is generally more powerful than the original non-standardized test.
Additionally, we present a bootstrap version of the test based on (using the AIC penalization factor). We generate a bootstrap sample by random draws with replacement from a consistent non-parametric estimator of the bivariate joint distribution that takes into account the censoring scheme. For this loss-ALAE data set, we could draw bootstrap samples either from the bivariate Kaplan–Meier estimator of Dabrowska (1989), or from the estimator of Akritas (1994) and Denuit et al. (2006). Let be the counterpart of for one bootstrap iteration, we write the re-centered bootstrap test statistic as , where for simplicity we use the same parameter values (a, bn, an) = (1, n−1/2, 0:025n−1/2 log log n) as those in Chen and Fan (2005). In this empirical application we use 100 bootstrap repetitions. The bootstrap p-values in Tables 3 and 4 overwhelmingly support the conclusion that the Gumbel copula fits the loss-ALAE data the best among the seven copulas we considered. This finding is consistent with existing results in the literature. The fact that the results in Tables 3 and 4 are so close to each other confirms the statement in Denuit et al. (2006) that the limited amount of censored points present in this Loss-ALAE data does not seem to affect the copula selection result.
Table 3.
Bootstrap p-values of the test for the original dataset subject to censoring.
| Benchmark |
p-value of 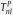
|
AIC | Two-step estimate |
|---|---|---|---|
| Gumbel | 1.0000 | −0.1447 | 1.4428 |
| Clayton | 0.0000 | −0.0000 | 0.5152 |
| Frank | 0.0000 | −0.1009 | 0.0473 |
| Joe | 0.1010 | −0.1263 | 1.6466 |
| Gaussian | 0.0517 | −0.1125 | 0.4668 |
| Survival Clayton | 0.1414 | −0.1380 | 0.7825 |
| Mix Clayton & Gumbel | 0.9900 | −0.1420 | (0.1505, 1.4433, 0.0003) |
Table 4.
Bootstrap p-values of the test for the subset without censoring.
| Benchmark |
p-value of 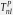
|
AIC | Two-step estimate |
|---|---|---|---|
| Gumbel | 1.0000 | −0.2560 | 1.4254 |
| Clayton | 0.0000 | −0.1203 | 0.5098 |
| Frank | 0.0000 | −0.2160 | 0.0494 |
| Joe | 0.1052 | −0.2384 | 1.6105 |
| Gaussian | 0.0202 | −0.2286 | 0.4604 |
| Survival Clayton | 0.0909 | −0.2472 | 0.7440 |
| Mix Clayton & Gumbel | 0.9963 | −0.2530 | (0.1572, 1.4256, 0.0002) |
Finally, by comparing the bootstrap p-values in Tables 3 and 4 with the Monte Carlo p-values in Tables 1 and 2, we notice that the standardized “bootstrap RC” test is in general more powerful than the standardized “Monte Carlo RC” test, which in turn is more powerful than the non-standardized “Monte Carlo RC” test. Nevertheless, it is noteworthy that the standardized “bootstrap RC” test is computationally much more intensive than the standardized “Monte Carlo RC” test. For an AMD Athlon(tm) 64 Processor, 1.18 GHz and 384 Mb of RAM, for each benchmark case, the standardized “bootstrap RC” test (with 100 bootstrap replications) takes about 10,500 computer seconds, whereas the standardized “Monte Carlo RC” test (with 500,000 Monte Carlo repetitions) only takes about 350 computer seconds. Moreover, we are happy to see that the standardized “Monte Carlo RC” test and the standardized “bootstrap RC” test yield very similar rankings and lead to the same conclusion that the Gumbel copula fits the loss-ALAE data the best.
6. Conclusion
Many models of semiparametric multivariate survival functions are characterized by nonparametric marginal survival functions and parametric copula functions, where different copulas imply different dependence structures. In this paper, we first establish large sample properties of the two-step estimator of copula dependence parameter when the parametric copula function may be misspecified and when data may be subject to an independent but otherwise general right censorship. We then provide a penalized pseudo-likelihood ratio test for selecting among multiple semiparametric copula models for multivariate survival data. An empirical application to the famous Loss-ALAE insurance data set indicates the usefulness of our theoretical results.
Although our theoretical results allow for general right censoring scheme, we still assume that the data is independent and is subject to independent censoring. In some economic and financial applications, data could be serially dependent and may be subject to dependent censorship. The two-step estimator and its large sample properties have been extended to time series settings in Chen and Fan (2006a,b), but their results do not allow for any censoring. We shall extend the results in this paper to allow for time series and/or dependent censoring in another paper.
Acknowledgements
We thank a guest co-editor and the anonymous referees for detailed suggestions which greatly improved the paper. We thank Professors Frees and Valdez for kindly providing the loss-ALAE data, which were collected by the US Insurance Services Office (ISO). Chen and Fan acknowledge financial support from the National Science Foundation. Ying acknowledges financial support from the National Science Foundation and the National Institute of Health. Part of the work was initiated during Chen and Ying's visit to the Institute for Mathematical Sciences at the National University of Singapore whose hospitality and support are acknowledged.
Appendix A. Technical proofs
We first introduce additional notation: , , and the marginal cumulative hazard function of Xj, j = 1, 2.
Lemma A.1. Suppose that Conditions C1 and C5 are satisfied. Then: (i) the marginal Kaplan–Meier estimators are uniformly strongly consistent: a.s. for j = 1, 2; (ii) they can be expressed as martingle integrals:
where op() is uniform in x ∈ [0, τj], for j = 1, 2.
Proof of Lemma A.1. Because of Condition C5, the risk set size in (−∞, τj] is of order n. Consequently, the uniform strong consistency is a special case of Theorem 3 of Lai and Ying (1991). The martingale integral approximation follows from formula (3.2.13) of Gill (1980) and the consistency of the Kaplan–Meier estimator.
Lemma A.2. Let , j = 1, 2. There exists τ0 > 0 such that for every ∊ > 0, there is an η > 0 such that
Proof of Lemma A.2. For notational convenience, subscript j 1, 2 will be omitted. By definition,
The right-hand side is bounded by , x ≤ τ0 for suitably chosen τ0, provided that , which holds for all large n. Thus,
| (A.1) |
By a theorem of van Zuijlen (1978, Theorem 1.1), for any ∊ > 0, there exists η such that
| (A.2) |
Since , it follows from (A.1), (A.2) and the fact that for all that the lemma holds.
Proof of Proposition 3.1. The main ideas here are to use the uniform consistency of the Kaplan–Meier estimator and the identifiability Condition C2. Write
| (A.3) |
We first show that the first term on the right-hand side of (A.3) is of order op(1), uniformly in . Under Condition C5, , j = 1, 2, are bounded away from 0. By continuity of ℓ() on and Lemma A.1, the first term, with summation over t such that both and are bounded away from 0, is of order op(1), uniformly in . i.e., for every η > 0,
| (A.4) |
It remains to show that for every ∊ > 0, there exists η > 0 such that
| (A.5) |
and
| (A.6) |
By Lemma A.2 and Condition C4(iii), there exists K > 0 such that
Therefore, to show (A.5) and (A.6), it suffices to show that for any ∊* > 0, there exists η such that
| (A.7) |
By Condition C4(ii) and the Markov inequality, to show (A.7), we only need to show that for any K* > 0, there exists η such that
| (A.8) |
But, again by the Markov inequality, the left-hand side of (A.8) is bounded by
which can be made arbitrarily small by Condition C1.
We next show that the second term is also of order op(1). By Condition C4(ii), it suffices to show that for every K > 0,
converges to 0 uniformly in . But this sequence converges to 0 a.s. for every α and has uniformly bounded derivatives over the compact set , and, therefore, the convergence must be uniform.
Proof of Proposition 3.2. The proof can be done by essentially combining the techniques of Shih and Louis (1995) and Chen and Fan (2005). A critical part is how to appropriately control the tail behavior.
By the mean-value theorem, we can linearly expand the pseudo-likelihood score function at to get
| (A.9) |
where for some on the line segment between and . Under Condition A4, we can apply the same argument for proving (A.5) to show that is asymptotically negligible as η → 0. This in conjunction with Condition A2 and the consistency of and , implies that in probability as n → ∞.
Again by the mean-value theorem,
| (A.10) |
where (, ) lies on the line segment between () and ().
By Lemma A.1,
| (A.11) |
Let denote the right-hand side of (A.11) with the summation restricted to those terms such that We next show that for some ∊j > 0,
| (A.12) |
where Op(1) is uniform over η > 0. For any ξ ∈ (0, 1), since
it follows from Lenglart's inequality (Gill, 1980, Theorem 2.4.2) that
| (A.13) |
where Op(1) is uniform in x and the second equality follows from Lemma A.2 and van Zuijlen (1978, Theorem 1.1). From (A.13), Lemma A.2 (with ξ = 2ξj) and Condition A3, we have, ignoring the right tail,
Hence, (A.12) holds with ∊j = 1 − 2ξj, j = 1, 2.
In view of (A.12), we can essentially pretend that ℓαj in (A.10) does not blow up at the tail. Therefore, (A.11) implies that for j = 1, 2,
| (A.14) |
From (A.9)–(A.11) and (A.14), we see that is asymptotically a sum of independent zero-mean random vectors. Given Condition A1, Proposition 3.2 now follows from the standard multivariate central limit theorem for independent but non-identically distributed random variables.
Proof of Propositions 3.3. The consistency of the variance estimator clearly follows from the laws of large numbers, the consistency of the Kaplan–Meier estimator and of , when the possible “tail instability” is ignored. To control the tail behavior, we can applied the same techniques as in the proofs of Propositions 3.1 and 3.2. The details are omitted.
Proof of Proposition 4.2. For i = 1, …, M, by the definition of , we have
Hence,
where is between and . By conditions C2–C5, A1–A4 and Proposition 3.2, we have
Hence,
As a result, we get for all i = 2, …, M,
where
By Proposition 3.2, we have Dn = Op(n−1).
For generalized non-nested models, Using a proof similar to that of Proposition 3.2, we obtain:
hence converges in distribution to a . Therefore,
converges in distribution to a .
For generalized nested models, the term Ai,n becomes zero almost surely, we have
where by Proposition 3.2, 2nDi,n is distributed as a weighted sum of independent random variables.
Proof of Proposition 4.3. Note that
Let
Then
For fixed alternatives, maxi=2,…,M Kin = +∞ and so P (Tn > Zα) → 1. For local alternatives such that maxi=2,…,MKin > 0,
Hence limn→∞ P (Tn > Zα) > α.
Appendix B. Expressions of copulas and their derivatives
In the Appendix B we describe the seven copulas and their derivatives that we have used in the empirical application Section 5.3 Let (X1, X2) be the lifetime variables of interest with joint survival function Fo(x1, x2) = Pr(X1 > x1, X2 > x2) and continuous marginal survival functions . Let H (x1, x2) denote the corresponding joint cumulative distribution function (cdf) with marginal distributions . By the Sklar's (1959) theorem, there exists a unique copula function Ch on [0, 1]2 such that
or equivalently
holds with
| (B.1) |
where the copula function Co() is sometimes called the survival copula (of Ch).
It is easy to see that, for any j ∈ {1, 2}
| (B.2) |
in fact, for any partial derivative of order k higher than 2 we have that
| (B.3) |
where ji ∈ {1, 2}. Note that this last equation implies that
| (B.4) |
where co and ch are the copula densities associated to Co and Ch, respectively.
Using relations (B.2)–(B.4), by replacing vj = 1 − uj in the expressions of partial derivatives of a copula Ch and its density ch, we immediately obtain the expressions for the partial derivatives of the survival copula Co and its density co. Therefore, in the following we only provide expressions for the partial derivatives of several copula functions Ch and their densities ch that we have used in the empirical application.
Gumbel copula
The Gumbel copula and its density are given by
| (B.5) |
and
with T1 = ((α − 1)(− log(Ch))−1 + 1). Following Frees and Valdez (1998), we can express the partial derivative of Ch with respect to vj, j = 1, 2, as
| (B.6) |
Hence, a little algebra implies4
The partial derivative of the copula density ch with respect to vj, j = 1, 2, is given by
where
Clayton copula
The Clayton copula and its density are given by
and
Hence the second order partial derivative of Ch with respect to vj, j = 1, 2, is given by
where
The first order partial derivative of the copula density ch with respect to vj, j = 1, 2, is given by
Frank copula
The Frank copula and its density are given by
and
After some algebra, the second order partial derivative of Ch with respect to vj, j = 1, 2, is given by
where
and the first order derivative of the copula density ch with respect to vj, j = 1, 2, is given by
Joe copula
The Joe copula and its density are given by
and
where and .
The second order partial derivative of the copula Ch with respect to vj, j = 1, 2, is given by
After some tedious algebra, the first order partial derivative of the copula density ch with respect to vj, j = 1, 2, is given by
Gaussian copula
The Gaussian copula and its density are given by
where ϕα is the bivariate standard normal distribution with correlation α, Φ is the scalar standard normal distribution, and
where ϕ is the density function of Φ, and ϕα is the density function of ϕα.
The second order partial derivative of the copula Ch with respect to vj, j = 1, 2, is given by
The first order partial derivative of the copula density ch with respect to vj, j = 1, 2, is given by
Mixture copula
A mixture copula Ch(v1, v2; α), with its parameter α = (α1, α2, λ), is simply given by
where is one copula (such as the Clayton copula in our application) with its parameter α1, and is another copula (such as the Gumbel copula in our application) with its parameter α2. Then it is clear that the partial derivatives of Ch are simply the linear combination of the partial derivatives of the two copulas:
Footnotes
Since our test is developed for semiparametric copula-based survival functions instead of distribution functions, we use the survival copulas of these seven copula functions in implementing our test. However, we present our empirical results in terms of copulas of the corresponding semiparametric distribution functions in order to compare our results with existing results just cited.
When computing the test statistic , we have used a = 1 and bn = 10/n2.
In the empirical application we have used both analytical derivatives and numerical derivatives, while the results based on analytical derivatives perform slightly better. Since these analytical derivatives for copulas are tedious to compute, we include them in this Appendix B so that readers could use them in other applications as well.
We leave the dependence on (v1, v2) implicit, to ease the notational burden.
References
- Akritas M. Nearest neighbor estimation of a bivariate distribution under random censoring. Annals of Statistics. 1994;22:1299–1327. [Google Scholar]
- Chen X, Fan Y. Pseudo-likelihood ratio tests for model selection in semiparametric multivariate copula models. The Canadian Journal of Statistics. 2005;33:389–414. [Google Scholar]
- Chen X, Fan Y. Estimation and model selection of semiparametric copula-based multivariate dynamic models under copula misspecification. Journal of Econometrics. 2006a;135:125–154. [Google Scholar]
- Chen X, Fan Y. Estimation of copula-based semiparametric time series models. Journal of Econometrics. 2006b;130:307–335. [Google Scholar]
- Chen X, Fan Y. A model selection test for bivariate failure-time data. Econometric Theory. 2007;23:414–439. [Google Scholar]
- Dabrowska D. Kaplan–Meier estimate on the plane: Weak convergence, LIL, and the bootstrap. Journal of Multivariate Analysis. 1989;29:308–325. [Google Scholar]
- Davison AC, Hinkley DV. Bootstrap Methods and Their Application. Cambridge University Press; 1997. [Google Scholar]
- Denuit M, Purcaru O, Van Keilegom I. Bivariate Archimedean copula modelling for censored data in non-life insurance. Journal of Actuarial Practice. 2006;13:5–32. [Google Scholar]
- Frees E, Valdez E. Understanding relationships using copulas. North American Actuarial Journal. 1998;2:1–25. [Google Scholar]
- Genest C, Ghoudi K, Rivest L. A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika. 1995;82:543–552. [Google Scholar]
- Gill R. Math. Centre Tracts. Vol. 124. Mathematisch Centrum; Amsterdam: 1980. Censoring and Stochastic Integrals. [Google Scholar]
- Hansen RP. Manuscript. Brown University; 2003. A test for superior predictive ability. [Google Scholar]
- Joe H. Multivariate Models and Dependence Concepts. Chapman & Hall/CRC; London: 1997. [Google Scholar]
- Klugman S, Parsa R. Fitting bivariate loss distributions with copulas. Insurance: Mathematics and Economics. 1999;24:139–148. [Google Scholar]
- Lai T, Ying Z. Estimating a distribution function with truncated and censored data. Annals of Statistics. 1991;19:417–442. [Google Scholar]
- Li D. On default correlation: A copula function approach. Journal of Fixed Income. 2000:43–54. [Google Scholar]
- Nelsen R. An Introduction to Copulas. Springer; New York: 1999. [Google Scholar]
- Oakes D. Bivariate survival models induced by frailties. Journal of the American Statistical Association. 1989;84:487–493. [Google Scholar]
- Oakes D. Multivariate survival distributions. Journal of Nonparametric Statistics. 1994;3:343–354. [Google Scholar]
- Romano JP, Wolf M. Stepwise multiple testing as formalized data snooping. Econometrica. 2005;73:1237–1282. [Google Scholar]
- Shih J, Louis T. Inferences on the association parameter in copula models for bivariate survival data. Biometrics. 1995;51:1384–1399. [PubMed] [Google Scholar]
- Sin C, White H. Information criteria for selecting possibly misspecified parametric models. Journal of Econometrics. 1996;71:207–225. [Google Scholar]
- Sklar A. Fonctions de r'epartition'a n dimensionset leurs marges. Publications of the Institute of Statistics University Paris. 1959;8:229–231. [Google Scholar]
- van Zuijlen MCA. Properties of the empirical distribution function for independent nonidentically distributed random variables. Annals of Probability. 1978;6:250–266. [Google Scholar]
- Wang W, Wells M. Model selection and semiparametric inference for bivariate failure-time data. Journal of the American Statistical Association. 2000;95:62–76. [Google Scholar]
- White H. A reality check for data snooping. Econometrica. 2000;68:1097–1126. [Google Scholar]