

Abstract
In this article, we propose generalized Bayesian dynamic factor models for jointly modeling mixed-measurement time series. The framework allows mixed-scale measurements associated with each time series, with different measurements having different distributions in the exponential family conditionally on time-varying latent factor(s). Efficient Bayesian computational algorithms are developed for posterior inference on both the latent factors and model parameters, based on a Metropolis Hastings algorithm with adaptive proposals. The algorithm relies on a Greedy Density Kernel Approximation (GDKA) and parameter expansion with latent factor normalization. We tested the framework and algorithms in simulated studies and applied them to the analysis of intertwined credit and recovery risk for Moody’s rated firms from 1982–2008, illustrating the importance of jointly modeling mixed-measurement time series. The article has supplemental materials available online.
Keywords: Adaptive Metropolis Hastings, Bayesian, Dynamic Factor Model, Exponential Family, Mixed-Measurement Time Series
1 Introduction
Multiple co-evolving time series or data streams consisting of either discrete (binary, categorical and counts) or continuous outcomes are ubiquitous in many applications areas. An effective approach of jointly modeling mixed-measurement time series and thus sharing information is essential to characterizing the dependence among the variables and can improve prediction and interpolation across missing data regions. In this paper, we propose generalized Bayesian dynamic factor models for jointly modeling mixed-measurement time series. Efficient computational algorithms are also developed for Bayesian inference and prediction.
There has been a rich history of jointly modeling mixed outcomes involving binary, categorical and continuous variables, using either underlying Gaussian models (Muthen (1984)) or generalized latent trait models (GLTM) that specify GLMs for each response with shared latent factors (Moustaki and Knott (2000) and Dunson (2000)). Underlying Gaussian models assume categorical manifest variables arise by thresholding normal underlying variables. This leads to substantial computational simplifications, as algorithms for Gaussian latent factor models can be easily adapted. However, the price to be paid for computational efficiency is lack of modeling flexibility in that categorical variables will be assigned probit models and count variables cannot be naturally accommodated. Although substantial flexibility can be gained through using mixtures of underlying Gaussian models (Yang and Dunson (2010)), there is an associated price in terms of computational and modeling complexity.
The GLTM framework represents a compromise in that it is much more flexible than the underlying Gaussian framework, while maintaining a simple parametric form. For example, counts can be characterized via Poisson log-linear models, and categorical variables via logistic regressions. Dunson (2003) applied GLTMs to dynamic modeling of mixed scale multivariate longitudinal data, specifying GLMs for each variable. Time-varying Gaussian latent factors were included, assuming a discrete Markov model. However, substantial computational challenges result outside of the underlying Gaussian framework. In particular in Bayesian analysis, one can no longer specify conditionally-conjugate priors and implement simple Gibbs sampling algorithms. Although adaptive rejection sampling can be used within Gibbs samplers, the sampler chains are commonly poorly behaved due to high posterior dependence in the model parameters leading to slow mixing (Ghosh and Dunson (2009)). Such problems are particularly prevalent in dynamic factor models. Therefore, latent factor models with distributions in the exponential family are much more challenging computationally than the underlying normal model class.
When it comes to multivariate time series analysis, the literature has focused primarily on joint models for multiple time series with normal (or conditionally normal) observations. Latent factor models, among other multiple time series analysis approaches, are useful tools for both dimension reduction and characterizing dependency between multiple time series (Anderson (1963) and Hamann et al. (2005)). In the absence of mixed-measurement data, the latent time-varying factors can be analyzed using either principal component analysis in an approximated dynamic factor framework (see e.g. Stock and Watson (2002), Bai (2003), Bai and Ng (2002), Zhang et al. (2012) and Mohamed et al. (2008)), frequency domain methods (Boashash (2006)), or filtering and smoothing techniques as in the state-space framework (Aguilar and West (2000) and Jungbacker and Koopman (2008)). Alternatively, Zhang and Nesselroade (2007) used an underlying Gaussian variable approach to jointly model multiple categorical time series. However, little effort has been made to jointly model mixed-measurement time series.
Motivated by providing a flexible and computationally efficient framework for mixed-measurement time series analysis, we propose the use of generalized Bayesian dynamic factor model. The framework allows mixed scale measurements in different time series, with the different measurements having distributions in the exponential family conditional on time-specific dynamic latent factors. Efficient computational algorithms for Bayesian inference are also developed, which, as shown later, can be easily extended to mixed-measurement time series with missing values and/or mixed-frequency. Briefly, a Metropolis Hastings algorithm with adaptive proposals is developed to efficiently obtain posterior samples of time-varying latent factors. The algorithm is based on a Greedy Density Kernel Approximation (GDKA) via a mixture of normal distributions and further combined with the forward filtering backward sampling algorithm. In addition, parameter expansion with latent factor normalization is proposed to improve the efficiency of sampling model parameters. These steps are further embedded in a higher-level MCMC sampler, which gives efficient updating, improved inference, and prediction.
We introduce the general framework of Bayesian dynamic factor modeling for mixed-measurement time series in Section 2. Section 3 describes computational algorithms developed for Bayesian inference on both latent factors and model parameters. Section 4 applies the model and algorithms to simulated data sets. In section 5 the model is applied to jointly modeling corporate default risk, bond recovery rates and business cycles. Section 6 contains a discussion of the model and results.
2 Proposed Modeling Framework
Consider p mixed-measurement time series yt = {yit} (i = 1, …, p, and t = 1, …, T), with yit denoting the value of the ith time series at time point t, and the points assumed to be equally-spaced. Each time series can have a different measurement scale, so, for example, y1t may be binary, y2t a count and y3t continuous. We follow the setting of Dunson (2003) and jointly model the mixed-measurement time series yt via m common latent dynamic factors ηt = (ηt1, …, ηtm)′ (t = 1, …, T) and time series-specific observed covariates zit.
Conditional on a factor path (η1, …, ηT), the observation yit is modeled as coming from a distribution in the exponential family with canonical parameter θit:
| (2.1) |
The canonical parameters are defined by a generalized linear model linked to the latent factors and observed covariates:
| (2.2) |
where hi(·) is the link function for the ith time series, αi is the intercept term, zit is a b × 1 vector of observed covariates at time t, βi is a b × 1 parameter vector, ηt is m × 1 latent factor vector at time t, and Λi is 1 × m factor loading vector. Let denote the factor loading matrix. Considering identifiability of factors, Λ is lower-triangular with positive elements on the diagonal.
For simplicity in exposition, a stationary VAR(1) vector autoregressive process is assumed for the equally spaced m-dimensional factor ηt (2.3). However, the methods are easily modified to place arbitrary Gaussian process priors on continuous time factors to accommodate unequally-spaced and mixed-frequency time series. For example, a simple yet flexible choice corresponds to the Ornstein-Uhlenbeck (O-U) process prior (Barndorff-Nielsen and Shephard (2001)).
Considering the identifiability of latent factors, the covariance matrix of η1 is set to Im, and mean is set to 0 (in this paper, N(mean, precision) is used in this paper to represent Normal distributions), and we let
| (2.3) |
Conditional on the factor path (η1, …, ηT), the covariates z1:T and all other model parameters Θ, the observations y1:T are independent of each other, which implies that the likelihood is of the form
| (2.4) |
Further combined with the Bayesian computational algorithms explored in the next section, the model allows missing data on a subset of the time series and/or mixed-frequency.
3 Computational Algorithms for Bayesian Inference
For Bayesian computation in dynamic generalized latent trait models, Dunson (2003) proposed to use one-at-a-time Gibbs updates with adaptive rejection sampling (ARS) to sample from the full conditional posterior distributions of the model parameters and latent factors. There are several problems that arise with this approach. First, ARS can be slow as many sampling and updating steps are needed. Second, due to high posterior dependence in the unknowns, one-at-a-time Gibbs samplers tend to be very slow to converge and mix. This is particularly the case as the number of time points increases, with computation becoming completely infeasible for moderate to large T. To address these problems, we propose a Metropolis Hastings algorithm with adaptive proposals, which relies on a Greedy Density Kernel Approximation (GDKA) via mixture of normal distributions, to efficiently draw samples of latent factors in a block. For efficient updating of model parameters, parameter expansion techniques are proposed and combined with latent factor normalization to improve mixing.
3.1 Sampling Latent Factors – Background
Posterior computation in latent factor time series models shares many characteristics with similar issues in state-space models, where sequential filtering and backward sampling (FFBS) using Monte Carlo is pivotal. In the absence of mixed-measurement data, when smoothing distributions of the states do not have closed forms, computational techniques based on sequential Monte Carlo (Liu and West (2001)), particle filtering and using approximated distributions have been proposed for non-linear and non-Gaussian state-space models (see e.g. Harrison and Stevens (1971), Sorenson and Alspach (1971), Alspach (1974) and more recently Ravines and Schmidt (2007)). Stroud et al. (2003) further proposed to jointly update all unobserved states by using a Metropolis Hastings proposal that approximates the exact conditional posterior. Closer to our perspective is the recent work of Niemi and West (2010), who proposed adaptive mixture approximations by matching moments for the smoothing distributions in non-linear state-space models. However, most of the these algorithms are not designed for cases with multidimensional mixed-measurement response data, in which presence of multiple exponential family distributions of data makes sequential approximation of smoothing distributions more computationally challenging, especially when missing data exist.
In this paper, we proposed a fast and efficient Greedy Density Kernel Approximation (GDKA) to the smoothing distributions via mixtures of Gaussian kernels. The GDKA needs to be performed for each filtering step and chooses mixture Gaussian backward sampling distributions. Assuming the approximations are reasonably accurate, Metropolis Hastings steps based on the approximated mixture of normal distributions as proposals (the actual proposal distributions are based on the mixtures of normals approximation, modified to have heavier tails) jointly update latent factors efficiently.
3.2 Sampling Latent Factors – Approximating Filtering Distributions
Let αt(ηt) denote the forward filtering function at time t
We have the recursive relationship between time t and t+1
| (3.5) |
For simplicity of exposition, we focus on the case ηt is one-dimensional. Clearly, the computational bottleneck is that αt(ηt) does not have an analytic form with mixed-measurement time series, making it infeasible to perform filtering and smoothing. To tackle this, we propose to use a Greedy Density Kernel Approximation (GDKA) to approximate the forward filtering functions αt(ηt) over a compact domain Ω via mixtures of K Gaussian kernels:
| (3.6) |
Suppose there are Nt pairs of over domain Ω available compromising a training set, and let be a Nt × 1 vector with . Then GDKA via a mixture of K Gaussian kernels has the form:
where Ctk (k = 1, …, K) are centers (means) of Gaussian kernels, and φt is the Gaussian precision, which are set to be the same for all K kernels. Letting Ht denote the distance matrix with , (i = 1, …, Nt, k = 1, …, K), and wt = (wt1, …, wtK)T be a K ×1 vector of the weights, we can represent the fitting/approximation problem in the regression form:
| (3.7) |
Given the means and variances of the Gaussian kernels, the best approximation can be achieved by minimizing the residual errors. The optimal weights are:
| (3.8) |
If we cannot be sure that Ht is well conditioned or even a full ranked matrix, a regularized least square solution is:
| (3.9) |
It is trivial to prove that with the non-negative constraints, the quadratic optimization problem always has a unique solution.
Clearly, specification of number of kernels used (K), choice of training pairs, Gaussian centers Ctk and Gaussian precision φt is critical for the approximation. In details, to form the training pairs, a grid of Nt equally-spaced αt are chosen within a compact domain on which the density αt(ηt) is above certain threshold. In our studies, we chose the threshold of αt(ηt) to be > 10−3 relative to the mode of the filtering distribution (Note that the filtering distributions have to be uni-modal if the observations are assumed to be coming from distributions in the exponential family). Gaussian centers are chosen from the Nt training points αt. Given equation (3.7), choosing a greedy set of K Gaussian centers from Nt values of αt can be achieved using the forward-selection algorithm as in the variable selection settings in linear regression problems. For the value of K, in our preliminary simulation studies, we found that K = 20 provides reasonably good approximations to a variety of distributions based on our algorithm, so in all our studies, we chose K to be 20. A greedy search step is also included within GDKA to find a reasonable value of φt. A detailed step-by-step procedure for GDKA is shown in Section A (in the appendix), and an example is shown in Figure S1 to show the fine approximation.
With the approximated αt(ηt), forward filtering can be conducted sequentially. Let ψt(ηt+1) = ∫ αt(ηt)f(ηt+1|ηt)dηt ∝ f(ηt+1|yi1, …, yi,t, ∀i) denote the one-step prediction function (the integral part in the filtering function). Then we have:
| (3.10) |
with Aη, μη and Φη defined in (2.3), and wtk, μtk, φtk from (3.6).
With the approximated closed-form ψt(ηt+1), we can evaluate αt+1(ηt+1), generate Nt+1 training pairs and approximate αt+1(ηt+1) using the same GDKA algorithm we used to approximate αt(ηt), and obtain the updated filtering function αt+1(ηt+1):
| (3.11) |
The normalizing constant is not involved in the computation, and the nature of the recursion relationship implies that we can start with approximating α1(ηt) ∝ π0(η1)L(η1|yi1, ∀i), and then proceed with sequentially approximating each αt(ηt).
3.3 Sampling Latent Factors – Backward Sampling Distributions
Given the approximated filtering functions, backward sampling distributions πt(·) (t = 1, …, T) can be approximated straightforwardly via π̂t(·):
| (3.12) |
with Aη, Φη defined in (2.3), and wt−1,k, μt−1,k, φt−1,k from (3.6).
Given (3.12) the joint posterior distribution of all latent factors can be approximated by a sequential product of mixture of normals:
| (3.13) |
3.4 Sampling Latent Factors – Metropolis Hastings Updating
Using the approximated joint posterior distribution π̂(η1:T |y1:T ) of the latent factors as proposal distributions, sample paths of latent factors can be drawn from a Metropolis Hastings step. For practical reasons, the approximated joint posterior distribution π̂(η1:T |y1:T ) is further combined with a mixture of corresponding heavier-tailed Cauchy distributions π̃(η1:T |y1:T ), forming the proposal distribution g(η1:T |y1:T ) (as shown in (3.14)), to avoid irregular behaviors of the Markov chain in the tail region:
| (3.14) |
where 0 ≪ pη < 1 is the weight of the approximated joint distribution. pη = 0.95 is used in all the following computations.
The Metropolis Hastings step in the (m + 1)th iteration of the MCMC then proceeds by:
Generate the entire block of candidate values γm+1 for η = η1:T from the proposal distribution ~ g(·), with g(·) following (3.14).
Accept the candidate and let η (m+1) = γ (m+1) with probability where π(·) is the unnormalized posterior full conditional joint distribution of latent factors. η1:T. Otherwise, let η (m+1) = η (m).
3.5 Sampling Model Parameters
For models with other parameters Θ in addition to the latent factors, the above latent factor sampler is applied at each stage of an MCMC algorithm that also includes steps for updating Θ. To reduce slow-mixing which is common in MCMC algorithms for latent factor models, we combine parameter expansion with latent factor normalization to induce default priors and improve computational efficiency for model parameters.
Parameter Expansion (PX) has been introduced as a useful approach for both introducing new families of prior distributions and improving computational efficiency (Liu and Wu (1999), Gelman (2004) and Kinney and Dunson (2007)). Ghosh and Dunson (2009) used parameter expansion in Bayesian Gaussian factor analysis to induce heavy-tailed priors for factor loadings and improve mixing of samplers simultaneously. In this paper, we extend the parameter expansion technique to the Bayesian dynamic factor model setting with mixed-measurement data. Basically, parameter expansion introduces a working model that is over-parameterized, and parameters in the working model are then transformed back to parameters in the inferential model.
Considering model (2.1)–(2.3) as our inferential model, we define the following working PX-factor model:
| (3.15) |
where is an unconstrained working factor loading matrix having a lower triangular structure, is an m×1 working latent factor vector, Ψ1 = diag(ψ1, …, ψm) is a diagonal covariance matrix, and is the intercept term, with , for k ≤ m. is a diagonal matrix of AR(1) coefficients, with to guarantee stationarity. Note that the PX-factor model is clearly over-parameterized, having redundant parameters in both the covariance matrix Ψ1 and mean .
In order to transform the working model parameters back to inferential model parameters, we let:
| (3.16) |
where
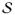 (x) = −1 for x < 0,
(x) = 1 for x ≥ 0, and
. Then, instead of placing priors directly on αi and Λi, with ηt~ N(0, I), we specify priors on α*,
and
. In particular, we let
(x) = −1 for x < 0,
(x) = 1 for x ≥ 0, and
. Then, instead of placing priors directly on αi and Λi, with ηt~ N(0, I), we specify priors on α*,
and
. In particular, we let
| (3.17) |
Hence, in the one-factor case, we obtain
| (3.18) |
with priors
| (3.19) |
To efficiently draw samples of parameters from the inferential model, we draw samples from the working model, followed by a post-processing step to transform working-model draws back to the parameters in the inferential model.
3.6 Sampling Model Parameters – Latent Factor Normalization
Parameter expansion can greatly reduce the autocorrelation of factor loadings, however, it has limited effect on improving the mixing of other parameters (e.g. the intercept term, see Figure (S12)). To further improve computational efficiency, we combine latent factor normalization with parameter expansion in sampling the model parameters from the full conditional distributions. In detail, suppose is a realization of latent factors in model (3.15) with , let η̃t = (η̃1,t, …, η̃m,t)′ denote the normalized latent factors, with
Then in matrix form we have:
| (3.20) |
where ν is a m × 1 vector with , and Δ is a m × m diagonal matrix with .
PX with Latent Factor Normalization Algorithm
Considering the working PX-factor model (3.15) and priors (3.17), given a realization of latent factors , in order to obtain a sample of model parameter Θ = (αi, Λi) (i = 1, …, p) from the full conditional distribution f(Θ|η1:T ), we can first sample Θ̃ from the full conditional distribution using the normalized PX model (3.21) via normalized latent factors η̃1:T (i = 1, …, m):
| (3.21) |
with the induced priors (3.22) for the parameters of normalized PX-factor model derived from (3.17):
| (3.22) |
and transform Θ̃ to obtain a sample of Θ via the following transformations via (3.23).
| (3.23) |
4 Simulation Examples
4.1 Mixed-Measurement Time Series
To access the efficiency of the algorithms, we first consider the simulation example jointly modeling a 3-dimensional mixed-measurement time series (Dt) consisting of Poisson counts (Yt), continuous (Zt) and binary responses (Wt), with T=50, 100, 150. 200 and 500 respectively (as shown in (4.24)). In each case, 10% of the data in each time series are randomly missing, allowing us to evaluate the model in dealing with missing values. The time-varying latent factors are modeled to follow an O-U process.
| (4.24) |
We run the sampler for 10,000 iterations, discarding the first 2,000 iterations as burn-in. The results are later compared with those obtained by simply using WinBUGS or extended Kalman filters. Taking T=200 case as an example, we set the values of a–f to be 2, 2, 3, 2, 0.5 and 1 respectively, and for the time-varying latent factors α = 0, β = 1 and σ = 1. The simulated time series are shown in Figure 1.
Figure 1.
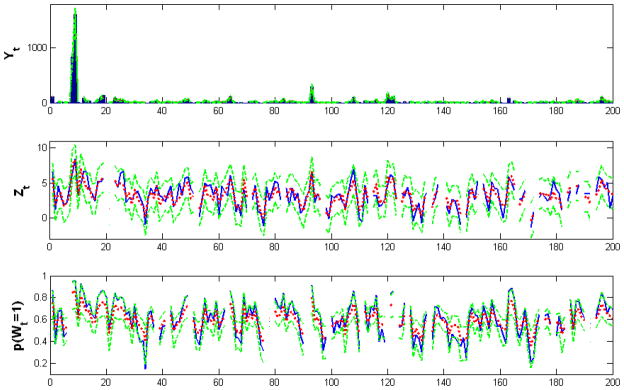
Illustration of simulated dataset and interval validation to show the model fitting. Solid lines (and the histogram for the first figure): simulated data. A 3-dimensional mixed-measurement time series Dt = [Yt, Zt, Wt] up to T=200 is simulated, where Yt is count time series, Zt is continuous and Wt is binary. 10% data in each time series are randomly missing.; dotted lines: posterior mean; dashed lines: 95% posterior C.I.
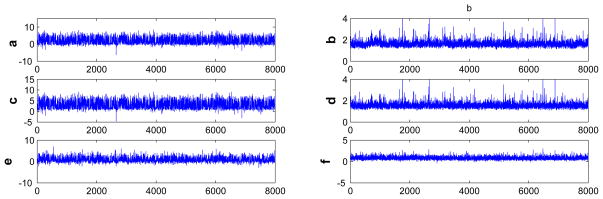
We introduce priors on the parameters in the PX working model as shown in (3.17). Specifically, half-Cauchy priors are placed on the variance components of latent factor autoregressions as recommened by Gelman (2006), while Inv-Gamma(0.01,0.01) priors are given to all other variances. To visualize the mixing the MCMC chain, trace-plots of the posterior samples of model parameters (intercepts and factor loadings shown in Figure 2) and latent factors (Figure 3) are shown.
Figure 2.
Traceplot of Posterior Samples of Model Parameters: Intercepts (a,c,e) and factor loadings (b,d,f) shown. The parameters are defined in (4.24).
Figure 3.
Traceplot of Posterior Samples of Latent Factors: Six time points shown. The latent factors are defined in (4.24).
A summary of effective sample size and sample autocorrelation of posterior samples are further listed in Table 1. A summary of effective sample size and sample autocorrelation of posterior samples are further listed in Table 1.We compare the mixing of our MCMC sampler with that of WinBUGS (Traceplots shown in Figure 4 and S2, and the summary of effective sample size and autocorrelation shown in Table S1), which is based on a Gibbs sampler and use of adaptive-rejection sampler or random-walk MCMC for full conditional distributions without closed forms. Our sampler relying on GDKA, parameter expansion and latent factor normalization leads to tremendous gains in the mixing of MCMC chains for both model parameters and latent factors. Furthermore, it is important to note that all three techniques contribute to improving the efficiency of the MCMC sampler, as not implementing one of them tends to give poor mixing of the chains for at least some model parameters (see e.g. Figure 6 and S12). Especially, we find that while Metropolis Hastings via GDKA is critical for latent factor filtering and sampling, parameter expansion substantially improves computational performance for factor loadings, and latent factor normalization helps the mixing of chains for other model parameters (e.g. intercepts).
Table 1.
MCMC Summary for T=100 and T=150 respectively shows improved mixing, compared to Table S1, which is obtained using WinBUGS. Using T=100 and T=150 as examples, in each case, 10000 posterior samples are drawn for each unknown with the first 2000 as burn-in. Effective sample size (ESS) and sample autocorrelation with lag 10 and 30 of the 8000 posterior samples are shown for selected parameters as representatives (c, d, η1 and η50 are defined as in (4.24)).
| # of Time Points | T=100 | T=150 | ||||||
|---|---|---|---|---|---|---|---|---|
|
| ||||||||
| Parameters | c | d | η1 | η50 | c | d | η1 | η50 |
| ESS | 1815 | 6500 | 1875 | 1740 | 1905 | 6025 | 1982 | 1887 |
| Autocorr-Lag 10 | 0.045 | 0.008 | 0.043 | 0.039 | 0.019 | 0.025 | 0.019 | 0.018 |
| Autocorr-Lag 30 | 0.007 | −0.005 | 0.012 | 0.009 | −0.009 | −0.005 | −0.011 | −0.013 |
Figure 4.
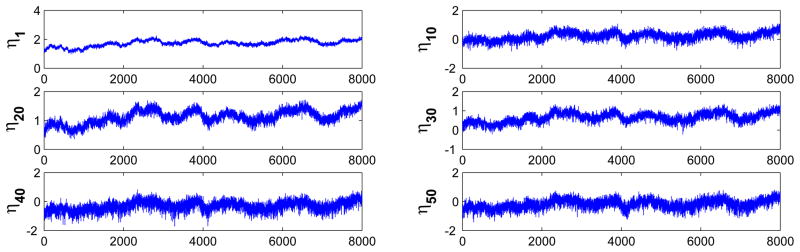
Traceplot Produced by WinBugs of Posterior Samples of Latent Factors. The traceplots are compared with those in Figure 3, also showing that our algorithm improve the mixing of the Markov Chain.
Figure 6.

Traceplots and Autocorrelation Plots of Posterior Samples. Note that our modification can effectively reduce both the autocorrelation of factor loading matrix (Λ1 as a representative here) and the intercept (α1 as a representative) very well, as compared to those in Figure S12. α1 and Λ1 are defined in (5.27).
On the other hand, since extended Kalman filters have been used to approximate non-Gaussian filtering and sampling distributions using Laplace normal approximations, especially when the length of time series is not long, we compared the results of our method with those of Kalman filters with all simulated datasets. A comparison of acceptance ratio clearly shows that our sampler gave much better acceptance ratio, especially with increased length of the time series. Low acceptance rates of extended Kalman filter inevitably lead to MCMC inefficiency, illustrated by the increased autocorrelation and decreased effective sample size (a comparison between Table 1 and Table S1).
To show the model fitting, internal validations are performed, with posterior means and 95% confidence intervals (C.I.s) of the simulated time series shown in Figure 1.
The use of our MCMC sampler seems to provide a reasonable inference to the unknown quantities. Furthermore, the framework and computational algorithms allows missing values on a subsect of the time series. Figure S3 shows that the model gives good interpolations of missing data based on the posterior marginal distributions.
Efficient adaptive Metropolis Hastings via GDKA to sample time-varying latent factors is one of the key steps in our sampling scheme, and it is well known that the acceptance rates of Metropolis Hastings steps tend to decrease rapidly as the number of time points increases (Niemi and West (2010)). To evaluate this, we generated 100 simulated datasets for each T and look at the overall performance. Table 2 lists the acceptance rates of the Metropolis Hastings steps to sample latent factors using our sampling scheme, showing that the algorithm is efficient even for big time series with T=500, which has much higher acceptance ratio than extend Kalman filters. The accuracy of inference to unknown quantities is also further confirmed based on the 100 simulated datasets by checking whether the posterior estimates would recover the true values of model parameters under such a complex model, with Table S3 showing that in almost all cases the 95% posterior C.I.s cover the true values with all 100 simulated datasets.
Table 2.
Acceptance Ratio for the Metropolis-Hastings update with GDKA for latent factors compared with extended Kalman filters (E-KF). Mean, minimum and maximum acceptance rates based on 100 simulated datasets are shown. Note that our algorithm both has higher acceptance ratio and more stable performance with mixed-measurement observations with possible missing values.
| T (# of Time Points) | 50 | 100 | 150 | 200 | 500 |
|---|---|---|---|---|---|
|
| |||||
| GDKA (mean) | 73.1% | 59.4% | 43.3% | 30.4% | 12.4% |
| (min) | 70.3% | 57.3% | 40.6% | 27.4% | 8.1% |
| (max) | 76.1% | 61.3% | 46.8% | 33.1% | 13.3% |
|
| |||||
| E-KF(mean) | 41.1% | 25.3% | 1.7% | ~0 | 0 |
| (min) | 30.1% | 14.1% | 0% | 0 | 0 |
| (max) | 43.3% | 27.1% | 7.7% | 0.3% | 0 |
Furthermore, it is worth mentioning that although we show that our algorithm updates latent factors in a single block and infers model parameters efficiently with relatively big time series (T=500), the performance of the proposed algorithm is expected to decrease with bigger time series. In those cases, a reasonable strategy could be combining our algorithm with the idea of block sampling scheme, where the big time series can be divided to a few blocks with T smaller than 500 and updated sequentially in each block, which will definitely help in problems with extremely big time series.
4.2 Mixed Discrete Time Series
Time series with discrete outcomes having a variety of measurement scales (count, binary, categorical) are also commonly collected in various fields of study. Discrete variables contain less information than continuous variables (Chin and Lee (2008)), so it is of great help to share information between time series with mixed discrete outcomes whenever it is possible.
In this simulation study, 4-dimensional time series Dt consisting of a mixture of binomial counts (Yt and Zt) and binary responses (Wt and Vt) up to time T are jointly modeled, as shown in (4.25). Similarly, 10% of the simulated data in each time series are randomly missing to evaluate the model in dealing with missing data.
| (4.25) |
Taking T=100 case as an example, we set the values of a–h to be 0.5, 1, 1, −1.5, 1, −2, 0.5 and −3 respectively. An AR(1) autoregressive structure is applied to the time-varying latent factors, with γ = 0.368 and σε = 0.658. The simulated time series are shown in Figure S4. Similarly, to obtain posterior samples, we run our MCMC sampler for 10,000 iterations, discarding the first 2,000 samples as burn-in. Again, the effective sample size and autocorrelation shown in Table 3 show good mixing of the Markov Chain, which is further illustrated by the trace-plots of intercepts, factor loadings (Figure S5) and latent factors (Figure S6). In addition, with T=100, the Metropolis Hastings step for latent factors update gives a good acceptance ratio of 56.1%.
Table 3.
MCMC Summary for T=100 (selected parameters shown) shows good mixing of the Markov Chain. 10000 posterior samples are drawn for each unknown with the first 2000 as burn-in. Effective sample size (ESS) and sample autocorrelation with lag 10 and 30 of the 8000 posterior samples are shown for selected parameters as representatives (a – h, η1 and η50 are defined as in (4.25)).
| Parameters | a | b | c | d | e | f | g | h | η1 | η50 |
|---|---|---|---|---|---|---|---|---|---|---|
| ESS | 5726 | 6449 | 5742 | 6488 | 5030 | 2659 | 4057 | 2043 | 5998 | 5710 |
| Autocorr-Lag 10 | 0.007 | 0.008 | 0.009 | 0.011 | 0.012 | 0.029 | 0.017 | 0.029 | −0.004 | −0.005 |
| Autocorr-Lag 30 | 0.001 | −0.006 | 0.003 | −0.002 | 0.007 | 0.013 | 0.011 | 0.018 | 0.013 | 0.014 |
Internal validations with posterior mean and 95% C.I. of the simulated time series are shown in Figure S7. Again, the framework provides good fit to the simulated data, which is reinforced by the missing data interpolation results shown in Figure S8.
4.3 Mixed-Measurement-Mixed-Frequency Time Series
Another challenge with mixed-measurement time series is that time series are often sampled at different frequencies. For example, some time series are observed every month or quarter while others are recorded every year. In empirical financial analysis, daily and intra-daily time series are also often readily available for analysis. To model the time series simultaneously, the literature and methodology have been focused on either aggregating the higher-frequency data to the lower frequency, or interpolating the lower-frequency data to the higher-frequency (Ghysels et al. (2005), Andreou et al. (2010) and Ghysels et al. (2007)). Neither of these is generally satisfactory. First of all, temporal aggregation loses information and may lead to poor prediction. Secondly, the approaches via data interpolation transform the mixed-frequency problem to a missing data problem, assuming that the model operates at the highest frequency of the time series, while data in the lower-frequency time series are periodically missing. However, commonly used interpolation methods generally do not efficiently and fully exploit the sample information, especially when massive missing data exist, which is very likely to occur when performing data interpolation in mixed-measurement-mixed-frequency time series analysis.
We apply our generalized dynamic factor model and computational algorithms to mixed-measurement-mixed-frequency time series analysis, in which the observed time series are simultaneously modeled via dynamic latent factors at specifically defined frequencies discussed later. Under this scenario, neither data aggregation nor interpolation is required in the inference or prediction, which improves the computational efficiency with mixed-frequency observations.
In detail, we treat the low-frequency time series as high-frequency time series with “missing data” and low “observed” frequency. For the p-dimensional mixed-measurement-mixed-frequency time series, let t be the time index of the highest frequency time series, and yt = {yit} (i = 1, …, p and t = 1, …, T), with observed frequencies ω = (ω1 …, ωp)′. Let be the corresponding ordered p-dimensional time series by descending frequency. Let , with denoting the highest common frequency from to . Then can be modeled following (2.1), (2.2) and (2.3) via m common factors ηt = (η1t, …, ηmt)′, with each latent factor ηit (i = 1, …, m) constructed to follow an AR(1) process with frequency . In particular, in the one-factor model case, is the highest common frequency of all observed time series.
In the following simulation study, we considered jointly modeling a 3-dimensional mixed-measurement-mixed-frequency time series yt with observed frequency omega; = (3omega;0, omega;0, omega;0)′ respectively (shown in (4.26)). The simulated data are generated through two common latent factors (ηt = (η1t, η2t)′) at the frequency of 3ω0, and chosen in accordance with empirical applications to form multivariate mixed-measurement-mixed-frequency time series, where the first time series (Y1t) can be considered as monthly recorded data, while the other two as quarterly recorded data. Specifically,
| (4.26) |
The simulated data and latent factors up to T=90 are shown in Figure S9 (90 time points for Y1t, and 30 time points observed for Y2t and Y3t). Again, analysis of posterior samples indicates good mixing the the Markov Chain (Table S2), and internal validation shows good fitting of the model to the simulated mixed-measurement-mixed-frequency data (Figure S10).
5 Intertwined Corporate Default, Recovery Rate and Business Cycle
It has been noted that corporate default rates and bond recovery rates on defaults are negatively correlated (Altman et al. (2005)). Since recovery rates play a critical role in pricing and risk models, treating recovery rates as either constant or a stochastic variable independent of default rates while neglecting inverse relationship leads to inaccurate estimation of the loss function and suboptimal capital allocation. Furthermore, according to the current Basel proposal, banks can opt to provide their own recovery rate forecasts for the calculation of regulatory capital (Creal et al. (2011)). Thus there is an immediate need for statistical models explaining the relationship between the corporate default risk and bond recovery rates (and probably some other credit risk indicators), which can be used in default prediction and credit risk modeling. Macroeconomic conditions, on the other hand, may affect both default and recovery rates (see e.g. Nickell et al. (2000)), where the number of defaults tends to increase with lower recovery rates in economic recessions (Altman et al. (2005)).
In this study, we apply the generalized Bayesian dynamic factor models to jointly modeling corporate default counts, bond recovery rates and business cycle indicators over time. Default counts are model by binomial distribution with the default probability modeled via logistic link function. Recovery rates, which are between 0 and 1, are modeled via logistic-Normal model. Unemployment rate is used as an indicator for business cycle. The relationship between them are modeled via shared common unobserved systematic risk factor(s).
5.1 Data
The 5 time series (shown in Figure 5) we have are annual recovery rates, corporate default counts and unemployment rate data from 1982 to 2008 (Latest public data obtained from Moody’s Default and Recovery Database), denoted as:
where y1t: annual default counts within investment-grade cooperates. y2t: annual default counts within speculative-grade cooperates. y3t: all-bonds annual recovery rates. y4t: senior-secured bonds annual recovery rates. y5t: annual unemployment rate of the United States.
Figure 5.

Data consisting of 5 Mixed-Measurement Time Series Shown. (A): Annual Default Counts: Speculative-Grade Cooperates. (B): Annual Default Counts: Investment-Grade Cooperates. (C): Annual Recovery Rates: All Bonds. (D): Annual Recovery Rates: Senior-Secured Bonds. (E): Annual Unemployment Rate.
5.2 Model Specification
Default counts are modeled as coming from binomial distributions. Recovery rates and unemployment rates are modeled as coming from logistic-Normal distributions. The inferential model is shown in (5.27). Default priors are placed on the corresponding parameter expanded working model.
| (5.27) |
The 5 time series are jointly modeled via one or two factor models, based on the previous studies showing that default counts and recovery rates are negatively correlated, and they may be further associated with but do not match business cycle. Inference of number of factors is based on comparing fit for the one and two factor models.
5.3 Results
We are interested in the inference of both parameters and latent factors, as well as the relationship between corporate default counts, bond recovery rates and business cycle.
In the one-factor model, the latent factor can be interpreted as credit risk within the period. We explore the posterior distribution of the unknowns using the algorithms discussed earlier. Two results show the efficiency of the MCMC sampler: Firstly, the acceptance ratio of latent factors in the Metropolis Hastings update is 81%. Secondly, parameter expansion and latent factor normalization promote the mixing of the Markov chain, and greatly improve the sampling efficiency (as shown in Figure 6), compared to those obtained via only parameter expansion (Figure S12) or WinBUGS (results not shown).
We constructed point and interval estimates of the credit risk factor within the period. This is shown in Figure 7. Clearly, the figure shows that credit pressure peaks around 1990, 2001 and 2008, which are all well-known financial crises.
Figure 7.

1982–2008 Credit Pressure Reconstruction. Dotted line: posterior mean of the credit risk factor, and dashed lines: 95% posterior C.I.
Furthermore, Figure 8 shows the fitting of the model to the data, with posterior retrospective mean and 95% intervals shown with dotted lines and dashed lines respectively. Note that the fitting of annual recovery rates and default counts are good under the one-factor setting (The fitting of recovery rate for senior-secured bonds seems not as good as others, indicating the possibility of existence of additional factors. Two-factor model gives a better fit, as shown later), indicating that a common credit risk factor may be used to model the inverse relationship between them. Fitting of unemployment rate data, however, is not as good, indicating the idea that business cycle, though may be related to credit cycle, have effects from additional latent factors.
Figure 8.

Model Fitting using One-Factor Generalized Dynamic Factor Model. The solid lines (and the histograms for the first two panels) show real historical data, the dotted lines indicate posterior means and the dashed lines show posterior 95% C.I. (A): Annual Default Counts: Speculative-Grade Cooperates. (B): Annual Default Counts: Investment-Grade Cooperates. (C): Annual Recovery Rates: All Bonds. (D): Annual Recovery Rates: Senior-Secured Bonds. (E): Annual Unemployment Rate.
In comparison, we also fit the data with a two-factor model, with the two factors chosen to be corresponding to the speculative-grade-cooperate default counts and unemployment rates time series, which can be considered as representing the credit risk factor and the business cycle factor. Again, we have high acceptance rates for the two latent factors (83% and 78% respectively) and the model fitting is shown in Figure 9. Clearly, the two-factor model gives improved fitting for unemployment data and senior-secured bonds recovery rate data, but has trivial improvement on others. This indicates that default and recovery risk, though related to, is not solely determined by the business cycle.
Figure 9.

Model Fitting using Two-Factor Generalized Dynamic Factor Model. The solid lines (and the histograms for the first two panels) show real historical data, the dotted lines indicate posterior means and the dashed lines show posterior 95% C.I. (A): Annual Default Counts: Speculative-Grade Cooperates. (B): Annual Default Counts: Investment-Grade Cooperates. (C): Annual Recovery Rates: All Bonds. (D): Annual Recovery Rates: Senior-Secured Bonds. (E): Annual Unemployment Rate.
Furthermore, we specifically looked at the posterior distributions of factor loadings to obtain a better understanding of the relationship between the time series (Histograms of posterior samples of factor loadings shown in Figure S11 and the posterior summaries are shown in Table 4). Table 4 clearly shows that default counts (the first and second times series) and bond recovery rates (the third and fourth time series) have strong negative correlation in terms of the credit risk factor (factor one), with the factor loadings of the first factor being strictly positive for default counts and strictly negative for bond recovery rates, at the 95% confidence level. In addition, we are not sure if unemployment rate is strongly correlated with default counts or bond recovery rates, although there is some weak evidence showing that default counts may be negatively associated and bond recovery rates may be positively associated with unemployment rates. This further demonstrates that systematic default and recovery risk does not coincide with business cycle risk, which is consistent with the related findings in Das et al. (2007), Bruche and Gonzlez-Aguado (2010) and Creal et al. (2011).
Table 4.
Posterior Summary of Factor Loadings Λij (i = 1, …, 5 and j = 1, 2) in the Two-Factor Model, where Λij is the factor loading of the jth factor for the ith time series (Λ12 = 0).
| Factor Loadings | Mean | Medium | SD | 95% HPD C.I. |
|---|---|---|---|---|
|
| ||||
| Λ11 | 1.312 | 0.927 | 1.957 | [0.478,3.127] |
| Λ21 | 1.322 | 0.936 | 1.986 | [0.503,3.195] |
| Λ22 | −0.0828 | −0.0717 | 0.0808 | [−0.225,0.035] |
| Λ31 | −0.592 | −0.422 | 0.842 | [−1.424,−0.172] |
| Λ32 | 0.0642 | 0.0547 | 0.0735 | [−0.038,0.196] |
| Λ41 | −0.683 | −0.497 | 1.076 | [−1.706,−0.128] |
| Λ42 | 0.119 | 0.104 | 0.131 | [−0.033,0.383] |
| Λ51 | 0.0586 | 0.0440 | 0.115 | [−0.077,0.213] |
| Λ52 | 0.219 | 0.186 | 0.159 | [0.099,0.454] |
6 Discussion
This paper proposes the use of Bayesian generalized dynamic factor models for jointly modeling mixed-measurement time series, and efficient computational algorithms are developed. The proposed framework allows mixed-scale measurements associated with each time series, with different measurements having different distributions in the exponential family, and thus provides a more flexible framework for multivariate time series analysis. Although our illustration examples are based on specific k-factor models, the broader question of inference on the number of factors and model selection in (generalized) factor analysis, especially in the mixed-measurement observation framework, is interesting and challenging. Reversible jump MCMC algorithms can be used to allow for model uncertainly (Lopes and West (2004) and Lopes et al. (2011)). Alternatively, sparse spike-and-slab priors were proposed to induce sparsity in the factor loading matrix (see e.g. West (2003) and Carvalho et al. (2008)). More recently, non-parametric infinite factor models were introduced using either a multiplicative gamma process shrinkage prior on factor loadings (Bhattacharya and Dunson (2011)) or Indian-Buffet Process (IBP) prior on the factor loading matrix (Knowles and Ghahramani (2010)). However, translating these non-parametric approaches to the generalized dynamic factor model framework with mixed measurement is challenging and as yet unexplored.
Supplementary Material
Acknowledgments
This research was partially supported by grant R01ES17240 from the National Institute of Environmental Health Sciences (NIEHS) of the National Institutes of Health (NIH).
Footnotes
Appendix: the Detailed Greedy Density Kernel Approximation (GDKA) procedure, and supplemental tables and figures (Table S1–S3 and Figure S1–S12) as supporting results.
Matlab Codes: Matlab codes for modeling mixed-measurement time series using the generalized dynamic factor models. (codes.zip)
Contributor Information
Kai Cui, Department of Statistical Science, Duke University.
David B. Dunson, Department of Statistical Science, Duke University
References
- Aguilar O, West M. Bayesian dynamic factor models and portfolio allocation. Journal of Business and Economic Statistics. 2000;18:338–357. [Google Scholar]
- Alspach DL. Gaussian sum approximations in nonlinear filtering and control. Information Sciences. 1974;7:271– 290. [Google Scholar]
- Altman EI, Brady B, Resti A, Sironi A. The link between default and recovery rates: Theory, empirical evidence, and implications. Journal of Business. 2005;78(6):2203–2228. [Google Scholar]
- Anderson T. The use of factor analysis in the statistical analysis of multiple time series. Psychometrika. 1963;28(1):1–25. [Google Scholar]
- Andreou E, Ghysels E, Kourtellos A. Regression models with mixed sampling frequencies. Journal of Econometrics. 2010;158(2):246–261. [Google Scholar]
- Bai J. Inferential theory for factor models of large dimensions. Econometrica. 2003;71(1):135–171. [Google Scholar]
- Bai J, Ng S. Determining the number of factors in approximate factor models. Econometrica. 2002;70(1):191–221. [Google Scholar]
- Barndorff-Nielsen OE, Shephard N. Non-Gaussian Ornstein-Uhlenbeck-based models and some of their uses in financial economics. Journal Of The Royal Statistical Society Series B. 2001;63(2):167–241. [Google Scholar]
- Bhattacharya A, Dunson DB. Sparse Bayesian infinite factor models. Biometrika. 2011;98(2):291–306. doi: 10.1093/biomet/asr013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boashash B. Time Frequency Signal Analysis and Processing: A Comprehensive Reference. Oxford University Press; 2006. [Google Scholar]
- Bruche M, Gonzlez-Aguado C. Recovery rates, default probabilities, and the credit cycle. Journal of Banking & Finance. 2010;34(4):754–764. [Google Scholar]
- Carvalho CM, Chang J, Lucas JE, Nevins JR, Wang Q, West M. High-Dimensional Sparse Factor Modelling: Applications in Gene Expression Genomics. Journal of the American Statistical Association. 2008;103(484):1438–1456. doi: 10.1198/016214508000000869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chin R, Lee BY. Principles and Practice of Clinical Trial Medicine. 1 Academic Press; 2008. [Google Scholar]
- Creal DD, Schwaab B, Koopman SJ, Lucas A. Tinbergen Institute Discussion Papers 11-042/2/DSF16. Tinbergen Institute; 2011. Observation driven mixed-measurement dynamic factor models with an application to credit risk. [Google Scholar]
- Das SR, Duffie D, Kapadia N, Saita L. Common failings: How corporate defaults are correlated. Journal of Finance. 2007;62(1):93–117. [Google Scholar]
- Dunson DB. Bayesian latent variable models for clustered mixed outcomes. Journal of the Royal Statistical Society. Series B (Statistical Methodology) 2000;62(2):355–366. [Google Scholar]
- Dunson DB. Dynamic latent trait models for multidimensional longitudinal data. Journal of the American Statistical Association. 2003;98:555–563. [Google Scholar]
- Gelman A. Parameterization and Bayesian modeling. Journal of the American Statistical Association. 2004;99:537–545. [Google Scholar]
- Gelman A. Prior distributions for variance parameters in hierarchical models. Bayesian Analysis. 2006;3:514–534. [Google Scholar]
- Ghosh J, Dunson DB. Default prior distributions and efficient posterior computation in Bayesian factor analysis. Journal of Computational and Graphical Statistics. 2009;18(2):306–320. doi: 10.1198/jcgs.2009.07145. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ghysels E, Santa-Clara P, Valkanov R. There is a risk-return trade-off after all. Journal of Financial Economics. 2005;76(3):509–548. [Google Scholar]
- Ghysels E, Sinko A, Valkanov R. Midas regressions: Further results and new directions. Econometric Reviews. 2007;26(1):53–90. [Google Scholar]
- Hamann E, Deistler M, Scherrer W. Factor models for multivariate time series. In: Taudes A, editor. Adaptive Information Systems and Modelling in Economics and Management Science, volume 5 of Interdisciplinary Studies in Economics and Management. Springer; Vienna: 2005. pp. 243–251. [Google Scholar]
- Harrison PJ, Stevens C. A Bayesian approach to short-term forecasting. Operational Research Quarterly (1970–1977) 1971;22(4):341–362. [Google Scholar]
- Jungbacker B, Koopman SJ. Tinbergen Institute Discussion Papers 08-007/4. Tinbergen Institute; 2008. Likelihood-based analysis for dynamic factor models. [Google Scholar]
- Kinney SK, Dunson DB. Fixed and random effects selection in linear and logistic models. Biometrics. 2007;63(3):690–698. doi: 10.1111/j.1541-0420.2007.00771.x. [DOI] [PubMed] [Google Scholar]
- Knowles D, Ghahramani Z. Nonparametric Bayesian sparse factor models with application to gene expression modelling. Annals of Applied Statistics 2010 [Google Scholar]
- Liu J, West M. Combined parameter and state estimation in simulation-based filtering. In: Doucet A, JFGDF, Gordon NJ, editors. Sequential Monte Carlo Methods in Practice. Springer-Verlag; New York: 2001. [Google Scholar]
- Liu JS, Wu YN. Parameter expansion for data augmentation. Journal of the American Statistical Association. 1999;94:1264–1274. [Google Scholar]
- Lopes HF, Gamerman D, Salazar E. Generalized spatial dynamic factor models. Computational Statistics & Data Analysis. 2011;55(3):1319–1330. [Google Scholar]
- Lopes HF, West M. Bayesian model assessment in factor analysis. Statistica Sinica. 2004;14:41–67. [Google Scholar]
- Mohamed S, Heller K, Ghahramani Z. Bayesian Exponential Family PCA. Proceedings of the 21st Conference on Advances in Neural Information Processing Systems (NIPS21).2008. [Google Scholar]
- Moustaki I, Knott M. Generalized latent trait models. Psychometrika. 2000;65(3):391–411. [Google Scholar]
- Muthen B. A general structural equation model with dichotomous, ordered categorical, and continuous latent variable indicators. Psychometrika. 1984;49(1):115–132. [Google Scholar]
- Nickell P, Perraudin W, Varotto S. Stability of rating transitions. Journal of Banking & Finance. 2000;24(1–2):203–227. [Google Scholar]
- Niemi J, West M. Adaptive mixture modelling metropolis methods for Bayesian analysis of non-linear state-space models. Journal of Computational and Graphical Statistics. 2010;19:260–280. doi: 10.1198/jcgs.2010.08117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ravines HSM, Schmidt A. Working papers. Universidade Federal do Rio de Janeiro; 2007. An efficient sampling scheme for generalized dynamic models. [Google Scholar]
- Sorenson H, Alspach D. Recursive Bayesian estimation using Gaussian sums. Automatica. 1971;7(4):465–479. [Google Scholar]
- Stock JH, Watson MW. Macroeconomic forecasting using diffusion indexes. Journal of Business & Economic Statistics. 2002;20(2):147–62. [Google Scholar]
- Stroud JR, Mller P, Polson NG. Nonlinear state-space models with state-dependent variances. Journal of the American Statistical Association. 2003;98(462):377–386. [Google Scholar]
- West M. Bayesian Statistics. Oxford University Press; 2003. Bayesian factor regression models in the “large p, small n” paradigm; pp. 723–732. [Google Scholar]
- Yang M, Dunson D. Bayesian semiparametric structural equation models with latent variables. Psychometrika. 2010;75(4):675–693. [Google Scholar]
- Zhang G, Ferrari S, Cai C. A comparison of information functions and search strategies for sensor planning in target classification. IEEE Transactions on Systems, Man, and Cybernetics - Part B: Cybernetics. 2012;42(1):2–16. doi: 10.1109/TSMCB.2011.2165336. [DOI] [PubMed] [Google Scholar]
- Zhang Z, Nesselroade JR. Bayesian estimation of categorical dynamic factor models. Multivariate Behavioral Research. 2007;42(4):729. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.