

Abstract
The paper introduces dyadic brain modelling, offering both a framework for modelling the brains of interacting agents and a general framework for simulating and visualizing the interactions generated when the brains (and the two bodies) are each coded up in computational detail. It models selected neural mechanisms in ape brains supportive of social interactions, including putative mirror neuron systems inspired by macaque neurophysiology but augmented by increased access to proprioceptive state. Simulation results for a reduced version of the model show ritualized gesture emerging from interactions between a simulated child and mother ape.
Keywords: dyadic brain modelling, ontogenetic ritualization, gesture in apes, mirror neuron systems, computer simulation, neural models
1. Ape gesture and ontogenetic ritualization
The extent to which manual gestures can be said to be learned versus inherited genetically is a matter of current debate. Some authors argue that gestures are either ‘species typical’ or produced by only a single individual [1,2], arguing against a significant role for learning in differentiating the gestural repertoires of different groups of apes of a given species. However, a few group-specific gestures have been observed in ape populations, suggesting a role for social learning [3]. Gestural behaviour is contextualized by the comprehension and attentional states of others, and failed gestural communicative attempts often result in production of a series of semantically similar gestures [4–6]. We do not review the broad literature on ape gestural production and comprehension here, but reviews can be found elsewhere [3,7–9] and in the paper [10] to which this is the sequel. Instead, we focus on ontogenetic ritualization which was proposed, following Plooj [11], by Tomasello and co-workers [12,13] as a means whereby some ape gestures could emerge through repeated interactions between pairs of individuals:
(i) Individual A performs praxic behaviour1 X and individual B consistently reacts by doing Y.
(ii) Subsequently, B anticipates A's overall performance of X by starting to perform Y before A completes X.
(iii) Eventually, A anticipates B's anticipation, producing a ritualized form XR of X to elicit Y.
Even though the role of this process remains controversial, we argue that using computational neuroscience to hypothesize brain mechanisms that could support ontogenetic ritualization can generate new ideas for primatological as well as neurophysiological and neuroimaging studies, and may rephrase the debate in fresh ways.
We earlier offered a conceptual model of the brain mechanisms that could support this process, using an example of a child's initial pulling on a mother eventually yielding a ‘beckoning’ gesture [10]. We hypothesized six more or less distinct stages through which the learning would proceed. In §3, we spell out those stages. We then provide a computational model and show through simulations how development can proceed through these stages without explicit programming. We do so in the context of prior modelling of the macaque mirror system and related circuitry. This is part of a comprehensive approach to the evolution of the language-ready brain [14–16] in which the ability of the last common ancestor of humans and great apes (LCA-a) to create novel communicative manual gestures is postulated to be a crucial intermediary between the mirror system for manual action of the last common ancestor of humans and macaques (LCA-m) and mechanisms supporting language parity [17] in the human brain. Such parity is the ability of the hearer (or observer) of an utterance to access (more or less correctly) the meaning intended by the speaker (or signer). In particular, to bring this enterprise into the realm of computational neuroscience of extant species, we seek to assess to what extent brain mechanisms in the macaque may be conserved in the ape (e.g. chimpanzee) brain, and to what extent different mechanisms must be posited between the species.
A macaque's recognition of manual actions has only been demonstrated to activate mirror neurons for transitive actions [18]. Yet, apes are responsive to non-transitive manual gesture, and we may plausibly infer that apes have mirror neurons responsive to many of these gestures. Note, though, that ontogenetic ritualization yields an ability by one ape to emit a gesture and by another ape to recognize that gesture, but does not necessarily posit that motor skill for the observer. Further changes would be required to yield mirror neurons in each brain active for both production and perception of the gesture. We see here the importance of the concept of potential mirror neurons and quasi-mirror neurons [14, p. 132]. The specifics of mirror neuron activation as observed in macaque and human are important considerations for this modelling work, but we focus below on our previous modelling of the mirror system. Readers may find further analyses elsewhere in this special issue.
2. Prior modelling as basis for a new overall model
Although primate neurophysiology offers a range of studies of mirror neurons, very little attention has been paid to whether and how mirror neuron activity helps guide the monkey's behaviour in response to observing the actions of another. Where much work on mirror systems focuses on a single agent recognizing another's action, ‘interactive’ designs allow more specifically social questions to be explored [19–21]. Here, we bring such considerations into the realm of computational neuroscience by advocating dyadic brain modelling to trace changes in the brains of two agents during interactive behavioural shaping.
(a). Prior modelling
There are two key distinctions:
— Event-level versus trajectory-level modelling. In many psychological models, each task event or action is considered as an indivisible whole, and emphasis is placed on the stringing together of distinct behavioural events by decision processes. By contrast, trajectory-level modelling analyses, for example, the trajectory of a hand movement and the temporal relation of shifting neural firing patterns during that trajectory.
— Proximal versus distal goals. All the actions in a behaviour may be steps towards a single shared goal, the distal goal, yet each has a distinct proximal goal that defines that particular action.
We build on the augmented competitive queuing (ACQ) model (figure 1; [22]) which addresses the flexible scheduling of actions to achieve a distal goal. Crucially, and unlike most of the literature, this model emphasizes the utility of a mirror system in recognizing one's own action. Separate subsystems assess the executability of actions (e.g. the availability of suitable affordances) and their desirability (an estimate of the expectation that executing that action will lead on to attainment of the distal goal). The model is event-level: the system chooses the action with the highest value of priority = executability × desirability which is then executed to completion. The mirror system within ACQ monitors self-actions, indicating whether an intended action proceeded as expected or whether the output resembled another action, the apparent action. The mirror system's evaluation of the end-result of attempting the intended action is used to update the estimate of its executability, downgrading it if the apparent action departs too far from the intended action. A method called temporal difference learning [23] is used to update the desirability of the apparently executed action, whether it is the intended action or a different apparent action: the desirability of an action is greater the more likely it is to be on a path to attaining the distal goal, and the closer it is along the path to the action that actually achieves it.
Figure 1.

A view of ACQ, the augmented competitive queuing model [22]. The agent works towards its distal goal by choosing the most desirable action that is currently executable. The model includes learning mechanisms for updating estimates of executability and desirability. The mirror system monitors self-actions, indicating whether an intended action succeeded or whether the output resembled another action, the apparent action.
An extension of ACQ [24] handles multiple possible distal goals, with the desirability of an action depending on the current selection of distal goal. This then requires modelling processes setting the current distal goal. Achievement of a distal goal—e.g. eat versus drink—may remove that goal, leading to promotion of another distal goal and consequent resetting of desirability, and so behaviour.
In contrast to ACQ, our earlier models of the reach-to-grasp action (the Fagg–Arbib–Rizzolatti–Sakata (FARS) model [25]) and of mirror neuron learning mechanisms (MNS and MNS2 [26,27]) are both trajectory level, addressing neurophysiological data on reach-to-grasp behaviour in macaques [28]. Our MNS models demonstrate how the activity of mirror neurons can build up during the successful completion of an observed action, whether that action is executed by the self or the other. In the case of the reach to grasp, the models address the neurophysiological data on ‘build up’ or anticipatory activity of visual mirror neurons before the hand reaches the object [29]. The models also address learning to recognize new actions. A study [30,31] complementary to FARS addresses human data on perturbation of the reach to grasp when either the position or size of the target object is varied [32,33]. In this study, we will consider a range of actions to be executed by apes, not just the reach to grasp. Controllers will track the trajectory and change it if the goal changes and terminate it if the goal is reached.
As will be clear from other papers in this special issue, the role and nature of mirror neurons, and their modelling, still poses questions which are very much open in the literature [34–36]. What is insufficiently emphasized elsewhere is this importance of trajectory-level analysis: an action may be corrected in mid-flight or halted when its goal is reached, whereas an agent may recognize and respond to another's action before it is completed. Nonetheless, the programme of dyadic brain modelling to which we now turn will surely benefit from insights from alternative models of mirror neuron systems and their interaction with other brain regions.
(b). Dyadic brain modelling
Our prior modelling considered one brain at a time, either performing an action or passively observing the action of another, with a focus on visual input to each brain and (primarily) manual output. We lift our models to the domain of true social neuroscience by modelling dyads (figure 2). Dyadic brain modelling focuses on what happens in the brains of two interacting agents, where the actions of one influence the actions of the other, with both brains changing in the process. Macal & North [37] discuss interacting agents in general, and Steels [38] has used simulation of embodied agents in evolutionary games in a fashion relevant to studies of (cultural) language evolution. Our innovation here is to provide the agents with ‘brains’ whose structure is indeed based on prior work in brain modelling. The current model is simplified, but provides proof of concept for future work which can increasingly address neuroscience data to explore the role of mirror systems and related brain regions in primate social interaction and do so in an evolutionary context.
Figure 2:

Schematic for dyadic brain modelling. Each brain has the same architecture which it is our challenge to assess on the basis of empirical data and lessons learned from prior modelling. However, each agent/brain starts in a different state, and thus the actions and learning processes that unfold will differ between the two agents. (Online version in colour.)
For conspecifics and for now, we assume that each brain has the same overall architecture but each agent/brain starts in a different state (in terms both of neural firing and synaptic encoding of skills, goals and memories), and thus the actions and learning processes that unfold will differ between the two agents.
(c). The overall model
We now summarize changes required in going from figure 1 to generate our new model (figure 3). We then show how this model covers all the processes necessary to accomplish ontogenetic ritualization of beckoning. However, the requirements below are not beckoning-specific, but represent abilities of general utility to macaques and/or chimpanzees.
(i) There is a mechanism for social decision-making that can use recognition of the distal or proximal goal of another as a basis for possible updating of one's own goals.
(ii) Decision-making occurs in two stages. A distal goal is set; this goal then sets up the desirability values used by ACQ to schedule a sequence of actions to achieve that goal.
(iii) The actions available to (the extended version of) ACQ are all trajectory level. Depending on the stage of learning, a mirror system for an action may be sensitive to a goal and more or less sensitive to trajectory. We now augment visual input (where appropriate) by attention to proprioceptive input.
-
(iv) Each action in the repertoire of child and mother (the agents of our dyad) will be terminated when it is signalled that its proximal goal is reached. Moreover, ACQ can abort a whole behaviour once its distal goal is reached.
We see the above additions as an extension of our models of what is common to macaque and chimpanzee. We now turn to a hypothesis on what is different about the chimpanzee:
(v) Proprioceptive information becomes increasingly available to mechanisms underlying the learning of novel actions.
Figure 3.

The overall model. Updating the current distal goal is an explicit part of the model of each brain in the dyad, and this in turn controls desirability. The mirror system plays an ACQ-like role in the analysis of self-actions as well as recognizing the actions and intentions of others. Perception of the physical and social scene sets up decisions on the current distal goal as well as providing input to diverse processes. Among the factors not shown here are that modelling is at the trajectory level, and that proprioception plays a key role in the generation and monitoring of one's own actions.
3. A model-based analysis of beckoning as a case study of gesture acquisition
We now outline learning and behavioural mechanisms which enable the interactions of the two apes to support the six stages charted by Gasser et al. [10] and then introduce an extended model to represent the brain of each member of the dyad. Later, we present a reduced, computationally implemented version of the model and then present simulation results demonstrating a number of behaviours critical to our overall hypothesis.
(a). Child (C) reaches out, grabs and tugs on mother (M), causing M to move towards C as a response
(c1, c2, m1, m2, etc. are the actions of child and mother, respectively.)
C's distal goal is ‘bond socially with mother’ and ACQ-C (the child's version of ACQ) schedules the actions
c1: reach to grasp M's upper arm.
c2: tug on M till she moves towards C. This combines a proximal goal of tugging with the distal goal of ‘bonding’.
Initially, M has no specific goal. However, once she recognizes C's distal goal, she creates her own distal goal of bonding with proximal goal ‘move close to C', and ACQ-M then schedules
m1: move in the direction of C.
m2: embrace C.
All four actions are assumed already in the repertoire of C or M as body-centred actions. The mother's action recognition system (MNS-M) recognizes C's distal goal on the basis of the proximal goal of c2, but this recognition is (in this example) at first based on the haptic2 input of C's tugging, not on visual recognition. This stage can be seen as the ‘praxic alternative’ to a ritualized gesture, because if later a gestural communicative bout fails, then C can always revert back to this praxic action sequence.
(b). C reaches out and grabs M, and M moves towards C as soon as C begins to tug
This stage could proceed over many trials as MNS-M comes to recognize c2 more swiftly: with a visual stimulus, the MNS model learns to strengthen recognition neurons earlier and earlier in the trajectory. We now exploit this property during the haptic trajectory induced in M by c2. As M recognizes the proximal goal of c2, and thus C's distal goal, more quickly, she can respond earlier and earlier. Eventually, C no longer needs to complete c2. Here, we exploit the notion that any action can be truncated when its proximal or distal goal is achieved.
(c). C reaches out and makes contact with M, and this is enough to get M to move towards C
Eventually, C need only complete c1 for M to respond. ACQ-C continues to schedule c1, but now c2 is no longer executed, because c1 alone achieves the distal goal. MNS-M then comes to associate c1, rather than c2, with C's distal goal. This stage, like the previous two, seems not to be a distinction between macaque and chimpanzee. As a further result of stage (b), the increasingly early termination of the intended c1, ‘reach to grasp firmly enough to tug’, appears more and more similar to the action ĉ1, ‘reach to touch’, and ACQ-C will increase the desirability of the latter action so that it comes to replace c2 in C's behaviour. And, MNS-M will recognize this modified action as also having ‘bonding’ as its distal goal in this context.
(d). C reaches out towards M, attempting to make contact, but M responds before contact is made
In this stage, contact with M is still C's proximal goal, and the action is still transitive. Although MNS-M still linked tactile feedback to M's responses, we can now see robust visually guided adaptive behaviour emerge. That is, M is able to respond now solely on the basis of the visual trajectory of C's arm and hand. Seeing M's response, C can now truncate c1 (or ĉ1). However, C's action is still initiated as a movement towards M's arm and so may still be deemed transitive.
(e). C reaches out towards M, no longer attempting to make contact, yet M still responds by moving towards C
We now postulate that the brains of ‘chimpanzees’ M and C have far stronger pathways bringing proprioceptive input (as distinct from visual, haptic and auditory input) than would be available in the macaque brain. Hecht et al. [39] used diffusion tensor imaging to conclude that chimpanzees have stronger ‘connections’ between superior temporal sulcus and inferior parietal cortex (viewed as the posterior mirror system) than do monkeys and that this may allow more processing of the finer details of the spatial/kinematic structure of observed actions. Challenges for future research in these fields include specifying what exactly is involved in such connectivity changes (and see [40]), and how these data affect modelling projects: do these results implicate new connections between modules, stronger existing connections between modules on a per-species basis, or actual processing differences between and/or within modules? In any case, our postulate means that (in this scenario) as M responds earlier in recognition of C's goal, C comes to associate the distal (not the proximal) goal with the proprioceptive state (part way along the original transitive trajectory) of that response. It is not that C loses the ability to perform action c1 in appropriate circumstances, but rather a new action č emerges in C's repertoire: performing a reach that has achieving that proprioceptive state (rather than contact with M) as its proximal goal—but still with the distal goal (bonding with M) that constitutes the meaning of what is now a novel gesture.
(f). C ‘beckons’ towards M
The ritualized gesture č is part of the action repertoire of C, and C now ‘beckons’ to elicit M's response. As in the above stage, M is capable of recognizing his gesture and responding appropriately. Note that apes tend to use visual-only gestures when they have the other's attention. Thus, C might retain the tug strategy when M is otherwise engaged, but use č for times when M is attending visually. Learning this gesture has not removed C's original behaviour but has refined its context.
Each agent contains the same essential machinery—both are ‘apes’—but throughout their interactions, their roles dictate differential learning, and so allow an analysis of specific changes in specific networks for each agent, and how behaviour adapts as a result.
4. Methods: a reduced model and its implementation
Section 2 culminated with figure 3 as a general framework for modelling each brain. Section 3 then sketched how the model could support ontogenetic realization. We now describe a simulation framework for dyadic brain modelling (figure 4) and then present a simplified model we have implemented (figure 5). Section 5 samples the simulation results.
Figure 4.

A general computational framework for dyadic brain simulation and visualization of the interaction of two agents. (Clearly, the methodology is not limited to simulating a mother and child, but could be adapted to model the neural underpinnings of social interactions of two or more agents.) Top right: A view of the two avatars (small, child; large, mother in this example) as displayed by the animation software Maya. In the current simulations, all that changes in these displays is the position of each body in the ground plane, and the angles that define arm postures. Rest of figure: Simulation overview. The two model brains are implemented as separate python scripts that can only communicate through Maya's animation script. (Online version in colour.)
Figure 5.

(a) Schematic of the reduced version of the brain architecture for both agents of the dyad. In the simple simulations reported here to demonstrate ontogenetic ritualization, only some parts are implemented as neural rather than algorithmic models, differently for mother and child. ‘M’ indicates modules implemented ‘neurally’ for mother, ‘C’ for child. Other modules are implemented algorithmically. (b) Action recognition for manual actions as implemented for mother. (c) Motor control as implemented for child.
The two model brains are implemented in separate python scripts (figure 4), using freely available python packages, including numpy (www.numpy.org) for mathematical calculations and pybrain (www.pybrain.org) for neural network algorithms. Each script is linked to Maya animation software through a third python script executed in the Maya python shell. Each brain script can communicate to Maya, via this shell script, through file read–write cycles managed through their separate pipe. Each brain script implements functions from a ‘brain module’ library—for action recognition, decision-making and motor control—to maintain consistency in their implementation. Each brain script can read relevant joint and effector position information about the virtual world in their shared file, and write commands to it for the brain's avatar to execute. Each ‘brain’ uses sensory data on the relation of its body parts to each other and the world, but Maya draws the bodies in a coordinate space appropriate to the view of an external observer.
We now turn to the simplifications of the model of figure 3 used in the present simulations. The overall architecture of each brain (figure 5a) is the same, but to reduce computation time, we have implemented learning in the mirror system only for mother, and motor learning for the reach-to-grasp only for child. Decision-making processes are implemented similarly for both agents, and follow the ACQ paradigm described above (e.g. combining executability and desirability to yield priority). Our simulations consist of multiple episodes, each a single explicit case of interaction between the two agents. An episode may vary from (roughly) 50 to 100 simulation timesteps (though the presumed interaction may last only a few seconds). Visual and haptic sensory inputs to each model represent the output of visual and somatosensory cortical areas, and these inputs may be the result of the others’ ongoing motor output.3 Action recognition modules, processing visual and haptic information to recognize self and others’ actions, can affect social behaviour by linking recognition of others’ actions and goals with one's own. Such modules may also provide feedback to learn about the trajectory that achieves a goal. Motivational and socio-cognitive processing selects distal goals which yield new action policies. Each agent is initialized in different motivational states: the child to ‘bond’ with the mother (a social goal), and the mother to remain idle. Following the paradigm of ACQ, these different goal states lead to different behavioural policies for each of mother and child: the mother remains idle, whereas the child executes a sequence of actions to lead to bonding. However, as a result of learning and recognition processes, these interactions adapt, and the mother's rapid updating of her goal leads to anticipatory responses that achieve the bonding goal for both.
Figure 5b shows how manual action recognition is implemented for mother. (Action recognition is managed algorithmically for C in this implementation, meaning we do not simulate a neural network for this process, but instead situate our code to achieve the desired behaviour.) C's wrist (x,y,z) information is input to a neural network with recurrent, self-excitatory hidden units to maintain temporal information about the inputs. These are converted from three-dimensional absolute coordinates in Maya to yield three-dimensional coordinates relative to C's posture: the wrist trajectory being relative to his starting posture. The recurrent network is based on the MNS2 model of action recognition [27]. Its outputs activate to the degree to which they recognize the time-series data. These units, along with haptic units representing haptic feedback if present (i.e. that another has grasped one's arm, for example), then pass activation to goal-layer neurons, via modifiable weights, which compete between each other. If one passes some activation threshold, they switch the internal state of M, so that she shares the bonding goal of C and will cooperate towards achieving that goal.4
M's motor control elements are managed algorithmically, as is walking in C. C's reach-to-grasp (figure 5c) is implemented as an inverse-kinematic controller managing transport of the arm to a target. We model the learned target positions in shoulder-centred coordinates, but achieve inverse-kinematic solutions through the animation software. Target data are based on a weighted-sum of visual and proprioceptive data, but learning processes may bias each modality's influence. An action will terminate when its proximal goal is reached, and an ongoing behaviour will terminate when its distal goal is reached (which may involve recognition of the other's behaviour).
With this, we turn to some further details of the figure 5 model.5 In each episode, C is initialized with bonding with M as his distal goal, whereas M is at first passive. This leads to setting C's proximal goal and action. Because the avatars are initialized at some distance from each other, the child must first walk towards his mother. When walk is selected, a target position is computed for the agent to walk towards, namely the threshold at which the child can reach towards the mother.
When the child reaches this threshold, the ‘reach-to-grasp’ action becomes executable, and because it is more ‘desirable’ in the sense that it is more closely associated with the goal, it is selected for execution. The controller for this action has two sources of sensory data, visual (which can suffice for object-directed actions) and postural (which would suffice for proprioceptively guided action). Each alone can determine a target for the reaching action: targetvisual for object-directed actions, and targetpostural for proprioceptively guided actions. The functional target is the weighted average:
where a + b = 1, with a and b controlled by learning processes. This integrated target coordinate can then be used to compute the motor error vector for the inverse-kinematics solver:
Unlike the FARS model [25] and the ILGM model [41] where we simulate the pre-shape and enclose of the hand relative to a target affordance, we here simply simulate ‘grasping’ as having the arm tip (look, Ma, no hands!) within some threshold of another surface. When grasping occurs, both agents get haptic feedback indicating grasp/contact. If the grasp is achieved, but M still does not respond—i.e. the distal goal has not been achieved—C's ACQ-like action scheduler will then set up the next action of tugging M towards him. C will thus move his arm towards his shoulder. As M is tugged, her arm is controlled by keeping it within the threshold distance of C's ‘hand’. Eventually, the combined mirror system output and the presence of strong haptic input will drive M's recognition of C's distal goal, and so ‘flip’ her distal goal state from idle to ‘bonding’. This will cause her to reach for the child's shoulder in a ‘hugging’ manner. This goal achievement is mutual, and appropriate reward information is passed to both agents.
Learning processes adapt the above to quickly generate new patterns of behaviour. M's action recognition module (figure 5b) is centred around a recurrent neural network (RNN) modelled after the MNS2 model [27]. The RNN receives filtered visual input of C's wrist: the codes must be relative, so recognition is possible in different locations. The RNN is comprised of three linear input units, eight hidden, self-excitatory (recurrent) sigmoidal units and three output units 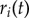 each of which is passed through a nonlinear function to obtain a normalized firing rate
each of which is passed through a nonlinear function to obtain a normalized firing rate 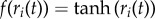 for all i.
for all i.
The network is trained through the backpropagation-through-time algorithm [42] available through pybrain, and is trained on a set of three different reaching actions of C—the two others being reaching to locations other than M's wrist—each corresponding to a single output unit of the RNN. During simulations, C's reach will activate a specific output unit to the degree to which its trajectory matches the training data (the first episode reach). The firing rate activations from the RNN, along with any haptic input hi from grasping, are broadcast to the goal neurons gi before effecting motivational state change, represented by binary activations in nodes ml:
where 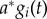 is the leak component, and a and b are constants. The goal-layer threshold (thresholdg) can take a range of values to generate different patterns of behaviour. Over time, this threshold may be reached more quickly—and so the mother may respond sooner—by modulating the weights W connecting RNN recognition activity in the form of
is the leak component, and a and b are constants. The goal-layer threshold (thresholdg) can take a range of values to generate different patterns of behaviour. Over time, this threshold may be reached more quickly—and so the mother may respond sooner—by modulating the weights W connecting RNN recognition activity in the form of 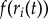 to the goal-layer changes that follow:
to the goal-layer changes that follow: 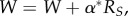 where
where 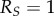 is the social reinforcement following goal achievement, and α is the learning rate.
is the social reinforcement following goal achievement, and α is the learning rate.
C maintains the potential for a full reach-to-grasp-to-pull, but learns over time to (i) pull less, and then (ii) reach less effortfully. He learns at first that M responds to his pulling, and so pulls her for shorter distances—remaining sensitive to her responses—before learning to only intend to make contact with her wrist. Then, as C reaches, he learns postural targets he can move to without invoking praxic control mechanisms. In each episode, he updates his postural target as the position at which he terminates his action. Simultaneously, he learns to value this postural target over his visual target, as it is effective with less effort: b increases relative to a while keeping a + b = 1, and so his postural target increasingly biases his performance towards reaching to positions closer to him in space. Because it is less effortful and so more desirable, the postural target comes to be selected as the ‘proximal’ goal in service of the distal goal of bonding. This leads to gesturing behaviour that is not constrained by the peripersonal reach threshold: the child can gesture from a greater distance removed from his mother.
5. Results
We can replicate the mirror system responses from Bonaiuto et al. [27], showing anticipatory recognition of reach-to-grasp actions but—unlike past research—we then link these responses with differential behaviour on the part of the observer. Figure 6 shows a sample RNN output for M's MNS during a reach-to-grasp action by C. One curve corresponds to the mirror system representation of the reach to grasp, whereas the other curves represent ‘dummy’ reaching actions M had been previously trained to recognize (reaches not directed at her wrist). Because of these anticipatory responses, M may initiate an appropriate (new) course of action before C's action is completed, thus facilitating, for example, truncation of the reach-to-grasp action.
Figure 6.
Mother mirror system output. The output of M's recurrent neural network implementation of the mirror neuron system is shown. The activations of the three output units relate to how well they can recognize C's reaching action, with the output neuron encoding the ‘reach’ action, appropriately, responding strongly to C's reach. The timecourse shown is over the course of C's whole reaching action (18 simulation timesteps), and the activation is normalized to 1. The dummy actions are alternative reaches to other targets.
Our simulations show how a ‘beckoning’ gesture emerges over time, across a wide range of parameter settings. Figure 7 shows selected frame shots, whereas a movie (see endnote 5) shows the animation across multiple episodes of the interaction of mother and child, which demonstrate stages in the process of ontogenetic ritualization. Some parameters are artificially selected to yield more realistic patterns of behaviour, whereas others can be systematically varied to achieve faster (or slower) timecourses of gestural acquisition as well as longer or shorter gestural forms for C. Changes in certain parameters correspond to the speed of M's recognition, and may correlate with sensitivity (or not) to gestural forms and understanding others’ goals, whereas others may correlate with C's ability to quickly learn postures and/or seek out less effortful options for action. Future work will more systematically explore this parameter space, replacing particular parameters with more nuanced control mechanisms, or else seek to relate these parameters, and their possible variation, with available data in primate communication and social cognition.
Figure 7.

Simulation screen-grabs. Our avatars are simple animated agents capable of ‘walking’ and moving limbs, and interacting with each other. (a) The agents initialized to start an episode. (b) The child pulling the mother towards him. (c) The mother completing the child's goal of bonding. (d) The mother responding to the child's learned gesture. (Online version in colour.)
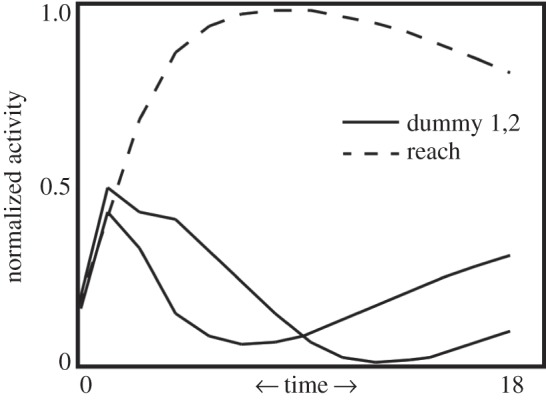
Changing both learning rates and state-change thresholding in M can drastically alter the pattern of gesture acquisition. Figure 8 shows the normalized time to response by M and the corresponding responses by C for different settings for the given set of parameters. The time axis is normalized to 1 for each curve, based on the time until M's response for the first episode. The enlarged symbol for each curve represents the episode at which C began gesturing to M. We can see that each setting creates a unique timecourse of interaction, with some leading to relatively rapid acquisition of a gesture, whereas others lead to more interactions being necessary for a gestural form to emerge. The weight update determines how rapidly the connection weights between M's mirror system and her internal state change grow, and thus how quickly she reaches threshold in changing her state. The other parameter directly concerns this threshold. More rapid connection weight growth, or lower thresholding, leads to more rapid response from M. Conversely, slower weight growth and larger thresholding lead to slower response from M, and so also slower emergence of a gesture by C. These results, while preliminary, demonstrate how dynamic these interactions are, with subtle variations in one agent drastically affecting the future learning and behaviour of another. Currently, these results are too simple to make direct comparisons with data from primatological studies, but we suggest there is potential in using similar simulations to bridge the fields of computational neuroscience, primatology and comparative psychology.
Figure 8.
Parametric and behavioural variation. We show the number of episodes until the emergence of gesturing behaviour in C, as a function of parameter values in M's action-recognition module. The connection weights between M's mirror system and her goal neurons are updated by a constant, which we vary here. The threshold for these neurons to signal distal goal change in M, and a new action policy, is also varied here. Enlarged graph symbols (see inset) indicate the episode (x-axis) at which C began gesturing to M. These and other parameter value shifts result in varied patterns of behaviour between M and child. The y-axis represents the within-episode time duration; we normalize this because episodes where the child can gesture are much quicker than episodes where he must first walk, then reach, towards the mother in service of his goal. As can be seen, ontogenetic ritualization reduces time to completion by more than half.
6. Discussion
This paper has two overall goals:
(1) To introduce the notion of dyadic brain modelling (figure 2; compare fig. 1 of [43]), offering both a framework for modelling each brain of interacting agents (figure 3) and a general framework for simulating and visualizing the interactions generated when the overall brain (and the two bodies) are each coded up in computational detail (figure 4). We also noted the importance of trajectory-level generation and recognition of actions, and the need of each agent to keep track of both proximal and distal goals of self and other.
(2) To extend the conceptual analysis of ontogenetic ritualization offered in Gasser et al. [10] to develop (i) a detailed analysis of how to integrate and extend prior models of the macaque brain and incorporate an expanded role for proprioception to supply a more explicit account of the underlying processing, and (ii) to instantiate this analysis in a computational model of dyadic interaction (figure 5) which, though simplified, is able to support ontogenetic ritualization. This has implications for future back and forth between computational neuroscience and primatology.
Irrespective of progress on our second goal, we wish to encourage workers in cognitive neuroscience more generally to think explicitly in terms of interacting processes within and between brains rather than, for example, simply attributing functions to ‘mirror neuron systems’ without taking account of the other brain mechanisms with which they interact. Moreover, we advocate attention, both in experiments and modelling, to the role of mirror systems in monitoring self-actions (not just the actions of others), and to how the output of mirror neurons interacts with other processes to set goals that schedule the agent's behaviour—including the effect of one agent's actions on the other.
(a). Gesture acquisition
We make two more points about the debate on gesture acquisition in apes:
(1) Even if ontogenetic ritualization is demonstrated (see [13] for one of the very few longitudinal studies), it yields only a gesture generated by one ape and recognized by another. However, there are two ‘saves’: (i) our model suggests that ontogenetic ritualization is relatively ‘easy’. Thus, if particular praxic actions are common across groups, then gestures obtained by ritualizing them may be widespread. Note that this invalidates the decision by Hobaiter & Byrne [2] to rule that any widespread gesture cannot have emerged through ontogenetic ritualization. (ii) We know that new praxic actions can be acquired by apes by simple imitation—this provides, for example, the basis for chimpanzee ‘cultures’ [44,45]. Thus, it seems plausible to suggest that gestures, too, can spread by forms of social learning. Showing how to model this putative process sets a near term research goal.
(2) Hobaiter & Byrne [2] suggest that their data rule out the need for learning, but modelling their hypothesis would require showing how different apes refine a gestural repertoire in different ways within an innate ‘gestural space’. That is, further work will need to address what contextual variables (social, motivational and ecological) are most important in determining differential sampling of innate gestures. This is somewhat reminiscent of how human infants acquire a stock of phonemes and syllabic structures for their mother tongue (see [46] for one such model). However, the ape focuses on a set of gestures with specific meanings, whereas human language exhibits duality of patterning: phonemes and syllables are meaningless; only words (and other morphemes) that combine them have meanings. Additionally, phonemes exist in some culture surrounding the learner, whereas young apes do not appear to produce the gestures of their mother [47], and so learning may not be adapting towards some local cultural standard.
(b). More elaborate gesturing behaviour
This includes sensitivity to audience comprehension and invoking ‘semantically related’ gestures if comprehension fails [4], gesturing in sequence bouts [5] and ‘complex’ forms of gesturing [48], suggesting that ‘iconic’ gestures may be used in gorilla populations. Note also the suggestion that ‘pantomime’ may be used by orangutans to demonstrate complex notions [49]—though this seems to be more a matter of creating a few iconic gestures than a general capacity for pantomime as a means to create an open-ended set of novel gestures. Elsewhere ([14], ch. 8), we are careful to spell out the type of pantomime that we claim was exhibited by distant ancestors subsequent to LCA-a but which marked an evolutionary advance over the capacities of LCA-a and which is not available to modern apes. These and other behavioural reports from primatologists set further challenges for dyadic brain modelling.
(c). Localization
Not only do the FARS and MNS models described earlier examine action generation and recognition in more detail than offered in §4, they also include hypotheses on the anatomical localization of the functions of their constituent submodules in the macaque brain. We will need further data on homologies between macaque and, for example, chimpanzee brains to develop and test hypotheses on the ape brain that are grounded in macaque neurophysiology, and we need further data on homologies between chimpanzee and human brains to develop and test hypotheses on the ape brain that are grounded in human brain imaging. Such data support new dyadic brain simulation studies whether for monkeys, apes or humans (and cross-species). We note that the techniques of synthetic brain imaging [50] and synthetic event-related potentials [51] allow computational models expressing detailed neural or schema networks to be used to generate predictions for brain imaging and event-related potential studies in whatever species is being modelled. Note also our earlier discussion of comparative results from diffusion tensor imaging [39,40]),
(d). The brain is a system of systems
Comprehensive models of action generation and action scheduling as well as action recognition need to be developed and integrated along with new experimental techniques which provide far more insights into how brain regions interact than offered by single-cell recording or structural equation modelling. In this way, researchers can assess the extent to which what are treated as unitary functions are, in fact, realized by competition and cooperation of multiple regions—just as action recognition requires the integration of dorsal and ventral pathways. Similarly, brain regions will be revealed as having circuits dedicated to more or less distinct functions.
(e). Population coding and event versus trajectory levels
A major shortcoming of our MNS models and the model of figure 5 is that they model just a few mirror neurons, each associated with a single action. Mirror neurons that respond selectively to one type of action (but note: only among those examined in a single study) are called strictly congruent, whereas others are only broadly congruent. We argue [14] that mirror neurons, to the extent that their activity correlates with actions, do so as a population code: firing of a single neuron is not a ‘yes/no’ code for whether or not a specific action is being executed or observed; rather, each neuron expresses a ‘confidence level’ (the higher the firing rate, the greater the confidence) that some feature of a possible action—such as the relation of thumb to forefinger, or of wrist relative to object—is present in the current action. We can then think of each neuron as casting a more or less insistent ‘vote’ for the presence of actions with that neuron's ‘favourite feature’—but it is only the population of neurons that encodes the current action. Future models must incorporate population coding in this way. Such population codes can readily exhibit fractionation of existing actions [52] as well as the encoding of novel actions in a way ‘yes/no’ coding cannot.
Additionally, the key point about the MNS models [26,27] is that they are trajectory-level models which can support recognition of an action before it is completed—thus, crucially, allowing anticipatory reaction while observing an ongoing action. Again, the ACQ model [22] is unique in relating mirror neurons to self-action, with an emphasis on learning executability and desirability. The current implementation exploits these properties in simplified form, but serves as proof of concept for later research (hopefully involving other groups as well as ourselves) which will address an increasing range of data from macaque neurophysiology and primate behaviour.
(f). Social brain modelling
The past decade has seen increasing study of brain mechanisms of social interaction. For example, Phil. Trans. R. Soc. B devoted a 2003 theme issue (compiled by C. D. Frith & D. M. Wolpert) to ‘Decoding, imitating and influencing the actions of others: the mechanisms of social interaction’. However, none of the articles addresses dyadic brain simulation. Griffin & Gonzalez [53] studied ‘models of dyadic social interaction’, but these are models for analysis of observed dyadic interactions, not models of the brains that generate them. The paper which comes closest to our approach is ‘A unifying computational framework for motor control and social interaction’ [54], but this extends the notion of forward and inverse models to a conceptual model of a single agent engaged in social interaction, with no modelling of brain data. However, it is worth noting that it is closely related to a model of mental state inference using visual control parameters [55] which extends our original MNS model [26].
We see all this as offering steps towards a computational comparative neuroprimatology [10] and its application to studies of evolution of the human language-ready brain [14].
Endnotes
Here, we use the term praxic behaviour for practical interactions with the physical environment (which can include the body of another agent), as distinct from communicative actions.
Haptic refers to the sense of touch and related muscle sense.
The simulation is simplified by the fact that the python script for each agent can read information about the current state of the other agent from the Maya animation script. We thus avoid the need to simulate retinal input to each agent and consequent visual processing to extract state information about the other. However, simulation is still required to infer the action or goal of the other agent from the ongoing trajectory of observed state features plus haptic input.
More generally, recognition of another's goals may, but need not, lead to goal-switching in the observer, and new goals may be quite different from the other's, leading not to cooperation, but to competition for example.
For details of the latest version of the simulation, see neuroinformatics.usc.edu/research/ape-gestural-learning.
Funding statement
This material is based in part on work supported by the National Science Foundation under grant no. 0924674 (M.A.A, Principal Investigator).
References
- 1.Genty E, Breuer T, Hobaiter C, Byrne RW. 2009. Gestural communication of the gorilla (Gorilla gorilla): repertoire, intentionality and possible origins. Anim. Cogn. 12, 527–546. ( 10.1007/s10071-009-0213-4) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Hobaiter C, Byrne RW. 2011. The gestural repertoire of the wild chimpanzee. Anim. Cogn. 14, 745–767. ( 10.1007/s10071-011-0409-2) [DOI] [PubMed] [Google Scholar]
- 3.Arbib MA, Liebal K, Pika S. 2008. Primate vocalization, gesture, and the evolution of human language. Curr. Anthropol. 49, 1053–1076. ( 10.1086/593015) [DOI] [PubMed] [Google Scholar]
- 4.Cartmill EA, Byrne RW. 2007. Orangutans modify their gestural signaling according to their audience's comprehension. Curr. Biol. 17, 1345–1348. ( 10.1016/j.cub.2007.06.069) [DOI] [PubMed] [Google Scholar]
- 5.Hobaiter C, Byrne RW. 2011. Serial gesturing by wild chimpanzees: its nature and function for communication. Anim. Cogn. 14, 827–1838. ( 10.1007/s10071-011-0416-3) [DOI] [PubMed] [Google Scholar]
- 6.Liebal K, Pika S, Tomasello M. 2004. Great ape communicators move in front of recipients before producing visual gestures. Interact. Stud. 5, 199–219. ( 10.1075/is.5.2.03lie) [DOI] [Google Scholar]
- 7.Liebal K, Call J. 2012. The origins of non-human primates’ manual gestures. Phil. Trans. R. Soc. B 367, 118–128. ( 10.1098/rstb.2011.0044) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Pika S, Liebal K. 2012. Developments in primate gesture research. Amsterdam, The Netherlands: John Benjamins. [Google Scholar]
- 9.Pollick AS, de Waal FBM. 2007. Ape gestures and language evolution. Proc. Natl Acad. Sci. USA 104, 8184–8189. ( 10.1073/pnas.0702624104) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Gasser B, Cartmill EA, Arbib MA. 2013. Ontogenetic ritualization of primate gesture as a case study in dyadic brain modeling. Neuroinformatics 12, 93–109. ( 10.1007/s12021-013-9182-5) [DOI] [PubMed] [Google Scholar]
- 11.Plooj FX. 1979. How wild chimpanzee babies trigger the onset of mother–infant play. In Before speech (ed. Bullowa M.), pp. 223–243. Cambridge, UK: Cambridge University Press. [Google Scholar]
- 12.Tomasello M, Call J. 1997. Primate cognition, p. 528 New York, NY: Oxford University Press. [Google Scholar]
- 13.Halina M, Rossano F, Tomasello M. 2013. The ontogenetic ritualization of bonobo gestures. Anim. Cogn. 16, 653–666. ( 10.1007/s10071-013-0601-7) [DOI] [PubMed] [Google Scholar]
- 14.Arbib MA. 2012. How the brain got language: the mirror system hypothesis. Oxford, UK: Oxford University Press. [Google Scholar]
- 15.Rizzolatti G, Arbib MA. 1998. Language within our grasp. Trends Neurosci. 21, 188–194. ( 10.1016/S0166-2236(98)01260-0) [DOI] [PubMed] [Google Scholar]
- 16.Arbib MA. 2013. Complex imitation and the language-ready brain. A response to 12 commentaries. Lang. Cogn. 5, 273–312. ( 10.1515/langcog-2013-0020) [DOI] [Google Scholar]
- 17.Liberman AM, Mattingly IG. 1985. The motor theory of speech perception revised. Cognition 21, 1–36. ( 10.1016/0010-0277(85)90021-6) [DOI] [PubMed] [Google Scholar]
- 18.Umiltà MA, Kohler E, Gallese V, Fogassi L, Fadiga L, Keysers C, Rizzolatti G. 2001. I know what you are doing. A neurophysiological study. Neuron 31, 155–165. ( 10.1016/S0896-6273(01)00337-3) [DOI] [PubMed] [Google Scholar]
- 19.Chang SWC, Gariepy J-F, Platt ML. 2013. Neuronal reference frames for social decisions in primate frontal cortex. Nat. Neurosci. 16, 243–250. ( 10.1038/nn.3287) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Yoshida K, Saito N, Iriki A, Isoda M. 2011. Representation of others’ action by neurons in monkey medial frontal cortex. Curr. Biol. 21, 249–253. ( 10.1016/j.cub.2011.01.004) [DOI] [PubMed] [Google Scholar]
- 21.Fujii N, Hihara S, Nagasaka Y, Iriki A. 2008. Social state representation in prefrontal cortex. Soc. Neurosci. 4, 73–84. ( 10.1080/17470910802046230) [DOI] [PubMed] [Google Scholar]
- 22.Bonaiuto JJ, Arbib MA. 2010. Extending the mirror neuron system model, II: what did I just do? A new role for mirror neurons. Biol. Cybern. 102, 341–359. ( 10.1007/s00422-010-0371-0) [DOI] [PubMed] [Google Scholar]
- 23.Sutton RS, Barto AG. 1998. Reinforcement learning: an introduction. Cambridge, MA: MIT Press. [Google Scholar]
- 24.Arbib MA, Bonaiuto JJ. 2012. Multiple levels of spatial organization: world graphs and spatial difference learning. Adapt. Behav. 20, 287–303. ( 10.1177/1059712312449545) [DOI] [Google Scholar]
- 25.Fagg AH, Arbib MA. 1998. Modeling parietal-premotor interactions in primate control of grasping. Neural Netw. 11, 1277–1303. ( 10.1016/S0893-6080(98)00047-1) [DOI] [PubMed] [Google Scholar]
- 26.Oztop E, Arbib MA. 2002. Schema design and implementation of the grasp-related mirror neuron system. Biol. Cybern. 87, 116–140. ( 10.1007/s00422-002-0318-1) [DOI] [PubMed] [Google Scholar]
- 27.Bonaiuto JJ, Rosta E, Arbib MA. 2007. Extending the mirror neuron system model, I: audible actions and invisible grasps. Biol. Cybern. 96, 9–38. ( 10.1007/s00422-006-0110-8) [DOI] [PubMed] [Google Scholar]
- 28.Jeannerod M, Arbib MA, Rizzolatti G, Sakata H. 1995. Grasping objects: the cortical mechanisms of visuomotor transformation. Trends Neurosci. 18, 314–320. ( 10.1016/0166-2236(95)93921-J) [DOI] [PubMed] [Google Scholar]
- 29.Gallese V, Fadiga L, Fogassi L, Rizzolatti G. 1996. Action recognition in the premotor cortex. Brain 119, 593–609. ( 10.1093/brain/119.2.593) [DOI] [PubMed] [Google Scholar]
- 30.Hoff B, Arbib MA. 1991. A model of the effects of speed, accuracy and perturbation on visually guided reaching. In Control of arm movement in space: neurophysiological and computational approaches (eds Caminiti R, Johnson PB, Burnod Y.), pp. 285–306. Heidelberg, Germany: Springer. [Google Scholar]
- 31.Hoff B, Arbib MA. 1993. Models of trajectory formation and temporal interaction of reach and grasp. J. Mot. Behav. 25, 175–192. ( 10.1080/00222895.1993.9942048) [DOI] [PubMed] [Google Scholar]
- 32.Paulignan Y, Jeannerod M, MacKenzie C, Marteniuk R. 1991. Selective perturbation of visual input during prehension movements. 2. The effects of changing object size. Exp. Brain Res. 87, 407–420. ( 10.1007/BF00231858) [DOI] [PubMed] [Google Scholar]
- 33.Paulignan Y, MacKenzie C, Marteniuk R, Jeannerod M. 1991. Selective perturbation of visual input during prehension movements. 1. The effects of changing object position. Exp. Brain Res. 83, 502–512. ( 10.1007/BF00229827) [DOI] [PubMed] [Google Scholar]
- 34.Keysers C, Perrett DI. 2004. The neural correlates of social perception: a Hebbian network perspective. Trends Cogn. Sci. 8, 501–507. ( 10.1016/j.tics.2004.09.005) [DOI] [PubMed] [Google Scholar]
- 35.Tessitore G, Prevete R, Catanzariti E, Tamburrini G. 2010. From motor to sensory processing in mirror neuron computational modelling. Biol. Cybern. 103, 471–485. ( 10.1007/s00422-010-0415-5) [DOI] [PubMed] [Google Scholar]
- 36.Caggiano V, Fogassi L, Rizzolatti G, Pomper JK, Thier P, Giese MA, Casile A. 2011. View-based encoding of actions in mirror neurons of area F5 in macaque premotor cortex. Curr. Biol. 21, 144–148. ( 10.1016/j.cub.2010.12.022) [DOI] [PubMed] [Google Scholar]
- 37.Macal CM, North MJ. 2010. Tutorial on agent-based modelling and simulation. J. Simul. 4, 151–162. ( 10.1057/jos.2010.1053) [DOI] [Google Scholar]
- 38.Beuls K, Steels L. 2013. Agent-based models of strategies for the emergence and evolution of grammatical agreement. PLoS ONE 8, e58960 ( 10.1371/journal.pone.0058960) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Hecht EE, Gutman DA, Preuss TM, Sanchez MM, Parr LA, Rilling JK. 2013. Process versus product in social learning: comparative diffusion tensor imaging of neural systems for action execution–observation matching in macaques, chimpanzees, and humans. Cereb. Cortex 23, 1014–1024. ( 10.1093/cercor/bhs097) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Rilling JK, Glasser MF, Preuss TM, Ma X, Zhao T, Hu X, Behrens TEJ. 2008. The evolution of the arcuate fasciculus revealed with comparative DTI. Nat. Neurosci. 11, 426–428. ( 10.1038/nn2072) [DOI] [PubMed] [Google Scholar]
- 41.Oztop E, Bradley NS, Arbib MA. 2004. Infant grasp learning: a computational model. Exp. Brain Res. 158, 480–503. ( 10.1007/s00221-004-1914-1) [DOI] [PubMed] [Google Scholar]
- 42.Werbos PJ. 1990. Backpropagation through time: what it does and how to do it. Proc. IEEE 78, 1550–1560. ( 10.1109/5.58337) [DOI] [Google Scholar]
- 43.Jeannerod M. 2005. How do we decipher others’ minds? In Who needs emotions: the brain meets the robot (eds Fellous J-M, Arbib MA.), pp. 147–169. Oxford, UK: Oxford University Press. [Google Scholar]
- 44.Whiten A, Goodall J, McGrew C, Nishida T, Reynolds V, Sugiyama Y, Tutin CES, Wrangham R, Boesch C. 1999. Cultures in chimpanzees. Nature 399, 682–685. ( 10.1038/21415) [DOI] [PubMed] [Google Scholar]
- 45.Whiten A, Hinde RA, Laland KN, Stringer CB. 2011. Culture evolves. Phil. Trans. R. Soc. B 366, 938–948. ( 10.1098/rstb.2010.0372) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Oudeyer P-Y. 2005. The self-organization of speech sounds. J. Theor. Biol. 233, 435–449. ( 10.1016/j.jtbi.2004.10.025) [DOI] [PubMed] [Google Scholar]
- 47.Schneider C, Call J, Liebal K. 2012. Onset and early use of gestural communication in nonhuman great apes. Am. J. Primatol. 74, 102–113. ( 10.1002/ajp.21011) [DOI] [PubMed] [Google Scholar]
- 48.Perlman M, Tanner JE, King BJ. 2012. A mother gorilla's variable use of touch to guide her infant: insights into iconicity and the relationship between gesture and action. In Developments in non-human primate gesture research (eds Pika S, Liebal K.), pp. 55–73. Amsterdam, The Netherlands: John Benjamins Publishing Company. [Google Scholar]
- 49.Russon AE, Andrews K. 2011. Orangutan pantomime: elaborating the message. Biol. Lett. 7, 627–630. ( 10.1098/rsbl.2010.0564) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Arbib MA, Billard AG, Iacoboni M, Oztop E. 2000. Synthetic brain imaging: grasping, mirror neurons and imitation. Neural Netw. 13, 975–997. ( 10.1016/S0893-6080(00)00070-8) [DOI] [PubMed] [Google Scholar]
- 51.Barrès V, Simons A, Arbib MA. 2013. Synthetic event-related potentials: a computational bridge between neurolinguistic models and experiments. Neural Netw. 37, 66–92. ( 10.1016/j.neunet.2012.09.021) [DOI] [PubMed] [Google Scholar]
- 52.Fogassi L, Ferrari P-F, Gesierich B, Rozzi S, Chersi F, Rizzolatti G. 2005. Parietal lobe: from action organization to intention understanding. Science 308, 662–667. ( 10.1126/science.1106138) [DOI] [PubMed] [Google Scholar]
- 53.Griffin D, Gonzalez R. 2003. Models of dyadic social interaction. Phil. Trans. R. Soc. Lond. B 358, 573–581. ( 10.1098/rstb.2002.1263) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Wolpert DM, Doya K, Kawato M. 2003. A unifying computational framework for motor control and social interaction. Phil. Trans. R. Soc. Lond. B 358, 593–602. ( 10.1098/rstb.2002.1238) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Oztop E, Wolpert D, Kawato M. 2005. Mental state inference using visual control parameters. Brain Res. Cogn. Brain Res. 22, 129–151. ( 10.1016/j.cogbrainres.2004.08.004) [DOI] [PubMed] [Google Scholar]