

Abstract
The 61 CTSA Consortium sites are home to valuable programs and infrastructure supporting translational science and all are charged with ensuring that such investments translate quickly to improved clinical care. Catalog of Assets for Translational and Clinical Health Research (CATCHR) is the Consortium's effort to collect and make available information on programs and resources to maximize efficiency and facilitate collaborations. By capturing information on a broad range of assets supporting the entire clinical and translational research spectrum, CATCHR aims to provide the necessary infrastructure and processes to establish and maintain an open‐access, searchable database of consortium resources to support multisite clinical and translational research studies. Data are collected using rigorous, defined methods, with the resulting information made visible through an integrated, searchable Web‐based tool. Additional easy‐to‐use Web tools assist resource owners in validating and updating resource information over time. In this paper, we discuss the design and scope of the project, data collection methods, current results, and future plans for development and sustainability. With increasing pressure on research programs to avoid redundancy, CATCHR aims to make available information on programs and core facilities to maximize efficient use of resources.
Keywords: CTSA, resource identification, translational discovery
Introduction
The road to translational discovery and clinical innovation is wrought with logistical, financial, and regulatory hurdles. The “translational valley of death,” as it is often described, is a challenge further compacted by increasing financial costs and limited funding; scarcity of integrated information systems; asset gaps and redundancy; and deficient mechanisms for identifying and linking scattered resources.1, 2 The National Institutes of Health (NIH) Clinical and Translational Science Award (CTSA) program has charged 61 of the nation's top academic health centers with developing solutions and systems to address the major bottlenecks in translational research, with the goal of more rapid development of effective treatments for patients.3, 4, 5, 6
As the NIH‐designated academic institutional homes for clinical and translational (C&T) research, it is the responsibility of the CTSA Consortium to develop and implement strategies for working through these barriers, ensuring that its collective and individual investments lead to discoveries that rapidly translate into improved clinical care. The CTSA Consortium sites host valuable programs and infrastructure supporting translational science and are required to provide a home for these resources. These include NIH‐funded high‐end instrumentation and core lab equipment, clinical research centers, biobanks, innovative process‐driven programs to facilitate research, and networked tools that enable cutting‐edge research and education. However, even within each institution, resources can be difficult to quickly identify and access. Many sites have therefore developed local solutions including Web‐based systems to search and request core services, staff that serve as resource navigators, and research support programs that offer various services.7 See Table 1 for anticipated stakeholder use cases, which are trying to be addressed by the Consortium. Yet, nationally, the challenges identifying needed resources remain. Thus, these valuable assets must be identified and profiled on a national scale.
Table 1.
Potential resource identification use cases for various stakeholder groups
| Stakeholder use cases for resource identification | |
|---|---|
| Academic medical centers | Maximize use of high‐dollar instrumentation investment |
| Research foundation | Rapidly launch clinical studies in rare disease cohorts |
| Industry | Sponsor small molecule and biologics discovery for novel therapeutic targets |
| Individual investigators | Identify project‐specific instrumentation, services, and collaborators |
| Government | Explore geographic distribution of infrastructure and expertise |
These problems have been apparent; numerous surveys have captured national or regional resource‐related data during the evolution of the network, but to date, there has been no concerted effort to consolidate and make data from those efforts organized and publicly available. Despite publication of Consortium survey results,8, 9, 10 data quickly become outdated and are often published in aggregate, making resources therein unidentifiable by site and with no contact information for resources. As recommended by the 2013 Committee to Review the CTSA Program at the National Center for Advancing Translational Sciences (NCATS), the Consortium is positioned to “fully develop the role of facilitator and accelerator of clinical and translational research…” by “…developing, refining, widely disseminating, and implementing novel research and health informatics tools.”11 (p. 47) Catalog of Assets for Translational and Clinical Health Research (CATCHR) is the Consortium's integrated effort to fulfill the goal of resource data capture and release in order to support multisite studies and make assets visible.
As charged by the CTSA Consortium Steering Committee and supported administratively by the CTSA Consortium Coordinating Center (C4), collectively the Lead Administrators at each site have enabled efficient collection of data on assets at their respective sites. Lead administrators are an integral part of the data collection process from beginning to end, working closely with C4 to both collect and verify data. Resource (asset) identification, data collection, and routine maintenance are facilitated at the individual site level to ensure thoroughness and accuracy of site‐specific data for the lifespan of this project. Lead administrators identify contact information for assets, facilitate timely submission of survey responses, and coordinate site‐wide data refreshes over time.
CATCHR captures information on a broad range of assets supporting the entire C&T research spectrum, from early discovery to comparative effectiveness and community engagement research. The mission is to provide the necessary infrastructure and efficient processes to establish and maintain a searchable database of Consortium resources to support multisite C&T research studies. Data have been and will be collected using rigorous, defined methods, with the resulting information made available in a Web‐based tool that will be searchable, linkable, and open‐access with Consortium data all in one place. CATCHR also aims to make enabling assets visible to the Consortium as a whole; NIH, potential research collaborators and stakeholders including industry, other federal sponsors, disease foundations, community partners, and to the lay public in order to streamline central and generalizable translational functions such as those shown in Figure 1.
Figure 1.
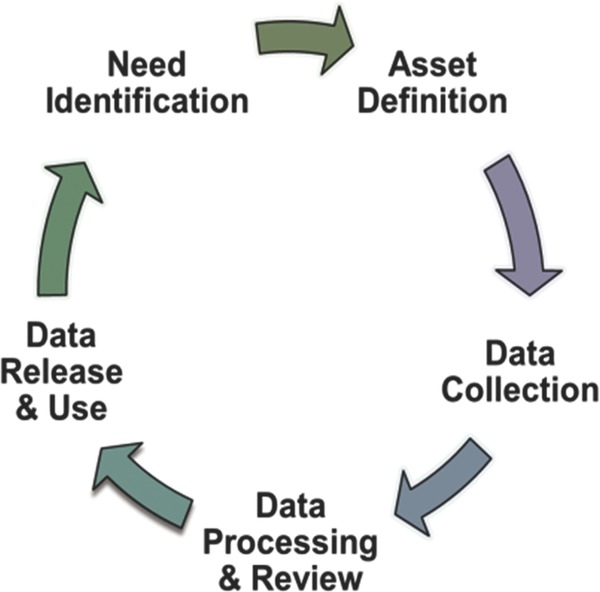
Overview of general CATCHR methods and sustainability approach.
Methods
The design and scope of the project focus on assets at CTSAs that are: (1) not consistently captured elsewhere; (2) higher‐dollar public investments; and (3) necessary for key steps of translational science. The first step in the cataloging process is asset selection and definition with the help of domain experts. Once an asset and variables are defined, C4 assesses the best approach to data collection. These methods include use of public data, survey tools, or mixed methods. Once preliminary data have been collected, these are vetted through a review/approval process with CTSA sites before public release. Figure 1 depicts an overview of general methods and approach to sustainability of the tool.
Selecting and defining assets
Selecting and accurately defining CATCHR assets has been a collaborative effort involving content domain experts, Consortium groups, and a variety of committees. The growing list of over 30 assets is highly diverse and spans the entire spectrum of C&T research, from early discovery to community‐engaged and comparative effectiveness research. The assets were chosen based on scope, value, research enablement, uniqueness, being definable, and/or by demand. An asset is defined based on expert feedback and a critical evaluation of existing peer‐reviewed literature. CTSA investigators and leadership are engaged throughout the process to ensure that asset definitions reflect the most current trends and developments within the C&T landscape. The selection of variables is tailored to each unique asset to ensure that data collected are both valuable and structured. This ensures that the approach to identifying resources is both methodical and deliberate. Quality data collection resulting from a controlled set of unique variables is crucial for the effectiveness of CATCHR's targeted search mechanisms.
Criteria for choosing variables are dependent on both the asset definition and the distinct needs of associated stakeholder groups in relation to that specific asset. The variables collected are meant to represent a high‐level characterization of each asset. In order to ensure that data remain relevant, variables collected for each asset focus not on highly granular data that change rapidly, but rather on more static information, such as general services provided. While selected variables are unique to each individual asset, they must also remain comprehensive in order to broadly characterize the resources available at each CTSA institution and its affiliate sites. In this way, industry, foundation, and academic collaborators alike can easily identify which institutions have the resources and/or expertise needed for a particular project or in an effort to streamline central translational functions such as clinical trial start‐up and formation of research networks.
Data collection
A variety of data collection methods are being utilized depending on the complexity and public availability of the asset variables. When possible, public data sources are used, such as Websites and publications, followed by phone or e‐mail interviews, with the goal of decreasing the work burden on the contacts and administrators at the CTSA sites. For more complex assets with well‐defined owners, REDCap surveys have been used to collect information on resources such as Clinical Research Units, Local Pilot Funding Programs, and Electronic Health Records. Intensive methodical tracking and follow‐up with the sites has been required throughout the process.
One approach to preliminary data collection is the use of publicly available, verified sources of information. This process includes mining reliable sources of public information and the assessment of contractual agreements. These public sources include databases and registries that are curated and regularly maintained; examples include; NIH listings and grant databases, FDA facility registries, network listings, and researcher profiles. For some assets, the CATCHR team worked with Consortium groups to make use of historical survey tools and data. In some instances, previously collected data were integrated into the CATCHR framework. The CATCHR team also worked with Consortium groups to support the dissemination, tracking, and follow‐up of Consortium surveys as an extension of the CATCHR project.
Phone or e‐mail interviews were instituted as a means of verifying data collected from public sources of unsubstantiated information such as Web pages, fact sheets, and presentations. Once a search for publicly accessible information has been exhausted, individual resource administrators are contacted and encouraged to review the collected data and fill in gaps of information where possible. As a result of this personal interaction, many investigators and facility directors throughout the Consortium are newly introduced to the mission and leveraging power of the CTSA Consortium as a whole. Though cataloged resources are interwoven within the CTSA landscape, many resources are not directly affiliated with each institution's CTSA program. In this way, CATCHR serves as an introduction mechanism, essentially binding the breadth of the Consortium with its many indirectly related components and institutionally supported resources.
In some instances where public data are sparse or unavailable, C4 works with domain experts to develop survey questions relevant to asset data collection and then creates a REDCap survey tool. In collaboration with appropriate Consortium domain experts and/or committees and CTSA site institutional leaders (ILs), as appropriate, the CATCHR team identifies appropriate target participants and disseminates, tracks, and performs quality assurance of data collected before integration into the centralized framework.
To increase efficiency and leverage existing infrastructure, REDCap12 is used as the mechanism for collecting survey data and centrally storing, managing, and querying all collected data. Integrated with the online CATCHR user interface, REDCap editing tools will remain active indefinitely to support an evolving, dynamic database that will serve as a current reflection of resources available within the Consortium.
Data validation
The accuracy of the data is critical to the success of the project in achieving its goals. An IL, such as a PI, a Lead Administrator, or a person appointed by the PI or Lead Administrator assumes responsibility for monitoring the development of the initial data set and supervising regular review and management to assure the long‐term utility, dependability, and sustainability of CATCHR. For this purpose, all CATCHR data will be reviewable and editable by individual CTSA sites at all times; see Figure 2 for a screenshot of the online data editing interface.
Figure 2.
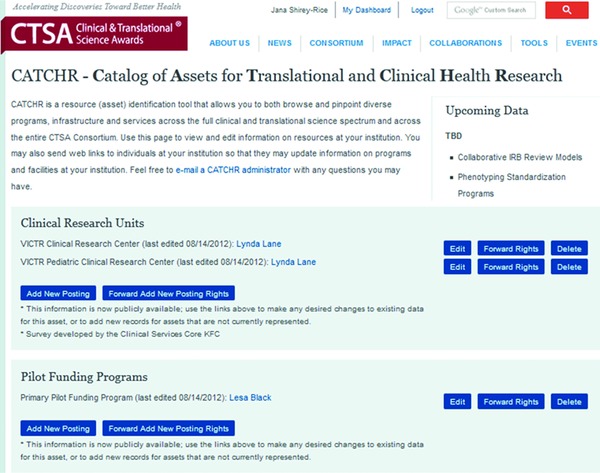
CATCHR data editing interface including options for editing existing data, forwarding edit rights to others, and adding new resources.
Site‐level data review and edit rights are held by all CTSA Lead Administrators. It is expected that each site's data maintenance and updates will be ongoing for the life of the initiative. Upon completion of preliminary data collection on each asset, C4 notifies the CTSA Lead Administrators or ILs of data availability for review prior to public release, and the timeline for public data release and publication through the user interface. Released data will include a “date of last edit” to allow users discretion over which data are used, and data not updated within 12 months will be suppressed with an automated notification to the institutional contacts. Data will be refreshed and curated by sites, and asset questions will be refined as needs, technologies, and Consortium directions change over time; historical data will be archived. To maintain flexibility and resource usefulness, C4 will carry out data collection on new assets and update definitions and variables as needed and requested by stakeholders.
Results
Roughly 30 assets were initially proposed when the CTSA cataloging effort first commenced. These assets contain an average of 12 variables each, and over 1,200 data elements have been collected, to date. More than 700 participants have directly contributed data, and over 1,300 unique C&T resources (i.e., programs, infrastructure, instrumentation, etc.) from 61 institutions and affiliate sites have been cataloged thus far. These assets were strategically chosen to represent the diversity and complexity of the Consortium's translational mission and areas of research. These assets can be categorized according to utility and represent a wide array of enabling resources; research infrastructure and instrumentation; research processes and support mechanisms; networking and collaboration tools; as well as patient‐oriented research programs. Examples of assets include drug discovery programs, biobanks, medicinal chemistry facilities, commercialization facilitation programs, national and regional network memberships, community engagement research infrastructure, and clinical research units (see Figures 3 and 4 for sample aggregate data); see Figure 5 and Table S1 for a complete listing of assets with definitions and variables.
Figure 3.
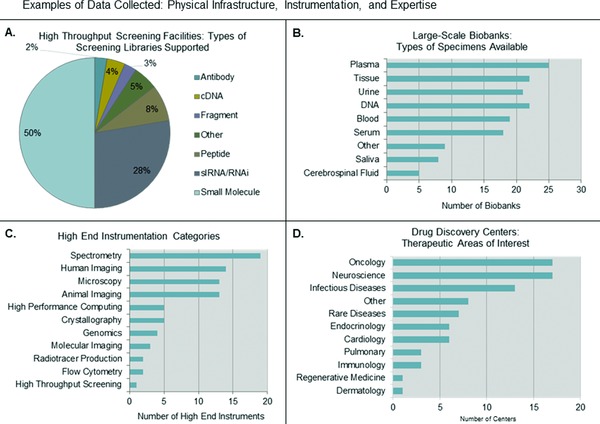
Aggregate data on physical infrastructure, instrumentation, and expertise assets. (A) Represents 44 high‐throughput screening facilities from 40 sites. (B) Represents 31 biobanks from 31 sites. (C) Represents 81 high‐end instruments from 36 sites as awarded through the NIH HEI grant program. (D) Represents 24 drug discovery centers from 23 sites.
Figure 4.
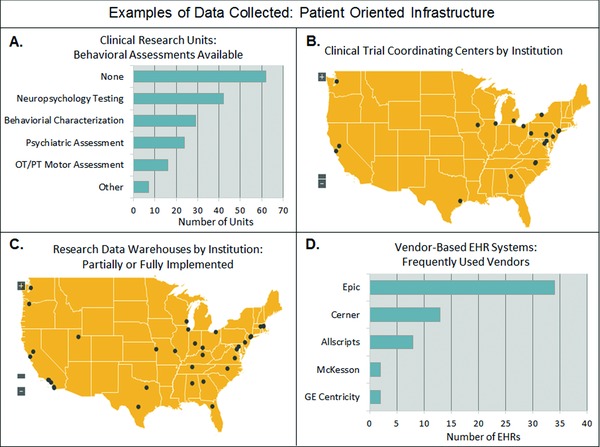
Aggregate data on patient‐oriented infrastructure assets. (A) Represents 118 Clinical Research Units from 59 sites. (B) Represents 20 clinical trial coordinating centers from 19 sites. (C) Includes 41 research data warehouses from 37 sites. (D) Represents 59 vendor‐based EHR systems from 46 sites.
Figure 5.
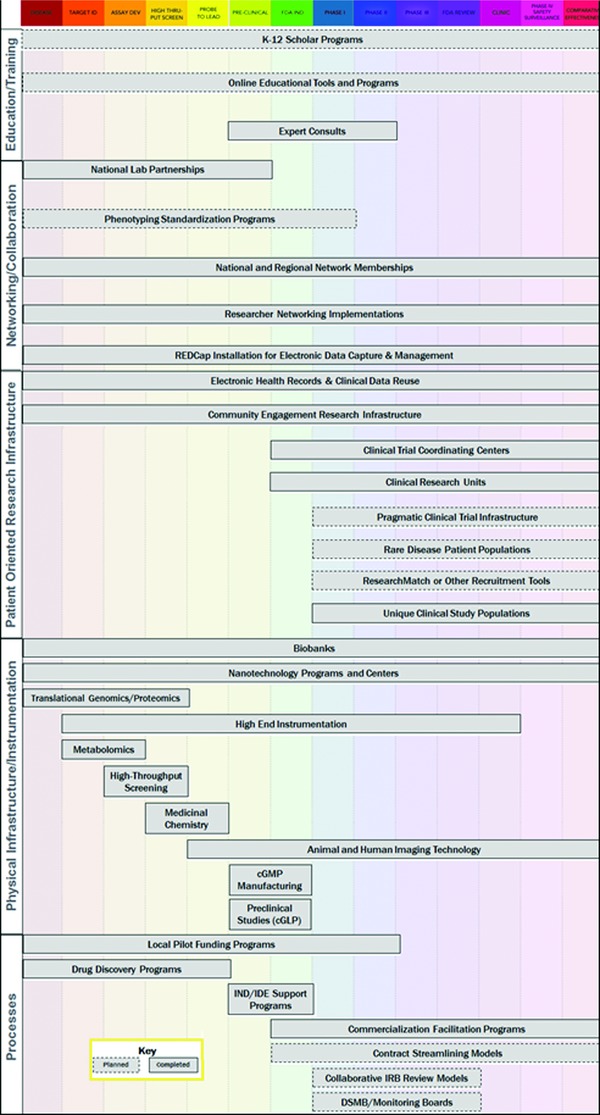
Distribution of completed and planned CATCHR assets along the translational science spectrum.
An online searchable interface (see Figure 6) will allow users to search assets based on selected criteria in a Boolean manner. Users provide their name and a few details about their search, which will unlock access to asset contact information and allow the CATCHR team to track user metrics. Output data include the CTSA site, name of the asset or facility, contact information for each asset, and a date of last edit so that users may be informed of the “freshness” of the data.
Figure 6.
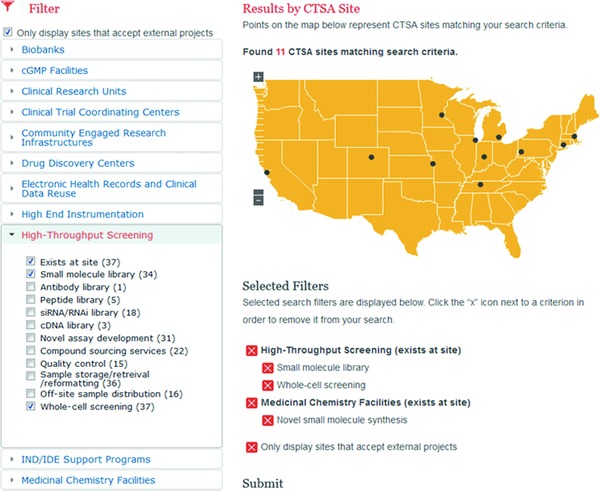
CATCHR online user interface depicting an example search for high‐throughput screening and medical chemistry facilities.
Discussion
Anticipated use
CATCHR was constructed as a curated, Consortium‐wide inventory of C&T assets on the principle that NIH‐funded resources should be visible, quickly identifiable, and easily accessible for their intended users. By collating together data of this magnitude, the utility of the tool is estimated to be as diverse as the approximately 61 medical institutions that it represents. CATCHR has created an opportunity for the Consortium to make data available to multiple constituents, including NIH/government, the lay public, the media, the CTSA Consortium sites, disease foundations, investigators and research teams, pharmaceutical and biotech companies, translational science societies, venture capital groups, CTSA site resource navigators, consortium committees and workgroups, and state and local health departments in order to achieve goals outlined in use cases shown above (Table 1). Projected utility among these diverse groups is expected to include study planning and initiation, funding offering development, information gathering for reporting, resource development planning, resource‐based project planning, funding agency planning, and partnership formation. Uses of CATCHR for these applications will be tracked over time to guide further resource development. Establishing new partnerships and projects is a major emphasis of the project. Because CATCHR highlights not only the individual, but the cohesive strengths of the Consortium sites, it is expected that the resource will aid in existing collaborative research efforts and entice the start‐up of new multisite projects.
Integration of feedback and support of consortium participation/use
To improve the quality and usability of the resource and allow for external guidance and review, qualitative methods for evaluating the tool are in place. Metrics reported by users including stakeholder group identity, geographic location, purposes of searches, structured and unstructured feedback, and data accessed will inform continuous development and improvement. This type of ongoing evaluation will help to: (1) ascertain key information needs among target users; (2) assess and understand expected search patterns by various user groups; and (3) explore the utility and appropriateness of the information as presented in various visual formats.
CATCHR will also grow to better reflect the needs of its users by evolving based on their utilization of the tool. User data collected through the interface, such as assets most frequently accessed and problems frequently reported, will be used to guide review prioritization. The C4 will maintain an immediate feedback communication option within CATCHR that will prompt users to suggest modifications or additions to asset display. These online feedback methods will ensure that CATCHR develops in parallel with the goals of the Consortium and its constituents. Of course, integrating feedback and promoting Consortium‐wide ownership of the tool will require continuous, critical evaluation that moves beyond even the most rigorous of qualitative evaluation methods.
Future plans for sustainability
Plans are in place to affirm that CATCHR remains curated as a sustainably updated resource. To ensure that data remain current and reflective of the existing C&T landscape, it will be strategically refreshed and curated by sites, and asset questions will be refined as needs, technologies, and Consortium directions change over time. In terms of maintaining current data, data editing tools will remain active indefinitely, creating an evolving, dynamic database that will always serve as a current reflection of resources available within the Consortium. As CATCHR serves as a centralized tool representing the Consortium's resources, its ultimate utility involves joint efforts of all 61 sites. Data collection on new assets will continue and updating definitions and variables will be a part of the administrative functions of the coordination center. In conjunction with regular yearly data revisions, in‐depth data reviews on two to four assets will be performed per year in order to capture changes in asset definitions and relevance as technologies and research evolve over time. User statistics will be maintained so that assets that are rarely or never viewed may be recommended for elimination. Public data will also be searched to verify data accuracy.
Linkage to other resources
CATCHR was developed to support the visibility and accessibility of Consortium‐wide resources, not in competition with existing resource identification services, but rather in conjunction with them. CATCHR fulfills an intrinsic need within the research community in that it provides both a broad and high‐level view of the CTSA Consortium's very unique and valuable scientific portfolio. Still, its value can be optimized by leveraging the power of existing resources that meet similar, but distinct needs. Linking to resources such as Science Exchange13 and eagle‐i,14, 15 would add transaction functionality and granularity for core‐like assets, model organisms, and reagents.
Conclusions
With increasing cuts to NIH budgets and building pressure on research programs to avoid redundancy, CATCHR can help to make available information on equipment, core facilities, and programs to maximize efficient use of resources. Core facilities provide critical access to services, expert consultations, and instrumentation that is required for cutting‐edge translational research. They represent large federal and institutional investments that are often underutilized and duplicated within institutions and across geographical regions.16 One of the major barriers to utilization of cores and research support programs is the lack of readily available, accurate information. Under the CTSA program, CATCHR aims to provide this consolidated source of information on contacts and general services. While Web‐based search engines yield somewhat useful but varying results, their utility is limited by accuracy of linked Websites (often containing outdated information). Manual searches using multiple search engines and tools is also extremely time consuming for investigators and can be the rate‐limiting step in establishing collaborations and initiating multisite studies. By combining data and information from many sources in one place and making it searchable and publicly available, the burden is drastically decreased.
CATCHR provides value and time savings but is not designed to meet all project and resource identification needs. For instance, there are no plans to include detailed data on model organisms, highly technical reagents or assays, or transactional capabilities to support purchase of core services. The CATCHR team does, however, plan to catalog and link resources listed in other programs that provide those valuable functions such as eagle‐i and Science Exchange. CATCHR also does not currently contain data on resources at non‐CTSA institutions but may have the capacity to do so in future development. Finally, the success of the project will be driven (and limited) by efforts by ILs, lead administrators, and resource contacts to keep data current. For more information, please visit https://www.ctsacentral.org/catchr/portfolio.
Sources of Funding
Federal funds from National Center for Accelerating Translational Sciences (NCATS), NIH, through the CTSA Program, grants 15U54TR000123, 2UL1TR000109, 3UL1TR000058, 4UL1TR000086, 5UL1TR000130, 6UL1TR000041, 7UL1TR000050, 8UL1TR000038, 9UL1TR000055, 10UL1TR000100, 11UL1TR000128, 12UL1TR000433, 13UL1TR000149, 14UL1TR000161, 15UL1TR000142, 16UL1TR000075, 17UL1TR000157, 18UL1TR000154, 19UL1TR000002, 20UL1TR000040, 21UL1TR000150, 22UL1TR000114, 23UL1TR000442, 24UL1TR000451, 25UL1TR000001, 26UL1TR000165, 27UL1TR000439, 28UL1TR000153, 29UL1TR000067, 30UL1TR000430, 31UL1TR000436, 32UL1TR000427, 33UL1TR000006, 34UL1TR000003, 35UL1TR000083, 36UL1TR000124, 37UL1TR000090, 38UL1TR000064, 39UL1TR000460, 40UL1TR000073, 41UL1TR000093, 42UL1TR000043, 43UL1TR000071, 44UL1TR000005, and 45UL1TR000445.
Supporting information
Disclaimer: Supplementary materials have been peer‐reviewed but not copyedited.
Supplementary Table 1.
Acknowledgments
The authors would like to thank the leadership of the CTSA Strategic Goal 5 Committee for thoughtful oversight and guidance on the project plan and design, as well as the CTSA Steering Committee Cochairs. Franco Scaramuzza contributed vital work on the design of the CATCHR logo and Web page content. Dr. Daniel Rosenblum, MD, Medical Officer, NCATS, NIH, also provided critical input on this work. Resource navigators, program directors, and facility contacts for those assets that have been included in CATCHR, to date, played an invaluable role in providing information and collaborating with the project team in order to establish the current data set. The manuscript was approved by the CTSA Consortium Publications Committee. The information provided and the opinions expressed in this document are those of the authors and do not reflect the scientific opinion or official policy of the US Government.
This project has been funded in whole or in part with Federal funds from NCATS, NIH, through the CTSA.
References
- 1. Zerhouni EA. Translational research: moving discovery to practice. Clin Pharmacol Ther. 2007; 81(1): 126–128. [DOI] [PubMed] [Google Scholar]
- 2. Collins FS. Reengineering translational science: the time is right. Sci Transl Med. 2011; 3(90): 1–6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3. Zerhouni EA. Translational and clinical science–time for a new vision. N Engl J Med. 2005; 353(15): 1621–1623. [DOI] [PubMed] [Google Scholar]
- 4. Zerhouni EA, Alving B. Clinical and translational science awards: a framework for a national research agenda. Transl Res. 2006; 148(1): 4–5. [DOI] [PubMed] [Google Scholar]
- 5. Dilts DM, Rosenblum D, Trochim WM. A virtual national laboratory for reengineering clinical translational science. Sci Transl Med. 2012; 4(118): 1–4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. CTSA Principal Investigators , Shamoon H, Center D, Davis P, Tuchman M, Ginsberg H, Califf R, Stephens D, Mellman T, Verbalis J, Nadler L, et al. Preparedness of the CTSA's structural and scientific assets to support the mission of the National Center for Advancing Translational Sciences (NCATS). Clin Transl Sci. 2012; 5(2): 121–129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Rosenblum D. Access to core facilities and other research resources provided by the clinical and translational science awards. Clin Transl Sci. 2012; 5(1): 78–82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Berro M, Burnett BK, Fromell GJ, Hartman KA, Rubinstein EP, Schuff KG, Speicher LA. IND/IDE Taskforce of the Clinical and Translational Science Award Consortium. Support for investigator‐initiated clinical research involving investigational drugs or devices: the clinical and translational science award experience. Acad Med. 2011; 86(2): 217–223. [DOI] [PubMed] [Google Scholar]
- 9. DuBois JM, Schilling DA, Heitman E, Steneck NH, Kon AA. Instruction in the responsible conduct of research: an inventory of programs and materials within CTSAs. Clin Transl Sci. 2010; 3(3): 109–111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Kiriakis J, Gaich N, Johnston SC, Kitterman D, Rosenblum D, Salberg L, Rifkind A. Observational study of contracts processing at 29 CTSA sites. Clin Transl Sci. 2013; 6(4): 279–285. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. National Research Council The CTSA Program at NIH: Opportunities for Advancing Clinical and Translational Research. Washington, DC: National Academies Press; 2013. Available at: http://www.nap.edu/catalog.php?record_id=18323. Accessed August 13, 2013. [PubMed] [Google Scholar]
- 12. Harris PA, Taylor R, Thielke R, Payne J, Gonzalez N, Conde JG. Research electronic data capture (REDCap)–a metadata‐driven methodology and workflow process for providing translational research informatics support. J Biomed Inform. 2009; 42(2): 377–381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Science Exchange, Inc. Science Exchange. Science Exchange 2013. Available at: https://www.scienceexchange.com/. Accessed August 13, 2013.
- 14. Vasilevsky N, Johnson T, Corday K, Torniai C, Brush M, Segerdell E, Wilson M, Shaffer C, Robinson D, Haendel M. Research resources: curating the new eagle‐i discovery system. Database (Oxford). 2012;2012:bar067. Available at: https://www.eagle‐i.net/. Accessed August 13, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. President and Fellows of Harvard College. eagle‐i. eagel‐i 2013. Available at: https://www.eagle‐i.net/. Accessed August 13, 2013.
- 16. Farber GK, Weiss L. Core facilities: maximizing the return on investment. Sci Transl Med. 2011; 3(95): 1–3. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Disclaimer: Supplementary materials have been peer‐reviewed but not copyedited.
Supplementary Table 1.