

Abstract
Assessing between-study variability in the context of conventional random-effects meta-analysis is notoriously difficult when incorporating data from only a small number of historical studies. In order to borrow strength, historical and current data are often assumed to be fully homogeneous, but this can have drastic consequences for power and Type I error if the historical information is biased. In this paper, we propose empirical and fully Bayesian modifications of the commensurate prior model (Hobbs et al., 2011) extending Pocock (1976), and evaluate their frequentist and Bayesian properties for incorporating patient-level historical data using general and generalized linear mixed regression models. Our proposed commensurate prior models lead to preposterior admissible estimators that facilitate alternative bias-variance trade-offs than those offered by pre-existing methodologies for incorporating historical data from a small number of historical studies. We also provide a sample analysis of a colon cancer trial comparing time-to-disease progression using a Weibull regression model.
Keywords: clinical trials, historical controls, meta-analysis, Bayesian analysis, survival analysis, correlated data
1 Introduction
1.1 Background
Clinical trials are not designed without consideration of earlier results from similar studies. Prior distributions derived from historical data, data from previous studies in similar populations, can be used prospectively to provide increased precision of parameter estimates. Our understanding of the “standard care” group in a trial can almost always be augmented by information derived from previous investigations. In a seminal article, Pocock (1976) considers incorporating historical control data into clinical trial analysis given that it satisfies six “acceptability” conditions. Conventionally, acceptable evidence from multiple trials is synthesized using random-effects meta-analyses (Spiegelhalter et al., 2004, p.268). Such borrowing of strength to assess “population averaged” effects in the full comparative evaluation of a new treatment has long been encouraged by the Center for Devices and Radiological Health (CDRH) at the U.S. Food and Drug Administration (FDA); see http://www.fda.gov/cdrh/osb/guidance/1601.html.
However, for the case of just a few historical studies, this approach is overly sensitive to the hyperprior distribution on the variance parameter that controls the amount of cross-study borrowing. Furthermore, with only one historical study, assessing the uncertainty of the between-study variability is difficult (Spiegelhalter, 2001; Gelman, 2006). Therefore, implementing the conventional meta-analytic approach to borrow strength from only one historical study requires informative prior distributions that may have drastic consequences for power and Type I error.
In this paper we propose empirical and fully Bayesian modifications to the “commensurate prior” approach (Hobbs et al., 2011) and extend the method to regression analysis using general and generalized linear regression models, in the context of two successive clinical trials. Throughout the paper we assume that the current trial compares a novel intervention to a previously studied control therapy that was used in the first trial, and thus historical data are available only for the control group. Furthermore, commensurate priors are constructed to inform about fixed regression effect parameters.
The goal of our proposed methodology is to formulate Bayesian hierarchical models that facilitate more desirable bias-variance trade-offs than those offered by pre-existing methodologies for incorporating historical data from a small number of historical studies. Sutton and Abrams (2001) consider empirical Bayesian methods in meta-analysis. Alternative solutions include “robust” Cauchy priors (Fúquene et al., 2009), meta-analytic-predictive methods (Neuenschwander et al., 2010), and power priors (Ibrahim and Chen, 2000; Neelon and O’Malley, 2010). Proper implementation of power prior models for non-Gaussian data requires formidable numerical computation that may prohibit their use in practice for clinical trial design. Therefore, we do not consider the commensurate power prior methodology proposed by Hobbs et al. (2011).
1.2 Connection to meta-analysis
Before developing our method, we briefly discuss the conventional random-effects meta-analytic approach for incorporating historical data. Let y denote a vector of i.i.d. responses of length n from patients enrolled in a current trial, such that where di is an indicator of novel treatment. Suppose that we have patient-level data for patients assigned to the current control arm from H historical trials. Let y0,h denote response vectors of length n0,h for the historical data, , where h = 1, …, H. Suppose that current trial’s objective is to compare the novel treatment to the previously studied control, and thus the posterior distribution of λ is of primary interest for treatment evaluation. Historical data is incorporated for the purpose of facilitating more precise estimates of μ and λ.
The conventional random-effects meta-analytic approach for borrowing strength from the historical data (see e.g. Spiegelhalter et al., 2004, p.268) assumes that μ0,1, …, μ0,H, and μ are exchangeable:
The model allows for both between-study heterogeneity and within-study variability. Parameters ξ and η2 characterize the population mean and between-study variance, respectively. The estimate of ξ is a weighted average of the observed historical and current study effects, with weights .
The estimates of the μ0,h and μ are “shrunk” toward ξ by an amount depending on the relative between-study and within-study variances. Following Spiegelhalter et al. (2004, p.94), B = σ2/(σ2+η2) controls the amount of shrinkage of the estimate of μ towards ξ. Relatively small values of η2 suggest that the data provide little evidence for heterogeneity with respect to the effect of control among the trial populations. This results in more borrowing of strength from the historical data. Fixing η2 = 0 induces a model that assumes “full homogeneity.”
Often the data provides sufficient information to estimate location parameters μ, μ0,h, ξ, and within-study variances and σ 2 using common noninformative prior distributions, h = 1, …, H. Table 1 lists common noninformative and “weakly informative” prior distributions for η2 suggested by Spiegelhalter et al. (2004, p.170), Gelman (2006), and Daniels (1999).
Table 1.
Common priors for η2
| prior | form | |
|---|---|---|
|
| ||
| uniform variance | p(η2) = U(0, a) | |
| inverse gamma | p(η2) = G−1(∊, ∊) | |
| uniform standard deviation |
|
|
| half-Cauchy | p(η) ∝ (η2 + b)−1 | |
| uniform shrinkage | p(η2) ∝ σ2/{(σ2 + η2)2}, , for all h | |
The first option for p(η2) considered by Spiegelhalter et al. (2004) is a uniform prior distribution with a relatively large range (a = 100). Gelman (2006) does not recommend it because it tends to unduly favor higher values, resulting in excessive heterogeneity. Spiegelhalter et al. (2004) also consider the inverse gamma prior for η2 with both hyperparameters small, say ∊ = 0.001. This prior distribution is often used because it is proper and conditionally conjugate. However, it is sharply peaked near zero and thus induces strong prior preference for homogeneity. As detailed in Gelman (2006), inferences with this prior are sensitive to the choice of ∊ for datasets in which homogeneity is feasible, and in the limit (∊ → 0) results in an improper posterior density.
Both authors consider a uniform density on η, which is equivalent to p(η2) ∝ 1/η (Gelman, 2006). Assuming a uniform prior on the scale of η facilitates more homogeneity. However, for small H this prior tends overestimate heterogeneity. Gelman (2006) proposes a “weakly informative” half-Cauchy prior distribution on η with scale parameter, b, as a sensible compromise between the inverse gamma and uniform priors. For large values of b, (e.g. 25), this family of prior distributions has better behavior near 0, compared to the inverse gamma family; gentle slopes in the tails constrain the posterior away from large values and allow the data to dominate.
Daniels (1999) derives properties of the proper uniform shrinkage prior, which is equivalent to assuming a U(0, 1) prior on the shrinkage parameter, B. One attractive property of “uniform shrinkage” is that the density is maximized at zero, but less sharply peaked compared to the inverse gamma family. However, in this context, it requires identical within-study variances , for h = 1,…, H, which is an undesirable assumption.
Denote the difference between the current and hth historical intercept, or unknown bias (Pocock, 1976), by Δh = μ−μ0,h, and let Δ = (μ−μ0,1, …, μ−μ0,H). Denote the parameter vector
, let
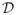 = (y, y0) denote the collection of current and historical response data, where y0 = (y0,1, …, y0,H), and let L(
|θ) denote the joint likelihood. Figure 1 illustrates the propriety of each of the aforementioned prior distributions for η2 in this context on the scale of log(η2). The left plot portrays the relative prior densities, p{log(η2)} ∝ η2p(η2). The plot illustrates each prior’s relative proclivity for homogeneity. In this context, assuming η2 is uniform over the interval [0, 100] induces a preference for heterogeneity, while the excessive tail behavior of the inverse gamma prior, which is characterized by a vertical dotted line on the far left side, induces a preference for homogeneity. The other three alternatives induce varying compromises. The center and right plots of Figure 1 contain marginal posterior distributions for log(η2) for truly unbiased historical data for H = 1 and = 3 historical trials. Specifically, the plots depict
= (y, y0) denote the collection of current and historical response data, where y0 = (y0,1, …, y0,H), and let L(
|θ) denote the joint likelihood. Figure 1 illustrates the propriety of each of the aforementioned prior distributions for η2 in this context on the scale of log(η2). The left plot portrays the relative prior densities, p{log(η2)} ∝ η2p(η2). The plot illustrates each prior’s relative proclivity for homogeneity. In this context, assuming η2 is uniform over the interval [0, 100] induces a preference for heterogeneity, while the excessive tail behavior of the inverse gamma prior, which is characterized by a vertical dotted line on the far left side, induces a preference for homogeneity. The other three alternatives induce varying compromises. The center and right plots of Figure 1 contain marginal posterior distributions for log(η2) for truly unbiased historical data for H = 1 and = 3 historical trials. Specifically, the plots depict
Figure 1.

Prior distribution for log(η2) and posterior distributions for log(η2) for truly unbiased historical data: for H = 1 and = 3 historical studies. Values in parentheses are approximate posterior standard deviations on the scale η2.
where θtr contains fixed Δtr = 0. We also set true parameters λtr = 0 and ; fixed historical sample sizes n0,h = 60, and current sample size n = 180, and assumed equal allocation of patients to treatment and control in the current trial. The log-transformation of η2 facilitates comprehensive characterization of the distributions over a vast portion of the parameter space. However, given the asymmetry of the parameter space (i.e., in this context homogeneity is realized for values < −3) it is difficult to assess uncertainty on the log-scale. Thus, legends in the center and right plots of Figure 1 provide approximate posterior standard deviations on the scale of η2 in parentheses.
Figure 1 illustrates the primary drawback to using meta-analysis to incorporate historical data from one historical study. Looking from the left to center plots reveals that relatively little Bayesian updating of p{log(η2)} has occurred despite the fact that the historical data is unbiased. The uniform prior on η2 is relatively unchanged, while the inverse gamma prior results in a posterior that covers a wide range of homogeneity, yet it is still very diffuse given that its posterior standard deviation on the η2 scale is greater than 400, 000. The center plot reaffirms the aforementioned authors’ preferences for the uniform standard deviation, half-Cauchy, or uniform shrinkage priors, which facilitate sensible compromises. Yet, even these posteriors are still diffuse, facilitating little borrowing of strength from the historical data in this setting. The right plot illustrates that for H = 3, a relative “convergence” to the preference for homogeneity begins to emerge, although the priors still systematically influence the relative degree of homogeneity.
The remainder of the paper proceeds as follows. Section 2 introduces our proposed commensurate prior models and evaluates their frequentist properties for Gaussian data. Section 3 introduces general linear and general linear mixed models for Gaussian data. Then in Section 4 we expand the method to include non-Gaussian responses for generalized linear and generalized linear mixed models. Section 5 offers an illustrative time-to-event analysis that demonstrates the benefit of our proposed method, while Section 6 evaluates the frequentist and Bayesian operating characteristics of our method using simulation. Finally, Section 7 concludes, discusses our findings, and suggests avenues for further research.
2 Commensurate prior models
Hobbs et al. (2011) consider the simple case involving incorporation of data from one historical trial into the analysis of a single-arm trial. The authors define the location commensurate prior for μ to be the product of the historical likelihood and a normal prior on μ with mean μ0 and precision or “commensurability parameter” τ. The general formulation follows from Pocock (1976), who suggested that historical parameters are biased representations of their concurrent counterparts. Pocock (1976) also suggested that models for incorporating historical information must account for unknown bias Δ = μ−μ0 in the historical data. The commensurate prior is essentially a structural prior distribution that describes the extent to which a parameter in a new trial varies about the analogous parameters in a set of historical trials when the direction of the bias is unknown. The approach assumes that the current analysis should borrow strength from the historical data in the absence of evidence for heterogeneity. Thus, lack of evidence for large absolute bias, |Δ|, relative to the data’s informativeness, implies commensurability. A one-to-one relationship exists between the commensurability parameter and the between-study variance parameter η2 for the random-effects meta-analytic models discussed in the previous section for the case of one historical study. Pocock (1976) proposes repeated analysis under several fixed values of 1/τ, while Hobbs et al. (2011) propose a fully Bayesian approach that assumes a diffuse uniform prior distribution on log(τ).
There are two issues with the pre-existing formulation. First, the diffuse prior of Hobbs et al. (2011) on log(τ) (an attempt at objectivity) is actually quite informative, in that it strongly favors either full homogeneity or heterogeneity (on the scale of η, nearly 83% of the a priori probability is placed on values less than 0.05 or larger than 10, the effective range for substantial to very little shrinkage). Second, the historical likelihood should perhaps more properly be considered data instead of a component of the prior. Nevertheless, Hobbs et al. (2011) demonstrate that analysis using commensurate priors may lead to more powerful procedures than an analysis that ignores the historical data, even when Type I error is controlled at 0.05. Henceforth, we proceed with two modifications of the preceding commensurate prior methodology. We consider the historical data to be a part of the likelihood, and propose new empirical and fully Bayesian modifications for estimating τ from the data. Our proposed commensurate prior models lead to preposterior admissible estimators that facilitate alternative bias-variance trade-offs from those offered by pre-existing methodologies for incorporating historical data from a small number of historical studies. The proposed methodology provides the most gains for the case of only one historical study. Before applying this methodology in practice we must assess frequentist properties in the context of other important factors, such as potential disparities in sample size among the historical and current studies.
2.1 One historical study
As demonstrated in Subsection 1.2, in a random-effects meta-analysis it is difficult to estimate η2 if the number of historical studies is small. As illustrated in Figure 1, for only one historical trial in the above context, the data provide very little information about η2. Yet, if evidence regarding the efficacy and safety profile of the current control arm derives from a single study because data is exceptionally expensive, the patient population is sparse, or the therapy is unusually hazardous, then it may be highly desirable to facilitate more borrowing of strength from the existing evidence. This is especially true if the trial implements adaptive decision rules that are designed to minimize the number of patients that are exposed to the inferior treatment. Consequently, in practice inference often proceeds under the assumption of full homogeneity, η2 = 0, which violates Pocock’s (1976) proposition that one must allow for unknown bias in the historical controls. Assuming homogeneity yields designs with undesirable frequentist operating characteristics.
Let θ denote the parameter vector . For H = 1, the joint posterior distribution under the commensurate prior model is proportional to
| (1) |
Throughout this paper we refer to μ ~ N(μ|μ0, 1/τ ) as the commensurate prior, and to p(μ0) as the initial prior, since it characterizes information before the historical data was observed. The commensurate prior assumes that μ is a non-systematically biased representation of μ0. For one historical study a one-to-one relationship exists between τ and the meta-analytic between-study variance, η2: τ = 1/(2η2). Larger values of τ indicate increased commensurability, and induce increased borrowing of strength from the historical data.
Define , and
If we assume a flat prior for μ0 (no initial information), reference priors for the within-study variances, , the joint posterior in (1) can be written as
| (2) |
where Γ−1 denotes the inverse gamma distribution. We can reduce dimensionality in the numerical marginalization of θ by replacing the product of the initial prior and the historical likelihood with a normal approximation; Section 4 discusses this approach in generality for generalized linear models. Subsection 2.3 proposes fully Bayesian as well as empirical approaches for estimating τ.
2.2 Multiple historical studies
For H > 1 historical studies, we propose an extension of the commensurate prior model in the previous subsection that assumes homogeneity among the historical studies by formulating the commensurate prior for μ conditional on the historical population mean. Usually data from only a few historical studies will be available. If the historical studies are markedly heterogenous, one may need to consider whether the historical data satisfies Pocock’s “acceptability” conditions (Pocock, 1976), or fix the degree of heterogeneity to acknowledge the conflict.
Following our previous notation, the parameter vector contains one parameter for the historical population mean, μ0: so that , where μ0,1 = … = μ0,H = μ0. Denote the hth historical within-study variance divided by the sample size by . The relationship between τ and the meta-analytic between-study variance η2 is more complicated than before. For H > 1, τ−1 characterizes the meta-analytic between-study variability, plus the difference between the summed variability among the sample means ȳ and the ȳ0,hs, and the population mean (previously ξ) when heterogeneity is estimated η2 versus when full homogeneity is assumed,
Moreover, constraining the H historical means, μ0,h, to be equal to each other but perhaps not to the current mean, μ inserts an asymmetry into the model that is not present in the usual exchangeability model. As in the previous section, the data typically provide sufficient information to estimate parameters λ, μ0, σ, and σ0,h (given no initial information) under common noninformative prior distributions, h = 1, …, H. The joint posterior distribution is proportional to
| (3) |
The joint posterior distribution follows from (2) by replacing with ȳ0 with , and with , where
2.3 Estimation of τ
In this subsection we propose empirical and fully Bayesian methods for estimating τ, and evaluate frequentist properties of the corresponding models for estimating λ in the context of our proposed commensurate prior model.
2.3.1 Empirical Bayesian
In this subsection we consider parametric empirical Bayesian (EB) estimation (see e.g. Morris, 1983; Kass and Steffey, 1989; Carlin and Louis, 2009) in the context of our proposed commensurate prior models. Define . For known σ2 and v0, the marginal distribution of the current and historical data given hyperparameter τ, m(y, y0|τ ) = ∫θq(θ|τ, y, y0)dθ, follows from (2) and (3) as
| (4) |
EB inference for θ proceeds by replacing the scalar hyperparameter τ in (2) and (3) with its marginal maximum likelihood estimate (MMLE). Larger values of τ indicate an increasing lack of empirical evidence for heterogeneity, and lead to increased borrowing of strength from the historical data. Figure 2 contains marginal distributions of the data in (4) for three observed values of |Δ̂ |, where Δ̂ = μ̂−μ̂0 under the scenario that produced Figure 1 for one historical study. For sufficiently small |Δ̂ |, m(y, y0|τ ) is monotonically increasing as a function of τ, evident in the left plot corresponding to the case when Δ̂ = 0. It follows that arg maxτ>0 m(y, y0|τ ) = ∞, if . The center and right plots reveal that larger values of |Δ̂|, yield more peaked, unimodal functions.
Figure 2.

Marginal density of y, y0 |τ (4) as a function of τ for three values of |Δ̂|, where Δ̂ = μ̂ – μ̂0 and σ2 = 1, u0 = 1/n0, n0 = 60, n = 180, nd = 90.
Let ν = τ−1. We propose fixing ν* at the value that maximizes the marginal density of the data in (4), restricted to a pre-specified interval capturing the effective range of borrowing of strength. This leads to the following estimate for ν:
| (5) |
where 0 < lν < uν. Bounding the MMLE precludes full homogeneity when evidence for heterogeneity is not strong. That is, decreasing (increasing) lν will induce more (less) borrowing of strength from the historical data when unrestricted maximization results in infinite 1/ν*. Restricting ν* ∈ [2(0.052), 2(102)], which corresponds to η ∈ [0.05, 10] for one historical study, usually captures the effective range of borrowing of strength. However, these limits should be selected via formal evaluation of the induced frequentist operating characteristics and bias-variance trade-offs in context.
Let
= (y,
y0) denote the current and historical data, and
denote a set of fixed parameters characterizing a true state of the model. Define
. Given θtr, Z2 follows a non-central χ2 distribution,
. Let FZ2|θtr (·) denote its cumulative density function. The probability that ν* is fixed at lν in the EB inference of θ is
.
Various maximization techniques can be used to estimate ν* for the intractable case when variances are unknown, including Markov chain Monte Carlo (MCMC) methods considered by Geyer and Thompson (1992) and Doucet et al. (2002). EB inference typically “underestimates” variability in θ, since posterior uncertainty in ν* is unacknowledged in the analysis. However, in the following sections we demonstrate that our EB procedure has several desirable properties when compared to conventional random effects meta-analytic models.
2.3.2 Fully Bayesian
The EB procedure yields approximate full homogeneity when evidence for heterogeneity is not strong (although this can be adjusted via careful selection of the lower bound, lν). However, even for this scenario approximate full homogeneity may not be warranted. In this subsection we discuss fully Bayesian estimation in the context of our proposed commensurate prior models. By accounting for prior uncertainty when estimating τ, the fully Bayesian approach takes full account of uncertainty in the parameter estimates. Specifically, we consider two families of priors for τ, a conditionally conjugate gamma distribution, as well as a variant of the “spike and slab” distribution introduced by Mitchell and Beauchamp (1988) for variable selection.
For known σ2 and u0, the marginal posterior distribution of τ|y, y0 follows from (2) and (3) as
| (6) |
Assuming a flat prior on τ clearly leads to an improper posterior, e.g. and for is divergent.
A default choice for p(τ ) is the gamma family of distributions, p(τ ) = Γ (cτ̃, c), since, from (1) and (3), it leads to the following conjugate full conditional posterior distribution,
| (7) |
For this parameterization τ̃ > 0 can be thought of as a prior guess at τ, while scalar c > 0 represents degree of confidence, with a smaller value corresponding to weaker prior belief.
We also propose an alternative prior for τ that derives from the aptly named “spike and slab” distribution (Mitchell and Beauchamp, 1988). As the nomenclature suggests, the distribution is locally uniform between two limits, 0 ≤
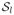 <
<
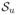 except for a bit of probability mass concentrated at point
except for a bit of probability mass concentrated at point
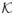 >
. Let p0 denote the prior probability that
≤ τ ≤
. Then, formally, the prior assumes
>
. Let p0 denote the prior probability that
≤ τ ≤
. Then, formally, the prior assumes
| (8) |
The reason that the spike and slab approach is appropriate in this context derives from the fact that sufficiently small values of Δ̂ result in marginal densities of the data (4) with nearly flat, gradually decreasing slopes as functions of τ, for sufficiently large τ. This is illustrated in the left plot of Figure 2. Therefore, given little evidence for heterogeneity, the marginalized likelihood prefers a large value for τ, but is virtually flat over a vast portion of the parameter space, providing little information to distinguish among values. This suggests a sensible approach may be to choose one carefully selected large value of τ (a “spike”), that characterizes commensurability. We demonstrate in the following sections that, when properly calibrated, this prior yields desirable frequentist properties. While the fully Bayesian methods are at less risk of dramatically overestimating τ, all of our methods are somewhat subjective and can therefore produce poor results if the model is incorrectly specified (the usual Bayesian “good model” assumption), thus making model checking an important component of this approach in practice.
2.3.3 Point estimation of λ
In this subsection we evaluate the proposed empirical and fully Bayesian commensurate prior models for estimating λ under squared error loss (SEL) and compare results to the full homogeneity model and the associated “no borrowing” model that ignores the historical data completely. Recall that we have assumed that the current trial’s objective is to compare a novel treatment to the previously studied control therapy. Thus, posterior inference on the novel treatment effect parameter, λ, is of primary interest. Let
= (y,
y0), and define
| (9) |
| (10) |
For known σ2 and u0, it follows from (2) and (3) that the marginal posterior distribution of λ, τ|
can be represented as the following product:
| (11) |
If the historical data are ignored, the marginal posterior for λ|y follows as
| (12) |
Let denote a set of fixed parameters. The preposterior risk under squared error loss (Carlin and Louis, 2009, p. 433), conditional on θtr is
| (13) |
Under fully Bayesian inference, the marginal posterior expectation of λ|
follows as
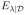 (λ) = ∫ λ̂τ q(τ|
)dτ. EB inference sets
(λ) = λ̂1/ν*, where ν* is defined in (5). The no borrowing and homogeneity models result in
(λ) = λ̂0 and λ̂∞, respectively.
(λ) = ∫ λ̂τ q(τ|
)dτ. EB inference sets
(λ) = λ̂1/ν*, where ν* is defined in (5). The no borrowing and homogeneity models result in
(λ) = λ̂0 and λ̂∞, respectively.
Preposterior risk (13) can be simulated using the following relationships derived from the conditional likelihood of
|θtr,
| (14) |
| (15) |
Figure 3 contains preposterior risk under SEL and bias as functions of Δtr resulting from inference under no borrowing, full homogeneity, as well as empirical and fully Bayesian commensurate prior models for H = 1, 2, and 3 historical studies under the same scenario that produced Figure 1: n = 180, nd = 90, n0,h = 60, (σtr)2 = 1 and
. Results are shown for an EB commensurate model that restricts ν* ∈ [2(0.052), 2(102)] = [0.005, 200], a fully Bayesian model that assumes a spike and slab prior for τ with hyperparameters,
= 0.005,
= 2,
= 200, and p0 = 0.99, as well as two fully Bayesian models assuming gamma priors for τ with hyperparameters c = τ̃−1 and τ̃ = 100, and 20, respectively.
Figure 3.

Preposterior risk under squared error loss and bias as functions of Δtr for H = 1, 2, and 3 historical studies.
Under no borrowing the posterior mean of λ|
is unbiased. Therefore, preposterior risk under SEL for the no borrowing inference follows from (12) as (σtr)2/{nd (1 – nd/n)}, and thus is constant as a function of Δtr. The plots reveal that all models obtain preposterior biases of zero when Δtr = 0. Assuming homogeneity a priori offers maximal variance reduction in this context, and thus is associated with the largest reductions in preposterior risk for Δtr near zero. Therefore, the resulting estimator is preposterior admissible. However, homogeneity leads to prohibitively biased estimators with sharply, monotonically increasing preposterior risk for |Δtr| > 0, rapidly trumping the gains in variance reduction. The top row of plots in Figure 3 reveal that preposterior risk for homogeneity exceeds no borrowing in this context for H = 1, 2, and 3 when |Δtr| > 0.2, > 0.16, and > 0.1, respectively.
In contrast to the no borrowing and homogeneity models, the commensurate prior models offer preposterior admissible estimators, with alternative bias variance trade-offs that facilitate more borrowing of strength for Δtr near zero and less borrowing for large values of |Δtr|. Numerous alternative bias variance trade-offs are attainable via adjustment to the model hyperparameters.
2.4 Comparison to meta-analysis
This subsection compares frequentist properties of our proposed commensurate prior models (2) and (3) with results for the meta-analysis models in Section 1.2 for the scenario that produced Figure 1 for the case when sampling level variances are unknown. Tables 2 and 3 augment Figure 3 and synthesize the relative bias-variance trade-offs when using the corresponding posterior expectation of λ|
as an estimator. Table 2 contains the percent change from no borrowing in preposterior risk under SEL given θtr for the five meta-analysis models, our proposed EB and fully Bayesian commensurate prior models, and the model that assumes full homogeneity. Negative values indicate reductions in preposterior risk. Table 3 contains the corresponding preposterior bias. Results are shown for H = 1, 2, and 3 historical studies and fixed true values of Δtr indicating various degrees of historical bias. Results are shown for fixed true standard deviation values
. The spike and slab prior uses the same hyperparameters that were proposed in the previous subsection with the exception of p0 which we now adjust to 0.7. If the historical data is ignored, the marginal posterior for λ|y now follows as
Table 2.
Percent change from no borrowing in preposterior risk under squared error loss for the specified model. For this scenario the result under no borrowing is equal to .
| Δtr = 0 | Δtr = 0.25 | Δtr = 0.5 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| H = 1 | 2 | 3 | H = 1 | 2 | 3 | H = 1 | 2 | 3 | |
| unif. var. | −1 | −3 | −11 | −1 | −1 | −1 | 0 | 1 | 4 |
| unif. shrink | −4 | −9 | −14 | −2 | −2 | −1 | 0 | 3 | 7 |
| half-Cauchy | −4 | −14 | −21 | −1 | 1 | 3 | 1 | 8 | 14 |
| unif. sd | −3 | −14 | −21 | −1 | 0 | 5 | 1 | 7 | 16 |
| inv. gamma | −12 | −20 | −25 | −1 | 4 | 9 | 8 | 20 | 31 |
|
| |||||||||
| emp. Bayes | −13 | −17 | −22 | 7 | 11 | 20 | 8 | 9 | 16 |
| spike & slab | −13 | −17 | −22 | 1 | 5 | 11 | 9 | 10 | 11 |
| Gamma(1,0.01) | −16 | −22 | −24 | 0 | 5 | 8 | 25 | 35 | 38 |
|
| |||||||||
| homogeneity | −19 | −28 | −32 | 25 | 61 | 86 | 152 | 337 | 475 |
Table 3.
Preposterior bias for the specified model:
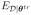 {
(λ)}− λtr
{
(λ)}− λtr
| Δtr = 0 | Δtr = 0.25 | Δtr = 0.5 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| H = 1 | 2 | 3 | H = 1 | 2 | 3 | H = 1 | 2 | 3 | |
| unif. var. | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.01 | 0.02 |
| unif. shrink | 0.00 | 0.00 | 0.00 | 0.01 | 0.02 | 0.03 | 0.01 | 0.02 | 0.03 |
| half-Cauchy | 0.00 | 0.00 | 0.00 | 0.01 | 0.03 | 0.04 | 0.01 | 0.03 | 0.04 |
| unif. sd | 0.00 | 0.00 | 0.00 | 0.01 | 0.03 | 0.05 | 0.01 | 0.02 | 0.04 |
| inv. gamma | 0.00 | 0.00 | 0.00 | 0.03 | 0.05 | 0.07 | 0.03 | 0.05 | 0.07 |
|
| |||||||||
| emp. Bayes | 0.00 | 0.00 | 0.00 | 0.03 | 0.04 | 0.05 | 0.02 | 0.02 | 0.03 |
| spike & slab | 0.00 | 0.00 | 0.00 | 0.03 | 0.03 | 0.04 | 0.02 | 0.02 | 0.02 |
| Gamma(1,0.01) | 0.00 | 0.00 | 0.00 | 0.05 | 0.06 | 0.07 | 0.07 | 0.08 | 0.08 |
|
| |||||||||
| homogeneity | 0.00 | 0.00 | 0.00 | 0.10 | 0.14 | 0.17 | 0.19 | 0.28 | 0.34 |
| (16) |
As in the previous subsection, preposterior risk under SEL given θtr follows as
. Note that marginal posteriors for λ|
corresponding to the commensurate prior models discussed in the previous subsection are now intractable due to required marginalization of the sampling variances.
First we consider the case when Δtr = 0. For the case of one historical study, Table 3 shows that all estimators are unbiased, yet Table 2 reveals that the meta-analysis estimators correspond to only slight reductions in preposterior risk under SEL, with the exception of the inverse gamma prior. In contrast, the commensurate models facilitate relatively large reductions in preposterior risk compared to the first four meta-analytic models. As in Figure 3, the gamma prior facilitates the largest reductions in preposterior risk, nearly approaching the reduction produced by highly subjective, full homogeneity.
When H > 1, inference using the uniform standard deviation and half-Cauchy priors in the meta-analysis framework provides considerably more reduction in preposterior risk than for H = 1. The inverse gamma prior facilitates even more reduction in preposterior risk. The uniform variance and uniform shrinkage priors offer considerably less reduction in preposterior risk. The commensurate prior models still facilitate more borrowing of strength than the first four models for meta-analysis leading to estimators with more reduction in preposterior risk, but less reduction than that obtained by full homogeneity.
When 0 < Δtr ≤ 0.5, the tables suggest that preposterior risk and bias are non-decreasing in H for all models. The highly subjective homogeneity model yields highly biased estimators corresponding to substantial increases in preposterior risk. The gamma model estimator is most biased among the commensurate prior estimators, which leads to large increases in preposterior risk for Δtr = 0.5. The spike and slab model estimator provides perhaps the best overall bias-variance trade-off among the commensurate prior estimators, given that it is least biased and results in relatively smaller increases in preposterior risk. Moreover, it provides equal or less bias than the half-Cauchy meta-analysis prior estimator when H > 1. Among the meta-analysis models, only the inverse gamma prior facilitates meaningful variance reduction from borrowing of strength for the case of one historical study. However, when Δtr = 0.5 the inverse gamma meta-analysis prior results in an increase in relative preposterior risk that is nearly two and three times larger than that for the spike and slab commensurate prior estimator for H = 2 and = 3, respectively.
3 General linear models
In this section we introduce general linear and general linear mixed commensurate prior models for Gaussian response data in the context of two successive clinical trials. In addition, we assume that both trials identically measure p – 1 covariates representing fixed effects which are to be incorporated into the analysis. As before, we assume that the second (current) trial compares a novel intervention to a previously studied control therapy that was used in the first trial, and thus historical data are available only for the control group. Furthermore, commensurate priors are constructed to inform about fixed regression effect parameters.
3.1 Fixed effect models
Assume y0 is a vector of n0 responses from patients in the historical study of an intervention that is to be used as a control in a current trial testing a newly developed intervention for which no reliable prior data exist. Let y be the vector of n responses from subjects in both the treatment and control arms of the current trial. Suppose that both trials are designed to identically measure p – 1 covariates of interest. Let X0 be an n0 × p design matrix and X be an n × p design matrix, both of full column rank p, such that the first columns of X0 and X are vectors of 1s corresponding to intercepts.
Suppose and y ~ Nn(Xβ + dλ, σ2) where λ is the (scalar) treatment effect and d is an n × 1 vector of 0 – 1 indicator variables for the new treatment. Let yi,Xi, di represent data corresponding to the ith subject in the current trial, i = 1, …, n. Commensurability in the linear model depends upon similarity among the intercepts and covariate effects. Yet, the strength of empirical evidence for heterogeneity among the current and historical data may vary across covariates. We formulate the commensurate linear model by replacing τ in Section 2 with a vector τ = (τ1, …, τp) containing a commensurability parameter, τg, for each associated pair of parameters in βg and β0g. The commensurate priors follow as , for g = 1, …, p, and the βgs are assumed a priori independent.
Let and Δ = β–β0, let diag{u} denote the diagonal matrix consisting of the elements of vector u, and let Ia denote the identity matrix of dimension a. The joint posterior distribution of θ|τ, y, y0 follows as proportional to
| (17) |
Let β̂λ = (XTX)−1XT (y–dλ) and , and . Under a flat prior, the full conditional posterior for λ is proportional to N (λ̂β, σ2/nd). Let Vτ denote the precision matrix that results from averaging the commensurate prior over the historical likelihood:
| (18) |
Thus, assuming a flat initial prior and marginalizing β0 results in a conditional posterior for β|y, y0, λ, σ2, , τ proportional to
| (19) |
Notice that the full conditional posterior mean for λ, λ̂β, is a function of residuals (y – Xβ), whereas the conditional posterior mean of β in (19) is an average of the historical and concurrent data relative to the estimated commensurability parameter vector τ. As τ approaches 0, the posterior for β converges to a normal density with mean β̂λ and variance , recovering the standard result from linear regression that ignores all of the historical data. In this case, λ̂β also converges to the “no borrowing” estimate of the treatment effect. Moreover, as τg approaches infinity, for all g = 1, …, p, precision , fully incorporating the historical data, recovering full homogeneity. Full conditional posteriors for β0, σ2, and under noninformative priors are provided in Appendix A.
3.2 Mixed models
In this subsection, we extend the model to include random effects. We begin with a familiar and useful one-way ANOVA model. Then following McCulloch and Searle (2001, p.156), we give the linear mixed model for general variance-covariance structures between and within levels of the random components.
3.2.1 One-way random effects model
Following the notation of Browne and Draper (2006), suppose y0jk = μ0 + u0k + ∊0jk, where for k = 1, …, n0j, j = 1, …, m0, and . Variance component represents the conditional variance of y0jk|u0j, while the marginal variance of y0jk follows as . Note that observations from different subjects are assumed to be uncorrelated. The model for responses in the current trial follows yig = μ + ui + diλ + ∊ig, for g = 1, …, ni; i = 1, …, m, where and . As before, di = 1 indicates treatment and di = 0 corresponds to the standard of care for the ith subject in the current trial. Therefore, fixed effects μ and λ represent the intercept and treatment effect for a patient receiving the new intervention. Given no initial information, the commensurate prior for μ is proportional to a normal distribution with mean μ0 and precision τ.
Following the recommendations of Gelman (2006), we use independent noninformative uniform priors on σu0 and the current random-effects standard deviation, for large m (≥ 5), which is equivalent to a product of inverse-χ2 densities with −1 degrees of freedom, . For small m (< 5), we use the half-Cauchy prior discussed in Section 1.2.
Let θ denote the parameter vector. The joint posterior distribution for θ|τ, y, y0 is proportional to
| (20) |
where 1u is a 1 × u column vector of 1s, and Ju is a u × u matrix of 1s. The Gibbs sampler is implemented by sampling the latent variables u0j and ui.
To ease the subsequent algebra required to marginalize (20), note that times the inverted marginal estimated historical covariance for all observations in subject j, , is equal to , which has n0j − 1 eigenvalues equaling 1 and one non-unit eigenvalue equal to , where . Similarly, has ni − 1 eigenvalues equaling 1 and one non-unit eigenvalue equal to , where . Let
| (21) |
After marginalizing μ0, the conditional posterior for μ|λ, u0, u, , τ is proportional to . Full conditional posteriors for the remaining parameters can be found in Appendix B.
Several alternative prior specifications for the correlation structure may be more natural for incorporating prior information on the variance components. For example, we could formulate our prior opinion about the model smoothness by specifying a prior on the variance ratio, or the degrees of freedom it induces (Hodges and Sargent, 2001). For discussion about degrees of freedom and how they can be used to sensibly determine variance component priors, as well as the general marginal posterior for the variance ratio, see Reich and Hodges (2008), and Cui et al. (2010).
3.2.2 Linear mixed model
The one-way random effects model presented above is a special case of a linear mixed model for which between-subject observations are independent, all within subject observations have identical covariance (compound symmetry within groups), and there are no fixed regression effects (only intercepts). In this subsection we extend to the general linear mixed model.
Following the notation presented above, denote and . Suppose X0 and X are n0 × p and n × p design matrices such that the first columns contain vectors of 1s corresponding to the intercepts, β and β0 are vectors of identically measured regression coefficients of length p representing fixed covariate effects, and d is an n × 1 new intervention indicator. Furthermore, let u0, u and Z0, Z denote m0 × 1 and m × 1 random effects vectors and their respective n0 × m0 and n × m design matrices for the historical and current data.
Adopting the notation of McCulloch and Searle (2001, p.156), we formulate the general linear mixed model by first assuming normally distributed random effects with covariances D0 and D, u0 ~ N (0, D0) and u ~ N (0, D). Models for the historical and concurrent responses are y0 = X0β0 + Z0u0 + ∊0 and y = Xβ + Zu + dλ + ∊, where ∊0 ~ Nn0 (0, R0) and ∊ ~ Nn(0, R); R0 and R represent the conditional covariances of y0|u0 and y|u. The marginal covariances for y0 and y are and Σ = ZDZT + R, respectively. The precision matrix Vτ in (18) follows as
| (22) |
The conditional posterior distribution for β|λ, D0, R0, D, R, τ is proportional to
| (23) |
where β̃λ = (XTΣX)−1XT (y − dλ), and , are the usual integrated least squares estimates. Treating the random effects as latent variables and adopting conjugate Wishart priors for D−1 and R−1 and their historical counterparts, namely D−1 ~ W (ϕD̃, ϕ) and R−1 ~ W(ρR̃, ρ), posterior inference may proceed via the Gibbs sampler. The remaining full conditional posteriors can be found in Appendix C.
If we assume that observations are uncorrelated across subjects, the covariance structures simplify to , and . The resulting model extends the one-way random effects model above to incorporate fixed covariate effects. Using the same priors as before, the full conditional posteriors for and follow as and . See Kass and Natarajan (2006) for an empirical Bayes approach using an inverted Wishart prior on Σ for general covariance structures and design matrices.
4 Generalized linear models
In this section we extend the methodology to incorporate generalized linear models for non-Gaussian error distributions. The methodology is generalized to include data from exponential families assuming Gaussian approximations of the product of the initial prior and historical likelihood using the Bayesian Central Limit Theorem (see e.g. Carlin and Louis, 2009, p.108). For a flat initial prior, the approximation takes mean equal to the historical MLE and variance equal to the inverted observed Fisher information matrix. These approximations are used frequently in Bayesian analysis for data assumed to follow from exponential families (Spiegelhalter et al., 2004, p.23; Gelman et al., 2004, p.101). While computational methods can handle the full model, the approximations facilitate dimension reduction for the numerical problem of estimating the crucial MMLE of τ when using EB inference, since β0 is readily marginalized analytically.
We first present the general method for fixed effects models, and then discuss logistic regression models for binary outcomes and a Weibull regression model. We then extend the general method to incorporate random effects, and illustrate in two important specific cases: a probit regression model for binary outcomes, and a Poisson regression model for count data. The Weibull regression model is used to analyze patient-level data from two successive colorectal cancer trials in Section 5 for both the approximate and full commensurate prior models.
4.1 Fixed effect models
Let y0 and y denote column vectors of length n0 and n consisting of independent measurements from a distribution that is a member of the exponential family, fY (y). That is, we suppose and such that the log-likelihoods are of form
| (24) |
| (25) |
for j = 1, …, n0 and i = 1, …, n (McCulloch and Searle, 2001, p.139). Following the notation of Section 3, let g(μ0) = X0β0 and g(μ) = Xβ + dλ, for known “link” function g() where E [y0] = μ0 and E [y] = μ.
Using the Bayesian Central Limit Theorem, we replace the product of the initial prior and historical likelihood, fY0 (y0|β0)p(β0), with an asymptotic normal approximation, p̂(β0|y0). This density is an approximate sequential Bayesian update of the initial prior for β0. For a flat initial prior, the approximation takes mean equal to the historical MLE (computed numerically via Newton-Raphson or Fisher scoring) and variance equal to the inverted observed Fisher information matrix, , where Ŵ0 = W0(μ̂0) is an n0 × n0 diagonal matrix having jj–element
| (26) |
where , for j = 1, …, n0 (McCulloch and Searle, 2001, p.141). Following Subsection 3.1, the commensurate prior for β is proportional to Np(β0, diag{τ}−1). Let θ denote the general parameter vector, θ = (β, β0,ν, ν0,λ). Assuming a flat prior for λ, the approximate joint posterior distribution of θ|τ, y, y0 is proportional to
| (27) |
After marginalizing over β0, the precision matrix in (18) follows as,
| (28) |
and the posterior distribution of β, λ|τ, y, y0 is proportional to
| (29) |
Non-Gaussian data results in intractable non-conjugate full conditional distributions, therefore posterior inference requires alternative MCMC sampling methods (see e.g. Carlin and Louis, 2009), such as the Metropolis algorithm.
4.1.1 Binary response
Let y0 and y denote the historical and current data such that y0j ~ Ber {π0(X0j)}, π0(X0j) ∈ [0, 1], for j = 1, …, n0, and yi ~ Ber {π (Xi, di)}, π (Xi, di) ∈ [0, 1], for i = 1, …, n. The logistic link function transforms the expectations of y0 and y such that and . The diagonal elements of Ŵ0 in (27) and (28) now consist of the estimated historical sampling variance, Ŵ0jj = π̂0(X0j) {1 − π̂0(X0j)}, where π̂0(X0j) = (1 + e−X0jβ̂0)−1. Assuming a flat prior for λ, the posterior distribution of β, λ|τ, y, y0 is proportional to
Sampling proceeds by Metropolis, though switching to a probit link function can lead to closed form full conditionals (Albert and Chib, 1993). Fúquene, Cook, and Pericchi (2009) propose an approach using a robust Cauchy prior for univariate logistic models.
4.1.2 Time-to-event response
Following the notation of Kalbfleisch and Prentice (2002, p.52), data for the historical and current trials consist of triples (t0j, δ0j, X0j) for j = 1, …, n0 and (ti, δi, Xi) for i = 1, …, n. Here, t0j, ti > 0 are the observed, possibly censored, failure times; δ0j, δi are noncensoring indicators (0 if censored, 1 if failure); and X0j and Xi are row vectors of p covariates associated with historical subject j and current subject i. Let t̃0j and t̃i be the underlying uncensored failure times, with corresponding densities f(t0j) and f(ti). Denote the survival functions for the jth historical and ith current individuals by Pr(t̃i > t) = F (t) and Pr(t̃0j > t0) = F (t0).
Log-linear models are commonly used for analyzing time-to-event data. Suppose y0 = log(t0) = X0β0 + σ0e0 and y = log(t) = Xβ + dλ + σe where e0 = (y0 − X0β0)/σ0 and e = (y − Xβ − d λ)/σ. Assuming that censoring times are conditionally independent of each other and of the independent failure times given X0 and X (noninformative censoring), the historical and current data likelihoods follow as and . Assuming a flat prior for λ, the commensurate prior model follows from (27) where ML estimates for β0 and σ0 are computed numerically via Newton-Raphson or Fisher-Scoring; see Kalbfleisch and Prentice (2002, p.66–69). For discussion about censoring mechanisms see Kalbfleisch and Prentice (2002, p.193) or Klein and Moeschberger (2003, p.63).
Weibull regression arises when e0 and e are assumed to follow the extreme value distribution, f(u) = exp {u − exp (u)}. This results in a parametric regression model which has both a proportional hazards and an accelerated failure-time representation. The hazard function, h(t) = −d log F(t)/dt, is monotone decreasing for shape parameter σ > 1, increasing for σ < 1, constant for σ = 1. We assume commensurate priors for both the regression coefficients, β, and log transformation of the shape parameter, σ. Let and ζ = {βT, log(σ)}T denote column vectors of length p + 1. Let e0, δ0, and exp(e0) − δ0 denote vectors of length n0 such that the jth element is equal to e0j, δ0j, and exp(e0j) − δ0j, j = 1, …, n0. ML equations for the historical coefficients follow as and . Let ê0j = (y0j − X0jβ̂0)/σ̂0. The observed Fisher information matrix, Ψ̂0(ζ̂0), follows as
| (30) |
where Ê0 is the vector of length n0 containing elements Ê0j = (ê0j +1) exp{ê0j − log(σ̂0)}− δ0j/σ̂0, and the diagonal elements of Ŵ0 are , for j = 1, …, n0 (see Breslow and Clayton, 1993). Assuming no initial prior information for ζ0 and that the prior on λ is flat, the posterior distribution for ζ, λ|τ, y, y0 follows directly from (29) by replacing in (27) and (28) with Ψ̂0(ζ̂0). Note that the exponential model is a special case where σ0 = σ = 1, since this leads to probability density functions for t0 and t following and where μ0 = exp(X0β0) and μ = exp(Xβ + dλ); t0/μ0 is a vector of length n0 with jth element equal to t0j/exp(X0jβ0), and similarly, t/μ is a vector of length n with ith element equal to ti/exp(Xiβ + diλ).
4.2 Mixed models
As with the general linear models in Section 3, we now extend our generalized linear model to the mixed model case. Following the notation of Subsection 3.2, let y0j and yi denote response vectors of lengths n0j and ni consisting of conditionally independent measurements given random effects u0j and ui, j = 1, …, m0; i = 1, …, m, where u0 and u are vectors of length m0 and m. For generalized linear mixed models, we assume the conditional distributions of y0 given u0 and y given u have p.d.f.s from the exponential family, and , where log fY0 (y0|u0) and log fY (yi|u) follow (24) and (25). In addition, assume that the random effects follow distributions u0 ~ fU0 (u0) and u ~ fU (u). The marginal likelihoods follow as and .
Assuming that the conditional means are E (y0|u0) = μ0 and E (y|u) = μ, let g(μ0) = X0β0 + Z0u0 and g(μ) = Xβ + dλ + Zu, where g() is a known link function (note that Z0, Z, X0, X, d and parameters D, D0 are defined in Subsection 3.2.2). Following Subsection 4.1 for normally distributed random effects, u0 ~ N (0, D0) and u ~ N (0, D), the posterior distribution of β, λ|τ, y, y0, follows from (29) with Ŵ0 in (27) and (28) replaced by . See McCulloch (1997), McCulloch and Searle (2001, p.263), or Breslow and Clayton (1993) for algorithms for computing ML estimates for fixed effects and prediction of random effects.
4.2.1 Binary response
Suppose that the historical responses follow y0jk|u0j ~ Ber {π0(X0j)}, where y0jk denotes observation k for the jth patient, k = 1, …, n0j, j = 1, …, m0. The current responses follow yig|ui ~ Ber {p(Xig, di)}, where yig denotes observation g for the ith patient, g = 1, …, ni, i = 1, …, m. Since the logit link function was discussed in Section 4.1.1, we will consider the probit link. Given u0 ~ N (0, D0), the probit uses the standard normal c.d.f., Φ(), to transform the means of y0 and y such that π0(X0, Z0) = Φ(β0X0 + Z0u0) and p(X, d, Z) = Φ(Xβ + dλ + Zu). The posterior distribution of β, λ|τ, y, y0 follows from (29) by replacing Ŵ0 in (27) and (28) with , and setting
where ϕ() is the standard normal p.d.f. (McCulloch and Searle, 2001, p.136).
4.2.2 Count response
Suppose that the historical responses follow , where log(μ0jk) = X0jkβ0 + u0j and . Here, y0jk denotes the kth count observed for the jth patient, where k = 1, …, n0j and j = 1, …, m0. Similarly, let yig denote the gth count observed for the ith patient, where , log(μig) = Xigβ + ug, and , for g = 1, …, ni and i = 1, …, m. The posterior distribution of β, λ|τ, y, y0 follows from (29) by replacing Ŵ0 in (27) and (28) with , and setting
5 Case study: analysis of successive colon cancer trials
In this section, we illustrate our method using data from two successive randomized controlled colorectal cancer clinical trials originally reported by Saltz et al. (2000) and Goldberg et al. (2004), respectively. The initial trial randomized N0 = 683 patients with previously untreated metastatic colorectal cancer between May 1996 and May 1998 to one of three regimens: Irinotecan alone; Irinotecan and bolus Fluorouracil plus Leucovorin (IFL); or a regimen of Fluorouracil and Leucovorin (5FU/LV) (“standard therapy”). IFL resulted in significantly longer progression-free survival and overall survival than both Irinotecan alone and 5FU/LV and became the standard of care treatment (Saltz et al., 2000).
The subsequent trial compared three new (at the time) drug combinations in N = 795 patients with previously untreated metastatic colorectal cancer, randomized between May 1999 and April 2001. Patients in the first drug group received the current “standard therapy,” the IFL regimen identical to that used in the historical study. The second group received Oxaliplatin and infused Fluorouracil plus Leucovorin (abbreviated FOLFOX), while the third group received Irinotecan and Oxaliplatin (abbreviated IROX); both of these latter two regimens were new as of the beginning of the second trial.
Both trials recorded two bi-dimensional measurements on each tumor for each patient at regular cycles. The Saltz trial measured patients every 6 weeks for the first 24 weeks and every 12 weeks thereafter until death or disease progression, while the Goldberg trial measured every 6 weeks for the first 42 weeks, or until death or disease progression. We computed the sum of the longest diameter in cm (“ld sum”) for up to 9 tumors for each patient at baseline. In both trials, disease progression was defined as a 25% or greater increase in measurable tumor or the appearance of new lesions.
This section offers a fixed effects time-to-event analysis using the Weibull regression model presented in Subsection 4.1.2 to compare disease progression among the FOLFOX and IFL regimens. The historical data consists of the IFL treatment arm from the initial study, while the current data consists of patients randomized to IFL or FOLFOX in the subsequent trial. For simplicity, we omit data from the Irinotecan alone and 5FU/LV arms in the Saltz study, and the IROX arm in the Goldberg study. The model incorporates baseline ld sum as a predictor.
We restricted our analysis to patients that had measurable tumors and observed baseline covariates bringing the total sample size to 586: 224 historical and 362 current observations. Among the current patients, 176 are controls (IFL) and 186 are patients treated with the new regimen (FOLFOX). Figure 4 contains Kaplan-Meier estimated time to progression curves for subjects on each treatment regimen in both trials. The plots suggest that the time to progression experience for subjects on IFL was similar in both the Saltz (left panel) and Goldberg trials (center), and that FOLFOX (right) is associated with somewhat prolonged time-to-progression.
Figure 4.

Separate Kaplan-Meier curves for time to disease progression corresponding to subjects on IFL in the Saltz trial (left), IFL in the Goldberg trial (center), and FOLFOX in the Goldberg trial.
Following the log-linear model notation of Subsection 4.1.2 for progression times t0 and t, let y0 = X0β0 + σ0e0 and y = Xβ + dλ + σe, where y0 = log(t0) and y = log(t); here, X0 and X are n0 × 2 and n × 2 design matrices with columns corresponding to (1, ld sum at baseline), and d is the FOLFOX indicator. Thus, the β0 and β parameters contain intercepts as well as a regression coefficient corresponding to the baseline covariate, while exp(λ) represents the acceleration factor associated with FOLFOX. Note that since F(t|d = 1) = F (teλ|d = 0) for all t, a negative value is indicative of decreased survival. Exploratory data analysis on the covariate and age at baseline suggested that the trials enrolled patients from comparable populations. The first, second, and third quartiles for baseline tumor sum are 5, 8.5, 12.8 in the Saltz trial and 4.7, 7.9, 12.7 in the Goldberg trial; for age they are 54, 62, 69 in the Saltz trial and 53, 61, 69 in the Goldberg trial.
Table 4 summarizes results from separate and pooled classical linear regression fits to the historical (t0, X0) and current (t, X, d) data. The “current” values constitute a “no borrowing” analysis. Results from the current data alone suggest that the estimated acceleration factor corresponding to FOLFOX is highly significant at the 0.05 level. Point estimates (posterior means) and posterior standard deviations corresponding to both the Gaussian approximation and full commensurate prior models are provided in Table 5. The fully Bayesian spike and slab model uses the same hyperparameters for p(τ) that were used to produce Tables 2 and 3 in Section 2.4. For the EB model , for j = 1, 2, and 3 denote the MMLEs of the commensurability parameters corresponding to the intercept, regression coefficient for ld sum at baseline, and log-shape parameters, respectively. The s were maximized over a restriction to the interval (0.005, 200), the same interval used in Section 2.3. Table 5 reveals that posterior inferences using the Gaussian approximated and full MCMC models provide congruous results in this context. Posterior distributions for the τs are highly right-skewed, with large standard deviations inducing compromises among the evidence supplied by the historical and current data.
Table 4.
Weibull model fits to colorectal cancer data n0 = 224, n = 362.
| Separate analyses | Pooled analysis | |||||
|---|---|---|---|---|---|---|
| Historical | Current | est | sd | |||
| est | sd | est | sd | |||
| Intercept | 5.503 | 0.058 | 5.555 | 0.067 | 5.533 | 0.045 |
| BL ld sum | −0.043 | 0.051 | −0.115 | 0.045 | −0.092 | 0.034 |
| FOLFOX | – | – | 0.417 | 0.092 | 0.453 | 0.077 |
| log(σ) | −0.291 | 0.060 | −0.153 | 0.039 | −0.186 | 0.033 |
Table 5.
Commensurate prior Weibull model fits to colorectal cancer data n0 = 224, n = 362. Gaussian approximate model (top), full model (bottom).
| EB | Approximate | Gamma(1, 0.01) | ||||
|---|---|---|---|---|---|---|
| spike & slab | ||||||
| est | sd | est | sd | est | sd | |
| Intercept | 5.540 | 0.054 | 5.544 | 0.058 | 5.546 | 0.059 |
| BL ld sum | −0.100 | 0.040 | −0.103 | 0.041 | −0.105 | 0.042 |
| FOLFOX | 0.436 | 0.084 | 0.434 | 0.085 | 0.432 | 0.087 |
| log(σ) | −0.152 | 0.038 | −0.159 | 0.039 | −0.158 | 0.038 |
| τ1 | 200 | – | 153.7 | 84.0 | 123.4 | 106.3 |
| τ2 | 200 | – | 157.1 | 81.8 | 124.2 | 106.2 |
| τ3 | 40.0 | – | 121.6 | 97.2 | 98.7 | 90.7 |
| EB | Full Model | Gamma(1, 0.01) | ||||
|---|---|---|---|---|---|---|
| spike & slab | ||||||
| est | sd | est | sd | est | sd | |
| Intercept | 5.541 | 0.054 | 5.547 | 0.058 | 5.546 | 0.058 |
| BL ld sum | −0.100 | 0.040 | −0.103 | 0.042 | −0.105 | 0.042 |
| FOLFOX | 0.435 | 0.085 | 0.431 | 0.086 | 0.432 | 0.085 |
| log(σ) | −0.152 | 0.038 | −0.158 | 0.038 | −0.158 | 0.038 |
| τ1 | 200 | – | 153.2 | 84.4 | 124.8 | 107.3 |
| τ2 | 200 | – | 153.8 | 83.9 | 123.8 | 106.7 |
| τ3 | 40.0 | – | 126.1 | 96.1 | 102.5 | 93.7 |
Incorporating the Saltz data into the analysis of the Goldberg trial using our proposed method leads to more precise parameter estimates (i.e., reductions to the posterior standard deviation for the FOLFOX effect of nearly 9%, 8%, and 5% for the EB, spike and slab, and gamma models, respectively). The two fully Bayesian commensurate prior analyses offer relatively similar amounts of borrowing of strength from the historical data. Moreover, these models provide considerably less borrowing of strength than that provide by pooling, which facilitates a 16% reduction in posterior standard deviation for estimating the FOLFOX effect. The EB procedure leads to more precise, naive estimates, and thus more borrowing of strength overall when compared to the fully Bayesian results. However, EB inference actually leads to less borrowing of strength from the historical data for estimating log(σ).
Note that our commensurate prior models estimate time-to-progression to be nearly exp(0.43) times larger on average in the FOLFOX group, and since the posteriors for log(σ) are less than 0, the hazard rates are increasing slightly over time. This finding is consistent with those of Goldberg et al. (2004), who determined FOLFOX to have superior time-to-progression and response rate compared to IFL.
6 Simulation study
In this section we use simulation to evaluate the Bayesian and frequentist operating characteristics of our proposed empirical Bayesian commensurate prior model for the challenging case of one historical study. Figure 5 plots coverage and width of the 95% highest posterior density (HPD) intervals for λ by for the Gaussian (left) and exponential (right) time-to-event models described in Sections 3 and 4. Results for Gaussian data are compared for the no borrowing, half-Cauchy meta-analytic, EB commensurate, and homogeneity models under simulated data for n0 = 90 historical patients, equal allocation of n = 180 current patients, and fixed true parameters, μtr = 0, and . Results for the exponential model are compared for the no borrowing, EB commensurate, and homogeneity models simulated for μtr = 2, n0 = 200, and equal allocation of n = 100 current patients.
Figure 5.

Coverage and width of 95% HPD intervals for λ by Δtr or exp(Δtr) for Gaussian and exponential data for one historical study.
Figure 5 reveals that all four of the Gaussian models (left) provide 95% highest posterior density coverage and achieve their minimum interval widths when the historical data are unbiased, Δtr = 0. As |Δtr| > 0, we see that the interval widths increase. While coverage for the relatively conservative half-Cauchy models deviates little from the no borrowing model, the highly subjective full homogeneity model provides increasingly poorer coverage. The EB commensurate prior model offers a sensible compromise that offers more precision given lack of strong empirical evidence for heterogeneity, yet protects against poor coverage provided that the historical data is estimated to be highly biased. Results for the exponential model given in the right column of Figure 5 follow the same general trends. A referee encourages us to remind the reader that coverage probabilities of EB intervals are sometimes too small (Carlin and Louis, 2009, Chapter 5); we would expect our fully Bayesian spike and slab or gamma prior models would perform slightly better in this regard.
Next we present a sensitivity analysis for the four Gaussian models. Following Freedman et al. (1984), suppose the parameter space of λtr is partitioned into three intervals characterizing three true states of nature: λtr < −δ implies failure, −δ ≤ λtr ≤ δ implies equivalence, and λtr > δ implies efficacy. Suppose that the current trial analysis evaluates decision rules using posterior tail densities such that
| (31) |
We approximated the probability surfaces of the four stopping rules in (31) using simulation for a myriad of true values of
and λtr for no borrowing, half-Cauchy meta-analytic, EB commensurate, and homogeneity models. We formulated a metric that facilitates comprehensive assessment of the four models by synthesizing the amount of probability allocated to the correct and incorrect decision spaces. Let = (y, y0) denote the collection of current and historical response data, and let L(|θ) denote the joint likelihood, where
. Let I(a) denote the indicator function of the event a, and let ϕ(·|θtr) denote the probability of a decision rule given a fixed set of parameters, θtr i.e.
| (32) |
For fixed true values σtr, , and the metric of comparison follows as
| (33) |
where c ∈ [0, 1] is a positive scalar that weights the relative importance of an inconclusive result. The metric M(c) ∈ [−1, 1], a generalized version of expected 0 – 1 loss, is evaluated for c = 1/2 and δ = 0.33 under prior p(Δtr) = N(0, s2), for three values of s: s = 0, 1, 30, characterizing likely degrees of bias. All results are computed for p(λtr) = N(0, 1/4). Larger values of M(c) indicate overall more desirable probability allocation among the four decision rules. The prior distributions on Δtr and λtr essentially weight the relative importance of different subsets of the decision rule probability surfaces.
Table 6 summarizes the simulation results for M(c) in (33). The top portion of the table contains results for the unrealistic case of a priori absolute certainty that the historical data is unbiased. In this scenario the highly subjective full homogeneity model exceeds our proposed EB commensurate model by 0.03. This occurs largely because borrowing of strength in this context yields unbiased results for λ. For the more likely cases when the a priori assessment of historical bias is more uncertain in the middle and bottom portions of Table 6, the EB commensurate model provides the best overall probability allocation as measured by M(c), while the highly subjective full homogeneity model provides the least desirable results. These results are sensitive to alternative weights we might subjectively assign to the outcomes we are penalizing.
Table 6.
Simulation results for M(c) and its components in (33) for p(Δtr) = N(0, s2) and c = 1/2.
| M(c) | s=0 | |||||||
|---|---|---|---|---|---|---|---|---|
| +Eff | +Fail | +Equi | −Eff | −Fail | −Equi | −Inc | ||
| no borrow | 0.19 | 0.13 | 0.13 | 0.20 | 0.00 | 0.00 | 0.01 | 0.26 |
| half-Cauchy | 0.20 | 0.13 | 0.14 | 0.20 | 0.00 | 0.00 | 0.01 | 0.26 |
| emp. Bayes | 0.29 | 0.14 | 0.15 | 0.24 | 0.00 | 0.00 | 0.01 | 0.23 |
| homog. | 0.32 | 0.15 | 0.15 | 0.25 | 0.00 | 0.00 | 0.01 | 0.22 |
|
| ||||||||
| s=1 | ||||||||
|
| ||||||||
| no borrow | 0.19 | 0.13 | 0.13 | 0.20 | 0.00 | 0.00 | 0.01 | 0.26 |
| half-Cauchy | 0.21 | 0.13 | 0.14 | 0.20 | 0.00 | 0.00 | 0.01 | 0.25 |
| emp. Bayes | 0.24 | 0.14 | 0.15 | 0.21 | 0.00 | 0.00 | 0.02 | 0.24 |
| homog. | 0.14 | 0.14 | 0.15 | 0.12 | 0.00 | 0.00 | 0.07 | 0.21 |
|
| ||||||||
| s=30 | ||||||||
|
| ||||||||
| no borrow | 0.19 | 0.13 | 0.13 | 0.20 | 0.00 | 0.00 | 0.01 | 0.26 |
| half-Cauchy | 0.21 | 0.13 | 0.14 | 0.20 | 0.00 | 0.00 | 0.01 | 0.25 |
| emp. Bayes | 0.23 | 0.14 | 0.14 | 0.21 | 0.00 | 0.00 | 0.02 | 0.24 |
| homog. | 0.07 | 0.14 | 0.14 | 0.08 | 0.00 | 0.00 | 0.07 | 0.21 |
7 Discussion
In this paper, we provided empirical and fully Bayesian modifications of commensurate prior formulations (Hobbs et al., 2011), and extended the method to facilitate linear and generalized linear models. The proposed models are shown to lead to preposterior admissible estimators that facilitate alternative bias-variance trade-offs than those offered by pre-existing methodologies for incorporating historical data from a small number of historical studies. The method was also used to analyze data from two recent studies in colorectal cancer.
Future work looks toward extending the methodology to include time-dependent covariates, smoothed hazards, multiple events, Bayesian semi-parametric Cox models as e.g. Ibrahim, Chen, and Sinha (2001, p.47), and non-normal formulations of the commensurate prior itself. We are also currently pursuing the use of commensurate priors with adaptive randomization that allows the sample size or allocation ratio in the ongoing trial to be altered if this is warranted. For example, if historical and concurrent controls emerge as commensurate, we might assign fewer patients to the control group, thus enhancing the efficiency of the ongoing trial by imposing “information” balance.
Acknowledgments
Acknowledgements
The authors are grateful to Drs. B. Nebiyou Bekele, Donald Berry, Joseph Ibrahim, Telba Irony, Valen Johnson, Peter Müller, Brian Neelon, A. James O’Malley, and Luis Raul Pericchi for helpful discussions, and Drs. Xiaoxi Zhang and Laura Cisar from Pfizer for permission to use the Saltz et al. (2000) colorectal cancer dataset, as well as Erin Green and Brian Bot from the Mayo Clinic, Rochester for help with the Saltz et al. (2000) and Goldberg et al. (2004) datasets. The authors would like to also thank two anonymous referees who improved the quality of the presentation. The work of the first author was supported in part by the University of Texas M.D. Anderson’s Cancer Center Support Grant NIH P30 CA016672. The work of the second author was supported in part by National Cancer Institute grant CA25224. The work of the third author was supported in part by National Cancer Institute grant 2-R01-CA095955-05A2.
Appendix A
Full conditional posterior distributions for β0, σ, and σ0 assuming noninformative priors for the commensurate prior linear model presented in Subsection 3.1 are as follows:
Appendix B
Here we present full conditional posterior distributions corresponding to the commensurate prior one-way random effects model presented in Subsection 3.2. Let
and . Full conditional posteriors for μ0, λ, u, u0, and follow as:
Appendix C
Here we present full conditional posteriors for the general commensurate prior linear mixed model presented in Subsection 3.2. The full conditional posteriors for λ, β0, u, u0, D−1, , R−1, and follow as:
where || . || denotes the inner product.
Contributor Information
Brian P. Hobbs, Department of Biostatistics, M.D. Anderson Cancer Center, Houston, TX, 77030, USA
Daniel J. Sargent, Department of Health Sciences Research, Mayo Clinic, Rochester, MN, 55905, USA
Bradley P. Carlin, Division of Biostatistics, University of Minnesota, Minneapolis, Minnesota, 55455, USA
References
- Albert JH, Chib S. Bayesian analysis of binary and polychotomous response data. Journal of the American Statistical Association. 1993;88:669–679. [Google Scholar]
- Breslow NE, Clayton DG. Approximate inference in generalized linear mixed models. Journal of the American Statistical Association. 1993;88:9–25. [Google Scholar]
- Browne WJ, Draper D. A comparison of Bayesian and likelihood-based methods for fitting multilevel models. Bayesian Analysis. 2006;1:473–514. [Google Scholar]
- Carlin BP, Louis TA. Bayesian Methods for Data Analysis. 3 Boca Raton, FL: Chapman and Hall/CRC Press; 2009. [Google Scholar]
- Cui Y, Hodges JS, Kong X, Carlin BP. Partitioning degrees of freedom in hierarchical and other richly-parameterised models. Technometrics. 2010;52:124–136. doi: 10.1198/TECH.2009.08161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Daniels MJ. A prior for the variance in hierarchical models. The Canadian Journal of Statistics. 1999;27:567–578. [Google Scholar]
- Doucet A, Godsill SJ, Robert CP. Marginal maximum a posteriori estimation using Markov chain Monte Carlo. Statistics and Computing. 2002;12:77–84. [Google Scholar]
- Freedman LS, Lowe D, Macaskill P. Stopping rules for clinical trials incorporating clinical opinion. Biometrics. 1984;40:575–586. [PubMed] [Google Scholar]
- Fúquene JA, Cook JD, Pericchi LR. A case for robust Bayesian priors with applications to clinical trials. Bayesian Analysis. 2009;4:817–846. [Google Scholar]
- Gelman A. Prior distributions for variance parameters in hierarchical models. Bayesian Analysis. 2006;1:515–534. [Google Scholar]
- Gelman A, Carlin JB, Stern HS, Rubin DB. Bayesian Data Analysis. 2 Boca Raton, FL: Chapman and Hall/CRC Press; 2004. [Google Scholar]
- Geyer CJ, Thompson EA. Constrained Monte Carlo maximum likelihood for dependent data. Journal of the Royal Statistical Society Series B. 1992;54:657–699. [Google Scholar]
- Goldberg RM, Sargent DJ, Morton RF, Fuchs CS, Ramanathan RK, Williamson SK, Findlay BP, Pitot HC, Alberts SR. A randomized controlled trial of fluorouracil plus leucovorin, irinotecan, and oxaliplatin combinations in patients with previously untreated metastatic colorectal cancer. Journal of Clinical Oncology. 2004;22:23–30. doi: 10.1200/JCO.2004.09.046. [DOI] [PubMed] [Google Scholar]
- Hobbs BP, Carlin BP, Mandekar SJ, Sargent DJ. Hierarchical commensurate and power prior models for adaptive incorporation of historical information in clinical trials. Biometrics. 2011;67:1047–1056. doi: 10.1111/j.1541-0420.2011.01564.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hodges JS, Sargent DJ. Counting degrees of freedom in hierarchical and other richly-parameterised models. Biometrika. 2001;88:367–379. [Google Scholar]
- Ibrahim JG, Chen M-H. Power prior distributions for regression models. Statistical Science. 2000;15:46–60. [Google Scholar]
- Ibrahim JG, Chen M-H, Sinha D. Bayesian Survival Analysis. New York: Springer-Verlag; 2001. [Google Scholar]
- Kalbfleisch JD, Prentice RL. The Statistical Analysis of Failure Time Data. 2 New York: Wiley; 2002. [Google Scholar]
- Kass RE, Natarajan R. A default conjugate prior for variance components in generalized linear mixed models. Bayesian Analysis. 2006;1:535–542. [Google Scholar]
- Kass RE, Steffey D. Approximate Bayesian inference in conditionally independent hierarchical models (parametric empirical Bayes models) Journal of the American Statistical Association. 1989;84:717–726. [Google Scholar]
- Klein JP, Moeschberger ML. Survival Analysis: Techniques for Censored and Truncated Data. 2 New York: Springer-Verlag; 2003. [Google Scholar]
- McCulloch CE. Maximum likelihood algorithms for generalized linear mixed models. Journal of the American Statistical Association. 1997;92:162–170. [Google Scholar]
- McCulloch CE, Searle SR. Generalized, Linear, and Mixed Models. New York: Wiley; 2001. [Google Scholar]
- Mitchell TJ, Beauchamp JJ. Bayesian variable selection in linear regression. Journal of the American Statistical Association. 1988;83:1023–1032. [Google Scholar]
- Morris CN. Parametric empirical Bayes inference: theory and applications. Journal of the American Statistical Association. 1983;78:47–55. [Google Scholar]
- Neelon B, O’Malley AJ. Bayesian analysis using power priors with application to pediatric quality of care. Journal of Biometrics and Biostatistics. 2010;1:103. doi: 10.4172/2155-6180.1000103. [DOI] [Google Scholar]
- Neuenschwander B, Capkun-Niggli G, Branson M, Spiegelhalter DJ. Summarizing historical information on controls in clinical trials. Clinical Trials. 2010;7:5–18. doi: 10.1177/1740774509356002. [DOI] [PubMed] [Google Scholar]
- Pocock SJ. The combination of randomized and historical controls in clinical trials. Journal of Chronic Diseases. 1976;29:175–188. doi: 10.1016/0021-9681(76)90044-8. [DOI] [PubMed] [Google Scholar]
- Reich BJ, Hodges JS. Identification of the variance components in the general two-variance linear model. Journal of Statistical Planning and Inference. 2008;138:1592–1604. [Google Scholar]
- Saltz LB, Cox JV, Blanke C, et al. the Irinoteca Study Group . Irinotecan plus fluorouracil and leucovorin for metastatic colorectal cancer. The New England Journal of Medicine. 2000;343:905–914. doi: 10.1056/NEJM200009283431302. [DOI] [PubMed] [Google Scholar]
- Spiegelhalter DJ. Bayesian methods for cluster randomized trials with continuous responses. Statistics in Medicine. 2001;20:435–452. doi: 10.1002/1097-0258(20010215)20:3<435::aid-sim804>3.0.co;2-e. [DOI] [PubMed] [Google Scholar]
- Spiegelhalter DJ, Abrams KR, Myles JP. Bayesian Approaches to Clinical Trials and Health-Care Evaluation. London: Wiley; 2004. [Google Scholar]
- Sutton AJ, Abrams KR. Bayesian methods in meta-analysis and evidence synthesis. Statistical Methods in Medical Research. 2001;10:277–303. doi: 10.1177/096228020101000404. [DOI] [PubMed] [Google Scholar]