

Abstract
A fully automated smoothing procedure for uniformly-sampled datasets is described. The algorithm, based on a penalized least squares method, allows fast smoothing of data in one and higher dimensions by means of the discrete cosine transform. Automatic choice of the amount of smoothing is carried out by minimizing the generalized cross-validation score. An iteratively weighted robust version of the algorithm is proposed to deal with occurrences of missing and outlying values. Simplified Matlab codes with typical examples in one to three dimensions are provided. A complete user-friendly Matlab program is also supplied. The proposed algorithm – very fast, automatic, robust and requiring low storage –provides an efficient smoother for numerous applications in the area of data analysis.
1. Introduction
In this paper, a fast robust version of a discretized smoothing spline is introduced. The proposed method, based on the discrete cosine transform (DCT), allows robust smoothing of equally spaced data in one and higher dimensions. The next paragraphs of the present section briefly describe the underlying penalized least squares approach, in the particular case of one-dimensional data. Section 2 provides a review of the generalized cross-validation which is used to estimate the smoothing parameter. When data are evenly spaced, it is shown (section 3) that the linear system can be greatly simplified and solved by means of the DCT. An iterative robust scheme of this DCT-based penalized regression is then proposed in order to deal with weighted, missing (section 4) and outlying (section 5) values. It is finally explained, in section 6, how the smoothing technique proposed in this paper can be applied to multidimensional data. To illustrate the effectiveness of the smoother, several examples related to one-, two- and three-dimensional data are presented (section 7). Two simplified Matlab functions and one complete optimized Matlab code are also provided.
In statistics and data analysis, smoothing is used to reduce experimental noise or small-scale information while keeping the most important imprints of a dataset. Consider the following model for the one-dimensional noisy signal y:
| (1) |
where ε represents a Gaussian noise with mean zero and unknown variance, and ŷ is supposed to be smooth, i.e. has continuous derivatives up to some order (typically ≥2) over the whole domain. Smoothing y relies upon finding the best estimate of ŷ. Data smoothing is generally carried out by means of parametric or nonparametric regression. Parametric regression requires some a priori knowledge of the so-called regression equation that can represent the data well. The majority of observed values, however, cannot be parameterized in terms of predetermined analytical functions so that nonparametric regression is usually the best option for smoothing of data (Takezawa, 2005). To cite a few instances, some of the most common approaches to nonparametric regression used in data processing include kernel regression (Hastie and Loader, 1993) like moving average filtering, local polynomial regression (Watson, 1964) and the Savitzky-Golay filter (Savitzky and Golay, 1964). Another classical approach to smoothing is the penalized least squares regression. This method was first introduced in the early 1920’s by Whittaker (Whittaker, 1923) and has been extensively studied ever since (Wahba, 1990a). This technique consists in minimizing a criterion that balances the fidelity to the data, measured by the residual sum-of-squares (RSS), and a penalty term (P) that reflects the roughness of the smooth data. One thus seeks to minimize:
| (2) |
where || || denotes the Euclidean norm. The parameter s is a real positive scalar that controls the degree of smoothing: as the smoothing parameter increases, the smoothing of ŷ also increases. When the roughness penalty is written in terms of the square integral of the pth derivative of ŷ, the penalized regression is known as a smoothing spline (Schoenberg, 1964; Takezawa, 2005; Wahba, 1990a). Another simple and straightforward approach to express the roughness is by using a second-order divided difference (Weinert, 2007; Whittaker, 1923) which yields, for a one-dimensional data array:
| (3) |
where D is a tridiagonal square matrix defined by:
for 2 ≤ i ≤ n−1 where n is the number of elements in ŷ, and hi represents the step between ŷi and ŷi+1. Assuming repeating border elements (y0 = y1 and yn+1 = yn), gives:
This procedure is similar to the Whittaker smoothing (Eilers, 2003; Weinert, 2007; Whittaker, 1923) apart from the repeating boundaries. Such boundary conditions lead to further numerical simplifications with evenly spaced data (Buckley, 1994), as explained further in section 3.
Now, using equations (2) and (3), minimization of F(ŷ) gives the following linear system that allows the determination of the smoothed data:
| (4) |
where In is the n×n identity matrix and D T stands for the transpose of D. Because (In+sDTD) is a symmetric pentadiagonal matrix, the latter equation can be numerically solved very efficiently with a technical computing software (Eilers, 2003; Weinert, 2007). Computation of ŷ using Matlab (The MathWorks, Natick, MA, USA) and equation (4) has been recently introduced by Eilers (2003) and Weinert (2007). In the case of evenly-spaced data, Weinert has proposed a relatively fast algorithm based on Cholesky decomposition (Weinert, 2007). This algorithm, however, loses efficiency when an estimation of the smoothing parameter is required, as explained in the following section.
2. Estimation of the smoothing parameter
As indicated by equation (4), the output ŷ is strongly influenced by the smoothing parameter s. Assuming the model given by equation (1), it is appropriate to use the smoothing parameter that yields the best estimate of the original data and thus avoids over-or under-smoothing as much as possible. Such a correct value can be estimated by the method of generalized cross-validation (GCV).
The GCV method has been introduced by Craven and Wahba (Craven and Wahba, 1978; Wahba, 1990b) in the context of smoothing splines. Assuming that one wants to solve the smoothing linear system
where H is the so-called hat matrix, the GCV method chooses the parameter s that minimizes the GCV score (Craven and Wahba, 1978; Golub, Heath and Wahba, 1979):
where Tr denotes the matrix trace. Finding s which minimizes the GCV score thus requires Tr(H) to be known. Here, according to equation (4), H is given by:
| (5) |
To calculate the GCV score, Eilers (Eilers, 2003) and Weinert (Weinert, 2007) have both proposed algorithms that involve the determination of H at each iterative step of the minimization. Such a process is very time-consuming and can be avoided. Indeed, Tr(H) can be simply reduced to:
| (6) |
where are the eigenvalues of DTD. The GCV score thus reduces to:
| (7) |
Finding the s value that minimizes the GCV score yielded by equation (7) makes the smoothing algorithm fully automated. Because the components of ŷ appear in the expression of the GCV score, ŷ has to be calculated at each step of the minimization process. This can be avoided for the particular case of equally spaced data as demonstrated in the next section.
3. Smoothing of evenly spaced data
Equation (4) can be efficiently solved with a Matlab code using the so-called left matrix division (see Matlab documentation) applied to sparse matrices. Solving such a linear system, however, may rapidly become time-consuming with an increasing number of data. This algorithm can be greatly simplified and sped up if the data are evenly spaced. Indeed, in numerous conditions, experimental acquisition and data measurement lead to equally-spaced or evenly-gridded datasets. An efficient algorithm for smoothing of uniformly sampled data is described in the present section. A generalization for multidimensional data will be described in a further paragraph (section 6). Assuming now that data are equally spaced with hi=1, ∀i, the divided difference matrix D (in equation 4) can be rewritten as the simple difference matrix:
An eigendecomposition of D yields
where Λ is the diagonal matrix containing the eigenvalues of D defined by (Yueh, 2005):
| (8) |
Because U is a unitary matrix (i.e. U−1 = U T and UU T = In), equation (4) leads to
| (9) |
where the components of the diagonal matrix Γ, according to equation (8), are given by:
| (10) |
It is worth noting that UT and U are actually n-by-n type-2 discrete cosine transform (DCT) and inverse DCT matrices, respectively (Strang, 1999). Thus, the smooth output ŷ can also be expressed as:
| (11) |
where DCT and IDCT refer to the discrete cosine transform and the inverse discrete cosine transform, respectively.
In the case of equally-spaced data, the GCV score can also be simplified considerably. The trace of the hat matrix [see equations (6) and (8)] indeed reduces to:
Note that when n becomes large, one has:
| (12) |
Moreover, using equation (9), the residual sum of squares (RSS) can be written as:
where DCTi refers to the ith component of the discrete cosine transform. The GCV score given by equation (7) thus becomes:
| (13) |
with λi given by equation (8).
It is much more convenient to use an algorithm based on equation (11) rather than equation (4) when data are equispaced. The DCT has indeed a computational complexity of O(n log(n)) whereas equation (4) requires a Cholesky factorization whose computational complexity is O(n3). Note also that the computation of the GCV score from equation (13) is straightforward and does not require any matrix operation and manipulation, which makes the automated smoothing very fast. A simplified Matlab code for fully automated smoothing is given in Appendix I. The abovementioned smoothing procedure requiring DCT is similar to that introduced by Buckley (1994). It is shown in the following section how this DCT-based smoother can be adapted to weighted data and missing values.
4. Dealing with weighted data and occurrence of missing values
Occurrence of missing data due to measurement infeasibility or instrumentation failure is frequent in practice. It can also be convenient to give outliers a low weight or, on the contrary, allocate a relatively high weight to high-quality data. Let W be the diagonal matrix diag(wi) that contains the weights wi∈[0,1] corresponding to the data yi. In the presence of weighted data, RSS becomes:
The minimization of F(ŷ) (equation 2) thus yields:
which can be rewritten as:
Letting A ≡ sDTD + W and using the abovementioned hat matrix H, this equation can also be expressed as:
This implicit formula can be solved using an iterative procedure:
| (14) |
where ŷ{k} refers to ŷ calculated at the kth iteration step. It can be shown that this equation converges, for any ŷ{0}, since the linear system is positive definite. Indeed, the matrix D is real nonsingular, then sDTD is positive definite if s>0. In addition, W is positive semidefinite (because wi ≥ 0); A is thus positive definite and, according to the theorem 3 of (Keller, 1965), convergence of ŷ{k} towards the desired solution ŷ is ensured for any s > 0.
Note that, in the presence of missing values, W is simply defined by wi = 0 if yi is missing, while an arbitrary finite value is assigned to yi. In that case, the algorithm performs both smoothing and interpolation. Contrarily to classical methods which usually operate with linear or cubic local interpolations, missing data are assigned to values that are estimated using the entire dataset.
In the case of evenly spaced data, one can take advantage of the DCT by rewriting equation (14) as:
which, similarly to equation (11), becomes:
| (15) |
with Λ given by equation (10). The iterative convergent process defined by equation (15), with the additional determination of the GCV score, allows automatic smoothing with weighted and/or missing data. When weighted and/or missing data occur, equation (7) describing the GCV score, however, becomes invalid since the weighted residuals (wRSS) must be accounted for. Moreover, the number of missing data must be taken into account in the expression of the average square error. In the presence of weighted data, the GCV score is therefore given by:
where nmiss represents the number of missing data and n is the number of elements in y. Note that the GCV score given by the latter equation, in comparison with equation (13), requires ŷ to be known, so that ŷ must be calculated at each iteration of the GCV minimization. Smoothing of weighted data will thus involve additional computation time.
5. Robust smoothing
In regression analysis, it is habitually assumed that the residuals follow a normal distribution with mean zero and constant variance, usually unknown. In spite of that, faulty data, erroneous measurements or instrumentation malfunction may lead to observations that lie abnormally far from the others. The main drawback of the penalized least squares methods is their sensitivity to these outliers. Besides outlying points, high leverage points also adversely affect the outcome of regression models. In statistics, the leverage denotes a measure of the influence (between 0 and 1) of a given point on a fitting model due to its location in the space of the inputs. More precisely, the points which are far-removed from the main body of points will have high leverage (Chatterjee and Hadi, 1986). To minimize or cancel the side effects of high leverage points and outliers, one can assign a low weight to them using an iteratively re-weighted process, as often used in robust local regression. This method consists in constructing weights with a specified weighting function by using the current residuals and updating them, from iteration to iteration, until the residuals remain unchanged (Rousseeuw and Leroy, 1987). In practice, five iterative steps are sufficient.
Several weighting functions are available for robust regression. The most common one, the so-called bisquare weight function, will be used hereinafter although other weight functions would be suitable as well (Heiberger and Becker, 1992). The bisquare weights are given by:
where ui is the studentized residual which is adjusted for standard deviation and leverage and is defined as (Rousseeuw and Leroy, 1987):
| (16) |
In equation (16), ri − yi − ŷi is the residual of the ith observation, hi is its corresponding leverage and σ̂ is a robust estimate for the standard deviation of the residuals given by 1.4826 MAD, where MAD denotes the median absolute deviation (Rousseeuw and Croux, 1993). The leverage values hi are all given by the diagonal elements of the hat matrix H (Hoaglin and Welsch, 1978). However, a faster and economical alternative for robust smoothing can be obtained using an average leverage:
where an approximated value for Tr(H)/n is given by equation (12). The approximated studentized residuals finally reduce to:
The use of the bisquare weights in combination with these approximated studentized residuals provides a robust version of the abovementioned smoother. Note that if yi represents a missing data, ri is not involved in the calculation of the MAD(r). Appendix II contains a simplified Matlab code for robust smoothing using the method described in this paper.
6. Multidimensional smoothing of evenly gridded data
Because a multidimensional DCT is basically a composition of one-dimensional DCTs along each dimension (Strang, 1999), equation (11) can be immediately extended to two-dimensional or N-dimensional regularly gridded data. A detailed description of the extension of equation (11) to higher dimensions is given in (Buckley, 1994). In the case of N-dimensional data, equation (11) becomes:
| (17) |
where DCTN and IDCTN refer to the N-dimensional discrete cosine transform and inverse discrete cosine transform, respectively, and ∘ stands for the Schur (elementwise) product. As an extension of equation (10), ΓN is a tensor of rank N defined by:
| (18) |
Here, the operator ÷ symbolizes the element-by-element division and 1N is an N-rank tensor of ones. ΛN, similarly to equation (8), is the following N-rank tensor (Buckley, 1994):
| (19) |
where nj denotes the size of ΛN along the jth dimension. Automated determination of s requires the GCV score which, in the case of multidimensional data, can be written as:
where || ||F denotes the Frobenius norm, || ||1 is the 1-norm, and is the number of elements in y. Similarly to equation (7), the GCV score with no weighted and no missing data can be rewritten as follows:
The same procedure as described in section 5 can also be directly applied to weighted or missing data. The iterative process illustrated by equation (15) thus becomes:
| (20) |
A robust version can also be immediately obtained using the studentized residuals given by (16) with the following average leverage:
7. Matlab codes and examples
Equations (11) and (15) with optimal smoothing by means of the GCV method are relatively easy to implement in Matlab. Simplified Matlab codes for automatic smoothing (smooth.m) and robust smoothing (rsmooth.m) of 1-D and 2-D datasets are given in appendices I and II. These two programs have a similar syntax and both require the 2-D (inverse) discrete cosine transform (dct2 and idct2) provided by the Matlab image processing toolbox. The input represents the dataset to be smoothed, while the output represents the smoothed data. A complete documented Matlab function for smoothing of 1-D to N-D data (smoothn), with automated and robust options, and which can deal with weighted and/or missing data, is also supplied in the supplemental material. The pseudocode for smoothn is given in Figure 1. No Matlab toolbox is needed for the use of smoothn. Updated versions of this function are downloadable from the author’s personal website (Garcia, 2009). The first four examples illustrated hereinafter can be run in Matlab using the function smoothndemo also available in the supplemental material.
Figure 1.

Pseudocode of the automatic robust smoothing algorithm. The variable names and acronyms are described in the text. The complete Matlab code is supplied in the supplemental material (smoothn.m). When robust option is required, minimization of the GCV score is performed at the first robust iterative step only (see 4.c.ii) and the last estimated smoothness parameter (s) is used during the successive steps. This makes the algorithm faster without altering the final results significantly.
2-D smoothing with missing values
To illustrate the effectiveness of the DCT-based smoothing algorithm, highly corrupted 2-D data have been smoothed and the result has been compared with the original data. The original matrix data (300× 300) consisted of a function of two variables obtained by translating and scaling Gaussian distributions created by the Matlab “peaks” function. The corrupted data were obtained by first adding a Gaussian noise with mean zero (Figure 2A), then randomly removing half of the data, and finally creating a 50× 50 square of missing data (Figure 2B). The automatic smoother was able to recover satisfactorily the original surface (Figure 2C) with an average relative error (defined by ||smoothed – original||/||original||) smaller than 5% (see also the absolute error mapping on Figure 2D).
Figure 2.

Automatic smoothing of two-dimensional data with missing values. A. Noisy data. B. Corrupted data with missing values. C. Smoothed data restored from B. D. Absolute errors between the restored and original data.
Robust smoothing
Penalized least squares methods are very sensitive to outlying data. Figure 3A demonstrates how outliers may adversely bend the smoothed curve (see also 1-D example in Appendix II). Clearly, the smoothed values do not reflect the behavior of the bulk of the data points. To overcome the distortion due to a small fraction of outliers, the data can be smoothed using the robust procedure described in section 5. Figure 3B shows that the robust smoothing is resistant to outliers. An example for 2-D robust smoothing is also given in Appendix II.
Figure 3.

Non robust versus robust smoothing. Outliers may bend the smoothed curve (A). A robust smoothing may get rid of this drawback (B).
3-D smoothing
Figure 4 now illustrates 3-D automated smoothing by means of the smoothn program supplied in the supplementary material. Gaussian noise with mean zero and standard deviation of 0.06 has been added to a 3-D function defined by f(x,y,z) = x exp(−x2 − y2 − z2) in the [−2;2]3 domain (Figure 4A). Figure 4B shows that smoothn significantly reduced the additive noise. Note that smoothn could also be applied to higher dimensions.
Figure 4.

Automatic smoothing of three-dimensional data.
Smoothing of parametric curves
Discrete cosine transform (DCT) and inverse DCT are linear operators and thus work with complex numbers. This property can be used to smooth parametric curves defined by (x(t),y(t)), where t is equispaced. By way of example, Figure 5 depicts a noisy cardioid (dots) whose parametric equations are x(t) = 2 cos(t)[1-cos(t)] +
 (0,0.2) and y(t) = 2 sin(t)[1-cos(t)] +
(0,0.2), where
refers to the normal distribution and t is equally spaced between 0 and 2π. Let us now define the complex function z(t) = x(t) + i y(t), where i is the unit complex number, and its smoothed output ẑ(t). The parametric curve defined by (Re(ẑ(t)), Im(ẑ(t))), where Re and Im refer to the real and imaginary parts, respectively, provides a smooth cardioid (solid line, see Figure 5).
(0,0.2) and y(t) = 2 sin(t)[1-cos(t)] +
(0,0.2), where
refers to the normal distribution and t is equally spaced between 0 and 2π. Let us now define the complex function z(t) = x(t) + i y(t), where i is the unit complex number, and its smoothed output ẑ(t). The parametric curve defined by (Re(ẑ(t)), Im(ẑ(t))), where Re and Im refer to the real and imaginary parts, respectively, provides a smooth cardioid (solid line, see Figure 5).
Figure 5.
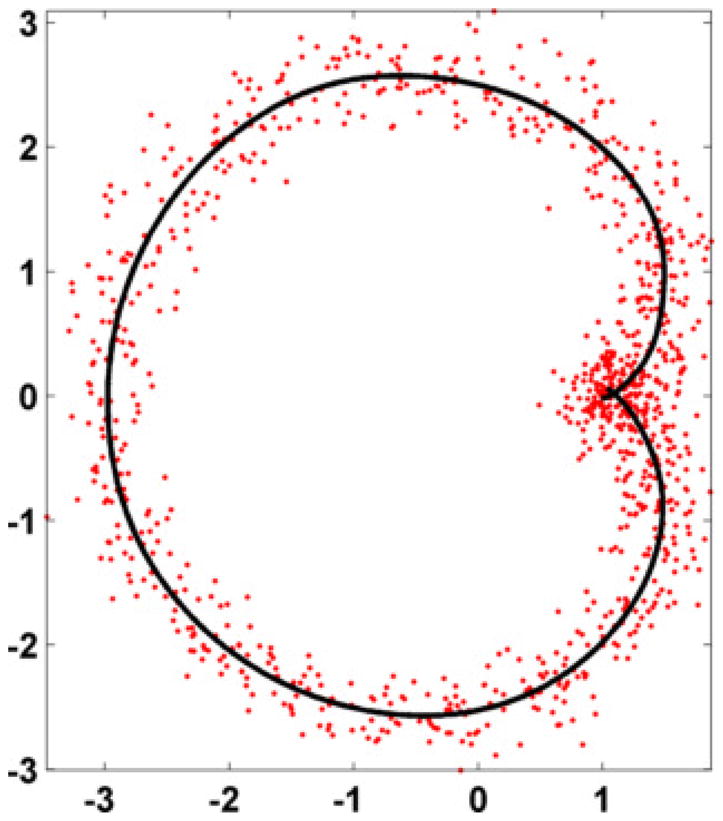
Automatic smoothing of a noisy cardioid.
Applications to surface temperature anomalies
Automatic smoothing with the minimization of the GCV score has finally been tested on temperature data available in the Met Office Hadley Centre’s website (Brohan, Kennedy, Harris, Tett and Jones, 2006; Kennedy, 2007). Figure 6 illustrates the evolution of global average land temperature anomaly (in °C) with respect to 1961–1990. The smooth curve clearly depicts the continuing rise of global temperature that occurs since the 1970’s. Figure 7 shows the earth surface temperature difference of August 2003 with respect to 1961–1990. The top panel represents a mapping of the best estimates of temperature anomalies as provided by the Met Office Hadley Centre. Note that numerous temperature data are missing due to nonexistent station measurements. A smooth map of Earth temperature anomalies with filled gaps can be automatically obtained using the DCT-based algorithm described in the present paper (Figure 7, bottom panel).
Figure 6.

Global average land temperature anomaly (ºC) with respect to 1961–1990: smoothed versus original year-averaged data. Year-averaged data are available in http://hadobs.metoffice.com/crutem3/diagnostics/global/nh+sh/annual.
Figure 7.

August 2003 surface temperature difference (ºC) with respect to 1961–1990: smoothed (bottom panel) versus original year-averaged (top panel) data. Year-averaged dataset is available in http://hadobs.metoffice.com/hadcrut3/index.html. The smoothed output has been upsampled for a better visualization of the surface temperatures.
Resolution of Figure 7, bottom panel, has been increased to obtain a better visualization of surface temperatures. A basic upsampling of the smoothed data was performed by padding zeros after the last element of DCTN(ŷ) along each dimension before using the inverse DCT operator, as follows:
where nupsampled represents the number of elements after upsampling. It is worth reminding that DCT assumes repeating boundary conditions whereas periodic boundaries would have been more appropriate for the east-west edges. Such conditions caused east-west discordances at the level of New-Zealand and Antarctica.
8. Discussion
The best choice of the smoothing algorithm to be used in data analysis depends specifically upon the original data and on the properties of the additive noise. As a consequence, the search for a perfect universal smoother remains illusory (Eilers, 2003). In this paper, a robust, fast and fully automated smoothing procedure has been proposed, and its efficacy has been illustrated on a few cases in the previous section. The user, however, should be aware of some limitations of the algorithm. Better results will be obtained if ŷ itself is sufficiently smooth, i.e. if it has continuous derivatives up to some desired order over the whole domain of interest. Moreover, because the algorithm process involves a discrete cosine transform, the inherent repeating conditions may slightly distort the smoothed output on the boundaries, especially when the total number of data is small. The GCV criterion is used to make the smoothing procedure fully automated and good results are expected if the additive noise ε in equation (1) follows a Gaussian distribution with nil mean and constant variance. It has been reported, however, that the GCV remains fairly adapted even with nonhomogenous variances and non-Gaussian errors (Wahba, 1990b). Alternatively, if the measurement errors in the data present variable standard deviations and if the variances are known ( ), the response variances can be transformed to a constant value using weights given by . In addition, if outlying data occur, it could be convenient to perform a robust smoothing. Finally, the GCV criterion may cause problems when the sample size is small, which could make the automated version unsatisfactory with a small number of data. If this occurs, the smoothing parameter s must be tuned manually until a visually acceptable result is obtained.
Appendix I
A simplified Matlab code (smooth) for 1-D and 2-D smoothing of equally-gridded data, and two examples are given below. The input represents the dataset to be smoothed and the output represents the smoothed data. This code has been written with Matlab R2007b.
function z = smooth(y)
[n1,n2] = size(y); n = n1*n2;
Lambda = bsxfun(@plus,repmat(−2+2*cos((0:n2−1)*pi/n2),n1,1),…
−2+2*cos((0:n1−1).’*pi/n1));
DCTy = dct2(y);
fminbnd(@GCVscore,−15,38);
z = idct2(Gamma.*DCTy);
function GCVs = GCVscore(p)
s = 10^p;
Gamma = 1./(1+s*Lambda.^2);
RSS = norm((DCTy(:).*(Gamma(:)−1)))^2;
TrH = sum(Gamma(:));
GCVs = RSS/n/(1−TrH/n)^2;
end
end
1-D Example:
x = linspace(0,100,2^8); y = cos(x/10)+(x/50).^2 + randn(size(x))/10; z = smooth(y); plot(x,y,‘.’,x,z)
2-D Example:
xp = linspace(0,1,2^6); [x,y] = meshgrid(xp); f = exp(x+y)+sin((x−2*y)*3) + randn(size(x))/2; g = smooth(f); figure, subplot(121), surf(xp,xp,f), zlim([0 8]) subplot(122), surf(xp,xp,g), zlim([0 8])
Appendix II
A simplified Matlab code (rsmooth) for robust smoothing of 1-D and 2-D equally-sampled data, and two examples are given below. The syntax is similar to that of smooth (see Appendix I). A complete optimized code (smoothn) allowing smoothing in one or more dimensions is also available in the supplemental material and in the author’s personal website (Garcia, 2009).
function z = rsmooth(y)
[n1,n2] = size(y); n = n1*n2;
N = sum([n1,n2]~=1);
Lambda = bsxfun(@plus,repmat(−2+2*cos((0:n2−1)*pi/n2),n1,1),...
−2+2*cos((0:n1−1).’*pi/n1));
W = ones(n1,n2);
zz = y;
for k = 1:6
tol = Inf;
while tol>1e−5
DCTy = dct2(W.*(y−zz)+zz);
fminbnd(@GCVscore,−15,38);
tol = norm(zz(:)−z(:))/norm(z(:));
zz = z;
end
tmp = sqrt(1+16*s);
h = (sqrt(1+tmp)/sqrt(2)/tmp)^N;
W = bisquare(y−z,h);
end
function GCVs = GCVscore(p)
s = 10^p;
Gamma = 1./(1+s*Lambda.^2);
z = idct2(Gamma.*DCTy);
RSS = norm(sqrt(W(:)).*(y(:)−z(:)))^2;
TrH = sum(Gamma(:));
GCVs = RSS/n/(1−TrH/n)^2;
end
end
function W = bisquare(r,h)
MAD = median(abs(r(:)−median(r(:))));
u = abs(r/(1.4826*MAD)/sqrt(1−h));
W = (1−(u/4.685).^2).^2.*((u/4.685)<1);
end
1-D Example:
x = linspace(0,100,2^8); y = cos(x/10)+(x/50).^2 + randn(size(x))/10; y([70 75 80]) = [5.5 5 6]; z = smooth(y); zr = rsmooth(y); subplot(121), plot(x,y,‘.’,x,z), title(‘Non robust’) subplot(122), plot(x,y,‘.’,x,zr), title(‘Robust’)
2-D Example:
xp = linspace(0,1,2^6); [x,y] = meshgrid(xp); f = exp(x+y)+sin((x−2*y)*3) + randn(size(x))/2; f(20:3:35,20:3:35) = randn(6,6)*10+20; g = smooth(f); gr = rsmooth(f); subplot(121), surf(xp,xp,g), zlim([0 8]), title(‘Non robust’) subplot(122), surf(xp,xp,gr), zlim([0 8]), title(‘Robust’)
Footnotes
9. Supplemental material
The supplemental material contains four Matlab programs (smoothn, smoothndemo, dctn and idctn). The function smoothn includes all the properties described in this paper. It carries out manual or automatic smoothing of 1-D to N-D uniformly-sampled data, and can deal with weighted and/or missing values. A robust option is also offered. Enter “help smoothn” in the Matlab command window to obtain a detailed description and the syntax for smoothn. Updated versions of smoothn are also downloadable from the author’s personal website (Garcia, 2009). The second program smoothndemo illustrates the first four examples from section 7. Enter “smoothndemo” in the Matlab command window to create four Matlab figures corresponding to the Figures 2 to 5 of this manuscript. The script of smoothndemo can be of help for a better understanding of smoothn. Finally, dctn and idctn allow computation of discrete cosine transform (DCT) and inverse DCT of N-dimensional arrays. These two functions are necessary for the use of smoothn. The functions smoothn, smoothndemo, dctn and idctn have been written with Matlab R2007b.
References
- Brohan P, Kennedy JJ, Harris I, Tett SFB, Jones PD. Uncertainty estimates in regional and global observed temperature changes: A new data set from 1850. J Geophys Res. 2006;111:D12106. doi: 10.1029/2005JD006548. [DOI] [Google Scholar]
- Buckley MJ. Fast computation of a discretized thin-plate smoothing spline for image data. Biometrika. 1994;81:247–258. [Google Scholar]
- Chatterjee S, Hadi AS. Influential observations, high leverage points, and outliers in linear regression. Statistical Science. 1986;1:379–393. [Google Scholar]
- Craven P, Wahba G. Smoothing noisy data with spline functions. Estimating the correct degree of smoothing by the method of generalized cross-validation. Numerische Mathematik. 1978;31:377–403. [Google Scholar]
- Eilers PH. A perfect smoother. Anal Chem. 2003;75:3631–3636. doi: 10.1021/ac034173t. [DOI] [PubMed] [Google Scholar]
- Garcia D. Matlab functions in BioméCardio. 2009 http://www.biomecardio.com/matlab.
- Golub G, Heath M, Wahba G. Generalized cross-validation as a method for choosing a good ridge parameter. Technometrics. 1979;21:215–223. [Google Scholar]
- Hastie T, Loader C. Local regression: automatic kernel carpentry. Statistical Science. 1993;8:120–129. [Google Scholar]
- Heiberger RM, Becker RA. Design of an S function for robust regression using iteratively reweighted least squares. Journal of Computational and Graphical Statistics. 1992;1:181–196. [Google Scholar]
- Hoaglin DC, Welsch RE. The hat matrix in regression and ANOVA. The American Statistician. 1978;32:17–22. [Google Scholar]
- Keller HB. On the Solution of Singular and Semidefinite Linear Systems by Iteration. Journal of the Society for Industrial and Applied Mathematics: Series B, Numerical Analysis. 1965;2:281–290. [Google Scholar]
- Kennedy J. Met Office Hadley Centre observations datasets. 2007 http://hadobs.metoffice.com/crutem3.
- Rousseeuw PJ, Leroy AM. Robust regression and outlier detection. John Wiley & Sons, Inc; New York, NY, USA: 1987. [Google Scholar]
- Rousseeuw PJ, Croux C. Alternatives to the median absolute deviation. Journal of the American Statistical Association. 1993;88:1273–1283. [Google Scholar]
- Savitzky A, Golay MJE. Smoothing and differentiation of data by simplified least squares procedures. Anal Chem. 1964;36:1627–1639. [Google Scholar]
- Schoenberg IJ. Spline functions and the problem of graduation. Proc Natl Acad Sci USA. 1964;52:947–950. doi: 10.1073/pnas.52.4.947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strang G. The discrete cosine transform. SIAM Rev. 1999;41:135–147. [Google Scholar]
- Takezawa K. Introduction to nonparametric regression. John Wiley & Sons, Inc; Hoboken, NJ: 2005. [Google Scholar]
- Wahba G. Spline models for observational data. Society for Industrial Mathematics; Philadelphia: 1990a. [Google Scholar]
- Wahba G. Spline models for observational data. Society for Industrial Mathematics; Philadelphia: 1990b. Estimating the smoothing parameter; pp. 45–65. [Google Scholar]
- Watson GS. Smooth regression analysis. The Indian Journal of Statistics, Series A. 1964;26:359–372. [Google Scholar]
- Weinert HL. Efficient computation for Whittaker-Henderson smoothing. Computational Statistics & Data Analysis. 2007;52:959–974. [Google Scholar]
- Whittaker ET. On a new method of graduation. Proceedings of the Edinburgh Mathematical Society. 1923;41:62–75. [Google Scholar]
- Yueh WC. Eigenvalues of several tridiagonal matrices. Applied Mathematics E-Notes. 2005;5:66–74. [Google Scholar]