

Abstract
The homodyned K-distribution appears naturally in the context of random walks and provides a useful model for the distribution of the received intensity in a wide range of non-Gaussian scattering configurations, including medical ultrasonics. An estimation method for the homodyned K-distribution based on the first moment of the intensity and two log-moments (XU method), namely the X and U-statistics previously studied in the special case of the K-distribution, is proposed as an alternative to a method based on the first three moments of the intensity (MI method) or the amplitude (MA method), and a method based on the signal-to-noise ratio (SNR), the skewness and the kurtosis of two fractional orders of the amplitude (labeled RSK method). Properties of the X and U statistics for the homodyned K-distribution are proved, except for one conjecture. Using those properties, an algorithm based on the bisection method for monotonous functions was developed. The algorithm has a geometric rate of convergence. Various tests were performed to study the behavior of the estimators. It was shown with simulated data samples that the estimations of the parameters 1/α and 1/(κ + 1) of the homodyned K-distribution are preferable to the direct estimations of the clustering parameter α and the structure parameter κ (with respective relative root mean squared errors (RMSEs) of 0.63 and 0.13 as opposed to 1.04 and 4.37, when N = 1000). Tests on simulated ultrasound images with only diffuse scatterers (up to 10 per resolution cell) indicated that the XU estimator is overall more reliable than the other three estimators for the estimation of 1/α, with relative RMSEs of 0.79 (MI), 0.61 (MA), 0.53 (XU) and 0.67 (RSK). For the parameter 1/(κ + 1), the relative RMSEs were equal to 0.074 (MI), 0.075 (MA), 0.069 (XU) and 0.100 (RSK). In the case of a large number of scatterers (11 to 20 per resolution cell), the relative RMSEs of 1/α were equal to 1.43 (MI), 1.27 (MA), 1.25 (XU) and 1.33 (RSK), and the relative RMSEs of 1/(κ + 1) were equal to 0.14 (MI), 0.16 (MA), 0.17 (XU) and 0.20 (RSK). The four methods were also tested on simulated ultrasound images with a variable density of periodic scatterers to test images with a coherent component. The addition of noise on ultrasound images was also studied. Results showed that the XU estimator was overall better than the three other ones. Finally, on the simulated ultrasound images, the average computation times per image were equal to 6.0 ms (MI), 8.0 ms (MA), 6.8 ms (XU) and 500 ms (RSK). Thus, a fast, reliable, and novel algorithm for the estimation of the homodyned K-distribution was proposed.
Keywords: homodyned K-distribution, statistical parameter estimation, random walks, non-Gaussian scattering, optical propagation through turbulent media, microwave sea echo, land clutter, medical ultrasonics, echo envelope
1. Introduction
The homodyned K-distribution appears naturally in the context of a limiting random walk modeling physical scattering process, with a constant-amplitude coherent component and with a negative binomial distribution for the number of steps [13, 15]. As a special case, the K-distribution [21, 14] corresponds to a vanishing coherent component of the amplitude of that process. Also, the Rice distribution corresponds to the limiting case where the scatterer clustering parameter implicit in the negative binomial distribution is infinite [24, 30, 15]. Finally, the Rayleigh distribution [29, 15] corresponds to the Rice distribution with a vanishing coherent component. Both the Rice and the Rayleigh distributions correspond to a Gaussian random walk, but not the homodyned K-distribution (nor the K-distribution). The random variable of these distributions is called the amplitude and is denoted by A. The intensity I is defined as the square of the amplitude.
K-distributions and, more generally, homodyned K-distributions turned out to provide a useful model for the received amplitude in a wide range of non-Gaussian scattering configurations, such as optical propagation through turbulent media [27], microwave sea echo [38], land clutter [26] and medical ultrasonics [33, 8, 23, 10, 28, 25]. See [6] for a presentation of the homodyned K-distribution and related distributions in the context of ultrasound imaging.
The homodyned K-distribution is determined by three parameters that carry a physical meaning: the mean intensity μ; the scatterer clustering parameter α (i.e. the clustering parameter in the negative binomial distribution); and the structure parameter κ (i.e. the ratio of the coherent signal power to the diffuse signal power). Given a sample of the received amplitude, one is then interested in estimating those three parameters, or related parameters, such as the signal-to-noise ratio (SNR) of the intensity and the ratio of coherent signal to diffuse signal, denoted k in [8, 11]. The goal is then to use the estimated parameters in the context of tissue characterization or quantitative ultrasound (QUS) based on medical ultrasound images. See [25, 11] as examples.
A simple estimation method of the homodyned K-distribution based on the first three moments of the intensity E[I], E[I2], and E[I3] was proposed in [8]. In [11], the SNR, the skewness and the kurtosis of two fractional orders (namely, 0.72 and 0.88) of the amplitude were used as statistics for the estimation of the homodyned K-distribution. In the case of the estimation method of [11], one obtains an overdetermined non-linear system of equations that is solved in the sense of the least mean square.
In this paper, an estimation method based on the first moment of the intensity E[I], the U-statistics E[log I] − log E[I] and the X-statistics E[I log I]/E[I] − E[log I] is proposed. These two statistics were introduced in the context of K-distributions in [26] and [4], respectively. Moreover, an algorithm with geometric rate of convergence for the computation of this new estimator is proposed.
The remaining part of this paper is organized as follows. In Section 2, the definition of the homodyned K-distribution is recalled. In Section 3, the proposed estimation method is explained. Experimental results based on simulations of sample sets and of ultrasound images are presented in Section 4. The results are discussed in Section 5, and we conclude in Section 6.
Table 1 presents the definition of the main parameters and statistics discussed in this paper. Given a sample set {A1, …, AN}, the notation means the average value of the function f over the sample set, i.e. . In particular, the notation I̅, for instance, means . The notation is used for the partial derivative with respect to, say, α. For example, the notation PK does not mean partial derivative, but rather that K is used as a subscript (identifying the K-distribution).
Table 1.
Main parameters and statistics discussed in this paper.
| Definition | Notion | |
|---|---|---|
| A and I = A2 | amplitude and intensity | |
| I̅ | mean intensity of a sample A1, … AN | |
|
|
U-statistics | |
|
|
X-statistics | |
| Homodyned K-distribution with parameters ε ≥ 0, σ2 > 0 and α > 0 | ||
| α | scatterer clustering parameter | |
| ε2 | coherent signal power | |
| 2σ2α | diffuse signal power | |
| μ = ε2 + 2σ2α | total signal power (mean intensity) | |
| κ = ε2/(2σ2α) | structure parameter | |
| γ = ε2/(2σ2) = κα | algorithmic parameter | |
|
|
ratio of the coherent to diffuse signal | |
| Rice distribution with parameters ε ≥ 0 and | ||
|
|
mean intensity | |
|
|
structure parameter | |
|
|
ratio of the coherent to diffuse signal | |
2. The homodyned K-distribution
The reader is referred to [15] for a presentation of the homodyned K-distribution and the related Rice distribution in the context of random walks, and to [6] for a presentation in the context of ultrasound imaging. The reader may consult [2] for the notions of Bessel functions.
The 2-dimensional homodyned K-distribution is defined by
| (2.1) |
where ε ≥ 0, σ2 > 0 and α > 0, and J0 denotes the Bessel function of the first kind of order 0. The limiting case of a homodyned K-distribution with parameters ε, and α, where is a positive real number and α → ∞, yields the Rice distribution
| (2.2) |
where I0 denotes the modified Bessel function of the first kind of order 0.
The compound representation of Theorem 2.1 is useful in simulating the homodyned K-distribution, and in evaluating its values.
Theorem 2.1 (Jakeman-Tough [15])
The compound representation of the homodyned K-distribution is
| (2.3) |
where 𝒢(w | α, 1) = wα−1e−w/Γ(α) is the gamma distribution with mean and variance α, and Γ denotes the Euler gamma function.
Two functions of the three parameters of the homodyned K-distribution are invariant under scaling of the mean intensity μ = ε2 + 2σ2α: 1) the scatterer clustering parameter α; 2) the structure parameter κ = ε2/(2σ2α), i.e. the ratio of the coherent signal power ε2 to the diffuse signal power 2σ2α. Let us mention also the ratio of the coherent to diffuse signal adopted in [8, 11]. It was found convenient to also consider the parameter γ = κα = ε2/(2σ2). This parameter should not be confused with the structure parameter of the Rice distribution . See Table 1 for a summary of these parameters. The special case where ε = 0 yields the K-distribution PK(A | σ2, α) [21, 15] and the Rayleigh distribution [29].
3. A new method for estimating the homodyned K-distribution
A new method for estimating the parameters (ε, σ2, α) of the homodyned K-distribution based on an independent and identically distributed (i.i.d.) sample set (A1, …, AN) of positive real numbers is now discussed.
Two statistics will play an important role in the sequel: 1) the U-statistics defined by and 2) the X-statistics defined as . For parametric models, such as the homodyned K-distribution or the Rice distribution, the U-statistics is defined as E[log I] − log E[I], where expectation is taken with respect to the distribution. Similarly, the X-statistics is defined as E[I log I]/E[I] − E[log I]. A subindex (such as “HK”) is then used to identify the distribution (e.g. “UHK”).
For later reference, it is instructive to observe the following result.
Lemma 3.1
For any non-constant random variable, the U-statistics is negative.
For any non-constant random variable, the X-statistics is positive.
The proof of Lemma 3.1 is presented in Appendix A.
3.1. Proposed estimator
The proposed method of estimation consists in solving the following (non-linear) system of equations in the variables ε2, σ2, and α:
| (3.1) |
Sufficient conditions for this system to admit a solution are presented below. For that purpose, it will be convenient to adopt the following change of variables
| (3.2) |
Proposition 3.2
Let be distributed according to the homodyned K-distribution PHK(A | ε, σ2, α). With the notation of (3.2), one has
| (3.3) |
| (3.4) |
where γE denotes the Euler constant, ψ is the digamma function, pFq(a1, …, ap; b1, …, bq; z) is the generalized hypergeometric series and Kp denotes the modified Bessel function of the second kind of order p.
As one can see, Equations (3.3) and (3.4) depend only on the variables γ and α. Thus, the proposed method amounts to solving the second and third equations of (3.1) in the variables γ and α, and then using the identities
| (3.5) |
with the estimator I̅ of the mean intensity μ.
The proof of Proposition 3.2 is presented in Appendix A.
3.2. Estimating γ, when α is known
Let α > 0 be known. A method for finding γ > 0 satisfying Equation (3.4) is now discussed. Thus, one wants to solve the equation XHK(γ, α) = X.
In Appendix B, the following result is shown.
Theorem 3.3
Notation as above.
One has the left boundary condition limγ→0 XHK(γ, α) = XK(α), where XK(α) = 1 + 1/α.
One has the right boundary condition limγ→∞ XHK(γ, α) = 0.
For any α > 0, the function XHK(γ, α) is decreasing in the variable γ.
See Fig. 1 for an illustration of Theorem 3.3. Part c) of Theorem 3.3 implies that a binary search algorithm can be used to find the unique solution to Equation (3.4), whenever it exists. See Section 3.4 for details.
Fig. 1.

Illustration of the typical behavior of the X-statistics for the homodyned K-distribution as a function of γ ≥ 0 with a fixed value of α > 0 (here, α = 2.1).
Corollary 3.4
Let X > 0. Then, there is at most one solution to the equation XHK(γ, α) = X.
If X ≤ 1, then there is a solution for any α > 0.
If X > 1, then there is a solution if and only if 0 < α = α0, where .
Thus, one obtains a well-defined function
| (3.6) |
on the domain described by Corollary 3.4.
3.3. Estimating γ and α
From Corollary 3.4, one knows that for any α in an interval of the form (0, α0] or (0, ∞), there exists a unique solution γ = γ(α, X) to the equation XHK(γ, α) = X. Substituting this solution in the second equation of (3.1), one obtains a function UHK(γ(α, X), α) in the variable α. Thus, one now wants to solve the equation UHK(γ(α, X), α) = U.
See Appendix C for a proof of the following result.
Theorem 3.5
Let X > 0.
One has the left boundary condition limα→0 UHK(γ(α, X), α) = 0.
Let X > 1. One has the right boundary condition limα→α0 UHK(γ(α, X), α) = UK(α0), where UK(α) = − γE − log α + ψ(α), XK(α) = 1 + 1/α, and .
Let X ≤ 1. One has the right boundary condition limα→∞ UHK(γ(α, X), α) = URi(κ0), where , and . The function XRi(κ) is decreasing and has the interval (0, 1] for range.
Since the function XRi(κ) is decreasing on its domain [0, ∞) and has range (0, 1], the function is well-defined on the interval X ∈ (0, 1].
Conjecture 1
The function UHK(γ(α, X), α) is decreasing on its domain.
See Fig. 2 for an illustration of Theorem 3.5 and the conjecture. The conjecture implies that a binary search algorithm can be used to find the unique solution to the second and third equations of (3.1), whenever a solution exists. The details are presented in Section 3.4. In Appendix D, a discussion on the Conjecture is presented.
Fig. 2.
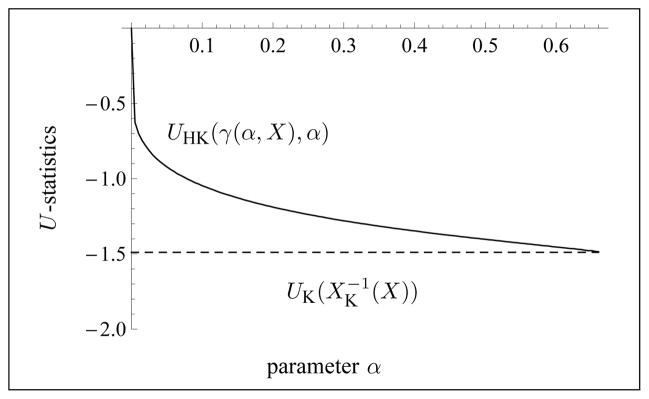
Illustration of the typical behavior of the U-statistics for the homodyned K-distribution as a function of α > 0, with a fixed value of X > 0 and γ = γ(α, X). Here, X = 2.5. Since X > 1, the upper bound for α is α0 = 1/(X − 1).
Combining Theorems 3.3 and 3.5 with the conjecture yields the following result.
Corollary 3.6
Let U < 0 and X > 0 be given. Then, there exists a simultaneous solution to the system UHK(γ, α) = U and XHK(γ, α) = X if and only if
-
X > 1 and
or
X ≤ 1 and .
Moreover, if a solution exists, it is unique.
Thus, one obtains well-defined functions
| (3.7) |
where X and U are restricted to the domain described by parts a) and b) of Corollary 3.6. See Fig. 3 for an illustration of this domain.
Fig. 3.

Illustration of the domain in the (X, U)-plane in which the parameters γ ≥ 0 and α are well-defined. The domains where either the K-distribution, the Rice distribution, or the Rayleigh distribution model apply are also indicated. The Rayleigh distribution corresponds to the vertical line.
3.4. Algorithms for solving the system (3.1)
The algorithm presented in Fig. 4 is used as sub-routine in the algorithm of Fig. 5 that computes the unique solution (according to Conjecture 1) to the system (3.1), whenever U and X satisfy the conditions of Corollary 3.6.
Fig. 4.

Algorithm for computing the function γ(α, X) of equation (3.6). Left: block diagram; right: flow chart.
Fig. 5.

Algorithm for solving simultaneously XHK(γ, α) = X and UHK(γ, α) = U. Left: block diagram; right: flow chart.
First of all, Fig. 4 gives a binary search algorithm for computing the function γ(α, X) of equation (3.6) (α being known) by solving the equation XHK(γ, α) = X. Since (from Theorem 3.3) the function XHK(γ, α) is decreasing in the variable γ and since (by assumption) X is between the upper bound XK(α) = 1 + 1/α and the lower bound 0, it follows that the algorithm of Fig. 4 converges to the unique solution of the equation XHK(γ, α) = X, as follows from the Intermediate Value Theorem. Note that this binary search algorithm corresponds to the bisection method [9] and converges at a geometric rate; namely, after each iteration the distance between the current value of γ and the solution decreases by a factor of 2.
Having this algorithm as a tool, one can solve the equation UHK(γ(α, X), α) = U using the binary search algorithm of Fig. 5 for similar reasons as above, based on Conjecture 1. Indeed, according to the Conjecture, the function UHK(γ(α, X), α) is decreasing and Theorem 3.5 gives the upper and lower bounds of that function. Note that the assumptions on X and U of the algorithm are those of Corollary 3.6. Moreover, observe that the assumption of the sub-routine of Fig. 4 is satisfied whenever it is called in the algorithm of Fig. 5. Details on the computation of the functions XHK and UHK are given in Appendix E. Since the value of γ = γ(α, X) is computed for each value of α considered in the algorithm of Fig. 5, an error on that computation propagates on the error in the estimation of α. So, one has to allow enough precision. In the implementation of the reported tests, we adopted a tolerance of 10−4 and 10−2 in the algorithms of Figs 4 and 5, respectively.
3.5. Overall algorithm
We now discuss an extension of the above method in the case where the system (3.1) has no solution, i.e. whenever U and X do not satisfy the conditions of Corollary 3.6. Also, there is a further issue on the size of α with respect to numerical considerations. On that matter, one has to know that the various functions appearing in the expression of XHK and UHK (such as the digamma function) have a finite support in any implementation. Therefore, in practice, one has to limit the size of α to a finite interval (0, αmax]. So, we resort to the algorithm of Fig. 6 for a practical implementation of the proposed approach. This algorithm finds a solution to the system:
| (3.8) |
as follows directly from Conjecture 1 (i.e., the function UHK(γ(α, X), α) is decreasing in the variable α). Observe that a solution to the system (3.1) such that α ≤ αmax is automatically a solution to the system (3.8). Note that in the algorithm of Fig. 6, a homodyned K-distribution with parameters ε, σ2, α > αmax is approximated by the distribution with parameters
Fig. 6.

Algorithm for estimating the parameters ε2, σ2, α of the homodyned K-distribution with the constraint that α is less than an upper bound αmax. Left: block diagram; right: flow chart.
| (3.9) |
where .
In the reported tests, we chose αmax = 59.5, i.e. as large as possible but within a range for which the various functions used in the C++ implementation of the method could be supported numerically. In view of the numerical behavior of the function XHK at integral values of α (see Appendix E), one might as well choose an odd integer divided by 2 for the value of αmax. Finally, we have checked numerically that the Kullback-Leibler distance [20] between a homodyned K-distribution with parameters ε, σ2, α and the distribution with parameters as in equation (3.9) is less than 1.8 × 10−4 for parameter values in the range and α, αmax ∈ {59.5, 61.5, …, 79.5}. Note that the Kullback-Leibler distance is independent of the scaling factor μ, so that we assumed μ = 1 in the numerical computations. Thus, we are inclined to think that a homodyned K-distribution with α > αmax is approximated sufficiently well by the algorithm of Fig. 6 and that the choice of αmax ≥ 59.5 is not crucial, at least if k ≤ 2. However, we do not have a proof of this hypothesis because the analytical computations appeared to be intractable.
3.6. Are k and α the right parameters to estimate
The biases and normalized standard deviations reported in [11] are rather high. For instance, from [11, Fig. 3], the relative biases for k and α go up to about 600% and 100%, respectively, and their normalized standard deviations reach to about 300%. This suggests that one should consider a transformation of these parameters. In [8], the parameter β = 1/α is considered rather than α itself. For one estimation, the two solutions are equivalent, but for numerous estimations, the biases and standard deviations are not necessarily equivalent, because the averaging operator is not invariant under a transformation unless that transformation is linear. Thus, for instance, the relative bias of 1/α might be lower than the relative bias of α.
In this study, the parameters 1/(κ + 1) and 1/α were adopted. As will be presented in Section 4.1, the relative biases and normalized standard deviations were improved considerably with that choice of transformations. So, in the applications considered, the parameters 1/(κ + 1) and 1/α are estimated in each frame of a sequence of ultrasound images, and those estimated values are then averaged out over all frames. See Section 4.2 for such an application.
The advantage of the proposed choice of parameters is that, even if α = ∞ (corresponding to the Rice model), the parameter 1/α has a meaningful finite value (namely 0). In fact, the parameters 1/(κ + 1) and 1/α have values within the intervals (0, 1] and [0, ∞), respectively, even in the case of the Rice, Rayleigh or K-distribution model. See Section 5.6 for further discussion on this issue.
4. Experimental results
4.1. Comparison of estimators based on simulation of data samples
In order to compare the reported experimental results with those of [11], it was decided to present the results in terms of the scatterer clustering parameter α and the ratio of coherent to diffuse signal , where κ = ε2/(2σ2α) is the structure parameter. Following the same approach as in [11], 100 sets of values of the parameters k and α were considered in the domains k ∈ {0.1, 0.2, …, 0.9, 1.0} and α ∈ {1, 2, …, 9, 10}, and the value of σ2 was taken as 1/α, so that the diffuse signal power 2σ2α = 2 was kept constant. For each of these sets, 1000 samples of size N = 1000 each were simulated, according to the homodyned K-distribution model. The parameters from each sample were then estimated using 1) the moments of intensity method [8] (MI), 2) a method based on the first three moments of the amplitude (MA), 3) the proposed method based on the mean intensity and the X and U statistics (XU), and 4) the method [11] based on the SNR, skewness and kurtosis of two fractional orders of the amplitude (RSK). For each estimation method, the relative biases (E[k̂] − k)/k and (E[α̂] − α)/α, the normalized standard deviations and , and the relative root mean squared errors (RMSE) defined by and were computed, based on the 1000 estimates k̂ and α̂ of those parameters. The relative bias and normalized standard deviation of the proposed estimator are presented in Fig. 7. As in [11], the computation of the bias and standard deviation did not include the instances where α was outside a reasonable range (i.e., α ≥ 59.5 for the MI, MA and XU methods). In Table 2, the sums of the quantities represented in Fig. 7 over the sets of parameters that were considered are presented for each of the tested methods. See Appendix F for the implementation of the MI method in the reported tests. The implementation of the MA method follows a similar strategy as the one presented in Section 3. We decided to skip the details in this paper since the MA method performed less well than the proposed estimator. For the MI and MA methods, a minimization problem similar to Equation (3.8) is considered to circumvent the case where the system of non-linear equations has no solution.
Fig. 7.

Relative bias and normalized standard deviation (SD) of the parameter estimates based on the XU estimator. The sample size is N = 1000. The computation of the biases and standard deviations excluded the instances where α was greater than αmax.
Table 2.
Improvements in bias and variance of estimators. The sample size is N = 1000. Estimation methods: 1) MI [8]; 2) MA; 3) XU (proposed method); 4) RSK [11]. The computation of the biases and standard deviations excluded the instances where α was greater than αmax for the MI, MA, XU methods. A star (*) indicates the best relative RMSE value among the four estimators.
| MI | MA | XU | RSK | |
|---|---|---|---|---|
| Total absolute value of the relative bias of α̂ | 47.9 | 19.6 | 17.5 | 23.9 |
| Total absolute value of the relative bias of κ̂ | 42.2 | 33.2 | 34.7 | 60.7 |
|
| ||||
| Total normalized standard deviation of α̂ | 108.9 | 73.7 | 70.3 | 84.5 |
| Total normalized standard deviation of κ̂ | 117.0 | 92.0 | 91.1 | 62.1 |
|
| ||||
| Total value of the relative RMSE of α̂ | 120.3 | 76.7 | 72.7* | 88.2 |
| Total value of the relative RMSE of κ̂ | 126.6 | 99.1 | 99.1 | 92.7* |
Next, the relative RMSE of the various tested estimators were evaluated for the parameters k, α, as well as the parameters κ, , 1/(κ + 1) and 1/α, but without excluding high values of α for the MI, MA and XU methods (since 1/α = 0 is a solution). The results are presented in Table 3.
Table 3.
Relative RMSE of estimators for various parameters of the homodyned K-distribution. The sample size is N = 1000. Estimation methods: 1) MI [8]; 2) MA; 3) XU (proposed method); 4) RSK [11]. For the MI, MA, XU methods, the computation of the biases and standard deviations did not exclude any values of α, because 1/α = 0 is a solution. A star (*) indicates the best MSE value among the four estimators.
| MI | MA | XU | RSK | |
|---|---|---|---|---|
| Mean relative RMSE of α̂ | 1.69 | 1.06 | 1.04 | 0.88* |
| Mean relative RMSE of | 1.37 | 0.64 | 0.63* | 0.67 |
| Mean relative RMSE of k̂ | 1.26 | 0.99 | 0.99 | 0.93* |
| Mean relative RMSE of κ̂ | 6.90 | 4.29* | 4.37 | 4.87 |
| Mean relative RMSE of | 1.04 | 0.86 | 0.85* | 0.88 |
| Mean relative RMSE of | 0.18 | 0.12 | 0.13 | 0.11* |
4.2. Estimation based on simulated ultrasound images
4.2.1. Experimental setup
The reported computational simulations were inspired by the work of [11, III-D-2]. Namely, radiofrequency (RF) data were simulated using the Field II ultrasound simulation program [17, 18]. A single-element oscillating focused (f/4) transducer with a focal length of 50.8 mm was used. Its center frequency was 10 MHz, and it was excited with a Gaussian windowed sinusoidal pulse with a 50% fractional bandwidth at −6 dB. The excitation pulse length was 0.616 mm, i.e. 4 times the wavelength (that information is missing from [11]). The sampling frequency was 200 MHz and the scan lines to produce an image were separated by 0.43 mm. The speed of sound was equal to 1540 m/s. These choices amount to an axial and a lateral discretization of 0.00385 mm and 0.43 mm per pixel, respectively. As in [11], no tissue attenuation was added in these simulations. The ultrasound echo envelope was computed as the norm of the Hilbert transform of the RF data (see [19]). The resulting unfiltered and uncompressed B-mode image was then decimated along the beam axis by a factor of 10 in order to have an independent identically distributed sample modeled by a single homodyned K-distribution.
A computational phantom of height 17.2 mm, length 20.7 mm, and width 1.72 mm was also considered. The center of the volume was located at the geometric focus of the transducer. The resolution cell (a volume which corresponds to the smallest resolvable detail [5]) was obtained by scanning one scatterer located at the geometric focus of the transducer and considering the −20 dB contour of the echo envelope (as in [8]). The resolution cell size was then estimated using the correlation length method (as in [8]) along the axial and lateral directions. The resolution cell volume (based on an ellipsoid model) was 0.2153 mm3 (the ellipsoid semi-principal axis in the beam direction measured 0.2180 mm and the two other semi-principal axes were 0.4856 mm long). Thus, a density (i.e., average number of scatterers per unit volume) of Ns scatterers per resolution cell corresponded to Ns × 2844 scatterers within the numerical phantom (Ns was variable in the reported tests).
4.2.2. Variation of the density of randomly located scatterers
Randomly located scatterers were placed in the phantom volume at spatial locations distributed according to a uniform distribution. The amplitude of each scatterer (related to the contrast in acoustic impedance between the scatterer and the surrounding medium) was distributed according to a normal distribution of mean 0 and variance 1, as in [17] (that information is missing in [11]). Sequences of ultrasound images were simulated with an average number of randomly located scatterers per resolution cell varying from 1 to 10 (for a total of 10 simulated sequences). For each value of the scatterer density, a total of 60 images were simulated. See Fig. 8 for examples of simulated images.
Fig. 8.

Examples of simulated B-mode images with Ns randomly located scatterers per resolution cell, Nc periodic scatterers per resolution cell, with or without noise added to the RF signal. Top left: Ns = 1, Nc = 0, no noise; Top right: Ns = 10, Nc = 0, no noise. Middle left: Ns = 3, Nc = 0, no noise; Middle right: Ns = 3, Nc = 3, no noise. Bottom left: Ns = 3, Nc = 0, RF SNR of 20 dB; Bottom right: Ns = 3, Nc = 3, RF SNR of 20 dB. A log-compression was applied to the echo envelope solely for visualization purposes.
For each simulated sequence, the estimated values of 1/(κ + 1) and 1/α were averaged over the 60 images of the sequence within a region of interest (ROI), based on the XU estimator. The ROI consisted of the rectangle covered by 6 resolution cells in the axial direction and of about 35 resolution cells in the lateral direction (for a sample size of N = 13299 pixels), centered at the geometric focus of the transducer. In Fig. 9, the theoretical and estimated values (with the XU estimator) of these parameters are presented. For the theoretical values, the parameter 1/(κ + 1) should be equal to 1, since there are no periodic scatterers in this simulation (see Section 4.2.3). Also, the parameter 1/α should be inversely proportional to the number of randomly located scatterers per resolution cell. In fact, from [33, Eq. (4)], the parameter α is of the form αsNs, where Ns is the number of randomly located scatterers per resolution cell and αs > 0 is related to the homogeneity of the scattering cross-sections. Thus, one obtains 1/α = 1/(α sNs). The constant 1/αs was obtained with the Blacknell-Tough estimator [4], assuming a K-distribution. Namely, for each simulated sequence, corresponding to an average of i = 1, …, 10 randomly located scatterers per resolution cell, the estimated value of 1/α[i] was averaged over the 60 images. Then, the average was considered as the constant 1/αs (because the index i in the sum represents Ns). In the reported tests, a value of 1/αs = 2.243 was obtained in that manner.
Fig. 9.
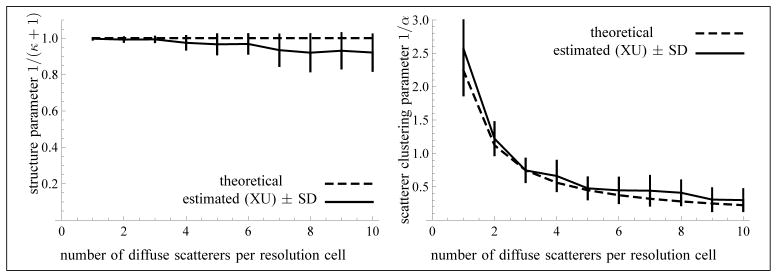
Values of the parameter 1/(κ + 1) (left) and of the scatterer clustering parameter 1/α (right) as a function of the average number of randomly located scatterers per resolution cell. No coherent component was included in these simulations. The sample size of each frame is 13299 and the number of frames is N = 60 (used for the computation of the standard deviations). The computation of the biases and standard deviations did not exclude any values of α, because 1/α = 0 is a possible solution.
4.2.3. Variation of the coherent component
A fixed density of 3 randomly located scatterers per resolution cell was considered. Coherent scattering was created by using periodically spaced scatterers along the transducer axis. So, their coordinates in the plane perpendicular to the transducer axis were random, whereas their coordinates along that axis were separated by a distance of around λ/2, where λ is the wavelength. This corresponds to a subresolvable periodic alignment of scatterers. The amplitude of the periodic scatterers was fixed to the constant 1 for each simulation of 60 images, in order to match the average intensity value of the randomly located scatterers. Indeed, the amplitude of the randomly located scatterers was distributed according to a Gaussian distribution of mean 0 and variance 1, which implies a Rayleigh distribution of mean 1 for the intensity (i.e., the square of the amplitude). The average number of periodic scatterers per resolution cell (i.e., their density) varied from 0 to 9 (with a step of 1), for a total of 10 simulations of 60 images each.
For each simulated sequence, the estimated values of 1/(κ +1) and 1/α were averaged over the 60 images of the sequence within the ROI of Section 4.2.2. In Fig. 10, the theoretical and estimated values of these parameters (with the XU method) are presented. As a first approximation, the theoretical value of κ is equal to the ratio of periodic to randomly located scatterers. Moreover, one would expect that the theoretical value of α is constant and corresponds to a density of 3 randomly located scatterers per resolution cell (and no periodic scatterers) times the constant αs of Section 4.2.2. Hence, it can be deduced as in that section.
Fig. 10.
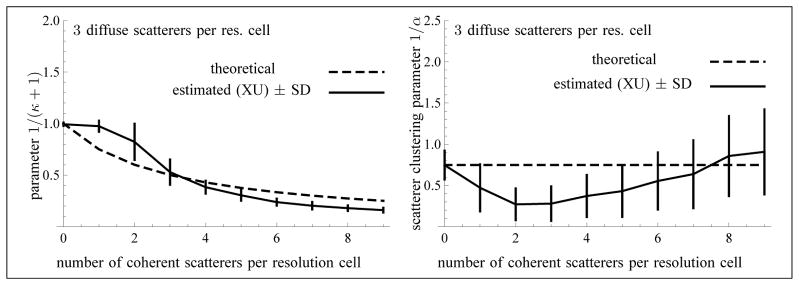
Values of the parameter 1/(κ + 1) (left) and of the scatterer clustering parameter 1/α (right) as a function of the number of coherent scatterers per resolution cell. The sample size of each frame is 13299 and the number of frames is N = 60 (used for the computation of the standard deviations). The computation of the biases and standard deviations did not exclude any values of α, because 1/α = 0 is a possible solution.
4.2.4. Presence of noise
The simulations of Sections 4.2.2 and 4.2.3 were repeated with the addition of noise on the RF signals (prior to the computation of the echo envelope) to create RF signals with SNRs of 20 dB, 10 dB or 5 dB. Namely, an SNR of n dB on the RF signal was simulated by adding to the RF signal a Gaussian noise of mean 0 and of variance τ2 equal to 10−n/10 E[IRF], where IRF denotes the square of the RF signal. In that manner, the SNR of the RF signal was equal to E[IRF]/τ2 = 10n/10, which corresponds indeed to n dB. A comparison with the simulations with no added noise is presented in Table 4. Four methods were tested: 1) the MI method [8]; 2) the MA method; 3) the XU (proposed) method; and 4) the RSK method [11]. In that table, the relative RMSE are reported. Note that the value of the constant 1/αs of Section 4.2.2 has to be evaluated for each level of noise. We obtained the values 2.225, 2.106, and 1.896 for SNRs of 20 dB, 10 dB, and 5 dB, respectively.
Table 4.
Improvements in mean relative RMSE, mean CV and mean RFJC of estimators. The sample size of each frame is 13299 and the number of frames is N = 60 (used for the computation of the standard deviations). Estimation methods: 1) MI [8]; 2) MA; 3) XU (proposed method); 4) RSK [11]. For the methods MI, MA, and XU, the computation of the biases and standard deviations did not exclude any values of α, because 1/α = 0 is a solution. A star (*) indicates the best relative RMSE value among the four estimators.
| Simulations 4.2.2 | Simulations 4.2.3 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||
| Method | MI | MA | XU | RSK | MI | MA | XU | RSK | |
| No noise | No noise | ||||||||
|
| |||||||||
| rel. RMSE of | 0.79 | 0.61 | 0.53* | 0.67 | CV of | 0.99 | 0.65 | 0.61* | 0.75 |
| rel. RMSE of | 0.074 | 0.075 | 0.069* | 0.100 | RFJC of | 4.37 | 5.27 | 5.73* | 3.95 |
|
| |||||||||
| RF SNR of 20 dB | RF SNR of 20 dB | ||||||||
|
| |||||||||
| rel. RMSE of | 0.80 | 0.62 | 0.53* | 0.67 | CV of | 0.99 | 0.65 | 0.61* | 0.74 |
| rel. RMSE of | 0.074 | 0.075 | 0.069* | 0.100 | RFJC of | 4.37 | 5.25 | 5.78* | 3.97 |
|
| |||||||||
| RF SNR of 10 dB | RF SNR of 10 dB | ||||||||
|
| |||||||||
| rel. RMSE of | 0.83 | 0.66 | 0.56* | 0.70 | CV of | 0.99 | 0.64 | 0.61* | 0.76 |
| rel. RMSE of | 0.076 | 0.078 | 0.071* | 0.101 | RFJC of | 4.31 | 5.04 | 5.54* | 3.96 |
|
| |||||||||
| RF SNR of 5 dB | RF SNR of 5 dB | ||||||||
|
| |||||||||
| rel. RMSE of | 0.89 | 0.72 | 0.61* | 0.76 | CV of | 0.98 | 0.67 | 0.61* | 0.78 |
| rel. RMSE of | 0.080 | 0.085 | 0.077* | 0.107 | RFJC of | 4.11 | 4.55 | 5.03* | 3.99 |
5. Discussion
5.1. Comparison of estimators based on simulations of data samples
As can be seen from Table 2, the XU method for the homodyned K-distribution yielded the lowest total relative RMSE for the parameter α. On the other hand, the total relative RMSE for the parameter k was lowest with the RSK method, whereas the MA and XU methods ranked second.
Note that the values obtained for α and k with the RSK method agree with [11, Table 1]. The values obtained for α with the MI method agree with [11, Table 1], but not the values obtained for k. This is explained by the fact that in the present study, as well as in [11], estimated values were excluded when α was outside its range. However, in [11], estimated values were excluded whenever α was outside its domain for either method [8] or [11]. In the present study, estimated values were excluded for a given estimator only if α was outside its domain for that estimator. We proceeded in that manner in order to test the performance of each method as it stands alone.
Moreover, Table 3 indicates clearly that it is preferable to estimate the parameters 1/(κ + 1) and 1/α rather than k (or κ or ) and α. The XU method yielded a lower relative RMSE than the MI method, whereas it was barely better than the MA method, for the parameters α, 1/α and . On the other hand, the reported tests on simulated images indicate that the XU estimator is preferable to the MA estimator. The RSK method presented the lowest relative RMSE for the parameters α, k and 1/(κ + 1), but the XU method was best for the parameters 1/α and .
5.2. Estimation based on simulated ultrasound images
5.2.1. Variation of the density of randomly located scatterers
Table 4 (left part) shows that the XU estimation method performs better than the other tested methods. These results are in agreement with the RMSEs obtained on simulated data samples of Section 4.1, as far as the XU and RSK methods are concerned. On the other hand, the XU method appears to be much better than the MA method on simulated images, whereas the tests performed on simulated data samples did not stress this fact. This is explained by the fact that the X and U statistics arise in the limiting case where the fractional exponent of the fractional moment estimator is small [4] (i.e., near 0 or 1), since higher order moments are more sensitive to noise. Note that the estimates improve in the presence of less noise on the RF signal.
As can be seen from Fig. 9, the estimation of the parameters 1/(κ + 1) and 1/α is reliable up to 3 scatterers per resolution cell (1/α > 0.7) in the context of the reported tests. This is due to the behavior of the estimator for large values of α when κ = 0. Namely, the normalized bias and standard deviation of the estimator of increase with the size of α, as can be seen from Fig. 7 (right) on the axis k = 0. Moreover, the normalized standard deviation of the estimator of α increases with the size of α (left of Fig. 7), which is consistent with the asymptotic expression 1/α2 of the Fisher information of the K-distribution [1] (corresponding to k = 0). Indeed, the larger the value of α, the smaller the information revealed by the data, so that a larger sample size is needed for a finer estimation. Henceforth, the limitation of the XU estimator for large values of α is intrinsic to the model. To further study this issue, we have experimented with simulated ultrasound images with 11 to 20 scatterers per resolution cell. The relative RMSEs for 1/α were equal to 1.43 (MI), 1.27 (MA), 1.25 (XU) and 1.33 (RSK); for 1/(κ + 1), we obtained 0.14 (MI), 0.16 (MA), 0.17 (XU) and 0.20 (RSK). So, the XU estimator is better than the three others for 1/α, but for 1/(κ + 1), the MI estimator is best, whereas the XU estimator is still better than the RSK estimator.
One way to remedy this limitation is to consider the median of the estimator over a sequence of images. Fig. 11 shows that this approach yields much better results for the parameter 1/(κ + 1) and slightly better results for 1/α. Taking the median over all frames, instead of the mean, reduced the normalized bias1 of the XU estimator for the parameter 1/(κ + 1) down to 0.08 in the case of the simulations with 11 to 20 diffuse scatterers. So, the bias was smaller when using the median instead of the mean. Moreover, the standard deviation (or the median absolute deviation - MAD -) is proportional to for the average of an estimator over N images. Thus, taking the median value of the estimator over a sequence of images greatly improves its performance.
Fig. 11.
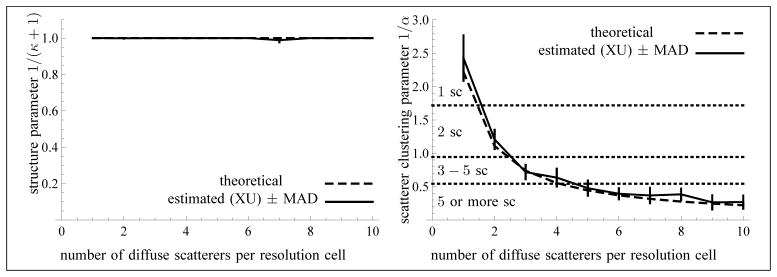
Median values of the parameter 1/(κ + 1) (left) and of the scatterer clustering parameter 1/α (right) as a function of the average number of randomly located scatterers per resolution cell. No coherent component was included in these simulations. The sample size of each frame is 13299 and the number of frames is N = 60 (used for the computation of the median absolute deviations).
Note also from Fig. 11 that although the XU estimator does not allow the exact number of scatterers per resolution cell for 1/α < 0.7 to be distinguished, this estimator nevertheless indicates the range of the number of scatterers. This is consistent with the fact that the homodyned K-distribution gets close to a Rice distribution2 as α increases, so that it becomes harder to determine the exact value of α. So, again, this phenomenon is intrinsic to the model.
5.2.2. Variation of the coherent component
As can be seen from Fig. 10, the estimation of the parameter 1/(κ + 1) is quite reliable except when the number of coherent scatterers is 1 or 2. Also, the estimated parameter 1/α is smaller than the expected constant value, in the case of the simulations with a variable coherent component. So, as it stands, the proposed theoretical model is only an approximation. For that reason, we have chosen two evaluation measures that do not depend on a theoretical ground-truth in Table 4 (right). For the parameter 1/α, the coefficient of variation (CV) of the estimated parameter indicates the variability of the estimator with respect to its mean. If θ̂ is the estimator of a parameter θ, the CV is defined as . For the parameter 1/(κ + 1), the root Fisher’s J criterion (RFJC) applied to pairs of distinct values of the parameter is an indicator of the discrimination power of the estimator. For two distinct values of a parameter θ, say θ1 and θ2, the RFJC is defined as .
Table 4 (right) shows that the XU estimation method performed better than the other tested methods, even with RF SNRs of 20 dB to 5 dB. Note that overall, the estimates improved in the presence of less noise on the RF signal, as expected.
5.3. Computational load
In the case of the experiments of Section 4.1, one estimation took on average 1.0 ms (MI), 1.6 ms (MA), 1.8 ms (XU) and 295.2 ms (RSK). In the case of the experiments of Sections 4.2.2 and 4.2.3, the computation times per image were equal to 6.0 ms (MI), 8.0 ms (MA), 6.8 ms (XU), and 500 ms (RSK). So, the MI, MA and XU methods share a comparable efficiency, whereas the RSK method is slower. That being said, the implementation for the first three methods was in C++, whereas the RSK method was implemented with Matlab. Nevertheless, the first three methods resort to a binary search algorithm with geometric rate of convergence, whereas the RSK method does not.
5.4. Hypothesis underlying the simulations of ultrasound images
As in [8, 11], we have made the hypothesis that the scatterers are dimensionless (upon using the Field II ultrasound simulation program [17, 18]). In the case of biological tissues, this hypothesis is false. In fact, the cell nuclei may be viewed as weak scatterers embedded in cytoplasm, considered as the ambient medium (see [31, 34]). Assuming spherical nuclei with a radius of 4.5 μm, one obtains a volume of 382 μm3. For flowing red blood cells, which do not have a nucleus, the cells themselves are viewed as scatterers (of volume 94 μm3 [32]), whereas the plasma is considered as the ambient medium. The point is that a sufficiently large density of scatterers with non-zero volume creates a scattering field that departs from the scattering behavior of uniformly distributed dimensionless scatterers, due to the so-called packing factor [36, 37]. Thus, the simulations reported in the present study are to be interpreted in the context of a low density of uniformly distributed weak scatterers of sufficiently small size (with respect to the resolution cell). The study of the homodyned K-distribution in the context of more realistic simulations with scatterers of finite dimensions would need to be addressed.
5.5. Conjecture 1
The statement that the algorithm of Fig. 4 converges to a unique solution is proved in Appendix B. For the algorithm of Fig. 5, all statements of Theorem 3.5 are proved in Appendix C. But Conjecture 1 remains to be proven to obtain the convergence of the algorithm of Fig. 5 to a unique solution of the system of equations (3.1). Yet, we have explained in Appendix D how that conjecture would follow from two claims. The former claim is illustrated in Fig. 12, whereas the latter is proved in Appendix D. We are convinced that the first claim is also true, but we do not know if this strategy for proving the conjecture is the easiest one. Note that the algorithm of Fig. 6 also relies on the conjecture.
Fig. 12.
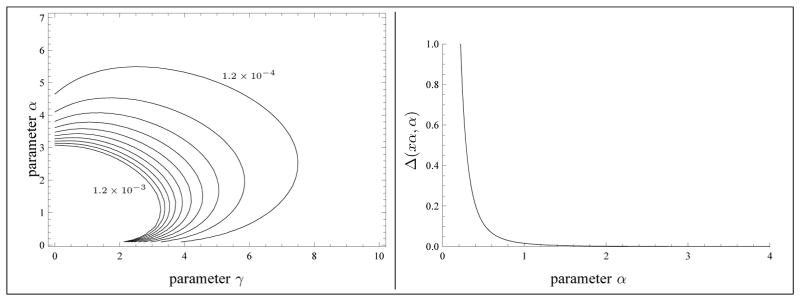
Left: A few level curves of the function Δ( γ, α) by steps of 1.2 × 10−4. The function Δ is increasing in the direction pointing to the origin. Right: Typical graph of Δ(xα, α) for a fixed value of x.
5.6. Upper bound on the parameter α
If one does not impose an upper bound on α (unlike what was done in Section 3.5), then one can consider the following minimization problem, which is similar to Eq. (3.8)
| (5.1) |
where κ = ε2/(2σ2α) and β = 1/α. Observe that a solution to the system (3.1) yields automatically the solution μ = I̅, κ = ε2/(2σ2α) = γ/α and β = 1/α to the system (5.1).
The first case where the conditions of Corollary 3.6 are not satisfied (i.e., when the system (3.1) has no solution) corresponds to X > 1 and . Since is the lower bound of the function UHK(γ(α, X), α) (c.f. Theorem 3.3), it follows that |UHK − U| is minimized at α = α0 = 1/(X − 1), assuming the conjecture. But then, one must have γ(α0, X) = 0, because of Theorem 3.3. Thus, one obtains the K-distribution model with μ = I̅, κ = 0 and α = α0 (and hence β = 1/α0).
The other case to consider corresponds to X ≤ 1 and . Then, |UHK − U| is minimized at α = ∞, assuming the conjecture. Indeed, the lower bound of the function UHK(γ (α, X), α) is equal to and is reached asymptotically at infinity (c.f. Theorem 3.5, part c)). Thus, one obtains the Rice distribution. In fact, as α → ∞, the homodyned K-distribution with parameters ε2, and α tends to the Rice distribution with parameters ε2 and . Moreover, from Appendix B, Proof of Theorem 3.5, Part c), we have XRi(κ) = limα→∞ XHK(γ, α), where and . Furthermore, one obtains β = limα→∞ 1/α = 0. The special case where X = 1 yields the Rayleigh distribution because XRi(0) = 1. Thus, if one is willing to include the Rice distribution to the homodyned K-distribution model as a limit case, then the system (5.1) always admits a solution.
However, the value of α is unbounded with that formulation, which is problematic in any implementation. For that reason, we adopted the minimization formulation of Eq. (3.8). Note that the MI and MA methods present a similar behavior. Moreover, the RSK method also restricts the parameters k and α to a bounded domain.
5.7. Biomedical applications
The K-distribution was used in the context of breast cancer classification in [33]. The parameters of the K-distribution have also been studied in the context of tissue characterization under shear wave propagation [3]. The homodyned K-distribution was used for cardiac tissue characterization [10], cancerous lesion classification [25, 12, 22], breast lesion classification [35] and determination of red blood cell aggregation [7]. In all these applications, the statistical parameters of the distributions considered are viewed as classifying features. The underlying assumption is that the scattering properties of the biological tissues leave a signature on the echo envelope of the received RF signal.
6. Conclusions
A method for the estimation of the parameters of the homodyned K-distribution was proposed, based on the first moment of the intensity and two log-moments (i.e., the U and X statistics). It was proven that the proposed algorithm converges to an estimation of the parameters. It was shown that it is preferable to estimate the parameters 1/(κ + 1) and 1/α, rather than k or κ, and α. The experimental results reported here show that the resulting estimator is, overall, more reliable than the method [8] based on the first three intensity moments, or a method based on the first three moments of the amplitude, or the estimator [11] based on the SNR, the skewness and the kurtosis of two fractional orders of the amplitude. These results hold even in the presence of noise corresponding to RF SNRs of 20 dB to 5 dB. For simulated data samples, the method [11] was slightly better for the parameter 1/(κ + 1). For simulated ultrasound images with more than 10 scatterers per resolution cell, the estimator [8] was slightly better for the parameter 1/(κ + 1). Otherwise, the proposed estimator ranked best among the four tested estimation methods. Moreover, the proposed method has a geometric rate of convergence, since it is based on the bisection algorithm for monotonous functions. Thus, a fast, reliable, and novel algorithm for the estimation of the homodyned K-distribution was proposed. On theoretical grounds, the uniqueness of the solution produced by the proposed method remains to be proven.
Acknowledgments
We thank Mr. D. P. Hruska and Prof. M. L. Oelze for letting us use their Matlab implementation of their method [11] in the reported tests. This research was jointly supported by the Collaborative Health Research Program of the Natural Sciences and Engineering Research Council of Canada (NSERC, 365656-09) and Canadian Institutes of Health Research (CPG-95288), and by the Discovery grant program of NSERC (138570-11). The authors thank the anonymous reviewers for their helpful comments on the presentation of this work.
Appendix A. The statistics U and X for the homodyned K-distribution
In this appendix and those which follow, the software Mathematica (Wolfram Research, Inc., Champaign, IL, USA, version 7.0) was used whenever possible for the computations of integrals or limits. We have indicated any step that could not be obtained directly from that software.
Proof of Lemma 3.1
Part a). The function log I is concave. Therefore, from Jensen’s inequality [16], one obtains E[log I] < log E[I], since the random variable I is non-constant.
Part b). The function I log I is convex. Thus, E[I log I] > E[I] log E[I]. From part a), one concludes that E[I log I] > E[I]E[log I].
Proof of Proposition 3.2
Part a). First of all, using the change of variable I = A2, one computes
| (A.1) |
which is a Laplace transform equal to , where Γ(0, x) is the incomplete gamma function . Then, taking a2 = σ2w, multiplying by 𝒢(w|α, 1), and integrating with respect to w, one obtains
| (A.2) |
Subtracting log E[I] from equation (A.2), with the identity E[I] = ε2 + 2σ2α, and setting γ = ε2/(2σ2) yields the result.
Part b). Again, using the change of variable I = A2, one computes
| (A.3) |
This Laplace transform is equal to . Then, subtracting by (corresponding to the term − E[I]E[log I]), taking a2 = σ2w, and multiplying by 𝒢(w | α, 1), one obtains
| (A.4) |
Then, integrating with respect to w yields
| (A.5) |
which gives an expression for E[I log I]−E[I]E[log I]. Dividing equation (A.5) by E[I] = ε2 +2σ2α and setting γ = ε2/(2σ2) yields the result. ■
Appendix B. Estimating γ, when α is known
Proof of Theorem 3.3
Part a). By definition of the hypergeometric series as a power series, one has pFq(a1, …, ap; b1, …, bq; x) = 1 at x = 0. Using this fact, one concludes that the sum of the last four terms in Equation (3.4) is equal to 0 at γ = 0. Next, from [2, p.375, (9.6.9)], one has the asymptotic behavior at x = 0. Hence, the second term of equation (3.4) admits the asymptotic form , at γ = 0. Collecting all terms, one obtains . Since γ = 0 corresponds to the K-distribution, this also shows that XK(α) = 1 + 1/α.
Part b). Writing equation (A.4) in terms of γ and α, and dividing by μ = E[I], one obtains
| (B.1) |
The third term of equation (B.1) is irrelevant because its integral with respect to w is equal to 0. Thus, one has
| (B.2) |
Claim 1
for any x > 0.
Proof
Let . On one hand, limx→0 f (x) = 0. On the other hand, , for x > 0. This last statement is equivalent to , for x > 0, or 4z < e2z, for z > 0 (with the change of variable z = 1/x). But now, the function g(z) = e2z −4z has an absolute minimum at (because for z < z0, whereas for z > z0), and furthermore, g(z0) = 2(1 − log 2) > 0. So, g(z) > 0 for all z > 0, which completes the proof of the claim. ■
From the claim, . Therefore, the absolute value of the function F (w, γ, α) of equation (B.2) admits the upper bound
| (B.3) |
Integrating equation (B.3) with respect to w yields . Thus, limγ→∞ XHK(γ, α) = 0.
Part c). From equation (B.2), the function XHK(γ, α) can be written as the sum of the two following functions
| (B.4) |
It is now shown that the first function is decreasing in γ and that the second one is strictly decreasing in γ.
First of all, one computes
| (B.5) |
where . So, one concludes that , from Claim 2 below.
Claim 2
For γ > 0 and α > 0, E(1 + α, γ) ≤ e−γ/α.
Proof
Since e−γt ≤ e−γ for t ≥ 1 and t−α−1 > 0, one computes immediately . ■
Next, one may write XHK,B(γ, α) as , where
| (B.6) |
Hence, . Thus, in order to show that XHK,B is strictly decreasing, it is sufficient to show that XHK,C(γ, α) > 0 and that XHK,C(γ, α) is decreasing. Therefore, it is sufficient to prove Claims 3 and 4 below.
Claim 3
For γ > 0 and α > 0, .
Proof
One computes
Claim 4
For α> 0, limγ→∞ XHK,C(γ, α) = 0.
Proof
Observe that |Γ(0, 1/x)| = Γ(0, 1/x) ≤ x, for x > 0. Indeed, let f(x) = Γ(0, 1/x) − x. Then, limx→0 f(x) = 0, and , because e1/x > 1/x, for x > 0. Hence, one has . But, .
This completes the proof of the Theorem. ■
Appendix C. Estimating γ and α
Lemma C.1
limα→0 XHK(α/x, α) = ∞, for any x > 0.
limα→0 UHK(α/x, α) = − log(1 + x), for any x > 0.
Proof
Part a). Setting γ = α/x, equation (3.4) reads as
| (C.1) |
Using the definition of the hypergeometric series, one sees immediately that 1 ≤ 1F2(α; 1 + α; α/x) ≤ 1F2(1/2; 1, 1; α/x), for α ≤ 1/2; moreover, . Therefore, , for α sufficiently small. Now, 1F2(1/2; 1, 1; α/x) is a power series in the variable α; moreover, and , for n > 1. Therefore, for α sufficiently small. Arguing as above, limα→0 1F2(1 + α; 2 + α, 2 + α; α/x) = 1. In the same manner, one sees that 1 ≤ 2F3(1, 1; 2, 2, 1− α; α/x) ≤ 2F3(1, 1; 2, 2, 1/2; α/x), for α ≤ 1/2; but, one has that limα→0 2F3(1, 1; 2, 2, 1/2; α/x) = 1. Similarly, for 2F3(1, 1; 2, 2, 2 − α; α/x). From there, one obtains
| (C.2) |
Using the limiting form K1(z) ~ z−1 [2, p.375, (9.6.9)] valid for small arguments z, one computes
| (C.3) |
Finally, combining (C.1), (C.2), and (C.3), one has .
Part b). Setting γ = α/x, equation (3.3) reads as
| (C.4) |
Using the definition of the hypergeometric series, one sees immediately that 1 ≤ 2F3(1, 1; 2, 2, 2 − α; α/x) ≤ 2F3(1, 1; 2, 2, 3/2; α/x), for α ≤ 1/2; but, on the other hand, one has limα→0 2F3(1, 1; 2, 2, 3/2; α/x) = 1. So, limα→0 2F3(1, 1; 2, 2, 2 − α; α/x) = 1. Since , one concludes that . Next, one writes 1F2(α; 1 + α, 1 + α; α/x) = 1 + h(x, α), where . Let us observe that (for α sufficiently small), and from there it follows that . Finally, one has .
Lemma C.2
For any γ > 0 and α > 0 .
Proof
From the proof of Proposition 3.2, part a), one has
| (C.5) |
So, one computes
| (C.6) |
where . Since the function E(α, γ) is obviously decreasing in the variable α for a fixed value of γ, the result follows. ■
Proof of Theorem 3.5
Part a). Let x > 0 be fixed for now. From Lemma C.1, part a), and Theorem 3.3, part c), one has that γ (α, X) > α/x, for α sufficiently small. Then, from Lemma C.2, one obtains that UHK(α/x, α) < UHK(γ (α, X), α) < 0, for α sufficiently small. Therefore, using Lemma C.1, part b), one has −log(1 + x) = limα→0 UHK(α/x, α) ≤ lim supα→0 UHK(γ (α, X), α) ≤ 0. Since x > 0 can be taken arbitrarily small, one deduces that limα→0 UHK(γ (α, X), α) = 0.
Part b). Let X > 1. From Theorem 3.3, one has that implies that γ( α, X) = 0. Then, taking γ = 0 and in Equation (3.3) yields the result.
Part c). Let X ≤ 1. The homodyned K-distribution with parameters ε2, , α tends to the Rice distribution with parameters ε2 and , as α → ∞. The structure parameter κ for that Rice distribution is equal to , and this is the same value for the homodyned K-distribution (because ). Therefore, limα→∞ XHK(κα, α) = XRi(κ), since γ = κα. In the same manner, one obtains limα→∞ UHK(κα, α) = URi(κ). Now, take and let 0 < η < κ. Then, for α sufficiently large, one has (κ − η) α < γ( α, X) < (κ + η) α. Therefore, one obtains UHK((κ − η) α, α) < UHK(γ (α, X), α) < UHK((κ + η) α, α), since from Lemma C.2, the function UHK(γ, α) is increasing in the variable γ. Taking the limit as α→∞ (which is possible since 0 < X ≤ 1 implies that γ( α, X) is well-defined for any α > 0), one deduces that URi(κ − η) ≤ lim infα→∞ UHK(γ (α, X), α) ≤ lim supα→∞ UHK(γ (α, X), α) ≤ URi(κ + η). Since η > 0 can be taken arbitrarily small, the result follows.
Next, an argument similar to the proof of Theorem 3.3 (i.e., making the change of variable I = A2 and computing Laplace transforms) shows that and . Finally, from basic calculus, one obtains the statement on the function XRi(κ). ■
Appendix D. Discussion on Conjecture 1
Let f(α) = UHK(γ (α, X), α) (X being known). Then, Conjecture 1 amounts to the inequality
| (D.1) |
where γ = γ (α, X). Since γ(α, X) is defined by the identity XHK(γ (α, X), γ) ≡ X, the implicit function Theorem implies that . Moreover, since , we conclude that equation (D.1) is equivalent to
| (D.2) |
In particular, it is sufficient to prove the inequality Δ(γ, α) > 0, for any γ > 0 and α > 0. For that purpose, it is sufficient to show the two following claims.
Claim 5
For any fixed value of x > 0, the function Δ(αx, α) is decreasing in the variable α > 0.
We have not succeeded in proving the Claim 5, but Fig. 12 convinced us that it is true.
Claim 6
For any fixed value of x > 0, limα→∞ Δ( αx, α) = 0.
Proof
Using the identity γ = xα and making the change of variable w = αw′, we obtain from Equation (C.6)
| (D.3) |
The distribution 𝒢(w′ | α, 1/α) is concentrated on w′ = 1 as α→∞. Therefore, , for large values of κ. Similarly, we have
| (D.4) |
Thus, for large values of α.
Next, we have for the X-statistics
| (D.5) |
Hence, for large values of α. Also, the partial derivative of X with respect to α is given by
| (D.6) |
So, for large values of α.
Finally, since limα→∞ (log α − ψ( α))/α = 0, the claim follows. ■
Appendix E. Implementation issues
Using standard identities of the Euler gamma function and permuting the terms, one rewrites (3.4) as
| (E.1) |
which is valid for α > 1. If α < 1, the last term is replaced by .
Either expression can be computed directly for α > 0, if α is not an integer. When α is a positive integer, the four terms of lines three and four of (E.1) tend to ±∞. Nevertheless, it can be shown that the corresponding sum has a finite value. In the implementation used in the reported tests, we chose the simplest solution that consists in approximating XHK(γ, α) by interpolation of the values XHK(γ, n − 10−7) and XHK(γ, n + 10−7) in the interval n − 10−7 ≤ α ≤ n + 10−7, where n is an integer. On the other hand, the first two terms of (E.1) are well-defined for any value of α > 0.
Similar remarks apply to the computation of UHK. In particular, one obtains
| (E.2) |
which is valid for α > 1. If α < 1, the last term is replaced by . These expressions are valid for α not an integer. One uses an approximation as explained above for values of α near integers.
Appendix F. Method [8] revisited
The method [8] is equivalent to solving the following (non-linear) system of equations in the variables ε2, σ2, and α:
| (F.1) |
Sufficient and necessary conditions for this system to admit a solution are presented below. For that purpose, the change of variables (3.2) was adopted.
Proposition F.1
Let be distributed according to the homodyned K-distribution PHK(A | ε, σ2, α). With the notation of (3.2), one has
| (F.2) |
| (F.3) |
As one can see, Equations (F.2) and (F.3) depend only on the variables γ and α. Thus, the method [8] amounts to solving Equations (F.2) and (F.3) in the variables γ and α, and then using Equations (3.5) with μ = E[I].
Let α > 0 be known. Using Equation (F.2), one deduces the value of γ ≥ 0 explicitly.
Proposition F.2
Let M > 1 be a real number and α be fixed. Then, there exists at most one solution γ ≥ 0 to the equation MHK(γ, α) = M, namely
| (F.4) |
If M ≤ 2, then there is a solution for any α > 0.
If M > 2, then there is a solution if and only if .
Thus, one obtains a well-defined function γ = γ( α, M) on the domain described by Proposition F.2. Next, proceeding as in Section 3.3, the expression of Equation (F.4) is substituted in Equation (F.3), thus yielding a function LHK(γ (α, M), α) in the single variable α.
Proposition F.3
Let M > 1 be a real number.
One has the left boundary condition limα→0 LHK(γ (α, M), α) = ∞.
If M ≤ 2, then limα→∞ LHK(γ (α, M), α) = LRi(κ0), where .
If M > 2, then limα→α0 LHK(γ (α, M), α) = LK(α0), where .
The function LHK(γ (α, M), α) is decreasing on its domain.
In Proposition F.3, part b), the functions MK(α) = 2 (1+1/α) and LK(α) = 6 (1+1/α) (1+2/α) correspond to the computation of the M and L statistics for the K-distribution. In part c), the functions and correspond to the computation of the M and L statistics for the Rice distribution.
Part d) of the Proposition implies that a binary search algorithm can be used to find the unique solution to Equations (F.2) and (F.3), whenever a solution exists.
Corollary F.4
Let M > 1 and L > 1 be given. Then, there exists a simultaneous solution to the system MHK(γ, α) = M and LHK(γ, α) = L if and only if
-
M ≤ 2 and .
or
M > 2 and .
Moreover, if a solution exists, it is unique.
Thus, one obtains well-defined functions γ = γ(M, L) and α = α(M, L), where M and L are restricted to the domain described by parts a) and b) of Corollary F.4.
Footnotes
The bias may be defined as E[θ̂] − θ, where θ̂ is the parameter estimator and θ is the gold-standard, or as median(θ̂) − θ, when using the median instead of the mean.
We checked numerically that the Kullback-Leibler distance between a homodyned K-distribution with parameters ε, σ2, α and the Rice distribution with parameters ε and is less than 8.8 × 10−3 for values in the range and α ∈ {10, 11, …, 20}. This represents a very good approximation. Note that the Kullback-Leibler distance is independent of the scaling factor μ so that one may assume that μ = 1.
AMS subject classifications. 62F10, 62H35, 62P10, 62P35, 33C10, 33C20, 33B15
References
- 1.Abraham DA, Lyons AP. Novel physical interpretation of K-distributed reverberation. IEEE J of Oceanic Eng. 2002;27:800–813. [Google Scholar]
- 2.Abramowitz M, Stegun IA, editors. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. New York: Dover; 1972. [Google Scholar]
- 3.Alavi M, Destrempes F, Schmitt C, Montagnon E, Cloutier G. Shear wave propagation modulates quantitative ultrasound K-distribution echo envelope model statistics in homogeneous viscoelastic phantoms. 2012 IEEE International Ultrasonics Symposium; Dresden. 7–10 October 2012. [Google Scholar]
- 4.Blacknell D, Tough RJA. Parameter estimation for the K-distribution based on [z log (z)] IEE Proc-Radar, Sonar Navig. 2001;148:309–312. [Google Scholar]
- 5.Burckhardt CB. Speckle in ultrasound B-mode scans. IEEE Trans Son Ultrason. 1978;SU-25:1–6. [Google Scholar]
- 6.Destrempes F, Cloutier G. A critical review and uniformized representation of statistical distributions modeling the ultrasound echo envelope. Ultrasound in Medicine and Biology. 2010;36:1037–1051. doi: 10.1016/j.ultrasmedbio.2010.04.001. [DOI] [PubMed] [Google Scholar]
- 7.Destrempes F, Franceschini E, Yu FTH, Cloutier G. Relation between the backscatter coefficient and echo envelope statistical parameters in the context of red blood cell aggregation. 8th International Conference on Ultrasonic Biomedical Microscanning; St-Paulin (Québec), Canada. 24–27 September 2012. [Google Scholar]
- 8.Dutt V, Greenleaf JF. Ultrasound echo envelope analysis using a homodyned K distribution signal model. Ultrasonic Imaging. 1994;16:265–287. doi: 10.1177/016173469401600404. [DOI] [PubMed] [Google Scholar]
- 9.Gerald CF, Wheatley PO, editors. Applied Numerical Analysis. 7. Addison-Wesley; 2003. [Google Scholar]
- 10.Hao X, Bruce CJ, Pislaru C, Greenleaf JF. Characterization of reperfused infarcted myocardium from high-frequency intracardiac ultrasound imaging using homodyned k distribution. IEEE Trans Ultrason Ferroelectr Freq Control. 2002;49:1530–1542. doi: 10.1109/tuffc.2002.1049735. [DOI] [PubMed] [Google Scholar]
- 11.Hruska DP, Oelze ML. Improved Parameter Estimates Based on the Homodyned K Distribution. IEEE Trans Ultrason Ferroelectr Freq Control. 2009;56:2471–2481. doi: 10.1109/TUFFC.2009.1334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Hruska DP, Sanchez J, Oelze ML. Improved diagnostics through quantitative ultrasound imaging. IEEE Conf Eng Med Biol Soc. 2009:1956–1959. doi: 10.1109/IEMBS.2009.5333465. [DOI] [PubMed] [Google Scholar]
- 13.Jakeman E. On the statistics of K-distributed noise. J Phys A. 1980;13:31–48. [Google Scholar]
- 14.Jakeman E, Pusey PN. A model for non-Rayleigh sea echo. IEEE Trans Antennas Propag. 1976;24:806–814. [Google Scholar]
- 15.Jakeman E, Tough RJA. Generalized k distribution: a statistical model for weak scattering. J Opt Soc Am A. 1987;4:1764–1772. [Google Scholar]
- 16.Jensen J. Sur les fonctions convexes et les inégalités entre les valeurs moyennes. Acta Mathematica. 1906;30:175–193. [Google Scholar]
- 17.Jensen JA. A program for simulating ultrasound systems. Med Biol Comput. 1996;34:351–353. [Google Scholar]
- 18.Jensen JA, Svendsen NB. Calculation of pressure fields from arbitrarily shaped, apodized, and excited ultrasound transducers. IEEE Trans Ultrason Ferroelectr Freq Control. 1992;39:262–267. doi: 10.1109/58.139123. [DOI] [PubMed] [Google Scholar]
- 19.Kallel F, Bertrand M, Meunier J. Speckle motion artifact under tissue rotation. IEEE Trans Ultrason Ferroelectr Freq Control. 1994;41:105–122. doi: 10.1109/58.764845. [DOI] [PubMed] [Google Scholar]
- 20.Kullback S, Leibler RA. On information and sufficiency. Annals of Mathematical Statistics. 1951;22:79–86. [Google Scholar]
- 21.Lord RD. The use of the Hankel transform in statistics. I. Biometrika. 1954;41:44–55. [Google Scholar]
- 22.Mamou J, Coron A, Oelze ML, Saegusa-Beecroft E, Hata M, Lee P, Machi J, Yanagihara E, Laugier P, Feleppa EJ. Three-dimensional high-frequency backscatter and envelope quantification of cancerous human lymph nodes. Ultrasound Med Biol. 2011;37:2055–2068. doi: 10.1016/j.ultrasmedbio.2010.11.020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Molthen RC, Shankar PM, Reid JM. Characterization of ultrasonic B-scans using non-Rayleigh statistics. Ultrasound Med Biol. 1995;21:161–170. doi: 10.1016/s0301-5629(94)00105-7. [DOI] [PubMed] [Google Scholar]
- 24.Nakagami M. Study of the resultant amplitude of many vibrations whose phases and amplitudes are at random. J Inst Elec Commun Engrs Japan. 1940;24:17–26. [Google Scholar]
- 25.Oelze ML, O’Brien WD., Jr Quantitative ultrasound assessment of breast cancer using a multiparameter approach. IEEE Utrasound Symposium; 2007. pp. 981–984. [Google Scholar]
- 26.Oliver CJ. In: Wave Propagation and Scattering. Uscinski BJ, editor. Oxford: Clarendon; 1986. pp. 155–173. [Google Scholar]
- 27.Parry G, Pusey PN. K-distributions in atmospheric propagation of laser light. J Opt Soc Am. 1979;69:796–798. [Google Scholar]
- 28.Prager RW, Gee AH, Treece GM, Berman LH. Decompression and speckle detection for ultrasound images using the homodyned K-distribution. Pattern Recognition Letters. 2003;24:705–713. [Google Scholar]
- 29.Rayleigh Lord. On the resultant of a large number of vibrations of the same pitch and of arbitrary phase. Philosophical Magazine. 1880;10:73. [Google Scholar]
- 30.Rice SO. Mathematical analysis of random noise. Bell System Technical Journal. 1945;24:46–156. [Google Scholar]
- 31.Saha RK, Kolios MC. Effects of cell spatial organization and size distribution on ultrasound backscattering. IEEE Trans Ultrason Ferroelectr Freq Control. 2011;58:2118–2131. doi: 10.1109/TUFFC.2011.2061. [DOI] [PubMed] [Google Scholar]
- 32.Savéry D, Cloutier G. High-frequency ultrasound backscattering by blood: Analytical and semianalytical models of the erythrocyte cross section. J Acoust Soc Am. 2007;121:3963–3971. doi: 10.1121/1.2715452. [DOI] [PubMed] [Google Scholar]
- 33.Shankar PM, Reid JM, Ortega H, Piccoli CW, Goldberg BB. Use of non-Rayleigh statistics for the identification of tumors in ultrasonic B-scans of the breast. IEEE Trans on Med Imag. 1993;12:687–692. doi: 10.1109/42.251119. [DOI] [PubMed] [Google Scholar]
- 34.Taggart R, Baddour RE, Giles A, Czarnota GJ, Kolios MC. Ultrasonic characterization of whole cells and isolated nuclei. Ultrasound Med Biol. 2007;33:389–401. doi: 10.1016/j.ultrasmedbio.2006.07.037. [DOI] [PubMed] [Google Scholar]
- 35.Trop I, Destrempes F, El Khoury M, Allard L, Chayer B, Cloutier G. The added value of statistical parameters based on sonographic backscattering properties of tissues in the management of breast lesions. 98th Assembly and Annual Meeting of the Radiological Society of North America; Chicago. 25–28 November 2012. [Google Scholar]
- 36.Twersky V. Transparency of pair-correlated random distributions of small scatterers with applications to the cornea. J Opt Soc Am. 1975;65:524–530. doi: 10.1364/josa.65.000524. [DOI] [PubMed] [Google Scholar]
- 37.Twersky V. Low-frequency scattering by correlated distributions of randomly oriented particles. J Acoust Soc Am. 1987;81:1609–1618. [Google Scholar]
- 38.Ward KD. Compound representation of high resolution sea clutter. Electron Lett. 1981;17:561–566. [Google Scholar]