

Abstract
Heritability estimates for body mass index (BMI) variation are high. For mothers and their offspring higher BMI correlations have been described than for fathers. Variation(s) in the exclusively maternally inherited mitochondrial DNA (mtDNA) might contribute to this parental effect. Thirty-two to 40 mtDNA single nucleotide polymorphisms (SNPs) were available from genome-wide association study SNP arrays (Affymetrix 6.0). For discovery, we analyzed association in a case-control (CC) sample of 1,158 extremely obese children and adolescents and 435 lean adult controls. For independent confirmation, 7,014 population-based adults were analyzed as CC sample of n = 1,697 obese cases (BMI≥30 kg/m2) and n = 2,373 normal weight and lean controls (BMI<25 kg/m2). SNPs were analyzed as single SNPs and haplogroups determined by HaploGrep. Fisher's two-sided exact test was used for association testing. Moreover, the D-loop was re-sequenced (Sanger) in 192 extremely obese children and adolescents and 192 lean adult controls. Association testing of detected variants was performed using Fisher's two-sided exact test. For discovery, nominal association with obesity was found for the frequent allele G of m.8994G/A (rs28358887, p = 0.002) located in ATP6. Haplogroup W was nominally overrepresented in the controls (p = 0.039). These findings could not be confirmed independently. For two of the 252 identified D-loop variants nominal association was detected (m.16292C/T, p = 0.007, m.16189T/C, p = 0.048). Only eight controls carried the m.16292T allele, five of whom belonged to haplogroup W that was initially enriched among these controls. m.16189T/C might create an uninterrupted poly-C tract located near a regulatory element involved in replication of mtDNA. Though follow-up of some D-loop variants still is conceivable, our hypothesis of a contribution of variation in the exclusively maternally inherited mtDNA to the observed larger correlations for BMI between mothers and their offspring could not be substantiated by the findings of the present study.
Introduction
Twin, adoption and family studies have shown that the heritability of the variation in body mass index (BMI) is high [1]–[4]. Genetic factors explain about 40% to 70% of the variance of the BMI [5]. Some family and adoption studies showed higher correlations in BMI between mothers and their offspring compared to fathers and their offspring e.g. [4, 6, 7]. In a study of 540 adult Danish adoptees, for instance, BMI correlation between biological mothers and offspring were 0.15 compared with 0.11 between biological fathers and offspring [4]. Among maternal half-brothers this effect was also shown as depicted by a two-fold higher BMI correlation (r = 0.21) compared to paternal half-brothers (r = 0.11) [8].
During the last years, several monogenic and polygenic forms of obesity have been elucidated (summarized in [5]). Large-scale genome-wide association studies (GWAS) and independent confirmation (up to 250,000 individuals in total) revealed several BMI and/or body weight associated loci. However, these studies have only focused on autosomal SNPs e.g. [9]–[11].
The circular mitochondrial DNA (mtDNA) comprises 16,569 bps. Somatic cells usually harbor about 1,000 to 10,000 mtDNA molecules [12]. mtDNA encodes 37 genes of which 13 are protein coding subunits of the oxidative phosphorylation system (OXPHOS) [13]. In addition, mtDNA consists of a 1,100 bps non-coding control region known as the mitochondrial displacement (D)-loop [13]. The D-loop consists of two to three hypervariable parts [14], [15]. Both transcription and replication are coordinated at the D-loop [12] (Table 1).
Table 1. Functionally relevant regions of the D-loop.
| Region a | Description/Function | Location Start b | Location End b | Reference | Number of detected variants in location | Mean number of variants per case | Mean number of variants per control | p-value |
| HV1a | Hypervariable regions | m.16024 | m.16365 | [14] | 126 | 2.39 | 2.39 | 0.977 |
| HV1b | m.16024 | m.16382 | [45] | 127 | 2.39 | 2.40 | 0.953 | |
| HV2a | m.73 | m.340 | [14] | 69 | 4.25 | 4.33 | 0.686 | |
| HV2b | m.57 | m.371 | [45] | 73 | 4.30 | 4.38 | 0.707 | |
| HV3 | m.438 | m.574 | [15] | 35 | 0.75 | 0.64 | 0.232 | |
| Mt5 (CE) | Intra- and interspecific control element (CE) | m.16194 | m.16208 | [46] | 1 | 0.01 | 0 | 0.319 |
| Mt3 (L-strand CE) | cis elements which were first detected in 5' region of nuclear encoded mitochondrial OXPHOS genes, and later on also in the mtDNA D-loop; these elements are potentially involved in a coordinated expression of nuclear-encoded and mtDNA OXPHOS genes | m.16499 | m.16506 | [47] | 0 | 0 | 0 | NaN |
| Mt4 (L-strand CE) | m.371 | m.379 | [47] | 1 | 0 | 0.01 | 0.319 | |
| Mt3 (H-strand CE) | m.384 | m.391 | [47] | 1 | 0.02 | 0 | 0.083 | |
| mtTF1 BS | binding sites (BS) of mitochondrial transcription factor A (TFAM, formerly known as mtTF1) | m.233 | m.260 | [48] | 12 | 0.12 | 0.09 | 0.537 |
| mtTF1 BS | m.276 | m.303 | [48] | 5 | 0.12 | 0.12 | 1.000 | |
| mtTF1 BS | m.418 | m.445 | [48] | 0 | 0 | 0 | NaN | |
| mtTF1 BS | m.525 | m.552 | [48] | 4 | 0.01 | 0.02 | 0.178 | |
| LSP (including mtTF1 BS) c | Light strand and heavy strand promoters | m.392 | m.445 | [49] | 1 | 0.01 | 0.01 | 0.563 |
| HSP1 | m.545 | m.567 | [49] | 4 | 0.02 | 0.01 | 0.414 | |
| HSP1 (including mtTF1 BS) | m.525 | m.567 | - - | 6 | 0.02 | 0.02 | 0.738 | |
| HSP2 d | m.632 | m.655 | [27] | 1 | 0 | 0.01 | 0.319 | |
| CSB1 | potentially involved in direction of transcription termination and heavy strand primer formation | m.210 | m.234 | [41] | 8 | 0.12 | 0.06 | 0.101 |
| CSB2 | m.299 | m.315 | [41], [50] | 9 | 1.48 | 1.52 | 0.368 | |
| CSB3 | m.346 | m.363 | [41] | 1 | 0.01 | 0 | 0.319 | |
| ETAS1 | potentially involved in premature termination of heavy strand synthesis | m.16081 | m.16140 | [41] | 12 | 0.39 | 0.36 | 0.578 |
| ETAS2 | m.16294 | m.16356 | [41] | 25 | 0.59 | 0.73 | 0.103 | |
| TAS | m.16157 | m.16172 | [42], [51] | 8 | 0.12 | 0.11 | 0.878 |
functionally relevant regions of the D-loop adapted from www.mitomap.org [32], bmtDNA position according to rCRS [29], cLSP region alone also indicated at m.392 to m.445 [49], dHSP2 was indicated at www.mitomap.org [32] as m.645 [52]–[54], however, more recent investigation mapped start of HSP2 at m.644 [26], [27]; m.632 to m.655 was selected as HSP2 region, as Lodeiro et al. [27] randomized these 24 nucleotides around the transcription start and did not detect transcription in vitro, thus, these 24 nucleotides might be important HSP2 control elements (e.g. transcription factor binding sites).
CE, control element; CSB, conserved sequence block; ETAS, extended termination associated sequence, HSP, heavy strand promoter; HV, hypervariable region; LSP, light strand promoter; mtTF1 BS, mitochondrial transcription factor A (TFAM) binding side (TFAM, formerly known as mtTF1), OXPHOS, oxidative phosphorylation; TAS, termination associated sequence.
As mtDNA is exclusively maternally inherited, variation in mtDNA might contribute to the above mentioned higher correlation in BMI between mothers and their offspring. Up to date, only two GWAS of mtDNA variants in association with BMI have been performed [16], [17]. Yang et al. reported association of the mitochondrial haplogroup X with a lower BMI in a sample of 2,286 unrelated adult Caucasians [16]. The finding was not confirmed in an independent sample [16]. A GWAS on both European-American and African-American case-control (CC) samples of obese and lean children did not reveal association of BMI with any mtDNA variant or with heteroplasmy [17].
In the current analysis, we analysed GWAS data of mtDNA variants in extreme early onset obesity by using a CC sample of 1,158 extremely obese children and adolescents and 435 lean adult controls of German descent. Our findings were followed-up in 7,014 German population-based adults. Moreover, in a sub-sample of 384 individuals of the initial CC sample, the D-loop was re-sequenced in order to detect further variants potentially associated with obesity.
Subjects and Methods
Study subjects
Ethics statement
Written informed consent was given by all participants. The study was approved by the Ethics Committees of the Universities of Marburg, Essen, Greifswald and Kiel, and the Bavarian Medical Association. It was conducted in accordance with the Declaration of Helsinki.
Discovery GWAS sample
The CC GWAS sample consisted of 1,158 (extremely) obese children and adolescents and 435 normal weight or lean adult controls. The controls and 453 cases were derived from a CC GWAS sample [18]. The additional 705 cases were index cases from a family-based GWAS sample of 705 obesity trios (one (extremely) obese child or adolescent [ = index case] and both biological parents) [18]. Lean adults as controls who were never overweight or obese during childhood (as assessed by interview) were used as this was thought to reduce the chances of misclassification compared with the use of lean children as controls who might become overweight or obese in adulthood [19]. The measured body mass index (BMI; in kg/m2) was assessed for extremeness using age- and sex-specific percentile criteria for the German population from the National Nutrition Survey I [20]. According to this reference population, 84% of all cases were extremely obese (BMI ≥99th percentile). The lean controls had a mean BMI of 18.31±1.11 kg/m2 (Table S1).
Confirmation GWAS sample
For confirmation of initial findings, three population-based adult GWAS samples were used (n = 7,014, Table S1). (1) KORA: this sample is a sub-sample of KORA F4, which is an epidemiological study group of the region of Augsburg (Cooperative Health Research in the Region of Augsburg) [21] and comprised 1,743 adult participants (890 females). (2) SHIP: “The Study of Health in Pomerania” is a population-based project in Northeast Germany comprising 4,308 individuals aged 20 to 79 years at recruitment. Of these, 4,073 individuals (2,067 females) were genotyped with the Affymetrix Genome-Wide Human SNP Array 6.0 and included in the analysis [22]. (3) POPGEN: the 1,198 individuals (524 females) of POPGEN (age: 19 to 77 years) genotyped with the Affymetrix Array 6.0 are from a population-genetic research project founded at the University Hospital of Schleswig-Holstein [23]. 738 subjects (336 females) were recruited via the local population registry and 460 (188 females) as blood donors. BMI of the individuals recruited via the local population registry was estimated by self-report, while BMI of the blood donors was measured.
As simulations have shown that genetic markers with an effect in the extremes of a trait are detected more solidly within a CC design compared with a linear regression design [24], we converted the population-based samples into a CC sample categorizing all individuals with a BMI ≥30 kg/m2 as obese cases (n = 1,697) and those with a BMI <25 kg/m2 as normal weight and lean controls (n = 2,373; Table S1).
D-loop sample
The D-loop was re-sequenced in 192 extremely obese cases and 192 lean controls. These individuals were derived from the initial CC GWAS sample apart from 14 cases and six controls. Mean age and BMI were similar to those found in the initial CC GWAS sample (Table S1).
Molecular genetic analysis
Genotyping
All individuals were genotyped by the Affymetrix Genome-Wide Human SNP Array 6.0. This array covers 115 to 119 mtDNA SNPs (Table S2). The following quality control (QC) criteria were applied: (1) SNP call-rate above 95%, (2) minor allele frequency (MAF) above 1%, and (3) cluster graphs checked independently by two raters for clear separation of both alleles. Only 32 to 40 SNPs passed these criteria as most of the mtDNA SNPs were monomorphic or had a very low MAF (Table S2).
Variant detection by re-sequencing (Sanger) of mitochondrial D-loop
Primers were selected according to Cardoso et al. [25] (Fig. S1). Instead of H616 [25], H715 was chosen to include the sequence of the second heavy strand promoter (HSP2), whose start is located at m.644 [26], [27], i.e. outside of the actual D-loop (m.576 to m.16024, [28]) (Fig. S1). The outer primers L15988 and H715 were used for amplification of the D-loop (primer annealing temperature: 65°C).
Re-sequencing was performed by LGC Genomics Berlin, Germany using all four primers. Received electro-pherograms were evaluated manually using Seqman Pro (v.10.1.0 (174), 419, DNASTAR, Inc., Madison (WI), USA). The D-loop sequence of the revised Cambridge Reference Sequence (rCRS, [29]) was copied into a Microsoft Office Excel 2007 (Microsoft Coop., Redmond (WA)) sheet, so that each cell comprised ten nucleotides and each line 60 nucleotides. Deviations from this reference were noted below the reference in a separate Excel sheet for each individual. Evaluation of electropherograms was performed by two independent raters. Discrepancies were resolved unambiguously by either reaching consensus or re-sequencing.
Variant detection by re-sequencing (Sanger) of complete mitochondrial DNA
Complete mtDNA was re-sequenced in five cases and five controls of the discovery GWAS sample by Seqlab Göttingen, Germany. Evaluation of received electropherograms was performed manually as described above.
Determination of haplogroups
The haplogroup of each individual of the discovery and confirmation sample was determined with HaploGrep [30], [31]. For this analysis, HaploGrep software provided at http://haplogrep.uibk.ac.at/was downloaded. All available mtDNA SNPs from each individual (32 to 40 mtDNA SNPs, Table S2/Table S3) were entered. Each individual's haplogroup was determined based on PhyloTree.org (mtDNA tree build 11, [31]) which is implemented in the software. Only those individuals whose haplogroup quality value was rated ≥90% were included into statistical analyses. At this quality threshold haplogroup assignment is quite reliable according to HaploGrep's manual. For association testing, haplogroups were assigned to major haplogroups.
Statistic tests
For discovery, association testing was performed using Fisher's two-sided exact test for both single SNP and haplogroup analysis. Analyses were also performed stratified by gender. Odds ratios and confidence intervals were determined. For independent confirmation, nominally associated SNPs or haplogroups were followed-up in the confirmation sample – in the whole sample or stratified by gender depending on the discovery finding.
Frequencies of detected variants by D-loop re-sequencing were compared between cases and controls using Fisher's two-sided exact test. Moreover, average number of variants in 23 defined functionally relevant regions of the D-loop (adapted from www.mitomap.org; Table 1, [32]) was compared between cases and controls with a t-test.
Results
Single SNP analysis
Association analysis was performed with 35 mtDNA SNPs in the whole discovery GWAS sample of 1,158 (extremely) obese children and adolescents and 435 lean and normal weight adult controls. Five further SNPs were analyzed in this sample excluding the 705 cases from the family-based trio GWAS sample, as these five SNPs did not pass QC in this sample (Table S3). Nominal association was found for m.8994G/A (p = 0.002), whose minor allele A was more frequent among the controls (3.92% vs. 1.30%; Table 2). m.8994 is located in the ATP6 gene. The G/A transition at m.8994 is synonymous. Stratified by gender, nominal association was found for both male and female subjects (Table 2). In female subjects, nominal association was found for three further SNPs, while in male subjects one further SNP was nominally associated (Table 2).
Table 2. Nominally associated mtDNA SNPs in discovery and follow-up in confirmation.
| Discovery | Confirmation | |||||||||
| SNP a | MAF cases [%] b | MAF controls [%] b | Odds Ratio | Confidence Interval c | p-value d | MAF cases [%] b | MAF controls [%] b | Odds Ratio | Confidence Interval c | p-value d |
| All | n = 1,158 | n = 435 | n = 1,697 | n = 2,373 | ||||||
| m.8994G/A | 1.30 | 3.92 | 0.32 | 0.15–0.69 | 0.002 | 3.24 | 2.41 | 1.36 | 0.92–2.02 | 0.120 |
| Males | n = 508 | n = 171 | n = 828 | n = 930 | ||||||
| m.8994G/A | 0.79 | 2.94 | 0.26 | 0.05–1.23 | 0.048 | 2.78 | 2.16 | 1.30 | 0.68–2.51 | 0.441 |
| m.11674C/T | 0.59 | 3.51 | 0.16 | 0.03–0.78 | 0.010 | 2.06 | 1.63 | 1.27 | 0.63–2.56 | 0.593 |
| Females | n = 650 | n = 264 | n = 869 | n = 1,443 | ||||||
| m.4769A/G | 3.38 | 0.76 | 4.60 | 1.12–40.6 | 0.022 | 2.99 | 2.36 | 1.28 | 0.76–2.15 | 0.348 |
| m.8994G/A | 1.69 | 4.55 | 0.36 | 0.14–0.91 | 0.019 | 3.68 | 2.57 | 1.45 | 0.87–2.41 | 0.132 |
| m.12612A/G | 8.00 | 2.88 | 0.58 | 0.36–0.95 | 0.023 | 10.60 | 9.01 | 1.20 | 0.90–1.59 | 0.216 |
| m.13708G/A | 9.12 | 13.69 | 0.61 | 0.38–0.98 | 0.040 | 10.87 | 12.81 | 1.08 | 0.83–1.42 | 0.238 |
mtDNA position according to rCRS [29].
MAF, minor allele frequency.
95% confidence of odds ratio for minor allele.
Fisher's exact test, two-sided, p-values below 0.05 are highlighted in bold.
Follow-up of m.8994G/A in a sample of 1,697 obese cases and 2,373 normal weight controls from three adult population-based GWAS samples did not lead to an independent confirmation of the initial finding. SNPs initially associated in only female or male subjects could neither be confirmed. In addition, direction of effect for most of these SNPs was different between discovery and confirmation (Table 2).
Haplogroup analysis
Using HaploGrep [30] based on phylotree build 11 [31], we identified 80 haplogroups with a quality value ≥90%. This quality threshold was reached by 96% of all study subjects from both discovery and confirmation. Most of the identified haplogroups (94% to 95% depending on sample) could be assigned to eight European major haplogroups (H, U, T, V, J, K, W, X).
For discovery analysis, we detected nominal association with obesity for haplogroup W (p = 0.034; Table 3, Table S4), which was – just as the minor allele A of m.8994 – more frequent among the lean adult controls. All individuals of haplogroup W were minor allele carriers of m.8994. Stratified by gender, nominal association of haplogroup W remained only for male subjects (p = 0.012). Among the females we detected nominal association for haplogroup J (p = 0.032). Compared to the single SNP GWAS findings, none of the initially associated haplogroups could be confirmed in the independent sample, and directions of effect were opposite (Table 3).
Table 3. Nominally associated mt haplogroups in discovery and follow-up in confirmation.
| Discovery | Confirmation | |||||||||
| Haplo-group a | Frequency Cases [%] | Frequency Controls [%] | Odds Ratio | Confidence Interval b | p-value c | Frequency Cases [%] | Frequency Controls [%] | Odds Ratio | Confidence Interval b | p- value c |
| all | n = 1,114 | n = 422 | n = 1,623 | n = 2,271 | ||||||
| W | 1.17 | 2.84 | 0.40 | 0.17–0.97 | 0.034 | 2.71 | 1.94 | 1.41 | 0.90–2.20 | 0.126 |
| males | n = 491 | n = 163 | n = 793 | n = 890 | ||||||
| W | 0.41 | 3.07 | 0.13 | 0.01–0.81 | 0.012 | 2.14 | 1.69 | 1.28 | 0.60–2.77 | 0.592 |
| females | n = 623 | n = 259 | n = 830 | n = 1,381 | ||||||
| J | 8.19 | 13.13 | 0.58 | 0.36–0.94 | 0.032 | 10.96 | 9.27 | 1.20 | 0.89–1.61 | 0.211 |
only individuals with HaploGrep's quality ≥90% were included (∼96% of all individuals).
95% confidence interval for odds ratio.
Fisher's exact test, two-sided, p-values below 0.05 are highlighted in bold.
Re-sequencing of mtDNA D-loop
We re-sequenced the D-loop in 192 extremely obese cases and 192 lean controls, which were derived from the initial discovery sample apart from 20 individuals. This was done, because prior complete re-sequencing of mtDNA of 10 individuals (eight of these had haplogroup W) revealed that among the individuals of haplogroup W inter-individual variability in the D-loop (Table S5) was larger compared with the coding region (Table S6). Moreover, the coverage of the D-loop by only one SNP on the SNP array (Table S3) was insufficient for association analysis for D-loop variants. Finally, the D-loop is an important control region pertaining to transcription and replication of mtDNA, and variation in this region might have an impact on these processes and interfere with body weight.
We excluded one case and one control each from the 384 individuals whose D-loop was re-sequenced from further analysis, as we detected 9 and 4 clearly visible point heteroplasmies. Point heteroplasmies are usually rather infrequent especially in blood cells [33], [34], from which DNA was extracted, and might be an indication for contamination with foreign DNA [35].
In the remaining 382 individuals we detected a total of 252 deviations from the rCRS [29], four of which were not located in the actual D-loop (i.e. between m.576 and m.16024, Table S7/Table S8). Of these, 223 were single nucleotide exchanges at 213 positions, as at 10 positions tri-allelic exchanges were present, three were complex nucleotide exchanges (i.e. a combination of a single nucleotide exchange and an insertion as for instance m.16183A/CC), 18 were insertions and eight were deletions. A major part of the detected variants have been already described (www.mitomap.org, last edited on Apr 23, 2013, Table S7/Table S8) [32].
Each one point heteroplasmy was detected in four cases and nine controls. Moreover, we detected length heteroplasmies at four previously known length heteroplasmic mtDNA regions (Fig. 1).
Figure 1. Detected length heteroplasmies.
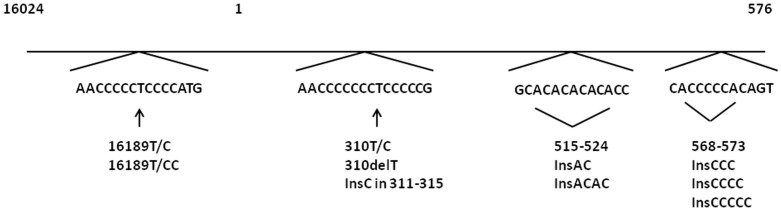
Detection of length heteroplasmies, i.e. mixtures of various lengths of a certain mtDNA region in one individual, occurred at four locations in the D-loop (m.16024 to m.576), predominantly at poly-C tracts. Numbering according to rCRS [29].
The average number of variants per individual was 8.3. This frequency did not differ between cases and controls (p = 0.989). We also compared the frequencies of each of the 252 detected variants between cases and controls, and found m.16292C/T (p = 0.007) and m.16189T/C (p = 0.048) to be nominally associated with obesity. m.16292C/T was present only in eight controls, of which five had haplogroup W, whose frequency was nominally higher in the initial CC GWAS sample and tended to be higher among the controls of the D-loop sample (p = 0.062). By contrast, m.16189T/C had a higher frequency among the cases (17% vs. 9%).
A transition at m.16189 might create an uninterrupted poly-C tract of 10 Cs (Fig. 1), in case no further transition has occurred between m.16184 and m.16193. Among the cases, 15% had such an uninterrupted poly-C tract, while only 10% among the controls (p = 0.116).
We detected no differences when comparing average number of variants per individual between cases and controls for the 23 functionally relevant D-loop locations (Table 1).
Discussion
Due to its maternal inheritance, we addressed the question if variation in mtDNA might contribute to the observed larger correlation for BMI between mothers and their offspring than between fathers and their offspring [4], [6], [7] or maternal versus paternal half-brothers [8]. Therefore, we performed an association study for mtDNA SNPs predominantly from the mtDNA coding region in extremely obese children and adolescents versus lean adult controls and re-sequenced the D-loop in a sub-sample of this CC study group.
For the coding region variants, no single variant or haplogroup was robustly associated with obesity. The results are in accordance with a previous study [17]. Yang et al. showed association of haplogroup X with lower BMI in a sample of 2,286 unrelated adult Caucasians; however, these data were not confirmed in an independent sample [16]. In our study, haplogroup X was not associated with BMI/leanness in the young or the adult sample. Nevertheless, in the adults the direction of effect was the same as described previously (Table 3; [16]).
We considered that our initial findings were spurious, as the direction of effect of each haplogroup and of all but one SNP differed between discovery and confirmation (Table 2). However, an additional explanation might be that different mtDNA SNPs and/or haplogroups might be relevant for children and adolescents than for adults pertaining to BMI [18]. This could explain why we were not able to replicate association of haplogroup X [16] with low BMI in the discovery (p = 1.0), while a minor trend (p = 0.12, consistence of direction of risk allele) was found in the adults (confirmation). Obviously, based on the sample sizes we cannot exclude the existence of associations of small effect sizes.
Haplogroup assignment was performed with HaploGrep [30] based on Phylotree built 11 [31] with the genotype information of the up to 40 mtDNA SNPs from the SNP array. Bandelt et al. rated HaploGrep to be more sophisticated than the other programs which are able to assign haplogroups automatically [36]. All major European haplogroups – except haplogroup I – were found, and their frequencies were in accordance with those expected among West Europeans (www.mitomap.org, [32]) or Germans ([37]; Table S9). Individuals could not be assigned to haplogroup I, as SNPs at m.10034, m.16129 and m.16391 leading to haplogroup I or any variant which would have led to a sub-haplogroup of haplogroup I were absent from the SNP array (www.phylotree.org, built 11; Fig. S2; [31]). Haplogroup I branches-off of N1e'l (www.phylotree.org, built 11; Fig. S2; [31]). In West Europeans and Germans, Haplogroup N occurs with a frequency of 1% (www.mitomap.org, [32]) and 0.6% [37], respectively, but among the individuals of the current study samples, the frequency was 2.5 to 3.5% (Table S9). Thus, individuals actually belonging to haplogroup I might have “remained” in haplogroup N1 (Fig. S2).
Haplogroup association testing was restrained to major haplogroups, because of the limited number of SNPs on the SNP array which disabled a refined haplogroup determination for some individuals. Moreover, given a major haplogroup is present at a low percentage in a population as for instance haplogroup W in the present study samples (∼2%, Table S9), refined haplogroup association testing would have to be done in a sample with a much larger sample size as those of the present study samples. Nevertheless, variants biologically relevant for obesity might be found in the sub-haplogroups and hence these variants or sub-haplogroups might have been masked by association testing of only the respective major haplogroup.
Pertaining to the D-loop variants, two (m.16292C/T and m.16189T/C) of the 252 detected variants were nominally associated with obesity among the 191 cases and 191 controls of the D-loop sample. m.16292C/T was only found in eight controls of which five had haplogroup W that was initially overrepresented among the controls of the CC GWAS sample (p = 0.048; D-loop sample: p = 0.062). As haplogroup W could not be confirmed independently in the present study, a follow-up of this variant does not seem useful.
m.16189T/C is located with a poly-C tract between m.16184 and m.16193. This variant as well as m.16189T/CC and m.16189delT led to an uninterrupted poly-C tract given no other transition or insertion except of C has occurred between m.16184 and m.16193 (Fig. 1). In the present study, frequency of the uninterrupted poly-C tract tended to be higher among the cases. Parker et al., by contrast, reported the uninterrupted poly-C tract to be associated with leanness among 161 Australian mothers and their 20-year-old offspring [38].
Moreover, all individuals of the present D-loop sample with an uninterrupted poly-C tract showed length heteroplasmy at this tract. This might be the result of strand slippage during the replication process generating tracts of variable length of predominantly 10 to 12 Cs [39], [40]. Moreover, length patterns were different between maternal lineages but nearly identical within a maternal lineage [39]. In addition, the termination associated element (TAS, m.16157 to m.16172, Table 1), which is involved in premature determination of the H-strand synthesis in order to create the triple stranded D-loop [28], [41], [42] is located near this C tract. As binding of proteins at the TAS element was shown, binding capacity and thus mtDNA transcription and replication might be influenced by the nearby uninterrupted C tract [43]. Among 837 healthy adult Taiwanese (mean BMI = 24.5 kg/m2), the lowest mtDNA content was found among individuals with an uninterrupted C tract compared with individuals of the wild-type or an otherwise interrupted C tracts [44]. Nevertheless, mean BMI between the three groups was similar [44]. Further investigation is needed whether 1) the detected overrepresentation by trend of the uninterrupted C tract in the obese can be confirmed in an independent sample and 2) the uninterrupted C-tract has an influence on mtDNA levels and BMI among Europeans.
Finally, as some D-loop variants only occurred at very low frequencies (in only one or two individuals), a refined association analysis of these variants potentially in combination with the 23 functionally relevant regions in a larger study sample could be subject of further investigation.
All in all, though follow-up of some D-loop variants still is conceivable, our hypothesis of a contribution of variation in the exclusively maternally inherited mtDNA to the observed greater correlations in BMI between mothers and their offspring than between fathers and their offspring could not be substantiated by the findings of the present study.
Supporting Information
Selection of primers for the re-sequencing of the mtDNA D-Loop.
(DOCX)
Haplogroup I branching off of N1e'l.
(DOCX)
Phenotypical characteristics of subjects.
(DOCX)
Quality control of SNPs.
(DOCX)
SNPs of mtDNA in association with obesity in discovery.
(DOCX)
Frequency of major haplogroups in cases and controls in discovery and confirmation.
(DOCX)
D-loop variants detected by re-sequencing (Sanger) of complete mtDNA of each five lean and obese individuals.
(DOCX)
Coding region variants detected by re-sequencing (Sanger) of complete mtDNA of each five lean and obese individuals.
(DOCX)
D-loop variants (single nucleotide exchanges) detected by re-sequencing (Sanger) of mtDNA and frequencies in cases and controls.
(DOCX)
D-loop variants (complex nucleotide exchanges, insertions and deletions) detected by re-sequencing (Sanger) of mtDNA and frequencies in cases and controls.
(DOCX)
Distribution of haplogroup frequencies (in%) in study samples compared with West Europeans and Germans.
(DOCX)
Acknowledgments
We thank all participants for their voluntary contribution. We acknowledge the excellent technical assistance of Jitka Andrä and Sieglinde Düerkop.
Funding Statement
This work was supported by grants of the German Research Foundation (HI865/2-1), the German Federal Ministry of Education and Research (01KU0903, 01GS0830, 01GS0820), the European Community's Seventh Framework Program (FP7/2007–2013, grant number 245009) and the IFORES program of the University of Duisburg-Essen. The KORA research platform (KORA), Cooperative Research in the Region of Augsburg) was initiated and financed by the Helmholtz Zentrum München - German Research Center for Environmental Health, which is funded by the German Federal Ministry of Education and Research and by the State of Bavaria. Data of the Study of Health of Pomerania (SHIP) were provided by the research alliance “Community Medicine” of the medical faculty of the Ernst-Moritz-Arndt University of Greifswald and supported by grants of the German Federal Ministry of Education and Research (01ZZ9603, 01ZZ0103, 01ZZ0701, D352300006 and 03ZIK012). Genotyping in SHIP was partly funded by Siemens Healthcare. The popgen 2.0 network is supported by a grant from the German Federal Ministry of Education and Research (01EY1103). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Stunkard AJ, Foch TT, Hrubec Z (1986) A twin study of human obesity. JAMA 256(1): 51–4. [PubMed] [Google Scholar]
- 2. Stunkard AJ, Harris JR, Pedersen NL, McClearn GE (1990) The body-mass index of twins who have been reared apart. N Engl J Med 322(21): 1483–7. [DOI] [PubMed] [Google Scholar]
- 3.Bouchard C, Pérusse L (1993) Genetic aspects of obesity. Ann N Y Acad Sci 699: : 26–35. Review. [DOI] [PubMed] [Google Scholar]
- 4. Sørensen TI, Holst C, Stunkard AJ (1998) Adoption study of environmental modifications of the genetic influences on obesity. Int J Obes Relat Metab Disord 22(1): 73–81. [DOI] [PubMed] [Google Scholar]
- 5. Hebebrand J, Hinney A, Knoll N, Volckmar AL, Scherag A (2013) Molecular genetic aspects of weight regulation. Dtsch Arztebl Int 110(19): 338–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Zonta LA, Jayakar SD, Bosisio M, Galante A, Pennetti V (1987) Genetic analysis of human obesity in an Italian sample. Hum Hered 37(3): 129–39. [DOI] [PubMed] [Google Scholar]
- 7. Price RA, Gottesman II (1991) Body fat in identical twins reared apart: roles for genes and environment. Behav Genet 21(1): 1–7. [DOI] [PubMed] [Google Scholar]
- 8. Magnusson PK, Rasmussen F (2002) Familial resemblance of body mass index and familial risk of high and low body mass index. A study of young men in Sweden. Int J Obes Relat Metab Disord 26(9): 1225–31. [DOI] [PubMed] [Google Scholar]
- 9. Speliotes EK, Willer CJ, Berndt SI, Monda KL, Thorleifsson G, et al. (2010) Association analyses of 249,796 individuals reveal 18 new loci associated with body mass index. Nat Genet 42(11): 937–48. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Bradfield JP, Taal HR, Timpson NJ, Scherag A, Lecoeur C, et al. (2012) A genome-wide association meta-analysis identifies new childhood obesity loci. Nat Genet 44(5): 526–31. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Berndt SI, Gustafsson S, Mägi R, Ganna A, Wheeler E, et al. (2013) Genome-wide meta-analysis identifies 11 new loci for anthropometric traits and provides insights into genetic architecture. Nat Genet 45(5): 501–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Falkenberg M, Larsson NG, Gustafsson CM (2007) DNA replication and transcription in mammalian mitochondria. Annu Rev Biochem 76: : 679–99.Review. [DOI] [PubMed] [Google Scholar]
- 13.Taylor RW, Turnbull DM (2005) Mitochondrial DNA mutations in human disease. Nat Rev Genet 6(5): : 389–402. Review. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Wilson MR, Stoneking M, Holland MM, DiZinno JA, Budowle B (1993) Guidelines for the use of mitochondrial DNA sequencing in forensic science. Crime Lab Digest 20: 68–77. [Google Scholar]
- 15. Lutz S, Weisser HJ, Heizmann J, Pollak S (1998) Location and frequency of polymorphic positions in the mtDNA control region of individuals from Germany. Int J Legal Med 111(2): 67–77. [DOI] [PubMed] [Google Scholar]
- 16. Yang TL, Guo Y, Shen H, Lei SF, Liu YJ, et al. (2011) Genetic association study of common mitochondrial variants on body fat mass. PLoS One 6(6): e21595. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Grant SF, Glessner JT, Bradfield JP, Zhao J, Tirone JE, et al. (2012) Lack of relationship between mitochondrial heteroplasmy or variation and childhood obesity. Int J Obes (Lond) 36(1): 80–3. [DOI] [PubMed] [Google Scholar]
- 18. Scherag A, Dina C, Hinney A, Vatin V, Scherag S, et al. (2010) Two new Loci for body-weight regulation identified in a joint analysis of genome-wide association studies for early-onset extreme obesity in French and german study groups. PLoS Genet 22 6(4): e1000916. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Hinney A, Nguyen TT, Scherag A, Friedel S, Brönner G, et al. (2007) Genome wide association (GWA) study for early onset extreme obesity supports the role of fat mass and obesity associated gene (FTO) variants. PLoS One 2(12): e1361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Hebebrand J, Heseker H, Himmelmann GW, Schäfer H, Remschmidt H (1994) Altersperzentilen für den Body Mass Index aus Daten der Nationalen Verzehrstudie einschlieβlich einer Übersicht zu relevanten Einflussfaktoren. Aktuelle Ernährungsmedizin 19: 259–265. [Google Scholar]
- 21. Rückert IM, Heier M, Rathmann W, Baumeister SE, Döring A, et al. (2011) Association between markers of fatty liver disease and impaired glucose regulation in men and women from the general population: the KORA-F4-study. PLoS One 6(8): e22932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Völzke H, Alte D, Schmidt CO, Radke D, Lorbeer R, et al. (2011) Cohort profile: the study of health in Pomerania. Int J Epidemiol 40(2): 294–307. [DOI] [PubMed] [Google Scholar]
- 23.Nöthlings U, Krawczak M (2012) [PopGen. A population-based biobank with prospective follow-up of a control group]. Bundesgesundheitsblatt Gesundheitsforschung Gesundheitsschutz 55(6–7): : 831–5. German. [DOI] [PubMed] [Google Scholar]
- 24. Pütter C, Pechlivanis S, Nöthen MM, Jöckel KH, Wichmann HE, et al. (2011) Missing heritability in the tails of quantitative traits? A simulation study on the impact of slightly altered true genetic models. Hum Hered 72(3): 173–81. [DOI] [PubMed] [Google Scholar]
- 25. Cardoso S, Villanueva-Millán MJ, Valverde L, Odriozola A, Aznar JM, et al. (2012) Mitochondrial DNA control region variation in an autochthonous Basque population sample from the Basque Country. Forensic Sci Int Genet 6(4): e106–8. [DOI] [PubMed] [Google Scholar]
- 26. Zollo O, Tiranti V, Sondheimer N (2012) Transcriptional requirements of the distal heavy-strand promoter of mtDNA. Proc Natl Acad Sci U S A 109(17): 6508–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Lodeiro MF, Uchida A, Bestwick M, Moustafa IM, Arnold JJ, et al. (2012) Transcription from the second heavy-strand promoter of human mtDNA is repressed by transcription factor A in vitro. Proc Natl Acad Sci U S A 109(17): 6513–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Anderson S, Bankier AT, Barrell BG, de Bruijn MH, Coulson AR, et al. (1981) Sequence and organization of the human mitochondrial genome. Nature 290(5806): 457–65. [DOI] [PubMed] [Google Scholar]
- 29. Andrews RM, Kubacka I, Chinnery PF, Lightowlers RN, Turnbull DM, et al. (1999) Reanalysis and revision of the Cambridge reference sequence for human mitochondrial DNA. Nat Genet 23(2): 147. [DOI] [PubMed] [Google Scholar]
- 30. Kloss-Brandstätter A, Pacher D, Schönherr S, Weissensteiner H, et al. (2011) HaploGrep: a fast and reliable algorithm for automatic classification of mitochondrial DNA haplogroups. Hum Mutat 32(1): 25–32. [DOI] [PubMed] [Google Scholar]
- 31. van Oven M, Kayser M (2009) Updated comprehensive phylogenetic tree of global human mitochondrial DNA variation. Hum Mutat 30(2): E386–E394 http://www.phylotree.org. [DOI] [PubMed] [Google Scholar]
- 32.Ruiz-Pesini E, Lott MT, Procaccio V, Poole JC, Brandon MC, et al. (2007) An enhanced MITOMAP with a global mtDNA mutational phylogeny. Nucleic Acids Res 35 (Database issue): D823–D828. [DOI] [PMC free article] [PubMed]
- 33. Calloway CD, Reynolds RL, Herrin GL Jr, Anderson WW (2000) The frequency of heteroplasmy in the HVII region of mtDNA differs across tissue types and increases with age. Am J Hum Genet 66(4): 1384–97. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Budowle B, Allard MW, Wilson MR (2002) Critique of interpretation of high levels of heteroplasmy in the human mitochondrial DNA hypervariable region I from hair. Forensic Sci Int 126(1): 30–3. [DOI] [PubMed] [Google Scholar]
- 35. Andréasson H, Nilsson M, Budowle B, Frisk S, Allen M (2006) Quantification of mtDNA mixtures in forensic evidence material using pyrosequencing. Int J Legal Med 120(6): 383–90. [DOI] [PubMed] [Google Scholar]
- 36. Bandelt HJ, van Oven M, Salas A (2012) Haplogrouping mitochondrial DNA sequences in Legal Medicine/Forensic Genetics. Int J Legal Med 126(6): 901–16. [DOI] [PubMed] [Google Scholar]
- 37. Pliss L, Tambets K, Loogväli EL, Pronina N, Lazdins M, et al. (2006) Mitochondrial DNA portrait of Latvians: towards the understanding of the genetic structure of Baltic-speaking populations. Ann Hum Genet 70(Pt 4): 439–58. [DOI] [PubMed] [Google Scholar]
- 38. Parker E, Phillips DI, Cockington RA, Cull C, Poulton J (2005) A common mitochondrial DNA variant is associated with thinness in mothers and their 20-yr-old offspring. Am J Physiol Endocrinol Metab 289(6): E1110–4. [DOI] [PubMed] [Google Scholar]
- 39. Bendall KE, Sykes BC (1995) Length heteroplasmy in the first hypervariable segment of the human mtDNA control region. Am J Hum Genet 57(2): 248–56. [PMC free article] [PubMed] [Google Scholar]
- 40. Chinnery PF, Elliott HR, Patel S, Lambert C, Keers SM, et al. (2005) Role of the mitochondrial DNA 16184–16193 poly-C tract in type 2 diabetes. Lancet 366(9497): 1650–1. [DOI] [PubMed] [Google Scholar]
- 41. Sbisà E, Tanzariello F, Reyes A, Pesole G, Saccone C (1997) Mammalian mitochondrial D-loop region structural analysis: identification of new conserved sequences and their functional and evolutionary implications. Gene 205(1–2): 125–40. [DOI] [PubMed] [Google Scholar]
- 42. Roberti M, Musicco C, Polosa PL, Milella F, Gadaleta MN, et al. (1998) Multiple protein-binding sites in the TAS-region of human and rat mitochondrial DNA. Biochem Biophys Res Commun 243(1): 36–40. [DOI] [PubMed] [Google Scholar]
- 43. Poulton J, Luan J, Macaulay V, Hennings S, Mitchell J, et al. (2002) Type 2 diabetes is associated with a common mitochondrial variant: evidence from a population-based case-control study. Hum Mol Genet 11(13): 1581–3. [DOI] [PubMed] [Google Scholar]
- 44. Liou CW, Lin TK, Chen JB, Tiao MM, Weng SW, et al. (2010) Association between a common mitochondrial DNA D-loop polycytosine variant and alteration of mitochondrial copy number in human peripheral blood cells. J Med Genet 47(11): 723–8. [DOI] [PubMed] [Google Scholar]
- 45. Meyer S, Weiss G, von Haeseler A (1999) Pattern of nucleotide substitution and rate heterogeneity in the hypervariable regions I and II of human mtDNA. Genetics 152(3): 1103–10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Ohno K, Tanaka M, Suzuki H, Ohbayashi T, Ikebe S, et al. (1991) Identification of a possible control element, Mt5, in the major noncoding region of mitochondrial DNA by intraspecific nucleotide conservation. Biochem Int 24(2): 263–72. [PubMed] [Google Scholar]
- 47. Suzuki H, Hosokawa Y, Nishikimi M, Ozawa T (1991) Existence of common homologous elements in the transcriptional regulatory regions of human nuclear genes and mitochondrial gene for the oxidative phosphorylation system. J Biol Chem 266(4): 2333–8. [PubMed] [Google Scholar]
- 48. Fisher RP, Topper JN, Clayton DA (1987) Promoter selection in human mitochondria involves binding of a transcription factor to orientation-independent upstream regulatory elements. Cell 50(2): 247–58. [DOI] [PubMed] [Google Scholar]
- 49. Chang DD, Clayton DA (1984) Precise identification of individual promoters for transcription of each strand of human mitochondrial DNA. Cell 36(3): 635–43. [DOI] [PubMed] [Google Scholar]
- 50. Pham XH, Farge G, Shi Y, Gaspari M, Gustafsson CM, et al. (2006) Conserved sequence box II directs transcription termination and primer formation in mitochondria. J Biol Chem 281(34): 24647–52. [DOI] [PubMed] [Google Scholar]
- 51. Ingman M, Gyllensten U (2001) Analysis of the complete human mtDNA genome: methodology and inferences for human evolution. J Hered 92(6): 454–61. [DOI] [PubMed] [Google Scholar]
- 52. Montoya J, Christianson T, Levens D, Rabinowitz M, Attardi G (1982) Identification of initiation sites for heavy-strand and light-strand transcription in human mitochondrial DNA. Proc Natl Acad Sci U S A 79(23): 7195–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53. Montoya J, Gaines GL, Attardi G (1983) The pattern of transcription of the human mitochondrial rRNA genes reveals two overlapping transcription units. Cell 34(1): 151–9. [DOI] [PubMed] [Google Scholar]
- 54. Yoza BK, Bogenhagen DF (1984) Identification and in vitro capping of a primary transcript of human mitochondrial DNA. J Biol Chem 259(6): 3909–15. [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Selection of primers for the re-sequencing of the mtDNA D-Loop.
(DOCX)
Haplogroup I branching off of N1e'l.
(DOCX)
Phenotypical characteristics of subjects.
(DOCX)
Quality control of SNPs.
(DOCX)
SNPs of mtDNA in association with obesity in discovery.
(DOCX)
Frequency of major haplogroups in cases and controls in discovery and confirmation.
(DOCX)
D-loop variants detected by re-sequencing (Sanger) of complete mtDNA of each five lean and obese individuals.
(DOCX)
Coding region variants detected by re-sequencing (Sanger) of complete mtDNA of each five lean and obese individuals.
(DOCX)
D-loop variants (single nucleotide exchanges) detected by re-sequencing (Sanger) of mtDNA and frequencies in cases and controls.
(DOCX)
D-loop variants (complex nucleotide exchanges, insertions and deletions) detected by re-sequencing (Sanger) of mtDNA and frequencies in cases and controls.
(DOCX)
Distribution of haplogroup frequencies (in%) in study samples compared with West Europeans and Germans.
(DOCX)