

Abstract
The receptive fields of early visual neurons are anchored in retinotopic coordinates (Hubel and Wiesel, 1962). Eye movements shift these receptive fields and therefore require that different populations of neurons encode an object's constituent features across saccades. Whether feature groupings are preserved across successive fixations or processing starts anew with each fixation has been hotly debated (Melcher and Morrone, 2003; Melcher, 2005, 2010; Knapen et al., 2009; Cavanagh et al., 2010a,b; Morris et al., 2010). Here we show that feature integration initially occurs within retinotopic coordinates, but is then conserved within a spatiotopic coordinate frame independent of where the features fall on the retinas. With human observers, we first found that the relative timing of visual features plays a critical role in determining the spatial area over which features are grouped. We exploited this temporal dependence of feature integration to show that features co-occurring within 45 ms remain grouped across eye movements. Our results thus challenge purely feedforward models of feature integration (Pelli, 2008; Freeman and Simoncelli, 2011) that begin de novo after every eye movement, and implicate the involvement of brain areas beyond early visual cortex. The strong temporal dependence we quantify and its link with trans-saccadic object perception instead suggest that feature integration depends, at least in part, on feedback from higher brain areas (Mumford, 1992; Rao and Ballard, 1999; Di Lollo et al., 2000; Moore and Armstrong, 2003; Stanford et al., 2010).
Keywords: crowding, feature integration, remapping, spatiotopy, trans-saccade, visual stability
Introduction
Our visual experience depends on how the brain integrates visual information into a coherent percept. Recently there has been intense focus on the spatial relationships among visual objects that determine how those objects are represented in early brain areas (Levi, 2008; Pelli, 2008; Pelli and Tillman, 2008; Whitney and Levi, 2011). To discriminate visual objects from one another, the visual system must attribute each object's constituent features appropriately. Features from a single object must be grouped and simultaneously separated from the features of nearby objects. Failures of accurate feature integration are particularly obvious in peripheral vision: despite being easily identified when presented alone, a target object in the periphery can be difficult to identify when distractor objects closely surround it (Bouma, 1970; Pelli and Tillman, 2008). A widely held account of such “visual crowding” is that the phenomenon arises because visual features are integrated in early visual cortex (Parkes et al., 2001): when crowding occurs, features of nearby objects are irreversibly integrated; when crowding is absent, they are segmented. Figure 1 demonstrates the critical spatial dependence of visual grouping. Fixate each left dot: features of the letter U are integrated with features of the flanking letters in the upper image, but segmented from them in the lower image.
Figure 1.
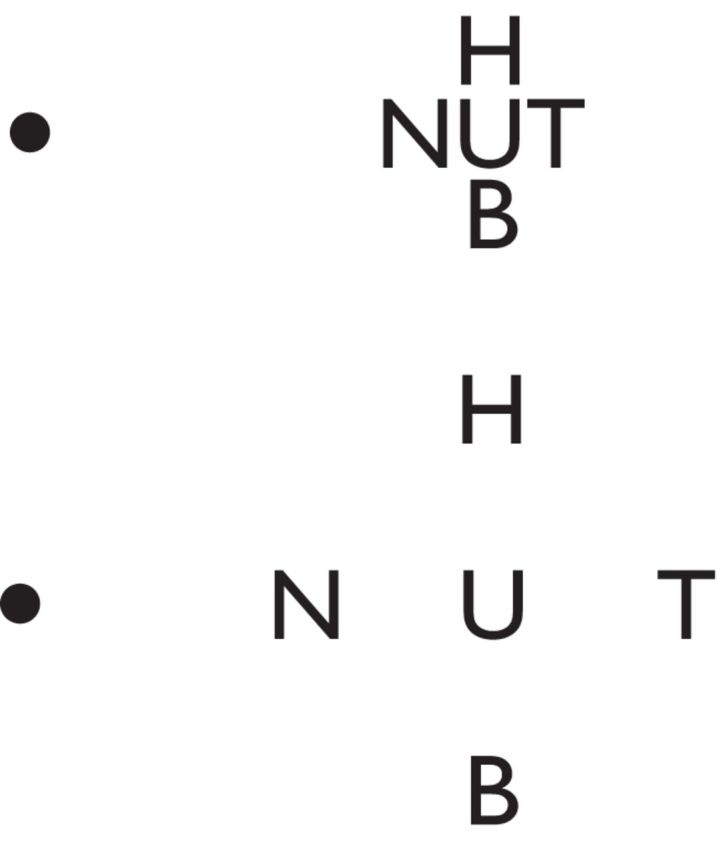
Visual crowding. When fixating the upper spot, the central letter U on the right is difficult to identify because the flanking letters fall within its critical spacing, and features within this area are inappropriately integrated. When fixating the lower spot, the U can be identified more easily because the flanking letters fall outside this compulsory integration zone.
Although studies of visual crowding have thus far described how the spatial relationships among objects determine their discriminability, far less attention has been devoted to how the elementary features of visual objects are integrated over time and across saccadic eye movements. Eye movements pose a fundamental challenge to the visual system because neurons in early brain areas that process visual features have receptive fields anchored in retinotopic coordinates (Hubel and Wiesel, 1962). Following an eye movement, the receptive fields of such neurons necessarily represent a different area of space than before the eye movement. For visual features to be integrated across eye movements, therefore, information must be integrated across time as well as different parts of the retinas. However, under prominent models of crowding, this is unlikely to occur because feature integration involves feedforward interactions that depend only on the current retinal positions of features (Pelli, 2008; Freeman and Simoncelli, 2011). The few investigations of trans-saccadic integration of featural information have led to conflicting results, and so it remains unclear whether or not visual processing starts anew following each fixation (Melcher and Morrone, 2003; Melcher, 2005, 2007; d'Avossa et al., 2007; Gardner et al., 2008; Afraz and Cavanagh, 2009; Knapen et al., 2009, 2010; Morris et al., 2010; Demeyer et al., 2011; Harrison et al., 2013b; Mathôt and Theeuwes, 2013).
Critical spacing, the spatial boundary within which features become crowded, is a sensitive measure to understand the ways in which the brain integrates visual features (Pelli and Tillman, 2008; Harrison et al., 2013a, 2014). In the present study, we devised a paradigm in which we exploited visual crowding to test the critical timing of feature integration (Experiment 1), as well as trans-saccadic perception (Experiment 2).
Materials and Methods
Overview of experiments.
In all experiments, an observer's task was to report the orientation of a target letter while we manipulated the distance between the target and flanking distractor letters. Critical spacing was calculated as the target–flanker separation at which target identification accuracy was 62.5%. In Experiment 1, we measured how critical spacing is affected by the timing of a target relative to the flankers. As outlined in Figure 2, there were three timing conditions for the target and flankers: (1) synchronous onsets and offsets (i.e., standard crowding; Fig. 2A), (2) asynchronous onsets (Fig. 2B), or (3) asynchronous offsets (Fig. 2C). It is important to note that, in all conditions, the target and flankers were presented concurrently for 58 ms. In the onset-asynchrony condition (Fig. 2B), we extended the duration of the flankers such that their onset preceded the target's, while the target and flanker offsets remained synchronous. In the offset-asynchrony condition (Fig. 2C), flanker durations again varied, but the flanker offsets lagged the target offset, while the target–flanker onsets were synchronous.
Figure 2.

Schematic overview of temporal sequences of displays from Experiment 1. In all conditions, an observer's task was to fixate the spot and identify the orientation of the middle U. A, Standard crowding, in which the target and flankers' onsets and offsets were synchronous. A, B, In two other conditions, we varied the onset time of the flankers relative to the target (B), or the offset time of the flankers relative to the target (C). Note that, as designated by the thick black frames in each display sequence, the target and flankers appeared concurrently for 58 ms in all conditions. As shown by the dotted frames in B and C, we increased the duration of the flankers by a variable amount to introduce an onset asynchrony or offset asynchrony, respectively. Movie 1 shows a demonstration of the effects of onset and offset asynchrony on the discriminability of a crowded letter.
In Experiment 2, we tested whether the effects of relative timing on critical spacing are preserved across eye movements. We therefore measured critical spacing immediately after observers executed a goal-directed saccade (see Fig. 5A). In all trials, the target and flankers were presented concurrently for 58 ms following the eye movement. In half the trials, the flankers' onset before the saccade at the screen position corresponding to their postsaccadic locations. In these trials, flanker onsets were asynchronous to the target, but, due to the intervening saccade, these preceding flankers occupied retinal coordinates that were different from the postsaccade flankers that surrounded the target. We were thus able to assess whether temporal dependencies of crowding operate in a retinotopic (eye centered) or a spatiotopic (world centered) frame of reference.
Figure 5.

Nonretinotopic feature integration in crowding. A, Example gaze-contingent displays used to test whether the flanker onset-asynchrony advantage in crowding transfers across eye movements. In both conditions, observers were required to execute a saccade (arrow) to remain fixated on the spot. The eye movement triggered the onset of the flanked target, which was the same in both conditions. Note that the target and flankers were presented concurrently after the saccade at the same retinal coordinates in both conditions (solid black frames). In the postsaccade condition, all stimuli appeared only after the completion of the saccade. In the trans-saccade condition, flankers were presented in the spatiotopic, but not retinotopic, positions they would assume when the target was presented (dotted black frame). Thus, flankers preceded the saccade and remained on the screen until the offset of the target. B, Critical spacing measurements for five observers are plotted on the left axis, and the postsaccade minus trans-saccade critical spacing difference for each observer and the group is plotted on the right axis. Note that the critical spacing values shown here are greater than those in Figure 3 because observers had to concurrently perform the saccade task, and the target was presented at a greater eccentricity than previous experiments (Bouma, 1970). Individuals' error bars show 1 SD, while the error bars around the mean show 95% confidence intervals. Asterisk indicates that the mean reduction in critical spacing was statistically significant (the lower and upper 95% confidence intervals were 0.05 and 2.21°, respectively).
Observers.
Five experienced psychophysical observers (three females), including both authors, participated in Experiments 1 and 2. Four observers from Experiment 1 plus an additional observer participated in the eye-movement experiment. The five observers from Experiment 1 participated in the spatial and temporal uncertainty control experiments, while the authors participated in the eye-movement control experiment. With the exception of the authors, all participants were naive to the purposes of the experiments. All had normal or corrected-to-normal vision.
Experimental setup.
Stimuli and eye tracking were programmed with the Psychophysics Toolbox Version 3 (Brainard, 1997; Pelli, 1997) and Eyelink Toolbox (Cornelissen et al., 2002) in Matlab (MathWorks). Head position was fixed with a head and chin rest positioned 57 cm from a widescreen Viewsonic VX2265wm LCD monitor (1680 × 1050 pixels, 120 Hz). For fixation compliance in all experiments and for gaze-contingent stimulus control, eye movements were recorded at 500 Hz using an EyeLink 1000 (SR Research). The latency of the monitor was 8 ms, measured with an optical transient recorder OTR-3 (Display-Metrology & Systems). The eye tracker was calibrated using the native nine-point calibration routine before the first trial, and every 80 trials during the experiment. Calibration was also performed if, at the start of a trial, an observer's gaze deviated vertically or horizontally from the initial fixation point by >2° for >2 s.
Crowding stimuli and procedure.
Examples of the stimulus configuration and temporal design are shown in Figure 2. Stimuli were presented on a uniform gray background (luminance, 42 cd/m2). Relative to the background luminance, the white fixation spot and letter stimuli were 70 and 45% Michelson contrast, respectively. Probe and flankers were Sloan letters adjusted to a size of 0.5 × 0.5° to ensure the edge-to-edge (and center-to-center) distance from the probe to each horizontal flanker was equal to the distance from the probe to each vertical flanker. The probe was the letter U oriented north, south, east, or west, positioned at an eccentricity of 9° always in the right visual field and positioned on the horizontal meridian. To serve as flankers, four letters were randomly drawn without replacement from a set of 17 letters (A, B, D, E, F, H, I, J, L, K, M, N, P, R, S, T, and V) on each trial. The center-to-center target–flanker distance was selected from one of nine possible distances pseudorandomly to ensure the same sample size for each distance. The minimum distance was 0.75°, and greater distances ranged in half-degree steps from 1 to 4.5°. Each trial began with the onset of the fixation spot (0.2° width) in the center of the display. After a random latency, drawn from a normally distributed time interval (μ = 750 ms, σ = 125 ms), the probe and/or flankers appeared. Following the offset of the letter stimuli, the fixation spot remained on the screen. An observer was required to make a response by pressing one of four buttons (up, down, left, or right, corresponding to the target orientation) in order for the next trial to begin, and could take a break by delaying a response. Each condition was tested in a separate session of ∼10 min duration, and each participant completed 2160 trials.
In separate blocks counterbalanced across observers, we manipulated the onset or offset timing of the flankers relative to the target, which was always presented for 58 ms (Fig. 2). For trials in which there was an asynchronous onset (Fig. 2B), the flanker onset preceded the target onset by 17–450 ms, but their offset was synchronous. Conversely, for trials in which there was an asynchronous offset (Fig. 2C), the flanker offset lagged the target offset by 17–450 ms, but their onset was synchronous. So, for example, if there was an onset asynchrony of 50 ms, the flankers' total duration was 108 ms: flankers were displayed for 50 ms, then the target stimulus was displayed with the flankers for 58 ms, and all stimuli would offset together. With an offset asynchrony of 50 ms, the flankers' total duration was also 108 ms: the target and flankers onset synchronously, and after 58 ms the target only would offset while the flankers were displayed for a further 50 ms. Although the duration of the flankers covaried with asynchrony, the total flanker durations were matched across onset-asynchrony and offset-asynchrony conditions. Therefore any difference in performance between onset-asynchrony and offset-asynchrony conditions must involve an interaction with the relative timing of the target.
Eye-movement experiment.
The basic design of this experiment is shown in Figure 5A. Following the displacement of a fixation spot, observers were required to make a saccade to the center of the display and to judge the orientation of the crowded target presented immediately following the eye movement. To measure critical spacing, we used the same method as for Experiment 1. Because four of the five observers had previously completed many testing sessions for Experiment 1, we increased the target eccentricity to 11° to mitigate the effect of any perceptual learning, which otherwise could have resulted in floor effects.
We measured critical spacing under two conditions: one in which the execution of a saccade triggered the onset of the target and flankers (“postsaccade” condition; see Fig. 5A, left column), and one in which the flankers appeared before the saccade, and the execution of a saccade triggered the onset of the target only (“trans-saccade” condition; see Fig. 5A, right column). Note that in both conditions the target was presented with the flankers at the end of the eye movement, the retinal coordinates of the target and flankers were matched across conditions, and all stimuli offset synchronously in both conditions.
Other details of Experiment 2 were as follows. The fixation spot initially appeared at 7.4° below the center of the display. The trial continued after an observer's gaze remained within a 2 × 2° region of the fixation spot for >500 ms, or else a gaze calibration was performed. After correct fixation was recorded by the eye tracker, the flankers were presented for trans-saccade trials, or, for postsaccade trials, the screen remained blank except for the fixation spot. Following a further 450 ms, the fixation spot jumped to the center of the display, requiring the observer to execute a saccade to remain fixated on the spot. When a saccade was detected by the eye tracker (the observer's gaze deviated from the initial fixation position by >2°), the probe and flankers were presented for 58 ms. The observer was then required to make a response. Observers completed 360 trials per condition.
Control experiments.
We conducted two control experiments to test the extent to which spatial and temporal cues could account for the changes in crowding observed in Experiment 1. In the onset asynchrony conditions in Experiment 1, flankers provided information about the target location (the target would always be presented at the midpoint of the four flankers) and the approximate onset time of the target. This advance information may have resulted in changes in target identification accuracy relative to standard crowding (Posner et al., 1980). In the first control experiment, therefore, we retained the same spatial cues as the 450 ms onset-asynchrony and offset-asynchrony conditions, but we introduced a change in flanker identity during each trial: the left–right and top–bottom positions of the horizontal and vertical flankers, respectively, were reversed when the probe onset in the onset-asynchrony condition, and when the probe offset in the offset-asynchrony condition. With this manipulation, position information was matched with Experiment 1, but the visual features surrounding the target were different from those that preceded or lagged the target in the onset-asynchrony and offset-asynchrony conditions, respectively.
We ran a temporal uncertainty control experiment to rule out the possibility that temporal cues altered critical spacing in Experiment 1. The target–flanker distance was varied as outlined for Experiment 1 to allow comparison with those conditions. However, when the flankers were displayed in the absence of the target (during the asynchronous periods), they were shifted to 7.5° from the target. In this experiment, therefore, temporal cues were matched with Experiment 1, but the moving flankers disrupted any spatial cueing.
Finally, we conducted an eye-movement control experiment in which we tested the extent to which crowding was affected by saccade-induced motion transients. In Experiment 2, there were differences in retinal motion across conditions: in the trans-saccade condition, the saccade introduced retinal motion that was absent in the postsaccade condition. For this control experiment, therefore, we repeated the eye-movement experiment, but blanked off the flankers in the trans-saccade condition before the saccade so that there was no retinal motion of the flankers during the saccade. Thus, for both the trans-saccade and postsaccade conditions, the target and flankers appeared abruptly only at the end of the saccade. We used a method described in detail previously (Hunt and Cavanagh, 2011; Harrison et al., 2013a) to estimate each observer's average saccade latency so that, for trans-saccade trials, we could offset the flankers before saccade onset. Timing of trials was as described above for the eye-movement experiment. For both conditions, detection of the saccade triggered the onset of the target and flankers. Target eccentricity was 11°, and six target–flanker separations (0.75, 1, 1.5, 2.5, 4.5, and 8°) were tested with equal probability across conditions. Each observer completed 288 trials per condition. On average, the flankers offset 54 ± 8 ms before each saccade. Trials in which the flankers offset after saccade onset were discarded (12.5% of trials for P.J.B., 8.7% of trials for W.J.H.).
Statistical analyses.
Critical spacing was taken as the midpoint of the psychometric function (the target–flanker spacing giving 62.5% correct target identifications), fit with Psignifit 3.0 (Fründ et al., 2011). Confidence intervals (Figs. 3, 4) were also computed using Psignifit, which corrects for biases in psychometric analyses (Wichmann and Hill, 2001). To model temporal integration thresholds for each observer, we fit a standard cumulative Gaussian function to critical spacing data measured over the different onset and offset asynchronies. Confidence intervals were generated via standard bootstrapping procedures described in detail previously (Efron and Tibshirani, 1993). In brief, we resampled with replacement the original data 2000 times, calculated the corresponding 2000 critical spacing values for each condition shown in Figure 3B, and fit each bootstrapped set of data with a Gaussian function, producing a distribution of 2000 temporal integration thresholds. From this distribution of thresholds, the 2.5th and 97.5th quantiles were taken as 95% confidence intervals.
Figure 3.
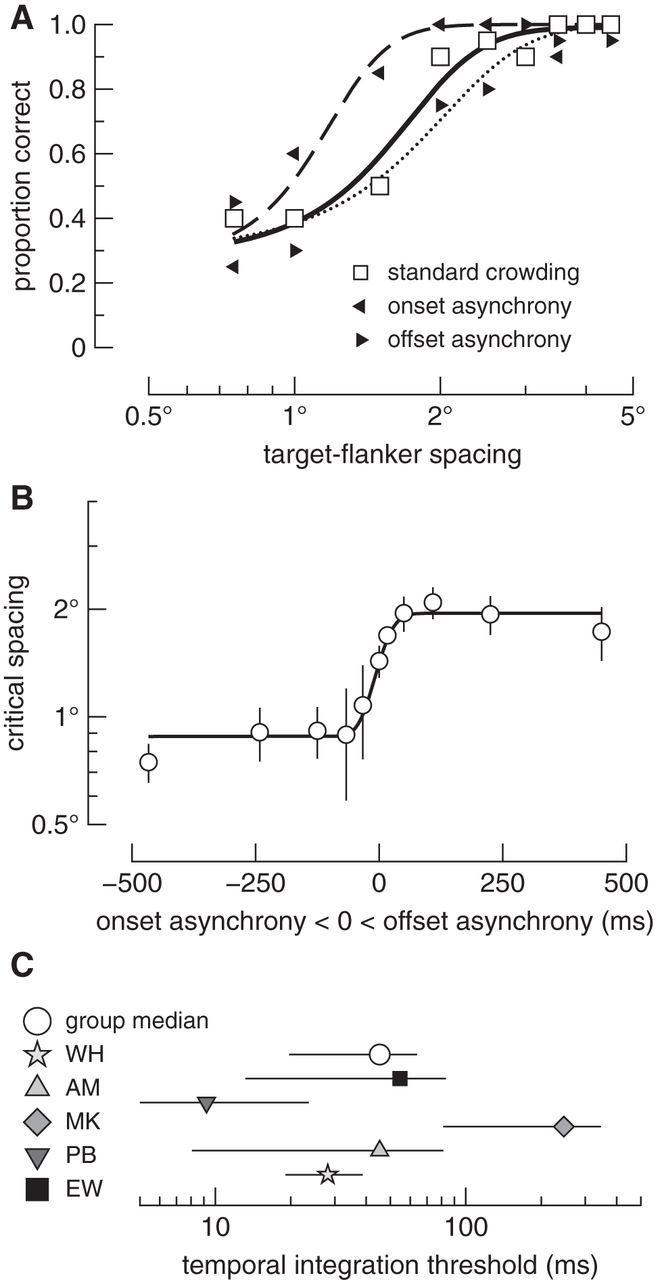
Critical spacing depends on the relative timing of features. A, Proportion correct as a function of target–flanker spacing for three conditions in Experiment 1. Data are from a representative observer. Proportion correct for each condition is shown as different symbols, as denoted in the inset legend. The solid, dashed, and dotted curves show psychometric function fits for the standard crowding, onset asynchrony, and offset asynchrony conditions, respectively. Data here are for the 450 ms asynchrony conditions. B, Mean critical spacing as a function of the onset and offset asynchrony of features. Onset and offset asynchronies are shown as negative and positive values on the x-axis, respectively. Time 0 shows critical spacing with synchronous target and flanker onsets and offsets. The solid line is a fitted cumulative Gaussian function, from which the SD was taken as the temporal integration threshold. Error bars show ±1 SE. C, Median temporal integration thresholds. Data points are the SDs of Gaussians and show the time over which features are bound into objects for five subjects and the group. Error bars are 95% bootstrapped confidence intervals.
Figure 4.

Critical spacing from Experiment 1 and two control experiments. A–D, All points show group means (n = 5) with 95% bootstrapped confidence intervals. The dotted region extending across columns is the confidence interval for the standard crowding condition (58 ms target–flanker duration, with synchronous onset and offset) to allow easy comparison across conditions. A, Critical spacing when target–flanker onsets and offsets were temporally synchronous. This point is equivalent to time 0 in Figure 3B. B, With 500 ms stimulus duration, critical spacing was significantly greater when target–flanker onsets and offsets were synchronous than when their onsets were asynchronous (compare D, circle). Therefore, the absolute durations of flankers alone cannot account for the change in critical spacing in asynchronous conditions. C, D, Results from conditions in which the target and flankers offset (C) and onset (D) with a temporal asynchrony of 450 ms. Experiment 1 data (circles) are replotted from Figure 3B. In the spatial uncertainty control experiment (squares), the identities of the flankers changed at the target onset for the onset-asynchronous condition, or at target offset for the offset-asynchronous condition. In the temporal uncertainty control experiment (diamonds), the flankers moved position before the target onset in the onset-asynchrony condition, or after the target offset in the offset-asynchrony condition.
For the gaze-contingent experiment, a trial was excluded if the saccade endpoint deviated horizontally from the target by >2° or deviated vertically by >4°. Trials were also excluded if the probe appeared >5 ms following the end of the saccade. This time was far below the temporal threshold required for a leading-flanker advantage reported in Experiment 1 (Fig. 3C), and thus the reduction in critical spacing in the trans-saccade condition of Experiment 2 (Fig. 5B) cannot be attributed to a retinotopic alignment of leading flankers and the subsequent probe.
Results
Experiment 1: feature integration depends on relative timing
We first established that critical spacing is highly sensitive to asynchronies in the onset and offset times of nearby features (Movie 1). This novel finding allowed us to test trans-saccadic perception in Experiment 2. An observer's task was to fixate a spot in the center of the display and report the orientation of the letter U presented at 9° eccentricity to the right of fixation. We systematically varied the distance of flanking letters to compute critical spacing (see Materials and Methods). In addition to measuring critical spacing when target and flanker onset and offset times were synchronous, as per standard crowding, we measured critical spacing when the relative onset and offset times of target and flankers were asynchronous (Fig. 2). In all conditions, the target letter and nearby flankers were displayed concurrently for an equal duration (58 ms). In temporally asynchronous conditions, flanker onsets preceded the target onset (onset asynchrony; Fig. 2B), or flanker offsets lagged the target offset (offset asynchrony; Fig. 2C).
Binding temporally asynchronous features into letters. When the viewer watches the video while fixating the blue spot, the letters on the right side of the display are easily identified while those on the left are barely visible. These differences in discriminability occur despite the spatial arrangements and stimulus durations being identical for the left and right streams; only the relative timing of the featural elements differs. This video demonstrates that the visual system relies on the relative timing of visual features to group those features into a coherent object.
The relative timing of target and flankers strongly affected the critical spacing of crowding. Accuracy data for a representative observer are shown in Figure 3A. The open square symbols and solid curve show proportion correct and psychometric fit, respectively, for the standard crowding condition. As expected (Bouma, 1970), the proportion of correct target identifications depended on the distance between target and flanking letters: accuracy declined with reductions in target-flanker spacing. Data and fit for the 450 ms onset-asynchrony condition are plotted as leftward triangle symbols and the dashed curve, whereas data and fit for the 450 ms offset-asynchrony condition are plotted as rightward triangles and the dotted curve. Note that the dashed and dotted curves are displaced from the solid curve in opposite directions. Therefore, flankers that preceded the target and those that lagged the target resulted in diametrically opposed changes in crowding relative to when onsets and offsets were synchronous.
We took the midpoint of each psychometric function as the critical spacing of crowding (see Materials and Methods). For the group, critical spacing with synchronous features was 1.5 ± 0.1° (mean ± SEM; Fig. 3B, time 0). Expressed as a proportion of target eccentricity (Bouma, 1970), ϕ, this is a critical spacing of 0.17 ϕ. Although critical spacing is often approximated as 0.5 ϕ when observers are required to discriminate between multiple potential target letters (Bouma, 1970; Pelli et al., 2004), it is common for observers to have interactions zones closer to 0.1 ϕ when discriminating the orientation of a single letter (Levi et al., 2002; Harrison et al., 2014), as was the case in the present study. When there was an onset asynchrony of 450 ms such that the flankers onset before the target, critical spacing decreased by almost 50% to 0.8 ± 0.1°, suggesting that the target was more easily segmented from the flankers than during standard crowding. In stark contrast to this leading-flanker advantage, temporally asynchronous offsets increased critical spacing by 33%: when flankers offset 450 ms after the target, critical spacing was 2.0 ± 0.3°. The flanker durations were matched across asynchrony conditions, and so the variable flanker durations alone cannot account for the opposing facilitatory and inhibitory effects. Similarly, because the same target–flanker distances were tested across conditions, and the target appeared concurrently with the flankers for the same duration across all conditions, a model in which features are combined according to their spatial proximity alone (Pelli, 2008) cannot account for these changes in critical spacing. Instead, our data show that critical spacing strongly depends on the relative timing of target and flankers.
We quantified the temporal window of feature integration by fitting a cumulative Gaussian to critical spacing data measured across the range of temporal asynchronies shown in Figure 3B. This function models the time over which the leading-flanker advantage and lagging-flanker disadvantage in critical spacing occur. A temporal integration threshold is defined as the SD of the function (see Materials and Methods). As shown by the gray-filled data points in Figure 3C, there was a relatively large amount of variation across individuals' threshold estimates. In particular, participant M.K.'s threshold meant our data were highly skewed; whereas the other four observers' thresholds range was restricted to between 10 and 55 ms. The source of this individual variability remains an open question, but there are large idiosyncratic differences in the spatial profile of crowding between observers (Petrov and Meleshkevich, 2011), and there could also be large idiosyncratic differences in the temporal profile of crowding. Despite these individual differences, the range of the 95% confidence intervals around the median threshold was relatively restricted. For all observers, the median threshold was 45 ms, with 95% confidence intervals ranging from 20 to 64 ms (Fig. 3C, open circle). Therefore features are integrated or segmented on average within a 45 ms window: when flankers onset before the target, the target is easily segmented from the already-integrated flankers, increasing its discriminability. Features of a target and flankers with a common onset are integrated, impairing target individuation as in standard crowding. Flankers lagging the target by >45 ms (on average) continue to interfere with target segmentation.
It is possible that the reduction in crowding in the onset-asynchrony condition resulted from a change in the visibility of the flankers due to their longer duration, rather than the temporal asynchrony per se. That is, when the flankers' onset preceded the target by 450 ms, their extended duration may have made them more (or less) visible, resulting in a reduction in critical spacing (Fig. 3B, left-most data point). This is unlikely because flankers with the same duration caused more crowding in the offset-asynchrony condition (Fig. 3B, right-most data point). Nonetheless, we ruled out this possibility with a control condition in which we presented the target and flankers for 500 ms with synchronous onsets and offsets. In this case, the absolute duration of the flankers was the same as in the temporally asynchronous condition with 450 ms asynchrony, but there was no target–flanker asynchrony because the duration of the target was also 500 ms. The mean critical spacing for this condition is plotted in Figure 4B. For comparison, we replotted data from the standard crowding condition, the 450 ms offset-asynchrony condition, and the 450 ms onset-asynchrony condition as circular symbols in Figure 4A, C, and D, respectively. Compared with the onset-asynchrony condition (Fig. 4D, circle), critical spacing was significantly greater when target and flankers were presented synchronously for 500 ms (Fig. 4B; p < 0.05, bootstrapped). This result reveals that the magnitude of crowding can be reduced more by a stimulus onset asynchrony than by an increase in the duration of the crowded target.
Spatial and temporal uncertainty control experiments
In two control experiments, we confirmed that the critical spacing of feature integration depends on an interaction between the relative timing of features and their spatial configuration. In Experiment 1, it is possible that flankers that preceded the target could have altered critical spacing by reducing uncertainty about the impending target position (Yeshurun and Rashal, 2010). To test this hypothesis, we ran a control experiment in which the spatial configuration of stimuli was the same as Experiment 1, but the identities of the flankers were changed at the target onset. For example, if the letter F was a flanker while the target was displayed, its identity was different (e.g., a J) when the target was not displayed. This manipulation ensured that the spatial cuing information conveyed by asynchronous flankers matched Experiment 1. Therefore, if the changes in critical spacing with asynchronous flankers in Experiment 1 were due to changes in spatial uncertainty, this control experiment should produce the same pattern of results.
Despite advance position information cues being the same, critical spacing with leading flankers that changed identities was significantly greater compared with leading flankers that did not change identities (Fig. 4D, square vs circle, respectively). That is, reducing spatial uncertainty alone is not sufficient to alter critical spacing. A recent study similarly found that, when used in combination with a spatial cue indicating the upcoming target location, flanker previews led to a narrower critical spacing than a preview of the flanker locations (Scolari et al., 2007); however, our results from Experiment 1 together with those from this control experiment reveal that spatial cues are neither necessary nor sufficient to explain the leading-flanker advantage. Furthermore, with leading flankers that changed identities, critical spacing was no different than when target–flanker onsets were synchronous (Fig. 4A,D). This result makes it unlikely that advance information played a role in the reduction of critical spacing with onset asynchronies in Experiment 1, and instead indicates that an abrupt change in feature identities interrupts feature segmentation and/or restarts feature integration. In the offset-asynchrony condition, critical spacing increased significantly when flankers changed identities compared with when flanker identities were unchanged (Fig. 4C, square vs circle, respectively). This result again shows that the flankers' position information alone is insufficient to drive the results found in Experiment 1.
In a second control experiment, we ruled out temporal uncertainty as affecting observers' performance in Experiment 1. In this experiment, we measured critical spacing with asynchronous onsets and offsets with the timing of stimuli identical to the 450 ms conditions in Experiment 1. Critically, we moved the flankers during the asynchronous period relative to when the target and flankers were displayed together (see Materials and Methods). That is, we changed the spatial configuration of stimuli, but retained the same temporal cues present in Experiment 1. By comparing critical spacing with moving flankers versus critical spacing with static flankers, we were able to assess the degree to which temporal cues affect critical spacing.
All participants from Experiment 1 participated in this control experiment so we could directly compare critical spacing with motion transients (Fig. 4C,D, diamonds) against critical spacing with standard flankers (Fig. 4A, circles). These new data clearly fall within the confidence interval of standard crowding (with a 58 ms target duration) from Experiment 1; critical spacing with moving flankers was not different from critical spacing during standard crowding. Thus, temporal uncertainty alone cannot account for the results presented in Experiment 1.
To summarize the results of Experiment 1, we found a reduction in critical spacing, the area over which features are integrated, when flankers onset before the target onset, whereas we found an increase in critical spacing when flankers offset after the target offset. Neither the flanker duration nor spatial and temporal cuing by the flankers can account for these results. The changes in crowding require an asynchrony of ∼45 ms, although there are large individual differences in this value.
Experiment 2: The coordinate frame of temporal feature integration
In Experiment 1, we found that the visual system uses the relative timing of visual features to determine the area over which features are integrated. This finding allowed us to test trans-saccadic feature integration in Experiment 2. We tested whether temporal feature integration transfers across eye movements. To date, there has been no strong evidence that visual features are integrated across saccades (Cavanagh et al., 2010a), leaving open an explanation for how our subjective experience of visual objects goes uninterrupted across shifts of gaze (Krauzlis and Nummela, 2011). Recent evidence suggests that immediately before a saccade, visual processing is altered in a way that predicts where features will fall on the retinas (Dorr and Bex, 2013; Harrison et al., 2013b), making it unlikely that visual processing starts de novo following a saccade. If feature integration occurs solely at early levels of the visual system where neurons' receptive fields are anchored in retinotopic coordinates (Pelli, 2008; Freeman and Simoncelli, 2011), an eye movement that shifts features on the retinas should disrupt feature integration. Alternatively, if feature integration involves brain areas that represent objects according to their positions in external space (Duhamel et al., 1997), temporal integration should continue across shifts of gaze position.
Observers executed a goal-directed saccade and then reported the orientation of a crowded target presented immediately following the saccade (Fig. 5A). The postsaccadic target was flanked by distractors at the same retinal locations across conditions. In one block of trials, only the fixation spot was present until immediately after the saccade, at which time the target and flankers were presented (“postsaccade” condition). In a separate block of trials, flankers were also displayed before the saccade (“trans-saccade” condition). Across conditions, therefore, the target and flankers were retinotopically matched following the saccade. Importantly, in the trans-saccade condition, the leading flankers were mismatched in retinotopic coordinates relative to their postsaccade positions, but were matched in their spatiotopic (world-centered) coordinates. If temporal feature integration exclusively involves retinotopic brain areas in the early stages of visual processing, critical spacing should not vary systematically between these conditions. Alternatively, if temporal integration can operate in nonretinotopic coordinates, we may observe a leading flanker advantage in the trans-saccadic condition.
As shown in Figure 5B, critical spacing was significantly less in the trans-saccade condition than the postsaccade condition for all observers. That is, following the eye movement, observers' ability to discriminate a target surrounded by flankers depended on what they viewed before the saccade. Therefore, immediately following a saccade, feature integration did not start anew; the trans-saccade flankers facilitated target segmentation. Experiment 2 reveals that feature integration does not depend solely on the retinotopic position of features because the retinotopic proximity of target and flankers was matched across trans-saccade and postsaccade conditions.
Retinal motion control experiment
In a control experiment, we tested whether trans-saccade integration occurs in the absence of saccade-induced retinal motion. In Experiment 2, we found that critical spacing was lower in the trans-saccade condition, in which flankers appeared before a saccade, than in the postsaccade condition, in which target and flankers appeared postsaccade. The difference in critical spacing could have been at least partly driven by motion transients in the trans-saccade condition caused by the eye movement shifting the flankers across the retinas. We conducted a control experiment that removed saccade-induced motion transients: we compared the same conditions as in Experiment 2, except the flankers in the trans-saccade condition were blanked off before the onset of the saccade. This eliminated any retinal motion of the flankers during the eye movement. In the postsaccade and trans-saccade condition, the target and flankers onset at the end of the saccade. Therefore, during and following the eye movement, retinal input was the same across conditions. In the trans-saccade condition only, flankers were displayed before the saccade at the screen position corresponding to their postsaccade location.
As shown in Figure 6A, the psychometric fits for the trans-saccade condition are shifted to the left of the fits for the postsaccade condition. Therefore, critical spacing was less in the trans-saccade condition than in the postsaccade condition for both observers (Fig. 6B). These results likely underestimate the benefit of a presaccadic flanker preview in the trans-saccade condition, because saccadic remapping processes are strongest within 50 ms before a saccade (Duhamel et al., 1992; Rolfs et al., 2011; Jonikaitis et al., 2013). In our experiment, flankers switched off ∼54 ms before the saccade (see Materials and Methods), and therefore before the peak of remapping. Nonetheless, results from this experiment reveal that presaccadic flankers facilitate postsaccadic target segmentation, even when the flankers are not visible during the saccade.
Figure 6.

Trans-saccade integration in the absence of saccade-induced retinal motion. A, Proportion correct and psychometric fits for the eye-movement control experiment for two observers. Data for the postsaccade and trans-saccade conditions are shown as open and filled symbols, respectively, while fits are shown as dotted and solid lines, respectively. B, Critical spacing for each observer (filled symbols) and the mean (open symbol). Error bars show 95% confidence intervals.
Discussion
We investigated how visual features are integrated across time and eye movements. Our data show that visual features are integrated over a rapid time course and over a spatial region that can change with feature timing and with eye movements. By quantifying changes in the spatial extent of crowding over time, we showed that the area over which features are integrated is highly dynamic within a 45 ms window. When a target onset was temporally asynchronous relative to surrounding features, we observed improved target discrimination even when the retinotopic position of the target features mismatched the preceding features because of an intervening saccade. Thus, perception does not require that features remain in the same retinotopic coordinates, but instead visual features can be integrated across eye movements, facilitating trans-saccadic object perception. Our results challenge standard models of feature binding that depend exclusively on the retinotopic receptive fields of neurons in early visual areas (Pelli, 2008). The temporal integration window we defined suggests that the integration of features depends not only on the spatial proximity of early visual neurons by which the features are coded, but also on the relative timing of those features.
Researchers have previously demonstrated that perceived space is sometimes compressed around the time of saccadic eye movements (Honda, 1989; Ross et al., 1997). Although others have exploited such perceptual mislocalizations to backward mask or unmask targets across saccades (De Pisapia et al., 2010), such misperceptions of space cannot account for our data. Cicchini et al. (2013) found that a brief stimulus flashed just before a saccade is misperceived as appearing at the position of a postsaccadic reference stimulus. In Experiment 2, we presented stimuli before and after a saccade in the trans-saccade condition but not the postsaccade condition, raising the possibility that positions of stimuli were perceived differently across our conditions. However, based on the findings of Cicchini et al., it is unlikely the position of stimuli were misperceived in the trans-saccade condition of our experiment for two reasons. First, the flankers onset ∼450 ms before the saccade, well before mislocalizations occur. Second, following the saccade, the flankers remained displayed in the same screen coordinates as before the saccade, and thus the postsaccadic reference would anchor the presaccadic flankers to veridical screen coordinates. For multiple reasons, it is also unlikely that the stimuli in the postsaccade condition of Experiment 2 were mislocalized. First, stimuli that are visible after the saccade are barely mislocalized (Ross et al., 1997; Lappe et al., 2000). Second, complex stimuli that are present immediately after a saccade, as in our postsaccade condition, act as a stable reference by which other stimuli are judged (Deubel et al., 1996, 1998). And finally, misperceptions would cause stimuli to appear closer to the fovea (Kaiser and Lappe, 2004), and reduce the perceived eccentricity of the target. Because the magnitude of crowding depends on the perceived rather than the physical location of stimuli (Dakin et al., 2011), such misperceived stimuli would thus be expected to result in less crowding in the postsaccade condition than the trans-saccade condition, which is opposite to our result.
The present study helps to explain previously reported data. Our observation that integration and segmentation occur within 50 ms explains the recent finding that visual crowding is invariant at display presentation durations of >250 ms (Wallace et al., 2013). When we extended the target–flanker stimulus duration to 500 ms, we found a reduction in crowding compared with a 58 ms stimulus (Fig. 3A,B). Tripathy and Cavanagh (2002) also found that the extent of crowding was greater with a stimulus duration of 13–27 ms compared with 360 ms. The effect of stimulus duration on crowding must therefore saturate between ∼58 and 250 ms. Furthermore, our data help to explain “visual marking,” the reduction of search times in visual search experiments following a preview of a subset of distractor items before target onset (Watson and Humphreys, 1997). Under these conditions, our data reveal that the previewed distractors are likely segmented from other elements appearing later in the display, resulting in reduced search times (Vlaskamp and Hooge, 2006). Indeed, the minimum distractor preview time required for facilitated search in visual marking experiments is similar to the feature integration times found here.
The results from the first control experiment confirm that flankers that outlast the target affect feature integration, and this is exacerbated by a change in flanker identity (Fig. 4C). Similar changes in target identification accuracy as a function of relative timing have been reported for object substitution masking (Enns and Di Lollo, 1997; Di Lollo et al., 2000). However, object substitution is distinct from crowding. In contrast to crowding, object substitution masking is independent of the target–mask separation and, to degrade target identification accuracy, multiple targets need to be presented on each trial (Di Lollo et al., 2000). In our experiments, observers always knew the upcoming target location, which would prevent object substation masking, and, furthermore, crowding is obviously highly dependent on the target–mask (i.e., target–flanker) separation. Our finding that asynchronous offsets led to an increase in critical spacing for crowding emphasizes that the spatial area over which features are integrated is flexible and involves a strong temporal component. Thus, the temporal dependence of crowding may require similar feedback mechanisms as those that are thought to be involved in object substitution masking (Di Lollo et al., 2000), and this feedback may be important for trans-saccadic vision. We discuss the role of feedback below.
The apparent spatiotopy of feature binding found in the present study is likely mediated by brain areas that alter visual processing predictively of eye movements (Duhamel et al., 1992; Sommer and Wurtz, 2008) in anticipation of where features will be shifted on the retinas (Harrison et al., 2013b). Importantly, the dynamic properties of remapping neurons negate the need for visual features themselves to be explicitly represented in spatiotopic coordinates. Brain areas with remapping neurons may be part of a network involving object recognition areas, such as the lateral occipital complex (Malach et al., 1995), and visual memory areas, such as the intraparietal sulcus (Xu and Chun, 2006). Oculomotor brain areas specify the position of an object in spatiotopic coordinates (Duhamel et al., 1997), or rapidly update the retinotopic coordinates with each saccade (Duhamel et al., 1992; Rolfs et al., 2011), and could thus link an object's position and identity via reciprocal neural connections (Moore and Armstrong, 2003; Cavanagh et al., 2010a). Indeed, the activity of neurons in the frontal eye fields, an oculomotor control center, discriminates between a target and distractor in <30 ms (Stanford et al., 2010), corresponding closely to the temporal integration threshold found in the present study.
Our data are thus consistent with re-entrant models of vision (Mumford, 1992; Rao and Ballard, 1999; Di Lollo et al., 2000), in which information from higher brain areas is fed back to alter low-level visual processing and object perception (Moore and Armstrong, 2003; Demeyer et al., 2011). Feedback processes have been implicated in crowding previously (Yeshurun and Rashal, 2010; Harrison et al., 2013a, 2013b), as well as in feature integration more generally (Bouvier and Treisman, 2010). Together, our results suggest that re-entrant processing helps to group and segment features in nonretinotopic coordinates. In natural environments in which our vision is densely cluttered, these processes could facilitate the detection of changes within objects to which we attend across saccades (Cavanaugh and Wurtz, 2004). Improved target discrimination in the trans-saccade condition may be achieved via suppressed activity in V4 neurons resulting from the rapid changes in the retinal signal across eye movements (Motter, 2006). Motter showed that transient signals in V4 can be suppressed when the timing of a flashed stimulus matches the expected time course of changes in inputs across eye movements. It is possible, therefore, that the flankers in the trans-saccade condition were effectively suppressed following the saccade, releasing the target from crowding. Furthermore, changes in the firing rates of V1 neurons over a wide spatial range can distinguish activation caused by an eye movement from the movement of a visual stimulus, which is signaled by changes in local firing rates immediately following a saccade (Kagan et al., 2008). These complimentary processes may be capable of making the target letter more salient in the trans-saccade condition than in the postsaccade condition, because in the trans-saccade condition only, a global change of the presaccadic flankers shifting on the retinas was followed by the local onset of the target. Our temporal manipulation can be applied easily to neuroimaging techniques to address the underlying mechanisms.
We found that the relative timing of visual features plays a critical role in determining how the visual system groups those features. Changes in feature integration over time continue when visual features are displaced on the retinas. Our study thus shows that feature binding does not start anew following shifts of gaze position, and helps to explain why our perception of visual objects goes uninterrupted despite eye movements constantly shifting the image on the retinas.
Footnotes
This work was supported by National Institutes of Health Grants R01 EY19281 and R01 EY018664. We thank MiYoung Kwon for her help with preparing the manuscript.
References
- Afraz A, Cavanagh P. The gender-specific face aftereffect is based in retinotopic not spatiotopic coordinates across several natural image transformations. J Vis. 2009;9(10):10.1–17. doi: 10.1167/9.10.10. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bouma H. Interaction effects in parafoveal letter recognition. Nature. 1970;226:177–178. doi: 10.1038/226177a0. [DOI] [PubMed] [Google Scholar]
- Bouvier S, Treisman A. Visual feature binding requires reentry. Psychol Sci. 2010;21:200–204. doi: 10.1177/0956797609357858. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brainard DH. The psychophysics toolbox. Spat Vis. 1997;10:433–436. doi: 10.1163/156856897X00357. [DOI] [PubMed] [Google Scholar]
- Cavanagh P, Hunt AR, Afraz A, Rolfs M. Visual stability based on remapping of attention pointers. Trends Cogn Sci. 2010a;14:147–153. doi: 10.1016/j.tics.2010.01.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cavanagh P, Hunt AR, Afraz A, Rolfs M. Attentional pointers: response to Melcher. Trends Cogn Sci. 2010b;14:474–475. doi: 10.1016/j.tics.2010.08.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cavanaugh J, Wurtz RH. Subcortical modulation of attention counters change blindness. J Neurosci. 2004;24:11236–11243. doi: 10.1523/JNEUROSCI.3724-04.2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cicchini GM, Binda P, Burr DC, Morrone MC. Transient spatiotopic integration across saccadic eye movements mediates visual stability. J Neurophysiol. 2013;109:1117–1125. doi: 10.1152/jn.00478.2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cornelissen FW, Peters EM, Palmer J. The eyelink toolbox: eye tracking with MATLAB and the Psychophysics Toolbox. Behav Res Methods Instrum Comput. 2002;34:613–617. doi: 10.3758/BF03195489. [DOI] [PubMed] [Google Scholar]
- Dakin SC, Greenwood JA, Carlson TA, Bex PJ. Crowding is tuned for perceived (not physical) location. J Vis. 2011;11(9):2. doi: 10.1167/11.9.2. pii. [DOI] [PMC free article] [PubMed] [Google Scholar]
- d'Avossa G, Tosetti M, Crespi S, Biagi L, Burr DC, Morrone MC. Spatiotopic selectivity of BOLD responses to visual motion in human area MT. Nat Neurosci. 2007;10:249–255. doi: 10.1038/nn1824. [DOI] [PubMed] [Google Scholar]
- Demeyer M, De Graef P, Verfaillie K, Wagemans J. Perceptual grouping of object contours survives saccades. PLoS One. 2011;6:e21257. doi: 10.1371/journal.pone.0021257. [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Pisapia N, Kaunitz L, Melcher D. Backward masking and unmasking across saccadic eye movements. Curr Biol. 2010;20:613–617. doi: 10.1016/j.cub.2010.01.056. [DOI] [PubMed] [Google Scholar]
- Deubel H, Schneider WX, Bridgeman B. Postsaccadic target blanking prevents saccadic suppression of image displacement. Vision Res. 1996;36:985–996. doi: 10.1016/0042-6989(95)00203-0. [DOI] [PubMed] [Google Scholar]
- Deubel H, Bridgeman B, Schneider WX. Immediate post-saccadic information mediates space constancy. Vision Res. 1998;38:3147–3159. doi: 10.1016/S0042-6989(98)00048-0. [DOI] [PubMed] [Google Scholar]
- Di Lollo V, Enns JT, Rensink RA. Competition for consciousness among visual events: the psychophysics of reentrant visual processes. J Exp Psychol Gen. 2000;129:481–507. doi: 10.1037/0096-3445.129.4.481. [DOI] [PubMed] [Google Scholar]
- Dorr M, Bex PJ. Peri-saccadic natural vision. J Neurosci. 2013;33:1211–1217. doi: 10.1523/JNEUROSCI.4344-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Duhamel JR, Colby CL, Goldberg ME. The updating of the representation of visual space in parietal cortex by intended eye movements. Science. 1992;255:90–92. doi: 10.1126/science.1553535. [DOI] [PubMed] [Google Scholar]
- Duhamel JR, Bremmer F, Ben Hamed S, Graf W. Spatial invariance of visual receptive fields in parietal cortex neurons. Nature. 1997;389:845–848. doi: 10.1038/39865. [DOI] [PubMed] [Google Scholar]
- Efron B, Tibshirani R. An introduction to the bootstrap. New York: Chapman and Hall; 1993. [Google Scholar]
- Enns JT, Di Lollo V. Object substitution: a new form of masking in unattended visual locations. Psychol Sci. 1997;8:135–139. doi: 10.1111/j.1467-9280.1997.tb00696.x. [DOI] [Google Scholar]
- Freeman J, Simoncelli EP. Metamers of the ventral stream. Nat Neurosci. 2011;14:1195–1201. doi: 10.1038/nn.2889. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fründ I, Haenel NV, Wichmann FA. Inference for psychometric functions in the presence of nonstationary behavior. J Vis. 2011;11(6):16. doi: 10.1167/11.6.16. pii. [DOI] [PubMed] [Google Scholar]
- Gardner JL, Merriam EP, Movshon JA, Heeger DJ. Maps of visual space in human occipital cortex are retinotopic, not spatiotopic. J Neurosci. 2008;28:3988–3999. doi: 10.1523/JNEUROSCI.5476-07.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harrison WJ, Mattingley JB, Remington RW. Eye movement targets are released from visual crowding. J Neurosci. 2013a;33:2927–2933. doi: 10.1523/JNEUROSCI.4172-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harrison WJ, Retell JD, Remington RW, Mattingley JB. Visual crowding at a distance during predictive remapping. Curr Biol. 2013b;23:793–798. doi: 10.1016/j.cub.2013.03.050. [DOI] [PubMed] [Google Scholar]
- Harrison WJ, Remington RW, Mattingley JB. Visual crowding is anisotropic along the horizontal meridian during smooth pursuit. J Vis. 2014;14(1):21. doi: 10.1167/14.1.21. pii. [DOI] [PubMed] [Google Scholar]
- Honda H. Perceptual localization of visual stimuli flashed during saccades. Percept Psychophys. 1989;45:162–174. doi: 10.3758/BF03208051. [DOI] [PubMed] [Google Scholar]
- Hubel DH, Wiesel TN. Receptive fields, binocular interaction and functional architecture in the cat's visual cortex. J Physiol. 1962;160:106–154. doi: 10.1113/jphysiol.1962.sp006837. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hunt AR, Cavanagh P. Remapped visual masking. J Vis. 2011;11(1):13. doi: 10.1167/11.1.13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jonikaitis D, Szinte M, Rolfs M, Cavanagh P. Allocation of attention across saccades. J Neurophysiol. 2013;109:1425–1434. doi: 10.1152/jn.00656.2012. [DOI] [PubMed] [Google Scholar]
- Kagan I, Gur M, Snodderly DM. Saccades and drifts differentially modulate neuronal activity in V1: effects of retinal image motion, position, and extraretinal influences. J Vis. 2008;8(14):19.1–25. doi: 10.1167/8.14.19. [DOI] [PubMed] [Google Scholar]
- Kaiser M, Lappe M. Perisaccadic mislocalization orthogonal to saccade direction. Neuron. 2004;41:293–300. doi: 10.1016/S0896-6273(03)00849-3. [DOI] [PubMed] [Google Scholar]
- Knapen T, Rolfs M, Cavanagh P. The reference frame of the motion aftereffect is retinotopic. J Vis. 2009;9(5):16.1–7. doi: 10.1167/9.5.16. [DOI] [PubMed] [Google Scholar]
- Knapen T, Rolfs M, Wexler M, Cavanagh P. The reference frame of the tilt aftereffect. J Vis. 2010;10(1):8. doi: 10.1167/10.1.8. pii. [DOI] [PubMed] [Google Scholar]
- Krauzlis RJ, Nummela SU. Attention points to the future. Nat Neurosci. 2011;14:130–131. doi: 10.1038/nn0211-130. [DOI] [PubMed] [Google Scholar]
- Lappe M, Awater H, Krekelberg B. Postsaccadic visual references generate presaccadic compression of space. Nature. 2000;403:892–895. doi: 10.1038/35002588. [DOI] [PubMed] [Google Scholar]
- Levi DM. Crowding—an essential bottleneck for object recognition: a mini-review. Vision Res. 2008;48:635–654. doi: 10.1016/j.visres.2007.12.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levi DM, Hariharan S, Klein SA. Suppressive and facilitatory spatial interactions in peripheral vision: peripheral crowding is neither size invariant nor simple contrast masking. J Vis. 2002;2(2):167–177. doi: 10.1167/2.2.3. [DOI] [PubMed] [Google Scholar]
- Malach R, Reppas JB, Benson RR, Kwong KK, Jiang H, Kennedy WA, Ledden PJ, Brady TJ, Rosen BR, Tootell RB. Object-related activity revealed by functional magnetic resonance imaging in human occipital cortex. Proc Natl Acad Sci U S A. 1995;92:8135–8139. doi: 10.1073/pnas.92.18.8135. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathôt S, Theeuwes J. A reinvestigation of the reference frame of the tilt-adaptation aftereffect. Sci Rep. 2013;3:1152. doi: 10.1038/srep01152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Melcher D. Spatiotopic transfer of visual-form adaptation across saccadic eye movements. Curr Biol. 2005;15:1745–1748. doi: 10.1016/j.cub.2005.08.044. [DOI] [PubMed] [Google Scholar]
- Melcher D. Predictive remapping of visual features precedes saccadic eye movements. Nat Neurosci. 2007;10:903–907. doi: 10.1038/nn1917. [DOI] [PubMed] [Google Scholar]
- Melcher D. The missing link for attention pointers: comment on Cavanagh et al. Trends Cogn Sci. 2010;14:473. doi: 10.1016/j.tics.2010.08.007. author reply 474–5. [DOI] [PubMed] [Google Scholar]
- Melcher D, Morrone MC. Spatiotopic temporal integration of visual motion across saccadic eye movements. Nat Neurosci. 2003;6:877–881. doi: 10.1038/nn1098. [DOI] [PubMed] [Google Scholar]
- Moore T, Armstrong KM. Selective gating of visual signals by microstimulation of frontal cortex. Nature. 2003;421:370–373. doi: 10.1038/nature01341. [DOI] [PubMed] [Google Scholar]
- Morris AP, Liu CC, Cropper SJ, Forte JD, Krekelberg B, Mattingley JB. Summation of visual motion across eye movements reflects a nonspatial decision mechanism. J Neurosci. 2010;30:9821–9830. doi: 10.1523/JNEUROSCI.1705-10.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Motter BC. Modulation of transient and sustained response components of V4 neurons by temporal crowding in flashed stimulus sequences. J Neurosci. 2006;26:9683–9694. doi: 10.1523/JNEUROSCI.5495-05.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mumford D. On the computational architecture of the neocortex. II. The role of cortico-cortical loops. Biol Cybern. 1992;66:241–251. doi: 10.1007/BF00198477. [DOI] [PubMed] [Google Scholar]
- Parkes L, Lund J, Angelucci A, Solomon JA, Morgan M. Compulsory averaging of crowded orientation signals in human vision. Nat Neurosci. 2001;4:739–744. doi: 10.1038/89532. [DOI] [PubMed] [Google Scholar]
- Pelli DG. The VideoToolbox software for visual psychophysics: transforming numbers into movies. Spat Vis. 1997;10:437–442. doi: 10.1163/156856897X00366. [DOI] [PubMed] [Google Scholar]
- Pelli DG. Crowding: a cortical constraint on object recognition. Curr Opin Neurobiol. 2008;18:445–451. doi: 10.1016/j.conb.2008.09.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pelli DG, Tillman KA. The uncrowded window of object recognition. Nat Neurosci. 2008;11:1129–1135. doi: 10.1038/nn.2187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pelli DG, Palomares M, Majaj NJ. Crowding is unlike ordinary masking: distinguishing feature integration from detection. J Vis. 2004;4(12):1136–1169. doi: 10.1167/4.12.12. [DOI] [PubMed] [Google Scholar]
- Petrov Y, Meleshkevich O. Asymmetries and idiosyncratic hot spots in crowding. Vis Res. 2011;51:1117–1123. doi: 10.1016/j.visres.2011.03.001. [DOI] [PubMed] [Google Scholar]
- Posner MI, Snyder CR, Davidson BJ. Attention and the detection of signals. J Exp Psychol Gen. 1980;109:160–174. doi: 10.1037/0096-3445.109.2.160. [DOI] [PubMed] [Google Scholar]
- Rao RP, Ballard DH. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nat Neurosci. 1999;2:79–87. doi: 10.1038/4580. [DOI] [PubMed] [Google Scholar]
- Rolfs M, Jonikaitis D, Deubel H, Cavanagh P. Predictive remapping of attention across eye movements. Nat Neurosci. 2011;14:252–256. doi: 10.1038/nn.2711. [DOI] [PubMed] [Google Scholar]
- Ross J, Morrone MC, Burr DC. Compression of visual space before saccades. Nature. 1997;386:598–601. doi: 10.1038/386598a0. [DOI] [PubMed] [Google Scholar]
- Scolari M, Kohnen A, Barton B, Awh E. Spatial attention, preview, and popout: which factors influence critical spacing in crowded displays? J Vis. 2007;7(2):7.1–23. doi: 10.1167/7.2.7. [DOI] [PubMed] [Google Scholar]
- Sommer MA, Wurtz RH. Brain circuits for the internal monitoring of movements. Ann Rev Neurosci. 2008;31:317–338. doi: 10.1146/annurev.neuro.31.060407.125627. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stanford TR, Shankar S, Massoglia DP, Costello MG, Salinas E. Perceptual decision making in less than 30 milliseconds. Nat Neurosci. 2010;13:379–385. doi: 10.1038/nn.2485. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tripathy SP, Cavanagh P. The extent of crowding in peripheral vision does not scale with target size. Vision Res. 2002;42:2357–2369. doi: 10.1016/s0042-6989(02)00197-9. [DOI] [PubMed] [Google Scholar]
- Vlaskamp BN, Hooge IT. Crowding degrades saccadic search performance. Vision Res. 2006;46:417–425. doi: 10.1016/j.visres.2005.04.006. [DOI] [PubMed] [Google Scholar]
- Wallace JM, Chiu MK, Nandy AS, Tjan BS. Crowding during restricted and free viewing. Vision Res. 2013;84:50–59. doi: 10.1016/j.visres.2013.03.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Watson DG, Humphreys GW. Visual marking: prioritizing selection for new objects by top-down attentional inhibition of old objects. Psychol Rev. 1997;104:90. doi: 10.1037/0033-295X.104.1.90. [DOI] [PubMed] [Google Scholar]
- Whitney D, Levi DM. Visual crowding: a fundamental limit on conscious perception and object recognition. Trends Cogn Sci. 2011;15:160–168. doi: 10.1016/j.tics.2011.02.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wichmann FA, Hill NJ. The psychometric function: I. Fitting, sampling, and goodness of fit. Percept Psychophys. 2001;63:1293–1313. doi: 10.3758/BF03194544. [DOI] [PubMed] [Google Scholar]
- Xu Y, Chun MM. Dissociable neural mechanisms supporting visual short-term memory for objects. Nature. 2006;440:91–95. doi: 10.1038/nature04262. [DOI] [PubMed] [Google Scholar]
- Yeshurun Y, Rashal E. Precueing attention to the target location diminishes crowding and reduces the critical distance. J Vis. 2010;10(10):16. doi: 10.1167/10.10.16. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Binding temporally asynchronous features into letters. When the viewer watches the video while fixating the blue spot, the letters on the right side of the display are easily identified while those on the left are barely visible. These differences in discriminability occur despite the spatial arrangements and stimulus durations being identical for the left and right streams; only the relative timing of the featural elements differs. This video demonstrates that the visual system relies on the relative timing of visual features to group those features into a coherent object.