

Abstract
The house dust mites are major sources of indoor allergens for humans, which induce asthma, rhinitis, dermatitis, and other allergic diseases. Der f 25 is a triosephosphate isomerase, representing the major allergen identified in Dermatophagoides farinae. The objective of this study was to predict the B and T cell epitopes of Der f 25. In the present study, we analyzed the physiochemical properties, function motifs and domains, and structural-based detailed features of Der f 25 and predicted the B cell linear epitopes of Der f 25 by DNAStar protean system, BPAP, and BepiPred 1.0 server and the T cell epitopes by NetMHCIIpan-3.0 and NetMHCII-2.2. As a result, the sequence and structure analysis identified that Der f 25 belongs to the triosephosphate isomerase family and exhibited a triosephosphate isomerase pattern (PS001371). Eight B cell epitopes (11–18, 30–35, 71–77, 99–107, 132–138, 173–187, 193–197, and 211–224) and five T cell epitopes including 26–34, 38–54, 66–74, 142–151, and 239–247 were predicted in this study. These results can be used to benefit allergen immunotherapies and reduce the frequency of mite allergic reactions.
1. Introduction
The house dust mites (HDM) are major sources of indoor allergens for humans, which induce asthma, rhinitis, dermatitis, and other allergic diseases [1]. Their major allergens (Dermatophagoides pteronyssinus [Der p] and Dermatophagoides farinae [Der f]) coexist in most geographical regions with a high proportion (up to 85%) of asthmatics being typically HDM allergic; hence, sensitization is attributed as a risk factor for developing asthma. Recently, a birth cohort study showed that sensitization to HDM at age of 2 years was associated with current wheeze at age of 12 years in both monosensitized and polysensitized HDM-sensitized children [2]. In previous studies, fourteen D. farinae allergens (Der f 1–3, 6, 7, 10, 11, 13–18, and 22) were reported before other seventeen allergens belonging to twelve different groups were identified by a procedure of proteomics combined with two-dimensional immunoblotting from D. farinae extracts [3, 4]. Among the novel identified D. farinae allergens, Der f 25 is a triosephosphate isomerase (TPI) with a molecular weight of 34 kDa, showing 75.6% by immunoblotting and 60% by skin prick positive reaction to dust mite allergic patients, respectively. It represented the major allergen in D. farinae [4].
TPI is an enzyme (EC 5.3.1.1) that catalyzes the reversible interconversion of the triose phosphate isomers dihydroxyacetone phosphate and D-glyceraldehyde 3-phosphate [5]. It has been found in nearly every organism searched for the enzyme, including animals such as mammals and insects as well as in fungi, plants, and bacteria. Moreover, some TPIs have been identified as an allergen in fish, midges, crustaceans, and various plants [6–12].
Currently, specific immunotherapy is the only allergen-specific approach for its treatment of mite allergy. The administration of increasing doses of allergen extracts to patients is the method most commonly applied. However, the use of crude extracts has several disadvantages. It could induce severe anaphylactic side reactions or lead to sensitization towards new allergens present in the mixture [13, 14]. Different strategies have been designed to try to overcome these negative effects, as the use of allergen-derived B cell peptides, allergen-derived T cell epitope containing peptides, or vaccination with allergen-encoding DNA [15]. Known epitopes for some of these mite allergens are described in detail in Cui's review [16]. However, there is no report about the epitope of Der f 25 allergen. In the present study, we firstly identified the B and T cell epitopes of Der f 25 allergen by in silico approach. It implied their potential utility in a peptide-based vaccine design for mite allergy.
2. Methodology
2.1. Sequence Retrieval and Phylogenetic Analysis
The complete amino acid sequence of Der f 25 was acquired from the Nucleotide database of NCBI (http://www.ncbi.nlm.nih.gov/) with the accession number of KC305500.1. The amino acid sequence was also used as query to search for homologous sequences through the Swiss-Prot/TrEMBL (Uniprot) (http://www.uniprot.org/) and tBLASTn in NCBI (http://blast.ncbi.nlm.nih.gov/Blast.cgi).
The homologous amino acid sequences were retrieved and aligned using Clustal X 2.1 [17]. Phylogenetic tree was obtained by using ML (maximum-likelihood) method on the basis of the JTT amino acid sequence distance implemented in MEGA 5.1 [18]; the reliability was evaluated by the bootstrap method with 1000 replications.
2.2. Domain Architecture Analyses
The possible domains and characteristic motifs and patterns contained in Der f 25 were investigated by Pfam v27.0 (http://pfam.sanger.ac.uk/) [19], Prosite (http://prosite.expasy.org/scanprosite/) [20], InterPRO v46.0 (http://www.ebi.ac.uk/interpro/), and Superfamily v1.75 (http://supfam.cs.bris.ac.uk/SUPERFAMILY/index.html) [21].
2.3. Physiochemical Analysis and Posttranslational Patterns and Motifs
Physiochemical analysis including molecular weight, theoretical pI, amino acid composition, instability index, aliphatic index, and grand average of hydropathicity (GRAVY) of Der f 25 was performed by using ProtParam tool (http://web.expasy.org/protparam/). Der f 25 characteristic pattern was checked for original sequence and further analysis was performed to highlight the presence of functional motifs by using the Prosite database (http://prosite.expasy.org/) [20]. Biologically meaningful motifs and susceptibility to posttranslational modifications were derived from multiple alignments and the ScanProsite tool. Phosphorylation motifs with more than 80% of probability of occurrence were analyzed by using NETPhos v2.0 (http://www.cbs.dtu.dk/services/NetPhos/) and NETPhosK v1.0 (http://www.cbs.dtu.dk/services/NetPhosK/) [22].
2.4. Secondary Structure Prediction
Der f 25 secondary structural elements were predicted by PSIPRED (http://bioinf.cs.ucl.ac.uk/psipred/) [23], which threads sequence segments through protein data bank (PDB) library (http://www.rcsb.org/) to identify conserved substructures. Furthermore, the secondary structure elements were also identified with the result obtained with NetSurfP ver. 1.1 (http://www.cbs.dtu.dk/) [24].
2.5. Homology Modeling and Validation
The Der f 25 protein sequence was searched for homology in the PDB. As well, the homologous templates suitable for Der f 25 were selected by PSI-BLAST server (http://blast.ncbi.nlm.nih.gov/Blast.cgi) and SWISS-MODEL server (http://swissmodel.expasy.org/) [25, 26]. The best template was retrieved from the results of previous methods and used for homology modeling. Der f 25 modeled protein structure was built through alignment mode in SWISS-MODEL using the complete amino acid sequence. An initial structural model was generated and checked for recognition of errors in 3D structure by PROCHECK [27], ERRAT [28], and VERIFY 3D [29] programs in structural analysis and verification server (SAVES) (http://nihserver.mbi.ucla.edu/SAVES/). The final model structure quality of Der f 25 was assessed by QMEAN [30], by checking protein stereology with ProSA program [31] and the protein energy with ANOLEA (http://protein.bio.puc.cl/cardex/servers/anolea/) [32]. The Ramachandran plot for all the models was generated, showing the majority of the protein residues in the favored regions.
2.6. Conservation Analysis and Poisson-Boltzmann Electrostatic Potential
Der f 25 model was submitted to ConSurf server (http://consurf.tau.ac.il/) in order to generate evolutionary related conservation scores helping to identify functional regions in the proteins. Functional and structural key residues in Der f 25 sequence were confirmed by ConSeq server [33].
APBS molecular modeling software implemented in PyMOL 0.99 was used to investigate the electrostatic Poisson-Boltzmann (PB) potentials of Der f 25 model structure. AMBER99 in PDB2PQR server (http://nbcr-222.ucsd.edu/pdb2pqr_1.8/) was used to assign the charges and radii to all of the atoms (including hydrogens) [34]. Fine grid spaces of 0.35 Å were used to solve the linearized PB equation in sequential focusing multigrid calculations in a mesh of 130 points per dimension at 310.00 K. The dielectric constants were 2.0 and 80.0 for the protein and water. The output mesh was processed in the scalar OpenDX format to render isocontours and maps onto the surfaces with PyMOL 0.99. Potential values are given in units of kT per unit charge (k Boltzmann's constant; T temperature).
2.7. In Silico Prediction of B Cell Epitopes
Three immunoinformatics tools including DNAStar protean system, bioinformatics predicted antigenic peptides (BPAP) system (http://imed.med.ucm.es/Tools/antigenic.pl), and BepiPred 1.0 server (http://www.cbs.dtu.dk/services/BepiPred/) were used to predicate the B cell epitopes of Der f 25. The ultimate consensus epitope results were obtained by combining the results of the three tools together with the method published earlier [35]. In the DNAStar protean system, four properties (hydrophilicity, flexibility, accessibility, and antigenicity) of the amino acid sequence were chosen as parameters for epitopes prediction. The BPAP system and the BepiPred 1.0 server only need the amino acid sequence and provide more straightforward results which are combined with physicochemical properties of amino acids such as hydrophilicity, flexibility, accessibility, turns, and exposed surface [36].
2.8. In Silico Prediction of T Cell Epitopes
T cell epitopes are principally predicted indirectly by identifying the binding of peptide fragments to the MHC complexes. The binding significance of each peptide to the given MHC molecule is based on the estimated strength of binding exhibited by a predicted nested core peptide at a set threshold level. For HLA-DR-based T cell epitope prediction, the artificial neural network-based alignment (NN-align) method NetMHCIIpan-3.0 (http://www.cbs.dtu.dk/services/NetMHCIIpan/) [37] was applied. For HLA-DQ alleles, NetMHCII-2.2 (http://www.cbs.dtu.dk/services/NetMHCII/) [38] was used. In this study, HLA-DR 101, HLA-DR 301, HLA-DR 401, and HLA-DR 501 were used to predict HLA-DR-based T cell epitope prediction. The ultimate HLA-DR-based T cell epitope results were obtained by combining those four results together that if three of them showed epitope, then the consensus result was epitope. This method was also used in HLA-DQ-based T cell epitope prediction. HLA-DQA10101-DQB10501, HLA-DQA10501-DQB10201, HLA-DQA10501-DQB10301, and HLA-DQA10102-DQB10602 were used to predict HLA-DQ-based T cell epitope prediction. As a result, the ultimate consensus epitope results were obtained by combining the results of the HLA-DR-based T cell epitope and HLA-DQ-based T cell epitope.
B cell and T cell epitopes identified by computational tools were mapped onto linear sequence and on the three-dimensional model of Der f 25 to determine their position and secondary structure elements involved.
3. Results
3.1. Sequence Retrieval and Sequence Analysis
The amino acid sequence of Der f 25 was obtained from the Nucleotide database of NCBI. Uniprot and tBLASTn were used to search the homologous sequences of Der f 25. As a result, thirty-six sequences were obtained and in order to determine the relationships between Der f 25 and its homologous sequences, phylogenetic analysis was performed and the evolutionary tree inferred by the ML method was showed in Figure 1. Phylogenetic analysis result showed that there are proteins including Der f 25 clustered into the same group, belonging to TIPs. Moreover, domain analysis results showed that Der f 25 belongs to the TIM phosphate binding superfamily (SUPERFAMILY number SSF51351 and InterPro number IPR016040) and TPI family (SUPERFAMILY number SSF51352 and InterPro number IPR000652).
Figure 1.
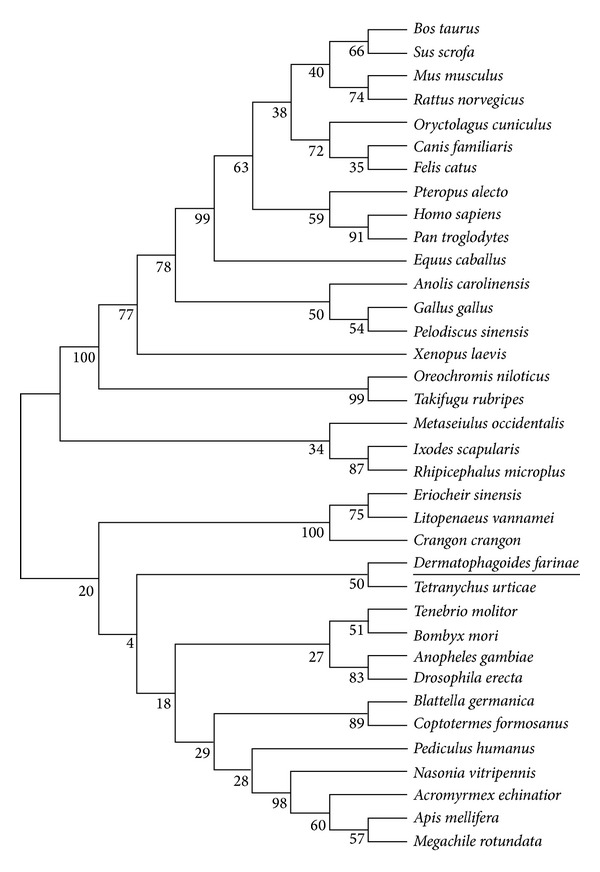
Phylogenetic relationship of Der f 25 amino acid sequence with other homologs.
After searching for characteristic motifs or patterns, we found that Der f 25 exhibited a TPI pattern, PS00171 (162–172, AYEPVWAIGTG) (Figure 2). Phosphorylation sites including two Ser (95 and 221) and two Thr (146 and 171) residues were predicted and showed in Figure 2. Two types of kinases (PKC for 95, 146, and 171 and DNAPK for 221) were predicted to be phosphorylated for Der f 25 complete sequence.
Figure 2.
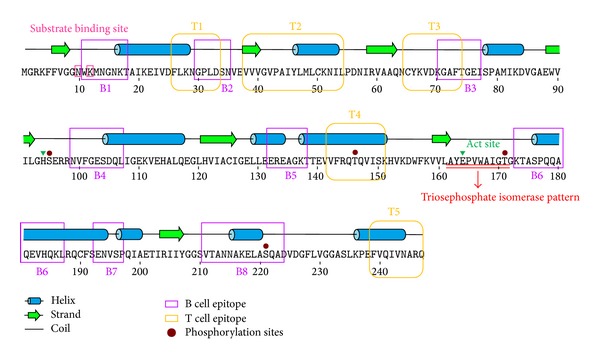
Sequences and second structure analysis of Der f 25 allergen. Ten α-helices and seven β-sheets were identified in Der f 25.
The primary structure of Der f 25 contained 247 amino acids and the molecular weight is 27134.1. The theoretical pI is 6.24 and the aliphatic index is 95.06. The GRAVY is −0.103 meaning that Der f 25 exhibited hydrophilic character. The instability index is 30.57 meaning that the sequence of Der f 25 is stable.
3.2. Homology Modeling and Validation
Searching for the proteins with known tertiary structure in the PDB yielded Tenebrio molitor TPI (PDB accession number: 2I9E) showing the highest sequence identity (74%) with Der f 25. The SWISS-MODEL server was also used to identify the best possible template and found a high score of 365 and very low E-value of e-101 for 2I9E template. Hence, the 2I9E template was used for homology modeling. As indicated by the Ramachandran plot (Figure 3(b)), 93% residues in Der f 25 model were within the most favored regions, 7% residues in the additional allowed region, 0% residues in the generously allowed regions, and 0% residues in the disallowed region; 93.4% residues in 2I9E template were within the most favored regions, 6.6% residues in the additional allowed region, 0% residues in the generously allowed regions, and 0% residues in the disallowed region. The goodness factor (G-factor) based on the observed distribution of stereochemical parameters (main chain bond angles, bond length, and phi-psi torsion angles) returned accurate values for a reliable model (Table 1), in comparison with the template 2I9E (Table 1). As indicated by the ERRAT program, the result showed that the overall quality factor is 97.034 for Der f 25 and 97.789 for 2I9E meaning that both of the two structures have good high resolution. As indicated by the VERIFY 3D program, the result showed that 99.6% and 99.8% of Der f 25 and 2I9E template residues had an average 3D (atomic model)-1D (amino acid sequence) score >0.2 also meaning that those two structures were good. ProSa analysis returned Z-scores of −10.1 and −10.24 for Der f 25 and 2I9E (Table 1), respectively. Q values for Der f 25 and 2I9E structures are 0.772 and 0.798, respectively. Root mean square deviations (RMSD) between Der f 25 structural model and 2I9E template Cα backbone are 0.062 Å (Table 1). Based on these validations, it is shown that the homology model was adopted for this study.
Figure 3.
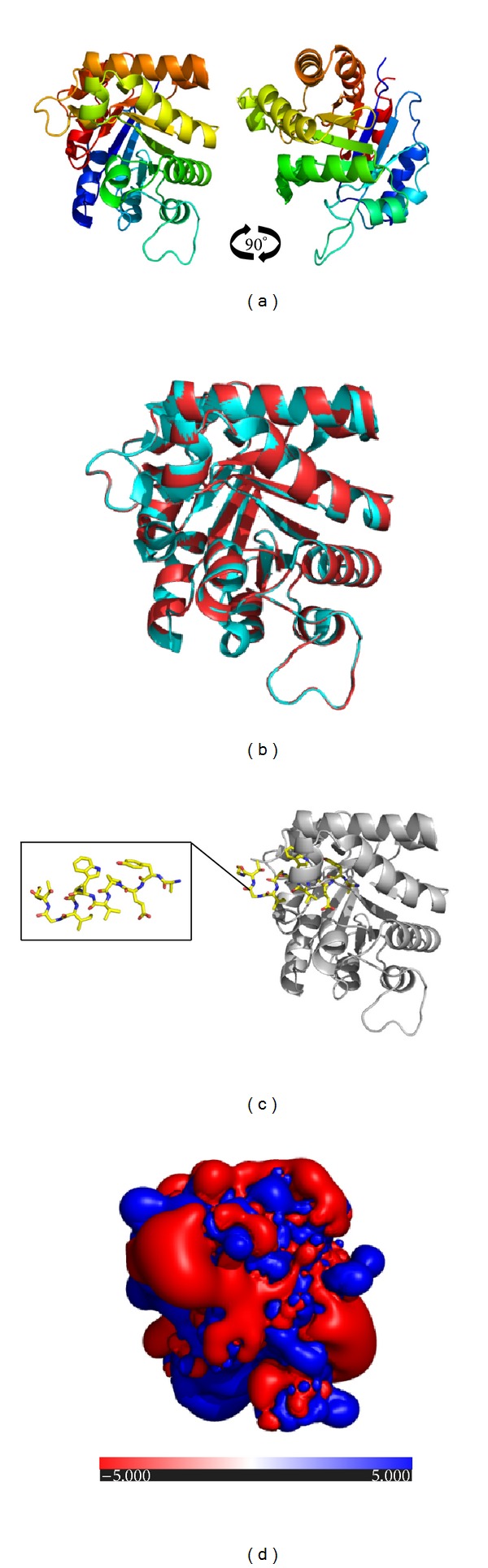
Structural analysis of Der f 25. (a) Protein structure of Der f 25 homology model. (b) Superimposition between Der f 25 and 2I9E template. Der f 25 is depicted in red and 2I9E template is depicted in cyan. (c) Distribution of characteristic pattern in Der f 25. (d) Electrostatic potential representation on the Der f 25 protein surface.
Table 1.
Parameters used for proteins structural assessment.
| Protein | Structural assessment methods | Ramachandran plot (%) | G-factor | MCBL (%) | CBA (%) | Z-score | Q value | RMSD |
|---|---|---|---|---|---|---|---|---|
| Der f 25 | PROCHECK analysis | 93.0E | 0.10I | 100.0 | 99.0 | |||
| 7.0F | 0.42J | |||||||
| 0.0G | 0.23K | |||||||
| 0.0H | ||||||||
| ProSa | −10.1 | |||||||
| QMEAN | 0.772 | |||||||
| RMSD | 0L | |||||||
|
| ||||||||
| 2I9E | PROCHECK analysis | 93.4%E | 0.25I | 100.0 | 98.9 | |||
| 6.6%F | 0.55J | |||||||
| 0.0G | 0.37K | |||||||
| 0.0H | ||||||||
| ProSa | −10.24 | |||||||
| QMEAN | 0.798 | |||||||
| RMSD | 0.056L | |||||||
MCBL: distribution of the main chain bond lengths; CBA: distribution of the covalent bond angles.
EResidues in favorable regions; Fresidues in allowed regions; Gresidues in generally allowed regions; Hresidues in disallowed regions; I G-factor score of the dihedral bonds; J G-factor score of the covalent bonds; Koverall G-factor score; Lroot mean square deviation between Cα Der f 25 structure and 2I9E template.
3.3. Structure Analyses
Secondary structure prediction of Der f 25 with PSIPRED identified ten α-helices and seven β-sheets (Figure 2) in Der f 25. Alternatively, NetSurfP v1.1 predicted nine α-helices and eight β-sheets. These results were predicated by different servers and have subtle distinction. The best template 2I9E was used for homology modeling; the overall 3D structure of Der f 25 was shown in Figure 3(a). Sequence polymorphism was responsible for the changes in the spatial distribution of the skeleton alpha carbons, which is reflected in differences between the structures of Der f 25 and 2I9E. A superposition of the Der f 25 with the 2I9E template is shown in Figure 3(b) and the values for superimposed Cα are 0.062 Å. As a TPI protein, Der f 25 has two active sites; His in the 94th position is an electrophile while Glu in the 164th position is the proton acceptor. It has two substrate binding sites, the Asn in the 10th position and the Lys in the 12th position. Moreover, the characteristic pattern predicted by ScanProsite tool is shown in Figure 3(c).
3.4. Conservational Analysis and Electrostatic Potential
ConSurf conservational analysis of structural and functional key amino acids showed that the Der f 25 protein surfaces were not well conserved, with almost forty high variability residues in different superficial areas. All of the amino acids in the TPI pattern (AYEPVWAIGTG) are conserved. Surface electrostatic potential analysis reveals several prominent charged residues, with half of the side exhibiting large positive values (blue regions) and the other half showing predominantly negative values (red regions) (Figure 3(d)).
3.5. B Cell Epitopes Prediction
Surface accessibility and fragment flexibility are important features for predicting antigenic epitopes. In addition, the existence of regions with high hydrophobicity also provides strong evidence for epitope identification. Antigenic index directly showed the epitope forming capacity of the Der f 25 sequence. Based on these sequence properties, the final predicting regions of DNAStar were 11–19, 28–35, 68–77, 95–111, 130–139, 173–187, 193–197, and 211–225. Also, the predicted results of the BPAP system were 20–26, 32–52, 54–70, 86–93, 138–168, 175–209, and 218–242 and BepiPred 1.0 server were 11–18, 30–34, 71–78, 99–107, 132–138, 168–183, 194–199, and 210–224. Furthermore, the final potential B cell epitopes of Der f 25 were selected on the basis of the results of these three tools. The ultimate results of the three immunoinformatics tools finally predicted eight peptides (11–18, 30–35, 71–77, 99–107, 132–138, 173–187, 193–197, and 211–224) (Table 2) and these peptides were also shown in Figures 2 and 4.
Table 2.
Predicted B and T cell epitopes of Der f 25 allergen.
| Peptide | Type of epitope | Position | Sequence |
|---|---|---|---|
| P1 | B | 11–18 | W KMN G N KT |
| P2 | B | 30–35 | G PL DSN |
| P3 | B | 71–77 | G AFTG E I |
| P4 | B | 99–107 | NV F G ESDQL |
| P5 | B | 132–138 | E R E A G KT |
| P6 | B | 173–18 | KTASPQQAQE VHQK L |
| P7 | B | 193–197 | E NVSP |
| P8 | B | 211–224 | VTANNA K E LASQA D |
| P9 | T | 26–34 | FL K N G PL DS |
| P10 | T | 38–54 | VV V G VP AI YLMLCK NIL |
| P11 | T | 66–74 | Y K V D K G AFTG E I |
| P12 | T | 142–151 | VF RQTQVISK |
| P13 | T | 239–247 | FVQIVNA RQ |
Charged residues are shown in a bold font; hydrophobic residues are depicted in italic.
Figure 4.
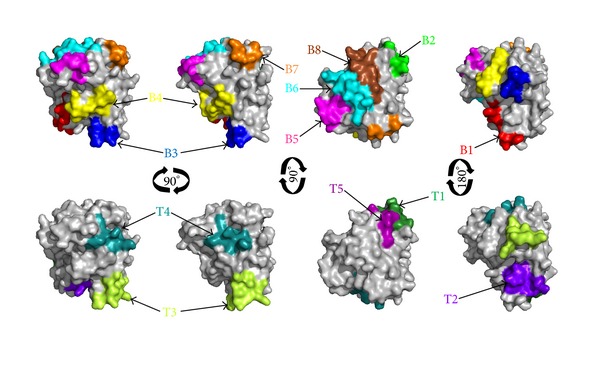
B cell and T cell epitopes superimposition on the surface of Der f 25 allergen structure.
3.6. T Cell Epitopes Prediction
NetMHCIIpan-3.0 and NetMHCII-2.2 were used to identify the T cell epitope of Der f 25. For HLA-DR-based T cell epitope prediction, the final predicting regions of HLA-DR 101, HLA-DR 301, HLA-DR 401, and HLA-DR 501 were shown in Table 1 and the ultimate results of HLA-DR-based T cell epitope prediction finally predicted five peptides (26–34, 38–54, 66–74, 142–151, and 239–247). For HLA-DQ alleles, the final results of HLA-DQA10101-DQB10501, HLA-DQA10501-DQB10201, HLA-DQA10501-DQB10301, and HLA-DQA10102-DQB10602 were also shown in Table 3 and the ultimate results of these four methods finally predicted one peptide, 39–48. As a result, Der f 25 was predicted to have five T cell epitope sequences including 26–34, 38–54, 66–74, 142–151, and 239–247 (Table 2) as shown in Figures 2 and 4.
Table 3.
The results of B and T cell epitopes predictions.
| Tools | Location of the prediction results | |
|---|---|---|
| B cell epitope prediction | DNAStar protean | 11–19, 28–35, 68–77, 95–111, 130–139, 173–187, 193–197, 211–225. |
| BPAP | 20–26, 32–52, 54–70, 86–93, 138–168, 175–209, 218–242. | |
| BepiPred | 11–18, 30–34, 71–78, 99–107, 132–138, 168–183, 194–199, 210–224. | |
|
| ||
| T cell epitope prediction (HLA-DR) | DRB1*01:01 | 5–13, 11–19, 10–18, 13–21, 24–32, 26–34, 39–47, 46–54, 50–58, 53–61, 57–65, 58–66, 60–68, 66–74, 73–81, 82–90, 89–97, 90–98, 104–112, 107–115, 114–122, 119–127, 122–130, 143–151, 142–150, 156–164, 157–165, 161–169, 163–171, 167–175, 187–195, 190–198, 191–199, 195–203, 197–205, 203–211, 205–213, 227–235, 228–236, 232–240, 235–243, 239–247. |
| DRB3*01:01 | 53–61, 66–74, 81–89, 191–199. | |
| DRB4*01:01 | 26–34, 38–46, 46–54, 48–56, 50–58, 107–115, 142–150, 158–166, 160–168, 238–246, 239–247. | |
| DRB5*01:01 | 5–13, 11–19, 13–21, 20–28, 24–32, 26–34, 39–47, 46–54, 59–67, 66–74, 73–81, 89–97, 90–98, 143–151, 146–154, 150–158, 163–171, 165–173, 166–174, 203–211, 228–236, 238–246, 239–247. | |
|
| ||
| T cell epitope prediction (HLA-DQ) | HLA-DQA10101-DQB10501 | 153–161, 154–162, 159–167, 160–168. |
| HLA-DQA10102-DQB10602 | 33–41, 40–48, 42–50, 57–65, 77–85, 117–125, 154–162, 192–200, 206–214, 213–221, 230–238, 237–245. | |
| HLA-DQA10501-DQB10201 | 19–27, 39–47, 37–45, 82–90, 100–108, 112–120, 122–130, 126–134, 158–166, 195–203, 220–228. | |
| HLA-DQA10501-DQB10301 | 6–14, 34–42, 38–46, 39–47, 58–66, 66–74, 69–77, 72–80, 74–82, 77–85, 82–90, 85–93, 107–115, 117–125, 121–129, 133–141, 161–169, 166–174, 167–175, 169–177, 172–180, 192–200, 195–203, 203–211, 205–213, 206–214, 207–215, 213–221, 215–233, 228–236, 230–238, 232–240, 237–245. | |
4. Discussion
The prevalence of human atopic disorders including allergic rhinitis, asthma, and atopic dermatitis is increasing during the past several decades. House dust mite allergies constitute more than 50% of allergic patients and often have severe forms of respiratory allergy, such as asthma [1]. Characterization of mite allergens will be beneficial in the diagnosis and treatment of mite-induced atopic illnesses.
Among the identified allergens, Der f 25 is a new protein with a molecular weight of 34 kDa, representing the major allergen in D. farinae [4]. The objective of this study was to predict the B and T cell epitopes of Der f 25. Firstly, in order to better understand the structure and function of Der f 25, we analyzed the basic sequence properties and studied the 2D and 3D structures of Der f 25. Phylogenetic analysis result showed that Der f 25 protein clustered into the TIPs group; domain analysis also proved a strong evidence illustrating that Der f 25 belongs to the TPI family. In 2D structure analysis, it is clearly shown that Der f 25 composed of ten α-helices and seven β-sheets. The 3D structure of Der f 25 was performed by homology modelling which was widely used in many areas of structure-based analysis and study [39]. PDB server was used to search templates of Der f 25 and found that the structure of Tenebrio molitor TPI (2I9E) was the best template with the highest identity. Also, small dissimilates in RMSD were observed between Der f 25 and 2I9E template. The built model structure is feasible by the Ramachandran plot analysis, ERRAT program, VERIFY 3D program ProSa analysis, Q values, and RMSD. All of these validations showed that the homology model was available. The similar methods for the structures modelling were also successfully conducted in other allergens of Api SI and Api SII [40], Der f 5 [41], Ole e 2 [42] Ole e 11 [39], and Ole e 12 [43]. Based on the conservational analysis of the primary sequence of Der f 25, it is found that almost forty high variability residues sit in different superficial areas of protein surface. The active sites His in 94th position and Glu in 164th position as well as the substrate binding sites Asn in 10th position and Lys in 12th position are the completely conserved sites.
In silico prediction has already become a familiar and useful tool for selecting epitopes from immunological relevant proteins, which can save the expense of synthetic peptides and the working time [44]. Recently, many algorithms have been developed to predict B cell epitopes on a protein sequence based on propensity values of amino acid properties of hydrophilicity, antigenicity, segmental mobility, flexibility, and accessibility [45]. In the present study, we used three algorithms (DNAStar protean system, BPAP, and BepiPred 1.0 server) to predict the B cell epitopes. The previous study showed that the use of bioinformatics approach to predict B cell epitopes correlated well with the experimental approach [46]. Earlier study showed that allergen epitopes were comprised of a high proportion of hydrophobic amino acids [47]. The amino acids Ala, Ser, Asn, Gly, and particularly Lys play a key role in the IgE binding allergenic epitopes [48]. In our results, nearly half of the total residues lying in B cell epitopes were hydrophobic (Table 2). Moreover, each predicted B cell epitope has one or more special five amino acids and the common residues in all B cell epitopes were Gly and Lys (Table 2). Electrostatic interactions are known to determine the orientation of the molecules and stabilize antigen-antibody complexes [49]. Surface electrostatic potential analysis result showed that a great part of Der f 25 side exhibits large positive values (blue regions). Most parts of B cell epitopes are distributed in the blue regions and showed a strong negative potential. As a result, eight peptides (11–18, 30–35, 71–77, 99–107, 132–138, 173–187, 193–197, and 211–224) were predicted as the B cell epitopes. However, these B cell epitopes need further investigation in clinical samples.
In the last several years, some methods have substantially improved their accuracy to predict T cell epitopes such as NetMHCpan-3.0 and NetMHCII-2.2. NetMHCpan-3.0 is based on artificial neural networks and is trained on 52,062 quantitative peptide binding data covering all HLA as well as two mouse molecules. In this study, it was used to predict the HLA-DR-based T cell epitopes. For HLA-DQ-based T cell epitopes prediction, NetMHCII-2.2 was used. Although limited binding-affinity data are available for HLA-DQ, it was recently reported to provide the best performance in predicting this locus [50]. As a result, NetMHCIIpan-3.0 and NetMHCII-2.2 were used to predict the T cell epitopes in Der f 25 allergens and predicted 7 potential T cell epitope sequences including 26–34, 38–54, 66–74, 142–151, and 239–247. Despite the high accuracy of these predictions, this approach has not yet been applied to peptide-based vaccine development for allergic diseases.
Allergen-specific immunotherapy (SIT) represents the only allergen-specific and disease-modifying approach with long lasting effects for the treatment of allergic patients [51]. However, SIT can induce side effects, ranging from mild and local to severe and life-threatening symptoms, such as anaphylactic shock [52]. Severe side effects are frequently observed in patients with house dust mite (HDM) allergy [53]. The continuous exposure to HDM allergens further complicates the treatment of patients with HDM allergy. Additionally, the quality of natural HDM allergen extracts and vaccines based on these extracts is often poor. Attenuated allergenic molecules, that is, hypoallergens or synthetic peptide fragments, have been used as high dose and safer alternatives to conventional extract-based SIT [54]. Vaccination with a combination of small peptides that together extend across the entire native allergenic protein theoretically could preserve T cell activation while avoiding IgE-based immune responses. IgE recognizes conformational epitopes of larger peptides (B cell epitopes) and proteins while T cell receptors recognize small linear peptides of 8 to 10 amino acids (T cell epitope). By immunizing with small peptides, T cell activation could occur while IgE binding would be lost [55, 56]. Then, we predicted B and T cell epitopes of Der f 25 allergen, the major allergen in HDM, using in silico method which can be used to benefit allergen immunotherapies and reduce the frequency of allergic reactions. However, their accuracies need to be confirmed in the further experiments.
5. Conclusion
In this study, we have a better understanding of the 2D and 3D structures of Der f 25 and have predicted eight B cell epitopes (11–18, 30–35, 71–77, 99–107, 132–138, 173–187, 193–197, and 211–224) and five T cell epitope including 26–34, 38–54, 66–74, 142–151, and 239–247 of this TPI. All these results can be used to benefit allergen immunotherapies and reduce the frequency of mite allergic reactions.
Acknowledgments
This project was sponsored by National Natural Science Foundation of China (31340073, 81001329, 81273274, and 30972822), National Major Scientific and Technological Special Project for “Significant New Drugs Development” (2011ZX09302-003-02), Jiangsu Province Major Scientific and Technological Special Project (BM2011017), and A Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Authors' Contribution
Xiaohong Li, Hai-Wei Yang, and Hao Chen contributed to this paper equally as first author.
References
- 1.Eifan AO, Calderon MA, Durham SR. Allergen immunotherapy for house dust mite: clinical efficacy and immunological mechanisms in allergic rhinitis and asthma. Expert Opinion on Biological Therapy. 2013;13(11):1543–1556. doi: 10.1517/14712598.2013.844226. [DOI] [PubMed] [Google Scholar]
- 2.Lodge CJ, Lowe AJ, Gurrin LC, et al. House dust mite sensitization in toddlers predicts current wheeze at age 12 years. Journal of Allergy and Clinical Immunology. 2011;128(4):782–788. doi: 10.1016/j.jaci.2011.06.038. [DOI] [PubMed] [Google Scholar]
- 3.An S, Shen C, Liu X, et al. Alpha-actinin is a new type of house dust mite allergen. PLoS ONE. 2013;8(12) doi: 10.1371/journal.pone.0081377.e81377 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.An S, Chen L, Long C, et al. Dermatophagoides farinae allergens diversity identification by proteomics. Molecular & Cellular Proteomics. 2013;12(7):1818–1828. doi: 10.1074/mcp.M112.027136. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Wierenga RK, Kapetaniou EG, Venkatesan R. Triosephosphate isomerase: a highly evolved biocatalyst. Cellular and Molecular Life Sciences. 2010;67(23):3961–3982. doi: 10.1007/s00018-010-0473-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Bauermeister K, Wangorsch A, Garoffo LP, et al. Generation of a comprehensive panel of crustacean allergens from the North Sea Shrimp Crangon crangon. Molecular Immunology. 2011;48(15-16):1983–1992. doi: 10.1016/j.molimm.2011.06.216. [DOI] [PubMed] [Google Scholar]
- 7.Chen Y-H, Lee M-F, Lan J-L, et al. Hypersensitivity to Forcipomyia taiwana (biting midge): clinical analysis and identification of major For t 1, For t 2 and For t 3 allergens. Allergy. 2005;60(12):1518–1523. doi: 10.1111/j.1398-9995.2005.00918.x. [DOI] [PubMed] [Google Scholar]
- 8.Hoppe S, Steinhart H, Paschke A. Identification of a 28 kDa lychee allergen as a triose-phosphate isomerase. Food and Agricultural Immunology. 2006;17(1):9–19. [Google Scholar]
- 9.Nakamura R, Satoh R, Nakajima Y, et al. Comparative study of GH-transgenic and non-transgenic amago salmon (Oncorhynchus masou ishikawae) allergenicity and proteomic analysis of amago salmon allergens. Regulatory Toxicology and Pharmacology. 2009;55(3):300–308. doi: 10.1016/j.yrtph.2009.08.002. [DOI] [PubMed] [Google Scholar]
- 10.Pastor C, Cuesta-Herranz J, Cases B, et al. Identification of major allergens in watermelon. International Archives of Allergy and Immunology. 2009;149(4):291–298. doi: 10.1159/000205574. [DOI] [PubMed] [Google Scholar]
- 11.Sudha VT, Arora N, Gaur SN, Pasha S, Singh BP. Identification of a serine protease as a major allergen (Per a 10) of Periplaneta Americana. Allergy. 2008;63(6):768–776. doi: 10.1111/j.1398-9995.2007.01602.x. [DOI] [PubMed] [Google Scholar]
- 12.Sander I, Flagge A, Merget R, Halder TM, Meyer HE, Baur X. Identification of wheat flour allergens by means of 2-dimensional immunoblotting. Journal of Allergy and Clinical Immunology. 2001;107(5):907–913. doi: 10.1067/mai.2001.113761. [DOI] [PubMed] [Google Scholar]
- 13.Eifan AO, Calderon MA, Durham SR. Allergen immunotherapy for house dust mite: clinical efficacy and immunological mechanisms in allergic rhinitis and asthma. Expert Opinion on Biological Therapy. 2013;13(11):1543–1556. doi: 10.1517/14712598.2013.844226. [DOI] [PubMed] [Google Scholar]
- 14.Frati F, Scurati S, Puccinelli P, et al. Development of an allergen extract for sublingual immunotherapy—evaluation of staloral. Expert Opinion on Biological Therapy. 2009;9(9):1207–1215. doi: 10.1517/14712590903146869. [DOI] [PubMed] [Google Scholar]
- 15.Thomas WR. The advent of recombinant allergens and allergen cloning. Journal of Allergy and Clinical Immunology. 2011;127(4):855–859. doi: 10.1016/j.jaci.2010.12.1084. [DOI] [PubMed] [Google Scholar]
- 16.Cui Y. Immunoglobulin e-binding epitopes of mite allergens: from characterization to immunotherapy. Clinical Reviews in Allergy & Immunology. 2013:1–10. doi: 10.1007/s12016-013-8396-5. [DOI] [PubMed] [Google Scholar]
- 17.Thompson JD, Higgins DG, Gibson TJ. CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. Nucleic Acids Research. 1994;22(22):4673–4680. doi: 10.1093/nar/22.22.4673. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kumar S, Nei M, Dudley J, Tamura K. MEGA: a biologist-centric software for evolutionary analysis of DNA and protein sequences. Briefings in Bioinformatics. 2008;9(4):299–306. doi: 10.1093/bib/bbn017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Bateman A, Coin L, Durbin R, et al. The Pfam protein families database. Nucleic Acids Research. 2004;32:D138–D141. doi: 10.1093/nar/gkh121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Sigrist CJA, de Castro E, Cerutti L, et al. New and continuing developments at PROSITE. Nucleic Acids Research. 2013;41(1):D344–D347. doi: 10.1093/nar/gks1067. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Gough J, Karplus K, Hughey R, Chothia C. Assignment of homology to genome sequences using a library of hidden Markov models that represent all proteins of known structure. Journal of Molecular Biology. 2001;313(4):903–919. doi: 10.1006/jmbi.2001.5080. [DOI] [PubMed] [Google Scholar]
- 22.Blom N, Gammeltoft S, Brunak S. Sequence and structure-based prediction of eukaryotic protein phosphorylation sites. Journal of Molecular Biology. 1999;294(5):1351–1362. doi: 10.1006/jmbi.1999.3310. [DOI] [PubMed] [Google Scholar]
- 23.Jones DT. Protein secondary structure prediction based on position-specific scoring matrices. Journal of Molecular Biology. 1999;292(2):195–202. doi: 10.1006/jmbi.1999.3091. [DOI] [PubMed] [Google Scholar]
- 24.Petersen B, Petersen TN, Andersen P, Nielsen M, Lundegaard C. A generic method for assignment of reliability scores applied to solvent accessibility predictions. BMC Structural Biology. 2009;9(1, article 51) doi: 10.1186/1472-6807-9-51. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Arnold K, Bordoli L, Kopp J, Schwede T. The SWISS-MODEL workspace: a web-based environment for protein structure homology modelling. Bioinformatics. 2006;22(2):195–201. doi: 10.1093/bioinformatics/bti770. [DOI] [PubMed] [Google Scholar]
- 26.Kiefer F, Arnold K, Künzli M, Bordoli L, Schwede T. The SWISS-MODEL repository and associated resources. Nucleic Acids Research. 2009;37(1):D387–D392. doi: 10.1093/nar/gkn750. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Laskowski RA, MacArthur MW, Moss DS, et al. PROCHECK: a program to check the stereochemical quality of protein structures. Journal of Applied Crystallography. 1993;26(2):283–291. [Google Scholar]
- 28.Colovos C, Yeates TO. Verification of protein structures: patterns of nonbonded atomic interactions. Protein Science. 1993;2(9):1511–1519. doi: 10.1002/pro.5560020916. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Bowie JU, Luthy R, Eisenberg D. A method to identify protein sequences that fold into a known three-dimensional structure. Science. 1991;253(5016):164–170. doi: 10.1126/science.1853201. [DOI] [PubMed] [Google Scholar]
- 30.Benkert P, Tosatto SCE, Schomburg D. QMEAN: a comprehensive scoring function for model quality assessment. Proteins: Structure, Function and Genetics. 2008;71(1):261–277. doi: 10.1002/prot.21715. [DOI] [PubMed] [Google Scholar]
- 31.Wiederstein M, Sippl MJ. ProSA-web: interactive web service for the recognition of errors in three-dimensional structures of proteins. Nucleic acids research. 2007;35(supplement 2):W407–W410. doi: 10.1093/nar/gkm290. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Melo F, Devos D, Depiereux E, et al. ANOLEA: a www server to assess protein structures. Proceedings of the International Conference on Intelligent Systems for Molecular Biology (ISMB '97); 1997; pp. 187–190. [PubMed] [Google Scholar]
- 33.Ashkenazy H, Erez E, Martz E, Pupko T, Ben-Tal N. ConSurf 2010: calculating evolutionary conservation in sequence and structure of proteins and nucleic acids. Nucleic Acids Research. 2010;38(2):W529–W533. doi: 10.1093/nar/gkq399. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Dolinsky TJ, Nielsen JE, McCammon JA, Baker NA. PDB2PQR: an automated pipeline for the setup of Poisson-Boltzmann electrostatics calculations. Nucleic Acids Research. 2004;32(supplement 2):W665–W667. doi: 10.1093/nar/gkh381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Yang X, Yu X. An introduction to epitope prediction methods and software. Reviews in Medical Virology. 2009;19(2):77–96. doi: 10.1002/rmv.602. [DOI] [PubMed] [Google Scholar]
- 36.Zheng L-N, Lin H, Pawar R, Li Z-X, Li M-H. Mapping IgE binding epitopes of major shrimp (Penaeus monodon) allergen with immunoinformatics tools. Food and Chemical Toxicology. 2011;49(11):2954–2960. doi: 10.1016/j.fct.2011.07.043. [DOI] [PubMed] [Google Scholar]
- 37.Karosiene E, Rasmussen M, Blicher T, et al. NetMHCIIpan-3.0, a common pan-specific MHC class II prediction method including all three human MHC class II isotypes, HLA-DR, HLA-DP and HLA-DQ. Immunogenetics. 2013;65(10):711–724. doi: 10.1007/s00251-013-0720-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Nielsen M, Lund O. NN-align. An artificial neural network-based alignment algorithm for MHC class II peptide binding prediction. BMC Bioinformatics. 2009;10, article 296 doi: 10.1186/1471-2105-10-296. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Jimenez-Lopez JC, Kotchoni SO, Rodríguez-García MI, et al. Structure and functional features of olive pollen pectin methylesterase using homology modeling and molecular docking methods. Journal of Molecular Modeling. 2012;18(12):4965–4984. doi: 10.1007/s00894-012-1492-2. [DOI] [PubMed] [Google Scholar]
- 40.Georgieva D, Greunke K, Arni RK, Betzel C. Three-dimensional modelling of honeybee venom allergenic proteases: relation to allergenicity. Zeitschrift fur Naturforschung C: Journal of Biosciences. 2011;66(5-6):305–312. doi: 10.1515/znc-2011-5-615. [DOI] [PubMed] [Google Scholar]
- 41.Khemili S, Kwasigroch JM, Hamadouche T, Gilis D. Modelling and bioinformatics analysis of the dimeric structure of house dust mite allergens from families 5 and 21: der f 5 could dimerize as der p 5. Journal of Biomolecular Structure and Dynamics. 2012;29(4):663–675. doi: 10.1080/073911012010525018. [DOI] [PubMed] [Google Scholar]
- 42.Jimenez-Lopez JC, Rodriguez-Garcia MI, Alche D. Olive tree genetic background is a major cause of profilin (Ole e 2 allergen) polymorphism and functional and allergenic variability. Communications in Agricultural and Applied Biological Sciences. 2013;78(1):213–219. [PubMed] [Google Scholar]
- 43.Jimenez-Lopez JC, Kotchoni SO, Hernandez-Soriano MC, et al. Structural functionality, catalytic mechanism modeling and molecular allergenicity of phenylcoumaran benzylic ether reductase, an olive pollen (Ole e 12) allergen. Journal of Computer-Aided Molecular Design. 2013;27(10):873–895. doi: 10.1007/s10822-013-9686-y. [DOI] [PubMed] [Google Scholar]
- 44.Li G-F, Wang Y, Zhang Z-S, et al. Identification of immunodominant Th1-type T cell epitopes from Schistosoma japonicum 28 kDa glutathione-S-transferase, a vaccine candidate. Acta Biochimica et Biophysica Sinica. 2005;37(11):751–758. doi: 10.1111/j.1745-7270.2005.00111.x. [DOI] [PubMed] [Google Scholar]
- 45.Pomés A. Relevant B cell epitopes in allergic disease. International Archives of Allergy and Immunology. 2010;152(1):1–11. doi: 10.1159/000260078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Nair S, Kukreja N, Singh BP, Arora N. Identification of B cell epitopes of alcohol dehydrogenase allergen of Curvularia lunata. PLoS ONE. 2011;6(5) doi: 10.1371/journal.pone.0020020.e20020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Wolff N, Yannai S, Karin N, et al. Identification and characterization of linear B-cell epitopes of β-globulin, a major allergen of sesame seeds. Journal of Allergy and Clinical Immunology. 2004;114(5):1151–1158. doi: 10.1016/j.jaci.2004.07.038. [DOI] [PubMed] [Google Scholar]
- 48.Oezguen N, Zhou B, Negi SS, et al. Comprehensive 3D-modeling of allergenic proteins and amino acid composition of potential conformational IgE epitopes. Molecular Immunology. 2008;45(14):3740–3747. doi: 10.1016/j.molimm.2008.05.026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Sinha N, Mohan S, Lipschultz CA, Smith-Gill SJ. Differences in electrostatic properties at antibody-antigen binding sites: implications for specificity and cross-reactivity. Biophysical Journal. 2002;83(6):2946–2968. doi: 10.1016/S0006-3495(02)75302-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Wang P, Sidney J, Kim Y, et al. Peptide binding predictions for HLA DR, DP and DQ molecules. BMC Bioinformatics. 2010;11(1, article 568) doi: 10.1186/1471-2105-11-568. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Compalati E, Braido F, Canonica GW. An update on allergen immunotherapy and asthma. Current Opinion in Pulmonary Medicine. 2014;20(1):109–117. doi: 10.1097/MCP.0000000000000016. [DOI] [PubMed] [Google Scholar]
- 52.Burks A, Calderon MA, Casale T, et al. Update on allergy immunotherapy: American Academy of Allergy, Asthma & Immunology/European Academy of Allergy and Clinical Immunology/PRACTALL consensus report. Journal of Allergy and Clinical Immunology. 2013;13(5):1288–1296. doi: 10.1016/j.jaci.2013.01.049. [DOI] [PubMed] [Google Scholar]
- 53.Moed H, Gerth van Wijk R, Hendriks RW, et al. Evaluation of clinical and immunological responses: a 2-year follow-up study in children with allergic rhinitis due to house dust mite. Mediators of Inflammation. 2013;2013:8 pages. doi: 10.1155/2013/345217.345217 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Passalacqua G, Canonica GW. Specific immunotherapy in asthma: efficacy and safety. Clinical and Experimental Allergy. 2011;41(9):1247–1255. doi: 10.1111/j.1365-2222.2010.03688.x. [DOI] [PubMed] [Google Scholar]
- 55.Pascal M, Konstantinou GN, Masilamani M, et al. In silico prediction of Ara h 2 T cell epitopes in peanut-allergic children. Clinical & Experimental Allergy. 2013;43(1):116–127. doi: 10.1111/cea.12014. [DOI] [PubMed] [Google Scholar]
- 56.Nilsson OB, Adedoyin J, Rhyner C, et al. In vitro evolution of allergy vaccine candidates, with maintained structure, but reduced B cell and T cell activation capacity. PLoS ONE. 2011;6(9) doi: 10.1371/journal.pone.0024558.e24558 [DOI] [PMC free article] [PubMed] [Google Scholar]