

Abstract
Implicit learning about where a visual search target is likely to appear often speeds up search. However, whether implicit learning guides spatial attention or affects post-search decisional processes remains controversial. Using eye tracking, this study provides compelling evidence that implicit learning guides attention. In a training phase, participants often found the target in a high-frequency, “rich” quadrant of the display. When subsequently tested in a phase during which the target was randomly located, participants were twice as likely to direct the first saccadic eye movement to the previously rich quadrant than to any of the sparse quadrants. The attentional bias persisted for nearly 200 trials after training and was unabated by explicit instructions to distribute attention evenly. We propose that implicit learning guides spatial attention but in a qualitatively different manner than goal-driven attention.
Keywords: Spatial attention, implicit learning, probability cueing, saccadic eye movement
Introduction
A major driver of spatial attention is one’s prior knowledge about where important events may appear. For example, when picking up a friend at the airport, we are likely to prioritize the anticipated arrival gate over other locations. Such knowledge-guided attention is a critical component of all influential models of attention and is captured by a single term – top-down attention (Desimone & Duncan, 1995; Egeth & Yantis, 1997; Fecteau & Munoz, 2006; Treisman, 2009; Wolfe, 2007). However, decades of memory research shows that human memory, and hence the resulting knowledge, may be divided into explicit (or, declarative) and implicit (or, nondeclarative) memory (Schacter, 1996; Squire, 2004). Likewise, recent work on spatial attention has revealed differences between explicit, goal-driven attention and experience-driven attention (Anderson, Laurent, & Yantis, 2011; Awh, Belopolsky, & Theeuwes, 2012; Jiang, Swallow, Rosenbaum, & Herzig, 2013; Jiang, Swallow, & Rosenbaum, 2013; Rosenbaum & Jiang, 2013). To date, the vast majority of attention research has focused on goal-driven attention, yet its characteristics may not generalize to attention driven by implicit learning. Using eye tracking and behavioral measures, this study examines implicitly learned attention and its interaction with explicit knowledge.
Several previous studies suggest a close relationship between implicit learning and spatial attention. In an early study, Lewicki, Czyzewska, and Hoffman (1987) demonstrated that the locations of targets across trials can be learned to facilitate search. Other data show that people can implicitly learn to associate the semantic features of a cue (e.g., a word that refers to a living or nonliving category) with a likely target location (Lambert & Sumich, 1996). Lambert and colleagues proposed that spatial orienting could be controlled by derived (i.e., learned) cues as well as by endogenous and exogenous cues (Lambert & Sumich, 1996; Lambert, Naikar, McLachlan, & Aitken, 1999; Lambert, Norris, Naikar, & Aitken, 2000). However, the derived cueing effect was numerically small (typically on the order of 5-15 ms) and showed complex dependencies on extraneous factors (e.g., whether the cue and target occupied the same locations, whether the target was on the nasal or temporal side). More importantly, the RT facilitation in these studies could have reflected enhanced perceptual sensitivity, attentional guidance, increased readiness to respond, or all of these factors.
Similar ambiguities apply to another experimental paradigm used to study spatial attention: the serial reaction time task (SRT; Nissen & Bullemer, 1987). In this paradigm a single stimulus was presented on the screen and participants pressed the spatially aligned key to report its position. The target’s location was either randomly chosen or followed a pre-specified sequence. Many studies showed that RT was faster when the sequence was predictive of the target’s location than when it was random (for a review, see Stadler & Frensch, 1998). These findings may suggest that implicit learning contributed to spatial sequence learning. However, learning in the SRT task often included multiple components, including spatial sequence learning, motor sequence learning, and their combination (Mayr, 1996; Willingham, Nissen, & Bullemer, 1989). In addition, because the display typically contained just a single stimulus, the SRT task involved primarily temporal sequence learning rather than the prioritization of spatial attention.
The most direct test of how implicit learning affects spatial attention came from studies that employed visual search, a standard experimental paradigm for investigating spatial attention (Wolfe, 1998). A critical question about implicit learning in this paradigm is whether it guides spatial attention or whether it speeds up decisional processes. This question was initially raised in studies of contextual cueing and remains unresolved. In studies on contextual cueing, participants perform visual search on displays that occasionally repeat. Although they are unaware of the display repetition, participants are faster at finding the target on repeated displays than unrepeated ones (Chun & Jiang, 1998). The attentional guidance view conceptualizes contextual cueing as a form of attentional guidance (e.g., as a “context map” that affects attentional priority; Chun, 2000). The attentional guidance account is contrasted with a post-selection decision account, which states that implicit learning does not affect the deployment of spatial attention before the target is found. Rather, learning only influences processes that occur after the target has been found, at the stage of response mapping and execution (Kunar, Flusberg, Horowitz, & Wolfe, 2007). Empirical evidence for the two views has been mixed. For example, a reduction in visual search slope, a hallmark of attentional guidance, is associated with contextual cueing in some studies (Chun & Jiang, 1998) but not others (Kunar et al., 2007). Eye movement data are also difficult to interpret, as they show only a small (though significant) preference toward moving the eyes to the target’s location first on repeated displays (Peterson & Kramer, 2001; Zhao et al., 2012). Inconsistencies across studies may be partly attributed to the complexity of the experimental paradigm. For contextual cueing to direct attention toward the target’s location the repeated context must first be matched to an implicit memory of that display. The dependence of contextual cueing on a matching process could make it difficult to isolate its effects on attentional guidance.
A more straightforward paradigm to examine implicit learning in visual search is “probability cueing.” In this paradigm, participants search for a target among distractors. Unbeknownst to them, the target is more likely to appear in some locations than others. Although participants report no knowledge of the target’s location probability, visual search is faster when the target appears in the high-frequency, “rich” locations than in other locations (Druker & Anderson, 2010; Geng & Behrmann, 2002; Jiang, Swallow, Rosenbaum, et al., 2013; Miller, 1988; Umemoto, Scolari, Vogel, & Awh, 2010). Because none of the displays are repeated, probability cueing does not depend on identifying repeated contexts. However, evidence for the attentional guidance view is also mixed in this paradigm. In some studies, probability cueing reduced visual search slope, fulfilling a hallmark of attentional guidance (Geng & Behrmann, 2005; Jiang, Swallow, & Rosenbaum, 2013). In other studies, probability cueing was found on displays with a single item (Druker & Anderson, 2010). According to Kunar et al. (2007), attentional guidance is not needed when the set size is one. The presence of probability cueing under this condition indicates that it may reflect late, response and decision-related processes. Eye tracking data are equally ambiguous. One study constrained the target’s location such that it never repeated on consecutive trials. Participants in that study were no more successful at landing their first saccade on a target in the rich region than one in the sparse region (Walthew & Gilchrist, 2006). However, another study using a similar design reached the opposite conclusion (Jones & Kaschak, 2012).
The question of whether implicit learning can guide spatial attention is theoretically important for understanding the nature of spatial attention, yet it remains empirically unsettled. The goal of the current study is to test the attentional guidance account. In turn, the study has important theoretical implications for understanding the relationship between implicit learning and spatial attention, and for understanding different forms of attentional guidance.
This study uses the first saccadic eye movement as an index of spatial attention. Unlike RT which measures all processes that happen in a trial, the first saccade in a search trial occurs long before target detection and is a relatively pure index of attentional guidance (Eckstein, Drescher, & Shimozaki, 2006; Jones & Kaschak, 2012; Peterson & Kramer, 2001). If implicit learning induces an attentional bias toward high-frequency, target-rich regions of space, then the first saccade should be more likely directed toward those locations. Two previous studies examining first saccades found inconsistent results (Jones & Kaschak, 2012; Walthew & Gilchrist, 2006). However, several aspects of those studies weaken their conclusions. For example, it is possible that participants became aware of the probability manipulation in either study; neither one assessed explicit awareness. This is particularly problematic because each study used a small number of fixed locations and a large difference in the likelihood that a target would appear on one side of the screen rather than the other (66% rather than 33%). In addition, both studies constrained the target’s location to prevent it from repeating on consecutive trials. This manipulation introduced statistics that could have interfered with implicitly learning where the target was likely to appear (for an analysis, see Druker & Anderson, 2010).
To address these concerns, the current study used a subtler manipulation of spatial probability. The target could appear in any one of 100 locations (25 per quadrant). The rich quadrant had a 50% probability of containing the target, whereas any of the sparse quadrants had a 16.7% probability of containing the target. This ratio (3:1:1:1) produced chance-level explicit recognition in a previous study (Jiang, Swallow, Rosenbaum, & Herzig, 2013). In addition, to eliminate nonrandom statistical regularities, we allowed the target’s location to repeat on consecutive trials. The only constraint was that the target appeared in the rich quadrant 50% of the time. As noted by other researchers (Walthew & Gilchrist, 2006), in this design the target is more likely to repeat its location on consecutive trials in the rich quadrant than the sparse quadrants, confounding short-term location repetition priming with long-term statistical learning. However, owing to the use of a large number of possible target locations (100 rather than 8), location repetition rarely happened in our study. More importantly, to remove any confound between short-term priming and long-term learning, we assessed attentional guidance in a testing phase. In this phase, the target was equally likely to appear in any quadrant (25% probability). Therefore transient priming was equivalent across all quadrants. If implicit learning had produced a persistent spatial bias toward the rich quadrant, then the first saccades should continue to favor this quadrant even in the testing phase (Figure 1). Additional experiments were conducted to test the role of explicit instructions about the target’s location probability. These experiments provided additional insight into whether implicitly guided attention is distinguishable from guidance based on explicit knowledge.
Figure 1.
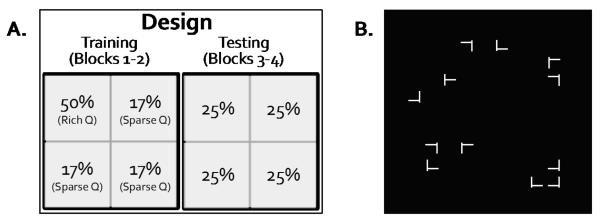
An illustration of the design and stimuli used in this study. A. The target was more probable in a high-frequency, “rich” quadrant in the training phase but equally probable in all quadrants in the testing phase. B. A sample visual search display.
Experiment 1. Incidental location probability learning: RT and first saccades
Participants conducted visual search for a T target among L distractors. In the training phase the T was more often located in the rich quadrant than in any of the sparse quadrants across multiple trials. In the testing phase, the T was equally likely to appear in any quadrant. We measured visual search RT and eye movements. If implicit learning of the target’s location probability guides attention, then participants should be more likely to direct their first saccades toward the rich quadrant in the training phase, and this preference should persist in the testing phase. But if implicit learning affects only post-search decisional processes, then an RT gain should not be accompanied by more frequent first saccades toward the rich quadrant.
Method
Participants
A pre-specified sample size of 12 was used in all experiments. The sample size was selected because it provided an estimated power greater than 0.90 based on our previous behavioral work (Cohen’s d = 1.6 in Jiang, Swallow, Rosenbaum, et al., 2013’s Experiment 3). All participants were naïve to the purpose of the study and completed one experiment. They were students from the University of Minnesota between 18 and 35 years old. Participants signed an informed consent prior to the study and were compensated for their time. There were 8 females and 4 males in Experiment 1 with a mean age of 20.1 years.
Equipment
Participants were tested individually in a normally lit room. Viewing distance was fixed at 86 cm with a chinrest. The experiment was coded with Psychtoolbox (Brainard, 1997; Pelli, 1997) implemented in MATLAB (www.mathworks.com) on a Windows XP computer. The stimuli were displayed on a 17” CRT screen with a vertical refresh rate of 75 Hz and a screen resolution of 1024 × 768 pixels. Monocular eye tracking was obtained at 120 Hz using an ISCAN-ETL 300 that tracked the left eye position based on pupil and corneal reflectance.
Materials
Each visual search display contained 12 items presented among randomly selected locations in an invisible 10 × 10 grid (13.7° × 13.7°), with the constraint that there were 3 items per quadrant. The search items were white and the background was black (Figure 1). The 12 items included one T stimulus and 11 L stimuli. The T (size: 0.91° × 0.91°) was randomly rotated to the left or to the right. The Ls (size: 0.91° × 0.91°) could be rotated in four possible orientations (0°, 90°, 180°, or 270°), randomly selected for each item.
Design
Following 10 trials of practice using randomly positioned items, participants completed 4 experimental blocks, with 96 trials in each block. In the first two blocks (the training phase), the T appeared in one, “rich”, visual quadrant on 50% of the trials, and appeared in any one of the three “sparse” quadrants on 16.7% of the trials. Which quadrant was rich was counterbalanced across participants but remained the same for a given participant. In the last two blocks (the testing phase), the T was equally likely to appear in any quadrant (25%). Participants were not informed of the target’s location probability. They were asked to find the T and report its orientation as quickly and as accurately as possible. Because the orientation of the T was randomly selected for each trial, the location probability manipulation did not predict the manual response.
Procedure
Eye position was calibrated using a five-point calibration procedure. Following calibration, participants performed a block of visual search. On each trial they fixated a central fixation square (0.23°x0.23°). Upon stable fixation, the experimenter initiated the search trial with a mouse click, which immediately brought out the search display. The display remained until participants made a keyboard response (either the left or right arrow key) for the T’s orientation. The response erased the search display and was followed by a sound feedback about response accuracy. Participants were free to move their eyes during the trial, but were asked to minimize eye blinks. Eye blinks were allowed between trials. After each block participants took a short break. Calibration of the eye position was repeated before the next block.
Recognition test
At the completion of the experiment, we assessed explicit awareness first informally by asking participants whether they thought the target was equally likely to appear anywhere on the display. Regardless of their answer, they were told that the target was more often located in one quadrant than the others. We then assessed explicit awareness formally by asking participants to select the rich quadrant.
Data analysis
Search accuracy and RT comprised the behavioral data. For the eye data, we first flagged bad data, defined as (1) the horizontal or vertical position had a value less than 0, or (2) the pupil diameter was less than 4 standard deviations below the mean pupil size. These time points corresponded to times when the eye tracker lost the eye data momentarily or when participants blinked. The percentage of trials in which the eye data were flagged as bad was less than 2% in all three experiments. The bad samples were replaced using linear interpolation between the preceding good sample and the next good sample. The eye data were then smoothed using a moving window average between 3 adjacent samples. Saccades were identified by finding the time points during which the velocity of the eye position exceeded 30°/s. A graph plot of the eye position data verified that the velocity criterion accurately identified saccades. Trials on which a saccade could not be reliably detected were removed from the eye data analysis (this removed 3.2%, 3.7%, and 3.4% of the data from Experiments 1, 2, and 3, respectively). We then calculated the number of saccades for each trial, the latency of the first saccade, as well as the quadrant to which the first saccade was directed. We also computed the proportion of time in which the eye position was in each quadrant.
Results
1. Behavioral data
Visual search accuracy was over 99% and was unaffected by any experimental factors, smallest p > .10. This was also the case in subsequent experiments, so accuracy will not be further reported. Behavioral analysis focused on correct trials. In addition, trials with an RT longer than 10 s were excluded as outliers (0.26%, 0.17%, and 0.20% of trials were excluded in Experiments 1, 2, and 3, respectively).
Figure 2 shows mean RT as a function of target quadrant and experimental block. An ANOVA on target quadrant (rich or sparse), phase (training or testing), and block (the first or second block of each phase) revealed significant main effects of all three factors. RT was faster when the target was in the rich quadrant than the sparse quadrants, demonstrating probability cueing, F(1, 11) = 18.22, p < .001, ηp2 = .62. RT was faster in the testing phase than the training phase, F(1, 11) = 53.77, p < .001, ηp2 = .83, and faster in the second block than in the first block of each phase, F(1, 11) = 33.64, p < .001, ηp2 = .75.
Figure 2.

Experiment 1’s visual search RT as a function of the target’s quadrant (rich or sparse) and block. The target was more often located in the rich quadrant in the first two blocks, but was equally likely to appear in any quadrant in the last two blocks. Error bars show ±1 S.E. of the mean.
A marginally significant interaction between quadrant and phase showed that probability cueing declined in the testing phase, F(1, 11) = 3.28, p = .097, ηp2 = .23. Additional analyses confirmed, however, that probability cueing was significant both during the training phase, F(1, 11) = 12.83, p < .01, ηp2 = .54, and during the testing phase, F(1, 11) = 6.78, p < .05, ηp2 = .38 [footnote1]. The only other significant effect was the interaction between phase and block: the RT improvement from the first to the second block was most obvious during the training phase, F(1, 11) = 28.80, p < .001, ηp2 = .72. None of the other effects reached significance, F < 1.
Consistent with several previous reports, a substantial probability cueing effect was observed in the first block (Jiang, Swallow, Rosenbaum, et al., 2013; Jiang, Swallow, & Rosenbaum, 2013; Smith, Hood, & Gilchrist, 2010; Umemoto et al., 2010). The 96 trials in the first block were therefore adequate for acquiring stable probability cueing. The difference early in training could also reflect short-term location repetition priming effects. Importantly, however, RT was comparable on the first trial in the training phase that the target appeared in the rich quadrant and the first trial that it appeared in the sparse quadrant, p > .50.
What was the nature of learning? In the recognition phase, 3 of the 12 participants correctly identified the target quadrant, which was expected if participants were randomly guessing (chance would be 25%). In addition, the three participants who made the correct recognition choice initially reported that they thought the target was equally likely to appear anywhere on the display. It is possible that recognition rates may have been higher if we had probed awareness immediately after training. However, the chance-level recognition rate was inconsistent with the results from the testing phase, during which probability cueing remained strong. Participants therefore demonstrated probability cueing immediately before the recognition test on which they failed to correctly report the rich quadrant. Thus, probability cueing in Experiment 1 was a form of implicit learning.
2. Eye data
Participants made an average of 7.2 saccades per trial (S.E. = 0.4), which is consistent with the nature of the task: The T/L search task was associated with highly inefficient search rates and may require serial scanning of the display (Wolfe, 1998). Of interest, however, was that on 37.6% of the trials the first saccade was directed toward the rich quadrant. This value is significantly higher than chance (25%), t(11) = 2.77, p < .05, Cohen’s d = 1.67. In fact, participants were about 1.8 times more likely to direct the first saccade toward the rich quadrant than toward any one of the sparse quadrants.
To further examine how the proportion of first saccades change over time and to determine whether this index was influenced by the target’s actual location, we plotted first saccade data separately for experimental block and target location (Figure 3). An ANOVA on the target’s location (T-in-rich or T-in-sparse), phase (training or testing), and block (first or second block of each phase) revealed just one marginally significant effect: phase, F(1, 11) = 4.27, p = .063, ηp2 = .28. As shown in Figure 3, the preference for the rich quadrant declined marginally from training to testing. Despite the marginal difference, the first saccade was biased toward the rich quadrant in both the training phase (t(11) = 2.96, p < .05, Cohen’s d = 1.78) and the testing phase (t(11) = 2.31, p < .05, Cohen’s d = 1.39). None of the other main effects or interaction effects reached significance, smallest p = .09. It is notable that first saccades were unrelated to the target’s actual location. Regardless of whether the target itself was in the rich or sparse quadrants, the first saccade was biased toward the rich quadrant. Because the first saccade was insensitive to the target’s actual location, it appeared to have been made before participants had acquired any information about where the target actually was. Appendix A presents an additional analysis demonstrating that the direction of the first saccade influenced search RT.
Figure 3.
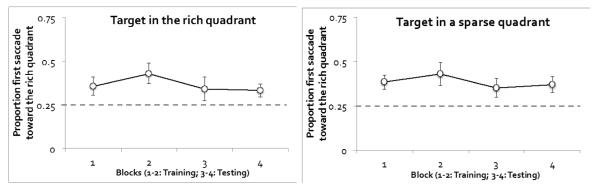
Eye data from Experiment 1: Proportion of first saccades toward the rich quadrant. The dotted gray line shows chance level. Trials were separated by the location of the target. Error bars show ±1 S.E. of the mean.
The latency of the first saccade was unrelated to its direction. As shown in Table 1, the median latency was comparable whether the first saccade was directed to the rich quadrant or to the sparse quadrants, F < 1, and this factor did not interact with phase, F < 1.
Table 1.
The mean of participants’ median latency of the first saccade (ms) in the training and testing phases. S.E. of the mean is shown in the parenthesis.
| Training phase | Testing phase | |||
|---|---|---|---|---|
| Experiment | Toward Rich | Toward Sparse | Toward Rich | Toward Sparse |
| 1 | 250 (18) | 251 (20) | 268 (19) | 275 (25) |
| 2 | 247 (12) | 273 (25) | 269 (17) | 300 (17) |
| 3 | 316 (30) | 301 (22) | 282 (22) | 289 (20) |
Unlike first saccades, the proportion of time that the eyes spent in a quadrant was primarily determined by whether that quadrant contained the target. As shown in Table 2, when the target was in the rich quadrant, the eyes were in that quadrant about 50% of the trial’s duration (defined by RT). Similarly, when the target was in a sparse quadrant, the eyes were in that quadrant for about 40% of the trial’s duration. Because the proportion of time that the eyes spent in a quadrant is an aggregate measure of processes that happened in the entire trial, it should be sensitive to where the target was. More importantly, this index was also sensitive to where the target was likely to be. The eyes were in the quadrant that contained the target 50% of the time if that quadrant was also the rich quadrant, but only 40% of the time if it was a sparse quadrant (p < .01). In addition, when the target was in a sparse quadrant, the eyes were in the rich quadrant 24% of the time, significantly higher than the time they were in a sparse quadrant that did not contain the target (17%; p < .01). These findings were replicated in subsequent experiments and will not be reported further.
Table 2.
Proportion of time the eyes spent in a given quadrant in Experiment 1. Data were separated for trials in which the target was in the rich quadrant and when it was in a sparse quadrant. S.E. of the mean is shown in parenthesis.
| Target in the rich quadrant | Target in a sparse quadrant | ||||
|---|---|---|---|---|---|
| Phase | Eye in T quad (rich) |
Eye in non-T quad (avg(sparse)) |
Eye in T quad (sparse) |
Eye in non-T quad (rich) |
Eye in non-T quad (sparse) |
| Training | 52% (2%) | 16% (0.7%) | 39.6% (0.8%) | 23.9% (1%) | 18.3% (0.3%) |
| Testing | 50% (1.5%) | 16.7% (0.5%) | 41.7% (1.3%) | 24% (1.3%) | 17.1% (0.3%) |
Discussion
Experiment 1 provided compelling evidence that implicit learning produced a persistent change in spatial attention. Following about 200 trials of training in which a visual search target was more often found in a high-frequency “rich” quadrant, participants continued to favor that quadrant in the testing phase, even though the target was no longer more likely to appear in that quadrant. Importantly, the preference was reflected not only in search RT but also in first saccades. Because the first saccade was made soon after trial onset but long before the behavioral response, it reflected attentional guidance rather than post-search decisional processes. Recognition test responses showed no evidence of explicit awareness.
Two previous studies using eye tracking produced conflicting results on whether implicit learning affected spatial attention (Jones & Kaschak, 2012; Walthew & Gilchrist, 2006). However, these studies did not assess explicit awareness so it was unclear whether attention was directed by explicit expectations or implicit learning. In addition, in an attempt to remove short-term location repetition priming, those studies constrained the target’s location, introducing nonrandom statistics that may have interfered with learning. By removing such constraints and testing the long-term persistence of attention, Experiment 1 provides clear evidence for the attentional guidance account.
Because Experiment 1 did not directly manipulate decisional factors, the data cannot address whether probability cueing also influenced decision related processes, over and above its effect on attentional guidance. This is a separate question that should be examined in the future. The theoretical significance of Experiment 1 lies in its demonstration that implicit learning clearly guides spatial attention, a finding that previously found mixed support in more complex experimental paradigms (Kunar et al., 2007; Walthew & Gilchrist, 2006). [footnote2]
Experiment 2. Explicit instructions
So far we have shown that spatial attention can be guided by implicit learning, but does implicit learning affect spatial attention in the same way that explicit knowledge does? Most existing theories imply that the answer is yes (Desimone & Duncan, 1995; Wolfe, 2007). For example, contextual cueing could be incorporated into Guided Search as an additional source of top-down guidance. However, other studies have proposed that goal-driven attention and implicitly driven attention are dissociable (Jiang, Swallow, & Capistrano, 2013; Lambert et al., 1996, 1999, 2000). For example, Lambert et al. (1999) showed that implicitly learned attentional orienting had a different time course than endogenous attentional orienting. “Derived cueing” declined as the interval between the cue and the target increased from 100 ms to 600 ms. In contrast, endogenous spatial cueing has been found to be more effective at longer intervals (Posner, 1980). Using visual search, Jiang, Swallow, & Capistrano (2013) proposed that implicitly learned attention affected the procedural aspect of attention whereas goal-driven attention affected the declarative aspect of attention. However, because these studies used RT as an index of attention, they could not fully distinguish attentional guidance from decisional effects. The goal of Experiment 2 is to use eye tracking to examine how top-down knowledge modulates the persistence of an implicitly learned attentional bias.
In Experiment 2 participants were informed of the target’s location probability both before the training phase and before the testing phase. Previous research on implicit learning has found diverse effects of explicit knowledge (Stadler & Frensch, 1998). Explicit knowledge facilitated serial reaction learning (Curran & Keele, 1993; Frensch & Miner, 1994) and artificial grammar learning (Dulany, Carlson, & Dewey, 1984). However, it did not enhance contextual cueing (Chun & Jiang, 2003) or probabilistic perceptual-motor sequence learning (Flegal & Anderson, 2008; Sanchez & Reber, 2003). One factor that could account for these discrepant results is the complexity of the underlying statistics: explicit instructions facilitated performance if the underlying statistics were simple. The statistics underlying probability cueing can be easily described and therefore could potentially influence performance in this task.
The use of explicit instructions about where the target was likely to appear in Experiment 2 addresses two questions. One is the effect of explicit knowledge of the target’s distribution on attentional guidance. If participants can use the instructions to guide attention, then the rich quadrant should be more effectively prioritized in the training phase of Experiment 2 than in Experiment 1 (when participants were given no information). The other question is whether explicit knowledge that the previously learned bias is incorrect can weaken or eliminate probability cueing. If top-down knowledge modulates implicit learning, then probability cueing should be weakened or absent in the testing phase of Experiment 2 (relative to Experiment 1). However, if implicit learning is dissociable from goal-driven attention, then explicit instructions may not affect the persistence of implicitly learned attention.
Method
Participants
Twelve new participants completed Experiment 2. There were 8 females and 4 males with a mean age of 21.1 years.
Procedure
This experiment was identical to Experiment 1 except for the instructions that participants received. At the beginning of Blocks 1 and 2, a blue outline square framed the rich quadrant. Participants were told that: “It is important to keep in mind that the T is NOT evenly distributed. The T is more often located in the region indicated by the blue square. The T will be in that quadrant 50% of the time and in each of the other quadrants 17% of the time. It helps to prioritize that quadrant.” At the beginning of Blocks 3 and 4, participants were informed that: “It is important to keep in mind that the T is EVENLY distributed for the following blocks. The T will be in each quadrant 25% of the time.” An experimenter verbally reinforced these instructions and encouraged participants to prioritize the rich quadrant in Blocks 1 and 2, and to abandon any systematic biases in Blocks 3 and 4. Just like Experiment 1, the target was more often located in the rich quadrant in the training phase (Blocks 1 and 2) and was equally probable in all quadrants in the testing phase (Blocks 3 and 4).
Results
Figure 4 shows mean RT as a function of the target quadrant and experimental block. An ANOVA on target quadrant (rich or sparse), phase (training or testing), and block (the first or second block of each phase) revealed significant main effects of all three factors. RT was faster when the target was in the rich quadrant rather than the sparse quadrants, F(1, 11) = 55.77, p < .001, ηp2 = .84, faster in the testing phase than the training phase, F(1, 11) = 17.98, p < .001, ηp2 = .62, and faster in the second block of each phase than the first block, F(1, 11) = 30.39, p < .001, ηp2 = .73. In addition, a significant interaction between target quadrant and phase showed that probability cueing declined in the testing phase compared with the training phase, F(1, 11) = 11.92, p < .01, ηp2 = .52. Nonetheless, follow-up tests showed that probability cueing was highly significant both in the training phase, F(1, 11) = 55.11, p < .001, ηp2 = .83, and in the testing phase, F(1, 11) = 12.33, p < .01, ηp2 = .53. The only other interaction effect that reached significance was between phase and block, as the RT improvement across the two blocks was most obvious in the training phase, F(1, 11) = 13.44, p < .01, ηp2 = .55. None of the other interaction effects were significant, all ps > .10.
Figure 4.

Experiment 2’s visual search RT as a function of the target quadrant and experimental block. Error bars show ±1 S.E. of the mean.
To examine the impact of instructions, we compared data between Experiment 1 (incidental learning) and Experiment 2 (intentional learning). In the training phase, the size of probability cueing (RT difference between rich and sparse conditions) was 539 ms in Experiment 1 and 687 ms in Experiment 2. Although explicit instructions increased probability cueing numerically, this effect failed to reach statistical significance, F < 1. In the testing phase, the size of probability cueing was 233 ms in Experiment 1 and 287 ms in Experiment 2. This difference also did not reach statistical significance, F < 1. A full ANOVA including experiment (1 vs. 2) and the other factors (rich or sparse, phase, and block) revealed no interaction between experiment and any other factors, smallest p = .10. Although one might expect probability cueing to be diminished by an explicit instruction to treat all quadrants equally, this was not supported by our data.
2. Eye data
Participants made on average of 6.6 saccades (S.E. = 0.4). Averaged across the entire experiment, participants directed the first saccade toward the rich quadrant on 47.3% (S.E. = 3.2%) of the trials, which was significantly higher than chance, t(11) = 6.91, p < .001, Cohen’s d = 4.17.
Figure 5 plots the proportion of first saccades toward the rich quadrant, separately for trials in which the target itself was in the rich quadrant or in a sparse quadrant, and for different experimental blocks. An ANOVA on target’s location (T-in-rich or T-in-sparse), phase (training or testing), and block (the first or second block of each phase) revealed significant main effects of phase, F(1, 11) = 11.36, p < .01, ηp2 = .51, and block, F(1, 11) = 5.01, p < .05, ηp2 = .31. The preference for the rich quadrant was significantly stronger in the training phase than the testing phase, even though the preference was higher than chance in both phases (52.5% in the training phase, t(11) = 8.74, p < .001, Cohen’s d = 5.27; 41.4% in the testing phase, t(11) = 4.30, p < .001, Cohen’s d = 2.59). The preference also increased somewhat in the second block relative to the first block of each phase. None of the other effects reached significance, all ps > .06. As was the case in Experiment 1, first saccades were not influenced by the location of the target. If anything, the preference toward the rich quadrant was slightly stronger when the target itself was in a sparse quadrant than in the rich quadrant, F(1, 11) = 4.36, p = .061, ηp2 = .28.
Figure 5.
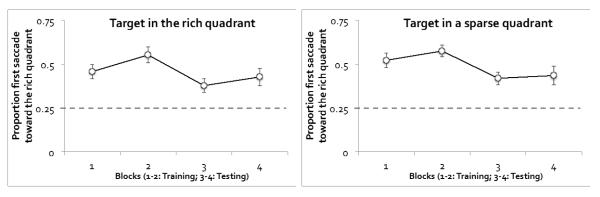
Eye data from Experiment 2: Proportion of first saccades toward the rich quadrant. The dotted gray line shows chance level. Trials were separated by the location of the target. Error bars show ±1 S.E. of the mean.
As shown in Table 1, the latency of the first saccade was marginally faster when directed to the rich quadrant than when directed to a sparse quadrant, F(1, 11) = 3.67, p = .08, ηp2 = .25, and this effect did not interact with experimental phase, F < 1.
How did explicit instructions affect the preference to saccade toward the rich quadrant? To address this question we compared the data between Experiment 1 (incidental learning) and Experiment 2 (intentional learning). In the training phase, the preference for the rich quadrant was significantly stronger in participants who were told to prioritize the rich quadrant, t(22) = 2.40, p = .045, Cohen’s d = 1.45 for the instruction by target quadrant interaction. Explicit instructions strengthened the prioritization of the rich quadrant, suggesting that participants in Experiment 2 used the instructions to guide search. However, in the testing phase, the preference for the rich quadrant continued despite their knowledge that the target would be randomly distributed. The preference for the rich quadrant was stronger, though not significantly so, in Experiment 2 than in Experiment 1, t(22) = 1.16, p > .40. The interaction between phase (training or testing) and experiment (1 or 2) was not significant, F(1, 22) = 2.12, p > .10. These data showed that explicit awareness of the target’s likely location had little impact on the persistence of the learned attentional bias.
Discussion
When explicitly asked to prioritize the rich quadrant during the training phase, probability cueing moderately increased. Compared with participants who received no instructions, those who received the explicit instructions showed a numerically larger probability cueing effect in RT, and a significantly greater tendency to direct their first saccadic eye movements toward the rich quadrant. These data supported the idea that spatial attention could be driven by multiple top-down cues, including an explicit goal and probabilistic learning. The relatively large advantage in the rich quadrant likely reflected the summation of both cues. Consistent with this interpretation, when participants were asked to discontinue prioritization of the rich quadrant, the attentional bias toward the rich quadrant declined significantly. This decline showed that participants followed the instructions. However, they were unable to completely extinguish the learned attentional bias. Participants who were asked to distribute attention evenly were just as persistent in prioritizing the previously rich quadrant as those who had received no instruction (Experiment 1).
Taken together, the training and testing data showed that spatial attention could be driven by both an explicit goal and by probability learning. However, explicit instructions to distribute attention evenly were ineffective in extinguishing the learned attentional bias. These data are consistent with the idea that implicitly learned attention may be dissociable from goal-driven attention (see also Lambert et al., 1999, for a similar argument in the Posner spatial cueing paradigm).
Experiment 2 provides initial evidence that implicitly learned attention is persistent even though the target’s location distribution was random and that participants were told to distribute attention evenly. However, because participants received explicit instructions in the training phase, the persisting attentional bias in the testing phase cannot be unequivocally attributed to implicit learning alone. Therefore, the next experiment will more directly establish the persistence of implicitly learned attention in participants who received explicit knowledge only during the testing phase.
Experiment 3. Incidental learning followed by explicit instructions
Participants in Experiment 3 acquired probability cueing under incidental learning conditions (like Experiment 1). Based on results from Experiment 1, we expected that an implicitly learned attentional bias would develop. To examine the interaction between explicit knowledge and the implicitly learned attentional bias, we provided explicit instructions before the testing phase (like Experiment 2). Participants were told that the target would be randomly placed and that they should abandon any systematic biases during search.
Method
Participants
Twelve new participants completed Experiment 3. There were 8 females and 4 males with a mean age of 23.5 years.
Design and Procedure
This experiment is similar to the first two experiments except for the instructions. Like Experiment 1, participants received no information about the target’s location probability in the training phase, so learning was incidental. In the testing phase, however, participants were told that the target would be randomly distributed on the display. They were encouraged to abandon any systematic biases toward certain regions of the display.
Results and Discussion
1. Behavioral data
Figure 6 shows visual search RT in Experiment 3. An ANOVA on target quadrant (rich or sparse), phase (training or testing), and block (the first or second block of each phase) revealed significant main effects of all three factors. RT was faster when the target was in the rich quadrant rather than a sparse quadrant, F(1, 11) = 25.01, p < .001, ηp2 = .70, faster in the testing phase than the training phase, F(1, 11) = 151.51, p < .001, ηp2 = .93, and faster in the second block than the first block of each phase, F(1, 11) = 20.61, p < .001, ηp2 = .65. The only two-way interaction that reached significance was between phase and block, F(1, 11) = 5.19, p < .05, ηp2 = .32, as the RT improvement in the second block was more obvious in the training phase than the testing phase. Target quadrant did not interact with phase or block, Fs < 1. However, a significant three-way interaction was observed, F(1, 11) = 9.21, p < .05, ηp2 = .46. Probability cueing appeared to increase from Block 1 to Block 2 in the training phase, but decrease from Block 3 to Block 4 in the testing phase, although neither trend reached significance on its own, ps > .12. For our purposes, it is important to note that probability cueing strongly persisted in the testing phase, F(1, 11) = 19.75, p < .001, ηp2 = .64 for the main effect of target quadrant. This was found even though participants were told to distribute attention evenly.
Figure 6.

Experiment 3’s visual search RT as a function of the target quadrant and experimental block. Error bars show ±1 S.E. of the mean.
A direct comparison between Experiments 1 and 3 using experiment as a between-subject factor and target quadrant (rich or sparse), phase, and block as within-subject factors revealed no main effect or interaction effects involving experiment, largest p = .10. Thus, search RT was relatively insensitive to the instructions provided in Experiment 3.
2. Eye data
Participants made an average of 5.9 (S.E. = 0.23) saccades in each trial of visual search. Across the entire experiment, the first saccades were directed toward the rich quadrant on 41.3% of the trials (S.E. = 6%), which was significantly higher than chance, t(11) = 2.71, p < .05, Cohen’s d = 1.63.
As shown in Figure 7, the first saccade was biased toward the rich quadrant regardless of whether the target itself was in the rich quadrant or in a sparse quadrant, F(1, 11) = 3.75, p = .08 for the main effect of the target’s quadrant. Notably, this bias was maintained in the testing phase, F < 1 for the main effect of phase. Similar to RT, the saccade bias toward the rich quadrant increased from Block 1 to Block 2, but stabilized or slightly decreased from Block 3 to Block 4, resulting in a marginally significant interaction between phase and block, F(1, 11) = 4.19, p = .07, ηp2 = .28. None of the other effects involving target quadrant, phase, or block were significant, all ps > .10. Participants directed 39.6% of the first saccades toward the rich quadrant in the training phase, which was significantly higher than chance, t(11) = 2.23, p < .05, Cohen’s d = 1.34. This preference was maintained at 42.4% in the testing phase, again significantly above chance, t(11) = 2.90, p < .05, Cohen’s d = 1.75.
Figure 7.
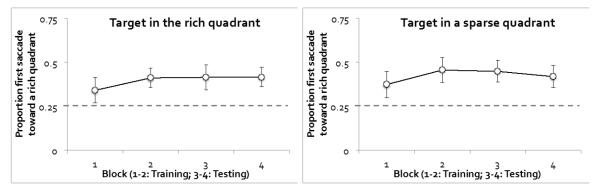
Eye data from Experiment 3: Proportion of first saccades toward the rich quadrant. The dotted gray line shows chance level. Trials were separated by the location of the target. Error bars show ±1 S.E. of the mean.
Similar to Experiment 1, saccade latency was unaffected by whether the first saccade was directed to the rich or sparse quadrants, F < 1, and this effect did not interact with experimental phase, F(1, 11) = 3.05, p > .10.
To examine whether explicit instructions modulated the proportion of first saccades, we compared the testing phase data from Experiments 1 and 3. In the testing phase, participants who were told to distribute attention evenly were just as likely to saccade toward the previously rich quadrant as participants who received no instructions, F(1, 22) = 1.14, p > .10. Similar to Experiment 2, the interaction between phase (training or testing) and experiment (1 or 3) was not significant, F(1, 22) = 1.71, p > .20.
General Discussion
By measuring the direction of the first saccadic eye movements in a visual search task, this study provides compelling evidence for the attentional guidance account of implicit learning. Like many real-world tasks, the item that participants searched for (target) in our study is more likely to be found in some locations than others. Although participants are unaware of this manipulation, they are faster at finding the target in the rich quadrant than the sparse quadrants. In addition, the first saccade is almost twice as likely to be directed toward the rich quadrant than to any of the sparse quadrants. The rapidity of the first saccade and its insensitivity to the actual location of the target indicate that it reflects attentional guidance rather than just post-detection decisional processes.
Our study supports theories that include implicit learning as a major source of top-down attention (Chun & Jiang, 1998; Desimone & Duncan, 1995; Wolfe, 2007). However, our study also showed qualitative differences between implicitly learned attention and goal-driven attention. In particular, the first saccade data showed that probability cueing persists over the long-term, even when it is no longer valid. For nearly 200 trials, the target’s location was random, yet an attentional bias toward the previously rich quadrant persisted. In contrast, goal-driven attention is highly sensitive to the validity of the spatial cue (Jonides, 1980). In addition, Experiments 2 and 3 showed that the attentional bias persisted even though participants were asked to distribute attention evenly. Knowing that the target’s location will be random does not weaken the spatial bias toward the previously rich quadrant.
These data are difficult to explain if implicit learning and goal-driven attention reflect a single mechanism. Suppose that following implicit learning, the rich quadrant has a higher weight (w2) on an attentional priority map than the sparse quadrants (w1), where w2 > w1. If goal-driven attention modulates the same attentional priority map as implicit learning, then the explicit instruction to equally prioritize all quadrants should modulate these weights and reduce the discrepancy between them. However, our study found no evidence that explicit instructions eliminated or weakened probability cuing. These data therefore support the idea that implicitly learned attention is at least partly dissociated from goal-driven attention (Jiang, Swallow, & Capistrano, 2013; Lambert et al., 1997, 1999, 2000).
Additional evidence for the dissociation between implicit learning and goal-driven attention comes from studies that examined the spatial reference frame of attention. Jiang, Swallow, and Capistrano (2013) asked participants to perform visual search on a monitor laid flat on a stand. Participants walked to different standing positions around the monitor before each visual search trial, but the target-rich quadrant remained in the same part of the monitor. When explicitly instructed to prioritize the rich quadrant on the monitor, participants showed faster RT when the target appeared in the rich quadrant rather than in a sparse quadrant. However, when explicit instructions were withheld, probability cueing failed to develop even after several hundred trials of training. Thus, whereas goal-driven attention can be directed toward a frequently attended region in the external environment, implicitly learned attention is viewer-centered and depends on consistent viewpoints (Jiang & Swallow, 2013; Jiang, Swallow & Sun, 2013).
In one proposal, probability cueing is considered a form of procedural attention acquired through reinforcement learning (Jiang, Swallow, & Capistrano, 2013). Successful target detection reinforces the preceding attentional shifts (which can be described as a Euclidian vector), increasing the likelihood that they would occur during future search attempts. This type of reinforcement could produce transient location repetition priming observed in previous studies (Maljkovic & Nakayama, 1996). However, in those experiments the target’s location was random, resulting in the reinforcement of multiple vectors over a period of time. The only detectable effect in these cases is transient priming. In contrast, when the target is more often found in some regions over a period of time as in the current studies, some vectors are more strongly reinforced than others, increasing the likelihood that they will occur again.
Although the current study did not test the nature of procedural attention, other studies have shown that it is unlikely to be low-level, oculomotor learning. First, probability cueing was observed when the display was presented for 150 ms and when fixation was ensured with an eye tracker (Geng & Behrmann, 2005). Second, frequently saccading toward a rich quadrant did not produce probability cueing if the target’s location was pre-cued by a central arrow (Jiang, Swallow, & Rosenbaum, 2013). The lack of probability cueing under this condition argues against implicitly learned attention as a “use dependent” mechanism (Diedrichsen, White, Newman, & Lally, 2010). Instead, the data suggest that probability cueing reflects reinforcement learning, and therefore depends on credit assignment (Rescorla & Wagner, 1972). When present, a valid arrow cue may be given credit for successful target detection, rather than the specific attentional movements that led to its discovery. Saccading toward the rich quadrant is therefore neither necessary nor sufficient to yield probability cueing. Instead, probability cueing is likely to reflect high-level, attentional learning that is not directly tied to systems involved in saccade generation. Rather, by proposing that probability cueing is a form of procedural attention, we are suggesting that it is also a form of premotor attention (Rizzolatti, Riggio, Dascola, & Umiltá, 1987) that may be involved in planning oculomotor behaviors. In contrast, goal-driven attention can be abstracted from online attentional shifts and is a prime candidate for configuring the priority map of spatial attention (Jiang, Swallow, & Capistrano, 2013).
The present experiments also show that the impact of learning is not restricted to covert attention. When allowed to move their eyes (as is the case in the current study), participants were more likely to direct their first saccade toward the rich quadrant. The manifestation of probability cueing in RT and eye movements is consistent with the proposal that attention and eye movements are tightly coupled (Kowler, 2011).
To what degree can other paradigms of implicit learning be considered a form of procedural attention? For example, contextual cueing has been posited to be either a form of top-down attention (Chun & Jiang, 1998; Chun, 2000) or a mechanism that affects response selection (Kunar et al., 2007). Neither theory is fully compatible with the idea that contextual cueing might reflect reinforcement learning of attentional vectors. However, we believe that the dual-system view is a strong contender for explaining contextual cueing. First, empirical data have revealed two forms of contextual cueing, one based on explicit knowledge (scene-based contextual cueing; Brockmole & Henderson, 2006), and the other established through implicit learning (array-based contextual cueing; Chun & Jiang, 1998). Similar to probability cueing, the implicit form of contextual cueing is unaffected by top-down knowledge (Chun & Jiang, 2003). Second, recent findings suggest that implicit contextual cueing may reflect a change in procedural attention. Specifically, the repeated spatial layout itself does not cue the target’s location in the absence of visual search (Jiang, Sigstad, & Swallow, 2013). Implicit contextual cueing appears to depend on the actual visual search process, consistent with the idea that it affects online attentional shifts.
The suggestion that implicitly learned attention is separate from goal-driven attention raises several questions for future research. First, what are the neural substrates of the two forms of spatial attention? Neurophysiological studies have shown that neurons in the parietal cortex represent visual space using multiple coordinates (e.g., eye- and head- centered representation), and some neurons are capable of remapping their receptive fields in anticipation of an impending saccade (Colby & Goldberg, 1999). The heterogeneity of neurons in the parietal cortex may support the multiple subsystems of spatial attention. Neuroimaging studies have implicated several other brain regions in spatial attention, including the frontal eye fields, posterior parietal cortex, basal ganglia, the thalamus, superior colliculus, and the cerebellum (Corbetta & Shulman, 2002). It is conceivable that a subset of these regions is more important for goal-driven attention (e.g., the fronto-parietal regions), whereas others are more important for implicitly learned attention (e.g., the basal ganglia and superior colliculus). This question should be tested in future neuroimaging and patient studies.
Second, how do the two subsystems of spatial attention interact, especially when goal-driven attention and implicit learning present conflicting signals? Although Experiments 2 and 3 test how goal driven and implicit attention could interact, goal-driven attention serves primarily to “neutralize” or enhance the probability manipulation in these studies. It did not introduce a new spatial bias. Two previous studies have addressed this question in search RT. In one study (Jiang, Swallow, & Rosenbaum, 2013), after acquiring probability cueing, participants were shown central arrows that directed their attention to the arrow-cued quadrant. This manipulation substantially weakened probability cueing. However, probability cueing can survive instructions to direct attention elsewhere. In a second study (Jiang et al., 2014), after acquiring an attentional bias toward one part of a tabletop, participants changed their seating position 90°. In the absence of an instruction, the attentional bias rotated with the participant. That is, the bias was viewer-centered. However, when explicitly asked to favor one quadrant of the screen, participants demonstrated two attentional biases: One to the explicitly prioritized region, and one to the region that was consistent with the learned, viewer-centered attentional bias acquired during training. Although people are very good at following explicit attentional cues, the learned implicit bias that remains continues to influence behavior (in a viewer-centered rather than environment-centered reference frame). Future eye tracking studies may yield additional insight on the interaction between explicit instructions and the implicitly learned bias.
Conclusion
A long-standing tradition in attention research has been to consider it a heterogeneous construct (Chun, Golomb, & Turk-Browne, 2011). However, previous research has not clearly isolated implicit learning as a major source of attentional guidance, and has instead pointed to effects in post-search decisional processes (Kunar et al., 2007). Moreover, to the extent that implicit learning guides attention it has been assumed that it does so by interfacing with the same systems that voluntarily guide attention in space (e.g., priority maps; Chun & Jiang, 1998, Desimone & Duncan, 1995; Wolfe, 2007). Using eye tracking and behavioral measures, the current study provides compelling evidence that implicit learning guides spatial attention. The study also shows that implicitly learned attention differs from goal-driven attention: it persists even after the probabilistic cue is no longer valid and despite instructions to distribute attention evenly. We believe that this form of attention reflects changes in the online shift of spatial attention – procedural attention. Future studies should seek convergent evidence from neuroscience and should examine other ways in which goal-driven and implicitly learned attention differ.
Acknowledgements
This study was supported in part by NIH MH102586-01. Eye tracking was made available through the Center for Cognitive Sciences at the University of Minnesota. Jie Hwa Ong helped with data collection. Kate Briggs coordinated the Research Experience Program through which participants were recruited. We thank Mike Dodd, Anthony Lambert, Michael Ziessler, and an anonymous reviewer for comments on an earlier draft of this paper.
Appendix [footnote3]
In an additional analysis, we examined whether search RT was influenced by the direction of the first saccade. Here we present data from the testing phase (Appendix Table 1), which de-confounded long-term learning from short-term priming (though the same pattern of results were found in the training phase).
Appendix Table 1.
Mean RT in the three experiments. Trials were separated based on the direction of the first saccade and the actual location of the target (see text). S.E. is shown in parenthesis.
| First Saccade to Rich | First Saccade to Sparse | ||||
|---|---|---|---|---|---|
| Target Location | Rich | Sparse | Same Sparse | Different Sparse |
Rich |
| Case | 1 | 2 | 3 | 4 | 5 |
| Experiment 1 | 1543 (195) | 1974 (75) | 1630 (139) | 2008 (90) | 1756 (138) |
| Experiment 2 | 1511 (134) | 1988 (103) | 1779 (145) | 1960 (105) | 1737 (157) |
| Experiment 3 | 1383 (89) | 2042 (141) | 1635 (120) | 1841 (84) | 1524 (103) |
| All experiments | 1479 (83) | 2001 (62) | 1681 (76) | 1936 (54) | 1672 (77) |
There were five types of trials depending on the first saccade quadrant and the actual location of the target. When the first saccade landed in the rich quadrant, the target could also be located there (Case 1) or in a sparse quadrant (Case 2). When the first saccade landed in a sparse quadrant, the target could have been located in that quadrant (Case 3), located in another sparse quadrant (Case 4), or located in the rich quadrant (Case 5). Appendix Table 1 lists the mean RT for each of the five conditions, separately for Experiments 1, 2, and 3. An ANOVA on condition (Cases 1-5) and experiment (1-3) revealed a significant main effect of condition, F(4, 132) = 30.62, p < .001, ηp2 = .48, but no main effect of experiment (F < 1) or experiment by condition interaction (F(8, 132) = 1.20, p > .30). We therefore pooled data from all experiments.
Evidence that the direction of the first saccade contributed to search RT came from the finding that RT was faster when the target landed in the first saccade quadrant than when it was in a different quadrant. For example, RT was faster in Case 1 (first saccade and the target were both in the rich quadrant) than in Case 2 (first saccade went to the rich quadrant but the target was in a sparse quadrant), t(35) = 7.86, p < .001, or in Case 5 (first saccade went to a sparse quadrant but the target was in the rich quadrant), t(35) = 3.84, p < .001. Also, RT was faster in Case 3 (first saccade and the target were in the same sparse quadrant) than in Case 4 (first saccade and the target were in different sparse quadrants), t(35) = 5.10, p < .001.
In addition, these data also support the idea that participants acquired an attentional bias toward the rich quadrant. In both Case 1 and Case 3 the first saccade was directed to the target quadrant, but RT was significantly influenced by whether that quadrant was rich (Case 1) or sparse (Case 3), t(35) = 3.44, p = .002. This indicated that RT was determined not only by the first saccade, but also by subsequent saccades, which may also be biased toward the rich quadrant. Similarly, consider Cases 2 and 5. In both cases the first saccade mismatched with the target quadrant, but the cost of erroneously making a first saccade to the rich quadrant (Case 2) was greater than the cost of erroneously making a first saccade to a sparse quadrant (Case 5), t(35) = 5.86, p < .001. The five t-tests reported here were all planned contrasts and the p values survived the Bonferroni correction threshold (p = .01).
Footnotes
The three experiments yielded results that were consistent with this conclusion, successfully replicating each other.
It is important to note that although moving the eyes could be conceptualized as involving decision more broadly, such a decision would be attentional in nature. In this situation, the decision to prioritize a region of space biases eye movements toward that region. Such an account is compatible with our theoretical position (i.e., implicit learning affects attentional processes prior to target detection).
We thank an anonymous reviewer for suggesting this analysis.
Reference
- Anderson BA, Laurent PA, Yantis S. Value-driven attentional capture. Proceedings of the National Academy of Sciences. 2011;108(25):10367–10371. doi: 10.1073/pnas.1104047108. doi:10.1073/pnas.1104047108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Awh E, Belopolsky AV, Theeuwes J. Top-down versus bottom-up attentional control: a failed theoretical dichotomy. Trends in Cognitive Sciences. 2012;16(8):437–443. doi: 10.1016/j.tics.2012.06.010. doi:10.1016/j.tics.2012.06.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brainard DH. The Psychophysics Toolbox. Spatial Vision. 1997;10(4):433–436. [PubMed] [Google Scholar]
- Brockmole JR, Henderson JM. Recognition and attention guidance during contextual cueing in real-world scenes: evidence from eye movements. Quarterly Journal of Experimental Psychology. 2006;59(7):1177–1187. doi: 10.1080/17470210600665996. doi:10.1080/17470210600665996. [DOI] [PubMed] [Google Scholar]
- Chun Contextual cueing of visual attention. Trends in Cognitive Sciences. 2000;4(5):170–178. doi: 10.1016/s1364-6613(00)01476-5. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Contextual cueing: implicit learning and memory of visual context guides spatial attention. Cognitive Psychology. 1998;36(1):28–71. doi: 10.1006/cogp.1998.0681. doi:10.1006/cogp.1998.0681. [DOI] [PubMed] [Google Scholar]
- Chun, Marvin M, Golomb JD, Turk-Browne NB. A taxonomy of external and internal attention. Annual Review of Psychology. 2011;62:73–101. doi: 10.1146/annurev.psych.093008.100427. doi:10.1146/annurev.psych.093008.100427. [DOI] [PubMed] [Google Scholar]
- Chun, Marvin M, Jiang Y. Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2003;29(2):224–234. doi: 10.1037/0278-7393.29.2.224. [DOI] [PubMed] [Google Scholar]
- Colby CL, Goldberg ME. Space and attention in parietal cortex. Annual Review of Neuroscience. 1999;22:319–349. doi: 10.1146/annurev.neuro.22.1.319. doi:10.1146/annurev.neuro.22.1.319. [DOI] [PubMed] [Google Scholar]
- Corbetta M, Shulman GL. Control of goal-directed and stimulus-driven attention in the brain. Nature Reviews Neuroscience. 2002;3(3):201–215. doi: 10.1038/nrn755. doi:10.1038/nrn755. [DOI] [PubMed] [Google Scholar]
- Desimone R, Duncan J. Neural mechanisms of selective visual attention. Annual Review of Neuroscience. 1995;18:193–222. doi: 10.1146/annurev.ne.18.030195.001205. doi:10.1146/annurev.ne.18.030195.001205. [DOI] [PubMed] [Google Scholar]
- Diedrichsen J, White O, Newman D, Lally N. Use-dependent and error-based learning of motor behaviors. Journal of Neuroscience. 2010;30(15):5159–5166. doi: 10.1523/JNEUROSCI.5406-09.2010. doi:10.1523/JNEUROSCI.5406-09.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Druker M, Anderson B. Spatial probability aids visual stimulus discrimination. Frontiers in Human Neuroscience. 2010;4 doi: 10.3389/fnhum.2010.00063. doi:10.3389/fnhum.2010.00063. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eckstein MP, Drescher BA, Shimozaki SS. Attentional cues in real scenes, saccadic targeting, and Bayesian priors. Psychological Science. 2006;17(11):973–980. doi: 10.1111/j.1467-9280.2006.01815.x. doi:10.1111/j.1467-9280.2006.01815.x. [DOI] [PubMed] [Google Scholar]
- Egeth HE, Yantis S. Visual attention: control, representation, and time course. Annual Review of Psychology. 1997;48:269–297. doi: 10.1146/annurev.psych.48.1.269. doi:10.1146/annurev.psych.48.1.269. [DOI] [PubMed] [Google Scholar]
- Fecteau JH, Munoz DP. Salience, relevance, and firing: a priority map for target selection. Trends in Cognitive Sciences. 2006;10(8):382–390. doi: 10.1016/j.tics.2006.06.011. doi:10.1016/j.tics.2006.06.011. [DOI] [PubMed] [Google Scholar]
- Geng JJ, Behrmann M. Probability cuing of target location facilitates visual search implicitly in normal participants and patients with hemispatial neglect. Psychological Science. 2002;13(6):520–525. doi: 10.1111/1467-9280.00491. [DOI] [PubMed] [Google Scholar]
- Geng JJ, Behrmann M. Spatial probability as an attentional cue in visual search. Perception & Psychophysics. 2005;67(7):1252–1268. doi: 10.3758/bf03193557. [DOI] [PubMed] [Google Scholar]
- Jiang YV, Sigstad HM, Swallow KM. The time course of attentional deployment in contextual cueing. Psychonomic Bulletin & Review. 2013;20(2):282–288. doi: 10.3758/s13423-012-0338-3. doi:10.3758/s13423-012-0338-3. [DOI] [PubMed] [Google Scholar]
- Jiang YV, Swallow KM. Spatial reference frame of incidentally learned attention. Cognition. 2013;126(3):378–390. doi: 10.1016/j.cognition.2012.10.011. doi:10.1016/j.cognition.2012.10.011. [DOI] [PubMed] [Google Scholar]
- Jiang YV, Swallow KM, Capistrano CG. Visual search and location probability learning from variable perspectives. Journal of Vision. 2013;13(6):13. doi: 10.1167/13.6.13. doi:10.1167/13.6.13. [DOI] [PubMed] [Google Scholar]
- Jiang YV, Swallow KM, Rosenbaum GM. Guidance of spatial attention by incidental learning and endogenous cuing. Journal of Experimental Psychology: Human Perception and Performance. 2013;39(1):285–297. doi: 10.1037/a0028022. doi:10.1037/a0028022. [DOI] [PMC free article] [PubMed] [Google Scholar] [Retracted]
- Jiang YV, Swallow KM, Rosenbaum GM, Herzig C. Rapid acquisition but slow extinction of an attentional bias in space. Journal of Experimental Psychology: Human Perception and Performance. 2013;39(1):87–99. doi: 10.1037/a0027611. doi:10.1037/a0027611. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang YV, Swallow KM, Sun L. Egocentric Coding of Space for Incidentally Learned Attention: Effects of Scene Context and Task Instructions. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2014;40(1):233–250. doi: 10.1037/a0033870. doi:10.1037/a0033870. [DOI] [PubMed] [Google Scholar]
- Jones JL, Kaschak MP. Global statistical learning in a visual search task. Journal of Experimental Psychology: Human Perception and Performance. 2012;38(1):152–160. doi: 10.1037/a0026233. doi:10.1037/a0026233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jonides J. Towards a model of the mind’s eye’s movement. Canadian Journal of Psychology. 1980;34(2):103–112. doi: 10.1037/h0081031. [DOI] [PubMed] [Google Scholar]
- Kowler E. Eye movements: the past 25 years. Vision Research. 2011;51(13):1457–1483. doi: 10.1016/j.visres.2010.12.014. doi:10.1016/j.visres.2010.12.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kunar M, Flusberg S, Horowitz T, Wolfe J. Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology: Human Perception & Performance. 2007;33(4):816–828. doi: 10.1037/0096-1523.33.4.816. doi: http://dx.doi.org/10.1037/0096-1523.33.4.816. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lambert AJ, Sumich AL. Spatial orienting controlled without awareness: a semantically based implicit learning effect. The Quarterly journal of Experimental Psychology. 1996;49A(2):490–518. doi: 10.1080/713755621. doi:10.1080/713755621. [DOI] [PubMed] [Google Scholar]
- Lambert A, Naikar N, McLachlan K, Aitken V. A new component of visual orienting: Implicit effects of peripheral information and subthreshold cues on covert attention. Journal of Experimental Psychology: Human Perception and Performance. 1999;25(2):321–340. doi:10.1037/0096-1523.25.2.321. [Google Scholar]
- Lambert A, Norris A, Naikar N, Aitken V. Effects of informative peripheral cues on eye movements: Revisiting William James’ “derived attention”. Visual Cognition. 2000;7(5):545–569. doi: http://dx.doi.org/10.1080/135062800407194. [Google Scholar]
- Lewicki P, Czyzewska M, Hoffman H. Unconscious acquisition of complex procedural knowledge. Journal of Experimental Psychology: Learning, Memory, & Cognition. 1987;13(4):523–530. doi: http://dx.doi.org/10.1037/0278-7393.13.4.523. [Google Scholar]
- Maljkovic V, Nakayama K. Priming of pop-out: II. The role of position. Perception & Psychophysics. 1996;58(7):977–991. doi: 10.3758/bf03206826. [DOI] [PubMed] [Google Scholar]
- Mayr U. Spatial attention and implicit sequence learning: evidence for independent learning of spatial and nonspatial sequences. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1996;22(2):350–364. doi: 10.1037//0278-7393.22.2.350. [DOI] [PubMed] [Google Scholar]
- Miller J. Components of the location probability effect in visual search tasks. Journal of Experimental Psychology: Human Perception and Performance. 1988;14(3):453–471. doi: 10.1037//0096-1523.14.3.453. [DOI] [PubMed] [Google Scholar]
- Nissen M, Bullemer P. Attentional requirements of learning: Evidence from performance measures. Cognitive Psychology. 1987;19(1):1–32. doi: http://dx.doi.org/10.1016/0010-0285%2887%2990002-8. [Google Scholar]
- Pelli DG. The VideoToolbox software for visual psychophysics: transforming numbers into movies. Spatial Vision. 1997;10(4):437–442. [PubMed] [Google Scholar]
- Peterson MS, Kramer AF. Attentional guidance of the eyes by contextual information and abrupt onsets. Perception & Psychophysics. 2001;63(7):1239–1249. doi: 10.3758/bf03194537. [DOI] [PubMed] [Google Scholar]
- Posner MI. Orienting of attention. The Quarterly Journal of Experimental Psychology. 1980;32(1):3–25. doi: 10.1080/00335558008248231. [DOI] [PubMed] [Google Scholar]
- Rescorla RA, Wagner AR. A theory of Pavlovian Conditioning: Variations in the effectiveness of reinforcement and nonreinforcement. In: Black AH, Prokasy WF, editors. Classical Conditioning II. Appleton-Century-Crofts; 1972. pp. 64–99. [Google Scholar]
- Rizzolatti G, Riggio L, Dascola I, Umiltá C. Reorienting attention across the horizontal and vertical meridians: evidence in favor of a premotor theory of attention. Neuropsychologia. 1987;25(1A):31–40. doi: 10.1016/0028-3932(87)90041-8. [DOI] [PubMed] [Google Scholar]
- Rosenbaum GM, Jiang YV. Interaction between scene-based and array-based contextual cueing. Attention, Perception & Psychophysics. 2013;75(5):888–899. doi: 10.3758/s13414-013-0446-9. doi:10.3758/s13414-013-0446-9. [DOI] [PubMed] [Google Scholar]
- Schacter DL. Searching for Memory: the Brain, the Mind, and the Past. Basic Books; New York, NY: 1996. [Google Scholar]
- Smith AD, Hood BM, Gilchrist ID. Probabilistic cuing in large-scale environmental search. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2010;36(3):605–618. doi: 10.1037/a0018280. doi:10.1037/a0018280. [DOI] [PubMed] [Google Scholar]
- Squire LR. Memory systems of the brain: a brief history and current perspective. Neurobiology of Learning and Memory. 2004;82(3):171–177. doi: 10.1016/j.nlm.2004.06.005. doi:10.1016/j.nlm.2004.06.005. [DOI] [PubMed] [Google Scholar]
- Treisman A. Attention: Theoretical and psychological perspectives. In: Gazzaniga MS, editor. The New Cognitive Neurosciences. MIT Press; Cambridge, MA: 2009. pp. 89–204. [Google Scholar]
- Umemoto A, Scolari M, Vogel EK, Awh E. Statistical learning induces discrete shifts in the allocation of working memory resources. Journal of Experimental Psychology: Human Perception and Performance. 2010;36(6):1419–1429. doi: 10.1037/a0019324. doi:10.1037/a0019324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Walthew C, Gilchrist ID. Target location probability effects in visual search: an effect of sequential dependencies. Journal of Experimental Psychology: Human Perception and Performance. 2006;32(5):1294–1301. doi: 10.1037/0096-1523.32.5.1294. doi:10.1037/0096-1523.32.5.1294. [DOI] [PubMed] [Google Scholar]
- Willingham DB, Nissen MJ, Bullemer P. On the development of procedural knowledge. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1989;15(6):1047–1060. doi: 10.1037//0278-7393.15.6.1047. [DOI] [PubMed] [Google Scholar]
- Wolfe J. What can 1 million trials tell us about visual search? Psychological Science. 1998;9(1):33–39. doi: http://dx.doi.org/10.1111/1467-9280.00006. [Google Scholar]
- Wolfe J. Guided Search 4.0: Current progress with a model of visual search. In: Gray W, editor. Integrated Models of Cognitive Systems. Oxford University Press; New York: 2007. pp. 99–119. [Google Scholar]
- Zhao G, Liu Q, Jiao J, Zhou P, Li H, Sun H. Dual-state modulation of the contextual cueing effect: Evidence from eye movement recordings. Journal of Vision. 2012;12(6):11. doi: 10.1167/12.6.11. doi:10.1167/12.6.11. [DOI] [PubMed] [Google Scholar]