

Abstract
Least Squares (LS) and its minimum variance counterpart, Weighted Least Squares (WLS), have become very popular when estimating the Diffusion Tensor (DT), to the point that they are the standard in most of the existing software for diffusion MRI. They are based on the linearization of the Stejskal-Tanner equation by means of the logarithmic compression of the diffusion signal. Due to the Rician nature of noise in traditional systems, a certain bias in the estimation is known to exist. This artifact has been made patent through some experimental set-ups, but it is not clear how the distortion translates in the reconstructed DT, and how important it is when compared to the other source of error contributing to the Mean Squared Error (MSE) in the estimate, i.e. the variance. In this paper we propose the analytical characterization of log-Rician noise and its propagation to the components of the DT through power series expansions. We conclude that even in highly noisy scenarios the bias for log-Rician signals remains moderate when compared to the corresponding variance. Yet, with the advent of Parallel Imaging (pMRI), the Rician model is not always valid. We make our analysis extensive to a number of modern acquisition techniques through the study of a more general Non Central-Chi (nc-χ) model. Since WLS techniques were initially designed bearing in mind Rician noise, it is not clear wether or not they still apply to pMRI. An important finding in our work is that the common implementation of WLS is nearly optimal when nc-χ noise is considered. Unfortunately, the bias in the estimation becomes far more important in this case, to the point that it may nearly overwhelm the variance in given situations. Furthermore, we evidence that such bias cannot be removed by increasing the number of acquired gradient directions. A number of experiments have been conducted that corroborate our analytical findings, while in vivo data have been used to test the actual relevance of the bias in the estimation.
Keywords: Diffusion Tensor, Least Squares, Rician, Non-Central-Chi, Bias
1 Introduction
Diffusion Tensor Magnetic Resonance Imaging (DT-MRI) is a modality within Nuclear Magnetic Resonance (NMR) which exploits the diffusion of the spins associated to water molecules in the soft tissues to infer the macroscopic anisotropy of certain anatomies. Although other applications are possible, its clinical use is mostly devoted to neurosciences and brain imaging, where it has allowed tracking the principal directions and connectivity of nerve fibers in the white matter in vivo (Basser et al., 1994; Basser and Pierpaoli, 1996).
DT-MRI aims at characterizing the macroscopic statistics of the diffusion process at each imaged voxel. In the white matter, water molecules are supposed to move preferentially along the nerve fibers but not in the transverse directions, for which the myelin coats surrounding the neural axons restrict the diffusion. This assumption is reasonable as long as the diffusion time used in the experiment is short enough compared to the time scale of water exchange between compartments.
Although the statistics of diffusion in a restricted medium (neural axon) filled with an isotropic material (water) are rather complex, see Söderman and Jönsson (1995), the physical space of the voxel comprises a large number of pores containing a large number of water molecules each. If the pores are coherently oriented, the overall statistics will be the ensemble average of a large number of independent and roughly equally distributed individual statistics, yielding a 3-D multivariate Gaussian process with zero mean and anisotropic variance D, the so-called Diffusion Tensor (DT). As a covariance matrix, the DT can be represented as a 3 × 3 symmetric matrix with real, positive eigenvalues and orthogonal eigenvectors.
On the other hand, DT-MRI shows well-known limitations when the microscopic pores are not coherently oriented, as it is the case in scenarios of fibers crossing, bending, or kissing (Tuch, 2004; Wedeen et al., 2005). A number of approaches have appeared in the recent years to overcome these problems, such as Diffusion Spectrum Imaging (DSI) (Wedeen et al., 2005) or High Angular Resolution Diffusion Imaging (HARDI) (Jansons and Alexander, 2003; Özarslan et al., 2006; Tournier et al., 2007; Tristán-Vega et al., 2009b, 2010; Tuch, 2004). Despite this consideration, DT-MRI is nowadays a well-accepted and wide-spread technique, having shown its enormous potential for the diagnosis and treatment of several diseases including brain tumors and injuries, epilepsy, schizophrenia, or Alzheimer among others, see Sundgren et al. (2004); Taylor et al. (2004) for some reviews on this topic.
The ubiquitousness of DT-MRI applications justifies the importance of the research and development of new techniques for data processing and interpretation. At the heart of these techniques, especially those involving quantitative parameters, is the proper estimation of the DT from noisy MRI data sets. This is done by means of a Pulse Gradient Spin Echo (PGSE) sequence (Stejskal and Tanner, 1965): by applying a strong sensitizing pulsed gradient in the magnetic field, the obtained signals suffer a net attenuation compared to the unweighted T2 images. Such signals are the so-called Diffusion Weighted Images (DWI). Their attenuation strongly depends on the direction of the pulsed gradient, so that the larger fading corresponds to those orientations parallel to the primary directions in which the stochastic water diffusion proceeds.
Given the symmetry of the DT, only six free parameters are required to fully describe the diffusion process, which can be estimated by applying, at least, six different sensitizing gradients along independent directions (additionally, a T2 unweighted image is required to measure the attenuation). Then, a well posed linear system with six equations and six unknowns can be arranged and solved with standard methods. However, this former idea is not very useful in practice, since DWI are much more effected by acquisition noise, traditionally modeled as Rician distributed (Gudbjartsson and Patz, 1995), than anatomical MRI due to the strong attenuations necessary to measure diffusion (Basser and Pajevic, 2000). This artifact has lead to the use of redundant gradient directions to arrange an overdetermined system of linear equations which may be solved by means of Least Squares (LS) approaches.
A relevant reference in this sense is Salvador et al. (2005), since it formalizes the estimation based on Weighted Least Squares (WLS) and formally describes an iterative correction for WLS which is today a common methodology in DT-MRI software. For log-Rician distributed noise (coming from the linearization of the PGSE equation, see section 2.3), the author empirically derives the optimal weights to be used in order for the Gauss-Markov theorem to ensure that the estimate has minimum variance. Additionally, it is analytically evidenced that for a moderate Signal to Noise Ratio (SNR) the bias in the estimation is close to zero, and hence the estimator is the Best Linear Unbiased Estimator (BLUE) (Kay, 1993), which is to say that it is the optimal linear estimator in the sense of the Mean Squared Error (MSE).
Of course, other approaches for the estimation of the DT are possible, including: non-linear LS (Koay et al., 2006); LS with outlier rejection (Chang et al., 2005; Mangin et al., 2002); Maximum Likelihood (ML) and Maximum a Posteriori (MAP) estimation (Andersson, 2008; Landman et al., 2007); log-Euclidean computing to ensure the Positive Definite (PD) property of the DT (Arsigny et al., 2006; Fillard et al., 2007); variational frameworks featuring built-in spatial regularization (Tschumperle and Deriche, 2003; Wang et al., 2004); or sequential techniques for online estimation (Brion et al., 2010; Poupon et al., 2008) (which are indeed based on LS). Even so, LS and WLS are still the standard in most of DT-MRI software and commercial machinery due to their simplicity, computational efficiency, and optimality properties.
Since the work by Salvador appeared (and even before), some imaging protocols based on multiple-coil sensing have become very popular. Parallel Magnetic Resonance Imaging (pMRI) is based on the simultaneous acquisition of the different parts of the MRI volume by a number of independent coils with a given spatial distribution within the MRI scanner. It allows to reduce the geometric distortions produced by phase evolutions between subsequent echoes in Echo Planar Images (EPI), and to improve the SNR of the acquisitions by the combination of the signals proceeding from each of the radio frequency antennas. Under certain assumptions, the sum of their squared magnitudes (SoS) closely resembles the optimal combination in the sense of the MSE (Gilbert et al., 2007), and hence this is a popular approach. To reduce the geometric artifacts, the k-space at each receiver is subsampled, and the lost data is interpolated by somehow combining the redundant information. Despite the variety of techniques available, see Larkman and Nunes (2007) for a review, two of them are the most widely accepted today: Sensitivity Encoding (Pruessmann et al., 1999, SENSE), which performs the reconstruction of the composite signal from the signals at each coil in the spatial domain, and the GeneRalized Autocalibrated Partially Parallel Acquisition (Griswold et al., 2002, GRAPPA) protocol, which linearly interpolates the down-sampled k-space using a set of complex weights learnt from the low frequency spectrum (the so-called AutoCalibrating Signal, ACS). The latter has the additional advantage that it does not need a prior knowledge on the spatial sensitivity of the coils, hence the term Autocalibrated.
Naturally, the reconstruction procedure alters the statistics of the image (Thunberg and Zetterberg, 2007). With SENSE the noise can still be modeled as Rician, although a spatial pattern of variation of the noise power, the g-factor, is introduced (Larkman and Nunes, 2007). This is not an issue for the estimation of the DT as long as the estimator does not need to characterize the noise power, as it is the case with LS/WLS. However, the g-factor also stands for a decrease in the SNR which highly effects the bias in the calculation.
On the contrary, with fully sampled pMRI and also with GRAPPA, a whole complex spatial domain is reconstructed at each of the receiving coils which are further combined, in most of cases, using SoS. Obviously, the Rician statistics no longer apply to this case; if the signals at each coil are considered roughly uncorrelated, Non Central-Chi (nc-χ) statistics arise (Constantinides et al., 1997). However, this assumption is too coarse, and correlations between coils do exist (Aja-Fernández and Tristán-Vega, 2011; Thunberg and Zetterberg, 2007). Moreover, GRAPPA interpolation introduces very strong correlations between the channels. Nonetheless, it has been evidenced in a recent work that these correlations can be obviated with the introduction of an effective (reduced) number of receiving coils and an effective (increased) power of noise (Aja-Fernández and Tristán-Vega, 2011; Aja-Fernández et al., 2010b, 2011), so that the nc-χ can be considered general enough to model these signals. Additionally, GRAPPA images show also a spatial distribution of noise power similar to the g-factor in SENSE (Breuer et al., 2009).
pMRI systems are the standard today, to the point that they are used by all current scanner manufacturers. Given the concerns above, specially those referred to non-Rician signals, it remains evident that LS/WLS techniques for DT estimation have to be revisited. First, it is not clear whether or not the weights proposed by Salvador et al. (2005) for WLS are still valid with nc-χ signals. Second, even when the variance of the estimator were the minimum, certain biases might appear directly depending on the SNR. This artifact has been empirically reported even for Rician signals by Basser and Pajevic (2000); Jones and Basser (2004), and it is expected to become more noticeable with SENSE due to the amplification of the noise power associated to the g-factor. As a summary, it is not clear how pMRI/multi-coil reconstruction algorithms effect the estimation of the DT with LS/WLS.
In the present paper we propose an analytical study of the log-statistics of both Rician and nc-χ statistics, theoretically justifying and extending the findings in Salvador et al. (2005) to the nc-χ case (section 2.1). We use Taylor series to derive tractable, yet accurate expansions allowing easy intuitions on the behavior of noise-driven errors (section 2.2). These developments serve to generalize the popular WLS methodology to the nc-χ case, and to provide useful hints on when the error in the estimation can be reduced in a number of practical situations. The present work extends our preliminary results in Aja-Fernández et al. (2010a); Tristán-Vega et al. (2009a), providing full analytical derivations and applying a similar methodology for the ordinary LS, as well as illustrating our main results with in vivo data.
2 Methods
2.1 Theory
In this section we briefly review the principles underlying DT-MRI and the estimation of the DT, aiming to justify the importance of the statistics of noise in the logarithmic domain. The main results are the general model for noise in eq. 3 and the general model for the statistical parameters of noise in the logarithmic domain in eqs. 7 and 8. Both are novel contributions in our work, and apply for most of the nowadays MRI imaging protocols.
2.1.1 The DT model in diffusion MRI
When a short sensitizing gradient is applied along a unit direction gi = [gi,1, gi,2, gi,3]T, the T2 baseline image, A0, suffers an attenuation driven by the Stejskal-Tanner equation (Stejskal and Tanner, 1965):
| (1) |
where D is the diffusion tensor and b is a constant that comprises, along with the gyromagnetic ratio γ, the magnitude of the sensitizing gradients ∥G∥, the duration of the pulses δ, and the diffusion time Δ (LeBihan et al., 1986); the short pulses condition implies δ ≪ Δ.
2.1.2 Linearization of the Stejskal-Tanner equation
A straightforward way to estimate D is taking the logarithm of eq. 1:
| (2) |
taking advantage of the symmetry of the DT. For N > 6, eq. 2 represents an overdetermined linear system with 6 unknowns (the 6 free components of D) and N equations, which can be easily solved with LS techniques.
2.1.3 General statistical characterization of noise in MRI
The signal M actually acquired is a noisy version of A in eq. 2. For fully sampled pMRI and GRAPPA with SoS combination, its Probability Density Function (PDF) corresponds to a nc-χ variable (Aja-Fernández et al., 2011)1:
| (3) |
which stands for the probability (density) of obtaining a measurement t at a given voxel of the MRI volume, provided that 1) the ideal, noise-free signal is AL, 2) the (effective) noise power in the image domain is σ2, and 3) the (effective) number of coils is L. For a definition of these effective parameters, see Aja-Fernández et al. (2011). Finally, IL−1 is the modified Bessel function of the first kind and order L − 1, and u(t) is Heaviside’s function. AL is related to the in-phase component Al,c and the quadrature component Al,s of the complex signal at the l-th coil, Al,c + jAl,s, as:
| (4) |
which is the ideal measurement in the absence of noise (i.e. with σ = 0). Consistently, if we consider a single coil system with L = 1, eq. 3 reduces to the Rician PDF traditionally considered for MRI data sets:
| (5) |
Therefore, the first meaningful remark is that the nc-χ statistics can be used as a general model for the noise distribution in MRI even with pMRI protocols, with or without subsampling (note that the effective value of L and σ has to be fixed accordingly), whenever SoS is used.
2.1.4 General statistical characterization of the log-statistics
From eq. 2, the linearized estimation of D requires the statistical characterization of log M (or log ML). The corresponding PDF may be obtained from eq. 3 using the fundamental theorem of probability:
| (6) |
whose mean μ = E{log ML} and variance ν = Var{log ML} are computed in Appendix A:
| (7) |
| (8) |
where ρ is defined from the SNR, AL/σ, as , and:
In the previous equations, ψ(·) is the polygamma function, ψ1) (·) is its first derivative, and 2F2(⋯) is the confluent hypergeometric function of the first kind (Abramowitz and Stegun, 1972). Particularizing eq. 7 for L = 1 and doing some algebra yields the result reported by (Salvador et al., 2005, eq. (11)):
| (9) |
with Γ(u) the upper incomplete Gamma function. Hence, eq. 7 generalizes the analytical result in Salvador et al. (2005) to the nc-χ case, while eq. 8 is a novel contribution which has not been provided even for the Rician case.
2.2 Operative approximations to the log-statistics
Although eqs. 7 and 8 provide closed forms for the statistics of log-MRI signals, their complexity does not allow a further analysis. Instead, we use the following first-order approximations derived in Appendix B:
| (10) |
| (11) |
where Landau’s symbol O denotes the corresponding term decays as fast as its argument. Note in eq. 10 that the log-Rician bias drops to O(ρ−3). Indeed, we prove in Appendix C a much stronger condition: it drops to zero like exp(−ρ). This is consistent with the observation made by Salvador et al. (2005) that the bias in the Rician case should remain small for moderate SNR. At the same time, nc-χ signals are expected to show far larger biases (O(ρ−2)).
2.3 Estimation of the DT for nc-χ signals
In this section we introduce the problem statement of DT estimation as a linearized problem. The main results to highlight are: 1) The estimation is nearly unbiased in the Rician case, but not in the more general nc-χ case (section 2.3.1). 2) The usual implementation with WLS has nearly-minimum variance even in the general nc-χ case (section 2.3.3).
2.3.1 Linearized problem with log-nc-χ signals
The model in eq. 2 has to be rewritten in terms of the measured composite signals for each gradient direction gi, say ML,i:
| (12) |
As opposed to Salvador et al. (2005), we assume the baseline AL,0 is known (noise-free). Since the SNR in the baseline image is far above that in the DWI, this assumption does not involve any substantial implication in our developments. From eq. B.3, εi has non-zero mean unless ρ is very large. This implies that the estimation of D will be notably biased except for the particular log-Rician case, that shows a bias in the order of exp(−ρ).
2.3.2 Solution based on (ordinary) LS
When no prior knowledge on the statistics of εi is available, the optimal solution to eq. 12 is given by the LS formulation (Kay, 1993):
| (13) |
where Y is an N × 1 vector comprising the DWI data, log(AL,0) − log(ML,i); X is the 6 × 1 vector of unknowns, (bDij); and G is the N × 6 concatenation of each row . This estimator has not minimum variance.
2.3.3 Solution based on WLS
If the variance of εi can be characterized, the linear estimator with the minimum variance is provided in Kay (1993):
| (14) |
where W is the inverse of the covariance matrix of the data, CYY. Since the noise in each DWI is independent, W reduces to a diagonal matrix of the form:
| (15) |
since AL,0 is considered noise-free. Interestingly, the optimal weights are not proportional to ρi (i.e. to ), even for Rician noise, except for moderate-high SNR. However, we neglect the term (3L − 4) in eq. 15 for several reasons:
If 3L − 4 ≪ 2ρi, the estimator will very approximately resemble the one with minimum variance. In practice, effective values of L greater than 8-10 are hard to find (Aja-Fernández and Tristán-Vega, 2011; Aja-Fernández et al., 2011), translating in ρi ≫ 12.5 ⇒ AL,i ≫ 5σ. This is not a very large value in the white matter for the b-values commonly used in DTI.
Such formulation is identical to that in Salvador et al. (2005), and is the one implemented in most of the software for the estimation of the DT.
That way it is not needed to know the value of σ, since any weight proportional to ρi (i.e. to ) can be used. Otherwise, we should estimate σ, losing one of the key advantages of WLS over ML.
To our knowledge, no justification had been given for the use of these weights other than the empirical study in Salvador et al. (2005). Finally, note the weights Wii depend on AL,i (not ML,i), so they cannot be known a priori; this pitfall may be obviated by iteratively estimating X and updating W (Salvador et al., 2005). In what follows we assume W is known without uncertainty.
2.4 MSE in the components of the DT for LS and WLS
Once we have described the MSE in the log-signals in eqs. 10 and 11, we now study how this error is propagated to the DT when it is estimated as described in section 2.3. The MSE is computed as the sum of the variance plus the squared bias, and for WLS it is provided by Tristán-Vega et al. (2009a):
| (16) |
| (17) |
where: L = (GTWG)−1 (symmetric); ; CXX is the covariance matrix of the error; ζ is its element-wise bias; Δij stands for the error in the estimation of Dij. For LS, the following values are derived in Appendix D:
| (18) |
| (19) |
where 1 is an N × 1 vector of all ones and L′ = (GT G)−1. In the remaining, the following remarks will be useful:
Even if the weights W are nearly optimal, nc-χ signals introduce a certain bias, so the BLUE is (roughly) achieved only for Rician signals with WLS.
The size (trace, determinant) of GTWG and GT G asymptotically behaves like the number of gradients N (Tristán-Vega et al., 2009a). Hence, the size of L and L′ behaves like 1/N.
It follows that the variance, asymptotically driven by its first term tr(L) or tr(L′GTW−1GL′), decays like 1/N.
For the bias (WLS), N2 cancels the 1/N2 decay from L2, being asymptotically constant with N. With LS, W−1G and GTW−1 cancel L′2.
The dependency with the SNR comes from L through W in WLS (or through W itself in LS): the variance decays as 1/ρ, and the squared bias as 1/ρ2.
Finally, while the squared bias directly depends on L2, the dominant term of the variance is constant with L.
3 Experiments and results
3.1 Accuracy of the Taylor series expansions
First of all, we test the correctness of eqs. 7 and 8 and the accuracy of the series expansions in eqs. 10 and 11. To that end, we have generated synthetic nc-χ signals following the first equality in eq. B.2, for different numbers of receiving coils L and for values of AL/σ ranging from very low to very high SNR. The sample statistics thus obtained are compared to the true expressions, and to their counterparts computed from the series expansions, in Fig. 1. Obviously, the actual statistics perfectly fit the empirical values. As expected, the power series expansions are very accurate for large SNR, but show large deviations for smaller AL/σ. Such deviation increases with the number L of antennas, but it can be concluded that the approximations are adequate for AL/σ > 7 whenever L < 8. Although modern machinery may comprise up to 32 coils, noise correlations carry on a drastic reduction in the effective L which in practice makes it difficult to reach L > 10. With GRAPPA the SNR is lower, but at the same time the correlation-like artifacts reduce even more the effective number of coils L. Hence, our approximations are valid for a wide range of realistic cases. Of course, for L = 1 we come back to the Rician case, for which the bias is almost negligible.
Fig. 1.
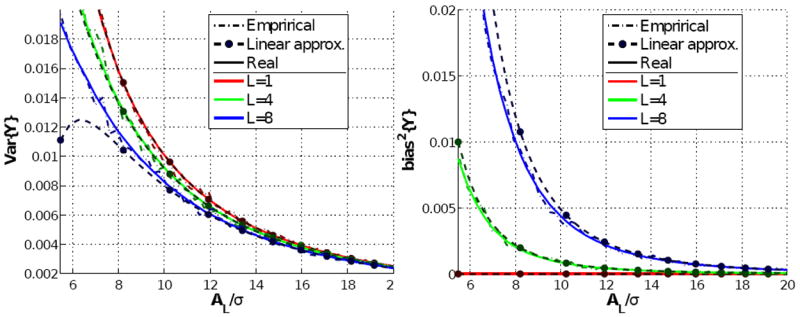
The variance (left) and the squared bias (right) of logarithmic nc-χ signals as a function of the normalized SNR, AL/σ, and for different typical numbers of receiving coils. For each curve, we show: the true value theoretically obtained from eqs. 7 and 8; the first-order approximation we propose in eqs. 10 and 11; a sample estimate reckoned by means of Montecarlo simulation over a set of 2,000 independent samples.
3.2 Asymptotic behavior of the bias and the variance: isotropic case
As shown in previous sections, the bias and the variance suffer certain amplification with respect to the DWI after DT reconstruction, depending on the matrix G of gradient directions and the matrix W of signal amplitudes. We first consider a simplified scenario of isotropic diffusion, i.e. W = 2ρIN for IN the identity matrix. Note that in this case both LS and WLS converge to the same estimator: if all the samples show the same SNR, the Gauss-Markov theorem states that LS has minimum variance. In this case L = L′ = (GT G)−1 and either eq. 17 or (19) reduce to:
| (20) |
From the previous equation, it remains evident that the study of L′ = (GT G)−1 is particularly useful. It is shown in appendix E that, if the gradients gi are considered to be fairly distributed on the unit sphere, ν/∥ν∥ is an eigenvector of L′ associated to the eigenvalue 3/N. On the other hand, the trace of L′ can be evaluated for antipodal symmetric gradient directions, and the following expression results fairly accurate: tr((GT G)−1)≃ 29.3/N. Hence, the following approximation holds:
| (21) |
since the remaining eigenvectors of L′ are orthogonal to ν. The previous equation is quite illustrative: it explicitly shows that the squared bias does not depend on the number of gradients, while the variance linearly decreases with 1/N. Since the dominant term in the variance is the one in ρ−1 (independent of L), it is also clear that the larger the number of receiving coils the more important the relative contribution of the bias to the MSE, which shall be only marginal for L = 1 (Rician noise). Fig. 2 quantitatively illustrates this reasoning. It aims at measuring the impact of the bias in the total MSE for different scenes: as an example, consider a system with effective L = 8, as chosen in the picture; with 51 gradient directions, the contribution of the bias is more important than that of the variance for all AL/σ < 16.7 (ρ < 139.95). Alternatively, for L = 8 and a mean AL/σ ≃ 17 in the DWI, it makes no sense to use more than 51 gradient directions (as long as the Gaussian assumption underlying the tensor model holds), since the dominant source of error is the bias and it cannot be reduced by increasing N. For lower SNR (say AL/σ = 10, ρ = 50), the limiting number of gradients is as small as N = 15, so we may conclude that the bias in the estimations cannot be neglected in practical scenarios. As an additional remark, note that we are dealing with AL/σ = 10, 17, which are well above the minimum value for which the power series expansions are reliable. Finally, let us consider the following example: suppose a GRAPPA reconstruction with effective L = 6, N = 15, and AL/σ = 7.5 in our region of interest. From Fig. 2, increasing the number of gradients is not really worthy, since the squared bias will become higher than the variance and remain as a constant, residual error as N increases. In this situation, the only chance is to increase the SNR.
Fig. 2.
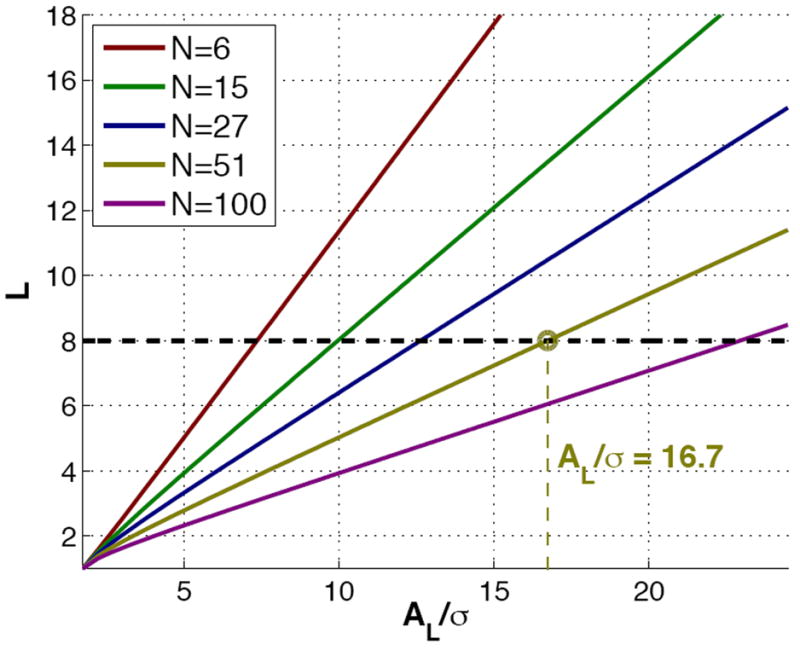
For each normalized SNR AL/σ, we depict the minimum effective number of coils L such that the squared bias equals the variance in an isotropic scenario. The linear behavior is easily explained from eq. 21. Note also that for L = 1 (Rician noise) all the curves collapse to the point AL/σ = 0: for Rician noise the bias is very small, so that we need a very low SNR to achieve a non-negligible bias.
3.3 Asymptotic behavior of the bias and the variance: anisotropic case
Of course, the most interesting case relies on anisotropic diffusion. To further test the conclusions above, we have designed a hypothetical system with typical values L = 8 (for other values of L, the linearity of the graphics in Fig. 2 allows to easily extrapolate the experiment), N = 15, 27, and 51, b = 1500s/mm2, and Mean Diffusivity (MD) 0.8 · 10−3mm2/s. Now the diffusion is not isotropic; instead, we consider different Fractional Anisotropies (FA) for a prolate, cigar-shaped tensor (λ1 > λ2 = λ3) and an oblate, disk-shaped tensor (λ1 = λ2 > λ3). Fig. 3 shows the minimum value of the SNR for which the squared bias is kept below the variance, as a function of the FA, computed from eqs. 17 and 19. LS and WLS are not equivalent in this case, and as such they are considered separately2. For FA= 0 we have an isotropic diffusion, and all the curves collapse to exactly the same point, which is the cut of the horizontal line L = 8 with each N = 15, 27, 51 in Fig. 2 (once attenuated by a factor exp(−b · MD)). As the FA increases, however, the squared bias becomes even more important, so that we need a SNR one order of magnitude higher to keep a relatively small bias contribution. Yet, the most conflicting case (the one requiring the largest SNR) arises with prolate tensors with large FA, which is indeed the most interesting one. For example, with N = 51 and FA= 0.8, the squared bias is greater than the variance for ρ0 < 104 (AL0 < 140σ); though such SNR corresponds to the cleaner baseline image, it is still representative for white matter areas. Besides, for AL0 ≃ 300σ (this SNR may be considered an upper limit for many realistic data sets) the bias will be roughly 1/4 of the variance, which is clearly not negligible.
Fig. 3.
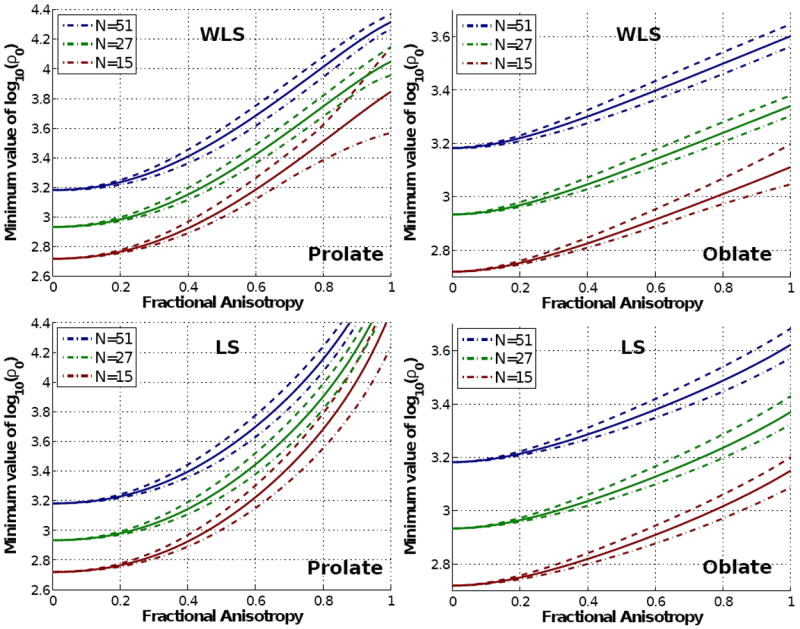
Log-plot of the minimum value of (related to the SNR in the baseline) which keeps the squared bias below the variance in the components of the DT for different tensor shapes. We show minimum, mean, and maximum values among all possible spatial orientations of the distinctive eigenvector of the tensor. The upper row shows the results for WLS reconstruction, and the bottom row those for LS.
With ordinary LS, the results are qualitatively similar, the bias gaining relative importance as the FA increases. Still, the minimum SNR for prolate tensors is slightly increased, approaching ρ0 = 105 (AL = 450σ) in the worst case: the impact of the bias is at least as important as it is with WLS. Since the variance with LS is also higher, it remains evident that WLS is the preferred.
3.4 Numerical analysis of the error in the DT components (synthetic data)
The previous results are instructive and provide useful hints for the design of pMRI acquisitions. However, we have made certain assumptions that might introduce (hopefully low) systematic errors in our model. Mainly:
The weights used for WLS are not strictly the optimal.
We have considered the ideal weights for WLS are known a priori instead of estimated (the first two issues do not compromise the study for LS).
The T2-baseline image has been considered noise-free.
For these reasons, we have intended a series of experiments avoiding these modeling assumptions. A synthetic 128 × 128 synthetic 2-D tensor field 3 has been generated, see Fig. 4, comprising tensors with three different combinations of eigenvalues (mm2/s): [1.5 · 10−3, 0.4 · 10−3], [2 · 10−3, 0.1 · 10−3] and [2 · 10−3, 1.25 · 10−3]. DWI are simulated using eq. 1 for b = 1, 000 s/mm2. Two scenarios are designed: (i) N = 16 gradients, ρ0 = 1, 250 (AL,0 = 1, 000, σ = 20); (ii) N = 8 gradients, ρ0 = 2,500 (AL,0 = 1, 000; ). Two cases are assumed:
nc-χ noise from fully sampled pMRI (hereafter, pMRI-SoS) with L = 8. A sensitivity map is coded for each coil so that . The images at each coil are corrupted with a complex Gaussian noise N(0, σ2) and the composite image computed with SoS.
Standard Rician noise generated from one single receiving coil (L = 1; note we are considering one single coil with the same effective sensitivity as the whole 8-coil ensemble used for the nc-χ case).
Fig. 4.

The synthetic tensor fields generated. The Stejskal-Tanner equation is used to compute the synthetic DWI (possibly at each coil); the k-space is computed via the Fourier transform, and then corrupted with Gaussian noise. For pMRI-SoS the image domains at each coil are combined with SoS. Finally, iterative WLS is used to reconstruct the DT.
We use WLS in both cases to reconstruct the DT. In order to study the bias and the variance of the error in the estimation, data from 100 realizations of each experiment are considered (see Fig 4 for one such realization).
Fig. 5 shows the histograms of the estimated components of the tensor, with the ideal centroids marked as red spots. Our first point is that the dispersion of the clouds in both columns are comparable in all cases: doubling the number of gradient directions is exchangeable with doubling the input SNR. Comparing the offset of the clouds with respect to the noise-free centroids, it remains evident that the bias in the second scenario (right column) is smaller. Under the point of view of the output MSE, the second scenario is obviously preferable. As expected from our previous developments, nc-χ signals produce a significantly greater bias than Rician. In particular, single-coil, Rician acquisitions show a nearly negligible bias in all cases, as Appendix C suggests. Attending exclusively to the bias in the estimation of the DT, the acquisitions using SENSE are preferable to GRAPPA for a similar input SNR after pMRI reconstruction, since the former arise Rician signals meanwhile the noise statistics for the latter have to be characterized as nc-χ.
Fig. 5.
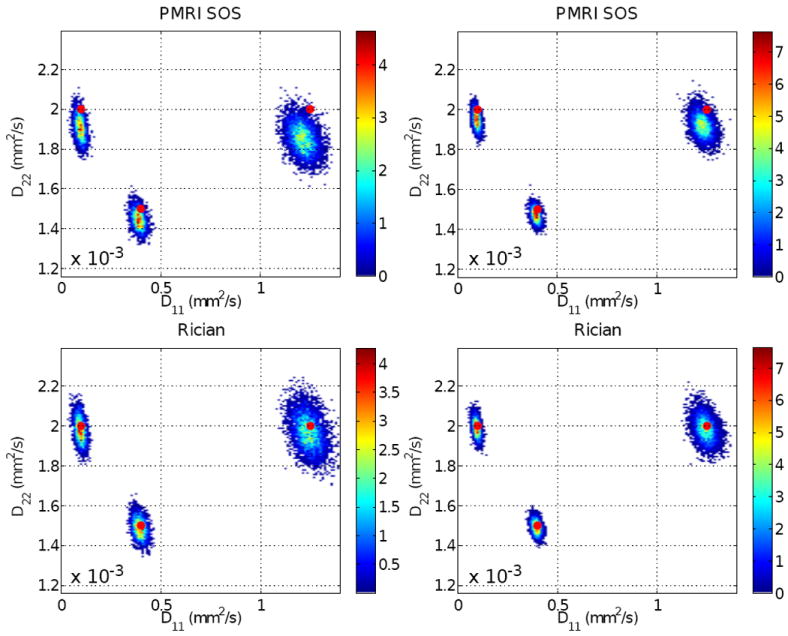
Histograms of the estimated (diagonal) components of the DT (note in Fig. 4 that the noise-free, ideal tensors are always diagonal). Left column: σ = 20, N = 16. Right column: σ = 14.1, N = 8. The value of ρ in the second column is twice that in the first column, but the number of gradients is halved so that the output variance is ideally the same.
To empirically check the impact of the analysis above on tensor-derived measures, we now study the behavior of the relative root MSE (rRMSE) in the estimated eigenvalues, and , with respect to the ground-truth, λ1 and λ2:
| (22) |
against variations of both σ and N. With the setting-up described before, Fig. 6 shows the corresponding values, averaged for all realizations and pixels in the tensor field. The slope of the error as a function of the noise power σ is larger for nc-χ systems: for moderate-low SNR, the bias grows along with the variance, both of them perceptibly contributing to the rRMSE. For Rician systems, the bias is almost negligible, so that the rRMSE grows as long as the variance does. If we now consider the dependence with N, the rRMSE is monotonically reduced until a point where no further improvement is achieved: this is the point where the bias is dominant over the variance and it makes no sense to keep on increasing the number of gradients. This point is clearly reached before for nc-χ systems.
Fig. 6.
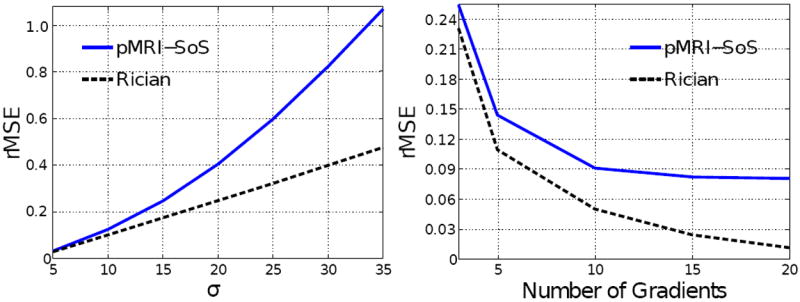
Evolution of the rRMSE in the estimated eigenvalues as a function of the power of noise in the receiver σ2 (left: N = 5 gradients has been used; note in a 2-D scenario the minimum number of gradients to estimate the DT is N = 3) and the number of diffusion gradients N (right: σ = 10 has been used).
Though the numerical analysis performed above is limited to a few toy examples, it serves to conclude that the theoretical findings in the present paper apply even in non-ideal conditions (regarding our assumptions about the WLS weights and the noise power in the T2 baseline). To further justify this statement, we provide in the next section a final set of examples with in vivo data illustrating the accuracy of the model proposed.
3.5 Numerical analysis of the error in the DT components with in vivo data
For the last experiment, 20 identical and independent repetitions of a DWI data set with one baseline image and 15 gradient directions were successively taken from a healthy volunteer. To keep a reasonable acquisition time, one axial slice was collected in a 3T, 8-coil (without down-sampling) Philips scanner using a diffusion parameter b=1,200s/mm2. The diffusion tensor at each voxel was estimated using standard WLS. Fig. 7 (a) shows the corresponding T2-baseline image and the color orientation map obtained. Figs. 7 (c) and (d) show respectively the squared bias and the variance computed either as sample estimates (left) or with the expressions provided in eq. 17 (right). Finally, Fig. 7 (b) shows the fraction of the MSE corresponding to the squared bias in each case.
Fig. 7.
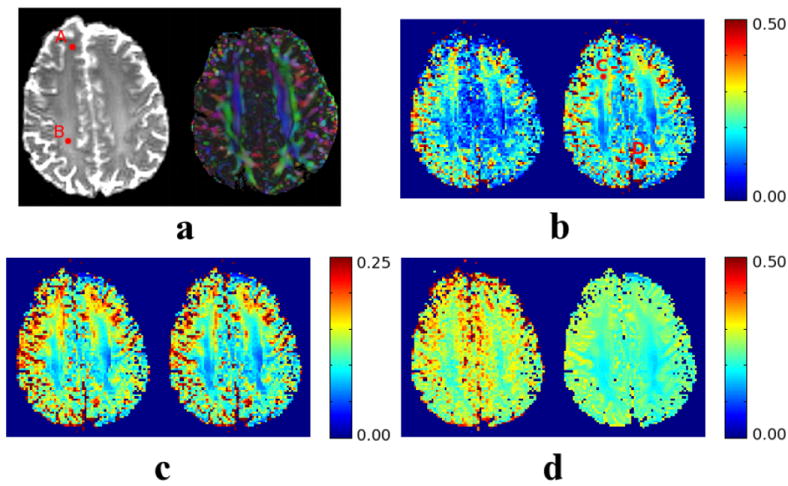
An axial slice of the brain of a healthy volunteer, acquired in a 3T, 8-coil Philips scanner. We show the baseline image and orientation color (a), and: the fraction of the MSE corresponding to the squared bias (b, relative units), the squared bias (c, absolute units), and the variance (d, absolute units). In all the cases, we show on the left hand side the sample values computed from 20 independent acquisitions and on the right hand side the values computed with our analytical expressions. The regions of interest are those corresponding to the white matter (vivid colors in a, right).
For the analytical computation of the bias and variance, we have computed the effective noise power and the effective number of coils Leff = 4.2 (Aja-Fernández and Tristán-Vega, 2011). Note these values are quite different from the original σ2 = 0.054 and L = 8 due to the noise correlations between the receivers. The first comment is that the SNR ρ in the baseline is well above the lower limit for which the series expansions are valid, at least in the white matter: in the locations flagged as A and B, they equal ρA = 96 and ρB = 280, hence we expect the analytical expressions to be faithful approximations of the sample computations. This assertion becomes clear comparing the squared bias and the variance in each case: the analytical bias is virtually identical to the estimated one, while a larger difference may be appreciated in the variance map. Note, however, these differences correspond to grey matter areas, for which the SNR in the DWI is typically much reduced and the series expansions are not reliable. In white matter areas, the approximations are still very accurate. Finally, the maps of the fraction of the MSE corresponding to the bias are also practically identical, at least for the regions of interest (white matter). Remarkably, this fraction may reach nearly 0.25 in C, meaning that the bias is one third of the variance, or even 0.5 in D, meaning that the squared bias equals the variance. Since the computation of the sample bias and variance avoids all the assumptions made throughout this paper, we may conclude our theoretical framework is representative enough of a real case. We would like to stress this experiment is not intended as a systematic empirical study of the error with real data, but as a means to validate the assumptions in our theoretical model. Such study would imply repeating the experiment for different b-values, input SNR, acquisition protocols, etc. Varying all these degrees of freedom for a one-subject, one-session acquisition is not feasible, and would require the design of an entire methodology to deal with this limitation.
4 Discussion
The analysis carried out suggests a number of interesting discussions. The most immediate is that the WLS formulation derived for Rician signals is equally valid for nc-χ distributions. In fact, these same weights can be used as long as the power of noise in each gradient image is similar, since the 1/Ai term comes from the logarithmic compression and not from the noise model itself. This result is especially relevant, since it allows concluding that the current WLS software available for both research tools and commercial machinery perfectly fits the characteristics of most pMRI protocols without any adaptation. Although, in a strict sense, the weights proportional to the squared envelope are not the optimal, we have proved that this is not the case in the conventional Rician case either; moreover, higher order terms may be neglected for moderate SNR permitting to obviate the characterization of the non-stationary power of noise.
In our study, the generalization of the Rician model to nc-χ statistics is critical. In fact, the latter can be seen as a canonical model for parallel and non-parallel MRI with SoS reconstruction. Although WLS are still (closely) valid and we have minimum variance, nc-χ signals drive to biases far larger compared to Rician, thus compromising the optimality of WLS which no longer approaches the BLUE: the larger the number of receiving coils L, the more important the effect of the bias. For GRAPPA, the k-space interpolation carries on a reduction on the effective L, so it seems that the problem could be alleviated; however, the interpolation notably worsens the SNR at the same time (in eq. 16, the decrease in L is compensated by the increase in the size of L through W−1), so the artifact is even accentuated. Note that the same formalism, and hence the same comments, hold for fully sampled pMRI when correlations between the receiving antennas are considered (Aja-Fernández and Tristán-Vega, 2011). For L = 1 (Rician noise), the bias exponentially decays with the SNR, so it will be perceptible only for drastically low SNR.
While the variance in the estimation is easily reduced by increasing the number of acquired gradient directions N, the squared bias is asymptotically constant with this parameter. Paradoxically, some situations may arise in which the dominating source of error is the squared bias, and thus increasing the number of gradient directions does not necessarily improve the estimation. On the other hand, improving the SNR simultaneously reduces the variance (in the order of SNR−1) and even more the bias (order SNR−2). This situation is more likely to arise with pMRI acquisitions, since the k-space subsampling induces a reduction in the SNR. While SENSE is borne with Rician noise and hence the bias will be kept in a reasonable level, GRAPPA systems show nc-χ noise, and thus the bias may become a very relevant issue.
Because of the previous concerns, the need for improving the input SNR becomes patent. The possibility of averaging the magnitude of the signals reconstructed from several independent acquisitions has been explored by Clarke et al. (2008). The authors propose to remove the bias inherent to this process with a simple profile-correction based on the ML estimate of the average (Sijbers et al., 1998). In terms of the output SNR in the tensor components, and for equivalent acquisition times, it results more profitable repeating the acquisition of each gradient direction than increasing the number of gradient directions themselves 4, as long as the number of averages is large enough for the bias removal to be reliable.
On the other hand, unbiased filtering is today a popular approach for a posteriori predicting the value of the unbiased signal out from noisy data, without substantially smoothing anatomical information, for Rician (Manjón et al., 2008; Tristán-Vega and Aja-Fernández, 2010; Tristán-Vega et al., 2011) and nc-χ data (Brion et al., 2011). Note we are only considering noise-driven artifacts, and leaving apart other sources of error like those coming from interpolation or characterization of coil sensitivities.
With regard to the use of LS instead of WLS, we have reasoned that the effect of the bias is asymptotically the same in both cases, so all the comments above hold for LS. Yet, this estimator has not minimum variance, so WLS is the preferred unless the computation time is an issue. WLS is slower for two reasons: first, the iterative computation of the weights in W; second, since W depends on the DWI signal itself, it does not allow the pre-computation of LGTW as LS does with L′GT.
As a final remark, the elegant algebraic formulation proposed for the error in the estimation has been possible because the DT linearly relates to the (log) DWI signal by means of a simple matrix product. This feature is shared by several of the most popular HARDI approaches, so a similar analytical study could be performed for Q-Balls (Tuch, 2004) or OPDT-like estimators (Tristán-Vega et al., 2010) by means of the spectral characterization of such matrices. The impact of Rician bias has been otherwise pointed out empirically by Clarke et al. (2008), so, in light of the present work, it is expected that some important distortions shall be driven by nc-χ signals. At the same time, the study carried out here for the DT components can be generalized to any measurement linearly related to them. For example, the considerations regarding the bias will be equally valid for the mean diffusivity. But if we study some other parameters like the FA, which is related to the DT components in a non-linear way, its estimation can be biased even when the DT components are not. In any case, the guidelines suggested here for the trade-off between the SNR and the number of gradients are still valid.
5 Conclusion
The analysis carried out in this paper applies for most of the nowadays imaging schemes, thanks to the generalization to a nc-χ model. Regardless of their simplicity, Least Squares approaches are still of high interest in the estimation of the DT: as long as log-statistics can be assimilated to Gaussian (i.e. for high enough SNR), WLS is indeed the optimal estimator (linear or nonlinear) in the sense of the MSE, being equivalent to ML with much lower complexity (Kay, 1993). However, important distortions may arise for medium-low SNR, which will obviously translate in systematic errors in the calculation of quantitative parameters of clinical interest such as the FA or the MD. These artifacts are especially annoying for nc-χ systems, for which the biases are far more important. Although it seems tempting to increase the number of acquired gradients to improve the estimation, we have evidenced that, for some scenarios, this procedure can be nearly worthless. The only chance in these situations is to improve the SNR by increasing the voxel size, averaging a set of independent magnitude signals (and correcting the profile to remove the bias), or filtering the data set. In fact, Fig. 3 itself provides useful quantitative hints for the design of DWI acquisitions depending on the input SNR, the required number of diffusion gradients, and the imaging protocol to be used.
Acknowledgments
Work partially funded by grants SAN126/VA33/09 and VA0339A10-2 (Junta de Castilla y León), GRS 292/A/08 (Consejería de Sanidad de Castilla y León), and TEC2007-67073/TCM (Ministerio de Educación y Cultura, Spain – European Regional Development Fund). The corresponding author is supported by the Fulbright Program/Spanish Ministry of Education. The authors would like to specially thank Javier Sánchez-González at Philips-Spain for his very valuable help when conducting the in-vivo experiments.
A Statistical characterization of log-nc-χ signals
The expectation of DL = log ML can be computed from eq. 3 by considering the power series expansion of IL−1:
| (A.1) |
The previous integral can be expressed in terms of the polygamma function ψ (Abramowitz and Stegun, 1972):
| (A.2) |
which now depends only on and can be related to the confluent hypergeomteric function of the first kind (Abramowitz and Stegun, 1972):
| (A.3) |
To compute the variance, we first elaborate on the second order moment:
| (A.4) |
and again the integral can be written in terms of the polygamma function and its derivative ψ1), depending only on ρ:
| (A.5) |
In this case, only some of the terms in the summation drive to a hypergeometric function, compelling us to define the function:
which is depicted in Fig. 8. With this notation, we may write:
| (A.6) |
Fig. 8.
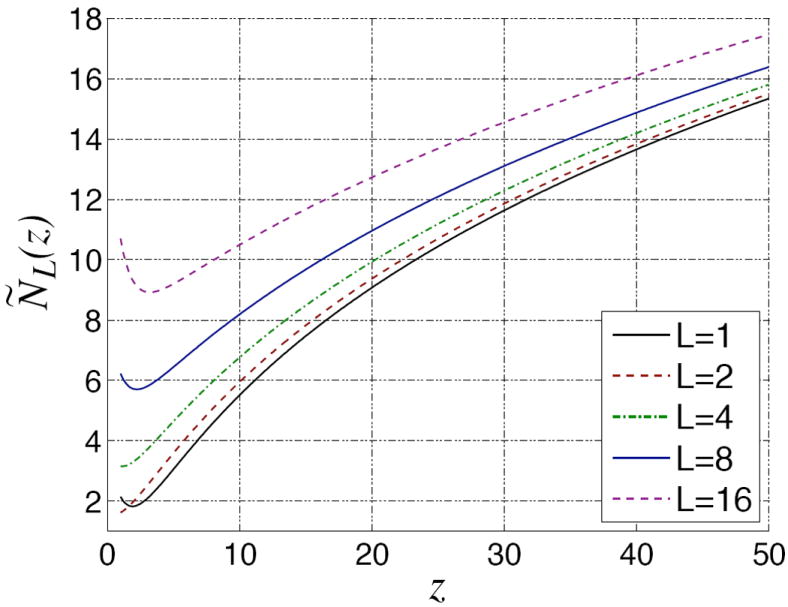
An sketch of the function for several values of L. It is continuous and shows a monotonic behavior in the range of interest.
Finally, the variance is computed as the mean squared value minus the squared mean of log ML, yielding:
| (A.7) |
B Taylor series of the logarithmic statistical parameters
Since the MSE is the sum of the squared bias plus the variance, these are the parameters of interest. Without any loss of generality, we introduce a phase shift in eq (4) such that the same real signal A is acquired at all coils:
| (B.1) |
Note the PDF of log ML in eq. 6 depends only on the net squared signal , so any combination of Al whose squared sum yields will rise identical statistics. With this notation, the Taylor series expansion of log(ML) for reasonable SNR (ρ > 20 ⇒ AL > 6.3σ in the worst case, see Fig. 1) is:
| (B.2) |
with δ the Kronecker delta function and nl,c, nl,s ~ N (0, σ2) the uncorrelated noises in the complex domain. Though this Taylor series is only convergent for , in practice we are dropping the left tails of the Gaussians, which for any reasonable SNR will be negligible. It follows:
| (B.3) |
From eq. B.2, all the terms in σ3/A3 correspond to cross products comprising odd order moments of zero-mean Gaussians, so they are all identically zero and we gain one order of convergence up to σ4/A4. The result in eq. 10 becomes now obvious from the previous expression. For the variance, a parallel development of log ML to order 3 yields the corresponding value in eq. 11.
C Bias of log-Rician signals
In the Rician case we have L = 1, so the bias in eq. 10 drops to O(ρ−3). Indeed, we may use the result in eq. 9 to write the bias in the form:
| (C.1) |
where E1 is the exponential integral function (Abramowitz and Stegun, 1972), which fulfills the following property for ρ > 0:
| (C.2) |
If we choose any positive ρ0 > 0, the monotonicity of log(1+1/ρ) assures that the bias of log-Rician signals is bounded by log(1 + 1/ρ0) exp(−ρ) for ρ > ρ0 i.e., it decreases exponentially, hence faster than any negative power of ρ. As an illustration, suppose the DWI attenuation is 0.1, so the signal of interest is − log(0.1) ≃ 2.3. For SNR ρ = 1, the bias is in the order of 0.1 ≪ 2.3.
D Bias and variance in the DT with LS
From the closed form solution in eq. 13, the covariance matrix of the vector X of unknowns (tensor components) is easily computed using its definition:
| (D.1) |
And for the vector bias:
| (D.2) |
where 1 is an N × 1 vector of all ones and L′ = (GT G)−1. The total MSE in eq. 19 for all tensor components comes from the sum of the trace of the covariance matrix in eq. D.1 and the squared norm of the bias in eq. D.2.
E Spectral characterization of L′ = (GT G)−1
The aim in this appendix is to show that ν/∥ν∥ is (approximately) and eigenvector of (GT G)−1 associated to the eigenvalue 3/N. It suffices to prove that ν/∥ν∥ is an eigenvector of GT G associated to the eigenvalue N/3; applying the definition:
| (E.1) |
Now, we realize that the gi have to be fairly distributed on the surface of the unit sphere, so that we can model their components as independent, uniform random variables, gj~U (−1, 1); although this assumption may seem naive, it accurately fits real scenarios even for small N. With this consideration, the above summations are seen as sample estimates of the moments of gj:
| (E.2) |
Footnotes
We have dropped down the subindices i to keep a reasonably simple notation.
Note no approximations other than the power series expansions are considered now. Neither eq. 21, nor the result in Appendix E are required.
All the above methods apply for the 2-D case with identical derivations, just set ν = [1, 0, 1]T and a different constant for tr{(GT G)−1}~C/N in eq. 21. A 2-D analysis allows performing reliable numerical simulations with a reasonable computational load and intuitively representing the errors in 2-D charts.
We are not considering here other side effects like deviations from the tensor model, or applications requiring a larger number of gradients (HARDI).
Contributor Information
Antonio Tristán-Vega, Email: atriveg@bwh.harvard.edu, Laboratory for Mathematics in Imaging (Harvard Medical School).
Santiago Aja-Fernández, Email: santi@bwh.harvard.edu, Laboratory of Image Processing, Universidad de Valladolid (Spain).
Carl-Fredrik Westin, Email: westin@bwh.harvard.edu, Laboratory for Mathematics in Imaging (Harvard Medical School).
References
- Abramowitz M, Stegun IA, editors. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Dover; New York: 1972. [Google Scholar]
- Aja-Fernández S, Tristán-Vega A. Influence of noise correlation in multiple-coil statistical models with sum of squares reconstruction. Magnetic Resonance in Medicine. 2011 doi: 10.1002/mrm.23020. [DOI] [PubMed] [Google Scholar]
- Aja-Fernández S, Tristán-Vega A, Casaseca-de-la-Higuera P. DWI acquisition schemes and diffusion tensor estimation: A simulation-based study. Proceedings of the 32nd IEEE EMBS Conference; IEEE; Sep, 2010a. pp. 3317–3320. [DOI] [PubMed] [Google Scholar]
- Aja-Fernández S, Tristán-Vega A, Hoge S. Statistical noise model in GRAPPA-reconstructed images. Proceedings of the International Society of Magnetic Resonance in Medicine. 2010b:3859. [Google Scholar]
- Aja-Fernández S, Tristán-Vega A, Hoge S. Statistical noise analysis in GRAPPA using a parametrized non-central chi approximation model. Magnetic Resonance in Medicine. 2011 Apr;65(4):1195–1206. doi: 10.1002/mrm.22701. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Andersson JL. Maximum a posteriori estimation of diffusion tensor parameters using a Rician noise model: Why, how and but. NeuroImage. 2008;42(4):1340–1356. doi: 10.1016/j.neuroimage.2008.05.053. [DOI] [PubMed] [Google Scholar]
- Arsigny V, Fillard P, Pennec X, Ayache N. Log-Euclidean metrics for fast and simple calculus on diffusion tensors. Magnetic Resonance in Medicine. 2006;56(2):411–421. doi: 10.1002/mrm.20965. [DOI] [PubMed] [Google Scholar]
- Basser P, Mattiello J, Lebihan D. MR diffusion tensor spectroscopy and imaging. Biophysial Journal. 1994 Jan;66(1):259–267. doi: 10.1016/S0006-3495(94)80775-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Basser P, Pajevic S. Statistical artifacts in diffusion tensor MRI (DT–MRI) caused by background noise. Magnetic Resonance in Medicine. 2000;44:41–50. doi: 10.1002/1522-2594(200007)44:1<41::aid-mrm8>3.0.co;2-o. [DOI] [PubMed] [Google Scholar]
- Basser P, Pierpaoli C. Microstructural and physiological features of tissues elucidated by Quantitative–Diffusion–Tensor MRI. Journal of Magnetic Resonance. 1996 Jun;111(3):209–219. doi: 10.1006/jmrb.1996.0086. [DOI] [PubMed] [Google Scholar]
- Breuer FA, Kannengiesser SA, Blaimer M, Seiberlich N, Jakob PM, Griswold MA. General formulation for quantitative g-factor calculation in GRAPPA reconstructions. Magnetic Resonance in Medicine. 2009;62(3):739–746. doi: 10.1002/mrm.22066. [DOI] [PubMed] [Google Scholar]
- Brion V, Kezele I, Riff O, Descoteaux M, Mangin J-F, Poupon C, Poupon F. MICCAI Workshop on Computational Diffusion MRI. Beijing, China: 2010. Real-time Rician noise correction applied to real-time HARDI and HYDI. [Google Scholar]
- Brion V, Poupon C, Riff O, Aja-Fernández S, Tristán-Vega A, Mangin J-F, LeBihan D, Poupon F. Procs Medical Image Computing and Computer-Assisted Intervention Vol – of Lecture Notes in Computer Science. Springer–Verlag; Sep, 2011. Parallel MRI noise correction: an extension of the LMMSE to non central χ distributions. [DOI] [PubMed] [Google Scholar]
- Chang L-C, Jones DK, Pierpaoli C. RESTORE: Robust estimation of tensors by outlier rejection. Magnetic Resonance in Medicine. 2005;53(5):1088–1095. doi: 10.1002/mrm.20426. [DOI] [PubMed] [Google Scholar]
- Clarke R, Scifo P, Rizzo G, Dell’Acqua F, Scotti G, Fazio F. Noise correction on Rician distributed data for fibre orientation estimators. IEEE Transactions on Medical Imaging. 2008 Sep;27(9):1242–1251. doi: 10.1109/TMI.2008.920615. [DOI] [PubMed] [Google Scholar]
- Constantinides C, Atalar E, McVeigh E. Signal-to-noise measurements in magnitude images from NMR phased arrays. Magnetic Resonance in Medicine. 1997;38:852–857. doi: 10.1002/mrm.1910380524. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fillard P, Pennec X, Arsigny V, Ayache N. Clinical DT–MRI estimation, smoothing, and fiber tracking with log-euclidean metrics. IEEE Transactions on Medical Imaging. 2007 Nov;26(11):1472–1482. doi: 10.1109/TMI.2007.899173. [DOI] [PubMed] [Google Scholar]
- Gilbert G, Simard D, Beaudoin G. Impact of an improved combination of signal from array coils in diffusion tensor imaging. IEEE Transactions on Medical Imaging. 2007 Nov;26(11):1428–1436. doi: 10.1109/TMI.2007.907699. [DOI] [PubMed] [Google Scholar]
- Griswold M, Jakob P, Heidemann R, Nittka M, Jellus V, Wang J, Kiefer B, Haase A. Generalize autocalibrating partially parallel acquisitions (GRAPPA) Magnetic Resonance in Medicine. 2002;47:1202–1210. doi: 10.1002/mrm.10171. [DOI] [PubMed] [Google Scholar]
- Gudbjartsson H, Patz S. The Rician distribution of noisy MRI data. Magnetic Resonance in Medicine. 1995;34:910–914. doi: 10.1002/mrm.1910340618. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jansons K, Alexander D. Persistent Angular Structures: new insights from diffusion magnetic resonance imaging data. Inverse Problems. 2003;19:1031–1046. [Google Scholar]
- Jones D, Basser P. Squashing peanuts and smashing pumpkins: how noise distorts diffusion weighted MR data. Magnetic Resonance in Medicine. 2004;52:979–993. doi: 10.1002/mrm.20283. [DOI] [PubMed] [Google Scholar]
- Kay S. Estimation Theory. Prentice–Hall; Upper Saddle River, New Jersey 07458 (USA): 1993. Fundamentals of Statistical Signal Processing. [Google Scholar]
- Koay CG, Chang L-C, Carew JD, Pierpaoli C, Basser PJ. A unifying theoretical and algorithmic framework for least squares methods of estimation in diffusion tensor imaging. Journal of Magnetic Resonance. 2006;182(1):115–125. doi: 10.1016/j.jmr.2006.06.020. [DOI] [PubMed] [Google Scholar]
- Landman B, Bazin P-L, Prince J, Hopkins J. Diffusion tensor estimation by maximizing Rician likelihood. Procs. of IEEE 11th International Conference on Computer Vision; Oct, 2007. pp. 1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Larkman D, Nunes R. Parallel magnetic resonance imaging. Physics of Medical Biology. 2007;52:15–55. doi: 10.1088/0031-9155/52/7/R01. invited topical review. [DOI] [PubMed] [Google Scholar]
- LeBihan D, Breton E, Lallemand D, Grenier P, Cabanis E, Laval-Jeantet M. MR imaging of intravoxel incoherent motions: application to diffusion and perfusion in neurologic disorders. Radiology. 1986 Nov;161(2):401–407. doi: 10.1148/radiology.161.2.3763909. [DOI] [PubMed] [Google Scholar]
- Mangin J, Poupon C, Clark C, Le Bihan D, Bloch I. Distortion correction and robust tensor estimation for MR diffusion imaging. Medical Image Analysis. 2002;6:191–198. doi: 10.1016/s1361-8415(02)00079-8. [DOI] [PubMed] [Google Scholar]
- Manjón J, Carbonell-Caballero J, Lull J, García-Martí G, Martí-Bonmatí L, Robles M. MRI denoising using Non-Local Means. Medical Image Analysis. 2008;12:514–523. doi: 10.1016/j.media.2008.02.004. [DOI] [PubMed] [Google Scholar]
- Özarslan E, Sepherd T, Vemuri B, Blackband S, Mareci T. Resolution of complex tissue microarchitecture using the Diffusion Orientation Transform (DOT) NeuroImage. 2006;31:1086–1103. doi: 10.1016/j.neuroimage.2006.01.024. [DOI] [PubMed] [Google Scholar]
- Poupon C, Roche A, Dubois J, Mangin J-F, Poupon F. Real-time MR Diffusion Tensor and Q-ball imaging using Kalman filtering. Medical Image Analysis; special issue on the 10th international conference on medical imaging and computer assisted intervention - MICCAI 2007; 2008. pp. 527–534. [DOI] [PubMed] [Google Scholar]
- Pruessmann K, Weiger M, Scheidegger M, Boesiger P. SENSE: Sensitivity encoding for fast MRI. Magnetic Resonance in Medicine. 1999;42:952–962. [PubMed] [Google Scholar]
- Salvador R, Peña A, Menon D-K, Carpenter T-A, Pickard J-D, Bullmore E-T. Formal characterization and extension of the linearized diffusion tensor model. Human Brain Mapping. 2005;24:144–155. doi: 10.1002/hbm.20076. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sijbers J, den Dekker A, Scheunders P, Van Dyck D. Maximum-likelihood estimation of Rician distribution parameters. IEEE Transactions on Medical Imaging. 1998 Jun;17(3):357–361. doi: 10.1109/42.712125. [DOI] [PubMed] [Google Scholar]
- Söderman O, Jönsson B. Restricted diffusion in cylindrical geometry. Journal of Magnetic Resonance. 1995;117:94–97. [Google Scholar]
- Stejskal E-O, Tanner J-E. Spin diffusion measurements: Spin echoes in the presence of a time-dependent field gradient. Journal of Chemical Physics. 1965;42:288–292. [Google Scholar]
- Sundgren P, Dong Q, Gómez-Hassan D, Mukherji S, Maly P, Welsh R. Diffusion tensor imaging of the brain: review of clinical applications. Neuroradiology. 2004;46(5):339–350. doi: 10.1007/s00234-003-1114-x. [DOI] [PubMed] [Google Scholar]
- Taylor W, Hsu E, Krishnan K, MacFall J. Diffusion tensor imaging: background, potential and utility in psychiatric research. Biological Psychiatry. 2004;55(3):201–207. doi: 10.1016/j.biopsych.2003.07.001. [DOI] [PubMed] [Google Scholar]
- Thunberg P, Zetterberg P. Noise distribution in SENSE- and GRAPPA-reconstructed images: a computer simulation study. Magnetic Resonance Imaging. 2007;25:1089–1094. doi: 10.1016/j.mri.2006.11.003. [DOI] [PubMed] [Google Scholar]
- Tournier J-D, Calamante F, Connelly A. Robust determination of the fibre orientation distribution in diffusion MRI: Non-negativity constrained super-resolved spherical deconvolution. NeuroImage. 2007;35:1459–1472. doi: 10.1016/j.neuroimage.2007.02.016. [DOI] [PubMed] [Google Scholar]
- Tristán-Vega A, Aja-Fernández S. DWI filtering using joint information for DTI and HARDI. Medical Image Analysis. 2010;14:205–218. doi: 10.1016/j.media.2009.11.001. [DOI] [PubMed] [Google Scholar]
- Tristán-Vega A, García-Pérez V, Aja-Fernández S, Westin C-F. Efficient and robust Nonlocal Means denoising of MR data based on salient features matching. Computer Methods and Programs in Biomedicine. 2011 doi: 10.1016/j.cmpb.2011.07.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tristán-Vega A, Westin C-F, Aja-Fernández S. Medical Image Computing and Computer-Assisted Intervention. Lecture Notes in Computer Science. Springer-Verlag; Sep, 2009a. Bias of least squares approaches for diffusion tensor estimation from array coils in DT-MRI; pp. 919–926. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tristán-Vega A, Westin C-F, Aja-Fernández S. Estimation of fiber orientation probability density functions in High Angular Resolution Diffusion Imaging. NeuroImage. 2009b;47:638–650. doi: 10.1016/j.neuroimage.2009.04.049. [DOI] [PubMed] [Google Scholar]
- Tristán-Vega A, Westin C-F, Aja-Fernández S. A new methodology for the estimation of fiber populations in the white matter of the brain with the Funk-Radon transform. NeuroImage. 2010;49:1301–1315. doi: 10.1016/j.neuroimage.2009.09.070. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tschumperle D, Deriche R. Proceedings of IEEE ICCV. Vol. 1. Nice, France: 2003. Variational frameworks for DT-MRI estimation, regularization and visualization; pp. 116–121. [Google Scholar]
- Tuch D. Q–Ball imaging. Magnetic Resonance in Medicine. 2004;52:1358–1372. doi: 10.1002/mrm.20279. [DOI] [PubMed] [Google Scholar]
- Wang Z, Vemuri B, Chen Y, Mareci T. A constrained variational principle for direct estimation and smoothing of the diffusion tensor field from complex DWI. IEEE Transactions on Medical Imaging. 2004;23(8):930–939. doi: 10.1109/TMI.2004.831218. [DOI] [PubMed] [Google Scholar]
- Wedeen V, Hagmann P, Tseng W-Y, Reese T, Weisskoff R. Mapping complex tissue architecture with diffusion spectrum imaging. Magnetic Resonance in Medicine. 2005;54:1377–1386. doi: 10.1002/mrm.20642. [DOI] [PubMed] [Google Scholar]