

Abstract
We propose a semiparametric method for conducting scale-invariant sparse principal component analysis (PCA) on high dimensional non-Gaussian data. Compared with sparse PCA, our method has weaker modeling assumption and is more robust to possible data contamination. Theoretically, the proposed method achieves a parametric rate of convergence in estimating the parameter of interests under a flexible semiparametric distribution family; Computationally, the proposed method exploits a rank-based procedure and is as efficient as sparse PCA; Empirically, our method outperforms most competing methods on both synthetic and real-world datasets.
Keywords: High dimensional statistics, Principal component analysis, Elliptical distribution, Robust statistics
1 Introduction
Principal component analysis (PCA) is a powerful tool for dimension reduction and feature selection. Let be n observations of a d-dimensional random vector X with covariance matrix Σ. PCA aims at estimating the leading eigenvectors u1, …, um of Σ.
When the dimension d is small compared with the sample size n, u1, …, um can be consistently estimated by the leading eigenvectors of the sample covariance matrix (Anderson, 1958). However, when d increases at the same order or even faster than n, this approach can lead to poor estimates. In particular, Johnstone and Lu (2009) showed that the angle between and u1 may not converge to 0 if d/n → c for some constant c > 0. To handle this challenge, one popular assumption is to impose sparsity constraint on the leading eigenvectors. For example, when estimating the leading eigen-vector u1 := (u11, …, u1d)T, we may assume that s := card({j : u1j ≠ = 0}) < n. Under this assumption, different variants of sparse PCA have been developed, more details can be found in d’Aspremont et al. (2004), Zou et al. (2006), Shen and Huang (2008), Witten et al. (2009), Journée et al. (2010), and Zhang and El Ghaoui (2011). The theoretical properties of sparse PCA in feature selection and parameter estimation have been investigated by Amini and Wainwright (2009), Ma (2013), Paul and Johnstone (2012), Vu and Lei (2012), and Berthet and Rigollet (2012).
There are several drawbacks of the classical PCA and sparse PCA: (i) It is not scale-invariant, i.e., changing the measurement scale of variables makes the estimates different (Chatfield and Collins, 1980); (ii) It is not robust to possible data contamination or outliers (Puri and Sen, 1971); (iii) The theory of sparse PCA relies heavily on the Gaussian or sub-Gaussian assumption, which may not be realistic for many real-world applications.
In the low dimensional settings, remedies for the drawbacks (ii) and (iii) include generalizing the Gaussian distribution to elliptical distribution (Fang et al., 1990), and considering some robust estimators (Huber and Ronchetti, 2009). One research line is to develop various PCA estimators for the elliptical data (Möttönen and Oja, 1995; Choi and Marden, 1998; Marden, 1999; Visuri et al., 2000; Croux et al., 2002; Jackson and Chen, 2004). The theoretical properties of these elliptical distribution based PCA estimators have been established under the classical asymptotic framework (i.e., the dimension d is fixed) by Hallin et al. (2010), Oja (2010), and Croux and Dehon (2010). Along another research line, multiple robust PCA estimators have been proposed to address the outlier and heavy tailed issues via replacing the sample covariance matrix by a robust scatter matrix. Such robust scatter matrix estimators include M-estimator (Maronna, 1976), S-estimator (Davies, 1987), median absolute deviation (MAD) proposed by Hampel (1974), and Sn and Qn estimators (Rousseeuw and Croux, 1993). These robust scatter matrix estimators have been exploited to conduct robust (sparse) principal component analysis (Gnanadesikan and Kettenring, 1972; Maronna and Zamar, 2002; Hubert et al., 2002; Croux and Ruiz-Gazen, 2005; Croux et al., 2013). The theoretical performances of PCA based on these robust estimators in low dimensions were further analyzed in Croux and Haesbroeck (2000).
In this article we propose a new method for conducting sparse principal component analysis on non-Gaussian data. Our method can be viewed as a scale-invariant version of sparse PCA but is applicable to a wide range of distributions belonging to the meta-elliptical family (Fang et al., 2002). The meta-elliptical family extends the elliptical family. In particular, a continuous random vector follows a meta-elliptical distribution if there exists a set of univariate strictly increasing functions such that f(X) := (f1(X1), …, fd(Xd))T follows an elliptical distribution with location parameter 0 and scale parameter Σ0, whose diagonal values are all 1. We call Σ0 the latent generalized correlation matrix. By treating as nuisance parameters, our method estimates the leading eigenvector θ1 of Σ0 by exploiting a rank-based estimating procedure and can be viewed as a scale-invariant PCA conducted on f(X). Theoretically we show that when s is fixed, it achieves a parametric rate of convergence in estimating the leading eigenvector. Computationally, it is as efficient as sparse PCA. Empirically, we show that the proposed method outperforms the classical sparse PCA and two robust alternatives on both synthetic and real-world datasets.
The rest of this paper is organized as follows. In the next section, we review the elliptical distribution family and introduce the meta-elliptical distribution. In Section 3, we present the statistical model, introduce the rank-based estimators, and provide computational algorithm for parameter estimation. In Section 4, we provide theoretical analysis. In Section 5, we provide empirical studies on both synthetic and real-world datasets. More discussion and comparison with related methods are put in the last section.
2 Elliptical and Meta-elliptical Distributions
In this section, we briefly review the elliptical distribution and introduce the meta-elliptical distribution family. We start by first introducing the notation: Let and be a d-dimensional matrix and a d-dimensional vector. We denote vI to be the subvector of v whose entries are indexed by a set I. We also denote MI,J to be the submatrix of M whose rows are indexed by I and columns are indexed by J. Let MI* and M*J be the submatrix of M with rows in I, and the submatrix of M with columns in J. Let supp(v) := {j : vj ≠ = 0}. For 0 < q < ∞, we define the ℓ0, ℓq and ℓ∞ vector norms as ||v||0 := card(supp(v)), and . We define the matrix ℓmax norm as the elementwise maximum value: ||M||max := max{|Mij|}. Let Λj(M) be the j-th largest eigenvalue of M. In particular, we denote Λmin(M) := Λd(M) and Λmax(M) := Λ1(M) to be the smallest and largest eigenvalues of M. Let ||M||2 be the spectral norm of M. We define and be the d-dimensional unit sphere. For any two vectors and any two squared matrices , we denote the inner product of a and b, A and B by 〈a, b〉 := aTb and 〈A, B〉:= Tr(ATB). For any matrix , we denote diag(M) to be the diagonal matrix with the same diagonal entries as M. For any univariate function f, we denote f(M) = [f(Mjk)] to be a d × d matrix with f applied on each entry of M. Let Id be the identity matrix in . For two random vectors X and Y, we denote if they are identically distributed.
2.1 Elliptical Distribution
We briefly overview the elliptical distribution. In the sequel, we say a random vector X = (X1, …, Xd)T is continuous if the marginal distribution are all continuous. X possesses density if it is absolutely continuous with respect to the Lebesgue measure.
Definition 2.1 (Elliptical distribution). A random vector Z = (Z1, …, Zd)T follows an elliptical distribution if and only if Z has a stochastic representation: . Here , q := rank(A), , ξ ≥ 0 is a random variable independent of U, is uniformly distributed on the unit sphere in . Letting Σ := AAT, we denote Z ~ ECd(μ, Σ, ξ). We call Σ the scatter matrix.
In Definition 2.1, there can be multiple A’s corresponding to the same Σ, i.e., there exist such that . To make the representation unique, we always parameterize an elliptical distribution by the scatter matrix Σ instead of A.
The model family in Definition 2.1 is not identifiable. For example, Σ is unique only up to a constant scaling, i.e., for some constant c > 0, if we define ξ* = ξ/c and A* = cA, then . To make the model identifiable, we require the condition that max1≤i≤dΣii=1. We define Σ0 := diag(Σ)−1/2 · Σ · diag(Σ)−1/2 to be the generalized correlation matrix.
2.2 Meta-elliptical Distribution
Real world data are usually nonGaussian and asymmetric. To illustrate the nonGaussianity and asymmetry issues, we consider the stock log return data in S&P 500 index, collected from Yahoo! Finance (finance.yahoo.com) from January 1, 2003 to January 1, 2008, including 452 stocks and 1,257 data points. Table 1 illustrates the nonGaussianity issue of the stock log-return data. Here we conduct the three marginal normality tests as in Table 1 at the significant level of 0.05. It is clear that at most 24 out of 452 stocks would pass any of three normality test. Even with Bonferroni correction there are still over half stocks that fail to pass any normality tests. Figure 1 plots the histograms of three typical stocks, “eBay Inc.”, “Macy’s Inc.”, and “Wells Fargo”, in the sectors of information technology, consumer discretionary, and financials separately. We see that the log-return values are skewed to the left.
Table 1.
Normality test of the stock log-return data. This table illustrates the number of 452 stocks rejecting the null hypothesis of normality at the significance level 0.05.
| Significance level | Kolmogorov-Smirnov | Shapiro-Wilk | Lilliefors |
|---|---|---|---|
| 0.05 | 428 | 449 | 449 |
| 0.05/452 | 269 | 448 | 426 |
Figure 1.

Illustration of the asymmetry issue of the log-return stock data.
Though the elliptical distribution family has been widely used to model heavy-tail data (Oja, 2010), it assumes that the distribution contours to exhibit ellipsoidal structure. To relax this assumption, Fang et al. (2002) introduced the concept of meta-elliptical distribution under a copula framework. In this section we introduce the concept of meta-elliptical using a different approach, which extends the family defined in Fang et al. (2002).
First, we define two sets of symmetric matrices:
The meta-elliptical distribution family is defined as follows:
Definition 2.2 (Meta-elliptical distribution). A continuous random vector X = (X1, …, Xd)T follows a meta-elliptical distribution, denoted by X ~ MEd(Σ0, ξ; f1, …, fd), if there exist univariate strictly increasing functions f1, …, fd such that
| (2.1) |
Here, Σ0 is called the latent generalized correlation matrix. When
we say that X follows a nonparanormal distribution, denoted by X ~ NPNd(Σ0; f1, …, fd).
The meta-elliptical is a strict extension to the nonparanormal defined in Liu et al. (2012). They both assume that after unspecified marginal transformations the data follow certain distributions. However, the nonparanormal exploits a Gaussian base distribution while the meta-elliptical exploits an elliptical base distribution.
On the other hand, we would like to point out that Definition 2.2 extends the family originally defined in Fang et al. (2002) in three aspects: (i) The generating variable ξ does not have to be absolutely continuous; (ii) The parameter Σ0 is strictly enlarged from to ; (iii) X does not necessarily possess density. Moreover, even if these two definitions are the same confined in the distribution set with density existing, we define the meta-elliptical in fundamentally different ways by characterizing the transformation functions instead of characterizing the density functions. By exploiting this new definition, we find that several results provided in the later sections can be easier to understand.
The meta-elliptical family is rich and contains many useful distributions, including multivariate Gaussian, rank-deficient Gaussian, multivariate t, logistic, Kotz, symmetric Pearson type-II and type-VII, the nonparanormal, and various other asymmetric distributions such as multivariate asymmetric t distribution (Fang et al., 2002). To illustrate the modeling flexibility of the meta-elliptical family, Figure 2 visualizes the density functions of two meta-elliptical distributions.
Figure 2.

Densities of two 2-dimensional meta-elliptical distributions. (A) The component functions have the form f1(x) = sign(x)|x|2 and f2(x) = x3, and after transformation follows a Gaussian distribution. (B) The component functions have the form f1(x) = f2(x) = log(x), and after transformation follows a Cauchy distribution. In both cases the latent generalized correlation matrix has all off-diagonal values to be 0.5.
3 Methodology
We propose a new scale-invariant sparse PCA method based on the meta-elliptical distribution family. More specifically, under a meta-elliptical model X ~ MEd(Σ0, ξ; f1, …, fd), the proposed method aims at estimating the leading eigenvector of Σ0. Since the diagonal entries of Σ0 are all 1, the proposed method is scale-invariant. From Definition 2.2, the proposed method is equivalent to conducting scale-invariant sparse PCA on the transformed data (f1(X1), …, fd(Xd))T which follow an elliptical distribution.
3.1 Statistical Model
The statistical model of our proposed method is defined as follows:
Definition 3.1. We consider the following model, denoted by , which is defined to be the set of distributions:
| (3.1) |
This model allows asymmetric and heavy tail distributions with nontrivial tail dependency. It can be used as a powerful tool for modeling real-world data.
3.2 Method
We now provide the proposed method that exploits the model (3.1). One of the key components of the proposed rank based method is the Kendall’s tau correlation matrix estimator, which will be explained in the next section.
3.2.1 Kendall’s tau based Correlation Matrix Estimator
The Kendall’s tau statistic was introduced by Kendall (1948) for estimating pairwise correlation and has been used for principal component analysis in low dimensions (Croux et al., 2002; Gibbons and Chakraborti, 2003). More specifically, let X := (X1, …, Xd)T be a d-dimensional random vector and let be an independent copy of X. The Kendall’s tau correlation coefficient between Xj and Xk is defined as
The next proposition shows that for meta-elliptical distribution family, we have a one-to-one map between and τ(Xj, Xk).
Theorem 3.2. Given X ~ MEd (Σ0, ξ; f1, …, fd) meta-elliptically distributed, we have
| (3.2) |
Proof. It is obvious that the Kendall’s tau statistic is invariant under strictly increasing transformations to the marginal variables. Moreover, Lindskog et al. (2003) show that the Kendall’s tau statistic is invariant to different generating variables ξ’s. Combining these two results and Equation (6.6) of Kruskal (1958), we obtain the desired result.
Let with x := (xi1, …, xid)T be n data points of X. The sample version Kendall’s tau statistic is defined as:
It is easy to see that is an unbiased estimator of τ(Xj, Xk). Using , we define the Kendall’s tau correlation matrix as follows:
Definition 3.3 (Kendall’s tau correlation matrix). We define the Kendall’s tau correlation matrix to be a d by d matrix with element entry to be
| (3.3) |
3.2.2 Rank-based Estimators
Given the model , Theorem 3.2 provides a natural way to estimate θ1. In particular, we solve the following optimization problem:
| (3.4) |
where , k is a sufficiently large tuning parameter, and is the Kendall’s tau correlation matrix. Equation (3.4) is a combinatorial optimization problem and hard to compute. The corresponding global optimum is denoted by .
Because the estimator is very hard to compute, we consider an alternative way to estimate θ1 using the truncated power algorithm proposed by Yuan and Zhang (2013). This algorithm yields an estimator .. Here is a hypothesized value for s (the number of nonzero elements of θ1) and can be treated as a tuning parameter.
More specifically, we apply the classical power method, but within each iteration t we project the intermediate vector xt to the intersection of the d-dimension sphere and the ℓ0 ball with radius k > 0. In detail, we sort the absolute values of the elements of xt from the highest to the lowest, find the highest k absolute values, truncate all the others to zero, and then normalize the truncated vector such that it lies in . To provide the detailed algorithm, we first introduce some additional notation. For any vector and an index set J ˄ {1, …, d}, we define the truncation function TRC(·,·) to be
| (3.5) |
where I(·) is the indicator function. The truncated power algorithm is presented in Algorithm 1.
The formulation of the truncated power algorithm is nonconvex and the performance of the estimator relies on the selection of the initial vector v(0). In practice, we use the estimate obtained from the SPCA algorithm (Zou et al., 2006) as the initial vector. We set the termination criteria to be ||v(t)−v(t−1)||2≤ 10−4.
In Section 4, we show that, by appropriately setting the initial vector v(0), the algorithm converges and the corresponding estimator is a consistent estimator of θ1. In practice, we find that this algorithm always converges on all the synthetic and real-world data.
Algorithm 1.
Truncated Power Method

|
3.3 Estimating the Top m Leading Eigenvectors
We exploit the iterative deflation method to estimate the top m leading eigenvectors θ1, …, θm of Σ0. This method is proposed by Mackey (2009) and its empirical performance is further evaluated in Yuan and Zhang (2013). In detail, for any positive semidefinite matrix , its deflation with respect to the vector is defined as:
In this way, D(Γ, v) is positive semidefinite, left and right orthogonal to v, and symmetric. To estimate θ1, …, θm, we exploit the following approach: (i) The estimate (can be either or ) of θ1 is calculated using Equation (3.4) or the truncated power method; (ii) Given , we estimate by plugging into Equation (3.4) or the truncated power method (Γ(1) := Σ0).
4 Theoretical Properties
In this section we provide the theoretical properties of the estimators and . In the analysis, we adopt the double asymptotic framework in which the dimension d increases with the sample size n. This framework more realistically reflects the challenges of many high dimensional applications (Bühlmann and van de Geer, 2011).
4.1 Latent Generalized Correlation Matrix Estimation
In this section we focus on estimating the latent generalized correlation matrix Σ0. In the next theorem we prove the rate of convergence for uniformly over all indices j, k. This is an important result, which indicates that the Gaussian parametric rate in estimating the correlation matrix obtained by Bickel and Levina (2008) can be extended to the meta-elliptical distribution family using the Kendall’s tau statistic.
Theorem 4.1. Let x1, …, xn be n observations of X ~ MEd(Σ0,ξ; f1, …, fd) and let be defined as in Equation (3.3). We have, with probability at least 1 − d−5/2,
| (4.1) |
Proof. The result follows from Theorem 4.2 in Liu et al. (2012) but with a slightly different probability bound. A detailed proof is provided in Appendix A.2 for self-completeness.
4.2 Leading Eigenvector Estimation
We analyze the estimation errors of the global optimum and the estimator obtained from the truncated algorithm. We say that the model holds if the data are drawn from one probability distribution in . The next theorem provides an upper bound on the angle between and θ1.
Theorem 4.2. Let be the global optimum to Equation (3.4), the model hold, and k ≥ s. For any two vectors and , let . Then we have, with probability at least 1 − d−5/2,
| (4.2) |
when λj := Λj(Σ0) for j = 1,2.
Proof. The key idea of the proof is to exploit the results in Theorem 4.1 in bounding the estimation error. Detailed proofs are presented in Appendix A.3.
Remark 4.3. When s, λ1, λ2 do not scale with (n, d) and k ≥ s is a fixed constant, the rate of convergence in parameter estimation is , which is the minimax optimal parametric rate shown in Vu and Lei (2012) under certain model class.
In the next corollary, we provide a feature selection result for the proposed method. Given that the selected tuning parameter k is large enough, we show that the support set of θ1 can be consistently recovered in a fast rate by imposing a constraint on the minimum absolute value of the signal part of θ1.
Corollary 4.4 (Feature selection). Let be the global optimum to Equation (3.4), the model hold, and k ≥ s. Let Τ:= supp(θ1), and . If we further have , then .
Proof. The key of the proof is to construct a contradiction given Theorem 4.2 and the condition on the minimum value of . Detailed proof is shown in Appendix A.4
In the next theorem, we provide a result on the convergence rate of the estimator obtained by exploiting the truncated power algorithm. This theorem, coming from Yuan and Zhang (2013), indicates that under sufficient conditions converges to θ1 in a rate.
Theorem 4.5. If the model holds, the conditions in Theorem 1 in Yuan and Zhang (2013) hold, and k ≥ s, we have, with probability at least 1 − d−5/2,
for some generic constant C not scaling with (n; d; s).
The result in Theorem 4.5 is a direct consequence of Theorem 1 in Yuan and Zhang (2013) and therefore the proof is omitted. Here we note that, similar as Corollary 4.4, it can be shown that under certain conditions, with high probability.
4.3 Principal Component Estimation
In this section, we consider estimating the latent principal components of the meta-elliptically distributed data. To estimate the latent principal components instead of the eigenvectors of the latent generalized correlation matrix, one needs to obtain good estimates of the unknown transformation functions f1, …, fd.
Let X ~ MEd(Σ0, ξ; f1, …, fd) follow a meta-elliptical distribution and x1, …, xn be n observations of X with xi := (xi1, …, xid)T. Let Z := (f1(X1), …, fd(Xd))T be the transformed random vector. By definition, Z ~ ECd(0, Σ0, ξ) is elliptically distributed. Let Qg be the marginal distribution function of Z (From Proposition A.2, we know all the elements of Z share the same marginal distribution functions). If Qg is known, we can estimate f1, …, fd as follows. For j = 1, …, d, let be defined as
We define
| (4.3) |
to be an estimator of fj. When Qg(·) = Φ(·), where Φ(·) is the distribution function of the standard Gaussian, we have the following theorem, showing that converges to fj(·) uniformly over an expanding interval with high probability.
Theorem 4.6 (Han et al. (2013)). Suppose that X ~ NPNd(Σ0; f1, …, fd) and for j = 1, …, d, let be the inverse function of fj. For any 0 < γ 1, we define
then . Here .
Using Theorem 4.6, we have the following theorem, which shows that, under appropriate conditions, we can recover the first principal component of any data point x.
Theorem 4.7. For any observation x := (x1, …, xd)T of X ~ NPNd(Σ; f1, …, fd), under the conditions of Theorem 4.2, letting
and b be any positive constant such that (s + k)n−b/2 = o(1),we have
where .
Proof. Theorem 4.7 is proved by combining the results in Theorems 4.2 and 4.6. More details are presented in Appendix A.5.
5 Experiments
In this section we evaluate the empirical performance of the proposed method on both synthetic and real-world datasets and compare its performance with the classical sparse PCA and two additional robust sparse PCA procedures. We use the truncated power method proposed by Yuan and Zhang (2013) for parameter estimation. The following four methods are considered:
Pearson: the classical high dimensional scale-invariant PCA using the Pearson’s sample correlation matrix as the input;
Sn: The sparse PCA using the robust Sn correlation matrix estimator (Rousseeuw and Croux, 1993; Maronna and Zamar, 2002) as the input;
Qn: The sparse PCA using the robust Qn correlation matrix estimator (Rousseeuw and Croux, 1993; Maronna and Zamar, 2002) as the input;
Kendall: The proposed method using the Kendall’s tau correlation matrix as the input.
Here the robust Qn and Sn correlation matrix estimates are calculated by the R package robustbase (Rousseeuw et al., 2009). We also tried the sparse robust PCA procedure proposed in Croux, Filzmoser, and Fritz. (2013), implemented in the R package pcaPP. However, we found that the grid algorithm, which is used in their paper to estimate sparse eigenvectors, has convergence problem when the dimension is high, which makes the obtained estimator perform very bad. Therefore, we did not include this procedure in the draft for comparison.
5.1 Numerical Simulations
In the simulation study we sample n data points from a given meta-elliptical distribution. Here we set d = 100. We first construct Σ0 using a similar idea as in Yuan and Zhang (2013): First a covariance matrix is synthesized through the eigenvalue decomposition, where the first two eigenvalues are given and the corresponding eigenvectors are pre-specified to be sparse. More specifically, let
We set u1 and u2 as follows:
The latent generalized correlation matrix Σ0 is Σ0 = diagΣ()−1/2 · Σ · diag(Σ)−1/2. We then consider six different schemes to generate the data matrix :
Scheme 1: Let x1, …, xn be n observations of X ~ Nd(0, Σ0).
Scheme 2: Let x1, …, xn be n observations of X ~ Nd(0, Σ0), but with 5% entries in each xi randomly picked up and replaced by −5 or 5.
Scheme 3: Let x1, …, xn be n observations of X ~ NPNd(Σ0; f1, …, f1) with f1(x) = x3.
Scheme 4: Let x1, …, xn be n observations of X ~ MEd(Σ0, ξ1; f0, …, f0) with f0(x) = x and . Here and with . In this setting, X follows a multivariate t distribution with degree of freedom κ (Fang et al., 1990). Here we set κ = 3.
Scheme 5: Let x1, …, xn be n observations of X ~ MEd(Σ0, ξ2; f0, …, f0) with ξ2 ~ F (d, 1), i.e., ξ2 follows an F-distribution with degree of freedom d and 1.
Scheme 6: Let x1, …, xn be n observations of X ~ MEd(Σ0, ξ3; f0, …, f0) with ξ3 follows an exponential distribution with the rate parameter 1.
Here Schemes 1 to 3 represent three different versions of the Gaussian data: (i) The perfect Gaussian data; (ii) The Gaussian data contaminated by outliers; (iii) The Gaussian data contaminated by marginal transformations. Schemes 4-6 represent three different elliptical distributions, which are all heavy-tailed and belong to the meta-elliptical family.
For n = 50, 100, 200, we repeatedly generate the data matrix X according to Schemes 1 to 6 for 1,000 times. To show the feature selection results for estimating the support set of the leading eigenvector θ1, Figure 3 plots the false positive rates against the true positive rates for the four different estimators under different schemes.
Figure 3.

ROC curves under Scheme 1 to Scheme 6. Here n = 100 and d = 100.
To illustrate the parameter estimation performance, we conduct a quantitative comparison of the estimation accuracy of the four competing method. For all methods, we fix the tuning parameter (i.e., the cardinality of the estimate’s support set) to be 10. Table 2 shows the averaged distances between the estimated leading eigenvector and θ1, with standard deviations presented in the parentheses. Here the distance between two vectors is defined as .
Table 2.
Quantitative comparison on the datasets under the six generating schemes. The averaged distances with standard deviations in parentheses are presented. Here n is changing from 50 to 200 and d is fixed to be 100.
| Scheme | n | Pearson | Sn | Qn | Kendall |
|---|---|---|---|---|---|
| Scheme 1 | 50 | 0.422(0.555) | 0.607(0.473) | 0.555(0.259) | 0.473(0.266) |
| 100 | 0.121(0.158) | 0.188(0.140) | 0.158(0.110) | 0.140(0.201) | |
| 200 | 0.068(0.071) | 0.072(0.072) | 0.071(0.018) | 0.072(0.024) | |
|
| |||||
| Scheme 2 | 50 | 0.911(0.878) | 0.882(0.631) | 0.878(0.105) | 0.631(0.131) |
| 100 | 0.806(0.715) | 0.737(0.264) | 0.715(0.169) | 0.264(0.213) | |
| 200 | 0.484(0.354) | 0.381(0.093) | 0.354(0.222) | 0.093(0.246) | |
|
| |||||
| Scheme 3 | 50 | 0.822(0.907) | 0.921(0.473) | 0.907(0.154) | 0.473(0.101) |
| 100 | 0.562(0.700) | 0.737(0.140) | 0.700(0.214) | 0.140(0.202) | |
| 200 | 0.228(0.356) | 0.410(0.072) | 0.356(0.156) | 0.072(0.255) | |
|
| |||||
| Scheme 4 | 50 | 0.947(0.679) | 0.704(0.678) | 0.679(0.095) | 0.668(0.227) |
| 100 | 0.910(0.247) | 0.269(0.248) | 0.247(0.157) | 0.238(0.239) | |
| 200 | 0.873(0.079) | 0.084(0.084) | 0.079(0.232) | 0.074(0.063) | |
|
| |||||
| Scheme 5 | 50 | 0.977(0.911) | 0.910(0.854) | 0.911(0.028) | 0.854(0.102) |
| 100 | 0.976(0.718) | 0.722(0.532) | 0.718(0.028) | 0.532(0.214) | |
| 200 | 0.978(0.297) | 0.305(0.147) | 0.297(0.029) | 0.147(0.244) | |
|
| |||||
| Scheme 6 | 50 | 0.959(0.848) | 0.862(0.771) | 0.848(0.060) | 0.771(0.143) |
| 100 | 0.931(0.548) | 0.569(0.373) | 0.548(0.108) | 0.373(0.250) | |
| 200 | 0.840(0.156) | 0.165(0.103) | 0.156(0.223) | 0.103(0.170) | |
Both Figure 3 and Table 2 show that when the data are non-Gaussian but follow a meta-elliptical distribution, Kendall constantly outperforms Pearson in terms of feature selection and parameter estimation. Moreover, when the data are indeed Gaussian distributed, there is no obvious difference between Kendall and Pearson, indicating that our proposed rank-based method is a good alternative to the classical scale-invariant sparse PCA under the meta-elliptical model.
We then compare Kendall with Sn and Qn. In Scheme 1, for the Gaussian data, Kendall slightly outperforms Sn and Qn. For the data with outliers, Sn and Qn performs better than the classical sparse PCA estimates, but are not as robust as Kendall. For different elliptical distributions explored in Schemes 4 to 6, Kendall has the best overall performance compared to Sn and Qn. The results for the non-elliptically distributed data, as explored in Scheme 3, shows a significant difference between our proposed method and the other two robust sparse PCA approaches. In this case we are interested in, instead of the correlation matrix of the meta-elliptically distributed data, the latent generalized correlation matrix, which Sn and Qn fail to recover.
5.2 Equity Data Analysis
In this section we investigate the performance of the four competing methods on the equity data explored in Section 2.2. The data come from Yahoo! Finance (finance.yahoo.com). We collect the daily closing prices for J = 452 stocks that are consistently in the S&P 500 index from January 1, 2003 to January 1, 2008. This gives us altogether T = 1, 257 data points, each data point corresponds to the vector of closing prices on a trading day. Let St = [Stt,j] denote the closing price of stock j on day t. We are interested in the log-return data X = [Xtj] with Xtj := log(Stt,j/Stt−1,j).
We evaluate the ability of using only a small number of stocks to represent the trend of the whole stock market. To this end, we run the four competing methods on the log-return data X and obtain the top four leading eigenvectors. Here the iterative deflation method discussed in Section 3.3 is exploited with the same tuning parameter k in each deflation step. Let Ak be the support set of the estimated leading eigenvectors by one of the four methods. We define and as
where I(·) is the indicator function. In this way, we can calculate the proportion of successful matches of the market trend using the stocks in Ak as:
We visualize the result by plotting (card(Ak), ρAk) in Figure 4, which shows that Kendall summarizes the trend of the whole stock market better than the other three methods.
Figure 4.

Successful matches of the market trend proportions only using the stocks in the support sets of the estimated loading vectors. The horizontal-axis represents the cardinalities of the estimates’ support sets; the vertical-axis represents the percentage of successful matches.
Moreover, we examine the stocks selected by the four competing methods. The 452 stocks are categorized into 10 Global Industry Classification Standard (GICS) sectors, including Consumer Discretionary (70 stocks), Consumer Staples (35 stocks), Energy (37 stocks), Financials (74 stocks), Health Care (46 stocks), Industrials (59 stocks), Information Technology (64 stocks), Telecommunications Services (6 stocks), Materials (29 stocks), and Utilities (32 stocks). Table 3 provides a more detailed description of these ten categories with their numbers and abbreviations provided.
Table 3.
The ten categories of the stocks with their numbers and abbreviations provided.
| Name | Number | Abbreviation |
|---|---|---|
| Consumer Discretionary | 70 | CD |
| Consumer Staples | 35 | CS |
| Energy | 37 | E |
| Financials | 74 | F |
| Health Care | 46 | HC |
| Industrial | 59 | I |
| Information Technology | 64 | IT |
| Telecommunications Services | 6 | TS |
| Materials | 29 | M |
| Utilities | 32 | U |
We estimate the top four leading eigenvectors using the four competing methods with the same k = 30 in each deflation step. The obtained non-zero features’ categories are presented in Table 4. We see that, in general, Kendall has the best ability in grouping the stocks of the same category together. Therefore, Kendall provides a more interpretable result.
Table 4.
The categories of the nonzero terms in the top four leading eigenvectors calculated by the four competing methods. The abbreviations are listed in Table 3. (Note: 30F means 30 stocks are from the Financials category.)
| Method | PC1 | PC2 | PC3 | PC4 |
|---|---|---|---|---|
| Pearson | 29F,1I | 6CD,5F,8I,1IT,10M | 8F,2E,3M,17U | 8CD,1F,1I,20IT |
| Sn | 29F,1I | 2CD,2F,12I,14M | 3I,27IT | 3F,27U |
| Qn | 29F,1I | 2CD,2F,12I,1IT,13M | 2I,28IT | 3F,27U |
| Kendall | 30F | 15I, 15M | 10CD, 10F,10I | 3I, 27IT |
6 Discussion
We propose a new scale-invariant sparse principal component analysis method for high dimensional meta-elliptical data. Our estimator is semiparametric but achieves a fast rate of convergence in parameter estimation, and is robust to both modeling assumption and data contamination. Therefore, the new estimator can be a good alternative to the classical sparse PCA method.
Although the rank-based Kendall’s tau statistic has been exploited for principal component analysis in low dimensions (see, for example, Croux et al. (2002)), our work is fundamentally different from the existing literature. The main difference can be elaborated in the following three aspects: (i) We generalize the Kendall’s tau statistic to high dimensions, while the current literature only focuses on the low dimension settings; (ii) Our theoretical analysis are fundamentally different from the previous low dimensional analysis, which exploits classical semiparametric theory under which the dimension d is usually fixed; (iii) Most existing methods and theories are built upon the Gaussian or elliptical model, while we consider the meta-elliptical model.
There is another trend in exploiting robust (sparse) PCA (see, for example, Maronna and Zamar (2002) and Croux et al. (2013)). The empirical comparisons conducted in this paper indicate that, confined in the meta-elliptical family, the proposed rank-based method can be more efficient in parameter estimation and feature selection than these additional robust procedures. Moreover, our proposed method achieves the nearly parametric rate of convergence in parameter estimation, while to the best of our knowledge the performance of these robust sparse PCA procedures in high dimensions is mostly unknown.
Vu and Lei (2012) and Ma (2013) considered sparse principal component analysis and studied the rates of convergence under various modeling and sparsity assumptions. Our method is different from theirs in two aspects: (i) Their analysis relies heavily on the Gaussian or sub-Gaussian assumption, which no longer holds under the meta-elliptical model; (ii) They exploit the Pearson’s sample covariance or correlation matrix as the algorithm input, while we advocate the usage of the Kendall’s tau correlation matrix in the meta-elliptical model.
Liu et al. (2012) and Xue and Zou (2012) proposed a procedure called the nonparanormal SKEPTIC, which exploits the nonparanormal family for graph estimation. The non-paranormal SKEPTIC also adopts rank-based methods in high dimensions. Our method is different from theirs in three aspects: (i) We advocate the use of meta-elliptical family, of which the nonparanormal is a subset; (ii) We advocate the use of the Kendall’s tau, which is adaptive over the whole meta-elliptical family but instead of the Spearman’s rho statistic; (iii) Their focus is on graph estimation, in contrast, this paper focuses on principal component analysis. In a preliminary version of this work (Han and Liu, 2012), they mainly focused on estimating the first leading eigenvector of the latent generalized correlation matrix by directly solving Equation (3.4), which is practically intractable. In contrast, we exploit a computationally feasible procedure (truncated power method) for scale-invariant sparse PCA, and provide theoretical guarantee of convergence for this algorithm. Moreover, our method estimates the latent principal components, which are crucial in practical applications, and we provide the theoretical analysis of convergence for the corresponding estimators.
For the principal component estimation algorithm in Section 4.3, when Qg is unknown, we could estimate f1, …, fd using the following method:
Test whether the original data is elliptically distributed by using some existing techniques (Li et al., 1997; Huffer and Park, 2007; Sakhanenko, 2008). If yes, we set . Here and are the marginal sample mean and standard deviation for the j-th entry.
- If not, we construct a set of marginal distribution functions:
For any Qg ∈ Π, we calculate using Equation (4.3).
We transform the data using .
We test whether the transformed data is elliptically distributed by using the techniques exploited in step 1.
We iterate steps 3-5 until we cannot reject the null hypothesis in step 5 for some Qg. This is a heuristic method whose theoretical justification is left for future investigation. Other future directions include analyzing the robustness property of the method to more noisy and dependent data.
Acknowledgement
We thank the associate editor and two anonymous reviewers for their very helpful and constructive comments and suggestions. Fang Han’s research is supported by Google fellowship in statistics. Han Liu’s research is supported by NSF Grants III-1116730 and NSF III-1332109, an NIH sub-award and a FDA sub-award from Johns Hopkins University.
A Appendix
A.1 Properties of the Elliptical Distribution
The next proposition provides two alternative ways to characterize an elliptical distribution and their proofs can be found in Fang et al. (1990).
Proposition A.1 (Fang et al. (1990)). A random vector Z = (Z1, …, Zd)T satisfies that Z ~ ECd(μ,Σ,ξ) if and only if Z has the characteristic function exp(it′μ)φ(t′Σt), where and φ is a properly-defined characteristic function. We denote Z ~ ECd(μ,Σ,φ) in this setting. If ξ is absolutely continuous and Σ is non-singular, then the density of Z exists and is of the form:
where g : [0, ∞) → [0,∞). We denote Z ~ ECd(μ,Σ, g). Here ξ, φ and g uniquely determine one of the other.
The next proposition provides three important properties of the elliptical distribution.
Proposition A.2. If a random vector Z is elliptically distributed, we have:
For any ,, and any matrix , v + BTZ is elliptically distributed. In particular, if Z ~ ECd(μ,Σ,ξ), then v + BTZ ~ ECq(v + BTμ, BTΣB,ξ).
Let Z ~ ECd(μ,Σ,ξ) and Σ0 be the generalized correlation matrix of Z. If rank(Σ) = q and , then , , and Cor(Z) = Σ0.
If Z ~ ECd(0,Σ,φ) with diag(Σ) = Id, then the marginal distributions of Z are the same.
Proof. The proof of the first two assertions can be found in Fang et al. (1990). To prove the third assertion, we use Proposition A.1 to obtain the characteristic function of Zj for any , where and ej is the j-th canonical basis in , i.e., 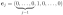 for 1 ≤ j ≤ d. The result follows from the one-to-one map between the characteristic functions and the random variables.
for 1 ≤ j ≤ d. The result follows from the one-to-one map between the characteristic functions and the random variables.
A.2 Proof of Theorem 4.1
Proof. Realizing that is a 2nd order U-statistic and sign (xij − xi′k) (xik − xi′k) is bounded in [−1; 1], using Equation (5.7) in Hoeffding (1963), we have
Therefore, we have
Taking the union bound, we have
This completes the proof.
A.3 Proof of Theorem 4.2
Proof. Under the model , we define λj := Λj(Σ0) and θj to be the corresponding eigenvector for j = 1, …, d. We then define and let
For all , we have
| (A.1) |
and
Moreover, by definition,
| (A.2) |
Combining Equation (A.1) with Equation (A.2), we have
Therefore, letting be the global optimum to Equation (3.4), we have
| (A.3) |
The last inequality holds because θ1 is feasible in the optimization constraint in (3.4), implying that
Therefore, using Equation (A.3),
| (A.4) |
where the last inequality is by the Hölder inequality. Letting , we have
implying that
| (A.5) |
Therefore, combining Equation (A.4) with Equation (A.5), we get
which is equivalent to saying that
Using Theorem 4.1, we have, with probability at least 1 − d−5/2,
This completes the proof.
A.4 Proof of Corollary 4.4
Proof. Without loss of generality, we may assume that because otherwise we can simply conduct appropriate sign changes in the proof. We first note that card . if , then . This implies that,
We then have
implying that
| (A.6) |
Therefore, applying Theorem 4.2, we get
| (A.7) |
This completes the proof.
A.5 Proof of Theorem 4.7
Proof. Without loss of generality, we assume that . We define , where . we further define
for some 0 < b < 1. Moreover, we define the event Mn as
Thus, conditioning on Mn, using Theorem 4.6, we have
| (A.8) |
Since fj(xj) ~ Nd(0, 1), using Mill’s inequality, we have
| (A.9) |
Finally, using Mill’s inequality again, we have
| (A.10) |
Combining Equations (A.8), (A.9), and (A.10), we have the desired result.
References
- Amini A, Wainwright M. High-dimensional analysis of semidefinite relaxations for sparse principal components. The Annals of Statistics. 2009;37(5B):2877–2921. [Google Scholar]
- Anderson TW. An Introduction to Multivariate Statistical Analysis. Vol. 2. Wiley; 1958. [Google Scholar]
- Berthet Q, Rigollet P. Optimal detection of sparse principal components in high dimension. forthcoming in the Annals of Statistics. 2012 [Google Scholar]
- Bickel P, Levina E. Regularized estimation of large covariance matrices. The Annals of Statistics. 2008;36(1):199–227. [Google Scholar]
- Bühlmann P, van de Geer S. Statistics for High-Dimensional Data: Methods, Theory and Applications. Springer; 2011. [Google Scholar]
- Chatfield C, Collins A. Introduction to Multivariate Analysis. Vol. 166. Chapman & Hall; 1980. [Google Scholar]
- Choi K, Marden J. A multivariate version of Kendall’s τ. Journal of Non-parametric Statistics. 1998;9(3):261–293. [Google Scholar]
- Croux C, Dehon C. Influence functions of the Spearman and Kendall correlation measures. Statistical Methods & Applications. 2010;19(4):497–515. [Google Scholar]
- Croux C, Filzmoser P, Fritz H. Robust sparse principal component analysis. Technometrics. 2013;55(2):202–214. [Google Scholar]
- Croux C, Haesbroeck G. Principal component analysis based on robust estimators of the covariance or correlation matrix: influence functions and e ciencies. Biometrika. 2000;87(3):603–618. [Google Scholar]
- Croux C, Ollila E, Oja H. Sign and rank covariance matrices: statistical properties and application to principal components analysis. Statistics in Industry and Technology. 2002:257–269. [Google Scholar]
- Croux C, Ruiz-Gazen A. High breakdown estimators for principal components: the projection-pursuit approach revisited. Journal of Multivariate Analysis. 2005;95(1):206–226. [Google Scholar]
- d’Aspremont A, El Ghaoui L, Jordan M, Lanckriet G. A direct formulation for sparse pca using semidefinite programming. SIAM Review. 2004;49(3):434–448. [Google Scholar]
- Davies P. Asymptotic behaviour of S-estimates of multivariate location parameters and dispersion matrices. The Annals of Statistics. 1987;15(3):1269–1292. [Google Scholar]
- Fang H, Fang K, Kotz S. The meta-elliptical distributions with given marginals. Journal of Multivariate Analysis. 2002;82(1):1–16. [Google Scholar]
- Fang K, Kotz S, Ng K. Symmetric Multivariate and Related Distributions. Chapman&Hall; 1990. [Google Scholar]
- Gibbons JD, Chakraborti S. Nonparametric Statistical Inference. Vol. 168. CRC press; 2003. [Google Scholar]
- Gnanadesikan R, Kettenring JR. Robust estimates, residuals, and outlier detection with multiresponse data. Biometrics. 1972;28(1):81–124. [Google Scholar]
- Hallin M, Paindaveine D, Verdebout T. Optimal rank-based testing for principal components. The Annals of Statistics. 2010;38(6):3245–3299. [Google Scholar]
- Hampel FR. The influence curve and its role in robust estimation. Journal of the American Statistical Association. 1974;69(346):383–393. [Google Scholar]
- Han F, Liu H. Transelliptical component analysis. Advances in Neural Information Processing Systems. 2012;25:368–376. [Google Scholar]
- Han F, Zhao T, Liu H. CODA: High dimensional copula discriminant analysis. Journal of Machine Learning Research. 2013;14:629–671. [Google Scholar]
- Hoe ding W. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association. 1963;58(301):13–30. [Google Scholar]
- Huber PJ, Ronchetti E. Robust Statistics. 2nd edition Wiley; 2009. [Google Scholar]
- Hubert M, Rousseeuw PJ, Verboven S. A fast method for robust principal components with applications to chemometrics. Chemometrics and Intelligent Laboratory Systems. 2002;60(1):101–111. [Google Scholar]
- Hu er FW, Park C. A test for elliptical symmetry. Journal of Multivariate Analysis. 2007;98(2):256–281. [Google Scholar]
- Jackson D, Chen Y. Robust principal component analysis and outlier detection with ecological data. Environmetrics. 2004;15(2):129–139. [Google Scholar]
- Johnstone I, Lu A. On consistency and sparsity for principal components analysis in high dimensions. Journal of the American Statistical Association. 2009;104(486):682–693. doi: 10.1198/jasa.2009.0121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Journée M, Nesterov Y, Richtárik P, Sepulchre R. Generalized power method for sparse principal component analysis. Journal of Machine Learning Research. 2010;11:517–553. [Google Scholar]
- Kendall MG. Rank Correlation Methods. Griffin; 1948. [Google Scholar]
- Kruskal W. Ordinal measures of association. Journal of the American Statistical Association. 1958;53(284):814–861. [Google Scholar]
- Li R, Fang K, Zhu L. Some Q-Q probability plots to test spherical and elliptical symmetry. Journal of Computational and Graphical Statistics. 1997;6(4):435–450. [Google Scholar]
- Lindskog F, McNeil A, Schmock U. Kendall’s tau for elliptical distributions. Springer; 2003. [Google Scholar]
- Liu H, Han F, Yuan M, La erty J, Wasserman L. High dimensional semiparametric gaussian copula graphical models. The Annals of Statistics. 2012;40(4):2293–2326. [Google Scholar]
- Ma Z. Sparse principal component analysis and iterative thresholding. forthcoming in the Annals of Statistics. 2013 [Google Scholar]
- Mackey L. Deflation methods for sparse PCA. Advances in Neural Information Processing Systems. 2009;21:1017–1024. [Google Scholar]
- Marden J. Some robust estimates of principal components. Statistics & Probability Letters. 1999;43(4):349–359. [Google Scholar]
- Maronna RA. Robust M-estimators of multivariate location and scatter. The Annals of Statistics. 1976;4(1):51–67. [Google Scholar]
- Maronna RA, Zamar RH. Robust estimates of location and dispersion for high-dimensional datasets. Technometrics. 2002;44(4):307–317. [Google Scholar]
- Möttönen J, Oja H. Multivariate spatial sign and rank methods. Journal of Nonparametric Statistics. 1995;5(2):201–213. [Google Scholar]
- Oja H. Multivariate Nonparametric Methods with R: An Approach Based on Spatial Signs and Ranks. Vol. 199. Springer; 2010. [Google Scholar]
- Paul D, Johnstone I. Augmented sparse principal component analysis for high dimensional data. Arxiv preprint arXiv:1202.1242. 2012 [Google Scholar]
- Puri ML, Sen PK. Nonparametric Methods in Multivariate Analysis. Wiley; 1971. [Google Scholar]
- Rousseeuw P, Croux C, Todorov V, Ruckstuhl A, Salibian-Barrera M, Verbeke T, Maechler M. Robustbase: basic robust statistics. R package. 2009 URL http://CRAN.R-project.org/package=robustbase. [Google Scholar]
- Rousseeuw PJ, Croux C. Alternatives to the median absolute deviation. Journal of the American Statistical Association. 1993;88(424):1273–1283. [Google Scholar]
- Sakhanenko L. Testing for ellipsoidal symmetry: A comparison study. Computational Statistics & Data Analysis. 2008;53(2):565–581. [Google Scholar]
- Shen H, Huang J. Sparse principal component analysis via regularized low rank matrix approximation. Journal of Multivariate Analysis. 2008;99(6):1015–1034. [Google Scholar]
- Visuri S, Koivunen V, Oja H. Sign and rank covariance matrices. Journal of Statistical Planning and Inference. 2000;91(2):557–575. [Google Scholar]
- Vu V, Lei J. Minimax rates of estimation for sparse PCA in high dimensions. International Conference on Artificial Intelligence and Statistics (AISTATS) 2012;15:1278–1286. [Google Scholar]
- Witten D, Tibshirani R, Hastie T. A penalized matrix decomposition, with applications to sparse principal components and canonical correlation analysis. Biostatistics. 2009;10(3):515–534. doi: 10.1093/biostatistics/kxp008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xue L, Zou H. Regularized rank-based estimation of high-dimensional non-paranormal graphical models. The Annals of Statistics. 2012;40(5):2541–2571. [Google Scholar]
- Yuan X, Zhang T. Truncated power method for sparse eigenvalue problems. Journal of Machine Learning Research. 2013;14:899–925. [Google Scholar]
- Zhang Y, El Ghaoui L. Large-scale sparse principal component analysis with application to text data. Advances in Neural Information Processing Systems. 2011;24 [Google Scholar]
- Zou H, Hastie T, Tibshirani R. Sparse principal component analysis. Journal of Computational and Graphical Statistics. 2006;15(2):265–286. [Google Scholar]