

Abstract
Motivation: One of the challenging questions in modelling biological systems is to characterize the functional forms of the processes that control and orchestrate molecular and cellular phenotypes. Recently proposed methods for the analysis of metabolic pathways, for example, dynamic flux estimation, can only provide estimates of the underlying fluxes at discrete time points but fail to capture the complete temporal behaviour. To describe the dynamic variation of the fluxes, we additionally require the assumption of specific functional forms that can capture the temporal behaviour. However, it also remains unclear how to address the noise which might be present in experimentally measured metabolite concentrations.
Results: Here we propose a novel approach to modelling metabolic fluxes: derivative processes that are based on multiple-output Gaussian processes (MGPs), which are a flexible non-parametric Bayesian modelling technique. The main advantages that follow from MGPs approach include the natural non-parametric representation of the fluxes and ability to impute the missing data in between the measurements. Our derivative process approach allows us to model changes in metabolite derivative concentrations and to characterize the temporal behaviour of metabolic fluxes from time course data. Because the derivative of a Gaussian process is itself a Gaussian process, we can readily link metabolite concentrations to metabolic fluxes and vice versa. Here we discuss how this can be implemented in an MGP framework and illustrate its application to simple models, including nitrogen metabolism in Escherichia coli.
Availability and implementation: R code is available from the authors upon request.
Contact: j.norkunaite@imperial.ac.uk; m.stumpf@imperial.ac.uk
Supplementary information: Supplementary data are available at Bioinformatics online.
1 INTRODUCTION
It is generally impossible to simultaneously measure the abundance of all the molecular entities making up biological systems. In gene expression assays, for example, we typically measure messenger RNA expression, but not the activity of transcription factors and/or the occupancy of transcription-factor binding sites. Similarly, in metabolomic analyses (Chou and Voit, 2012; Voit, 2013), key metabolites can be measured using, e.g. mass spectrometry or nuclear magnetic resonance quantification, but it is rarely possible to comprehensively quantify the metabolites even within a single pathway. Typically, more interesting than metabolite and enzyme abundance are the fluxes through biochemical reactions and metabolic networks (Orth et al., 2010; Schuster et al., 1999). Fluxes, 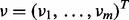 , correspond to the rates at which molecules,
, correspond to the rates at which molecules, 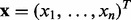 , are turned over by the m reactions; regulation of fluxes in light of changes in environmental and physiological conditions is also intimately linked to cellular physiology.
, are turned over by the m reactions; regulation of fluxes in light of changes in environmental and physiological conditions is also intimately linked to cellular physiology.
Although the fluxes are of central concern, they are hard to measure directly. Estimates for intracellular fluxes can be obtained by tracking products from isotope-labeled (13C and 15N metabolic flux analysis) metabolites through the metabolic network (Blank and Ebert, 2012; Zamboni, 2011). However, such an approach is restricted to a metabolically steady-state analysis and is not appropriate for capturing dynamical flux variations. Instead, theoretical analysis has often progressed by assuming stationarity of the metabolic processes, which in turn allows for characterizing the sets of steady-state fluxes under a set of suitable assumptions (Klamt and Stelling, 2003; Schwartz and Kanehisa, 2006; Voit and Almeida, 2004). Flux-balance analysis is the most popular example of this strategy, but it becomes questionable once the steady-state assumption can no longer be upheld. Furthermore, as more data on enzyme abundance become available, we should attempt to include such information and the impact on metabolic processes (Colijn et al. 2009; Rossell et al., 2013).
Here we provide a new framework that allows us to model metabolic fluxes and their dynamics, and which deals with the missing data problem in metabolic analysis in a flexible and consistent manner. Gaussian processes (GP) belong to the armoury of non–parametric Bayesian methods and have been widely used to describe dynamical processes (Kirk and Stumpf, 2009) and to infer hidden states, e.g. transcription-factor activities (Honkela et al., 2010). In applications to metabolic modelling, parametric approaches can offer potentially incorrect representations of the underlying fluxes (Voit, 2013). The strengths of GP models arise from their non-parametric nature, which enables us to put priors directly on a function rather than on the parameters of a parametric function. With a multiple-output GPs (MGPs), single GP framework can be extended to handle many outputs, enabling us to learn the unknown relationships between metabolic species. In turn, MGPs can be used to infill the sparsely sampled data (Boyle and Frean, 2004). This means that by using MGPs, it is possible to impute the missing data in between the metabolic measurements more efficiently.
Here we develop a more general framework that uses so-called derivative GPs (Solak et al., 2003), which allow us to link metabolite abundance, x (or concentrations) and fluxes  . This in turn enables us to also treat time course data on metabolites and monitor the changes that occur in fluxes, e.g. over the course of physiological responses, such as to changes in the environment (Bryant et al., 2013).
. This in turn enables us to also treat time course data on metabolites and monitor the changes that occur in fluxes, e.g. over the course of physiological responses, such as to changes in the environment (Bryant et al., 2013).
2 METHODS
2.1 GP regression
Gaussian process regression (GPR) can be applied to recover an underlying dynamical process from noisy observations. A GP defines a prior distribution over all possible functions, and to specify a GP, we need expressions for the mean and covariance function that describe the behaviour of the system output over time (Haykin and Moher, 2010). Below we review the standard GPR methodology.
In a typical regression problem, we connect inputs x and outputs z via functions, 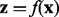 , where
, where 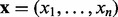 and
and 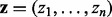 are continuous n-dimensional real-valued vectors. The observed values of the dependent variable, z, can be related to the independent variables,
are continuous n-dimensional real-valued vectors. The observed values of the dependent variable, z, can be related to the independent variables, 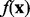 through,
through,
where ε is a noise term, which is here assumed to be independent and identically distributed according to a Gaussian distribution, 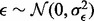 . In GPR, we place a GP (Haykin and Moher, 2010; McKay, 1998) prior over the functions
. In GPR, we place a GP (Haykin and Moher, 2010; McKay, 1998) prior over the functions 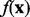 ,
, 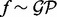 , meaning that at any finite number of input points
, meaning that at any finite number of input points  the values
the values 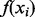 have a multivariate Gaussian distribution with zero mean and covariance function, K,
have a multivariate Gaussian distribution with zero mean and covariance function, K,
Different functional forms can be chosen for the covariance function (Rasmussen and Williams, 2006), either to simplify computations or to reflect constrains imposed by the data. A flexible and generic choice is to set the covariance function to
where 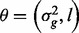 represent a set of unknown hyper-parameters, and
represent a set of unknown hyper-parameters, and 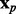 and
and 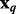 are inputs. Thus,
are inputs. Thus, 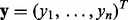 has a multivariate normal distribution with zero mean and covariance matrix
has a multivariate normal distribution with zero mean and covariance matrix 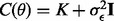 , with I the identity matrix. The unknown set of hyper-parameters, θ, can be estimated from the data by evaluating the following log-likelihood function,
, with I the identity matrix. The unknown set of hyper-parameters, θ, can be estimated from the data by evaluating the following log-likelihood function,
| (1) |
using either a maximum likelihood approach or by sampling from the posterior distribution with Markov chain Monte Carlo methods (Neal, 1997).
For any finite number of input (test) points,  , we define the joint prior probability distribution
, we define the joint prior probability distribution
With the GP prior, it is possible to evaluate the posterior distribution over the functions; the values of f evaluated at inputs  and conditioned on the observations y are jointly distributed as (Rasmussen and Williams, 2006),
and conditioned on the observations y are jointly distributed as (Rasmussen and Williams, 2006),
| (2) |
where
and
Although Equation (2) defines an appropriate GP posterior, which allows us to make predictions about a single variable y, it remains unclear how to deal with several variables simultaneously: if outputs are correlated then the standard GPR framework may fail in providing an adequate description.
2.2 Multiple–output GPs
Boyle and Frean (2004) introduced MGPs, where a set of dependent GPs is constructed via multiple-input multiple-output linear filters. This perspective can capture the dependencies between several variables by solving a convolution integral and specifying a suitable covariance function, which in turn includes the cross and auto correlations among related variables. Our construction of derivative processes below builds on MGPs.
Dealing with linear filters is central to signal processing where such filters describe a physical systems that can generate an output signal in response to a given input signal (Haykin and Moher, 2010; Roberts, 2008). Linear filters are characterized by their kernel function (an impulse response) h(t), and the output z(t) can be expressed via convolution integral,
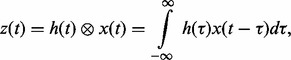 |
where the symbol ‘ ’ denotes the convolution operator. To transmit the signal that has the mathematical properties of a GP, the kernel function, h(t) must be absolutely integrable, i.e.
’ denotes the convolution operator. To transmit the signal that has the mathematical properties of a GP, the kernel function, h(t) must be absolutely integrable, i.e.
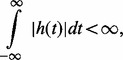 |
Then if the input X(t) is specified to be a Gaussian white noise process, the output process, Z(t), will also be a GP.
Specifying a stable linear time-invariant filter with M white noise processes as inputs,  , K outputs,
, K outputs,  and
and 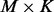 impulse responses results in a dependent GP model (Boyle and Frean, 2005). A multiple-input multiple-output filter can thus be defined as
impulse responses results in a dependent GP model (Boyle and Frean, 2005). A multiple-input multiple-output filter can thus be defined as
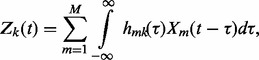 |
where 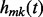 are kernel functions and
are kernel functions and 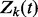 is the kth output. As discussed previously, the observed variables might differ from expected variables owing to the measurement noise, and we thus consider
is the kth output. As discussed previously, the observed variables might differ from expected variables owing to the measurement noise, and we thus consider
| (3) |
where 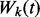 is a Gaussian white noise process with variance
is a Gaussian white noise process with variance 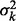 .
.
Multiple-input multiple-output filters are able to capture the relationships between several variables 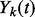 ; in the model, these kind of dependencies are build in via shared input noise sources that enable the specification of valid covariance functions. For the sake of simplicity, let the impulse response be a Gaussian kernel,
; in the model, these kind of dependencies are build in via shared input noise sources that enable the specification of valid covariance functions. For the sake of simplicity, let the impulse response be a Gaussian kernel, 
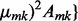 . Then evaluating the convolution integral leads to the following covariance function,
. Then evaluating the convolution integral leads to the following covariance function,
 |
(4) |
where 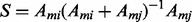 and
and 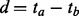 is the temporal separation between two input points, (see Boyle and Frean (2004) appendix for derivation and generalization to multidimensions). Constructing intermediate matrices Cij permits the definition of a positive definite symmetric covariance matrix C between K variables,
is the temporal separation between two input points, (see Boyle and Frean (2004) appendix for derivation and generalization to multidimensions). Constructing intermediate matrices Cij permits the definition of a positive definite symmetric covariance matrix C between K variables,
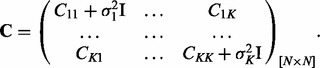 |
Here 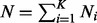 is total number of observations, and Ni the number of observations of variable i. Having defined the covariance matrix, we can use the log-likelihood, which has the form (1) for the inference of the hyper-parameters
is total number of observations, and Ni the number of observations of variable i. Having defined the covariance matrix, we can use the log-likelihood, which has the form (1) for the inference of the hyper-parameters 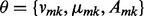 . Again, following Bayesian framework, we can use the results from the GPR section to evaluate the joint predictive distribution (2) for all outputs. Alternatively, for a particular variable i, predictions can be made using the appropriate marginal distribution, which is Gaussian, with mean
. Again, following Bayesian framework, we can use the results from the GPR section to evaluate the joint predictive distribution (2) for all outputs. Alternatively, for a particular variable i, predictions can be made using the appropriate marginal distribution, which is Gaussian, with mean 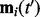 and variance
and variance 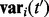 , given by
, given by
| (5) |
where
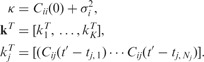 |
2.3 Derivative processes
For a GP that is derived through a linear filter, 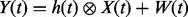 , where X(t) is a white noise GP, h(t) is a kernel function and W(t) is an additive noise, it is easy to formulate the expression of a derivative process. Taking a derivative of Y with respect to t, it is possible to obtain a new process U that is also a GP (Boyle, 2007),
, where X(t) is a white noise GP, h(t) is a kernel function and W(t) is an additive noise, it is easy to formulate the expression of a derivative process. Taking a derivative of Y with respect to t, it is possible to obtain a new process U that is also a GP (Boyle, 2007),
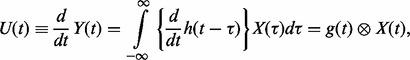 |
Thus, it is possible to construct the derivative process by convolving a white noise GP X(t) with a derivative kernel function g(t). This definition enables us to consider derivative processes and the corresponding original processes as a collection of dependent GPs. This is true because the derivative processes and the original processes are derived from exactly the same input, X(t).
To construct a dependent model for several related variables 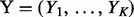 and their derivatives
and their derivatives 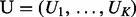 , it is necessary to define a suitable covariance structure, which in principal arises from the initial covariance function (4). For example, for a set of four dependent outputs (two original and two derivative processes), the following equations can be applied to compute the covariances (Girard, 2004; Kirk, 2011; Solak et al., 2003),
, it is necessary to define a suitable covariance structure, which in principal arises from the initial covariance function (4). For example, for a set of four dependent outputs (two original and two derivative processes), the following equations can be applied to compute the covariances (Girard, 2004; Kirk, 2011; Solak et al., 2003),
- Autocovariance function of derivative process Ui
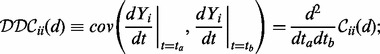
- Cross-covariance function between two derivative processes Ui and Uj
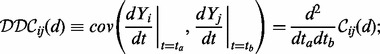
- Covariance between original process Yi and corresponding derivative process Ui
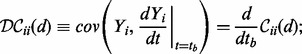
- Covariance between original process Yi and derivative process Uj
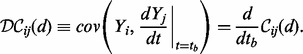
Let R denote a block matrix,
which describes the correlations between observations 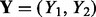 and their ‘function’ values
and their ‘function’ values 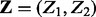 , and corresponding derivative variables
, and corresponding derivative variables 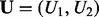 evaluated at any finite number of test points
evaluated at any finite number of test points 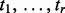 . In a similar manner, let H denote
. In a similar manner, let H denote
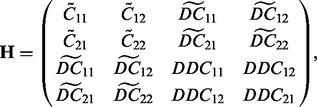 |
where the 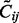 matrices contain the correlations between functions Z1 and Z2 evaluated at a finite set of test points
matrices contain the correlations between functions Z1 and Z2 evaluated at a finite set of test points 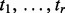 ;
; 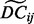 the correlations between functions
the correlations between functions 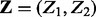 and derivative variables
and derivative variables 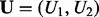 evaluated at the same test points; and finally, DDCij consists of auto/cross-correlations between derivative variables U1 and U2. The matrices
evaluated at the same test points; and finally, DDCij consists of auto/cross-correlations between derivative variables U1 and U2. The matrices 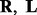 and H are building components of the overall covariance matrix K, which is symmetric and positive definite,
and H are building components of the overall covariance matrix K, which is symmetric and positive definite,
At a finite number of input points 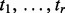 , the matrix
, the matrix 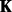 allows us to place a joint prior over observations Y, functions Z and derivatives U,
allows us to place a joint prior over observations Y, functions Z and derivatives U,
Evaluating a GP posterior
| (6) |
where
enables us to make joint predictions for the original and derivative processes simultaneously. Alternatively, if there is no need to sample from the posterior process, we can use marginal Gaussian distributions to make predictions for individual output. The marginal distributions for output i and its derivative process at any input point 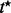 ,
,
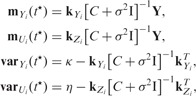 |
(7) |
where  is the mean of the original process,
is the mean of the original process, 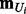 the mean of the derivative process,
the mean of the derivative process, 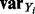 the variance of the original process and
the variance of the original process and 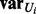 the variance of the derivative process, and furthermore
the variance of the derivative process, and furthermore
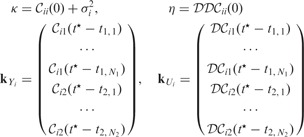 |
Equations (6) and (7) can easily be extended to make predictions about any number of variables.
3 APPLICATIONS AND RESULTS
To demonstrate the performance of derivative processes, we consider two simulation examples—a system of two oscillating signals and a simple model of linear metabolic pathway—before turning to a more complicated metabolic process and, finally, some real metabolic network data. The derivative processes can be used to address the flux estimation problem from time course data. Here GPs describe the dynamics of metabolites, and the corresponding derivative processes capture the functional forms of the associated fluxes. Below, all examples were implemented using the free statistical computing platform R www.r-project.org.
3.1 Oscillating signals
A simple oscillating signal can be expressed as 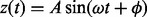 , where A is the amplitude,
, where A is the amplitude, 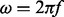 the angular frequency and
the angular frequency and 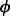 the phase angle. This is a particularly useful example because it is easy to evaluate the performance of derivative processes, as the derivative signals have a known analytic form. We consider a simple system that consists of two oscillating signals,
the phase angle. This is a particularly useful example because it is easy to evaluate the performance of derivative processes, as the derivative signals have a known analytic form. We consider a simple system that consists of two oscillating signals, 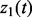 and
and 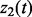 ,
,
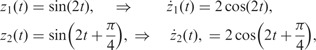 |
with 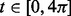 . To model real experimental measurements, we add random noise to the simulated trajectories,
. To model real experimental measurements, we add random noise to the simulated trajectories, 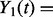
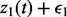 ,
, 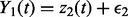 , where
, where 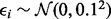 ; we have observations of both signals at regular time intervals,
; we have observations of both signals at regular time intervals, 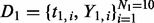 and
and 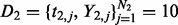 . To build a single model that captures the relationship between the two signals, we apply the dependent GP framework (3) (K = 2) on a combined dataset
. To build a single model that captures the relationship between the two signals, we apply the dependent GP framework (3) (K = 2) on a combined dataset 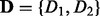 ; each signal can be expressed as a superposition of three GPs—two of which are constructed via convolution between a noise source and a Gaussian kernel, and the third one is an additive noise. We set parameters Ai of each Gaussian kernel to be
; each signal can be expressed as a superposition of three GPs—two of which are constructed via convolution between a noise source and a Gaussian kernel, and the third one is an additive noise. We set parameters Ai of each Gaussian kernel to be 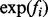 and noise levels to
and noise levels to 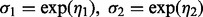 , leading to a set of hyper-parameters
, leading to a set of hyper-parameters 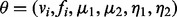 ,
, 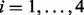 . To build the model the following priors are chosen:
. To build the model the following priors are chosen: 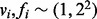 ,
, 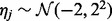 and
and 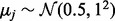 ,
, 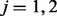 ; the maximum a posteriori (MAP) estimate
; the maximum a posteriori (MAP) estimate 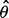 is determined using a multistarting Nelder–Mead optimization algorithm (Nelder and Mead, 1965). Dependent GP posteriors (6) allow us to make joint predictions about both signals and their derivative processes at any finite number of input points, and the resulting posterior processes are summarized in Figure 1. From these posterior processes, it can be seen that the mean behaviour of our model agrees with trajectories of underlying noiseless signals, and to make predictions about derivative processes, it is enough to consider only samples from the original sinusoidal trajectories.
is determined using a multistarting Nelder–Mead optimization algorithm (Nelder and Mead, 1965). Dependent GP posteriors (6) allow us to make joint predictions about both signals and their derivative processes at any finite number of input points, and the resulting posterior processes are summarized in Figure 1. From these posterior processes, it can be seen that the mean behaviour of our model agrees with trajectories of underlying noiseless signals, and to make predictions about derivative processes, it is enough to consider only samples from the original sinusoidal trajectories.
Fig. 1.

Predictions with MGPs model for two oscillating signals. (a and b) Dashed lines represent true behaviour of noiseless 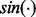 trajectories; dots correspond to the noisy observations for both signals (data); solid lines are the mean behaviour of the MGPs model (predictions with original GPs); light areas correspond to two standard deviations at each prediction point. (c and d) Dashed lines represent true behaviour of noiseless
trajectories; dots correspond to the noisy observations for both signals (data); solid lines are the mean behaviour of the MGPs model (predictions with original GPs); light areas correspond to two standard deviations at each prediction point. (c and d) Dashed lines represent true behaviour of noiseless 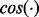 trajectories; solid lines show the mean behaviour of the MGPs model (predictions with derivative processes); light areas correspond to two standard deviations at each prediction point
trajectories; solid lines show the mean behaviour of the MGPs model (predictions with derivative processes); light areas correspond to two standard deviations at each prediction point
3.2 Linear pathway
Next we consider a linear metabolic pathway with two regulatory signals (see Goel et al. (2008) Supplementary Material for details), which is summarized in Figure 3a. Here the flow from x1 to x2 is negatively regulated by metabolite x3, and x3 increases the transformation of x2 into x3. A set of ordinary differential equations (ODEs) can be used to describe the dynamics of these two metabolites, x2 and x3 (x1 is the constant external input),
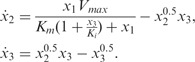 |
(8) |
Fig. 3.
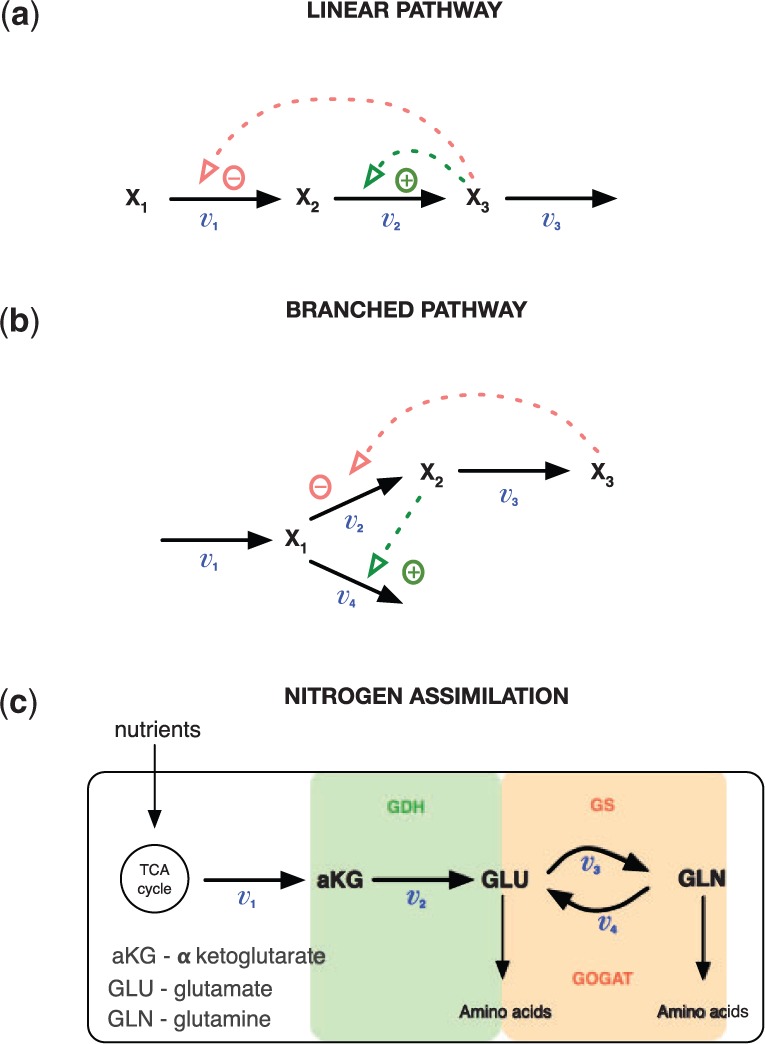
Pathway information. (a) A simple linear metabolic pathway; red and green dashed lines correspond to the inhibition and activation signals. (b) Illustrates a branched pathway with positive (green) and negative (red) regulatory signals. (c) Illustrates a metabolic pathway in E.coli, here vi, 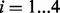 denote the fluxes;
denote the fluxes; 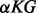 , GLU and GLN correspond to the metabolites; TCA is a short notation for the citrate cycle in E.coli
, GLU and GLN correspond to the metabolites; TCA is a short notation for the citrate cycle in E.coli
To apply the derivative process approach, we simulate the ODE model with the following parameter values 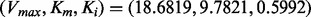 and initial conditions
and initial conditions 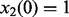 ,
, 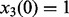 . In this model, the concentration of x1 is assumed to be constant and equal to 2. The dataset consists of selected points from simulated trajectories with added Gaussian noise
. In this model, the concentration of x1 is assumed to be constant and equal to 2. The dataset consists of selected points from simulated trajectories with added Gaussian noise 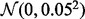 . Again we combine the ‘noisy’ measurements, and fit the dependent GP model to make predictions about the original trajectories and their derivatives. To obtain a functional expressions for fluxes v1 and v2 we need to estimate a dynamical variations of metabolic,
. Again we combine the ‘noisy’ measurements, and fit the dependent GP model to make predictions about the original trajectories and their derivatives. To obtain a functional expressions for fluxes v1 and v2 we need to estimate a dynamical variations of metabolic, 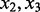 , derivatives. The derivative processes provide the predictions for the left side of Equation (8) at any finite number of time points, whereas the original GPs describe the solution on the same ODE (8). This enables us to link the metabolite measurements to metabolic fluxes. Figure 2 illustrates the predictions with posterior processes, where solid blue lines correspond to the mean behaviour of the model, dashed lines to the original x2 and x3 trajectories and solid green lines to their derivatives. In addition, if we assume that we are able to measure flux
, derivatives. The derivative processes provide the predictions for the left side of Equation (8) at any finite number of time points, whereas the original GPs describe the solution on the same ODE (8). This enables us to link the metabolite measurements to metabolic fluxes. Figure 2 illustrates the predictions with posterior processes, where solid blue lines correspond to the mean behaviour of the model, dashed lines to the original x2 and x3 trajectories and solid green lines to their derivatives. In addition, if we assume that we are able to measure flux 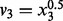 , we can obtain the functional expressions for fluxes v1 and v2 that are summarized in Figure 2c and d. The dark pink lines illustrate predicted fluxes from noisy metabolite measurements, dashed lines are real fluxes (calculated from ODEs (8)) and light pink area corresponds to the confidence region.
, we can obtain the functional expressions for fluxes v1 and v2 that are summarized in Figure 2c and d. The dark pink lines illustrate predicted fluxes from noisy metabolite measurements, dashed lines are real fluxes (calculated from ODEs (8)) and light pink area corresponds to the confidence region.
Fig. 2.
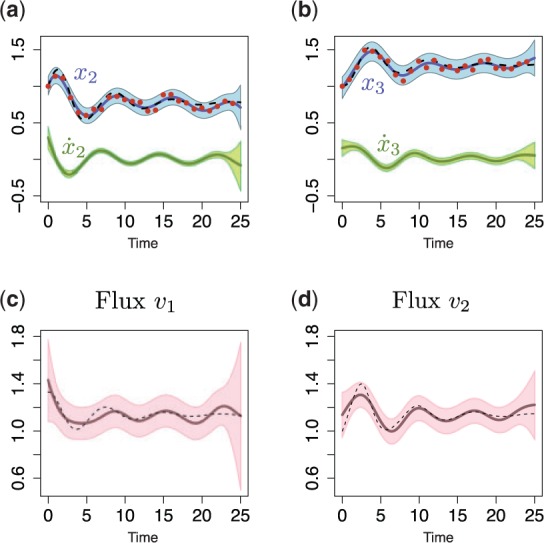
Predictions with MGPs model for linear metabolic pathway. (a and b) Dashed lines represent a simulated x2 and x3 trajectories from ODE model; dots correspond to the sparse noisy observations for x2 and x3 (data); solid blue/green lines are the mean behaviour of the MGPs model (blue, predictions with original GPs; green, predictions with derivative process); light areas correspond to two standard deviations at each prediction point. (c and d) Dark lines are predicted fluxes, light areas correspond to the confidence region, and dashed lines represent true behaviour of noise-free fluxes v1 and v2 (calculated from ODE system)
3.3 Branched pathway
We now turn to an example of metabolic pathway that was originally proposed by Voit (2013) (see Example of actual characterization); Figure 3b illustrates a schematic representation of a branched pathway with two regulatory responses, where x3 inhibits the conversions of x1 into x2, and x2 positively regulates reaction v4. The following ODE model describes the dynamics of the metabolites that are involved in this pathway,
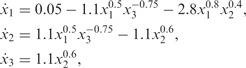 |
(9) |
where 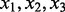 denote the metabolites. For a given pathway (Fig. 3b), the change in metabolite concentration can be described by the differences between incoming and outgoing fluxes. For this reason, we are able to obtain the following expressions for fluxes
denote the metabolites. For a given pathway (Fig. 3b), the change in metabolite concentration can be described by the differences between incoming and outgoing fluxes. For this reason, we are able to obtain the following expressions for fluxes 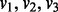 and v4,
and v4,
 |
(10) |
These expressions define a system of linear equations that is underdetermined, as we have more fluxes to estimate than available equations, and it cannot be solved using standard Gaussian elimination techniques. For this reason, additional information is required to uniquely determine fluxes v1 and v4. In this example, we will focus only on estimation of fluxes v2 and v3 from available data rather than try to address a uniqueness problem of v1 and v4.
The above ODE model enables us to generate simulated time course data using the initial conditions 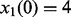 ,
, 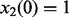 and
and 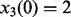 . Next, we apply the dependent GP framework (3) (K = 2) on the combined dataset
. Next, we apply the dependent GP framework (3) (K = 2) on the combined dataset 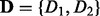 , where
, where 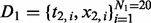 and
and 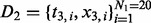 contains the measurements of metabolites x2 and x3 with added random Gaussian noise
contains the measurements of metabolites x2 and x3 with added random Gaussian noise 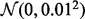 (we chose a low noise level so that predictions with derivative processes could be easily compared with the original fluxes in the example in Voit (2013). For a set of model hyper-parameters
(we chose a low noise level so that predictions with derivative processes could be easily compared with the original fluxes in the example in Voit (2013). For a set of model hyper-parameters 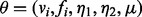 ,
, 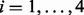 we use the following priors,
we use the following priors, 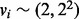 ,
, 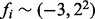 ,
, 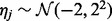 ,
, 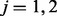 and
and 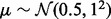 , and calculate the MAP estimate
, and calculate the MAP estimate 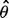 as before. Figure 4 illustrates the predictions with posterior processes using Equation (7); (a and b) graphs summarize metabolite data. The dark blue lines correspond to the mean behaviour of the original GPs and agree well with simulated x2 and x3 dynamics; the green lines describe the derivatives of the same metabolites and can be understood as a slope estimates. In Figure 4c and d, dark pink lines illustrate the predicted metabolic fluxes v2 and v3 under consideration of pathway Figure 3b. From ODE model (9), we can calculate original fluxes over the time (in real situations this would not be possible). Figure 4c and d shows a good agreement between predicted and original fluxes.
as before. Figure 4 illustrates the predictions with posterior processes using Equation (7); (a and b) graphs summarize metabolite data. The dark blue lines correspond to the mean behaviour of the original GPs and agree well with simulated x2 and x3 dynamics; the green lines describe the derivatives of the same metabolites and can be understood as a slope estimates. In Figure 4c and d, dark pink lines illustrate the predicted metabolic fluxes v2 and v3 under consideration of pathway Figure 3b. From ODE model (9), we can calculate original fluxes over the time (in real situations this would not be possible). Figure 4c and d shows a good agreement between predicted and original fluxes.
Fig. 4.
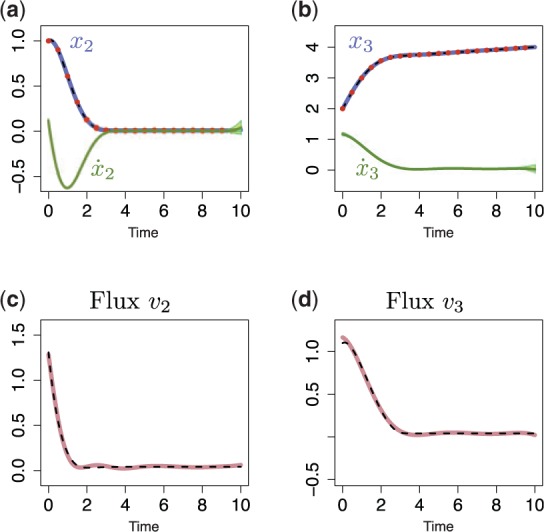
Predictions with MGP model for a branched metabolic pathway. (a and b) Dashed lines represent simulated x2 and x3 trajectories from the ODE model; red dots correspond to the sparse observations for x2 and x3 (data); solid lines are the mean behaviour of the MGPs model (blue, predictions with original GPs; green, predictions with derivative process); light areas correspond to two standard deviations at each prediction point. (c and d) Dark lines are predicted fluxes; dashed lines represent true behaviour of fluxes v2 and v3 (calculated from the ODE system)
3.4 Escherichia coli nitrogen assimilation
Finally, we apply our technique to the experimental data from E. coli, where we have measurements of the abundance of several key metabolites involved in nitrogen assimilation. Nitrogen is one of the key chemical elements that acts as a nutrient for the cells; ammonium is a preferred source of nitrogen for E. coli growth (Schumacher et al., 2013; van Heeswijk et al., 2013). In E. coli, ammonium can be absorbed via two pathways: glutamate dehydrogenase (GDH) that operates during cell growth in ammonium-rich environments, and glutamine synthetase-glutamate synthase (GS-GOGAT) that operates during cell growth in low-ammonium conditions (van Heeswijk et al., 2013). Here, we are focussing on experimental conditions, where after a period of nitrogen starvation, the bacterial cultures are spiked with ammonium (Schumacher et al., 2013); Figure 5a shows experimentally obtained measurements for α-ketoglutarade (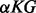 ), glutamate (GLU) and glutamine (GLN) metabolites over the time after ammonium spike; red dots correspond to a wild-type (WT) E. coli metabolic measurements, and in squares—isogenic glnG deletion (ΔglnG) measurements. Below we focus on the pathway summarized in Figure 3c, which includes both GDH and GS-GOGAT. For modelling purposes, we assume that fluxes v3 and v4 can be summarized by the overall flux v3 that describes the flow from GLU to GLN, as there is not enough information to discriminate between them. From the pathway, we can construct a system of linear equations that describe the dependencies between fluxes and metabolites,
), glutamate (GLU) and glutamine (GLN) metabolites over the time after ammonium spike; red dots correspond to a wild-type (WT) E. coli metabolic measurements, and in squares—isogenic glnG deletion (ΔglnG) measurements. Below we focus on the pathway summarized in Figure 3c, which includes both GDH and GS-GOGAT. For modelling purposes, we assume that fluxes v3 and v4 can be summarized by the overall flux v3 that describes the flow from GLU to GLN, as there is not enough information to discriminate between them. From the pathway, we can construct a system of linear equations that describe the dependencies between fluxes and metabolites,
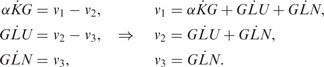 |
(11) |
Fig. 5.
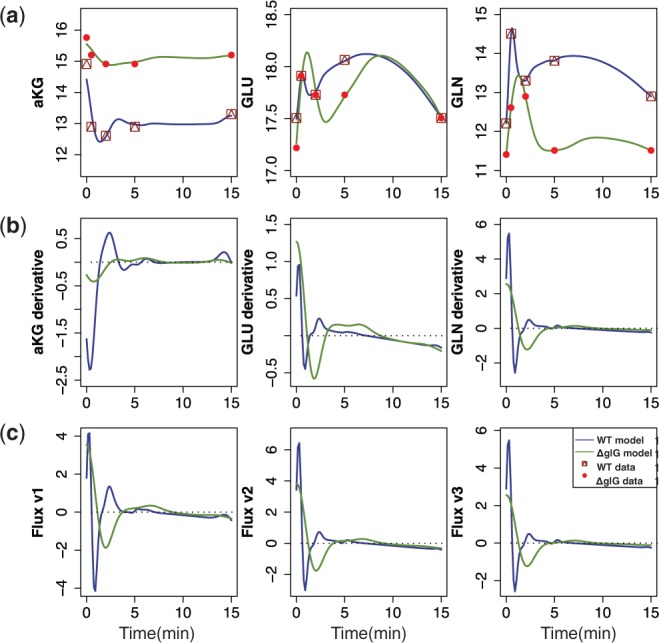
Predictions with MGPs model for E. coli (WT and ΔglnG). (a) The symbols indicate experimentally measured concentrations of 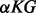 , GLU and GLN metabolites (dots for WT, squares for ΔglnG). Solid lines correspond to the mean behaviour of dependent GPs model. (b) Predicted derivative behaviour for
, GLU and GLN metabolites (dots for WT, squares for ΔglnG). Solid lines correspond to the mean behaviour of dependent GPs model. (b) Predicted derivative behaviour for 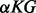 , GLU and GLN metabolites, where solid lines correspond to the mean behaviour of dependent derivative processes. (c) Predicted fluxes v1, v2 and v3 for convenience, dotted line illustrates horizontal 0-axis
, GLU and GLN metabolites, where solid lines correspond to the mean behaviour of dependent derivative processes. (c) Predicted fluxes v1, v2 and v3 for convenience, dotted line illustrates horizontal 0-axis
We fit a dependent GP model (3) (K = 3) to the WT data and then to ΔglnG data (collected from a strain where glnG is absent). In the model, 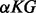 is expressed as a sum of three GPs: the first GP describes
is expressed as a sum of three GPs: the first GP describes 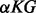 , the second expresses the relationship between
, the second expresses the relationship between 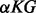 and GLU and the third one describes additive noise; GLN is modelled similarly. However, GLU is modelled as the sum of four GPs, where the first three describe GLU; the dependence between GLU and
and GLU and the third one describes additive noise; GLN is modelled similarly. However, GLU is modelled as the sum of four GPs, where the first three describe GLU; the dependence between GLU and 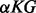 ; the dependence between GLU and GLN; and the fourth is an additive noise. Choosing kernel functions to be Gaussian
; the dependence between GLU and GLN; and the fourth is an additive noise. Choosing kernel functions to be Gaussian 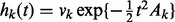 , we obtain the MAP estimate for all hyper-parameters (17 in total). The predictions with posterior process (7) are summarized in Figure 5, where solid blue lines describe predictions with dependent GP models for WT E. coli, and green lines for ΔglnG. Using the relationship (11), we can estimate fluxes v1, v2 and v3 (Fig. 5c).
, we obtain the MAP estimate for all hyper-parameters (17 in total). The predictions with posterior process (7) are summarized in Figure 5, where solid blue lines describe predictions with dependent GP models for WT E. coli, and green lines for ΔglnG. Using the relationship (11), we can estimate fluxes v1, v2 and v3 (Fig. 5c).
To evaluate our predictions, we can compare flux v3 and GS protein levels in WT and ΔglnG E. coli (see Supplementary Fig. S1). In E. coli, glnG encodes the transcription factor, NtrC (nitrogen regulator) that controls GS expression levels, and in its active form, GS catalyses glutamine synthesis (van Heeswijk et al., 2013). Experimentally, it was observed that in ΔglnG case protein, GS levels were significantly lower compared with the GS levels in WT E. coli (see Supplementary Fig. S1C and D). Because there is less enzyme available to catalyse the reaction in ΔglnG, the flux v3 in the mutant will be noticeably reduced compared with the WT flux v3 (see Supplementary Fig. S1A and B).
4 DISCUSSION AND CONCLUSIONS
Flux estimation has become central to many analyses into the metabolic processes and mechanisms. Typically, the estimates for a set of fluxes are obtained in a point-wise manner at discrete time points. It is clear that this fails to capture the temporal behaviour of the fluxes and additional consideration of parametric models is compulsory to fully explain the fluxes; further, this approach is susceptible to noise that is present in experimentally measured metabolite data.
Here we have addressed these problems and proposed a novel non-parametric Bayesian approach to modelling metabolic fluxes. This is based on MGPs that enable the construction of derivative processes. Because the derivative processes and original processes share the same input source, we can complement the dependent GP model and make joint predictions about original and derivative processes at any finite number of input points. Such derivative processes can be applied to characterize the temporal behaviour of metabolic fluxes from time course data—without having to make reference, e.g. transcriptomic data, to explain temporal variation—and here we have demonstrated the applicability on simple models and a real-world example.
GPs, including our approach, propagate uncertainty in line with the assumed covariance structures. This can lead to large confidence intervals, especially if the dependencies among different observations are not considered explicitly. With increasing number of metabolic species within the pathway, the derivative process approach might become computationally costly due to the inference of a large number of hyper-parameters and a matrix inversion step; however, this limitation potentially might be addressed by considering a sparse approximation for the full covariance matrix of all metabolic species (Alvarez and Lawrence, 2009). These can in principle deal with genome-level data.
Supplementary Material
ACKNOWLEDGEMENT
The authors thank Jake Bundy and Volker Behrends for the E. coli metabolite data.
Funding: Leverhulme Trust (to J.Ž. and M.P.H.S.), the Royal Society (to J.P. and M.P.H.S.), HFSP (to P.K. and M.P.H.S.) and BBSRC (to T.T. and M.P.H.S.).
Conflict of Interest: none declared.
REFERENCES
- Alvarez AM, Lawrence DN. Sparse convolved Gaussian processes for multi-output regression. Adv. Neural Inf. Process. Syst. 2009;21:57–64. [Google Scholar]
- Blank LM, Ebert BE. From measurement to implementation of metabolic fluxes. Curr. Opin. Biotechnol. 2012;24:13–21. doi: 10.1016/j.copbio.2012.10.019. [DOI] [PubMed] [Google Scholar]
- Boyle P. 2007. Gaussian processes for regression and optimisation. Doctoral dissertation. Victoria University of Wellington. [Google Scholar]
- Boyle P, Frean M. Technical report. Victoria University of Wellington; 2004. Multiple-output Gaussian process regression. [Google Scholar]
- Boyle P, Frean M. Dependent Gaussian processes. Adv. Neural Inf. Process. Syst. 2005;17:217–224. [Google Scholar]
- Bryant WA, et al. Analysis of metabolic evolution in bacteria using whole-genome metabolic models. J. Comp. Biol. 2013;20:755–764. doi: 10.1089/cmb.2013.0079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chou I-C, Voit EO. Estimation of dynamic flux profiles from metabolic time series data. BMC Syst. Biol. 2012;6:84. doi: 10.1186/1752-0509-6-84. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Colijn C, et al. Interpreting expression data with metabolic flux models: predicting Mycobacterium tuberculosis mycolic acid production. PLoS Comput. Biol. 2009;5:1–14. doi: 10.1371/journal.pcbi.1000489. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goel G, et al. System estimation from metabolic time-series data. Bioinfromatics. 2008;24:2505–2511. doi: 10.1093/bioinformatics/btn470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Girard A. 2004. Approximate methods for propagation of uncertainty with Gaussian process models. Doctoral dissertation. University of Glasgow. [Google Scholar]
- Haykin S, Moher M. Communication Systems. 5th edn. Asia: Wiley; 2010. [Google Scholar]
- van Heeswijk WC, et al. Nitrogen assimilation in Escherichia coli: puttin molecular data into a systems perspective. Microbiol. Mol. Rev. 2013;77:628–695. doi: 10.1128/MMBR.00025-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Honkela A, et al. Model-based method for transcription factor target identification with limited data. Proc. Natl Acad. Sci. USA. 2010;107:7793–7798. doi: 10.1073/pnas.0914285107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jia G, et al. Parameter estimation of kinetic models from metabolic profiles: two-phase dynamic decoupling method. Bioinformatics. 2011;27:1964–1970. doi: 10.1093/bioinformatics/btr293. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kirk P. 2011. Inferential stability in systems biology. Doctoral dissertation. Imperial College London. [Google Scholar]
- Kirk P, Stumpf MPH. Gaussian process regression bootstrapping. Bioinformatics. 2009;25:1300–1306. doi: 10.1093/bioinformatics/btp139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Klamt S, Stelling J. Two approaches for metabolic pathway analysis? Trends Biotechnol. 2003;21:64–69. doi: 10.1016/s0167-7799(02)00034-3. [DOI] [PubMed] [Google Scholar]
- McKay DJC. Introduction to Gassign processes. In: Bishop CM, editor. Neural Networks and Machine Learning. NATO ASI Series. Springer-Verlag; 1998. pp. 133–165. [Google Scholar]
- Neal RM. Monte Carlo implementation of Gaussian process models for Bayesian regression and classification. Arxiv Preprint Physics/9701026. 1997 Technical report 9702, Department of Statistics, University of Toronto. [Google Scholar]
- Nelder JA, Mead R. A simplex method for function minimization. Comp. J. 1965;199:133–154. [Google Scholar]
- Orth JD, et al. What is flux balance analysis? Nat. Biotechnol. 2010;28:245–248. doi: 10.1038/nbt.1614. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rasmussen CE, Williams CKI. Gaussian Processes for Machine Learning. 1st edn. Cambridge: The MIT Press; 2006. [Google Scholar]
- Roberts MJ. Fundamentals of Signals and Systems. 1st edn. New York: Mc Graw Hill; 2008. [Google Scholar]
- Rossell S, et al. Inferring metabolic state in uncharacterized environments using gene-expression measurements. PLoS Comput. Biol. 2013;9:1–11. doi: 10.1371/journal.pcbi.1002988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwartz J-M, Kanehisa M. Quantitative elementary mode analysis of metabolic pathways: the example of yeast glycolysis. BMC Bioinformatics. 2006;7:186. doi: 10.1186/1471-2105-7-186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Solak E, et al. Derivative observations in Gaussian process models of dynamic systems. Adv. Neural Inf. Process. Syst. 2003;15:1033–1040. [Google Scholar]
- Schumacher J, et al. Nitrogen and carbon status are integrated at the transcriptional level by the nitrogen regulator NtrC in vivo. MBio. 2013;4:1–9. doi: 10.1128/mBio.00881-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schuster S, et al. Detection of elementary flux modes in biochemical networks: a promising tool for pathway analysis and metabolic engineering. Trends Biotechnol. 1999;17:53–60. doi: 10.1016/s0167-7799(98)01290-6. [DOI] [PubMed] [Google Scholar]
- Voit EO, Almeida J. Decoupling dynamical systems for pathway identification from metabolic profiles. Bioinformatics. 2004;20:1670–1681. doi: 10.1093/bioinformatics/bth140. [DOI] [PubMed] [Google Scholar]
- Voit EO. Characterizability of metabolic pathway systems from time series data. Math. Biosci. 2013;5:1–11. doi: 10.1016/j.mbs.2013.01.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zamboni N. 13C metabolic flux analysis in complex systems. Curr. Opin. Biotechnol. 2011;22:103–108. doi: 10.1016/j.copbio.2010.08.009. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.