

Abstract
In recent years, there has been considerable interest in estimating conditional independence graphs in high dimensions. Most previous work has assumed that the variables are multivariate Gaussian, or that the conditional means of the variables are linear; in fact, these two assumptions are nearly equivalent. Unfortunately, if these assumptions are violated, the resulting conditional independence estimates can be inaccurate. We propose a semi-parametric method, graph estimation with joint additive models, which allows the conditional means of the features to take on an arbitrary additive form. We present an efficient algorithm for our estimator's computation, and prove that it is consistent. We extend our method to estimation of directed graphs with known causal ordering. Using simulated data, we show that our method performs better than existing methods when there are non-linear relationships among the features, and is comparable to methods that assume multivariate normality when the conditional means are linear. We illustrate our method on a cell-signaling data set.
Keywords: Conditional independence, Graphical model, Lasso, Nonlinearity, Non-Gaussianity, Sparse additive model, Sparsity
1. Introduction
In recent years, there has been considerable interest in developing methods to estimate the joint pattern of association within a set of random variables. The relationships between d random variables can be summarized with an undirected graph Γ = (V, S) in which the random variables are represented by the vertices V = {1, . . . , d} and the conditional dependencies between pairs of variables are represented by edges S ⊂ V × V . That is, for each j ∈ V , we want to determine a minimal set of variables on which the conditional densities pj({Xj | {Xk, k ≠ j}) depend,
There has also been considerable work in estimating marginal associations between a set of random variables (see e.g. Basso et al., 2005; Meyer et al., 2008; Liang & Wang, 2008; Hausser & Strimmer, 2009; Chen et al., 2010). But in this paper we focus on conditional dependencies, which, unlike marginal dependencies, cannot be explained by the other variables measured.
Estimating the conditional independence graph Γ based on a set of n observations is an old problem (Dempster, 1972). In the case of high-dimensional continuous data, most previous work has assumed either multivariate Gaussianity (see e.g. Friedman et al., 2008; Rothman et al., 2008; Yuan & Lin, 2007; Banerjee et al., 2008) or linear conditional means (see e.g. Meinshausen & Bühlmann, 2006; Peng et al., 2009) for the features. However, as we will see, these two assumptions are essentially equivalent. Some recently proposed methods relax the multivariate Gaussian assumption using univariate transformations (Liu et al., 2009, 2012; Xue & Zou, 2012; Dobra & Lenkoski, 2011), restrictions on the graph structure (Liu et al., 2011), or flexible random forests (Fellinghauer et al., 2013). However, we will see that these methods may not capture realistic departures from multivariate Gaussianity.
For illustration, consider the cell signaling data set from Sachs et al. (2005), which consists of protein concentrations measured under a set of perturbations. We analyze the data in more detail in Section 5·3. Pairwise scatterplots of three of the variables are given in Fig. 1 (a)-(c) for one of 14 experiments. The data have been transformed to be marginally normal, as suggested by Liu et al. (2009), but the transformed data clearly are not multivariate normal, as confirmed by a Shapiro–Wilk test, which yields a p-value less than 2 × 10−16.
Fig. 1.
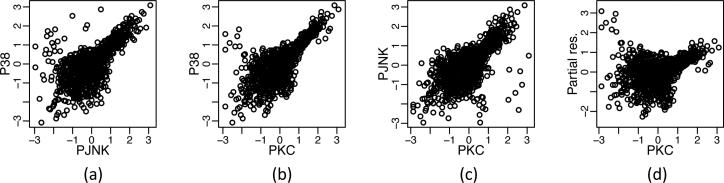
Cell signaling data from Sachs et al. (2005). (a)–(c) Pairwise scatterplots for PKC, P38 and PJNK. (d) Partial residuals from the linear regression of P38 on PKC and PJNK. The data are transformed to have normal marginal distributions, but are clearly not multivariate normal.
Can the data in Fig. 1 be well-represented by linear relationships? In Fig. 1 (d), we see strong evidence that the conditional mean of the protein P38 given PKC and PJNK is nonlinear. This is corroborated by the fact that the p-value for including quadratic terms in the linear regression of P38 onto PKC and PJNK is less than 2 × 10−16. Therefore in this data set, the features are not multivariate Gaussian, and marginal transformations do not remedy the problem.
In order to model this type of data, we could specify a more flexible joint distribution. How-ever, joint distributions are difficult to construct and computationally challenging to fit, and the resulting conditional models need not be easy to obtain or interpret. Alternatively, we can specify the conditional distributions directly; this has the advantage of simpler interpretation and greater computational tractability. In this paper, we will model the conditional means of non-Gaussian random variables with generalized additive models (Hastie & Tibshirani, 1990), and will use these in order to construct conditional independence graphs.
Throughout this paper, we will assume that we are given n independent and identically distributed observations from a d-dimensional random vector . Our observed data can be written as .
2. MODELING CONDITIONAL DEPENDENCE RELATIONSHIPS
Suppose we are interested in estimating the conditional independence graph for a random Γ vector . If the joint distribution is known up to some parameter θ, it suffices to estimate θ via e.g. maximum likelihood. One practical difficulty is specification of a plausible joint distribution. Specifying a conditional distribution, such as in a regression model, is typically much less daunting. We therefore consider pseudo-likelihoods (Besag, 1974, 1975) of the form
For a set of arbitrary conditional distributions, there need not be a compatible joint distribution (Wang & Ip, 2008). However, the conditionally specified graphical model has an appealing the-oretical justification, in that it minimizes the Kullback–Leibler distances to the conditional distributions (Varin & Vidoni, 2005). Furthermore, in estimating conditional independence graphs, our scientific interest is in the conditional independence relationships rather than in the joint distribution. So in a sense, modeling the conditional distribution rather than the joint distribution is a more direct approach to graph estimation. We therefore advocate an approach for non-Gaussian graphical modeling based on conditionally specified models (Varin et al., 2011).
3. PREVIOUS WORK
3·1. Estimating graphs with Gaussian data
Suppose for now that X has a joint Gaussian distribution with mean 0 and precision matrix Θ. The negative log-likelihood function evaluated at Θ, up to constants, is
| (1) |
In this case, the conditional relationships are linear,
| (2) |
where βjk = −Θjk/ Θkk and ∈j ~ N1(0, 1/Θjj). To estimate the graph Γ, we must determine which βjk are zero in (2), or equivalently, which Θjk are 0 in (1). This is simple when n > > d.
In the high-dimensional setting, when the maximum likelihood estimate is unstable or undefined, a number of approaches to estimate the conditional independence graph Γ have been proposed. Meinshausen & Bühlmann (2006) proposed fitting (2) using an l1-penalized regression. This is referred to as neighborhood selection:
| (3) |
Here λ is a nonnegative tuning parameter that encourages sparsity in the coefficient estimates. Peng et al. (2009) improved upon the neighborhood selection approach by applying l1 penalties to the partial correlations; this is known as sparse partial correlation estimation.
As an alternative to (3), many authors have considered estimating Θ by maximizing an l1-penalized joint log likelihood (see e.g. Yuan & Lin, 2007; Banerjee et al., 2008; Friedman et al., 2008). This amounts to the optimization problem
| (4) |
known as the graphical lasso. Here, 0 indicates that W must be positive definite. The sparsity pattern of the solution to (4) serves as an estimate of Γ.
At first glance, neighborhood selection and sparse partial correlation estimation may seem semi-parametric: a linear model may hold in the absence of multivariate normality. However, while (2) can accurately model each conditional dependence relationship semi-parametrically, the accumulation of these specifications sharply restricts the joint distribution: Khatri & Rao (1976) proved that if (2) holds, along with some mild assumptions, then the joint distribution must be multivariate normal, regardless of the distribution of the errors εj in (2). In other words, even though (3) does not explicitly involve the multivariate normal likelihood, normality is implicitly assumed. Thus, if we wish to model non-normal data, non-linear conditional models are necessary.
3·2. Estimating graphs with non-Gaussian data
We now briefly review three existing methods for modeling conditional independence graphs with non-Gaussian data. The normal copula or nonparanormal model (Liu et al. 2009, Liu et al. 2012, Xue & Zou 2012, studied in the Bayesian context by Dobra & Lenkoski 2011) assumes that X has a nonparanormal distribution: that is, {h1(X1), . . . , hd(Xd)} ~ Nd(0, Θ) for monotone functions h1, . . . , hd. After these are estimated, one can apply any of the methods mentioned in Section 3·1 to the transformed data. The conditional model implicit in this approach is
| (5) |
This restrictive assumption may not hold, as seen in Fig. 1.
Forest density estimation (Liu et al., 2011) replaces the need for distributional assumptions with graphical assumptions: the underlying graph is assumed to be a forest, and bivariate densities are estimated non-parametrically. Unfortunately, the restriction to acyclic graphs may be inappropriate in applications, and maximizing over all possible forests is infeasible.
The graphical random forests (Fellinghauer et al., 2013) approach uses random forests to flexibly model conditional means, and allows for interaction terms. However, random forests do not correspond to a well-defined statistical model or optimization problem, and results on its feature selection consistency are in general unavailable. In contrast, our proposed method corresponds to a statistical model for which we can prove results on edge selection consistency.
4. METHOD
4·1. Jointly additive models
In order to estimate a conditional independence graph using pseudolikelihood, we must estimate the variables on which the conditional distributions pj (·) depend. However, since density estimation is generally a challenging task, especially in high dimensions, we focus on the simpler problem of estimating the conditional mean Exj (Xj | {Xk: (j, k) ∈ S} ), under the assumption that the conditional distribution and the conditional mean depend on the same set of variables. Thus, we seek to estimate the conditional mean fj(·) in the regression model Xj | {Xk, k ≠ j} = fj (Xk, k ≠ j) + ∈j) + ∈j where ∈j is a mean-zero error term. Since estimating arbitrary functions fj(·) is infeasible in high dimensions, we restrict ourselves to additive models
| (6) |
where fjk(·) lies in some space of functions . This amounts to modeling each variable using a generalized additive model (Hastie & Tibshirani, 1990). Unlike Fellinghauer et al. (2013), we do not assume that the errors ∈j are independent of the additive components fjk(·), but merely that the conditional independence structure can be recovered from the functions fjk(·).
4·2. Estimation
Since we believe that the conditional independence graph is sparse, we fit (6) using a penalty that performs simultaneous estimation and selection of the fjk(·). Specifically, we link together d sparse additive models (Ravikumar et al., 2009) using a penalty that groups the parameters corresponding to a single edge in the graph. This results in the problem
| (7) |
We consider fjk(xk) = Ψjkβjk, where Ψjk is a n × r matrix whose columns are basis functions used to model the additive components fjk, and βjk is an r-vector containing the associated coefficients. For instance, if we use a linear basis function, Ψjk = xk, then r = 1 and we model only linear conditional means, as in Meinshausen & Bühlmann (2006). Higher-order terms allow us to model more complex dependencies. The standardized group lasso penalty (Simon & Tibshirani, 2012) encourages sparsity and ensures that the estimates of fjk(·) and fkj(·) will be simultaneously zero or non-zero. Problem (7) is an extension of sparse additive modeling (Ravikumar et al., 2009) to graphs, and generalizes neighborhood selection (Meinshausen & Bühlmann, 2006) and sparse partial correlation (Peng et al., 2009) to allow for flexible conditional means.
Algorithm 1. Given initial values for the , perform Steps 1–3 for (j, k) ∈ V × V, and repeat until convergence.
Step 1. Calculate the vector of errors for the jth and kth variables:
Step 2. Regress the errors on the specified basis functions:
Step 3. Threshold:
Algorithm 1 uses block coordinate descent to achieve the global minimum of the convex problem (7) (Tseng, 2001). Performing Step 2 requires an r × r matrix inversion; this must be performed only twice per pair of variables. Estimating 30 conditional independence graphs with r = 3 on a simulated data set with n = 50 and d = 100 takes 1.1 seconds on a 2.8 GHz Intel Core i7 Macbook Pro. The R package spacejam, available at cran.r-project.org/package=spacejam, implements the proposed approach.
4·3. Tuning
A number of options for tuning parameter selection are available, such as generalized crossvalidation (Tibshirani, 1996), the Bayesian information criterion (Zou et al., 2007), and stability selection (Meinshausen & Bühlmann, 2010). We take an approach motivated by the Bayesian information criterion, as in Peng et al. (2009). For the jth variable, the criterion is
| (8) |
where DFj(λ) is the degrees of freedom used in this regression. We seek the value of λ that minimizes . When a single basis function is used, we can approximate the degrees of freedom by the number of non-zero parameters in the regression (Zou et al., 2007; Peng et al., 2009). But with r > 1 basis functions, we use
| (9) |
where . Although (9) was derived under the assumption of an orthogonal design matrix, it is a good approximation for the non-orthogonal case (Yuan & Lin, 2006). Chen & Chen (2008) proposed modifications of the Bayesian information criterion for high-dimensional regression, which Gao & Song (2010) extended to the psuedo-likelihood setting. We leave evaluation of these alternatives for future work.
In order to perform Algorithm 1, we must select a set of basis functions. Domain knowledge or experience with similar data may guide basis choice. In the absence of domain knowledge we use cubic polynomials, which can approximate a wide range of functions. In Section 5·1, we use several different bases, and find that even misspecified sets of functions can provide more accurate graph estimates than methods that assume linearity.
5. NUMERICAL EXPERIMENTS
5·1. Simulation setup
As discussed in Section 2, it can be difficult to specify flexible non-Gaussian distributions for continuous variables. However, construction of multivariate distributions via conditional distributions is straightforward when the variables can be represented with a directed acyclic graph. The distribution of variables in a directed acyclic graph can be decomposed as , where SD denotes the directed edge set of the graph. This is a valid joint distribution regardless of the choice of conditional distributions pj(xj | {xk : (k, j) ∈ SD) (Pearl, 2000, Chapter 1.4). We chose structural equations of the form
| (10) |
with ∈j ~ N(0, 1). If the fjk are chosen to be linear, then the data are multivariate normal, and if the fjk are non-linear, then the data will typically not correspond to a well-known multivariate distribution. We moralized the directed graph in order to obtain the conditional independence graph (Cowell et al., 2007, Chapter 3.2). Here we have used directed acyclic graphs simply as a tool to generate non-Gaussian data; the full conditional distributions of the random variables created using this approach are not necessarily additive.
We first generated a directed acyclic graph with d = 100 nodes and 80 edges chosen at random from the 4950 possible edges. We used two schemes to construct a distribution on this graph. In the first setting, we chose , where the bjk1, bjk2, and bjk3 are independent and normally distributed with mean zero and variance 1, 0.5, and 0.5, respectively. In the second case, we chose fjk(xk) = xk, resulting in multivariate normal data. In both cases, we scaled the fjk(xk) to have unit variance, and generated n = 50 observations. We compared our method to sparse partial correlation (Peng et al., 2009, R package space), graphical lasso (Yuan & Lin, 2007, R package glasso), neighborhood selection (Meinshausen & Bühlmann, 2006, R package glasso), nonparanormal (Liu et al., 2012, R package huge), forest density estimation (Liu et al., 2011, code provided by authors), the method of Basso et al. (2005, R package minet), and graphical random forests (Fellinghauer et al., 2013, code provided by authors). In performing neighborhood selection, we declared an edge between the jth and kth variables if or . We performed our method using three sets of basis functions: , , .
5·2. Simulation results
Figure 2 summarizes the results of our simulations. For each method, the numbers of correctly and incorrectly estimated edges were averaged over 100 simulated data sets for a range of 100 tuning parameter values. When the fjk(·) are non-linear, our method with the basis dominates the basis sets or , which in turn tend to enjoy superior performance relative to all other methods, as seen in Fig. 2 (a). Furthermore, even though the basis sets and do not entirely capture the functional forms of the data-generating mechanism, they still outperform methods that assume linearity, as well as competitors intended to model non-linear relationships.
Fig. 2.

Summary of simulation study. The number of correctly estimated edges is displayed as a function of incorrectly estimated edges, for a range of tuning parameter values, in the (a) non-linear and (b) Gaussian set-ups, averaged over 100 simulated data sets. Dots indicate the average model size chosen by minimizing BIC(λ). The lines display our method with , ( ), (
), ( ), and (
), and ( ), as well as the methods of Liu et al. (2012)(
), as well as the methods of Liu et al. (2012)( ), Basso et al. (2005) (
), Basso et al. (2005) ( ), Liu et al. (2011) (
), Liu et al. (2011) ( ), Fellinghauer et al. (2013) (
), Fellinghauer et al. (2013) ( ), Yuan & Lin (2007) (
), Yuan & Lin (2007) ( ), Meinshausen & Bühlmann (2006) (
), Meinshausen & Bühlmann (2006) ( ), and Peng et al. (2009) (
), and Peng et al. (2009) ( ).
).
When the conditional means are linear and the number of estimated edges is small, all methods perform roughly equally, as seen in Fig. 2 (b). As the number of estimated edges increases, sparse partial correlation performs best, while the graphical lasso, the nonparanormal and the forest-based methods perform worse. This agrees with the observations of Peng et al. (2009) that sparse partial correlation and neighborhood selection tend to outperform the graphical lasso. In this setting, since non-linear terms are not needed to model the conditional dependence relationships, sparse partial correlation outperforms our method with two basis functions, which performs better than our method with three basis functions. Nonetheless, the loss in accuracy due to the inclusion of non-linear basis functions is not dramatic, and our method still tends to outperform other methods for non-Gaussian data, as well as the graphical lasso.
5·3. Application to cell signaling data
We apply our method to a data set consisting of measurements for 11 proteins involved in cell signaling, under 14 different perturbations (Sachs et al., 2005). To begin, we consider data from one of the 14 perturbations with n = 911, and compare our method using cubic polynomials to neighborhood selection, the nonparanormal, and graphical random forests with stability selection. Minimizing BIC(λ) for our method yields a graph with 16 edges. We compare our method to competing methods, selecting tuning parameters such that each graph estimate contains 16 edges, as well as 10 and 20 edges, for the sake of comparison. Figure 3 displays the estimated graphs, along with the directed graph presented in Sachs et al. (2005).
Fig. 3.

Cell signaling data set; graph reported in Sachs et al. (2005) is shown on the left. On the right, graphs were estimated using data from one perturbation of the data set. From top to bottom, panels contain graphs with 20, 16 and 10 edges. From left to right, comparisons are to Peng et al. (2009); Liu et al. (2012); Fellinghauer et al. (2013). We cannot specify an arbitrary graph size using graphical random forests, so graph sizes for that approach do not match exactly.
The graphs estimated using different methods are qualitatively different. If we treat the directed graph from Sachs et al. (2005) as the ground truth, then our method with 16 edges correctly identifies 12 of the edges, compared to 11, 9, and 8 using sparse partial correlation, the nonparanormal, and graphical random forests, respectively.
Next, we examined the other 13 perturbations, and found that for graphs with 16 edges, our method chooses on average 0.93, 0.64 and 0.2 more correct edges than sparse partial correlation, nonparanormal, and graphical random forests, respectively, yielding p = 0.001, 0.19 and 0.68 using the paired t-test. Since graphical random forests does not permit arbitrary specification of graph size, when graphs with 16 edges could not be obtained, we used the next largest graph, resulting in a larger number of correct edges for their method.
In Section 1, we showed that these data are not well-represented by linear models even after the nonparanormal transformation. The superior performance of our method in this section confirms this observation. The qualitative differences between our method and graphical random forests indicate that the approach taken for modeling non-linearity does affect the results obtained.
6. EXTENSION TO DIRECTED GRAPHS
In certain applications, it can be of interest to estimate the causal relationships underlying a set of features, typically represented as a directed acyclic graph. Though directed acyclic graph estimation is in general NP-hard, it is computationally tractable when a causal ordering is known. In fact, in this case, a modification of neighborhood selection is equivalent to the graphical lasso (Shojaie & Michailidis, 2010b). We extend the penalized likelihood framework of Shojaie & Michailidis (2010b) to non-linear additive models by solving
where indicates that k precedes j in the causal ordering. When Ψjk = xk, the model is exactly the penalized Gaussian likelihood approach of Shojaie & Michailidis (2010b).
Figure 4 displays the same simulation scenario as Section 5·1, but with the directed graph estimated using the known causal ordering. Results are compared to the penalized Gaussian likelihood approach of Shojaie & Michailidis (2010b). Our method performs best when the true relationships are non-linear, and performs competitively when the relationships are linear.
Fig. 4.

Summary of the directed acyclic graph simulation. The simulation is exactly as in Section 5·1 and Fig. 2. Again, (a) contains the non-linear simulation and (b) contains the Gaussian simulation. For each method, the number of correctly and incorrectly estimated edges are averaged over 100 simulated data sets, for a range of 100 tuning parameter values. The curves displayed are those of our method with ( ), (
), ( ), and (
), and ( ), as well as the method of Shojaie & Michailidis (2010b) (
), as well as the method of Shojaie & Michailidis (2010b) ( ).
).
7. THEORETICAL RESULTS
In this section, we establish consistency of our method for undirected graphs. Similar results hold for directed graphs, but we omit them due to space considerations. The theoretical development follows the sparsistency results for sparse additive models (Ravikumar et al., 2009).
First, we must define the graph for which our method is consistent. Recall that we have the random vector , and is a matrix where each row is an independent draw from . For each (j,k) ∈ V × V consider the orthogonal set of basis functions ψjkt(·), . Define the population level parameters as
Let , sj = |Sj|, and . Then
where ∈1, . . . , ∈d are errors, and Σk∈Sjfjk(Xk) is the best additive approximation to E(Xj | Xk : k ≠ j), in the least-squares sense. We wish to determine which of the fjk(·) are zero.
On observed data, we use a finite set of basis functions to model the fjk(·). Denote the set of r orthogonal basis functions used in the regression of xj on xk by Ψjk = {ψjk1(xk),..., ψjkr(xk)}, a matrix of dimension n × r such that . Let denote the first r components of . Further, let be the concatenated basis functions in {Ψjk : k ∈ Sj} and βSj be the corresponding coefficients. Also let , , and , and Λmin(ΣSj,Sj) be the minimum eigenvalue of ΣSj,Sj. Define the subgradient of the penalty in (7) with respect to βjk as gjk(β). On the set Sj, we write the concatenated subgradients as gSj, a vector of length sjr.
Let be the parameter estimates from solving (7), let be the corresponding estimated edge set, and let S* = {(j,k) : k ∈ Sj or j ∈ Sk} be the graph obtained from the population level parameters. In Theorem 1, proved in the Appendix, we give precise conditions under which as n → ∞.
THEOREM 1. Let the functions fjk be sufficently smooth, in thesense that if , then , uniformly in (j,k) ∈ V × V for some . For j = 1,..., d, Assume the that the basis functions satisfy Λmin(ΣSj, Sj) ≥ Cmin > 0 with probality tending to 1. Assume the irrrepresentability condition holds with probality
| (11) |
for (j,k) ∉ S* and some δ > 0, where . Assume the followint conditions on the number of edges , the neighborhood size sj, the regularization parameter λ, and the truncation dimension r:
where . Further, assume the variables ξjkt ≡ ψjkt(Xk)∈j have exponential tails, that is pr(|ξjkt| > z) ≤ ae−bz2 for some a,b > 0.
Then, the graph estimated using our method is consistent: as n → ∞.
Remark 1. The conditions on |S*|, sj, λ, and r hold if, for instance, λ ∝ n−γλ, d ∝ exp(n γd), r ∝ nγr, maxjSj ∝ nγs, m = 2, and ρ* > δ > 0 for positive constants γλ, γd, γr, γs, and δ, while γr + γs < 2γλ < 1 − γr − γs − γd, 2γs + γλ and n → ∞.
8. EXTENSION TO HIGH DIMENSIONS
In this section, we propose an approximation to our method that can speed up computations in high dimensions. Our proposal is motivated by recent work in the Gaussian setting (Witten et al., 2011; Mazumder & Hastie, 2012): the connected components of the conditional independence graph estimated using the graphical lasso (4) are precisely the connected components of the marginal independence graph estimated by thresholding the empirical covariance matrix. Consequently, one can obtain the exact solution to the graphical lasso problem in substantially reduced computational time by identifying the connected components of the marginal independence graph, and solving the graphical lasso optimization problem for the variables within each connected component.
We now apply the same principle to our method in order to quickly approximate the solution to (7). Let be the maximal correlation between Xj and Xk over the univariate functions in such that f(Xk) and g(Xj) have finite variance. Define the marginal dependence graph ΓM = (V, SM), where (j, k) ∈ SM when . If thejth and kth variables are in different connected components of ΓM, then they must be conditionally independent. Theorem 2, proved in the Appendix, makes this assertion precise.
THEOREM 2. Let C1, . . . , Cl be the connected components of ΓM. Suppose the space of functions contains linear functions. If j ∈ Cu and k ∉ Cu for some 1 ≤ u ≤ l, then (j, k) ∉S*.
Theorem 2 forms the basis for Algorithm 2. There, we approximate using the canonical correlation (Mardia et al., 1980) between the basis expansions Ψkj and Ψjk: .
Algorithm 2. Given λ1 and λ2, perform Steps 1–4.
Step 1. For (j, k) ∈ V × V, calculate , the canonical correlation between Ψkj and Ψjk.
Step 2. Construct the marginal independence graph when .
Step 3. Find the connected components C1, . . . , Cl of .
Step 4. Perform Algorithm 1 on each connected component with λ = λ1.
In order to show that (i) Algorithm 2 provides an accurate approximation to the original algorithm, (ii) the resulting estimator outperforms methods that rely on Gaussian assumptions when those assumptions are violated, and (iii) Algorithm 2 is indeed faster than Algorithm 1, we replicated the graph used in Section 5·1 five times. This gives d = 500 variables, broken into five components. We took n = 250, and set .
In Fig. 5, we see that when λ2 is small, there is little loss in statistical efficiency relative to Algorithm 1, which is a special case of Algorithm 2 with λ2 = 0. Further, we see that our method outperforms neighborhood selection even when λ2 is large. Using Algorithm 2 with λ2 = 0.5 and λ2 = 0.63 led to a reduction in computation time by 25% and 70%, respectively.
Fig. 5.

Performance of Algorithm 2. The number of correctly and incorrectly estimated edges are averaged over 100 simulated data sets, for each of 100 tuning parameter values. The curves displayed are from our method with λ2 = 0 ( ), λ2 = 0.5 (
), λ2 = 0.5 ( ) and λ2 = 0.63 (
) and λ2 = 0.63 ( ), as well as the method of Meinshausen & Bühlmann (2006) (
), as well as the method of Meinshausen & Bühlmann (2006) ( ).
).
Theorem 2 continues to hold if maximal correlation is replaced with some other measure of marginal association , provided that dominates maximal correlation in the sense that implies that . That is, any measure of marginal association, such as mutual information, which detects the same associations as maximal correlation (i.e. if ) can be used in Algorithm 2.
9. DISCUSSION
A possible extension to this work involves accommodating temporal information. We could take advantage of the natural ordering induced by time, as considered by Shojaie & Michailidis (2010a), and apply our method for directed graphs. We leave this to future work.
ACKNOWLEDGMENTS
We thank two anonymous reviewers and an associate editor for helpful comments, Thomas Lumley for valuable insights, and Han Liu and Bernd Fellinghauer for providing R code. D.W. and A.S. are partially supported by National Science Foundation grants, D.W. is partially supported by a National Institutes of Health grant.
APPENDIX 1: TECHNICAL PROOFS
A·1. Proof of Theorem 1
First, we restate a theorem which will be useful in the proof of the main result.
Theorem A1. (Kuelbs & Vidyashankar, 2010) Let {ξn,j,i : i = 1, . . . , n; j ∈ An} be a set of random variables such that ξn,j,i is independent of ξn,j,i′ for i ≠ i′. That is, ξn,j,i, i = 1, . . . , n denotes independent observations of feature j, and the features are indexed by some finite set An. Assume E(ξn,j,i) = 0, and there exist constants a > 1 and b > 0 such that pr(|ξn,j,i| ≥ x) ≤ ae−bx2 for all x > 0. Further, assume that |An| < ∞ for all x all n and that |An| → ∞ as n → ∞. Denote . Then
We now prove Theorem 1 of Section 7.
Proof of Theorem 1. First, is a solution to (7) if and only if
| (A1) |
where is the subgradient vector satisfying when , otherwise .
We base our proof on the primal-dual witness method of Wainwright (2009). That is, we construct a coefficient-subgradient pair and show that they solve (7) and produce the correct sparsity pattern, with probability tending to 1. For (j, k) ∈ S*, we construct and the corresponding subgradients using our method, restricted to edges in S* :
| (A2) |
For (j, k) ∈ S*c, we set , and use (A1) to solve for the remaining when k ∉ Sj. Now, is a solution to (7) if
| (A3) |
In addition, provided that
| (A4) |
Thus, it suffices to show that that conditions (A3) and (A4) hold with high probability.
We start with the condition (A4). The stationary condition for is given by
Denote by the truncation error from including only r basis terms. We can write . And so
or
| (A5) |
using the assumption that is invertible. We will now show that the inequality
| (A6) |
holds with high probability. This implies that if .
From (A5) we have that
Thus, to show (A6) it suffices to bound T1, T2, and T3.
We first bound T1. By assumption, uniformly in k. Thus, uniformly in j.
This implies that
In the above, we used that .
We now bound T2. Here, we use Theorem A1 which bounds the l∞ norm of the average of high-dimensional independent vectors. First, by the definition of ∈j we must have that E{ψjkt(Xk)∈j} = 0, i.e. the errors are uncorrelated with the covariates.
Let zjkt ≡ ψjkt(xk)Τ ∈j, which is the sum of n independent random variables with exponential tails. We have that
the maximum of 2r|S*| elements. We can thus apply Theorem A1, with An indexing the 2r|S*| elements above, to obtain
We now bound T3. We have that for (j, k) ∈ S*, so
Altogether, we have shown that
By assumption,
which implies that with probability tending to 1 as n → ∞.
We now consider the dual problem, condition (A3). We must show that for each (j, k) ∉ S* . From the discussion of condition (A4), we know that
We will proceed by bounding , and , which will a bound for the quantity of interest, .
We first bound M1. When bounding T1 earlier, we saw that n−1/2||wj||2 = Op(sj/rm). Now is a projection matrix with eigenvalues equal to 1, and by design n−1/2Ψjk is orthogonal, so that all the singular values of n−1/2Ψjk are 1. Therefore
and
which tends to zero because sj(λrm)−1 → 0 uniformly in j.
We now bound M2. First, note that
Then, applying Theorem A1, as in the bound for T2, we get
Thus, when
We now bound M3. By the irrepresentability assumption, we have that with probability tending to 1.
Thus, since , we have that for (j, k) ∈ S*c
with probability tending to 1. Further, since we have strict dual feasibility, i.e, for (j, k) ∈ S*c, with probability tending to 1, the estimated graph is unique.
A·2. Proof of Theorem 2
We now prove Theorem 2 of Section 8.
Proof of Theorem 2. Consider a variable j ∈ Cu. Our large-sample model minimizes E|Xj − Σk≠j fjk(Xk)|2 over functions . We have that
By assumption, . Thus, collecting terms, get
Minimization of this quantity with respect to only involves the last term, which achieves its minimum at zero when fjk(·) = 0 almost everywhere for each k ∉ Cu.
REFERENCES
- Banerjee O, El Ghaoui L, D'Aspremont A. Model selection through sparse maximum likelihood estimation for multivariate Gaussian or binary data. J. Mach. Learn. Res. 2008;9:485–516. [Google Scholar]
- Basso K, Margolin AA, Stolovitzky G, Klein U, Dalla-Favera R, Califano A. Reverse engineering of regulatory networks in human B cells. Nature Genet. 2005;37:382–390. doi: 10.1038/ng1532. [DOI] [PubMed] [Google Scholar]
- Besag JE. Spatial interaction and the statistical analysis of lattice systems. J. R. Statist. Soc. B. 1974;36:192–236. [Google Scholar]
- Besag JE. Statistical analysis of non-lattice data. The Statistician. 1975;24:179–195. [Google Scholar]
- Chen J, Chen Z. Extended Bayesian information criteria for model selection with large model spaces. Biometrika. 2008;95:759–771. [Google Scholar]
- Chen YA, Almeida JS, Richards AJ, Müller P, Carroll RJ, Rohrer B. A nonparametric approach to detect nonlinear correlation in gene expression. J. Comp. Graph. Stat. 2010;19:552–568. doi: 10.1198/jcgs.2010.08160. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cowell RG, Dawid P, Lauritzen SL, Spiegelhalter DJ. Probabilistic Networks and Expert Systems: Exact Computational Methods for Bayesian Networks. Springer; New York: 2007. chap. 3.2.1. [Google Scholar]
- Dempster AP. Covariance selection. Biometrics. 1972;28:157–175. [Google Scholar]
- Dobra A, Lenkoski A. Copula Gaussian graphical models and their application to modeling functional disability data. Ann. App. Statist. 2011;5:969–993. [Google Scholar]
- Fellinghauer B, Bühlmann P, Ryffel M, Von Rhein M, Reinhardt JD. Stable graphical model estimation with random forests for discrete, continuous, and mixed variables. Comp. Stat. & Data An. 2013;64:132–152. [Google Scholar]
- Friedman J, Hastie TJ, Tibshirani RJ. Sparse inverse covariance estimation with the graphical lasso. Biostatistics. 2008;9:432–441. doi: 10.1093/biostatistics/kxm045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gao X, Song PX-K. Composite likelihood Bayesian information criteria for model selection in high-dimensional data. J. Am. Statist. Assoc. 2010;105:1531–1540. [Google Scholar]
- Hastie T, Tibshirani RJ. Generalized Additive Models. Chapman & Hall/CRC; Boca Raton: 1990. [Google Scholar]
- Hausser J, Strimmer K. Entropy inference and the james–stein estimator, with application to nonlinear gene association networks. J. of Mach. Learn. Res. 2009;10:1469–1484. [Google Scholar]
- Khatri CG, Rao CR. Characterizations of multivariate normality. I. through independence of some statistics. J. Mult. An. 1976;6:81–94. [Google Scholar]
- Kuelbs J, Vidyashankar A. Asymptotic inference for high-dimensional data. Ann. Statist. 2010;38:836–869. [Google Scholar]
- Liang K-C, Wang X. Gene regulatory network reconstruction using conditional mutual information. EURASIP J. Bioinf. and Syst. Biol. 2008:253894–253894. doi: 10.1155/2008/253894. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu H, Han F, Yuan M, Lafferty J, Wasserman LA. High-dimensional semiparametric Gaussian copula graphical models. Ann. Statist. 2012;40:2293–2326. [Google Scholar]
- Liu H, Lafferty J, Wasserman LA. The nonparanormal: Semiparametric estimation of high dimensional undirected graphs. J. Mach. Learn. Res. 2009;10:2295–2328. [Google Scholar]
- Liu H, Xu M, Gu H, Gupta A, Lafferty J, Wasserman LA. Forest density estimation. J. Mach. Learn. Res. 2011;12:907–951. [Google Scholar]
- Mardia K, Kent J, Bibby J. Multivariate Analysis. Academic press; Waltham: 1980. [Google Scholar]
- Mazumder R, Hastie TJ. Exact covariance thresholding into connected components for large-scale graphical lasso. J. of Mach. Learn. Res. 2012;13:781–794. [PMC free article] [PubMed] [Google Scholar]
- Meinshausen N, Bühlmann P. High-dimensional graphs and variable selection with the lasso. Ann. Statist. 2006;34:1436–1462. [Google Scholar]
- Meinshausen N, Bühlmann P. Stability selection. J. R. Statist. Soc. B. 2010;72:417–473. [Google Scholar]
- Meyer PE, Lafitte F, Bontempi G. Minet: A R/Bioconductor package for inferring large transcriptional networks using mutual information. BMC Bioinformatics. 2008;9:461–471. doi: 10.1186/1471-2105-9-461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pearl J. Causality: Models, Reasoning, and Inference. Vol. 47. Functional Causal Models. Cambridge Univ Press; 2000. pp. 27–38. chap. 1.4. [Google Scholar]
- Peng J, Wang P, Zhou N, Zhu J. Partial correlation estimation by joint sparse regression models. J. Am. Statist. Assoc. 2009;104:735–746. doi: 10.1198/jasa.2009.0126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ravikumar P, Lafferty J, Liu H, Wasserman LA. Sparse additive models. J. R. Statist. Soc. B. 2009;71:1009–1030. [Google Scholar]
- Rothman A, Bickel P, Levina E, Zhu J. Sparse permutation invariant covariance estimation. Electronic Journal of Statistics. 2008;2:494–515. [Google Scholar]
- Sachs K, Perez O, Pe'er D, Lauffenburger D, Nolan G. Causal protein-signaling networks derived from multiparameter single-cell data. Science. 2005;308:523–529. doi: 10.1126/science.1105809. [DOI] [PubMed] [Google Scholar]
- Shojaie A, Michailidis G. Discovering graphical Granger causality using the truncating lasso penalty. Bioinformatics. 2010a;26:517–523. doi: 10.1093/bioinformatics/btq377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shojaie A, Michailidis G. Penalized likelihood methods for estimation of sparse high-dimensional directed acyclic graphs. Biometrika. 2010b;97:519–538. doi: 10.1093/biomet/asq038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simon N, Tibshirani RJ. Standardization and the group lasso penalty. Statistica Sinica. 2012;22:983–1001. doi: 10.5705/ss.2011.075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tibshirani RJ. Regression shrinkage and selection via the lasso. J. R. Statist. Soc. B. 1996;58:267–288. [Google Scholar]
- Tseng P. Convergence of a block coordinate descent method for nondifferentiable minimization. J. Opt. Theo. App. 2001;109:475–494. [Google Scholar]
- Varin C, Reid N, Firth D. An overview of composite likelihood methods. Statistica Sinica. 2011;21:5–42. [Google Scholar]
- Varin C, Vidoni P. A note on composite likelihood inference and model selection. Biometrika. 2005;92:519–528. [Google Scholar]
- Wainwright MJ. Sharp thresholds for high-dimensional and noisy sparsity recovery using ℓ1 constrained quadratic programming. IEEE Trans. Info. Theo. 2009;55:2183–2202. [Google Scholar]
- Wang Y, Ip E. Conditionally specified continuous distributions. Biometrika. 2008;95:735–746. [Google Scholar]
- Witten DM, Friedman J, SIMON N. New insights and faster computations for the graphical lasso. J. Comp. Graph. Stat. 2011;20:892–900. [Google Scholar]
- Xue L, ZOU H. Regularized rank-based estimation of high-dimensional nonparanormal graphical models. Ann. Statist. 2012;40:2541–2571. [Google Scholar]
- Yuan M, Lin Y. Model selection and estimation in regression with grouped variables. J. R. Statist. Soc. B. 2006;68:49–67. [Google Scholar]
- Yuan M, Lin Y. Model selection and estimation in the Gaussian graphical model. Biometrika. 2007;94:19–35. [Google Scholar]
- Zou H, Hastie TJ, Tibshirani RJ. On the degrees of freedom of the lasso. Ann. Statist. 2007;35:2173–2192. [Google Scholar]