

The crystal structure of zebrafish (D. rerio) complement 1qA globular domain (Dare-C1qAgD) was determined from X-ray diffraction data collected to 2.05 Å resolution. The crystal belonged to the orthorhombic space group P212121, with unit-cell parameters a = 50.347, b = 85.059, c = 95.560 Å.
Keywords: complement 1q A chain, C1q globular domain, zebrafish, Danio rerio
Abstract
Complement 1q (C1q) is the first component of the complement system which can initiate the classical complement pathway. In human, C1q is composed of 18 polypeptide chains: six C1qA chains, six C1qB chains and six C1qC chains. Each chain has a signal peptide and is comprised of a collagen-like region and a C-terminal C1q globular domain (C1qgD), which is organized as a heterotrimer. C1qgD can recognize antigen–antibody complexes containing IgG and IgM or can bind directly to the C-reactive protein. Although the classical complement pathway is found from fish to mammals, only the human C1qgD structure has been determined. Compared with that of mammals, fish C1q exhibits similar immune functions and genome arrangement. In order to illustrate the structure of C1qgD in fish, zebrafish (Danio rerio) C1qA globular domain (Dare-C1qAgD) was expressed, purified and crystallized. X-ray diffraction data were collected from a crystal to a resolution of 2.05 Å; the crystal belonged to the orthorhombic space group P212121, with unit-cell parameters a = 50.347, b = 85.059, c = 95.560 Å. It contained three molecules in the asymmetric unit. The Matthews coefficient value V M was 2.31 Å3 Da−1, with a calculated solvent content of 46.7%. The data will help to give insight into the structural basis of C1qA in fish species.
1. Introduction
The complement system is a vital anti-invasion component of the immune system. It can be activated by three different biochemical pathways: the classical complement pathway, the alternative pathway and the lectin pathway (Fujita, 2002 ▶). Complement 1q (C1q) is the first subcomponent for the activation of the classical pathway, and its signalling can be initiated through the recognition of antibody–antigen complexes and direct binding of C-reactive protein using the C1q globular region (McGrath et al., 2006 ▶). In addition, C1q can also induce the clearance of apoptotic cells and plays a major role in immune tolerance (Navratil et al., 2001 ▶). As no obvious structural features are shared by its ligands, C1q acts as a charge pattern-recognition molecule (Gaboriaud et al., 2003 ▶). The crystal structure of the human C1q globular region showed that it is a heterotrimer and is composed of C1qA, C1qB and C1qC subunits. The globular regions of C1qA, C1qB and C1qC are organized into the C1q globular domain (C1qgD), which forms a jelly-roll topology fold created by two antiparallel β sheets (Gaboriaud et al., 2003 ▶). Among the three subcomponents, C1qA is the most important chain for C1q function. For instance, C1qA-deficient (C1qa−/−) mice showed a higher mortality and higher titres of auto-antibodies (Botto et al., 1998 ▶). In addition, C1qA can also be targeted by virus proteins, and the interaction of C1qA and IgG can then be blocked (Zhang et al., 2009 ▶).
C1q molecules can be found in all of the Chordata classes, even in the cephalochordate amphioxus and urochordata (Huang et al., 2008 ▶). Zebrafish, Danio rerio, C1q (Dare-C1q) has conserved chromosomal characteristics in comparison to mammals. Dare-C1qgD exhibited conserved functional involvement in the C1q-dependent classical pathway (Ghai et al., 2007 ▶). To date, only the three-dimensional structure of human C1qgD has been solved to 1.9 Å resolution (Gaboriaud et al., 2003 ▶). The structure of fish C1q remains unclear. Zebrafish acts as a model organism for studying the evolution of immunity, and can help in understanding many evolutionary mechanisms in vertebrates (Hu et al., 2010 ▶). In this study, zebrafish C1qA globular domain (Dare-C1qAgD) was cloned, expressed, purified and crystallized, and the sequences were aligned between different species. Given that only the crystal structure of human C1qgD has been determined, the results will be helpful in understanding the structural basis of C1qgD in fish species.
2. Materials and methods
2.1. Macromolecule production
The gene for Dare-C1qAgD was amplified from a zebrafish cDNA library kept in our laboratory using Ex Taq DNA polymerase [TakaraBiotechnology (Dalian) Co. Ltd]. The primers were designed according to the published zebrafish C1qA gene (GenBank accession No. NP_001018363; Hu et al., 2010 ▶). After the gene was cloned, expression primers were designed by adding a unique NdeI recognition site in the 5′-terminus of the upper primer and a stop codon and a specific XhoI recognition site in the 3′-terminus of the lower primer. The PCR product was digested with the restriction enzymes NdeI and XhoI, and the double-digested product was then inserted into the pET-21a vector (Novagen, Merck KGaA, Darmstadt, Germany). The recombinant plasmid was confirmed by sequencing and the ligation product was transformed into the expression Escherichia coli strain BL21 (DE3) (Table 1 ▶). The Dare-C1qAgD protein was expressed as inclusion bodies. The inclusion bodies were extracted and washed, and then dissolved in guanidine–HCl buffer [6 M guanidine–HCl, 50 mM Tris–HCl pH 8.0, 10 mM EDTA, 100 mM NaCl, 10%(v/v) glycerol, 10 mM DTT] to a concentration of 30 mg ml−1 (Yao et al., 2012 ▶).
Table 1. Dare-C1qAgD production information.
| Source organism | Danio rerio |
| DNA source | Amplified from a zebrafish cDNA library |
| Forward primer | CCAACATATGAAAGCCAGCGAGAAACCGGCATTC |
| Reverse primer | CCGCTCGAGTTACTCTGCATTGCGATAGATTAAAAAC |
| Cloning vector | pMD18-T |
| Expression vector | pET-21a |
| Expression host | E. coli BL21 (DE3) |
| Complete amino-acid sequence of the construct produced | KASEKPAFSVLRNEASQAQYKQPVTFNDKLSDANDDFQIKTGYFTCKVPGVYYFVFHASSEGRLCLRLKSTSAPPVSLSFCDFNSKSVSLVVSGGAVLTLLKGDKVWIEPFAGDGGVGQMPKRLYAVFNGFLIYRN |
The preparation of the Dare-C1qAgD protein was carried out essentially as described previously (Garboczi et al., 1996 ▶) with some modifications in our laboratory (Chen et al., 2011 ▶). The Dare-C1qAgD protein was refolded by the dilution method, in which the inclusion bodies were gradually added into refolding buffer (100 mM Tris–HCl pH 8.0, 2 mM EDTA, 400 mM l-arginine–HCl, 0.5 mM oxidized glutathione, 5 mM reduced glutathione). After 12 h, the refolded Dare-C1qAgD protein was concentrated at 277 K and then purified by Superdex 200 size-exclusion chromatography (GE Healthcare). Further purification was conducted by Resource S ion-exchange chromatography (GE Healthcare), in which Resource S buffer A (6.3 mM Na2HPO4, 13.7 mM NaH2PO4) and buffer B (6.3 mM Na2HPO4, 13.7 mM NaH2PO4, 1 M NaCl) were used (Fig. 1 ▶).
Figure 1.

Purification of Dare-C1qAgD by Superdex 200 size-exclusion chromatography and Resource S ion-exchange chromatography. (a) The gel-filtration profile of refolded Dare-C1qAgD on Superdex G-200 FPLC. The inset shows the reduced SDS–PAGE gel (15%) of the corresponding purified protein; lane M contains molecular-weight markers (labelled in kDa) and lane 1 indicates the purified protein sample. (b) The result of further purification of Dare-C1qAgD by Resource S ion-exchange chromatography. The target protein eluted at a NaCl concentration of 5–12%. The inset shows a reduced SDS–PAGE gel (15%) of the purified protein; lane M contains molecular-weight markers (labelled in kDa) and lane 1 contains the purified protein sample.
2.2. Crystallization
Purified Dare-C1qAgD protein was buffer-exchanged into crystallization buffer (50 mM NaCl, 20 mM Tris–HCl pH 8.0) and then concentrated to 5 mg ml−1. Screening of crystallization conditions was carried out with the Index, Crystal Screen, Crystal Screen 2 and PEG/Ion kits (Hampton Research, California, USA) at 277 K using the sitting-drop vapour-diffusion method. Drops were prepared by mixing 1 µl protein solution with 1 µl reservoir solution and equilibrating against 150 µl of the same reservoir solution. A crystal was obtained after one month in the condition 0.2 M ammonium sulfate, 20%(w/v) polyethylene glycol 3350 pH 6.0 (Table 2 ▶).
Table 2. Crystallization.
| Method | Sitting-drop method |
| Plate type | 48-well VDX plate |
| Temperature (K) | 277 |
| Protein concentration (mg ml−1) | 5 |
| Buffer composition of protein solution | 20 mM Tris–HCl pH 8.0, 50 mM NaCl |
| Composition of reservoir solution | 0.2 M ammonium sulfate, 20%(w/v) PEG 3350 pH 6.0 |
| Volume and ratio of drop | 2 µl, 1:1 Dare-C1qAgD:reservoir solution |
| Volume of reservoir (µl) | 150 |
2.3. Data collection and processing
Diffraction data were collected from a Dare-C1qAgD crystal on beamline BL17U at the Shanghai Synchrotron Radiation Facility (SSRF; Shanghai, People’s Republic of China) at a wavelength of 0.97892 Å using an ADSC Quantum 315r image-plate detector. The Dare-C1qAgD crystal was soaked in the well solution containing an additional 33%(v/v) glycerol as a cryoprotectant for 3 min before diffraction. Diffraction was carried out in a nitrogen-gas stream at a temperature of 100 K. The data were indexed, integrated, scaled and merged using HKL-2000 (Otwinowski & Minor, 1997 ▶; Table 3 ▶).
Table 3. Data collection and processing.
Values in parentheses are for the outer shell.
| Diffraction source | BL17U, Shanghai Synchrotron Radiation Facility |
| Wavelength (Å) | 0.97892 |
| Temperature (K) | 100 |
| Detector | ADSC 315 imaging plate |
| Crystal-to-detector distance (mm) | 300 |
| Rotation range per image (°) | 1 |
| Total rotation range (°) | 180 |
| Exposure time per image (s) | 0.5 |
| Space group | P212121 |
| Unit-cell parameters (Å, °) | a = 50.347, b = 85.059, c = 95.560, α = 90.0, β = 90.0, γ = 90.0 |
| Mosaicity (°) | 0.5 |
| Resolution range (Å) | 50.00–2.05 (2.12–2.05) |
| Total No. of reflections | 181316 |
| No. of unique reflections | 26479 |
| Completeness (%) | 99.6 (100.0) |
| Multiplicity | 6.8 (7.2) |
| 〈I/σ(I)〉 | 22.222 (11.750) |
| R merge † (%) | 7.4 (19.6) |
| Overall B factor from Wilson plot (Å2) | 29.5 |
R
merge = 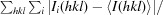
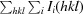 .
.
3. Results and discussion
The refolded Dare-C1qAgD protein was purified by size-exclusion chromatography (Fig. 1 ▶). The elution volume was 90 ml, which showed that the molecular weight of the purified Dare-C1qAgD protein was 14 kDa (peak 1). This result demonstrated that the peak corresponded to the target protein, which was then confirmed by SDS–PAGE (Fig. 1 ▶ a). The isoelectric point of Dare-C1qAgD was 9.18, which was predicted by the GENETYX program. As a result, Resource S ion-exchange chromatography was used for further purification. The purified protein was confirmed to have a high purity by SDS–PAGE (Fig. 1 ▶ b).
Commercial crystallization kits were used to obtain Dare-C1qAgD crystals. An ideal crystal appeared after one month in condition 35 of PEG/Ion [0.2 M ammonium sulfate, 20%(w/v) polyethylene glycol 3350 pH 6.0] without any need for further optimization (Fig. 2 ▶). The crystal belonged to space group P212121 and diffracted to 2.05 Å resolution. Although the theoretical maximum resolution was calculated to be 1.7 Å under the above conditions, when we tried to set the resolution cutoff to lower than 2 Å the completeness of the outermost shell dropped sharply to less than 60% (Fig. 3 ▶, Table 3 ▶).
Figure 2.

Typical crystal of Dare-C1qAgD.
Figure 3.

The diffraction image of the Dare-C1qAgD crystal.
A multiple sequence alignment of C1qAgD amino-acid sequences was carried out by ClustalW2. According to the result, Dare-C1qAgD shares 27, 31, 39 and 38% sequence identity with the amphioxus, chicken, mouse and human C1qAgD, respectively (Supplementary Fig. S11). Although C1qAgDs are found from invertebrates to vertebrates, their amino-acid sequences share relatively low similarity.
C1q has endured through the efficient conversion from innate immunity to adaptive immunity from invertebrates to vertebrates throughout the evolutionary process. To date, only the three-dimensional structure of human C1qgD has been solved; the structure of C1qgD from other species is unknown. Here, the Dare-C1qAgD protein was first crystallized. The results will be helpful for understanding the evolution of C1q, and they provide a structural basis for studying the B and C subunits of C1q from fish species.
Supplementary Material
Supporting Information.. DOI: 10.1107/S2053230X14010747/fw5454sup1.pdf
Acknowledgments
This work was supported by the State Key Program of the National Natural Science Foundation of China (grant No. 31230074), the 973 Project of the China Ministry of Science and Technology (grant No. 2013CB835302) and the Graduate Student Scientific Research and Innovation Program of China Agricultural University (grant No. 2012YJ068). We acknowledge the assistance of the staff at the Shanghai Synchrotron Radiation Facility (SSRF).
Footnotes
Supporting information has been deposited in the IUCr electronic archive (Reference: FW5454).
References
- Botto, M., Dell’Agnola, C., Bygrave, A. E., Thompson, E. M., Cook, H. T., Petry, F., Loos, M., Pandolfi, P. P. & Walport, M. J. (1998). Nature Genet. 19, 56–59. [DOI] [PubMed]
- Chen, R., Qi, J., Yao, S., Pan, X., Gao, F. & Xia, C. (2011). Acta Cryst. F67, 1633–1636. [DOI] [PMC free article] [PubMed]
- Fujita, T. (2002). Nature Rev. Immunol. 2, 346–353. [DOI] [PubMed]
- Gaboriaud, C., Juanhuix, J., Gruez, A., Lacroix, M., Darnault, C., Pignol, D., Verger, D., Fontecilla-Camps, J. C. & Arlaud, G. J. (2003). J. Biol. Chem. 278, 46974–46982. [DOI] [PubMed]
- Garboczi, D. N., Ghosh, P., Utz, U., Fan, Q. R., Biddison, W. E. & Wiley, D. C. (1996). Nature (London), 384, 134–141.
- Ghai, R., Waters, P., Roumenina, L. T., Gadjeva, M., Kojouharova, M. S., Reid, K. B. M., Sim, R. B. & Kishore, U. (2007). Immunobiology, 212, 253–266. [DOI] [PubMed]
- Hu, Y.-L., Pan, X.-M., Xiang, L.-X. & Shao, J.-Z. (2010). J. Biol. Chem. 285, 28777–28786. [DOI] [PMC free article] [PubMed]
- Huang, S. et al. (2008). Genome Res. 18, 1112–1126. [DOI] [PMC free article] [PubMed]
- McGrath, F. D., Brouwer, M. C., Arlaud, G. J., Daha, M. R., Hack, C. E. & Roos, A. (2006). J. Immunol. 176, 2950–2957. [DOI] [PubMed]
- Navratil, J. S., Watkins, S. C., Wisnieski, J. J. & Ahearn, J. M. (2001). J. Immunol. 166, 3231–3239. [DOI] [PubMed]
- Otwinowski, Z. & Minor, W. (1997). Methods Enzymol. 276, 307–326. [DOI] [PubMed]
- Yao, S., Qi, J., Liu, J., Chen, R., Pan, X., Li, X., Gao, F. & Xia, C. (2012). Acta Cryst. F68, 20–23. [DOI] [PMC free article] [PubMed]
- Zhang, J., Li, G., Liu, X., Wang, Z., Liu, W. & Ye, X. (2009). J. Gen. Virol. 90, 2751–2758. [DOI] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting Information.. DOI: 10.1107/S2053230X14010747/fw5454sup1.pdf