

Significance
One of the most common strategies in studying complex systems is to investigate and interpret whether any “hidden order” is present by fitting observed statistical regularities via data analysis and then reproducing such regularities with long-time or equilibrium dynamics from some generative model. Unfortunately, many different models can possess indistinguishable long-time dynamics, so the above recipe is often insufficient to discern the relative quality of competing models. In this paper, we use the example of collective online behavior to illustrate that, by contrast, time-dependent modeling can be very effective at disentangling competing generative models of a complex system.
Keywords: branching processes, complex systems
Abstract
Human activities increasingly take place in online environments, providing novel opportunities for relating individual behaviors to population-level outcomes. In this paper, we introduce a simple generative model for the collective behavior of millions of social networking site users who are deciding between different software applications. Our model incorporates two distinct mechanisms: one is associated with recent decisions of users, and the other reflects the cumulative popularity of each application. Importantly, although various combinations of the two mechanisms yield long-time behavior that is consistent with data, the only models that reproduce the observed temporal dynamics are those that strongly emphasize the recent popularity of applications over their cumulative popularity. This demonstrates—even when using purely observational data without experimental design—that temporal data-driven modeling can effectively distinguish between competing microscopic mechanisms, allowing us to uncover previously unidentified aspects of collective online behavior.
The recent availability of datasets that capture the behavior of individuals participating in online social systems has helped drive the emerging field of computational social science (1), as large-scale empirical datasets enable the development of detailed computational models of individual and collective behavior (2–4). Choices of which movies to watch, which mobile applications (“apps”) to download, or which messages to retweet are influenced by the opinions of our friends, neighbors, and colleagues (5). Given the difficulty in distinguishing between potential explanations of observed behavior at the individual level (6), it is useful to examine population-level models and attempt to reproduce empirically observed popularity distributions using the simplest possible assumptions about individual behavior. Such generative models have arisen in a wide range of disciplines—including economics (7, 8), evolutionary biology (9, 10), and physics (11). When studying generative models, the microscopic dynamics are known exactly, so it is possible to explore the population-level mechanisms that emerge in a controlled manner. This contrasts with studies driven by empirical data, in which confounding effects can always be present (6). The value of explanations based on mechanisms has long been appreciated in sociology (12–14), and they have recently received increased attention due to the availability of extensive data from online social networks (15–18).
One well-studied rule for choosing between multiple options is cumulative advantage (also known as preferential attachment), in which popular options are more likely to be selected than unpopular ones. This leads to a “rich-get-richer” agglomeration of popularity (7, 9, 19–22). Bentley et al. (5, 23, 24) proposed an alternative model, in which members of a population randomly copy the choices made by other members in the recent past. As a result, products whose popularity levels have recently grown the fastest are the most likely to be selected (whether or not they are the most popular overall). In the present paper, we show that models of app-installation decisions that are biased heavily toward recent popularity rather than cumulative popularity provide the best fit to empirical data on the installation of Facebook apps. We use the model to identify the timescales over which the influence of Facebook users upon each others’ choices is strongest, and we argue that the interaction between these timescales and the diurnal variation in Facebook activity yields many of the observed features of the popularity distribution of apps. More generally, we illustrate how to incorporate temporal dynamics in modeling and data analysis to differentiate between competing models that produce the same long-time (i.e., after transients have died out) behavior.
We use the Facebook apps dataset that was first reported in ref. 15 by Onnela and Reed-Tsochas. These data include the records, for every hour from June 25, 2007 to August 14, 2007, of the number of times that every Facebook app (of the n = 2,705 total available during this period) was installed. At the time, Facebook users had two streams of information about apps: a “cumulative information” stream gave an “all-time best-seller” list, in which all apps were ranked by their cumulative popularity (i.e., the total number of installations to date), and a “recent activity information” stream consisted of updates provided by Facebook on the recent app installation activity by a user’s friends. Users could also visit the profiles of their friends to see which applications a friend had installed.
The data thus consist of N time series ni(t), where the “popularity” ni(t) of app i at time t is the total number of users who have installed app i by hour t of the study period. The discrete time index t counts hours from the start of the study period (t = 0) to the end (t = tmax ≡ 1,209). The distribution of ni values is heavy-tailed (SI Appendix, Fig. S1), so the popularities ni(t) of the apps cover a very wide range of scales. Facebook apps first became available on May 24, 2007, corresponding to t ≈ −720 in our notation. By time t = 0, when the data collection began, 980 apps had already launched (with unknown launch times); the remaining apps in our dataset were launched during the study period. Among the latter, we pay particular attention to those for which we have at least tLES ≡ 650 h (i.e., more than one-half of the data collection window) of data. We call these apps the “launched-early-in-study” (LES) apps. Denoting by ti the launch time of app i, the 921 LES apps i are those that satisfy ti > 0 and ti < tmax − tLES = 559. We set ti = 0 for apps that were launched before the study period.
To measure the change in app popularity during hour t, we define the “increment” in popularity of app i at time t as fi(t) = ni(t) − ni(t − 1) [with fi(t) = 0 for t ≤ ti] (15). The total app installation activity of users during hour t is then as follows:
| [1] |
We show in SI Appendix, section SI1 that F(t) has large diurnal fluctuations superimposed on a linear-in-time aggregate growth.
We define the “age-shifted popularity” and “age-shifted increment” of app i at age a to enable comparison of apps when they are the same age (i.e., at the same number of hours after their launch). An examination of the trajectories of the largest LES apps reveals that their popularity grows exponentially for some time before reaching a steady-growth regime in which increases approximately linearly with age. The corresponding age-shifted increment functions reach a “plateau” at large a, although they have a superimposed 24-h oscillation (SI Appendix, Figs. S3 and S4). To study the entire set of LES apps, we scale the increment of app i by its temporal average over the first tLES = 650 observations for each app. This weights very popular apps and other (less popular) apps in a similar manner (25). For a given set of LES apps, we define the “mean scaled age-shifted growth rate” as follows:
| [2] |
where 〈⋅〉 denotes an ensemble average over all apps in the set .
The mean scaled age-shifted growth rate reveals several interesting features (Fig. 1A). First, at large ages (e.g., a ≥ 150 h), the function r(a) has 24-h oscillations superimposed on a nearly constant curve. The behavior of r(a) is very different for smaller ages; we dub this the “novelty regime,” as it represents the (approximately 1-wk) time period that immediately follows the launch of apps. The r(a) curve for the entire LES set is similar to those found by splitting the LES set into two disjoint subsets based on ordered launch times—the 460 applications with earlier launch times (ti ≤ 260; early-launch) and the 461 applications with later launch times (ti ≥ 261; late-launch). The small difference between the r(a) curves for these cases gives an estimate of the inherent variability within the data and sets a natural target for how well stochastic simulations can fit the data. We find similar results for other subsets of the same size (SI Appendix, section SI3).
Fig. 1.

(Left) Mean scaled age-shifted growth rate r(a), (Center) distributions of app popularity, and (Right) popularity over time for the top-five apps, showing turnover. (A and B) Behavior of the entire LES set of applications and its two subsets (which are described in the text); (C) trajectories of the top-five apps in the dataset (ordered by popularity at t = 0; note apps that were not in the t = 0 top-five are not shown here but can be seen in SI Appendix, Fig. S7). (D–F) Cumulative-information model (γ = 1), for which (E) shows popularity distributions at t = tmax (upper symbols) and for LES app growth to age a = tLES (lower symbols); empirical data are in black. (G–I) Recent-activity model with short memory (γ = 0, H = 168, T = 5). (J–L) Recent-activity model with long-memory (γ = 0, H = 168, T = 50).
To directly measure the growth of new apps in their first tLES hours, we show the distribution of for the entire LES set in Fig. 1B. We also show the corresponding distributions for the two LES subsets (early and late launch). The similarity of distributions for early-born apps and late-born apps implies that the launch time, at least in the period that we examined, does not have a strong effect on the growth of new apps. This contrasts with Yule–Simon models of popularity (7, 21, 26) and related preferential-attachment models used to model citations (11). In these models, early-born apps have more time to accumulate popularity and hence exhibit a different aging behavior to later-born apps (27).
In Fig. 1C, we examine changes in the rank order of the top-5 list of apps by plotting the trajectories of the largest apps (ranked by their popularity at time t = 0) over the duration of the study (and see SI Appendix, Fig. S7, for plots of top-10 lists). Reproducing realistic levels of turnover in such lists is a challenging test for models of popularity dynamics (24, 28).
The popularity dynamics for the novelty regime seem to be app-specific (Fig. 1A and SI Appendix, Fig. S4), but a simple model can satisfactorily describe the postnovelty regime. We introduce a general stochastic simulation framework with a “history-window parameter” H and consider an app to be within its “history window” for the first H hours that data on the app are available. The history window of LES apps extends from their launch time to H hours later; for non-LES apps, we define the history window to be the first H hours (t = 0 to t = H) of the study. We conduct stochastic simulations by modeling F(t) computational “agents” in time step t, each of whom installs one app at that time step. We take the values of F(t) from the data (Eq. 1). Note that our simulated agents do not correspond directly to Facebook users, as we do not have data at the level of individual users. In reality, a Facebook user can, for example, install several different apps during an hour; in our simulations, however, such actions would be modeled by the choices of several agents.
We simulate the choices of the agents as follows. First, for any app i that is in its history window at time t, we copy the increment fi(t) directly from the data. This determines the choices of FH(t) of the agents, where FH(t) is the number of installations of all apps that are within their history window at time t. Each of the remaining F(t) − FH(t) agents then installs any one of the apps that are not in their history window. An installation probability pi(t) is allocated based on model-specific rules (see below), and the F(t) − FH(t) agents each independently choose app i with probability pi(t). These rules ensure that the total number of installations in each hour exactly matches the data and that the history window of each app is reproduced exactly.
We investigate several possible choices for pi(t) by comparing the results of simulations with the characteristics of the data highlighted in Fig. 1 A–C. The history-window parameter H plays an important role in capturing the app-specific novelty regime. However, if H is very large, then most of the simulation is copied directly from the data and the decision probability pi(t) becomes irrelevant. It is therefore desirable to find models that fit the data well while keeping H as small as possible. Motivated by the information available to Facebook users during the data collection period, we propose a model based on a combination of a “cumulative rule” and a “recent activity rule” . See the schematic in Fig. 2.
Fig. 2.

Schematic of the model. The squares indicate the number of installations at time t of two example apps; their size represents the number of installations of an app in a particular hour. The circles represent agents, and the arrows indicate the adoption of an app. In the history window (ages 0 to H), we copy the installation history directly from the data. Outside of the history windows, we simulate the actions of F(t) agents by assigning probabilistic rules for how they choose which app to install. An agent who uses (Left) the recent-activity rule at a given time copies the choice of an agent who acted in the recent past, so apps that were recently more popular are more likely to be chosen. By contrast, an agent who uses (Right) the cumulative rule at a given time installs the app with the larger number of accumulated installations. We represent this cumulative popularity using the dashed contour, which increases in width with time as more installations occur.
An agent who uses the cumulative rule at time t chooses app i with a probability proportional to its cumulative popularity ni(t − 1), yielding the following:
| [3] |
where the constant K is determined by the normalization . In contrast, an agent who follows the recent-activity rule at time t copies the installation choice of an agent who acted in an earlier time step, with some memory weighting (Eq. 4 below). Consequently, apps that were recently installed by many agents [i.e., apps with large fi(τ) values for τ ≈ t] are more likely to be installed at time step t even if these apps are not yet globally popular [i.e., ni(t − 1) can be small]. In reality, the information available to Facebook users on the recent popularity of apps was limited to observations of the installation activity of their network neighbors. As we lack any information on the real network topology, we make the simplest possible assumption: that the network is sufficiently well-connected (see ref. 29 for a study of Facebook networks from 2005) to enable all agents in the model to have information on the aggregate (system-wide) installation activity. When applying the recent-activity rule, an agent chooses app i with a probability proportional to the recent level of that app’s installation activity:
| [4] |
where L is determined by the normalization . The “memory function” W(τ) determines the weight assigned to activity from τ hours ago and thereby incorporates human-activity timescales (30). In SI Appendix, we consider several examples of plausible memory functions and also examine the possibility of heterogeneous app fitnesses.
If our dataset included the early growth of every app, then a constant weighting function W(t) ≡ 1 would reduce to . However, because of our finite data window, many apps have large values of ni(0), so we cannot capture the cumulative rule by using a suitable weighting function in the recent-activity rule. Instead, we introduce a tunable parameter γ ∈ [0, 1] so that the population-level installation probability pi used in the simulation is a weighted sum,
| [5] |
that interpolates between the extremes of γ = 0 (recent-activity rule) and γ = 1 (cumulative rule). The model ignores externalities between apps, an assumption that is supported by the results of ref. 15.
To explore our model, we start by considering the case γ = 1, in which agents consider only cumulative information. In Fig. 1 D–F, we compare the results of stochastic simulations with the data (Fig. 1 A–C) using a history window of H = 168 h (i.e., 1 wk). Clearly, the cumulative model does not match the data well. Although the app popularity distributions at t = tmax are reasonably similar (Fig. 1E), the largest popularities are overpredicted by the model. By contrast, the popularity of the LES apps—which include many of the less popular apps—is underpredicted. In particular, their mean scaled age-shifted growth rate has a lower long-term mean than that of the data (Fig. 1D). Recall from Eq. 2 that each app’s increments are scaled by their temporal average before ensemble averaging to calculate r(a). As a result, any error in predicting the value of has an effect on the entire r(a) curve. This explains why, for example, the values of r(a) for a < H are overpredicted in Fig. 1D, despite the fact that the increments in this regime are copied from the data. The corresponding temporal averages are too low, so the scaled increment values are too high. In Fig. 1F, we illustrate that the ordering among the top-five apps does not change in time for this model, so it does not produce realistic levels of app-popularity turnover (Fig. 1C and SI Appendix, Fig. S7). In SI Appendix, sections SI6 and SI7, we demonstrate that several alternative models based on cumulative information also match the data poorly.
We next consider the case in which γ is small, so recent information dominates (5, 24). In Fig. 3, we show results for stochastic simulations using an exponential response-time distribution to determine the weights W(t) assigned to activity from t hours earlier for varying history-window lengths H and response-time parameters T. The colors in the (H, T) parameter plane represent the L2 error, which is given by the L2 norm of the difference between the simulated r(a) curve and the r(a) curve from the data. A value of 3.11 is representative of inherent fluctuations in the data (SI Appendix, section SI3), and the bright colors in Fig. 3 represent parameter values for which the difference between the model’s mean growth rate and the empirically observed growth rate is less than the magnitude of fluctuations present in the data. Observe that the model requires a history window of approximately 1 wk (i.e., H ≈ 168 h) to match the data. As γ increases, cumulative information is weighted more heavily, and the region of “good-fit” parameters moves toward larger T and larger H (SI Appendix, section SI3). As noted previously, large-H models trivially provide good fits (because they mostly copy directly from data), but the γ = 0 case provides a good fit to the data even with a relatively short history window H.
Fig. 3.
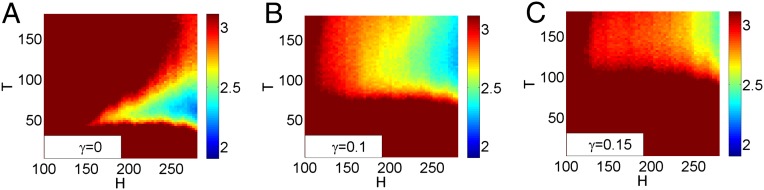
Parameter planes showing the L2 error (SI Appendix, section SI3) for the r(a) curve for the recent-activity–dominated model described in the text. The parameter H is the length of the history window, and T is the mean of the exponential response-time distribution. For each point in the plane, we average values of the L2 error over 24 realizations. We show all values above 3.11 as dark red.
In Fig. 1 G–I, we compare model results with data for parameter values H = 168, T = 5, and γ = 0 (i.e., the “recent-activity, short-memory” case). This reproduces the app popularity distributions of the data rather well, but the mean scaled age-shifted growth rates are markedly different. In contrast, Fig. 1 J–L compare model results with data for parameter values H = 168, T = 50, and γ = 0 (i.e., the “recent-activity, long-memory” case). These parameters are just inside the good-fit region of Fig. 3A, so the r(a) curve in Fig. 1J matches the data well. Moreover, the popularity distributions at t = tmax and at age tLES (Fig. 1K) are both reasonably matched by the model, which also allows realistic turnover in the top-10 list (Fig. 1L and SI Appendix, Fig. S7). These considerations highlight the importance of using temporal data to develop and fit models of complex systems. Distributions at single times can be insensitive to model differences, and the r(a) curves are crucial for distinguishing between competing models. In SI Appendix, section SI4, we show that the recent-activity (γ = 0) case still gives good fits to the data if the exponential response-time distribution is replaced by a lognormal, gamma, or uniform distribution.
Another noteworthy feature of the recent-activity case is its ability to produce heavy-tailed popularity distributions in stochastic simulations even if no history is copied from the data (H = 0). Even if all apps initially have the same number of installations, random fluctuations lead to some apps becoming more popular than others, and the aggregate popularity distribution becomes heavy-tailed (10, 23, 24, 31). In SI Appendix, section SI5, we show that this situation is described by a near-critical branching process, for which power-law popularity distributions are expected (32–36).
Our model suggests that app adoption among Facebook users was guided more by recent popularity of apps (as reflected in installations by friends within 2 days) than by cumulative popularity. The fact that the model is a near-critical branching process might help to explain the prevalence of heavy-tailed popularity distributions that have been observed in information cascades on social networks, such as the spreading of retweets on Twitter (4, 17, 18) or news stories on Digg (37). The branching-process analysis is also applicable to the random-copying models of Bentley et al. (5, 23, 24). Although most random-copying models consider only short (e.g., single time-step) memory (5, 23), the simulation study of ref. 24 includes a uniform response-time distribution and demonstrates the role of memory effects in generating turnover. As shown in Fig. 1 and detailed in SI Appendix, section SI7, generating realistic turnover of rank order in the top-10 apps is a significant challenge for all models based on cumulative information, even those that include a time-dependent decay of novelty (38, 39). In SI Appendix, section SI9, we show that our model can also explain the results of the fluctuation-scaling analysis of the Facebook apps data in ref. 15 that highlighted the existence of distinct scaling regimes (depending on app popularity).
Our approach also highlights the need to address temporal dynamics when modeling complex social systems. Online experiments have been used successfully in computational social science (1), but it is challenging to run experiments in online environments that people actually use (as opposed to creating new online environments with potentially distinct behaviors). If longitudinal data are available, as in the present case, it is possible to evaluate a model’s fit based not only on long-time behavior but also on dynamical behavior. Given that several models successfully produce similar long-time behavior, the investigation of temporal dynamics is critical for distinguishing between competing models. As more observational data with high temporal resolution from online social networks become available, we believe that this modeling strategy, which leverages temporal dynamics, will become increasingly essential.
Supplementary Material
Acknowledgments
We thank Andrea Baronchelli, Ken Duffy, James Fennell, James Fowler, Sandra González-Bailón, Stephen Kinsella, Jack McCarthy, Yamir Moreno, Peter Mucha, Puck Rombach, and Frank Schweitzer for helpful discussions. We thank the Science Foundation Ireland/Higher Education Authority Irish Centre for High-End Computing for the provision of computational facilities. We acknowledge funding from Science Foundation Ireland Grant 11/PI/1026 (to J.P.G. and D.C.), Future and Emerging Technologies (FET)-Proactive Project PLEXMATH FP7-ICT-2011-8 Grant 317614 (to J.P.G., D.C., and M.A.P.), FET-Open Project FOC-II FP7-ICT-2007-8-0 Grant 255987 (to F.R.-T.), the John Fell Fund from University of Oxford (to M.A.P.), and DeGruttola National Institute of Allergy and Infectious Diseases Grant R37A1051164 (to J.-P.O.).
Footnotes
The authors declare no conflict of interest.
This article is a PNAS Direct Submission.
This article contains supporting information online at www.pnas.org/lookup/suppl/doi:10.1073/pnas.1313895111/-/DCSupplemental.
References
- 1.Lazer D, et al. Social science. Computational social science. Science. 2009;323(5915):721–723. doi: 10.1126/science.1167742. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Aral S, Walker D. Identifying influential and susceptible members of social networks. Science. 2012;337(6092):337–341. doi: 10.1126/science.1215842. [DOI] [PubMed] [Google Scholar]
- 3.Bond RM, et al. A 61-million-person experiment in social influence and political mobilization. Nature. 2012;489(7415):295–298. doi: 10.1038/nature11421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.González-Bailón S, Borge-Holthoefer J, Rivero A, Moreno Y. The dynamics of protest recruitment through an online network. Sci Rep. 2011;1:197. doi: 10.1038/srep00197. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Bentley RA, Earls M, O’Brien MJ. I’ll Have What She’s Having: Mapping Social Behavior. Cambridge, MA: MIT; 2011. [Google Scholar]
- 6.Shalizi CR, Thomas AC. Homophily and contagion are generically confounded in observational social network studies. Sociol Methods Res. 2011;40(2):211–239. doi: 10.1177/0049124111404820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Simon HA. On a class of skew distribution functions. Biometrika. 1955;42(3/4):425–440. [Google Scholar]
- 8.De Vany A. Hollywood Economics: How Extreme Uncertainty Shapes the Film Industry. London: Routledge; 2003. [Google Scholar]
- 9.Yule GU. A mathematical theory of evolution, based on the conclusions of Dr. JC Willis, FRS. Philos Trans R Soc Lond B Biol Sci. 1925;213:21–87. [Google Scholar]
- 10.Ewens WJ. Mathematical Population Genetics: I. Theoretical Introduction. New York: Springer; 2004. [Google Scholar]
- 11.Redner S. How popular is your paper? An empirical study of the citation distribution. Eur Phys J B. 1998;4(2):131–134. [Google Scholar]
- 12.Hedström P, Swedberg R. Social Mechanisms: An Analytical Approach to Social Theory. Cambridge, UK: Cambridge Univ Press; 1998. [Google Scholar]
- 13.Granovetter M. Threshold models of collective behavior. Am J Sociol. 1978;83(6):1420–1443. [Google Scholar]
- 14.Schelling TC. Micromotives and Macrobehavior. New York: WW Norton & Company; 2006. [Google Scholar]
- 15.Onnela J-P, Reed-Tsochas F. Spontaneous emergence of social influence in online systems. Proc Natl Acad Sci USA. 2010;107(43):18375–18380. doi: 10.1073/pnas.0914572107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Romero DM, Meeder B, Kleinberg J. 2011. Differences in the mechanics of information diffusion across topics: Idioms, political hashtags, and complex contagion on Twitter. Proceedings of the 20th International Conference on World Wide Web (Association for Computing Machinery, New York), pp 695–704.
- 17.Bakshy E, Hofman JM, Mason WA, Watts DJ. 2011. Everyone’s an influencer: Quantifying influence on Twitter. Proceedings of the Fourth ACM International Conference on Web Search and Data Mining (Association for Computing Machinery, New York), pp 65–74.
- 18.Lerman K, Ghosh R, Surachawala T. 2012. Social contagion: An empirical study of information spread on Digg and Twitter follower graphs. arXiv:1202.3162.
- 19.de Solla Price DJ. A general theory of bibliometric and other cumulative advantage processes. J Am Soc Inf Sci. 1976;27(5):292–306. [Google Scholar]
- 20.Barabási A-L, Albert R. Emergence of scaling in random networks. Science. 1999;286(5439):509–512. doi: 10.1126/science.286.5439.509. [DOI] [PubMed] [Google Scholar]
- 21.Simkin MV, Roychowdhury VP. Re-inventing Willis. Phys Rep. 2011;502(1):1–35. [Google Scholar]
- 22.Bianconi G, Barabási A-L. Competition and multiscaling in evolving networks. Europhys Lett. 2001;54(4):436–442. [Google Scholar]
- 23.Bentley RA, Hahn MW, Shennan SJ. Random drift and culture change. Proc Biol Sci. 2004;271(1547):1443–1450. doi: 10.1098/rspb.2004.2746. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Bentley RA, Ormerod P, Batty M. Evolving social influence in large populations. Behav Ecol Sociobiol. 2011;65(3):537–546. [Google Scholar]
- 25.Szabo G, Huberman BA. Predicting the popularity of online content. Commun ACM. 2010;53(8):80–88. [Google Scholar]
- 26.Cattuto C, Loreto V, Pietronero L. Semiotic dynamics and collaborative tagging. Proc Natl Acad Sci USA. 2007;104(5):1461–1464. doi: 10.1073/pnas.0610487104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Simkin MV, Roychowdhury VP. A mathematical theory of citing. J Am Soc Inf Sci Technol. 2007;58(11):1661–1673. [Google Scholar]
- 28.Evans TS, Giometto A. 2011. Turnover rate of popularity charts in neutral models. arXiv:1105.4044.
- 29.Traud AL, Mucha PJ, Porter MA. Social structure of Facebook networks. Physica A. 2012;391(16):4165–4180. [Google Scholar]
- 30.Barabási A-L. Bursts: The Hidden Patterns Behind Everything We Do, From Your E-mail to Bloody Crusades. New York: Dutton Adult; 2010. [Google Scholar]
- 31.Evans TS, Plato ADK. Exact solution for the time evolution of network rewiring models. Phys Rev E Stat Nonlin Soft Matter Phys. 2007;75(5 Pt 2):056101. doi: 10.1103/PhysRevE.75.056101. [DOI] [PubMed] [Google Scholar]
- 32.Harris TE. The Theory of Branching Processes. New York: Dover Publications; 2002. [Google Scholar]
- 33.Zapperi S, Bækgaard Lauritsen K, Stanley HE. Self-organized branching processes: Mean-field theory for avalanches. Phys Rev Lett. 1995;75(22):4071–4074. doi: 10.1103/PhysRevLett.75.4071. [DOI] [PubMed] [Google Scholar]
- 34.Adami C, Chu J. Critical and near-critical branching processes. Phys Rev E Stat Nonlin Soft Matter Phys. 2002;66(1 Pt 1):011907. doi: 10.1103/PhysRevE.66.011907. [DOI] [PubMed] [Google Scholar]
- 35.Goh KI, Lee DS, Kahng B, Kim D. Sandpile on scale-free networks. Phys Rev Lett. 2003;91(14):148701. doi: 10.1103/PhysRevLett.91.148701. [DOI] [PubMed] [Google Scholar]
- 36.Gleeson JP, Ward JA, O’Sullivan KP, Lee WT. Competition-induced criticality in a model of meme popularity. Phys Rev Lett. 2014;112(4):048701. doi: 10.1103/PhysRevLett.112.048701. [DOI] [PubMed] [Google Scholar]
- 37.Ver Steeg G, Ghosh R, Lerman K. 2011. What stops social epidemics? arXiv:1102.1985.
- 38.Wu F, Huberman BA. Novelty and collective attention. Proc Natl Acad Sci USA. 2007;104(45):17599–17601. doi: 10.1073/pnas.0704916104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Wang D, Song C, Barabási A-L. Quantifying long-term scientific impact. Science. 2013;342(6154):127–132. doi: 10.1126/science.1237825. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.