

SUMMARY
Estimating the causal effect of an intervention on a population typically involves defining parameters in a nonparametric structural equation model (Pearl, 2000, Causality: Models, Reasoning, and Inference) in which the treatment or exposure is deterministically assigned in a static or dynamic way. We define a new causal parameter that takes into account the fact that intervention policies can result in stochastically assigned exposures. The statistical parameter that identifies the causal parameter of interest is established. Inverse probability of treatment weighting (IPTW), augmented IPTW (A-IPTW), and targeted maximum likelihood estimators (TMLE) are developed. A simulation study is performed to demonstrate the properties of these estimators, which include the double robustness of the A-IPTW and the TMLE. An application example using physical activity data is presented.
Keywords: Causal effect, Counterfactual outcome, Double robustness, Stochastic intervention, Targeted maximum likelihood estimation
1. Introduction
Most causal inference problems are addressed by defining parameters of the distribution of the counterfactual outcome that one would obtain in a controlled experiment in which an exposure variable A is set to some prespecified value a deterministically. A widely used example of this framework is the causal effect for a binary treatment, in which the expectation of the outcome in a hypothetical world in which everybody receives treatment is compared with its counterpart in a world in which nobody does. Other common way of addressing causal problems consists in considering parameters that reflect the difference between the distribution of a counterfactual outcome in such hypothetical intervened world and the distribution of the actual outcome; these parameters are often referred to as population intervention parameters (Hubbard and van der Laan, 2005).
To estimate such exposure-specific counterfactual parameters from observational data, one has to assume that all subjects in the population have a positive probability of receiving the exposure level a under consideration. This assumption is often referred to as experimental treatment assignment, or positivity assumption and can be highly unrealistic in most cases. Additionally, when the exposure of interest is not a variable that can be directly manipulated (e.g., social or behavioral phenomena), any policy intervention targeting a change in the exposure distribution will result in a population whose exposure is stochastic rather than deterministic, and the causal effect as described in the previous paragraph loses its appeal as a measure of the gain obtained by implementing such a policy.
An example that illustrates these ideas is presented in Section 6. These data were collected by Tager, Hollenberg, and Satariano (1998) and analyzed by Bembom and van der Laan (2007) with the main goal of assessing the effect of vigorous physical activity on mortality in the elderly. First, as argued by Bembom and van der Laan (2007), experimental treatment assignment assumptions as needed to identify the causal effect of a static treatment are quite unrealistic because health problems are expected to prevent an important proportion of the population from high levels of physical activity. Second, it is clear that it is not possible to put in practice a policy in which every subject is enforced to a physical activity level dictated by a deterministic rule. Therefore, any intervention on the population that targets changes in physical activity levels will induce a random postintervention exposure. These and other reasons why deterministic interventions are not always the best approach to estimate causal effects are discussed in Korb et al. (2004) and Eberhardt and Scheines (2006). Korb et al. (2004) define an intervention on a variable A in a causal model as an action that intends to change the distribution of A. This general definition includes as special cases static and dynamic deterministic interventions (through degenerate distributions), but it also allows the definition of the causal effect in terms of a non degenerate distribution, as exploited in this article.
In our example, the question of whether higher levels of leisure-time physical activity (LTPA) cause a reduction in mortality rates in the elderly can be better addressed by considering the effect of a policy that aims to cause an increase in the mean of LTPA, possibly depending on covariates such as health status or socioeconomic level. As we will see in Section 2, this problem can be formulated by considering the effect of an intervention of the treatment mechanism. We focus the discussion on the definition and estimation of the effect of this specific type of interventions.
Despite the previous considerations, current developments and applications have almost exclusively focused on deterministic interventions. Among the few works using stochastic interventions Figure Cain et al. (2010), who used a stochastic intervention in the context of comparing dynamic treatment regimes with a grace period; and Taubman et al. (2009), who considered an intervention in the body mass index defined by a truncation of the original exposure distribution.
Other type of stochastic interventions of interest arises in applications in which the interest relies in estimating the effect of a policy that enforces the exposure level below a certain threshold. Such policies can modify the distribution of the exposure in various ways. For example, if a policy that constrains air pollution emissions below a cutoff point is put in place, it is reasonable to think that the probability mass associated with values above that cutoff in the original exposure mechanism will be relocated around the cutoff after the intervention. This is because under such a policy, high-polluting companies will not have any incentive to go below the enforced cutoff point.
Alternative threshold-like interventions can lead to a truncated version of the original density, relocating the mass above the threshold across all values of the exposure distribution below the threshold (as opposed to relocating it in the cutoff point). In fact, as proven by Stitelman, Hubbard, and Jewell (2010), the intervention obtained by considering a dichotomous version of a continuous treatment and defining a usual static intervention (e.g., the body mass index intervention in Taubman et al., 2009), corresponds to a stochastic intervention on the original continuous treatment that truncates its density below the value defining the dichotomization.
Our major goal is to introduce stochastic intervention causal parameters as a way of measuring the effect that certain policies have on the outcome of interest. As we will see, estimation of the these parameters requires weaker assumptions than estimation of other causal parameters (e.g., marginal structural models [MSM]), relaxing assumptions about positivity and consistency of the initial estimators, and thus providing a more flexible way of estimating causal effects. We will start in Section 2 by defining the parameter of interest, in Section 3 we present its efficient influence curve, and discuss the double robustness of estimators that solve the efficient influence curve equation. This section also provides the tools for defining the targeted maximum likelihood estimators (TMLE) in Section 4.3. In Section 5 we present a simulation study demonstrating consistency and efficiency properties of the estimators, and in Section 6 we present an application example.
2. Data and Parameter of Interest
Consider an experiment in which an exposure variable A, a continuous or binary outcome Y and a set of covariates W are measured for n randomly sampled subjects. Let O = (W, A, Y) represent a random variable with distribution P0, and O1,…, On represent n i.i.d. observations of O. Assume that the following nonparametric structural equation model (NPSEM, Pearl, 2000) holds:
| (1) |
where UW, UA and UY are exogenous random variables such that UA ⫫ UY holds, and either UW ⫫ UY or UW ⫫ UA holds (randomization assumption). The true distribution P0 of O can be factorized as
where we denote g0(A|W) ≡ P0(A|W), , QW,0(W) ≡ P0(W) and Pf = ∫fdP for a given function f.
Counterfactual outcomes under stochastic interventions are denoted by , and are defined as the outcome of a causal model in which the equation in the NPSEM (1) corresponding to A is removed, and A is set equal to a with probability Pδ (g0)(A = a|W). The latter is called the intervention distribution, which we allow to depend on the true exposure mechanism g0. Any stochastic intervention of interest can be defined in this way, and in this article we focus the discussion on the intervention distribution:
| (2) |
for a known function δ(W). This is a shifted version of the current treatment mechanism, where the shifting value is allowed to vary across strata defined by the covariates. As discussed in Section 6, one can be interested in the effect of a policy that encourages people to exercise more, leading to a population where the distribution of physical activity is shifted according to certain health and socioeconomic variables. As implicitly stated in (2), we will assume that the functional form of the exposure mechanism induced by the intervention differs from the original exposure mechanism only through its conditional expectation given the covariates.
2.1 Identification
Let denote the exposure variable under the intervened system (i.e., is distributed according to Pδ (g)). We have that
where and are the support of A and W, respectively. From the NPSEM (1) we have that , where Ya is the counterfactual outcome when the exposure is set to level a with probability one. Note also that the usual randomization assumption A⫫Ya|W implies , and therefore . Under the consistency assumption (A = a implies Ya = Y) the latter quantity is identified by P(Y = y|A = a, W = w). Our counterfactual distribution can be written as
We define the parameter of interest as a mapping that takes an element in a statistical model and maps it into a number in the reals. The true value of the parameter is given by the mapping evaluated at the true distribution , and is denoted by ψ0 = Ψ(P0). Our causal and statistical parameter of interest is then given by
| (3) |
Note that this parameter depends only on . Therefore, in an abuse of notation, we will use the expressions Ψ(Q) and Ψ(P) interchangeably.
3. Efficient Influence Curve
In this section, we derive the efficient influence curve for the parameter in (3) when Pδ (g0) is given by (2), which can be written as
| (4) |
The last equality can be checked by changing the index in the summation to A − δ(W). Equation (4) corresponds exactly with computing the marginal mean of Y from the joint distribution of (W, A, Y) with A replaced by A + δ(W). Note also that if δ(W) = 0, equation (4) is equal to the expectation of Y under P.
The efficient influence curve is a key element in semiparametric efficient estimation, because it defines the linear approximation of any efficient and regular asymptotically linear estimator (see Web Appendix A), and therefore provides an asymptotic bound for the variance of all regular asymptotically linear estimators (Bickel et al., 1997).
RESULT 1
The efficient influence curve of (4) is
| (5) |
Because this influence curve as well as the parameter of interest depend only on Q, we will also use the notations D(P)(O) and D(Q)(O) interchangeably.
Proof
See Web Appendix A.
This efficient influence curve can be decomposed in three parts corresponding to the orthogonal decomposition of the tangent space implied by the factorization of the likelihood:
| (6) |
This decomposition of the score is going to be useful later on during the construction of a TMLE of ψ0. The following result provides the conditions under which an estimator that solves the efficient influence curve equation is consistent.
RESULT 2
Let be the estimating function implied by the efficient influence curve D(P)(O):
let w(g)(a, w) = g(a − δ(w)|w)/g(a|w), and let , − a.e. We have that if either g is such that w(g) = w(g0), or
Proof
See Web Appendix A.
As a consequence of result 2, under regularity conditions stated in Theorem 1 of van der Laan and Rubin (2006), a substitution estimator of Ψ(P0) that solves the efficient influence curve equation will be consistent if either one of w(g0) and is estimated consistently, and it will be efficient if and only if both w(g0) and are estimated consistently. We only rely on consistent estimation of the weight function w(g0). This consistency can be easier to obtain than consistent estimation of the density g0, which is required for double robustness of parameters in MSM (Neugebauer and van der Laan, 2007). Because Ψ(P) depends on both and g, double robustness is a very unexpected result. Some intuition about it is provided by the definition of the parameter in (4): if is known, a consistent estimator can always be obtained by computing the empirical mean of ; if the weight function w(g0) is known, a consistent estimate of ψ0 would be given by a weighted average of Y with weights w(g0)(A, W).
3.1 Positivity Assumption
Alternatives to definition and estimation of causal effects in the context of continuous or categorical multilevel treatments are given by MSM and parameters like the ones presented in Petersen et al. (2010). One of the assumptions required to estimate those parameters (the positivity assumption) is given by
for a user-specified weight function h. The function h(a) = 1 is commonly used, because it implies giving equal weights to all the possible treatment values.
From the formula of the efficient influence curve, the positivity assumption needed to identify and estimate our parameter of interest is given by
| (7) |
Suppose for some small ∈. Because the function δ is user given, we can try to define it in a way so that it is useful to answer the causal question of interest, and yet it does not produce unstable weights. As a result, the positivity assumption as needed to estimate our parameter of interest is more easily achievable than the positivity assumption as required to estimate other causal parameters for continuous exposures.
4. Estimators
In this section, we present three possible estimators for the parameter of interest. A brief review of concepts in semiparametric efficient estimation can be found in the Web Appendix A. The TMLE and the augmented inverse probability of treatment weighting (A-IPTW) estimators solve the efficient influence curve equation, and therefore, from Result 2, are consistent estimators if either one of and wg0(A|W) is estimated consistently. They are efficient if and only if both of these quantities are estimated consistently. The IPTW is inefficient, and will be consistent only if the estimator of w(g0)(A|W) is consistent. The TMLE is expected to perform better than the A-IPTW if the positivity assumption is violated, which will be the case if the causal question of interest requires the use of a function δ that produces unstable weights in (7). The TMLE is also a better alternative than when the efficient estimating equation has multiple solutions, or its solution goes out of the natural bounds for the parameter of interest.
The estimators presented in this section require initial estimates of and g0(A|W), which can be obtained through machine learning techniques, parametric, or semi-parametric models. The consistency of these initial estimators will determine the consistency and efficiency of the estimators of ψ0, as discussed previously. Parametric models are commonly used for the sole sake of their nice analytical properties, but they encode assumptions about the distribution of the data that are not legitimate knowledge about the phenomenon under study and usually cause a large amount of bias in the estimated parameter. As an alternative, we recommend the use of machine learning techniques such as the super learner (van der Laan, Polley, and Hubbard, 2007). Super learner is a methodology that uses crossvalidated risks to find an optimal estimator among a library defined by the convex hull of a user-supplied list of candidate estimators. One of its most important theoretical properties is that its solution converges to the oracle estimator (i.e., the candidate in the library that minimizes the loss function with respect to the true probability distribution). Proofs and simulations regarding these and other asymptotic properties of the super learner can be found in van der Laan, Dudoit, and Keles (2004) and van der Laan and Dudoit (2003).
Influence curve based variance estimators are provided for these three estimators. Consistency of the variance estimators also depends on the consistency of the initial estimates of and g0. These dependencies can be avoided at the cost of computational time and effort by using bootstrapped estimates of the variance.
4.1 IPTW
Given an estimator of the exposure density, the IPTW estimator of ψ0 is defined as
The IPTW is an asymptotically linear estimator with influence curve
therefore, the variable converges in distribution to , whose variance can be estimated by . This variance estimator is conservative, as proved in van der Laan and Robins (2003) and corroborated in the simulation section.
4.2 A-IPTW
The A-IPTW is the value ψn,2 that solves the equation , for initial estimates and of and g0.
If the estimators and are consistent, the A-IPTW is an asymptotically linear estimator with influence curve . As in the case of the IPTW, the variable converges in law to a random variable with distribution , whose variance can be estimated as . van der Laan and Robins (2003) (sections 2.3.7 and 2.7.1) show that inference based on this variance estimator is valid only if is consistent, providing exact inference when is consistent, and conservative inference when is inconsistent.
4.3 Targeted Maximum Likelihood Estimator
Targeted maximum likelihood estimation (van der Laan and Rubin, 2006) is a loss-based semiparametric estimation method that yields a substitution estimator of a target parameter of the probability distribution of the data that solves the efficient influence curve estimating equation, and thereby yields a double robust locally efficient estimator of the parameter of interest, under regularity conditions.
To define a TMLE for ψ0, we need first to define three elements: (1) A loss function L(Q) for the relevant part of the likelihood required to evaluate Ψ(P), which in this case is . This function must satisfy , where Q0 denotes the true value of Q; (2) An initial estimator of Q0; (3) A parametric fluctuation Q(∈) through such that the linear span of contains the efficient influence curve D(P) defined in (5). These elements are defined below:
Loss Function
As loss function for Q, we will use , where for continuous Y we set ; for binary Y we set , , and LW(QW) = −log QW(W). It can be easily verified that this function satisfies .
Parametric Fluctuation
Given an estimator of Q0, with components , we define the (k + 1)th fluctuation of as follows:
where , , and H3(W) = D3(Pk)(O), with D2 and D3 defined as in (6). We define these fluctuations using a two-dimensional ∈ with two different parameters ∈1 and ∈2. It is theoretically correct to define these fluctuations using any dimension for ∈, as long as the condition is satisfied, where <·> denotes linear span. The convenience of the particular choice made here will be clear once the TMLE is defined.
Targeted Maximum Likelihood Estimator
The TMLE is defined by the following iterative process:
Initialize k = 0.
Estimate ∈ as .
Compute .
Update k = k + 1 and iterate steps (ii) through (iv) until convergence (i.e., until ).
First of all, note that the value of ∈2 that minimizes the part of the loss function corresponding to the marginal distribution of W in the first step (i.e., ) is . Therefore, the iterative estimation of ∈ only involves the estimation of ∈1. The k th step estimation of ∈1 is obtained by minimizing , which implies solving the estimating equation
| (8) |
where
The TMLE of ψ0 is defined as , assuming this limit exists. In practice, the iteration process is carried out until convergence in the values of is achieved, and an estimator is obtained. The variance of ψn,3 can be estimated by , which like the A-IPTW variance estimator is consistent only if both and are consistent, is conservative if is consistent but is not, and is inconsistent in any other case.
5. Simulation Study
To provide an example of the finite sample properties of the estimators discussed in Section 4, a simulation study was performed. We focus on just one data-generating distribution, which provides a limited but useful situation to demonstrate our claims about consistency and efficiency.
Assuming that we are interested in estimating the effect of a constant shift of δ(W1, W2) = 2, the true parameter value for this data-generating distribution is ψ0 = 22.95, and the efficiency bound equals .
For sample sizes n = 50, 100, 200, and 500, we simulated 2000 samples from the previous data-generating distribution, and estimated ψ0 using the three estimators proposed in the previous section. As initial estimators of and g0(A|W) we considered four cases: (1) correctly specified model for both and g0(A|W), (2) incorrectly specified model for but correctly specified for g0(A|W), (3) correctly specified model for but incorrectly specified for g0(A|W), and (4) incorrectly specified model for both and g0(A|W); where misspecification of the models was performed by considering the correct distribution and link function but only main terms in the linear predictor.
TML estimation of ψ0 was performed using the R tmle.shift() function presented in Web Appendix B. The average and variance of the estimates across the 2000 samples was computed as an approximation to the expectation and variance of the estimator (Table 1), respectively.
Table 1.
Expectation of the estimators for different sample sizes and model specifications. True value is 22.95
| n | Model | TMLE | IPTW | A-IPTW |
|---|---|---|---|---|
| 50 | 1 | 22.99 | 22.66 | 22.99 |
| 2 | 22.99 | 22.49 | 22.99 | |
| 3 | 22.88 | 22.66 | 22.91 | |
| 4 | 22.01 | 22.49 | 22.04 | |
| 100 | 1 | 22.95 | 22.81 | 22.95 |
| 2 | 22.96 | 22.61 | 22.95 | |
| 3 | 22.89 | 22.81 | 22.92 | |
| 4 | 21.97 | 22.61 | 22.00 | |
| 200 | 1 | 22.99 | 22.89 | 22.99 |
| 2 | 22.99 | 22.68 | 22.99 | |
| 3 | 22.94 | 22.89 | 22.96 | |
| 4 | 21.99 | 22.68 | 22.02 | |
| 500 | 1 | 22.97 | 22.93 | 22.97 |
| 2 | 22.97 | 22.71 | 22.97 | |
| 3 | 22.93 | 22.93 | 22.96 | |
| 4 | 21.97 | 22.71 | 22.00 |
The results in Table 1 confirm the double robustness of the TMLE and A-IPTW, which had been proven analytically in Result 2. The TMLE and A-IPTW are unbiased even for small sample sizes, whereas the IPTW needs larger sample sizes to achieve unbiasedness.
Regarding the variance of the estimators, Table 2 shows that the IPTW estimator is inefficient, and its influence curve based variance estimator is very conservative. The variances of the TMLE and A-IPTW are approximately equal to the efficiency bound if the models for and g0 are correctly specified, although the same equality is observed if only is misspecified. This is because, as stated in Result 2, we only need consistent estimation of the weights w(g0)(A, W), which can be obtained through a possibly misspecified estimator of g0. On the other hand, the variance of these estimators is considerably affected by misspecification of the model for (models 3 and 4), even if is correctly specified.
Table 2.
Standard error of the estimator (times ). Expectation of the influence curve based estimator of the variance (times ) in parentheses. Efficiency bound is 17.81
| n | Model | TMLE | IPTW | A-IPTW |
|---|---|---|---|---|
| 50 | 1 | 17.94 (17.66) | 20.33 (26.80) | 17.94 (17.66) |
| 2 | 17.94 (17.67) | 19.16 (25.03) | 17.94 (17.66) | |
| 3 | 18.92 (17.81) | 20.33 (26.80) | 18.94 (18.08) | |
| 4 | 18.21 (18.07) | 19.16 (25.03) | 18.25 (17.77) | |
| 100 | 1 | 17.93 (17.74) | 20.36 (27.63) | 17.93 (17.74) |
| 2 | 17.93 (17.75) | 19.04 (25.72) | 17.93 (17.75) | |
| 3 | 18.96 (18.14) | 20.36 (27.63) | 18.98 (18.45) | |
| 4 | 18.34 (18.37) | 19.04 (25.72) | 18.35 (18.06) | |
| 200 | 1 | 17.77 (17.77) | 20.17 (28.00) | 17.77 (17.77) |
| 2 | 17.77 (17.78) | 18.93 (25.97) | 17.77 (17.77) | |
| 3 | 18.62 (18.35) | 20.17 (28.00) | 18.64 (18.68) | |
| 4 | 17.98 (18.57) | 18.93 (25.97) | 18.00 (18.24) | |
| 500 | 1 | 17.38 (17.79) | 20.40 (28.37) | 17.39 (17.79) |
| 2 | 17.38 (17.80) | 18.94 (26.24) | 17.39 (17.80) | |
| 3 | 18.50 (18.49) | 20.40 (28.37) | 18.52 (18.84) | |
| 4 | 17.74 (18.71) | 18.94 (26.24) | 17.76 (18.36) |
The fact that influence curve based variance estimators of the TMLE and A-IPTW are consistent even for misspecified can be taken to be a coincidence associated with this particular data-simulating scheme. As explained in Section 4, this type of consistency does not hold in general.
Because all estimators considered are asymptotically linear, 95% normal-based confidence intervals can be computed. Their coverage probabilities are presented in Table 3. The conservativeness of the IPTW can also be appreciated here. The consistent TMLE- and A-IPTW-based confidence intervals have perfect asymptotic coverage probability. Intervals associated to inconsistent estimators (model 4) have, as expected, confidence levels below the nominal value. In this simulation we do not observe significant differences between the TMLE and the A-IPTW.
Table 3.
Coverage probability of normal-based confidence intervals
| n | Model | TMLE | IPTW | A-IPTW |
|---|---|---|---|---|
| 50 | 1 | 0.93 | 0.97 | 0.93 |
| 2 | 0.93 | 0.96 | 0.93 | |
| 3 | 0.92 | 0.97 | 0.92 | |
| 4 | 0.90 | 0.96 | 0.89 | |
| 100 | 1 | 0.94 | 0.98 | 0.94 |
| 2 | 0.94 | 0.98 | 0.94 | |
| 3 | 0.93 | 0.98 | 0.94 | |
| 4 | 0.89 | 0.98 | 0.89 | |
| 200 | 1 | 0.95 | 0.98 | 0.95 |
| 2 | 0.95 | 0.97 | 0.95 | |
| 3 | 0.94 | 0.98 | 0.95 | |
| 4 | 0.87 | 0.97 | 0.87 | |
| 500 | 1 | 0.95 | 0.99 | 0.95 |
| 2 | 0.95 | 0.98 | 0.95 | |
| 3 | 0.94 | 0.99 | 0.95 | |
| 4 | 0.78 | 0.98 | 0.78 |
6. Application
With the objective of illustrating the procedure described in the previous sections, we revisit the problem analyzed by Bembom and van der Laan (2007) of assessing the extent to which physical activity in the elderly is associated with reductions in cardiovascular morbidity and mortality, and improvement in, or prevention of metabolic abnormalities. Tager et al. (1998) followed a group of people over 55 years of age living around Sonoma, California, over a time period of about 10 years as part of a longitudinal study of physical activity and fitness (Study of Physical Performance and Age Related Changes in Sonomans—SPPARCS). The goal in analyzing the data that were collected as part of this study is to examine the effect of baseline vigorous LTPA on subsequent 5 year all-cause mortality.
In this article, we use the same measure of LTPA used by Bembom and van der Laan (2007), which is a continuous score based on the number of hours that the participants were engaged in vigorous physical activities such as jogging, swimming, bicycling on hills, or racquetball in the last 7 days, and the standard intensity values in metabolic equivalents (MET: metabolic equivalent of task) of such activities, where one MET is approximately equal to the oxygen consumption required for sitting quietly.
The primary confounding factors that we adjust for are described in Table 4. Age and gender are natural confounders, and the rest of the variables intend to account for the subject’s underlying level of general health. Of the 2092 subjects enrolled in the SPPARCS study, 40 were missing information in at least one of this variables; our analysis is based on the remaining 2052 subjects.
Table 4.
Confounders
| Variable | Description |
|---|---|
| Gender | Female |
| Male | |
| Age | Age in years |
| Health | Self-rated health status:
|
| NRB | Score of self-reported physical functioning rescaled between 0 and 1 |
| Card | Previous occurrence of any of the following cardiac events: Angina, myocardial infarction, congestive heart failure, coronary by-pass surgery, and coronary angioplasty |
| Chron | Presence of any of the following chronic health conditions: stroke, cancer, liver disease, kidney disease, Parkinson’s disease, and diabetes mellitus |
| Smoking | Never smoked Current smoker Ex-smoker |
| Decline | Activity decline compared to 5 or 10 years earlier |
In the sequel of this section, the vector containing the confounders will be denoted by W, the continuous MET score by A, and the indicator of 5-year all-cause mortality by Y. We are interested in estimating the effect of a policy that will produce an increase of 12 METs (corresponding, for instance, to bicycling during 3 hours at less than 10 mph per week) in the average of the conditional distribution physical activity, given the covariates. Note that our intervention could also be defined by using different values of MET in each strata defined by the covariates W.
Initial estimators of the conditional density g0(A|W) and the conditional expectation are presented below.
6.1 Initial Estimator of g0
For the estimation of the density g0(A|W), we consider the estimator presented in Díaz-Munoz and van der Laan (2011). We now provide a summary of the rationale behind this estimator. Consider k + 1 values α0, α1,…, αk spanning the range of the data and defining k bins. Now, consider the following class of histogram-like candidate estimators of the conditional density g0(A|W)
where the choice of the α values and the number of bins index the candidates in the class. The probabilities in the numerator are estimated through the super learner. The final estimator of the density consists of a convex combination of these estimators that minimizes the crossvalidated empirical risk. For further reference and properties of this estimator in the context of estimation of causal effects, the reader is referred to the original paper.
As an example, Figure 1 shows two contrasting estimated densities gn(A|W) for different profiles W, in which a subject with better general health status is more likely to have higher levels of physical activity. As pointed out in Díaz-Munoz and van der Laan (2011), this methodology allows the detection of high density areas in the exposure mechanism, like the one detected at zero in Figure 1a. This spike appears because this is a zero-inflated exposure, in which a large proportion of the population do not practice any amount of physical activity.
Figure 1.
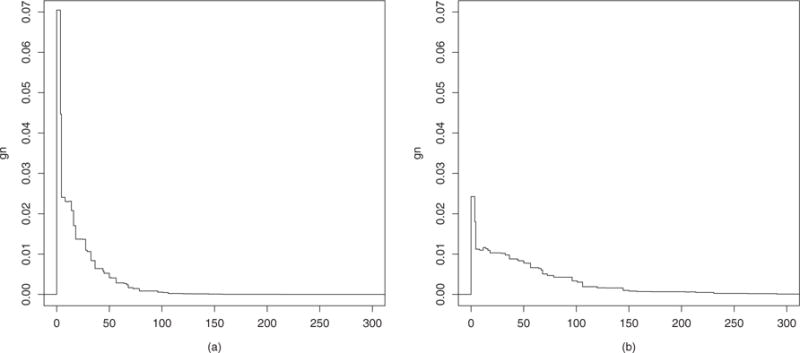
Estimated conditional density of A given the profiles: (a) age = 77, gender = female, health = fair, nrb = 0.9, card = no, smoke = ex-smoker, decline = yes, chron = yes; and (b) age = 71, gender = male, health = good, nrb = 0.88, card = no, smoke = never smoked, decline = no, chron = no.
6.2 Initial Estimator of
For the initial estimator of we used the super learner (van der Laan et al., 2007). Table 5 shows the candidates used, their crossvalidated risks, and their coefficients in the final super learner predictor. To get a consistent estimator of the library of candidate estimators should be as large as possible. Because this is an illustrating example, we allow ourselves to use this small library.
Table 5.
Super learner output for estimation of
| Crossvalidated risk | Coef. | |
|---|---|---|
| Generalized linear model (GLM) main effects | 0.1079 | 0.0000 |
| GLM main eff. and two way interactions | 0.1143 | 0.0835 |
| Generalized additive model (GAM) degree 2 | 0.1073 | 0.0000 |
| GAM degree 3 | 0.1071 | 0.9165 |
| Bayes’ GLM main effects | 0.1078 | 0.0000 |
6.3 Estimators of ψ0
Table 6 shows the three estimates of ψ0 with their standard errors, as described in Section 4. As an example, the TML estimated value of ψn,3 = 0.16 indicates that if a policy that increases the average LTPA by the equivalent of 12 METs is implemented, the estimated risk of death in the intervened population will be 16%.
Table 6.
Estimates of ψ0
| TMLE | A-IPTW | IPTW | ||
|---|---|---|---|---|
| ψ0 | 0.1600(0.0104) | 0.1599(0.0105) | 0.1454(0.0135) | |
|
|
−0.0179(0.0071) | −0.0179(0.0071) | −0.0324(0.0117) |
If the objective is to perform a comparison with the current risk of death, we can define a population intervention parameter as
This is a parameter that compares the expected risk of death in the intervened population with the current risk of death, and therefore describes the gain obtained by carrying out the intervention of interest. For a given estimator ψn of ψ0, an asymptotically linear estimator of is given by . Its influence curve can be computed as D1(P)(O) = D(P)(O) − {Y − EP(Y)}, and its variance is estimated through the sample variance of D1(P)(O). Here D(P)(O) is the influence curve of each of the estimators defined in Section 4. The estimates of and their standard errors are presented in Table 6. Confidence intervals and p-values for hypothesis testing can be computed based on the normal approximations for asymptotically linear estimators described in Section 4 and Web Appendix A. In light of the results from the simulation section and the theoretical properties of the estimators, we rely on the TMLE and A-IPTW to measure the effect of the intervention of interest. The estimated value of means that if a policy increasing the average time of physical activity by the equivalent of 12 METs (corresponding, for instance, to bicycling during 3 hours per week at less than 10 mph) is put in place, the risk of all-cause mortality in the elderly would be reduced by 1.79%. These results are consistent with the findings of Bembom and van der Laan (2007).
7. Discussion
In this article, we define a new parameter measuring the causal effect of a population intervention that (as opposed to most of the parameters presented in the literature) accounts for the fact that in most cases the postintervention exposure continues to be a random variable. We argue that this parameter makes more intuitive sense when the objective is to assess the causal effect of policies intending to modify an exposure variable that cannot be directly intervened upon. For example, as argued in Bembom and van der Laan (2007), it makes little sense to assess the effect of a realistic policy in terms of a static intervention in which every subject in a population of elderly people is required to increase his level of physical activity to the maximum, or even to a level defined by a deterministic function of the covariates. Such interventions are never possible due to particular health conditions, physical functioning constraints, or simple inability to enforce every subject to comply with the treatment level dictated by the intervention. Hence, deterministic interventions do not provide an accurate tool to measure the causal effect of a realistic policy that renders a stochastic exposure.
Another appealing feature of the framework presented in this article is that it provides a natural way of defining and estimating causal effects for continuous variables, or discrete variables with more than two levels, which are currently defined through the specification of a working MSM (Neugebauer and van der Laan, 2007). The positivity assumption required to estimate our proposed causal parameter can be made weaker than the positivity assumption required to estimate MSM parameters.
Three estimators of the parameter were proposed, two of which are double robust to misspecification of the models for the treatment mechanism g0 and the conditional expectation , even when the parameter depends on these two quantities. This double robustness property is proven analytically, and corroborated in a simulation study.
Supplementary Material
Acknowledgments
We thank Dr Ira Tager from the Division of Epidemiology at the UC Berkeley School of Public Health for kindly making available the dataset that was used in our data analysis, as well as Tad Haight and Oliver Bembom for their support in providing information about the dataset.
Footnotes
Supplementary Materials
Web Appendices and Tables referenced in Sections 3, 4, 5, and 6 are available under the Paper Information link at the Biometrics website http://www.biometrics.tibs.org/.
References
- Bembom O, van der Laan M. A practical illustration of the importance of realistic individualized treatment rules in causal inference. Electronic Journal of Statistics. 2007 doi: 10.1214/07-EJS105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bickel P, Klaassen C, Ritov Y, Wellner J. Efficient and Adaptive Estimation for Semiparametric Models. New York, New York: Springer-Verlag; 1997. [Google Scholar]
- Cain LE, Robins JM, Lanoy E, Logan R, Costagliola D, Hernán MA. When to start treatment? A systematic approach to the comparison of dynamic regimes using observational data. The International Journal of Biostatistics. 2010;6 doi: 10.2202/1557-4679.1212. Art. No.: 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Díaz-Munoz I, van der Laan MJ. Super learner based conditional density estimation with application to marginal structural models. (U.C. Berkeley Division of Biostatistics Working Paper Series (Working Paper 282)).The International Journal of Biostatistics. 2011 doi: 10.2202/1557-4679.1356. Available at: http://www.bepress.com/ucbbiostat/paper282. [DOI] [PubMed]
- Eberhardt F, Scheines R. Interventions and causal inference. Department of Philosophy, Carnegie Mellon University; Pittsburgh, Pennsylvania: 2006. (Paper 415). [Google Scholar]
- Hubbard A, van der Laan M. Population intervention models in causal inference. Division of Biostatistics, University of California; Berkeley, California: 2005. (Technical Report 191). [Google Scholar]
- Korb K, Hope L, Nicholson A, Axnick K. Varieties of causal intervention. In: Zhang CW, Guesgen H, Yeap W-K, editors. PRICAI 2004: Trends in Artificial Intelligence. Vol. 3157. Heidelberg, Germany: Springer Berlin; 2004. pp. 322–331. (Lecture Notes in Computer Science). [Google Scholar]
- Neugebauer R, van der Laan M. Nonparametric causal effects based on marginal structural models. Journal of Statistical Planning and Inference. 2007;137:419–434. [Google Scholar]
- Pearl J. Causality: Models, Reasoning, and Inference. Cambridge, UK: Cambridge University Press; 2000. [Google Scholar]
- Petersen ML, Porter KE, Gruber S, Wang Y, van der Laan MJ. Diagnosing and responding to violations in the positivity assumption. Statistical Methods in Medical Research. 2010 doi: 10.1177/0962280210386207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stitelman OM, Hubbard AE, Jewell NP. (U.C. Berkeley Division of Biostatistics Working Paper Series (Working Paper 264)).The impact of coarsening the explanatory variable of interest in making causal inferences: Implicit assumptions behind dichotomizing variables. 2010 Available at: http://www.bepress.com/ucbbiostat/paper264.
- Tager IB, Hollenberg M, Satariano WA. Association between self-reported leisure-time physical activity and measures of cardiorespiratory fitness in an elderly population. American Journal of Epidemiology. 1998;147:921–931. doi: 10.1093/oxfordjournals.aje.a009382. [DOI] [PubMed] [Google Scholar]
- Taubman SL, Robins JM, Mittleman MA, Hernán MA. Intervening on risk factors for coronary heart disease: An application of the parametric g-formula. International Journal of Epidemiology. 2009;38:1599–1611. doi: 10.1093/ije/dyp192. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Laan M, Dudoit S. Technical Report. Division of Biostatistics, University of California; Berkeley, California: 2003. Unified cross-validation methodology for selection among estimators and a general cross-validated adaptive epsilon-net estimator: Finite sample oracle inequalities and examples. [Google Scholar]
- van der Laan M, Robins J. Unified Methods for Censored Longitudinal Data and Causality. New York: Springer; 2003. [Google Scholar]
- van der Laan MJ, Rubin D. Targeted maximum likelihood learning. The International Journal of Biostatistics. 2006;2 doi: 10.2202/1557-4679.1043. Art. No.: 11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Laan MJ, Dudoit S, Keles S. Asymptotic optimality of likelihood-based cross-validation. Statistical Applications in Genetics and Molecular Biology. 2004;3 doi: 10.2202/1544-6115.1036. Art. No.: 4. [DOI] [PubMed] [Google Scholar]
- van der Laan MJ, Polley EC, Hubbard AE. Super learner. Statistical Applications in Genetics and Molecular Biology. 2007;6 doi: 10.2202/1544-6115.1309. Art. No.: 25. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.