

Abstract
Computerized adaptive testing (CAT) is a sequential experiment design scheme that tailors the selection of experiments to each subject. Such a scheme measures subjects’ attributes (unknown parameters) more accurately than the regular prefixed design. In this paper, we consider CAT for diagnostic classification models, for which attribute estimation corresponds to a classification problem. After a review of existing methods, we propose an alternative criterion based on the asymptotic decay rate of the misclassification probabilities. The new criterion is then developed into new CAT algorithms, which are shown to achieve the asymptotically optimal misclassification rate. Simulation studies are conducted to compare the new approach with existing methods, demonstrating its effectiveness, even for moderate length tests.
Keywords: computerized adaptive testing, cognitive diagnosis, large deviation, classification
1. Introduction
Cognitive diagnosis has recently gained prominence in educational assessment, psychiatric evaluation, and many other disciplines. Various modeling approaches have been discussed in the literature both intensively and extensively (e.g., Tatsuoka, 1983). A short list of such developments includes the rule space method (Tatsuoka, 1985, 2009), the reparameterized unified/fusion model (RUM) (DiBello, Stout, & Roussos, 1995; Hartz, 2002; Templin, He, Roussos, & Stout, 2003), the conjunctive (noncompensatory) DINA and NIDA models (Junker & Sijtsma, 2001; de la Torre & Douglas, 2004), the compensatory DINO and NIDO models (Templin & Henson, 2006), the attribute hierarchy method (Leighton, Gierl, & Hunka, 2004). Tatsuoka (2002) discussed a model usually referred to as the conjunctive DINA model that has both conjunctive and disjunctive components in its attribute specifications to allow for multiple strategies and a discussion of identifiability is also provided. See also Rupp, Templin, and Henson (2010) for more approaches to cognitive diagnosis.
Another important development in educational measurement is computerized adaptive testing (CAT), that is, a testing mode in which item selection is sequential and individualized to each subject. In particular, subsequent items are selected based on the subject’s (e.g., examinee’s) responses to prior items. CAT was originally proposed by Lord (1971) for item response theory (IRT) models as a method through which items are tailored to each examinee to “best fit” his or her ability level θ. More capable examinees avoid receiving problems that are too simple and less capable examinees avoid receiving problems that are too difficult. Such individualized testing schemes perform better than traditional exams with a prefixed set of items because the optimal selection of testing problems is examinee dependent. It also leads to greater efficiency and precision than that which can be found in traditional tests. For the traditional CAT under IRT settings, items are typically chosen to maximize the Fisher information (MFI) (Lord, 1980; Thissen & Mislevy, 2000) or to minimize the expected posterior variance (MEPV) (van der Linden, 1998; Owen, 1975).
It is natural to consider incorporating CAT design into cognitive diagnosis. The sequential nature of CAT could conceivably bring major benefits to cognitive diagnosis. First, diagnostic classification models are multidimensional with simultaneous consideration of different attributes. To fully delineate each dimension with sufficient accuracy would certainly demand a large number of items to cover all attributes. Thus, the ability to reduce test length in CAT can be attractive. Second, it is often desirable to provide feedback learning or remedial training after diagnosis; see Junker (2007). The CAT design can serve as a natural framework under which a feedback online learning system may be incorporated.
A major difference between classical IRT models and diagnostic classification models (DCM) is that the parameter space of the latter is usually discrete, for the purpose of diagnosis. Thus, standard CAT methods developed for IRT (such as the MFI or MEPV method) do not apply. Several alternative methods have already been developed in the literature. The parameter spaces of most DCMs admit a partially ordered structure (von Davier, 2005). Under such a setting, Tatsuoka and Ferguson (2003) developed a general theorem on the asymptotically optimal sequential selection of items for finite partially ordered parameter spaces. In particular, the asymptotically optimal design maximizes the convergence rate of the parameters’ posterior distribution to the true parameter. Xu, Chang, and Douglas (2003) investigated two methods based on different ideas. One method is based on the Shannon entropy of the posterior distribution. The other method is based on the Kullback–Leibler (KL) information that describes the global information of a set of items for parameter estimation. The concept of global information was introduced by Chang and Ying (1996). Cheng (2009) further extended the KL information method by taking into account the posterior distribution and the distances between the alternative parameters and the current estimate when computing the global information. Arising from such extensions are two new methods known as the posterior-weighted KL algorithm (PWKL) and the hybrid KL algorithm (HWKL). See Tatsuoka (2002) for a real-data application of CAT.
A key component in the study of CAT lies in evaluating the efficiency of a set of items, i.e., what makes a good selection of exam problems for a particular examinee. Efficiency is typically expressed in terms of the accuracy of the resulting estimator. In classic IRT, items are selected to carry maximal information about the underlying parameter θ. This is reflected by the MFI and the MEPV methods (Lord, 1980; Thissen & Mislevy, 2000; van der Linden, 1998; Owen, 1975). On the other hand, for diagnostic classification models, parameter spaces are usually discrete, and the task of parameter estimation is equivalent to a classification problem. In this paper, we address the problem of CAT for cognitive diagnosis (CD-CAT) by focusing on the misclassification probability. The misclassification probability, though conceptually a natural criterion, is typically not in a closed form. Thus, it is not a feasible criterion. Nonetheless, under very mild conditions, we show that this probability decays exponentially fast as the number of items (m) increases, that is, P(α̂ ≠ α0) ≈ e−m×I, where α̂ is an estimator of the true parameter α0. We use the exponential decay rate, denoted by I, as a criterion. That is, a set of items is said to be asymptotically optimal if it maximizes the rate I (instead of directly minimizing the misclassification probability). The rate I is usually easy to compute and often in a closed form. Therefore, the proposed method is computationally efficient. In Section 3.3, we derive the specific form of the rate function for the Bernoulli response distribution that is popular in cognitive diagnosis. Based on the rate function I, we propose CD-CAT procedures that correspond to this idea. Simulation studies are conducted to compare our procedure with several existing methods for CD-CAT.
This paper is organized as follows. Section 2 provides a general introduction to the problem of CD-CAT, including an overview of existing methods. In Section 3, we introduce the idea of asymptotically optimal design and the corresponding CD-CAT procedures. We examine the connection of our new approach to previously developed methods in Section 4. Further discussion is provided in Section 5. Finally, Section 6 contains simulation studies.
2. Computerized Adaptive Testing for Cognitive Diagnosis
2.1. Problem Setting
Let the random variable X be the outcome of an experiment e. The distribution of X depends on the experiment e and an underlying parameter α. We use α0 ∈
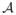 to denote the true parameter and e1, …, em ∈
to denote the true parameter and e1, …, em ∈
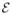 to denote different experiments. In the context of cognitive diagnosis, α corresponds to the “attribute profile” or “knowledge state” of a subject, e is an item or an exam problem, and X is the subject’s response to the item e. Suppose that independent outcomes X1, …, Xm of experiments e1, …, em are collected. For each e ∈
and α ∈
, let f(x|e, α) be the probability density (mass) function of X. Throughout this paper, we suppose that the parameter space α takes finitely many values in
= {1, …, J} and that there are κ types of experiments
= {1, …, κ}.
to denote different experiments. In the context of cognitive diagnosis, α corresponds to the “attribute profile” or “knowledge state” of a subject, e is an item or an exam problem, and X is the subject’s response to the item e. Suppose that independent outcomes X1, …, Xm of experiments e1, …, em are collected. For each e ∈
and α ∈
, let f(x|e, α) be the probability density (mass) function of X. Throughout this paper, we suppose that the parameter space α takes finitely many values in
= {1, …, J} and that there are κ types of experiments
= {1, …, κ}.
Let superscripts indicate independent outcomes, e.g., Xi is the outcome of the ith experiment ei ∈
. The experiments are possibly repeated, i.e., ei = ej (i.e., i.i.d. outcomes can be collected from the same experiment). Suppose that the prior distribution of the parameter α is π(α). Given the observed responses X1, …, Xm, the posterior distribution of α is
| (1) |
To simplify the notation, we let Xm = (X1, …, Xm) and em = (e1, …, em), e.g.,
| (2) |
Thus, a natural estimator of α is the posterior mode
| (3) |
For any two distributions P and Q, with densities p and q, the Kullback–Leibler (KL) divergence/information is
| (4) |
For two parameter values α0 and α1, let De(α0, α1) = Ee,α0{log[f(X|e, α0)/f(X|e, α1)]} be the KL divergence between the outcome distributions of experiment e, where the notation Ee,α0 indicates that X follows distribution f(x|e, α0). We say that an experiment e separates parameter values α0 and α1 if De(α0, α1) > 0. Note that De(α0, α1) = 0 if the two distributions f(x|e, α0) and f(x|e, α1) are identical and statistically indistinguishable. Otherwise, if De(α0, α1) > 0 and independently and identically distributed (i.i.d.) outcomes can be generated from the experiment e, the parameters α0 and α1 are eventually distinguishable. An experiment with a large value of De(α0, α1) is powerful in differentiating α0 and α1. To simplify the discussion, we assume that for each pair of distinct parameters α0 ≠ α1 there exists an experiment e ∈
that separates α0 and α1; otherwise, we simply merge the inseparable parameters and reduce the parameter space. This is discussed in Appendix B; see also Chiu, Douglas, and Li (2009), Tatsuoka (1991), Tatsuoka (1996) for discussions of parameter identifiability for specific models. To illustrate these ideas, we provide two stylized examples that are frequently considered.
Example 1 (Partially ordered sets, Tatsuoka and Ferguson (2003))
Consider that the parameter space
is a partially ordered set with a binary relation “≤”. The set of experiment is identical to the parameter space, i.e.
=
. The outcome distribution of experiment e and parameter α is given by f(x|e, α) = f(x) if e ≤ α0, and f(x|e, α) = g(x) otherwise.
The following example can be viewed as an extension of Example 1 where the distributions f and g are experiment-dependent.
Example 2 (DINA model, Junker and Sijtsma (2001))
Consider a parameter space α = (a1, …, ak) ∈
= {0, 1}k and e = (ε1, …, εk) ∈ {0, 1}k. In the context of educational testing, each ai indicates if a subject possesses a certain skill. Each experiment corresponds to one exam problem and εi indicates if this problem requires skill i. A subject is capable of solving an exam problem if and only if he or she possesses all the required skills, i.e., e ≤ α, defined as εi ≤ ai for all i = 1, …, k. The outcome in this context is typically binary: X = 1 for the correct solution to the exam problem and X = 0 for the incorrect solution. We let ξ = 1(e ≤ α) be the ideal response. The outcome follows a Bernoulli distribution
The parameter se is known as the slipping parameter and ge is the guessing parameter. Both the slipping and the guessing parameters are experiment specific. The general form of DINA model allows heterogeneous slipping and guessing parameters for different exam problems with identical skill requirements. Thus, in addition to the attribute requirements, the model also specifies the slipping and the guessing parameters for each exam problem.
In practice, there may not be completely identical items. For instance, one may design two exam problems requiring precisely the same skills. However, it is difficult to ensure the same slipping and the guessing parameters. Thus, we can only expect independent (but not identically distributed) outcomes. In the previous discussion, we assume that i.i.d. outcomes can be collected from the same experiment. This assumption is imposed simply to reduce the complexity of the theoretical development, and is not really required by the proposed CAT procedures (Algorithm 1). More discussion on this issue is provided in Remark 2.
2.2. Existing Methods for the CD-CAT
2.2.1. Asymptotically Optimal Design by Tatsuoka and Ferguson (2003)
Tatsuoka and Ferguson (2003) proposes a general theorem on the asymptotically optimal selection of experiments when the parameter space is a finite and partially ordered set. It is observed that the posterior probability of the true parameter α0 converges to one exponentially fast, that is, 1 − π(α0|Xm, em) ≈ e−m×H as m → ∞. The authors propose the selection of experiments (items) that maximize the asymptotic convergence rate H.
In particular, the asymptotically optimal selection of experiments can be represented by the KL divergence in the following way. Let he be the proportion of experiment e among the m experiments. For each alternative α1 ≠ α0, define Dh(α0, α1) =
 heDe(α0, α1), where h = (h1, …, hκ) and Σj hj =1. Then the asymptotically optimal selection solves the optimization problem h* = arg maxh[minα1≠α0
Dh(α0, α1)]. The authors show that several procedures achieve the asymptotic optimal proportion h* under their setting.
heDe(α0, α1), where h = (h1, …, hκ) and Σj hj =1. Then the asymptotically optimal selection solves the optimization problem h* = arg maxh[minα1≠α0
Dh(α0, α1)]. The authors show that several procedures achieve the asymptotic optimal proportion h* under their setting.
2.2.2. The KL Divergence Based Algorithms
There are several CD-CAT methods based on the Kullback–Leibler divergence. The basic idea is to choose experiments such that the distribution of the outcome X associated with the true parameter α0 looks most dissimilar to the distributions associated with the alternative parameters. The initial idea was proposed by Chang and Ying (1996), who define the global information by summing the KL information over all possible alternatives, i.e.,
| (5) |
If an experiment e has a large value of KLe(α0), then the outcome distributions associated with α0 and the alternative parameters are very different. Thus, e is powerful in differentiating the true parameter α0 from other parameters. For a sequential algorithm, let α̂m be the estimate of α based on the first m outcomes. The next experiment is chosen to maximize KLe(α̂m) (Xu et al., 2003).
This idea is further extended by Cheng (2009), who proposes the weighting of each De(α̂m, α1) in (5) by the posterior probability conditional on Xm, that is, each successive experiment maximizes PWKLe(α̂m) = Σα≠α0 De(α̂m, α)π(α|Xm, em). An α with a higher value of π(α|Xm, em) is more difficult to differentiate from the posterior mode α̂m. Thus, it carries more weight when choosing subsequent items. This method is known as the posterior-weighted Kullback–Leiber (PWKL) algorithm. The author also proposes a hybrid method that adds to De(α̂m, α) further weights inversely proportional to the distance between α and α̂m, so that alternative parameters closer to the current estimate receives even more weight.
2.2.3. The SHE Algorithm
The Shannon entropy of the posterior distribution is defined as
where
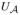 is the uniform distribution on the set
and D(·||·) is the KL divergence defined in (4). Thus, the experiment that minimizes the Shannon entropy of the posterior distribution makes the posterior distribution as different from the uniform distribution as possible. In particular, let f(xm+1|e, Xm, em) be the posterior predictive distribution of the (m + 1)-th outcome if the (m + 1)-th experiment is chosen to be e. The sequential item selection algorithm chooses em+1 to minimize the expected Shannon entropy SHE(e), where
is the uniform distribution on the set
and D(·||·) is the KL divergence defined in (4). Thus, the experiment that minimizes the Shannon entropy of the posterior distribution makes the posterior distribution as different from the uniform distribution as possible. In particular, let f(xm+1|e, Xm, em) be the posterior predictive distribution of the (m + 1)-th outcome if the (m + 1)-th experiment is chosen to be e. The sequential item selection algorithm chooses em+1 to minimize the expected Shannon entropy SHE(e), where
The idea of minimizing the Shannon entropy is very similar to that of the minimum expected posterior variance method developed for IRT.
3. The Misclassification Probability, Optimal Design, and CAT
In this section, we present the main method of this paper. For a discrete parameter space, estimating the true parameter value is equivalent to classifying a subject into one of J groups. Given that the main objective is the estimation of the attribute parameter α, a natural goal of optimal test design would be the minimization of the misclassification probability. In the decision theory framework, this probability corresponds to the Frequentist risk associated with the zero-one loss function; see Chapter 11 of Cox and Hinkley (2000). Let α0 denote the true parameter. The misclassification probability of some estimator α̂(Xm) based on m experiments is then
| (6) |
We write em and α0 in the subscript to indicate that the outcomes X1, …, Xi are independent outcomes from f(Xi|ei, α0) respectively. Similarly, we will use Eem, α0 to denote the corresponding expectation. Throughout this paper, we consider α̂ to be the posterior mode in (3). If one uses a uniform prior over the parameter space
, i.e.,
, then the posterior mode is identical to the maximum likelihood estimate. Thus, the current framework includes the situation in which the MLE is used. Under mild conditions, one can show that p(em, α0) → 0 as m → ∞. A good choice of items should admit small p(em, α0). However, direct use of p(em, α0) as an efficiency measure is difficult, mostly due to the following computational limitations. The probability (6) is usually not in an analytic form. Regular numerical routines (such as Monte Carlo methods) fail to produce accurate estimate of p(em, α0). For instance, when m = 50, this probability could be as small as a few percentage points. Evaluating such a probability for a given relative accuracy is difficult, especially this probability has to be evaluated many times—essentially once for each possible combination of items. Therefore, (6) is not a feasible criterion from a computational viewpoint. Due to these concerns, we propose the use of an approximation of (6) based on large deviations theory. In particular, as we will show, under very mild conditions, the following limit can be established:
| (7) |
That is, the misclassification probability decays to zero exponentially fast and it can be approximated by p(em, α0) ≈ e−mI. We call the limit I the rate function; it depends on both the experiment selection and the true parameter α0. The selection of experiments that maximizes the rate function is said to be asymptotically optimal in the sense that the misclassification probability based on the asymptotically optimal design achieves the same exponential decay rate as the optimal design that minimizes the probability in (6). In addition, the rate function has favorable properties from a computational point of view. It only depends on the proportion of each type of experiments. Therefore, the asymptotically optimal proportion does not depend on the total number of experiments m, which simplifies the computation. In addition, the rate I is in closed form for most standard distributions. Minimizing the misclassification probability is equivalent to adopting a zero-one loss function. In practice, there may be other sensible loss functions under specific scenarios. In this paper, we focus on the zero-one loss function and the misclassification probability.
We emphasize that the asymptotic optimality discussed in the previous paragraph is different from the one in Tatsuoka and Ferguson (2003). In fact, these two criteria often yield different “optimal designs.” To make a difference, we refer to the latter as “Tatsuoka and Ferguson’s asymptotic optimality” and reserve the term asymptotic optimality, as specified momentarily in Definition 1, for designs that maximize the rate function I.
3.1. The Misclassification Rate Function and the Asymptotically Optimal Design
We now consider the misclassification rate function. To facilitate the discussion, we assume that m × he independent outcomes are collected from experiment e ∈
. Furthermore, we assume that the proportion he does not change with m, except for some slight variation due to rounding. We say that such a selection of he is stable. Under the asymptotic regime where m → ∞, the parameter h = (h1, …, hκ) forms the exogenous experiment design parameter to be tuned. Under this setting, the rate function (when exists) is
| (8) |
The limit depends on the proportion of each experiment contained in h and the true parameter α0. We establish the above approximation and provide the specific form of Ih,α0 in Theorem 2.
For two sets of experiments corresponding to two vectors h1 and h2, if Ih1,α0 > Ih2,α0, it suggests that the misclassification probability of h1 decays to zero at a faster speed than h2 and, therefore, h1 is a better design. We propose the use of Ih,α0 as a measure of efficiency.
Definition 1
We say that an experiment design corresponding to a set of proportions h = (h1, …, hκ) is asymptotically optimal if h maximizes the rate function Ih,α0 as in (8).
One computationally appealing feature of asymptotically optimal design is that the asymptotically optimal proportion h generally does not depend on the particular form of the prior distribution. Since asymptotic optimality describes the amount of information in the data, item selection is relatively independent from the a priori information of the attributes.
3.2. The Analytic Form of the Rate Function
In this subsection, we present specific forms of the rate function. To facilitate discussion, we use a different set of superscripts. Among the m responses, m × he of them are from experiment e. Let Xe,l be the lth (independent) outcomes of type e experiments for l = 1, …, m × he. Note that the notation e includes all the information about an experiment. For instance, in the setting of the DINA model, e includes the attribute requirements (the Q-matrix entries) as well as the slipping and the guessing parameters.
We start the discussion with a specific alternative parameter α1. The posterior distribution prefers an alternative parameter α1 ≠ α0 to α0 if
We insert the specific form of the posterior in (1) and the above inequality implies that
| (9) |
For each e, define
| (10) |
that is the log-likelihood ratio between the two parameter values α0 and α1. For a given e and different l, ’s are i.i.d. random variables. Therefore, the right-hand side of (9) is the weighted sum of κ sample averages of i.i.d. random variables. Due to the entropy inequality, we have that . If equality occurs, experiment e does not have power in differentiating α1 from α0. This occurs often in diagnostic classification models such as the DINA model (Section 2.1, Example 2).
In what follows, we provide the specific form of the rate function for the probability
Let ge(s|α1) be the distribution of under e and α0, and let
| (11) |
be its associated natural exponential family where φe,α1 (θ) = log[∫ eθs ge(s|α1)ds] is the log-moment-generating function. The exponential family is introduced for the purpose of defining the rate function. It is not meant for the data (response) generating process. In addition, it implicitly assumes that φe,α1 is finite in a neighborhood of the origin. Let
| (12) |
where is the derivative. We define
| (13) |
where the infimum is subject to the constraint that . Furthermore, we define a notation
| (14) |
if all the elements of h are zero except for the one corresponding to the experiment e, that is, Ie(α1) is the rate if all outcomes are generated from experiment e. Further discussion of evaluation of I(α1, h) is provided momentarily in Remark 1.
The following two theorems establish the asymptotic decay rate of the misclassification probabilities. Their proofs are provided in Appendix A. Recall that the vector h = (he: e ∈
) represents the asymptotic proportions, i.e.,
as m → ∞.
Theorem 1
Suppose that for each α1 ≠ α0 and each e ∈
, equation
has a solution. Then for every α1 ≠ α0, e ∈
, and h ∈ [0, 1]κ s.t.
he = 1, we have that
| (15) |
Note that both I(α1, h) and Ie(α1) depend on the true parameter α0. To simplify the notation, we omit the index of α0 in the writing I(α1, h) and Ie(α1) because all the discussions are for the same true parameter α0. Nonetheless, it is necessary and important to keep the dependence in mind. The rate function (15) has its root in statistical hypothesis testing. Consider testing the null hypothesis H0: α = α0 against an alternative HA: α = α1. We reject the null hypothesis if π(α1|Xm, em) > π(α0|Xm, em). Thus, the misclassification probability is the same as the Type I error probability. Its asymptotic decay rate I(α1, h) is known as the Chernoff index (Serfling, 1980, Chapter 10).
Remark 1
Without much effort, one can show that the constraint for the minimization in (13) can be reduced to
, that is, the infimum is achieved on the boundary. Let (
: e ∈
) be the solution to the optimization problem. Using Lagrange multipliers, one can further simplify the optimization problem in (13) to the case in which the solution satisfies
. Thus, the rate function can be equivalently defined as I(α1, h) =
heLe(θ|α1), where θ satisfies
. Using the specific form of Le in (12) and the fact that φe,α1’s are convex, we obtain that
| (16) |
Thus, the numerical evaluation of I(α, h) is a one-dimensional convex optimization problem that can be stated in a closed form for most standard distributions.
While Theorem 1 provides the asymptotic decay rate of the probability that the posterior mode happens to be at one specific alternative parameter α1, the next theorem gives the overall misclassification rate.
Theorem 2
Let p(em, α0) be the misspecification probability given by (6) and define the overall rate function
| (17) |
Then under the same conditions as in Theorem 1, Ih,α0 = infα1≠α0 I(α1, h).
Here, we include the index α0 in the rate function Ih,α0 to emphasize that the misclassification probability depends on the true parameter α0. Thus, the asymptotically optimal selection of experiments h* is defined as
| (18) |
An algorithm to compute h* numerically is included in Appendix C.
3.3. Intuitions and Examples
According to Theorem 1, for a specific parameter α1, the probability that the posterior favors α1 over the true parameter α0 for a given asymptotic design h admits the approximation P(α̂(Xm, em) = α1|e1, …, em, α0) ≈ e−m×I(α1,h). Thus, the total misclassification probability is approximated by
| (19) |
Among the above summands, there is one (or possibly multiple) α′ that admits the smallest I(α′, h). Then the term e−mI(α′,h) is the dominating term of the above sum. Note that the smaller I(α1, h) is, the more difficult it is to differentiate between α0 and α1. According to the representation in (17), upon considering the overall misclassification probability, it is sufficient to consider the alternative parameter that is the most difficult to differentiate from α0. This agrees with the intuition that if a set of experiments differentiates well between parameters that are similar to each other, it also differentiates well between less similar parameters. Thus, the misclassification probability only considers the most similar parameters to α0. Similar observations have been made for the derivation of the Chernoff index, i.e., one only considers the alternative models most similar to the null. In practice, it is usually easy to identify these most indistinguishable parameters so as to simplify the computation of (17). For instance, in the case of the DINA model, the most indistinguishable attribute parameter must be among those that have only one dimension misspecified.
For DCM’s, the α′ is generally not unique if h* is chosen to be asymptotically optimal. Consider the DINA model and a true parameter α0. Let N0 be the set of attributes closest to α0. Each α1 ∈ N0 is different from α0 by only one attribute. Thus, N0 is the set of parameters most difficult to distinguish from α0. The asymptotically optimal design h* must be chosen in such a way that I(α1, h*) are identical for all α1 ∈ N0. Thus, all α1 ∈ N0 are equally difficult to distinguish from α0 based on the item allocation h*. Otherwise, one can always reduce the proportion of certain items that are overrepresented and replace them with underrepresented items. Thus, the rate can be further improved. Note that the definition of N0 may change under the reduced parameter space. See Tatsuoka and Ferguson (2003) for such a discussion when the parameter space is a partially ordered set.
Example 3 (A simple example to illustrate α′)
Consider the DINA model with three attributes. The true attribute profile is α0 = (1, 1, 0). There are three types of experiments in the item bank, e1 = (1, 0, 0), e2 = (0, 1, 0), and e3 = (0, 0, 1). Each type of item is used to measure one attribute. The corresponding slipping and guessing parameters are (s1, g1) = (0.1, 0.1), (s2, g2) = (0.2, 0.2), and (s3, g3) = (0.1, 0.1). Consider a design , that is, equal numbers of items are selected for each of the three types. Then the second attribute is the most difficult to identify because its slipping and guessing parameters (s2, g2) are larger. In this case, the attribute parameter that minimizes I(α, h) over α ≠ α0 and is most indistinguishable from α0 is α′ = (1, 0, 0), which differs from α0 in its second attribute. The asymptotically optimal design should spend more items to measure the second attribute than the other two. We will later revisit this example and compute h*.
Example 4 (Calculations for the Bernoulli distribution)
We illustrate the calculation of the rate function for models such as the DINA with Bernoulli responses. It is sufficient to compute I(α1, h) for each true parameter α0 and alternative α1 ≠ α0. A separating experiment e will produce two different Bernoulli outcome distributions and where p1 ≠ p0. Then the log-likelihood ratio is
The log-moment-generating function of under f(x|α0, e) is
| (20) |
For the purpose of illustration, we compute Ie(α1). The solution to is
where . Then the misclassification probability is approximated by
| (21) |
The parameter θ* depends explicitly on p1, p0, and φe,α1. Supposing that p0 < p1, the parameter p* is the cutoff point. If the average response value is below p*, then the likelihood is in favor of α0 and vice versa.
When there are more types of items, the rate function I(α1, h) is the sum of all the φe,α1 (θ) in (20) weighted by their own proportions, i.e., I(α1, h) = − infθ
heφe,α1 (θ). Then take the infimum over α1 ≠ α0 for the overall rate function Ih,α0.
Example 3 Revisited
We apply the calculations in Example 4 to the specific setting in Example 3, where α0 = (1, 1, 0). We consider the alternative parameters closest to α0: α1 = (0, 1, 0), α2 = (1, 0, 0), and α3 = (1, 1, 1). Using the notation in (14) for each individual item and the formula in (21), we have that Ie1(α1) = 0.51, Ie2(α2) = 0.22, and Ie3(α3) = 0.51.
For each h = (he1, he2, he3) and i = 1, 2, 3, we have that I(αi, h) = hei Iei(αi). Thus, the asymptotically optimal allocation of experiments is inversely proportional to the rates Iei(αi), that is, and .
Comparison with the KL Information
Typically, an experiment with a large KL information De(α0, α1) also has a large rate Ie(α1). This positive association is expected in that both indexes describe the information contained in the outcome of experiment e. However, these two indexes sometimes do yield different choices of items. Consider the setting in Example 2. Let experiment e1 have parameters s1 = 0.1 and g1 = 0.5 and let e2 have parameters s2 = 0.6 and g2 = 0.01. Both e1 and e2 differentiate α0 and α1 in such a way that the ideal response of α0 is negative and that of α1 is positive. We compute the rate functions and the KL information:
Thus, according to the rate function, e2 is a better experiment, while the KL information gives the opposite answer. Thus, the KL information method does not always coincide with the rate function. This is also reflected in the simulation study. More detailed connections and comparisons are provided in Section 4. A similar difference exists between Tatsuoka and Ferguson’s criterion and the rate function. Therefore, the criterion proposed in this paper is fundamentally different from the existing ideas.
Remark 2
In practice, it is generally impossible to have two responses collected from exactly the same item. The approximation of the misclassification probability can be easily adapted to the situation when all the m items are distinct. Consider that a sequence of outcomes X1, …, Xm, has been collected from experiments e1, …, em. For α1 ≠ α0, we slightly abuse the notation and let be the log-likelihood ratio of the ith outcome (generated from experiment ei) and let be the log-MGF. Then an analogue of Theorem 1 would be
where . Furthermore, the misclassification probability can be approximated by − log p(em, α0) ≈ infα1≠α0 Iem(α1).
3.4. An Adaptive Algorithm Based on the Rate Function
We now describe a CAT procedure corresponding to the asymptotic theorems. At each step, one first obtains an estimate of α based on the existing outcomes, X1, …, Xm. Then each successive item is selected as if the true parameter is identical to the current estimate.
Algorithm 1
Start with a prefixed set of experiments (e1, …, em0). For every m, Outcomes Xm = (X1, …, Xm) of experiments em = (e1, …, em) have been collected. Choose em+1 as follows:
Compute the posterior mode α̂m ≜ α̂(Xm, em). Let α′ be the attribute that has the second highest posterior probability, that is, α′ = arg maxα≠α̂m π(α|Xm, em).
Let α0 = α̂m. The next item em+1 is chosen to be the one that admit the largest rate function with respect to α′, that is, em+1 = arg supe Ie(α′) where Ie(α′) is defined as in (14) (recall that Ie(α′) depends on the true parameter value α0 that is set to be α̂m).
The attribute is estimated by the posterior mode based on previous responses. Then α′ is selected to have the second highest posterior probability. Thus, α′ is the attribute profile that is most difficult to differentiate from α0 = α̂m given the currently observed responses Xm. Thus, the experiment em+1 maximizing Ie(α1) is the experiment that best differentiates between α̂m and α′. Thus, the rationale behind Algorithm 1 is to first find the attribute profile α′ most “similar” to α̂m and then to select the experiment that best differentiates between the two. We implement this algorithm and compare it with other existing methods in Section 6.
4. Relations to Existing Methods
4.1. Connection to the Continuous Parameter Space CAT for IRT Models
If the parameter space is continuous (as is the case in IRT), the efficiency measure (6) and its approximation are not applicable, in that P (θ̂(X) ≠ θ0) = 1, where θ is the continuous ability level. To make an analogue, we need to consider a slightly different probability
| (22) |
This is known as an indifference zone in the literature of sequential hypothesis testing. One can establish similar large deviations approximations so that the above probability is approximately e−mI (ε). Thus, the proposed measure is closely related to the maximum Fisher information criterion and expected minimum posterior variance criterion. For IRT models, θ̂(X) asymptotically follows a Gaussian distribution with mean centered around θ0. Then minimizing its variance is the same as minimizing the probability
for all δ > 0. One may consider that, by choosing ε very small in (22), in particular ε ≈ δm−1/2, maximizing the rate function is approximately equivalent to minimizing the asymptotic variance. This connection can be made rigorous by the smooth transition from the large deviations to the moderate deviations approximations.
4.2. Connection to the KL Information Methods and Global Information
The proposed efficiency measure is closely related to the KL information. Consider a specific alternative α1. We provide another representation of the rate function for P(π(α1|Xm, em) > π(α0|Xm, em)). To simplify our discussion and without loss of too much generality, suppose that only one type of experiment, e, is used and that X1, …, Xm are thus i.i.d. The calculations for multiple types of experiments are completely analogous, but more tedious. The alternative parameter α1 admits a higher posterior probability if where si = log f (Xi |α1, e) − log f (Xi |α0, e) are i.i.d. random variables following distribution g(s). Then the rate function takes the form Ie(α1) = − infθ [φ(θ)], where φ (θ) = log ∫ g(s)eθs is the log-MGF of the log likelihood ratio. Let θ* = arg infθ φ(θ) and g(s|θ) = g(s)eθs−φ(s). With some simple calculation, we obtain that
which is the Kullback–Leibler information between g(s|θ*) and g(s).
Then the rate function is the minimum KL information between the log-likelihood ratio distribution and the zero-mean distribution within its exponential family. An intuitive connection between the proposed method and the existing method based on KL information is as follows. The KL, or the posterior-weighted KL method maximizes the KL information between the response distributions under the true and alternative model. Our method maximizes the KL information of the log-likelihood ratio instead of directly that of the outcome variable. This is because the maximum likelihood estimator (or the posterior mode estimator) maximizes the sum of the log-likelihoods.
The rate function in (17) is the minimum of I (α, h) over all α ≠ 3 α0. This is different from the approach taken by most existing methods, which typically maximize a (possibly weighted) average of the KL information or Shannon entropy over the parameter space. Instead, this approach recalls Tatsuoka and Ferguson’s asymptotically optimal experiment selection, which involves maximizing the smallest KL distance.
4.3. Connection to the Tatsuoka and Ferguson’s Criterion
Using the notation in Section 2.2.1, the posterior mode converges to unity exponentially fast almost surely. This convergence implies that
as m → ∞ where α′ is the largest posterior mode other than α0. The above probability is approximately the misclassification probability p(em, α0). TF’s criterion and ours are very closely related in that a large H typically implies a small p(em, α0). This is because it is unlikely for π(α0|Xm, em) to fall below some level if it converges faster to unity. However, these two criteria are technically distinct. As shown later in Section 6.1, they yield different optimal designs and the corresponding misclassification probabilities could be different.
5. Discussion
Finite Sample Performance
The asymptotically optimal allocation of experiments h* maximizes the rate function. It can be shown that h* converges to the optimal allocation that minimizes the misclassification probability as m tends to infinity. However, for finite samples, h* may be different from the optimal design. In addition, h* is derived under a setting in which outcomes are independently generated from experiments whose selection has been fixed (independent of the outcome). Therefore, the theorems here answer the question of what makes a good experiment and they serve as theoretical guidelines for the design of CAT procedures. Also, as the simulation study shows, the algorithms perform well.
Results Associated with Other Estimators
The particular form of the rate function relies very much on the distribution of the log-likelihood ratios. This is mostly because we primarily focus on the misclassification probability of the maximum likelihood estimator or posterior mode. If one is interested in (asymptotically) minimizing the misclassification probability of other estimators, such as method of moment based estimators, similar exponential decay rates can be derived and they will take different forms.
Infinite Discrete Parameter Space
We assume that the parameter space is finite. In fact, the analytic forms of Ih,α0 and I (α, h) can be extended to the situation when the parameter space is infinite but still discrete. The approximation results in Theorem 2 can be established with additional assumptions on the likelihood function f (x|e, α). With such approximation results established, Algorithm 1 can be straightforwardly applied.
Summary
To conclude the theoretical discussion, we would like to emphasize that using the misclassification probability as an efficiency criterion is a very natural approach. However, due to computational limitations, we use its approximation via large deviations theory. The resulting rate function has several appealing features. First, it only depends on the proportion of outcomes collected from each type of experiment and is free of the total number of experiment m. In addition, the rate function is usually in a closed form for stylized parametric families. For more complicated distributions, its evaluation only consists of a one dimensional minimization and is computationally efficient. In addition, as the simulation study shows, the asymptotically optimal design shows nice finite sample properties.
6. Simulation
6.1. A Simple Demonstration of the Asymptotically Optimal Design
In this subsection, we consider (nonadaptive) prefixed designs selected by different criteria. We study the performance of the asymptotically optimal design h* for a given α0. We consider the DINA model with true attribute profile α0 = (1, 1, 0). We also consider four types of experiments with the following attribute requirements:
We compare the asymptotically optimal design proposed by the current paper, denoted by LYZ, and the optimal design by Tatsuoka and Ferguson (2003), denoted by TF. We consider two sets of different slipping and guessing parameters that represent two typical situations.
Setting 1. s1 = s2 = s3 = s4 = 0.05 and g1 = g2 = g3 = g4 = 0.5. Under this setting, the asymptotically optimal proportions by LYZ are , and ; the optimal proportions by TF are , and .
Setting 2. c1 = c2 = c3 = c4 = 0.05, g1 = g2 = g3 = 0.5, and g4 = 0.8. Under this selection, the asymptotically optimal proportions by LY are , and ; the optimal proportions by TF are , and .
We simulate outcomes from the above prefixed designs with different test lengths m = 20, 50, 100. Tables 1 and 2 show the misclassification probabilities computed via Monte Carlo. LYZ admits smaller misclassification probabilities (MCP) for all the samples sizes. The advantage of LYZ manifests even with small sample sizes. For instance, when m = 20 in Table 2, the misclassification probability of LYZ is 13 % and that of TF is 27 %.
Table 1.
The misclassification probabilities (MCP) under Setting 1.
| m | LYZ | TF |
|---|---|---|
| 20 | 6.5E–02 | 8.5E–02 |
| 50 | 3.2E–03 | 1.0E–02 |
| 100 | 4.5E–05 | 3.7E–04 |
Table 2.
The misclassification probabilities (MCP) under Setting 2.
| m | LYZ | TF |
|---|---|---|
| 20 | 1.3E–01 | 2.7E–01 |
| 50 | 2.2E–02 | 3.7E–02 |
| 100 | 1.1E–03 | 5.5E–03 |
6.2. The CAT Algorithms
We compare Algorithm 1 with other adaptive algorithms in the literature, such as the SHE and PWKL as given in Section 2.2. We compare the behavior of these three algorithms, along with the random selection method (i.e., at each step an item is randomly selected from the item bank), in several settings.
General Simulation Structure
Let K be the length of the attribute profile. The true attribute α0 is uniformly sampled from the space {0, 1}K, i.e., each attribute has a 50 % chance of being positive. Each test begins with a fixed choice of m0 = 2K items with slipping and guessing probabilities, s = g = 0.05. In particular, each attribute is tested by 2 items testing solely that attribute, i.e., items with attribute requirements of the form (0, …, 0, 1, 0, …, 0). After the prefixed choice of items, subsequent items are chosen from a bank containing items with all possible attribute requirement combinations and prespecified slipping and guessing parameters. Items are chosen sequentially based on either Algorithm 1, SHE, PWKL, or random (uniform) selection over all possible items. The misclassification probabilities are computed based on 500,000 independent simulations that provide enough accuracy for the misclassification probabilities.
For illustration purposes, we choose the random selection method as the benchmark. For each adaptive method, we compute the ratio of the misclassification probability of that method and the misclassification probability of the random (uniform) selection method. The log of this ratio as test length increases is plotted under each setting in Figures 1, 2, 3, and 4.
Figure 1.

This plot shows the log-ratio of the misclassification probabilities of the given method and those of the random selection method. The x-coordinate is the test length, that is counted beginning with the first adaptive item (beyond the buffer).
Figure 2.

This plot shows the log-ratio of the misclassification probabilities of the given method and those of the random selection method. The x-coordinate is the test length, that is counted beginning with the first adaptive item (beyond the buffer).
Figure 3.

This plot shows the log-ratio of the misclassification probabilities of the given method and those of the random selection method. The x-coordinate is the test length, that is counted beginning with the first adaptive item (beyond the buffer).
Figure 4.

This plot shows the log-ratio of the misclassification probabilities of the given method and those of the random selection method. The x-coordinate is the test length that is counted beginning with the first adaptive item (beyond the buffer).
A summary of the simulation results is as follows. The PWKL immediately underperforms the other two methods in all settings. The SHE and the LYZ methods perform similarly early on, but eventually the LYZ method begins to achieve significantly lower misclassification probabilities. From the plots, we can see that this pattern of behavior does not change as we vary K. However, as K grows larger, more items are needed for the asymptotic benefits of the LYZ method to become apparent. In addition, the CPU time varies for different dimension and different methods. To run 100 independent simulations, the LYZ and the KL methods take less than 10 seconds for all K. The SHE method is slightly more computationally costly and takes as much as a few minutes for 100 simulations when K = 8. The specific simulation setting as given as follows.
Setting 3. The test bank contains two sets of items. Each set contains 2K− 1 types items containing all the possible attribute requirements. For one set, the slipping and the guessing parameters are (s, g) = (0.10, 0.50); for the other set, the parameters are (s, g) = (0.60, 0.01). Thus, there are 2(2K − 1) types items in the bank that can be selected repeatedly. The simulation is run for K = 3, 4, 5, 6. The results are presented in Figure 1.
Setting 4. With a similar setup, we have two different sets of the slipping and the guessing parameters (s, g) = (0.15, 0.15) and (s, g) = (0.30, 0.01). The basic pattern remains. The results are presented in Figure 2.
Setting 5. We increase the variety of items available. The test bank contains items with any of four possible pairs of slipping and guessing parameters: (s1, g1) = (0.01, 0.60), (s2, g2) = (0.20, 0.01), (s3, g3) = (0.40, 0.01), and (s4, g4) = (0.01, 0.20); in addition, items corresponding to each of the 2K − 1 possible attribute requirements are available. Items corresponding to a particular set of attribute are limited to either (s1, g1) and (s2, g2) or (s3, g3) and (s4, g4). Thus, combining the different attribute requirements and item parameters, there are a total of 2(2K − 1) types of items in the bank, each of which can be selected repeatedly. The simulation is run for K = 3, 4, …, 8. The results are presented in Figure 3.
-
Setting 6. We add correlation by generating a continuous ability parameter θ ~ N (0, 1). The individual αk are independently distributed given θ, such that
Setting 6 follows Setting 5 in all other respects. The results are presented in Figure 4.
Acknowledgments
We would like to thank the editors and the reviewers for providing valuable comments. This research is supported in part by NSF CMMI-1069064, NSF SES-1323977, and NIH 5R37GM047845.
Appendix A. Technical Proofs
Proof of Theorem 1
The proof of Theorem 1 uses standard large deviations technique and exponential change of measure. Consider a specific alternative parameter α1 ≠ α0. We use e ∈
to indicate different types of experiments.
Suppose that me independent outcomes have been generated from experiment e. Note that me/m → he. The log-likelihood ratios are as defined in (10), and follow joint distribution:
Let A = log π(α0) − log π(α1). We choose θm such that . Let be chosen as in the statement of the theorem. According to Remark 1, we have that and further that as m → ∞. We further consider the exponential change of measure, Q, under which the log-likelihood ratios follow joint density
| (A.1) |
where ge(s|θ, α1) is the exponential family defined in (11).
Note that under Q or equivalently under the joint density (A.1), the ’s are jointly independent. For a given experiment e, the ’s are i.i.d. Following the standard results for natural exponential families, for each e, , where EQ denotes the expectation with respect to the density (A.1). The total sum has expectation
To simplify the notation, we use Σe,l and Πe,l to denote the sum and the product over all the outcomes. We write
We plug in the forms of ge(s|α1) and ge(s|θ, α1) and continue the calculation:
where Le is defined as in (12). Note that . We continue the above calculation and obtain that
| (A.2) |
Thus, we have shown an upper bound.
For the lower bound, by the central limit theorem, there exists ε, δ > 0 such that for m large enough, we may write the expectation term in the above display as
Thus, we obtain a lower bound that
| (A.3) |
Combining (A.2), (A.3), and the fact that , we conclude the proof of Theorem 1 using the definition of I(h, α1) in (13).
Proof of Theorem 2
Based on the proof of Theorem 1, the proof of Theorem 2 is simply an application of the Bernoulli’s inequality. Thus, we only lay out the key steps. First,
Let α′ be an alternative parameter admitting the smallest rate, that is, I (α′, h) = Ih, α0. Thus, we have that
We take the log on both sides and obtain that
Appendix B. Identifiability Issues
Throughout this paper, we assume that all the parameters are separable from each other by the set of experiments. In the case that there are two or more parameters that are not separable, we need to reduce the parameter spaces as follows. We write α1 ~ α2 if De(α1, α2) = 0 for all e ∈
. It is not difficult to verify that the binary relationship “~” is an equivalence relation. Let [α] = {α1 ∈
: α1 ~ α} be the set of parameters related to α by ~. Then, the reduced parameter set is defined as the quotient set
To further explain, if α1 ~ α2, then the response distributions are identical f (x|e, α1) = f (x|e, α2) for all e. We are not able to distinguish α1 and α2. If [α1] ≠ [α2], then there exists at least one e such that f (x|e, α1) and f (x|e, α2) are distinct distributions. Therefore, all equivalence classes in the new parameter space
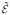 are identifiable.
are identifiable.
Appendix C. Computation of the Asymptotically Optimal Design
For some true parameter value α0 ∈
, we wish to optimize
over all nonnegative h such that Σj hj = 1. Combine Equations (16), (17), and (18) to rewrite the problem as that of finding
| (C.1) |
Consider the innermost quantity as a function of h and θ. For any particular α, fα (h, θ) = Σj hj(−φj,α(θ)) is linear in h, and so I (α, h) = supθfα(h, α) is convex in h. Additionally, the set { } forms a (d − 1)-simplex with its d vertices at the standard basis vectors; a (d − 1)-simplex is simply a (d − 1)-dimensional polytope formed from the convex hull of its d vertices. By convexity, for each α, I (α, h) must attain its maximal value at one of these vertices. Let sv be a generic notation for a d -dimensional simplex with vertices at v = {v1, …, vd }. Based on the above discussion, we can find supper and lower bounds for suph∈sv infα∈A I (α, h). In particular, we have that
and that
Furthermore, as I (α, h) is a continuous function of h, the two bounds converge to each other as the size of the simplex sv converges to zero. With these constructions, now consider the following algorithm for finding h* and Ih*,α0. In the algorithm, we use L to denote a set, each element of which is a simplex, and “←” to denote value assignment.
Algorithm 2
Set ε > 0 indicating the accuracy level of the algorithm. Let
and L = {sv0}, i.e., . Set LB ← LB(sv0) and UB ← UB(sv0)
Perform the following steps:
-
Let sv* ∈ L be the simplex with the largest UB(sv*), i.e.,
Divided sv* into 2κ−1 smaller simplexes, with their vertices at either the original vertices v* or their midpoints (Edelsbrunner & Grayson, 2000). Denote these 2κ−1 subsimplexes by sv1, …, sv2κ−1. A simple example for the κ = 3 case is illustrated in Figure 5.
- Remove sv* from L and add sv1, …, sv2κ−1 to L, i.e.,
Let .
For each sv ∈ L, if UB(sv) < LB then remove sv from L, that is, L ← L\{sv}.
Set UB ← supsv∈L UB(sv).
Figure 5.

This figure depicts the 2-simplex sv with vertices v and their midpoints vmdpt. This simplex has 4 subdivisions associated with the following sets of vertices: {v1, v4, v5}, {v2, v5, v6}, {v3, v4, v6}, and {v4, v5, v6}.
Repeat the above steps until UB – LB < ε and output
This algorithm will efficiently solve the problem of finding the optimal h, with easily controllable error in both the objective function and h. This algorithm can in fact be used to find the maximum over the simplex of the minimum of any assortment of convex functions. In particular, this can be used to solve Tatsuoka and Ferguson’s algorithm, since the KL distance is linear (and hence convex) in h.
References
- Chang HH, Ying Z. A global information approach to computerized adaptive testing. Applied Psychological Measurement. 1996;20:213–229. [Google Scholar]
- Cheng Y. When cognitive diagnosis meets computerized adaptive testing CD-CAT. Psychometrika. 2009;74:619–632. [Google Scholar]
- Chiu C, Douglas J, Li X. Cluster analysis for cognitive diagnosis: theory and applications. Psychometrika. 2009;74:633–665. [Google Scholar]
- Cox D, Hinkley D. Theoretical statistics. London: Chapman & Hall; 2000. [Google Scholar]
- de la Torre J, Douglas J. Higher order latent trait models for cognitive diagnosis. Psychometrika. 2004;69:333–353. [Google Scholar]
- DiBello LV, Stout WF, Roussos LA. Unified cognitive psychometric diagnostic assessment likelihood-based classification techniques. In: Nichols PD, Chipman SF, Brennan RL, editors. Cognitively diagnostic assessment. Hillsdale: Erlbaum Associates; 1995. pp. 361–390. [Google Scholar]
- Edelsbrunner H, Grayson DR. Edgewise subdivision of a simplex. Discrete & Computational Geometry. 2000;24:707–719. [Google Scholar]
- Hartz SM. Unpublished doctoral dissertation. University of Illinois; Urbana-Champaign: 2002. A Bayesian framework for the unified model for assessing cognitive abilities: blending theory with practicality. [Google Scholar]
- Junker B. Using on-line tutoring records to predict end-of-year exam scores: experience with the ASSISTments project and MCAS 8th grade mathematics. In: Lissitz RW, editor. Assessing and modeling cognitive development in school: intellectual growth and standard settings. Maple Grove: JAM Press; 2007. [Google Scholar]
- Junker B, Sijtsma K. Cognitive assessment models with few assumptions, and connections with nonpara-metric item response theory. Applied Psychological Measurement. 2001;25:258–272. [Google Scholar]
- Leighton JP, Gierl MJ, Hunka SM. The attribute hierarchy model for cognitive assessment: a variation on Tatsuoka’s rule-space approach. Journal of Educational Measurement. 2004;41:205–237. [Google Scholar]
- Lord FM. Robbins–Monro procedures for tailored testing. Educational and Psychological Measurement. 1971;31:3–31. [Google Scholar]
- Lord FM. Applications of item response theory to practical testing problems. Hillsdale: Erlbaum; 1980. [Google Scholar]
- Owen RJ. Bayesian sequential procedure for quantal response in context of adaptive mental testing. Journal of the American Statistical Association. 1975;70:351–356. [Google Scholar]
- Rupp AA, Templin J, Henson RA. Diagnostic measurement: theory, methods, and applications. New York: Guilford Press; 2010. [Google Scholar]
- Serfling RJ. In: Approximation theorems of mathematical statistics. Shewhart W, Wilks S, editors. New York: Wiley-Interscience; 1980. [Google Scholar]
- Tatsuoka KK. Rule space: an approach for dealing with misconceptions based on item response theory. Journal of Educational Measurement. 1983;20:345–354. [Google Scholar]
- Tatsuoka KK. A probabilistic model for diagnosing misconceptions in the pattern classification approach. Journal of Educational Statistics. 1985;12:55–73. [Google Scholar]
- Tatsuoka K. ONR-Technical Report No RR-91-44. Princeton: Educational Testing Services; 1991. Boolean algebra applied to determination of the universal set of misconception states. [Google Scholar]
- Tatsuoka C. Doctoral dissertation. Cornell University; 1996. Sequential classification on partially ordered sets. [Google Scholar]
- Tatsuoka C. Data-analytic methods for latent partially ordered classification models. Applied Statistics. 2002;51:337–350. [Google Scholar]
- Tatsuoka KK. Cognitive assessment: an introduction to the rule space method. New York: Routledge; 2009. [Google Scholar]
- Tatsuoka C, Ferguson T. Sequential classification on partially ordered sets. Journal of the Royal Statistical Society, Series B, Statistical Methodology. 2003;65:143–157. [Google Scholar]
- Templin J, Henson RA. Measurement of psychological disorders using cognitive diagnosis models. Psychological Methods. 2006;11:287–305. doi: 10.1037/1082-989X.11.3.287. [DOI] [PubMed] [Google Scholar]
- Templin J, He X, Roussos LA, Stout WF. External Diagnostic Research Group Technical Report. 2003. The pseudo-item method: a simple technique for analysis of polytomous data with the fusion model. [Google Scholar]
- Thissen D, Mislevy RJ. Testing algorithms. In: Wainer H, et al., editors. Computerized adaptive testing: a primer. 2. Mahwah: Lawrence Erlbaum Associates; 2000. pp. 101–133. [Google Scholar]
- van der Linden WJ. Bayesian item selection criteria for adaptive testing. Psychometrika. 1998;63:201–216. doi: 10.1007/s11336-008-9097-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- von Davier M. Research report. Princeton: Educational Testing Service; 2005. A general diagnosis model applied to language testing data. [Google Scholar]
- Xu X, Chang H-H, Douglas J. A simulation study to compare CAT strategies for cognitive diagnosis. Paper presented at the annual meeting of the American Educational Research Association; Chicago. April 2003.2003. [Google Scholar]