

Abstract
It is a long established convention that the relationship between sounds and meanings of words is essentially arbitrary—typically the sound of a word gives no hint of its meaning. However, there are numerous reported instances of systematic sound–meaning mappings in language, and this systematicity has been claimed to be important for early language development. In a large-scale corpus analysis of English, we show that sound–meaning mappings are more systematic than would be expected by chance. Furthermore, this systematicity is more pronounced for words involved in the early stages of language acquisition and reduces in later vocabulary development. We propose that the vocabulary is structured to enable systematicity in early language learning to promote language acquisition, while also incorporating arbitrariness for later language in order to facilitate communicative expressivity and efficiency.
Keywords: language acquisition, language evolution, vocabulary, arbitrariness of the sign
1. Introduction
One of the central ‘design features’ of human language is that the relationship between the sound of a word and its meaning is arbitrary [1,2]; given the sound of an unknown word, it is not possible to infer its meaning. Such a view has been the conventional perspective on vocabulary structure and language processing in the language sciences throughout much of the past century (see [3] for review). Since de Saussure's [1] notion of the arbitrariness of the sign, such a property has been assumed to be a language-universal property and has even assumed a definitional characteristic: according to Hockett [2], for instance, a communication system will not count as a language unless it demonstrates such arbitrariness. By contrast, throughout most of human intellectual history [4,5], the sound of a word was often assumed to directly express its meaning, a view recently revived in studies exploring sound symbolism [6–8]. So, is spoken language arbitrary or systematic?
Sound–meaning mappings may be non-arbitrary in two ways [9]. First, through absolute iconic representation where some feature of the language directly imitates the referent, as in onomatopoeia. For example, incorporating the sound that a dog makes into the sign for the sound itself (i.e. woof woof) is one example of this absolute iconicity. Second, the sound–meaning mapping could be an instance of relative iconicity, where statistical regularities can be detected between similar sounds and similar meanings though these may not be restricted to imitative forms [3]. In this case, the iconicity is not transparent, but is generally only observable once knowledge of the sound- and meaning-relationships is determined. An example of this is for certain phonoaesthemes [6], such as sl- referring to negative or repellent properties (e.g. slime, slow, slur, slum). Other phonoaesthemes may indeed represent absolute iconicity (such as sn- referring to the nose via onomatopoeic properties of its functions), and there is debate about which phonoaesthemes are indeed absolute or relative in their iconicity. Nevertheless, in the literature, both of these forms of iconicity have been referred to as systematicity in sound–meaning mappings, to contrast with arbitrariness. In spoken language, it is not clear that absolute iconicity could occur without relative iconicity. In the case of onomatopoeia, for instance, the iconic relationship between the actual sound the animal makes and the linguistic sign carries some relationship to the nature of the beast (front vowels are more likely in words for small animals' calls than large animals' calls, compare cheep cheep for chicks versus roar for a lion). Hence, such instances of absolute iconicity are likely to be reflected in relative sound similarity measures.
Arbitrariness of form–meaning mappings introduces a profound cost for learning: as the mapping between the sign and its referent has to be formed anew for each word, knowing all the other words in the vocabulary does not assist in learning a new word. Besides the cost for processing and learning of the language, to Renaissance scholars the absence of apparent systematicity between form and meaning was seen as an offensive property of language [4]. Arbitrariness was interpreted in terms of the story of the Tower of Babel, in which a previously globally understood language was confounded through divine intervention. There are numerous accounts of scholars aiming to rediscover the ‘universal language’—the pre-Babel tongue where form and meaning were perfectly aligned. John Wilkins, a founder of the Royal Society, produced one of the most complete systems of language that related forms closely to meanings, a system exemplifying relative iconicity [10]. Wilkins' language, entertainingly depicted in Eco's [4] treatise, formed a hierarchy of categories of increasing specificity, with each category and subcategory indicated by a particular letter. For instance, in Wilkins' system, plants begin with the letter ‘g’, and animals with the letter ‘z’. Then, for the subcategories of animals, exanguious animals begin with ‘zα’, fish begin with ‘za’, birds with ‘ze’ and beasts with ‘zi’. For further subcategories, additional letters are appended. Such a language would clearly result in much inheritance of information across words. So, on encountering a new word, the general meaning could be determined based on its form.
However, computational modelling and experimental studies of vocabulary acquisition have suggested that arbitrariness may, contrary to initial expectations, actually result in a learning advantage. In a series of connectionist computational models, which learned to map phonological forms of words onto meaning through an associative learning mechanism, Gasser [11] demonstrated that, as the size of the vocabulary increased, arbitrariness in the mappings between inputs and outputs of the model resulted in better learning. This result was interpreted as being due to greater flexibility in the interleaving of new items into an already learned set of mappings. For systematic sound–meaning mappings, the resources assigned to the new word are recruited from those already assigned to mapping between similar words, whereas for arbitrary mappings, the resources for learning the new word can be drawn from anywhere in the system. For an associative learning system, learning to form a mapping can be similar to discovering the principal components from the input–output pairings [12]. For systematic mappings, the set of mappings can be effectively described with a single component, and space on this component can become crowded. For arbitrary mappings, a separate component is required for every mapping individually, reducing the possibilities for interference between words represented by distinct components.
In a series of experimental and computational studies, Monaghan et al. [13] demonstrated that for learning novel words, arbitrariness in the sound–meaning mapping was advantageous compared with a vocabulary with a systematic form–meaning mapping. However, this advantage was only prominent when an additional contextual cue was provided for the learner within the language, either in the form of co-occurrence with a word that related to the general categorical meaning of the word, or in terms of a morphological feature that related to category. For instance, in this contextual cue condition, utterances comprised a marker word (either ‘weh’, which always occurred when the referent was an object or ‘muh’ which always occurred when the referent was an action) along with a referring word (e.g. ‘paab’), which was heard simultaneously with viewing a picture referent. Arbitrariness or systematicity was carried in the relationships between the sounds of the referring words and the category distinction between objects and actions in the set of referents. Without the marker word (‘weh’ or ‘muh’), learning was not advantageous in the arbitrary condition. In the same study, the computational studies were connectionist models that implemented an associative learning mechanism in order to learn to map form onto meaning representations, either with or without context. Again, when context was present, the arbitrary mapping was optimal for learning. Analysis of the computational model's solution to the mapping demonstrated that arbitrariness permits maximizing of the potential information in the learning situation, resulting in effective mapping being achieved. In the systematic condition, words with similar sounds occurred in similar contexts, reducing distinctiveness in the environment for identifying the intended referent and resulting in less effective mappings being formed. These effects were precisely in line with Wilkins' own errors in transcription, whereby closely related words suffered mislabelling: Eco notes that Gade (barley) was written in place of Gape (tulip) in Wilkins' essay [4].
In contrast to the view of the arbitrariness of the sign, there are a growing number of corpus analyses and behavioural studies that demonstrate some systematicity in spoken language. For some features of meaning, such as vowel quality relating to size, the sound-symbolic properties are language-universal [6,7,9]; for instance, the non-words ‘mil’ and ‘mal’ are typically understood to express small and large, respectively, across cultures. High and low vowel contrasts, exemplified by the i/a distinction, have also been shown to occur in small/large expressives, respectively, across most, if not all, languages [14]. There are also numerous language-specific properties, such as phonoaesthemes, that refer to clusters of phonemes relating to specific meanings. For example, in English, words associated with the nose and its functions tend to begin with sn-, or words referring to light often begin with gl- [6]. Preferences for certain sound–meaning relationships, have been demonstrated to affect learning of novel adjectives [15], verbs [16,17], nouns [18,19] and mixes thereof [20], though these studies generally test a forced choice between two alternatives. When the semantic distinction is not immediately available, as in a forced-choice test between two objects from different categories, then learning is less evident but still present under some learning conditions [21].
Sound symbolism has been proposed to be vitally important for language acquisition because inherent properties of meaning in sound would enable children to discover that words refer to the world around them. Sound-symbolic words not only represent their meaning, but can literally incorporate the senses to which they refer within the sound, as in onomatopoeia. This mechanism could facilitate acquisition not only of particular sound–meaning mappings, but also the knowledge that there are mappings between sounds and meaning [8]. Such preferences for certain sound–meaning mappings have now been shown for young children. For instance, there are numerous studies with adults demonstrating that nonsense words such as bouba and kiki are found to reliably relate to rounded and angular objects, respectively (see [21] for review). However, Ozturk et al. [22] demonstrated that four-month-old children have a similar preference, indicating that substantial knowledge about language is not required in order to form these preferences. Similarly, Walker et al. [23] showed that three- to four-month-old infants were able to form cross-modal correspondences between spatial height and angularity with auditory pitch, demonstrating that cross-modal correspondence preferences can precede substantial language learning rather than being a consequence of the fact that a particular language instantiates these correspondences [24].
Yet, we have seen that systematicity in sound–meaning mappings in the vocabulary comes at a cost in terms of reducing the distinctiveness of words that have similar meanings, potentially increasing confusion over intended meaning [9,13]. So, given this tension between the linguistic convention of arbitrariness and the growing body of studies demonstrating sound symbolism in language and its proposed importance for early language acquisition, the long-standing question remains open as to how arbitrary language actually is. Are the observed systematic clusters, such as phonoaesthemes, merely a ‘negligible fraction’ [25] of the lexicon or is systematicity a more substantial feature of spoken language? This is an important question to address because it provides insight not only into the properties of the vocabulary that support acquisition and processing, but also more generally into the manner in which mappings between representations are constructed in the brain. There is evidence that systematicity in mappings between sensory regions of the cortex may be more efficient [26]; consequently, there is potentially a balance to find between implementational constraints in the brain with potential advantages of arbitrariness for communicative efficiency. We return to this point in the Discussion.
To our knowledge, there are three previous published studies that have developed a measure of the properties of sound–meaning mappings present in natural language. Tamariz [27] investigated subsamples of Spanish vocabulary, relating distances in sound space to distances in meaning space, where meanings were derived from the contextual occurrence of words [28]. For carefully selected subsets of Spanish words, she demonstrated that the relationship between sound and meaning contained a small degree of systematicity, particularly in the relationship between consonants and categories of meaning. Otis & Sagi [29] examined the relationships between sets of letters and meaning for phonaesthemes, where meanings were derived from Infomap [30], a variant of latent semantic analysis [31]. They focused on sets of phonoaesthemes proposed in the literature [32], which formed statistically significant clusters of related meanings. They found that, of 46 phonaesthemes proposed by Hutchins [32] as present in the English language, 27 were statistically significant clusters, including sn- and gl-. Third, a study [33] of a small sample of the most frequent monomorphemic words of English resulted in an estimate of sound symbolism and found results consistent with those of Tamariz [27].
However, there has as yet been no comprehensive analysis of the relationships between form and meaning for a large-scale representative vocabulary. The first aim of this study was to determine the properties of the form–meaning mapping for a broad and representative set of words in English. Previous studies have focused on a single measure of sound and of meaning and have assessed only subsamples of the vocabulary. We sampled all the monosyllabic words in English for the analyses. Monosyllabic words constitute 70.9% of all word uses in English [34], and so confining analyses to just these words is a reasonable approximation to the whole vocabulary. To ensure that the limitation to monosyllabic words did not adversely affect the results, we also gathered a corpus of all monomorphemic words of all lengths (we refer to this in the following as polysyllabic). However, we assume that language processing and language acquisition are influenced by the frequency with which words occur in the linguistic environment, and so caution must be taken to ensure that the many long multisyllabic words that occur very rarely in language [35] do not skew the results towards a non-representative subsample of the vocabulary. Furthermore, this study examines the robustness of the observed sound–meaning mapping to different representations of sound and meaning, to ensure that estimates of systematicity or arbitrariness of the vocabulary are not prone to a particular interpretation of sound or meaning similarity.
The second aim of this study was to examine the contribution of individual words to the overall system of form–meaning mappings. This enables us to determine whether the relationship between form and meaning in the vocabulary is due to small clusters of words that are related or unrelated across form and meaning representations, or whether the properties of the mapping are generalizable across the whole vocabulary. Furthermore, it means that the relationship between an individual word's systematicity and its psycholinguistic properties can also be measured. In particular, we related systematicity at the word level to the age at which a word is learned. If sound symbolism is critical for language acquisition, then we would expect to see enhanced systematicity for the words that children first acquire.
2. Material and methods
(a). Materials
(i). Corpus preparation
We took all the English monosyllabic words from the CELEX database [32]. We also extracted all the monomorphemic words from the CELEX database in preparation for the polysyllabic analyses. To ensure that the measure of sound–meaning systematicity in the vocabulary was not due to the particular representation of sound or meaning, we computed several measures of sound and meaning similarity.
For sound similarity, we tested the three alternative approaches following Monaghan et al. [36]. Testing multiple sound measures is important in order to ensure that apparent relationships between sound and meaning are not due to particular types of representation of sound similarity. First, each phoneme in the word was converted to a phonological feature representation [37], and then the sound similarity between each pair of words was determined to be the minimum number of phonological feature changes required to convert one word to the other (phoneme feature edit distance). This measure closely corresponds to psycholinguistic measures of sound similarity [38,39]. The second sound similarity measure was optimal string alignment Damerau–Levenshtein distance over phonemes [40], where sound similarity is the number of phoneme changes required to convert one word to the other (phoneme edit distance). The third measure was the Euclidean distance between phonological feature representations of words (phoneme feature Euclidean distance). In the results, we first report similarity based on the phoneme feature edit distance, before indicating whether the effects are robust to different sound similarity measures.
For meaning similarity, we constructed two representations of meaning. The first was based on contextual co-occurrence vectors [28], which were generated by counting words appearing within a ±3 word window with each of 446 context words in the British National Corpus [41]. Words with similar meaning tend to have similar usage, which is in turn reflected in terms of similar co-occurrence vectors [30,31]. As with the sound distance measures, an additional measure of meaning was used. This was in order to ensure that relationships between sound and meaning did not depend on a particular choice of one of the representations. For instance, it could be the case that words used in similar contexts tend to have similar (or distinct) sounds because some processing constraint on production encourages (or prohibits) similar-sounding words occurring close together in utterances. Hence, the second meaning representation was based on semantic features derived from WordNet, which reflected groupings of words according to hierarchical relations and grammatical properties [37]. Both types of meaning representation reflect behavioural responses to semantic similarity between words as measured through free associations and semantic priming studies [28], though to varying degrees [42]. For each type of meaning representation, meaning similarity was 1-cosine distance between the representations for each word pair, such that small distances indicate similar meanings. In the results, we first report the meaning similarity measure based on contextual co-occurrence vectors. The semantic feature representation was not available for the monomorphemic polysyllabic words because it was derived only for monosyllabic words.
There were 5138 monosyllabic words with both co-occurrence- and feature-based semantic representations. However, this vocabulary set contained both simple and complex morphological forms; inflectional and derivational morphology both express systematic sound to grammatical category relations that reflect semantic aspects of words [43]. In order to remove the contribution of morphology to the systematicity of the vocabulary, we derived the subset of word lemmas, which omitted morphologically inflected forms (e.g. cat but not cats was included), n = 3203, and also monomorphemes (e.g. warm but not warmth was included), n = 2572, which omitted all complex morphological and compound forms, based on CELEX classifications. The polysyllabic monomorphemic set of words, with contextual co-occurrence vectors, comprised 5604 words.
One potential source of sound–meaning systematicity in the vocabulary is due to etymology; word variants with the same historical meaning may consequently have similar phonological forms [44]. For instance, for the phonaestheme gl-, glass, gleam, glitter, glisten and glow, are all proposed to derive from Proto-Indo-European root *ghel-, meaning ‘to shine, glitter, glow, be warm’ [45]. Less distantly, gleam, glimmer and glimpse are proposed to derive from the Old English root *glim-, meaning ‘to glow, shine’ [46]. We consulted etymological entries [45,46] for each of the monosyllabic monomorphemic words. Words with proposed common roots in one or more of Old English, Old French, Old Norse, Greek, Latin, Proto-Germanic or Proto-Indo-European were omitted. There were 2572 monomorphemic words with etymology entries, of which 1732 words had no listed common origins, which were assessed to determine systematicity of the vocabulary independent of proposed common origins of words.
(ii). Psycholinguistic properties
For each monomorphemic word, we determined the age at which words are acquired by consulting age of acquisition ratings from Kuperman et al. [47]. In order to assess the role of age of acquisition, it is important to control for a set of other psycholinguistic variables, which may be correlated with age of acquisition. We generated measures of log-frequency, orthographic similarity (neighbourhood size, based on Coltheart's N [40]) and word length from CELEX [34]. A word's neighbourhood is defined as the number of other words in the vocabulary that are generated by changing one letter of the target word and is a predictor of speed and accuracy of word retrieval [48]. All psycholinguistic variables were available for 2787 words.
(b). Procedure
(i). Testing form–meaning mappings
To test the relationship between sound–meaning mappings, measures of sound and meaning similarity were computed for every word pair, resulting in (5138 × 5137)/2 distinct pairs of distances. To determine the relationship between sound and meaning for the entire set of words, the correlation between these pairs was measured. Note that this calculation assesses the relative iconicity of words. Figure 1 illustrates the cross-correlation between distances within the sound space and within the meaning space. A positive value indicates that distances in sound space are related to distances in meaning space, whereas values close to zero indicate that distances in sound and meaning are not related, i.e. arbitrary. In order to determine whether the correlation between sound and meaning is significant, we applied the Mantel test [49], where every word's meaning was randomly reassigned, then the correlations between sound and randomized meaning were computed, with 10 000 random reassignments of words' meanings. The position in this distribution of the correlation resulting from the sound–meaning mappings in the actual language against the correlations from random reassignments, in a Monte Carlo test, indicates the significance of the systematicity or arbitrariness of the vocabulary.
Figure 1.
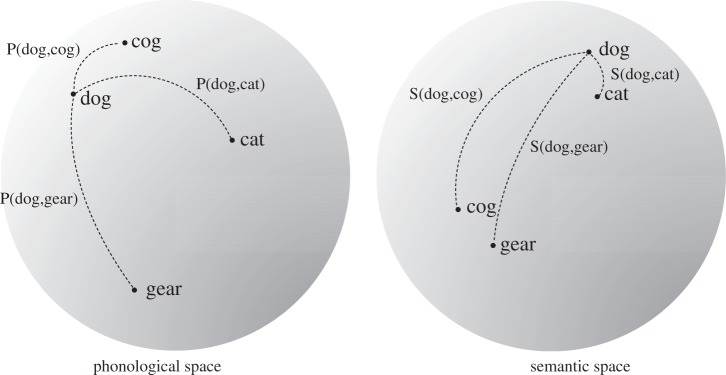
Example of correlating distances in the sound and meaning spaces. Points indicate sound and meaning representations of words, P(x,y) and S(x,y) indicate distances in sound and meaning spaces, respectively, between words x and y. Only four of the 5138 words are indicated, and distances only from the word ‘dog’ are shown. Correlations are performed by pairing P(dog,cat) with S(dog,cat), P(dog,gear) with S(dog,gear), etc.
Mantel tests were conducted for each of the sound and meaning distance measures, for all words, word lemmas, monomorphemes and monomorphemic words with no common etymology.
(ii). Testing arbitrariness of individual words
In order to determine the contribution of each word to the overall systematicity or arbitrariness of the language, we computed each word's individual systematicity. Each target word was omitted from the set of pairs of sound and meaning distances, and the correlation of the vocabulary with this word omitted was then reassessed. The size and direction of change in the new correlation against the original correlation including the target word was then recorded. Positive values indicate that the omitted word contributed to systematicity of the vocabulary, whereas negative values demonstrate that the word was arbitrary in terms of its sound–meaning mapping.
3. Results
(a). Correlations between sound and meaning
The results for the Mantel tests of sound–meaning mappings for the phoneme feature edit distance measure for sound and the contextual co-occurrence measure for meaning are shown in figure 2. For all words, we found that the English vocabulary was more systematic than expected by chance, p < 0.0001, though the amount of variance explained was very small (r2 < 0.002). For the word lemmas—that is, considering words with no derivational or inflectional morphology—the results were similar, p < 0.0001. Analysing the monomorphemic word set, i.e. removing all morphology from the words, again did not change the results—word roots were more systematic than expected by chance, p < 0.0001. Finally, for the analyses of words with no common etymology, the results again supported systematicity in sound–meaning mappings, p = 0.0002: only one of the randomized rearrangements of meaning distances resulted in a higher correlation than the actual word set.
Figure 2.

Correlation between sound and meaning (diamonds), against distribution of 10 000 randomized sound–meaning mappings, for all words, lemmas, monomorphemes and words with no proposed common etymology. Distribution shows mean (–), first and third quartiles (box) and range (bars) of randomized mappings. Positive values for correlation indicate a systematic relationship between sound and meaning.
We next tested the various combinations of sound distance and meaning distance measures to ensure that the results were generalizable across these different ways of determining similarity. The results for each word set are shown in table 1. The results were similar: for the co-occurrence semantic similarity and each phonological similarity measure, there was greater than chance systematicity, explaining small amounts of variance in the vocabulary. For the semantic feature similarity measure, the results were again similar for all phonological similarity measures and for all word sets, with the exception of the words with no common etymology, where the relationship was found to be marginally significant.
Table 1.
Correlations between different implementations of measures of sound similarity and meaning similarity for each word set.
| word set | meaning similarity measure | sound similarity measure | r | Mantel test, p |
|---|---|---|---|---|
| word forms | co-occurrence | phoneme feature edit | 0.035 | 0.0001 |
| phoneme edit | 0.035 | 0.0001 | ||
| Euclidean distance | 0.028 | 0.0001 | ||
| feature | phoneme feature edit | 0.033 | 0.0001 | |
| phoneme edit | 0.016 | 0.0001 | ||
| Euclidean distance | 0.014 | 0.0001 | ||
| word lemmas | co-occurrence | phoneme feature edit | 0.031 | 0.0001 |
| phoneme edit | 0.032 | 0.0001 | ||
| Euclidean distance | 0.028 | 0.0001 | ||
| feature | phoneme feature edit | 0.015 | 0.0001 | |
| phoneme edit | 0.016 | 0.0001 | ||
| Euclidean distance | 0.012 | 0.0033 | ||
| monomorphemes | co-occurrence | phoneme feature edit | 0.034 | 0.0001 |
| phoneme edit | 0.036 | 0.0001 | ||
| Euclidean distance | 0.031 | 0.0001 | ||
| feature | phoneme feature edit | 0.011 | 0.0001 | |
| phoneme edit | 0.011 | 0.0001 | ||
| Euclidean distance | 0.008 | 0.0001 | ||
| etymology | co-occurrence | phoneme feature edit | 0.035 | 0.0002 |
| phoneme edit | 0.044 | 0.0001 | ||
| Euclidean distance | 0.030 | 0.0010 | ||
| feature | phoneme feature edit | 0.008 | 0.0654 | |
| phoneme edit | 0.009 | 0.0548 | ||
| Euclidean distance | 0.008 | 0.0716 |
In order to determine the generality of the effects to polysyllabic words, we repeated the analyses on the 5604 monomorphemic polysyllabic word set. The results supported the original monosyllabic analyses: for the phoneme feature edit measure, r = 0.009, p = 0.005, for the phoneme edit measure, r = 0.016, p = 0.0160 and for the Euclidean distance measure, r = 0.012, p = 0.0018.
(b). Arbitrariness of individual words
In order to assess the distribution of systematicity across the vocabulary, we measured the systematicity of individual words in the language by determining whether omitting each word increased or decreased the correlation between sound and meaning for the whole vocabulary. The landscape of systematicity and arbitrariness of individual words is shown in figure 3, which shows the systematicity of the sound space of words. The plot projects the relative position of monomorphemic words according to their sound similarity onto a two-dimensional plane using multiple dimensional scaling, with the systematicity of each word on the vertical axis, and the landscape was then smoothed using linear interpolation. As illustrated, the vocabulary indicates both peaks of sound symbolism as well as troughs of arbitrariness.
Figure 3.

Systematicity and arbitrariness of the sound space for monomorphemic words. Positive peaks indicate ‘sound symbolic’ regions, and negative peaks indicate decorrelated, arbitrary sound–meaning regions of the vocabulary. (Online version in colour.)
In order to determine the properties of this landscape, we examined whether the overall systematicity of the vocabulary is driven by small pockets of sound symbolism, or whether it is a general characteristic of the entire set of words. If the systematicity of the vocabulary is confined to, and driven by, a small set of clusters—illustrated in the peaks of figure 3—then the distribution of systematicity should exhibit divergence from the distribution of individual words' systematicity when words' meanings are randomly reassigned, as in the randomization for the Mantel test in the previous section. Alternatively, if systematicity is due to the distribution across the whole vocabulary, then the distribution should not diverge from a randomized distribution. Note that any distribution of systematicity across the whole vocabulary would result in peaks and troughs, but the issue is whether these peaks and troughs differ from that expected from the general distribution.
We assessed the distribution of peaks and troughs across the space by comparing the distribution of systematicity to 1000 distributions resulting from randomly reassigning the meaning representations of words and determining the systematicity of each word following this randomization. If systematicity of the whole vocabulary is a consequence of a few small pockets of sound symbolism, then the actual distribution of systematic words should be significantly different from the distribution resulting from randomized distributions. Figure 4 shows the probability density function distribution of the systematicity values for the set of monomorphemic words, indicating that it lies within the range of the set of randomized distributions. We conducted Wilcoxon signed-rank tests comparing the distribution of systematicity of actual words against each of the randomizations. None was significantly different from chance with Bonferroni correction, minimum p = 0.2. Thus, the apparent peaks (and troughs) of sound symbolism in the vocabulary are anticipated from the distribution of systematicity across the whole vocabulary. Therefore, the observed systematicity of the vocabulary is not a consequence only of small pockets of sound symbolism, but is rather a feature of the mappings from sound to meaning across the vocabulary as a whole.
Figure 4.

Probability density distribution of words' systematicity (negative, word is arbitrary; positive, word is systematic) for actual vocabulary (solid line) and 1000 randomizations (grey shading), indicating that the landscape of peaks and troughs are consistent with general distribution of systematicity over the whole vocabulary rather than driven by peaks of systematicity.
Finally, we determined whether systematicity is differently expressed in the vocabulary across stages of language development. If sound symbolism is critical for language acquisition [8,50], then we would predict greater systematicity for words that are implicated in early language acquisition than those related to later language use. We related each individual monomorphemic word's systematicity to the estimated age at which it was acquired, controlling for other psycholinguistic variables [47] using multiple linear regression. For these other psycholinguistic variables, there was no significant effect of log-frequency, β = −0.046, t = −1.864, p = 0.063, orthographic length, β = −0.025, t = 0.872, p = 0.383 or phonological length, β = 0.003, t = 0.122, p = 0.903, and there was a small effect of orthographic similarity, β = 0.054, t = 2.081, p = 0.038. Critically, for age of acquisition, we found that early-acquired words contributed more to systematicity than late-acquired words, β = −0.075, t = −3.022, p = 0.003. Figure 5 illustrates the mean systematicity for words binned into age of acquisition years from age 2 to 13 and older (note that words are not reliably judged to be acquired before 2 years old). The significant effect in the regression analysis is due to sound symbolism being more available during early stages of language acquisition, whereas arbitrariness is dominant within the developed adult vocabulary. The effect of age of acquisition relating to systematicity of words was robust over analyses using all words, word lemmas, words with no common etymology and applying the different measures of sound and meaning similarity.
Figure 5.

Systematicity by age of acquisition. Mean and standard error for systematicity of words binned by each year of age of acquisition, indicating that words acquired early tend to be more systematic.
One possible driver of the age of acquisition results is the different distribution of nouns and verbs at different stages of language acquisition—a large proportion of early-acquired words are nouns. If nouns are more systematic than verbs, then part of speech may be the source of the age of acquisition effect rather than systematicity being an inherent and independent property of early-acquired words generally. In order to control for this, we determined for the monosyllabic monomorphemes whether the word was a noun or a verb (in terms of most frequent usage in CELEX); if the word was from another category we omitted it from the analyses. This resulted in 2252 nouns and 329 verbs. Whether the word was a noun or verb was entered as an additional predictor variable into the regression analysis. This resulted in a significant effect of phoneme length, β = 0.057, t = 2.261, p = 0.024, a significant effect of orthographic similarity, β = 0.056, t = 2.035, p = 0.042 and a significant effect of age of acquisition, β = −0.086, t = −3.30, p = 0.001. No other variables were significant. This indicates that the age of acquisition effects are robust and not due to effects of grammatical category.
The advantage of considering all words simultaneously is that they can be assessed against the same distribution of form–meaning mappings, and thus can be directly compared for the arbitrariness or systematicity present in vocabulary at different stages of language acquisition. However, using this method, the systematicity measure for the early-acquired words is determined by comparison with the whole vocabulary. To establish whether systematicity is present in the early-acquired words only for those words that children acquire first, we measured the sound–meaning mapping among the 300 monomorphemic monosyllabic words that children acquire up to the age of 4 years old. For co-occurrence vector semantic similarity and phoneme feature edit distance similarity (other similarity measures result in similar effects), the mapping was systematic, r = 0.045, p = 0.0442.
4. Discussion
We have shown that the sound–meaning mapping is not entirely arbitrary, but that systematicity is more pronounced in early language acquisition than in later vocabulary development. This seems to conflict with the ‘design feature’ and Saussurian view of the arbitrariness of the sign [1,2], the dominant view throughout the past century of language science, which contends that form–meaning mappings are arbitrary. Some systematicity may be anticipated from the morphological structure of the vocabulary—we know that derivational and inflectional morphology carries information about words' usage and can indicate certain features of meaning [43], such as the distinction between nouns and verbs, or the tense of the action being described, or the relationship between the length of morpheme and the quantity implied by comparatives and superlatives (e.g. long, longer, longest) [51]. However, even for the monomorphemic words, when morphology was not exerting an influence on the sound–meaning mappings, the vocabulary is more systematic than expected by chance. Furthermore, we have demonstrated that the observed systematicity is also not due to common historical roots for words. For monomorphemic words with no shared etymological origin, there is greater systematicity than expected by chance.
The analyses of the landscape of the form–meaning mappings demonstrated that systematicity in the vocabulary is not a consequence of small clusters of sound symbolism, rather, it is a general property of the whole language. Systematicity, then, is not a consequence of small exceptional clusters of form–meaning correlation, which could have indicated that the structure of the vocabulary is affected or has been altered by specific isolated features of sound relating to meaning. Instead, the general property of systematicity indicates that the vocabulary is more likely to be configured by principles that apply across the whole language.
Crucially, the presence of systematicity of form–meaning mappings varies across the vocabulary. For words that feature early in language acquisition, systematicity is prominent, but for later-acquired words, the form–meaning mappings reveal increasing arbitrariness. The enhanced systematicity for the early vocabulary supports views that systematicity is useful for language acquisition [15–18,20]. Systematicity promotes understanding of the communicative function of language early in development, as the form provides information to the learner about the meaning, potentially enabling the child to learn that words have referents. The corpus analyses we have conducted are entirely consistent with views that sound symbolism may be necessary for bootstrapping word learning. The greater systematicity for early-acquired words is also consistent with studies that have demonstrated that, under certain conditions, and for small sets of words, sound symbolism facilitates identification of the actual referent associated with the spoken word [6,8], and also studies of form–meaning mappings in sign languages, where iconicity improves acquisition [52].
Systematicity has been suggested to lie at the origins of language. Ramachandran & Hubbard [7] proposed that non-arbitrary preferences across modalities—such as between visual appearances of objects and certain sounds or shapes of the mouth (as in the example of the sounds bouba and kiki relating to rounded and angular objects, respectively)—became conventionalized in human communication. Though any one cross-modal preference may have been too weak to propagate a proto-language, multiple cross-modal correspondences could have interacted to create a system where spoken sounds communicated the intended referent (see also [44] for discussion of cross-modal processes and language evolution).
The systematicity of early language also accords with the ontogenesis of topographic maps in the neocortex [26], where similar stimuli are encoded in close cortical space [53]. Computational models of cortical topography demonstrate that it is more efficient to encode cross-modal correspondences that exploit the topography within each modality [54,55]. Representations that activate regions that are close together in one sensory cortical area can be mapped onto close regions in another sensory cortex with less white matter than mappings that do not reflect areal topography. Hence, there are pressures within the neural substrate towards forging systematic mappings between modalities. It may be that this mechanism for systematicity accounts for how sound symbolism may come to be expressed in language—if encouraged to generate a novel word for a concept, a similar-sounding word would respect cross-modal constraints. Similarly, the same mechanism may well explain how systematicity can initially promote learning mappings between sound and meaning, as is observed in words that occur in early language acquisition [8].
Yet, systematicity comes at a cost in terms of efficiency of information transmission [5], because it reduces the distinctiveness available within the sounds of words used to refer to similar sensory experiences. This apparent tension appears to be addressed within the vocabulary by reducing systematicity as the vocabulary increases—for words acquired between ages 2 and 6, the vocabulary is systematic; after this age, the vocabulary is more arbitrary, with most arbitrariness observed for words acquired at age 13 and older. For the child with a small vocabulary, ensuring distinctiveness among a smaller set of words is less critical because the distribution of the set of words entails that distinctions in meaning are likely to be greater. In the contextual co-occurrence vectors, this difference is evident. For words acquired up to 3 years of age, mean cosine distance between meaning vectors is 0.224 (s.d. = 0.099), whereas the distance between vectors for words acquired from age 3 upwards is 0.116 (s.d. = 0.071), which is significantly different, t = 44.996, p < 0.001. This has the consequence that systematicity in form–meaning mappings can be tolerated because fine discriminations between the meanings of words do not have to be discerned from only the phonological form of the word. This result is not a trivial consequence of comparing a smaller and a larger vocabulary, because it could have been the case that earlier-acquired words densely occupied a smaller region of the possible meaning space [56], in which case meaning distinctiveness would not differentiate first-acquired words compared with the entire vocabulary.
The increased arbitrariness for later-acquired words assists the mature language user in determining nuanced distinctions in meaning, as arbitrariness maximizes the information available in the communicative discourse [11,13], especially important when distinctions between meanings, in terms of contextual information, are less available. This arbitrariness of the later-acquired words is also important in establishing that the results are not just due to increasing levels of noise in the semantic representations for later, more complex, potentially lower frequency words. If the later-acquired words effects were merely due to increasing noise, then the systematicity of the words would decline to chance level, whereas in fact the systematicity polarizes to below chance level, thus indicating that these representations are carrying important information complementary to the early-acquired words.
The results are also consistent with a number of other observations about the relationship between meaning and communicative distinctiveness. When nuanced distinctions are not so critical, as is the case for certain circumscribed sets of words in the vocabulary, such as expressives [9] (where identifying the difference between, for instance, gigantic and ginormous is not absolutely essential for communicative effectiveness), then systematicity appears to be more tolerated in the language. Consequently, expressives seem to be one of the very few language-universal properties where systematicity is observed [14,57]. Relatedly, and in addition to the systematicity observed in monomorphemic words, morphology provides an additional source of systematicity in form–meaning mappings. Thus, ending in –ed, such as for mapped or learned, is a strong indicator that the word is a verb and that it refers to an event that is past, whereas ending in –er is a strong indicator of a noun (as in mapper, learner). This systematicity is likely to be advantageous because it provides information about the general category of the word, rather than at the level of the individual word [43,58]. For mapping from form onto such category levels, systematicity in the spoken word is beneficial [21,59], but for the more specific task of individuating words' meanings, arbitrariness is advantageous, at least for larger vocabularies [13]. For both categorization and individuation, division of labour within the structure of the word may be beneficial [13,27,60].
The greater systematicity for early-acquired words is consistent with computational models that demonstrate that pressures from vocabulary size prohibit systematicity. Gasser reported that the arbitrariness advantage for mappings between form and meaning was only observed in his computational model when the vocabulary exceeded a certain size, where the precise size was dependent on the distinctiveness available in the signal [11]. Thus, while the vocabulary is small, as in early stages of acquisition, there is no pressure against systematicity in the mappings. Only when the vocabulary is larger is arbitrariness required for efficient learning.
In spoken language, the issue of distinctiveness is closely related to arbitrariness, because the dimensions available to create variation in the signal are limited to sequences of sounds, expressed in segmental and prosodic phonology [61]. Hence, it is not possible to ensure that words with similar meanings have distinct sounds without simultaneously introducing divergence between form and meaning. In spoken language, there is thus a conflation between absolute and relative iconicity. However, in sign languages, distinctiveness can be distinguished from arbitrariness due to several properties. First, in sign languages, the number of dimensions available to form distinctiveness may potentially be much greater [62], and the aspect of the sign that can relate to meaning for each word can vary accordingly. British Sign Language, for instance, expresses signs (at least) in terms of initial hand shapes and positions, hand shape changes, hand movements, as well as facial expression. Second, the sign can relate to various visual properties of the referent, using any of the phonological features of the sign (hand shape/position and hand shape changes/movements). By contrast, in spoken language, iconic relationships can only occur between the sound of the word and sound properties of the referent—a much more restricted set. Third, the dimensions in the sign can be expressed simultaneously, meaning that the dimensions can add to distinctiveness because they are processed in parallel. By contrast, in spoken language, the sequential nature of speech production and processing requires that distinctiveness be available early in the word, again meaning that systematicity in spoken language would result in a greater reduction in distinctiveness than in sign language. Thus, absolute iconicity between form and meaning can be accommodated in sign language without compromising distinctiveness, and potentially also without also introducing relative iconicity in the mappings, because independent aspects of the signal can be varied to maximize distinctiveness but also to permit iconic relationships between sign and meaning.
Consider, for instance, the sign for cat and the sign for dog in British Sign Language and in spoken English. The sign for cat has initial hand configuration as open with fingers apart and slightly bent, with starting position of the hands at each side of the face, and then short movement of the hands outwards. The sign for dog has initial hand configured as index and middle fingers of each hand extended and pointing downwards. Starting hand position is in front of the body, and then short movements up and down. Dog and cat have some similarities in terms of meaning—they could occur in similar contexts in discussions about household pets—yet the signs are distinct in each of the expressed dimensions, with different salient features of each animal iconically represented in the sign—for the cat it is the appearance of the whiskers, for the dog it is its behaviour reminiscent of begging. By contrast, in spoken English, the distinction is expressed in terms of different consonants and vowels, none of which are transparently iconically related to the animal. Reflecting properties of the referent in spoken forms of these words would necessitate reducing the distinctiveness in the sounds of the words—sound similarity can only be accomplished by changing the same signal dimensions as are used to ensure distinctiveness. Increasing the dimensions by which signs can be distinguished means that arbitrariness would not be required until a substantially larger vocabulary is required. Such general principles are consistent with observations that speakers maintain a steady rate of information when communicating, where the interplay between the word's context and the sound of the word itself remains stable [63,64].
5. Conclusion
Over 2300 years ago, Plato reported the dialogue between Hermogenes and Cratylus over whether the nature of a word resides in its form, or whether the word is arbitrarily related to its meaning [5]. This debate can now be resolved with a classic dialectic synthesis: they are both right, but for different regions of the vocabulary. The structure of the vocabulary serves both to promote language acquisition through sound symbolism [6–8] as well as to facilitate efficient communication in later language through arbitrariness maximizing the information present in the speech signal [9,13].
Acknowledgements
We thank Dale Barr, Simon Garrod, Jim Hurford, Bob Ladd, Pamela Perniss, Mark Seidenberg and Gabriella Vigliocco for helpful comments on an earlier draft of this paper.
References
- 1.de Saussure F. 1916. Course in general linguistics. New York, NY: McGraw-Hill. [Google Scholar]
- 2.Hockett CF. 1960. The origins of speech. Sci. Am. 203, 89–96. ( 10.1038/scientificamerican0960-88) [DOI] [PubMed] [Google Scholar]
- 3.Perniss P, Thompson RL, Vigliocco G. 2010. Iconicity as a general property of language: evidence from spoken and signed languages. Front. Psychol. 1, 227 ( 10.3389/fpsyg.2010.00227) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Eco U. 1995. The search for the perfect language. London, UK: Blackwell. [Google Scholar]
- 5.Plato. 1961. Cratylus. In The collected dialogues (eds Hamilton E, Cairns H.), pp. 421–476. Princeton, NJ: Princeton University Press. [Google Scholar]
- 6.Bergen BK. 2004. The psychological reality of phonaesthemes. Language 80, 290–311. ( 10.1353/lan.2004.0056) [DOI] [Google Scholar]
- 7.Ramachandran VS, Hubbard EM. 2001. Synaesthesia: a window into perception, thought and language. J. Conscious. Stud. 8, 3–34. [Google Scholar]
- 8.Spector F, Maurer D. 2009. Synesthesia: a new approach to understanding the development of perception. Dev. Psychol. 45, 175–189. ( 10.1037/a0014171) [DOI] [PubMed] [Google Scholar]
- 9.Gasser M, Sethuraman N, Hockema S. 2010. Iconicity in expressives: an empirical investigation. In Empirical and experimental methods in cognitive/functional research (eds Newman J, Rice S.), pp. 163–180. Stanford, OR: CSLI Publications. [Google Scholar]
- 10.Wilkins J. 1668. An essay towards a real character and a philosophical language. London, UK: Sa. Gellibrand. [Google Scholar]
- 11.Gasser M. 2004. The origins of arbitrariness of language. In Proc. 26th Annual Conf. of the Cognitive Science Society, Chicago, USA, 5–7 August 2004, pp. 434–439. Mahwah, NJ: Lawrence Erlbaum. [Google Scholar]
- 12.Cottrell GW, Munro P. 1988. Principal components analysis of images via back propagation. In Proc. SPIE 1001, Visual Communications and Image Processing ‘88: Third in a Series, 1070. [Google Scholar]
- 13.Monaghan P, Christiansen MH, Fitneva SA. 2011. The arbitrariness of the sign: learning advantages from the structure of the vocabulary. J. Exp. Psychol. Gen. 140, 325–347. ( 10.1037/a0022924) [DOI] [PubMed] [Google Scholar]
- 14.Hinton L, Nichols J, Ohala J. (eds). 1994. Sound symbolism. Cambridge, UK: Cambridge University Press. [Google Scholar]
- 15.Kantartzis K, Kita S, Imai M. 2009. Japanese sound-symbolism facilitates word learning in English-speaking children. In Proc. 31st Annual Conf. of the Cognitive Science Society, Amsterdam, The Netherlands, 29 July–1 August 2009, pp. 591–595. Mahwah, NJ: Erlbaum. [Google Scholar]
- 16.Imai M, Kita S, Nagumo M, Okada H. 2008. Sound symbolism facilitates early verb learning. Cognition 109, 54–65. ( 10.1016/j.cognition.2008.07.015) [DOI] [PubMed] [Google Scholar]
- 17.Imai M, Kita S. 2014. The sound symbolism bootstrapping hypothesis for language acquisition and language evolution. Phil. Trans. R. Soc. B 369, 20130298 ( 10.1098/rstb.2013.0298) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kovic V, Plunkett K, Westermann G. 2010. The shape of words in the brain. Cognition 114, 19–28. ( 10.1016/j.cognition.2009.08.016) [DOI] [PubMed] [Google Scholar]
- 19.Nielsen A, Rendall D. 2012. The source and magnitude of sound-symbolic biases in processing artificial word material and their implications for language learning and transmission. Lang. Cogn. 4, 115–125. ( 10.1515/langcog-2012-0007) [DOI] [Google Scholar]
- 20.Nygaard LC, Cook AE, Namy LL. 2009. Sound to meaning correspondences facilitate word learning. Cognition 112, 181–186. ( 10.1016/j.cognition.2009.04.001) [DOI] [PubMed] [Google Scholar]
- 21.Monaghan P, Mattock K, Walker P. 2012. The role of sound symbolism in word learning. J. Exp. Psychol. Learn. Mem. Cogn. 38, 1152–1164. ( 10.1037/a0027747) [DOI] [PubMed] [Google Scholar]
- 22.Ozturk O, Krehm M, Vouloumanos A. 2013. Sound symbolism in infancy: evidence for sound–shape cross-modal correspondences in 4-month-olds. J. Exp. Child Psychol. 114, 173–186. ( 10.1016/j.jecp.2012.05.004) [DOI] [PubMed] [Google Scholar]
- 23.Walker P, Bremner JG, Mason U, Spring J, Mattock K, Slater A, Johnson S. 2010. Preverbal infants’ sensitivity to synaesthetic cross-modality correspondences. Psychol. Sci. 21, 21–25. ( 10.1177/0956797609354734) [DOI] [PubMed] [Google Scholar]
- 24.Peña M, Mehler J, Nespor M. 2011. The role of audiovisual processing in early conceptual development. Psychol. Sci. 22, 1419–1421. ( 10.1177/0956797611421791) [DOI] [PubMed] [Google Scholar]
- 25.Ohala J. 1994. The frequency code underlies the sound-symbolic use of voice pitch. In Sound symbolism (eds Hinton L, Nichols J, Ohala JJ.), pp. 325–347. Cambridge, UK: Cambridge University Press. [Google Scholar]
- 26.Kaas JH. 1997. Topographic maps are fundamental to sensory processing. Brain Res. Bull. 44, 107–112. ( 10.1016/S0361-9230(97)00094-4) [DOI] [PubMed] [Google Scholar]
- 27.Tamariz M. 2005. Exploring systematicity between phonological and context-cooccurrence representations of the mental lexicon. Mental Lexicon 3, 259–278. ( 10.1075/ml.3.2.05tam) [DOI] [Google Scholar]
- 28.Huettig F, Quinlan P, McDonald S, Altmann GTM. 2006. Word co-occurrence statistics predict language-mediated eye movements in the visual world. Acta Psychol. 121, 65–80. ( 10.1016/j.actpsy.2005.06.002) [DOI] [PubMed] [Google Scholar]
- 29.Otis K, Sagi E. 2008. Phonoaesthemes: a corpora-based analysis. In Proc. 30th annual meeting of the cognitive science society (eds Love BC, McRae K, Sloutsky VM.), pp. 65–70. Austin, TX: Cognitive Science Society. [Google Scholar]
- 30.Schütze J. 1997. Ambiguity resolution in language learning. Stanford, CA: CSLI Publications. [Google Scholar]
- 31.Landauer TK, Dumais ST. 1997. A solution to Plato's problem: the latent semantic analysis theory of the acquisition, induction, and representation of knowledge. Psychol. Rev. 104, 211–240. ( 10.1037/0033-295X.104.2.211) [DOI] [Google Scholar]
- 32.Hutchins SS. 1997. The psychological reality, variability, and compositionality of English phonesthemes. Dissertation Abstracts International 59, 4500B University Microfilms no. AAT 9901857. [Google Scholar]
- 33.Shillcock RC, Kirby S, McDonald S, Brew C. 2001. Filled pauses and their status in the mental lexicon. In Proc. 2001 Conf. of Disfluency in Spontaneous Speech, Edinburgh, UK, 29–31 August 2001, pp. 53–56. Edinburgh, UK: International Speech Communication Association. [Google Scholar]
- 34.Baayen RH, Pipenbrock R, Gulikers L. 1995. The CELEX Lexical database. Philadelphia, PA: University Pennsylvania. [Google Scholar]
- 35.Zipf G. 1949. Human behavior and the principle of least effort. New York, NY: Addison-Wesley. [Google Scholar]
- 36.Monaghan P, Christiansen MH, Farmer TA, Fitneva SA. 2010. Measures of phonological typicality: robust coherence and psychological validity. Mental Lexicon 5, 281–299. ( 10.1075/ml.5.3.02mon) [DOI] [Google Scholar]
- 37.Harm MW, Seidenberg MS. 2004. Computing the meaning of words in reading: cooperative division of labor between visual and phonological processes. Psychol. Rev. 111, 662–720. ( 10.1037/0033-295X.111.3.662) [DOI] [PubMed] [Google Scholar]
- 38.Miller GA, Nicely PE. 1955. An analysis of perceptual confusions among some English consonants. J. Acoust. Soc. Am. 27, 338–352. ( 10.1121/1.1907526) [DOI] [Google Scholar]
- 39.Bailey TM, Hahn U. 2005. Phoneme similarity and confusability. J. Mem. Lang. 52, 347–370. ( 10.1016/j.jml.2004.12.003) [DOI] [Google Scholar]
- 40.Yarkoni T, Balota D, Yap M. 2008. Moving beyond Coltheart's N: a new measure of orthographic similarity. Psychon. Bull. Rev. 15, 971–979. ( 10.3758/PBR.15.5.971) [DOI] [PubMed] [Google Scholar]
- 41.Burnard L. (ed.). 1995. British national corpus: users reference guide British national corpus, v. 1.0. Oxford, UK: Oxford University. [Google Scholar]
- 42.Vigliocco G, Vinson DP, Lewis W, Garrett MF. 2004. Representing the meanings of object and action words: the featural and unitary semantic space hypothesis. Cogn. Psych. 48, 422–488. ( 10.1016/j.cogpsych.2003.09.001) [DOI] [PubMed] [Google Scholar]
- 43.Seidenberg MS, Gonnerman LM. 2000. Explaining derivational morphology as the convergence of codes. Trends Cogn. Sci. 4, 353–361. ( 10.1016/S1364-6613(00)01515-1) [DOI] [PubMed] [Google Scholar]
- 44.Cuskley C, Kirby S. 2013. Synaesthesia, cross-modality and language evolution. In Oxford handbook of synaesthesia (eds Simner J, Hubbard EM.), pp. 869–907. Oxford, UK: Oxford University Press. [Google Scholar]
- 45.Klein E. 1966. A comprehensive etymological dictionary of the English language: dealing with the origin of words and their sense development thus illustrating the history of civilization and culture. Amsterdam, The Netherlands: Elsevier. [Google Scholar]
- 46.OED Online. 2013. Oxford, UK: Oxford University Press (accessed 5 July). See http://www.oed.com/.
- 47.Kuperman V, Stadthagen-Gonzalez H, Brysbaert M. 2012. Age-of-acquisition ratings for 30,000 English words. Behav. Res. Methods 44, 978–990. ( 10.3758/s13428-012-0210-4) [DOI] [PubMed] [Google Scholar]
- 48.Pollatsek A, Perea R, Binder KS. 1999. The effects of ‘neighborhood size’ in reading and lexical decision. J. Exp. Psychol. Hum. Percept. Perf. 24, 1142–1158. ( 10.1037/0096-1523.25.4.1142) [DOI] [PubMed] [Google Scholar]
- 49.Mantel N. 1967. The detection of disease clustering and a generalized regression approach. Cancer Res. 27, 209–220. [PubMed] [Google Scholar]
- 50.Maurer D, Pathman T, Mondloch CJ. 2006. The shape of boubas: sound–shape correspondences in toddlers and adults. Dev. Sci. 9, 316–322. ( 10.1111/j.1467-7687.2006.00495.x) [DOI] [PubMed] [Google Scholar]
- 51.Haspelmath M. 2008. Frequency vs. iconicity in explaining grammatical asymmetries. Cogn. Linguist. 19, 1–33. ( 10.1515/COG.2008.001) [DOI] [Google Scholar]
- 52.Thompson RL, Vinson DP, Woll B, Vigliocco G. 2012. The road to language learning is iconic: evidence from British Sign Language. Psychol. Sci. 23, 1443–1448. ( 10.1177/0956797612459763) [DOI] [PubMed] [Google Scholar]
- 53.Diamond ME, Petersen RS, Harris JA. 1999. Learning through maps: functional significance of topographic organization in primary sensory cortex. J. Neurobiol. 41, 64–68. ( 10.1002/(SICI)1097-4695(199910)41:1<64::AID-NEU9>3.0.CO;2-N) [DOI] [PubMed] [Google Scholar]
- 54.Walsh V. 2003. A theory of magnitude: common cortical metrices of time, space and quality. Trends Cogn. Sci. 7, 483–488. ( 10.1016/j.tics.2003.09.002) [DOI] [PubMed] [Google Scholar]
- 55.Spence C. 2011. Crossmodal correspondences: a tutorial review. Atten. Percept. Psychophys. 73, 971–995. ( 10.3758/s13414-010-0073-7) [DOI] [PubMed] [Google Scholar]
- 56.Steyvers M, Tenenbaum JB. 2005. The large-scale structure of semantic networks: statistical analyses and a model of semantic growth. Cogn. Sci. 29, 41–78. ( 10.1207/s15516709cog2901_3) [DOI] [PubMed] [Google Scholar]
- 57.Evans N, Levinson S. 2009. The myth of language universals: language diversity and its importance for cognitive science. Brain Behav. Sci. 32, 429–492. ( 10.1017/S0140525X0999094X) [DOI] [PubMed] [Google Scholar]
- 58.Onnis L, Christiansen MH. 2008. Lexical categories at the edge of the word. Cogn. Sci. 32, 184–221. ( 10.1080/03640210701703691) [DOI] [PubMed] [Google Scholar]
- 59.Farmer TA, Christiansen MH, Monaghan P. 2006. Phonological typicality influences on-line sentence comprehension. Proc. Natl Acad. Sci. USA 103, 12 203–12 208. ( 10.1073/pnas.0602173103) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.St. Clair MC, Monaghan P, Ramscar M. 2009. Relationships between language structure and language learning: the suffixing preference and grammatical categorization. Cogn. Sci. 33, 1319–1329. ( 10.1111/j.1551-6709.2009.01065.x) [DOI] [PubMed] [Google Scholar]
- 61.Nygaard LC, Herold DS, Namy LL. 2009. The semantics of prosody: acoustic and perceptual evidence of prosodic correlates to word meaning. Cogn. Sci. 33, 127–146. ( 10.1111/j.1551-6709.2008.01007.x) [DOI] [PubMed] [Google Scholar]
- 62.Sandler W, Lillo-Martin D. 2006. Sign language and linguistic universals. Cambridge, UK: Cambridge University Press. [Google Scholar]
- 63.Jaeger T. 2010. Redundancy and reduction: speakers manage syntactic information density. Cogn. Psychol. 61, 23–62. ( 10.1016/j.cogpsych.2010.02.002) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Piantadosi ST, Tily H, Gibson E. 2012. The communicative function of ambiguity in language. Cognition 122, 280–291. ( 10.1016/j.cognition.2011.10.004) [DOI] [PubMed] [Google Scholar]