

Abstract
The ACE and ADE models have been heavily exploited in twin studies to identify the genetic and environmental components in phenotypes. However, the validity of the likelihood ratio test (LRT) of the existence of a variance component, a key step in the use of such models, has been doubted because the true values of the parameters lie on the boundary of the parameter space of the alternative model for such tests, violating a regularity condition required for a LRT (e.g., Carey in Behav. Genet. 35:653–665, 2005; Visscher in Twin Res. Hum. Genet. 9:490–495, 2006). Dominicus, Skrondal, Gjessing, Pedersen, and Palmgren (Behav. Genet. 36:331–340, 2006) solve the problem of testing univariate components in ACDE models. Our current work as presented in this paper resolves the issue of LRTs in bivariate ACDE models by exploiting the theoretical frameworks of inequality constrained LRTs based on cone approximations. Our derivation shows that the asymptotic sampling distribution of the test statistic for testing a single bivariate component in an ACE or ADE model is a mixture of χ2 distributions of degrees of freedom (dfs) ranging from 0 to 3, and that for testing both the A and C (or D) components is one of dfs ranging from 0 to 6. These correct distributions are stochastically smaller than the χ2 distributions in traditional LRTs and therefore LRTs based on these distributions are more powerful than those used naively. Formulas for calculating the weights are derived and the sampling distributions are confirmed by simulation studies. Several invariance properties for normal data (at most) missing by person are also proved. Potential generalizations of this work are also discussed.
Keywords: ACE model, variance components, likelihood ratio test, χ̄2 distribution
1. Introduction
1.1. Testing Variance Components in ACDE Models
The ACE and ADE models (see, e.g., Neale & Cardon, 1992) are widely used in twin studies to estimate variance components in phenotypes due to additive (A) and dominant (D) genetic effects and environmental effects shared between the twins (C) or unique to each of the twin (E). Because the four components usually cannot be estimated simultaneously in a model, either the C or the D component has to be dropped, giving an ACE or an ADE model. A typical p-variate ACE model assumes that the pair of p phenotypic measures on a twin pair follows a 2p-variate normal distribution with mean structures μMZ = μDZ = (μ′, μ′)′ and covariance structures and for monozygotic (MZ) and dizygotic (DZ) twin pairs, where μ is the p × 1 vector of the phenotypic means, A, C and E are p × p non-negative definite (n.n.d.) symmetric matrices giving the variance components, and wC = 1 and wA = 0.5 are weights. In an ADE model, D replaces C with wD = 0.25. An important issue of interest in twin studies is whether a particular variance component contributes to phenotypic variation and correlation. In terms of the above ACE model, this corresponds to one of the following three null hypothesis testing problems: and .
The likelihood ratio test (LRT) is usually used to address the above null hypothesis testing problems. Let f(x|θ) be the density function of data x with parameter vector θ in an unbounded parameter space Θ. If the parameter spaces specified by the null and alternative hypotheses are Θ0 ⊂ Θ1 ⊆ Θ, under some regularity conditions, the LRT statistic T has an asymptotic null distribution of , with the degrees of freedom (dfs) df = dimΘ1 − dimΘ0. When testing the variance components, a naive user of the LRT would use dfs and 2p* for testing a single component and two components, respectively.
Several critical regularity conditions are needed for the χ2 sampling distribution to hold in large samples. They include: (i) that the true parameter value θ0 be an interior point of both Θ0 and Θ1; and (ii) that the Fisher information matrix (FIM)
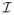 (θ0) have full rank. Unfortunately, for testing variance components, regularity condition (i) does not hold and the test statistic may not have the desired χ2 distribution. The validity of the regular LRT for testing those hypotheses has been questioned (e.g., Carey, 2005; Visscher, 2006). To see this, we note that the alternative hypotheses are directional because the variance components A and C should both be n.n.d. by definition. As a result, under the null hypothesis the true parameter value θ0 lies on the boundary of Θ1. It should be noted that the boundary problem cannot be removed by the use of an alternative parametrization of the model. For example, if the Cholesky decomposition is used with A = LL′, where L is lower triangular, the boundary conditions are still present as lii ≥ 0. Even worse, the FIM under this parametrization is singular at the true value because the Jacobian of the transformation does not have full rank at L = 0, violating the second regularity condition above.
(θ0) have full rank. Unfortunately, for testing variance components, regularity condition (i) does not hold and the test statistic may not have the desired χ2 distribution. The validity of the regular LRT for testing those hypotheses has been questioned (e.g., Carey, 2005; Visscher, 2006). To see this, we note that the alternative hypotheses are directional because the variance components A and C should both be n.n.d. by definition. As a result, under the null hypothesis the true parameter value θ0 lies on the boundary of Θ1. It should be noted that the boundary problem cannot be removed by the use of an alternative parametrization of the model. For example, if the Cholesky decomposition is used with A = LL′, where L is lower triangular, the boundary conditions are still present as lii ≥ 0. Even worse, the FIM under this parametrization is singular at the true value because the Jacobian of the transformation does not have full rank at L = 0, violating the second regularity condition above.
1.2. LRT with True Parameter on Boundary
The issue of boundary problems in LRT has long been noted in general parametric models (Chernoff, 1954; Self & Liang, 1987; Shapiro, 1987), in psychometric models (Shapiro, 1985, 2007), in variance component models (Stram & Lee, 1994), and in ACDE models (Dominicus et al., 2006). For the general hypothesis testing problem, Chernoff (1954) derived the distribution of test statistic T for a boundary true parameter value using local cone approximations to the parameter spaces of the null and alternative models. Because the sets of n.n.d. matrices are cones, the parameter spaces Θ0 and Θ1 are identical to their approximation cones for our problems. The details regarding the cone approximation will not be discussed in this paper. As follows from Chernoff (1954, Theorem 2), the statistic T for testing variance components asymptotically takes the same distribution as it would when testing Θ0 against Θ1 with a single observation from N(θ0,
(θ0)−1).
Self and Liang (1987) further explored the problem of boundary LRT and summarized several typical scenarios in which θ0 lies on the boundary of either the null or the alternative models. They noted that in most cases, the resultant asymptotic distribution of T is a mixture of χ2’s with different dfs, though situations exist in which non-χ2 distribution components are present. As will be discussed later, the current problems are more complicated and cannot be reduced to any of the scenarios they discussed.
The mixture of χ2’s, or the χ̄2 distribution, was studied in detail by Shapiro (1985, 1988, 2007). Some important conclusions are summarized in Appendix A. In particular, Properties 1 and 2 guarantee that for testing variance components, the LRT statistic T has a χ̄2 distribution as long as nuisance parameters are not involved in inequality constraints or constraints involving the variance components.
Dominicus et al. (2006) applied the results of Self and Liang (1987) to the tests in univariate ACDE models. When testing a single (univariate) variance component, the sampling distribution is a 50:50 mixture of (a point mass on 0) and . This is equivalent to using half the p-value from . When simultaneously testing two (univariate) components, the sampling distribution becomes a mixture of χ2’s with 0, 1 and 2 dfs, with w1 = 0.5 and w0 and w2 depending on the sample size ratio between the twin types.
Beyond univariate analysis, bivariate ACDE models are also widely used to study the genetic and environmental contributions to a pair of correlated phenotypes. In this paper, we discuss the problem of testing a bivariate ACE model in which the variance components are of full rank under the alternative hypothesis and give analytical formulas for the mixing probabilities. The test of a single component is simpler and will be discussed in the next section, while the more complicated test of A = C = 0 will be proved in Appendix D and summarized in Section D.3. We present simulation studies and an example in Sections D.4 and D.5, and conclude the paper in Section D.6.
2. Testing a Single Component A = 0
2.1. Formulation of the Problem
In this section we consider testing a single bivariate variance component
. The test for C can be obtained by switching the weights wA and wC. We define a = (a1, a2, a3)′ = vechA and define c and e similarly. Let θ be the parameter vector and its FIM be
(θ). Because E, C and other parameters in the model are not being tested, it follows from Property 2 in Appendix A that the weights in the χ̄2 distribution can be determined using Θ0 = {03},
and
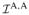 , effectively removing nuisance parameters from consideration. We further define
, effectively removing nuisance parameters from consideration. We further define
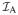 = (
)−1 and have
= (
)−1 and have
| (1) |
Following Chernoff (1954), we consider a ~ N(03,
(θ0)−1) and its projection â1 onto Θ1. The weights wk’s are defined as the probability for â1 to contribute to a
component in the sampling distribution of
. Although the nuisance parameters are not directly involved in this formulation, it should still be noted that
is a function of those nuisance parameters, which need to be estimated by fitting the data to the model under the null hypothesis.
To derive the expression of wk, we first study the geometry of . Note that the quadratic inequality can be written as a′Va ≥ 0 with
| (2) |
The eigenvalues of V are , and −1, with corresponding eigenvectors (1, 0, 1)′, (−1, 0, 1)′ and (0, 1, 0)′, so the quadratic form a′Va = 0, along with a1, a3 ≥ 0, defines an elliptic cone with axis (1, 0, 1)′. The a1- and a3-axes are on this cone. Θ1 is the part of the space inside this cone. For any a ∈ ℝ3, if a ∈ Θ1, we have â1 = a. If a ∉ Θ1, it is projected onto the boundary of Θ1. Especially, a part of the space (points in the polar cone to be discussed later) will be projected onto 0, the apex of the cone.
It is usually the case that the boundary of the parameter space can be expressed as a union of several planary cones when separate inequalities are imposed on different parameters. Self and Liang (1987) summarize several situations of this type. It should be noted that the geometry of Θ1 does not fall into this case because n.n.d. is a nonlinear constraint involving all parameters, and Self and Liang’s results do not apply (see correction to Stram & Lee, 1994). Kuriki and Takemura (2000) consider the n.n.d. constraint of a p × p matrix in general, but their results do not apply to the current situation either because they assume the non-duplicated elements in the matrix follow a normal distribution with a special covariance matrix. Below we derive the proportions wk of the χ̄2 distribution.
2.2. Mixture Probabilities
The elliptic cone Θ1 can be viewed as the limit of a sequence of convex polyhedral cones. Given any convex polyhedral cone, the space ℝ3 can be divided into four types of area, with points in each area projecting onto different parts of the polyhedral cone and giving rise to different mixture components in the sampling distribution of T. The weights in χ̄2 distribution are given by the proportions of points from
that lie in the four different types of region. Especially, if
is a scalar matrix (scalar multiple of identity matrix), the weights are the proportions of the unit ball,
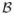 , that lie in the four different types of region. Below we enumerate the four types of region and calculate the corresponding weights assuming
is a scalar matrix. See Figure 1 for a visual aid.
, that lie in the four different types of region. Below we enumerate the four types of region and calculate the corresponding weights assuming
is a scalar matrix. See Figure 1 for a visual aid.
Figure 1.
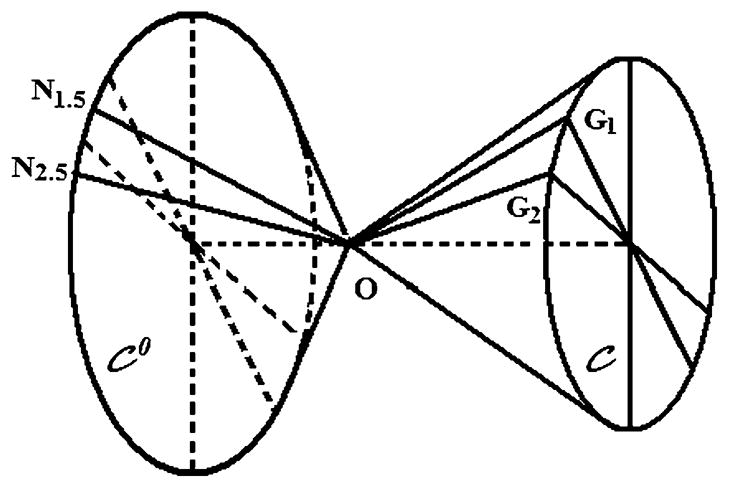
An elliptic cone
 and its polar cone
and its polar cone
 . Suppose the cone
is approximated by a polyhedral cone with edges g1 =OG1, g2 =OG2, etc. If the discretization is fine, the normal vector of the face OG1G2 can be approximated by ON1.5, which is a generatrix on the surface of
with longitude between those of g1 and g2. The projections of points inside the pyramid O – N1.5G1G2 to the polyhedral cone lie on the face OG1G2; the projections of points inside the pyramid O – G2N1.5N2.5 to the polyhedral cone lie on the edge OG2.
. Suppose the cone
is approximated by a polyhedral cone with edges g1 =OG1, g2 =OG2, etc. If the discretization is fine, the normal vector of the face OG1G2 can be approximated by ON1.5, which is a generatrix on the surface of
with longitude between those of g1 and g2. The projections of points inside the pyramid O – N1.5G1G2 to the polyhedral cone lie on the face OG1G2; the projections of points inside the pyramid O – G2N1.5N2.5 to the polyhedral cone lie on the edge OG2.
Points inside this polyhedral cone remain after projection and their squared distances to the origin follow a
distribution. If the area of unit sphere in this region (which is also the solid angle) is Ω, we have w3 = Ω/4π, where 4π is the total area of the unit sphere. Points outside the cone project onto the faces, edges or the apex. For a given face
 between two edges, a normal vector ni is uniquely determined, and the projections of points between ni and
lie on this face. The squared distances from those projections to the origin follow a
distribution. If the planary angle spanning
is ωi, the proportion of the unit ball that project onto
is ωi/4π, so w2 = ω/4π, where ω = Σiωi is the sum of angles between adjacent edges of the polyhedral cone. For a given edge, two normal vectors are determined by its adjacent faces, and the projections of points between the edge and those two normal vectors lie on this edge, giving rise to a
distribution. The collection of all the normal vectors {ni} determined by the faces {
} determines another polyhedral cone whose faces lie between those adjacent normal vectors. This is the polar cone of the polyhedral cone. The projections of points inside this polar cone are the origin 0 and they give rise to a point mass on 0 in the sampling distribution of T. Following similar arguments in our derivation of w3 and w2, we have w0 = Ω0/4π and w1 = ω0/4π, where Ω0 is the area of the unit sphere inside the polar cone, and ω0 is the surface angle of the polar cone.
between two edges, a normal vector ni is uniquely determined, and the projections of points between ni and
lie on this face. The squared distances from those projections to the origin follow a
distribution. If the planary angle spanning
is ωi, the proportion of the unit ball that project onto
is ωi/4π, so w2 = ω/4π, where ω = Σiωi is the sum of angles between adjacent edges of the polyhedral cone. For a given edge, two normal vectors are determined by its adjacent faces, and the projections of points between the edge and those two normal vectors lie on this edge, giving rise to a
distribution. The collection of all the normal vectors {ni} determined by the faces {
} determines another polyhedral cone whose faces lie between those adjacent normal vectors. This is the polar cone of the polyhedral cone. The projections of points inside this polar cone are the origin 0 and they give rise to a point mass on 0 in the sampling distribution of T. Following similar arguments in our derivation of w3 and w2, we have w0 = Ω0/4π and w1 = ω0/4π, where Ω0 is the area of the unit sphere inside the polar cone, and ω0 is the surface angle of the polar cone.
The above result for a polyhedral cone generalizes naturally to an elliptic cone by argument of limit, and the weights are related to the volumes and surface areas of the parts of Θ1 and inside the unit ball. It should be noted that although an elliptic cone does not have edges, the corresponding weight w1 is still positive and the component still exists.
When
is not a scalar matrix, a can be transformed to convert to the case discussed above. Consider any decomposition
= LL′ and then the spectral decomposition L−1VL−1′ = UΛU′. Note the eigenvalues must be of signs (−, −, +) as homogeneous transformations do not change the signs of eigenvalues. Let them be −λ1, −λ2 < 0 < λ3. Define ā = U′L′a and we have ā ~ N(0, n−1I), so the problem is converted to one with a scalar
. The quadratic form defining the boundary of Θ1 is given by ā′Λā = 0, or
. Using spherical coordinates with latitude φ and longitude ψ, we have λ1 cos2
φ cos2
ψ +λ2 cos2
φ sin2
ψ = λ3 sin2
φ. If we define function
| (3) |
where λ3 is the positive eigenvalue of S and λ1 and λ2 are the absolute values of its two negative eigenvalues, we have and the area of the part of the unit sphere inside the elliptic cone can be expressed as
| (4) |
So the weight w3 is given by
| (5) |
The polar cone of Θ1 is defined in Property 4 of Appendix A and can be determined as { , a3 ≤ 0}, where the κ’s are the reciprocals of the λ’s. The mixing probability w0 is therefore given by
| (6) |
The remaining two weights w1 and w2 are related to the surface areas of the cones. Although they can also be expressed as definite integrals and computed numerically, an easier way is to invoke Property 3 of Appendix A, and we have w1 = 0.5 − w3 and w2 = 0.5 − w0.
2.3. Complete Normal Data: Invariance Property
From the above discussions we can see that the weights of the χ̄2 distribution are entirely determined by λi’s, or the sizes of the eigenvalues of
. For an ACE model with complete normal data, the FIM
has a particular structure (see Appendix B) which can be exploited to establish the following proposition (see Appendix C for proofs of the propositions and corollaries).
Proposition 1
With complete normal data, for arbitrary nonsingular 2×2 matrix X, the sets of true values (C, E) and (C̃, Ẽ) = (X′CX, X′EX) give rise to the same χ̄2 distribution.
The above proposition states that the asymptotic sampling distribution is invariant under a particular type of transformation on (C, E) and can be employed to convert a general problem to a simpler situation which shares the same asymptotic distribution, as given by the following corollaries.
Corollary 1
For arbitrary true values C ≥ 0 and E > 0, the χ̄2 distribution is the same as for true values C̃ = diag{β1, β2} and Ẽ = diag{1 − β1, 1 − β2}, where β1 and β2 are the two eigenvalues of . In this case, either λ1 = λ3 or λ2 = λ3 in Equation (3).
Corollary 2
Especially, if the true values satisfy C = γE for some scalar γ ≥ 0, the weights of the χ̄2 distribution are given by and and are not dependent on the nuisance parameter E and sample size proportion nMZ/nDZ.
Corollary 1 shows that for complete normal data, the class of χ̄2 distribution is determined by the ratio between λ1 and λ2, or the relative sizes of the radii of the base ellipse of Θ1, whose height is always equal to one of the radii. Given our discussion of Θ1 and its polar cone above and Property 3 in Appendix A, it can easily be seen that the most conservative (stochastically largest) member in the class of χ̄2 has weights w0 = 0, w1 = 0.25, w2 = 0.5 and w3 = 0.25 (achieved when λ1 = λ2 and λ3 → 0), which is more powerful than the widely used . This can be used to obtain an upper bound of p-value given any true values of C and E and sample size proportions.
Corollary 2 gives the weights for the special case when C and E are proportional. We note that the weight for , the distribution for a naive user of LRT, is less than 15 %, and most weights are on the χ2’s with one and two dfs. This suggests the naive use of LRT would be too conservative because a χ2 distribution with larger df is (stochastically) larger than one with smaller df. In fact, the 95th percentile of distribution (7.815) is much larger than that of the χ̄2 distribution (5.485) and corresponds to its 98.4th percentile, so the naive use of LRT at the level of α = 0.05 has an actual asymptotic Type I error rate of 0.016.
2.4. Testing A = 0 when C is Singular
The above discussion of the LRT for A = 0 requires C > 0 and E > 0 in the population. When this requirement is not met, Properties 1 and 2 of Appendix A does not apply and the resulting sampling distribution of T may not be a mixture of χ2’s. Although E cannot be singular (because a singular E implies a singular covariance matrix for the MZ twins), a singular C is possible, indicating that the corresponding latent factor, if present at all, is unidimensional. When this is the case, the χ̄2 with four components as derived in Section 2.2 is no longer the correct asymptotic distribution of T and cannot be used in practice.
In practice, a singular C can be detected by a near singular Ĉ under the full ACE model, and its rank can be inferred from the (naive) confidence intervals of the two diagonal elements in the Cholesky decomposition of Ĉ. One option in this case is to incorporate an appropriate restriction on C for both the null and alternative hypotheses. If it is suspected that C = 0, we may consider testing the E model against the AE model, or
| (7) |
If it is suspected that C has rank 1, the following test can be performed:
| (8) |
in which the restriction of rank C = 1 can be imposed by the parametrization
. The results in Section 2.2 are appropriate for both the two tests above as long as the matrix
is calculated using only the block of the FIM corresponding to the free parameters in the alternative model. Especially, for complete normal data, the test of E model against AE model is independent of the nuisance parameter E, with the weights in the χ̄2 distribution given by Corollary 2.
3. Testing Both Components A = C = 0
The joint test of two bivariate variance components is more complicated. We give a brief formulation of the geometry of Θ1, introduce necessary notations and present the result in this section, but leave the calculation to Appendix D.
3.1. Formulation of the Problem and Notations
Let θ = (a′, c′)′ = (a1, a2, a3, c1, c2, c3)′ be the parameter vector being tested and
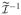 be the asymptotic covariance matrix of θ̂, which is a 6 × 6 block of the inverse of the FIM for all parameters in the model. From Property 2 of Appendix A, the weights can be determined using
, Θ0 = 06 and Θ1 = ΘA × ΘC.
be the asymptotic covariance matrix of θ̂, which is a 6 × 6 block of the inverse of the FIM for all parameters in the model. From Property 2 of Appendix A, the weights can be determined using
, Θ0 = 06 and Θ1 = ΘA × ΘC.
We first consider the decompositions
and
for the two diagonal blocks of
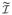 and also the spectral decompositions
and
. Note that the eigenvalues must be of signs (−, −, +). Now consider the transformation
and
. In the space of the transformed parameters θ̄ = (ā′, c̄′)′, the metric becomes
and also the spectral decompositions
and
. Note that the eigenvalues must be of signs (−, −, +). Now consider the transformation
and
. In the space of the transformed parameters θ̄ = (ā′, c̄′)′, the metric becomes
| (9) |
where . Let with λi > 0 and ΛC be similarly defined. Also let the orientation of the third eigenvector u3 be chosen to satisfy (1, 0, 1)L′u3 > 0 for both cones. If we write ā = (ā1, ā2, ā3)′ and c̄ = (c̄1, c̄2, c̄3)′, the sets ΘA and ΘC are represented by and .
Consider the elliptical coordinates (ra, ψa, φa, rc, ψc, φc) related to the Cartesian system θ̄ = (ā′, c̄′)′ by
where the κ’s are the reciprocals of the λ’s. Ranges of the new coordinates are ra, rc ≥ 0, 0 ≤ ψa, ψc < 2π and −π/2 ≤ φa, φc ≤ π/2. We have ΘA = {π/4 ≤ φa ≤ π/2} and ΘC = {π/4 ≤ φc ≤ π/2}. The Jacobian of this transformation is given by J = diag{JA, JC}, where JA = J̄Adiag{1, ra, ra} with J̄A = (ra, ta, r̃a) defined by
We further define J̃A = (ra, ta), and JC, J̄C, rc, tc, r̃c and J̃C are similarly defined. The following notation will also be used:
| (10) |
The polar cone of Θ1 is the part of ℝ6 whose projection onto Θ1 is 0. To express this polar cone, we introduce a new coordinate system
, which is related to θ̄ through θ̄* =
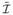 θ̄. Appendix D gives a brief proof that the polar cone of Θ1 is given by
, where
and
is similarly defined. We also define
.
θ̄. Appendix D gives a brief proof that the polar cone of Θ1 is given by
, where
and
is similarly defined. We also define
.
An elliptic coordinate system can also be used for and . If we express
we have and . The Jacobian matrix J* can be calculated similarly to J with notations J̄*, J̃*, r*, t*, r̃* similarly defined for both A and C. We also use , and t* and τ* as defined similarly to t and τ.
Following Chernoff (1954, Theorem 2), the LRT statistic T has asymptotically the same distribution as
, where θ̄1 ∈ Θ1 minimizes the quadratic form (θ̄1 − θ̄)′
(θ̄1 − θ̄) with θ̄ ~ N(0,
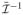 ). Note the matrix
serves as the metric tensor of the 6-dimensional space and θ̄1 is the projection of θ̄ onto Θ1 (with respect to
).
). Note the matrix
serves as the metric tensor of the 6-dimensional space and θ̄1 is the projection of θ̄ onto Θ1 (with respect to
).
3.2. Mixture Probabilities
If both the elliptic cones that define the boundaries of ΘA and ΘC are approximated by polyhedral cones, the projection of θ̄ on Θ1, θ̄1, may be located in the interior (3-face), on a face (2-face), on an edge (1-face), or at the apex (0-face) of either of the two polyhedral cones, leading to a partition of 16 different regions in ℝ6 with probabilities wij (i, j = 0, 1, 2, 3). T has a mixture of χ2 distributions with mixture weights wij (i, j = 0, 1, 2, 3) for df (i + j). When passing to the limiting elliptic cone, different regions may fuse together, but their corresponding weights need not converge to 0. Below we give the 10 of the 16 weights wij. They are derived in the Appendix D. The remaining six weights can be obtained by symmetry. Computationally, these weights can be calculated using numerical integration. Separate programs in R (R Development Core Team, 2010) have been coded to calculate the weights in Sections 2.2, 3.2 and 3.3. They are available from the first author upon request. We have
where function ς was defined in Equation (3);
where J̃22 = diag{J̃A, J̃C} is a 6×4 matrix;
where J̃12 = diag{ra, J̃C} and are 6×3 matrices;
where is a 6×4 matrix;
3.3. Complete Normal Data
With complete normal data, the FIM
is highly structured at C = E = 0 (see Equation (B.1) in Appendix B). Exploiting this structure, we have the following conclusion:
Proposition 2
With complete normal data, and ΛA = ΛC = diag{−1, −1, 1}, where , and αMZ and αDZ are sample size proportions. The asymptotic χ̄2 distribution is determined only by sample size ratio through ρ and is not related to the nuisance parameter E.
In this case,
 = ρI and we further have
, α1 = α2 = 1,
= ρI and we further have
, α1 = α2 = 1,
and τ =−τ* = ρ(cosφa cosφc cosΔψ + sinφa sinφc). Note the weights are related to ψa and ψc only through Δψ = ψa − ψc, so the number of integrals involved can all be reduced. Especially, for wij(i, j = 1, 2), and more simplification is possible. We have
These formulas are applied to the equal sample size case and the result is shown in Table 2. The final weight wk for the χ̄2 distributions can be determined by wk = Σi+j=k wij. Table 1 displays weights for various sample size ratios in an ACE or ADE model. Note only cases with nMZ > nDZ are shown because in practice available observations from MZ twins are inmost cases more than those from DZ twins. Along with the weights are the 95th and 99th percentiles of the χ̄2 distribution. The distribution is also included for comparison. We can see the weights for the different sample size ratios are very close to each other. There is a trend that the weights for higher dfs increases and those for lower dfs decreases when the sample sizes become similar. This suggests that the χ̄2 distribution for equal sample size is the most conservative. When compared to the distribution, all χ̄2 distributions put more weights on lower dfs while their weights for are negligible. As a result, they have much lower critical values. In fact, the 95th percentile of distribution (12.6) is more than twice that of any of the χ̄2 distributions and corresponds to the 99.7th percentile of the most conservative χ̄2 distribution in the table, so the incorrect use of LRT at the level of α = 0.05 has an actual Type I error rate of at most 0.003. This suggests that the incorrect use of would result in very conservative results. Comparing ACE and ADE models, the distributions for the ADE models are stochastically smaller. In particular, an ADE model with equal sample sizes has the same weights as an ACE model with nMZ = 4nDZ. This is because they happen to share the same value of ρ in Proposition 2.
Table 2.
The weights wij(i, j = 0, 1, 2, 3) for equal sample sizes when testing A = C = 0 calculated from equations in Section 3.3.
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.1113 | 0.1485 | 0.1265 | 0.0214 |
| 1 | 0.1485 | 0.0916 | 0.0778 | 0.0097 |
| 2 | 0.1265 | 0.0778 | 0.0245 | 0.0023 |
| 3 | 0.0214 | 0.0097 | 0.0023 | 0.0002 |
Table 1.
The weights (in percentages) of the χ̄2 distribution for testing A = C = 0 in a bivariate ACE model and for testing A = D = 0 in a bivariate ADE model.
| Model | Sample size proportions
|
Weights
|
Percentiles
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| αMZ | αDZ | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 95 | 99 | |
| Naive LRT | 0 | 0 | 0 | 0 | 0 | 0 | 1.00 | 12.59 | 16.81 | ||
|
| |||||||||||
| ACE | 0.5 | 0.5 | 11.13 | 29.69 | 34.47 | 19.85 | 4.38 | 0.46 | 0.02 | 6.16 | 9.68 |
| 0.6 | 0.4 | 11.39 | 30.12 | 34.56 | 19.49 | 4.03 | 0.39 | 0.02 | 6.11 | 9.61 | |
| 2/3 | 1/3 | 11.62 | 30.50 | 34.64 | 19.17 | 3.73 | 0.33 | 0.01 | 6.06 | 9.56 | |
| 0.7 | 0.3 | 11.75 | 30.71 | 34.68 | 18.98 | 3.56 | 0.31 | 0.01 | 6.04 | 9.53 | |
| 3/4 | 1/4 | 11.97 | 31.08 | 34.75 | 18.66 | 3.27 | 0.26 | 0.01 | 6.00 | 9.47 | |
| 0.8 | 0.2 | 12.22 | 31.50 | 34.82 | 18.29 | 2.95 | 0.21 | 0.01 | 5.95 | 9.41 | |
| ADE | 0.5 | 0.5 | 12.22 | 31.50 | 34.82 | 18.29 | 2.95 | 0.21 | 0.01 | 5.95 | 9.41 |
| 0.6 | 0.4 | 12.58 | 32.07 | 34.92 | 17.78 | 2.50 | 0.15 | 0.00 | 5.88 | 9.32 | |
| 2/3 | 1/3 | 12.81 | 32.44 | 34.98 | 17.44 | 2.21 | 0.12 | 0.00 | 5.83 | 9.27 | |
| 0.7 | 0.3 | 12.93 | 32.63 | 35.01 | 17.26 | 2.06 | 0.11 | 0.00 | 5.81 | 9.24 | |
| 3/4 | 1/4 | 13.11 | 32.92 | 35.05 | 16.99 | 1.84 | 0.09 | 0.00 | 5.78 | 9.20 | |
| 0.8 | 0.2 | 13.30 | 33.22 | 35.09 | 16.71 | 1.61 | 0.07 | 0.00 | 5.74 | 9.15 | |
4. Simulation Studies
4.1. Study 1
In the first simulation, we examine the accuracy of the weights derived in Section 2.2 for testing a single variance component in a bivariate ACE model. Four different sample size combinations are assumed: (nMZ, nDZ) = (100, 100), (150, 50), (500, 500), (750, 250). They vary in terms of the total sample size (N = 200 or 1000) and the ratio between the two groups (nMZ/nDZ = 1 or 3). For each sample size combination, 10,000 samples of sample covariance matrices are drawn from the ACE model with A = 0 and . Each sample is fitted to both the ACE and the CE model using OpenMx (Boker, Neale, Maes, Wilde, Spiegel, Brick, et al., 2011) and the statistic T is produced for each sample. The 1st–99th percentiles of T are then plotted against those of the analytical asymptotic χ̄2 distribution with weights given in Corollary 2. The four QQplots are displayed in Figure 2. The χ̄2 distribution fits the simulated distribution very well in all four conditions.
Figure 2.
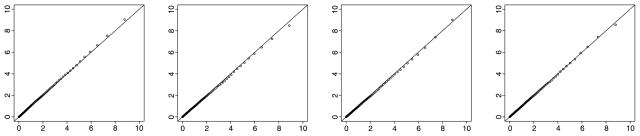
Plots of the 1st–99th percentiles of the simulated sampling distribution of T against those of the χ̄2 distribution in Simulation Study 2. The sample sizes (nMZ, nDZ) are (from left to right) (100, 100), (150, 50), (500, 500) and (750, 250). The true and null model is CE and the alternative model is ACE.
To obtain a clearer understanding of the origin of the mixture distribution in this case, we further examine the estimates  in the full ACE model. According to our analysis in Section 2.2, samples that give a full rank  contribute to the component and those that yield  = 0 contribute to the component, so the distribution of the rank of  should correspond to the weights in the mixture. The rank of  is determined for each sample of size nMZ = nDZ = 500 and we find 14.61 % produced  = 0, 70.84 % gave an  of rank 1, and 14.55 % yielded an  of full rank. These percentages are very close to the weights w0, w1 + w2 and w3 as given in Corollary 2, confirming our previous analysis.
4.2. Study 2
The second simulation studies (1) the accuracy of the χ̄2 distribution in testing a single bivariate variance component when a nuisance parameter is on the boundary, an issue raised in Section 2.4, and (2) the accuracy of the weights given in Section 3.3 for testing both variance components in a bivariate ACE model. In this study, the true model is an ACE model with A = C = 0. The same sample size combinations, number of replications and true value of E are assumed as in the first study. Each simulated sample is fitted to the E, AE, CE and ACE models, and a test statistic T can be computed for five tests: AE vs. ACE, CE vs. ACE, E vs. AE, E vs. CE, and E vs. ACE. The 1st–99th percentiles of T are plotted against those of a χ̄2 distribution. For the first four tests, the χ̄2 distribution is a mixture of χ2’s with zero–three dfs with weights given by Corollary 2. For the test of E vs. ACE, the χ̄2 distribution is a mixture of χ2’s with zero–six dfs with weights given in Table 1.
In Figure 3, the first and second panels display the QQplots for testing the AE and CE models against the ACE model when the true model is E. The plots show that the χ̄2 is stochastically much larger than the empirical distribution. The use of this χ̄2 distribution would give a larger critical value and more conservative results, though it is still less conservative than using the distribution. In this case, one possible solution is to constrain the boundary nuisance parameter on the boundary and test the E model against the AE and CE models. The QQplots for these tests are displayed in the third and fourth panels and show that the χ̄2 distribution is now appropriate. These results confirm our discussion in Section 2.4.
Figure 3.
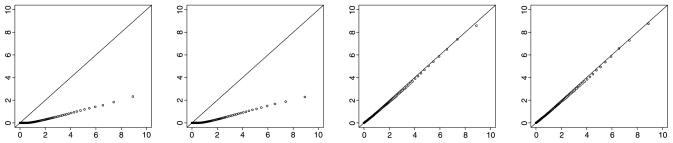
Plots of the 1st–99th percentiles of the simulated sampling distribution of T against those of the χ̄2 distribution in Simulation Study 2. The true model is E. The null and alternative models are (from left to right) AE vs. ACE, CE vs. ACE, E vs. AE and E vs. CE. The sample sizes are nMZ = nDZ = 500 for the left two panels and nMZ = 150 and nDZ = 50 for the right two panels.
Another focus of the present simulation is the test of two components. The QQplots are displayed in Figure 4, which show that the χ̄2 distribution with weights calculated in Table 1 fits the empirical distribution very well under all four sample size combinations. Similar to but more complex than testing a single component, these weights come from the wij ’s, which are proportions of (Â, Ĉ) that lie on the different types of boundary of ΘA ×ΘC with different ranks for the two matrices. These proportions for nMZ = nDZ have been tabulated in Table 2. Note weights with 1 and 2 in their subscripts need to be combined to give the proportions of  or Ĉ of rank 1, because the edges and faces of a polyhedral cone are no longer distinguishable in its limiting circular cone. For example, the proportion of the sample with both  and Ĉ of rank one corresponds to the sum w11 + w12 + w21 + w22. This is again confirmed in this simulation. Table 3 displays the observed proportions of replications for nMZ = nDZ = 500 that fall into different rank conditions, and the proportions are close to those given by analytical results.
Figure 4.
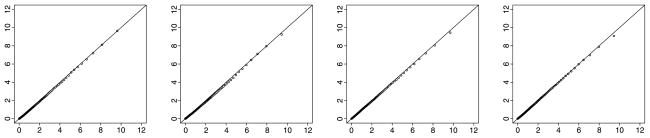
Plots of the 1st–99th percentiles of the simulated sampling distribution of T against those of the χ̄2 distribution in Simulation Study 2. The sample sizes (nMZ, nDZ) are (from left to right) (100, 100), (150, 50), (500, 500) and (750, 250). The true and null model is E and the alternative model is ACE.
Table 3.
Ranks of  and Ĉ of the ACE model in Simulation Study 2 with nMZ = nDZ = 500. The total count is 10,000.
| Rank Â
|
0
|
1
|
2
|
||||||
|---|---|---|---|---|---|---|---|---|---|
| Rank Ĉ | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 |
| Obs. proportions | 12.27 | 27.41 | 1.77 | 28.00 | 26.20 | 1.20 | 1.92 | 1.23 | 0.00 |
| Exp. probabilities | 11.13 | 27.50 | 2.14 | 27.50 | 27.17 | 1.20 | 2.14 | 1.20 | 0.02 |
4.3. Study 3
The previous simulation study confirms the validity of weights given in Section 3.3 for complete normal data. In this study, we check the validity of the analytical results in Section 3.2 for more general situations, in which the weights are determined directly from the FIM. The FIM
is specified as follows: the two diagonal blocks
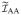 and
and
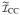 are correlation matrices with equal correlations 0.7 and 0.5, respectively, and the off diagonal block
are correlation matrices with equal correlations 0.7 and 0.5, respectively, and the off diagonal block
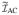 is a 3×3 matrix with equal elements of 0.3. Clearly this matrix does not satisfy the structure for complete normal data as given in Appendix B. The weights are calculated as 0.1129, 0.2982, 0.3203, 0.1888, 0.0656, 0.0130 and 0.0012 for dfs from 0 to 6. The sums of weights for odd and even dfs are both 0.5000, satisfying Property 3 in Appendix A.
is a 3×3 matrix with equal elements of 0.3. Clearly this matrix does not satisfy the structure for complete normal data as given in Appendix B. The weights are calculated as 0.1129, 0.2982, 0.3203, 0.1888, 0.0656, 0.0130 and 0.0012 for dfs from 0 to 6. The sums of weights for odd and even dfs are both 0.5000, satisfying Property 3 in Appendix A.
We now check this result against a Monte Carlo sample from χ̄2 obtained by fitting a random sample of size 10,000 from N(0,
) to the model N(θ,
) with n.n.d. constraints on θ = (a′,
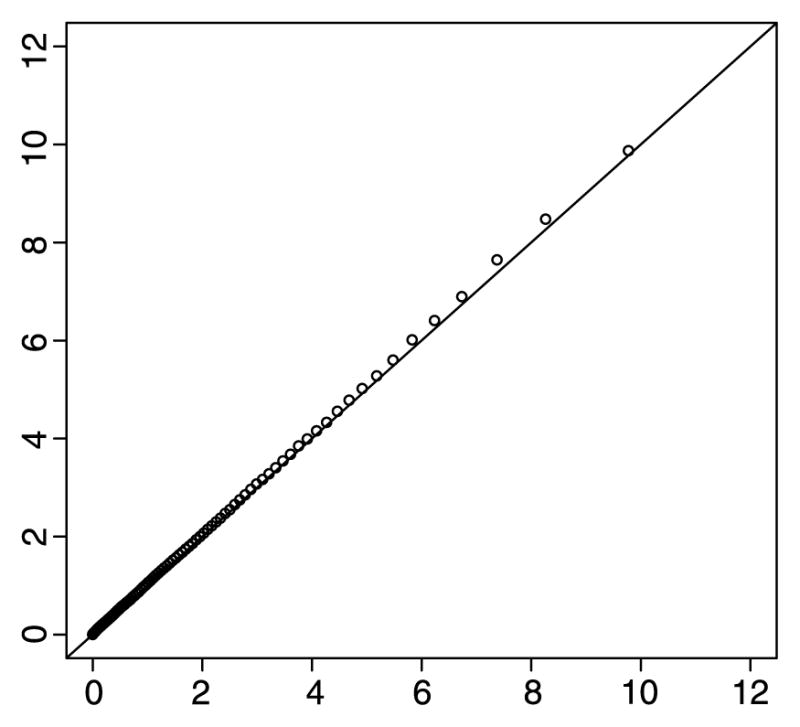
c′)′. This method of sampling from the asymptotic distribution follows directly from Chernoff (1954, Theorem 2). The restricted optimization was carried out in R using the nlm function. This sample is compared to a sample of size 106 generated from a χ̄2 distribution with weights calculated above and a QQplot is displayed in Figure 5. The QQplot shows that the χ̄2 gives an accurate description of the Monte Carlo sample.
Figure 5.
Plot of 1st–99th percentiles of the simulated sample in Simulation Study 3 against those of a χ̄2 distribution based on calculated weights.
5. An Example
After confirming the analytical asymptotic distributions with three simulation studies, we apply these results to a data set from the Medical College of Virginia Twin Study (Schieken, Eaves, Hewitt, Mosteller, Bodurtha, Moskowitz, et al., 1989) to demonstrate their use. The data are skinfold measures made on 11 year-old male twins through standard anthropometric techniques. The covariance matrices of four variables, two measures obtained for biceps (BIC) and subscapular (SSC) skinfolds on the twins, are presented in Table 4 for both MZ and DZ twins. The sample sizes are 84 and 33 for the MZ and DZ twins, respectively.1
Table 4.
The covariance matrices for skinfold measures on twins.
| MZ twin pairs (nMZ = 84)
|
DZ twin pairs (nDZ = 33)
|
|||||||
|---|---|---|---|---|---|---|---|---|
| BIC1 | SSC1 | BIC2 | SSC2 | BIC1 | SSC1 | BIC2 | SSC2 | |
| BIC1 | 0.1285 | 0.1538 | ||||||
| SSC1 | 0.1270 | 0.1759 | 0.1999 | 0.3007 | ||||
| BIC2 | 0.0982 | 0.1069 | 0.1233 | 0.0435 | 0.0336 | 0.1782 | ||
| SSC2 | 0.0999 | 0.1411 | 0.1295 | 0.1894 | 0.0646 | 0.0817 | 0.2095 | 0.3081 |
BIC = bicep; SSC = subscapular.
The sample is fitted to the full ACE, AE and E models using OpenMx (Boker et al., 2011). The estimates of the variance components are shown in Table 5. The full ACE model gives a Ĉ with very small entries, suggesting the AE model may hold in the population. The test statistic for testing the AE model against the full ACE model is T = 3.175, yielding a p-value of 0.365 under the traditional distribution of LRT. To use the χ̄2 distribution proposed in this research, we have to use the estimates  and Ê under the AE model. As  is not close to singular, the procedure proposed in Section 2.2 is valid. The eigenvalues of (A+E)−1A are 0.822 and 0.615 and the three eigenvalues that determine the shape of the elliptic cone are given by −1.0038, −1 and 1.0038 (which are normalized such that the sum is −1), satisfying Corollary 1. Because the three eigenvalues have similar magnitudes, the weights are close to those specified in Corollary 2. In fact, we have w3 = 0.1466, w2 = 0.3537, w1 = 0.3534 and w0 = 0.1463. The critical value for a 5 % level test is 5.486. The observed statistic is smaller than the critical value, yielding a non-significant result. However, the p-value is 0.152, much smaller than the one given by a distribution.
Table 5.
Estimates of the bivariate variance components and −2 ln L of three models when fitted to the skinfold data.
| ACE model | AE model | E model | ||||
|---|---|---|---|---|---|---|
| A | 0.1062 | 0.1172 | ||||
| 0.1401 | 0.1893 | 0.1359 | 0.1910 | |||
| C | 0.0116 | |||||
| −0.0040 | 0.0014 | |||||
| E | 0.0285 | 0.0283 | 0.1371 | |||
| 0.0264 | 0.0441 | 0.0266 | 0.0439 | 0.1495 | 0.2165 | |
| −2 ln L | −802.5753 | −799.4005 | −670.9482 | |||
The test statistics for testing the E model against the AE and ACE models are both above 100, far beyond the critical values set by the and distributions. Because the naive use of LRT is more conservative, a significant result would remain significant if the correct sampling distribution were used.
6. Summary and Discussion
6.1. A Brief Summary
Testing whether a particular variance component exists is one of the main purposes of the use of the ACE or ADE models. Unfortunately the traditional LRT for such purposes has been found invalid due to the boundary condition imposed by the n.n.d. of variance components, which implies that a regularity condition of LRT is violated (Carey, 2005; Visscher, 2006). The present research resolves the issue of testing the existence of one or two variance components in bivariate ACE and ADE models by deriving the correct asymptotic sampling distribution for the test statistic T. Our analysis shows that the geometry of the boundary condition involved is more complicated than those studied by Self and Liang (1987) and those in a univariate ACE or ADE models as discussed by Dominicus et al. (2006), and that the desired distribution is a mixture of χ2 distributions which can be calculated by projecting a multivariate normal distribution onto an elliptic cone (for testing a single component) or an oblique Cartesian product of two elliptic cones (for testing two components). The correct distributions are stochastically smaller than the χ2 distributions assumed by traditional LRTs and are more powerful. We provide formulas and computer program for the computation of the mixture weights, and our analytical derivations are confirmed by simulation studies.
Because our analytical results are entirely based on the FIM
of the model, it is appropriate for all practical situations in general, including the presence of missing data, ordered categorical data and covariates, as long as the central limit theorem holds. For complete normal data, several invariance properties are established in Sections 2.3 and 3.3 using the special structure of
. Interestingly, for a special type of missing data pattern, these invariance results are still valid. This special type is missing by person, or that variables related to one twin are always missing together. In this case, the FIM under the E model still have the desired structure (see Appendix B for the proof), so the results in Section 3.3 are still valid, though in this case nMZ, nDZ, αMZ and αDZ should be the sample sizes or percentages of complete MZ or DZ twin pairs. The invariance properties discussed in Section 2.3 are also valid.
6.2. Generalization to Higher Dimensions and Other Models
The current research tackles the bivariate ACE and ADE models only, which may be a bit disappointing as most readers would wish that such a study would resolve the LRTs for multivariate ACE or ADE models in general, once and for all. However, this is unfortunately not an easy task. The current research exploits the fact that the n.n.d. for 2 × 2 matrices is defined by a quadratic form on the three distinct elements, which is not true for higher dimensions. In higher dimensions, this restriction is represented by non-negative eigenvalues of the variance components and gives rise to more complicated geometry. Kuriki and Takemura (2000) studies this geometry and gives the weights for testing a single p×p variance component under the assumption that the non-duplicated elements in the covariance matrix have independent distributions with some specified variances, which is not the case for most practical situations.
Although an analytical expression is hard to derive for higher dimensions, Chernoff (1954, Theorem 2) does suggest a Monte Carlo strategy for simulation of the asymptotic distribution. Normally distributed vectors a can first be simulated from N(0,
), the asymptotic distribution for non-restricted estimates, and then fitted to the restricted space defined by the n.n.d. by minimizing the quadratic form (a1 − a)′
(a1 − a). The minimizer gives the desired sampling distribution. This method was employed by Silvapulle and Sen (2005, Section 3.5) for inequality constrained normal means and by Han and Chang (2010) for a genetic linkage model. It has also been used in Section 4.3 to validate the analytical results. Though expected to be computationally intensive when compared to analytical solutions, this simulation based approach is more efficient than bootstrapping, as only the parameters of interest are involved and the optimization is performed on a quadratic form. This method is also available for situations where the sampling distribution is not a mixture of χ2’s due to concavity of Θ1 or Θ0. Research along this line is beyond the scope of this article and will be published separately.
Though the current research concerns only the test of variance components in ACE and ADE models, its application can be more general. Mathematically, any test on three parameters θ1, θ2 and θ3 with an alternative hypothesis of the shape can be solved by the method laid out in Section 2.2. One of such problems is the test of two random effects in random coefficient models. Application to this area of study is beyond the scope of the current article.
Acknowledgments
The research is supported by the National Institute of Drug Abuse research education program R25DA026-119 to the second author. We wish to thank Dr. Alexander Shapiro for referring us to the unpublished results on χ̄2 distribution on his website.
Appendix A. Some Properties of the χ̄2 Distribution
Property 1
When the approximating cone
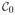 of Θ0 is a subset of the largest linear2 subspace of the approximating cone
of Θ0 is a subset of the largest linear2 subspace of the approximating cone
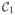 of Θ1 and both cones are convex, the statistic T has an asymptotic χ̄2 distribution. See Dr. Alexander Shapiro’s website for his proof.3 For the special case of Θ0 =
= 0, we denote the weight wk of
by wk(p,
(θ0)−1,
), where p is the dimension of Θ1 and
(θ0) is the FIM of the alternative model.
of Θ1 and both cones are convex, the statistic T has an asymptotic χ̄2 distribution. See Dr. Alexander Shapiro’s website for his proof.3 For the special case of Θ0 =
= 0, we denote the weight wk of
by wk(p,
(θ0)−1,
), where p is the dimension of Θ1 and
(θ0) is the FIM of the alternative model.
Property 2
If nuisance parameters ξ are present but are not on their boundary, when testing ψ = 0 against a constrained alternative ψ ∈ Ψ, the equation for the weights of the χ̄2 distribution is given by wk = wk(q,
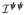 ,
), where q is the length of ψ,
is the block of
,
), where q is the length of ψ,
is the block of
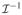 that corresponds to ψ, and
is the approximating cone to Ψ in ℝq.
that corresponds to ψ, and
is the approximating cone to Ψ in ℝq.
Property 3
The weights {wk} for odd and even k sum up to 0.5, respectively (Shapiro, 1987). See Dr. Alexander Shapiro’s website for proofs he receives from correspondence.4
Property 4
wk(p,
,
) = wp−k(p,
,
), where
is the polar cone of
, defined as the subset of ℝp whose projection onto
is the apex of
, or
= {x|x′
y ≤ 0,∀y ∈
}.
For more properties of the weights of a χ̄2 distribution, see Silvapulle and Sen (2005, Section 3.6).
Appendix B. The Fisher Information Matrix
We derive the FIM
(θ0) of a p-variate ACE model with complete normal data. In general, the typical element of the FIM of a covariance structure model is given by
, where Σ = Σ(θ) is the covariance structure and Δα = ∂Σ/∂θα. For the DZ twin group in an ACE model,
takes the shape
, where all blocks are symmetric. If we define the p × p binary matrix Kij = ∂C/∂cij (e.g.,
for p = 2), we have
and the derivatives w.r.t. A and E can be obtained similarly. If we further define K as the p2 × p(p + 1)/2 matrix whose columns are the vecKij ’s (e.g., K = diag{1, 12×1, 1} for p = 2) and
and
, the FIM for the DZ twins can be expressed as
The FIM
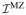 for the MZ twins can be obtained similarly by altering the weights. Let αMZ and αDZ be sample size proportions of the two types of twin, with αMZ + αDZ = 1. The overall FIM (of sample size one) is given by
αMZ
+ αDZ
for the MZ twins can be obtained similarly by altering the weights. Let αMZ and αDZ be sample size proportions of the two types of twin, with αMZ + αDZ = 1. The overall FIM (of sample size one) is given by
αMZ
+ αDZ
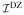 .
.
A special case of interest is when
and
are scalar multiples of the same matrix X. In this case,
and
are all scalar multiples of K′(X⊗X)K, so the FIM takes the shape
= Y⊗ [K′(X⊗X)K], where Y is some 3 × 3 matrix. When A = C = 0, we have a1 = a3 = 1, a2 = a4 = 0 and X = E−1, and the FIM becomes
| (B.1) |
where 13×3 is a 3×3 matrix of 1’s, wDZ = (wA,wC, 0)′ and wMZ = (1, 1, 0)′.
When data are missing by person, variables related to one twin are missing or present together. The covariance matrix of variables for the singletons is Σ0 = A+C+E for both MZ and DZ twins, and the FIM for the singletons is given by
. The FIM for the entire data set is the weighted sum of
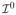 and the complete data FIM given earlier. Especially, when A = C = 0, we have Σ0 = E, and
. Summing over the twin and singleton groups, we have
and the complete data FIM given earlier. Especially, when A = C = 0, we have Σ0 = E, and
. Summing over the twin and singleton groups, we have
where α = αDZ +αMZ are proportions of complete twin data and β is the proportion of data with only a single twin.
Appendix C. Lemmas and Proofs
Lemma 1
Let Ω = {r|r′Qr < 1, r1 > 0, r2 > 0}, where and r = (r1, r2)′. Denote and t = arccos τ. We have
Proof
One only need to prove for the case of a1 = a2 = 1 and a3 = τ. This can be done through integration with the reparametrization (r1, r2) = R sin(t/2 ± θ)/sin t. The region Ω becomes {0 ≤ R ≤ 1, |θ| ≤ t/2} under the new coordinate system.
Lemma 2
The matrices K = diag{1, 12×1, 1}, and satisfies
K′B = I, K′M= K′ and MB = B;
M is exchangeable with X⊗X for arbitrary X;
{K′(X⊗X)−1K}−1 = B′(X⊗X)B for arbitrary X.
Proof
See Gupta and Nagar (1999, Section 1.2) or check by simple algebra.
Proof of Proposition 1
Given the relationship between the two sets of parameters, following the calculations in Appendix B, we have
and
for i = 1, 2 and j = MZ,DZ, where Y = K′(X⊗X)−1B with K and B defined in Lemma 2 in Appendix C. The relationship between blocks of the FIM can be further found as
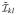 = Y
= Y
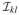 Y′ for k, l = a,
c,
e. From Equation (1), we have
Y′ for k, l = a,
c,
e. From Equation (1), we have
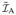 = Y
Y′. For any decomposition
= LL′, we have
= L̃L̃′, where L̃ = YL, and therefore L̃−1VL̃−1′= L−1Y−1VY−1′L−1′. From Lemma 2, we have Y−1 = (K′(X⊗X)−1B)−1 = K′(X⊗X)B, and simple algebra gives Y−1VY−1′= |X|2V. Therefore we have L̃−1VL̃−1′= |X|2L−1VL−1′, which implies Λ̃ = |X|2Λ, so the weights in the χ̄2 distribution must be the same for the two cases.
= Y
Y′. For any decomposition
= LL′, we have
= L̃L̃′, where L̃ = YL, and therefore L̃−1VL̃−1′= L−1Y−1VY−1′L−1′. From Lemma 2, we have Y−1 = (K′(X⊗X)−1B)−1 = K′(X⊗X)B, and simple algebra gives Y−1VY−1′= |X|2V. Therefore we have L̃−1VL̃−1′= |X|2L−1VL−1′, which implies Λ̃ = |X|2Λ, so the weights in the χ̄2 distribution must be the same for the two cases.
Proof of Corollary 1
The conclusion follows from Proposition 1, if we choose
, where U’s columns are eigenvectors of
. Note now both C̃ and Ẽ are diagonal matrices. Following our calculations in Appendix B, all nine blocks of the FIM must be diagonal and therefore
and L must be diagonal. Simple algebra shows that the eigenvalues −λ1,−λ2
< 0 < λ3 of L−1VL−1′ must satisfy λ3 = λ2 or λ3 = λ1, and the conclusion follows.
Proof of Corollary 2
From Corollary 1, the pair of true values C̃ = γI/(1 + γ) and Ẽ = I/(1 + γ) would yield the same sampling distribution. Because C̃ and Ẽ are both scalar matrices, as a special case treated in Appendix B, the FIM takes the form
= Y ⊗ [K′I4×4K] = Y ⊗ diag{1, 2, 1} for some 3 × 3 matrix Y, and consequently
= (
)−1 ∝ diag{1, 2, 1}. Simple algebra gives λ1 = λ2 = λ3 and Equations (5) and (6) give
.
Proof of Proposition 2
From Equation (B.1),
, where
and
. Consider the decomposition E = X′X and define
, L = K′(X ⊗ X)−1BD and
. Using Lemma 2, we have the relationship LL′= K′(X ⊗ X)−1M(X′ ⊗ X′)−1K = K′(E ⊗ E)−1K. We then consider the transformation
. Under the new parametrization,
and the quadratic forms defining the cones become ā′V̄ā ≥ 0 and c̄′V̄c̄ ≥ 0 with V̄ = L−1VL−1′. Again, remember L−1 = D−1K′(X ⊗ X)B (Lemma 2) and simple algebra gives
, so its three eigenvalues must be of the same size. This implies that both ΘA and ΘC are circular cones with the height equal to the base radius, and the weights are entirely determined by ρ in
.
Appendix D. Calculation of Weights for Testing Two Components
We derive the weights wij using the notations and coordinate systems defined in Section 3.1. Under the elliptic coordinate system, the FIM becomes G = J′
J, which is no longer a constant. The unit ball in ℝ6 is given by
, where the α’s are given in Equation (10).
The polar cone of Θ1 was defined in Section 3.1. As a brief proof, we note the inner product between (ra,ψa,φa, rc,ψc,φc) ∈ Θ1 and is given by
because . The unit ball in ℝ6 is given by in this new coordinate system.
Below we calculate the 10 weights by discretizing the cones. The elliptic cone ΘA is discretized by S equally spaced angles ψs between 0 and 2π, with s = 0, 1, …, S and ψ0 = 0 and ψS = 2π. They corresponds to generatrices , which discretizes the circular cone into a polyhedral cone with S faces. ΘC is similarly discretized with subscripts r = 0, 1, …, R. The weights will first be calculated using the polyhedral cones and then limits are taken to obtain weights wij for the original problem.
D.1. The Derivation of w33 and w00
The region of ℝ6 that corresponds to w33 is simply Θ1 = ΘA ×ΘC. Its volume V|| inside
can be calculated by integrating
over
.
where the double integral over (ra, rc) has been simplified using Lemma 1. The weight w33 is given by w33 = V||/V6 where V6 = π3/6 is the volume of a 6-dimensional ball. w00 is the proportion of the ball
that falls into the polar cone. It can be similarly calculated by integrating over
.
D.2. The Derivation of w23 and w10
The region of ℝ6 that corresponds to w23, after projected onto Θ1, lies on a face of the discretized ΘA and the interior of ΘC. Consider the face of ΘA,
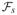 , lying between generatrices
. The normal vector to
× ΘC is given by
. For each s, the proportion of the unit ball
that falls into this region can be calculated as the product of two proportions: (1) p⊥ (s) = 1/2, because the normal vector determines a unidimensional subspace and half of it has the same direction of the normal vector; (2) p|| (s), the proportion of the 5-dimensional subspace spanned by
×ΘC inside
×ΘC.
, lying between generatrices
. The normal vector to
× ΘC is given by
. For each s, the proportion of the unit ball
that falls into this region can be calculated as the product of two proportions: (1) p⊥ (s) = 1/2, because the normal vector determines a unidimensional subspace and half of it has the same direction of the normal vector; (2) p|| (s), the proportion of the 5-dimensional subspace spanned by
×ΘC inside
×ΘC.
To calculate p||(s), we note that
, so its volume inside
is given by
where G̃ is the 5×5 block of G corresponding to the first, second, fourth, fifth and sixth columns and rows and we have
. Note the double integral over
has been simplified using Lemma 1. We have
, where
is the volume of a 5-dimensional unit ball. The weight w10 can be obtained by the duality between Θ1 and
as given in Property 4 in Appendix A.
D.3. The Derivation of w13 and w20
The projection of the region of ℝ6 that corresponds to w13 onto Θ1 lies on a 4-face gs ×ΘC for some s. This 4-face of Θ1 is sandwiched by the two 5-faces , whose normal vectors determine a plane orthogonal to this 4-face. The proportion of ℝ6 that project onto this 4-face is the product of (1) p⊥ (s), the proportion of the aforementioned plane sandwiched between the two normal vectors of the two adjacent 5-faces, and (2) p||(s), the proportion of the 4-dimensional space spanned by gs × ΘC that lies inside it.
To calculate p⊥ (s), we note the space between the two normal vectors of
can be represented by {
} , so its area inside
is given by
and p⊥ (s) = V⊥ (s)/V2, where V2 = π is the area of the unit disk.
For p||(s), we note gs × ΘC = {ψa = ψs,φa = π/4,π/4 < φc < π/2}. The volume of its part inside
is given by
where G̃ is the 4 × 4 block of G corresponding to its first, fourth, fifth and sixth columns and rows with . Again, the double integral w.r.t. (ra, rc) was simplified with Lemma 1. The weight w13 is given by w13 = limΣs V⊥ (s)V||(s)/V2V4, where is the volume of a 4-dimensional unit ball. The weight w20 can be obtained from the duality between and Θ1.
D.4. The Derivation of w03
The projection of the region that corresponds to w03 lies on the 3-face 0 × ΘC, which is adjacent to 5-dimensional surface ∂ΘA × ΘC of Θ1. The collection of normal vectors of this surface is the elliptic cone { }. Let p⊥ be the proportion of the 3-dimensional space spanned by this elliptic cone that falls inside this cone and p|| be the proportion of the 3-dimensional space spanned by the 3-face 0 × ΘC that falls inside 0 × ΘC. We have
where function ς is defined in Section 2.2. The weight w03 is given by w03 = p⊥p||.
D.5. The Derivation of w22 and w11
Both ΘA and ΘC need to be discretized to calculate w22. The projection of the region of ℝ6 that corresponds to w22 lies on the 4-face for some r and s, where is a face of the discretized ΘA between edges , and is similarly defined. This 4-face is adjacent to 5-faces and , whose normal vectors are given by { } and { }, respectively. The proportion of the 2-dimensional subspace between these two normal vectors is given by .
The 4-face
can be expressed as {
}. To calculate its volume inside
, we note the metric tensor G̃ is now given by the first, second, fourth and fifth rows and columns of G, and
, where J̃ = diag{J̃A,
J̃C} is a 6×4 matrix. We have
where the double integral w.r.t. (ra, rc) has been solved by Lemma 1. This 4-face takes a proportion of p||(s, r) = V||(s, r)/V4 out of the 4-dimensional space it spans. Combining the above two proportions, we have w22 = limΣsΣr p⊥ (s, r)p||(s, r). The weight w11 can be obtained similarly.
D.6. The Derivation of w12
The projection of the region of ℝ6 that corresponds to w12 lies on the 3-face
for some r and s. Its volume inside
is given by
where G̃ is given by the first, fourth and fifth columns and rows of G and with J̃ = diag{ra, J̃C}.
The part of ℝ6 whose projection lies on
is sandwiched between
and {
}. The latter is a part of the 3-dimensional subspace orthogonal to
. Similar to the derivation of V||(r, s), we can obtain the volume of this part of the normal space inside
as
where . The weight w12 is given by , where V3 = 4π/3 is the volume of a 3-dimensional unit ball.
Footnotes
Because the sample sizes are smaller than those used in the simulation studies, a separate simulation study using this sample size combination was conducted with the estimated AE model as the true model. The study showed that the χ̄2 distribution is valid for this case.
Linearity refers to the closure under linear operations and should not be confused with “being flat”.
The link can be found after Shapiro (1988).
The link can be found after Shapiro (1987).
Contributor Information
Hao Wu, BOSTON COLLEGE.
Michael C. Neale, VIRGINIA COMMONWEALTH UNIVERSITY
References
- Boker S, Neale M, Maes H, Wilde M, Spiegel M, Brick T, et al. OpenMx: an open source extended structural equation modeling framework. Psychometrika. 2011;76:306–317. doi: 10.1007/s11336-010-9200-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carey G. Cholesky problems. Behavior Genetics. 2005;35:653–665. doi: 10.1007/s10519-005-5355-9. [DOI] [PubMed] [Google Scholar]
- Chernoff H. On the distribution of the likelihood ratio. The Annals of Mathematical Statistics. 1954;25:573–578. [Google Scholar]
- Dominicus A, Skrondal A, Gjessing HK, Pedersen NL, Palmgren J. Likelihood ratio tests in behavioral genetics: problems and solutions. Behavior Genetics. 2006;36:331–340. doi: 10.1007/s10519-005-9034-7. [DOI] [PubMed] [Google Scholar]
- Gupta AK, Nagar DK. Matrix variate distributions. London: Chapman & Hall/CRC; 1999. [Google Scholar]
- Han SS, Chang JT. Reconsidering the asymptotic null distribution of likelihood ratio tests for genetic linkage in multivariate variance components models under complete pleiotropy. Biostatistics. 2010;11:226–241. doi: 10.1093/biostatistics/kxp054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kuriki S, Takemura A. Some geometry of the cone of nonnegative definite matrices and weights of associated chi-bar-squared distribution. Annals of the Institute of Statistical Mathematics. 2000;52:1–14. [Google Scholar]
- Neale MC, Cardon LR. Methodology for genetic studies of twins and families. Dordrecht: Kluwer Academic; 1992. [Google Scholar]
- R Development Core Team. R: a language and environment for statistical computing. R Foundation for Statistical Computing; Vienna, Austria: 2010. http://www.R-project.org. [Google Scholar]
- Schieken RM, Eaves LJ, Hewitt JK, Mosteller M, Bodurtha JM, Moskowitz WB, et al. Univariate genetic analysis of blood pressure in children: the MCV twin study. American Journal of Cardiology. 1989;64:1333–1337. doi: 10.1016/0002-9149(89)90577-8. [DOI] [PubMed] [Google Scholar]
- Self SG, Liang KY. Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under non-standard conditions. Journal of the American Statistical Association. 1987;82:605–610. [Google Scholar]
- Shapiro A. Asymptotic distribution of test statistics in the analysis of moment structures under inequality constraints. Biometrika. 1985;72:133–144. [Google Scholar]
- Shapiro A. A conjecture related to chi-rar-squared distributions. The American Mathematical Monthly. 1987;94:46–48. [Google Scholar]
- Shapiro A. Towards a unified theory of inequality constrained testing in multivariate analysis. International Statistical Review. 1988;56:49–62. [Google Scholar]
- Shapiro A. Statistical inference in moment structures. In: Lee S-Y, editor. Hand book of latent variable and related models. 2007. pp. 229–260. [Google Scholar]
- Silvapulle MJ, Sen PK. Constrained statistical inference: inequality, order, and shape restrictions. New York: Wiley; 2005. [Google Scholar]
- Stram DO, Lee JW. Variance components testing in the longitudinal mixed effects model. Biometrics. 1994;50:1171–1177. Corrected in Biometrics 51, 1196. [PubMed] [Google Scholar]
- Visscher PM. A note on the asymptotic distribution of likelihood ratio tests to test variance components. Twin Research and Human Genetics. 2006;9:490–495. doi: 10.1375/183242706778024928. [DOI] [PubMed] [Google Scholar]