

Abstract
In this study, Community Multiscale Air Quality (CMAQ) model was applied to predict ambient gaseous and particulate concentrations during 2001 to 2010 in 15 hospital referral regions (HRRs) using a 36-km horizontal resolution domain. An inverse distance weighting based method was applied to produce exposure estimates based on observation-fused regional pollutant concentration fields using the differences between observations and predictions at grid cells where air quality monitors were located. Although the raw CMAQ model is capable of producing satisfying results for O3 and PM2.5 based on EPA guidelines, using the observation data fusing technique to correct CMAQ predictions leads to significant improvement of model performance for all gaseous and particulate pollutants. Regional average concentrations were calculated using five different methods: 1) inverse distance weighting of observation data alone, 2) raw CMAQ results, 3) observation-fused CMAQ results, 4) population-averaged raw CMAQ results and 5) population-averaged fused CMAQ results. It shows that while O3 (as well as NOx) monitoring networks in the HRR regions are dense enough to provide consistent regional average exposure estimation based on monitoring data alone, PM2.5 observation sites (as well as monitors for CO, SO2, PM10 and PM2.5 components) are usually sparse and the difference between the average concentrations estimated by the inverse distance interpolated observations, raw CMAQ and fused CMAQ results can be significantly different. Population-weighted average should be used to account spatial variation in pollutant concentration and population density. Using raw CMAQ results or observations alone might lead to significant biases in health outcome analyses.
Keywords: Community Multiscale Air Quality (CMAQ) model, data fusing, inverse distance weighting, model performance, exposure, population weighted average
1. Introduction
Investigations of the effects of air pollution on population health are dependent on the quality of available air pollutant exposure estimates (Bell et al., 2004; Laden et al., 2000). Traditionally, exposure levels are estimated based on measurements made at near-by air monitoring stations that are limited in space and time (Bell et al., 2007). However, many of the populations in air pollution epidemiology studies are located in areas without sufficient air quality monitoring activities. In addition to the lack of spatial coverage of standard air quality monitoring networks, air quality measurements are limited by the capability of the analytical instruments and may not be able to provide sufficient temporal resolution or detailed chemical composition information to support detailed health outcome analyses.
Three-dimensional chemical transport models (CTMs) can provide detailed gaseous and particulate matter (PM) concentrations and their source and chemical composition information at one-hour resolution over large areas. The complete spatial and temporal coverage of CTMs makes them an ideal tool to fill in the spatial and temporal gaps in the exposure estimation solely based on air quality measurements at fixed monitors (Bell, 2006; Bravo et al., 2012). One of the challenges in applying CTM-predicted exposure in health outcome studies is to reduce the error in exposure classifications. Uncertainties in the meteorology and emissions inputs, the underlying chemical mechanisms and numerical techniques, as well as spatial resolution (i.e. grid size) of the CTM model itself can all lead to errors in the predicted concentrations. Even though previous studies showed that the long term performance of a three-dimensional regional air quality model for ozone and PM can generally meet the criteria recommended by the United States Environmental Protection Agency (US EPA), systematic biases do exist in the predicted concentrations which could lead to biases in the exposure estimations (Zhang et al., 2013b).
Data fusing techniques have been proposed to improve exposure estimations by adjusting the raw CTM model predictions with the ambient observation data (Fuentes and Raftery, 2005; Sahu et al., 2010). However, the effectiveness of these data fusing techniques on predicted air pollutants has only been examined for a small number of species for relatively short simulation periods (such as SO2 in Fuentes and Raftery et al. 2005). Many epidemiologic studies would benefit from long-term exposure inputs of multiple air pollutants such as carbon monoxide (CO), nitrogen oxides (NOx), ozone (O3), particulate matter with aerodynamic diameters less than 2.5 and 10 μm (PM2.5 and PM10), as well as a number of air toxics and PM components to address the public health implications of poor air quality in a more comprehensive manner. The number of available stations for these different species and their spatial and temporal coverage in a given area can be significantly different. No study to date has examined the effectiveness of data fusing techniques on multiple species in the same air quality domain over a long study period.
Recently, an air quality modeling project was carried out to provide air pollutant exposure estimation over a ten-year period (from 2001 to 2010) for the Air Quality and Reproductive Health Study (AQRH) with support from the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD). The AQRH study is designed to analyze data collected during the Consortium on Safe Labor (CSL) study (Zhang et al., 2010) and the Longitudinal Investigation of Fertility and the Environment (LIFE) study (Buck Louis et al., 2011) to provide improved understanding of the relationship between air quality and various measures of reproductive health. The CSL collected detailed electronic medical record information on 228,562 deliveries including both mother and baby records from 12 clinical centers comprising19 hospitals with 15 non-overlapping HRRs across the United States between 2002-2008. The LIFE study was a longitudinal study (2005-2009) that closely followed 501 couples trying to conceive for up to 12 cycles or through pregnancy for those who became pregnant.
The objectives of this paper are to: 1) evaluate the model performance of the three-dimensional regional air quality model, 2) evaluate the effectiveness of observation data fusing in improving regional air quality model predictions and 3) compare the difference in the exposure estimations using raw and observation-fused air quality modeling results. In this study, modelled concentrations in the surface layer are used to represent population exposure to air pollution. Exposure assessment in health effects studies typically include time-activity measures and either active monitoring or some assessment of indoor air as well as ambient measures. These methods can definitely increase the accuracy and precision of an individual’s exposure but typically the studies rely on volunteers who are willing to provide detailed information on their activity/mobility and only include subjects who accept the additional burden of personal monitoring. Our analyses reflect the ambient exposures of an entire population. While there is some error in exposure estimation at the ambient level, it is balanced with the inclusion of the full population. It may also be helpful to note that regulations are made at the ambient exposure level. Regardless of the individual level exposure, if an effect is observable at the population level, it is actionable.
2. Methods
2.1 The Community Multiscale Air Quality (CMAQ) Model
Among the many publicly available CTMs, the Community Multiscale Air Quality (CMAQ) model (Byun and Schere, 2006) is one of the most widely used regional air quality modeling systems in the United States in recent years (Simon et al., 2012). The CMAQ model has been deployed to evaluate air pollution control measures, test new atmospheric mechanisms and processes that control air pollution, and determine source contributions to air pollutants. The CMAQ model has also been used in a few recent studies (Arunachalam et al., 2011; Chang et al., 2012; Grabow et al., 2012; Tong et al., 2009) to estimate air pollution exposure. In this study, a recent version of the CMAQ model (version 4.7.1) with the SAPRC-99 photochemical mechanism (Carter, 2000) and the fifth generation aerosol model (AERO5) (Foley et al., 2010) was used. The SAPRC-99 mechanism was modified to treat a number of explicit air toxics pollutants and 16 gas phase polycyclic aromatic hydrocarbon (PAH) species. Details of this extended SAPRC-99 mechanism for air toxics and PAHs will be described in a separate manuscript as the current paper focuses on criteria pollutants.
2.2 Inverse Distance Weighting and Observation Data Fusing
Inverse distance weighting (Shepard, 1968) has been used to estimate air pollutant exposure based on monitoring data alone. For a given the spatial location, a search of the air monitor list is performed to find stations with available data within a given search radius. The search radius is applied based on the assumption that stations outside the radius have minimal impact on the estimated exposure. Once the stations within a given search radius are identified, the air pollutant concentration based on inverse distance weighting Cidw is estimated by Equations (1) and (2):
| (1) |
| (2) |
where x is the location where concentration needs to be estimated; N is the total number of monitors within the search radius; Ci is the measured concentration at the ith monitor within the search radius; xi is the location of the ith monitor; and wi(x) is the weighting factor for the ith monitor at location x. The function d calculates the distance between points x and xi. Inverse distance weighting works best for estimating exposure where air quality monitors are nearby. More advanced spatial interpolation techniques based on geostatistical methods such as kriging (Bogaert and Fasbender, 2007) have also been attempted interpolating air monitor data. However, the interpolated fields using kriging are often too smooth and are not likely to represent actual spatial variation of air pollutants. In fact, it is impossible to get very reliable estimates of pollutant concentrations at locations without nearby monitor sites, regardless whether inverse distance weighting or kriging is used for the interpolation (Bailey and Gatrell, 1995).
The CMAQ model can generally represent the spatial variation of the pollutants but the magnitude of the predicted concentrations is subject to biases in the emissions, meteorology and uncertainties due to other model components. In this study, a data fusing technique based on inverse distance weighting is developed to adjust gridded raw CMAQ predictions of major criteria pollutants and components of PM2.5 using the observations at nearby air monitors and the raw CMAQ results, as described below.
The difference between point observations (Co,i, hourly for gas phase criteria pollutants and daily for PM and its components) and the raw CMAQ predictions (Cp,i) are calculated for all grid cells where observations are available: ΔCi=Co,i-Cp,i. The inverse distance weighting method described above is then applied to interpolate these location-specific differences to all CMAQ grid cells:
| (3) |
where x is the center location of a grid cell in the model domain and ΔC(x) is the estimated difference between the expected pollutant concentration and the model prediction at the grid cell. The expected (i.e. observation-fused) concentration (Cp’) at each grid cell is calculated by
| (4) |
The resultant pollutant concentration field retains the general spatial distribution feature predicted by the original CMAQ model and, at the same time, leads to better agreement with observations at monitor sites. A search radius of 100 km is used in this study. If there are no observation sites within the search radius, no correction of the predicted CMAQ concentration is attempted in this study. It should be noted that when applying equations (3) and (4) to adjust model predictions, it is important to use observations that represent regional concentrations as concentrations modeled by CMAQ typically represent average concentrations within each model grid cell. Data from monitors located in areas with significant local source influences, such as curbside, near road or street canyon environments should not be used. While Kriging has been used in modeling spatial distribution of air quality measurements, it has not been used in interpolating the model error (i.e. ΔC). Choices of variogram and variogram parameters that are essential in Kriging of ΔC have not been studied before. A meaningful application of the Kriging method for data fusing requires a thorough study to figure out the proper way of applying Kriging for the ΔC field, and should be carried out in a future study.
3. Model Application
3.1 Model settings
A 10-year CMAQ air quality simulation (2001-2010) was carried for this study. A 36-km horizontal resolution domain that covers the entire continental United States and part of Canada and Mexico was used to estimate air pollutant exposure for the CSL study. The model domain is vertically divided into 16 layers that reach approximately 20 km above ground. The first layer (i.e. groud-level) thickness is approximately 30 m. Figure 1 shows the 36-km domain and the outlines of the hospital reference regions (HRRs) where the CSL hospitals are located. Model performance results shown in the following analyses are based on predictions based on the 36-km resolution simulations (referred to as 36-km results hereafter) and available observations within the HRR regions only. The simulation years (2001-2010) actually cover the entire duration of the CSL and the LIFE studies.
Figure 1.

CMAQ 36-km resolution model domain. Boxes 1-5 shows areas where the Hospital Referral Regions used in this study are located. Panels b1-b5 show the boundaries of the HRR regions (dashed lines) and locations of the observation stations within the HRR regions. Lambert projections are used for these plots.
3.2 Meteorology, Emission and Observation Data
The CMAQ simulations reported in this study were driven by meteorological inputs generated using the Weather Research and Forecasting (WRF) model v3.2.1. The WRF modeling approach has been documented in detailed in Zhang et al. (2013b) and is only briefly summarized below. The NCEP (National Centers for Environmental Prediction) FNL (Final) Operational Global Analysis dataset in 1°×1° resolution (downloaded from http://rda.ucar.edu/dsszone/ds083.2/) was processed to provide initial and boundary conditions for the WRF simulations. Other input data, including the land use/land cover and topographical data were based on the 30 sec resolution default WRF input data distributed along with the WRF model. The WRF simulations were divided into multiple runs to be executed at the same time to reduce total run time. Each WRF run simulates 7 days with fresh initial conditions based on the NARR (NCEP North American Regional Reanalysis) reanalysis processed by WRF Preprocessing System (WPS). The first day of each run, which overlaps the last day of the previous run, was considered as a spin-up day and discarded to avoid the influence of initial conditions on model results. For the CMAQ simulation, initial conditions for the first day were generated using a set of default values distributed with the CMAQ program, which represent clean continental concentrations. The last hour results of previous day provide initial conditions for the next day. Boundary conditions for the 36-km domain were generated using the CMAQ default profile as well. Since the regions of interest are sufficiently away from the boundaries, the influence of boundary conditions on model results is expected to be small. The CMAQ runs were divided into 6-month segments with 7-9 days overlap to reduce the effect of initial conditions on model results.
The general procedures to generate anthropogenic and biogenic emission inputs have also been documented in detail in Zhang et al. (2013b). In summary, the US Environmental Protection Agency (US EPA) 2001 Clean Air Interstate Rule (CAIR) emission inventory was used to generate anthropogenic emissions from area, non-road, mobile and point sources for 2001 to 2004. The 2005 National Emissions Inventory (NEI) version 4 (2005 NEI v4) was used to generate anthropogenic emissions for 2005-2010. Emissions of year 2002 to 2004 and 2006-2010 were adjusted based on the average annual emissions treads of criteria pollutants (download from http://www.epa.gov/ttn/chief/trends/). The 2001 CAIR inventory used MOBILE6 while 2005 NEI v4 used Motor Vehicle Emission Simulator (MOVES) for on-road vehicle emissions. This is different from the 2005 NEI v2 used in Zhang et al. (2013) in which the on-road emissions were based on MOBILE6. The MOVES-based on-road emissions generally give higher emission rates of CO and NOx than MOBILE6 (Kota et al., 2012b). The Sparse Matrix Operator Kernel Emissions (SMOKE) emission processing model (version 2.6) from US EPA was used to process the raw emission inventories to generate CMAQ model-ready emissions. Biogenic emissions were generated using the Biogenic Emissions Inventory System, v3.14 (BEIS3.14) incorporated in SMOKE. Open biomass burning emissions for years 2002-2010 were based on the satellite-based Fire INventory from NCAR (FINN) (Wiedinmyer et al., 2011). Open burning emissions for year 2001 were generated based on the annual fire emission inventory from the CAIR inventory. A temporal variation profile for open burning from a Western Regional Air Partnership (WRAP) report (WRAP, 2005) was used to distribute emissions to each hour of the day. Anthropogenic emissions from Canada and Mexico sources within the 36-km domain were also generated, based on inventories provided by US EPA for 2000 and were not adjusted for different years.
Observed hourly concentrations of ozone, CO, NO, NO2, SO2 and daily PM2.5 and PM10 mass and components from 2001-2010 were retrieved from the Air Quality System (AQS) maintained by the US EPA, http://www.epa.gov/ttn/airs/airsaqs/detaildata/downloadaqsdata.htm). Data included in the AQS represent regional or community concentrations at background, rural, suburban, urban and industrial areas. Table 1 shows the number of stations with valid data and number of hourly or daily data points for criteria pollutants within each HRR region.
Table 1.
Data availability of CO, NOx, O3 and PM2.5 observations for HRR regions 2001-2007.
| 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HRR | Available Stations | Number of data points | ||||||||||||
| CO | ||||||||||||||
| R1 | 17 | 15 | 13 | 14 | 13 | 13 | 13 | 125992 | 123283 | 113880 | 113496 | 107376 | 109872 | 112944 |
| R2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 17520 | 17519 | 17348 | 17568 | 17519 | 17519 | 17461 |
| R3 | 2 | 2 | 2 | 2 | 2 | 2 | 3 | 17215 | 17261 | 17145 | 17358 | 17376 | 17427 | 20297 |
| R4 | 5 | 5 | 5 | 5 | 6 | 6 | 5 | 43800 | 43800 | 43800 | 43920 | 49776 | 45216 | 43800 |
| R5 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 8701 | 8702 | 8584 | 8675 | 8679 | 8560 | 8499 |
| R6 | 2 | 2 | 5 | 5 | 5 | 5 | 5 | 17520 | 17520 | 21752 | 43920 | 43800 | 43799 | 34968 |
| R7 | 3 | 2 | 3 | 2 | 2 | 3 | 2 | 16553 | 17351 | 17292 | 17254 | 16418 | 15941 | 16909 |
| R8 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 17520 | 17520 | 10176 | 8784 | 8760 | 8760 | 8760 |
| R9 | 5 | 3 | 3 | 3 | 2 | 2 | 2 | 41879 | 26272 | 26208 | 24912 | 17520 | 17512 | 8793 |
| R10 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 17520 | 17520 | 17520 | 17568 | 17520 | 17520 | 17520 |
| R11 | 5 | 5 | 5 | 6 | 5 | 5 | 5 | 43800 | 43775 | 43800 | 43656 | 43800 | 43800 | 43800 |
| R12 | 6 | 5 | 5 | 5 | 5 | 6 | 6 | 43627 | 41398 | 43689 | 43776 | 43151 | 51055 | 52534 |
| R13 | 2 | 2 | 2 | 1 | 1 | 1 | 2 | 12384 | 12384 | 12384 | 8784 | 8760 | 8760 | 9504 |
| R14 | 3 | 3 | 3 | 2 | 2 | 2 | 1 | 16008 | 16008 | 14544 | 12432 | 12384 | 7248 | 8760 |
| R15 | 17 | 18 | 17 | 11 | 10 | 10 | 10 | 90193 | 92946 | 86184 | 69480 | 67056 | 55072 | 66432 |
|
| ||||||||||||||
| NOx | ||||||||||||||
| R1 | 19 | 17 | 15 | 16 | 15 | 14 | 14 | 143184 | 140820 | 131400 | 130464 | 119376 | 117402 | 120720 |
| R2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 816 | 8757 | 8623 | 8784 | 8760 | 8760 | 8760 |
| R3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 25222 | 25535 | 25683 | 26039 | 25622 | 26096 | 26030 |
| R4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 2232 | 26280 |
| R5 | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 20259 | 11847 | 12117 | 11837 | 12393 | 12169 | 11757 |
| R6 | 1 | 1 | 1 | 4 | 4 | 4 | 4 | 8760 | 8760 | 8760 | 35136 | 35040 | 35040 | 26208 |
| R7 | 4 | 3 | 3 | 2 | 2 | 2 | 2 | 22548 | 20743 | 17094 | 16190 | 15818 | 12928 | 14132 |
| R8 | 4 | 4 | 3 | 3 | 3 | 3 | 3 | 35040 | 28664 | 26280 | 26352 | 26280 | 26280 | 26280 |
| R9 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 12719 | 8760 | 8760 | 8784 | 8760 | 8760 | 8760 |
| R10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| R11 | 2 | 2 | 2 | 3 | 2 | 2 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| R12 | 15 | 14 | 16 | 15 | 15 | 16 | 17 | 96701 | 114935 | 126783 | 131373 | 128935 | 138465 | 139886 |
| R13 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 4032 | 8760 | 8760 | 8784 | 8760 | 8040 | 8760 |
| R14 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 8760 | 8760 | 8760 | 8784 | 8760 | 8727 | 8760 |
| R15 | 7 | 8 | 9 | 10 | 12 | 11 | 12 | 51862 | 62783 | 69480 | 71634 | 91256 | 94854 | 105118 |
|
| ||||||||||||||
| O3 | ||||||||||||||
| R1 | 19 | 17 | 15 | 16 | 15 | 16 | 16 | 143520 | 140820 | 131400 | 131135 | 125040 | 135912 | 132600 |
| R2 | 7 | 7 | 7 | 6 | 6 | 6 | 6 | 51626 | 51013 | 43856 | 39255 | 37914 | 40269 | 43633 |
| R3 | 10 | 9 | 9 | 10 | 11 | 11 | 11 | 61281 | 55215 | 55646 | 61664 | 68676 | 69636 | 70394 |
| R4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 26280 | 26280 | 26280 | 26352 | 26280 | 26280 | 26280 |
| R5 | 7 | 6 | 6 | 5 | 5 | 5 | 5 | 42079 | 36471 | 36127 | 27569 | 26544 | 28220 | 27719 |
| R6 | 15 | 15 | 15 | 15 | 15 | 15 | 15 | 66624 | 66624 | 66624 | 66624 | 66624 | 66624 | 66181 |
| R7 | 6 | 6 | 6 | 5 | 4 | 5 | 5 | 33679 | 38712 | 31196 | 25316 | 21697 | 25683 | 28437 |
| R8 | 5 | 5 | 4 | 4 | 4 | 4 | 4 | 25608 | 27976 | 25288 | 25632 | 25720 | 26304 | 26280 |
| R9 | 3 | 1 | 1 | 1 | 1 | 1 | 2 | 18813 | 8712 | 8760 | 8760 | 7440 | 5400 | 13608 |
| R10 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 10272 | 10272 | 10272 | 10272 | 10272 | 10272 | 10272 |
| R11 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 35952 | 35950 | 35952 | 35952 | 35952 | 35952 | 35952 |
| R12 | 22 | 21 | 23 | 21 | 20 | 21 | 22 | 158016 | 178457 | 183051 | 179652 | 172055 | 182241 | 183666 |
| R13 | 4 | 3 | 3 | 4 | 4 | 4 | 4 | 14688 | 11016 | 11016 | 16896 | 17568 | 15312 | 15408 |
| R14 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 11016 | 11016 | 11016 | 11016 | 11016 | 11016 | 11016 |
| R15 | 24 | 22 | 23 | 26 | 29 | 30 | 32 | 97162 | 90960 | 90504 | 113376 | 135944 | 148441 | 167951 |
|
| ||||||||||||||
| PM2.5 | ||||||||||||||
| R1 | 11 | 10 | 11 | 11 | 12 | 11 | 11 | 1930 | 1912 | 2063 | 2337 | 2310 | 2245 | 2238 |
| R2 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 1517 | 1540 | 1144 | 1183 | 1188 | 1172 | 1172 |
| R3 | 7 | 7 | 7 | 7 | 7 | 6 | 6 | 1373 | 1383 | 1327 | 1420 | 1382 | 1289 | 1288 |
| R4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 1169 | 1200 | 1216 | 1341 | 1420 | 1461 | 1458 |
| R5 | 5 | 5 | 5 | 5 | 4 | 4 | 4 | 950 | 1029 | 778 | 751 | 606 | 616 | 616 |
| R6 | 11 | 11 | 11 | 11 | 11 | 11 | 11 | 2026 | 2093 | 1640 | 1663 | 1659 | 1658 | 2047 |
| R7 | 12 | 11 | 11 | 11 | 10 | 8 | 8 | 2048 | 2005 | 2012 | 2026 | 1837 | 1652 | 1613 |
| R8 | 3 | 4 | 3 | 3 | 3 | 3 | 3 | 954 | 1094 | 966 | 766 | 494 | 493 | 486 |
| R9 | 10 | 9 | 9 | 7 | 7 | 7 | 8 | 1449 | 1220 | 1008 | 976 | 976 | 969 | 968 |
| R10 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 852 | 852 | 851 | 854 | 406 | 366 | 423 |
| R11 | 10 | 10 | 10 | 9 | 9 | 10 | 9 | 1746 | 1704 | 1690 | 1503 | 826 | 800 | 1057 |
| R12 | 14 | 14 | 14 | 8 | 8 | 3 | 3 | 1857 | 2081 | 1313 | 1240 | 1063 | 623 | 639 |
| R13 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 426 | 469 | 487 | 579 | 657 | 684 | 660 |
| R14 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 730 | 709 | 732 | 732 | 729 | 789 | 788 |
| R15 | 29 | 29 | 32 | 34 | 36 | 35 | 32 | 4250 | 4316 | 4365 | 4599 | 5983 | 6034 | 5402 |
1=Cedars-Sinai Medical Center; 2= Christiana Care Health System; 3=MedStar Health; 4=University of Miami; 5=University of Illinois at Chicago; 6=Indiana University – Clarian Health; 7=MedStar Health; 8=Baystate Medical Center; 9=Maimonides Medical Center, 10=Summa Health System; 11=MetroHealth Medical Center; 12=University of Texas; 13-15=Intermountain HealthCare
4. Results and Discussion
4.1 Evaluation of meteorology modeling results
Meteorological conditions are important to accurately model the formation and transport of air pollutants. It is necessary to validate the meteorology model results to insure the model is producing reliable observations and to provide confidence in air quality simulation results. Long term WRF model performance statistics have been shown in Zhang et al. (2013). For this study, the statistics to evaluate the area-wide performance of WRF in January and August 2006 based on observations from approximately 500 meteorology stations, including mean observation (OBS), mean prediction (PRED), mean bias (MB), gross error (GE), and root mean square error (RMSE), are shown in Table 2. The two months are selected to represent model performance in typical winter and summer conditions. The predicted temperature (TEMP) at 2 m above surface, and wind speed (WSPD) and wind direction (WDIR) at 10 m above surface are compared with the observation data from the National Climatic Data Center (NCDC) (available at http://rda.ucar.edu/datasets/ds463.3/). Model performance of TEMP in January and August are quite similar, suggesting that there is no significant seasonal bias in the model predictions. WSPD is under-predicted for both January and August. WDIR agrees well with observations for both months. The performance statistics slightly exceed the recommended ranges by Emery et al. (2001) but are in agreement with another WRF modeling study using a 36-km resolution domain (Zhang et al., 2012) and thus are considered acceptable for air quality simulations.
Table 2.
Performance statistics of WRF meteorology predictions for January and August 2006
| January | August | |||||
|---|---|---|---|---|---|---|
|
|
||||||
| TEMP | WSPD | WDIR | TEMP | WSPD | WDIR | |
| N | 65845 | 34970 | 27983 | 62062 | 38019 | 30012 |
| OBS | 279.3 (K) | 6.33 (m/s) | 239.3 (o)* | 297.3 | 6.29 | 188.8 |
| PRED | 280 | 4.7 | 267.8 | 296.9 | 3.65 | 221.3 |
| MB | 0.69 | −1.62 | 12.01 | −0.43 | −2.64 | 6.25 |
| GE | 2.84 | 2.72 | 47.88 | 2.57 | 3.02 | 47.9 |
| RMSE | 3.93 | 3.27 | 66.18 | 3.53 | 3.58 | 65.01 |
MB=∑(Pi-Oi)/N; GE=∑∣Pi-Oi∣/N; RMSE= (∑(Pi-Oi)2/N)0.5. Pi and Oi are ith paired predictions and observations. N is the number of total observation-prediction data pair.
4.2 Evaluation of raw CMAQ model results
Figure 2 shows the ozone model performance statistics for all monitors within the HRR regions based on raw CMAQ results from 2001 to 2010. Data points are color-coded by month of the year. Hourly predictions of ozone at each individual monitor within the HRR regions were used to compare with the corresponding hourly observed concentrations to calculate the normalized gross error (NGE) and normalized bias (NB). Predicted and observed daily peak ozone concentrations were used to calculate the unpaired peak accuracy (AUP). Definitions of the performance statistics are documented in the Supplementary Materials. The hourly NGE, NB and AUP were averaged for each month to calculate the mean NGE, MNB and mean AUP. Ozone concentrations lower than the cut-off concentration of 60 ppb were excluded from the analysis. The dashed lines on the figure show the EPA recommended model performance criteria (MNB<±15%, NGE<35% and AUP<±20%). The model predictions of ozone are well within the EPA guidelines. Several October data points exceeds the performance range because only a few days in each of these months have ozone concentrations higher than the cut-off concentration of 60 ppb. Results between 2005 and 2010 show slightly smaller MNB, NGE and AUP values, which is likely due to the fact that 2005 NEI emission inventory is more accurate than the 2001 CAIR emission inventory.
Figure 2.
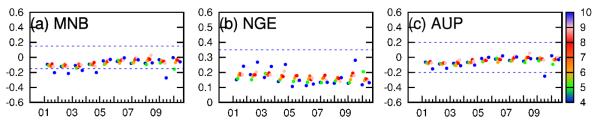
Monthly mean normalized bias (MNB), normalized gross error (NGE), and unpaired predict-to-observed peak ozone ratio (AUP) for O3 for all stations within the HRR regions based on raw CMAQ results. Blue dashed lines show the criteria recommended by US EPA. Data points are color-coded by month, with 4=April and 10=October. Winter months are not shown due to lower ozone concentrations in general.
Figure 3 shows that hourly CO, SO2, NOx (=NO+NO2) and NO2. CO and SO2 have larger errors than O3 based on MNB and NGE values. CO is over-predicted by as much as 75-80% as represented by the large negative MNB values while SO2 is often under-predicted by as much as a factor of two. CO over-prediction is more significant in the winter months than summer months and there is not a clear year-to-year variations in the model performance. The over-estimation of CO is likely due to emission inventory problems, as it has been reported that both MOVES and MOBILE model generally over-predict CO emissions from onroad vehicles (Kota et al., 2012a). This overstimation is more significant in the winter months due to less dilution of emissions caused by stronger surface radiative inversion for typical winter days. NO2 and NOx also have larger error than ozone and are generally over-predicted. Over-predictions are more significant in winter months. The amount of error in NO2 in terms of MNB is similar to that of NOx but NGE is smaller. Kota et al (2012a) also found that NO emissions from onroad vehicles were overestimated by onroad vehicle emission models, which could contribute to NOx overestimations. Emissions of NOx from diesel engines in port activities were also overestimated in the 2005 NEI v4 (Zhang and Ying, 2012), which could also lead to over-estimation of NO and NOx, especially in Houston and Los Angele areas where emissions from port activities are important.
Figure 3.

Mean normalized bias (MNB) and normalized gross error (NGE) of monthly-average (a) CO, (b) SO2, (c) NOx, and (d) NO2 for all the months from 2001 to 2010 all stations with the HRR regions based on raw CMAQ results. Different point types represent model performance criteria for different years. The points are color-coded by the month of the year, with 2=February and 10=October.
Mean Fractional Bias (MFB) and Mean Fractional Error (MFE) are the statistical parameters used to evaluate model predictions of PM2.5. The definitions of MFB and MFE are included in the Supplementary Materials. MFB ranges from −2 (extreme under-prediction) to 2 (extreme over-prediction), and MFE ranges from 0 to 2. Boyland and Russell (2006) proposed concentration dependent PM performance criteria and goals. Detailed discussion of this is also included in Supplementary Materials. Performance goals are the level of accuracy that is close to the best a model can be expected to achieve and performance criteria are the level of accuracy that is acceptable for standard modeling applications (Boylan and Russell, 2006). For concentrations higher than a few μg m−3, the MFB and MFE performance criteria approach to ±60% and ±75%, respectively.
Figure 4 shows the model performance of PM2.5 averaged for each month from 2001 to 2010. Daily average PM2.5 concentrations at the stations within each HRR region were averaged and compared with averaged observed concentrations. The daily model performance statistics were averaged to get monthly averaged results. The solid and dashed lines are model performance criteria and goals for PM (Boylan and Russell, 2006). Most of the PM2.5 results are well within the recommended model performance criteria and many are within the performance goals. This indicates that the model is capable of reproducing the observed PM2.5 concentrations most of the time. Larger under-predictions occur in summer months, likely due to under-predictions of secondary organic aerosol concentrations (Note, the MFB was calculated based on the difference between prediction and observation (i.e. prediction – observation), and thus negative values of MFB means under-prediction. This is different from the MNB calculations for the gas phase pollutants where negative value means over-prediction).
Figure 4.
(a) Mean fractional bias (MFB) and (b) mean fraction error (MFE) of monthly-average PM2.5 for all the months from 2001 to 2010 all stations with the HRR regions based on raw CMAQ results. The dashed and solid lines are model performance criteria and goal, respectively. Different point types represent model performance criteria for different years. The points are color-coded by the month of the year, with 2=February and 12=December. Units for concentrations are μg m−3.
Figure 5 shows model performance statistics of PM2.5 components. Figure 5(b) shows that elemental carbon (EC) are both under and over predicted by the CMAQ model but almost all data points are within the model performance criteria range. Organic compounds (Figure 5c), sulfate (Figure 5d) and nitrate (Figure 5f) are also under-predicted. Sulfate concentrations are under-predicted in the summer month especially for high concentration months. A number of studies have noticed the sulfate under-prediction issue. For example, a seven-year CMAQ model study shows that sulfate is universally under-predicted in the eastern US in the summer months (Zhang et al., 2013a). Luo et al. (2011) attributed this under-prediction of sulfate to overestimation of wet scavenging by the CMAQ cloud module. Ammonium often co-condenses with nitrate and sulfate so it is not surprising to see under-predictions of ammonium ion (Figure 5f).
Figure 5.

Mean fractional bias (MFB) and mean fractional error (MFE) of monthly-average (a) PM2.5 mass, (b) elemental carbon (EC), (c) organic compounds (OC), (d) nitrate, (e) sulfate and (f) sulfate for all the months from 2001 to 2010 at all stations with the HRR regions based on raw CMAQ results. Different point types represent model performance statistics for different years. The points are color-coded by the month of the year.
4.3 Evaluation of observation-fused CMAQ model results
Although the raw CMAQ results generally agree with observations and mostly meet model performance criteria for O3 and PM2.5, the discrepancy between model predictions and observations are still significant and could potentially lead to misclassification of exposure levels. The data fusing technique described in Section 2.2 was applied to further improve the agreement between model predictions and observations.
The accuracy of the data fusing technique was evaluated using cross-validation. During the cross-validation analysis, raw CMAQ predictions at a specific monitor site were adjusted using the data fusing technique described by equations (3) and (4) but observations at that specific monitor were excluded when applying equation (3). Figure 6 shows time series of PM10, PM2.5, O3, NOx and CO at selected monitor sites for July 2006. The cross-validation time series agree well with observations much better than raw CMAQ results. Peak concentrations of CO and NOx are not always captured in the cross-validation. This is because many peak concentration events at a specific monitor are often related with local emissions or meteorological conditions and thus not reflected concentrations measured by the nearby monitors. Similarly, low concentrations are not always captured either. Data fusing using all observation data can improve the agreement between fused data and observations but concentration peaks at locations without monitors are often underestimated even in the fused data set.
Figure 6.

Cross-validation time series (July 2006) of PM10, PM2.5, O3, NOx and CO at selected sites. Solid black and blue lines are fused and raw CMAQ results and red dots are observations.
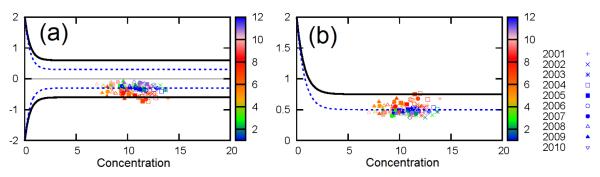
To further illustrate the effectiveness of data fusing at monitor locations, point-to-point comparisons were made for O3 and PM2.5 by comparing fused and raw CMAQ simulation results with observations as shown in Figure 7. Unlike the cross-validation analysis, all available data were used in generating the fused results. It is obvious that fused results agree with observations better than raw CMAQ results. The fused results do not completely agree with observations because the adjustment is calculated based on inverse distance weighting of all nearby stations. The agreement between fused results and observations does not show clear dependence on the number of stations around a monitor site, which suggests that the regional distribution of the pollutants and the distance of the nearby stations also have significant influences on the fused results.
Figure 7.

Scatter plot of observed (y-axis) and predicted (x-axis) daily average O3 (a, b) and PM2.5 (c,d) concentrations for each HRR region for July 2006. The predictions are based on fused (a,c) and raw (b,d) CMAQ results averaged at all monitors within an HRR region. The data points are color-coded by the number of monitors within an HRR region. Units are ppb for ozone and μg m−3 for PM2.5.
Statistical measures also suggest that the fused CMAQ model results agree much better with observations for both gas phase and particle phase species, as demonstrated in Figure S1-S4, which show the model performance analysis for the fused data set same as those in Figure 2 to Figure 5. For O3, the fused-data show a slight negative bias with NGE values approximately 0.1. NGE values from 2005-2010 are generally smaller than results from 2001-2004. As the number of available observations and monitors for ozone did not change significantly during 2001-2010, this suggests that raw CMAQ model performance still have an impact on the fused model results. Better raw CMAQ model results generally lead to better fused model results.
4.4 Comparison of exposure estimations
Figure 8(a) and 8(b) shows the monthly distribution of 8-hr ozone and peak 1-hr hour ozone exposure estimation for HRR region R15 (the HRR region that has the largest spatial coverage, see Figure 1(b)-3) based on five different methods to calculate HRR average exposures, respectively. All methods clearly show the seasonal variation of the 8-hr and 1-hr ozone exposure, with highest ozone exposure occur in June-August, 2006. For this region, even though the population-weighted exposure levels are most similar to the averaged results based on observations alone, especially for summer months, the differences between different estimation methods are quite small. All the methods show similar amount of day-to-day variations in each month. Population-averaged fused CMAQ exposures are most similar to the observation-based averages, especially in the summer months. This is because the ozone monitors are generally located in populated urban/suburban areas. Figure 8(c) shows the comparison of variation of 24-hr average PM2.5 exposure estimation for this HRR region in each month during year 2006. Exposure estimations based on averaging of the observations are similar to the population-weighted, observation-fused CMAQ results. Exposure to PM is highest in winter months, likely due to higher emissions due to heating and reduced vertical turbulent mixing of pollutants in the winter. Estimations based on other methods are significantly lower and do not predicted significant day-to-day variations. The fused-CMAQ shows significantly lower exposure estimations than population-averaged exposure, due to the fact that spatial coverage of PM2.5 monitor sites are not sufficient to cover non-populated areas and the concentrations in the less-populated areas are lower than concentrations in the more densely populated areas. Using raw-CMAQ results or non-population averaged CMAQ results might lead to significant biases in health outcome analysis.
Figure 8.

Box-whisker plot of daily average 8-hr ozone, peak 1-hr ozone and 24-hr PM2.5 for HRR region R15 in the CSL study for year 2006. The ranges, quartiles, and medians are calculated based on the daily concentrations for each month. “Fused” stands for fused CMAQ results, “CMAQ” stands for raw CMAQ results, “-P” is used to denote population-weighted averaging, “Obs.” stands for simple averaging of all available observations within an HRR region.
While HRR region R15 represent a large area with population located near monitor sites, HRR region R12 (see Figure 1(b)-4) represents a relatively smaller area with more ozone monitors. Figure 9(a) and 9(b) show that for ozone exposure, fused and population-weighted fused exposure estimations are similar to those based on averaged observed concentrations. This suggests that ozone monitors are dense enough and ozone concentrations are more uniform in this region. Figure 9(c) shows that the differences between fused-CMAQ, population weighted fused-CMAQ and observation based estimations are more evident for PM2.5, suggesting that observations within this HRR region is not dense enough to correctly represent the spatial distribution of population PM2.5 exposures. Although analysis for other gaseous species, PM10, and PM2.5 components are not shown the figure, the scarcity of the CO, SO2, PM10 and PM2.5 components monitors suggests very different exposure estimations using different methods. Using raw-CMAQ results or observation alone might lead to significant biases in health outcome analysis.
Figure 9.

Box-whisker plot of daily average 8-hr ozone, peak 1-hr ozone and 24-hr PM2.5 for HRR region R12 in the CSL study for year 2006. The ranges, quartiles, and medians are calculated based on the daily concentrations for each month. “Fused” stands for fused CMAQ results, “CMAQ” stands for raw CMAQ results, “-P” is used to denote population-weighted averaging, “Obs.” stands for simple averaging of all available observations within an HRR region.
4.5 Sensitivity of observation-fused results to the search radius
The observation-fused CMAQ results shown in previous sections are based on a search radius of 100 km. The search radius affects how many observations are used to adjust the concentration at a grid cell and also affects the number uncorrected of grid cells due to lack of nearby monitors. To study the sensitivity of average concentrations of ozone and particulate matter in each HRR to the selection of the search radius, a new set of fused data were generated using a search radius of 200 km. Table 3 shows the number of grid cells included in each HRR region and the fraction of grid cells that were uncorrected based on a given search radius for ozone, PM2.5 and PM10. As expected, increasing the search radius reduces the number of grid cells that have not been corrected. As the ozone observations are denser than PM measurements, there are more grid cells uncorrected for PM than for ozone even a 200-km search radius is used.
Table 3.
Percentage of uncorrected grid cells using a search radius of 100 and 200 km.
| 100 km | 200 km | ||||||
|---|---|---|---|---|---|---|---|
| HRR | # grids | O3 | PM10 | PM2.5 | O3 | PM10 | PM2.5 |
| R1 | 12 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R2 | 2 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R3 | 8 | 0.00% | 37.50% | 0.00% | 0.00% | 0.00% | 0.00% |
| R4 | 3 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R5 | 1 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R6 | 27 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R7 | 7 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R8 | 5 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R9 | 1 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R10 | 1 | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R11 | 4 | 25.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% |
| R12 | 41 | 24.39% | 51.22% | 53.66% | 0.00% | 12.20% | 2.44% |
| R13 | 14 | 28.57% | 35.71% | 28.57% | 0.00% | 0.00% | 0.00% |
| R14 | 24 | 62.50% | 66.67% | 62.50% | 0.00% | 16.67% | 12.50% |
| R15 | 331 | 48.94% | 53.78% | 66.77% | 10.57% | 27.49% | 38.07% |
Figure 10 shows the predicted monthly-average 8-hr ozone and 24-hr average PM2.5 concentrations for each HRR region during 2006 based on observation-fused CMAQ using a search radius of 100 and 200 km. The averages were calculated without population weighting. Except for a few data points with approximately 5-10% variations, the differences between 100-km and 200-km search radius results are small. This analysis suggest that for the HRR regions in this study, choice of a smaller or larger search radius does not affect the estimation of regional average exposure significantly.
Figure 10.

Comparison of monthly averaged (a) 8-hr ozone and (b) 24-hr average PM2.5 concentrations for each HRR region during 2006 using a search radius of 100 and 200 km. Dots are color-coded by month of the year (1=January and 12=December).
5. Conclusions
In this study, the CMAQ model performance during a 10-year simulation episode was evaluated against measurements. An inverse distance weighting based method was applied to produce data-fused regional pollutant concentration fields using the differences between observations and predictions at grid cells where air quality monitors were located. Although the raw CMAQ model is capable of producing satisfying results for O3 and PM2.5 based on EPA guidelines, using the observation data fusing technique to enhance CMAQ predictions can lead to significant improvement of model performance for both gaseous and all particulate pollutants, including PM2.5, PM10 and individual PM components. Regional average concentrations were calculated using five different methods: 1) inverse distance weighting of observation data alone, 2) raw CMAQ results, 3) observation fused CMAQ results, 4) population averaged raw CMAQ results and 5) population averaged fused CMAQ results. While monitoring networks in the HRR regions we studied are dense enough for O3 and NOx to provide consistent regional average exposure estimation based on monitoring data alone, PM2.5, PM10 and PM components as well as SO2 and CO observation sites are usually sparse and the difference between the average concentrations estimated by the inverse distance interpolated observations, raw CMAQ and fused CMAQ results can be significantly different. Population-weighted average should be used to account spatial variation in pollutant concentration and population density. Using raw-CMAQ results or observations at monitors alone might lead to significant biases in health outcome analyses. Making the additional effort to fuse the CMAQ results improved model performance for all criteria pollutants, with the most substantive improvements in PM, SO2 and CO measures. Improving the comprehensiveness and accuracy of exposure estimates move the field forward in our attempt to identify potential hazards associated with poor air quality and quantify the magnitude of associations between air pollutant and adverse health outcomes with greater confidence.
Supplementary Material
Research Highlights.
Ten-year CMAQ simulations for population air pollution exposures of gases and PM
Inverse-distance weighting is used to create observation-fused concentration fields
Differences in population exposure based on five estimation methods were studied
Population-weighted average should be used to account for spatial variability
Exposure based on raw CMAQ or observations alone might have significant biases
Acknowledgment
This work was supported by the Intramural Research Program of the Eunice Kennedy Shriver National Institute of Child Health and Human Development, National Institutes of Health. The data included in this paper were obtained from the Air Quality and Reproductive Health study supported through Contract No. HHSN275200800002I, Task Order No. HHSN27500008 awarded to The EMMES Corporation. The authors have no conflicts of interests to disclose. The authors want to acknowledge the Texas A&M Supercomputing Facility (http://sc.tamu.edu) and the Texas Advanced Computing Center (http://www.tacc.utexas.edu/) for providing computing resources essential for completing the research reported in this paper.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Arunachalam S, Wang BY, Davis N, Baek BH, Levy JI. Effect of chemistry-transport model scale and resolution on population exposure to PM2.5 from aircraft emissions during landing and takeoff. Atmospheric Environment. 2011;45:3294–3300. [Google Scholar]
- Bailey TC, Gatrell AC. Interactive Spatial Data Analysis. 1 ed. Poutledge: 1995. [DOI] [PubMed] [Google Scholar]
- Bell ML. The use of ambient air quality modeling to estimate individual and population exposure for human health research: a case study of ozone in the Northern Georgia Region of the United States. Environ Int. 2006;32:586–593. doi: 10.1016/j.envint.2006.01.005. [DOI] [PubMed] [Google Scholar]
- Bell ML, Dominici F, Ebisu K, Zeger SL, Samet JM. Spatial and temporal variation in PM2.5 chemical composition in the United States for health effects studies. Environmental Health Perspectives. 2007;115:989–995. doi: 10.1289/ehp.9621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bell ML, McDermott A, Zeger SL, Samet JM, Dominici F. Ozone and short-term mortality in 95 US urban communities, 1987-2000. Jama-Journal of the American Medical Association. 2004;292:2372–2378. doi: 10.1001/jama.292.19.2372. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bogaert P, Fasbender D. Bayesian data fusion in a spatial prediction context: a general formulation. Stochastic Environmental Research and Risk Assessment. 2007;21:695–709. [Google Scholar]
- Boylan JW, Russell AG. PM and light extinction model performance metrics, goals, and criteria for three-dimensional air quality models. Atmospheric Environment. 2006;40:4946–4959. [Google Scholar]
- Bravo MA, Fuentes M, Zhang Y, Burr MJ, Bell ML. Comparison of exposure estimation methods for air pollutants: Ambient monitoring data and regional air quality simulation. Environmental Research. 2012;116:1–10. doi: 10.1016/j.envres.2012.04.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buck Louis GM, Schisterman EF, Sweeney AM, Wilcosky TC, Gore-Langton RE, Lynch CD, Boyd Barr D, Schrader SM, Kim S, Chen Z, Sundaram R, on behalf of the, L.S. Designing prospective cohort studies for assessing reproductive and developmental toxicity during sensitive windows of human reproduction and development – the LIFE Study. Paediatric and Perinatal Epidemiology. 2011;25:413–424. doi: 10.1111/j.1365-3016.2011.01205.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Byun D, Schere KL. Review of the Governing Equations, Computational Algorithms, and Other Components of the Models-3 Community Multiscale Air Quality (CMAQ) Modeling System. Applied Mechanics Reviews. 2006;59:51–77. [Google Scholar]
- Carter WPL. Documentation of the SAPRC-99 Chemical Mechanism for VOC Reactivity Assessment, Report to the California Air Resources Board. 2000 Available at http://cert.ucr.edu/~carter/absts.htm#saprc99 and http://www.cert.ucr.edu/~carter/reactdat.htm.
- Chang HH, Reich BJ, Miranda ML. Time-to-Event Analysis of Fine Particle Air Pollution and Preterm Birth: Results From North Carolina, 2001-2005. American Journal of Epidemiology. 2012;175:91–98. doi: 10.1093/aje/kwr403. [DOI] [PubMed] [Google Scholar]
- Emery C, Tai E, Yarwood G. Enhanced meteorological modeling and performance evaluation for two texas episodes. Report to the Texas Natural Resources Conservation Commission, p.b.E., Internatioanl Corp (Ed.); Novato, CA: 2001. [Google Scholar]
- Foley KM, Roselle SJ, Appel KW, Bhave PV, Pleim JE, Otte TL, Mathur R, Sarwar G, Young JO, Gilliam RC, Nolte CG, Kelly JT, Gilliland AB, Bash JO. Incremental testing of the Community Multiscale Air Quality (CMAQ) modeling system version 4.7. Geoscientific Model Development. 2010;3:205–226. [Google Scholar]
- Fuentes M, Raftery A. Model evaluation and spatial interpolation by Bayesian combination of observations with outputs from numerical models. Biometrics. 2005;61:36–45. doi: 10.1111/j.0006-341X.2005.030821.x. [DOI] [PubMed] [Google Scholar]
- Grabow ML, Spak SN, Holloway T, Stone B, Mednick AC, Patz JA. Air Quality and Exercise-Related Health Benefits from Reduced Car Travel in the Midwestern United States. Environmental Health Perspectives. 2012;120:68–76. doi: 10.1289/ehp.1103440. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kota SH, Ying Q, Schade GW. MOVES vs. MOBILE6.2: Differences in Emission Factors and Regional Air Quality Predictions. Transportation Research Board Annual Meeting 2012; Washington DC. 2012a. [Google Scholar]
- Kota SH, Zhang H, Ying Q, Schade GW. Evaluation of CO and NOx emission factors from MOVES and MOBILE6.2 in Southeast Texas using a Source-Oriented CMAQ Model. Atmospheric Environment. 2012b Submitted. [Google Scholar]
- Laden F, Neas LM, Dockery DW, Schwartz J. Association of fine particulate matter from different sources with daily mortality in six US cities. Environmental Health Perspectives. 2000;108:941–947. doi: 10.1289/ehp.00108941. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo C, Wang YH, Mueller S, Knipping E. Diagnosis of an underestimation of summertime sulfate using the Community Multiscale Air Quality model. Atmospheric Environment. 2011;45:5119–5130. [Google Scholar]
- Sahu SK, Gelfand AE, Holland DM. Fusing point and areal level space-time data with application to wet deposition. Journal of the Royal Statistical Society Series C-Applied Statistics. 2010;59:77–103. [Google Scholar]
- Shepard D. A two-dimensional interpolation function for irregularly-spaced data. Proceedings of the 1968 23rd ACM national conference. ACM.1968. pp. 517–524. [Google Scholar]
- Simon H, Baker KR, Phillips S. Compilation and interpretation of photochemical model performance statistics published between 2006 and 2012. Atmospheric Environment. 2012;61:124–139. [Google Scholar]
- Tong DQ, Mathur R, Kang DW, Yu SC, Schere KL, Pouliot G. Vegetation exposure to ozone over the continental United States: Assessment of exposure indices by the Eta-CMAQ air quality forecast model. Atmospheric Environment. 2009;43:724–733. [Google Scholar]
- Wiedinmyer C, Akagi SK, Yokelson RJ, Emmons LK, Al-Saadi JA, Orlando JJ, Soja AJ. The Fire INventory from NCAR (FINN): a high resolution global model to estimate the emissions from open burning. Geoscientific Model Development. 2011;4:625–641. [Google Scholar]
- WRAP . 2002 Fire Emission Inventory for the WRAP Region –Phase II. Air Sciences Inc; 2005. [Google Scholar]
- Zhang H, Chen G, Hu J, Chen S-H, Wiedinmyer C, Kleeman MJ, Ying Q. Evaluation of a seven-year (2000-2006) high resolution WRF/CMAQ simulation for epidemiology studies in the eastern United States. Science of the Total Environment. 2013a doi: 10.1016/j.scitotenv.2013.11.121. submitted. [DOI] [PubMed] [Google Scholar]
- Zhang H, Ghen G, Hu J, Chen S-H, Wiedinmyer C, Kleeman M, Ying Q. Evaluation of a seven-year (2000-2006) high resolution WRF/CMAQ simulation for epidemiology studies in the eastern United States. Science of the Total Environment. 2013b doi: 10.1016/j.scitotenv.2013.11.121. Submitted. [DOI] [PubMed] [Google Scholar]
- Zhang H, Li J, Ying Q, Yu JZ, Wu D, Cheng Y, He K, Jiang J. Source apportionment of PM2.5 nitrate and sulfate in China using a source-oriented chemical transport model. Atmospheric Environment. 2012;62:228–242. [Google Scholar]
- Zhang H, Ying Q. Secondary organic aerosol from polycyclic aromatic hydrocarbons in Southeast Texas. Atmospheric Environment. 2012;55:279–287. [Google Scholar]
- Zhang J, Troendle J, Reddy UM, Laughon SK, Branch DW, Burkman R, Landy HJ, Hibbard JU, Haberman S, Ramirez MM, Bailit JL, Hoffman MK, Gregory KD, Gonzalez-Quintero VH, Kominiarek M, Learman LA, Hatjis CG, van Veldhuisen P. Contemporary cesarean delivery practice in the United States. American Journal of Obstetrics and Gynecology. 2010;203:326.e321–326.e310. doi: 10.1016/j.ajog.2010.06.058. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.