

Abstract
This paper introduces a new approach to prediction by bringing together two different nonparametric ideas: distribution free inference and nonparametric smoothing. Specifically, we consider the problem of constructing nonparametric tolerance/prediction sets. We start from the general conformal prediction approach and we use a kernel density estimator as a measure of agreement between a sample point and the underlying distribution. The resulting prediction set is shown to be closely related to plug-in density level sets with carefully chosen cut-off values. Under standard smoothness conditions, we get an asymptotic efficiency result that is near optimal for a wide range of function classes. But the coverage is guaranteed whether or not the smoothness conditions hold and regardless of the sample size. The performance of our method is investigated through simulation studies and illustrated in a real data example.
Keywords: prediction sets, conformal prediction, kernel density, distribution free, finite sample
1. INTRODUCTION
1.1 Prediction sets and density level sets
Suppose we observe iid data Y1, … , Yn ∈ ℝd from a distribution P . Our goal is to construct a prediction set Cn = Cn(Y1, … , Yn) ⊆ ℝd such that
| (1) |
for a fixed 0 < α < 1, where ℙ = P n+1 is the product probability measure over the (n + 1)-tuple (Y1, … , Yn+1). In general, we let ℙ denote P n or P n+1 depending on the context.
The prediction set problem has a natural connection to density level sets and density based clustering. Given a random sample from a distribution, it is often of interest to ask where most of the probability mass is concentrated. A natural answer to this question is the density level set L(t) = {y ∈ ℝd : p(y) ≥ t}, where p is the density function of P . When the distribution P is multimodal, a suitably chosen t will give a clustering of the underlying distribution (Hartigan 1975). When t is given, consistent estimators of L(t) and rates of convergence have been studied in detail (Polonik 1995; Tsybakov 1997; Baillo, Cuestas-Alberto & Cuevas 2001; Baillo 2003; Cadre 2006; Willett & Nowak 2007; Rigollet & Vert 2009; Rinaldo & Wasserman 2010). It often makes sense to define t implicitly using the desired probability coverage (1 − α):
| (2) |
Let μ(·) denote the Lebesgue measure on ℝd. If the contour {y : p(y) = t(α)} has zero Lebesgue measure, then it is easily shown that
| (3) |
where the min is over {C : P (C) ≥ 1 − α}. Therefore, the density based clustering problem can sometimes be formulated as estimation of the minimum volume prediction set.
The study of prediction sets has a long history in statistics under various names such as “tolerance regions” and “minimum volume sets”; see, for example, Wilks (1941), Wald (1943), Fraser & Guttman (1956), Guttman (1970), Aichison & Dunsmore (1975), Chatterjee & Patra (1980), Di Bucchianico, Einmahl & Mushkudiani (2001), Cadre (2006), and Li & Liu (2008). Also related is the notion of quantile contours (Wei 2008). In this paper we study a newer method due to Vovk, Gammerman & Shafer (2005) which we describe in Section 2.
1.2 Main results
Let Cn be a prediction set. There are two natural criteria to measure its quality: validity and efficiency. By validity we mean that Cn has the desired coverage for all P (for example, in the sense of (1)). We measure the efficiency of Cn in terms of its closeness to the optimal (oracle) set C(α). Since p is unknown, C(α) cannot be used as an estimator but only as a benchmark in evaluating the efficiency. We define the loss function of Cn by
| (4) |
where Δ, denotes the symmetric set difference. We say that Cn is efficient at rate rn for a class of distributions P if, for every P ∈ P, ℙ(R(Cn) ≥ rn) → 0 as n → ∞. Such loss functions have been used, for example, by Chatterjee & Patra (1980) and Li & Liu (2008) in nonparametric prediction set estimation and by Tsybakov (1997); Rigollet & Vert (2009) in density level set estimation.
In this paper, we construct Cn with the following properties.
Finite sample validity: Cn satisfies (1) for all P and n under no assumption other than iid.
Asymptotic efficiency: Cn is efficient at rate (log n/n)cp,α for some constant cp,α > 0 depending only on the smoothness of p.
For any y ∈ ℝd, the computational cost of evaluating 1(y ∈ Cn) is linear in n.
Our prediction set is obtained by combining the idea of conformal prediction (Vovk et al. 2005) with density estimation. We show that such a set, whose analytical form may be intractable, is sandwiched by two kernel density level sets with carefully tuned cut-off values. Therefore, the efficiency of the conformal prediction set can be approximated by those of the two kernel density level sets. As a by-product, we obtain a kernel density level set that always contains the conformal prediction set, and satisfies finite sample validity as well as asymptotic efficiency. In the efficiency argument, we refine the rates of convergence for plug-in density level sets at implicitly defined levels first developed in Cadre (2006); Cadre, Pelletier & Pudlo (2009), which may be of independent interest. We remark that, while the method gives valid prediction regions in any dimension, the efficiency of the region can be poor in higher dimensions.
1.3 Related work
The conformal prediction method (Vovk et al. 2005; Shafer & Vovk 2008) is a general approach for constructing distribution free, sequential prediction sets using exchangeability, and is usually applied to sequential classification and regression problems (Vovk, Nouretdinov & Gammerman 2009). We show that one can adapt the method to the prediction task described in (1). We describe this general method in Section 2 and our adaptation in Section 3.
In multivariate prediction set estimation, common approaches include methods based on statistically equivalent blocks (Tukey 1947; Li & Liu 2008) and plug-in density level sets (Chatterjee & Patra 1980; Hyndman 1996; Cadre 2006). In the former, an ordering function taking values in ℝ1 is used to order the data points. Then one-dimensional tolerance interval methods (e.g. Wilks (1941)) can be applied. Such methods usually give accurate coverage but efficiency is hard to prove. Li & Liu (2008) proposed an estimator, with a high computational cost, using the multivariate spacing depth as the ordering function. Consistency is only proved when the level sets are convex. On the other hand, the plug-in methods (Chatterjee & Patra 1980) give provable validity and efficiency in an asymptotic sense regardless of the shape of the distribution, with a much easier implementation. As mentioned earlier, our estimator can be approximated by plug-in level sets, which are similar to those introduced in Chatterjee & Patra (1980); Hyndman (1996); Cadre (2006); Park, Huang & Ding (2010). However, these methods do not give finite sample validity.
Other important work on estimating tolerance regions and minimum volume prediction sets includes Polonik (1997), Walther (1997), Di Bucchianico et al. (2001), and Scott & Nowak (2006). Scott & Nowak (2006) does have finite sample results but does not have the guarantee given in Equation (1) which is the focus of this paper. Bandwidth selection for level sets is discussed in Samworth & Wand (2010). There is also a literature on anomaly detection which amounts to constructing prediction sets. Recent advances in this area include Zhao & Saligrama (2009), Sricharan & Hero (2011) and Steinwart, Hush & Scovel (2005).
In Section 2 we introduce conformal prediction. In Section 3 we describe a construction of prediction sets by combining conformal prediction with kernel density estimators. The approximation result (sandwich lemma) and asymptotic properties are also discussed. A method for choosing the bandwidth is given in Section 4. Simulation and a real data example are presented in Section 5. Some technical proofs are given the Appendix.
2. CONFORMAL PREDICTION
Let Y1, …, Yn be a random sample from P and let Y = (Y1, …, Yn). Fix some y ∈ ℝd and let us tentatively set Yn+1 = y. Let σi = σ({Y1, … , Yn+1}, Yi) be a “conformity score” that measures how similar Yi is to {Y1, … , Yn+1}. We only require that σ be symmetric in the entries of it first argument. We test the hypothesis H0 : Yn+1 = y by computing the p-value
By symmetry, under H0 the ranks of the σi are uniformly distributed among {1/(n + 1), 2/(n + 1) … 1} and hence for any α ∈ (0, 1) we have where . Let
| (5) |
It follows that under H0 we have . Based on the above discussion, any conformity measure σ can be used to construct prediction sets with finite sample validity, with no assumptions on P . The only requirement is exchangeability of the data. In this paper we will where is an appropriate density estimator.
3. CONFORMAL PREDICTION WITH KERNEL DENSITY
3.1 The method
For a given bandwidth hn and kernel function K, let
| (6) |
be the usual kernel density estimator. For now, we focus on a given bandwidth hn. The theoretical and practical aspects of choosing hn will be discussed in Subsection 3.3 and Section 4, respectively. For any given y ∈ ℝd, let Yn+1 = y and define the augmented density estimator
| (7) |
Now we use the conformity measure and the p-value becomes
The resulting prediction set is . It follows that for all P and all n as required.
Figure 1 shows a one-dimensional example of the procedure. The top left plot shows a histogram of some data of sample size 20 from a two-component Gaussian mixture. The next three plots (top middle, top right, bottom left) show three kernel density estimators with increasing bandwidths as well as the conformal prediction sets derived from these estimators with α = 0.05. Every bandwidth leads to a valid set, but undersmoothing and oversmoothing lead to larger sets. The bottom middle plot shows the Lebesgue measure of the set as a function of bandwidth. The bottom right plot shows the estimator and prediction set based on the bandwidth whose corresponding conformal prediction set has the minimal Lebesgue measure.
Figure 1.
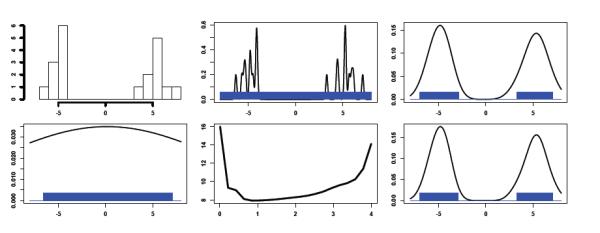
Top left: histogram of some data. Top middle, top right, and bottom left show three kernel density estimators and the corresponding conformal prediction sets with bandwidth 0.1, 1, and 10. Bottom middle: Lebesgue measure as a function of bandwidth. Bottom right: estimator and prediction set obtained from the bandwidth with smallest prediction set.
3.2 An approximation
The conformal prediction set is expensive to compute since we have to compute πn(y) for every y ∈ ℝd. Here we derive an approximation to that can be computed quickly and maintains finite sample validity. Define the upper and lower level sets of density p at level t, respectively:
| (8) |
The corresponding level sets of are denoted Ln(t) and , respectively. Let Y(1), … , Y(n) be the reordered data so that , and define the inner and outer sandwiching sets:
where ψK = supu,u′ |K(u) − K(u′)|. Then we have the following “sandwich” lemma, whose prrof can be found in Appendix B.
Lemma 3.1 (Sandwich Lemma). Let be the conformal prediction set based on the kernel density estimator. Assume that supu |K(u)| = K(0). Then
| (9) |
According to the sandwich lemma, also guarantees distribution free finite sample coverage and is easier to analyze. Moreover, it is much faster to compute since it avoids ever having to compute the kernel density estimator based on the augmented data. The inner set, , which is used as an estimate of C(α) in related work such as in Chatterjee & Patra (1980); Hyndman (1996); Cadre et al. (2009), generally does not have finite sample validity. We confirm this through simulations in Section 5. Next we investigate the efficiency of these prediction sets.
3.3 Asymptotic properties
The inner and outer sandwiching sets and are plug-in estimators of density level sets of the form: , where for the inner set and for the outer set . Here we can view as an estimate of t(α). In Cadre et al. (2009) it is shown that, under regularity conditions of the density p, the plug-in estimators and Ln() are consistent with convergence rate for a range of hn. Here we refine the results under more general conditions. We note that similar convergence rates for plug-in density level sets with a fixed and known level are obtained in Rigollet & Vert (2009). The extension to unknown levels is nontrivial and needs slightly stronger regularity conditions.
Intuitively speaking, the plug-in density level set Ln() is an accurate estimator of L(t(α)) if and are accurate estimators of p and t(α), and p is not too flat at level t(α). The following smoothness condition is assumed for p and K to ensure accurate density estimation.
A1. The density p is Hölder smooth of order β, with β > 0, and K is a valid kernel of order β. Hölder smoothness and valid kernels are standard assumptions for nonparametric density estimation. We give their definitions in Appendix A.
Remark: Assumption A1 can be relaxed in a similar way as in Rigollet & Vert (2009). The idea is that we only need to estimate the density very accurately in a neighborhood of ∂C(α) (the boundary of the optimal set). Therefore, it would be sufficient to have the strong β′-Hölder smoothness condition near ∂C(α), together with a weaker β′-Hölder smoothness condition (βt ≤ β) everywhere else. For presentation simplicity, we stick with the global smoothness condition in A1.
To control the regularity of p at level t(α), a common assumption is the γ-exponent condition, which was first introduced by Polonik (1995) and has been used by many others (see Tsybakov (1997) and Rigollet & Vert (2009) for example). In our argument, such an assumption is also related to estimating t(α) itself. Specifically, we assume
A2. There exist constants 0 < c1 ≤ c2 and ∈0 > 0 such that
| (10) |
The gamma exponent condition requires that the density to be neither flat (for stability of level set) nor steep (for accuracy of ). As indicated in Audibert & Tsybakov (2007), A1 and A2 cannot hold simultaneously unless γ(1 ^ β) ≤ 1. In the common case γ = 1, this always holds.
Assumptions A1 and A2 extend those in Cadre et al. (2009), where β = γ = 1 is considered. The next theorem states the quality of cut-off values used in the sandwiching sets and .
Theorem 3.2. Let , where is the kernel density estimator given by eq. (6), and Y(i) and in,α are defined as in Section 3.2. Assume that A1-A2 hold and choose . Then for any λ > 0, there exist constants Aλ, depending only on p, K and α, such that
| (11) |
We give the proof of Theorem 3.2 in Appendix C. Theorem 3.2 is useful for establishing the convergence of the corresponding level set. Observing that , it follows immediately that the cut-off value used in also satisfies (11). The next theorem, proved in Appendix C, gives the rate of convergence for our estimators.
Theorem 3.3. Under same conditions as in Theorem 3.2, for any λ > 0, there exist constants Bλ, depending on p, K and α only, such that, for all ,
| (12) |
Remark: In the most common cases γ = 1, or β ≥ 1/2, γβ ≤ 1, the term (log n/n)βγ/(2β+d) dominates the convergence rate. It matches the minimax risk rate of the plug-in density level set at a known level developed by Rigollet & Vert (2009). As a result, not knowing the cut-off value t(α) does not change the difficulty of estimation. When βγ/(2β + d) > 1/2, the rate is dominated by (log n/n)1/2 and does not agree with the known minimax lower bound and we do not know if the can be eliminated from the result.
Remark: The theorems above were stated for the optimal choice of bandwidth. The method is still consistent with similar arguments whenever and hn → 0, although the resulting rates will no longer be optimal.
Remark: The same conclusions in Theorems 3.2 and 3.3 hold under a weaker version of Assumption A1. To make this idea more precise, suppose the density function is only β-Hölder smooth in a neighborhood of the level set contour {y : p(y) = t(α)}, but less smooth everywhere else. Then the same proofs of Theorems 3.2 and 3.3 can be used to obtain a slower rate of convergence. After establishing this first consistency result, one can apply the argument again, with the analysis confined in the smooth neighborhood, to obtain the desired rate of convergence. However, in the interest of space and clarity, we will prove our results only under the more restrictive smoothness assumptions that we have stated.
Algorithm 1: Tuning With Sample Splitting.
Input: sample Y = (Y1, …, Yn), prediction set estimator level α, and candidate set H
Split the sample randomly into two equal sized subsamples, Y1 and Y2.
Construct prediction sets each at level 1 − α, using subsample Y1.
Let = arg minh μ().
4. Return , which is constructed using bandwidth and subsample Y2.
4. CHOOSING THE BANDWIDTH
As illustrated in Figure 1, the efficiency of depends on the choice of hn. The size of estimated prediction sets can be very large if the bandwidth is either too large or too small. Therefore, in practice it is desirable to choose a good bandwidth in an automatic and data driven manner. In kernel density estimation, the choice of bandwidth has been one of the most important topics and many approaches have been studied; see Loader (1999), Mammen, Miranda, Nielsen & Sperlich (2011), Samworth & Wand (2010) and references therein. Here we consider choosing the bandwidth by minimizing the volume of the conformal prediction set.
Let H = {h1, … , hm} be a grid of candidate bandwidths. We compute the prediction set for each h ∈ H and choose the one with the smallest volume. To preserve finite sample validity, we use sample splitting as described in Algorithm 1. We state the following result and omit its proof.
Proposition 4.1. If satisfies finite sample validity for all h, then , the output of the sample splitting tuning algorithm, also satisfies finite sample validity.
There are two justifications for choosing a bandwidth to make small. The first is pragmatic: in making predictions it seems desirable to have a small prediction set. The second reason is that minimizing μ(C) can potentially lead to good risk properties in terms of the loss μ(CΔC(α)) as we now show. Recall that R(C) = μ(CΔC(α)) and define ε(C) = μ(C) − μ(C(α)). To avoid technical complications, we will assume in this section that the sample space is compact and focus on the simple case γ = 1 in condition A2.
Lemma 4.2. Let be an estimator of C(α). Then Furthermore, if is finite sample valid and A2 holds with γ = 1, then for some constant c1.
The bandwidth selection algorithm makes small. The lemma gives at least us some assurance that making small will help to make small. The proof of Lemma 4.2 is given in Appendix D. (A similar result can be found in Scott & Nowak (2006).) However, it is an open question whether achieves the minimax rate.
5. NUMERICAL EXAMPLES
We first consider simulations on Gaussian mixtures and double-exponential mixtures in two and three dimensions. We apply the bandwidth selector presented in Section 4 to both and . The bandwidth used for is the same as that for . Therefore, in the results it is possible to see if is bigger than , or if is bigger than because of different bandwidths and data splitting.
5.1 2D Gaussian mixture
We first consider a two-component Gaussian mixture in ℝ2. The first component has mean () and variance diag(4, 1/4), and the second component has mean (0, ) and variance diag(1/4, 4) (see Figure 2). This choice of component centers is to make a moderate overlap between the data clouds from the two components. It makes the prediction set problem more challenging.
Figure 2.
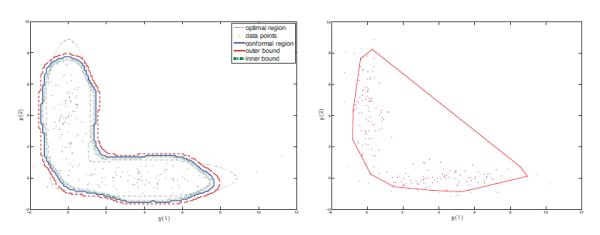
Conformal prediction set (left) and the convex hull of the multivariate spacing depth based tolerance set (right), with data from a two-component Gaussian mixture.
Table 1 shows the coverage and Lebesgue measure of the prediction set at level 0.9 (α = 0.1) over 100 repetitions. The coverage is excellent and the size of the set is close to optimal. Both the conformal set and the outer sandwiching set give correct coverage regardless of the sample size. It is worth noting that the inner sandwiching set (corresponding to the method in Hyndman (1996); Park et al. (2010)) does not give the desired coverage, which suggests that decreasing the cut-off value in is not merely an artifact of proof, but a necessary tuning. The observed excess loss also reflects a rate of convergence that supports our theoretical results on the symmetric difference loss. We compare our method with the approach introduced by Zhao & Saligrama (2009) (ĈZS), where the prediction set is constructed by ranking the distances from each data point to its kth nearest neighbor. It has been reported that the choice of k is not crucial and we use k = 6. (We remark further on the choice of k at the end of this section.) This method is similar to ours but does not have finite sample validity. We observe that the finite sample coverage ĈZS is less than the nominal level.
Table 1.
The simulation results for 2-d Gaussian mixture with α = 0.1 over 100 repetitions (mean and one standard deviation). The Lebesgue measure of the ideal set ≈ 28.02.
| Coverage | Lebesgue Measure | |||||
|---|---|---|---|---|---|---|
| n = 100 | n = 200 | n = 1000 | n = 100 | n = 200 | n = 1000 | |
| 0.886 ± 0.005 | 0.897 ± 0.002 | 0.900 ± 0.001 | 35.6 ± 0.7 | 34.3 ± 0.3 | 31.1 ± 0.2 | |
| 0.861 ± 0.004 | 0.882 ± 0.001 | 0.896 ± 0.001 | 29.8 ± 0.3 | 34.1 ± 0.2 | 32.2 ± 0.1 | |
| 0.907 ± 0.003 | 0.900 ± 0.001 | 0.907 ± 0.001 | 36.2 ± 0.4 | 36.9 ± 0.2 | 34.1 ± 0.1 | |
| 0.853 ± 0.004 | 0.867 ± 0.002 | 0.881 ± 0.001 | 28.1 ± 0.4 | 28.2 ± 0.2 | 28.0 ± 0.1 | |
Figure 2 shows a typical realization of the estimators. In both panels, the dots are data points when n = 200. The left panel shows the conformal prediction set with sample splitting (blue solid curve), together with the inner and outer sandwiching sets (red dashed and green dotted curves, respectively). Also plotted is the ideal set C(α) (grey dash-dotted curve). It is clear that all three estimated sets capture the main part of the ideal set, and they are mutually close. On the right panel we plot a realization of the depth based approach from Li & Liu (2008). This approach does not require any tuning parameter. However, it takes O(nd+1) time to evaluate 1(y ∈ Ĉ) for any single y. In practice it is recommended to compute the empirical depth only for all the data points and use the convex hull of all data points with high depth as the estimated prediction set. Such a convex hull construction misses the “L” shape of the ideal set. Moreover, in our implementation the running time of the kernel density method is much shorter even when n = 200.
Figure 3 shows the effect of bandwidth on the excess loss ε(Ĉ) = μ(Ĉ) − μ(Ĉ)(α)) based on a typical implementation with n = 200, where the y axis is the Lebesgue measure of the estimated sets. We observe that for the conformal prediction set Ĉ(α), the excess loss is stable for a wide range of bandwidths, especially that moderate undersmoothing does not harm the performance very much. An intuitive explanation is that the data near the contour are dense enough to allow for moderate undersmoothing. Similar phenomenon should be expected whenever α is not too small. Moreover, the selected bandwidth from the outer sandwiching set is close to that obtained from the conformal set. This observation may be of practical interest since it is usually much faster to compute .
Figure 3.
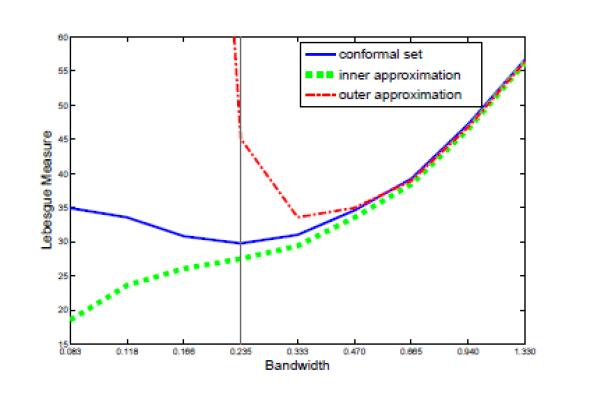
Lebesgue measure of prediction sets versus bandwidth.
Remark: The ĈZS method requires a choice of k. We tried k = 2, 3, … , 20. The coverage increases with k but does not reach the nominal 0.9 level even when k = 20. The Lebesgue measure also increases with k and after k = 20, it becomes larger than the conformal region.
5.2 Further simulations
We now investigate the performance of our method using distributions with heavier tails and in higher dimensions. These simulations confirm that our method always give finite sample coverage, even when the density estimation is very challenging.
Double exponential distribution
In this setting, the distribution also has two balanced components. The first component has independent double exponential coordinates: Y (1) ~ 2 DoubleExp(1)+2.2 log n, Y(2) ~ 0.5 DoubleExp(1), where DoubleExp(1) has density exp(−|y|)/2. The second component has the two coordinates switched. The centering at 2.2 log n is chosen so that there is moderate overlap between data clouds from two components. The results are summarized in Table 2.
Table 2.
The simulation results for 2-d double exponential mixture with α = 0.1 over 100 repetitions (mean and one standard deviation). The Lebesgue measure of the ideal set ≈ 55.
| Coverage | Lebesgue Measure | |||||
|---|---|---|---|---|---|---|
| n = 100 | n = 200 | n = 1000 | n = 100 | n = 200 | n = 1000 | |
| 0.895 ± 0.005 | 0.916 ± 0.003 | 0.91 ± 0.002 | 77.7 ± 3 | 76.6 ± 1.6 | 62.3 ± 0.6 | |
| 0.864 ± 0.006 | 0.897 ± 0.003 | 0.90 ± 0.001 | 66.5 ± 2.3 | 71.7 ± 1.2 | 58.3 ± 0.3 | |
| 0.893 ± 0.005 | 0.912 ± 0.003 | 0.92 ± 0.001 | 86.1 ± 7.4 | 78.2 ± 1.3 | 65.0 ± 0.4 | |
| 0.871 ± 0.004 | 0.892 ± 0.003 | 0.897 ± 0.001 | 58.2 ± 1.5 | 60.2 ± 1.0 | 55.2 ± 0.4 | |
Three-dimensional data
Now we increase the dimension of data. The Gaussian mixture is the same as in the 2-dimensional setup, with the third coordinate being an independent Gaussian with mean zero and variance 1/4. The results are summarized in Table 3.
Table 3.
The simulation results for 3-d Gaussian mixture with α = 0.1 over 100 repetitions (mean and one standard deviation). The Lebesgue measure of the ideal set ≈ 62.
| Coverage | Lebesgue Measure | |||||
|---|---|---|---|---|---|---|
| n = 100 | n = 200 | n = 1000 | n = 100 | n = 200 | n = 1000 | |
| 0.917 ± 0.004 | 0.902 ± 0.003 | 0.900 ± 0.002 | 109 ± 2.4 | 89 ± 1.5 | 74 ± 0.7 | |
| 0.875 ± 0.005 | 0.880 ± 0.003 | 0.889 ± 0.002 | 109 ± 2.1 | 98 ± 1.5 | 81 ± 0.7 | |
| 0.892 ± 0.004 | 0.898 ± 0.003 | 0.916 ± 0.002 | 118 ± 2.2 | 109 ± 1.6 | 96 ± 0.9 | |
| 0.869 ± 0.003 | 0.872 ± 0.002 | 0.879 ± 0.001 | 75 ± 1.3 | 69 ± 0.8 | 64 ± 0.4 | |
Remark: In the above two simulation settings, the conformal prediction sets are much larger than the ideal (oracle) set unless the sample size is very large (n = 1000). This is because of the difficulty of multivariate nonparametric density estimation. In fact, the kernel density estimator may no longer lead to a good conformity score in this case. However, the theory of conformal prediction is still valid as reflected by the coverage. Thus, one may use other conformity scores such as the k-nearest-neighbor radius, for which a non-conformal version has been reported in Zhao & Saligrama (2009). Other possible choices include Gaussian mixture density estimators and semi-parametric models. These extensions will be pursued in future work.
5.3 Application to Breast Cancer Data
In this subsection we apply our method to the Wisconsin Breast Cancer Dataset (available at the UCI machine learning repository). The data contains nine features of 699 patients among which 241 are malignant and 458 are benign. Although this data set is commonly used to test classification algorithms, it has been used to test prediction region methods in the literature (see Park et al. (2010) for example). In this example we use prediction sets to tell malignant cases from benign ones. Formally, we assume that the benign cases are sampled from a common distribution, and we construct a 95% prediction set corresponding to the high density region of the underlying distribution. Although the prediction sets are constructed using only the benign cases, the efficiency of the estimated prediction/tolerance set can be measured not only in terms of its Lebesgue measure, but also in terms of the number of false negatives (i.e., the number of malignant cases covered by the prediction set). Ideally the prediction set shall contain most of benign cases but few malignant cases and hence can be used as a classifier.
In our implementation, the data dimension is reduced to two using standard principal components analysis. Such a dimension reduction simplifies visualization and has also been used in Park et al. (2010). If no dimension reduction is used, the data concentrates near a low dimensional subset of the space, and other conformity scores, such as the k nearest neighbors radius, can be used instead of kernel density estimation. To test the out of sample performance of our method, we randomly choose 100 out of 458 benign cases as testing data. The prediction region is constructed using only the remaining 358 benign cases with coverage level 0.95 and kernel density bandwidth 0.8. We repeat this experiment 100 times. A typical implementation is plotted in Figure 4. In Table 4 we report the mean coverage on the testing data as well as the malignant data. The resulting conformal prediction sets give the desired coverage for the benign cases and low false coverage for the malignant cases. Note that in this case the inner density level set is equivalent to the method proposed in Park et al. (2010), which in general does not have finite sample validity. In our experiment, the average out-of-sample coverage is slightly below the nominal level (by about one standard deviation). In this example, we see that the conformal methods (Ĉ(α) and ) give similar empirical performance as the conventional non-conformal method (), with additional finite sample guarantee.
Figure 4.

Prediction sets for benign instances. Crosses: benign; diamonds: malignant. Blue dashed curve: ; Black dotted curve: ; Red solid curve: Ĉ(α).
Table 4.
Application to the breast cancer data with α = 0.05 over 100 repetitions. Reported are the mean and one estimated standard deviation of the empirical coverage on the testing benign data and the malignant data.
| method | |||
|---|---|---|---|
| test sample coverage | 0.9514 ± 0.0012 | 0.9488 ± 0.0012 | 0.9534 ± 0.0013 |
| malignant data coverage | 0.0141 ± 0.0002 | 0.0044 ± 0.0001 | 0.0420 ± 0.0004 |
APPENDIX A. DEFINITIONS
A.1 Hölder smooth functions
The Hölder class is a popular smoothness condition in nonparametric inferences (Tsybakov 2009, Section 1.2). Here we use the version given in (Rigollet & Vert 2009).
Let s = (s1, …, sd) be a d-tuple of non-negative integers and |s| = s1 + … + sd. For any x ∈ ℝd, let and Ds be the differential operator:
Given β > 0, for any functions f that are [β] times differentiable, denote its Taylor expansion of
degree [βJ at x0 by
Definition A.1 (Hölder class). For constants β > 0, L > 0, define the Hölder class Σ(β, L) to be the set of lβJ-times differentiable functions on ℝd such that,
| (A.1) |
A.2 Valid kernels
A standard condition on the kernel is the notion of β-valid kernels.
Definition A.2 (β-valid kernel). For any β > 0, function K : ℝd → ℝ1 is a β-valid kernel if (a) K is supported on [−1, 1]d; (b) ∫ K = 1; (c) ∫ |K|r < ∞, all r ≥ 1; (d) ∫ ysK(y)dy = 0 for all 1 ≤ |s| ≤ β.
The last condition is interpreted elementwise. In the literature, β-valid kernels are usually used with Hölder class of functions to derive fast rates of convergence. The existence of univariate β-valid kernels can be found in Section 1.2 of Tsybakov (2009). A multivariate β-valid kernel can be obtained by taking direct product of univariate β-valid kernels.
APPENDIX B. PROOF OF LEMMA 3.2
Proof Lemma 3.1. Let , where Pn is the empirical distribution defined by the sample Y = (Y1, …, Yn), and δy is the point mass distribution at y. Define functions
The functions G, Gn and defined above are the cumulative distribution function (CDF) of p(Y ) and its empirical versions with sample Y and aug(Y, y), respectively, where aug(Y, y) = (Y1, … , Yn, y). By (5) and Algorithm 1, the conformal prediction set can be written as
The proof is based on a direct characterization of and . First, for each y ∈ and i ≤ in,α, we have
As a result, and hence y ∈ Ĉ(α). Similarly, for each y ∈ and i ≥ in,α we have
Therefore, and hence y ∈ Ĉ(α).
APPENDIX C. PROOF OF THEOREM 3.3
The bias in the estimated cut-off level can be bounded in terms of two quantities:
Here Vn can be viewed as the maximum of the empirical process Pn − P over a nested class of sets, and Rn is the L∞ loss of the density estimator. As a result, Vn can be bounded using the standard empirical process and VC dimension argument, and Rn can be bounded using the smoothness of p and kernel K with a suitable choice of bandwidth. Formally, we provide upper bounds for these two quantities through the following lemma.
Lemma C.1. Let Vn, Rn be defined as above, then under Assumptions A1 and A2, for any λ > 0, there exist constants A1,λ and A2,λ depending on λ only, such that,
Proof. First, it is easy to check that the class of sets {Lf(t) : t > 0} are nested with VC (Vapnik-Chervonenkis) dimension 2 and hence by classical empirical process theory (see, for example, van der Vaart & Wellner (1996), Section 2.14) , there exists a constant C0 > 0 such that for all η > 0
| (A.2) |
Let η = , we have
| (A.3) |
The first result then follows by choosing . Next we bound Rn. Let p̄ = 𝔼[p̂n], and ∈n = (log n/n)β/(2β+d). By triangle inequality Rn ≤ || p̂n − p̄||∞ + ||p̄ − p||∞. Due to a result of Giné & Guillou (2002) (see also (49) in Chapter 3 of Prakasa Rao (1983)), under Assumption A1, there exist constants C1, C2 and B0 > 0 such that have for all B ≥ B0,
| (A.4) |
On the other hand, by Assumption A1, for some constant C3
| (A.5) |
In (A.3), (A.4) and (A.5) the constants Ci, i = 0, …, 3, depend on p and K only. Hence,
| (A.6) |
which concludes the second part by choosing . □
Proof of Theorem 3.2. Let αn = in,α/n = l(n + 1)αJ/n. We have |αn − α| ≤ 1/n. Recall that the ideal level t(α) can be written as t(α) = G−1(α) where the function G is the cumulative distribution function of p(Y ), as defined in Subsection 3.2. By the γ-exponent condition the inverse of G is well defined in a small neighborhood of α. When n is large enough, we can define t(αn) as t(αn) = G−1(αn).
Again, by the γ-exponent condition, . Therefore, for n large enough
| (A.7) |
Equation (A.7) allows us to switch to the problem of bounding . Recall that . The key of the proof is to observe that . Then it suffices to show that G−1 and G−1 are close at αn. In fact, by definition of Rn we have for all . As a result, we have
By definition of Vn,
By definition of G and Gn, the above inequality becomes
Let Wn = Rn + (2Vn/c1)1/γ . Suppose n is large enough such that
then on the event ,
where the last inequality uses the left side of the γ-exponent condition. Similarly, Gn(t(αn) + Wn) > αn. Hence, for n large enough, if then,
| (A.8) |
To conclude the proof, first note that . Then we can find constant such that for all n large enough,
| (A.9) |
Let Aλ = A2,λ. Combining equations (A.7) and (A.8), on the event
| (A.10) |
we have, for n large enough,
where the second last inequality is from the definition of En,λ and the last inequality is from the choice of . The proof is concluded by observing , a consequence of Lemma C.1. □
Proof of Theorem 3.3. In the proof we write tn for as a generic estimate of t(α) that satisfies (11). Observe that
| (A.11) |
Note that
| (A.12) |
and Therefore
| (A.13) |
Suppose n is large enough such that
| (A.14) |
Suppose n is large enough such that
where the constant A2,λ is defined as in Lemma C.1 and is defined as in equation (A.9). Then on the event En,λ as defined in equation (A.10), applying Theorem 3.2 and condition (10) on the right hand side of (A.14) yields
| (A.15) |
where Bλ, are positive constants depending only on p, K, α and γ. As a result, both and satisfies the claim of Theorem 3.3. The claim also holds for Ĉα by the sandwich Lemma. □
APPENDIX D. PROOFS OF LEMMA 4.3
Proof of Lemma 4.2. The first statement follows since
For the second statement, let I denote the indicator function for C and let I* denote the indicator function for C*. Note that, for all y, (I(y) − I*(y))(λ − p(y)) ≥ 0. Let λ = λα and define W∈ = {y : |p(y) − λ| > ∈}. From Assumption A2 with γ = 1 we have that μ(CΔC*) ≤ μ((CΔC*) ∩ WE) + c∈ for some c > 0. Hence,
Since 𝔼(P (C)) ≥ 1−α, if we take expected values of both sides we have that . The conclusion follows by setting .
Contributor Information
Jing Lei, Department of Statistics, Carnegie Mellon University Pittsburgh, PA 15213.
James Robins, Department of Biostatistics, Harvard University Boston, MA 02115.
Larry Wasserman, Department of Statistics and Machine Learning Department Carnegie Mellon University Pittsburgh, PA 15213.
REFERENCES
- Aichison J, Dunsmore IR. Statistical Prediction Analysis. Cambridge Univ. Press; 1975. [Google Scholar]
- Audibert J, Tsybakov A. Fast learning for plug-in classifiers. The Annals of Statistics. 2007;35:608–633. [Google Scholar]
- Baillo A. Total error in a plug-in estimator of level sets. Statistics & Probability Letters. 2003;65:411–417. [Google Scholar]
- Baillo A, Cuestas-Alberto J, Cuevas A. Convergence rates in nonparametric estimation of level sets. Statistics & Probability Letters. 2001;53:27–35. [Google Scholar]
- Cadre B. Kernel estimation of density level sets. Journal of multivariate analysis. 2006;97:999–1023. [Google Scholar]
- Cadre B, Pelletier B, Pudlo P. Clustering by estimation of density level sets at a fixed probability. 2009 manuscript. [Google Scholar]
- Chatterjee SK, Patra NK. Asymptotically minimal multivariate tolerance sets. Calcutta Statist. Assoc. Bull. 1980;29:73–93. [Google Scholar]
- Di Bucchianico A, Einmahl JH, Mushkudiani NA. Smallest nonparametric tolerance regions. The Annals of Statistics. 2001;29:1320–1343. [Google Scholar]
- Fraser DAS, Guttman I. Tolerance regions. The Annals of Mathematical Statistics. 1956;27:162–179. [Google Scholar]
- Giné E, Guillou A. Rates of strong uniform consistency for multivariate kernel density estimators. Annales de l’Institut Henri Poincare (B) Probability and Statistics. 2002;38:907–921. [Google Scholar]
- Guttman I. In: Statistical Tolerance Regions: Classical and Bayesian Griffin. Hartigan J, editor. London.; Clustering Algorithms John Wiley; New York: 1970. 1975. [Google Scholar]
- Hyndman R. Computing and Graphing Highest Density Regions. The American Statistician. 1996;50:120–125. [Google Scholar]
- Li J, Liu R. Multivariate spacings based on data depth: I. construction of nonparametric multivariate tolerance regions. The Annals of Statistics. 2008;36:1299–1323. [Google Scholar]
- Loader C. Bandwidth selection: classical or plug-in? The Annals of Statistics. 1999;27:415–438. [Google Scholar]
- Mammen E, Miranda MDM, Nielsen JP, Sperlich S. Do-Validation for kernel density estimation. Journal of the American Statistical Association. 2011;106:651–660. [Google Scholar]
- Park C, Huang JZ, Ding Y. A Computable Plug-In Estimator of Minimum Volume Sets for Novelty Detection. Operations Research. 2010;58:1469–1480. [Google Scholar]
- Polonik W. Measuring mass concentrations and estimating density contour clusters - an excess mass approach. The Annals of Statistics. 1995;23:855–881. [Google Scholar]
- Polonik W. Minimum volume sets and generalized quantile processes. Stochastic Processes and their Applications. 1997;69(1):1–24. [Google Scholar]
- Prakasa Rao B. Nonparametric Functional Estimation. Academic Press; 1983. [Google Scholar]
- Rigollet P, Vert R. Optimal rates for plug-in estimators of denslty level sets. Bernoulli. 2009;14:1154–1178. [Google Scholar]
- Rinaldo A, Wasserman L. Generalized density clustering. The Annals of Statistics. 2010;38:2678–2722. [Google Scholar]
- Samworth RJ, Wand MP. Asymptotics and optimal bandwidth selection for highest density region estimation. The Annals of Statistics. 2010;38:1767–1792. [Google Scholar]
- Scott CD, Nowak RD. Learning Minimum Volume Sets. Journal of Machine Learning Research. 2006;7:665–704. [Google Scholar]
- Shafer G, Vovk V. A tutorial on conformal prediction. Journal of Machine Learning Research. 2008;9:371–421. [Google Scholar]
- Sricharan K, Hero A. Efficient anomaly detection using bipartite k-NN graphs. In: Shawe-Taylor J, Zemel R, Bartlett P, Pereira F, Weinberger K, editors. Advances in Neural Information Processing Systems. Vol. 24. 2011. pp. 478–486. [Google Scholar]
- Steinwart I, Hush D, Scovel C. A Classification Framework for Anomaly Detection. Journal of Machine Learning Research. 2005;6:211–232. [Google Scholar]
- Tsybakov A. On nonparametric estimation of density level sets. The Annals of Statistics. 1997;25:948–969. [Google Scholar]
- Tsybakov A. Introduction to nonparametric estimation. Springer; 2009. [Google Scholar]
- Tukey J. Nonparametric estimation. II. Statistical equivalent blocks and multivarate tolerance regions,” The Annals of Mathematical Statistics. 1947;18:529–539. [Google Scholar]
- van der Vaart AW, Wellner JA. Weak Convergence and Empirical Processes. Springer; 1996. [Google Scholar]
- Vovk V, Gammerman A, Shafer G. Algorithmic Learning in a Random World. Springer; 2005. [Google Scholar]
- Vovk V, Nouretdinov I, Gammerman A. On-line preditive linear regression. The Annals of Statistics. 2009;37:1566–1590. [Google Scholar]
- Wald A. An extension of Wilks method for setting tolerance limits. The Annals of Mathematical Statistics. 1943;14:45–55. [Google Scholar]
- Walther G. Granulometric Smoothing. The Annals of Statistics. 1997;25(6):2273–2299. [Google Scholar]
- Wei Y. An approach to multivariate covariate-dependent quantile contours with application to bivariate conditional growth charts. Journal of the American Statistical Association. 2008;103(481):397–409. [Google Scholar]
- Wilks S. Determination of sample sizes for setting tolerance limits. The Annals of Mathematical Statistics. 1941;12:91–96. [Google Scholar]
- Willett R, Nowak R. Minimax optimal level-set estimation. IEEE Transactions on Image Processing. 2007;16:2965–2979. doi: 10.1109/tip.2007.910175. [DOI] [PubMed] [Google Scholar]
- Zhao M, Saligrama V. Bengio Y, Schuurmans D, Lafferty J, Williams CKI, Culotta A, editors. Anomaly Detection with Score functions based on Nearest Neighbor Graphs. Advances in Neural Information Processing Systems. 2009;22:2250–2258. [Google Scholar]