

Abstract
Objective
To propose a permutation based approach of anchor item detection and evaluate differential item functioning (DIF) related to language of administration (English vs. Spanish) for nine questions assessing patients’ perceptions of their providers from the Consumer Assessment of Healthcare Providers and Systems (CAHPS®) Medicare 2.0 survey.
Method and Study Design
CAHPS 2.0 health plan survey data collected from 703 Hispanics who completed the survey in Spanish were matched on personal characteristics to 703 Hispanics that completed the survey in English. Steps to be followed for the detection of anchor items using the permutation tests are proposed and these tests in conjunction with item response theory were used for the identification of anchor items and DIF detection.
Results
Four of the questions studied were selected as anchor items and three of the remaining questions were found to have DIF (p<.05). The three questions with DIF asked about seeing the doctor within 15 minutes of the appointment time, respect for what patients had to say, and provider spending enough time with patients.
Conclusion
Failure to account for language differences in CAHPS survey items may result in misleading conclusions about disparities in health care experiences between Spanish and English speakers. Statistical adjustments are needed when using the items with DIF.
Keywords: Measurement equivalence, differential item functioning, item response theory, patient-assessed quality of care, permutation test
Introduction
Consumer assessment surveys are used widely by health plans, health care providers, purchasers, and policymakers for quality assessment and improvement, and by consumers to choose the most appropriate health professionals, group practices, and health plans suitable to their needs [1]. The Consumer Assessments of Healthcare Providers and Systems (CAHPS®) surveys have been widely used to measure consumer experiences with providers and to study health disparities among racial-ethnic groups in the United States [2]. For example, Weech-Maldonado et al. [3] found that, those who speak a language other than English at home report less timely care and less adequate staff helpfulness than other patients. This could mean that there are disparities in care between patients that speak English fluently and those that do not. However, these two groups may differ in their interpretation of the survey questions or in their proclivities to respond to survey questions. With cultural and linguistic minority groups steadily increasing in the US, understanding cultural and linguistic differences in responding to surveys among subgroups of the population can ensure the accuracy of inferences made about disparities between them.
Hispanics constitute the largest and fastest growing ethnic minority group in the U.S., making up 12% of the population and they are expected to double in size to 24% of the U.S. population by the year 2050 [4]. Data from the 2007 American Community Survey [5] shows that Spanish was the primary language spoken at home for more then 34.5 million people, of whom almost half are limited in their English proficiency. National surveys that include geographic areas with a large proportion of Spanish-speakers routinely provide survey questions in both English and Spanish. As the demand for Spanish surveys continues to grow, it will be necessary to ensure that Spanish versions of instruments are culturally appropriate and psychometrically equivalent to their English versions.
Differential item functioning (DIF) occurs when there are group-mediated differences in the response patterns to survey questions (items) even when the individuals in the different groups are equivalent on the measured construct [6]. For example, DIF occurs when one group (e.g., Spanish speakers) receives different scores than another group (e.g., English speakers) despite having equal standing on the underlying construct of interest (e.g., health care access perception). There are many different possible causes for DIF including poor translations and lack of semantic or conceptual equivalence. Identifying DIF between cultural and linguistic subgroups in CAHPS surveys is important because the outcomes should reflect unbiased differences in experiences with health care providers, and not reflect differences due to other factors such as age, gender, language spoken, or cultural differences.
Few studies have evaluated the psychometric equivalence of CAHPS items in different subgroups. Marshall et. al. [7] used confirmatory factor analysis to show similarity in the underlying factors in the CAHPS 1.0 survey between Latinos and non-Latinos with Medicaid or commercial insurance. Bann, Iannacchione and Sekscenski [8] found DIF in some items between English and Spanish-speaking fee-for-service beneficiaries on the CAHPS 2.0 Medicare survey using Item Response Theory (IRT). In this study, we evaluated the equivalence of English and Spanish versions of the CAHPS 2.0 Medicare Survey using a new semi-parametric permutation test to identify anchor items in combination with an IRT-based method for DIF detection.
Methods
Data Sources
The Center for Medicare and Medicaid Services (CMS) collects information on experiences with health plans from Medicare beneficiaries at least 18 years old, living in the United States or Puerto Rico, and enrolled in managed care organizations each year [9]. In 2002, 600 members from each of 321 participating Medicare managed care plans [10] were sent a CAHPS® 2.0 Medicare survey in the language of their choice (English or Spanish). A total of 184,782 completed the survey (82% response rate), with 84% completed by mail and the rest by telephone. The CAHPS surveys were designed for both English and Spanish with focus groups and cognitive interviews conducted in both languages to maximize conceptual language equivalence [11]. The readability of the CAHPS surveys is estimated to be 7th grade level for both languages [12].
Participants
A total of 10,078 Hispanic CAHPS survey respondents completed the survey with 8,496 completing in English and 1,582 in Spanish. Hispanic Spanish responders tended to be younger and less educated then the Hispanic English survey responders. As such, if this full sample of 10,078 Hispanic participants was analyzed, any observed language DIF might possibly be attributed to age or education differences between the two language groups. To control for any possibility of confounding factors that can affect causal inferences about item functioning [13], we were able to identically match 703 Spanish-speaking Hispanic survey responders to English-speaking Hispanic responders on self-rated overall health, age, gender and education distribution. Therefore, this study is limited to the 1,406 Hispanic participants in CAHPS (48% by mail and 52% by phone), composed of identical/similar group of 703 Spanish and 703 English speaking responders.
Measures
The CAHPS 2.0 core health plan survey used in this study includes 9 questions asking for reports about specific experiences with doctors’ offices (see Table, Supplemental Digital Content 1, which describes the CAHPS items studied). These items represent 4 of the CAHPS composites: getting care quickly/timeliness, provider communication, office staff helpfulness, and getting needed care. The items were analyzed using a three ordered-category response scale, a big problem, a small problem, not a problem for the getting needed care item and never/sometimes, usually, always for all the other items.
Analysis Plan
We used an exact paired matching method based on ethnicity, age, self-rated overall health, gender and education to match Hispanics who completed the survey in English to the 703 Hispanic participants who completed the survey in Spanish. Chi-square statistics were used to compare the sample used in the study to the non-matched group dropped. To determine the presence of DIF in the CAHPS evaluations of providers, responses from Spanish and English speakers were compared using IRT.
We evaluated the extent to which the 9 CAHPS items had sufficient unidimensionality for IRT analyses [14] using confirmatory factor analysis (CFA) methods described elsewhere [15, 16]. Samejima’s graded response model [17, Text, Supplemental Digital Content 2, which describes the models and additional definitions] was used to estimate two types of parameters for each item. The slope or discriminating parameter measures the degree to which an item is related to the latent construct and how quickly the probability of endorsing a response option increases with increasing “trait level” while the location parameter estimates the level on the underlying scale to have a 50% probability of endorsing a particular item response option. The underlying scale can be envisioned as a summary score where higher values are reflective of more positive experiences with care. Bias or DIF occurs when Spanish and English speakers have different location parameters (uniform DIF) or different slope parameters (non-uniform DIF) indicative of the relationship between an item and the latent construct being stronger in one language group than the other [18]
DIF analysis requires the identification of anchor items for which the groups perform similarly and that will allow responses from the two groups to be linked in a way that parameters can be estimated in a common metric [19]. Multiple methods have been proposed for the selection of anchor items [20, 21] but the “purification” model-based likelihood ratio test method is commonly used [18]. The likelihood-based approach compares two models, one constraining the item of interest’s parameters to be equal across the two groups and the other one estimating those parameters separately for the two groups, under the assumption that “all other items are DIF-free.” A significant likelihood chi-square statistic is then used as an indication of potential DIF [22] and the procedure repeated with potential DIF items dropped [23]. Wood [24] proposed a rank-based approach applicable to any method of DIF testing for the empirically improvement of anchor items selection.
The importance of anchor items detection has been previously discussed [25] and is not trivial when there is a large amount of DIF in the items of interest. Zenisky, Hambleton and Robin [26] found that when at least 30% of items have DIF, lack of identification of anchor items can result in a substantial change in items that are detected as having DIF. Finch [27] noted that contamination of anchor items was an important limitation particularly for the likelihood ratio based approach, a finding echoed by Finch and French [28] in a simulation study. Wang [29] inferred that these limitations arise when the number of items with DIF increases since the assumption of “all other items are DIF-free” in the purification procedure will be incorrect in some cases. Shih and Wang [30] on the other hand reported that purification can result in a nearly perfect rate in selecting up to four DIF-free items. In this article, we propose a new iterative method for the identification of anchor items based on semi-parametric permutation tests.
In anchor item selection procedures, a significance test evaluates whether the difference between the two models posited (parameter constraint vs. no parameter constraint) could reasonably occur “just by chance” in a selection of a random sample. If such evidence is not found, an inference can be made about the observed difference being present in the population. The sampling distribution of the difference between parameters in a DIF-free environment can be used to evaluate whether the observed difference is likely to have only occurred by chance. Our proposed permutation test follows three steps:
First, for each item, fit the two models (constrained vs. not constrained) under the assumption that “all other items are DIF-free” and then estimate the difference between the parameters obtained from both models, a statistic that represents the model difference (Sdata)
Second, randomly assign survey responders to pseudo Spanish or English groups (i.e. permutation). This will be the ideal case scenario where there is no differential functioning of the items by language. With this new assignment of responders to the two groups, models in Step 1 are then fitted again and the model difference will now be referred to as Sk, where (k) indicates the permutated sample. The random assignment to group or permutation will be done P times (say P=1000), and the empirical distribution of the difference statistic obtained by S1, S2, …, SP, will represent what the distribution of the statistic would have been if there were no DIF in the item between the groups of interest.
In a third step, using the permutation empirical distribution S1, S2, …, SP, a two-sided test statistic is obtained and a p-value more than 0.05 used to infer that the item does not have DIF and can be considered a potential anchor item.
After all potential anchor items are identified; the above procedure is repeated using only the potential anchor items until no additional item with DIF is observed. The final “DIF-free” items obtained are used as anchor items in the DIF analysis.
To test for DIF in the non-anchor items, we use the likelihood-based approach but the identified anchor items are used as the only anchors and remain the same throughout the tests. In order to adjust for multiple comparisons, the Benjamini-Hochberg procedure [31] was used. The permutations were done using SAS version 9.1 and all the other analyses were conducted using Multilog 7 [32] and IRTLRDIF [22]. Results from the permutation method were qualitatively contrasted with IRTLRDIF estimates.
Results
Sample Description
Table 1 provides descriptive characteristics of the different Hispanic samples. The matched and unmatched samples were different with respect to several characteristics. The matched sample had more women, was less educated, and reported poorer health. These differences on the studied characteristics, suggest that if the full sample of Hispanics were used for DIF detection, any of the detectable DIF might not necessarily be attributable to the difference in language. But with the matched sample of 1406 Hispanics (703 English and 703 Spanish), a more definite link can be made between observed DIF and survey language.
Table 1.
Characteristics (%) the sample included and the one dropped from the analysis due to non-matching
| Variable | All Hispanics | Matched sample used | English speakers not matched | Spanish speakers not matched |
|---|---|---|---|---|
|
| ||||
| Sample Size | 10,078 | 703 | 7,793 | 879 |
| Age (%) | * | * | ||
| 18–44 years old | 1 | 0 | 1 | 1 |
| 45–64 years old | 8 | 0 | 8 | 11 |
| 65–69 years old | 25 | 29 | 24 | 21 |
| 70–74 years old | 30 | 34 | 29 | 30 |
| 75–79 years old | 20 | 24 | 20 | 20 |
| 80 + years old | 16 | 14 | 16 | 16 |
| Missing | 1 | 0 | 1 | 1 |
|
| ||||
| Gender (%) | * | |||
| Male | 45 | 43 | 45 | 44 |
| Female | 54 | 57 | 54 | 55 |
| Missing | 1 | 0 | 1 | 0 |
|
| ||||
| Education (%) | * | * | ||
| Eight grade or Less | 36 | 60 | 28 | 61 |
| Some High School | 19 | 14 | 21 | 13 |
| High School Graduate | 23 | 17 | 25 | 11 |
| Some College | 12 | 6 | 14 | 7 |
| College graduate | 4 | 2 | 4 | 4 |
| More then 4 yr of College | 3 | 1 | 4 | 1 |
| Missing | 3 | 0 | 4 | 4 |
|
| ||||
| Self-rated health (%) | * | * | ||
| Excellent | 8 | 7 | 8 | 15 |
| Very good | 17 | 8 | 20 | 10 |
| Good | 33 | 35 | 34 | 27 |
| Fair | 32 | 45 | 28 | 38 |
| Poor | 9 | 6 | 9 | 9 |
| Missing | 1 | 0 | 1 | 1 |
Note: As the matched sample was based on an identical one to one match of these characteristics, the Spanish and English matched sample have the same characteristics. Test statistics conducted are for comparison of the non-matched Spanish and English speakers to the matched sample.
Statistical significance at the 0.01 significance level
Items Description and Dimensionality
The means and standard deviations of the 9 CAHPS items and the total score (averaged over items), as well as a brief description of the items, are displayed in Table 2. The observed total scores had an average score of 2.49 in the Spanish group, statistically smaller than the 2.54 average in the English group. For all items except Items 2 and 9, the English group reported more positive experiences.
Table 2.
Sample size, mean and standard deviation (SD) of items on patient satisfaction and comparison test.
| Item | Abbreviated Item content | Spanish
|
English
|
Comparison Test | ||||
|---|---|---|---|---|---|---|---|---|
| N | Mean | SD | N | Mean | SD | |||
| Q19 | 1. Get advice needed | 251 | 2.32 | 0.80 | 309 | 2.46 | 0.77 | χ2 =6.5 * |
| Q30 | 2. See provider within 15 minutes | 616 | 1.81 | 0.75 | 604 | 1.75 | 0.84 | χ2 =40.4 ** |
| Q33 | 3. Provider listens to you | 630 | 2.58 | 0.63 | 624 | 2.70 | 0.59 | χ2 =19.6 ** |
| Q34 | 4. Provider explains things | 632 | 2.53 | 0.70 | 628 | 2.64 | 0.64 | χ2 =10.0 ** |
| Q35 | 5. Provider respects your opinion | 632 | 2.62 | 0.62 | 625 | 2.68 | 0.60 | χ2 =5.9 |
| Q36 | 6. Provider spent enough time with you | 631 | 2.31 | 0.69 | 618 | 2.53 | 0.70 | χ2 =68.0 ** |
| Q31 | 7. Office staff treat you with respect | 631 | 2.69 | 0.58 | 622 | 2.79 | 0.53 | χ2 =16.6 ** |
| Q32 | 8. Office staff helpful as you thought | 632 | 2.56 | 0.65 | 627 | 2.65 | 0.63 | χ2 =13.8 ** |
| Q12 | 9. Problem getting personal doctor | 284 | 2.86 | 0.45 | 463 | 2.71 | 0.56 | χ2 =27.4 ** |
| Q12 | 9. Problem getting personal doctor | 284 | 2.86 | 0.45 | 463 | 2.71 | 0.56 | χ2 =27.4 ** |
| Total score | 703 | 2.49 | 0.46 | 703 | 2.54 | 0.47 | t702 =−2.01 * | |
| Cronbach’s alpha CFA fit statistics | 0.83 | 0.85 | ||||||
| χ2 | 51.55 (df = 20, p<0.001) |
80.11 (df = 21, p<0.001) |
||||||
| CFI | 0.987 | 0.978 | ||||||
| TLI | 0.992 | 0.988 | ||||||
| RMSEA | 0.047 | 0.063 | ||||||
Note: The Item comparison test was obtained contrasting the 3 outcome level choices (1, 2 or 3) to the language using a chi-squared test. The total scores were compared using a t-test.
p-value < 0.05
p-value < 0.01
An exploratory factor analysis (EFA) conducted in Mplus[16] showed a first eigenvalue that was 5.2 and a second of 0.90, providing support for unidimensionality for the items. Within the language groups, internal consistency reliability (alpha) was 0.85 for English speakers and 0.83 for Spanish speakers. CFAs using weighted least square mean and variance adjusted (WLSMV) also supports unidimensionality (see Table 2): comparative fit index (CFI>0.98), Tucker-Lewis Index (TLI > 0.99) and residual correlations (< 0.07).
Identification of Anchor and Study Items
Using Step 1 described above on Item 1, the discrimination parameter was 1.34 from the constrained model, and 1.37 and 1.29 (i.e, difference of 0.08) for Spanish and English, respectively, from the unconstrained model (See Table, Supplemental Digital Content 3, which reported all parameter estimates). Across all the items, the magnitude of the difference in the discrimination parameter varied from 0.02 to 0.83. For the first and second location parameters the difference varied from 0.01 to 1.50 and from 0.03 to 2.33, respectively. Results of the permutation tests described in step 3 (tests of the likelihood of the differences described above observed just by chance) are reported in Table 3. (Also see Figure, Supplemental Digital Content 4, which illustrates an example of the permutation distribution)
Table 3.
Anchor item identification. P-values of step by step permutation tests
| Round 1 P-values | Round 2 P-values | Round 3 P-values | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Item | a | b1 | b2 | a | b1 | b2 | a | b1 | b2 |
| 1 | 0.82 | 0.74 | 0.44 | 0.39 | 0.27 | 0.82 | 0.35 | 0.24 | 0.80 |
| 2 | 0.84 | 0.00 | 0.72 | ||||||
| 3 | 0.36 | 0.89 | 0.07 | 0.12 | 0.84 | 0.04 | |||
| 4 | 0.50 | 0.73 | 0.66 | 0.85 | 0.77 | 0.96 | 0.77 | 0.71 | 0.96 |
| 5 | 0.81 | 0.14 | 0.05 | ||||||
| 6 | 0.06 | 0.03 | 0.00 | ||||||
| 7 | 0.36 | 0.99 | 0.06 | 0.44 | 0.13 | 0.64 | 0.46 | 0.12 | 0.69 |
| 8 | 0.05 | 0.92 | 0.43 | 0.31 | 0.22 | 0.96 | 0.27 | 0.21 | 0.90 |
| 9 | 0.44 | 0.28 | 0.01 | ||||||
Note: In the IRT graded response model used, a is the discrimination parameter and b1 and b2 are the item difficulty or location parameters.
On the first round of anchor item detection, Items 1, 3, 4, 7 and 8 showed no significant DIF in parameters (columns 2–4); on the second round, item 3 was also found to potentially have DIF. When this procedure was conducted again (Round 3) none of the remaining items (1, 4, 7 and 8) showed DIF. Therefore, these 4 items were retained as anchor items and the remaining 5 items (2, 3, 5, 6, and 9) were evaluated for DIF.
Differential Item Functioning Analysis Among Items 2, 3, 5, 6, 9
The last 3 columns of Table 4 list the likelihood ratio chi-squared test statistics and significance for the DIF analyses. The omnibus tests indicated that only item 9 is DIF-free at a 0.05 significance level. After adjusting for multiple comparisons, one more item (item 3) can be considered DIF-free. CAHPS item 2 (“see provider within 15 minutes of an appointment”), item 5 (“provider respects your opinion”) and item 6 (“provider spent enough time with you”) do not perform similarly for English and Spanish speakers. For these items, DIF is observed in only the location parameters.
Table 4.
Estimated Item Parameters and their Standard Errors From Graded Response Model with Differential Item Functioning tests (chi-squared estimate and p-value)
| Item | Language | Parameters and Std Error | DIF tests: Chi-square and p-values | |||||
|---|---|---|---|---|---|---|---|---|
| a (se) | b1 (se) | b2 (se) | Omnibus DIF: χ2(3) | a DIF: χ2(1) | b DIF: χ2(2) | |||
| Anchor | 1 | Both | 1.35 (0.15) | −1.34 (0.17) | −0.21 (0.11) | |||
| 4 | 2.59 (0.16) | −1.36 (0.08) | −0.46 (0.05) | |||||
| 7 | 2.23 (0.16) | −1.82 (0.12) | −0.9 (0.06) | |||||
| 8 | 2.57 (0.16) | −1.49 (0.09) | −0.44 (0.05) | |||||
| DIF Free | 3 | Both | 3.22 (0.22) | −1.48 (0.08) | −0.48 (0.04) | 11.2 (0.011) | 3.4 (0.065) | 7.8 (0.020) |
| 9 | 0.68 (0.13) | −4.56 (0.86) | −2.3 (0.45) | 1.0 (0.801) | ||||
| Showed DIF | 2 | English | 0.64 (0.04) | 0.31 (0.18) | 2.11 (0.21) | 98.2 (0.000) | 4.9 (0.027) | 93.2 (0.000) |
| Spanish | −0.8 (0.18) | 2.29 (0.23) | ||||||
| 5 | English | 3.31 (0.20) | −1.38 (0.09) | −0.45 (0.06) | 26.5 (0.000) | 0.1 (0.752) | 26.3 (0.000) | |
| Spanish | −1.56 (0.09) | −0.56 (0.05) | ||||||
| 6 | English | 2.42 (0.13) | −1.17 (0.09) | −0.17 (0.07) | 63.7 (0.000) | 0.1 (0.752) | 63.5 (0.000) | |
| Spanish | −1.33 (0.08) | 0.18 (0.06) | ||||||
Note: In columns 4–6 standard errors are in parenthesis and in columns 7–9 p-values are in parenthesis. In the IRT graded response model used, a is the discrimination parameter and b1 and b2 are the item difficulty or location parameters
The final parameter estimates and standard errors of all the items, with items 1, 4, 7, and 8 set as anchor items, are presented in columns 4–6 of Table 4. The estimates for the items with identified DIF were generated allowing for uniform DIF by specifying separate location parameter estimates for the two language groups while keeping the discrimination parameters the same between groups. For all other items, the parameter estimates for the two groups were constrained to be equal using MULTILOG. With the exception of low slopes values of 0.64 and 0.68, for items 2 and 9, respectively, the slopes of the remaining seven items were all above 1.0, ranging from 1.35 to 3.31, indicating that most of the items have a strong relationship with the patient evaluations of the provider construct being measured in these CAHPS survey items. Item 5 had the highest discrimination slope and, thus, was the most salient indicator of patients’ experiences with providers.
As the CAHPS items are scored with 3 response categories (1, 2, 3), a boundary response function (BRF), a plot which represents each item with 2 curves, one tracing the probability of scoring at or above 2 (i.e. usually or always) and the other the probability of scoring 3 (i.e., always) was used to display DIF (Figure 1). Inspection of the BRFs illustrates how the two language groups are not using the response categories in the same fashion for the DIF items. For example, a Spanish speaker with an evaluation of provider score of −1 on the IRT scale is expected to answer “usually or always” for item 2 about 47% of the time while an English speaker with the same level of evaluation of care will likely give the same answer only 30% of the time. This is equivalent to an expected item score of 1.58 and 1.42 for the Spanish and English speakers, respectively, a difference equal to a standardized effect of size 0.20 at the construct level -1 (See Supplemental Digital Content 2 for the definition of effect size). Even at the average construct score of 0, these percentages are 62% and 45% for the Spanish and English speakers, respectively, or the same standardized effect of size 0.20. For item 6, at the average latent score of 0, the probability of selecting “always” goes from 39% for Spanish to 60% for English speakers or a standardized effect of size −0.27. For this item, at the latent score of −1, this effect size was really small at only 0.03. When it comes to Item 5, the effect size was 0.09 and 0.22 at the latent scores of 0 and −1 respectively. Figure 1d also shows the scale score plot and the expected item score plots for the item with DIF are also presented in Supplemental Digital Content 5 (a figure that shows the plots).
Figure 1.
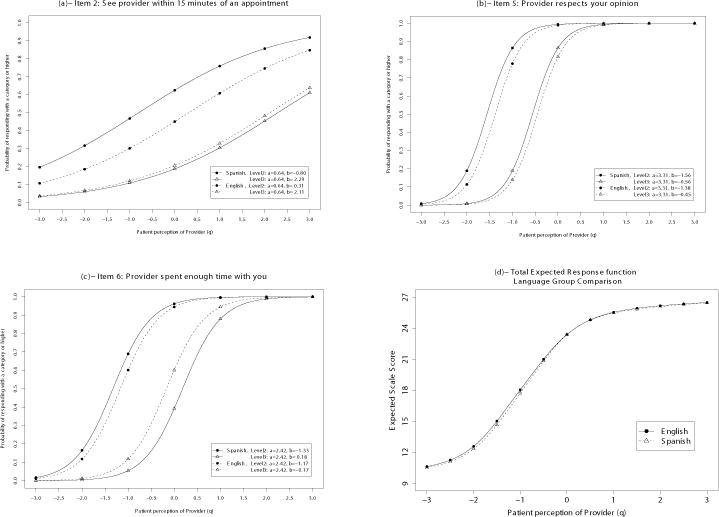
Boundary Response Function curve for each item with DIF and Total Expected Response function Curve
For qualitative comparison, using the standard IRTLRDIF (see Table, Supplemental Digital Content 6 which presents these results), item 9 was flagged as the sole anchor item and the DIF analysis itself revealed that only items 1 and 2 showed DIF. Because the permutation method identified more anchor items, it will possibly have higher power for detecting DIF [33].
Discussion
Our results indicate that the Spanish version of CAHPS is not entirely psychometrically equivalent to the English version. Using a semi-parametric method, we found that all the items studied were equivalent in discrimination parameter, indicating that analogous items in the different languages are equally related to the construct of patient evaluations of providers. However, 3 out of the 9 items displayed DIF in their location parameters, indicating that responses for these 3 items do not reflect the same degree of experience at the doctor’s office for Spanish compared to English speakers.
The patterns in observed DIF were inconsistent. In Item 2 (seeing a provider within 15 minutes of an appointment) and Item 6 (provider spending enough time with responders), the pattern of the BRFs revealed that English speakers were more likely to endorse the extreme response options (i.e., never/sometimes or always) than Spanish speakers with equal level on the construct. In Item 5 (provider respecting what the patient says), however, Spanish speakers were more likely to endorse the higher end of the scale compared with English speakers. These differences in response patterns to Items 2, 6 and 5 may be culturally driven. Late and hurried doctors are normative in Latin American countries and respect (respeto) is a very important value in Hispanic cultures. While Latino patients regard physicians as authority figures to be given respect, they also expect respect in return [34]. Spanish speakers are more tolerant of busy and late doctors than English speakers and therefore less likely to endorse extreme response options in Items 2 and 6, but less tolerant of disrespect and therefore more likely to endorse the extremes in Item 5.
As some studies have suggested that iterative purification method can be less effective at pure anchor detection [35, 36], the same limitations will be applicable to the permutation method. But as demonstrated in Wang and Shih [25], there is also evidence about the effectiveness of the iterative purification method. For the permutation method we used for the detection of anchor items, it is known to be sometimes conservative [37], thus it will take more extreme test statistics to reject a null hypothesis and the actual error rate is much less than the prescribed alpha level.
This study has limitations. The proposed permutation method yielded a larger number of anchor items than the IRTLR method, and identified only one item with DIF in common (item 2). It is not possible to evaluate the accuracy of these findings. A more comprehensive simulation study is needed for the evaluation of the performance of the new test. An additional limitation is that the study focused on Spanish speakers, and did not examine other fast-growing groups of native speakers. Also, the results of the sample characteristics comparison suggested that sample of Spanish speakers in CAHPS were different from the general population when it comes to education, health status, gender and age. This means that the results of these language differences may only generalize to Hispanics similar to the Spanish speakers from which our sample is drawn. Even among the population sampled, because CAHPS surveys are self-administered, low-literacy plan members might have been excluded [2], and a greater proportion of such persons might have been Spanish-speaking Hispanics.
In summary, with the rapidly growing population of Spanish speakers, Hispanic or not, making the ethnic makeup of the U.S. more complex, accurately translated patient surveys from English to Spanish are becoming a necessity. Equivalence in such translated instruments will allow researchers and policy makers to alleviate doubts about disparities in patients experience with health care providers that are being observed, and that might be attributed to cultural difference in evaluating care received. The results of this study suggest that a few of the CAHPS items display location DIF by language, and the current practice of using these items for disparity inference without controlling for the survey language may result in biased conclusions [38] and thus should be changed. If modification of the translation of items with DIF is possible, it should be made to eliminate DIF in these items.
Although language was the only cultural characteristics we studied as source of DIF in the CAHPS survey items, such differences can also exist in the matching variables (self reported health status, age, gender and education level) and similar analyses should be conducted on these potential sources of differences as well. Researchers are challenged to promote equivalence in measurements by using the technique employed in this study to examine tools they have translated for use among diverse population groups.
Supplementary Material
a- Supplemental Digital Content 1. Table that describes the CAHPS items studied (doc file).
b- Supplemental Digital Content 2. Text that explicitly defines the Samejima’s model used and the notion of effect size (doc file).
c- Supplemental Digital Content 3. Table reporting all parameter estimates from the restricted and the unrestricted models in the permutation steps (doc file).
d- Supplemental Digital Content 4. Figures of an example of the permutation distribution of the parameters and statistics (eps file).
e- Supplemental Digital Content 5. Figure of the expected item score plots (eps file).
f- Supplemental Digital Content 6. Table of results of the analyses using the standard IRTLRDIF for comparison with the proposed permutation method (doc file).
Acknowledgments
Claude Setodji received support from the University of California, Los Angeles, Resource Centers for Minority Aging Research Center for Health Improvement of Minority Elderly (RCMAR/CHIME) under NIH/NIA Grant P30-AG021684. Ron Hays was also supported by UCLA/DREW Project EXPORT, NCMHD, 2P20MD000182, and the UCLA Older Americans Independence Center, NIH/NIA Grant P30-AG0287. The content of this article does not necessarily represent the official views of the NIA or the NIH.
References
- 1.Hargraves JL, Hays RD, Cleary PD. Psychometric properties of the Consumer Assessment of Health Plans Study (CAHPS) 2.0 adult core survey. Health Serv Res. 2003;38(6, part 1):1509–1527. doi: 10.1111/j.1475-6773.2003.00190.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Morales LS, Elliott MN, Weech-Maldonado R, Spritzer KL, Hays RD. Differences in CAHPS® adult survey reports and ratings by race and ethnicity: An analysis of the National CAHPS® Benchmarking Data 1.0. Health Serv Res. 2001;36:595–617. [PMC free article] [PubMed] [Google Scholar]
- 3.Weech-Maldonado R, Morales LS, Spritzer K, Elliott M, Hays RD. Racial and ethnic differences in parents’ assessments of pediatric care in Medicaid managed care. Health Serv Res. 2001;36:575–594. [PMC free article] [PubMed] [Google Scholar]
- 4.Guzmán B. The Hispanic Population: Census 2000 Brief. Washington, DC: US Department of Commerce, Economics and Statistics Administration, US Census Bureau; 2001. Brief No. C2KBRO1–3. [Google Scholar]
- 5.US Census Bureau. American Community Survey. Selected social characteristics in the United States. 2007 Available at: http://factfinder.census.gov/servlet/ADPTable?_bm=y&-geo_id=01000US&-qr_name=ACS_2007_1YR_G00_DP2&-context=adp&-ds_name=ACS_2007_1YR_G00_&-tree_id=306&-_lang=en&-redoLog=false&-format. Accessed April 15, 2010.
- 6.Lord FM. Applications of Item Response Theory to Practical Testing Problems. Hillsdale, NJ: Lawrence Erlbaum Associates; 1980. [Google Scholar]
- 7.Marshall GN, Morales LS, Elliott M, Spritzer K, Hays RD. Confirmatory factor analysis of the Consumer Assessment of Health Plans Study (CAHPS) 1.0 core survey. Psychol Assess. 2001;13:216–229. doi: 10.1037//1040-3590.13.2.216. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Bann CM, Iannacchione VG, Sekscenski ES. Evaluating the effect of translation on Spanish speakers’ ratings of Medicare. Health Care Financ Rev. 2005;26:51–65. [PMC free article] [PubMed] [Google Scholar]
- 9.Goldstein E, Cleary PD, Langwell KM, et al. Medicare managed care CAHPS: a tool for performance improvement. Health Care Financ Rev. 2001;22:101–107. [PMC free article] [PubMed] [Google Scholar]
- 10.Zaslavsky AM, Zaborski LB, Cleary PD. Plan, geographical, and temporal variation of consumer assessments of ambulatory health care. Health Serv Res. 2004;39:1467–1485. doi: 10.1111/j.1475-6773.2004.00299.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Weidmer B, Brown J, Garcia L. Translating the CAHPS 1.0 survey instruments into Spanish. Medical Care. 1999;37:MS89–96. doi: 10.1097/00005650-199903001-00010. [DOI] [PubMed] [Google Scholar]
- 12.Morales LS, Weidmer BO, Hays RD. Readability of the CAHPS® 2.0 Child and Adult Surveys. In: Cynamon ML, Kulka RA, editors. Seventh Conference on Health Survey Research Methods: Conference Proceedings. Hyattsville, MD: US Department of Health and Human Services; 2001. pp. 83–90. (DHHS Publication No. (PHS) 01-1013). [Google Scholar]
- 13.Rosenbaum P, Rubin D. Constructing a control group using multivariate matched sampling methods that incorporate the propensity score. Am Statistician. 1985;39:33–38. [Google Scholar]
- 14.McLeod LD, Swygert KA, Thissen D. Factor analysis for items scored in two categories. In: Thissen D, Wainer H, editors. Test Scoring. Mahwah, NJ: Lawrence Erlbaum Associates; 2001. pp. 185–209. [Google Scholar]
- 15.Byrne B. Structural Equation Modeling with EQS and EQS/Windows: Basic Concepts Applications and Programming. Thousand Oaks, CA: Sage; 1994. [Google Scholar]
- 16.Muthén LK, Muthén BO. Mplus User’s Guide. 2. Los Angeles: Muthén & Muthén; 2001. [Google Scholar]
- 17.Samejima F. Evaluation of mathematical models for ordered polychotomous responses. Behaviormetrika. 1996;23:17–35. [Google Scholar]
- 18.Thissen D, Steinberg L, Wainer H. Detection of differential item functioning using the parameters of item response models. In: Holland PW, Wainer H, editors. Differential Item Functioning. Hillsdale, NJ: Lawrence Erlbaum Associates; 1993. pp. 67–113. [Google Scholar]
- 19.Embretson SE, Reise SP. Item Response Theory for Psychologists. Mahwah, NJ: Lawrence Erlbaum Associates; 2000. [Google Scholar]
- 20.Miller TR, Spray JA. Logistic discriminant function analysis for DIF identification of polytomously scored items. J Educ Meas. 1993;30:107–122. [Google Scholar]
- 21.Orlando M, Marshall GN. Differential item functioning in a Spanish translation of the PTSD Checklist: Detection and evaluation of impact. Psychol Assess. 2002;14:50–59. doi: 10.1037//1040-3590.14.1.50. [DOI] [PubMed] [Google Scholar]
- 22.Thissen D. IRTLRDIF [software for the computation of the statistics involved in item response theory likelihood-ratio tests for differential item functioning] (Version v.20b) 2001 Available at: www.unc.edu/~dthissen/dl.html.
- 23.Edelen MO, Thissen D, Teresi JA, et al. Identification of differential item functioning using item response theory and the likelihood-based model comparison approach: Application to the Mini-Mental State Examination. Med Care. 2006;44(11(suppl 3)):S134–S142. doi: 10.1097/01.mlr.0000245251.83359.8c. [DOI] [PubMed] [Google Scholar]
- 24.Woods CM. Empirical selection of anchors for tests of differential item functioning. Applied Psychological Measurement. 2009;33:42–57. [Google Scholar]
- 25.Wang W-C, Shih C-L. MIMIC methods for assessing differential item functioning in polytomous items. Applied psychological Measurement. 2010;34(3):166–180. [Google Scholar]
- 26.Zenisky AL, Hambleton RK, Robin F. Detection of differential item functioning in large-scale state assessments: A study evaluating a two-stage approach. Educational and Psychological Measurement. 2003;63(1):51–64. (2003) [Google Scholar]
- 27.Finch H. The MIMIC model as a method for detecting DIF: Comparison with Mantel-Haenszel, SIBTEST, and the IRT likelihood ratio. Applied Psychological Measurement. 2005;29:278–295. [Google Scholar]
- 28.Finch WH, French BF. Detection of crossing differential item functioning. A Comparison of Four Methods. Educational and Psychological Measurement. 2007;67:565–582. [Google Scholar]
- 29.Wang W. Effects of anchor item methods on the detection of differential item functioning within the family of Rasch models. J Exp Ed. 2004;72:221–261. [Google Scholar]
- 30.Shih C-L, Wang W-C. Differential item functioning detection using the multiple indicators, multiple causes MIMIC method with a pure short anchor. Applied Psychological Measurement. 2009;33:184–199. [Google Scholar]
- 31.Benjamini Y, Hochberg Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J R Stat Soc Ser B. 1995;57:289–300. [Google Scholar]
- 32.du Toit M. IRT from SSI: BILOG-MG, MULTILOG, PARSCALE, TESTFACT. Lincolnwood, IL: Scientific Software International; 2003. [Google Scholar]
- 33.Wang W-C. Effects of anchor item methods on the detection of differential item functioning within the family of Rasch models. Journal of Experimental Education. 2004;72:221–261. [Google Scholar]
- 34.Lassetter JH, Baldwin JH. Health care barriers for Latino children and provision of culturally competent care. J Pediatr Nurs. 2004;19:184–192. doi: 10.1016/j.pedn.2004.01.007. [DOI] [PubMed] [Google Scholar]
- 35.Wang W-C, Su Y-H. Factors influencing the Mantel and generalized Mantel-Haenszel methods for the assessment of differential item functioning in polytomous items. Applied Psychological Measurement. 2004;28:450–480. [Google Scholar]
- 36.French BF, Maller SJ. Iterative purification and effect size use with logistic regression for differential item functioning detection. Educational and Psychological Measurement. 2007;67:373–393. [Google Scholar]
- 37.Berger VW. Pros and cons of permutation tests in clinical trials. Stat Med. 2000;19:1319–1328. doi: 10.1002/(sici)1097-0258(20000530)19:10<1319::aid-sim490>3.0.co;2-0. [DOI] [PubMed] [Google Scholar]
- 38.Hays RD, Morales LS, Reise SP. Item response theory and health outcomes measurement in the 21st century. Med Care. 2000;38(suppl 9):II28–II42. doi: 10.1097/00005650-200009002-00007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Raju NS, van der Linden WJ, Fleer PF. IRT-based internal measures of differential functioning of items and tests. Appl Psychol Meas. 1995;19:353–368. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
a- Supplemental Digital Content 1. Table that describes the CAHPS items studied (doc file).
b- Supplemental Digital Content 2. Text that explicitly defines the Samejima’s model used and the notion of effect size (doc file).
c- Supplemental Digital Content 3. Table reporting all parameter estimates from the restricted and the unrestricted models in the permutation steps (doc file).
d- Supplemental Digital Content 4. Figures of an example of the permutation distribution of the parameters and statistics (eps file).
e- Supplemental Digital Content 5. Figure of the expected item score plots (eps file).
f- Supplemental Digital Content 6. Table of results of the analyses using the standard IRTLRDIF for comparison with the proposed permutation method (doc file).