

Abstract
In this paper, we develop a Bayesian approach to estimate a Cox proportional hazards model that allows a threshold in the regression coefficient based on a threshold in a covariate, when some fraction of subjects are not susceptible to the event of interest. A data augmentation scheme with latent binary cure indicators is adopted to simplify the Markov chain Monte Carlo implementation. Given the binary cure indicators, the Cox cure model reduces to a standard Cox model and a logistic regression model. Furthermore, the threshold detection problem reverts to a threshold problem in a regular Cox model. The baseline cumulative hazard for the Cox model is formulated non-parametrically using counting processes with a gamma process prior. Simulation studies demonstrate that the method provides accurate point and interval estimates. Application to a data set of Oropharynx cancer patients suggests a significant threshold in age at diagnosis such that the effect of gender on disease-specific survival changes after the threshold.
Keywords: threshold, Cox model, cure model, mixture model, Markov chain Monte Carlo
1. Introduction
This paper is motivated by a data set of patients with Oropharynx cancer. The clinicians suspect that gender is a prognostic factor for disease-specific survival. However, the Kaplan Meier curves of females and males overlap at early times and cross during the follow-up, which suggests no difference in survival between males and females. But for a cohort of young patients, males tend to have worse survival than females. This seems to indicate a potential threshold in the age of diagnosis such that the gender effect is different below this threshold than above it. Further inspection of the data reveals that the Kaplan Meier survival curve levels off to about 0.7. The stable plateau at the tail may be taken as empirical evidence of a cured fraction. The use of standard survival analysis for detection of the threshold may be inappropriate since not all patients will die of Oropharynx cancer. To this end, we propose a survival model that allows for a threshold in the age of diagnosis to investigate a potential interaction between age and gender when a fraction of patients are cured.
Motivated by the Oropharynx cancer data set, but not limited to it, this model has broad application in biomedical studies. For example, physicians will rely on a threshold in a biomarker or combination of biomarker signatures to guide the choice of therapy for an individual patient. The therapy targeting a specific biomarker generally will work effectively for patients when that biomarker is highly expressed, and thus it is convenient to find a threshold in the biomarker such that therapy should only be given to those patients with the biomarker levels exceeding the threshold. In general, better characterizing cancers at the molecular level will lead to more efficient treatment, and methodology to improve estimates of a threshold point will help this characterization.
Several authors considered a Cox model with an unknown threshold in the covariate. Liang et al. [1] and Pons [2] proposed approaches which can be used to study the model as described in the motivating example if no cure fraction is present in the data, where the influence of a covariate z1 (e.g. gender) jumps at a certain threshold of z2 (e.g. age). Luo and Boyett [3] studied a model where a constant is added to the regression on a covariate z1 after a threshold in z2. In this model, the baseline hazard changes after the threshold. Jensen and Lutkebohmert [4] and Kosorok and Song [5] considered a Cox-type regression model with a piecewise linear functional form of the covariates. However, the above models are not appropriate when a cured fraction is present in the population.
Othus et al. [6] estimated a threshold in a covariate in the cure model setting. They assume that there is a threshold in a covariate z2, where a sudden jump or fall occurs in the hazard value or cure probability. But their model is restricted to a simple binomial-exponential mixture model, in which a binomial model is used to estimate the cure rate and exponential distribution is used for the conditional survival. In this paper, we extend the threshold detection problem to a more general cure model in which a logistic regression is used to evaluate the effect of covariates on the cure rate and a standard proportional hazard model is used for the conditional survival. This mixture cure model (without threshold detection) has been studied by many authors [7, 8, 9], and they use EM type algorithms to compute the maximum likelihood estimates. We build on this previous research to implement a Bayesian estimation method for the Cox Proportional Hazards Cure Model, and extend it to allow a threshold in the regression coefficients. We will show that applying Bayesian methods in the mixture cure rate model is straightforward. Using a data augmentation scheme, the latent cure indicators are updated. As we demonstrate below, conditional on these indicators, the cure model reduces to a standard Cox model and a standard logistic regression model. Furthermore, our ultimate goal of detecting a threshold is simplified to a threshold problem in the regular Cox or logistic regression model.
The rest of the article is organized as follows: Section 2 outlines the model; Section 3 presents the Bayesian estimation and evaluation of model fit; Section 4 provides simulation studies; the analysis of the Oropharynx cancer data is presented in Section 5; the paper ends with a discussion in Section 6.
2. Model Description
The survival time, T, is assumed to be T = υT* + (1 − υ)∞, where υ is an indicator of whether a subject will eventually (υ = 1) or never (υ = 0) experience the event, and T* denotes the failure time if the subject is not cured. S(t|υ = 1) is the conditional survival function for patients who will experience the event, often called the latency distribution. The marginal survival function is S(t) = c + (1 − c)S(t|υ = 1), where c = P(υ = 0).
We consider a Cox proportional hazard model in the latency part of the cure model. Similar to Liang, Self and Liu (1990) and Pons (2003), a threshold, τ, could be present in a time-independent covariate z2 and the effect of z1 changes after τ, specifically,
| (1) |
where I(z2 ≤ τ) is a generic indicator function, which takes value of 1 if z2 ≤ τ. β1 represents the effect of z1 for z2 ≤ τ, and β2 represents the effect of z1 for z2 > τ. z0 is a vector of baseline covariates. Let β = (β0, β1, β2) and z̃(τ) = (z0, z1 I(z2 ≤ τ), z1 I(z2 > τ)), and z0 could include z2, but is distinct from z1. Λ0(t) is an unspecified cumulative baseline hazard function. S(t|z̃(τ), υ = 1) = exp{−Λ(t|z̃(τ), υ = 1)}.
A cure fraction c is modelled by a logistic regression or a probit model. In logistic regression, , and the vector of covariates x includes the intercept. In a probit model, c(x) = Φ(γx), and Φ is the CDF of a standard normal distribution. These models can be extended to include a threshold in a covariate similar to that in the latency model.
3. Bayesian Estimation and Model Selection
In practice, we observe (ti, δi, xi, zi), and i = 1, ⋯, n, where ti, denotes the observed survival time for the ith patient, δi is 0 if ti is censored and 1 otherwise and zi = (z0i, z1i, z2i) is a vector of covariates that may associate with the risk of experiencing the event, and xi is a vector of covariates associated with the chance of cure. xi and zi could be identical.
It follows that, υi = 1 if δi = 1, but if δi = 0, υi is unknown and it can be one or zero. The probability that a censored patient will eventually experience the event is given by
| (2) |
In Bayesian sampling, a data augmentation algorithm, described by Smith and Roberts [10] and Diebolt and Roberts [11], arises naturally for estimating the missing data, which in this case is an indicator of whether the patient is cured or uncured. A vector of υ = (υ1, ⋯, vn) is introduced as a vector of latent Bernoulli random variables. For patient i with δi = 0, υi ∼ Bernoulli(pυi). Conditional on the vector of (υ1, ⋯, υn), the model reduces to the standard Cox model for patients with υi = 1. In the incidence part, the model reduces to the standard logistic regression model, in which the vector of (υ1, ⋯, υn) is regressed on covariates (x1, ⋯, xn).
3.1. Bayesian Inference
We formulate the standard Cox model using counting processes ([12]). Let Ni(t) be the number of events occurred up to time t. Let λi(t) be the intensity function of Ni(t), i.e. E(dNi(t)|ℱ−t) = λi(t)dt, where dNi(t) is the increment of Ni over the small time interval [t, t + dt). If subject i experiences the event during this interval, dNi(t) will take the value 1, otherwise dNi(t) is 0. ℱ−t represents the available data just before time t. Then the proportional hazards model takes the form λi(t) = Yi(t)λ0(t) exp{βz̃i(τ)}, where Yi(t) is one if subject i is under observation at time t and zero otherwise.
The counting process increments dNi(t) in the time interval [t, t + dt) are assumed to be independent Poisson random variables with means λi(t)dt = Yi(t) exp{βz̃i(τ)}dΛ0(t), where dΛ0(t) is the increment in the cumulative baseline hazard function during the time interval [t, t + dt). Given υ, the formulation for the latency applies only to patients with υi = 1.
The time intervals are constructed based on the ordered distinct event times, {sj; j = 1, ⋯, J}, where J is the total number of distinct times, sJ is the maximum observed event time, and sJ+1 is infinity. The observed data D is assumed to be available within these intervals, such that D = {ℛj,
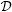 j, zi, j = 1, ⋯, J; i = 1, ⋯, n}, where ℛj is the risk set and
j is the event set in interval [sj, sj+1). Let θ = (β, dΛ0(j), j = 1,⋯, J), the likelihood function for the above model is
j, zi, j = 1, ⋯, J; i = 1, ⋯, n}, where ℛj is the risk set and
j is the event set in interval [sj, sj+1). Let θ = (β, dΛ0(j), j = 1,⋯, J), the likelihood function for the above model is
where
| (3) |
The gamma process is used as a prior for the cumulative baseline hazard function Λ0 [13]. That is , where is often assumed to be a known parametric function. For example, corresponds to the Weibull distribution, and c0 represents the degree of confidence in this prior guess. The prior distribution for β ∼ MVN(μ0, Σ0), where μ0 and Σ0 are pre-specified.
In this study, τ is a parameter to be estimated from the data. Let z2(1) < z2(2) < ⋯, < z2(K−1) be distinct ordered values of z2i, i = 1, ⋯, n, and z2(K) is the largest value of z2. We propose to sample τ in two steps. The first step follows the work of Carlin et al. [14] and Lange et al. [15], in which the threshold is treated as a discrete variable in an application to simple regression models and Poisson processes. We first sample τ from a categorical distribution taking the value z2(k) with probability πk; that is,
| (4) |
Given the intervals, the distribution of τ is assumed to be continuous with a uniform distribution, z2(1) < τ < z2(K). Thus having obtained a draw of z2(k) in step one, we will sample τ from Uniform [z2(k), z2(k+1)] in the second step, which will result in a continuous posterior distribution of τ.
As an alternative to the above Gibbs sampling approach, we can directly consider τ as a continuous variable, and the conditional posterior density of τ can be written as
We use the Adaptive Metropolis algorithm [16] to sample τ. Specifically, we consider the proposal distribution given at iteration l by
where τ* is a candidate value for τ simulated from proposal Q(l)(τ*,.). is the empirical estimate of the variance of the target distribution based on the entire history up to lth iteration. As suggested in Roberts and Rosenthal [16], we take B to be 0.05.
When no threshold is present in the model, τ is not identifiable [17]. It is possible to estimate the existence of a threshold in a mixture model as described by Skates et al. [18], in which Reversible Jump MCMC was used to move between a linear model with no threshold and a model with a threshold. But in our more complicated setting of a Cox model with a cured fraction, we have considered two other strategies to evaluate the presence of a threshold. First, we use model selection criteria to compare the models with and without a threshold. Second, we constrain τ in the range (min(z2), max(z2)), and let the non-identifiability be reflected in the posterior distribution of τ and β2 − β1. Our goal is to identify a sharp estimate of τ when the data clearly indicate a threshold. When the data do not clearly indicate a threshold, estimates of τ would have large uncertainty, and the contrast parameter of β2 − β1 would be close to zero.
We can thus carry out the following hybrid Gibbs sampling scheme:
-
Sample υi ∼ Bernouli(pυi) for patients with δ = 0, where pυi is defined as in (2).
Steps 2-4 are applied for patients with υi = 1.
-
Sample from
using Random Walk Metropolis algorithm as developed by Haario et al. [19].
-
Sample Λ0(j), j = 1, ⋯, J as
where dj is the number of events in [sj, sj+1).
Sample τ as defined in (4), or sample τ using the Adaptive Metropolis algorithm as developed by Roberts and Rosenthal [16].
Sample γ using Random Walk Metropolis algorithm [19] in the logistic regression model. For a probit model, the truncated normal sampling approach proposed by Albert and Chib[20], can be used. A multivariate normal prior was used for γ.
Update and , and update pυi as a function of c(xi) and S(ti|z̃i(τ), υi = 1). If there is no covariate in the incidence model, we can estimate the cure rate c by a logistic regression model with just an intercept or simply averaging over the indicator variables υ1, ⋯, υn.
3.2. Model Selection
We computed two Bayesian model comparison criterions for selecting the best model. To alleviate the concern that the standard Deviance Information Criterion (DIC) measure ([21]) does not properly reflect the correct effective number of parameters in mixture models, Celeux [22] recommended a modified DIC, termed DIC3, which estimates D(E[θ|y]) using the posterior mean of the observed likelihood averaged across the cured and uncured subjects. Specifically,
f(l)(yi) is approximated by
where m is the number of draws of the posterior distribution. , , and S(l) (ti|z̃i(τ), υi = 1) are the values of the parameters for the lth draw.
The log-pseudo marginal likelihood (LPML) ([23]) is a cross-validated leave-one-out measure of a models ability to predict the data. It is valid for small and large samples and does not suffer from a heuristic justification based on large sample normality. LPML is defined based on the conditional predictive ordinate (CPO) statistic for the ith observation, and CPOi is given by CPOi = f(Di|D(−i)), where Di denote the ith observation, and D(−i) denote the data with ith observation deleted. The log of the product of the CPO statistics under a given model is the LPML statistic for that model, . The model with larger LPML is preferred. A Monte Carlo approximation of CPOi is given by Chen et al. [24]: .
4. Simulations
Simulation studies were conducted to evaluate the proposed approach. All simulations consist of 1000 experimental replications, each with sample size of n = 200 or n = 400. Survival times, T, are generated from a logistic-exponential mixture model, where c(z) = (1 + exp(−γ1 − γ2z1 − γ3z2))−1, and S(t|υ = 1; z) = exp{−exp(β0z2 + β1z1I(z2 ≤ τ) + β2z1I(z2 > τ))t}. In this formulation, the baseline hazard function is constant with a rate of one. z1 and z2 are fixed by design. z1 = 0.5 for half of the sample size and z1 = −0.5 for the other half, and the covariate z2 is generated from uniform[0,10]. The τ is assumed to be 3, 5, 7, or 15 in which no threshold is present. Each subject is followed up until at most time = 5. Censoring times C are generated from an exponential distribution with censoring rate of 4.5. The data for each observation are (t, δ, z1, z2), where t = min(T, C, 5). With the choices of the parameters listed in Table 1, the expected censoring proportion including those cured is around 0.54 and the observed cure rate is around 0.43.
Table 1. List of parameters used in simulation and performance statistics.
| Parameter | True | Mean(ESE)a | SSEb | MSEc | CP d | Mean(ESE) | SSE | MSE | CP |
|---|---|---|---|---|---|---|---|---|---|
| n = 200 | n = 400 | ||||||||
|
|
|
||||||||
| τ | 5 | 5.01(0.98) | 0.72 | 0.52 | 95 | 5.00(0.39) | 0.39 | 0.15 | 96 |
| β0 | 0.05 | 0.05(0.04) | 0.04 | .002 | 95 | 0.05(0.03) | 0.03 | .001 | 94 |
| β1 | -1 | -0.98(0.50) | 0.51 | 0.26 | 95 | -0.97(0.29) | 0.29 | 0.08 | 95 |
| β2 | 1 | 1.02(0.40) | 0.40 | 0.16 | 94 | 1.00(0.24) | 0.23 | 0.05 | 95 |
| γ1 | 0.2 | 0.21(0.35) | 0.36 | 0.13 | 95 | 0.22(0.24) | 0.25 | 0.06 | 93 |
| γ2 | 0.5 | 0.57(0.35) | 0.36 | 0.13 | 94 | 0.52 (0.24) | 0.24 | 0.06 | 93 |
| γ3 | -0.1 | -0.11(0.06) | 0.06 | .004 | 95 | -0.10(0.04) | 0.04 | .002 | 93 |
| β2 − β1 | 2 | 2.00(0.64) | 0.63 | 0.40 | 96 | 1.97(0.37) | 0.37 | 0.14 | 97 |
| τ | 7 | 6.65(1.03) | 0.80 | 0.77 | 96 | 6.96(0.39) | 0.37 | 0.14 | 95 |
| β0 | 0.05 | 0.05(0.04) | 0.04 | .002 | 95 | 0.05(0.03) | 0.03 | .002 | 95 |
| β1 | -1 | -1.00(0.44) | 0.44 | 0.19 | 96 | -0.97(0.23) | 0.24 | 0.06 | 94 |
| β2 | 1 | 0.98(0.53) | 0.60 | 0.36 | 94 | 1.01(0.31) | 0.31 | 0.10 | 95 |
| γ1 | 0.2 | 0.21(0.35) | 0.36 | 0.13 | 95 | 0.22(0.24) | 0.25 | 0.06 | 93 |
| γ2 | 0.5 | 0.58(0.35) | 0.36 | 0.14 | 94 | 0.53(0.24) | 0.24 | 0.06 | 94 |
| γ3 | -0.1 | -0.11(0.06) | 0.06 | .004 | 95 | -0.10(0.04) | 0.04 | .001 | 94 |
| β2 − β1 | 2 | 1.98(0.70) | 0.75 | 0.57 | 96 | 1.98(0.38) | 0.39 | 0.15 | 96 |
| τ | 3 | 3.56(1.33) | 1.00 | 1.32 | 96 | 3.15(0.58) | 0.59 | 0.37 | 95 |
| β0 | 0.05 | 0.05(0.04) | 0.04 | .002 | 96 | 0.05(0.03) | 0.03 | .001 | 94 |
| β1 | -1 | -0.89(0.75) | 0.84 | 0.71 | 93 | -0.93(0.41) | 0.41 | 0.17 | 94 |
| β2 | 1 | 1.03(0.41) | 0.43 | 0.19 | 96 | 0.99(0.22) | 0.25 | 0.06 | 95 |
| γ1 | 0.2 | 0.20(0.35) | 0.35 | 0.12 | 95 | 0.21(0.24) | 0.25 | 0.06 | 93 |
| γ2 | 0.5 | 0.55(0.36) | 0.37 | 0.14 | 94 | 0.50(0.24) | 0.24 | 0.06 | 94 |
| γ3 | -0.1 | -0.10(0.06) | 0.06 | .004 | 95 | -0.10(0.04) | 0.04 | 0.00 | 93 |
| β2 − β1 | 2 | 1.91(0.86) | 0.94 | 0.89 | 97 | 1.93(0.46) | 0.49 | 0.25 | 95 |
| τ | No | 4.89(2.81) | 1.36 | – | – | 4.89(2.86) | 1.40 | – | – |
| β0 | 0.05 | 0.05(0.04) | 0.04 | .002 | 95 | 0.05(0.03) | 0.03 | .001 | 94 |
| β1 | -1 | -0.97(1.01) | 1.03 | 1.06 | 97 | -1.03(0.79) | 0.79 | 0.62 | 98 |
| β2 | -1 | -0.99(0.85) | 0.94 | 0.89 | 98 | -1.01(0.63) | 0.81 | 0.66 | 97 |
| γ1 | 0.2 | 0.21(0.35) | 0.35 | 0.13 | 94 | 0.22(0.24) | 0.25 | 0.06 | 94 |
| γ2 | 0.5 | 0.58(0.35) | 0.36 | 0.14 | 94 | 0.55(0.24) | 0.24 | 0.06 | 94 |
| γ3 | -0.1 | -0.11(0.06) | 0.06 | .004 | 95 | -0.10(0.04) | 0.04 | .002 | 93 |
| β2 − β1 | 0 | -0.02(1.45) | 1.42 | 2.01 | 95 | 0.02(1.13) | 1.15 | 1.31 | 96 |
average of the posterior means over 1000 data sets (average of the posterior standard deviations over the 1000 data sets)
standard deviation of the posterior means across 1000 data sets
mean square error
coverage of the 95 percentage highest posterior density (HPD) interval
The models were implemented in R. A Multivariate t-distribution with a degree of freedom of 3 was used as the proposal density in the random-walk Metropolis algorithm in sampling β and γ. The proposal density centered at the previous value, and the covariance was adaptive as developed by Haario [19], which uses the empirical covariance from an extended burn-in period. We proposed two algorithms to estimate the threshold. We found that the Adaptive Metropolis algorithm in Step 4 perform better than the discrete algorithm. For the rest of this article, the Adaptive Metropolis algorithm in Step 4 is used. Patients who survive after the last observed survival time are considered as cured in the estimation procedure. We observed that the chain mixes well. The priors are quite vague relative to the likelihood: a vector of 0's is the prior mean of β and γ; Σ0 is the prior covariance matrix with 100 on the diagonal for β and γ; In the gamma process prior,
is assumed to have an exponential distribution (k0 = 1) with η = 0.1 and c0 = 0.1, namely, dΛ0(j) ∼
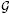 (0.1 × 0.1(sj+1 − sj), 0.1). The value of 0.1 for η underestimates the true value of η, but a small c0 of 0.1 gives large uncertainty about this η.
(0.1 × 0.1(sj+1 − sj), 0.1). The value of 0.1 for η underestimates the true value of η, but a small c0 of 0.1 gives large uncertainty about this η.
With a burn-in of 5000 iterations, an additional 10000 iterations were used for inference. Results from Table 1 indicate that the proposed model accurately estimates the true values of all the parameters regardless of different values of τ. The accuracy is further improved when sample size is increased to n = 400, as evidenced by significantly reduced standard deviations and MSE given about 95% coverage probability.
In the last scenario where no threshold is present in z2, the mean of τ is around 5 which is in the middle of the range z2 from 0 to 10, but with large standard deviations (ESE ≈ 3). The reason is that τ is constrained to be in the range of z2 in each Gibbs sampling step, thereby leading to an average z2 to be the estimate of τ, and the standard deviation is increased when n is increased to 400. Furthermore, the hypothesis of no threshold is strengthened by testing the contrast of β2 − β1 (the point estimates are very close to zero: -0.02 with n = 200 and 0.02 with n = 400;). From 1000 experimental replications, the 95% HPD intervals of the contrast include zero for about 95% of the times.
As a rule of thumb, if two models differ in DIC by more than three, the one with smaller DIC is preferred as the best fitting [21]. Based on both DIC3 and LPML, threshold models are preferred to the models which ignore the threshold (called non-threshold model) when a threshold is truly present. For example, when τ = 5, 88% (based on DIC3) and 80%(based on LPML) of the time the threshold model is chosen over the non-threshold model. In all cases studied, the correct models are chosen more frequently when n is increased to 400. When there is truly no threshold, DIC3 tends to prefer the simpler non-threshold model, evidenced by the non-threshold model chosen over the threshold model 92% (100%-8%) of the time. In contrast, LPML seems to have no penalty for more complicated models; half of the time the threshold model is chosen although no threshold is present. In addition, using three as a threshold for DIC3 comparisons seems to yield reasonable type I and II errors.
Normal priors for β and γ are routinely used in the regression models. In this application, we adopted very vague priors for these parameters (relative to the likelihood) in the above simulation studies and the oropharynx cancer example in the next section. However, the posterior distribution of τ could be sensitive to the gamma process prior. This prior consists of an initial estimate of the cumulative baseline hazard function , and a precision c0. In reality, an exponential distribution of is used mostly for convenience. It is easy to have a prior guess on the average event rate and assume it to be constant in the study period. Therefore, it is important to evaluate the robustness of the exponential distribution in the proposed model. For this purpose, we repeated the above simulation when τ = 5, and generated the baseline hazard function from three Weibull distributions: Scenario I: Weibull(0.9, 1.33), Scenario II: Weibull(1.1, 0.8) and Scenario III: Weibull(1, 1), where a is a scale parameter and b is a shape parameter in Weibull(a, b). In all the three scenarios, the average rate is one. We then applied the proposed model using an exponential distribution for with a rate equal to 1 (the same as the true rate) or 0.1 (much lower than the true rate). We also varied the degree of confidence in the prior guess by considering c0 = 0.01, 0.1, 5, and 10.
As shown in Table 3, the exponential prior (when k0 = 1) works well even when the hazard function is not exponential, and using the Weibull distribution did not improve the performance even when the parameters in the Weibull prior are the same as the truth. The independent assumption between the disjoint intervals in the posterior inference makes the parametric form of the hazard function less important and the rate per interval more important. As expected, when η is incorrectly specified (e.g. η = 0.1), a large precision, c0, resulted in considerably increased bias, ESE and MSE.
Table 3. Performance of τ under different gamma process priors.
| Scenario | Priora | Mean(Bias)b | ESEc | MSEd | CPe | ||
|---|---|---|---|---|---|---|---|
| η | k0 | c0 | |||||
| I | 0.1 | 1 | 0.01 | 4.97 (0.45) | 0.90 | 0.48 | 95 |
| 1 | 1 | 0.01 | 5.00 (0.04) | 0.90 | 0.49 | 95 | |
| 0.1 | 1 | 0.1 | 4.99 (0.11) | 0.91 | 0.47 | 95 | |
| 1 | 1 | 0.1 | 5.00 (.001) | 0.90 | 0.50 | 95 | |
| 0.1 | 1 | 5 | 4.93 (1.47) | 1.08 | 0.50 | 97 | |
| 1 | 1 | 5 | 5.02 (0.36) | 0.90 | 0.47 | 96 | |
| 0.1 | 1 | 10 | 4.84 (3.16) | 1.13 | 0.59 | 96 | |
| 1 | 1 | 10 | 5.00 (.008) | 0.91 | 0.44 | 96 | |
| *0.9 | 1.33 | 0.1 | 4.99 (0.12) | 0.88 | 0.46 | 96 | |
| *0.9 | 1.33 | 5 | 5.00 (0.09) | 0.79 | 0.52 | 94 | |
| II | 0.1 1 | 0.01 | 4.99 (0.11) | 1.06 | 0.55 | 96 | |
| 1 | 1 | 0.01 | 5.00 (0.04) | 1.05 | 0.54 | 96 | |
| 0.1 | 1 | 0.1 | 1.99 (0.23) | 1.07 | 0.50 | 96 | |
| 1 | 1 | 0.1 | 5.00 (0.09) | 1.05 | 0.52 | 96 | |
| 0.1 | 1 | 5 | 4.89 (2.20) | 1.15 | 0.54 | 97 | |
| 1 | 1 | 5 | 5.02 (0.34) | 0.98 | 0.53 | 96 | |
| 0.1 | 1 | 10 | 4.83 (3.42) | 1.17 | 0.69 | 97 | |
| 1 | 1 | 10 | 5.01 (0.26) | 0.95 | 0.50 | 95 | |
| *1.1 | 0.8 | 0.1 | 4.99 (0.24) | 1.05 | 0.51 | 96 | |
| *1.1 | 0.8 | 5 | 5.01 (0.17) | 1.05 | 0.58 | 97 | |
| III | 0.1 | 1 | 0.01 | 4.99 (0.21) | 0.97 | 0.49 | 96 |
| *1 | 1 | 0.01 | 5.00 (0.08) | 0.97 | 0.54 | 96 | |
| 0.1 | 1 | 0.1 | 5.01 (0.07) | 0.98 | 0.52 | 95 | |
| 1 | 1 | 0.1 | 4.99 (0.23) | 0.98 | 0.51 | 95 | |
| 0.1 | 1 | 5 | 4.92 (1.75) | 1.11 | 0.53 | 97 | |
| *1 | 1 | 5 | 5.01 (0.28) | 0.93 | 0.53 | 95 | |
| 0.1 | 1 | 10 | 4.82 (3.43) | 1.14 | 0.60 | 97 | |
| *1 | 1 | 10 | 5.00 (.007) | 0.92 | 0.50 | 95 | |
scenarios denoted by * are those when the prior matches the true distribution
average of the posterior means over 1000 data sets (bias is defined as |(Mean − 5)/5 × 100|)
average of the posterior standard deviation over 1000 data sets
mean square error
coverage of the 95 percentage HPD interval
5. Oropharynx Cancer Example
We now elaborate on and analyze the data from the motivating example in Section 1. The data was collected from 220 patients with Oropharynx cancer enrolled in the University of Michigan Head and Neck Cancer Specialized Programs of Research Excellence during the years 2003 to 2008. Of the 220 patients, 84 died, 55 of whom died from oral cavity cancer, and the remaining 136 were alive at the end of follow-up. Of the 220 patients, 36 are female and 184 are male; 11 patients had stage II, 37 had stage III and 172 had stage IV. The mean age is 58 (range from 22 to 86). A K-M survival curve (Figure 1) for the whole data set has a level region beyond about 60 months, which may indicate the appropriateness of a cure model. Patients who survive after the last observed survival time are considered as cured in our mixture model, which effectively eliminates the problem of lack of identifiability [25].
Figure 1. Kaplan Meier disease-specific survival plots for all ages.

The priors for β and γ are the same as in the simulation studies. They are very vague relative to the likelihood. To construct a reasonable prior for the baseline hazard, we fit our proposed model using data from all head and neck cancer patients excluding the Oropharynx cancer patients (n = 256), we obtained an estimate of 0.1 for the baseline hazard rate of η assuming the hazard is constant over time (a similar strategy was used in Ibrahim et al. [26] to construct a prior for the baseline hazard rate). We then set c0 to be 0.01 to reflect the uncertainty of our estimate of the hazard rate in the Oropharynx population. The prior for the other parameters are the same as in the simulation studies. With a burn-in of 20000 iterations, an additional 20000 iterations were used for inference. We observed that the chain mixes well and the results are robust to different choices of the initial values.
As shown in Table 4, there is no difference in disease-specific survival between females and males when age is not considered (see Model 1). However, a significant gender effect is revealed when the analysis is conditional on age. Model 2 indicates an interaction between gender and age in the latency and Model 3 provides an estimate of a threshold in age such that the gender effect changes after the threshold. Both DIC and LPML favor models that considered the interaction between age and gender (see Table 5). Model 1 has significantly higher DIC and lower LPML than other models. Although Model 2 has slightly lower DIC than Model 3, the two models are considered to fit the data equally well using the cutoff of three (the choice of three is good in terms of the desired error rates as shown in the above simulation studies). The slightly higher LPML in model 2 seems to suggest that fitting the interaction using the continuous age is better than dichotomizing the age, however, a threshold can be important in clinical practice as emphasized in the introduction. We are willing to trade a little bit of goodness of fit of the model for a useful application, and this slight sacrifice is negligible in terms of the pseudo Bayes factor for comparing Model 2 to Model 3, defined as PBF23 = exp(LPML2 − LPML3) = 2.7 ([27]). In Model 3, the point estimate of τ is 65, and males have significantly better prognosis in disease-specific survival for patients younger than τ, and females have significantly better prognosis for patients older than τ (95 % HPD interval of the contrast β2 − β1 is (1.8, 7.4)). Figure 2 presents the switched gender effect conditional on the point estimate of the threshold. This significant gender effect will not be detected when a threshold model is not considered.
Table 4. Parameter estimates and performance statistics for the Oropharynx cancer example.
| Covariate | Mean | SE | 95% HPD | |
|---|---|---|---|---|
| Model 1: Mixture cure model | ||||
| Latency | Sex (F vs M) | -0.16 | 0.54 | (-1.23, 0.85) |
| Age | -0.003 | 0.02 | (-0.04, 0.03) | |
| Stage | -0.13 | 0.42 | (-0.92, 0.74) | |
| Incidence | Sex(F vs M) | 0.28 | 0.56 | (-0.83, 1.45) |
| Age | -0.008 | 0.02 | (-0.04, 0.03) | |
| Stage | -0.34 | 0.49 | (-1.24, 0.68) | |
| Model 2: Mixture cure model with an interaction | ||||
| Latency | Sex(F vs M) | 0.002 | 0.56 | (-1.02, 1.08) |
| Age | 0.001 | 0.02 | (-0.03, 0.03) | |
| Stage | 0.13 | 0.44 | (-0.71, 1.03) | |
| Sex × Age | -0.18 | 0.05 | (-0.28, -0.09) | |
| Incidence | Sex(F vs M) | 0.28 | 0.52 | (-0.78, 1.30) |
| Age | -0.01 | 0.02 | (-0.04, 0.03) | |
| Stage | -0.20 | 0.45 | (-1.10, 0.66) | |
| Model 3: Mixture cure model with a threshold | ||||
| Latency | Threshold (τ) | 65 | 7 | (51,75) |
| Sex(age≤ τ)(F vs M) | 1.50 | 0.73 | (0.04, 2.91) | |
| Sex(age> τ)(F vs M) | -2.92 | 1.38 | (-5.45, -0.17) | |
| Age | 0.001 | 0.02 | (-0.03, 0.04) | |
| Stage | 0.03 | 0.45 | (-0.78, 0.95) | |
| Incidence | Sex (F vs M) | 0.35 | 0.52 | (-0.61, 1.36) |
| Age | -0.008 | 0.02 | (-0.04, 0.02) | |
| Stage | -0.26 | 0.44 | (-1.04, 0.67) | |
Table 5. Model Comparisons.
| Models | DIC3 (pD) | LPML |
|---|---|---|
| Model 1 | 795(66) | -470 |
| Model 2 | 780(65) | -464 |
| Model 3 | 783(66) | -466 |
| Model 4 | 788(66) | -467 |
| Model 5 | 794(66) | -475 |
| Model 6 | 781(66) | -464 |
| Model 7 | 783(66) | -465 |
Figure 2. (a) Kaplan Meier disease-specific survival plots for patients younger or equal to 65 (point estimate of τ) (b) Kaplan Meier disease-specific survival plots for patients older than 65.

To validate the presence of a cure fraction, we fitted the data using a regular Cox regression model with a threshold in age (called Model 4), namely, a Model 3 without the incidence part. A considerably increased DIC3 of 788, compared to Model 3, indicates that the model with a cure fraction is a good choice. Without the cure fraction, we did not find a clear threshold in age, as evidenced by a large 95 % HPD interval in τ ranging from 28 to 85. The gender effect before and after the τ is estimated with a large variance caused by the large uncertainty in estimating τ (results not shown).
In this application, we also considered three other models to evaluate the potential threshold of age in incidence. Model 5 assumes a threshold in the incidence rather than in the latency. A large DIC of 794 and a large 95 % HPD interval of τ from age 27 to 86 supports the absence of a threshold in age in the incidence. Model 6 adds an additional interaction of age and gender in incidence to Model 2. The interaction in the incidence is not significant, the 95 % HPD interval of the interaction is (-0.05, 0.13), and both the DIC and LPML are very close to Model 2. Based on Model 3, Model 7 updates the parameters in the logistic regression given each realization of the threshold in latency. That is, Model 7 assumes the same threshold in latency exists in incidence. Again the gender effect is similar before and after the threshold in incidence, and both the DIC and LPML are very close to Model 3. The two stable plateaus in the KM curves are not statistically different in both Figure 2(a) and Figure 2(b), which seems to further confirm that no threshold is present in the incidence. The results for Model 6-7 were not shown since the parameter estimations are similar to Model 2 and 3 respectively.
6. Discussion
In this paper, we develop a Bayesian approach to estimate a Cox Proportional Hazards Cure Model and extend the Cox model to allow a threshold in the regression coefficient. Personalized therapy is the future of oncology drug development. Dichotomizing a continuous biomarker is a common practice in clinical research because it facilitates a decision to be made about which therapy to give, and is easy to include in protocols. Compared to other methods in finding the optimal threshold for categorizing continuous variable by maximizing some likelihood function or test statistic [28, 29], our method has the advantages of 1) taking into account the sampling variation in estimating the threshold, as well as other parameters in the model that depend on the variable threshold; 2) obtaining a distribution of the threshold; 3) adjusting for other prognostic variables when estimating the threshold; 4) directly testing the absence or presence of a threshold; 5) evaluating the assumption of a sudden jump of a covariate at the threshold by comparing to a model with an interaction term using model selection criterions.
The introduction of the latent Bernoulli cure indicators greatly facilitates the MCMC algorithm. Given the indicators, the latency and incidence can be evaluated separately using standard methods, and the threshold detection problem reverts to a problem in the Cox model. Chen et al. [30] noted that Bayesian inference for a mixture cure model requires proper priors to avoid the possibility of improper posterior distributions. We avoid this issue by using very mildly informative but proper priors.
In this study, we are interested in a threshold in the latency. We found that the MCMC algorithm had high autocorrelation and slow convergence when we tried to estimate a threshold in both latency and incidence for the same covariate. If the threshold in the latency model is your primary interest, you can simply update the parameters in the logistic regression given each realization of the threshold in latency, as describe in Model 5 in the oropharynx cancer example.
In this paper, we have used a mixture cure model in which covariate effects are separately considered for incidence and latency, and thus the the threshold effect on covariates can also be considered separately on incidence and latency. We believe that a covariate that is important for long-term incidence may not be important for latency and vice versa. We did not consider this threshold detection problem in the Bounded Cumulative Hazard cure model [30, 26, 31, 32, 33]. But it would be a nice alternative cure model if you believe that a covariate is equally important in both latency and incidence.
The parameter estimates (point or interval estimates) are calculated using the MCMC iterations from the proposed model rather than based on asymptotic approximation as in frequentist approaches. Moreover, estimates of the contrast β2 − β1 can be calculated easily to evaluate the existence of a threshold. This ad-hoc way of testing presence or absence of a threshold combined with the model selection criterions works well in our study.
In this application, we estimate a threshold in a continuous variable such that the effect of a dichotomized variable changes before and after the threshold. With some modification of the design matrix X, this method can be used to estimate a changepoint in a covariate as described in Jensen and Lutkebohmert [4], where the covariate effect has a piecewise linear functional form. Extensions to multiple threshold detection using Reversible Jump MCMC [34] will be the subject of future research.
Table 2. % of times threshold model is chosen over non-threshold model.
| Selection Criterior | n | τ = 3 | τ = 5 | τ = 7 | No threshold |
|---|---|---|---|---|---|
| DIC3a | |||||
| 200 | 75 | 88 | 86 | 8 | |
| 400 | 97 | 100 | 100 | 6 | |
| LPML | |||||
| 200 | 75 | 80 | 80 | 50 | |
| 400 | 86 | 93 | 93 | 50 |
In DIC3, threshold model is selected if its DIC3 is less than the non-threshold model by more than three.
Acknowledgments
This work was partially supported by the University of Michigan Head and Neck Cancer Specialized Program of Research Excellence, grant number CA097248
References
- 1.Liang K, Self S, Liu X. The Cox proportional hazards model with change point An epidemiologic application. Biometrics. 1990;79:783–793. doi: 10.2307/2532096. [DOI] [PubMed] [Google Scholar]
- 2.Pons O. Estimation in a Cox regression model with a change-point according to a threshold in a covariate. Ann Statist. 2003;56:442–463. doi: 10.1214/aos/1051027876. [DOI] [Google Scholar]
- 3.Luo X, Boyett J. Estimation of a threshold parameter in Cox regression. Comm Statist Theory Methods. 1997;26:2329–2346. doi: 10.1093/biomet/79.3.531. [DOI] [Google Scholar]
- 4.Jensen U, Lutkebohmert C. A Cox-type regression model with change-points in the covariates. Lifetime Data Anal. 2008;14:276–285. doi: 10.1007/s10985-008-9083-3. [DOI] [PubMed] [Google Scholar]
- 5.Kosorok M, Song R. Inference under right censoring for transformation models with a change-point based on a covariate threshold. Ann Statist. 2007;35:957–989. doi: 10.1214/009053606000001244. [DOI] [Google Scholar]
- 6.Othus M, Li Y, Tiwari R. Change-point cure models with application to estimating the changepoint effect of age of diagnosis among prostate cancer patients. Journal of Applied Statistics. 2011;00:00. doi: 10.1080/02664763.2011.626849. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Kuk A, Chen C. A mixture model combining logistic regression with proportional hazards regression. Biometrika. 1992;79:531–541. doi: 10.1093/biomet/79.3.531. [DOI] [Google Scholar]
- 8.Peng Y, Dear K. A nonparametric mixture model for cure rate estimation. Biometrics. 2000;56:237–243. doi: 10.1111/j.0006-341x.2000.00237.x. doi:j.0006-341X.2000.00237.x. [DOI] [PubMed] [Google Scholar]
- 9.Sy J, Taylor J. Estimation in a Cox proportional hazards cure model. Biometrics. 2000;56:227–236. doi: 10.1111/j.0006-341x.2000.00227.x. doi:j.0006-341X.2000.00227.x. [DOI] [PubMed] [Google Scholar]
- 10.Smith AFM, Roberts GO. Bayesian computation via the Gibbs sampler and related Markov Chain Monte Carlo methods. J R Statist Soc B. 1993;55:3–23. [Google Scholar]
- 11.Diebolt J, Roberts CP. Estimation of finite mixture distributions through Bayesian sampling. J R Statist Soc B. 1994;56:363–375. [Google Scholar]
- 12.Andersen PK, Gill RD. Cox's regression model for counting processes: A large sample study. Ann Statist. 1982;10:1100–1120. doi: 10.1214/aos/1176345976. [DOI] [Google Scholar]
- 13.Kalbfleisch J. Non-parametric Bayesian analysis of survival time data. Journal of the Royal Statistical Society Series B. 1978;40:214–221. [Google Scholar]
- 14.Carlin BP, Gelfand AE, Smith AFM. Hierarchical Bayesian analysis of changepoint problems. Journal of the Royal Statistical Society Series C-Applied Statistics. 1992;41:389–405. doi: 10.2307/2347570. [DOI] [Google Scholar]
- 15.Lange N, Carlin BP, Gelfand AE. Hierarchical Bayes models for the progression of HIV infection using longitudinal CD4 T-Cell numbers. Journal of the American Statistical Association. 1992;87:615–626. doi: 10.2307/2290197. [DOI] [Google Scholar]
- 16.Roberts GO, Rosenthal JS. Examples of adaptive MCMC. Journal of Computational and Graphical Statistics. 2009;18:349–367. doi: 10.1198/jcgs.2009.06134. [DOI] [Google Scholar]
- 17.Andrews DWK. Testing when a parameter is on the boundary of the maintained hypothesis. Econometrica. 2001;69:683–773. doi: 10.1111/1468-0262.00210. [DOI] [Google Scholar]
- 18.Skates SJ, Pauler DK, Jacobs IJ. Screening based on the risk of cancer calculation from Bayesian hierarchical changepoint and mixture models of longitudinal markers. Journal of the American Statistical Association. 2001;96:429–439. doi: 10.1198/016214501753168145. [DOI] [Google Scholar]
- 19.Haario H, Saksman S, Tamminen J. An adaptive Metropolis algorithm. Bernoulli. 2001;7:223–242. doi: 10.2307/3318737. [DOI] [Google Scholar]
- 20.Albert J, Chib S. Bayesian analysis of binary and polychotomous response data. Journal of the American Statistical Association. 1993;88:669–679. doi: 10.2307/2290350. [DOI] [Google Scholar]
- 21.Spiegelhalter DJ, Best NG, Carlin B, Van de Linde A. Bayesian measures of model complexity and fit (with discussion) Journal of the Royal Statistical Society. 2002;64:583–639. doi: 10.1111/1467-9868.00353. [DOI] [Google Scholar]
- 22.Celeux G, Forbes F, Robert C, Titterington D. Deviance information criteria for missing data models. Bayesian Analysis. 2006;1:651–674. doi: 10.1214/06-BA122. [DOI] [Google Scholar]
- 23.Ibrahim JG, Chen MH, Sinha D. Bayesian Survival Analysis. New York: Springer; 2001. [Google Scholar]
- 24.Chen MH, Shao Q, Ibrahim JG. Monte carlo Methods in Bayesian Computation. New York: Springer; 2000. [Google Scholar]
- 25.Taylor JMG. Semi-parametric estimation in failure time mixture models. Biometrics. 1995;51:899–907. doi: 10.2307/2532991. [DOI] [PubMed] [Google Scholar]
- 26.Ibrahim JG, Chen MH, MacEachern SN. Bayesian variable selection for proportional hazards models. The Canadian Journal of Statistics. 1999;27:701–717. doi: 10.2307/3316126. [DOI] [Google Scholar]
- 27.Hanson TE. Inference for mixtures of finite Polya tree models. Journal of the American Statistical Association. 2006;101:1548–1565. doi: 10.1198/016214506000000384. [DOI] [Google Scholar]
- 28.Clark GM, Dressler LG, Owens MA, Pound G, Oldaker T, McGuire W. Prediction of relapse or survival in patients with node-negative breast cancer by DNA fow cytometry. N Engl J Med. 1989;320:627. doi: 10.1056/NEJM198903093201003. [DOI] [PubMed] [Google Scholar]
- 29.Sigurdsson H, Baldetorp B, Borg A, Dalberg M, Ferno MM, Killander D, Olsson H. Flow cytometry in primary breast cancer: improving the prognostic value of the fraction of cells in the s-phase by optimal categorisation of cut-off levels. Br J Cancer. 1990;62:786. doi: 10.1038/bjc.1990.380. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Chen M, Ibrahim J, Sinha D. A new Bayesian model for survival data with a surviving fraction. Journal of the American Statistical Association. 1999;94:909–910. doi: 10.2307/2670006. [DOI] [Google Scholar]
- 31.Kim S, Chen MH, Dey DK, Gamerman D. Bayesian dynamic models for survival data with a cure fraction. Lifetime Data Anal. 2007;13:17–35. doi: 10.1007/s10985-006-9028-7. doi:s10985-006-9028-7. [DOI] [PubMed] [Google Scholar]
- 32.Tighiouart M. Modeling correlated time-varying covariate effects in a Cox-type regression model. J Modern Appl Stat Meth. 2003;2:161–167. [Google Scholar]
- 33.Tsodikov A, Ibrahim JG, Yakovlev AY. Estimating cure rates from survival data: an alternative to two-component mixture models. Journal of the American Statistical Association. 2003;98:1063–1078. doi: 10.1198/01622145030000001007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Green PJ. Reversible-jump Markov Chain Monte Carlo computation and Bayesian model determination. Biometrika. 1995;82:711–732. doi: 10.2307/2337340. [DOI] [Google Scholar]