

Abstract
This paper is concerned with screening features in ultrahigh dimensional data analysis, which has become increasingly important in diverse scientific fields. We develop a sure independence screening procedure based on the distance correlation (DC-SIS, for short). The DC-SIS can be implemented as easily as the sure independence screening procedure based on the Pearson correlation (SIS, for short) proposed by Fan and Lv (2008). However, the DC-SIS can significantly improve the SIS. Fan and Lv (2008) established the sure screening property for the SIS based on linear models, but the sure screening property is valid for the DC-SIS under more general settings including linear models. Furthermore, the implementation of the DC-SIS does not require model specification (e.g., linear model or generalized linear model) for responses or predictors. This is a very appealing property in ultrahigh dimensional data analysis. Moreover, the DC-SIS can be used directly to screen grouped predictor variables and for multivariate response variables. We establish the sure screening property for the DC-SIS, and conduct simulations to examine its finite sample performance. Numerical comparison indicates that the DC-SIS performs much better than the SIS in various models. We also illustrate the DC-SIS through a real data example.
Keywords: Distance correlation, sure screening property, ultrahigh dimensionality, variable selection
1. INTRODUCTION
Various regularization methods have been proposed for feature selection in high dimensional data analysis, which has become increasingly frequent and important in various research fields. These methods include, but are not limited to, the LASSO (Tibshirani, 1996), the SCAD (Fan and Li, 2001; Kim, Choi and Oh, 2008; Zou and Li, 2008), the LARS algorithm (Efron, Hastie, Johnstone and Tibshirani, 2004), the elastic net (Zou and Hastie, 2005; Zou and Zhang, 2009), the adaptive LASSO (Zou, 2006) and the Dantzig selector (Candes and Tao, 2007). All these methods allow the number of predictors to be greater than the sample size, and perform quite well for high dimensional data.
With the advent of modern technology for data collection, researchers are able to collect ultrahigh dimensional data at relatively low cost in diverse fields of scientific research. The aforementioned regularization methods may not perform well for ultrahigh dimensional data due to the simultaneous challenges of computational expediency, statistical accuracy and algorithmic stability (Fan, Samworth and Wu, 2009). These challenges call for new statistical modeling techniques for ultrahigh dimensional data. Fan and Lv (2008) proposed the SIS and showed that the Pearson correlation ranking procedure possesses a sure screening property for linear regressions with Gaussian predictors and responses. That is, all truly important predictors can be selected with probability approaching one as the sample size diverges to ∞. Hall and Miller (2009) extended Pearson correlation learning by considering polynomial transformations of predictors. To rank the importance of each predictor, they suggested a bootstrap procedure. Fan, Samworth and Wu (2009) and Fan and Song (2010) proposed a more general version of independent learning which ranks the maximum marginal likelihood estimators or the maximum marginal likelihood for generalized linear models. Fan, Feng and Song (2011) considered nonparametric independence screening in sparse ultrahigh dimensional additive models. They suggested estimating the nonparametric components marginally with spline approximation, and ranking the importance of predictors using the magnitude of nonparametric components. They also demonstrated that this procedure possesses the sure screening property with vanishing false selection rate. Zhu, Li, Li and Zhu (2011) proposed a sure independent ranking and screening (SIRS) procedure to screen significant predictors in multi-index models. They further show that under linearity condition assumption on the predictor vector, the SIRS enjoys the ranking consistency property (i.e, the SIRS can rank the important predictors in the top asymptotically). Ji and Jin (2012) proposed the two-stage method: screening by Univariate thresholding and cleaning by Penalized least squares for Selecting variables, namely UPS. They further theoretically demonstrated that under certain settings, the UPS can outperform the LASSO and subset selection, both of which are one-stage approaches. This motivates us to develop more effective screening procedures using two-stage approaches.
In this paper, we propose a new feature screening procedure for ultrahigh dimensional data based on distance correlation. Szekely, Rizzo and Bakirov (2007) and Szekely and Rizzo (2009) showed that the distance correlation of two random vectors equals to zero if and only if these two random vectors are independent. Furthermore, the distance correlation of two univariate normal random variables is a strictly increasing function of the absolute value of the Pearson correlation of these two normal random variables. These two remarkable properties motivate us to use the distance correlation for feature screening in ultrahigh dimensional data. We refer to our Sure Independence Screening procedure based on the Distance Correlation as the DC-SIS. The DC-SIS can be implemented as easily as the SIS. It is equivalent to the SIS when both the response and predictor variables are normally distributed. However, the DC-SIS has appealing features that existing screening procedures including SIS do not possess. For instance, none of the aforementioned screening procedures can handle grouped predictors or multivariate responses. The proposed DC-SIS can be directly employed for screening grouped variables, and it can be directly utilized for ultrahigh dimensional data with multivariate responses. Feature screening for multivariate responses and/or grouped predictors is of great interest in pathway analyses. As in Chen, et al. (2011), pathway here means sets of proteins that are relevant to specific biological functions without regard to the state of knowledge concerning the interplay among such protein. Since proteins may work interactively to perform various biological functions, pathway analyses complement the marginal association analyses for individual protein, and aim to detect a priori defined set of proteins that are associated with phenotypes of interest. There is a surged interest in pathway analyses in the recent literature (Ashburner, et al., 2000; Mootha, et al., 2003; Subramanian, et al., 2005; Tian, et al., 2005; Bild, et al., 2006; Efron and Tibsirani, 2007; Jones, et al., 2008). Thus, it is of importance to develop feature screening procedures for multivariate responses and/or grouped predictors.
We systematically study the theoretic properties of the DC-SIS, and prove that the DC-SIS possesses the sure screening property in the terminology of Fan and Lv (2008) under very general model settings including linear regression models, for which Fan and Lv (2008) established the sure screening property of the SIS. The sure screening property is a desirable property for feature screening in ultrahigh dimensional data. Even importantly, the DC-SIS can be used for screening features without specifying a regression model between the response and the predictors. Compared with the model-based screening procedures (Fan and Lv, 2008; Fan, Samworth and Wu, 2009; Wang, 2009; Fan and Song, 2010; Fan, Feng and Song, 2011), the DC-SIS is a model-free screening procedure. This virtue makes the proposed procedure robust to model misspecification. This is a very appealing feature of the proposed procedure in that it may be very difficult in specifying an appropriate regression model for the response and the predictors with little information about the actual model in ultrahigh dimensional data.
We conduct Monte Carlo simulation studies to numerically compare the DC-SIS with the SIS and SIRS. Our simulation results indicate that the DC-SIS can significantly outperform the SIS and the SIRS under many model settings. We also assess the performance of the DC-SIS as a grouped variable screener, and the simulation results show that the DC-SIS performs very well. We further examine the performance of the DC-SIS for feature screening in ultrahigh dimensional data with multivariate responses; simulation results demonstrate that screening features for multiple responses jointly may have dramatic advantage over screening features with each response separately.
The rest of this paper is organized as follows. In Section 2, we develop the DC-SIS for feature screening and establish its sure screening property. In Section 3, we examine the finite sample performance of the DC-SIS via Monte Carlo simulations. We also illustrate the proposed methodology through a real data example. This paper concludes with a brief discussion in Section 4. All technical proofs are given in the Appendix.
2. INDEPENDENCE SCREENING USING DISTANCE CORRELATION
2.1. Some Preliminaries
Szekely, Rizzo and Bakirov (2007) advocated using the distance correlation for measuring dependence between two random vectors. To be precise, let φu(t) and φv(s) be the respective characteristic functions of the random vectors u and v, and φu,v(t, s) be the joint characteristic function of u and v. They defined the distance covariance between u and v with finite first moments to be the nonnegative number dcov(u, v) given by
| (2.1) |
where du and dv are the dimensions of u and v, respectively, and
with cd = π(1+d)/2/Γ{(1+d)/2}. Throughout this paper, ||a||d stands for the Euclidean norm of a ∈ ℝd, and ||φ||2 = φφ̄ for a complex-valued function φ with φ̄ being the conjugate of φ. The distance correlation (DC) between u and v with finite first moments is defined as
| (2.2) |
Szekely, Rizzo and Bakirov (2007) systematically studied the theoretic properties of the DC.
Two remarkable properties of the DC motivate us to utilize it in a feature screening procedure. The first one is the relationship between the DC and the Pearson correlation coefficient. For two univariate normal random variables U and V with the Pearson correlation coefficient ρ, Szekely, Rizzo and Bakirov (2007) and Szekely and Rizzo (2009) showed that
| (2.3) |
which is strictly increasing in |ρ|. This property implies that the DC-based feature screening procedure is equivalent to the marginal Pearson correlation learning for linear regression with normally distributed predictors and random error. In such a situation, Fan and Lv (2008) showed that the Pearson correlation learning has the sure screening property.
The second remarkable property of the DC is dcorr(u, v) = 0 if and only if u and v are independent (Szekely, Rizzo and Bakirov, 2007). We note that two univariate random variables U and V are independent if and only if U and T(V), a strictly monotone transformation of V, are independent. This implies that a DC-based feature screening procedure can be more effective than the marginal Pearson correlation learning in the presence of nonlinear relationship between U and V. We will demonstrate in the next section that a DC-based screening procedure is a model-free procedure in that one does not need to specify a model structure between the predictors and the response.
Szekely, Rizzo and Bakirov (2007, Remark 3) stated that
where Sj, j = 1, 2 and 3, are defined below:
| (2.4) |
where (ũ, ṽ) is an independent copy of (u, v).
Suppose that {(ui, vi), i = 1, ···, n} is a random sample from the population (u, v). Szekely, Rizzo and Bakirov (2007) proposed to estimate S1, S2 and S3 through the usual moment estimation. To be precise,
Thus, a natural estimator of dcov2(u, v) is given by
Similarly, we can define the sample distance covariances and . Accordingly, the sample distance correlation between u and v can be defined by
2.2. An Independence Ranking and Screening Procedure
In this section we propose an independence screening procedure built upon the DC. Let y = (Y1, ···, Yq)T be the response vector with support Ψy, and x = (X1, …, Xp)T be the predictor vector. We regard q as a fixed number in this context. In an ultrahigh-dimensional setting the dimensionality p greatly exceeds the sample size n. It is thus natural to assume that only a small number of predictors are relevant to y. Denote by F(y | x) the conditional distribution function of y given x. Without specifying a regression model, we define the index set of the active and inactive predictors by
| (2.5) |
We further write x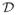 = {Xk : k ∈
= {Xk : k ∈
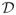 } and x
} and x = {Xk : k ∈
= {Xk : k ∈
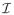 }, and refer to x as an active predictor vector and its complement x as an inactive predictor vector. The index subset
of all active predictors or, equivalently, the index subset
of all inactive predictors, is the objective of our primary interest. Definition (2.5) implies that y ⫫ x | x, where ⫫ denotes statistical independence. That is, given x, the remaining predictors x are independent of y. Thus the inactive predictors x are redundant when the active predictors x are known.
}, and refer to x as an active predictor vector and its complement x as an inactive predictor vector. The index subset
of all active predictors or, equivalently, the index subset
of all inactive predictors, is the objective of our primary interest. Definition (2.5) implies that y ⫫ x | x, where ⫫ denotes statistical independence. That is, given x, the remaining predictors x are independent of y. Thus the inactive predictors x are redundant when the active predictors x are known.
For ease of presentation, we write
based on a random sample {xi, yi}, i = 1, …, n. We consider using ωk as a marginal utility to rank the importance of Xk at the population level. We utilize the DC because it allows for arbitrary regression relationship of y onto x, regardless of whether it is linear or nonlinear. The DC also permits univariate and multivariate response, regardless of whether it is continuous, discrete or categorical. In addition, it allows for groupwise predictors. Thus, this DC based screening procedure is completely model-free. We select a set of important predictors with large ω̂k. That is, we define
where c and κ are pre-specified threshold values which will be defined in condition (C2) in the subsequent section.
2.3. Theoretical Properties
Next we study the theoretical properties of the proposed independence screening procedure built upon the DC. The following conditions are imposed to facilitate the technical proofs, although they may not be the weakest ones.
-
(C1) Both x and y satisfy the sub-exponential tail probability uniformly in p. That is, there exists a positive constant s0 such that for all 0 < s = ≤ 2s0,
-
(C2) The minimum distance correlation of active predictors satisfies
Condition (C1) follows immediately when x and y are bounded uniformly, or when they have multivariate normal distribution. The normality assumption has been widely used in the area of ultrahigh dimensional data analysis to facilitate the technical derivations. See, for example, Fan and Lv (2008) and Wang (2009).
Next we explore condition (C2). When x and y have multivariate normal distribution, (2.3) gives an explicit relationship between the DC and the squared Pearson correlation. For simplicity, we write dcorr(Xk, y) = T0 (|ρ(Xk, y)|) where T0(·) is strictly increasing given in (2.3). In this situation, condition (C2) requires essentially that , where Tinv(·) is the inverse function of T0(·). This is parallel to condition 3 of Fan and Lv (2008) where it is assumed that . This intuitive illustration implies that condition (C2) requires that the marginal DC of active predictors cannot be too small, which is similar to condition 3 of Fan and Lv (2008). We remark here that, although we illustrate the intuition by assuming that x and y are multivariate normal, we do not require this assumption explicitly in our context. The following theorem establishes the sure screening property for the DC-SIS procedure.
Theorem 1
Under condition (C1), for any 0 < γ < 1/2 − κ, there exist positive constants c1 > 0 and c2 > 0 such that
| (2.6) |
Under conditions (C1) and (C2), we have that
| (2.7) |
where sn is the cardinality of
.
The sure screening property holds for the DC-SIS under milder conditions than those for the SIS (Fan and Lv, 2008) in that we do not require the regression function of y onto x to be linear. Thus, the DC-SIS provides a unified alternative to existing model-based sure screening procedures. Compared with the SIRS, the DC-SIS can effectively handle grouped predictors and multivariate responses.
To balance the two terms in the right hand side of (2.6), we choose the optimal order γ = (1 − 2κ)/3, then the first part of Theorem 1 becomes
for some constant c1 > 0, indicating that we can handle the NP-dimensionality of order log p = o(n(1−2κ)/3. If we further assume that Xk and y are bounded uniformly in p, then we can obtain without much difficulty that
In this case, we can handle the NP-dimensionality log p = o (n1−2κ).
3. NUMERICAL STUDIES
In this section we assess the performance of the DC-SIS by Monte Carlo simulation. Our simulation studies were conducted using R code. We further illustrate the proposed screening procedure with an empirical analysis of a real data example.
In Examples 1, 2 and 3, we generate x = (X1, X2, ···, Xp)T from normal distribution with zero mean and covariance matrix Σ = (σij)p×p, and the error term ε from standard normal distribution
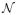 (0, 1). We consider two covariance matrices to assess the performance of the DC-SIS and to compare with existing methods: (i) σij = 0.8|i−j| and (ii) σij = 0.5|i−j|. We fix the sample size n to be 200 and vary the dimension p from 2,000 to 5,000. We repeat each experiment 500 times, and evaluate the performance through the following three criteria.
(0, 1). We consider two covariance matrices to assess the performance of the DC-SIS and to compare with existing methods: (i) σij = 0.8|i−j| and (ii) σij = 0.5|i−j|. We fix the sample size n to be 200 and vary the dimension p from 2,000 to 5,000. We repeat each experiment 500 times, and evaluate the performance through the following three criteria.
 : the minimum model size to include all active predictors. We report the 5%, 25%, 50%, 75% and 95% quantiles of
out of 500 replications.
: the minimum model size to include all active predictors. We report the 5%, 25%, 50%, 75% and 95% quantiles of
out of 500 replications.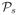 : the proportion that an individual active predictor is selected for a given model size d in the 500 replications.
: the proportion that an individual active predictor is selected for a given model size d in the 500 replications.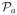 : the proportion that all active predictors are selected for a given model size d in the 500 replications.
: the proportion that all active predictors are selected for a given model size d in the 500 replications.
The
is used to measure the model complexity of the resulting model of an underlying screening procedure. The closer to the minimum model size the
is, the better the screening procedure is. The sure screening property ensures that
and
are both close to one when the estimated model size d is sufficiently large. We choose d to be d1 = [n/log n], d2 = 2[n/log n] and d3 = 3[n/log n] throughout our simulations to empirically examine the effect of the cutooff, where [a] denotes the integer part of a.
Example 1
This example is designed to compare the finite sample performance of the DC-SIS with the SIS (Fan and Lv, 2008) and SIRS (Zhu, Li, Li and Zhu, 2011). In this example, we generate the response from the following four models:
| (1.a) |
| (1.b) |
| (1.c) |
| (1.d) |
where 1(X12 < 0) is an indicator function. The regression functions E(Y | x) in models (1.a)–(1.d) are all nonlinear in X12. In addition, models (1.b) and (1.c) contain an interaction term X1X2, and model (1.d) is heteroscedastic. Following Fan and Lv (2008), we choose βj = (−1)U(a + |Z|) for j = 1, 2, 3 and 4, where
, U ~ Bernoulli(0.4) and Z ~
(0, 1). We set (c1, c2, c3, c4) = (2, 0.5, 3, 2) in this example to challenge the feature screening procedures under consideration. For each independence screening procedure, we compute the associated marginal utility between each predictor Xk and the response Y. That is, we regard x = (X1, …, Xp)T ∈ ℝp as the predictor vector in this example.
Tables 1 and 2 depict the simulation results for
,
and
. The performances of the DC-SIS, SIS and SIRS are quite similar in model (1.a), indicating that the SIS has a robust performance if the working linear model does not deviate far from the underlying true model. The DC-SIS outperforms the SIS and SIRS significantly in models (1.b), (1.c) and (1.d). Both the SIS and SIRS have little chance to identify the important predictors X1 and X2 in models (1.b) and (1.c), and X22 in model (1.d).
Table 1.
The 5%, 25%, 50%, 75% and 95% quantiles of the minimum model size
out of 500 replications in Example 1.
|
|
SIS | SIRS | DC-SIS | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||
| Model | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% |
| case 1: p = 2000 and σij = 0.5|i−j| | |||||||||||||||
|
| |||||||||||||||
| (1.a) | 4.0 | 4.0 | 5.0 | 7.0 | 21.2 | 4.0 | 4.0 | 5.0 | 7.0 | 45.1 | 4.0 | 4.0 | 4.0 | 6.0 | 18.0 |
| (1.b) | 68.0 | 578.5 | 1180.5 | 1634.5 | 1938.0 | 232.9 | 871.5 | 1386.0 | 1725.2 | 1942.4 | 5.0 | 9.0 | 24.5 | 73.0 | 345.1 |
| (1.c) | 395.9 | 1037.2 | 1438.0 | 1745.0 | 1945.1 | 238.5 | 805.0 | 1320.0 | 1697.0 | 1946.0 | 6.0 | 10.0 | 22.0 | 59.0 | 324.1 |
| (1.d) | 130.5 | 611.2 | 1166.0 | 1637.0 | 1936.5 | 42.0 | 304.2 | 797.0 | 1432.2 | 1846.1 | 4.0 | 5.0 | 9.0 | 41.0 | 336.2 |
|
| |||||||||||||||
| case 2: p = 2000 and σij= 0.8|i−j| | |||||||||||||||
|
| |||||||||||||||
| (1.a) | 5.0 | 9.0 | 16.0 | 97.0 | 729.4 | 5.0 | 9.0 | 18.0 | 112.8 | 957.1 | 4.0 | 7.0 | 11.0 | 31.2 | 507.2 |
| (1.b) | 26.0 | 283.2 | 852.0 | 1541.2 | 1919.0 | 103.9 | 603.0 | 1174.0 | 1699.2 | 1968.0 | 5.0 | 8.0 | 11.0 | 17.0 | 98.0 |
| (1.c) | 224.5 | 775.2 | 1249.5 | 1670.0 | 1951.1 | 118.6 | 573.2 | 1201.5 | 1685.2 | 1955.0 | 7.0 | 10.0 | 15.0 | 38.0 | 198.3 |
| (1.d) | 79.0 | 583.8 | 1107.5 | 1626.2 | 1930.0 | 50.9 | 300.5 | 728.0 | 1368.2 | 1900.1 | 4.0 | 7.0 | 17.0 | 73.2 | 653.1 |
|
| |||||||||||||||
| case 3: p = 5000 and σij = 0.5|i−j| | |||||||||||||||
|
| |||||||||||||||
| (1.a) | 4.0 | 4.0 | 5.0 | 6.0 | 59.0 | 4.0 | 4.0 | 5.0 | 7.0 | 88.4 | 4.0 | 4.0 | 4.0 | 6.0 | 34.1 |
| (1.b) | 165.1 | 1112.5 | 2729.0 | 3997.2 | 4851.5 | 560.8 | 1913.0 | 3249.0 | 4329.0 | 4869.1 | 5.0 | 11.8 | 45.0 | 168.8 | 956.7 |
| (1.c) | 1183.7 | 2712.0 | 3604.5 | 4380.2 | 4885.0 | 440.4 | 1949.0 | 3205.5 | 4242.8 | 4883.1 | 7.0 | 17.0 | 53.0 | 179.5 | 732.0 |
| (1.d) | 259.9 | 1338.5 | 2808.5 | 3990.8 | 4764.9 | 118.7 | 823.2 | 1833.5 | 3314.5 | 4706.1 | 4.0 | 5.0 | 15.0 | 77.2 | 848.2 |
|
| |||||||||||||||
| case 4: p = 5000 and σij = 0.8|i−j| | |||||||||||||||
|
| |||||||||||||||
| (1.a) | 5.0 | 10.0 | 26.5 | 251.5 | 2522.7 | 5.0 | 10.0 | 28.0 | 324.8 | 3246.4 | 5.0 | 8.0 | 14.0 | 69.0 | 1455.1 |
| (1.b) | 40.7 | 639.8 | 2072.0 | 3803.8 | 4801.7 | 215.7 | 1677.8 | 3010.0 | 4352.2 | 4934.1 | 5.0 | 8.0 | 11.0 | 21.0 | 162.0 |
| (1.c) | 479.2 | 1884.8 | 3347.5 | 4298.5 | 4875.2 | 297.7 | 1359.2 | 2738.5 | 4072.5 | 4877.6 | 8.0 | 12.0 | 22.0 | 83.0 | 657.9 |
| (1.d) | 307.0 | 1544.0 | 2832.5 | 4026.2 | 4785.2 | 148.2 | 672.0 | 1874.0 | 3330.0 | 4665.2 | 4.0 | 7.0 | 21.0 | 165.2 | 1330.0 |
Table 2.
The proportions of
and
in Example 1. The user-specified model sizes d1 = [n/log n], d2 = 2[n/log n] and d3 = 3[n/log n].
| SIS | SIRS | DC-SIS | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||||
|
|
|
|
|
|
|
|||||||||||
|
| ||||||||||||||||
| model | size | X1 | X2 | X12 | X22 | ALL | X1 | X2 | X12 | X22 | ALL | X1 | X2 | X12 | X22 | ALL |
| case 1: p = 2000 and σij = 0.5|i−j| | ||||||||||||||||
|
| ||||||||||||||||
| (1.a) | d1 | 1.00 | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 1.00 | 0.95 | 1.00 | 0.94 | 1.00 | 1.00 | 0.97 | 1.00 | 0.96 |
| d2 | 1.00 | 1.00 | 0.98 | 1.00 | 0.97 | 1.00 | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 1.00 | 0.98 | 1.00 | 0.98 | |
| d3 | 1.00 | 1.00 | 0.98 | 1.00 | 0.98 | 1.00 | 1.00 | 0.97 | 1.00 | 0.97 | 1.00 | 1.00 | 0.99 | 1.00 | 0.98 | |
|
| ||||||||||||||||
| (1.b) | d1 | 0.08 | 0.07 | 0.97 | 1.00 | 0.03 | 0.02 | 0.03 | 0.98 | 1.00 | 0.00 | 0.72 | 0.70 | 0.99 | 1.00 | 0.58 |
| d2 | 0.12 | 0.13 | 0.98 | 1.00 | 0.06 | 0.05 | 0.05 | 0.99 | 1.00 | 0.01 | 0.85 | 0.84 | 1.00 | 1.00 | 0.76 | |
| d3 | 0.15 | 0.17 | 0.99 | 1.00 | 0.07 | 0.06 | 0.06 | 0.99 | 1.00 | 0.01 | 0.89 | 0.88 | 1.00 | 1.00 | 0.82 | |
|
| ||||||||||||||||
| (1.c) | d1 | 0.12 | 0.13 | 0.01 | 0.99 | 0.00 | 0.04 | 0.03 | 0.51 | 1.00 | 0.01 | 0.93 | 0.93 | 0.77 | 1.00 | 0.65 |
| d2 | 0.17 | 0.18 | 0.03 | 0.99 | 0.00 | 0.07 | 0.05 | 0.67 | 1.00 | 0.01 | 0.97 | 0.96 | 0.84 | 1.00 | 0.79 | |
| d3 | 0.21 | 0.21 | 0.05 | 0.99 | 0.00 | 0.09 | 0.08 | 0.75 | 1.00 | 0.02 | 0.98 | 0.97 | 0.89 | 1.00 | 0.84 | |
|
| ||||||||||||||||
| (1.d) | d1 | 0.42 | 0.22 | 0.14 | 0.42 | 0.02 | 1.00 | 0.98 | 0.87 | 0.05 | 0.04 | 1.00 | 0.91 | 0.81 | 0.99 | 0.73 |
| d2 | 0.48 | 0.29 | 0.22 | 0.50 | 0.03 | 1.00 | 0.99 | 0.91 | 0.10 | 0.09 | 1.00 | 0.94 | 0.87 | 1.00 | 0.82 | |
| d3 | 0.56 | 0.32 | 0.26 | 0.54 | 0.04 | 1.00 | 0.99 | 0.93 | 0.12 | 0.11 | 1.00 | 0.96 | 0.92 | 1.00 | 0.88 | |
|
| ||||||||||||||||
| case 2: p = 2000 and σij = 0.8|i−j| | ||||||||||||||||
|
| ||||||||||||||||
| (1.a) | d1 | 1.00 | 1.00 | 0.63 | 1.00 | 0.63 | 1.00 | 1.00 | 0.62 | 1.00 | 0.62 | 1.00 | 1.00 | 0.78 | 1.00 | 0.77 |
| d2 | 1.00 | 1.00 | 0.71 | 1.00 | 0.72 | 1.00 | 1.00 | 0.70 | 1.00 | 0.69 | 1.00 | 1.00 | 0.84 | 1.00 | 0.84 | |
| d3 | 1.00 | 1.00 | 0.77 | 1.00 | 0.78 | 1.00 | 1.00 | 0.75 | 1.00 | 0.75 | 1.00 | 1.00 | 0.86 | 1.00 | 0.86 | |
|
| ||||||||||||||||
| (1.b) | d1 | 0.12 | 0.13 | 0.81 | 1.00 | 0.06 | 0.04 | 0.04 | 0.88 | 1.00 | 0.02 | 0.97 | 0.98 | 0.92 | 1.00 | 0.88 |
| d2 | 0.19 | 0.19 | 0.86 | 1.00 | 0.12 | 0.07 | 0.07 | 0.91 | 1.00 | 0.03 | 0.99 | 0.99 | 0.95 | 1.00 | 0.94 | |
| d3 | 0.22 | 0.23 | 0.88 | 1.00 | 0.15 | 0.09 | 0.11 | 0.93 | 1.00 | 0.06 | 1.00 | 0.99 | 0.96 | 1.00 | 0.96 | |
|
| ||||||||||||||||
| (1.c) | d1 | 0.17 | 0.16 | 0.03 | 0.99 | 0.00 | 0.04 | 0.04 | 0.53 | 1.00 | 0.02 | 1.00 | 1.00 | 0.75 | 1.00 | 0.75 |
| d2 | 0.22 | 0.22 | 0.06 | 1.00 | 0.01 | 0.08 | 0.08 | 0.71 | 1.00 | 0.03 | 1.00 | 1.00 | 0.85 | 1.00 | 0.86 | |
| d3 | 0.27 | 0.27 | 0.10 | 1.00 | 0.03 | 0.10 | 0.10 | 0.81 | 1.00 | 0.05 | 1.00 | 1.00 | 0.90 | 1.00 | 0.90 | |
|
| ||||||||||||||||
| (1.d) | d1 | 0.44 | 0.38 | 0.11 | 0.45 | 0.03 | 1.00 | 1.00 | 0.73 | 0.05 | 0.04 | 0.99 | 0.98 | 0.68 | 1.00 | 0.67 |
| d2 | 0.51 | 0.46 | 0.18 | 0.53 | 0.05 | 1.00 | 1.00 | 0.81 | 0.09 | 0.08 | 1.00 | 0.98 | 0.76 | 1.00 | 0.75 | |
| d3 | 0.55 | 0.49 | 0.22 | 0.57 | 0.06 | 1.00 | 1.00 | 0.84 | 0.14 | 0.11 | 1.00 | 0.99 | 0.80 | 1.00 | 0.80 | |
|
| ||||||||||||||||
| case 3: p = 5000 and σij = 0.5|i−j| | ||||||||||||||||
|
| ||||||||||||||||
| (1.a) | d1 | 1.00 | 1.00 | 0.94 | 1.00 | 0.94 | 1.00 | 0.99 | 0.92 | 1.00 | 0.92 | 1.00 | 0.99 | 0.96 | 1.00 | 0.95 |
| d2 | 1.00 | 1.00 | 0.95 | 1.00 | 0.95 | 1.00 | 1.00 | 0.95 | 1.00 | 0.95 | 1.00 | 1.00 | 0.97 | 1.00 | 0.97 | |
| d3 | 1.00 | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 1.00 | 0.98 | 1.00 | 0.98 | |
|
| ||||||||||||||||
| (1.b) | d1 | 0.06 | 0.06 | 0.94 | 1.00 | 0.02 | 0.02 | 0.02 | 0.96 | 1.00 | 0.00 | 0.59 | 0.60 | 0.98 | 1.00 | 0.46 |
| d2 | 0.09 | 0.09 | 0.96 | 1.00 | 0.03 | 0.03 | 0.03 | 0.97 | 1.00 | 0.01 | 0.72 | 0.72 | 0.99 | 1.00 | 0.61 | |
| d3 | 0.12 | 0.10 | 0.97 | 1.00 | 0.04 | 0.05 | 0.04 | 0.98 | 1.00 | 0.01 | 0.79 | 0.78 | 0.99 | 1.00 | 0.68 | |
|
| ||||||||||||||||
| (1.c) | d1 | 0.06 | 0.06 | 0.01 | 0.99 | 0.00 | 0.03 | 0.02 | 0.30 | 1.00 | 0.00 | 0.86 | 0.87 | 0.61 | 1.00 | 0.41 |
| d2 | 0.10 | 0.10 | 0.02 | 1.00 | 0.00 | 0.04 | 0.03 | 0.45 | 1.00 | 0.00 | 0.92 | 0.93 | 0.69 | 1.00 | 0.57 | |
| d3 | 0.12 | 0.12 | 0.02 | 1.00 | 0.00 | 0.05 | 0.05 | 0.53 | 1.00 | 0.00 | 0.94 | 0.95 | 0.73 | 1.00 | 0.64 | |
|
| ||||||||||||||||
| (1.d) | d1 | 0.39 | 0.21 | 0.11 | 0.40 | 0.01 | 1.00 | 0.97 | 0.82 | 0.02 | 0.02 | 0.99 | 0.87 | 0.74 | 0.99 | 0.65 |
| d2 | 0.44 | 0.24 | 0.14 | 0.45 | 0.01 | 1.00 | 0.98 | 0.88 | 0.04 | 0.03 | 0.99 | 0.90 | 0.81 | 0.99 | 0.75 | |
| d3 | 0.48 | 0.28 | 0.17 | 0.47 | 0.02 | 1.00 | 0.99 | 0.90 | 0.06 | 0.05 | 0.99 | 0.92 | 0.85 | 1.00 | 0.79 | |
|
| ||||||||||||||||
| case 4: p = 5000 and σij = 0.8|i−j| | ||||||||||||||||
|
| ||||||||||||||||
| (1.a) | d1 | 1.00 | 1.00 | 0.55 | 1.00 | 0.55 | 1.00 | 1.00 | 0.55 | 1.00 | 0.55 | 1.00 | 1.00 | 0.70 | 1.00 | 0.69 |
| d2 | 1.00 | 1.00 | 0.61 | 1.00 | 0.62 | 1.00 | 1.00 | 0.61 | 1.00 | 0.61 | 1.00 | 1.00 | 0.76 | 1.00 | 0.76 | |
| d3 | 1.00 | 1.00 | 0.67 | 1.00 | 0.67 | 1.00 | 1.00 | 0.64 | 1.00 | 0.64 | 1.00 | 1.00 | 0.80 | 1.00 | 0.80 | |
|
| ||||||||||||||||
| (1.b) | d1 | 0.10 | 0.09 | 0.74 | 1.00 | 0.05 | 0.02 | 0.02 | 0.83 | 1.00 | 0.00 | 0.94 | 0.94 | 0.90 | 1.00 | 0.82 |
| d2 | 0.12 | 0.13 | 0.81 | 1.00 | 0.07 | 0.03 | 0.04 | 0.87 | 1.00 | 0.01 | 0.97 | 0.97 | 0.93 | 1.00 | 0.89 | |
| d3 | 0.15 | 0.16 | 0.84 | 1.00 | 0.10 | 0.05 | 0.06 | 0.90 | 1.00 | 0.02 | 0.98 | 0.98 | 0.95 | 1.00 | 0.92 | |
|
| ||||||||||||||||
| (1.c) | d1 | 0.10 | 0.10 | 0.02 | 0.98 | 0.00 | 0.02 | 0.03 | 0.34 | 1.00 | 0.00 | 1.00 | 1.00 | 0.64 | 1.00 | 0.63 |
| d2 | 0.13 | 0.14 | 0.04 | 0.99 | 0.01 | 0.04 | 0.04 | 0.50 | 1.00 | 0.01 | 1.00 | 1.00 | 0.74 | 1.00 | 0.74 | |
| d3 | 0.16 | 0.18 | 0.05 | 0.99 | 0.01 | 0.05 | 0.05 | 0.61 | 1.00 | 0.02 | 1.00 | 1.00 | 0.79 | 1.00 | 0.79 | |
|
| ||||||||||||||||
| (1.d) | d1 | 0.42 | 0.32 | 0.09 | 0.40 | 0.01 | 1.00 | 1.00 | 0.66 | 0.02 | 0.01 | 0.99 | 0.97 | 0.63 | 0.98 | 0.59 |
| d2 | 0.48 | 0.39 | 0.12 | 0.44 | 0.02 | 1.00 | 1.00 | 0.74 | 0.04 | 0.03 | 0.99 | 0.97 | 0.70 | 1.00 | 0.68 | |
| d3 | 0.51 | 0.42 | 0.15 | 0.46 | 0.02 | 1.00 | 1.00 | 0.78 | 0.05 | 0.04 | 0.99 | 0.98 | 0.73 | 1.00 | 0.71 | |
Example 2
We illustrate that the DC-SIS can be directly used for screening grouped predictors. In many regression problems, some predictors can be naturally grouped. The most common example which contains group variables is the multi-factor ANOVA problem, in which each factor may have several levels and can be expressed through a group of dummy variables. The goal of ANOVA is to select important main effects and interactions for accurate predictions, which amounts to the selection of groups of dummy variables. To demonstrate the practicability of the DC-SIS, we adopt the following model:
where q1, q2 and q3 are the 25%, 50% and 75% quantiles of X12, respectively. The variables X with the coefficients ci’s and βi’s are the same as those in Example 1. We write
These four correlated variables naturally become a group. The predictor vector in this example becomes x = (X1, …, X11, x̃12, X13, …, Xp)T ∈ ℝp+2. We remark here that the marginal utility of the grouped variable x̃12 is defined by
The 5%, 25%, 50%, 75% and 95% percentiles of the minimum model size
are summarized in Table 3. These percentiles indicate that with very high probability, the minimum model size
to ensure the inclusion of all active predictors is small. Note that [n/log(n)] = 37. Thus, almost all
 and
and
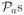 of the DC-SIS equal 100%. All active predictors including the grouped variable x̃12 can perfectly be selected into the resulting model across all three different model sizes. Hence, the DC-SIS is efficient to select the grouped predictors.
of the DC-SIS equal 100%. All active predictors including the grouped variable x̃12 can perfectly be selected into the resulting model across all three different model sizes. Hence, the DC-SIS is efficient to select the grouped predictors.
Table 3.
The 5%, 25%, 50%, 75% and 95% quantiles of the minimum model size
out of 500 replications in Example 2.
|
|
p = 2000 | p = 5000 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||
| 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% | |
| σij = 0.5|i−j| | 4.0 | 4.0 | 4.0 | 5.0 | 12.0 | 4.0 | 4.0 | 4.0 | 6.0 | 16.1 |
| σi j= 0.8|i−j| | 4.0 | 5.0 | 7.0 | 9.0 | 15.2 | 4.0 | 5.0 | 7.0 | 9.0 | 21.0 |
Example 3
In this example, we investigate the performance of the DC-SIS with multivariate responses. The SIS proposed in Fan and Lv (2008) cannot be directly applied for such settings. In contrast, the DC-SIS is ready for screening the active predictors by the nature of DC. In this example, we generate y = (Y1, Y2)T from normal distribution with mean zero and covariance matrix Σy|x = (σx,ij)2×2, where σx,11 = σx,22 = 1 and σx,12 = σx,21 = σ(x). We consider two scenarios for the correlation function σ(x):
(3.a): , where β1 = (0.8, 0.6, 0, …, 0)T.
(3.b): , where β2 = (2 − U1, 2 − U2, 2 − U3, 2 − U4, 0, …, 0)T with Ui’s being independent and identically distributed according to unisform distribution Uniform[0, 1].
Tables 4 and 5 depict the simulation results. Table 4 implies that the DC-SIS performs reasonably well for both models (3.a) and (3.b) in terms of model complexity. Table 5 indicates that the proportions that the active predictors are selected into the model are close to one, which supports the assertion that the DC-SIS processes the sure screening property. It implies that the DC-SIS can identify the active predictors contained in correlations between multivariate responses. This may be potentially useful in gene co-expression analysis.
Table 4.
The 5%, 25%, 50%, 75% and 95% quantiles of the minimum model size
out of 500 replications in Example 3.
|
|
p = 2000 | p = 5000 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||
| Model | 5% | 25% | 50% | 75% | 95% | 5% | 25% | 50% | 75% | 95% | |
| σij = 0.5|i−j| | (3.a) | 4.0 | 9.0 | 18.0 | 39.3 | 112.3 | 6.0 | 22.0 | 48.0 | 95.3 | 296.4 |
| (3.b) | 6.0 | 19.0 | 43.0 | 92.0 | 253.1 | 14.0 | 45.0 | 92.5 | 198.8 | 571.6 | |
|
| |||||||||||
| σij = 0.8|i−j| | (3.a) | 2.0 | 3.0 | 6.0 | 12.0 | 40.0 | 2.0 | 6.0 | 14.0 | 32.0 | 98.0 |
| (3.b) | 4.0 | 4.0 | 4.0 | 6.0 | 10.0 | 4.0 | 4.0 | 5.0 | 8.0 | 18.1 | |
Table 5.
The proportions of
and
in Example 3. The user-specified model sizes d1 = [n/log n], d2 = 2[n/log n] and d3 = 3[n/log n].
| p = 2000 | p = 5000 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| |||||||||||||||||
| (3.a) | (3.b) | (3.a) | (3.b) | ||||||||||||||
|
| |||||||||||||||||
|
|
|
|
|
|
|
|
|
||||||||||
|
| |||||||||||||||||
| size | X1 | X2 | ALL | X1 | X2 | X3 | X4 | ALL | X1 | X2 | ALL | X1 | X2 | X3 | X4 | ALL | |
| σij = 0.5|i−j| | d1 | 0.95 | 0.76 | 0.74 | 0.71 | 0.98 | 0.98 | 0.72 | 0.47 | 0.79 | 0.49 | 0.42 | 0.48 | 0.91 | 0.90 | 0.53 | 0.20 |
| d2 | 0.98 | 0.90 | 0.90 | 0.85 | 0.99 | 0.99 | 0.85 | 0.71 | 0.93 | 0.70 | 0.67 | 0.67 | 0.97 | 0.97 | 0.71 | 0.45 | |
| d3 | 1.00 | 0.95 | 0.95 | 0.91 | 0.99 | 1.00 | 0.90 | 0.81 | 0.97 | 0.81 | 0.80 | 0.75 | 0.98 | 0.99 | 0.78 | 0.55 | |
|
| |||||||||||||||||
| σij = 0.8|i−j| | d1 | 0.98 | 0.95 | 0.94 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.92 | 0.84 | 0.81 | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 |
| d2 | 1.00 | 0.98 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.98 | 0.95 | 0.93 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
| d3 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.96 | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | |
Example 4
The Cardiomyopathy microarray dataset was once analyzed by Segal, Dahlquist and Conklin (2003) and Hall and Miller (2009). The goal is to identify the most influential genes for overexpression of a G protein-coupled receptor (Ro1) in mice. The response Y is the Ro1 expression level, and the predictors Xk’s are other gene expression levels. Compared with the sample size n = 30 in this dataset, the dimension p = 6319 is very large.
The DC-SIS procedure ranks two genes, labeled Msa.2134.0 and Msa.2877.0, at the top. The scatter plots of Y versus these two gene expression levels with cubic spline fit curves in Figure 1 indicate clearly the existence of nonlinear patterns. Yet, our finding is different from Hall and Miller (2009) in that they ranked Msa.2877.0 and Msa.1166.0 at the top with their proposed generalized correlation ranking. A natural question arises: which screening procedure performs better in terms of ranking? To compare the performance of these two procedures, we fit an additive model as follows:
Figure 1.

The scatter plot of Y versus two genes expression levels identified by the DC-SIS.
The DC-SIS, corresponding to k = 1, regards Msa.2134.0 and Msa.2877.0 as the two predictors, while the generalized correlation ranking proposed by Hall and Miller (2009), corresponding to k = 2, regards Msa.2877.0 and Msa.1166.0 as predictors in the above model. We fit the unknown link functions ℓki using the R mgcv package. The DC-SIS method clearly achieves better performance with the adjusted R2 of 96.8% and the deviance explained of 98.3%, in contrast to the adjusted R2 of 84.5% and the deviance explained of 86.6% for the generalized correlation ranking method. We remark here that deviance explained means the proportion of the null deviance explained by the proposed model, with a larger value indicating better performance. Because both the adjusted R2 values and the explained deviance are very large, it seems unnecessary to extract any additional genes.
4. DISCUSSION
In this paper we proposed a sure independence screening procedure using distance correlation. We established the sure screening property for this procedure when the number of predictors diverges with an exponential rate of the sample size. We examined the finite-sample performance of the proposed procedure via Monte Carlo studies and illustrated the proposed methodology through a real data example. We followed Fan and Lv (2008) to set the cutoff d in this paper and examine the effect of different values of d. As pointed out by a referee, the choice of d is very important in the screening stage. Zhao and Li (2012) proposed an approach to selecting d for Cox models based on controlling false positive rate. Their approach is merely for model-based feature screening methods. Zhu, Li, Li and Zhu (2011) proposed an alternative method to determine d for the SIRS. One may adopt their procedure for the DC-SIS. We opt not to pursue this further. Certainly, the selection of d is similar to selection of the tuning parameter in regularization methods, and plays an important role in practical implementation. This is a good topic for future research.
Similar to the SIS, the DC-SIS may fail to identify some important predictors which are marginally independent of the response. Thus, it is of interest to develop an iterative procedure to fix such an issue. In the earlier version of this paper, we proposed an iterative version of DC-SIS. Our empirical studies including Monte Carlo simulation and real data analysis imply that the proposed iterative DC-SIS may be used to fix the problem in a similar spirit of ISIS (Fan and Lv, 2008). Theoretical analysis of the iterative DC-SIS needs further study. New methods to deal with identification of important predictors which are marginally independent of the response is an important topic for future research.
Acknowledgments
The authors thank the Editor, the AE and reviewers for their constructive comments, which have led to a dramatic improvement of the earlier version of this paper. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NSF or NIDA.
Biographies
Runze Li is Professor, Department of Statistics and The Methodology Center, The Pennsylvania State University, University Park, PA 16802-2111.rli@stat.psu.edu. His research was supported by National Institute on Drug Abuse (NIDA) grant P50-DA10075 and National Natural Science Foundation of China (NNSFC) grant 11028103.
Wei Zhong is the corresponding author and Assistant Professor of Wang Yanan Institute for Studies in Economics, Department of Statistics and Fujian Key Laboratory of Statistical Science, Xiamen University, China. wxz123@psu.edu. His research was supported by a NIDA grant P50-DA10075 as a graduate research assistant during his graduate study, and by the NNSFC grant 71131008 (Key Project).
Liping Zhu is Associate Professor of School of Statistics and Management, Shanghai University of Finance and Economics, China. zhu.liping@mail.shufe.edu.cn. His research was supported by a NNSFC grant 11071077 and a NIDA grant R21-DA024260.
APPENDIX
Appendix A: Some Lemmas
Lemmas 1 and 2 will be used repeatedly in the proof of Theorem 1. These two lemmas provide us two exponential inequalities, and are extracted from Lemma 5.6.1.A and Theorem 5.6.1.A of Serfling (1980, page 200–201).
Lemma 1
Let μ = E(Y). If Pr(a ≤ Y ≤ b) = 1, then
Lemma 2
Let h(Y1, ···, Ym) be a kernel of the U-statistic Un, and θ = E {h(Y1, ···, Ym)}.
If a ≤ h(Y1, ···, Ym) ≤ b, then, for any t > 0 and n ≥ m,
where [n/m] denotes the integer part of n/m.
Due to the symmetry of U-statistic, Lemma 2 entails that
Let us introduce some notations before giving the proof of Theorem 1. Let {X̃k, ỹ} be an independent copy of {Xk, y}, and define Sk1 = E||Xk − X̃k||1||y − ỹ||q, Sk2 = E||Xk − X̃k||1E||y − ỹ||q, and Sk3 = E{E(||Xk − X̃k||1|Xk)E(||y − ỹ||q|y)}, and their sample counterparts
By definitions of distance covariance and sample distance covariance, it follows that
Appendix B: Proof of Theorem 1
We aim to show the uniform consistency of the denominator and the numerator of ω̂k under regularity conditions respectively. Because the denominator of ω̂k has a similar form as the numerator, we deal with its numerator only below. Throughout proof, the notations C and c are generic constants which may take different values at each appearance.
We first deal with Ŝk1. Define , which is a usual U-statistic. We shall establish the uniform consistency of by using the theory of U-statistics (Serfling, 1980, Section 5). By using the Cauchy-Schwartz inequality,
This together with condition (C1) implies that Sk1 is uniformly bounded in p, that is, . For any given ε > 0, take n large enough such that Sk1/n < ε. Then it can be easily shown that
| (B.1) |
To establish the uniform consistency of Ŝk1, it thus suffices to show the uniform consistency of . Let h1(Xik, yi; Xjk, yj) = ||Xik − Xjk||1||yi − yj||q be the kernel of the U -statistic . We decompose the kernel function h1 into two parts: h1 = h11(h1 > M) + h11(h1 ≤ M) where M will be specified later. The U-statistic can now be written as follows,
Accordingly, we decompose Sk1 into two parts:
Clearly, and are unbiased estimators of Sk1,1 and Sk1,2, respectively.
We deal with the consistency of first. With the Markov’s inequality, for any t > 0, we can obtain that
Serfling (1980, Section 5.1.6) showed that any U-statistic can be represented as an average of averages of independent and identically distributed (i.i.d) random variables. That is, , where denotes the summation over all possible permutations of (1, …, n), and each Ω1(X1k, y1; ···; Xnk, yn) is an average of m = [n/2] i.i.d random variables (i.e., ). Since the exponential function is convex, it follows from Jensen’s inequality that, for 0 < t ≤ 2s0,
which together with Lemma 1 entails immediately that
By choosing t = 4εm/M2, we have . Therefore, by the symmetry of U-statistic, we can obtain easily that
| (B.2) |
Next we show the consistency of . With Cauchy-Schwartz and Markov’s inequality,
for any s′ > 0. Using the fact (a2 + b2)/2 ≥ (a + b)2/4 ≥ |ab|, we have
which yields that
The last inequality follows from the Cauchy-Schwartz inequality. If we choose M = cnγ for 0 < γ < 1/2 − κ, then Sk1,2 ≤ ε/2 when n is sufficiently large. Consequently,
| (B.3) |
It remains to bound the probability . We observe that the events satisfy
| (B.4) |
To see this, we assume that for all 1 ≤ i ≤ p. This assumption will lead to a contradiction. To be precise, under this assumption, . Consequently, , which is a contrary to the event . This verifies the relation (B.4) is true.
By invoking condition (C1), there must exist a constant C such that
The last inequality follows from Markov’s inequality for s > 0. Consequently,
| (B.5) |
Recall that M = cnγ. Combining the results (B.2), (B.3) and (B.5), we have
| (B.6) |
In the sequel we turn to Ŝk2. We write Ŝk2 = Ŝk2,1Ŝk2,2, where , and . Similarly, we write Sk2 = Sk2,1Sk2,2, where Sk2,1 = E{||Xik − Xjk||1} and Sk2,2 = E{||yi − yj||q}. Following arguments for proving (B.6) we can show that
| (B.7) |
Condition (C1) ensures that and are uniformly bounded. That is,
for some constant C. Using (B.7) repetitively, we can easily prove that
| (B.8) |
and
| (B.9) |
It follows from Bonferroni’s inequality, inequalities (B.8) and (B.9) that,
| (B.10) |
where the last inequality holds when ε is sufficiently small and C is sufficiently large.
It remains to the uniform consistency of Ŝk3. We first study the following U -statistic:
| (B.11) |
Here, h3(Xik, yi; Xjk, yj; Xlk, yl) is the kernel of U -statistic . Following the arguments to deal with , we decompose h3 into two parts: h3 = h31(h3 > M) + h31(h3 ≤ M). Accordingly
Following similar arguments for proving (B.2), we can show that
| (B.12) |
where m′ = [n/3] because is a third-order U -statistic.
Then we deal with . We observe that , which will be smaller than M if for all 1 ≤ i ≤ p. Thus, for any ε > 0, the events satisfy
By using the similar arguments to prove (B.5), it follows that
| (B.13) |
Then, we combine the results (B.12) and (B.13) with M = cnγ for some 0 < γ < 1/2 − κ to obtain that
| (B.14) |
By the definition of Ŝk3,
Thus, using similar techniques to deal with Ŝk1, we can obtain that
Using similar arguments for dealing with Sk1, we can show that Sk3 is uniformly bounded in p. Taking n large enough such that {(3n − 2)/n2}Sk3 ≤ ε and {(n − 1)/n2}Sk1 ≤ ε, then
| (B.15) |
The last inequality follows from (B.6) and (B.14). This, together with (B.6), (B.10) and the Bonferroni’s inequality, implies
| (B.16) |
for some positive constants c1 and c2. The convergence rate of the numerator of ω̂k is now achieved. Following similar arguments, we can obtain the convergence rate of the denominator. In effect the convergence rate of ω̂k has the same form of (B.16). We omit the details here. Let ε = cn−κ, where κ satisfies 0 < κ + γ < 1/2. We thus have
The first part of Theorem 1 is proven.
Now we deal with the second part of Theorem 1. If
⊈
 , then there must exist some k ∈
such that ω̂k < cn−κ. It follows from condition (C2) that |ω̂k − ωk| > cn−κ for some k ∈
, indicating that the events satisfy {
⊈
} ⊆ {|ω̂k − ωk| > cn−κ, for some k ∈
}, and hence
. Consequently,
, then there must exist some k ∈
such that ω̂k < cn−κ. It follows from condition (C2) that |ω̂k − ωk| > cn−κ for some k ∈
, indicating that the events satisfy {
⊈
} ⊆ {|ω̂k − ωk| > cn−κ, for some k ∈
}, and hence
. Consequently,
where sn is the cardinality of
. This completes the proof of the second part.
References
- Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, et al. Gene Ontology: Tool for the Unification of Biology. The Gene Ontology Consortium. Nature Genetics. 2000;25:25–29. doi: 10.1038/75556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bild A, Yao G, Chang JT, Wang Q, Potti A, et al. Oncogenic pathway signatures in human cancers as a guide to targeted therapies. Nature. 2006;439:353–357. doi: 10.1038/nature04296. [DOI] [PubMed] [Google Scholar]
- Candes E, Tao T. The Dantzig selector: statistical estimation when p is much larger than n (with discussion) Annals of Statistics. 2007;35:2313–2404. [Google Scholar]
- Chen LS, Paul D, Prentice RL, Wang P. A regularized Hotelling’s T2 test for pathway analysis in proteomic studies. Journal of the American Statistical Association. 2011;106:1345–1360. doi: 10.1198/jasa.2011.ap10599. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression (with discussion) Annals of Statistics. 2004;32:409–499. [Google Scholar]
- Efron B, Tibshirani R. On Testing the Significance of Sets of Genes. The Annals of Applied Statistics. 2007;1:107–129. [Google Scholar]
- Fan J, Feng Y, Song R. Nonparametric independence screening in sparse ultra-high dimensional additive models. Journal of the American Statistical Association. 2011;106:544–557. doi: 10.1198/jasa.2011.tm09779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and it oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Fan J, Lv J. Sure independence screening for ultrahigh dimensional feature space (with discussion) Journal of the Royal Statistical Society, Series B. 2008;70:849–911. doi: 10.1111/j.1467-9868.2008.00674.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J, Samworth R, Wu Y. Ultrahigh dimensional feature selection: beyond the linear model. Journal of Machine Learning Research. 2009;10:1829–1853. [PMC free article] [PubMed] [Google Scholar]
- Fan J, Song R. Sure independence screening in generalized linear models with NP-dimensionality. The Annals of Statistics. 2010;38:3567–3604. [Google Scholar]
- Hall P, Miller H. Using generalized correlation to effect variable selection in very high dimensional problems. Journal of Computational and Graphical Statistics. 2009;18:533–550. [Google Scholar]
- Ji P, Jin J. UPS delivers optimal phase diagram in high dimensional variable selection. Annals of Statistics. 2012;40:73–103. [Google Scholar]
- Jones S, Zhang X, Parsons DW, Lin JC-H, Leary RJ, et al. Core Signaling Pathways in Human Pancreatic Cancers Revealed by Global Genomic Analyses. Science. 2008;321:1801. doi: 10.1126/science.1164368. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim Y, Choi H, Oh HS. Smoothly clipped absolute deviation on high dimensions. Journal of the American Statistical Association. 2008;103:1665–1673. [Google Scholar]
- Mootha VK, Lindgren CM, Eriksson KF, Subramanian A, Sihag S, et al. PGC-1-Responsive Genes Involved in Oxidative Phosphorylation Are Coordinately Downregulated in Human Diabetes. Nature Genetics. 2003;34:267–273. doi: 10.1038/ng1180. [DOI] [PubMed] [Google Scholar]
- Segal MR, Dahlquist KD, Conklin BR. Regression approach for microarray data analysis. Journal of Computational Biology. 2003;10:961–980. doi: 10.1089/106652703322756177. [DOI] [PubMed] [Google Scholar]
- Serfling RJ. Approximation Theorems of Mathematical Statistics. New York: John Wiley & Sons Inc; 1980. [Google Scholar]
- Subramanian A, Tamayo P, Mootha VK, Mukherjee S, Ebert BL, et al. Gene Set Enrichment Analysis: A Knowledge-Based Approach for Interpreting Genome-Wide Expression Profiles. Proceedings of the National Academy of Sciences of the USA. 2005;102:15545–15505. doi: 10.1073/pnas.0506580102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Székely GJ, Rizzo ML. Brownian distance covariance. Annals of Applied Statistics. 2009;3:1233–1303. doi: 10.1214/09-AOAS312. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Székely GJ, Rizzo ML, Bakirov NK. Measuring and testing dependence by correlation of distances. Annals of Statistics. 2007;35:2769–2794. [Google Scholar]
- Tian L, Greenberg SA, Kong SW, Altschuler J, Kohane IS, Park PJ. Discovering Statistically Significant Pathways in Expression Profiling Studies. Proceedings of the National Academy of Sciences of the USA. 2005;102:13544–13549. doi: 10.1073/pnas.0506577102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via LASSO. Journal of the Royal Statistical Society, Series B. 1996;58:267–288. [Google Scholar]
- Wang H. Forward regression for ultra-high dimensional variable screening. Journal of the American Statistical Association. 2009;104:1512–1524. [Google Scholar]
- Zhao SD, Li Y. Principled sure independence screening for Cox models with ultra-high-dimensional covariates. Journal of Multivariate Analysis. 2012;105:397–411. doi: 10.1016/j.jmva.2011.08.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu LP, Li L, Li R, Zhu LX. Model-free feature screening for ultrahigh dimensional data. Journal of the American Statistical Association. 2011;106:1464–1475. doi: 10.1198/jasa.2011.tm10563. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H. The adaptive lasso and its oracle properties. Journal of the American Statistical Association. 2006;101:1418–1429. [Google Scholar]
- Zou H, Hastie T. Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, Series B. 2005;67:301–320. [Google Scholar]
- Zou H, Li R. One-step sparse estimates in nonconcave penalized likelihood models. Annals of Statistics. 2008;36:1509–1533. doi: 10.1214/009053607000000802. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zou H, Zhang HH. On the adaptive elastic-net with a diverging number of parameters. Annals of Statistics. 2009;37:1733–1751. doi: 10.1214/08-AOS625. [DOI] [PMC free article] [PubMed] [Google Scholar]