


Abstract
Ribosomal protein S1, consisting of six contiguous OB-folds, is the largest ribosomal protein and is essential for translation initiation in Escherichia coli. S1 is also one of the three essential host-derived subunits of Qβ replicase, together with EF-Tu and EF-Ts, for Qβ RNA replication in E. coli. We analyzed the crystal structure of Qβ replicase, consisting of the virus-encoded RNA-dependent RNA polymerase (β-subunit), EF-Tu, EF-Ts and the N-terminal half of S1, which is capable of initiating Qβ RNA replication. Structural and biochemical studies revealed that the two N-terminal OB-folds of S1 anchor S1 onto the β-subunit, and the third OB-fold is mobile and protrudes beyond the surface of the β-subunit. The third OB-fold mainly interacts with a specific RNA fragment derived from the internal region of Qβ RNA, and its RNA-binding ability is required for replication initiation of Qβ RNA. Thus, the third mobile OB-fold of S1, which is spatially anchored near the surface of the β-subunit, primarily recruits the Qβ RNA toward the β-subunit, leading to the specific and efficient replication initiation of Qβ RNA, and S1 functions as a replication initiation factor, beyond its established function in protein synthesis.
INTRODUCTION
Ribosomal protein S1 is one of the largest proteins in the 30S small subunit of ribosomes and is involved in the translation initiation of most natural mRNAs in Escherichia coli (1–7). Beyond its established function in protein synthesis as a component of ribosomes, S1 is also involved in various other biological functions (8). The first extra-ribosomal function of S1 was found more than 4 decades ago, as an essential host factor for the replication of RNA viruses, such as Qβ virus, in host cells (9,10).
Qβ virus has a single, positive strand genomic RNA and infects E. coli (10). Qβ replicase is responsible for the replication and transcription of Qβ viral RNA and is a tetrameric protein complex of the virus-encoded RNA-dependent RNA polymerase (β-subunit) and three host factors—translational elongation factor (EF) -Tu, EF-Ts and ribosomal protein S1 (9,11,12). The functions of the host factors, beyond their established functions in translation, are not fully understood.
Recently, the crystal structure of the core Qβ replicase, consisting of the β-subunit, EF-Tu and EF-Ts (13,14), and the structures of the core Qβ replicase, representing RNA polymerization, were reported (15,16). The crystallographic analysis revealed that EF-Tu and EF-Ts perform chaperone-like activities for the expression and assembly of the core Qβ replicase (14) and that EF-Tu assists in the separation of the double-stranded RNA of the template and the growing RNAs at the elongation stage. In addition, EF-Tu and the β-subunit together compose an exit tunnel for the single-stranded template RNA that splits away from the growing RNA (15). EF-Tu in Qβ replicase acts as an RNA elongation factor for the efficient and complete replication and transcription of the viral RNA, beyond its established function in translation elongation.
The fourth subunit of Qβ replicase, ribosomal protein S1, is essential for Qβ RNA replication (10). In particular, it is required for the synthesis of the negative strand RNA from the positive strand Qβ RNA, while it is dispensable for the synthesis of the positive strand RNA from the negative strand Qβ RNA. Until now, the structure of the holo Qβ replicase, consisting of the β-subunit and three host factors, has not been available. The mechanisms of the interactions between the core Qβ replicase and S1, and the molecular basis of S1 involvement in Qβ RNA replication, have remained elusive. Moreover, until now, the structure of S1, in either its free or ribosome-bound form, has not been available, and only the structures of the fourth and last OB-fold domains, among the six contiguous OB-fold domains, of S1 have been reported (17). In addition, the detailed molecular mechanism of the S1 interaction with the ribosome has remained obscure.
Here, we analyzed the crystal structure of Qβ replicase, consisting of the β-subunit, EF-Tu, EF-Ts and the N-terminal half of S1 containing three OB-fold motifs. The complex has the ability to synthesize the negative strand RNA from the positive strand Qβ RNA, as the holo Qβ replicase. Our structural and biochemical studies have revealed that S1 is anchored onto the β-subunit in the core Qβ replicase, via its N-terminal first and second OB-folds. The third OB-fold of S1 is mobile and protrudes toward the solvent beyond the surface of the β-subunit, but is anchored near the surface of the β-subunit. The biochemical studies also revealed that the mobile N-terminal third OB-fold is primarily responsible for the interaction with a specific RNA fragment, derived from a distinct internal region of the Qβ RNA. Furthermore, it was revealed that the RNA-binding ability of the third OB-fold is required for efficient replication initiation of Qβ RNA. These results, together with the previously identified long-distance interactions between the 3′-part of the Qβ RNA and the internal-site of the Qβ RNA (18,19), provide mechanistic insights into the efficient and specific recognition of Qβ RNA and the initiation of Qβ RNA replication by Qβ replicase, an essential process for viral replication and amplification in host cells.
MATERIALS AND METHODS
Expression and purification of ribosomal protein S1 and its variant
The gene encoding ribosomal protein S1 was polymerase chain reaction (PCR) amplified from E. coli (W3110 strain) genomic DNA and cloned in the pET22 (Novagen) vector at the Nde I and Xho I sites. DNA fragments encoding the ribosomal protein S1 gene (Figure 1A) were PCR amplified and cloned in the pET22 vector between the same sites. The S1 protein and its variants were over-expressed in E. coli BL21(DE3). The (His)6-tagged S1 and its variants were first purified on an Ni-NTA column (QIAGEN, Japan) and then further purified on HiTrap-Q and HiTrap-heparin columns and a HiLoad 16/60 Superdex 200 column (GE Healthcare, Japan), in a buffer containing 50 mM Tris-Cl, pH 7.5, 200 mM NaCl, 5 mM MgCl2 and 10 mM β-mercaptoethanol, and were stored at −80°C. Hfq reportedly binds Ni-NTA and is often found as a contaminant in the preparations of His-tagged proteins (20). To exclude the possibility of Hfq contamination in our preparations of S1 and its variants, we conducted western blotting of our samples, using an anti-Hfq antibody. The results showed that there was no significant Hfq contamination in our preparations (Supplementary Figure S1). Protein concentrations were calculated by using extinction coefficients (M−1 cm−1) of 46 730, 6970, 20 910, 33 690, 46 350 and 40 660 for S1, R1–2, R1–3, R1–4, R1–5 and R3–4, respectively (21).
Figure 1.
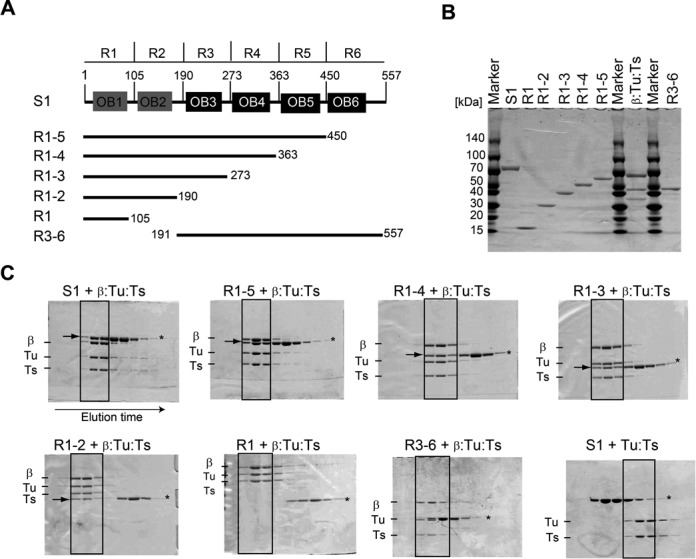
Interaction of S1 with the core Qβ replicase. (A) Schematic representation of ribosomal protein S1, consisting of six OB-fold motifs, and its variants used for the present study. (B) Purification of the S1 protein, its variants and the core Qβ replicase (β:Tu:Ts). Proteins were resolved by 4–20% (v/v) SDS polyacrylamide gel electrophoresis (PAGE) and stained with Coomassie Brilliant Blue (CBB). (C) Analysis of the interaction of core Qβ replicase with S1 variants by size-exclusion chromatography. The fractions were separated by 10% (v/v) or 12% (v/v) SDS-PAGE and stained with CBB. The arrows in the solid square in the gels indicate S1 or its variants bound to the core Qβ replicase (β:Tu:Ts) complex. Asterisks (*) in the gels indicate the bands of S1 or its variants.
Expression and purification of the core Qβ replicase and its complexes with S1 and its variants
The core Qβ replicase, consisting of the β-subunit, EF-Tu and EF-Ts, was expressed and purified as described previously (14). To prepare complexes of the core Qβ replicase with the S1 protein or its variants (Figure 2A), the core Qβ replicase and S1 or its variants (R1–2, R1–3, R1–4 and R1–5) were mixed (the molar ratio was 1: 2.5) and incubated on ice for 30 min to allow stable complex formation. The mixtures were separated on a HiLoad 16/60 Superdex 200 column, in a buffer containing 50 mM Tris-Cl, pH 7.0, 200 mM NaCl, 5 mM MgCl2 and 10 mM β-mercaptoethanol. The fractions containing the four proteins were pooled, concentrated and stored at −80°C.
Figure 2.
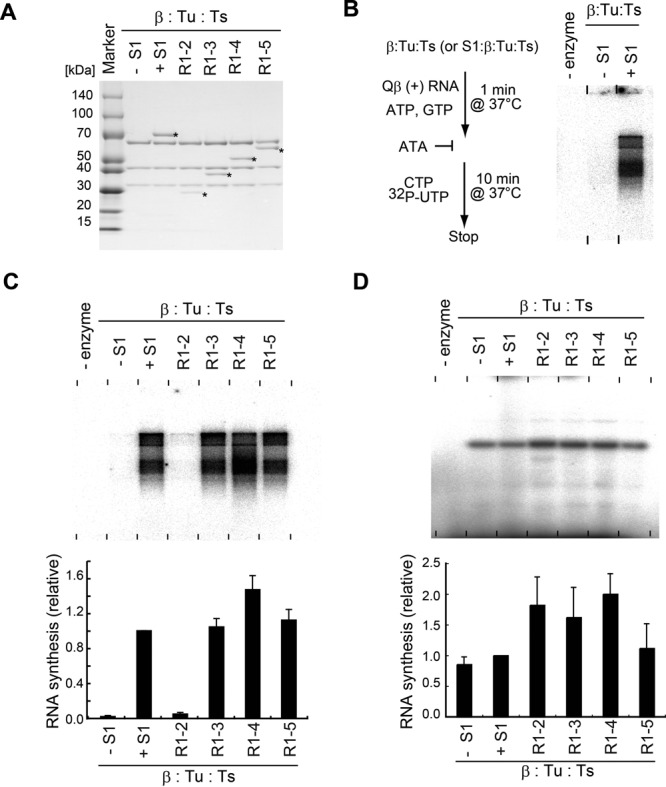
Minimal domains of S1 for Qβ negative RNA synthesis. (A) Purification of reconstituted complexes of core Qβ replicase and S1 variants. Protein complexes were resolved by 4–20% (v/v) SDS PAGE and stained with CBB. Asterisks (*) indicate the band of S1 and its variants. (B) In vitro S1-dependent negative strand RNA synthesis. Simplified flowchart of the assay. ATA, aurintricarboxylic acid, is an inhibitor of RNA synthesis initiation by Qβ replicase
Crystallization and structure determination of the complex of Qβ replicase with the S1 variant (QβSN)
For crystallization, the purified core Qβ replicase and the N-terminal half of S1 (R1–3) were mixed in a 1:1.2 molecular ratio and incubated for 30 min on ice. The mixture was purified by gel filtration chromatography on a HiLoad 16/60 Superdex 200 column. The purified quaternary complex was concentrated to 10–14 mg/ml and stored at −80°C. The complex was crystallized at 20°C by the sitting-drop vapor-diffusion method, by equilibration against 300 μl of reservoir solution, containing 100 mM Tris-HCl, pH 8.0, 200 mM lithium sulfate, 20% (v/v) PEG3350, and 5% (v/v) Jeffamine M-600. The crystal was cryoprotected in the reservoir solution supplemented with 15% (v/v) PEG200.
The diffraction data were collected at beamline BL-17A of the Photon Factory in Tsukuba, Japan. The data were integrated and scaled by HKL2000 (22). The initial structure was determined by molecular replacement, using the structure of the core Qβ replicase (14, PDB ID: 3AGP) as a search model, by Phaser (23). Model building and fitting were performed with Coot (24), and the refinements were performed with PHENIX (25), REFMAC (26) and BUSTER (27). The models of R1 and R2 in R1–3 were built by iterative cycles of model fitting and refinement. The crystallographic and refinement statistics are summarized in Supplementary Table S1. Water molecules were picked and modeled by using the ‘automated water picking’ program with PHENIX, followed by manual refinements. Ramachandran analyses of the determined structures showed that no residues are in the disallowed region. All structural figures were prepared by the PyMOL Molecular Graphics System (Schrödinger, LLC), and the protein–protein interfaces of the complex were analyzed with PISA (28).
In vitro negative strand synthesis by Qβ replicase variants
The plasmid (pT7QB), bearing the T7 promoter and the DNA corresponding to the Qβ positive strand RNA in pUC18, was purchased from Takara, Japan. The positive strand Qβ RNA was prepared with a MEGAScript T7 Transcription Kit (Invitrogen), using the pT7QB plasmid linearized by EcoT22I. The negative strand synthesis from the positive strand Qβ RNA was measured as described (19), with slight modifications. A reaction mixture (16 μl), containing 75 mM Tris-Cl, pH 7.5, 50 mM NaCl, 10 mM MgCl2, 1 mM ethylenediaminetetraacetic acid, 0.1 mM DTT (dithiothreitol), 7.5% (v/v) glycerol, 12.5-μg/ml Qβ RNA, 190-μM adenosine triphosphate, 470-μM GTP (guanosine triphosphate) and 9.2-nM Qβ replicase (or its variant), was incubated at 37°C for 1 min. Using the same buffer conditions, 20-μM aurintricarboxylic acid (29, ATA: Sigma-Aldrich, Japan), 190 μM CTP, 90 μM UTP and 5 μCi α-32P UTP (uridine triphosphate, 22.2 TBq/mmol, PerkinElmer) were added, and the mixture was further incubated at 37°C for 10 min. In the assays for the evaluation of mutations in OB3 (Figure 6C and D), the assay conditions were essentially the same, except that the NaCl concentration was 75 mM, to reduce the S1-independent RNA polymerization activity. The RNAs were extracted by phenol–chloroform treatment, ethanol precipitated, rinsed and dried. The RNAs were separated by 1% (w/v) denaturing agarose gel electrophoresis (Formaldehyde-Free RNA Gel Kit, Amresco), according to the manufacturer's protocol. The gels were dried, and the efficiencies of negative strand RNA synthesis were quantified by a BAS-5000 Phosphorimager (Fuji-Film, Japan). When the short RNA, DN3 (5′-GGGUUUAAAAUGUAAUAGGACCCACAUGAUCCCA-3′; 30), was used as the template RNA, 10 nM RNA was used under the same conditions as described above, and the RNA was separated by 10% (w/v) PAGE under denaturing conditions. The tRNA transcript used as a competitor RNA in Figure 4B was prepared as described (31,32).
Figure 6.
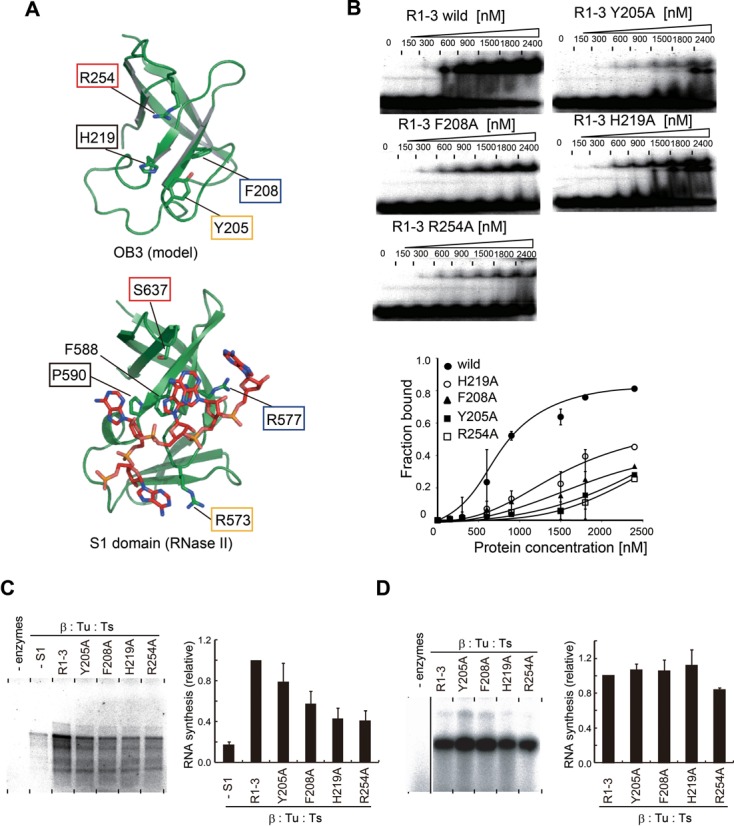
RNA-binding activity of OB3 for negative strand Qβ RNA synthesis. (A) A structural model of the OB-fold in R3 (upper). The amino acid residues putatively involved in RNA binding are shown in stick models. Structure of the S1 domain of ribonuclease II complexed with RNA (42). Residues involved in RNA binding are depicted by sticks. (B) The M-site RNA gel-retardation assays by the R1–3 domains of S1 and its mutants. The graph indicates the quantifications of M-site RNA fractions bound to R3 and its mutants. (C)In vitro negative strand synthesis by complexes of core Qβ replicase and R1–3 of S1 and its variants. Reaction mixtures were separated as in Figure 2B. (D) In vitro RNA synthesis using DN3 RNA as the template RNA, as in Figure 2D. The bars in the graphs in (C) and (D) are the standard deviations of more than two independent experiments.
Figure 4.
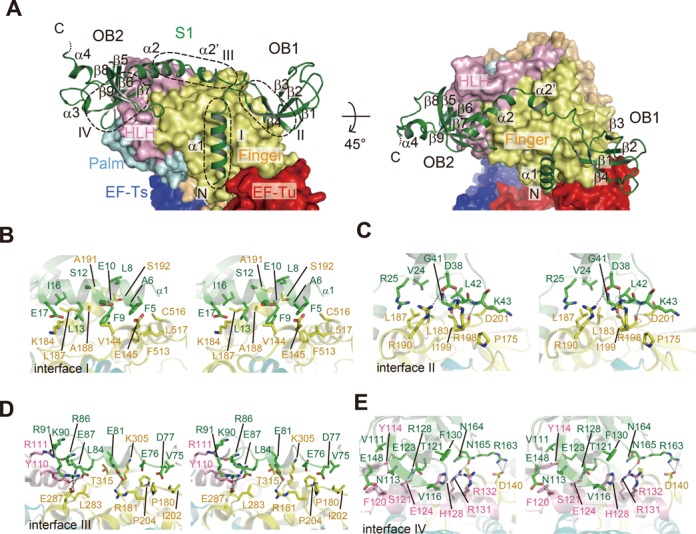
Interactions between the N-terminal half of S1 and the β-subunit. (A) Structure of R1–3 bound to the β-subunit, depicted by aribbon model. The finger, helix-loop-helix (HLH) and palm domains of the β-subunit are depicted by surface models. Contact interfaces between R1–3 of S1 and the β-subunit are depicted by dotted circles (interfaces I–IV). (B)–(E) Stereo views of the detailed interactions between the β-subunit and the S1 protein at each interface in (A).
Gel-retardation assay and ultraviolet cross-linking
The pT7QBM plasmid, bearing the T7 promoter and the DNA fragment corresponding to the M-site RNA (Figure 5A) in pUC18, was purchased from Operon, Japan. The M-site RNA was uniformly 32P-labeled with α-32P UTP by transcription from the linearized pT7QBM plasmid, using an in vitro transcription kit (Promega, Japan) according to the manufacturer's instructions. The 32P-labeled M-site RNA (20 000 cpm) was incubated in 10 μl of a solution, containing 50 mM Tris-Cl, pH 7.5, 5 mM MgCl2, 1 mM DTT, 40 mM NaCl, 3% (v/v) glycerol and various amounts of proteins, at room temperature for 10 min. Then, the solution was cooled on ice. The solutions were separated by 10% (w/v) native acrylamide gel electrophoresis (1x TBE) at room temperature. The tRNA transcript used as a competitor RNA in Figure 4B was prepared as described (31). The 32P-labeled M-site RNA (20 000 cpm) was incubated with Qβ replicase containing S1 variants (9.2 nM) in the reaction buffer described above, at 37°C for 10 min, and then the solution was cooled on ice. Following 254 nm irradiation under a handy ultraviolet (UV)-lamp for 10 min on ice, RNase A (0.1 μg/ml) was added and the reaction was incubated at 37°C for 10 min. The samples were separated by 4–20% (v/v) sodium dodecyl sulfate (SDS) polyacrylamide gel electrophoresis (PAGE). The gel was dried and the 32P-labeled band was quantified by a BAS-5000 Phosphorimager (Fuji-Film, Japan).
Figure 5.
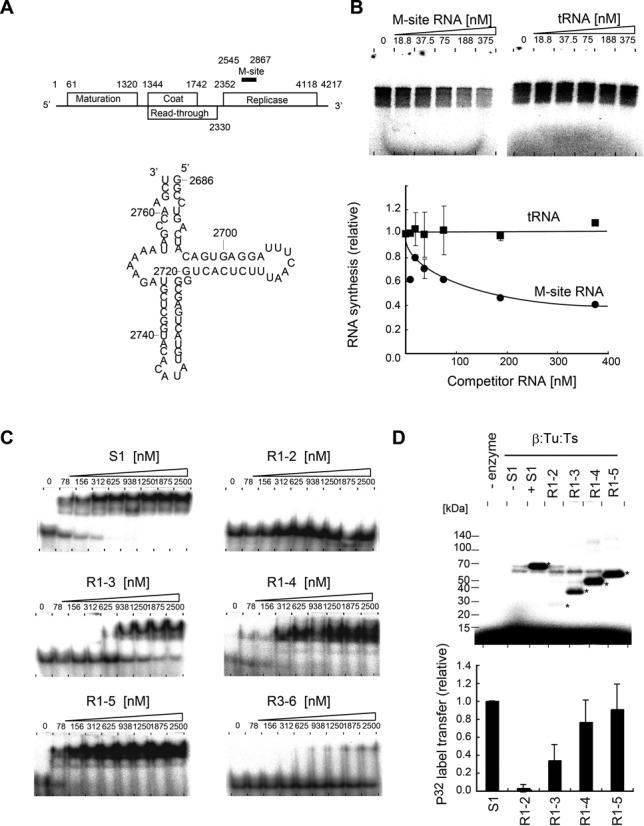
The N-terminal half of S1 binds the internal region of Qβ RNA. (A) Schematic presentation of the gene organization of Qβ RNA (18). Secondary structure of the M-site RNA used in the present study. The numbering of the RNA is that of the positive Qβ RNA. (B) In vitro negative strand RNA synthesis from positive strand Qβ RNA, in the presence of various amounts of M-site RNA (left) or tRNA (right). Reaction mixtures were separated as in Figure 2B. The graph below indicates the quantification of 32P-labeled RNA products in the gels. (C) The M-site RNA gel-retardation assays of full-length S1 and its variants in Figure 1A. (D) UV cross-linking of the M-site RNA and Qβ replicase containing S1 variants. The graph below indicates the quantification of 32P-labeled S1 or S1 variants. The bars in the graphs in (B) and (D) are the standard deviations of more than two independent experiments.
RESULTS
The two N-terminal OB-folds anchor S1 to the core Qβ replicase
Ribosomal protein S1 consists of six contiguous domains (R1–R6) containing OB-fold motifs. The domains are homologous to each other, but the first two N-terminal domains (R1 and R2) share less homology with the other four [R3, 4, 5 and 6 (1, 33); Figure 1A and Supplementary Figure S2].
A size-exclusion chromatography analysis of the interactions between the core Qβ replicase (ternary complex of the β-subunit, EF-Tu and EF-Ts) and truncated S1 variants (Figure 1B) suggested that the N-terminal region of S1, containing the first two OB-folds (R1–2; R1 and R2), stably interacts with the core Qβ replicase (Figure 1C). Other S1 variants possessing both R1 and R2, such as R1–3, R1–4, and R1–5, also stably interact with the core Qβ replicase. Neither the N-terminal R1 alone nor the C-terminal region (two-thirds of S1, R3–6) interacts with the core Qβ replicase. Isolated R2 alone does not interact with the core Qβ replicase (Supplementary Figure S3).
These results implied that R1 and R2 of S1 are required for S1 to interact with the core Qβ replicase and that R1 and R2 cooperatively mediate this interaction. The results are also consistent with previous studies showing that the trypsin-resistant fragment of S1 lacking the N-terminal one-third of S1, corresponding to R3–6, does not interact with the core Qβ replicase (34). Moreover, S1 does not bind the EF-Tu:EF-Ts binary complex, suggesting that S1 would bind either on the surface of the β-subunit or the surface spanning between the β-subunit and EF-Tu:EF-Ts in the core Qβ replicase, via the N-terminal R1 and R2 domains (R1–2).
The N-terminal half of S1 is required for negative strand Qβ RNA synthesis
The complexes of the core Qβ replicase and S1 variants (R1–2, R1–3, R1–4 or R1–5) were reconstituted and purified by size-exclusion chromatography (Figure 2A), and their ability to initiate negative strand RNA synthesis from the positive strand Qβ RNA was analyzed in vitro (Figure 2B and C). The in vitro assay system is capable of reproducing the initiation of S1-dependent negative strand RNA synthesis from the positive strand Qβ RNA (10). The core Qβ replicase, without S1, is unable to synthesize the negative strand RNA from the positive strand Qβ RNA in vitro significantly (Figure 2B).
Qβ replicase containing the N-terminal half of S1 (R1–3) can synthesize the negative strand RNA from the positive strand Qβ RNA, with almost the same efficiency as the holo Qβ replicase, while Qβ replicase with only the first two N-terminal domains (R1–2) cannot (Figure 2C). Other Qβ replicase variants with R1–4 or R1–5 of S1 can also synthesize the negative strand RNA from the positive strand Qβ RNA, similar to the holo Qβ replicase. On the other hand, when a short RNA, DN3 (30), was used as the template RNA under the same conditions, the complementary RNA was synthesized by all Qβ replicase variants with almost the same efficiency (Figure 2D).
These results implied that the R1–3 domains of S1 in Qβ replicase are required and sufficient for the initiation of negative strand RNA synthesis from the positive strand Qβ RNA. The R1 and R2 domains of S1 interact with the core Qβ replicase, but the Qβ replicase containing R1–2 lacks replication initiation activity. Thus, R3 of S1 is required primarily for the efficient and specific recognition of Qβ RNA by Qβ replicase, as described below.
Structure determination of Qβ replicase containing the N-terminal half of S1
Crystallization trials of holo Qβ replicase, containing full-length S1, were not successful. As described above, S1 consists of six contiguous OB-fold motifs (Figure 1A), and reportedly adopts an elongated and flexible form, not only in solution, but also when it is bound to ribosomes (1,35–37). The elongated and flexible conformation of S1 in the holo Qβ replicase may have impeded the crystal packing as well as the crystal growth. As described, the N-terminal half of S1 (R1–3) stably binds to the core Qβ replicase (Figure 1), and Qβ replicase containing the R1–3 domains (hereafter, termed QβSN) is capable of efficiently initiating negative strand RNA synthesis from the positive strand Qβ RNA, similar to the holo Qβ replicase (Figure 2). Thus, the active QβSN, instead of the holo Qβ replicase, was subjected to the crystallization trials. The crystals of QβSN were successfully obtained, and the structure was determined by molecular replacement, using the core Qβ replicase structure as a search model (14).
The crystal belongs to the space group P212121, with unit cell parameters of a = 132.2 Å, b = 150.8 Å and c = 189.8 Å. The crystal contains two QβSN complexes (Mol-A and Mol-B) in the asymmetric unit. The structure was refined to R factors of 26.0% (Rfree = 31.4%) at 2.9 Å resolution (Supplementary Table S1). The stoichiometry of the β-subunit, EF-Tu, EF-Ts and the S1 variant (R1–3) in the asymmetric unit is 1: 1: 1: 1, reflecting the biological unit of the Qβ replicase complex. The root-mean-square deviations of the structures of Mol-A and Mol-B in the asymmetric unit are 1.39 Å (Supplementary Figure S4). While the electron densities corresponding to R1 and R2 in R1–3 of S1 were clearly visible in the structure, those corresponding to R3 were not (Supplementary Figure S5). Thus, the model of R3 of S1 was not built in the structure (Figure 3A).
Figure 3.
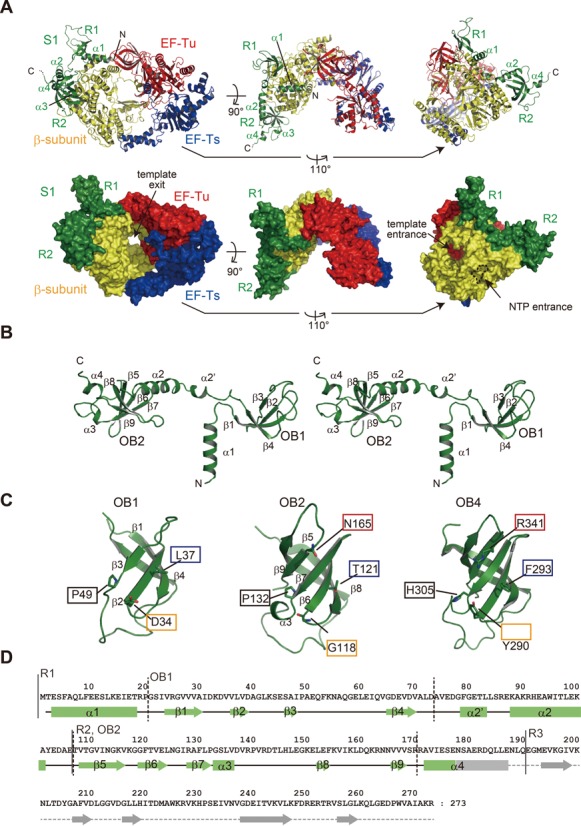
Complex structure of the core Qβ replicase and the N-terminal half of S1. (A) Overall structure of QβSN, the β-subunit, EF-Tu, EF-Ts and the N-terminal domains (R1 and R2) of S1. R3 of the S1 protein was not clearly visible in the structure. Ribbon models (upper panel) and surface models (lower panel). (B) Stereo view of the structure of R1–3. R3 was not visible in the determined structure. (C) Comparison of the structures of OB1 (left), OB2 (middle) and OB4 (right, 16, PDB ID: 2KHI). The amino acid residues putatively involved in RNA binding by OB4 are depicted, and the amino acid residues located at the corresponding positions in OB1 and OB2 are also shown. (D) Sequence of R1–3 of S1 along with the secondary structures. α-helices and β-sheets in R1 and R2 are depicted by solid squares and arrows, respectively. The secondary structure of the R3 domain was predicted based on the sequence alignments.
Overall structure of Qβ replicase containing the N-terminal half of S1
In the determined structure (Table 1 and Figure 3A), the R1–3 of S1 bind the core Qβ replicase via the N-terminal R1 and R2. The R1 and R2 of S1 interact only with the β-subunit, without blocking the entrances for the template RNAs and ribonucleosides, and the exit for the template RNA, in the core Qβ replicase (14,15). The composition analysis of the crystalline QβSN confirmed that intact R1–3 is indeed present within the crystal and excluded the possibility that a proteolyzed version of R1–3 of S1 was crystallized with the core Qβ replicase (Supplementary Figure S6). The crystal packing of the QβSN crystal revealed that there is sufficient space beyond the surface of the β-subunit, where the R3 of R1–3 of S1 is expected to be located (Supplementary Figure S7). However, as described, the electron densities corresponding to R3 were not clearly visible in the structure (Supplementary Figure S5). Hence, R3 of S1 in Qβ replicase would be relatively mobile and protruding toward the solvent beyond the surface of the β-subunit, but is anchored near the surface of the β-subunit using α4 as a linker, and R1 and R2 function to anchor S1 onto the β-subunit.
While the R2 of S1 contains five-stranded anti-parallel β-sheets (β5-β9, OB2) and adopts a standard OB-fold structure, R1 of S1 contains four-stranded anti-parallel β-sheets (β1–β4, OB1) and deviates from the standard OB-fold (Figure 3B–D). A comparison of the structures of OB1 and OB2 of S1 with that of the fourth OB-fold (17, OB4) in S1 revealed that the putative amino acid residues for nucleic acid binding are not conserved in OB1 and OB2 (Figure 3C and Supplementary Figure S2). The basic residues (His305 and Arg341) and aromatic residues (Tyr290 and Phe293) in OB4 would be involved in the interactions with the phosphate-backbone of RNA and the nucleobases of RNA, respectively (17). The corresponding positions in OB1 and OB2 structures are occupied by non-basic and non-aromatic residues (Figure 2C). The residue corresponding to Arg341 between the fourth and fifth β-sheets in OB4 is absent in OB1, since the fifth β-sheet is missing in OB1. Thus, OB1 and OB2 of S1 would not have RNA-binding activity, as discussed in more detail below.
As described below, the loops between the β-sheets in OB1, and the β-sheets and loops between the β-sheets in OB2 of S1, are utilized for interactions with the β-subunit. OB1 in R1 and OB2 in R2 are linked by the α2′ and α2 helices.
Interactions between S1 and the β-subunit
The R1 and R2 of S1 extensively interact with the β-subunit in the core Qβ replicase (Figure 4A, interfaces I–IV) and involve hydrophobic, hydrogen-bonding and van der Waals interactions.
The N-terminal α1 helix of S1 interacts with the finger domain of the β-subunit, primarily through hydrophobic interactions (interface-I, Figure 4B). The Phe5, Phe9, Leu13 and Ile16 residues in α1 form extensive hydrophobic interactions with hydrophobic residues in the finger domain of the β-subunit (Figure 4B). The loop between β2 and β3 in OB1 of R1 forms several hydrogen bonds with the finger domain of the β-subunit (interface II, Figure 4C). Asp39 forms hydrogen bonds with Arg190 and Arg198 in the β-subunit. The main chain carbonyl oxygen of Gly41 forms a hydrogen bond with the main chain amide group of Ile199 in the β-subunit, while the main chain amide group of Lys43 hydrogen bonds with the main chain carbonyl group of Ile199 in the β-subunit (Figure 4C). The α2 and α2′ helices, which form the linker between OB1 in R1 and OB2 in R2, interact with the finger and helix-loop-helix (HLH) domains of the β-subunit, through hydrogen-bonding and van der Waals interactions (interface III, Figure 4D and C). Glu81 in α2′ and Glu87 and Arg91 in α2 form hydrogen bonds with Arg181, the hydroxyl group of Tyr110, and Glu287 of the β-subunit, respectively, and the main chain carbonyl group of Arg86 forms a hydrogen bond with Arg111 of the β-subunit. Several van der Waals interactions reinforce the interactions between the β-subunit and S1 (Figure 4D). Three β-strands, β5, β6 and β7, and the loop between β8 and β9 in OB2 of R2 tightly bind the HLH domain of the β-subunit, by hydrogen bonding and van der Waals interactions (interface IV, Figure 4E and Supplementary Figure S8). Asn113 on β5 and Glu123 on β6 form hydrogen bonds with the hydroxyl group of Tyr114 in the β-subunit. Arg128 on β7 and Arg163 and Asn165 in the loop between β8 and β9 form hydrogen bonds with Glu124, Asp140 and Arg131 in the β-subunit, respectively. Glu148 also forms a hydrogen bond with Ser121 in the β-subunit (Figure 4E). van der Waals interactions also reinforce the stable interactions at interface IV.
The contact areas in each interface are 567, 356, 628 and 715 Å2 for interfaces I, II, III and IV, respectively. The structure explains the requirement of the N-terminal R1 and R2 of S1 for the stable interaction of S1 with the β-subunit quite well. Neither the R1 nor R2 domain itself interacts with the β-subunit. The interactions between the linker regions (α2′ and α2) and the β-subunit (interface III) would contribute to the enhancement of the affinity of R1–2 toward the β-subunit. Thus, R1 and R2 cooperatively interact with the β-subunit (Figure 1C).
The N-terminal half of S1 binds an internal region of Qβ RNA
It was previously suggested that Qβ replicase interacts with an internal region termed the M-site, ∼1400 nucleotides upstream from the 3′-end of Qβ RNA, via S1 in Qβ replicase, and S1 itself reportedly interacts with the M-site region (nucleotides 2545–2867) of Qβ RNA [(10,38) Figure 5A]. The M-site region in Qβ RNA is also reportedly required for the efficient replication of Qβ RNA in vivo as well as in vitro by the holo Qβ replicase (39–41).
In vitro S1-dependent negative strand RNA synthesis from the positive strand Qβ RNA was inhibited by the addition of ∼70-nucleotide-long RNA fragment (hereafter termed the M-site RNA, Figure 5A), derived from the M-site region of Qβ RNA. It is not inhibited by the addition of tRNA (Figure 5B), indicating that the initiation of negative strand RNA synthesis is dependent on the sequence and/or structure of the M-site region of the Qβ RNA. As described, the R1–3 domains of S1 are sufficient for negative strand RNA synthesis from the positive strand Qβ RNA by Qβ replicase in vitro (Figure 2C). Thus, it is likely that R1–3 of S1, anchored onto Qβ replicase, would recognize the M-site region of the Qβ RNA.
Gel-retardation assays of the M-site RNA by S1 variants (Figure 1A) showed that R1–2 and R3–6 do not bind the M-site RNA significantly, even at a high concentration (2.5 μM) of the respective domains. The absence of significant RNA-binding ability by R1–2 is consistent with the fact that the two OB-folds in R1–2, OB1 and OB2, lack the conserved putative amino acid residues for RNA binding, as described above (Figure 3C and Supplementary Figure S2). On the other hand, R1–3, R1–4 and R1–5 bound the M-site RNA efficiently, although the affinity of R1–3 toward the M-site RNA was weaker than those of R1–4, R1–5 and the full-length S1 protein (Figure 5C). The concentration of R1–3 that generated a 50% shift of the M-site RNA was estimated to be ∼600 nM, and those of R1–4, R1–5 and full-length S1 were estimated to be ∼100 nM. These results suggest that R3 is the primary RNA-binding domain, which can function together with R1 and R2 cooperatively, and that R4, R5 and R6 mutually function to enhance the RNA-binding ability of R3, together with R1 and R2.
UV-cross linking experiments using reconstituted Qβ replicases with S1 variants showed that the M-site RNA cross-links to the R1–3, R1–4, R1–5 and full-length S1 efficiently, in their respective complexes. On the other hand, the M-site RNA does not cross-link to R1–2 significantly in the complex of Qβ replicase with R1–2 (Figure 5D). The cross-linking efficiency of R1–3 was about half of those of R1–4, R1–5 and full-length S1. The M-site RNA-binding properties of the S1 variants (Figure 5C) correlate with those of the S1 variants incorporated into Qβ replicase (Figure 5D).
Together, these results suggested that the N-terminal half of S1 (R1–3) in the Qβ replicase is the minimal region of S1 involved in the recognition of the M-site of Qβ RNA. These results are also consistent with the results showing that the R1–3 domains of S1 are sufficient for the initiation of negative strand RNA synthesis from the positive strand Qβ RNA (Figure 2). The R1–2 domains in S1 do not have sufficient RNA-binding ability (Figure 5C), and the putative nucleic acid binding residues are not conserved in OB1 and OB2 of R1–2 (Figure 3C and Supplementary Figure S2). Thus, either R3 is the primary domain for the M-site RNA binding, or R3, together with the β-subunit in the Qβ replicase complex or with R1–2 of S1, cooperatively binds the RNA.
The N-terminal OB-folds of S1 are required for negative strand Qβ RNA synthesis
In the determined structure, the R3 domain of S1 was not clearly visible (Figure 3A). Based on the amino acid sequence alignment of R3 with other related proteins with available structures (33,42; Supplementary Figure S2), a model structure of R3 of S1 was constructed (Figure 6A). The model structure allowed us to identify several putative residues involved in RNA recognition, including Tyr205, Phe208, His219 and Arg254.
Gel-retardation assays of M-site RNA with mutants of R1–3 of S1 showed that the Tyr205Ala, Phe208Ala, His219Ala and Ag254Ala mutations in OB3 all reduced the affinity toward M-site RNA (Figure 6B). The concentration of R1–3 that generated a 50% shift of the M-site RNA was estimated to be ∼800 nM, and those of R1–3(H219A), R1–3(Y205A), R1–3(F208A) and R1–3(R254A) were estimated to be greater than 2.4 μM. These results suggested that the amino acid residues Tyr205, Phe208, His219 and Arg254, in OB3 of R1–3, are involved in M-site RNA recognition.
The complexes of the core Qβ replicases with R1–3 mutants, R1–3(H219A), R1–3(Y205A), R1–3(F208A) and R1–3(R254A), were prepared, purified and tested for their ability to synthesize the negative strand RNA from the positive strand Qβ RNA in vitro (Figure 6C). The R1–3 mutants all formed stable complexes with the core Qβ replicase, as revealed by a size-exclusion chromatography analysis, suggesting that the mutations in OB3 of R1–3 do not affect the complex formation.
The F208A, H219A and R254A mutations in OB3 of R1–3, in the complexes with Qβ replicase, reduced the activity of negative strand RNA synthesis initiation from the positive strand Qβ RNA significantly. The F208A, H219A and R254A mutations in R1–3 reduced the replication initiation activity by 50, 40, and 40% relative to the wild-type R1–3, respectively (Figure 6C). The R1–3(Y205A) mutation also slightly reduced the replication initiation activity of the mutant complex of Qβ replicase, by 80% relative to the wild type R1–3. On other hand, when a short RNA, DN3 (30), was used as the template RNA under the same conditions, the complementary RNA was equally synthesized by the Qβ replicases possessing R1–3 and its mutants (Figure 6D), indicating that the RNA polymerization activities of the Qβ replicase complex variants are not affected by the R1–3 variants.
There results suggested that either the intrinsic RNA-binding properties of R3 of S1 or the cooperative RNA-binding properties of R3 with either R1–2 or the β-subunit are required for the recognition of the M-site of Qβ RNA, and are sufficient for the initiation of negative strand RNA synthesis from the positive strand Qβ RNA.
DISCUSSION
Ribosomal protein S1 is one of the three host-derived factors of Qβ replicase and is essential for the replication of Qβ RNA (9,10). This is the first reported example of an extra-ribosome function among ribosomal proteins. S1 is indispensable for the initiation of the negative strand RNA synthesis from the positive strand Qβ RNA. However, the detailed mechanisms of the initiation of negative strand synthesis by Qβ replicase, containing S1, have remained enigmatic.
Previous genetic and biochemical analyses suggested that S1 binds an internal region on the positive strand Qβ RNA, termed the M-site, about 1400 nucleotides upstream of the 3′-end of the Qβ RNA (38, Figure 5A). The sequence and/or structure of the M-site region in Qβ RNA is required for the efficient initiation of negative strand RNA synthesis (39–41). Subsequently, long-distance interactions were detected between the 3′-terminal domain (3′-TD) of Qβ RNA and the internal-site just downstream of the M-site (distance ∼1000 nucleotides), and these interactions are required for the efficient initiation of negative strand RNA synthesis from the positive strand Qβ RNA (18,19; Figure 7A).
Figure 7.
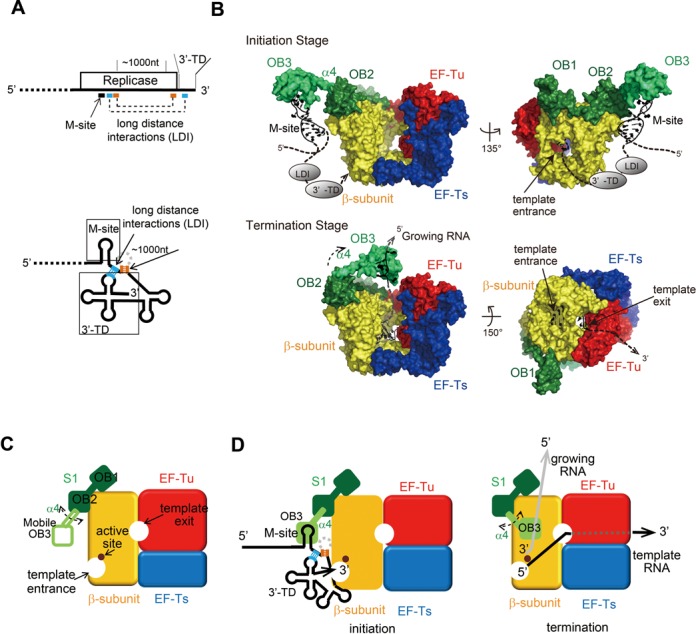
Mechanism of initiation of negative strand Qβ RNA synthesis. (A) One-dimensional simplified view of the 3′-half of Qβ RNA (above) and two-dimensional view of the 3′-half of Qβ RNA. The long distance interactions (LDI) in the RNA (18,19) are depicted by dotted lines, and the regions used for interactions in the Qβ RNA are shown. 3′-TD stands for 3′-terminal domain. (B) Structure of Qβ replicase containing R1–3. The mobile R3 was modeled. The R3 is capable of pivotal rotation, using the α helix (α4) between OB2 and OB3 as a swing arm for both initiation and termination of stages. The template Qβ RNA at the replication initiation stage (upper) and the template and growing RNAs at the replication termination stage (lower) are modeled. LDI and 3′-TD in Qβ RNA were simplified. See the Discussion section in the text. (C) Simplified cartoon of Qβ replicase containing the N-terminal half of S1. The β-subunit, EF-Tu, EF-Ts and S1 (OB1 and OB2) and the mobile OB3 of S1 are depicted. (D) A simplified model of the initiation of negative strand RNA synthesis (left). R3 interacts with the M-site of the Qβ RNA. A simplified model of RNA synthesis termination (right). The interaction between the growing RNA and the mobile R3 of S1 at the termination stage triggers the release of the RNA product from the complex (43).
The present study has shown that S1 is anchored to the β-subunit in Qβ replicase via its N-terminal R1 and R2 domains. The R3 domain itself does not interact with the β-subunit. Instead, it is exposed and protruding to the solvent and relatively mobile, but is spatially anchored near the surface of the β-subunit (Figures 3A and 7B and C). Our results also revealed that the N-terminal half of S1, R1–3, in Qβ replicase is sufficient for the initiation of negative strand synthesis from the positive strand Qβ RNA (Figure 2). The N-terminal half of S1 can bind to the M-site RNA in Qβ RNA (Figure 5), and the RNA-binding properties of the N-terminal half of S1 are mainly attributable to the OB3 domain in R3 of S1, as the R1–2 domain containing two OB-folds lacks significant RNA-binding ability (Figures 5 and 7D). Finally, the RNA-binding ability of the OB3 in R3 of S1 is required for efficient negative strand RNA synthesis initiation from the positive Qβ RNA by Qβ replicase (Figure 6).
Together, the present structural and biochemical studies suggest that the specific recognition of Qβ RNA through the M-site is either accomplished by the third mobile OB-fold of S1 or cooperatively with R1–2 or with the β-subunit (Figure 7B). Thus, Qβ replicase recruits Qβ RNA specifically and efficiently. In addition, the long-distance interactions between the internal sites downstream of the M-site and the 3′-TD of Qβ RNA allow the 3′-TD of Qβ RNA to be located in the proximity of the active site of the β-subunit (Figure 7A, B and D). This enhances the efficient initiation of negative strand synthesis from the positive strand Qβ RNA. Recent biochemical studies suggested that S1 could act as a termination factor of RNA polymerization by Qβ replicase (43). The N-terminal half of S1 (R1–3) is sufficient for the efficient release of the product RNA from the template RNA in a single-stranded form at the terminal stage. As revealed in this study, the R3 domain in the N-terminal half of S1 anchored on the β-subunit is mobile and protrudes toward the solvent beyond the surface of the β-subunit. Thus, OB3 would be capable of pivotal rotation near the surface of the β-subunit, using the α helix (α4) between OB2 and OB3 as a swing arm (Figures 3D and 7B and C). Therefore, the OB-fold in R3 would move and relocate toward the exit site of the growing RNA at the termination stage of RNA polymerization, and act as a termination factor, by binding to the growing RNA and preventing the template and growing RNAs from forming double-stranded RNA (Figure 7B and D).
In ribosomes, S1 is required for the efficient translation initiation of most natural mRNAs (1–7). A recent biochemical study showed that S1 is anchored onto the 30S ribosome via its two N-terminal OB-fold domains (R1 and R2), and the N-terminal half of S1 (R1–3) is required and sufficient for the recognition and unwinding of the structured 5′-leader mRNA (7). It is noteworthy that the functional domains of S1 in Qβ replicase required for the initiation of RNA replication, and those necessary in the ribosome for translation initiation, are the same. Since the structure of S1 incorporated within the ribosome has not been solved at atomic resolution, the detailed interactions of S1 with the ribosome have not been clarified yet. The present structure of the N-terminal half of S1 in Qβ replicase will provide mechanistic insights into the interaction of S1 with the 30S ribosome (Supplementary Figure S9).
The OB-fold preferentially recognizes single-stranded RNA. The M-site region is predicted to adopt a structured secondary structure (Figure 5A), and the deletion or truncation of one of the stems or an unpaired bulge in the M-site region reduces the efficiency of initiation replication by the holo Qβ replicase (41). S1 alone and S1 incorporated within the ribosome reportedly have helicase activity (7,44–47). The helicase activity of the N-terminal half of S1 anchored onto the β-subunit, as observed in ribosomes, might unfold the structured M-site region of the Qβ RNA. As a result, the N-terminal half of S1, especially OB3, would specifically bind to the single-stranded region in the M-site of Qβ RNA. The recognition and unfolding of the M-site region of Qβ RNA, by the N-terminal region of S1 in Qβ replicase, might proceed cooperatively by the three OB-folds in the N-terminal half of S1, and also might involve the interactions between the M-site region of Qβ RNA and the β-subunit. The detailed mechanism of Qβ RNA recognition by S1 in Qβ replicase awaits the further analysis of complex structures of Qβ replicase containing S1 and RNAs.
Besides its role in translation initiation, S1 is involved in various cellular functions, such as translational control, transcription, trans-translation, and mRNA stability (8). S1 regulates the translation of its own mRNA by binding to the 5′-region (48,49). It also interacts with the RNA polymerase complex in E. coli and promotes transcriptional cycles (50,51). S1 also functions in trans-translation and interacts with tmRNA (21,52,53). The ribosomal protein S1 is essential in E. coli to accomplish these processes, and thus E. coli would not be tolerant to mutations in the functional N-terminal half of S1. Hence, the Qβ virus might have evolved to utilize the functionally important domain of S1 for its propagation in host cells, as the Qβ virus also utilizes the essential translation elongation factors, EF-Tu and EF-Tu, as essential subunits of Qβ replicase. Alternatively, these translational factors might have been the original cofactors required for RNA replication, and the modern translational apparatus might have borrowed these replication factors for protein synthesis (15,54). The translational elongation factor, EF-Tu, in Qβ replicase functions as an RNA replication factor for the efficient and complete replication and transcription of the viral RNA (15). Especially, the RNA-binding domains of EF-Tu, domains 2 and 3, interact with the template RNA during the elongation process of replication and transcription of the viral RNA, and the RNA-binding domains (OB-folds) of S1 interact with the template and growing RNAs at the initiation and termination stages of replication, respectively. Thus, the RNA-binding domains, such as the OB-folds of the translation factors of EF-Tu and S1, might be a kind of ‘molecular fossil’ in the modern life systems, and may be the ancestors of modern translational factors. Ancient RNA-binding proteins, required for RNA replication systems, might have acquired additional domains to function in the modern translational apparatus in more sophisticated and specific manners.
ACCESSION NUMBER
Coordinates and structure factors have been deposited in the Protein Data Bank, under the accession code 4Q7J.
SUPPLEMENTARY DATA
Supplementary Data are available at NAR Online.
Acknowledgments
We thank Azusa Hamada of AIST for technical assistance and Dr Hiroji Aiba, at Suzuka University of Medical Science, for the Hfq antibody. We also thank the beam-line staffs of BL-17A and 1A (KEK, Tsukuba) for technical assistance during data collection.
FUNDING
Japan Society for the Promotion of Science (JSPS), Grant-in-Aid for Scientific Research (A), grant number 26251009, and ‘Funding Program for Next Generation World-Leading Researchers (NEXT Program, grant number 10104493)’ [to K.T.]; Takeda Science Foundation [to K.T.]; Mitsubishi Foundation [to K.T.]; Naito Foundation [to K.T.]; Kurata Hitachi Memorial Foundation [to K.T.]. Funding for open access charge: JSPS, Grant-in-Aid for Scientific Research (A), grant number 26251009.
Conflict of interest statement. None declared.
REFERENCES
- 1.Subramanian A.R. Structure and functions of ribosomal protein S1. Prog. Nucleic Acid Res. Mol. Biol. 1983;28:102–138. doi: 10.1016/s0079-6603(08)60085-9. [DOI] [PubMed] [Google Scholar]
- 2.Farwell M.A., Robert M.W., Rabinowitz J.C. The effect of ribosomal protein S1 from Escherichia coli and Micrococcus luteus on protein synthesis in vitro by E. coli and Bacillus subtilis. Mol. Microbiol. 1992;6:3375–3383. doi: 10.1111/j.1365-2958.1992.tb02205.x. [DOI] [PubMed] [Google Scholar]
- 3.Boni I.V., Isaeva D.M., Musychenko M.L., Tzareva N.V. Ribosome-messenger recognition: mRNA target sites for ribosomal protein S1. Nucleic Acids Res. 1991;19:155–162. doi: 10.1093/nar/19.1.155. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Tedin K., Resch A., Blasi U. Requirements for ribosomal protein S1 for translation initiation of mRNAs with and without a 5′ leader sequence. Mol. Microbiol. 1997;25:189–199. doi: 10.1046/j.1365-2958.1997.4421810.x. [DOI] [PubMed] [Google Scholar]
- 5.Sorensen M.A., Fricke J., Pedersen S. Ribosomal protein S1 is required for translation of most, if not all, natural mRNAs in Escherichia coli in vivo. J. Mol. Biol. 1998;280:561–569. doi: 10.1006/jmbi.1998.1909. [DOI] [PubMed] [Google Scholar]
- 6.Komarova A.V., Tchufistova L.S., Supina E.V., Boni I.V. Protein S1 counteracts the inhibitory effect of the extended Shine-Dalgarno sequence on translation. RNA. 2002;8:1137–1147. doi: 10.1017/s1355838202029990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Duval M., Korepanov A., Fuchsbauer O., Fechter P., Haller A., Fabbretti A., Choulier L., Micura R., Klaholz B.P., Romby P., et al. Escherichia coli ribosomal protein S1 unfolds structured mRNAs onto the ribosome for active translation initiation. PLoS Biol. 2013;11:e1001731. doi: 10.1371/journal.pbio.1001731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Hajnsdorf E., Boni I.V. Multiple activities of RNA-binding protein S1 and Hfq. Biochimie. 2012;94:1544–1553. doi: 10.1016/j.biochi.2012.02.010. [DOI] [PubMed] [Google Scholar]
- 9.Wahba A.J., Miller M.J., Niveleau A., Landers T.A., Carmichael G.G., Weber K., Hawley D.A., Slobin L.I. Subunit I of Q beta replicase and 30 S ribosomal protein S1 of Escherichia coli. Evidence for the identity of the two proteins. J. Biol. Chem. 1974;249:3314–3316. [PubMed] [Google Scholar]
- 10.Blumenthal T., Carmichael G.G. RNA replication: function and structure of Qbeta-replicase. Annu. Rev. Biochem. 1979;48:525–548. doi: 10.1146/annurev.bi.48.070179.002521. [DOI] [PubMed] [Google Scholar]
- 11.Kondo M., Gallerani R., Weissmann C. Subunit structure of Q-beta replicase. Nature. 1970;228:525–527. doi: 10.1038/228525a0. [DOI] [PubMed] [Google Scholar]
- 12.Blumenthal T., Landers T.A., Weber K. Bacteriophage Q replicase contains the protein biosynthesis elongation factors EF Tu and EF Ts. Proc. Natl Acad. Sci. U.S.A. 1972;69:1313–1317. doi: 10.1073/pnas.69.5.1313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Kidmose R.T., Vasiliev N.N., Chetverin A.B., Andersen G.R., Knudsen C.R. Structure of the Qbeta replicase, an RNA-dependent RNA polymerase consisting of viral and host proteins. Proc. Natl Acad. Sci. U.S.A. 2010;107:10884–10889. doi: 10.1073/pnas.1003015107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Takeshita D., Tomita K. Assembly of Qβ viral RNA polymerase with host translational elongation factors EF-Tu and -Ts. Proc. Natl Acad. Sci. U.S.A. 2010;107:15733–15738. doi: 10.1073/pnas.1006559107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Takeshita D., Tomita K. Molecular basis for RNA polymerization by Qβ replicase. Nat. Struct. Mol. Biol. 2012;19:229–237. doi: 10.1038/nsmb.2204. [DOI] [PubMed] [Google Scholar]
- 16.Takeshita D., Yamashita S., Tomita K. Mechanism for template-independent terminal adenylation activity of Qβ replicase. Structure. 2012;20:1661–1669. doi: 10.1016/j.str.2012.07.004. [DOI] [PubMed] [Google Scholar]
- 17.Salah P., Bisaglia M., Aliprandi P., Uzan M., Sizun C., Bontems F. Probing the relationship between Gram-negative and Gram-positive S1 proteins by sequence analysis. Nucleic Acids Res. 2009;37:5578–5588. doi: 10.1093/nar/gkp547. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Klovins J., Berzins V., van Duin J. A long-range interaction in Qβ RNA that bridges the thousand nucleotides between the M-site and the 3′ end is required for replication. RNA. 1998;4:948–957. doi: 10.1017/s1355838298980177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Klovins J., van Duin J. A long-range pseudoknot in Qβ RNA is essential for replication. J. Mol. Biol. 1999;294:875–884. doi: 10.1006/jmbi.1999.3274. [DOI] [PubMed] [Google Scholar]
- 20.Milojevic T., Sonnleitner E., Romeo A., Djinović-Carugo K., Bläsi U. False positive RNA binding activities after Ni-affinity purification from Escherichia coli. RNA Biol. 2013;10:1066–1069. doi: 10.4161/rna.25195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.McGinness K.E., Sauer R.T. Ribosomal protein S1 binds mRNA and tmRNA similarly but play distinct roles in translation of these molecules. Proc. Natl Acad. Sci. U.S.A. 2004;101:13454–13459. doi: 10.1073/pnas.0405521101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Otwinowski Z., Minor W. Processing of X-ray diffraction data collected in oscillation mode. Methods Enzymol. 1997;276:307–326. doi: 10.1016/S0076-6879(97)76066-X. [DOI] [PubMed] [Google Scholar]
- 23.McCoy A.J., Grosse-Kunstleve R.W., Adams P.D., Winn M.D., Storoni L.C., Read R.J. Phaser crystallographic software. J. Appl. Crystallogr. 2007;40:658–674. doi: 10.1107/S0021889807021206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Emsley P., Cowtan K. Coot: model-building tools for molecular graphics. Acta Crystallogr. D Biol. Crystallogr. 2004;60:2126–2132. doi: 10.1107/S0907444904019158. [DOI] [PubMed] [Google Scholar]
- 25.Adams P.D., Grosse-Kunstleve R.W., Hung L.W., Ioerger T.R., McCoy A.J., Moriarty N.W., Read R.J., Sacchettini J.C., Sauter N.K., Terwilliger T.C. PHENIX: building new software for automated crystallographic structure determination. Acta Crystallogr. D Biol. Crystallogr. 2002;58:1948–1954. doi: 10.1107/s0907444902016657. [DOI] [PubMed] [Google Scholar]
- 26.Murshudov G.N., Skubák P., Lebedev A.A., Pannu N.S., Steiner R.A., Nicholls R.A., Winn M.D., Long F., Vagin A.A. REFMAC5 for the refinement of macromolecular crystal structures. Acta Crystallogr. D Biol. Crystallogr. 2011;67:355–367. doi: 10.1107/S0907444911001314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Blanc E., Roversi P., Vonrhein C., Flensburg C., Lea S.M., Bricogne G. Refinement of severely incomplete structures with maximum likelihood in BUSTER-TNT. Acta Crystallogr. D Biol. Crystallogr. 2004;60:2210–2221. doi: 10.1107/S0907444904016427. [DOI] [PubMed] [Google Scholar]
- 28.Krissinel E., Henrick K. Inference of macromolecular assemblies from crystalline state. J. Mol. Biol. 2007;372:774–797. doi: 10.1016/j.jmb.2007.05.022. [DOI] [PubMed] [Google Scholar]
- 29.Blumenthal T., Landers T.A. The inhibition of nucleic acid-binding proteins by aurintricarboxylic acid. Biochem. Biophys. Res. Commun. 1973;55:680–688. doi: 10.1016/0006-291x(73)91198-4. [DOI] [PubMed] [Google Scholar]
- 30.Zamora H., Luce R., Biebricher C.K. Design of artificial short-chained RNA species that are replicated by Q beta replicase. Biochemistry. 1995;34:1261–1266. doi: 10.1021/bi00004a020. [DOI] [PubMed] [Google Scholar]
- 31.Tomita K., Fukai S., Ishitani R., Ueda T., Takeuchi N., Vassylyev D.G., Nureki O. Structural basis for template-independent RNA polymerization. Nature. 2004;430:700–704. doi: 10.1038/nature02712. [DOI] [PubMed] [Google Scholar]
- 32.Yamashita S., Takeshita D., Tomita K. Translocation and rotation of tRNA during template-independent RNA polymerization by tRNA nucleotidyltransferase. Structure. 2014;22:315–325. doi: 10.1016/j.str.2013.12.002. [DOI] [PubMed] [Google Scholar]
- 33.Bycroft M., Hubbard T.J., Proctor M., Freund S.M., Murzin A.G. The solution structure of the S1 RNA binding domain: a member of an ancient nucleic acid-binding fold. Cell. 1997;88:235–242. doi: 10.1016/s0092-8674(00)81844-9. [DOI] [PubMed] [Google Scholar]
- 34.Guerrier-Takada C., Subramanian A.R., Cole P.E. The activity of discrete fragments of ribosomal protein S1 in Q beta replicase function. J. Biol. Chem. 1983;258:13649–13652. [PubMed] [Google Scholar]
- 35.Sillers I.Y., Moore P.B. Position of protein S1 in the 30 S ribosomal subunit of Escherichia coli. J. Mol. Biol. 1981;153:761–780. doi: 10.1016/0022-2836(81)90417-4. [DOI] [PubMed] [Google Scholar]
- 36.Odom O.W., Deng H.Y., Subramanian A.R., Hardesty B. Relaxation time, interthiol distance, and mechanism of action of ribosomal protein S1. Arch. Biochem. Biophys. 1984;230:178–193. doi: 10.1016/0003-9861(84)90099-7. [DOI] [PubMed] [Google Scholar]
- 37.Walleczek J., Albrecht-Ehrlich R., Stöffler G., Stöffler-Meilicke M. Three-dimensional localization of the NH2- and carboxyl-terminal domain of ribosomal protein S1 on the surface of the 30 S subunit from Escherichia coli. J. Biol. Chem. 1990;265:11338–11344. [PubMed] [Google Scholar]
- 38.Meyer F., Weber H., Weissmann C. Interactions of Q beta replicase with Q beta RNA. J. Mol. Biol. 1981;153:631–660. doi: 10.1016/0022-2836(81)90411-3. [DOI] [PubMed] [Google Scholar]
- 39.Barrera I., Schuppli D., Sogo J.M., Weber H. Different mechanisms of recognition of bacteriophage Q beta plus and minus strand RNAs by Q beta replicase. J. Mol. Biol. 1993;232:512–521. doi: 10.1006/jmbi.1993.1407. [DOI] [PubMed] [Google Scholar]
- 40.Miranda G., Schuppli D., Barrera I., Hausherr C., Sogo J.M., Weber H. Recognition of bacteriophage Qbeta plus strand RNA as a template by Qbeta replicase: role of RNA interactions mediated by ribosomal proteins S1 and host factor. J. Mol. Biol. 1997;267:1089–1103. doi: 10.1006/jmbi.1997.0939. [DOI] [PubMed] [Google Scholar]
- 41.Schuppli D., Miranda G., Qiu S., Weber H. A branched stem-loop structure in the M-site of bacteriophage Qβ RNA is important for template recognition by Qβ replicase holoenzyme. J. Mol. Biol. 1998;283:585–593. doi: 10.1006/jmbi.1998.2123. [DOI] [PubMed] [Google Scholar]
- 42.Frazão C., McVey C.E., Amblar M., Barbas A., Vonrhein C., Arraiano C.M., Carrondo M.A. Unravelling the dynamics of RNA degradation by ribonuclease II and its RNA-bound complex. Nature. 2006;443:110–114. doi: 10.1038/nature05080. [DOI] [PubMed] [Google Scholar]
- 43.Vasilyev N.N., Kutlubaeva Z.S., Ugarov V.I., Chetverina H.V., Chetverin A.B. Ribosomal protein S1 functions as a termination factor in RNA synthesis by Qβ phage replicase. Nat. Commun. 2013;4 doi: 10.1038/ncomms2807. doi:10.1038/ncomms2807. [DOI] [PubMed] [Google Scholar]
- 44.Kolb A., Hermoso J.M., Thomas J.O., Szer W. Nucleic acid helix-unwinding properties of ribosomal protein S1 and the role of S1 in mRNA binding to ribosomes. Proc. Natl Acad. Sci. U.S.A. 1977;74:2379–2383. doi: 10.1073/pnas.74.6.2379. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Bear D.G., Ng R., Van Derveer D., Johnson N.P., Thomas G., Schleich T., Noller H.F. Alteration of polynucleotide secondary structure by ribosomal protein S1. Proc. Natl Acad. Sci. U.S.A. 1976;73:1824–1828. doi: 10.1073/pnas.73.6.1824. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Studer S.M., Joseph S. Unfolding of mRNA secondary structure by the bacterial translation initiation complex. Mol. Cell. 2006;22:105–215. doi: 10.1016/j.molcel.2006.02.014. [DOI] [PubMed] [Google Scholar]
- 47.Qu X., Lancaster L., Noller H.F., Bustamante C., Tinoco I., Jr Ribosomal protein S1 unwinds double-stranded RNA in multiple steps. Proc. Natl Acad. Sci. U.S.A. 2012;109:14458–14463. doi: 10.1073/pnas.1208950109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Skouv J., Schnier J., Rasmussen M.D., Subramanian A.R., Pedersen S. Ribosomal protein S1 of Escherichia coli is the effector for the regulation of its own synthesis. J. Biol. Chem. 1990;265:17044–17049. [PubMed] [Google Scholar]
- 49.Boni I.V., Artamonova V.S., Dreyfus M. The last RNA-binding repeat of the Escherichia coli ribosomal protein S1 is specifically involved in autogenous control. J. Bacteriol. 2000;182:5872–5879. doi: 10.1128/jb.182.20.5872-5879.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Sukhodolets M.V., Garges S. Interaction of Escherichia coli RNA polymerase with the ribosomal protein S1 and the Sm-like ATPase Hfq. Biochemistry. 2003;42:8022–8034. doi: 10.1021/bi020638i. [DOI] [PubMed] [Google Scholar]
- 51.Sukhodolets M.V., Garges S., Adhya S. Ribosomal protein S1 promotes transcriptional cycling. RNA. 2006;12:1505–1513. doi: 10.1261/rna.2321606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Wower I.K., Zwieb C.W., Guven S.A., Wower J. Binding and cross-linking of tmRNA to ribosomal protein S1, on and off the Escherichia coli ribosome. EMBO J. 2000;19:6612–6621. doi: 10.1093/emboj/19.23.6612. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Karzai A.W., Sauer R.T. Protein factors associated with the SsrA·SmpB tagging and ribosome rescue complex. Proc. Natl Acad. Sci. U.S.A. 2001;98:3040–3044. doi: 10.1073/pnas.051628298. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Weiner A.M., Maizels N. tRNA-like structures tag the 3′ ends of genomic RNA molecules for replication: Implications for the origin of protein synthesis. Proc. Natl Acad. Sci. U.S.A. 1987;84:7383–7387. doi: 10.1073/pnas.84.21.7383. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.