

Abstract
In regression analysis of counts, a lack of simple and efficient algorithms for posterior computation has made Bayesian approaches appear unattractive and thus underdeveloped. We propose a lognormal and gamma mixed negative binomial (NB) regression model for counts, and present efficient closed-form Bayesian inference; unlike conventional Poisson models, the proposed approach has two free parameters to include two different kinds of random effects, and allows the incorporation of prior information, such as sparsity in the regression coefficients. By placing a gamma distribution prior on the NB dispersion parameter r, and connecting a lognormal distribution prior with the logit of the NB probability parameter p, efficient Gibbs sampling and variational Bayes inference are both developed. The closed-form updates are obtained by exploiting conditional conjugacy via both a compound Poisson representation and a Polya-Gamma distribution based data augmentation approach. The proposed Bayesian inference can be implemented routinely, while being easily generalizable to more complex settings involving multivariate dependence structures. The algorithms are illustrated using real examples.
1. Introduction
In numerous scientific studies, the response variable is a count y = 0, 1, 2, ⋯, which we wish to explain with a set of covariates x = [1, x1, ⋯, xP]T as , where β = [β0, ⋯, βP]T are the regression coefficients and g is the canonical link function in generalized linear models (GLMs) (McCullagh & Nelder, 1989; Long, 1997; Cameron & Trivedi, 1998;Agresti, 2002; Winkelmann, 2008). Regression models for counts are usually nonlinear and have to take into consideration the specific properties of counts, including discreteness and nonnegativity, and often characterized by overdispersion (variance greater than the mean). In addition, we may wish to impose a sparse prior in the regression coefficients for counts, which is demonstrated to be beneficial for regression analysis of both Gaussian and binary data (Tipping, 2001).
Count data are commonly modeled with the Poisson distribution y ~ Pois(λ), whose mean and variance are both equal to λ. Due to heterogeneity (difference between individuals) and contagion (dependence between the occurrence of events), the varance is often much larger than the mean, making the Poisson assumption restrictive. By placing a gamma distribution prior with shape r and scale p/(1 – p) on λ, a negative binomial (NB) distribution y ~ NB(r, p) can be generated as Pois(y; λ)Gamma , where Γ(·) denotes the gamma function, r is the nonnegative dispersion parameter and p is a probability parameter. Therefore, the NB distribution is also known as the gamma-Poisson distribution. It has a variance rp/(1 – p)2 larger than the mean rp/(1 – p), and thus it is usually favored over the Poisson distribution for modeling overdispersed counts.
The regression analysis of counts is commonly performed under the Poisson or NB likelihoods, whose parameters are usually estimated by finding the maximum of the nonlinear log likelihood (Long, 1997;Cameron & Trivedi, 1998; Agresti, 2002; Winkelmann,2008). The maximum likelihood estimator (MLE), however, only provides a point estimate and does not allow the incorporation of prior information, such as sparsity in the regression coefficients. In addition, the MLE of the NB dispersion parameter r often lacks robustness and may be severely biased or even fail to converge if the sample size is small, the mean is small or if r is large (Saha & Paul, 2005; Lloyd-Smith, 2007).
Compared to the MLE, Bayesian approaches are able to model the uncertainty of estimation and to incorporate prior information. In regression analysis of counts, however, the lack of simple and efficient algorithms for posterior computation has seriously limited routine applications of Bayesian approaches, making Bayesian analysis of counts appear unattractive and thus underdeveloped. For instance, for the NB dispersion parameter r, the only available closed-form Bayesian solution relies on approximating the ratio of two gamma functions using a polynomial expansion (Bradlow et al., 2002); and for the regression coefficients β, Bayesian solutions usually involve computationally intensive Metropolis-Hastings algorithms, since the conjugate prior for β is not known under the Poisson and NB likelihoods (Chib et al., 1998; Chib & Winkelmann, 2001; Winkelmann, 2008).
In this paper we propose a lognormal and gamma mixed NB regression model for counts, with default Bayesian analysis presented based on two novel data augmentation approaches. Specifically, we show that the gamma distribution is the conjugate prior to the NB dispersion parameter r, under the compound Poisson representation, with efficient Gibbs sampling and variational Bayes (VB) inference derived by exploiting conditional conjugacy. Further we show that a lognormal prior can be connected to the logit of the NB probability parameter p, with efficient Gibbs sampling and VB inference developed for the regression coefficients β and the lognormal variance parameter σ2, by generalizing a Polya-Gamma distribution based data augmentation approach in Polson & Scott (2011). The proposed Bayesian inference can be implemented routinely, while being easily generalizable to more complex settings involving multivariate dependence structures. We illustrate the algorithm with real examples on univariate count analysis and count regression, and demonstrate the advantages of the proposed Bayesian approaches over conventional count models.
2. Regression Models for Counts
The most basic regression model for counts is the Poisson regression model (Long, 1997; Cameron & Trivedi,1998; Winkelmann, 2008), which can be expressed as
| (1) |
where xi = [1, xi1, ⋯, xiP]T is the covariate vector for sample i. The Newton-Raphson method can be used to iteratively find the MLE of β (Long, 1997). A serious constraint of the Poisson regression model is that it assumes equal-dispersion, i.e., = exp() In practice, however, count data are often overdispersed, due to heterogeneity and contagion (Winkelmann, 2008). To model overdispersed counts, the Poisson regression model can be modified as
| (2) |
where ∊i is a nonnegative multiplicative random-effect term to model individual heterogeneity (Winkelmann, 2008). Using both the law of total expectation and the law of total variance, it can be shown that
| (3) |
| (4) |
Thus Var and we obtain a regression model for overdispersed counts. We show below that both the gamma and lognormal distributions can be used as the nonnegative prior on ∊i.
2.1. The Negative Binomial Regression Model
The NB regression model (Long, 1997; Cameron & Trivedi, 1998; Winkelmann, 2008; Hilbe, 2007) is constructed by placing a gamma prior on ∊i as
| (5) |
where and Var[∊i] = r−1. Marginalizing out ∊i in (2), we have a NB distribution parameterized by mean and inverse dispersion parameter ϕ (the reciprocal of r) as , thus
| (6) |
| (7) |
The MLEs of β and ϕ can be found numerically with the Newton-Raphson method (Lawless, 1987).
2.2. The Lognormal-Poisson Regression Model
A lognormal-Poisson regression model (Breslow, 1984;Long, 1997; Agresti, 2002; Winkelmann, 2008) can be constructed by placing a lognormal prior on ∊i as
| (8) |
where and . Using (3) and (4), we have
| (9) |
| (10) |
Compared to the NB model, there is no analytical form for the distribution of yi if ∊i is marginalized out and the MLE is less straightforward to calculate, making it less commonly used. However, Winkelmann (2008) suggests to reevaluate the lognormal-Poisson model, since it is appealing in theory and may fit the data better. The inverse Gaussian distribution prior can also be placed on ∊i to construct a heavier-tailed alternative to the NB model (Dean et al., 1989), whose density functions are shown to be virtually identical to the lognormal-Poisson model (Winkelmann, 2008).
3. The Lognormal and Gamma Mixed Negative Binomial Regression Model
To explicitly model the uncertainty of estimation and incorporate prior information, Bayesian approaches appear attractive. Bayesian analysis of counts, however, is seriously limited by the lack of efficient inference, as the conjugate prior for the regression coefficients β is unknown under the Poisson and NB likelihoods (Winkelmann, 2008), and the conjugate prior for the NB dispersion parameter r is also unknown.
To address these issues, we propose a lognormal and gamma mixed NB regression model for counts, termed here the LGNB model, where a lognormal prior ln (0, σ2) is placed on the multiplicative random effect term ∊i and a gamma prior is placed on r. Denoting , and logit(pi) = ln , the LGNB model is constructed as
| (11) |
| (12) |
| (13) |
| (14) |
where φ = σ−2 and a0, b0, c0, d0, e0, f0 and g0 are gamma hyperparameters (they are set as 0.01 in experiments). Since yi ~ NB (r, pi) in (11) can be augmented into a gamma-Poisson structure as yi ~ Pois(λi), λi ~ Gamma , the LGNB model can also be considered as a lognormal-gamma-gamma-Poisson regression model. Denoting , we may equivalently express ψ = [ψ1, ⋯, ψN]T in the above model as
| (15) |
If we marginalize out h in (14), we obtain a beta prime distribution prior r ~ β’(a0, b0, 1, g0). If we marginalize out αp in (13), we obtain a Student-t prior for βp, the sparsity-promoting prior used in Tipping (2001);Bishop & Tipping (2000) for regression analysis of both Gaussian and binary data. Note that β is connected to pi with a logit link, which is key to deriving efficient Bayesian inference.
3.1. Model Properties and Model Comparison
Using the laws of total expectation and total variance and the moments of the NB distribution, we have
| (16) |
| (17) |
We define the quasi-dispersion κ as the coefficient associated with the mean quadratic term in the variance. As shown in (7) and (10), κ = ϕ in the NB model and in the lognormal-Poisson model. Apparently, they have different distribution assumptions on dispersion, yet there is no clear evidence to favor one over the other in terms of goodness of fit. In the proposed LGNB model, there are two free parameters r and σ2 to adjust both the mean in (16) and dispersion , which become the same as those of the NB model when σ2 = 0, and the same as those of the lognormal-Poisson model when ϕ = r−1 = 0. Thus the LGNB model has one extra degree of freedom to incorporate both kinds of random effects, with their proportion automatically inferred.
4. Default Bayesian Analysis Using Data Augmentation
As discussed in Section 3, the LGNB model has an advantage of having two free parameters to incorporate both kinds of random effects. We show below that it has an additional advantage in that default Bayesian analysis can be performed with two novel data augmentation approaches, with closed-form solutions and analytical update equations available for both Gibbs sampling and VB inference. One augmentation approach concerns the inference of the NB dispersion parameter r using the compound Poisson representation, and the other concerns the inference of the regression coefficients β using the Polya-Gamma distribution.
4.1. Inferring the Dispersion Parameter Under the Compound Poisson Representation
We first focus on inference of the NB dispersion parameter r and assume we know {pi}i=1,N and h, neglecting the remaining part of the LGNB model at this moment. We comment here that the novel Bayesian inference developed here can be applied to any other scenarios where the conditional posterior of r is proportional to Gamma(r; a0, 1/h), for which a hybrid Monte Carlo and a Metropolis-Hastings algorithms had been developed in Williamson et al. (2010) and Zhou et al. (2012), but VB solutions were not yet developed.
As proved in Quenouille (1949), y ~ NB(r, p) can also be generated from a compound Poisson distribution as
| (18) |
where Log(p) corresponds to the logarithmic distribution (Barndor-Nielsen et al., 2010) with fU(k) = −pk/[k ln(1 – p)], k ∈ {1, 2, …}, whose probability-generating function (PGF) is
| (19) |
Using the conjugacy between the gamma and Poisson distributions, it is evident that the gamma distribution is the conjugate prior for r under this augmentation.
4.1.1. Gibbs Sampling for r
Recalling (18), yi ~ NB(r, pi) can also be generated from the random sum with
| (20) |
Exploiting conjugacy between (14) and (20), given Li, we have the conditional posterior of r as
| (21) |
where here and below expressions like (r|−) correspond to random variable (RV) r, conditioned on all other RVs. The remaining challenge is finding the conditional posterior of Li. Denote , j = 1, ⋯ , yi. Since wij is the summation of j iid Log(pi) distributed RVs, using (19), the PGF of wij is
Therefore, we have Li ≡ 0 if yi = 0 and for 1 ≤ j ≤ yi
| (22) |
where fi(z) = − ln(1–piz) and F is a lower triangular matrix with F (1, 1) = 1, F(m, j) = 0 if j > m, and
| (23) |
if 1 ≤ j ≤ m. Using (22), we have
| (24) |
where Rr(0, 0) = 1 and
| (25) |
The values of F can be iteratively calculated and each row sums to one, e.g., the 4th and 5th rows of F are
Note that to obtain (22), we use the relationship proved in Lemma 1 of the supplementary material that
| (26) |
Gibbs sampling for r proceeds by alternately sampling (24) and (21). Note that to ensure numerical stability when r > 1, instead of using (25), we may iteratively calculate Rr in the way we calculate F in (23). We show in Figure 1 of the supplementary material the matrices Rr for r = .1, 1, 10 and 100.
Figure 1.
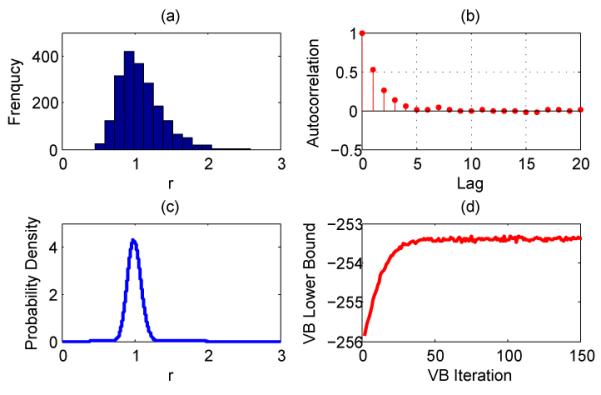
a) The histogram and (b) autocorrelation of collected Gibbs samples of the NB dispersion parameter r. (c) The inferred probability density function of r using VB. (d) The VB lower bound. Note that the calculated lower bound shows variations after convergence, which is expected since the Monte Carlo integration is used to calculate non-analytical expectation terms such as ⟨ln Γ(r+yi)⟩.
4.1.2. Variational Bayes Inference for r
Using VB inference (Bishop & Tipping, 2000; Beal,2003), we approximate the posterior p(r, L|X) with Q(r, L) = , and we have
| (27) |
| (28) |
where ⟨x⟩ = , = exp (⟨ln r⟩), ψ(x) is the digamma function, and
| (29) |
| (30) |
Equations (29)-(30) constitute the VB inference for the NB dispersion parameter r, with ⟨r⟩ = .
4.2. Inferring the Regression Coefficients Using the Polya-Gamma Distribution
Denote ωi as a random variable drawn from the Polya-Gamma (PG) distribution (Polson & Scott, 2011) as
| (31) |
We have . Thus the likelihood of ψi in (11) can be expressed as
| (32) |
Given the values of {ωi}i=1,N and the prior in (15), the conditional posterior of ψ can be expressed as
| (33) |
and given the values of ψ and the prior in (31), the conditional posterior of ωi can be expressed as
| (34) |
4.3. Gibbs Sampling Inference
Exploiting conditional conjugacy and the exponential tilting of the PG distribution in Polson & Scott (2011), we can sample in closed-form all latent parameters of the LGNB model described from (11) to (14) as
| (35) |
| (36) |
| (37) |
| (38) |
| (39) |
| (40) |
where Ω = diag(ω1⋯, ωN), A = diag(α0, ⋯ , αP), y = [y1, ⋯ , yN]T, Σ= (φI + Ω)−1, μ = Σ[(y – r)/2 + φXβ], Σβ= (φXTX + A)−1 and μβ = φΣβXTψ. Note that a PG distributed random variable can be generated from an infinite sum of weighted iid gamma random variables (Devroye, 2009; Polson & Scott, 2011). We provide in the supplementary material a method for accurately truncating the infinite sum.
4.4. Variational Bayes Inference
Using VB inference (Bishop & Tipping, 2000; Beal,2003), we approximate the posterior distribution with . To exploit conjugacy, defining QLi(Li) as in (27), Qr(r) as in (28), Qωi(ωi) = PG(γi1, γi2), , , Qh(h) = Gamma(), Qφ(φ) = Gamma() and Qαp(αp) = Gamma(), we have
| (41) |
| (42) |
| (43) |
| (44) |
| (45) |
| (46) |
where = diag(⟨ω1⟩, ⋯, ⟨ωN⟩), = diag(), tr[Σ] is the trace of Σ, ⟨ln r⟩ and ⟨Li⟩ are calculated as in (29), ⟨r⟩ = , ⟨ψTψ⟩ = , ⟨β⟩ = , ⟨βTβ⟩ = , ⟨ββT⟩ = , ⟨h⟩ = , ⟨α⟩ = and ⟨αp⟩ = . Although we do not have analytical forms for γi1 and γi2 in Qωi(ωi), we can use (36) to calculate ⟨ωi⟩ as
| (47) |
where the mean property of the PG distribution1 (Polson & Scott, 2011 is applied. To calculate ⟨ln(1+eψi)⟩ in (41) and in (47), we use the Monte Carlo integration algorithm (Andrieu et al., 2003).
5. Example Results
5.1. Univariate Count Data Analysis
The inference of the NB dispersion parameter r by itself plays an important role not only for the NB regression (Lawless, 1987; Winkelmann, 2008) but also for univariate count data analysis (Bliss & Fisher, 1953;Clark & Perry, 1989; Saha & Paul, 2005; Lloyd-Smith,2007), and it also arises in some recently proposed latent variable models for count matrix factorization (Williamson et al., 2010; Zhou et al., 2012). Thus it is of interest to evaluate the proposed closed-form Gibbs sampling and VB inference for this parameter alone, before introducing the regression analysis part.
We consider a real dataset describing counts of red mites on apple leaves, given in Table 1 of Bliss & Fisher (1953). There were in total 172 adult female mites found in 150 randomly selected leaves, with a 0 count on 70 leaves, 1 on 38, 2 on 17, 3 on 10, 4 on 9, 5 on 3, 6 on 2 and 7 on 1. This dataset has a mean of 1.1467 and a variance of 2.2736, clearly overdispersed. We assume the counts are NB distributed and we intend to infer r with a hierarchical model as
where i = 1; ⋯; N and we set a = b = α = β = 0:01. We consider 20,000 Gibbs sampling iterations, with the first 10,000 samples discarded and every fifth sample collected afterwards. As shown in Figure 1, the autocorrelation of Gibbs samples decreases quickly as the lag increases, and the VB lower bound converges quickly even starting from a bad initialization (r is initialized two times the converged value).
Table 1.
The MLEs or posterior means of the lognormal variance parameter σ2, NB dispersion parameter r, quasi-dispersion κ and regression coefficients β for the Poisson, NB and LGNB regression models on the NASCAR dataset, using the MLE, VB or Gibbs sampling for parameter estimations.
| Model | Poisson | NB | LGNB | LGNB |
|---|---|---|---|---|
|
| ||||
| Parameters | (MLE) | (MLE) | (VB) | (Gibbs) |
| σ 2 | N/A | N/A | 0.1396 | 0.0289 |
| r | N/A | 5.2484 | 18.5825 | 6.0420 |
| β 0 | −0.4903 | −0.5038 | −3.5271 | −2.1680 |
|
| ||||
| β1 (Laps) | 0.0021 | 0.0017 | 0.0015 | 0.0013 |
| β2 (Drivers) | 0.0516 | 0.0597 | 0.0674 | 0.0643 |
| β3 (TrkLen) | 0.6104 | 0.5153 | 0.4192 | 0.4200 |
The estimated posterior mean of r is 1.0812 with Gibbs sampling and 0.9988 with VB. Compared to the method of moments estimator (MME), MLE, and maximum quasi-likelihood estimator (MQLE) (Clark & Perry, 1989), which provides point estimates of 1.1667, 1.0246 and 0.99472, respectively, our algorithm is able to provide a full posterior distribution of r and is convenient to incorporate prior information. The calculating details of the MME, MLE and MQLE, the closed-form Gibbs sampling and VB update equations, and the VB lower bound are all provided in the supplementary material, omitted here for brevity.
5.2. Regression Analysis of Counts
We test the full LGNB model on two real examples, with comparison to the Poisson, NB, lognormal-Poisson and inverse-Gaussian-Poisson (IG-Poisson) regression models. The NASCAR dataset3, analyzed in Winner, consists of 151 NASCAR races during the 1975-1979 Seasons. The response variable is the number of lead changes in a race, and the covariates of a race include the number of laps, number of drivers and length of the track (in miles). The MotorIns dataset4, analyzed in Dean et al. (1989), consists of Swedish third-party motor insurance claims in 1977. Included in the data are the total number of claims for automobiles insured in each of the 315 risk groups, defined by a combination of DISTANCE, BONUS, and MAKE factor levels. The number of insured automobile-years for each group is also given. As in Dean et al. (1989), a 19 dimensional covariate vector is constructed for each group to represent levels of the factors. To test goodness-of-fit, we use the Pearson residuals, a metric widely used in GLMs (McCullagh & Nelder, 1989), calculated as
| (48) |
where and are the estimated mean and quasi-dispersion, respectively, whose calculations are described in detail in the supplementary material.
The MLEs for the Poisson and NB models are well-known and the update equations can be found in Winner; Winkelmann (2008). The MLE results for the IG-Poisson model on the MotorIns data were reported inDean et al. (1989). For the lognormal-Poisson model, no standard MLE algorithms are available and we choose Metropolis-Hastings (M-H) algorithms for parameter estimation. We also consider a LGNB model under the special setting that r = 1000. As discussed in Section 3.1, this would lead to a model which is approximately the lognormal-Poisson model, yet with closed-form Gibbs sampling inference. We use both VB and Gibbs sampling for the LGNB model. We consider 20,000 Gibbs sampling iterations, with the first 10,000 samples discarded and every fifth sample collected afterwards. As described in the supplementary material, we sample from the PG distribution with a truncation level of 2000. We initialize r as 100 and other parameters at random. Examining the samples in Gibbs sampling, we find that the autocorrelations of model parameters generally reduce to below 0.2 at the lag of 20, indicating fast mixing.
Shown in Table 1 are the MLEs or posterior means of key model parameters. Note that β0 of the LGNB model differs considerably from that of the Poisson and NB models, which is expected since β0 + σ2/2 + ln r in the LGNB model plays about the same role as β0 in the Poisson and NB models, as indicated in (16).
As shown in Tables 2, in terms of goodness of fit measured by Pearson residuals, the Poisson model performs the worst due to its unrealistic equal-dispersion assumption; the NB model, assuming a gamma distributed multiplicative random effect term, significantly improves the performances compared to the Poisson model; the proposed LGNB model, modeling extra-Poisson variations with both the gamma and lognormal distributions, clearly outperforms both the Poisson and NB models. Since for the lognormal-Poisson model with the M-H algorithm, we were not able to obtain comparable results even after carefully tuning the proposal distribution, we did not include it here for comparison. However, since the LGNB model reduces to the lognormal-Poisson model as r → ∞, the results of the LGNB model with r ≡ 1000 would be able to indicate whether the lognormal distribution alone is appropriate to model the extra-Poisson variations. Despite the popularity of the NB model, which models extra-Poisson variations only with the gamma distribution, the results in Tables 2 suggest the benefits of incorporating the lognormal random effects. These observations also support the claim in (Winkelmann, 2008) that the lognormal-Poisson model should be reevaluated since it is appealing in theory and may fit the data better. Compared to the lognormal-Poisson model, the LGNB model has an additional advantage that its parameters can be estimated with VB inference, which is usually much faster than sampling based methods.
Table 2.
Test of goodness of fit with Pearson residuals.
| Models (Methods) | NASCAR | MotorIns |
|---|---|---|
|
| ||
| Poisson (MLE) | 655.6 | 485.6 |
| NB (MLE) | 138.3 | 316.5 |
| IG-Poisson (MLE) | N/A | 319.7 |
| LGNB (r ≡ 1000, Gibbs) | 117.8 | 296.7 |
| LGNB(VB) | 126.1 | 275.5 |
| LGNB(Gibbs) | 129.0 | 284.4 |
A clear advantage of the Bayesian inference over the MLE is that a full posterior distribution can be obtained, by utilizing the estimated posteriors of σ2, r and β. For example, shown in Figure 2 are the estimated posterior distributions of the quasi-dispersion κ, represented with histograms. These histograms should be compared to κ = 0 in the Poisson model, and the NB model’s MLEs of κ = 0.1905 and κ = 0.0118, for the NASCAR and MotorIns datasets, respectively. We can also find that VB generally tends to overemphasize the regions around the mode of its estimated posterior distribution and consequently places low densities on the tails, whereas Gibbs sampling is able to explore a wider region. This is intuitive since VB relies on the assumption that the posterior distribution can be approximated with the product of independent Q functions, whereas Gibbs sampling only exploits conditional independence.
Figure 2.
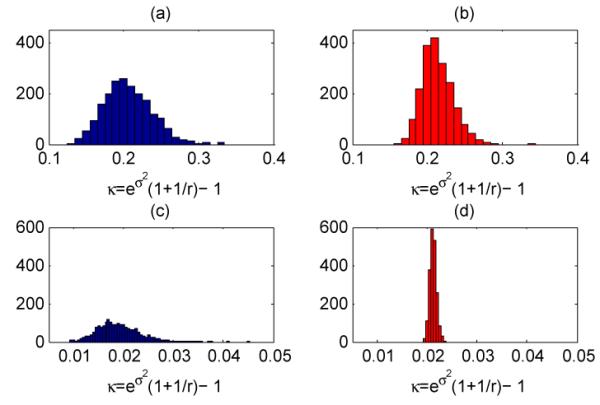
The histograms of the quasi-dispersion κ = eσ2 (1+1/r)–1 based on (a) the 2000 collected Gibbs samples for NASCAR, (b) the 2000 simulated samples using the VB Q functions for NASCAR, (c) the 2000 collected Gibbs samples for MotorIns, and (d) the 2000 simulated samples using the VB Q functions for MotorIns.
The estimated posteriors can also assist model interpretation. For example, based on in VB for the NASCAR dataset, we can calculate the correlation matrix for (β1, β2, β3)T as
which is typically not provided in MLE. Since β1 (Laps) and β3 (TrkLen) are highly positively correlated, we expect the corresponding covariates to be highly negatively correlated. This is confirmed, as the correlation coefficient between the number of laps and the track length is found to be as small as −0.9006.
6. Conclusions
A lognormal and gamma mixed negative binomial (LGNB) regression model is proposed for regression analysis of overdispersed counts. Efficient closed-form Gibbs sampling and VB inference are both presented, by exploiting the compound Poisson representation and a Polya-Gamma distribution based data augmentation approach. Model properties are examined, with comparison to the Poisson, NB and lognormal-Poisson models. As the univariate lognormal-Poisson regression model can be easily generalized to regression analysis of correlated counts, in which the derivatives and Hessian matrixes of parameters are used to construct multivariate normal proposals in a Metropolis-Hastings algorithm (Chib et al., 1998; Chib & Winkelmann, 2001; Ma et al., 2008; Winkelmann, 2008), the proposed LGNB model can be conveniently modified for multivariate count regression, in which we may be able to derive closed-form Gibbs sampling and VB inference. As the log Gaussian process can be used to model the intensity of the Poisson process, whose inference remains a major challenge (Møller et al., 1998;Adams et al., 2009; Murray et al., 2010; Rao & Teh, 2011), we may link the log Gaussian process to the logit of the NB probability parameter, leading to a log Gaussian NB process with tractable closed-form Bayesian inference. Furthermore, the NB distribution is shown to be important for the factorization of a term-document count matrix (Williamson et al., 2010; Zhou et al., 2012), and the multinomial logit has been used to model correlated topics in topic modeling (Blei & Lafferty, 2005; Paisley et al., 2011). Applying the proposed lognormal-gamma-NB framework and the developed closed-form Bayesian inference to these diverse problems is currently under active investigation.
Supplementary Material
Acknowledgements
The research reported here has been supported in part by DARPA under the MSEE program.
Footnotes
There is a typo in B.2 Lemma 2 and other related equations of Polson & Scott (2011), where tanh() should be corrected as tanh().
The inverse dispersion parameter ϕ = 1/0.9947 = 1.005 is mistakenly reported as the dispersion parameter r in Clark & Perry (1989) at Line 15, Page 314.
References
- Adams R, Murray I, MacKay D. Tractable nonparametric Bayesian inference in Poisson processes with Gaussian process intensities. ICML. 2009 [Google Scholar]
- Agresti A. Categorical Data Analysis. 2nd edition Wiley-Interscience; 2002. [Google Scholar]
- Andrieu C, de Freitas N, Doucet A, Jordan MI. An introduction to MCMC for machine learning. Machine Learning. 2003 [Google Scholar]
- Barndorff-Nielsen OE, Pollard DG, Shephard N. Integer-valued Lévy processes and low latency financial econometrics. Preprint. 2010 [Google Scholar]
- Beal MJ. PhD thesis. UCL: 2003. Variational Algorithms for Approximate Bayesian Inference. [Google Scholar]
- Bishop CM, Tipping ME. Variational relevance vector machines. UAI. 2000 [Google Scholar]
- Blei D, Lafferty JD. Correlated topic models. NIPS. 2005 [Google Scholar]
- Bliss CI, Fisher RA. Fitting the negative binomial distribution to biological data. Biometrics. 1953 [Google Scholar]
- Bradlow ET, Hardie BGS, Fader PS. Bayesian inference for the negative binomial distribution via polynomial expansions. Journal of Computational and Graphical Statistics. 2002 [Google Scholar]
- Breslow NE. Extra-Poisson variation in log-linear models. J. Roy. Statist. Soc., C. 1984 [Google Scholar]
- Cameron AC, Trivedi PK. Regression Analysis of Count Data. Cambridge, UK: 1998. [Google Scholar]
- Chib S, Winkelmann R. Markov chain Monte Carlo analysis of correlated count data. Journal of Business & Economic Statistics. 2001 [Google Scholar]
- Chib S, Greenberg E, Winkelmann R. Posterior simulation and Bayes factors in panel count data models. Journal of Econometrics. 1998 [Google Scholar]
- Clark SJ, Perry JN. Estimation of the negative binomial parameter κ by maximum quasi-likelihood. Biometrics. 1989 [Google Scholar]
- Dean C, Lawless JF, Willmot GE. A mixed Poisson-inverse-Gaussian regression model. Canadian Journal of Statistics. 1989 [Google Scholar]
- Devroye L. On exact simulation algorithms for some distributions related to Jacobi theta functions. Statistics & Probability Letters. 2009 [Google Scholar]
- Hilbe JM. Negative Binomial Regression. Cambridge University Press; 2007. [Google Scholar]
- Lawless JF. Negative binomial and mixed Poisson regression. Canadian Journal of Statistics. 1987 [Google Scholar]
- Lloyd-Smith JO. Maximum likelihood estimation of the negative binomial dispersion parameter for highly overdispersed data, with applications to infectious diseases. PLoS ONE. 2007 doi: 10.1371/journal.pone.0000180. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Long SJ. Regression Models for Categorical and Limited Dependent Variables. SAGE. 1997 [Google Scholar]
- Ma J, Kockelman KM, Damien P. A multivariate Poisson-lognormal regression model for prediction of crash counts by severity, using Bayesian methods. Accident Analysis and Prevention. 2008 doi: 10.1016/j.aap.2007.11.002. [DOI] [PubMed] [Google Scholar]
- McCullagh P, Nelder JA. Generalized linear models. 2nd edition Chapman & Hall; 1989. [Google Scholar]
- Møller J, Syversveen AR, Waagepetersen RP. Log Gaussian Cox processes. Scandinavian Journal of Statistics. 1998 [Google Scholar]
- Murray I, Adams RP, MacKay DJC. Elliptical slice sampling. AISTATS. 2010 [Google Scholar]
- Paisley J, Wang C, Blei DM. The discrete infinite logistic normal distribution for mixed-membership modeling. AISTATS. 2011 [Google Scholar]
- Polson NG, Scott JG. Default Bayesian analysis for multi-way tables: a data-augmentation approach. arXiv:1109.4180v1. 2011 [Google Scholar]
- Quenouille MH. A relation between the logarithmic, Poisson, and negative binomial series. Biometrics. 1949 [PubMed] [Google Scholar]
- Rao V, Teh YW. Gaussian process modulated renewal processes. NIPS. 2011 [Google Scholar]
- Saha K, Paul S. Bias-corrected maximum likelihood estimator of the negative binomial dispersion parameter. Biometrics. 2005 doi: 10.1111/j.0006-341X.2005.030833.x. [DOI] [PubMed] [Google Scholar]
- Tipping ME. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001 [Google Scholar]
- Williamson S, Wang C, Heller Katherine A., Blei DM. The IBP compound Dirichlet process and its application to focused topic modeling. ICML. 2010 [Google Scholar]
- Winkelmann R. Econometric Analysis of Count Data. 5th edition Springer; Berlin: 2008. [Google Scholar]
- Winner L. [Accessed 01/29/2012];Case Study – Negative Binomial Regression, NASCAR Lead Changes 1975-1979. URL http://www.stat.ufl.edu/~winner/cases/nb_nascar.doc.
- Zhou M, Hannah L, Dunson D, Carin L. Beta-negative binomial process and Poisson factor analysis. AISTATS. 2012 [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.