

Abstract
Non-convex sparsity-inducing penalties have recently received considerable attentions in sparse learning. Recent theoretical investigations have demonstrated their superiority over the convex counterparts in several sparse learning settings. However, solving the non-convex optimization problems associated with non-convex penalties remains a big challenge. A commonly used approach is the Multi-Stage (MS) convex relaxation (or DC programming), which relaxes the original non-convex problem to a sequence of convex problems. This approach is usually not very practical for large-scale problems because its computational cost is a multiple of solving a single convex problem. In this paper, we propose a General Iterative Shrinkage and Thresholding (GIST) algorithm to solve the nonconvex optimization problem for a large class of non-convex penalties. The GIST algorithm iteratively solves a proximal operator problem, which in turn has a closed-form solution for many commonly used penalties. At each outer iteration of the algorithm, we use a line search initialized by the Barzilai-Borwein (BB) rule that allows finding an appropriate step size quickly. The paper also presents a detailed convergence analysis of the GIST algorithm. The efficiency of the proposed algorithm is demonstrated by extensive experiments on large-scale data sets.
1. Introduction
Learning sparse representations has important applications in many areas of science and engineering. The use of an l0-norm regularizer leads to a sparse solution, however the l0-norm regularized optimization problem is challenging to solve, due to the discontinuity and non-convexity of the l0-norm regularizer. The l1-norm regularizer, a continuous and convex surrogate, has been studied extensively in the literature (Tibshirani, 1996; Efron et al., 2004) and has been applied successfully to many applications including signal/image processing, biomedical informatics and computer vision (Shevade & Keerthi, 2003; Wright et al., 2008; Beck & Teboulle, 2009; Wright et al., 2009; Ye & Liu, 2012). Although the l1-norm based sparse learning formulations have achieved great success, they have been shown to be suboptimal in many cases (Candes et al., 2008; Zhang, 2010b; 2012), since the l1-norm is a loose approximation of the l0-norm and often leads to an over-penalized problem. To address this issue, many non-convex regularizers, interpolated between the l0-norm and the l1-norm, have been proposed to better approximate the l0-norm. They include lq-norm (0 < q < 1) (Foucart & Lai, 2009), Smoothly Clipped Absolute Deviation (SCAD) (Fan & Li, 2001), Log-Sum Penalty (LSP) (Candes et al., 2008), Minimax Concave Penalty (MCP) (Zhang, 2010a), Geman Penalty (GP) (Geman & Yang, 1995; Trzasko & Manduca, 2009) and Capped-l1 penalty (Zhang, 2010b; 2012; Gong et al., 2012a).
Although the non-convex regularizers (penalties) are appealing in sparse learning, it is challenging to solve the corresponding non-convex optimization problems. In this paper, we propose a General Iterative Shrinkage and Thresholding (GIST) algorithm for a large class of non-convex penalties. The key step of the proposed algorithm is to compute a proximal operator, which has a closed-form solution for many commonly used non-convex penalties. In our algorithm, we adopt the Barzilai-Borwein (BB) rule (Barzilai & Borwein, 1988) to initialize the line search step size at each iteration, which greatly accelerates the convergence speed. We also use a non-monotone line search criterion to further speed up the convergence of the algorithm. In addition, we present a detailed convergence analysis for the proposed algorithm. Extensive experiments on large-scale real-world data sets demonstrate the efficiency of the proposed algorithm.
2. The Proposed Algorithm: GIST
2.1. General Problems
We consider solving the following general problem:
| (1) |
We make the following assumptions on the above formulation throughout the paper:
-
A1l(w) is continuously differentiable with Lipschitz continuous gradient, that is, there exists a positive constant β(l) such that
-
(A2)r(w) is a continuous function which is possibly non-smooth and non-convex, and can be rewritten as the difference of two convex functions, that is,
where r1(w) and r2(w) are convex functions.
-
(A3)
f(w) is bounded from below.
Remark 1
We say that w★ is a critical point of problem (1), if the following holds (Toland, 1979; Wright et al., 2009):
where ∂r1(w★) is the sub-differential of the function r1(w) at w = w★, that is,
We should mention that the sub-differential is nonempty on any convex function; this is why we make the assumption that r(w) can be rewritten as the difference of two convex functions.
2.2. Some Examples
Many formulations in machine learning satisfy the assumptions above. The following least square and logistic loss functions are two commonly used ones which satisfy assumption A1:
where is a data matrix and y = [y1, · · ·, yn]T ∈ ℝn is a target vector. The regularizers (penalties) which satisfy the assumption A2 are presented in Table 1. They are non-convex (except the l1-norm) and extensively used in sparse learning. The functions l(w) and r(w) mentioned above are nonnegative. Hence, f is bounded from below and satisfies assumption A3.
Table 1.
Examples of regularizers (penalties) r(w) satisfying the assumption A2 and the corresponding convex functions r1(w) and r2(w). λ > 0 is the regularization parameter; r(w) = Σi ri(wi), r1(w) = Σi r1,i(wi), r2(w) = Σi r2,i(wi), [x]+ = max(0, x).
| Name | ri (wi) | r1,i(wi) | r2,i(wi) | ||
|---|---|---|---|---|---|
| l1-norm | λ|wi| | λ|wi| | 0 | ||
| LSP | λ log(1 + |wi|/θ) (θ > 0) | λ|wi| | λ (|wi| − log(1 + |wi|/θ)) | ||
| SCAD |
|
λ|wi| |
|
||
| MCP |
|
λ|wi| |
|
||
| Capped l1 | λ min(|wi|, θ) (θ > 0) | λ|wi| | λ [|wi |− θ]+ |
2.3. Algorithm
Our proposed General Iterative Shrinkage and Thresholding (GIST) algorithm solves problem (1) by generating a sequence {w(k)} via:
| (2) |
In fact, problem (2) is equivalent to the following proximal operator problem:
where u(k) = w(k) − ∇l(w(k))/t(k). Thus, in GIST we first perform a gradient descent along the direction −∇l(w(k)) with step size 1/t(k) and then solve a proximal operator problem. For all the regularizers listed in Table 1, problem (2) has a closed-form solution (details are provided in the Appendix), although it may be a non-convex problem. For example, for the l1 and Capped l1 regularizers, we have closed-form solutions as follows:
where and . The detailed procedure of the GIST algorithm is presented in Algorithm 1. There are two issues that remain to be addressed: how to initialize t(k) (in Line 4) and how to select a line search criterion (in Line 8) at each outer iteration.
Algorithm 1.
GIST: General Iterative Shrinkage and Thresholding Algorithm
| 1: | Choose parameters η > 1 and tmin, tmax with 0 < tmin < tmax; |
| 2: | Initialize iteration counter k ← 0 and a bounded starting point w(0); |
| 3: | repeat |
| 4: | t(k) ∈ [tmin, tmax]; |
| 5: | repeat |
| 6: | ; |
| 7: | t(k) ← ηt(k); |
| 8: | until some line search criterion is satisfied |
| 9: | k ← k + 1 |
| 10: | until some stopping criterion is satisfied |
2.3.1. The Step Size Initialization: 1/t(k)
Intuitively, a good step size initialization strategy at each outer iteration can greatly reduce the line search cost (Lines 5–8) and hence is critical for the fast convergence of the algorithm. In this paper, we propose to initialize the step size by adopting the Barzilai-Borwein (BB) rule (Barzilai & Borwein, 1988), which uses a diagonal matrix t(k)I to approximate the Hessian matrix ∇2l(w) at w = w(k). Denote
Then t(k) is initialized at the outer iteration k as
2.3.2. Line Search Criterion
One natural and commonly used line search criterion is to require that the objective function value is monotonically decreasing. More specifically, we propose to accept the step size 1/t(k) at the outer iteration k if the following monotone line search criterion is satisfied:
| (3) |
where σ is a constant in the interval (0, 1).
A variant of the monotone criterion in Eq. (3) is a non-monotone line search criterion (Grippo et al., 1986; Grippo & Sciandrone, 2002; Wright et al., 2009). It possibly accepts the step size 1/t(k) even if w(k+1) yields a larger objective function value than w(k). Specifically, we propose to accept the step size 1/t(k), if w(k+1) makes the objective function value smaller than the maximum over previous m (m > 1) iterations, that is,
| (4) |
where σ ∈ (0, 1).
2.3.3. Convergence Analysis
Inspired by Wright et al. (2009); Lu (2012a), we present detailed convergence analysis under both monotone and non-monotone line search criteria. We first present a lemma which guarantees that the monotone line search criterion in Eq. (3) is satisfied. This is a basic support for the convergence of Algorithm 1.
Lemma 1
Let the assumptions A1–A3 hold and the constant σ ∈ (0, 1) be given. Then for any integer k ≥ 0, the monotone line search criterion in Eq. (3) is satisfied whenever t(k) ≥ β(l)/(1 − σ).
Proof
Since w(k+1) is a minimizer of problem (2), we have
| (5) |
It follows from assumption A1 that
| (6) |
Combining Eq. (5) and Eq. (6), we have
It follows that
Therefore, the line search criterion in Eq. (3) is satisfied whenever (t(k) − β(l))/2 ≥ σt(k)/2, i.e., t(k) ≥ β(l)/(1 − σ). This completes the proof the lemma.
Next, we summarize the boundedness of t(k) in the following lemma.
Lemma 2
For any k ≥ 0, t(k) is bounded under the monotone line search criterion in Eq. (3).
Proof
It is trivial to show that t(k) is bounded from below, since t(k) ≥ tmin (tmin is defined in Algorithm 1). Next we prove that t(k) is bounded from above by contradiction. Assume that there exists a k ≥ 0, such that t(k) is unbounded from above. Without loss of generality, we assume that t(k) increases monotonically to +∞ and t(k) ≥ ηβ(l)/(1 − σ). Thus, the value t = t(k)/η ≥ β(l)/(1 − σ) must have been tried at iteration k and does not satisfy the line search criterion in Eq. (3). But Lemma 1 states that t = t(k)/η ≥ β(l)/(1 − σ) is guaranteed to satisfy the line search criterion in Eq. (3). This leads to a contradiction. Thus, t(k) is bounded from above.
Remark 2
We note that if Eq. (3) holds, Eq. (4) is guaranteed to be satisfied. Thus, the same conclusions in Lemma 1 and Lemma 2 also hold under the the non-monotone line search criterion in Eq. (4).
Based on Lemma 1 and Lemma 2, we present our convergence result in the following theorem.
Theorem 1
Let the assumptions A1–A3 hold and the monotone line search criterion in Eq. (3) be satisfied. Then all limit points of the sequence {w(k)} generated by Algorithm 1 are critical points of problem (1).
Proof
Based on Lemma 1, the monotone line search criterion in Eq. (3) is satisfied and hence
which implies that the sequence f(w(k))k=0,1,··· is monotonically decreasing. Let w★ be a limit point of the sequence {w(k) }, that is, there exists a subsequence
 such that
such that
Since f is bounded from below, together with the fact that {f(w(k))} is monotonically decreasing, limk→∞f(w(k)) exists. Observing that f is continuous, we have
Taking limits on both sides of Eq. (3) with k ∈
, we have
| (7) |
Considering that the minimizer w(k+1) is also a critical point of problem (2) and r(w) = r1(w) − r2(w), we have
Taking limits on both sides of the above equation with k ∈
, by considering the semi-continuity of ∂r1(·) and ∂r2(·), the boundedness of t(k) (based on Lemma 2) and Eq. (7), we obtain
Therefore, w★ is a critical point of problem (1). This completes the proof of Theorem 1.
Based on Eq. (7), we know that limk∈
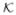 →∞ ||w(k+1) − w(k)||2 = 0 is a necessary optimality condition of Algorithm 1. Thus, ||w(k+1) − w(k)||2 is a quantity to measure the convergence of the sequence {w(k)} to a critical point. We present the convergence rate in terms of ||w(k+1) − w(k)||2 in the following theorem.
→∞ ||w(k+1) − w(k)||2 = 0 is a necessary optimality condition of Algorithm 1. Thus, ||w(k+1) − w(k)||2 is a quantity to measure the convergence of the sequence {w(k)} to a critical point. We present the convergence rate in terms of ||w(k+1) − w(k)||2 in the following theorem.
Theorem 2
Let {w(k)} be the sequence generated by Algorithm 1 with the monotone line search criterion in Eq. (3) satisfied. Then for every n ≥ 1, we have
where w★ is a limit point of the sequence {w(k)}.
Proof
Based on Eq. (3) with t(k) ≥ tmin, we have
Summing the above inequality over k = 0, · · ·, n, we obtain
which implies that
This completes the proof of the theorem.
Under the non-monotone line search criterion in Eq. (4), we have a similar convergence result in the following theorem (the proof uses an extension of argument for Theorem 1 and is omitted).
Theorem 3
Let the assumptions A1–A3 hold and the non-monotone line search criterion in Eq. (4) be satisfied. Then all limit points of the sequence {w(k) } generated by Algorithm 1 are critical points of problem (1).
Note that Theorem 1/Theorem 3 makes sense only if {w(k)} has limit points. By considering one more mild assumption:
-
A4
,
we summarize the existence of limit points in the following theorem (the proof is omitted):
Theorem 4
Let the assumptions A1–A4 hold and the monotone/non-monotone line search criterion in Eq. (3)/Eq. (4) be satisfied. Then the sequence {w(k)} generated by Algorithm 1 has at least one limit point.
2.3.4. Discussions
Observe that can be viewed as an approximation of l(w) at w = w(k). The GIST algorithm minimizes an approximate surrogate instead of the objective function in problem (1) at each outer iteration. We further observe that if t(k) ≥ β(l)/(1 − σ) > β(l) [the sufficient condition of Eq. (3)], we obtain
It follows that
where M(w, w(k)) denotes the objective function of problem (2). We can easily show that
Thus, the GIST algorithm is equivalent to solving a sequence of minimization problems:
and can be interpreted as the well-known Majorization and Minimization (MM) technique (Hunter & Lange, 2000).
Note that we focus on the vector case in this paper and the proposed GIST algorithm can be easily extended to the matrix case.
3. Related Work
In this section, we discuss some related algorithms. One commonly used approach to solve problem (1) is the Multi-Stage (MS) convex relaxation (or CCCP, or DC programming) (Zhang, 2010b; Yuille & Rangarajan, 2003; Gasso et al., 2009). It equivalently rewrites problem (1) as
where f1(w) and f2(w) are both convex functions. The MS algorithm solves problem (1) by generating a sequence {w(k)} as
| (8) |
where s2(w(k)) denotes a sub-gradient of f2(w) at w = w(k). Obviously, the objective function in problem (8) is convex. The MS algorithm involves solving a sequence of convex optimization problems as in problem (8). In general, there is no closed-form solution to problem (8) and the computational cost of the MS algorithm is k times that of solving problem (8), where k is the number of outer iterations. This is computationally expensive especially for large scale problems.
A class of related algorithms called iterative shrinkage and thresholding (IST), which are also known as different names such as fixed point iteration and forward-backward splitting (Daubechies et al., 2004; Combettes & Wajs, 2005; Hale et al., 2007; Beck & Teboulle, 2009; Wright et al., 2009; Liu et al., 2009), have been extensively applied to solve problem (1). The key step is by generating a sequence {w(k)} via solving problem (2). However, they require that the regularizer r(w) is convex and some of them even require that both l(w) and r(w) are convex. Our proposed GIST algorithm is a more general framework, which can deal with a wider range of problems including both convex and non-convex cases.
Another related algorithm called a Variant of Iterative Reweighted Lα (VIRL) is recently proposed to solve the following optimization problem (Lu, 2012a):
where α ≥ 1, 0 < q < 1, εi > 0. VIRL solves the above problem by generating a sequence {w(k)} as
In VIRL, t(k−1) is chosen as the initialization of t(k). The line search step in VIRL finds the smallest integer l with t(k) = t(k−1)ηl (η > 1) such that
The most related algorithm to our propose GIST is the Sequential Convex Programming (SCP) proposed by Lu (2012b). SCP solves problem (1) by generating a sequence {w(k)} as
where s2 is a sub-gradient of r2(w) at w = w(k). Our algorithm differs from SCP in that the original regularizer r(w) = r1(w) − r2(w) is used in the proximal operator in problem (2), while r1(w) minus a locally linear approximation for r2(w) is adopted in SCP. We will show in the experiments that our proposed GIST algorithm is more efficient than SCP.
4. Experiments
4.1. Experimental Setup
We evaluate our GIST algorithm by considering the Capped l1 regularized logistic regression problem, that is and . We compare our GIST algorithm with the Multi-Stage (MS) algorithm and the SCP algorithm in different settings using twelve data sets summarized in Table 2. These data sets are high dimensional and sparse. Two of them (news20, real-sim)1 have been preprocessed as two-class data sets (Lin et al., 2008). The other ten2 are multi-class data sets. We transform the multi-class data sets into two-class by labeling the first half of all classes as positive class, and the remaining classes as the negative class.
Table 2.
Data sets statistics: n is the number of samples and d is the dimensionality of the data.
| No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||
| datasets | classic | hitech | k1b | la12 | la1 | la2 | news20 | ng3sim | ohscal | real-sim | reviews | sports |
| n | 7094 | 2301 | 2340 | 2301 | 3204 | 3075 | 19996 | 2998 | 11162 | 72309 | 4069 | 8580 |
| d | 41681 | 10080 | 21839 | 31472 | 31472 | 31472 | 1355191 | 15810 | 11465 | 20958 | 18482 | 14866 |
All algorithms are implemented in Matlab and executed on an Intel(R) Core(TM)2 Quad CPU (Q6600 @2.4GHz) with 8GB memory. We set σ = 10−5, m = 5, η = 2, 1/tmin = tmax = 1030 and choose the starting points w(0) of all algorithms as zero vectors. We terminate all algorithms if the relative change of the two consecutive objective function values is less than 10−5 or the number of iterations exceeds 1000. The Matlab codes of the GIST algorithm are available online (Gong et al., 2013).
4.2. Experimental Evaluation and Analysis
We report the objective function value vs. CPU time plots with different parameter settings in Figure 1. From these figures, we have the following observations: (1) Both GISTbb-Monotone and GISTbb-Nonmonotone decrease the objective function value rapidly and they always have the fastest convergence speed, which shows that adopting the BB rule to initialize t(k) indeed greatly accelerates the convergence speed. Moreover, both GISTbb-Monotone and GISTbb-Nonmonotone algorithms achieve the smallest objective function values. (2) GISTbb-Nonmonotone may give rise to an increasing objective function value but finally converges and has a faster overall convergence speed than GISTbb-Monotone in most cases, which indicates that the non-monotone line search criterion can further accelerate the convergence speed. (3) SCPbb-Nonmonotone is comparable to GISTbb-Nonmonotone in several cases, however, it converges much slower and achieves much larger objective function values than those of GISTbb-Nonmonotone in the remaining cases. This demonstrates the superiority of using the original regularizer r(w) = r1(w) − r2(w) in the proximal operator in problem (2). (4) GIST-1 has a faster convergence speed than GIST-t(k−1) in most cases, which demonstrates that it is a bad strategy to use t(k−1) to initialize t(k). This is because {t(k)} increases monotonically in this way, making the step size 1/t(k) monotonically decreasing when the algorithm proceeds.
Figure 1.

Objective function value vs. CPU time plots. MS-Nesterov/MS-SpaRSA: The Multi-Stage algorithm using the Nesterov/SpaRSA method to solve problem (8); GIST-1/GIST-t(k−1)/GISTbb-Monotone/GISTbb-Nonmonotone: The GIST algorithm using 1/t(k−1)/BB rule/BB rule to initialize t(k) and Eq. (3)/Eq. (3)/Eq. (3)/Eq. (4) as the line search criterion; SCPbb-Nonmonotone: The SCP algorithm using the BB rule to initialize t(k) and Eq. (4) as the line search criterion. Note that on data sets ‘hitech’ and ‘real-sim’, MS algorithms stop early (the SCP algorithm has similar behaviors on data sets ‘hitech’ and ‘news20’), because they satisfy the termination condition that the relative change of the two consecutive objective function values is less than 10−5. However, their objective function values are much larger than those of GISTbb-Monotone and GISTbb-Nonmonotone.
5. Conclusions
We propose an efficient iterative shrinkage and thresholding algorithm to solve a general class of non-convex optimization problems encountered in sparse learning. A critical step of the proposed algorithm is the computation of a proximal operator, which has a closed-form solution for many commonly used formulations. We propose to initialize the step size at each iteration using the BB rule and employ both monotone and non-monotone criteria as line search conditions, which greatly accelerate the convergence speed. Moreover, we provide a detailed convergence analysis of the proposed algorithm, showing that the algorithm converges under both monotone and non-monotone line search criteria. Experiments results on large-scale data sets demonstrate the fast convergence of the proposed algorithm.
In our future work, we will focus on analyzing the theoretical performance (e.g., prediction error bound, parameter estimation error bound etc.) of the solution obtained by the GIST algorithm. In addition, we plan to apply the proposed algorithm to solve the multitask feature learning problem (Gong et al., 2012a;b).
Acknowledgments
This work is supported partly by 973 Program (2013CB329503), NSFC (Grant No. 91120301, 61075004, 61021063), NIH (R01 LM010730) and NSF (IIS-0953662, CCF-1025177, DMS1208952).
Appendix: Solutions to Problem (2)
Observe that and problem (2) can be equivalently decomposed into d independent univariate optimization problems:
where i = 1, · · ·, d and is the i-th entry of u(k) = w(k) − ∇l(w(k))/t(k). To simplify the notations, we unclutter the above equation by removing the subscripts and supscripts as follows:
| (9) |
l1-norm: w(k+1) = sign(u) max (0, |u| − λ/t).
-
LSP: We can obtain an optimal solution of problem (9) via: w(k+1) = sign(u)x, where x is an optimal solution of the following problem:Noting that the objective function above is differentiable in the interval [0, +∞) and the minimum of the above problem is either a stationary point (the first derivative is zero) or an endpoint of the feasible region, we havewhere
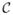 is a set composed of 3 elements or 1 element. If t2(|u| − θ)2 − 4t(λ − t|u|θ) ≥ 0,
is a set composed of 3 elements or 1 element. If t2(|u| − θ)2 − 4t(λ − t|u|θ) ≥ 0,
Otherwise,
= {0}. -
SCAD: We can recast problem (9) into the following three problems:We can easily obtain that (x2 is obtained using the similar idea as LSP by considering that θ > 2):Thus, we have
-
MCP: Similar to SCAD, we can recast problem (9) into the following two problems:We can easily obtain thatwhere , if θ−1 ≠ 0, and = {0,θλ} otherwise. Thus, we have
-
Capped l1: We can recast problem (9) into the following two problems:We can easily obtain thatThus, we have
Footnotes
Proceedings of the 30th International Conference on Machine Learning, Atlanta, Georgia, USA, 2013.
Contributor Information
Pinghua Gong, Email: gph08@mails.tsinghua.edu.cn, State Key Laboratory on Intelligent Technology and Systems, Tsinghua National Laboratory for Information Science and Technology (TNList), Department of Automation, Tsinghua University, Beijing 100084, China.
Changshui Zhang, Email: zcs@mail.tsinghua.edu.cn, State Key Laboratory on Intelligent Technology and Systems, Tsinghua National Laboratory for Information Science and Technology (TNList), Department of Automation, Tsinghua University, Beijing 100084, China.
Zhaosong Lu, Email: zhaosong@sfu.ca, Department of Mathematics, Simon Fraser University, Burnaby, BC, V5A 1S6, Canada.
Jianhua Z. Huang, Email: jianhua@stat.tamu.edu, Department of Statistics, Texas A&M University, TX 77843, USA
Jieping Ye, Email: jieping.ye@asu.edu, Computer Science and Engineering, Arizona State University, Tempe, AZ 85287, USA.
References
- Barzilai J, Borwein JM. Two-point step size gradient methods. IMA Journal of Numerical Analysis. 1988;8(1):141–148. [Google Scholar]
- Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences. 2009;2(1):183–202. [Google Scholar]
- Candes EJ, Wakin MB, Boyd SP. Enhancing sparsity by reweighted l1 minimization. Journal of Fourier Analysis and Applications. 2008;14(5):877–905. [Google Scholar]
- Combettes PL, Wajs VR. Signal recovery by proximal forward-backward splitting. Multiscale Modeling & Simulation. 2005;4(4):1168–1200. [Google Scholar]
- Daubechies I, Defrise M, De Mol C. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Communications on pure and applied mathematics. 2004;57(11):1413–1457. [Google Scholar]
- Efron B, Hastie T, Johnstone I, Tibshirani R. Least angle regression. The Annals of statistics. 2004;32(2):407–499. [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96(456):1348–1360. [Google Scholar]
- Foucart S, Lai MJ. Sparsest solutions of underdetermined linear systems via lq-minimization for 0 < q ≤ 1. Applied and Computational Harmonic Analysis. 2009;26(3):395–407. [Google Scholar]
- Gasso G, Rakotomamonjy A, Canu S. Recovering sparse signals with a certain family of nonconvex penalties and dc programming. IEEE Transactions on Signal Processing. 2009;57(12):4686–4698. [Google Scholar]
- Geman D, Yang C. Nonlinear image recovery with half-quadratic regularization. IEEE Transactions on Image Processing. 1995;4(7):932–946. doi: 10.1109/83.392335. [DOI] [PubMed] [Google Scholar]
- Gong P, Ye J, Zhang C. Multi-stage multi-task feature learning. NIPS. :1997–2005. 2012a. [PMC free article] [PubMed] [Google Scholar]
- Gong P, Ye J, Zhang C. Robust multi-task feature learning. SIGKDD. 2012b:895–903. doi: 10.1145/2339530.2339672. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gong P, Zhang C, Lu Z, Huang J, Ye J. GIST: General Iterative Shrinkage and Thresholding for Non-convex Sparse Learning. Tsinghua University; 2013. URL http://www.public.asu.edu/~jye02/Software/GIST. [PMC free article] [PubMed] [Google Scholar]
- Grippo L, Sciandrone M. Nonmonotone globalization techniques for the barzilai-borwein gradient method. Computational Optimization and Applications. 2002;23(2):143–169. [Google Scholar]
- Grippo L, Lampariello F, Lucidi S. A nonmonotone line search technique for newton’s method. SIAM Journal on Numerical Analysis. 1986;23(4):707–716. [Google Scholar]
- Hale ET, Yin W, Zhang Y. CAAM TR07-07. Rice University; 2007. A fixed-point continuation method for l1-regularized minimization with applications to compressed sensing. [Google Scholar]
- Hunter DR, Lange K. Quantile regression via an mm algorithm. Journal of Computational and Graphical Statistics. 2000;9(1):60–77. [Google Scholar]
- Lin CJ, Weng RC, Keerthi SS. Trust region newton method for logistic regression. Journal of Machine Learning Research. 2008;9:627–650. [Google Scholar]
- Liu J, Ji S, Ye J. SLEP: Sparse Learning with Efficient Projections. Arizona State University; 2009. URL http://www.public.asu.edu/~jye02/Software/SLEP. [Google Scholar]
- Lu Z. Iterative reweighted minimization methods for lp regularized unconstrained nonlinear programming. 2012a arXiv preprint arXiv:1210.0066. [Google Scholar]
- Lu Z. Sequential convex programming methods for a class of structured nonlinear programming. 2012b arXiv preprint arXiv:1210.3039. [Google Scholar]
- Shevade SK, Keerthi SS. A simple and efficient algorithm for gene selection using sparse logistic regression. Bioinformatics. 2003;19(17):2246–2253. doi: 10.1093/bioinformatics/btg308. [DOI] [PubMed] [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B (Methodological) 1996;58(1):267–288. [Google Scholar]
- Toland JF. A duality principle for non-convex optimisation and the calculus of variations. Archive for Rational Mechanics and Analysis. 1979;71(1):41–61. [Google Scholar]
- Trzasko J, Manduca A. Relaxed conditions for sparse signal recovery with general concave priors. IEEE Transactions on Signal Processing. 2009;57(11):4347–4354. [Google Scholar]
- Wright J, Yang AY, Ganesh A, Sastry SS, Ma Y. Robust face recognition via sparse representation. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2008;31(2):210–227. doi: 10.1109/TPAMI.2008.79. [DOI] [PubMed] [Google Scholar]
- Wright SJ, Nowak R, Figueiredo M. Sparse reconstruction by separable approximation. IEEE Transactions on Signal Processing. 2009;57(7):2479–2493. [Google Scholar]
- Ye J, Liu J. Sparse methods for biomedical data. ACM SIGKDD Explorations Newsletter. 2012;14(1):4–15. doi: 10.1145/2408736.2408739. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuille AL, Rangarajan A. The concave-convex procedure. Neural Computation. 2003;15(4):915–936. doi: 10.1162/08997660360581958. [DOI] [PubMed] [Google Scholar]
- Zhang CH. Nearly unbiased variable selection under minimax concave penalty. The Annals of Statistics. 2010a;38(2):894–942. [Google Scholar]
- Zhang T. Analysis of multi-stage convex relaxation for sparse regularization. Journal of Machine Learning Research. 2010b;11:1081–1107. [Google Scholar]
- Zhang T. Multi-stage convex relaxation for feature selection. Bernoulli. 2012 [Google Scholar]