An official website of the United States government
Here's how you know
Official websites use .gov
A
.gov website belongs to an official
government organization in the United States.
Secure .gov websites use HTTPS
A lock (
) or https:// means you've safely
connected to the .gov website. Share sensitive
information only on official, secure websites.
As a library, NLM provides access to scientific literature. Inclusion in an NLM database does not imply endorsement of, or agreement with,
the contents by NLM or the National Institutes of Health.
Learn more:
PMC Disclaimer
|
PMC Copyright Notice
Most new mutations are observed to arise in fathers, and increasing paternal age positively correlates with the risk of new variants. Interestingly, new mutations in X-linked recessive disease show elevated familial recurrence rates. In male offspring, these mutations must be inherited from mothers. We previously developed a simulation model to consider parental mosaicism as a source of transmitted mutations. In this paper, we extend and formalize the model to provide analytical results and flexible formulas. The results implicate parent of origin and parental mosaicism as central variables in recurrence risk. Consistent with empirical data, our model predicts that more transmitted mutations arise in fathers and that this tendency increases as fathers age. Notably, the lack of expansion later in the male germline determines relatively lower variance in the proportion of mutants, which decreases with paternal age. Subsequently, observation of a transmitted mutation has less impact on the expected risk for future offspring. Conversely, for the female germline, which arrests after clonal expansion in early development, variance in the mutant proportion is higher, and observation of a transmitted mutation dramatically increases the expected risk of recurrence in another pregnancy. Parental somatic mosaicism considerably elevates risk for both parents. These findings have important implications for genetic counseling and for understanding patterns of recurrence in transmission genetics. We provide a convenient online tool and source code implementing our analytical results. These tools permit varying the underlying parameters that influence recurrence risk and could be useful for analyzing risk in diverse family structures.
Introduction
New mutations are the sole source of disease risk for genetic disorders that eliminate reproductive fitness and for lethal alleles that can only exist in a mosaic state. Likewise, new mutations account for approximately one-third of disease risk in severe X-linked recessive conditions that diminish reproduction. In some instances, these new mutations are mitotic in origin (they arise during embryologic development of a parent) and are present in a low-level mosaic state. Such mutations can include single-nucleotide variations (SNVs), indels, nonrecurrent copy-number variations (CNVs), and other nonrecurrent copy-number-neutral structural variations.1 Importantly, these mutations can be present in the germline of parents and can be potentially recurrently transmitted to future offspring.2–4 Unexpected recurrences can occur, as evidenced by multiple affected children harboring the same apparently de novo variation. The birth of a single child with a severe genetic disease presents considerable psychological, social, and economic challenges; consequently, recurrence of the same disorder in a second child is a situation many couples prefer to avoid.5 Families who have had children affected by apparently de novo mutations can therefore benefit from well-informed risk counseling to make reproductive choices and plan prenatal care for additional pregnancies. These recurrence-risk estimates are an important aspect of the health care provided to such couples, particularly in severe and highly penetrant genetic disorders for which medical therapy remains limited.
Geneticists commonly use the value of <1% to estimate the risk of recurrence for simplex de novo mutations6 to be transmitted to additional pregnancies. However, consideration of the literature shows that this risk assessment is often inconsistent with empirical risk for some specific disorders,7 particularly those caused by mutations in genes located on the X chromosome.8,9 These examples provide insight into understanding exceptions to rarity of recurrence of apparently de novo mutations: males affected by X-linked recessive conditions necessarily harbor mutations on the chromosome inherited from their mothers. This maternal bias stands in contrast to the observations that most new mutations arise in the paternal lineage and that the risk of de novo mutation increases with paternal age.10,11 This paternal bias is broadly consistent with the mitotic origin of many de novo mutations and the additional mitoses experienced by germ cells as fathers age.
We hypothesized that sexual dimorphism in gametogenesis might underlie the juxtaposition of these contrasting biases in higher recurrence risk for X-linked disease and the increased paternal origin of most de novo transmitted mutations. To address this hypothesis, we developed a comprehensive, flexible mathematical model that describes the emergence of new transmitted variants. We show how recurrence risk can be computed on the basis of conditional probability analyses applied to these models in the context of observed affected offspring. These analyses give a comprehensive picture of the emergence of de novo variation and a systematic framework for quantitative analysis of recurrence. The main conclusion of our work is that the parent of origin and the presence of parental somatic mosaicism are major determinants of recurrence risk.
Material and Methods
Models of Mutation and Germline Development
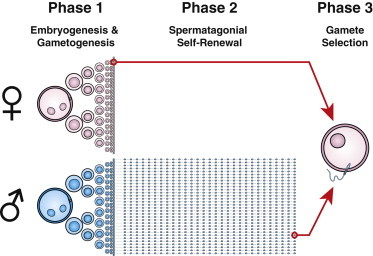
For our investigations, we utilized multitype Galton-Watson processes to model gametogenesis. These approaches are well established in probability theory and have been used for over a century; however, they have seldom been used in statistical genetics. Previous studies of mosaicism led us to hypothesize that this modeling framework could be useful in the analysis of sexual dimorphisms in gametogenesis.4 Our model of gametogenesis is composed of three stages (Figure 1). We can optionally include a fourth initial stage that allows stochastic exponential growth without mutation to exclude extremely early embryologic mutations that potentially cause the somatically mosaic parent to be affected. In the first stage of our main model, we consider clonal expansion that results in the initial germ pool during embryogenesis. This expansion phase is parameterized by three variables: the doubling rate of wild-type cells (p), the doubling rate of mutant cells (q), and the per-mitosis mutation rate (λ1). In the second male-specific stage, we consider the self-renewing process of spermatogenesis. This phase is relatively stable in terms of the total population size and is parameterized by five variables: the doubling rate of wild-type spermatogonial cells (α), the self-renewal rate of wild-type cells (β), the doubling rate of mutant spermatogonial cells (γ), the self-renewal rate of mutant cells (ξ), and the per-mitosis mutation rate (λ2). The final phase is meiosis, where diploid mutant cells give rise to haploid mutant gametes at a rate of 50% of the pool of mutant cells. We then select a single gamete from each parent to determine transmission.
Stochastic-Process Model of Sexual Dimorphisms during Gametogenesis
Phase 1: both males and females experience a stochastic exponential cell-expansion phase modeling embryogenesis and germ cell proliferation. Mutations can arise in any cell division, and if they persist in the clonal lineage, they could ultimately be available to be transmitted to the next generation.
Phase 2: in males, expansion is followed by a stochastic but nonexpanding self-renewal process modeling spermatogenesis.
Phase 3: a single sperm and egg are randomly sampled after meiosis to fertilize an offspring. Adapted from Campbell et al.4 with permission.
We previously developed exact formulas for analyzing single-phase Galton-Watson models.12 Here, we extended these sampling formulas to encompass the multistage process (see Appendix A). In brief, this approach requires composition of the output of each prior phase and the subsequent phase. We determined an exact integral expression for the mean and variance of the proportion of cells with mutations at a particular locus within a parent’s germ pool on the basis of the probability generating functions of the composite process. We also developed a recursive computational scheme to numerically determine the required integrands. Mathematica code implementing the formulas determined in Appendix A is provided on our website.
However, for numbers of mitoses consistent with human development, it is impractical to compute the number of terms in the generating-function expansions. Furthermore, numerical integration approaches based on a finite grid break down well in advance of useful numbers of mitoses. Therefore, we sought an alternative method to determine model properties and recurrence-risk estimates. We developed an exact matrix formulation for the first two moments of the multistage Galton-Watson model (Appendix B). We used these results and Taylor approximations for the moments of functions of random variables (in this case, a proportion) to determine approximations of the mean and variance of the proportion of mutants as a function of paternal age and other model parameters (Appendix B).
Updating the expected proportion of mutants given the observation of a transmitted mutation is essential to determining recurrence risk. We used the definition of conditional probability to determine an expression for the conditional expectation of the proportion of mutants on the basis of the unconditional moments of the proportion. Our results reveal that the conditional expectation of the proportion of mutants given an observed transmission is equivalent to the size-biased mean of the proportion, a more general mathematical result (Appendix C).
We subsequently explored the Beta-Binomial conjugate family13 as a useful and convenient Bayesian method to determine risk in diverse family structures. We parameterized a Beta distribution for the unconditional mean and variance of the proportion of mutants by using the results from the Galton-Watson model. We observed that the Beta-Binomial model gives exactly the same result as that obtained by the size-biased mean of the proportion of mutants for a single transmission. Therefore, we utilized the Beta-Binomial model as a flexible and effective method to estimate recurrence risk for arbitrary family sizes and the number of affected and unaffected offspring. Notably, unaffected offspring provide different information about the proportion of mutants in the germ pool of the transmitting parent depending on whether or not they inherit the risk haplotype—the chromosome on which the transmitted new mutation occurred. If haplotype information is unavailable, the information for updating the proportion is correspondingly diminished. Inheritance of the nonrisk haplotype conveys almost no information. To incorporate this consideration when haplotype information was unavailable, we computed a probability-weighted average recurrence risk by summing across the binomial number of unaffected offspring who share the risk haplotype with the affected individual and assuming 50/50 segregation of parental homologs.
Finally, we considered the information gained from experimental observation of somatic mosaicism in the parent of origin, for example, from molecular studies of parental blood. Identification of the mutation in parental somatic tissue is evidence that the mutation was present in the clonal lineage prior to the segregation of the germline, which occurs at approximately 15 divisions.4 To update the mutant proportion, we determined the expectation and variance given that a nonzero number of mutants was present in the parent before germ cell segregation (Appendix D).
Results
Empirical Recurrence Rates
To motivate our work, we conducted a survey of the existing literature and examined the available empirical data. Studies appropriately structured to address the issue of empirical recurrence rates are sparse.8Table 1 lists a selection of studies with sufficient observations (n > 50 families) to attempt useful comparisons. Recurrence of autosomal-dominant disease caused by new mutations appears to be rare. However, these data are most likely influenced by average family size in cultures where biomedical research has traditionally been undertaken. A second major observation is that recurrence rates are apparently higher for some sex-linked traits caused by mutations in genes on the X chromosome (Table 1). To better contextualize these observations, we sought to mathematically model the process of germ cell formation.
Table 1.
Selected Observed Recurrence Rates from the Literature
Note that these data might reflect heterogeneous mutational mechanisms.
Model of Gametogenesis
We previously developed a three-phase simulation model of gamete formation and selection4 (Figure 1). Phase 1 determines the size of the germ cell pool and consists of an exponential expansion occurring during 30 rounds of mitosis. The approximate number of mitoses between generations in human females is 30.15 According to our standard parameters for cellular fitness (Figure 2), this process defines 4.55 × 107 ± 2.28 × 107 cells, a number approximately 1 order of magnitude higher than that identified in second-trimester human embryos,16 allowing for additional expansion later in development. Phase 2 occurs only in males and represents the self-renewal process of spermatogenesis, during which spermatogonial stem cells asymmetrically divide, beginning at puberty, to produce sperm every 16 days.17 Phase 3 is meiosis and gamete selection, where 50% of gametes are produced from mutant germ cells and one gamete is randomly selected from each parent.
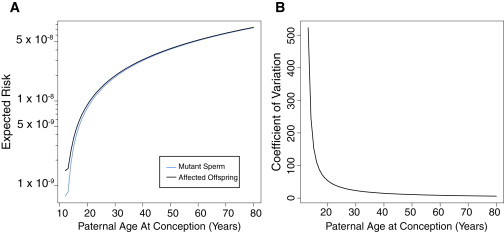
Analysis of the Mean and Variance of the Unconditional Proportion of Mutant Gametes
(A) Unconditional on the observation of an affected offspring, the mean proportion of mutant sperm and the expected risk of a first affected offspring (the sum of sperm and egg) are presented over various possible paternal ages according to our model. Mutation risk increases with paternal age.
(B) Coefficient of variation of the proportion of mutant sperm as a function of paternal age. Notably, the curve sharply decreases, indicating that although the proportion of mutant gametes increases, the variability among fathers of a given age decreases in relation to the mean. For these analyses, we set λ1 = λ2 = 1 × 10−10, p = q = 0.9, α = 0.05, β = 0.05, γ = 0.05, and ξ = 0.05 (see Material and Methods). An interactive version of this analysis is available online.
Risk of a First Affected Offspring
For our analyses, we considered each mitosis as equally likely to result in a mutation, although our framework is not limited in this regard. By varying the per-mitosis mutation rate (λ), we were able to effectively model mutations that cause sporadic genetic diseases with a variety of prevalence rates. As an example, parameterizing λ = 1 × 10−10 resulted in an expected proportion of offspring harboring a mutation of 2.06 × 10−8 in a mating with a 30-year-old male, which is consistent with previous estimates of human mutation rates per base pair per generation.18,19 Studies using massively parallel sequencing have identified a strong paternal bias in the origin of new mutations, which increases with age.10 Our modeling suggests that additional mitoses during spermatogenesis are a potential source of this bias, as previously hypothesized (Figure 2A).10 Because female gametes do not undergo mitosis after birth, risk of SNVs and nonrecurrent CNVs is not predicted to vary with maternal age.10
Interestingly, the variance of the proportion of mutants is relatively stable with paternal age. However, the expectation of the proportion is steadily increasing. Therefore, the coefficient of variation, defined as the ratio of the standard deviation to the expectation, decreases as a father ages (Figure 2B). This finding has direct consequences for recurrence risk as we update our expectation of the proportion of mutants on the basis of the observation of an affected child.
Recurrence Risk
Recurrence risk in the context of a new transmitted mutation is defined as the chance that parents will have a second child harboring the same DNA mutation as a previous child. Analysis of recurrence risk must consider two distinct underlying biological processes that can lead to recurrence: (1) when a mutation arises and is maintained in the lineage of clonally related cells ancestral to a mutant sperm or egg and (2) when an identical mutation arises more than once within the developing germ cells across multiple clonal sublineages. The contribution of the latter is highly influenced by the per-mitosis mutation rate of the given variant, but for most estimates of mutation rate, the contribution of independent mutations to recurrence risk is negligible. Therefore, our analysis of recurrence considered the clonal development, persistence, and selective forces20 on germ cells and the propagation of mutations within these clonal lineages.
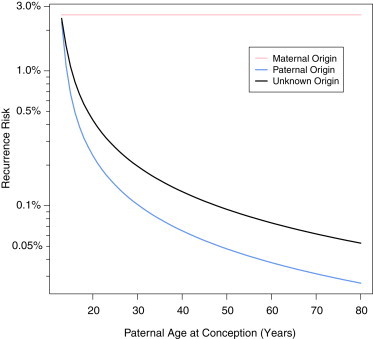
Our results show that recurrence risk depends on the parent of origin of the transmitted mutation. For maternally transmitted mutations, recurrence risk is considerably higher than empiric estimates for autosomal-dominant conditions but is consistent with observations for X-linked recessive disease (Tables 1 and 2). For paternally transmitted mutations, recurrence risk is similar overall to empirical risk estimates; however, the analyses revealed that paternal age is an important variable modifying recurrence risk. For young fathers who transmit a mutant gamete, recurrence risk is determined to be considerably higher because sampling a mutant is more unexpected and corresponds to a large increase in the expected risk of additional transmission (Figure 3). However, recurrence risk decreases with paternal age because observation of a transmitted mutation is more consistent with the expected increase in mutations in the paternal germ pool. In many real-life situations, knowledge of the parent of origin of new mutations is unavailable. In this circumstance, analysis of recurrence risk must consider the asymmetry in the parent of origin of new mutations. In this case, we calculate the recurrence risk by multiplying the sum of the risk for each parent by the probability that the sampled mutation was transmitted from that parent (Figure 3).
Table 2.
Selected Recurrence-Risk Estimates Calculated from Our Analyses
Information gained about recurrence risk from observation of unaffected offspring depends on the chromosome haplotype inherited from the parent who transmitted the mutant allele to the affected offspring. Inheriting the chromosome on which the mutation occurred (the risk haplotype) but with a wild-type allele provides much more information than inheriting the homologous chromosome’s haplotype. Absence of evidence of somatic mosaicism is treated as unknown because only a subset of tissue can be tested. Updating recurrence risk on the basis of additional offspring for an unknown transmitting parent is not considered in this manuscript. We caution against using this model-based table directly in clinical practice.
Analysis of Recurrence Risk as a Function of Parent of Origin and Paternal Age
Because oogenesis completes during embryogenesis, recurrence risk of maternally transmitted mutations is not expected to vary with maternal age. According to our model, recurrence risk of paternally transmitted mutations steadily decreases with age, despite an increasing risk of a first affected offspring. When the parent of origin is unknown, the overall recurrence risk is the probability-weighted sum of the recurrence risks for both parents. An interactive version of this analysis is available online.
The birth of additional offspring, either affected or unaffected, provides additional insight into the number of mutant gametes in the germ pool of the transmitting parent. Importantly, the information derived from unaffected offspring depends on the haplotype that they inherited from the transmitting parent. Inheriting the same haplotype as the affected sibling but with a wild-type allele provides information about the frequency of mutant diploid germ cells. Inheritance of the haplotype from the homologous parental chromosome provides almost no information. Table 2 lists posterior recurrence-risk estimates based on a Beta-Binomial Bayesian formulation (see Material and Methods) for a number of potential family structures. For transmitting mothers, the observation of a second affected offspring raises the recurrence risk of a third affected offspring to a potentially clinically actionable level. However, for transmitting fathers, risk of a third affected offspring is still less than 1% according to our model. Surprisingly, when information of an unexpected recurrence from an unknown parent is incorporated, the paternal bias of new mutations disappears and each parent is equally likely to have transmitted the mutation.
Parental Somatic Mosaicism and Recurrence Risk
Somatic mosaicism is the presence of a mutation in a subset of body tissues other than, or in addition to, the germline.21 Our previous studies suggest that parental somatic mosaicism for transmitted mutations (at least for nonrecurrent CNV alleles) is more common than previously identified and occurs at a rate of ∼4%.4 Detecting somatic mosaicism in a transmitting parent—for example, in peripheral blood—provides information regarding the timing of a mutation because the germline becomes segregated from the rest of the embryo within the first 15 mitoses.22,23 According to our analysis, compared to mutations for which no information is known, mutations that are also somatically mosaic in the transmitting parent are twice as likely to recur for mothers and, surprisingly, 51× more likely to recur in 30-year-old fathers (Table 2). For most reasonable mutation rates and paternal ages, somatically mosaic parents of either sex are at roughly equivalent risks of recurrence. Although definitively determining that mutant cells are exclusively confined to the parental germline is not experimentally feasible, our analyses suggest that recurrence risk for such parents is 2–3 orders of magnitude lower than that for parents with mutations that occurred before the segregation of the germline.
Recurrence-Risk Calculator
To make our analyses more accessible, we developed an online tool to explore how changes in parameters of the model and parent of origin influence estimates of recurrence. The parameters used for Table 2 are provided as the default. This tool is detailed in the Web Resources and might help to conceptualize the complex interplay among the factors that determine gametogenesis. Nonetheless, across a wide parameter space, the major conclusions remain: parent of origin and somatic mosaicism are major determinants of recurrence risk.
Discussion
Estimating recurrence risk is an important clinical concept that directly affects the medical management and reproductive choices of couples with children affected by genetic disease. Geneticists and genetic counselors often rely on empirical understanding of recurrence risk, but specific information is available for only the most common and well-understood diseases. Thus, frequently, they can only advise on the basis of experience with a broad spectrum of diseases and mutation types. Our analyses yield new insights into recurrence and implicate the parent of origin as a central variable in the analysis of risk, but we caution against using these estimates directly in routine clinical practice. Nonetheless, we have found that mutations of maternal origin determine higher recurrence risk than do paternal mutations. The analysis that underlies this finding requires detailed consideration of the fundamental developmental processes that lead to the transmission of new mutations. A comprehensive mathematical treatment of recurrence risk in humans is not available in the literature, and the authoritative reference does not consider the complexity of sampling stochastic clonal expansion or spermatogonial self-renewal.24 Other studies have considered the consequences of mosaicism (also called “premeiotic clusters”) but were directed more toward the study of population genetics.3,25,26
Our model predictions are consistent with the unexplained observation of increased recurrence risk among X-linked recessive diseases. This elevated recurrence risk is not a feature of a special choice of parameters in our model but is instead a result of the structural difference in gametogenesis between the sexes. For females, mutations during the clonal-expansion phase are rare, but the observation of a transmitted mutation is a strong indication that the maternal germline is rich in mutant gametes. In probabilistic terms, although the expected proportion of mutants is quite small, the prior variance in the proportion is quite large. Subsequently, the observation of a transmitted mutation has considerable information to update and increase the expected proportion of mutants in the maternal germ pool.
The situation for males is different. According to our model, and consistent with observations, the expected proportion of mutants is higher in males and steadily increases with age. However, our analyses show that the coefficient of variation of this proportion of mutants is modest and steadily decreases with paternal age. As such, observation of a transmitted mutation does not shift the expectation of the fraction of mutants in the sperm pool as strongly as for female germ cells. Observation of a transmitted mutation from the paternal side contains comparatively less information to alter the expected risk of recurrence.
Our model framework permits us to analyze the impact of mosaicism on recurrence risk. Emerging evidence suggests that parental somatic mosaicism for transmitted mutations is more common than previously thought and might have a clinically significant impact on recurrence risk. Our results indicate that compared to observation of a transmission alone, observation of somatic mosaicism increases recurrence risk 2-fold in mothers and more than 50-fold in fathers.
The conclusions of our model can be tested by analysis of the parent of origin and parental mosaicism in families where transmitted genetic disease is caused by new mutations, including families with and without observed recurrences. Although these analyses are not commonly performed, our results suggest that identification of the parent of origin is a key consideration for intrafamilial recurrence risk. In the absence of genome-wide data that permit phasing of the mutant allele, personalized assays such as single-gene sequencing or customized PCR to determine the parent of origin might be useful. Likewise, parental somatic mosaicism can be molecularly identified,8 and techniques with improved sensitivity should also be developed.
In addition to somatic-mosaicism status and parent of origin, the type of mutation in question most likely influences the parameters determining recurrence risk. The so-called “paternal-age effect” disorders20 provide particularly prominent examples. The high prevalence of Apert syndrome is attributed to mutant spermatogonial stem cells dividing more frequently than wild-type cells.17 Although the analysis we present in the text does not address this type of effect, our model and online explorer (see Web Resources) have provisions to modify these parameters. Likewise, some mutation types, such as CpG dinucleotide transitions or CNVs, might occur at higher or lower rates in spermatogonial stem cells or vary by sex. Moreover, genetic diversity in individual parents might influence mutation rate globally27 or for select mutation types during mitosis, as has been observed for meiotic mutational mechanisms.28 Our model can also accommodate inquiry into these aspects of human variation.
We suggest that our modeling framework is flexible and that our results are robust across many choices of parameters of mutation rate and cellular fitness. However, our modeling framework does not account for all sources of new disease-causing mutations. Importantly, we do not consider meiotic-origin mutations, such as nondisjunction events that mediate aneuploidy. As such, disorders such as Down syndrome and other conditions associated with increasing maternal age are not the focus of our work.
Other classes of deleterious mutations could cause recurrent disease under more complex patterns of inheritance. Our modeling is focused on autosomal-dominant alleles, in which a single copy of a mutant allele determines disease state. This model is also directly applicable for computing recurrence risk for X-linked recessive disease. In other unexpected recurrence situations involving new mutations, disease occurs through compound heterozygosity, in which a new mutation from one parent is randomly paired with a nonfunctional recessive allele inherited from the other parent. In these situations, familial recurrence rates would be half of what is predicted by our model, given that disease recurrence requires the nonfunctional familial allele from the other parent to also be transmitted to the offspring. Although our analysis focused on the inheritance of new mutations for couples, it might also contribute to understanding apparent violations of Mendelian expectations in some pedigrees.
In addition to their immediate applicability to recurrence risk of new mutations, our analytic results also represent a technical advance in the theory of branching processes. We extend the exact sampling formulas for multitype Galton-Watson processes to multiphase models, which in this application permitted us to consider both clonal-expansion and self-renewal phases of gametogenesis. This advance might extend the application of Galton-Watson models and sampling results to other contexts in biology, such as population genetics or the emergence of mutations in model organisms that can be experimentally assayed.29 We also developed an interesting result concerning the analysis of stochastic proportions. We showed that sampling a rare particle updates the expected proportion of that rare particle to the value determined by the size-biased distribution of the proportion. This general fact could have other uses in statistics and probability.
Our modeling framework considers only two types, wild-type and mutants. This simplifying choice is appropriate for the analysis of recurrent transmission of an index mutation within a family. We recognize that additional work is required for considering the full spectrum of variation that can emerge during clonal divisions and ultimately be transmitted by gametes between generations. We suggest that the basic structure of our model can be extended to considering an arbitrary number of mutation types. The framework of our model is to allow new mutants to arise and reproduce starting from a parental cell type. If we iterate this approach, allowing mutant cells from our model to initiate additional compound mutant lineages, then the basic mathematical structure as presented in Appendices A and B can be extended to considering arbitrary accumulation of mutations as well as back mutation. Future work in this area could advance the understanding of clonal heterogeneity, potentially of use in the study of malignancy.
Our results suggest that parent of origin and somatic-mosaicism status have considerable utility to inform estimation of recurrence risk. Our results naturally raise the question, “should clinicians quote a value different than <1%”? Empirical evidence,8 together with our model, suggests that for some clearly defined mutations, on average, risk is considerably higher. Large-scale empirical studies of parent of origin, parental somatic mosaicism, and mutational mechanisms are required for fully understanding recurrence risk. For any particular mutation, the interplay between these contributory factors determines risk, but their superposition makes it difficult to disentangle them. Further modeling based on improved empirical data would be an excellent approach. Nonetheless, we suggest that for families most concerned about recurrence, particularly those with younger fathers, investigations into parent of origin and mosaicism can help to reassure, improve family planning, or direct the potential use of preimplantation or prenatal genetic diagnostics.
Acknowledgments
We thank John Belmont for his insightful suggestions concerning X-linked disease, Arthur Beaudet for his comments about mutational mechanisms that might vary by sex, and Neil Hanchard for his insightful comments concerning locus heterogeneity and recurrence risk. I.M.C. is a fellow of the Baylor College of Medicine (BCM) Medical Scientist Training Program (T32 GM007330) and was supported by a fellowship from the National Institute of Neurological Disorders and Stroke (NINDS; F31 NS083159). This study was supported in part by grants from the National Heart, Lung, and Blood Institute (NHLBI; R01 HL101975) and Polish Ministry of Science and Higher Education (R13-0005-04/2008) to P.S.; grants from the NINDS (R01 NS058529) and the National Human Genome Research and NHLBI Baylor Hopkins Center for Mendelian Genomics (U54 HG006542) to J.R.L.; and a grant from the National Institute of General Medical Sciences (R15 GM093957) to P.O. J.R.L. holds stock ownership in 23andMe Inc. and Ion Torrent Systems Inc. and is a coinventor on multiple United States and European patents related to molecular diagnostics. The Department of Molecular and Human Genetics at BCM derives revenue from molecular genetic testing offered in the Medical Genetics Laboratories (http://www.bcm.edu/geneticlabs/).
Appendix A: Exact Formulas for Mutant Proportions in the Paternal Germline
A Two-Phase Model of Gametogenesis
This study considers sexual dimorphism in gametogenesis, mosaicism, and the consequences of these phenomena for mutation transmission between parents and offspring. Although we are considering diploid cells that precede the formation of haploid gametes, we consider cells as a whole rather than each homologous chromosome separately. Under this scheme, a cell with at least one mutation at a given locus is considered mutant, whereas a cell with only wild-type copies of DNA at that locus is considered wild-type. This simplification is reasonable for low mutation rates because the chance that two identical variations will arise on each of the homologs in a cellular lineage is extremely low.
For a single locus, the dynamics of this process can be modeled with only two types: wild-type and mutant. Our previous work12 provides exact sampling formulas for a single-phase two-type Galton-Watson model of clonal expansion with mutation, and this model is suitable to represent the female germline. Here, we extend our analyses to consider a two-stage, two-type Galton-Watson process suitable to represent the male germline. By two-stage we mean that the progeny distributions start according to the clonal-expansion rules as used in our earlier work but then switch at a fixed generation j from clonal expansion to self-renewal, under which the overall population size of the germ pool remains relatively stable. This self-renewal process proceeds for n − j = k generations. This two-stage model of expansion followed by an extended period of self-renewal reflects the characteristics of the male germline. The formulas for the model initiated from a single wild-type cell at generation 0 are presented below. In what follows, we define wild-type cells as type 0 and mutants as type 1.
Probability Generating Functions
The fundamental tool for analysis of Galton-Watson branching processes is the probability generating function (pgf). A pgf is a polynomial transformation used to represent a discrete probability distribution. The real valued arguments to pgfs are “dummy variables,” where powers of these arguments correspond to the possible values of the discrete random variable whose distribution is being analyzed. The coefficient of each polynomial term corresponds to the probability that the random variable being modeled takes on the values indexed in the exponents. For instance, for a variable X taking on the values {0,1,2}, let ϕ(u) be the pgf of X. We could write ϕ(u) = 0.25 + 0.5u + 0.25u2, indicating that X takes the value 0 with probability 0.25, the value 1 with probability 0.5, and the value 2 with probability 0.25. Joint distributions of two or more random variables can be similarly modeled with bivariate or multivariate pgfs. For instance, for the pair of random variables X and Y, each taking on values in {0,1,2}, we could write ϕ(u,v) = 0.25 + 0.5uv + 0.25u2, modeling a bivariate distribution where the only allowed values of the ordered pair (X,Y) are (0,0), (1,1), and (2,0) and where (1,1) occurs with probability 0.5.
The benefit of this notation is that various properties of discrete distributions can be determined by analytic properties of the pgf. For instance, the distribution of sums of independent discrete random variables can be analyzed by products of pgfs, and for multitype branching processes, function composition of the pgfs for the progeny determines the distribution of the evolution of the process.
Using pgfs in Our Two-Phase Model
In our previously published work,12 we defined progeny pgfs for the clonal-expansion process. ϕ0 represents the offspring of a wild-type cell, and ϕ1 is the pgf for the offspring of a mutant cell. The bivariate pgfs for wild-type (dummy variable u) and mutant cells (v) during clonal expansion are the following:
(Equation A1)
(Equation A2)
Wild-type cells double with probability p or expire with no progeny with probability 1 − p. Independently, dividing wild-type cells could either produce two wild-types with probability 1 − λ or give rise to one wild-type and one mutant with probability λ. Mutant cells can only give rise to two additional mutants with probability q or die without division with probability 1 − q.
The process of spermatogonial self-renewal proceeds by asymmetric cell division, in which spermatogonial cells most often produce a single renewal cell and only rarely double or expire with no progeny. As in clonal expansion, mutant cells can give rise to mutants, whereas wild-types can produce either wild-type or mutant offspring. We define the pgfs for the self-renewal process as ψ0 for wild-type and ψ1 for mutant spermatogonial cells:
(Equation A3)
(Equation A4)
Wild-type spermatogonial cells self-renew with probability β(1 − λ), divide with probability α, and expire with probability 1 − α − β. They generate mutant spermatogonial cells with probability βλ. Similarly, for mutant spermatogonial cells, they self-renew with probability ξ, divide with probability γ, and expire with probability 1 − γ − ξ.
As discussed above, male germline gametogenesis can be modeled by iterative composition of these progeny pgfs. The two-stage process has a total pgf that combines the j-fold compositions of the first-stage expansion process with n − j = k-fold composition of the second-stage self-renewal process. As a reminder, we use the Greek letter ϕ for the first-stage expansion-phase pgf and the letter ψ for the second-stage of self-renewal. By we intend the k-fold composition of the second-stage process starting from a single wild-type cell, and is the j-fold composition of the expansion phase; we use the subscript 1 for the corresponding functions beginning from mutants. represents the total pgf for the two-stage process starting from a single wild-type cell, whereas is the corresponding function for a process initiated by a mutant:
(Equation A5)
(Equation A6)
According to our prior work,12 if we let and be the number of wild-type and mutant cells, respectively, at generation n, then the mean and variance of the proportion of mutants in this two-stage process can be determined with the first and second derivatives of the bivariate pgf. The expression for the expected proportion of mutants is
(Equation A7)
A related expression involving second derivatives determines the variance. Applying the chain rule to consider the first derivatives, we have
(Equation A8)
(Equation A9)
The chain rule shows that the total derivative requires determination of derivatives for both wild-type and mutant cells in both the first- and second-stage processes. Similarly, computing second derivatives, as required for the variance determination, also depends on differentiating both pgfs for both stages. The derivatives for the first stage are available in our prior work. The derivatives for the second-stage process are determined as follows:
(Equation A10)
(Equation A11)
(Equation A12)
(Equation A13)
(Equation A14)
Suppressing (u,v) on the right-hand side, we have
(Equation A15)
(Equation A16)
And for mutants, we have
(Equation A17)
(Equation A18)
(Equation A19)
(Equation A20)
(Equation A21)
(Equation A22)
(Equation A23)
To compute the integrands for the mean and variance formulas, we first compute the inner function composition for the second-stage self-renewal process and then use this as the initial condition for evaluating the composition of the first-stage clonal-expansion process. It is important to note that evaluation of these function compositions proceeds from the “inside out”; that is, the compositions proceed from the final generation of the process backward toward ancestral cells and ultimately to the single wild-type progenitor cell. The superscripts index the number of function compositions, but these compositions are computed in the reverse order from the forward indexing of cell division. Thus, it is important to track the j and k indices for a fixed n. Recall that for a self-renewal process that proceeds for k generations after j generations of clonal expansion,
(Equation A24)
(Equation A25)
To initialize the two-stage composition, we start with the final round of clonal expansion, composed of the total composition representing k generations of self-renewal:
(Equation A26)
Again suppressing (u,v) on the right-hand side, we have
(Equation A27)
(Equation A28)
Subsequently for j>1,
(Equation A29)
(Equation A30)
(Equation A31)
Again for mutants,
(Equation A32)
(Equation A33)
(Equation A34)
(Equation A35)
(Equation A36)
(Equation A37)
Recursive Scheme for Pointwise Function Evaluation
Expansion of the polynomials defined above by recursive function composition proves impractical. As in our previous work,12 we developed a recursive scheme for pointwise function evaluation to permit numerical evaluation of the integrand for determining the exact mean and variance of the mutant proportion. We define this notation here:
(Equations A38)
(Equations A39)
(Equations A40)
(Equations A41)
We obtain the following recursive scheme:
(Equation A42)
(Equation A43)
(Equation A44)
(Equation A45)
(Equation A46)
(Equation A47)
(Equation A48)
(Equation A49)
(Equation A50)
(Equation A51)
(Equation A52)
(Equation A53)
The initial conditions are
(Equation A54)
(Equation A55)
(Equation A56)
(Equation A57)
(Equation A58)
(Equation A59)
(Equation A60)
(Equation A61)
(Equation A62)
(Equation A63)
(Equation A64)
(Equation A65)
For the female line composed of only clonal expansion, the initial conditions are
(Equation A66)
(Equation A67)
(Equation A68)
(Equation A69)
(Equation A70)
(Equation A71)
Mathematica code implementing these recurrences can be found on our website. We note that the spermatogonial self-renewal model can be extended to allow mutation at spermatogonial division:
(Equation A72)
We elected not to use this form for two reasons: (1) the main dynamics of the model are not substantively altered, and (2) we wished to conform with the simulation model used in our previously published work.4 Likewise, λ can be modeled to take on different values in the two phases of gametogenesis or vary by generation of cell division.
Appendix B: Taylor Approximations to the Moments of the Proportion of Mutants
Calculating the numerical integration of the formulas presented in Appendix A proves difficult. Approximations of the mean and variance of the proportion of mutants can be obtained with Taylor approximations of the moments of functions of random variables. In order to apply these approximations, we require the mean, variance, and covariance of the number of wild-type and mutant cells in each generation. In this problem, there are seven fundamental parameters that are determined from the progeny pgfs, and these are given in Table B1 below:
Table B1.
Model Parameter Determined by the Progeny Generating Function
Parameter
Description
μ00
expected wild-types born to a wild-type
μ01
expected mutants born to a wild-type
μ11
expected mutants born to a mutant
variance of wild-types born to a wild-type
variance of mutants born to a wild-type
variance of mutants born to a mutant
ρ01
the expectation of the product of the number of wild-types and mutants born to a wild-type
Importantly, the key structure of the model—where mutants can give additional mutants but wild-types make wild-types or mutants—is unchanged between the clonal-expansion and self-renewal phases. Depending on the previous generation, a single homogenous, linear recurrence in five-state variables determines the two means, the two variances, and the covariance of the number of wild-type and mutant cells in each generation. Specifying the initial state (the number of wild-type and mutant cells at the first generation) and the values of the parameters described above determines the evolution of the process. Let be the number of wild-type cells in generation n and be the number of mutants at n. Let . We obtain
(Equation B1)
(Equation B2)
Similarly, for we have
(Equation B3)
(Equation B4)
Finally, for the covariance, we have this identity:
(Equation B5)
Examining these recurrence formulas for generation n, we observe that they are homogeneous, first-order linear recurrences that depend only on the values of the previous generation, n − 1. Therefore, we can simplify and write a matrix expression for the vector: .
(Equation B6)
(Equation B7)
Because the two phases share the form A, we can determine the evolution of the two-phase process by matrix multiplication initializing from a single wild-type cell in generation 0. Let A1 be the matrix for phase 1 and A2 be the matrix for phase 2. Then,
(Equation B8)
Using the parameters of the pgfs, we can determine the values of the seven parameters that define the two phases (Table B2):
And therefore, using Taylor approximations, we can approximate the moments of the proportion of mutants:
(Equation B11)
(Equation B12)
R code implementing the above approximations as well as an interactive exploration tool that uses these approximations can be found on our website. These expressions can also be adjusted to account for potential mutation in spermatogonial division, as described in Appendix A.
Appendix C: A Size-Biased Result for Updating the Expected Mutant Proportion
To obtain the conditional mean of the proportion of mutants given the observation of a transmitted mutation, we apply the definition of conditional expectation. We note that there are many biological constraints, but for analysis of this model, transmission can only occur when and subsequently when . Let , X represent the number of transmitted mutations observed, and y be a dummy variable that represents the possible proportions of mutants for a given parent:
(Equation C1)
For a single Bernoulli trial, we note
(Equation C2)
Unconditionally, we note
(Equation C3)
Therefore,
(Equation C4)
which we notice is the mean of the size-biased distribution of θn. For clarity, .
Accounting for meiosis to determine the proportion of mutant haploid gametes, a factor of one-half appears in both the numerator and the denominator of these expressions. These factors cancel and therefore do not appear. R code implementing the above expressions can be found on our website.
Appendix D: Updating Risk on the Basis of Observation of Parental Somatic Mosaicism
Observation of the mutant allele in parental somatic tissues—for example, by amplification with PCR or other methods—represents important information for updating the expected proportion of mutants, which we equate with the risk of recurrence. To analyze the change in the expected proportion of mutants, we reason that observation of the transmitted mutation in parental somatic tissues gives information about the nonzero state of the number of mutants in the parent of origin at generation i. Here, i represents the cell-division number when the germline becomes sequestered from the portion of the embryo that will give rise to the somatic tissues. We note that i < j, where j is the generation when the clonal-expansion phase of gametogenesis ends. In our work, we set i = 15, consistent with the reported literature.22,23 To complete our analysis, we first consider the conditional expectations given the state of mutants at i without conditioning on observation of a transmission from parent to child. According to the law of total expectation,
(Equation D1)
The term is the quantity we seek to compute. E[θn] is available from the Taylor approximation, and we can compute the probability of 0 mutants in generation i by evaluating by using the i-fold composition of Equation A1. Therefore, if we can determine , we can determine the required result:
(Equation D2)
We take a similar approach to the variance. However, the variance is necessarily more complex and requires consideration of the result from the conditional mean analysis. The analysis requires , where I is an indicator that the number of mutant cells at generation i is 0. Subsequently,
(Equation D3)
We then use this fact to consider the conditional variance identity:
(Equation D4)
Therefore,
(Equation D5)
On the basis of the results above, we have both and . The key quantities to be approximated are and . Then, using the expressions above and calculating from the appropriate pgf, we are able to determine the updated expected mutant proportion. Let Z be a random variable with the same distribution as the number of wild-types cells when there are no mutants at i (that is, ). Let and be random variables that count the number of wild-type and mutant particles, respectively, at generation n and descend from the mth wild-type particle present at generation i. We proceed as follows:
(Equation D6)
And for clarity,
(Equation D7)
(Equation D8)
(Equation D9)
(Equation D10)
(Equation D11)
(Equation D12)
(Equation D13)
Using the identity for the covariance of random sums as used in Equation B5, we have
(Equation D14)
We can use the results from Appendix B to determine these moments, giving us the values required for calculating Equation D2. A similar approximation is available for the variance:
(Equation D15)
This expression along with the moments expressions in Appendix B gives us the values to calculate Equation D5. With the results of Equations D2 and D5, we again use the size-biasing result presented in Appendix C to update the risk given both observed transmission and the presence of the mutation in parental somatic tissues. In brief,
(Equation D16)
R code implementing the calculations using the formulas above and approximations from Appendix B is available on our website.
Web Resources
The URLs for data presented herein are as follows:
6.Röthlisberger B., Kotzot D. Recurrence risk in de novo structural chromosomal rearrangements. Am. J. Med. Genet. A. 2007;143A:1708–1714. doi: 10.1002/ajmg.a.31826. [DOI] [PubMed] [Google Scholar]
7.Pyott S.M., Pepin M.G., Schwarze U., Yang K., Smith G., Byers P.H. Recurrence of perinatal lethal osteogenesis imperfecta in sibships: parsing the risk between parental mosaicism for dominant mutations and autosomal recessive inheritance. Genet. Med. 2011;13:125–130. doi: 10.1097/GIM.0b013e318202e0f6. [DOI] [PubMed] [Google Scholar]
8.Helderman-van den Enden A.T.J.M., de Jong R., den Dunnen J.T., Houwing-Duistermaat J.J., Kneppers A.L., Ginjaar H.B., Breuning M.H., Bakker E. Recurrence risk due to germ line mosaicism: Duchenne and Becker muscular dystrophy. Clin. Genet. 2009;75:465–472. doi: 10.1111/j.1399-0004.2009.01173.x. [DOI] [PubMed] [Google Scholar]
9.Leuer M., Oldenburg J., Lavergne J.M., Ludwig M., Fregin A., Eigel A., Ljung R., Goodeve A., Peake I., Olek K. Somatic mosaicism in hemophilia A: a fairly common event. Am. J. Hum. Genet. 2001;69:75–87. doi: 10.1086/321285. [DOI] [PMC free article] [PubMed] [Google Scholar]
10.Kong A., Frigge M.L., Masson G., Besenbacher S., Sulem P., Magnusson G., Gudjonsson S.A., Sigurdsson A., Jonasdottir A., Jonasdottir A. Rate of de novo mutations and the importance of father’s age to disease risk. Nature. 2012;488:471–475. doi: 10.1038/nature11396. [DOI] [PMC free article] [PubMed] [Google Scholar]
11.Hehir-Kwa J.Y., Rodríguez-Santiago B., Vissers L.E., de Leeuw N., Pfundt R., Buitelaar J.K., Pérez-Jurado L.A., Veltman J.A. De novo copy number variants associated with intellectual disability have a paternal origin and age bias. J. Med. Genet. 2011;48:776–778. doi: 10.1136/jmedgenet-2011-100147. [DOI] [PubMed] [Google Scholar]
13.Gelman A., Carlin J.B., Stern H.S., Dunson D.B., Vehtari A. Third Edition. CRC Press; Boca Raton: 2013. Bayesian Data Analysis. [Google Scholar]
14.Mettler G., Fraser F.C. Recurrence risk for sibs of children with “sporadic” achondroplasia. Am. J. Med. Genet. 2000;90:250–251. [PubMed] [Google Scholar]
15.Drost J.B., Lee W.R. Biological basis of germline mutation: comparisons of spontaneous germline mutation rates among drosophila, mouse, and human. Environ. Mol. Mutagen. 1995;25(Suppl 26):48–64. doi: 10.1002/em.2850250609. [DOI] [PubMed] [Google Scholar]
16.Mamsen L.S., Lutterodt M.C., Andersen E.W., Byskov A.G., Andersen C.Y. Germ cell numbers in human embryonic and fetal gonads during the first two trimesters of pregnancy: analysis of six published studies. Hum. Reprod. 2011;26:2140–2145. doi: 10.1093/humrep/der149. [DOI] [PubMed] [Google Scholar]
17.Qin J., Calabrese P., Tiemann-Boege I., Shinde D.N., Yoon S.-R., Gelfand D., Bauer K., Arnheim N. The molecular anatomy of spontaneous germline mutations in human testes. PLoS Biol. 2007;5:e224. doi: 10.1371/journal.pbio.0050224. [DOI] [PMC free article] [PubMed] [Google Scholar]
19.Hurles M. Older males beget more mutations. Nat. Genet. 2012;44:1174–1176. doi: 10.1038/ng.2448. [DOI] [PubMed] [Google Scholar]
20.Goriely A., McVean G.A.T., Röjmyr M., Ingemarsson B., Wilkie A.O.M. Evidence for selective advantage of pathogenic FGFR2 mutations in the male germ line. Science. 2003;301:643–646. doi: 10.1126/science.1085710. [DOI] [PubMed] [Google Scholar]
22.Fujimoto T., Miyayama Y., Fuyuta M. The origin, migration and fine morphology of human primordial germ cells. Anat. Rec. 1977;188:315–330. doi: 10.1002/ar.1091880305. [DOI] [PubMed] [Google Scholar]
23.Marques-Mari A.I., Lacham-Kaplan O., Medrano J.V., Pellicer A., Simón C. Differentiation of germ cells and gametes from stem cells. Hum. Reprod. Update. 2009;15:379–390. doi: 10.1093/humupd/dmp001. [DOI] [PubMed] [Google Scholar]
25.Fu Y.-X., Huai H. Estimating mutation rate: how to count mutations? Genetics. 2003;164:797–805. doi: 10.1093/genetics/164.2.797. [DOI] [PMC free article] [PubMed] [Google Scholar]
26.Woodruff R.C., Zhang M. Adaptation from leaps in the dark. J. Hered. 2009;100:7–10. doi: 10.1093/jhered/esn058. [DOI] [PubMed] [Google Scholar]
27.Conrad D.F., Keebler J.E.M., DePristo M.A., Lindsay S.J., Zhang Y., Casals F., Idaghdour Y., Hartl C.L., Torroja C., Garimella K.V., 1000 Genomes Project Variation in genome-wide mutation rates within and between human families. Nat. Genet. 2011;43:712–714. doi: 10.1038/ng.862. [DOI] [PMC free article] [PubMed] [Google Scholar]
28.Berg I.L., Neumann R., Lam K.-W.G., Sarbajna S., Odenthal-Hesse L., May C.A., Jeffreys A.J. PRDM9 variation strongly influences recombination hot-spot activity and meiotic instability in humans. Nat. Genet. 2010;42:859–863. doi: 10.1038/ng.658. [DOI] [PMC free article] [PubMed] [Google Scholar]
29.Gao J.-J., Pan X.-R., Hu J., Ma L., Wu J.-M., Shao Y.-L., Ai S.-M., Liu S.-Q., Barton S.A., Woodruff R.C. Pattern of Mutation Rates in the Germline of Drosophila melanogaster Males from a Large-Scale Mutation Screening Experiment. G3 (Bethesda) 2014;4:1503–1514. doi: 10.1534/g3.114.011056. [DOI] [PMC free article] [PubMed] [Google Scholar]