

Abstract
Differential privacy is a cryptographically-motivated definition of privacy which has gained significant attention over the past few years. Differentially private solutions enforce privacy by adding random noise to a function computed over the data, and the challenge in designing such algorithms is to control the added noise in order to optimize the privacy-accuracy-sample size tradeoff.
This work studies differentially-private statistical estimation, and shows upper and lower bounds on the convergence rates of differentially private approximations to statistical estimators. Our results reveal a formal connection between differential privacy and the notion of Gross Error Sensitivity (GES) in robust statistics, by showing that the convergence rate of any differentially private approximation to an estimator that is accurate over a large class of distributions has to grow with the GES of the estimator. We then provide an upper bound on the convergence rate of a differentially private approximation to an estimator with bounded range and bounded GES. We show that the bounded range condition is necessary if we wish to ensure a strict form of differential privacy.
1. Introduction
Differential privacy (Dwork et al., 2006b) is a strong, cryptographically-motivated definition of privacy which has gained significant attention in the machine-learning and data-mining communities over the past few years (McSherry & Mironov, 2009; Chaudhuri et al., 2011; Friedman & Schuster, 2010; Mohammed et al., 2011). In differentially private solutions, privacy is guaranteed by ensuring that the participation of a single individual in a database does not change the outcome of a private algorithm by much. This is typically achieved by adding some random noise, either to the sensitive input data, or to the output of some function, such as a classifier, computed on the sensitive data. While this guarantees privacy, for most statistical and machine learning tasks, there is a subsequent loss in statistical efficiency, in terms of the number of samples required to estimate a function to a given degree of accuracy. Thus the main challenge in designing differentially private algorithms is to optimize the privacy-accuracy-sample size trade-off, and a body of literature has been devoted to this goal.
In this paper, we focus on differentially-private statistical estimation. We ask: what properties should a statistical estimator have, so that it can be approximated accurately with differential privacy? Privately approximating an estimator based on a functional T that performs well when data is drawn from a specific distribution F is easy: ignore the sensitive data, and output T (F). Thus the challenge is to design differentially private approximations to estimators that are accurate over a wide range of distributions.
Previous work (Smith, 2011) on differentially private statistical estimation shows how to construct differentially private approximations to estimators which have asymptotic normality guarantees under fairly mild conditions. In practical situations, however, we must take into account the effect of a finite number of samples. Moreover, it has been empirically observed (e.g., Chaudhuri et al., 2011; Vu & Slavkovic, 2009) that there is often a significant gap in statistical efficiency between a differentially private estimator and its non-private counterpart. Thus there is a need to study finite sample convergence rates for differentially private statistical estimators, in order to characterize the properties that make a statistical estimator amenable to differentially-private approximations.
In this paper, we provide upper and lower bounds on the finite sample convergence rates of such estimators. Our first finite sample result draws a connection between differentially private statistical estimators and Gross Error Sensitivity, a measure commonly used in the robust statistics literature (Huber, 1981). The Gross Error Sensitivity (GES) of a statistical functional T at a distribution F is the maximum change in the value of T (F) by an arbitrarily small perturbation of F by any point mass x in the domain. We provide a lower bound on the convergence rate of any differentially private statistical estimator, showing that an estimator that approximates T (Fn) well with differential privacy over a large class of distributions must have its convergence rate grow with the GES of T.
A natural question to ask next is whether bounded GES is sufficient for the existence of differentially private estimators that are accurate for large classes of distributions. We next show that at least for α-differential privacy, this is not the case. Any estimator based on a functional T that takes values in a range of length R and guarantees α-differential privacy for a wide class of distributions, has to have a finite sample convergence rate that grows with increasing R.
We then show that bounded range and GES are indeed sufficient for differentially private estimation. In particular, given an estimator based on a functional T which takes values in a bounded range, and has bounded GES for all distributions close to the underlying data distribution F, we show how to compute a differentially private approximation to T (F) based on sensitive data drawn from F. Our approximation preserves (α, δ)-differential privacy, a relaxation of α-differential privacy, and is based on the smoothed sensitivity method (Nissim et al., 2007). We provide a finite sample upper bound on the convergence rate of this estimator.
The statistical estimators in our upper bounds are computationally inefficient in general. We conclude by providing a separate explicit method for privately approximating M-estimators with certain properties. We prove that these differentially-private estimators enjoy similar privacy and statistical guarantees as those based on the smooth-sensitivity method, while being more efficiently computable.
Related Work
Differential privacy was proposed by (Dwork et al., 2006b), and has been used since in many works on privacy (e.g., Blum et al., 2005; Barak et al., 2007; Nissim et al., 2007; McSherry & Mironov, 2009; Chaudhuri et al., 2011). It has been shown to have strong semantic guarantees (Dwork et al., 2006b) and is resistant to many attacks (Ganta et al., 2008) that succeed against some other definitions of privacy.
Dwork & Lei (2009) is the first work to identify a connection between differential privacy and robust statistics; based on robust statistical estimators as a starting point, they provide differentially private algorithms for several common estimation tasks, including interquartile range, trimmed mean and median, and regression.
In further work, Smith (2011) shows how to construct a differentially private approximation
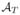 to certain types of statistical estimators T, and establishes asymptotic normality of his estimator provided certain conditions on T hold. We in contrast focus on finite sample bounds, with an aim towards characterizing the statistical properties of estimators that determine how closely they can be approximated with differential privacy. Lei (2011) considers M-estimation, and provides a simple and elegant differentially-private M-estimator which is statistically consistent.
to certain types of statistical estimators T, and establishes asymptotic normality of his estimator provided certain conditions on T hold. We in contrast focus on finite sample bounds, with an aim towards characterizing the statistical properties of estimators that determine how closely they can be approximated with differential privacy. Lei (2011) considers M-estimation, and provides a simple and elegant differentially-private M-estimator which is statistically consistent.
Finally, work on the sample requirement of differentially private algorithms include bounds on the accuracy of differentially private data release (Hardt & Talwar, 2010), and the sample complexity of differentially private classification (Chaudhuri & Hsu, 2011).
2. Preliminaries
The goal of this paper is to examine the conditions under which we can find private approximations to estimators. The notion of privacy we use is differential privacy (Dwork et al., 2006b;a).
Definition 1
A (randomized) algorithm
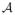 taking values in a range
taking values in a range
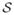 is (α, δ)-differentially private if for all S ⊆
, and all data sets D and D′ differing in a single entry,
is (α, δ)-differentially private if for all S ⊆
, and all data sets D and D′ differing in a single entry,
where Pr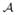 [·] is the distribution on
induced by the output of
given a data set.
[·] is the distribution on
induced by the output of
given a data set.
A (randomized) algorithm
is α-differentially private if it is (α, 0)-differentially private.
Here α > 0 and δ ∈ [0, 1] are privacy parameters, where smaller α and δ imply stricter privacy.
A general approach to developing differentially private approximations to functions is to add noise, either to the sensitive data, or to the output of a non-private function computed on the data. This work explores what properties statistical functionals need to have so that they can be accurately approximated with differential privacy.
Let
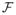 denote the space of probability distributions on a domain
denote the space of probability distributions on a domain
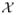 . A statistical functional T:
→ ℝ is a real-valued function of a distribution F. The plug-in estimator of θ = T (F) is given by θn:= T (Fn), where Fn is the empirical distribution corresponding to an i.i.d. sample of size n drawn from F.
. A statistical functional T:
→ ℝ is a real-valued function of a distribution F. The plug-in estimator of θ = T (F) is given by θn:= T (Fn), where Fn is the empirical distribution corresponding to an i.i.d. sample of size n drawn from F.
A common measure of the robustness of a statistical functional is the influence function, which measures how a functional T (F) responds to small changes to the input F.
Definition 2
The influence function
IF(x, T, F) for a functional T and distribution F at x ∈
is:
where δx denotes the point mass distribution at x.
It is a well-established result in theoretical statistics (see, e.g, Wasserman, 2006) that if T is Hadamard-differentiable, and if
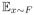 [IF(x, T, F)2] is bounded, then T (Fn) converges to T (F) as n → ∞.
[IF(x, T, F)2] is bounded, then T (Fn) converges to T (F) as n → ∞.
A related notion is that of gross error sensitivity, which measures the worst-case value of the influence function for any x ∈
.
Definition 3
The gross error sensitivity GES(T, F) for a functional T and distribution F is:
We also define the notions of influence function and gross error sensitivity at a fixed scale ρ > 0:
In this work, the data domain
will be a subset of ℝ. We overload notation and use F to denote a distribution as well as its cumulative distribution function. For two distributions F and G, we use dGC(F, G): = supx∈ℝ |F (x) − G(x)| to denote the Glivenko-Cantelli distance between F and G. For a distribution F from a family
and a radius r > 0, let
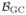 (F, r) denote the set of distributions G ∈
such that dGC(F, G) ≤ r. Finally, we use dTV(F, G) to denote the total variantion distance between F and G.
(F, r) denote the set of distributions G ∈
such that dGC(F, G) ≤ r. Finally, we use dTV(F, G) to denote the total variantion distance between F and G.
A statistical functional T is B-robust at F if GES(T, F) is finite. B-robustness has been studied in the robust statistics literature (Hampel et al., 1986; Huber, 1981), and plug-in estimators for B-robust functionals are considered to be resistant to outliers and changes in the input.
3. Lower Bounds
We begin by establishing lower bounds on the convergence rate of any differentially private approximation to a statistical functional T (F).
3.1. Lower Bounds based on Gross Error Sensitivity
We first show a lower bound on the error of any (α, δ)-differentially private approximation to T in terms of the gross error sensitivity of T at a distribution F.
Theorem 1
Pick any
and
. Let
be the family of all distributions over
, and let
be any (α, δ)-differentially private algorithm. For all n ∈ ℕ and all F ∈
, there exists a radius
and a distribution G ∈
with dTV(F, G) = ≤ ρ, such that either
Several remarks are in order. First of all, the form of Theorem 1 is slightly unconventional in the sense that applies not to particular distributions, but to a set of distributions. In particular, the bound states that either the convergence rate of F is high, or the convergence rate of some G close to F is high. Observe that for a fixed distribution F, it is trivial to construct a differentially private approximation to T (F) that is accurate for F – ignore any sensitive input data, and simply output T (F). This algorithm provides a perfectly accurate estimate when the input is drawn from F, but performs poorly otherwise; thus any lower bound that applies to all differentially private algorithms will have a similar form. On the other hand, the differentially private estimators in Theorem 1 have few restrictions: they are only expected to be accurate for distributions lying in a small neighborhood of F, and may be extremely inaccurate in general.
Second, for fixed n, ρ is a function , which decreases to zero as n → ∞; provided GESρ(T, F) remains the same as ρ diminishes, the lower bound grows weaker with increasing n. The lower bound thus does not rule out the existence of consistent private estimators.
Finally, we observe from the proof of Theorem 1 that
need not be the family of all distributions over
; the theorem will still apply if for every F ∈
, and for all x ∈
, (1 − ρ)F + ρδx also lies in the family
; for example if
is the set of all discrete distributions over
.
While Theorem 1 is very general, we present below an example that illustrates an implication of the theorem.
Example 1
Let
= [0, a], and let
be the set of all discrete distributions over
. Let T (F) be the mean of F.
Cosnider a fixed F ∈
, and a fixed n. Let ρ = ρ(n) as in Theorem 1. For any F,
. It can be shown that for any G ∈
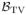 (F, ρ(n)), Var [G] ≤ Var [F] + ρ(1 − ρ)a2. Thus, the expected errors of the (non-private) plug-in estimators are bounded as
and
for all G ∈
(F, ρ(n)). On the other hand, Theorem 1 shows that for every differentially private estimator
, at least one of
(F, ρ(n)), Var [G] ≤ Var [F] + ρ(1 − ρ)a2. Thus, the expected errors of the (non-private) plug-in estimators are bounded as
and
for all G ∈
(F, ρ(n)). On the other hand, Theorem 1 shows that for every differentially private estimator
, at least one of
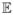 [|
(Fn) − T (F)|] and
[|
(Gn) − T (G)|] is Ω(ρa); this quantity is higher than the corresponding quantity for the non-private estimator so long as
.
[|
(Fn) − T (F)|] and
[|
(Gn) − T (G)|] is Ω(ρa); this quantity is higher than the corresponding quantity for the non-private estimator so long as
.
Proof of Theorem 1
Let x* be the x ∈
that maximizes |IFρ(x, T, F)|. Let γ > 0, and let
, and let G:= (1 − ρ)F + ρδx*. Observe that dTV(F, G) ≤ ρ and IFρ(x*, T, F) = (T (G) − T (F))/ρ.
Consider the following procedure for drawing n samples from G. First, draw a random sample Fn of size n from F (we overload the notation Fn to refer to both a random sample and its empirical distribution). Next, for each i = 1, 2, …, n, independently toss a biased coin with heads probability ρ; if the coin turns up heads, replace the i-th element of Fn by x*; otherwise, do nothing. This procedure constructs a random sample Gn of size n from G, and in the process constructs a coupling between samples of size n from F and G. In what follows, we will use this coupling to calculate the quantity
Let Fn be any randomly drawn sample of size n from F, and let Gn be a corresponding sample from G as drawn from the coupling procedure. Call a pair (Fn, Gn) ρ-close if they differ in at most n entries. As the median of Binomial(n, ρ) is ≤ ⌈ρn⌉ = ρn, the probability that at most ρn of the elements of Fn are converted to x* by the coupling process is at least 1/2.
In other words,
| (1) |
For any ρ-close pair (Fn, Gn), we can apply Lemma 31 with the parameters t:= T (F), t′:= T (G), γ:= 1/4, and
the lemma implies, for any ρ-close pair (Fn, Gn),
Therefore, conditioned on Fn, we have
by (1). Taking a final expectation over Fn ~ F,
The theorem follows.
3.2. Lower Bounds as a Function of Range
Is the bound in Theorem 1 tight? In other words, if T has bounded GES, can we compute accurate differentially private approximations to T (F) for all distributions F over a domain? We next show that at least for (α, 0)-differential privacy, Theorem 1 is not tight; if we wish to compute differentially private and accurate estimates of T (F) for all distributons F in a family, where T (F) can take any value in a range [λ, λ′], then the sample size must grow as a function of λ′ − λ.
Theorem 2
Let
be a family of distributions over
, and let
be any (α, 0)-differentially private algorithm. Suppose for all τ ∈ [λ, λ′], there exists some Fτ ∈
such that T(Fτ) = τ. Then there exists some F ∈
such that
Example 2
For any γ ∈ ℝ, let Uγ be the uniform distribution on [γ − 1, γ + 1], and let
be the family
= {Uγ: γ ∈ [−R, R]}. Let T (F) be the median of F. For every F ∈
, the non-private estimator T (Fn) converges to T (F) at a rate proportional to
, independent of R. However, Theorem 2 shows that for every differentially private estimator
, there is some F ∈
such that |
(Fn) − T (F)| grows with R.
Proof of Theorem 2
Let
and
. For each i = 1, 2, …, Γ, let Fi be a distribution in
such that
; such distributions are guaranteed to exist by assumption. Also, for each i = 1, 2, …, Γ, let
be an iid sample of size n from Fi, and define the half-open interval Ii:= [λ + (i −1)r, λ + ir). Observe that the intervals Ii are disjoint. To prove the theorem, let us assume the contrary:
| (2) |
This, along with a Markov’s inequality on , implies that . Therefore, for any i,
where the first step follows by assumption, the second step follows because the intervals {Ij} are disjoint, and the third step from Lemma 2 and the fact that for any i and j, any and differ in at most n entries. Rearranging, the inequality becomes Γ ≤ 1 + eαn, which is a contradiction since Γ = ⌊(λ′ − λ)/r⌋ > 1 + eαn. Therefore (2) cannot hold, so the theorem follows.
4. Upper Bounds
In this section, we show that bounded GES and bounded range are sufficient conditions for the existence of an (α, δ)-differentially private approximation to T. Our approximation uses the smooth-sensitivity method of Nissim et al. (2007), for which we provide a new statistical analysis in Section 4.1 (Theorem 3). We also provide a specific analysis for the case of linear functionals in Appendix B.
Let dH(D, D′) denote the Hamming distance between D and D′ (the number of entries in which D and D′ differ), and recall the following definitions from Nissim et al. (2007).
Definition 4
The local sensitivity of a function ϕ: ℝn → ℝ at a data set D ∈ ℝn, denoted by LS(ϕ, D), is
For β > 0, the β-smooth sensitivity of ϕ at D, denoted by SSβ(ϕ, D), is
Throughout, we assume D ∈ ℝn is an i.i.d. sample of size n drawn from a fixed distribution F, and Fn is the empirical CDF corresponding to this sample. For a statistical functional T, we use the overloaded notation SSβ(T, Fn) to denote the β-smooth sensitivity of T (Fn) at the data set Fn = D.
4.1. Estimator Based on Smooth Sensitivity
For a statistical functional T, let
be the randomized estimator given by
| (3) |
where
and Z is an independent random variable drawn from the standard Laplace density pZ (z) = 0.5e−|z|.
essentially computes T (Fn) and adds zero-mean noise, with the scale determined by the privacy parameters and the smooth sensitivity. Computing SSβ(α,
δ)(T, Fn) in general can be computationally challenging –see Nissim et al. (2007); our result thus demonstrates an upper bound.
The following guarantee is due to Nissim et al. (2007).
Proposition 1
is (α, δ)-differentially private.
To give a statistical guarantee for
, we begin with a standard tail bound based on the simple fact that PrZ [|Z| > t] ≤ e−t.
Proposition 2
For any t > 0,
It follows that the convergence rate of
depends on the β-smooth sensitivity of T at Fn, which can be bounded under the following conditions on T.
Condition 1 (Bounded range)
There exists a finite R > 0 such that the range of T is contained in an interval of length R.
Condition 2 (Bounded gross error sensitivity)
The sequence (Γn) given by
is bounded.
Even for non-private estimation, the robustness of an estimator depends not just on the influence functions at the target distribution F, but also on these quantities in a local neighborhood around F (Huber, 1981, p. 72). For convenience, Condition 2 is stated in terms of Glivenko-Cantelli distance, but can be easily changed to any distance under which Fn converges to F as n → ∞ with suitable modifications in the analysis.
We now state our main statistical guarantee for
.
Theorem 3
Assume Condition 1 and Condition 2 hold. Pick any η ∈ (0, 1/4). With probability ≥ 1–2η, the estimator
from (3) satisfies
where R is the quantity in Condition 1, and Γn is the quantity in Condition 2.
Proof
Follows from Proposition 2, Lemma 1, a union bound, and the triangle inequality.
The first term in the bound, |T (Fn) − T (F)|, is the error of the non-private plug-in estimate T (Fn). If T is Hadamard-differentiable, then T (Fn) − T (F) converges in distribution to a zero-mean normal random variable with variance n−1 ∫ IF(x, T, F)2dF (x); in this case, T (Fn) converges to T (F) at an asymptotic n−1/2 rate (Wasserman, 2006). Non-asymptotic rates can also be established in terms of other specific properties of T and F (see Appendix B for an example).
The second term in the bound from Theorem 3 is roughly the larger of
(for constant η), can be compared to the lower bounds from Section 3. The lower bound from Theorem 1 is close to A1 as long as GESρ(T, F) ≈ Γn for . This hold for sufficiently large n when limn→∞ Γn = GES(T, F). The lower bound from Theorem 2 decreases as R·exp(−Ω(αn)), which is a little better than A2, but is otherwise qualitatively similar in terms of its dependence on the range R2.
Example 3
If T (F) is the median of F, and
:= {Uγ: γ ∈ [−R, R]} is the family of uniform distributions on unit length intervals [γ − 1, γ + 1] from Example 2, then Γn = 1/2, and the bound in Theorem 3 reduces to
4.2. Bounding the Smooth Sensitivity
The proof of Theorem 3 (see Appendix C) is based on the following lemma, which establishes a high-probability bound on SSβ(T, Fn) under Conditions 1 and 2.
Lemma 1
Assume Condition 1 and Condition 2 hold. With probability ≥ 1 − η,
where R is the quantity in Condition 1, and Γn is the quantity in Condition 2.
5. Differentially-Private M-Estimation
We now provide a procedure for constructing differentially private approximations to M-estimators that satisfy certain conditions. Unlike our estimators in Section 4.1, these estimators are computationally efficient; however they only apply to a more restricted class of estimators.
5.1. M-Estimators
An M-estimator Tψ(Fn) is given as the solution θn ∈ ℝ to the equation
for some function ψ: ℝ × ℝ → ℝ. For a CDF G and θ ∈ ℝ, define
so Ψ (Fn, Tψ(Fn)) = 0. The derivative of Ψ with respect to its second argument, which is assumed to exist, is denoted by Ψ′. Throughout, we will assume ψ satisfies the following condition.
Condition 3 (Bounded ψ-range and monotonicity)
There exists a finite K > 0 such that the range of ψ is contained in [−K, K], and ψ is non-decreasing in its second argument.
Under this condition, the gross error sensitivity of Tψ at F can be bounded as
| (4) |
Previous works (Chaudhuri et al., 2011) and (Rubinstein et al., 2009) have provided differentially private and computationally efficient algorithms for M-estimation under assumptions that are very similar to Condition 3. The algorithm in Rubinstein et al. (2009), and one of the algorithms in Chaudhuri et al. (2011) are based on the sensitivity method, while the main algorithm in Chaudhuri et al. (2011) is based on an objective perturbation method. While both algorithms are computationally efficient, both require explicit regularization. This is problematic in practice because determining the regularization parameter privately through differentially-private parameter-tuning requires extra data – for a more detailed discussion of this issue, see Chaudhuri et al. (2011). In contrast, our algorithm is based on the Exponential Mechanism, and does not have an explicit regularization parameter; instead we assume that Ψ′ is smooth, and our guarantees depend on the value of the derivative Ψ′ (F, Tψ(F)).
5.2. Exponential Mechanism for M-Estimation
Fix a density μ on ℝ, and let
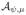 be the randomized estimator whose output has probability density
be the randomized estimator whose output has probability density
This estimator is derived from the exponential mechanism of McSherry & Talwar (2007), where the “cost” function is taken to be |Ψ(Fn, ·)|/K. In many M -estimators of interest, particularly those involving data lying in a bounded range, a prior knowledge of K is reasonable.
If it is known that Tψ (F) is contained in some interval, then one can take the prior density μ to be uniform over this interval. If no such prior knowledge is available, then μ can be taken to be a density with full support on ℝ such as the standard Cauchy density.
The privacy guarantee for
follows easily from known properties of the exponential mechanism (McSherry & Talwar, 2007).
Proposition 3
is (α, 0)-differentially private.
The accuracy guarantee for
relies on the following smoothness condition on Ψ at F.
Condition 4 (Smoothness)
There exist r1 > 0, r2 > 0, Λ1 > 0, and Λ2 > 0 such that
whenever dGC(G, F) ≤ r1 and |θ − Tψ(F)| ≤ r2.
Also, for ε > 0 and η ∈ (0, 1), define Nε,η:=min n ∈ ℕ: PrFn~F [|Tψ (Fn) − Tψ (F)| > ε] ≤ η to be the minimum sample size such that, with probability ≥ 1 − η, the non-private estimator Tψ(Fn) lies within distance ε of Tψ(F).
Theorem 4
Assume Condition 3 and Condition 4 hold. Let ε1:= min{r1, |Ψ′(F, Tψ(F))|/(6Λ1)}, ε2:= min{r2/2, |Ψ′(F, Tψ(F))|/(6Λ2)}, and Γ:= K/|Ψ′(F, Tψ(F))|. Pick any η ∈ (0, 1) and ε ∈ (0, ε2). Suppose
| (5) |
and one of the following holds:
- the range of Tψ is contained in an interval I of length R, μ is the uniform density on I, and
- is the standard Cauchy density, and
With probability at least 1 – 3η, the estimator
satisfies
The proof of Theorem 4 is in Appendix D. The condition in (5) required by Theorem 4 essentially states that the sample size n should be large enough for Fn and Tψ(Fn) to be in the neighborhoods of F and Tψ(F), respectively, where Ψ′ is locally Lipschitz-smooth.
It is straightforward to generalize the results to other prior densities μ. Observe that in the case the range of Tψ is [−R, R] for some unknown R, using the standard Cauchy density as μ yields a similar dependence on R (via log |Tψ(F)| ≤ log R) as what is obtained when μ is uniform over [−R, R]. The more probability mass μ assigns around Tψ(F), the better the bounds are.
Also note that the main scaling factor of Γ = K/|Ψ′(F, Tψ(F))| in the sample size bound is precisely the bound on GES(Tψ, F) from (4). A dependence on GES(Tψ, F) is to be expected as per Theorem 1.
6. Conclusions
The finite sample analysis reveals a concrete connection between differential privacy and robust statistics, The main results shown here suggest using B-robustness as a criterion for designing differentially-private statistical estimators, and also highlight the obstacles that even robust estimators face when the parameter space is very large or unbounded.
While our lower bounds may seem pessimistic, they apply to estimators that succeed for a wide class of distributions. One way of avoiding our lower bounds would be by using priors that allow an estimator to perform well on some input distributions but not-so-well on others; a future research direction is to investigate how this can help design better differentially private estimators.
Acknowledgments
KC would like to thank NIH U54 HL108460 for research support.
A. Lemmas from Section 3
Lemma 2
Let
be any (α, δ)-differentially private algorithm, and let D ∈
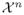 and D′ ∈
be two data sets which differ by ≤ k entries. Then, for any S,
and D′ ∈
be two data sets which differ by ≤ k entries. Then, for any S,
Proof
Let D = D0, D1, …, Dk = D′ be a sequence of data sets such that for any i, Di differs from Di+1 by a single entry. From Definition 1, for any S,
| (6) |
Composing Equation (6) k times, we get:
The lemma follows from noting that .
Lemma 3
Let D ∈
and D′ ∈
be two datasets that differ in the value of at most Δ entries, and let
be any (α, δ)-differentially private algorithm. For all
, and for all τ and τ′, if
, and if
, then
Proof
Without loss of generality, assume that: τ < τ′ and let . Let I = (τ − t, τ + t), and I′ = (τ′ − t, τ′ + t). Then I and I′ are disjoint. We first show that under the conditions of the lemma,
| (7) |
Suppose this is not the case. Then,
Here, the first step follows by assumption, the second step follows from the disjointedness of I and I′, the third step from Lemma 2, and the fourth step by assumption and the condition on δ. Now, as , the quantity on the right hand side of the above equation is at least
for . This is a contradiction, and thus Equation 7 holds. Using Equation 7, we can write:
The lemma now follows from the observation that .
B. Linear Functionals
A functional Ta of the form Ta(F) = ∫ a(x)dF (x) is called a linear functional. The influence function (at all scales ρ) of Ta and F is
and therefore the gross error sensitivity is
Note that the range of Ta has diameter bounded by (twice) the gross error sensitivity.
The estimator
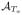 from (3) with δ = 0 (so β(α, 0) = 0) has the following statistical guarantee.
from (3) with δ = 0 (so β(α, 0) = 0) has the following statistical guarantee.
Theorem 5
Pick any linear functional Ta and η ∈ (0, 1). Let σ2 := ∫IF(x, Ta, F)2dF (x). With probability ≥ 1 − 2η, the estimator
from (3) satisfies
Proof
Follows from Bernstein’s inequality, Proposition 2, Lemma 4 (below), a union bound, and the triangle inequality.
Example 4
If T (F) = ∫xdF(x) is the mean of F (and therefore a linear functional with a(x) = x), and the data domain is
= [−R/2, R/2], then Γn = R. Therefore, the bound in Theorem 5 reduces to
where σ2 is the variance of F.
Lemma 4
If Ta is a linear functional, then
Proof
Observe that
, where the first supremum is over empirical distributions Gn and
for data sets differing in one entry. By the triangle inequality, this is at most 2 supx
∈
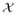 |a(x) − T (F)|/n = 2GES(Ta, F)/n.
|a(x) − T (F)|/n = 2GES(Ta, F)/n.
C. Proof of Lemma 1
Proof
Recall that the DKW inequality (Dvoretzky et al., 1956; Massart, 1990) implies PrFn~F [dGC(Fn, F) ≤ rn] ≥ 1 − η for . Since , the triangle inequality and Condition 2 imply that, with probability ≥ 1 − η,
| (8) |
for all CDF G with dGC(Fn, G) ≤ rn. Henceforth assume the bound in (8) holds.
Now pick any D1 ∈ ℝn. It suffices to show that e−βdH(D,D1). LS(T, D1) ≤ max{2Γn/n, R exp(−β(n · rn − 1))} for all such D1.
Suppose for now that (dH(D, D1) + 1)/n ≤ rn. Fix D2 ∈ ℝn such that dH(D1, D2) = 1. Let j ∈ {1, 2, …, n} be the index at which D1 and D2 differ, and D3 ∈ ℝn−1 be the database obtained from D1 by removing the j-th entry of D1. Finally, for i ∈ {1, 2, 3}, let Gi be the empirical CDF w.r.t. Di. By the triangle inequality, dGC(Fn, G3) ≤ dGC(Fn, G1) + dGC(G1, G3) ≤ (dH(D, D1)+1)/n ≤ rn. Therefore the bound in (8) implies GES1/n(T, G3) ≤ Γn. Let x1 be the j-th entry of D1, and x2 be the j-th entry of D2. Then, by the definitions of IF1/n and GES1/n,
Because this holds for all choices of D2, it follows that LS(T, D1) ≤ 2Γn/n, and therefore e−βdH(D, D1). LS(T, D1) ≤ 2Γn/n.
Now suppose instead that (dH(D, D1) + 1)/n > rn. By Condition 1, LS(T, D1) ≤ R. Therefore, we have e−βdH(D, D1). LS(T, D1) ≤ R · e−β(n·rn−1).
D. Proof of Theorem 4
The proof of Theorem 4 is based on the following lemmas, which characterize the prior density μ and the exponential mechanism density p
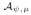 (Fn) around Tψ(F) and Tψ(Fn).
(Fn) around Tψ(F) and Tψ(Fn).
Lemma 5
Let μ be the uniform density on an interval I ⊂ ℝ of length R. If θ ∈ I, then μ([θ − ε, θ+ ε]) ≥ ε/R for any ε > 0.
Proof
If θ ∈ I, then the length of I ∩ [θ − ε, θ+ ε] is at least ε, and hence has mass at least ε/R under μ.
Lemma 6
Let μ be the standard Cauchy density . For any θ ∈ ℝ, for any ε > 0.
Proof
By Taylor’s theorem and the fact (a + b)2 ≤ 2(a2 + b2),
Lemma 7
Assume Condition 3 and Condition 4 hold. For 0 < ε ≤ min{r2/2,|Ψ′ (F, θ*)|/(6Λ2)},
where θ* = Tψ (F), θn = Tψ(Fn), cμ,ε = μ([θn − ε/6, θn + ε/6]), and Egood is the event in which
Proof
Define
By the monotonicity of Ψ due to Condition 3, we have |Ψ (Fn, θ)| ≥ sbad for all θ ∉ [θn − ε, θn + ε]. Also, define
Then,
Therefore, it remains to show that sbad − sgood ≥ 0.25|Ψ′ (F, θ*)|ε assuming the event Egood holds.
Pick any θ ∈ [θn − ε, θn + ε]. By Taylor’s theorem and the fact Ψ(Fn, θn) = 0, there exists some θ̃ ∈ [θn − ε, θn + ε] such that
| (9) |
Since ε ≤ min{r2/2, |Ψ′(F, θ*)|/(6Λ2)}, the triangle inequality and the event Egood imply
and therefore
| (10) |
by Condition 4. Because the event Egood also implies dGC(Fn, F) ≤ min{r1, |Ψ′(F, θ*)|/(6Λ1)}, we have
| (11) |
also by Condition 4. Therefore, using the triangle inequality and those from (10) and (11) in the equation (9) gives the bound
| (12) |
and, similarly,
| (13) |
Note that (12) implies the lower-bound
It remains to derive an upper-bound on sgood. Define θ0 := inf{θ ∈ ℝ: Ψ(Fn, θ) ≥ − |Ψ′(F, θ*)|ε/4} and θ1 := sup{θ ∈ ℝ: Ψ(Fn, θ) ≤ |Ψ′(F, θ*)|ε/4}. By monotonicity of Ψ from Condition 3, we have that if,
then θ ∈ [θ0, θ1], and vice versa. Now take any θ ∈ [θn − ε/6, θn + ε/6]. Note that by (12),
so θ ≥ θ0, and by (13),
so θ ≤ θ1. Therefore [θn − ε/6, θn + ε/6] ⊆ [θ0, θ1], and hence sgood ≤ 0.25|Ψ′(F, θ*)| ε. The claim is proved by combining the bounds on sbad and sgood.
We now prove Theorem 4.
Proof of Theorem 4
Let Egood be the event in which
By the DKW inequality, the definition of Nε2,η, the bound on the sample size n, and a union bound, we have
By Lemma 7, conditioned on the event Egood, we have
where we have used either Lemma 5 or Lemma 6 (with the fact |Tψ(Fn) −Tψ(F)| ≤ ε2 in the event Egood) and the bound on the sample size n. A union bound and the triangle inequality completes the proof.
E. Alternative to Condition 2
Consider the following alternative to Condition 2.
Condition 5 (Bounded gross error sensitivity with exponent p)
The sequence (Γp,n) given by
is bounded for some p ∈ [0, 1/2].
Condition 2 (roughly) corresponds to exponent p = 1/2, which is the weakest condition among all p ∈ [0, 1/2].
By essentially the same proof as that of Lemma 1, it follows that under Condition 1 and Condition 5, we have with probability ≥ 1 − η,
Using this in place of Lemma 1, the bound in Theorem 3 becomes
Footnotes
See Appendix A for omitted lemmas.
Appendix E shows how this discrepancy can be reduced with a stronger condition.
Appearing in Proceedings of the 29 th International Conference on Machine Learning, Edinburgh, Scotland, UK, 2012.
Contributor Information
Kamalika Chaudhuri, Email: kamalika@cs.ucsd.edu, University of California, San Diego, La Jolla, CA 92093.
Daniel Hsu, Email: dahsu@microsoft.com, Microsoft Research, New England, Cambridge, MA 02142.
References
- Barak B, Chaudhuri K, Dwork C, Kale S, Mc-Sherry F, Talwar K. Privacy, accuracy, and consistency too: a holistic solution to contingency table release. PODS. 2007 [Google Scholar]
- Blum A, Dwork C, McSherry F, Nissim K. Practical privacy: the SuLQ framework. PODS. 2005 [Google Scholar]
- Chaudhuri K, Hsu D. Sample complexity bounds for differentially private learning. COLT. 2011 [PMC free article] [PubMed] [Google Scholar]
- Chaudhuri K, Monteleoni C, Sarwate A. Differentially private empirical risk minimization. Journal of Machine Learning Research. 2011 [PMC free article] [PubMed] [Google Scholar]
- Dvoretzky A, Kiefer J, Wolfowitz J. Asymptotic minimax character of the sample distribution function and of the classical multinomial estimator. Annals of Mathematical Statistics. 1956;27(3):642–669. [Google Scholar]
- Dwork C, Lei J. Differential privacy and robust statistics. STOC. 2009 [Google Scholar]
- Dwork C, Kenthapadi K, McSherry F, Mironov I, Naor M. Our data, ourselves: Privacy via distributed noise generation. EUROCRYPT. 2006a [Google Scholar]
- Dwork C, McSherry F, Nissim K, Smith A. Calibrating noise to sensitivity in private data analysis. TCC. 2006b [Google Scholar]
- Friedman A, Schuster A. Data mining with differential privacy. KDD. 2010 [Google Scholar]
- Ganta SR, Kasiviswanathan SP, Smith A. Composition attacks and auxiliary information in data privacy. KDD. 2008 [Google Scholar]
- Hampel FR, Ronchetti EM, Rousseeuw PJ, Stahel WA. Robust Statistics - The Approach Based on Influence Functions. Wiley; 1986. [Google Scholar]
- Hardt M, Talwar K. On the geometry of differential privacy. STOC. 2010 [Google Scholar]
- Huber PJ. Robust Statistics. Wiley; 1981. [Google Scholar]
- Lei J. Differentially private M-estimators. NIPS. 2011 [Google Scholar]
- Massart P. The tight constant in the Dvoretzky-Kiefer-Wolfowitz inequality. Annals of Probability. 1990;18(3):1269–1283. [Google Scholar]
- McSherry F, Mironov I. Differentially private recommender systems: building privacy into the net. KDD. 2009 [Google Scholar]
- McSherry F, Talwar K. Mechanism design via differential privacy. FOCS. 2007 [Google Scholar]
- Mohammed N, Chen R, Fung BCM, Yu PS. Differentially private data release for data mining. KDD. 2011 [Google Scholar]
- Nissim K, Raskhodnikova S, Smith A. Smooth sensitivity and sampling in private data analysis. STOC. 2007 [Google Scholar]
- Rubinstein Benjamin IP, Bartlett Peter L, Huang Ling, Taft Nina. Learning in a large function space: Privacy-preserving mechanisms for svm learning. CoRR. 2009 abs/0911.5708. [Google Scholar]
- Smith A. Privacy-preserving statistical estimation with optimal convergence rates. STOC. 2011 [Google Scholar]
- Vu D, Slavkovic A. Differential privacy for clinical trial data: Preliminary evaluations. Data Mining Workshops, ICDMW; 2009. [Google Scholar]
- Wasserman L. All of non-parametric statistics. Springer; 2006. [Google Scholar]