

Abstract
Our conceptual model demonstrates our goal to investigate the impact of clinical decision support (CDS) utilization on cancer screening improvement strategies in the community health care (CHC) setting. We employed a dual modeling technique using both statistical and computational modeling to evaluate impact. Our statistical model used the Spearman’s Rho test to evaluate the strength of relationship between our proximal outcome measures (CDS utilization) against our distal outcome measure (provider self-reported cancer screening improvement). Our computational model relied on network evolution theory and made use of a tool called Construct-TM to model the use of CDS measured by the rate of organizational learning. We employed the use of previously collected survey data from community health centers Cancer Health Disparities Collaborative (HDCC). Our intent is to demonstrate the added valued gained by using a computational modeling tool in conjunction with a statistical analysis when evaluating the impact a health information technology, in the form of CDS, on health care quality process outcomes such as facility-level screening improvement. Significant simulated disparities in organizational learning over time were observed between community health centers beginning the simulation with high and low clinical decision support capability.
Keywords: Computational, Simulation, Modeling, Community health center, Systems-thinking, Construct-TM, Cancer screening, Network Theory
1. Introduction
According to the National Cancer Institute (NCI), an estimated 1,660,290 people in the United States were diagnosed with cancer in 2013, and, of these, 580,350 are expected to die of cancer [1]. Current estimates as to the number of these deaths that could have been avoided through screening vary from 3% to 35% depending upon assumptions regarding disease progression, prognosis, and environmental and lifestyle factors [2]. Three types of cancer screening—(1) the Pap test for cervical, (2) the mammography for breast, and (3) a battery of tests for colorectal cancer screening—have been found to detect cancer in its early stages and improve survival rates [3–11]. In spite of increased screening rates, Rutten et al. report that colorectal cancer screening rates found in their research lagged behind both Pap tests and mammography screenings [12]. Colorectal cancer screening performance rates are based on national guidelines and evidence-based best practices [3, 5, 13]. The American Cancer Society and the U.S. Preventive Services Task Force recommend that people over Age 50 be screened for colorectal cancer, that women over Age 40 receive annual mammograms, and that women be administered a Pap test at two-year intervals beginning either at the onset of sexual activity or at Age 21 [4, 14]. Although guidelines for the Pap test have been available since 1997, barriers to screening remain [12].
Several strategies to improve systems-level cancer screening rates employ evidenced-based practices (EBP) [15]. Clinical decision support (CDS) has been particularly effective in achieving greater levels of health care EBP. In randomized controlled trials, 90% of clinician-directed CDS interventions display significantly improved patient care [15, 16]. However, few studies exist that show the impact of clinical decision support and information system (IS) applications—designed specifically to aid in meeting EBP guidelines and performance benchmarks—on community health center (CHC) colorectal, breast, and cervical cancer screening practices [17].
According to the February 2010 Patient Protection and the Affordable Care Act, CHC’s play a critical role in providing quality care in underserved areas and to vulnerable populations [18]. About 1,250 CHC’s currently provide care to 20 million people at more than 7,900 service-delivery sites, with an emphasis on preventive and primary care [18, 19]. At least one CHC is located in every U.S. state, the District of Columbia, Puerto Rico, the U.S. Virgin Islands, and the Pacific Basin [19]. Slightly more than half, or 52%, of these centers serve rural America, with the remainder serving urban communities [19]. Over 45% of CHC patients participate in Medicaid, Medicare, CHIP (Child Health Insurance Protection), or some other form of public insurance, and nearly 40% are uninsured [19].
The Health Disparities Cancer Collaborative (HDCC) was a quality-improvement program designed to increase the cancer control activities of screening and follow-up among underserved populations. It operated from 2003 to 2005 among CHC’s supported by the Health Resources and Services Administration (HRSA) and National Cancer Institute (NCI) to serve financially, functionally, and culturally vulnerable populations [20, 21].
A sampling of 44 CHC’s were chosen to examine organizational structure, level of implementation of Chronic Care Model components, and contextual factors (e.g., teamwork and leadership) [22, 23]. The 2006 HDCC survey administered to community health centers captured organizational factors, patient characteristics, and provider characteristics that affected cancer screening quality outcomes. The survey respondent categories included (1) director (CEO) role, (2) chief financial officer (CFO) role, (3) provider (physicians, nurses) role, (4) general staff (e.g., lab, pharmacy, etc.) role, and (5) informatics officer (CIO) role. Topics such as clinic processes, management strategies, community outreach, information systems, leadership, and teams were explored. In an earlier study [24], we identified 99 unique questions and grouped them into 37 summary measures based on internal advisory team and subject matter expert recommendations. We calculated a consensus score for each of the 44 community health centers on each summary measure. The conceptual model—a modified Zapka framework henceforth referred to as the Zapka et al. framework [25–27]—outlines the complete list of summary measures, their respective categories (e.g., organizational, patient, or provider), and the overall study design (see Figure 1).
Figure 1. Conceptual Model.

Phase 1 – Tested Presence & Level of Use of CDS in Community Health Center (Statistical Model)*
Phase 2 – Tested Impact of CDS on Cancer Screening (Statistical Model)
Phase 3 – Computational Model of Phase 2 and other network factors impacting6 Cancer Screening Virtual Experience**
*results of Phase 1 published in separate manuscript
**Phase 3 published in two separate manuscripts
We employed two types of modeling in this secondary analysis of the NCI/HRSA HDCC survey data. Through empirical statistical modeling, the impact of clinical decision support use on cancer screening quality outcomes was examined reflected in the relationship between our proximal and distal outcomes. Then, computational modeling was used to examine the same phenomenon over a ten-year simulated period and generate hypotheses about CHC cancer screening behaviors in presence of CDS.
2. Rationale for a Dual Modeling Approach
Since the American health care system is layered, “build[ing] a research foundation that acknowledges this multilayer world” [28] is essential, and traditional modeling methods may fail to adequately capture its complexity. Further, practices inconsistent with evidence persist since evidence-based innovations are not readily accepted, and new technologies require 17 years on average to become widely adopted [28].
Recognizing these limitations, the National Cancer Institute and the Institute of Medicine are now encouraging a systems-thinking approach, which the NIH’s Office of Behavioral and Social Sciences Research (OBSSR) defines as follows:
Systems-thinking (systems-science) is an analytical approach that addresses a system and its associated external context as a whole that cannot be analyzed solely through reduction of the system to its component parts. Systems science methodologies provide a way to address complex problems, while taking into account the big picture and context of such problems. These methods enable investigators to examine the dynamic interrelationships of variables at multiple levels of analysis (e.g., from cells to society) simultaneously (often through causal feedback processes), while also studying the impact on the behavior of the system as a whole over time [29].
One methodology available for investigating and analyzing complex systems is computational modeling, which employs computer-based simulations, probabilistic models of systems or processes that emulate and so predict real-world behavior under varying assumptions and conditions. Simulation analyses provide a basis for developing hypotheses which can then be tested in actual intervention studies and/or technology implementations [30]. Computational modeling is becoming an increasingly trusted tool for analyzing complex, dynamic, adaptive, and nonlinear processes. By permitting investigation of their functioning, it addresses questions that traditional statistical methods alone cannot.
Groups, teams, organizations, and organizational command and control architectures [30] comprise one type of system to which computational modeling is being applied in order to discover new concepts, theories, and knowledge about them. Group or team behavior emerges from interactions within and between the agents or entities which comprise it. Not only humans but also objects, locations, methods, knowledge, and motivations may be considered as agents or entities making up such a system. Identifying key factors that contribute in varying degrees toward both individual and group-level actions is an important objective of such exploration [30].
In this study, a single point-in-time HDCC survey of CHC cancer screening practices was considered insufficient evidence to demonstrate the extent to which (1) the utilization of CDS impacts facility-level cancer screening improvement and (2) the 37 summary measures (i.e., organizational and/or practice factors, patient characteristics, and provider characteristics), singly and/or in interaction, contribute to continued CDS utilization over time. Therefore, we selected computational modeling to incorporate systems-thinking into this study.
The computational model’s main performance measures are the rates at which knowledge is acquired and at which learning subsequent to the acquisition of knowledge occurs. These learning rates are evidenced by (1) by the level of efficiency the model’s agents (organizations, roles, or objects) demonstrate in performing cancer-screening-specific tasks following the introduction of CDS and (2) the extent to which these agents utilize a set of defined knowledge resources designated as critical to overall community health center (CHC) cancer screening performance. Within the computational analysis portion of this study, CHC cancer-screening performance can be viewed as a function of task performance and knowledge absorption over time and will be referred to as delta k (Δk).
3. Methodology
3.1. Statistical Model: Assessing the Impact of CDS on Cancer Screening in Community Health Centers
Each community health center received a composite score on each of the 37 summary measures describing the community health center cancer screening practices (e.g., organizational and/or practice setting, provider characteristics, and patient characteristics). All of these 37 measures were used to describe overall CHC organizational behavior and also informed the construction of our “virtual” CHC used in the computational modeling section. The two outcome measures were used to determine the health center relative performance rankings ranging from high to low on each measure. Each health center was ranked based on the number of CDS components the facility had in use at the time of the survey, ranging from 0 to 4 for having none, one, two, three, or all four of the CDS components, respectively (e.g., (1) capacity of information systems to measure cancer screening, (2) use of provider prompts at point-of-care, (3) use of clinical reminders, and (4) ability to generate electronic correspondence to patients). In our model CDS “performance” was directly related to the CDS score. The facilities were also be ranked based on their performance for the 12-month provider self-reported cancer screening improvement scores from 0 to 3, where “0” represented self-reported improvement in none of the areas of breast, cervical, and colorectal cancer; “1” represented self-reported improvement in only one of those areas; on up to having provider self-reported improvement in all three areas. In our model cancer screening “performance” was also directly related to this score. The computational modeling exercise made use of these same two rankings to form a performance matrix and grouped the 44 CHC’s into categories of high performers vs. low performers. This portion of the study will be discussed in detail in the computational modeling methods section below.
3.1.1. Independent Measures
Four separate types of CDS were used in the study in the design a single composite construct to represent community health center activity. The first variable was labeled as the Capacity for Measuring Cancer Screening through CDS. Respondents indicated (yes/no) whether their health center’s computer system had the capacity to measure cancer-screening activities. Cancer Screening Activity was operationally defined in the survey to include providing timely notification of screening results, timely completion of additional diagnostic testing after abnormal screening results, a timely beginning of treatment, and documenting discussions about cancer screening [31]. A second and third independent variable measured (yes/no) whether provider prompts were used at the point-of-care and whether (yes/no) computerized patient reminders were in use at their health center, respectively. A fourth independent variable measured (yes/no) whether their facility could generate correspondence through the information system that reports cancer screening results to patients.
Consistent with the Chronic Care Model, the first three of the four components of the composite independent variable were labeled as clinical decision support (CDS) activity, and the fourth of these dependent variables was considered information systems (IS) activity. We used CDS to represent the composite construct of CDS/IS as defined by the Chronic Care Model. A score of “0” or “1” was assigned to each of the four CDS component independent variables for each facility. Each community health center was then given a composite score for overall CDS level of use ranging from 0 to 4 for having none, one, two, three, or all four CDS present in their health center.
3.1.2. Dependent Measures
Each community health center responded to the survey item asking providers if their facility had achieved cancer screening improvement over the preceding 12-month period in their facility-level colorectal, breast, and/or cervical cancer screening. The 12-month cancer screening improvement composite score/ranking (0 to 3) represents improvement in no area, only one area (breast, cervical, or colorectal cancer screening), two areas, or all three areas targeted in the Community Health Center Health Disparities Cancer Collaborative.
3.1.3. Modeling Approach
Spearman’s Rho Coefficient was employed to test association for CDS intensity-of-use and 12-month cancer screening improvement scores. This correlation is designed to test the strength of relationship between CDS use and cancer screening self-reported improvement. This measures the relative unit increase in CDS use ranking/scores and that of cancer screening improvement ranking/scores. Spearman’s Rho Correlation Coefficient reveals direction and strength of the relationship. Assuming a 0.05 significance level and 44 observations, a bivariate correlation of .41 will result in a power of .80 for testing the bivariate association between CDS intensity-of-use on cancer screening performance within health centers.
3.1.4. Statistical Model Results
At ρ = −0.103, the calculated Spearman’s rank correlation coefficient between ranked facility-level number of CDS components and self-reported 12-month cancer screening improvement scores for colorectal, breast, and/or cervical cancer screenings was not statistically significant (p = 0.513) as seen in Table 1. Therefore, no measurable association between CDS level of use and cancer screening improvement within the CHC setting was assumed.
Table 1.
Statistical Model Results of Impact
| Spearman Correlation Coefficients Prob > |r| under H0: Rho=0 Number of Observations | ||
|---|---|---|
| YCDS | YCSI | |
|
| ||
| YCDS | 1.00000 | −0.10347 |
| Community Health Center CDS Use Ranking | p=0.5143 | |
| Scores (0 to 4) | 44 | 42 |
|
| ||
| YCSI | −0.10347 | 1.00000 |
| “Community Health Center Provider Self-Reported Cancer Screening Improvement | p=0.5143 | |
| Rankings (0 to 3) | 42 | 42 |
3.2. Computational Model: Assessing the Impact of CDS on Cancer Screening in Community Health Centers as a function of learning rates by performance levels
3.2.1. Rationale for Using Construct-TM to Model Community Health Center Cancer Screening Performance
The phase of the study presented herein was a further exploratory analysis designed to discover hidden relationships and generate hypotheses concerning the contributions of model antecedents—defined in the context of this phase of the study as agents, tasks, knowledge, or beliefs—on community health center CDS intensity–of–use and cancer screening practices. It employed a series of probabilistic simulations.
To conduct the simulations comprising the second phase of our study, we selected Construct-TM, a multi-agent computational model designed to simulate the co-evolution of agents and socio-cultural environments [32]. It was developed by Computational Analysis of Social and Organizational Systems (CASOS), and, like other CASOS applications, Construct-TM incorporates network theory [30, 33–36].
The TM in Construct-TM’s name references the model’s inclusion of transactive memory, the ability of model entities “to know and learn about other members of the group” [36]. Simulated “individuals and groups” within Construct-TM “interact to communicate, learn, and make decisions in a continuous cycle” as they do in real-world organizational structures. “Social, knowledge and belief networks co-evolve” through this process. Reflecting the transactive nature of real-world constructs, Construct-TM can therefore be described as “a multi-agent model of network evolution” [36].
Construct-TM is specifically designed “to capture dynamic behaviors in organizations with different cultural and technological configurations, as well as model groups and organizations as complex systems” [32]. Carley et al. explains that Construct-TM is useful in this kind of analysis “due to its ability to manipulate heterogeneity in information processing, capabilities, knowledge, and resources revealed organizational settings,” and in doing so Construct-TM is better able to capture “the variability in human, technological, and organizational factors” [32]. The CHC data obtained in the NCI/HRSA HDCC organizational survey results fit this description [31]. Further suiting it to the modeling of this data, Construct-TM employs as agents decision-making units representing several levels of analysis—individuals, tasks, groups, and firm–level [32]. This study employed a specified subset of Construct-TM capabilities and is intended as a demonstration or proof-of-concept in the eventual use of network evolution methodology in the areas of technology use and/or adoption, cancer-related outcomes research, and health information technology applications development.
According to Carley, Construct-TM can employ any or all of three models—(1) the standard interaction model, (2) the standard influence model, and (3) the standard belief model [37, 38]. This study relied heavily on the standard interaction model because summary measures such as senior leadership, clinical leadership, and team activities are assumed responsible for the CHC values, beliefs, and attitudes that modify agent behavior and contribute to the within-CHC exchange of knowledge on health center cancer screening performance, strategies, and priority areas. This study also extensively employed Construct-TM’s standard influence model because summary measures related to provider perceptions, cancer screening reporting behaviors, delivery system design, outside collaboration, and quality-improvement strategies are assumed to shape the extent to which an agent can be influenced by others within the health center environment. Since the summary measures provided limited knowledge of the derivation of belief weights and their respective alterations, use of the standard belief model was minimal.
In the model formulation, two principles were assumed to govern behavior of CHC agents. One was homophily, the degree to which they were drawn together by particular domains of expertise, activity, or set of organizational practices; this was viewed as a critically important driver of interaction in the simulated network. The principle of influenceability, the degree to which agents are influenced by others, was also seen as critical in shaping agents’ behavior over time within the simulated CHC environment.
Carney et al. describe the staging of the data for input into Construct-TM, as well as details on the modeling methods, task definitions, knowledge definitions, and performance level descriptive statistics [39]. The focus of this manuscript will be on the comparative results of the two types of modeling used in this dual modeling experimental design.
Each HDCC survey summary measure was converted into one of four representative Construct-TM categories (i.e., agent, task, knowledge, or belief) in a process not unlike that Effken et al. employed in their analysis using another CASOS tool developed by Carley et al. and called OrgAhead to map nursing quality categories (i.e., organizational characteristics, patient characteristics, patient outcomes, and patient unit characteristics) into the simulation tool [40, 41]. As such, each of the 37 HDCC survey summary measures in this study would be assigned an identity from among one of the following: a representation of knowledge, a task, an agent, or a belief. We used a subset of the 37 measures to more specifically represent the cancer screening test agent used in our simulation (as see in Table 3 below). This corresponding identity would consist of a set of formalized definitions and parameters governing its behavior throughout the simulation. These mappings were guided by the internal advisory team and subject matter experts.
This study design allows for multiple scenarios to be tested under varying and virtually limitless conditions. To generate new hypotheses about a given phenomenon, trial and error would seem to be an obvious but possibly fruitless approach. However, Carley et al. stress the value of the more dynamic hypothesis-generating methods made possible by computational models in building new concepts, theories, and knowledge about complex systems [30]. They postulate the existence of some simple but nonlinear process underlying individual, team, group, or organizational behavior [30] that computational modeling can reveal but that basic tests of statistical associations may not. Thus, applying a computational model to point-in-time survey data—not originally designed to inform network analysis—such as that used in this study allows analysis beyond the original intent motivating the survey and provides almost limitless possibilities for exploratory analysis.
3.2.2. The Computational Modeling Process
Our computational modeling process included two steps. The first involved grouping the community health centers based on the conceptual model’s two major outcomes—CDS community health center intensity–of–use (its chief proximal outcome) and facility-level breast, cervical, and colorectal cancer screening improvement (its chief distal outcome). The statistical model treated these as two separate measures and employed their rank correlation to measure the strength of their relationship. In that analysis, the correlation served as a proxy to measure overall impact of CDS on cancer screening improvement.
For use in the computational model, we assigned a composite performance level to each CHC based on its location in the graph shown below. The CDS intensity–of–use measure, ranging from 0 to 4, forms the matrix x-axis, and the cancer screening improvement score, which can range from 0 to 3, forms its y-axis. The resulting matrix was divided into high, medium, and low regions for each measure. A CHC could then be assigned a qualitative, two-part coordinate based on its position, and this coordinate formed the unit of analysis of the virtual CHC’s within Construct-TM. Figures 2 and 3 display the distribution and plot matrix of CHC’s within this qualitative measure, respectively.
Figure 2.
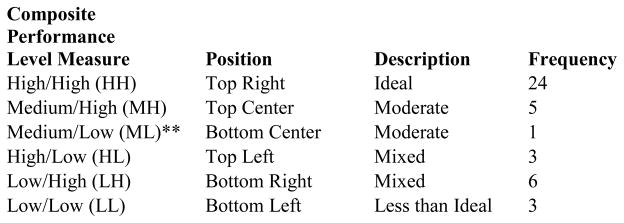
Basis of performance level assignment to community health centers
*No health centers were assigned to permutations not shown (e.g., HM, MM).
**Since only one health center occupied this level, Medium/Low was not included in the final analysis.
Figure 3.

HDCC performance level grid
In the second step, Construct-TM’s virtual health centers were parameterized using the normalized HDCC survey responses to each of the 37 summary measures (i.e., organizational, patient, and provider level factors). CHC behavior by performance level was determined by the survey questions’ possible values and their corresponding observed frequencies.
As previously mentioned we assigned each of the 37 summary measures to one or more of Construct-TM’s four categories—agent, task, knowledge element, and/or belief—from the HDCC survey respondents’ perspective or that of one of the defined agent classifications. Within the Construct-TM model, an agent is an entity to whom knowledge can be communicated. The following summary measures from the HDCC survey data were interpreted as knowledge communications to cancer screening agents: (1) work importance of cancer screening tests, (2) provider-level cancer screening rate reporting behavior, (3) facility-level cancer screening rate reporting behavior, (4) patient demographics-patient age, and (5) patient demographics-patient language. Table 2 lists variables from among our 37 summary measures, along with the key assumptions we used in our simulation to inform the “cancer screening test (CST) agent” classification. The selection of these variables to described agent behavior was done in conjunction with the internal research advisory team and subject matter experts informing the simulation design. The purpose of this study was to examine CST agent as it was projected to be influenced by CDS exclusively for comparison with our Spearman’s Rho test. Our companion manuscript highlighted the use of all five our agent classifications including provider perspective, administrator perspective, collaborator perspective, health information technology perspective, and CST perspective [39].
Table 2.
List of Cancer Screening Test Agent Variables and Assumptions
| Agent Categories | Task Knowledge Impacting Performance is Informed by: | Knowledge Absorption (Homophily Knowledge) is Informed by: | Rationale and/or Assumptions |
|---|---|---|---|
| Cancer Screening Test (CST) |
|
|
|
The final step was to complete the transformation of the HDCC survey data for input into Construct-TM. We created an Excel Spreadsheet Code Generator developed by programmers at CASOS to input our variables, assumptions, and definitions that were then automatically converted into Construct-TM XML coded input deck. Information input into the model in mathematical form consisted of (1) a glossary of the simulation’s variables, (2) agent, knowledge, and task definitions, (3) definitions of model nodes, to which simulation entities are assigned, and (4) types of networks to be used. For more details on this facet of the study please see our companion manuscript [39]
3.2.3. Computational Model Results: Ten-Year Performance of Cancer Screening Agent Simulation
Twenty-five runs were conducted on each of the five performance level groupings. The two-part performance levels, displayed in Figure 2, were derived from high, medium, and low levels of the two variables, CDS intensity–of–use and cancer screening improvement. The simulation’s measure of interest was the group cancer-screening agent’s rate of knowledge absorption over time, referred to as delta k (Δk). Figure 4a–e shows the results for each individual performance level and Figure 5 displays the group mean Δks calculated from 25 simulation runs over a 10-year period.
Figure 4.



Figure 4a–e: Performance Level Runs to test Knowledge Absorption of Cancer Screening Test Agents on CDS Tasks Only x 10yrs
Figure 5.

All CHC performance Level 10-year Comparison of Means
4. Dual Modeling Discussion
4.1. Statistical Model: On tests of statistical significance as a means of impact
Our statistical analysis did not demonstrate any significant association between facility-level rankings for intensity-of-use of CDS and the rankings of facility-level provider self-reported cancer screening improvement scores within health centers. This study’s finding was consistent with the mixed results of previous studies that did not always demonstrate a significant relationship between HIT of any kind and health outcomes in general, and cancer screening, in particular [42–44]. There may also be additional human, organizational, and/or socio-technical factors that confound the relationship between CDS and cancer screening [45] that were not measured in the current study. High-yield targets for future interventions or studies would include human factors analysis (e.g., computer interface issues), as well as facility, and/or provider-level incentive programs [46–48]. Our use of the computational modeling in tandem with this statistical analysis was intended to generate hypotheses and explore alternative ways of examining the same set of factors in explaining overall performance.
4.2. Computational Model: Viewing the Community Health Center as a Learning Organization
The virtual experiments that these simulation runs represented were intended to predict relative change of a CHC’s performance level of group knowledge absorption over time, termed its delta k (Δk). In the simulation, the cancer-screening agent’s Δk, evaluated with respect to the CDS task and its corresponding set of knowledge-exchange opportunities only, was captured at 520 intervals, representing weeks in a 10-year period. We hypothesized that the original scores used to designate high-performing CHC’s would be associated with relatively higher rates of knowledge absorption Δk than the scores designating low-performing firms over the 10-year period.
Previous studies identified metrics for organizational learning and described them in terms of clinical “know-how” [49], collective intuition [50], and overall organizational learning and/or organizational intelligence [51–54]. The findings derived from these simulations were consistent with previous studies that argued the following: (1) Organizations change over time; (2) a positive correlation exists between the rate of organizational learning and some measure of performance/success; (3) health information technology used in support of cancer outcomes should take into account the learning required to improve organizational capability; and (4) the health care facility should be viewed as a complex adaptive environment [51, 52].
4.3. Ten-Year Performance of Cancer-Screening Agent Simulation
The stark contrast in rate of knowledge absorption between high- and medium-CDS groups on the one hand and low-CDS groups on the other is demonstrated by the relative steepness in slope of the former’s averages charted over time. Further, the rate of knowledge absorption with respect to cancer screening improvement within the two clusters showed greater intra-cluster than inter-group consistency. Figure 5 reveals two clearly distinct knowledge-absorption performance subgroups—high-level performers (e.g., HH, MH, and HL) versus low-level ones (e.g., LL, LH).
Through task knowledge’s impact on performance, this simulation and succeeding analysis of its results examined the cancer-screening agent’s knowledge absorption when CDS was in use to support cancer-screening activities over the 10-year or 520-week period. Observing the 25-run, weekly average Δk of its cancer-screening agent for each of the five CHC performance levels simulated over a 10-year period revealed two major performance-level clusters with respect to knowledge absorption over time, or Δk. Specifically, these agents fell into sets of either high or low performers based solely on Δk over the 10-year period. This clustering effect was in addition to their original designations at the start of the simulation. The clustering observed at the simulation’s conclusion was based solely on Δk and represented a distinct difference in low and high performers with regard to this metric. Two observations regarding this clustering effect are noteworthy.
First, those firms ranking higher for CDS use at the simulation’s start belonged to the high-Δk cluster at its end, and firms marked lower at its start belonged to the low-Δk cluster at simulation end. Specifically, member firms ranked low in CDS utilization at simulation start and so classified as LL or LH were found to be members of the low-Δk performance cluster at simulation end. Members of the high-performing levels, rated as medium or high with respect to CDS utilization, were observed to be members of the high-Δk performance cluster at simulation end. The finding of a positive correlation between original performance level rankings with respect to CDS utilization and the 10-year Δk was consistent with previous findings that differentiated performance levels for HIT use in support of clinical outcomes into groups of high performing and low performing medical groups [55].
This clustering effect was also observed with regard to the second metric used in our initial classification by performance level—cancer screening improvement with respect to breast, cervical, and colorectal cancers. Within this category, opportunities for knowledge sharing, learning, and exchange also existed, and those CHC’s ranked higher in cancer screening self-reported improvement at simulation start also showed simulation-end clustering by level of knowledge-absorption proficiency Δk.
Second, not only was the amount of variation observed between the high- and the low-Δk clusters itself dramatic in its size, but there existed much more variability between the two clusters than was observed between the individual members of each cluster. In fact, the Δk’s of the high/high and high/low CHC’s were almost indistinguishable at the end of Year 10, and the medium/high CHC’s’ Δk’s were extremely close in size to theirs. In the low-Δk cluster, the low/low CHC’s presented at the bottom with the lowest 10-year Δk, and the CHC’s ranked low/high displayed only a slightly higher 10-year Δk. These findings were consistent with those observed in previous research where a positive correlation between the rate of organizational learning and some measure of performance/success was asserted [51].
These findings were consistent with studies that measured the concepts of organizational intelligence, intuition, and clinical “know-how,” all of which represent varying ways of measuring organizational learning over time [49, 50]. Specifically referencing clinical “know-how” and discussing its relationship to quality, efficiency, and safety in clinical care, Anderson et al. found that clinical decision support contributes to it positively [49]. A closely related concept is intuition. Salas et al. suggested that “decision-task” and “decision-environment” are part of an overall understanding of intuition within an organization [50].
This study used Δk as an overall measure of the virtual community health center clinical know-how and the related concept of intuition and as a metric of overall organizational learning over time. Defining a concrete measure consistent with clinical know-how and/or organizational intuition that would serve as their proxy in distinguishing high-learning organizations from low-learning ones over a 10-year period was this study’s intent. Thus, study results are consistent with the notion put forth by Feifer et al [51], that a correlation exists between the rate of learning, as measured in this simulation by Δk or rate of knowledge absorption, and performance, as measured by its proxies CDS use and cancer screening self-reported improvement scores for breast, cervical, and colorectal cancer. The value added-benefit of including a computational model to this study was (1) we were able to successfully simulate a correlation between the use of CDS and cancer screening performance where a statistical model showed no such correlation, (2) we successfully built this model on a point-in-time data source that represented a “snap shot” and project performance over an extended period of time, and (3) by projecting high vs. low performance into the future, we were able to identify parameter boundaries for each of these 37 summary measures to inform continued monitoring and tracking of performance meeting long-term health care quality objectives.
Conclusions
Combining statistical and computational models to create a dual modeling approach can be essential to defining critical associations with respect to clinical decision support outcomes and cancer screening improvement. This approach allows associations that can successfully predict high performance versus low performance over an extended period of time to be tested in a virtual environment. Riegelman et al. suggest that systems-thinking is understood by contrasting it with the traditional (i.e., statistical modeling) [56]. Although the computational modeling portion of the research can be considered as a hypothesis-generating exercise, it can also be viewed as a hypothesis test in its own right, where the hypothesis being tested was that measurable change in knowledge absorption Δk over time by performance level occurs with respect to cancer screening and CDS use. Since the model’s high-performing CHC’s exhibited a correspondingly higher rate of knowledge absorption over a simulated 10-year period than did low-performing ones, study results supported this hypothesis.
Despite varying evidence showing that CDS can have positive impacts on clinical and process performance measures our study was unable to duplicate this using statistical tests of correlation. However, in the construction of a “virtual experiment” using computational modeling methods, network theory, and simulation we were able to take the same data and examine the relationship in different way. We contextualized the variables of CDS and cancer screening on the basis of performance and learning as a means to more closely examine the potential impact of CDS on cancer screening behaviors. Our assumption was that the use of CDS should improve performance of the cancer screening task, and that such performance improvement should be measured in the rate of knowledge absorbed through the interactions among agents in the network. We successfully demonstrated through our computational models that the level use of CDS and its correlate cancer screening improvement score, indicated by performance level at the start of our simulation, were both highly associated with increased rates of learning. Thus, one critical hypothesis generated from our study is that impact studies of HIT such as CDS on clinical and organizational outcomes might be better observed in the context of agent learning (expressed as knowledge absorption) related to task performance. Our study contributes by providing evidence of the value of this dual modeling design.
Limitations
In terms of the statistical model we were challenged by the use of the provider self-reported cancer screening improvement scores as opposed to the actual facility-level cancer screening rates. Self-reported screening improvement may be subject to reporting bias. Prior research indicates that patient’s reports of cancer screening may overestimate the receipt of screening [57]. However, the question was asked here of all community health centers participating in the organizational survey, and thus, it is unlikely to be biased with respect to any particular factor tested in the statistical or computational models. Furthermore, primary care practices are subject to multiple performance measurement and quality improvement programs related to screening and prevention and so it is quite possible that the community health centers surveyed here have internal data to inform their answer to these questions. On the other hand, this organizational survey did not represent a quality improvement tool itself, and no financial incentives were delivered based upon the performance described in these self-reports. For this reason, there is no particular motivation for providers to inflate their reports of screening behavior. Prior studies of clinical vignettes have demonstrated that individual health care providers self-reported clinical behavior is commonly consistent with clinical practice as assessed by medical record review [58, 59].
In terms of computational model, limitations revolve around volume, model applicability, and validation. Any simulation benefits from rich, robust, and exhaustive data. Increases in data available to support assumptions translate into a more robust simulation model. The current study’s computational analysis had only 37 summary measures as primary inputs. Greater availability of data will benefit future research.
Because this study represented a tradeoff between model generalizability and applicability on the one hand and narrow focus on the cancer screening test agent on the other, choice of the set of summary measures used to define each agent’s behavior was rigorous and dramatically limited the number of ways in which the agent learned, interacted, and evolved within the simulation. Future research may employ less rigid criteria for inclusion of variables and/or a more sophisticated algorithm capable of testing all or any combination of variables.
Finally, the current study did not include external validation of the simulation model. Future studies designed solely to validate this network evolution model as a methodological framework that can be deployed on a larger scale are warranted.
Highlights.
We measure CDS impact on cancer screening using statistical and simulation models
Tests of statistical significance alone do not reveal dynamic changes over time
High performers for CDS use and cancer screening learn faster than low performers
Knowledge absorption rate provides a metric to quantify organizational learning
Computational modeling aids in the assessment of CDS impact on cancer screening
Acknowledgments
This research was supported by the Indiana University (IUPUI) School of Nursing Training in Research for Behavioral Oncology and Cancer Control Program (TRBOCC) - National Cancer Institute Pre-Doctoral Fellowship R25-CA117865-04
The manuscript development was supported by University of North Carolina Gillings School of Public Health and Lineberger Comprehensive Cancer Center Cancer Health Disparities Training Fellowship T32CA128582
Dr. Stephen H. Taplin and Dr. Stephen B. Clauser of the National Cancer Institute informed this research endeavor in many ways including support of the original survey administration, providing the foundation for this research agenda through their previous findings, and demonstrating a willingness to shape the future direction of this overall research project.
Geoffrey Morgan (Ph.D. Candidate) and Dr. Kathleen Carley of the Carnegie Mellon University, Computational Analysis of Social and Organizational Systems (CASOS), contributed greatly to development of the computational modeling portion of this research.
Footnotes
AUTHORS’ CONTRIBUTIONS
TJC and GM performed the computational analyses. TJC and GM interpreted the data and drafted the manuscript. TJC and GM conceived of the study and participated in its design and execution. TJC, AM, and JJ participated in the conceptual model development, design, and literature review. All authors read and approved the final manuscript. This work represents the opinion of the authors and cannot be construed to represent the opinion of the U.S. Federal Government.
STATEMENT OF CONFLICTS OF INTEREST
The authors declare that they have no conflicts of interests.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
Contributor Information
Timothy Jay Carney, Email: tcarney@.unc.edu.
Geoffrey P. Morgan, Email: gmorgan@cs.cmu.edu.
Josette Jones, Email: jofjones@iupui.edu.
Anna M. McDaniel, Email: amcdanie@iupui.edu.
Michael Weaver, Email: mtweaver@iupui.edu.
Bryan Weiner, Email: weiner@email.unc.edu.
David A. Haggstrom, Email: dahaggst@iupui.edu.
References
- 1.American Cancer, S. Cancer facts & figures. Cancer facts & figures. 2013 [Google Scholar]
- 2.U.S. National Institutes of Health, N.C.I.-N. Cancer Screening Overview. 2009 Mar; 2010]; Available from: http://www.cancer.gov/cancertopics/pdq/screening/overview/HealthProfessional.
- 3.U.S. Department of Health and Human Services: Healthy People 2010, H. Healthy People 2010 Objectives: Chapter Three Cancer. 1998 Available from: http://www.healthypeople.gov/Document/Html/Volume1/03Cancer.htm.
- 4.American Cancer Society, A.C.S. Cancer facts & figures. Cancer facts & figures. 2009 [Google Scholar]
- 5.Centers for Disease Control and Prevention, N.C.f.C.D.P.a.H.P., Division of Cancer Prevention and Control. Colorectal (Colon) Cancer: Fast Facts About Colorectal Cancer. 2009 Available from: http://www.cdc.gov/cancer/colorectal/basic_info/facts.htm.
- 6.Centers for Disease Control and Prevention, N.C.f.C.D.P.a.H.P., Division of Cancer Prevention and Control. The national breast and cervical cancer early detection program. 2005 Mar; 2010]; Available from: http://www.cdc.gov/cancer/nbccedp.
- 7.Müller AD, Sonnenberg A. Protection by endoscopy against death from colorectal cancer. A case-control study among veterans. Archives of internal medicine. 1995;155(16):1741–8. doi: 10.1001/archinte.1995.00430160065007. [DOI] [PubMed] [Google Scholar]
- 8.Newcomb PA, et al. Screening sigmoidoscopy and colorectal cancer mortality. Journal of the National Cancer Institute. 1992;84(20):1572–5. doi: 10.1093/jnci/84.20.1572. [DOI] [PubMed] [Google Scholar]
- 9.Selby JV, et al. A case-control study of screening sigmoidoscopy and mortality from colorectal cancer. The New England journal of medicine. 1992;326(10):653–7. doi: 10.1056/NEJM199203053261001. [DOI] [PubMed] [Google Scholar]
- 10.USPSTF, U.S.P.S.T.F. Guide to clinical preventive services: report of the US Preventive Services Task Force. Baltimore: Williams & Wilkins; 1996. [Google Scholar]
- 11.USPSTF, U.S.P.S.T.F. Screening for breast cancer: recommendations and rationale. Annals of internal medicine. 2002;137(5):344–6. doi: 10.7326/0003-4819-137-5_part_1-200209030-00011. [DOI] [PubMed] [Google Scholar]
- 12.Finney Rutten LJ, Nelson DE, Meissner HI. Examination of population-wide trends in barriers to cancer screening from a diffusion of innovation perspective (1987–2000) Preventive medicine. 2004;38(3):258. doi: 10.1016/j.ypmed.2003.10.011. [DOI] [PubMed] [Google Scholar]
- 13.Walsh JME, Terdiman JP. CLINICIAN’S CORNER - SCIENTIFIC REVIEW AND CLINICAL APPLICATIONS - Colorectal Cancer Screening: Clinical Applications. JAMA: the journal of the American Medical Association. 2003;289(10):1297. [Google Scholar]
- 14.Force, U.S.P.S.T. The guide to clinical preventive services: recommendations of the US Preventive Services Tack Force. Washington, D.C: Agency for Healthcare Research and Quality; 2006. [Google Scholar]
- 15.Kawamoto K, et al. A national clinical decision support infrastructure to enable the widespread and consistent practice of genomic and personalized medicine. BMC Medical Informatics and Decision Making. 2009:9. doi: 10.1186/1472-6947-9-17. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Osheroff JA, et al. A Roadmap for National Action on Clinical Decision Support. Journal of the American Medical Informatics Association: JAMIA. 2007;14(2):141. doi: 10.1197/jamia.M2334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Yano EM, et al. Primary Care Practice Organization Influences Colorectal Cancer Screening Performance. HEALTH SERVICES RESEARCH -CHICAGO- 2007;42(3):1130–1149. doi: 10.1111/j.1475-6773.2006.00643.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.House TW, editor. States, P.o.t.U. The President’s Proposal on Health Care Reform. Feb 22, 2010. p. 11. [Google Scholar]
- 19.HRSA, H.R.a.S.A; H.R.a.S.A. U.S. Department of Health and Human Services, Bureau of Primary Health Care, editor. Health Centers: America’s Primary Care Safety Net Reflections on Success, 2002–2007. Rockville, MD: Jun, 2008. [Google Scholar]
- 20.Harmon RG, Carlson RH. HRSA’s role in primary care and public health in the 1990s. Public health reports (Washington, DC: 1974) 1991;106(1) [PMC free article] [PubMed] [Google Scholar]
- 21.Iglehart JK. Spreading the safety net--obstacles to the expansion of community health centers. The New England journal of medicine. 2008;358(13):1321–3. doi: 10.1056/NEJMp0801332. [DOI] [PubMed] [Google Scholar]
- 22.Taplin SH, et al. Implementing Colorectal Cancer Screening in Community Health Centers: Addressing Cancer Health Disparities Through a Regional Cancer Collaborative. Medical care. 2008;46(9):S74–S83. doi: 10.1097/MLR.0b013e31817fdf68. [DOI] [PubMed] [Google Scholar]
- 23.Sperl-Hillen JM, et al. Do all components of the chronic care model contribute equally to quality improvement? Joint Commission journal on quality and safety. 2004;30(6):303–9. doi: 10.1016/s1549-3741(04)30034-1. [DOI] [PubMed] [Google Scholar]
- 24.Carney TJ, Weaver M, McDaniel AM, Jones J, Weiner B, Haggstrom DA. Organizational factors influencing the use of clinical decision support for improving cancer screening within community health centers. In Progress. 2013 [Google Scholar]
- 25.Zapka J. Innovative provider- and health system-directed approaches to improving colorectal cancer screening delivery. Medical care. 2008;46(9):62–7. doi: 10.1097/MLR.0b013e31817fdf57. [DOI] [PubMed] [Google Scholar]
- 26.Zapka JG, et al. Breast and cervical cancer screening: clinicians’ views on health plan guidelines and implementation efforts. Journal of the National Cancer Institute Monographs. 2005;35:46–54. doi: 10.1093/jncimonographs/lgi037. [DOI] [PubMed] [Google Scholar]
- 27.Zapka JG, et al. A framework for improving the quality of cancer care: the case of breast and cervical cancer screening. Cancer Epidemiol Biomarkers Prev. 2003;12:4–13. [PubMed] [Google Scholar]
- 28.Taplin SH, et al. Interfaces across the cancer continuum offer opportunities to improve the process of care. Journal of the National Cancer Institute Monographs. 2010;2010(40):104–10. doi: 10.1093/jncimonographs/lgq012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.NetLibrary I. Journal of organisational transformation & social change. 2009;1(1) 2003. [Google Scholar]
- 30.Carley KM. On Generating Hypotheses Using Computer Simulations. SYSTEMS ENGINEERING -NEW YORK- 1999;2:69–77. [Google Scholar]
- 31.Haggstrom DA, Clauser SB, Taplin SH. Implementation of the Chronic Care Model in the HRSA Health Disparities Cancer Collaborative. Presentation at Society of General Internal Medicine national meeting; 2008; Pittsburgh, PA.. [Google Scholar]
- 32.Schreiber C, et al. Construct - A Multi-Agent Network Model for the Co-Evolution of Agents and Socio-Cultural Environments. 2004 Available from: http://handle.dtic.mil/100.2/ADA460028.
- 33.Carley K c. International, and rd. Adaptive Organizations and Emergent Forms. 1998 [Google Scholar]
- 34.Carley KM, Carnegie-Mellon I Univ Pittsburgh Pa Inst Of Software Research. . A Dynamic Network Approach to the Assessment of Terrorist Groups and the Impact of Alternative Courses of Action. 2006 Available from: http://handle.dtic.mil/100.2/ADA477116.
- 35.Carley KM, et al. Toward an interoperable dynamic network analysis toolkit. 2007 [Google Scholar]
- 36.CASOS, C.f.C.A.o.S.a.O.S. Center for Computational Analysis of Social and Organizational Systems. 2009 Available from: http://www.casos.cs.cmu.edu/
- 37.Hirshman BR, et al. Specifying Agents in Construct. 2009 2007; Available from: http://handle.dtic.mil/100.2/ADA500804.
- 38.Schreiber C, et al. Construct - A Multi-Agent Network Model for the Co-Evolution of Agents and Socio-Cultural Environments. 2004 Available from: http://handle.dtic.mil/100.2/ADA460028.
- 39.Carney TJ, MGP, Jones J, McDaniel AM, Weaver M, Weiner B, Haggstrom DA. Examination of Network Characteristics of High vs. Low Performance Community Health Centers. 2013 In Progress. [Google Scholar]
- 40.Effken JA, et al. Using OrgAhead, a computational modeling program, to improve patient care unit safety and quality outcomes. International journal of medical informatics. 2005;74(7–8):7–8. doi: 10.1016/j.ijmedinf.2005.02.003. [DOI] [PubMed] [Google Scholar]
- 41.Effken JA, et al. Using computational modeling to transform nursing data into actionable information. Journal of biomedical informatics. 2003;36(4–5):351–361. doi: 10.1016/j.jbi.2003.09.018. [DOI] [PubMed] [Google Scholar]
- 42.Ferrante JM, et al. Principles of the patient-centered medical home and preventive services delivery. Annals of family medicine. 2010;8(2) doi: 10.1370/afm.1080. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Goins KV, et al. Implementation of systems strategies for breast and cervical cancer screening services in health maintenance organizations. The American journal of managed care. 2003;9(11):745–55. [PubMed] [Google Scholar]
- 44.Millery M, Kukafka R. Health Information Technology and Quality of Health Care: Strategies for Reducing Disparities in Underresourced Settings. Medical Care Research and Review. 2010;67(Supplement) doi: 10.1177/1077558710373769. [DOI] [PubMed] [Google Scholar]
- 45.Kilsdonk E, et al. Factors known to influence acceptance of clinical decision support systems. Studies in health technology and informatics. 2011;169:150–4. [PubMed] [Google Scholar]
- 46.Ketcham J, et al. Physician Clinical Information Technology and Health Care Disparities. Medical Care Research and Review. 2009;66(6):658–681. doi: 10.1177/1077558709338485. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Saleem J, et al. Provider Perceptions of Colorectal Cancer Screening Clinical Decision Support at Three Benchmark Institutions. 2009 Available from: http://www.pubmedcentral.nih.gov/articlerender.fcgi?artid=2815413. [PMC free article] [PubMed]
- 48.Yarbrough A, Smith T. Technology Acceptance among Physicians. Medical Care Research and Review. 2007;64(6):650–672. doi: 10.1177/1077558707305942. [DOI] [PubMed] [Google Scholar]
- 49.Anderson JA, Willson P. Knowledge management: organizing nursing care knowledge. Critical care nursing quarterly. 2009;32(1) doi: 10.1097/01.CNQ.0000343127.04448.13. [DOI] [PubMed] [Google Scholar]
- 50.Salas E, Rosen M, DiazGranados D. Expertise-Based Intuition and Decision Making in Organizations. Journal of Management. 2010;36(4):941–973. [Google Scholar]
- 51.Feifer C, et al. The Logic Behind a Multimethod Intervention to Improve Adherence to Clinical Practice Guidelines in a Nationwide Network of Primary Care Practices. Evaluation & the Health Professions. 2006;29(1):65–88. doi: 10.1177/0163278705284443. [DOI] [PubMed] [Google Scholar]
- 52.Niland JC, Rouse L, Stahl DC. An informatics blueprint for healthcare quality information systems. Journal of the American Medical Informatics Association: JAMIA. 2006;13(4) doi: 10.1197/jamia.M2050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.SAS Institute, I. Creating an Evidence-Based Practice Culture with Business Intelligence. 2004 [Google Scholar]
- 54.Wang XS, Nayda L, Dettinger R. Clinical decision intelligence: Medical informatics and bioinformatics - Infrastructure for a clinical-decision-intelligence system. IBM systems journal. 2007;46(1):151. [Google Scholar]
- 55.Shortell S, et al. An Empirical Assessment of High-Performing Medical Groups: Results from a National Study. Medical Care Research and Review. 2005;62(4):407–434. doi: 10.1177/1077558705277389. [DOI] [PubMed] [Google Scholar]
- 56.Riegelman RK. Essential Public Health. Jones and Bartlett Publishers, LLC; 2009. Public health 101: healthy people--healthy populations; p. 350. [Google Scholar]
- 57.Gordon NP, et al. Concordance of self-reported data and medical record audit for six cancer screening procedures. J Natl Cancer Inst. 1993;85(7):566–570. doi: 10.1093/jnci/85.7.566. [DOI] [PubMed] [Google Scholar]
- 58.Peabody JW, et al. Comparison of vignettes, standardized patients, and chart abstraction: a prospective validation study of 3 methods for measuring quality. JAMA: the journal of the American Medical Association. 2000;283(13):1715–1722. doi: 10.1001/jama.283.13.1715. [DOI] [PubMed] [Google Scholar]
- 59.Peabody JW, et al. Measuring the quality of physician practice by using clinical vignettes: a prospective validation study. Annals of internal medicine. 2004;141(10):771–780. doi: 10.7326/0003-4819-141-10-200411160-00008. [DOI] [PubMed] [Google Scholar]