

Abstract
This paper studies the asymptotic behaviors of the pairwise angles among n randomly and uniformly distributed unit vectors in as the number of points n → ∞, while the dimension p is either fixed or growing with n. For both settings, we derive the limiting empirical distribution of the random angles and the limiting distributions of the extreme angles. The results reveal interesting differences in the two settings and provide a precise characterization of the folklore that “all high-dimensional random vectors are almost always nearly orthogonal to each other”. Applications to statistics and machine learning and connections with some open problems in physics and mathematics are also discussed.
Keywords: random angle, uniform distribution on sphere, empirical law, maximum of random variables, minimum of random variables, extreme-value distribution, packing on sphere
1. Introduction
The distribution of the Euclidean and geodesic distances between two random points on a unit sphere or other geometric objects has a wide range of applications including transportation networks, pattern recognition, molecular biology, geometric probability, and many branches of physics. The distribution has been well studied in different settings. For example, Hammersley (1950), Lord (1954), Alagar (1976) and García-Pelayo (2005) studied the distribution of the Euclidean distance between two random points on the unit sphere . Williams (2001) showed that, when the underlying geometric object is a sphere or an ellipsoid, the distribution has a strong connection to the neutron transport theory. Based on applications in neutron star models and tests for random number generators in p-dimensions, Tu and Fischbach (2002) generalized the results from unit spheres to more complex geometric objects including the ellipsoids and discussed many applications. In general, the angles, areas and volumes associated with random points, random lines and random planes appear in the studies of stochastic geometry, see, for example, Stoyan, et al. (1995) and Kendall and Molchanov (2010).
In this paper we consider the empirical law and extreme laws of the pairwise angles among a large number of random unit vectors. More specifically, let X1, ⋯, Xn be random points independently chosen with the uniform distribution on , the unit sphere in . The n points X1, ⋯, Xn on the sphere naturally generate n unit vectors for i = 1,2 ⋯, n, where O is the origin. Let 0 ≤ Θij ≤ π denote the angle between and for all 1 ≤ i < j ≤ n. In the case of a fixed dimension, the global behavior of the angles Θij is captured by its empirical distribution
| (1) |
When both the number of points n and the dimension p grow, it is more appropriate to consider the normalized empirical distribution
| (2) |
In many applications it is of significant interest to consider the extreme angles Θmin and Θmax defined by
| (3) |
| (4) |
We will study both the empirical distribution of the angles Θij, 1 ≤ i < j ≤ n, and the distributions of the extreme angles Θmin and Θmax as the number of points n → ∞, while the dimension p is either fixed or growing with n.
The distribution of minimum angle of n points randomly distributed on the p-dimensional unit sphere has important implications in statistics and machine learning. It indicates how strong spurious correlations can be for p observations of n-dimensional variables (Fan et al., 2012). It can be directly used to test isotropic of the distributions (see Section 4). It is also related to regularity conditions such as the Incoherent Condition (Donoho and Huo, 2001), the Restricted Eigenvalue Condition (Bickel et al., 2009), the ℓq-Sensitivity (Gautier and Tsybakov, 2011) that are needed for sparse recovery. See also Section 5.1.
The present paper systematically investigates the asymptotic behaviors of the random angles {Θij;1 ≤ i < j ≤ n}. It is shown that, when the dimension p is fixed, as n → ∞, the empirical distribution μn converges to a distribution with the density function given by
On the other hand, when the dimension p grows with n, it is shown that the limiting normalized empirical distribution μn,p of the random angles Θij, 1 ≤ i < j ≤ n is Gaussian. When the dimension is high, most of the angles are concentrated around π/2. The results provide a precise description of this concentration and thus give a rigorous theoretical justification to the folklore that “all high-dimensional random vectors are almost always nearly orthogonal to each other,” see, for example, Diaconis and Freedman (1984) and Hall et al. (2005). A more precise description is given in Proposition 5 later in terms of the concentration rate.
In addition to the empirical law of the angles Θij, we also consider the extreme laws of the random angles in both the fixed and growing dimension settings. The limiting distributions of the extremal statistics Θmax and Θmin are derived. Furthermore, the limiting distribution of the sum of the two extreme angles Θmin + Θmax is also established. It shows that Θmin + Θmax is highly concentrated at π.
The distributions of the minimum and maximum angles as well as the empirical distributions of all pairwise angles have important applications in statistics. First of all, they can be used to test whether a collection of random data points in the p-dimensional Euclidean space follow a spherically symmetric distribution (Fang et al., 1990). The natural test statistics are either μn or Θmin defined respectively in (1) and (3). The statistic Θmin also measures the maximum spurious correlation among n data points in the p-dimensional Euclidean space. The correlations between a response vector with n other variables, based on n observations, are considered as spurious when they are smaller than a certain upper quantile of the distribution of |cos(Θmin)| (Fan and Lv, 2008). The statistic Θmin is also related to the bias of estimating the residual variance (Fan et al., 2012). More detailed discussion of the statistical applications of our studies is given in Section 4.
The study of the empirical law and the extreme laws of the random angles Θij is closely connected to several deterministic open problems in physics and mathematics, including the general problem in physics of finding the minimum energy configuration of a system of particles on the surface of a sphere and the mathematical problem of uniformly distributing points on a sphere, which originally arises in complexity theory. The extreme laws of the random angles considered in this paper is also related to the study of the coherence of a random matrix, which is defined to be the largest magnitude of the Pearson correlation coefficients between the columns of the random matrix. See Cai and Jiang (2011, 2012) for the recent results and references on the distribution of the coherence. Some of these connections are discussed in more details in Section 5.
This paper is organized as follows. Section 2 studies the limiting empirical and extreme laws of the angles Θij in the setting of the fixed dimension p as the number of points n going to ∞. The case of growing dimension is considered in Section 3. Their applications in statistics are outlined in Section 4. Discussions on the connections to the machine learning and some open problems in physics and mathematics are given in Section 5. The proofs of the main results are relegated in Section 6.
2. When The Dimension p Is Fixed
In this section we consider the limiting empirical distribution of the angles Θij, 1 ≤ i < j ≤ n when the number of random points n → ∞ while the dimension p is fixed. The case where both n and p grow will be considered in the next section. Throughout the paper, we let X1, X2, ⋯, Xn be independent random points with the uniform distribution on the unit sphere for some fixed p ≥ 2.
We begin with the limiting empirical distribution of the random angles.
Theorem 1 (Empirical Law for Fixed p)
Let the empirical distribution μn of the angles Θij, 1 ≤ i < j ≤ n, be defined as in (1). Then, as n → ∞, with probability one, μn converges weakly to the distribution with density
| (5) |
In fact, h(θ) is the probability density function of Θij for any i ≠ j(Θij’s are identically dis tributed). Due to the dependency of Θij’s, some of them are large and some are small. Theorem 1 says that the average of these angles asymptotically has the same density as that of Θ12.
Notice that when p = 2, h(θ) is the uniform density on [0, π], and when p > 2, h(θ) is unimodal with mode θ = π/2. Theorem 1 implies that most of the angles in the total of angles are concentrated around π/2. This concentration becomes stronger as the dimension p grows since (sinθ)p–2 converges to zero more quickly for θ ≠ π/2. In fact, in the extreme case when p → ∞, almost all of angles go to π/2 at the rate . This can be seen from Theorem 4 later.
It is helpful to see how the density changes with the dimension p. Figure 1 plots the function
| (6) |
which is the asymptotic density of the normalized empirical distribution μn,p defined in (2) when the dimension p is fixed. Note that in the definition of μn,p in (2), if “” is replaced by “”, the limiting behavior of μn,p does not change when both n and p go to infinity. However, it shows in our simulations and the approximation (7) that the fitting is better for relatively small p when “” is used.
Figure 1.
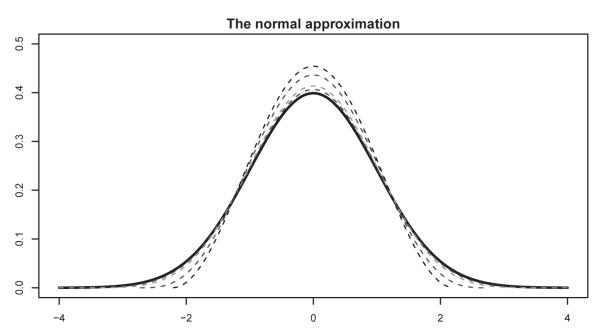
Functions hp(θ) given by (6) for p = 4, 5, 10 and 20. They are getting closer to the normal density (thick black) as p increases.
Figure 1 shows that the distributions hp(θ) are very close to normal when p ≥ 5. This can also be seen from the asymptotic approximation
| (7) |
We now consider the limiting distribution of the extreme angles Θmin and Θmax.
Theorem 2 (Extreme Law for Fixed p)
Let Θmin and Θmax be defined as in (3) and (4) respectively. Then, both n2/(p–1)Θmin and n2/(p–1)(π − Θmax) converge weakly to a distribution given by
| (8) |
as n → ∞, where
| (9) |
The above theorem says that the smallest angle Θmin is close to zero, and the largest angle Θmax is close to π as n grows. This makes sense from Theorem 1 since the support of the density function h(Θ) is [0,π].
In the special case of p = 2, the scaling of Θmin and π − Θmax in Theorem 2 is n2. This is in fact can also be seen in a similar problem. Let ζ1, ⋯, ζn be i.i.d. U[0,1]-distributed random variables with the order statistics ζ(1) ≤ ⋯ ≤ ζ(n). Set Wn: = min1≤i≤n – 1(ζ(i+1) − ζ(i)), which is the smallest spacing among the observations of ζi’s. Then, by using the representation theorem of ζ(i)’s through i.i.d. random variables with exponential distribution Exp(1) (see, for example, Proposition 4.1 from Resnick (2007)), it is easy to check that n2Wn converges weakly to Exp(1) with the probability density function e–xI(x ≥ 0).
To see the goodness of the finite sample approximations, we simulate 200 times from the distributions with n = 50 for p = 2,3 and 30. The results are shown respectively in Figures 2–4. Figure 2 depicts the results when p = 2. In this case, the empirical distribution μn should approximately be uniformly distributed on [0,π] for most of realizations. Figure 2 (a) shows that it holds approximately truly for n as small as 50 for a particular realization (It indeed holds approximately for almost all realizations). Figure 2(b) plots the average of these 200 distributions, which is in fact extremely close to the uniform distribution on [0,π]. Namely, the bias is negligible. For Θmin, according to Theorem 1, it should be well approximated by an exponential distribution with K = 1/(2π). This is verified by Figure 2(c), even when sample size is as small as 50. Figure 2(d) shows the distribution of Θmin + Θmax based on the 200 simulations. The sum is distributed tightly around π, which is indicated by the red line there.
Figure 2.

Various distributions for p = 2 and n = 50 based on 200 simulations. (a) A realization of the empirical distribution μn; (b) The average distribution of 200 realizations of μn; (c) the distribution of Θmin and its asymptotic distribution exp(−x/(2π))/(2π); (d) the distribution of Θmin + Θmax; the vertical line indicating the location π.
Figure 4.

Various distributions for p = 30 and n = 50 based on 200 simulations. (a) A realization of the normalized empirical distribution μn,p given by (2); (b) The average distribution of 200 realizations of μn,p; (c) the distribution of Θmin and its asymptotic distribution; (d) the distribution of Θmin + Θmax; the vertical line indicating the location π.
The results for p = 3 and p = 30 are demonstrated in Figures 3 and 4. In this case, we show the empirical distributions of and their asymptotic distributions. As in Figure 1, they normalized. Figure 3(a) shows a realization of the distribution and Figure 3(b) depicts the average of 200 realizations of these distributions for p = 3. They are very close to the asymptotic distribution, shown in the curve therein. The distributions of Θmin and Θmax are plotted in Figure 3(c). They concentrate respectively around 0 and π. Figure 3(d) shows that the sum is concentrated symmetrically around π.
Figure 3.

Various distributions for p = 3 and n = 50 based on 200 simulations. (a) A realization of the normalized empirical distribution μn,p given by (2); (b) The average distribution of 200 realizations of μn,p; (c) the distribution of Θmin and its asymptotic distribution; (d) the distribution of Θmin + Θmax; the vertical line indicating the location π.
When p = 30, the approximations are still very good for the normalized empirical distributions. In this case, the limiting distribution is indistinguishable from the normal density, as shown in Figure 1. However, the distribution of Θmin is not approximated well by its asymptotic counterpart, as shown in Figure 4(c). In fact, Θmin does not even tends to zero. This is not entirely surprising since p is comparable with n. The asymptotic framework in Section 3 is more suitable. Nevertheless, Θmin + Θmax is still symmetrically distributed around π.
The simulation results show that Θmax + Θmin is very close to π. This actually can be seen trivially from Theorem 2: Θmin → 0 and Θmax → π in probability as p → ∞. Hence, the sum goes to π in probability. An interesting question is: how fast is this convergence? The following result answers this question.
Theorem 3 (Limit Law for Sum of Largest and Smallest Angles)
Let X1, X2, ⋯, Xn be independent random points with the uniform distribution on for some fixed p ≥ 2. Let Θmin and Θmax be defined as in (3) and (4) respectively. Then, n2/(p–1)(Θmax + Θmin − π) converges weakly to the distribution of X – Y, where X and Y are i.i.d. random variables with distribution function F(x) given in (8).
It is interesting to note that the marginal distribution of Θmin and π − Θmax are identical. However, n2/(p–1)Θmin and n2/(p–1)(π − Θmax) are asymptotically independent with non-vanishing limits and hence their difference is non-degenerate. Furthermore, since X are Y are i.i.d., X – Y is a symmetric random variable. Theorem 3 suggests that Θmax + Θmin is larger or smaller than π “equally likely”. The symmetry of the distribution of Θmax + Θmin has already been demonstrated in Figures 2–4.
3. When Both n and p Grow
We now turn to the case where both n and p grow. The following result shows that the empirical distribution of the random angles, after suitable normalization, converges to a standard normal distribution. This is clearly different from the limiting distribution given in Theorem 1 when the dimension p is fixed.
Theorem 4 (Empirical Law for Growing p)
Let μn,p be defined as in (2). Assume limn→∞ pn = ∞. Then, with probability one, μn,p converges weakly to N(0,1) as n → ∞.
Theorem 4 holds regardless of the speed of p relative to n when both go to infinity. This has also been empirically demonstrated in Figures 2–4 (see plots (a) and (b) therein). The theorem implies that most of the random angles go to π/2 very quickly. Take any γp → 0 such that and denote by Nn,p the number of the angles Θij that are within γp of π/2, that is, . Then . Hence, most of the random vectors in the high-dimensional Euclidean spaces are nearly orthogonal. An interesting question is: Given two such random vectors, how fast is their angle close to π/2 as the dimension increases? The following result answers this question.
Proposition 5
Let U and V be two random points on the unit sphere in . Let Θ be the angle between and . Then
for all p ≥ 2 and ε ∈ (0,π/2), where K is a universal constant.
Under the spherical invariance one can think of Θ as a function of the random point U only. There are general concentration inequalities on such functions, see, for example, Ledoux (2005). Proposition 5 provides a more precise inequality.
One can see that, as the dimension p grows, the probability decays exponentially. In particular, take for some constant c > 1. Note that cosε ≤ 1 – ε2/2+ε4/24, so
for all sufficiently large p, where K’ is a constant depending only on c. Hence, in the high dimensional space, the angle between two random vectors is within of π/2 with high probability. This provides a precise characterization of the folklore mentioned earlier that “all high-dimensional random vectors are almost always nearly orthogonal to each other”.
We now turn to the limiting extreme laws of the angles when both n and p → ∞. For the extreme laws, it is necessary to divide into three asymptotic regimes: sub-exponential case logn → 0, exponential case logn → β ∈ (0,∞), and super-exponential case logn → ∞. The limiting extreme laws are different in these three regimes.
Theorem 6 (Extreme Law: Sub-Exponential Case)
Let p = pn → ∞ satisfy as n → ∞. Then
in probability as n → ∞;
As n → ∞, 2plogsinΘmin + 4logn − loglogn converges weakly to the extreme value distribution with the distribution function F(y) = 1 – e−Key/2, and . The conclusion still holds if Θmin is replaced by Θmax.
In this case, both Θmin and Θmax converge to π/2 in probability. The above extreme value distribution differs from that in (8) where the dimension p is fixed. This is obviously caused by the fact that p is finite in Theorem 2 and goes to infinity in Theorem 6.
Corollary 7
Let p = pn satisfy . Then p cos2 Θmin – 4logn+loglogn converges weakly to a distribution with the cumulative distribution function . The conclusion still holds if Θmin is replaced by Θmax.
Theorem 8 (Extreme Law: Exponential Case)
Let p = pn satisfy as n → ∞, then
and in probability as n → ∞;
- As n → ∞, 2plogsinΘmin + 4logn − loglogn converges weakly to a distribution with the distribution function
and the conclusion still holds if Θmin is replaced by Θmax.
In contrast to Theorem 6, neither Θmax nor Θmin converges to π/2 under the case that (logn)/p → β ∈ (0,∞). Instead, they converge to different constants depending on β.
Theorem 9 (Extreme Law: Super-Exponential Case)
Let p = pn satisfy as n → ∞. Then,
Θmin → 0 and Θmax → π in probability as n → ∞;
As n → ∞, 2plogsin converges weakly to the extreme value distribution with the distribution function F(y) = 1 – e−Key/2, with . The conclusion still holds if Θmin is replaced by Θmax.
It can be seen from Theorems 6, 8 and 9 that Θmax becomes larger when the rate β = lim(logn)/p increases. They are π/2, and π when β = 0, β ∈ (0,∞) and β = ∞, respectively.
Set . Then f(0) = π/2 and f(+∞) = π, which corresponds to Θmax in (i) of Theorem 6 and (i) of Theorem 9, respectively. So the conclusions in Theorems 6, 8 and 9 are consistent.
Theorem 3 provides the limiting distribution of Θmax + Θmin − π when the dimension p is fixed. It is easy to see from the above theorems that Θmax + Θmin − π → 0 in probability as both n and p go to infinity. Its asymptotic distribution is much more involved and we leave it as future work.
Remark 10
As mentioned in the introduction, Cai and Jiang (2011, 2012) considered the limiting distribution of the coherence of a random matrix and the coherence is closely related to the minimum angle Θmin. In the current setting, the coherence Ln,p is defined by
where . The results in Theorems 6, 8 and 9 are new. Their proofs can be essentially reduced to the analysis of max1≤i<j≤n ρij. This maximum is analyzed through modifying the proofs of the results for the limiting distribution of the coherence Ln,p in Cai and Jiang (2012). The key step in the proofs is the study of the maximum and minimum of pairwise i.i.d. random variables {ρij; 1 ≤ i < j ≤ n} by using the Chen-Stein method. It is noted that {ρij; 1 ≤ i < j ≤ n} are not i.i.d. random variables (see, for example, p.148 from Muirhead (1982)), the standard techniques to analyze the extreme values of {ρij; 1 ≤ i < j ≤ n} do not apply.
4. Applications to Statistics
The results developed in the last two sections can be applied to test the spherical symmetry (Fang et al., 1990):
based on an i.i.d. sample . Under the null hypothesis H0, Z/∥Z∥ is uniformly distributed on . It is expected that the minimum angle Θmin is stochastically larger under the null hypothesis than that under the alternative hypothesis. Therefore, one should reject the null hypothesis when Θmin is too small or formally, reject H0 when
where the critical value cα, according to Theorem 2, is given by
for the given significance level α. This provides the minimum angle test for sphericity or the packing test on sphericity.
We run a simulation study to examine the power of the packing test. The following 6 data generating processes are used:
Distribution 0: the components of X follow independently the standard normal distribution;
Distribution 1: the components of X follow independently the uniform distribution on [−1,1];
Distribution 2: the components of X follow independently the uniform distribution on [0,1];
Distribution 3: the components of X follow the standard normal distribution with correlation 0.5;
Distribution 4: the components of X follow the standard normal distribution with correlation 0.9;
Distribution 5: the components of X follow independently the mixture distribution 2/3exp(−x)I(x ≥ 0) + 1/3exp(x)I(x ≤ 0).
The results are summarized in Table 1 below. Note that for Distribution 0, the power corresponds to the size of the test, which is slightly below α = 5%.
Table 1.
The power (percent of rejections) of the packing test based on 2000 simulations
| Distribution | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| p = 2 | 4.20 | 5.20 | 20.30 | 5.55 | 10.75 | 5.95 |
| p = 3 | 4.20 | 6.80 | 37.20 | 8.00 | 30.70 | 8.05 |
| p = 4 | 4.80 | 7.05 | 64.90 | 11.05 | 76.25 | 11.20 |
| p = 5 | 4.30 | 7.45 | 90.50 | 18.25 | 99.45 | 11.65 |
The packing test does not examine whether there is a gap in the data on the sphere. An alternative test statistic is μn or its normalized version μn,p when p is large, defined respectively by (1) and (2). A natural test statistic is then to use a distance such as the Kolmogrov-Smirnov distance between μn and h(θ). In this case, one needs to derive further the null distribution of such a test statistic. This is beyond the scope of this paper and we leave it for future work.
Our study also shed lights on the magnitude of spurious correlation. Suppose that we have a response variable Y and its associate covariates (for example, gene expressions). Even when there is no association between the response and the covariate, the maximum sample correlation between Xj and Y based on a random sample of size n will not be zero. It is closely related to the minimum angle Θmin (Fan and Lv, 2008). Any correlation below a certain thresholding level can be spurious—the correlation of such a level can occur purely by chance. For example, by Theorem 6(ii), any correlation (in absolute value) below
can be regarded as the spurious one. Take, for example, p = 30 and n = 50 as in Figure 4, the spurious correlation can be as large 0.615 in this case.
The spurious correlation also helps understand the bias in calculating the residual σ2 = var(ε) in the sparse linear model
where S is a subset of variables {1,⋯ p}. When an extra variable besides XS is recruited by a variable selection algorithm, that extra variable is recruited to best predict ε (Fan et al., 2012). Therefore, by the classical formula for the residual variance, σ2 is underestimated by a factor of 1 – cos2(Θmin). Our asymptotic result gives the order of magnitude of such a bias.
5. Discussions
We have established the limiting empirical and extreme laws of the angles between random unit vectors, both for the fixed dimension and growing dimension cases. For fixed p, we study the empirical law of angles, the extreme law of angles and the law of the sum of the largest and smallest angles in Theorems 1, 2 and 3. Assuming p is large, we establish the empirical law of random angles in Theorem 4. Given two vectors u and v, the cosine of their angle is equal to the Pearson correlation coefficient between them. Based on this observation, among the results developed in this paper, the limiting distribution of the minimum angle Θmin given in Theorems 6-9 for the setting where both n and p → ∞ is obtained by similar arguments to those in Cai and Jiang (2012) on the coherence of an n × p random matrix (a detailed discussion is given in Remark 10). See also Jiang (2004), Li and Rosalsky (2006), Zhou (2007), Liu et al. (2008), Li et al. (2009) and Li et al. (2010) for earlier results on the distribution of the coherence which were all established under the assumption that both n and p → ∞.
The study of the random angles Θij’s, Θmin and Θmax is also related to several problems in machine learning as well as some deterministic open problems in physics and mathematics. We briefly discuss some of these connections below.
5.1 Connections to Machine Learning
Our studies shed lights on random geometric graphs, which are formed by n random points on the p-dimensional unit sphere as vertices with edge connecting between points Xi and Xj if Θij > δ for certain δ (Penrose, 2003; Devroye et al., 2011). Like testing isotropicity in Section 4, a generalization of our results can be used to detect if there are any implanted cliques in a random graph, which is a challenging problem in machine learning. It can also be used to describe the distributions of the number of edges and degree of such a random geometric graph. Problems of hypothesis testing on isotropicity of covariance matrices have strong connections with clique numbers of geometric random graphs as demonstrated in the recent manuscript by Castro et al. (2012). This furthers connections of our studies in Section 4 to this machine learning problem.
Principal component analysis (PCA) is one of the most important techniques in high-dimensional data analysis for visualization, feature extraction, and dimension reduction. It has a wide range of applications in statistics and machine learning. A key aspect of the study of PCA in the high-dimensional setting is the understanding of the properties of the principal eigenvectors of the sample covariance matrix. In a recent paper, Shen et al. (2013) showed an interesting asymptotic conical structure in the critical sample eigenvectors under a spike covariance models when the ratio between the dimension and the product of the sample size with the spike size converges to a nonzero constant. They showed that in such a setting the critical sample eigenvectors lie in a right circular cone around the corresponding population eigenvectors. Although these sample eigenvectors converge to the cone, their locations within the cone are random. The behavior of the randomness of the eigenvectors within the cones is related to the behavior of the random angles studied in the present paper. It is of significant interest to rigorously explore these connections. See Shen et al. (2013) for further discussions.
5.2 Connections to Some Open Problems in Mathematics and Physics
The results on random angles established in this paper can be potentially used to study a number of open deterministic problems in mathematics and physics.
Let x1, ⋯, xn be n points on and R = {x1, ⋯, xn}. The α-energy function is defined by
and where ∥·∥ is the Euclidean norm in . These are known as the electron problem (α = 0) and the Coulomb potential problem (α = 1). See, for example, Kuijlaars and Saff (1998) and Katanforoush and Shahshahani (2003). The goal is to find the extremal α-energy
and the extremal configuration R that attains ε(R,α). In particular, when α = −1, the quantity ε(R,−1) is the minimum of the Coulomb potential
These open problems, as a function of α, are: (i) α = −∞: Tammes problem; (ii) α = −1: Thomson problem; (iii) α = 1: maximum average distance problem; and (iv) α = 0: maximal product of distances between all pairs. Problem (iv) is the 7th of the 17 most challenging mathematics problems in the 21st century according to Smale (2000). See, for example, Kuijlaars and Saff (1998) and Katanforoush and Shahshahani (2003), for further details.
The above problems can also be formulated through randomization. Suppose that X1, ⋯, Xn are i.i.d. uniform random vectors on . Suppose R = {x1, ⋯, xn} achieves the infinimum supremum in the definition of ε(R,α). Since P(max1≤i≤n ∥Xi – xi∥ < ε) > 0 for any ε > 0, it is easy to see that ε(R,α) = ess · inf(E(R,α)) for α ≤ 0 and ε(R,α) = ess · sup(E(R,α)) for α > 0 with R = {X1, ⋯, Xn}, where ess · inf(Z) and ess · sup(Z) are the essential infinimum and the essential maximum of random variable Z, respectively.
For the Tammes problem (α = −∞), the extremal energy ε(R,−∞) can be further studied through the random variable Θmax. Note that ∥xi – xj∥2 = 2(1 – cosθij), where θij is the angle between vectors and . Then
where . Again, let X1, ⋯, Xn be i.i.d. random vectors with the uniform distribution on . Then, it is not difficult to see
where Δ:= ess · sup(Θmax) is the essential upper bound of the random variable Θmax as defined in (4). Thus,
| (10) |
The essential upper bound Δ of the random variable Θmax can be approximated by random sampling of Θmax. So the approach outlined above provides a direct way for using a stochastic method to study these deterministic problems and establishes connections between the random angles and open problems mentioned above. See, for example, Katanforoush and Shahshahani (2003) for further comments on randomization. Recently, Armentano et al. (2011) studied this problem by taking xi’s to be the roots of a special type of random polynomials. Taking independent and uniform samples X1, ⋯, Xn from the unit sphere to get (10) is simpler than using the roots of a random polynomials.
6. Proofs
We provide the proofs of the main results in this section.
6.1 Technical Results
Recall that X1,X2, ⋯ are random points independently chosen with the uniform distribution on , the unit sphere in , and Θij is the angle between and and ρij = cosΘij for any i ≠ j. Of course, Θij ∈ [0,π] for all i ≠ j. It is known that the distribution of (X1,X2, ⋯) is the same as that of
where {Y1,Y2, ⋯} are independent p-dimensional random vectors with the normal distribution Np(0,Ip), that is, the normal distribution with mean vector 0 and the covariance matrix equal to the p × p identity matrix Ip. Thus,
for all 1 ≤ i < j ≤ n. See, for example, the Discussions in Section 5 from Cai and Jiang (2012) for further details. Of course, ρii = 1 and |ρij| ≤ 1 for all i, j. Set
| (11) |
Lemma 11
((22) in Lemma 4.2 from Cai and Jiang (2012)) Let p ≥ 2. Then {ρij; 1 ≤ i < j ≤ n} are pairwise independent and identically distributed with density function
| (12) |
Notice y = cosx is a strictly decreasing function on [0,π], hence Θij = cos−1 ρij. A direct computation shows that Lemma 11 is equivalent to the following lemma.
Lemma 12
Let p ≥ 2. Then,
- {Θij; 1 ≤ i < ≥ j ≤ n} are pairwise independent and identically distributed with density function
(13) If “Θij” in (i) is replaced by “π − Θij”, the conclusion in (i) still holds.
Let I be a finite set, and for each α ∈ I, Xα be a Bernoulli random variable with pα = P(Xα = 1) = 1–P(Xα = 0) > 0. Set W = ∑α∈I Xα and λ = EW = ∑α∈I pα. For each α ∈ I, suppose we have chosen Bα ⊂ I with α ∈ Bα. Define
Lemma 13
(Theorem 1 from Arratia et al. (1989)) For each α ∈ I, assume Xα is independent of {Xβ; β ∈ I – Bα}. Then |P(Xα = 0 for all α ∈ I)–e−λ| ≤ b1 + b2.
The following is essentially a special case of Lemma 13.
Lemma 14
Let I be an index set and {Bα,α ∈ I} be a set of subsets of I, that is, Bα ⊂ I for each α ∈ I. Let also {ηα,α ∈ I} be random variables. For a given , set λ = ∑α∈I P(ηα > t). Then
where
and α(ηβ, β ∉ Bα) is the α-algebra generated by {ηβ, β ∉ Bα}. In particular, if ηα is independent of {ηβ, β ∉ Bα} for each α, then b3 = 0.
Lemma 15
Let p = pn ≥ 2. Recall Mn as in (11). For {tn ∈ [0,1]; n ≥ 2}, set
If limn→∞ pn = ∞ and limn→∞ hn = λ ∈ [0,∞), then limn→∞ P(Mn ≤ tn) = e−λ/2.
Proof
For brevity of notation, we sometimes write t = tn if there is no confusion. First, take I = {(i, j); 1 ≤ i < j ≤ n}. For u = (i, j) ∈ I, set Bu = {(k, l) ∈ I; one of k and l = i or j, but (k, l) ≠ u}, ηu = ρij and Au = Aij = {ρij > t}. By the i.i.d. assumption on X1, ⋯, Xn and Lemma 14,
| (14) |
where
| (15) |
and
By Lemma 11, A12 and A13 are independent events with the same probability. Thus, from (15),
| (16) |
for all n ≥ 2. Now we compute P(A12). In fact, by Lemma 11 again,
Recalling the Stirling formula (see, for example, p.368 from Gamelin (2001) or (37) on p.204 from Ahlfors (1979)):
as x = Re(z) → ∞, it is easy to verify that
| (17) |
as p → ∞. Thus,
as n → ∞. From (15), we know
as n → ∞. Finally, by (14) and (16), we know
6.2 Proofs of Main Results in Section 2
Lemma 16
Let X1,X2, ⋯ be independent random points with the uniform distribution on the unit sphere in .
Let p be fixed and μ be the probability measure with the density h(θ) as in (5). Then, with probability one, μn in (1) converges weakly to μ as n → ∞.
- Let p = pn and {φn(θ); n ≥ 1} be sequence of functions defined on [0,π]. If φn(Θ12) converges weakly to a probability measure ν as n → ∞, then, with probability one,
converges weakly to ν as n → ∞.(18)
Proof
First, we claim that, for any bounded and continuous function u(x) defined on ,
| (19) |
as n → ∞ regardless p is fixed as in (i) or p = pn as in (ii) in the statement of the lemma. For convenience, write un(θ) = u(φn(θ)). Then un(θ) is a bounded function with M: = supΘ∈[0,π] |un(θ)| < ∞. By the Markov inequality
for any ε > 0. From (i) of Lemma 12, {Θij; 1 ≤ i < j ≤ n} are pairwise independent with the common distribution, the last expectation is therefore equal to . This says that, for any ε > 0,
as n → ∞. Note that the sum of the right hand side over all n ≥ 2 is finite. By the Borel-Cantelli lemma, we conclude (19).
- Since φn(Θ12) converges weakly to ν as n → ∞, we know that, for any bounded continuous function u(x) defined on , as n → ∞. By (i) of Lemma 12, Eu(φn(Θij)) = Eu(φn(Θ12)) for all 1 ≤ i < j ≤ n. This and (19) yield
as n → ∞. Reviewing the definition of νn in (18), the above asserts that, with probability one, νn converges weakly to ν as n → ∞.
Proof of Theorem 1
This is a direct consequence of (i) of Lemma 16.
Recall X1, ⋯, Xn are random points independently chosen with the uniform distribution on , the unit sphere in , and Θij is the angle between and and ρij = cosΘij for all 1 ≤ i, j ≤ n. Of course, ρii = 1 and |ρij| ≤ 1 for all 1 ≤ i ≠ j ≤ n. Review (11) to have
To prove Theorem 2, we need the following result.
Proposition 17
Fix p ≥ 2. Then n4/(p–1)(1 – Mn) converges to the distribution function
in distribution as n → ∞, where
| (20) |
Proof
Set t = tn = 1 – xn−4/(p–1) for x ≥ 0. Then
| (21) |
as n → ∞. Notice
Thus, to prove the theorem, since F1(x) is continuous, it is enough to show that
| (22) |
as n → ∞, where K1 is as in (20).
Now, take I = {(i, j); 1 ≤ i < j ≤ n} For u = (i,j), ∈ I, set Bu = (k,l) ∈ I; one of k and l = i or j, but (k, l) ≠ u}, ηu = ρij and Au = Aij = {ρij > t}. By the i.i.d. assumption on X1, ⋯, Xn and Lemma 14,
| (23) |
where
| (24) |
and
By Lemma 11, A12 and A13 are independent events with the same probability. Thus, from (24),
| (25) |
for all n ≥ 2. Now we evaluate P(A12). In fact, by Lemma 11 again,
Set . We claim
| (26) |
as n → ∞. In fact, set s = x2. Then and . It follows that
as n → ∞, where the fact limn→∞t = limn→∞tn = 1 stated in (21) is used in the second step to replace by . So the claim (26) follows.
Now, we know from (24) that
as n → ∞, where (26) is used in the second step and the fact Γ(x + 1) = xΓ(x) is used in the last step. By (21),
as n → ∞. Therefore,
as n → ∞. Finally, by (23) and (25), we know
This concludes (22).
Proof of Theorem 2
First, since Mn = cosΘmin by (3), then use the identity for all to have
| (27) |
By Proposition 17 and the Slusky lemma, in probability as n ∞ ∞. Noticing 0 ≤ Θmin ≤ π, we then have Θmin → 0 in probability as n → ∞. From (27) and the fact that we obtain
in probability as n → ∞. By Proposition 17 and the Slusky lemma again, converges in distribution to F1(x) as in Proposition 17. Second, for any x > 0,
| (28) |
as n → ∞, where
| (29) |
Now we prove
| (30) |
In fact, recalling the proof of the above and that of Proposition 17, we only use the following properties about ρij:
{ρij; 1 ≤ i < j ≤ n} are pairwise independent.
ρijj has density function g(ρ) given in (12) for all 1 ≤ i < j ≤ n.
-
For each 1 ≤ i < j ≤ n, ρij is independent of {ρkl; 1 ≤ k < l ≤ n; {k, l} ⋂ {i, j} = ∅.
By using Lemmas 11 and 12 and the remark between them, we see that the above ties properties are equivalent to
(a) {Θij; 1 ≤ i < j ≤ n} are pairwise independent.
(b) Θij has density function h(θ) given in (13) for all 1 ≤ i < j ≤ n.
(c) For each 1 ≤ i < j ≤ n, Θij is independent of {Θkl; 1 ≤ k < l ≤ n; {k, l} ⋂ {i, j} = ∅}.
It is easy to see from (ii) of lemma 12 that the above three properties are equivalent to the corresponding (a) , (b) and (c) when “Θij” is replaced by “π — Θij” and “Θkl” is replaced by “π Θkl.” Also, it is key to observe that min{π − Θij; 1 ≤ i < j ≤ n} = π − Θmax. We then deduce from (28) that
as n → ∞, where K is as in (29).(31)
Proof of Theorem 3
We will prove the following:
| (32) |
for any x ≥ 0 and y ≥ 0, where K is as in (9). Note that the right hand side in (32) is identical to P(X ≥ x, Y ≥ y), where X and Y are as in the statement of Theorem 3. If (32) holds, by the fact that Θmin, Θmax, X,Y are continuous random variables and by Theorem 2 we know that for n ≥ 2 is a tight sequence. By the standard subsequence argument, we obtain that Qn converges weakly to the distribution of (X,Y) as n → ∞. Applying the map h(x,y) = x – y with to the sequence {Qn; n ≥ 2} and its limit, the desired conclusion then follows from the continuous mapping theorem on the weak convergence of probability measures.
We now prove (32). Set tx = n−2/(p–1)x and ty = π – n−2/(p–1)y. Without loss of generality, we assume 0 ≤ tx < ty < ∞ for all n ≥ 2. Then
| (33) |
where I:= {(i, j); 1 ≤ i < j ≤ n} and
For u=(i, j) ∈ I, set Bu ={(k, l) ∈ I; one of k and l = i or j, but (k, l) ≠ u}. By the i.i.d. assumption on X1, ⋯, Xn and Lemma 13
| (34) |
where
| (35) |
and
| (36) |
by Lemma 12. Now
| (37) |
By Lemma 12 again,
| (38) |
by setting η = π – θ. Now, set ν = cosη for η ∈ [0,π]. Write (sinη)p–2 = −(sinη)p–3(cosη)’. Then the integral in (38) is equal to
where
as n → ∞ by the Taylor expansion. Trivially,
as n → ∞. Thus, by (26),
as n → ∞. Combining all the above we conclude that
| (39) |
as n → ∞. Similar to the part between (38) and (39), we have
as n → ∞. This joint with (39) and (37) implies that
as n → ∞. Recalling (35) and (36), we obtain
and b1,n as n → ∞, where K is as in (9). These two assertions and (34) yield
6.3 Proofs of Main Results in Section 3
Proof of Theorem 4
Notice (p – 2)/p → 1 as p → ∞, to prove the theorem, it is enough to show that the theorem holds if “μn,p” is replaced by “.” Thus, without loss of generality, we assume (with a bit of abuse of notation) that
Recall p = pn. Set for p ≥ 2. We claim that
| (40) |
as n → ∞. Assuming this is true, taking for θ ∈ [0,π] and ν = N(0,1) in (ii) of Lemma 16, then, with probability one, μn,p converges weakly to N(0,1) as n → ∞.
Now we prove the claim. In fact, noticing Θ12 has density h(θ) in (13), it is easy to see that Yn has density function
| (41) |
for any as n is sufficiently large since limn→∞ pn = ∞. By (17),
| (42) |
as n → ∞. On the other hand, by the Taylor expansion,
as n → ∞. The above together with (41) and (42) yields that
| (43) |
for any . The assertions in (41) and (42) also imply that for n sufficiently large, where C is a constant not depending on n. This and (43) conclude
Proof of Proposition 5
By (i) of Lemma 12,
by making transform , where . The last term above is identical to
It is known that limx→+∞ Γ(x+a)/(xaΓ(x)) = 1, see, for example, Dong, Jiang and Li (2012). Then for all p ≥ 2, where K is a universal constant. The desired conclusion then follows.
Proof of Theorem 6
Review the proof of Theorem 1 in Cai and Jiang (2012). Replacing |ρij|, Ln in (2) and Lemma 6.4 from Cai and Jiang (2012) with ρij, Mn in (11) and Lemma 15 here, respectively. In the places where “n – 2” or “n – 4” appear in the proof, change them to “p – 1” or “p – 3” accordingly. Keeping the same argument in the proof, we then obtain the following.
(a) Mn → 0 in probability as n → ∞.
(b) Let . Then, as n → ∞,
converges weakly to an extreme value distribution with the distribution function F(y) = 1 – e−Key/2, and . From (11) we know
| (44) |
| (45) |
Then (a) above implies that Θmin → π/2 in probability as n → ∞, and (b) implies (ii) for Θmin in the statement of Theorem 6. Now, observe that
| (46) |
By the same argument between (30) and (31), we get π – Θmax → π/2 in probability as n → ∞, that is, Θmax → π/2 in probability as n → ∞. Notice
in probability as n → ∞. We get (i).
Finally, by the same argument between (30) and (31) again, and by (46) we obtain
converges weakly to F(y) = 1 – e−Key/2, and . Thus, (ii) also holds for Θmax.
Proof of Corollary 7
Review the proof of Corollary 2.2 from Cai and Jiang (2012). Replacing Ln and Theorem 1 there by Mn and Theorem 6, we get that
converges weakly to the distribution function . The desired conclusion follows since Mn = cosΘmin.
Proof of Theorem 8
Review the proof of Theorem 2 in Cai and Jiang (2012). Replacing |ρij|, Ln in (2) and Lemma 6.4 from Cai and Jiang (2012) with ρij, Mn in (11) and Lemma 15, respectively. In the places where “n – 2” and “n – 4” appear in the proof, change them to “p – 1” and “p – 3” accordingly. Keeping the same argument in the proof, we then have the following conclusions.
in probability as n → ∞.
- (ii) Let . Then, as n → ∞,
converges weakly to the distribution function
where
From (44) and (45) we obtain(47)
converges weakly to the distribution function(48)
as n → ∞. Now, reviewing (46) and the argument between (30) and (31), by (47) and (48), we conclude that in probability and 2plogsinΘmax + 4logn − loglogn converges weakly to the distribution function F(y) as in (49). The proof is completed.(49)
Proof of Theorem 9
Review the proof of Theorem 3 in Cai and Jiang (2012). Replacing |ρij|, Ln in (2) and Lemma 6.4 from Cai and Jiang (2012) with ρij, Mn in (11) and Lemma 15, respectively. In the places where “n – 2” or “n – 4” appear in the proof, change them to “p – 1” or “p – 3” accordingly. Keeping the same argument in the proof, we get the following results.
Mn → 1 in probability as n → ∞.
Acknowledgments
The research of Tony Cai was supported in part by NSF FRG Grant DMS-0854973, NSF Grant DMS-1209166, and NIH Grant R01 CA127334. The research of Jianqing Fan was supported in part by NSF grant DMS-1206464 and NIH grants NIH R01-GM072611 and R01GM100474. The research of Tiefeng Jiang was supported in part by NSF FRG Grant DMS-0449365 and NSF Grant DMS-1209166.
Contributor Information
Tony Cai, Statistics Department The Wharton School University of Pennsylvania Philadelphia, PA 19104, USA TCAI@WHARTON.UPENN.EDU.
Jianqing Fan, Department of Operation Research and Financial Engineering Princeton University Princeton, NJ 08540, USA JQFAN@PRINCETON.EDU.
Tiefeng Jiang, School of Statistics University of Minnesota Minneapolis, MN 55455, USA TJIANG@STAT.UMN.EDU.
References
- Ahlfors Lars V., Complex Analysis. McGraw-Hill; New York: 1979. [Google Scholar]
- Alagar Vangalur S. The distribution of the distance between random points. Journal of Applied Probability. 1976;13(3):558–566. [Google Scholar]
- Armentano Diego, Beltrán Carlos, Shub Michael. Minimizing the discrete logarithmic energy on the sphere: The role of random polynomials. Transactions of the American Mathematical Society. 2011;363(6):2955–2965. [Google Scholar]
- Arratia Richard, Goldstein Larry, Gordon Louis. Two moments suffice for poisson approximations: the chen-stein method. The Annals of Probability. 1989;17(1):9–25. [Google Scholar]
- Bickel Peter J., Ritov Yaacov, Tsybakov Alexandre B. Simultaneous analysis of lasso and dantzig selector. The Annals of Statistics. 2009;37(4):1705–1732. [Google Scholar]
- Cai Tony T., Jiang Tiefeng. Limiting laws of coherence of random matrices with applications to testing covariance structure and construction of compressed sensing matrices. The Annals of Statistics. 2011;39(3):1496–1525. [Google Scholar]
- Cai Tony T., Jiang Tiefeng. Phase transition in limiting distributions of coherence of high-dimensional random matrices. Journal of Multivariate Analysis. 2012;107:24–39. [Google Scholar]
- Castro Ery Arias, Bubeck Sébastien, Lugosi Gábor. Detecting positive correlations in a multivariate sample. 2012. arXiv preprint arXiv:1202.5536.
- Devroye Luc, György András, Lugosi Gábor, Udina Frederic. High-dimensional random geometric graphs and their clique number. Electronic Journal of Probability. 2011;16:2481–2508. [Google Scholar]
- Diaconis Persi, Freedman David. Asymptotics of graphical projection pursuit. The Annals of Statistics. 1984;12(3):793–815. [Google Scholar]
- Dong Zhishan, Jiang Tiefeng, Li Danning. Circular law and arc law for truncation of random unitary matrix. Journal of Mathematical Physics. 2012;53:013301–14. [Google Scholar]
- Donoho David L, Huo Xiaoming. Uncertainty principles and ideal atomic decomposition. IEEE Transactions on Information Theory. 2001;47(7):2845–2862. [Google Scholar]
- Fang Kai-Tai, Kotz Samuel, Ng Kai Wang. Symmetric Multivariate and Related Distributions. Chapman and Hall Ltd; London: 1990. [Google Scholar]
- Gamelin Theodore W. Complex Analysis. Springer; New York: 2001. [Google Scholar]
- García-Pelayo Ricardo. Distribution of distance in the spheroid. Journal of Physics A: Mathematical and General. 2005;38(16):3475–3482. [Google Scholar]
- Gautier Eric, Tsybakov Alexandre B. High-dimensional instrumental variables regression and confidence sets. 2011. arXiv preprint arXiv:1105.2454.
- Hall Peter, Marron JS, Neeman Amnon. Geometric representation of high dimension, low sample size data. Journal of the Royal Statistical Society: Series B. 2005;67(3):427–444. [Google Scholar]
- Hammersley John M. The distribution of distance in a hypersphere. The Annals of Mathematical Statistics. 1950;21(3):447–452. [Google Scholar]
- Jiang Tiefeng. The asymptotic distributions of the largest entries of sample correlation matrices. The Annals of Applied Probability. 2004;14(2):865–880. [Google Scholar]
- Katanforoush Ali, Shahshahani Mehrdad. Distributing points on the sphere, i. Experimental Mathematics. 2003;12(2):199–209. [Google Scholar]
- Kendall Wilfrid S, Molchanov Ilya. New Perspectives in Stochastic Geometry. Oxford University Press; 2010. [Google Scholar]
- Kuijlaars Arno, Saff E. Asymptotics for minimal discrete energy on the sphere. Transactions of the American Mathematical Society. 1998;350(2):523–538. [Google Scholar]
- Ledoux Michel. The Concentration of Measure Phenomenon. American Mathematical Society; 2001. [Google Scholar]
- Li Deli, Rosalsky Andrew. Some strong limit theorems for the largest entries of sample correlation matrices. The Annals of Applied Probability. 2006;16(1):423–447. [Google Scholar]
- Li Deli, Liu Weidong, Rosalsky Andrew. Necessary and sufficient conditions for the asymptotic distribution of the largest entry of a sample correlation matrix. Probability Theory and Related Fields. 2010;148(1-2):5–35. [Google Scholar]
- Li Deli, Qi Yongcheng, Rosalsky Andrew. On jiang’s asymptotic distribution of the largest entry of a sample correlation matrix. Journal of Multivariate Analysis. 2012;111:256–270. [Google Scholar]
- Liu Weidong, Lin Zhengyan, Shao Qiman. The asymptotic distribution and berry–esseen bound of a new test for independence in high dimension with an application to stochastic optimization. The Annals of Applied Probability. 2008;18(6):2337–2366. [Google Scholar]
- Lord Reginald Douglas. The distribution of distance in a hypersphere. The Annals of Mathematical Statistics. 1954;25(4):794–798. [Google Scholar]
- Muirhead Robb J. Aspects of Multivariate Statistical Theory. Wiley; New York: 1982. [Google Scholar]
- Penrose Mathew. Random Geometric Graphs. Oxford University Press; Oxford: 2003. [Google Scholar]
- Resnick Sidney I. Extreme Values, Regular Variation, and Point Processes. Springer-Verlag; New York: 2007. [Google Scholar]
- Shen Dan, Shen Haipeng, Zhu Hongtu, Marron JS. Surprising asymptotic conical structure in critical sample eigen-directions. 2013. arXiv preprint arXiv:1303.6171.
- Smale Steve. Mathematical problems for the next century. In: Arnold V, Atiyah M, Lax P, Mazur B, editors. Mathematics: Frontiers and Perspectives. 2000. pp. 271–294. [Google Scholar]
- Stoyan Dietrich, Kendall Wilfrid S, Mecke Joseph, Kendall DG, Sussex Chichester W. Stochastic Geometry and its Applications. 2nd ed ume 2. Wiley; New York: 1995. [Google Scholar]
- Tu Shu-Ju, Fischbach Ephraim. Random distance distribution for spherical objects: general theory and applications to physics. Journal of Physics A: Mathematical and General. 2002;35(31):6557–6570. [Google Scholar]
- Williams Mike. On a probability distribution function arising in stochastic neutron transport theory. Journal of Physics A: Mathematical and General. 2001;34(22):4653–4662. [Google Scholar]
- Zhou Wang. Asymptotic distribution of the largest off-diagonal entry of correlation matrices. Transactions of the American Mathematical Society. 2007;359(11):5345–5363. [Google Scholar]