

Abstract
Trace quantities of contaminating DNA are widespread in the laboratory environment, but their presence has received little attention in the context of high throughput sequencing. This issue is highlighted by recent works that have rested controversial claims upon sequencing data that appear to support the presence of unexpected exogenous species. I used reads that preferentially aligned to alternate genomes to infer the distribution of potential contaminant species in a set of independent sequencing experiments. I confirmed that dilute samples are more exposed to contaminating DNA, and, focusing on four single-cell sequencing experiments, found that these contaminants appear to originate from a wide diversity of clades. Although negative control libraries prepared from ‘blank’ samples recovered the highest-frequency contaminants, low-frequency contaminants, which appeared to make heterogeneous contributions to samples prepared in parallel within a single experiment, were not well controlled for. I used these results to show that, despite heavy replication and plausible controls, contamination can explain all of the observations used to support a recent claim that complete genes pass from food to human blood. Contamination must be considered a potential source of signals of exogenous species in sequencing data, even if these signals are replicated in independent experiments, vary across conditions, or indicate a species which seems a priori unlikely to contaminate. Negative control libraries processed in parallel are essential to control for contaminant DNAs, but their limited ability to recover low-frequency contaminants must be recognized.
Introduction
While contamination by foreign DNA is a concern for many experiments, it requires particular attention for those that rely on sensitive methods to describe samples that are themselves dilute or degraded. Low quality samples poorly compete with contaminant DNAs over the course of an experiment, and methods to characterize and eliminate contaminants have been rigorously evaluated in fields where such samples are common. These studies have found that free DNA at trace but detectable levels is widespread, often being found in “clean” new PCR tubes [1], dNTPs [2], and a variety of other sources [3]-[8]. Even extreme precautions, such as UV-treatment of reagents, the use of positive pressure laboratory ventilation systems, etc., appear sufficient only to reduce, rather than eliminate, the abundance of contaminant DNAs [9]-[11].
These results were established using PCR, but they have received surprisingly little attention in the context of high throughput sequencing, which shares with PCR the ability to potentially detect single DNA molecules. Moreover, sequencing samples are processed through a longer and more complex experimental pipeline, which typically includes a PCR amplification step, increasing their exposure to contaminants. The power of sequencing to recover, but not necessarily to identify, contaminant DNAs should grow as read depths increase and as library preparation methods require progressively smaller amounts of input material. Nevertheless, the presentation of contaminants in sequencing data is poorly understood. Although sequences from humans and a handful of other species have been found to contaminate sequencing samples and databases [12]-[17], the roster of potential contaminant species is unknown, as is their distribution within and between experiments, making it difficult to infer whether or not any given read originated from the intended sample.
To help create a framework for this inference, I sought to describe the diversity of contaminant reads in four independent sequencing experiments and how these reads are replicated across samples and negative controls. I used this information to evaluate whether contaminants may have evaded the heavy replication and plausible controls described in a recent paper to provide an alternative explanation for its claim that complete genes pass from food to human blood.
Materials and Methods
Inference of human contaminants in E. coli sequencing data
I downloaded data from Parkinson et al [18] from the European Nucleotide Archive. Run accession numbers are listed in Additional File 1, Table S1. Splitting apart the paired-end reads, I used bowtie version 1.0.0 [19] to attempt to map each end to the E. coli K12 reference genome, allowing up to three mismatches in the seed region (‘-n 3’) but otherwise using default parameters. Unmapped reads were then aligned to the human hg18 reference genome [20] with no mismatches permitted in the seed (‘-n 0’). Reads were considered a ‘hit’ if both ends from each pair mapped to within one kilobase of each other. The fraction of human reads was considered the total number of paired end reads meeting these criteria over the total number of pair-end reads. A generalized linear model was used to describe the relationship between the log of the sample DNA concentration and the frequency, modeled with the binomial distribution, of human-matching reads within the total library. This analysis was performed using the GLM2 package in R [21], [22].
Inference of contaminant reads and species composition in four sequencing experiments
I downloaded data from the short read archive corresponding to study accession numbers SRP002535 (referred to in the main text as the “Tumor” dataset [23]), SRP014866 (“Strandseq” [24]), SRP006834 (“RNAseq” [25]), and SRP017186 (“Sperm” [26]). The specific SRA accessions for each dataset are listed in Additional File 2, Table S2. Due to differences in scope and sequencing technology, the numbers of reads sequenced by these studies differed over orders of magnitude, and so samples from the RNAseq and Strandseq datasets were pooled to provide a more comparable number of total reads, whereas samples having close to the median number of reads in the Sperm and Tumor datasets were analyzed individually. Given the unusual library preparation of the RNAseq dataset [25], in which each read contains a barcode and an uncertain number of guanines, I determined the information content of each position in the library (Additional File 3, Figure S1) and, based upon these data, removed the first fifteen base pairs of each read. The Strandseq and Sperm studies used paired-end libraries; I split paired ends and processed each end independently.
For each dataset, I used bowtie as described above to screen out reads that aligned to the appropriate mouse or human reference genome (hg18 [20] for Sperm and Tumor; mm9 [27] for RNAseq and Strandseq), allowing three mismatches in the seed region. Using the Amazon EC2 image ami-ef42d586, which contains snapshots of the NCBI nucleotide databases from 02/04/2013, I used BLAST to search for hits to each unaligned read to the NR database, using flags –task megablast, -outfmt 6, and –num_alignments 5 (500 for the comparison of positive and blank samples from the Strandseq and RNAseq experiments).
Each experiment having different read lengths and qualities, I considered hits of 100% identity over 48, 75, 40, and 101 base pairs for the Tumor, Strandseq, RNAseq, and Sperm datasets, respectively, to be a perfect match. Due to its large size, the number of reads used for the Strandseq dataset was capped at 7.5 million.
For each BLAST match, I used the GI sequence identification number to locate the corresponding taxID from the NCBI taxonomy database, discarding reads that did not cross-reference. For each taxID, I ascended the tree to the fourth-lowest node and assigned the BLAST hit to that taxonomic category. Reads were discarded if they had BLAST hits to more than one of these categories, if they matched sequences from the species of the reference genome, or if they only matched sequences in the database that were taxonomically unclassifiable (e.g. taxID 155900, “uncultured organism”). Reads matching these criteria were also used for the comparison of positive and blank samples from the Strandseq and RNAseq experiments, where the taxonomy tree was ascended to the “genus” level and reads that matched to more than one genus were discarded.
Diversity of chloroplast DNAs in individual libraries
Using the sequencing data described in Additional File 2, Table S2 and the methods described above, I screened out reads in each of these 100 samples that matched the human hg18 genome. I then used bowtie to attempt to match each unmapped read to a database of chloroplast genomes (Additional Table S4, Table S3), allowing no mismatches in the seed region (‘-n 0’). These settings were specified to closely follow those used by Spisak et al [28]. As a further precaution against incorrect assignment, reads that matched chloroplasts using the above criteria were screened using BLAST against the NR database, removing those that had higher similarity to non-chloroplast sequences.
Other contaminant species detected in cell-free DNA sequencing samples
Downloading the data generated by Spisak et al [28] (European Nucleotide Archive accession number ERP002472), I created a representative subsample by combining one million reads from each sequencing sample. I screened these data against the Escherichia coli, Malassezia globusa and Propionibacterium acnes genomes and the Solanum lycopersicum chloroplast genome using bowtie as described above and in Spisak et al. To more closely follow the methods used by Spisak et al, matching reads were not subsequently screened against the NR database.
Results and Discussion
Contaminant read count is inversely related to sample concentration
High throughput sequencing quantifies the relative, not absolute, quantities of different DNAs in a library. If we assume that the amount of contaminant DNA contributed to each of a set of identically-prepared libraries is constant, we should expect that the number of reads matching contaminant genomes will increase as the concentration of the sample decreases. To illustrate this relationship, I reanalyzed data from a study that sequenced different dilutions of a single sample of E. coli DNA [18], examining how changes in the concentration of E. coli DNA affected the number of reads matching sequences in the human genome, a common laboratory contaminant [12], [14].
The authors of this study sought to demonstrate the efficacy of a novel low-concentration library preparation protocol. To this end, they used it to create libraries from 1ng, 100pg, and 10pg of a shared E. coli DNA sample; they also used 1 µg of this DNA to prepare a sequencing library using the standard Illumina protocol. As expected, there is an inverse relationship between the concentration of the sample and the frequency of contaminant reads (Figure 1A). For the four libraries prepared from the highest concentration of DNA (1ng), I found only three reads in total that mapped to the human but not to the E. coli genome. However, the frequency of these reads increased with decreasing sample concentration, to approximately 175 and 2,500 reads per million in the 100 and 10pg samples, respectively (z = -108.4, p<2e-16, see Methods). The protocol used to prepare the libraries can influence the amount of contamination, however: the protocol described above used a single tube to fragment input DNA, ligate adapters, and amplify fragments, potentially reducing the sample's exposure to contaminants. I found an intermediate frequency of contaminating reads in the library prepared from the standard Illumina protocol, despite its higher concentration of sample DNA (Figure 1B).
Figure 1. Reads matching the human genome are more prevalent in libraries prepared from dilute samples.
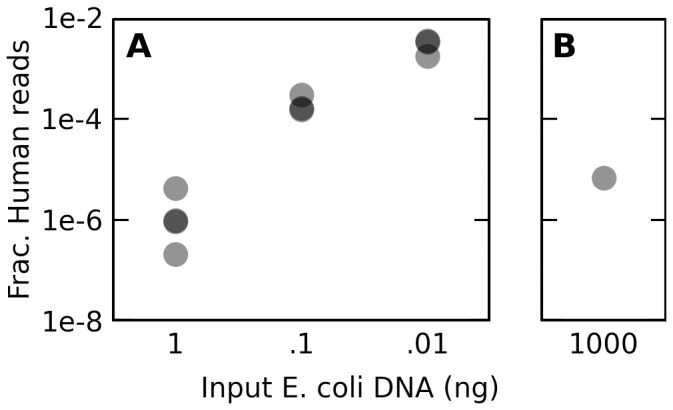
(a) The fraction of paired-end reads which preferentially map to the contaminant human genome instead of the E. coli K-12 genome, measured against the total number of reads in the library, is plotted against the amount of E. coli K-12 DNA used per tagmentation procedure as described by Parkinson et al [18]. Shading is used to highlight closely overlapping points (n = 4, 3, and 3 for the 1ng, 100pg, and 10pg libraries, respectively). Libraries listed at each concentration were not identically prepared, each using a different restriction enzyme or set of restriction enzymes at an intermediate step in the protocol (Additional File 1, Table S1), but the number and composition of enzymes used did not appreciably change the number of contaminant reads recovered. (b) The same fraction is plotted for a library prepared in the same experiment using a standard Illumina library preparation protocol. Despite a higher concentration of input DNA, an intermediate number of contaminant reads was detected.
This relationship between the concentration of the sample and the frequency of contaminant reads may differ in magnitude within and between experiments due to, for instance, differing preparation protocols, laboratory environments, and human error. Nevertheless, we can expect in general that libraries prepared from dilute samples will be more vulnerable to contaminating DNAs than will libraries prepared from more concentrated samples.
Unmapped reads from independent experiments match a wide range of species
Although contamination by DNA from humans [12], [14], plants [17], and a handful of bacterial species [13], [15], [16] has been described in sequencing data, there has been to my knowledge no systematic effort to describe the diversity of contaminants evident in sequencing data, making it difficult to gauge the likelihood that any given species inferred to be present from sequencing data originated from contamination. To address this issue, I performed a metagenomic analysis of potential contaminants in a set of four independent sequencing experiments [23]-[26].
In order to recover the greatest possible yield of contaminant DNAs, I chose experiments that worked with low quantities of input material. All of these experiments prepared libraries from individual cells, but they otherwise had different goals and used different species and experimental techniques (Table 1). I took several precautions to limit the impact of sequencing errors and to ensure that inferences of contaminant species were as conservative as possible. For each of these experiments I used permissive settings to screen out reads that could potentially map to the appropriate reference genome, and I then used BLAST to search for perfect matches to the remaining reads in the NR database across the entire or, depending on the dataset, close to the entire length of each read (see Methods). The use of BLAST for phylogenetic assignment, although once standard [29], has important shortcomings, including loss of information from non-global alignment, ignorance of population genetic and phylogenetic issues, and the use of sequence-level rather than clade-level confidence metrics [30]. However, alternative methods that take these issues into account, e.g. SAP [30] and EcoTag [31], are not computationally feasible at this scale. As highly conserved regions are less informative for taxonomic classification, I further screened out reads with reported BLAST hits to more than one broad taxonomic category.
Table 1. Description of the sequencing experiments used in this study.
| Experiment | Reference | Organism | RNA/DNA | Platform | Cell isolation | Pooled | Read length | Number of reads |
| RNAseq | [25] | Mouse | RNA | GA IIx | Cell picker | Yes | 56 | 93,471,748 |
| Tumor | [23] | Human | DNA | GA II | FACS | No | 48 | 8,568,573 |
| Strandseq | [24] | Mouse | DNA | GAIIx/Hiseq2000 | FACS | Yes | 75 | 100,026,526 |
| Sperm | [26] | Human | DNA | HiSeq2000 | Pipetting | No | 101 | 17,066,385 |
In all of these experiments I found reads matching sequences belonging to a wide diversity of groups (Figure 2), and the observed abundance of each group was broadly correlated across experiments. These groups include some which might seem unlikely contributors to contamination, such as Streptophyta, a phylum encompassing the land plants and some green algaes.
Figure 2. Reads that do not map to the reference genome match a diverse array of clades.

For each experiment (“Tumor” [23], “RNAseq” [25], “Sperm” [26], and “Strandseq” [24]), all reads were individually mapped to the appropriate reference genome using permissive parameters before being used to query the NR database using BLAST. BLAST hits were considered “perfect” if they matched with 100% identity over a dataset-specific length threshold (see Methods). A read was assigned to one of the depicted phylogenetic categories if it did not map or have a perfect BLAST hit to the reference genome, had a perfect BLAST hit to a species in that category, and had no BLAST hits to species outside that category. For each category and experiment, the fraction of reads meeting this criteria against the total number of reads in the experiment is depicted.
There are several potential sources for reads such as these that preferentially map to alternate genomes in sequencing experiments. In some cases, they may truly be evidence for an alternate organism in the sample, e.g. the serendipitous sequencing of new genomes of the bacterial endosymbiont Wolbachia in several Drosophila genome sequencing projects [32]. This seems unlikely for the reads described in Figure 2, because all of these experiments sequenced individual cells. Many of these reads map to organisms that seem likely to contaminate samples, such as Propionibacterium acnes, a pervasive skin bacterium, and the simplest explanation for the diversity detected may be that traces of many species are widespread in the laboratory environment. It is also possible for multiplexed libraries to cross-contaminate each other during sequencing [33], although this would not explain the diversity of species observed here.
Many reads observed here appear to map to alternate genomes due to sequencing errors. While most reads containing errors will presumably not perfectly match any species' genome, the large number of reads analyzed here ensures that many will coincidentally match genomes of species only related to those actually present in the sample. For instance, many reads in each experiment matched the chimpanzee genome, even though the sample organism was either mouse or human. Whether a given match to an exogenous species originated from a true contaminant or from a sequencing error can be difficult to distinguish. Indeed, some of the matches to the chimpanzee genome, particularly those from the mouse experiments, may be due to errors made during sequencing of contaminant human DNA. The choice of aligner may also play a role in species assignment. Here I have used an ungapped aligner, bowtie v.1.0, and so a missed base in the reference sequence would prevent mapping to the correct sequence and would preferentially match homologous sequences from related species. Similarly, incomplete reference genomes may lead to false inference of contamination, and differences in completeness of alternate genomes may bias the inference of the origins of contamination. However, these issues, driven by close homology, would be unlikely to shift the distribution of broad taxonomic categories shown in Figure 3.
Figure 3. Experiment-specific correlation between distributions of genera recovered from ‘blank’ and positive samples.

The “RNAseq” [25] and “Strandseq” [24] experiments sequenced libraries prepared from blank samples into which no cells had been introduced. Reads from these blank samples and from all other samples were separately pooled, screened against the mouse reference genome, and queried against the BLAST NR database. Reads were screened using the same criteria as described for Figure 2, but adjusted to the genus taxonomic level. The number of reads matching each genus in each dataset was counted, incremented by one, and log transformed. Values for the pooled positive samples (StrandSeq and RNAseq in rows A-B and C-D, respectively) are plotted with their Pearson correlation against values for the pooled negative samples (Strandseq and RNAseq in columns A-C and B-D, respectively). Matched positive and negative samples in (B) and (C) exhibit more correlated read counts than do mismatched positive and negative samples in (A) and (D).
It is possible that examination of error patterns and rates with different sequencing technologies would allow probabilistic attribution of each potential contaminant read to either experimental or sequencing errors, but for the purposes of this study the precise origins of each read will remain ambiguous. To reflect this ambiguity, I will refer to reads that match exogenous genomes as “contaminant matching reads.”
‘Blank’ negative controls effectively describe the distribution of contaminants per sample
The “RNAseq” and “Strandseq” (Table 1) experiments prepared negative control libraries from “blank” buffer samples into which no sample cell had been deposited. However, only a small number of such libraries were prepared, and each produced a relatively small number of reads, having in total 0.56% and 0.21% of the corresponding total number of reads in the positive samples from the RNAseq and Strandseq studies, respectively. It is possible that this low yield compromised their ability to represent the spectrum of contaminants found in the positive samples.
To address this possibility, I compared the frequency distribution of genera represented by contaminant matching reads in the positive and blank samples, discarding reads that promiscuously matched more than one genus. I found that the frequency distribution of recovered genera correlated well between positive and blank samples from the same experiment, suggesting that, despite their low yield, blank samples can serve as effective negative controls (Figure 3). Furthermore, the correlation is poorer between mismatched positive and blank samples taken from different experiments, consistent with the spectrum of contaminants being experiment-specific. For instance, reads matching the skin bacterium Propionibacterium acnes are more than 100-fold more frequent in the genomic DNA sample than they are in the RNA-seq dataset, perhaps reflecting the stricter guidelines for handling RNA.
Despite the strong correlation between the positive and blank libraries, the low yield of the blank libraries limited their ability to control for low frequency genera in the positive libraries, many of which were not represented in the blanks. As the lack of input DNA pushes the boundaries of preparation protocols, this low yield may be inevitable in true blanks. To increase overall yield and thereby lower the detection threshold for potential contaminants, it may be sufficient to increase the number of blank samples or to use a distinguishable carrier DNA (e.g. [34]). Sequencing data generated from libraries prepared in the same laboratory and with the same equipment may also be informative [17]. In cases where exclusion of contaminants is paramount, the use of techniques from ancient DNA sequencing may be considered (e.g. [9]).
Libraries prepared from a single tissue appear contaminated by different species
If a reagent or piece of equipment is heavily contaminated by a given species, then all exposed samples should share evidence of being contaminated by that species. In this scenario, one way to control for contamination would be to examine how exogenous species are distributed, considering as contaminants species that are recovered from most or all samples. However, while this assumption is reasonable if the contaminant concentration is high, we should expect a weaker correlation between exogenous species if the contaminant concentration is low. Indeed, at the lower limit, where each contaminant species contributes one DNA molecule, samples will necessarily be contaminated by different species. To examine whether these low-frequency contaminants are detectable and to what extent they differ between samples, I reanalyzed data from the “Tumor” experiment in which independent sequencing samples were prepared from the same tissue rather than from independent individuals. In this case, all differences between samples outside changes to the target genome can be attributed to contamination.
In this experiment, Navin et al [23] used FACS to isolate 100 individual nuclei from a section of a single tumor, and, processing them similarly through 96-well plates, used whole genome amplification to accumulate sufficient DNA for library preparation and sequencing. For each of these libraries, I first screened out loose matches to the human genome before searching for strong matches to a database of chloroplast genomes. Reads that matched chloroplast genomes were further screened against the NR database using BLAST, and chloroplast genomes with uneven read coverage, presumably caused by matches to low-complexity sequences, were screened out as well (Additional File 5, Figure S2). I found reads matching chloroplast DNAs in all samples, and different samples had different rosters of inferred contaminants (Figure 4; Additional File 6, Table S4), suggesting that contaminants can contribute unevenly to samples within a single experiment. Many of the species recovered are edible and commonly eaten, such as tomato and lettuce, although a slight majority (53%) of the reads from Figure 4 matched to oak and chestnut. Many reads also matched to Heliconia, but these could be due to Heliconia's close relation to the banana, which was not represented in the chloroplast database.
Figure 4. Heterogeneous species appear to contaminant samples from the same tissue and experiment.
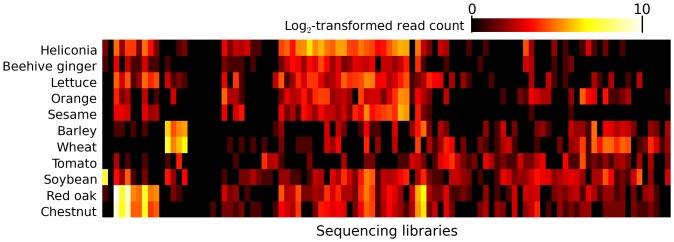
The “Tumor” [23] experiment dissociated 100 individual cells from a sample of a single tumor and sequenced libraries from each. Following the analysis pipeline of a study that claimed to find different plant species in different blood plasma samples from a single experiment, I used bowtie to screen each read in each library against the human reference genome before using it to query a database of chloroplast genomes. The number of such hits to each genome is depicted here, each count incremented by one and log-transformed. Only chloroplast genomes with at least 200 hits are shown. Rows and columns were clustered using a neighbor-joining algorithm.
Contaminants provide an alternative explanation for observations of plant DNAs in human blood
Highlighting the potential impact of contaminants in high throughput sequencing data is a controversial paper that claimed that complete genes pass from food to human blood [28]. The authors of this study based their claim on their observations of chloroplast sequences from edible plants in sequencing data from samples of blood plasma. They were able to replicate this observation in independent datasets, and, contrary to what might be expected from a single contamination event, found that the plant species recovered differed from sample to sample within a single experiment. Furthermore, while these reads could not be detected in a negative control sample of fetal blood, which circulates independently, they found many in the corresponding maternal plasma sample, which is presumably more exposed to the digestive system.
On the basis of their observation's heavy replication, heterogeneity among samples, absence from a plausible negative control, and, finally, their assumption that plant DNA would be unlikely to infiltrate stringent laboratory practices, the authors dismissed the possibility of contamination. However, as I have shown above, all of these assumptions about the nature of contamination are incorrect. DNA from plants is a common contaminant, and it should be expected to appear to replicate across independent experiments (Figure 2). Furthermore, the particular species inferred can vary considerably from sample to sample within an experiment (Figure 4). Finally, although the authors did find hundreds of reads matching plants in a maternal plasma sample, and none in a matched sample of whole fetal blood, the concentration of DNA in whole blood is tens-of-thousands-fold higher than that in blood plasma (approximately 60 µg/ml vs. 21ng/ml [35], [36]). Given the inverse relationship between sample DNA concentration and contaminant frequency (Figure 1), we should expect plasma samples to exhibit more evidence of contamination than full blood samples. Indeed, the corresponding maternal whole blood sample contained only one plant-matching read, a number statistically indistinguishable from zero, suggesting that using fetal whole blood as a negative control in this case was inappropriate. Contamination thus provides an alternative explanation for all of the observations originally used to support the authors' claim.
To further investigate this possibility, I used the same criteria used by Spisak et al [28] to assign reads to the tomato genome, their most frequent inferred contaminant, to search for reads matching three other potential contaminants in a representative sample of the same datasets (see Methods): E. coli, P. acnes and M. globosa. P. acnes and M. globosa are widely associated with the human skin flora [37], [38], although both have been detected in stool samples as well [39],[40]. Reads matching the genomes of each of these species were more frequent than reads matching the tomato chloroplast genome (Figure 5). While it cannot be proven that these reads did not originate from genes passing through the epithelium of the gastrointestinal tract, contamination appears to be their more likely source.
Figure 5. Reads matching the tomato chloroplast genome are less frequent than other contaminant matching reads in samples of cell-free DNA.
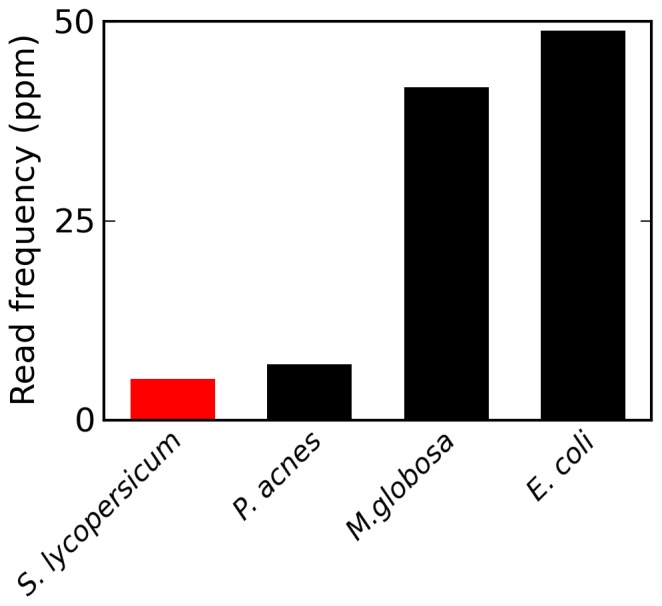
Spisak et al [28] used the frequency of reads matching chloroplast genomes as evidence that genes pass intact from food to the bloodstream, and found S. lycopersicum (tomato) to be the most common contaminant. Evenly sampling from all of the sequencing samples generated by Spisak et al, I used identical criteria to investigate potential matches to three other contaminant species, E. coli, P. acnes and M. globosa. P. acnes and M. globosa are associated with the human skin flora. The frequency of reads matching each of these contaminant reads, per million reads in the pooled samples, is depicted.
Conclusions
Contaminants can in some cases effectively mimic behavior intuitively expected from true signals, including replication across independent experiments and variation between samples, and can include species that are not typically considered potential contaminants. This calls into question several controversial works that have rested their claims on observations of rare matches to exogenous species in sequencing data [28], [41]-[43], and suggests that blank negative controls, prepared in parallel with experimental samples, are essential. Nevertheless, the rarest contaminants, being difficult to recover in these controls, may be intrinsically difficult to control for.
Supporting Information
Information per position in RNAseq dataset. The entropy of each position in each of 460 libraries was calculated, and the distribution of these among datasets is depicted for each position. Due to the protocol used to generate these data, each read began with a six base pair barcode, followed by at least three guanines. On the basis of this analysis, the first fifteen bases, highlighted in gray, were trimmed from each read.
(PDF)
Coverage of chloroplast genomes. Reads from the “Tumor” experiment were mapped to a database of chloroplast genomes, and the coverage of genomes with more than 200 matches is depicted here. The B. hypnoides genome was removed from further analysis due to the observed uneven coverage.
(PDF)
The European Nucleotide Archive accession numbers associated with each sample analyzed in Figure 1 .
(CSV)
The total number of hits to each chloroplast genome in each library from the Tumor dataset.
(CSV)
Acknowledgments
I would like to thank Patricia Wittkopp, Brian Metzger, Kraig Stevenson, Joseph Coolon, and Fabien Duveau for critical comments on the manuscript. I would also like to thank those listed above and other members of the Wittkopp laboratory for valuable discussions.
Data Availability
The author confirms that all data underlying the findings are fully available without restriction. All of the data used in this paper is available in public repositories. Specific accession numbers are listed in the Methods section and in Tables S1-S4.
Funding Statement
RWL was supported by NIH postdoctoral fellowship F32-GM100685 (http://www.nih.gov). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
References
- 1. Schmidt T, Hummel S, Herrmann B (1995) Evidence of contamination in PCR laboratory disposables. Naturwissenschaften 82(9): 423–31. [DOI] [PubMed] [Google Scholar]
- 2. Leonard JA, Shanks O, Hofreiter M, Kreuz E, Hodges L, et al. (2007) Animal DNA in PCR reagents plagues ancient DNA research. Journal of Archaeological Science 34(9): 1361–6. [Google Scholar]
- 3. Peters RP, Mohammadi T, Vandenbroucke Grauls CM, Danner SA, van Agtmael MA, et al. (2004) Detection of bacterial DNA in blood samples from febrile patients: underestimated infection or emerging contamination? FEMS Immunol Med Microbiol 42(2): 249–53. [DOI] [PubMed] [Google Scholar]
- 4. Ehricht R, Hotzel H, Sachse K, Slickers P (2007) Residual DNA in thermostable DNA polymerases - a cause of irritation in diagnostic PCR and microarray assays. Biologicals 35(2): 145–7. [DOI] [PubMed] [Google Scholar]
- 5. Evans GE, Murdoch DR, Anderson TP, Potter HC, George PM, et al. (2003) Contamination of Qiagen DNA extraction kits with Legionella DNA. J Clin Microbiol 41(7): 3452–3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Hughes MS, Beck LA, Skuce RA (1994) Identification and elimination of DNA sequences in Taq DNA polymerase. J Clin Microbiol 32(8): 2007–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Erlwein O, Robinson MJ, Dustan S, Weber J, Kaye S, et al. (2011) DNA extraction columns contaminated with murine sequences. PLoS One 6(8): e23484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Persing DH (1991) Polymerase chain reaction: trenches to benches. J Clin Microbiol 29(7): 1281–5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Champlot S, Berthelot C, Pruvost M, Bennett EA, Grange T, et al.. (2010) An efficient multistrategy DNA decontamination procedure of PCR reagents for hypersensitive PCR applications. PLoS One 5(9). [DOI] [PMC free article] [PubMed]
- 10. Gill P, Whitaker J, Flaxman C, Brown N, Buckleton J (2000) An investigation of the rigor of interpretation rules for STRs derived from less than 100 pg of DNA. Forensic Sci Int 112(1): 17–40. [DOI] [PubMed] [Google Scholar]
- 11. Corless CE, Guiver M, Borrow R, Edwards-Jones V, Kaczmarski EB, et al. (2000) Contamination and sensitivity issues with a real-time universal 16S rRNA PCR. J Clin Microbiol 38(5): 1747–52. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Longo MS, O'Neill MJ, O'Neill RJ (2011) Abundant human DNA contamination identified in non-primate genome databases. PLoS One 6(2): e16410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Binns M (1993) Contamination of DNA database sequence entries with Escherichia coli insertion sequences. Nucleic Acids Res 21(3): 779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Schmieder R, Edwards R (2011) Fast identification and removal of sequence contamination from genomic and metagenomic datasets. PLoS One 6(3): e17288. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Astua-Monge G, Lyznik A, Jones V, Mackenzie SA, Vallejos CE (2002) Evidence for a prokaryotic insertion-sequence contamination in eukaryotic sequences registered in different databases. Theor Appl Genet 104(1): 48–53. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Percudani R (2013) A Microbial Metagenome (Leucobacter sp.) in Caenorhabditis Whole Genome Sequences. Bioinform Biol Insights 7: 55–72. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Tosar JP, Rovira C, Naya H, Cayota A (2014) Mining of public sequencing databases supports a non-dietary origin for putative foreign miRNAs: underestimated effects of contamination in NGS. RNA 20: 754–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Parkinson NJ, Maslau S, Ferneyhough B, Zhang G, Gregory L, et al. (2012) Preparation of high-quality next-generation sequencing libraries from picogram quantities of target DNA. Genome Res 20: 754–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Langmead B, Trapnell C, Pop M, Salzberg SL (2009) Ultrafast and memory-efficient alignment of short DNA sequences to the human genome. Genome Biol 10(3): R25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. International Human Genome Sequencing Consortium (2001) Initial sequencing and analysis of the human genome. Nature 409(6822): 860–921. [DOI] [PubMed] [Google Scholar]
- 21. Marschner IC (2011) glm2: fitting generalized linear models with convergence problems. The R journal 3(2): 12–5. [Google Scholar]
- 22.R Core Team (2014) R: A language and environment for statistical computing. Vienna: the R Foundation for Statistical Computing. 3397 p. [Google Scholar]
- 24. Falconer E, Hills M, Naumann U, Poon SS, Chavez EA, et al. (2012) DNA template strand sequencing of single-cells maps genomic rearrangements at high resolution. Nat Methods 9(11): 1107–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Islam S, Kjällquist U, Moliner A, Zajac P, Fan JB, et al. (2011) Characterization of the single-cell transcriptional landscape by highly multiplex RNA-seq. Genome Res 21(7): 1160–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Lu S, Zong C, Fan W, Yang M, Li J, et al. (2012) Probing meiotic recombination and aneuploidy of single sperm cells by whole-genome sequencing. Science 338(6114): 1627–30. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Mouse genome sequencing consortium (2002) Initial sequencing and analysis of the mouse genome. Nature 420(6915): 520–62. [DOI] [PubMed] [Google Scholar]
- 28. Spisák S, Solymosi N, Ittzés P, Bodor A, Kondor D, et al. (2013) Complete genes may pass from food to human blood. PLoS One 8(7): e69805. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Altschul SF, Madden TL, Schaffer AA, Zhang J, Zhang Z, et al. (1997) Gapped Blast and psi-Blast: A new generation of protein database search programs. Nucleic Acids Res 25: 3389–402. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30. Munch K, Boomsma W, Huelsenbeck JP, Willerslev E, Nielsen R (2008) Statistical assignment of DNA sequences using Bayesian phylogenetics. Syst Biol 57(5): 750–7. [DOI] [PubMed] [Google Scholar]
- 31.OBITool Development Team. Available: http://www.grenoble.prabi.fr/trac/OBITools. Accessed 2014 August 17.
- 32.Salzberg SL, Dunning Hotopp JC, Delcher AL, Pop M, Smith DR, et al. (2005) Serendipitous discovery of Wolbachia genomes in multiple Drosophila species. Genome Biol 6(3) : R 23. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Kircher M, Sawyer S, Meyer M (2012) Double indexing overcomes inaccuracies in multiplex sequencing on the Illumina platform. Nucleic Acids Rsch 40(1): e3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Combs PA, Eisen MB (2013) Sequencing mRNA from cryo-sliced Drosophila embryos to determine genome-wide spatial patterns of gene expression. PLoS One 8(8): e71820. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Salazar LA, Hirata MH, Cavalli SA, Machado MO, Hirata RD (1998) Optimized procedure for DNA isolation from fresh and cryopreserved clotted human blood useful in clinical molecular testing. Clin Chem 44(8): 1748–50. [PubMed] [Google Scholar]
- 36. Cherepanova AV, Tamkovich SN, Bryzgunova OE, Vlassov VV, Laktionov PP (2008) Deoxyribonuclease activity and circulating DNA concentration in blood plasma of patients with prostate tumors. Ann N Y Acad Sci 1137: 218–21. [DOI] [PubMed] [Google Scholar]
- 37. Cogen AL, Nizet V, Gallo RL (2009) Skin microbiota: a source of disease or defence? Br J Dermatology 158(3): 442–55. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Yim SM, Kim JY, Ko JH, Lee YW, Choe YB, et al. (2010) Molecular analysis of Malassezia microflora on the skin of the patients with atopic dermatitis. Ann Dermatol 22(1): 41–7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Gossling J, Slack JM (1974) Predominant Gram-Positive Bacteria in Human Feces: Numbers, Variety, and Persistence. Infection and Immunity 9(4): 719–29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Gouba N, Raoult D, Drancourt M (2013) Plant and fungal diversity in gut microbiota as revealed by molecular and culture investigations. PLOS ONE 8(3): e59474. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Zhang L, Hou D, Chen X, Li D, Zhu L, et al. (2012) Exogenous plant MIR168a specifically targets mammalian LDLRAP1: evidence of cross-kingdom regulation by microRNA. Cell Res 22(1): 107–26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Shtarkman YM, Koçer ZA, Edgar R, Veerapaneni RS, D'Elia T, et al. (2013) Subglacial Lake Vostok (Antarctica) accretion ice contains a diverse set of sequences from aquatic, marine and sediment-inhabiting bacteria and eukarya. PLoS One 8(7): e67221. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Wang K, Li H, Yuan Y, Etheridge A, Zhou Y, et al. (2012) The complex exogenous RNA spectra in human plasma: an interface with human gut biota? 7(12): e51009. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Information per position in RNAseq dataset. The entropy of each position in each of 460 libraries was calculated, and the distribution of these among datasets is depicted for each position. Due to the protocol used to generate these data, each read began with a six base pair barcode, followed by at least three guanines. On the basis of this analysis, the first fifteen bases, highlighted in gray, were trimmed from each read.
(PDF)
Coverage of chloroplast genomes. Reads from the “Tumor” experiment were mapped to a database of chloroplast genomes, and the coverage of genomes with more than 200 matches is depicted here. The B. hypnoides genome was removed from further analysis due to the observed uneven coverage.
(PDF)
The European Nucleotide Archive accession numbers associated with each sample analyzed in Figure 1 .
(CSV)
The total number of hits to each chloroplast genome in each library from the Tumor dataset.
(CSV)
Data Availability Statement
The author confirms that all data underlying the findings are fully available without restriction. All of the data used in this paper is available in public repositories. Specific accession numbers are listed in the Methods section and in Tables S1-S4.