

Abstract
In recent years, a rich variety of shrinkage priors have been proposed that have great promise in addressing massive regression problems. In general, these new priors can be expressed as scale mixtures of normals, but have more complex forms and better properties than traditional Cauchy and double exponential priors. We first propose a new class of normal scale mixtures through a novel generalized beta distribution that encompasses many interesting priors as special cases. This encompassing framework should prove useful in comparing competing priors, considering properties and revealing close connections. We then develop a class of variational Bayes approximations through the new hierarchy presented that will scale more efficiently to the types of truly massive data sets that are now encountered routinely.
1 Introduction
Penalized likelihood estimation has evolved into a major area of research, with ℓ1[22] and other regularization penalties now used routinely in a rich variety of domains. Often minimizing a loss function subject to a regularization penalty leads to an estimator that has a Bayesian interpretation as the mode of a posterior distribution [8, 11, 1, 2], with different prior distributions inducing different penalties. For example, it is well known that Gaussian priors induce ℓ2 penalties, while double exponential priors induce ℓ1 penalties [8, 19, 13, 1]. Viewing massive-dimensional parameter learning and prediction problems from a Bayesian perspective naturally leads one to design new priors that have substantial advantages over the simple normal or double exponential choices and that induce rich new families of penalties. For example, in high-dimensional settings it is often appealing to have a prior that is concentrated at zero, favoring strong shrinkage of small signals and potentially a sparse estimator, while having heavy tails to avoid over-shrinkage of the larger signals. The Gaussian and double exponential priors are insufficiently flexible in having a single scale parameter and relatively light tails; in order to shrink many small signals strongly towards zero, the double exponential must be concentrated near zero and hence will over-shrink signals not close to zero. This phenomenon has motivated a rich variety of new priors such as the normal-exponential-gamma, the horseshoe and the generalized double Pareto [11, 14, 1, 6, 20, 7, 12, 2].
An alternative and widely applied Bayesian framework relies on variable selection priors and Bayesian model selection/averaging [18, 9, 16, 15]. Under such approaches the prior is a mixture of a mass at zero, corresponding to the coefficients to be set equal to zero and hence excluded from the model, and a continuous distribution, providing a prior for the size of the non-zero signals. This paradigm is very appealing in fully accounting for uncertainty in parameter learning and the unknown sparsity structure through a probabilistic framework. One obtains a posterior distribution over the model space corresponding to all possible subsets of predictors, and one can use this posterior for model-averaged predictions that take into account uncertainty in subset selection and to obtain marginal inclusion probabilities for each predictor providing a weight of evidence that a specific signal is non-zero allowing for uncertainty in the other signals to be included. Unfortunately, the computational complexity is exponential in the number of candidate predictors (2p with p the number of predictors).
Some recently proposed continuous shrinkage priors may be considered competitors to the conventional mixture priors [15, 6, 7, 12] yielding computationally attractive alternatives to Bayesian model averaging. Continuous shrinkage priors lead to several advantages. The ones represented as scale mixtures of Gaussians allow conjugate block updating of the regression coefficients in linear models and hence lead to substantial improvements in Markov chain Monte Carlo (MCMC) efficiency through more rapid mixing and convergence rates. Under certain conditions these will also yield sparse estimates, if desired, via maximum a posteriori (MAP) estimation and approximate inferences via variational approaches [17, 24, 5, 8, 11, 1, 2].
The class of priors that we consider in this paper encompasses many interesting priors as special cases and reveals interesting connections among different hierarchical formulations. Exploiting an equivalent conjugate hierarchy of this class of priors, we develop a class of variational Bayes approximations that can scale up to truly massive data sets. This conjugate hierarchy also allows for conjugate modeling of some previously proposed priors which have some rather complex yet advantageous forms and facilitates straightforward computation via Gibbs sampling. We also argue intuitively that by adjusting a global shrinkage parameter that controls the overall sparsity level, we may control the number of non-zero parameters to be estimated, enhancing results, if there is an underlying sparse structure. This global shrinkage parameter is inherent to the structure of the priors we discuss as in [6, 7] with close connections to the conventional variable selection priors.
2 Background
We provide a brief background on shrinkage priors focusing primarily on the priors studied by [6, 7] and [11, 12] as well as the Strawderman-Berger (SB) prior [7]. These priors possess some very appealing properties in contrast to the double exponential prior which leads to the Bayesian lasso [19, 13]. They may be much heavier-tailed, biasing large signals less drastically while shrinking noise-like signals heavily towards zero. In particular, the priors by [6, 7], along with the Strawderman-Berger prior [7], have a very interesting and intuitive representation later given in (2), yet, are not formed in a conjugate manner potentially leading to analytical and computational complexity.
[6, 7] propose a useful class of priors for the estimation of multiple means. Suppose a p-dimensional vector y|θ~
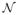 (θ, I) is observed. The independent hierarchical prior for θj is given by
(θ, I) is observed. The independent hierarchical prior for θj is given by
| (1) |
for j = 1, …, p, where
(μ, ν) denotes a normal distribution with mean μ and variance ν and
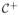 (0, s) denotes a half-Cauchy distribution on
(0, s) denotes a half-Cauchy distribution on
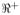 with scale parameter s. With an appropriate transformation ρj = 1/(1 + τj), this hierarchy also can be represented as
with scale parameter s. With an appropriate transformation ρj = 1/(1 + τj), this hierarchy also can be represented as
| (2) |
A special case where φ = 1 leads to ρj ~
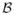 (1/2, 1/2) (beta distribution) where the name of the prior arises, horseshoe (HS) [6, 7]. Here ρj s are referred to as the shrinkage coefficients as they determine the magnitude with which θj s are pulled toward zero. A prior of the form ρj ~
(1/2, 1/2) is natural to consider in the estimation of a signal θj as this yields a very desirable behavior both at the tails and in the neighborhood of zero. That is, the resulting prior has heavy-tails as well as being unbounded at zero which creates a strong pull towards zero for those values close to zero. [7] further discuss priors of the form ρj ~
(a, b) for a > 0, b > 0 to elaborate more on their focus on the choice a = b = 1/2. A similar formulation dates back to [21]. [7] refer to the prior of the form ρj ~
(1, 1/2) as the Strawderman-Berger prior due to [21] and [4]. The same hierarchical prior is also referred to as the quasi-Cauchy prior in [16]. Hence, the tail behavior of the Strawderman-Berger prior remains similar to the horseshoe (when φ = 1), while the behavior around the origin changes. The hierarchy in (2) is much more intuitive than the one in (1) as it explicitly reveals the behavior of the resulting marginal prior on θj. This intuitive representation makes these hierarchical priors interesting despite their relatively complex forms. On the other hand, what the prior in (1) or (2) lacks is a more trivial hierarchy that yields recognizable conditional posteriors in linear models. [11, 12] consider the normal-exponential-gamma (NEG) and normal-gamma (NG) priors respectively which are formed in a conjugate manner yet lack the intuition the Strawderman-Berger and horseshoe priors provide in terms of the behavior of the density around the origin and at the tails. Hence the implementation of these priors may be more user-friendly but they are very implicit in how they behave. In what follows we will see that these two forms are not far from one another. In fact, we may unite these two distinct hierarchical formulations under the same class of priors through a generalized beta distribution and the proposed equivalence of hierarchies in the following section. This is rather important to be able to compare the behavior of priors emerging from different hierarchical formulations. Furthermore, this equivalence in the hierarchies will allow for a straightforward Gibbs sampling update in posterior inference, as well as making variational approximations possible in linear models.
(1/2, 1/2) (beta distribution) where the name of the prior arises, horseshoe (HS) [6, 7]. Here ρj s are referred to as the shrinkage coefficients as they determine the magnitude with which θj s are pulled toward zero. A prior of the form ρj ~
(1/2, 1/2) is natural to consider in the estimation of a signal θj as this yields a very desirable behavior both at the tails and in the neighborhood of zero. That is, the resulting prior has heavy-tails as well as being unbounded at zero which creates a strong pull towards zero for those values close to zero. [7] further discuss priors of the form ρj ~
(a, b) for a > 0, b > 0 to elaborate more on their focus on the choice a = b = 1/2. A similar formulation dates back to [21]. [7] refer to the prior of the form ρj ~
(1, 1/2) as the Strawderman-Berger prior due to [21] and [4]. The same hierarchical prior is also referred to as the quasi-Cauchy prior in [16]. Hence, the tail behavior of the Strawderman-Berger prior remains similar to the horseshoe (when φ = 1), while the behavior around the origin changes. The hierarchy in (2) is much more intuitive than the one in (1) as it explicitly reveals the behavior of the resulting marginal prior on θj. This intuitive representation makes these hierarchical priors interesting despite their relatively complex forms. On the other hand, what the prior in (1) or (2) lacks is a more trivial hierarchy that yields recognizable conditional posteriors in linear models. [11, 12] consider the normal-exponential-gamma (NEG) and normal-gamma (NG) priors respectively which are formed in a conjugate manner yet lack the intuition the Strawderman-Berger and horseshoe priors provide in terms of the behavior of the density around the origin and at the tails. Hence the implementation of these priors may be more user-friendly but they are very implicit in how they behave. In what follows we will see that these two forms are not far from one another. In fact, we may unite these two distinct hierarchical formulations under the same class of priors through a generalized beta distribution and the proposed equivalence of hierarchies in the following section. This is rather important to be able to compare the behavior of priors emerging from different hierarchical formulations. Furthermore, this equivalence in the hierarchies will allow for a straightforward Gibbs sampling update in posterior inference, as well as making variational approximations possible in linear models.
3 Equivalence of Hierarchies via a Generalized Beta Distribution
In this section we propose a generalization of the beta distribution to form a flexible class of scale mixtures of normals with very appealing behavior. We then formulate our hierarchical prior in a conjugate manner and reveal similarities and connections to the priors given in [16, 11, 12, 6, 7]. As the name generalized beta has previously been used, we refer to our generalization as the three-parameter beta (TPB) distribution.
In the forthcoming text Γ(.) denotes the gamma function,
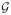 (μ, ν) denotes a gamma distribution with shape and rate parameters μ and ν,
(μ, ν) denotes a gamma distribution with shape and rate parameters μ and ν,
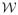 (ν, S) denotes a Wishart distribution with ν degrees of freedom and scale matrix S,
(ν, S) denotes a Wishart distribution with ν degrees of freedom and scale matrix S,
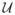 (α1, α2) denotes a uniform distribution over (α1, α2),
(α1, α2) denotes a uniform distribution over (α1, α2),
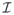 (μ, ν, ξ) denotes a generalized inverse Gaussian distribution with density function
, and Kμ(.) is a modified Bessel function of the second kind.
(μ, ν, ξ) denotes a generalized inverse Gaussian distribution with density function
, and Kμ(.) is a modified Bessel function of the second kind.
Definition 1
The three-parameter beta (TPB) distribution for a random variable X is defined by the density function
| (3) |
for 0 < x < 1, a > 0, b > 0 and φ > 0 and is denoted by
 (a, b, φ).
(a, b, φ).
It can be easily shown by a change of variable x = 1/(y + 1) that the above density integrates to 1. The kth moment of the TPB distribution is given by
| (4) |
where 2F1 denotes the hypergeometric function. In fact it can be shown that TPB is a subclass of Gauss hypergeometric (GH) distribution proposed in [3] and the compound confluent hypergeometric (CCH) distribution proposed in [10].
The density functions of GH and CCH distributions are given by
| (5) |
| (6) |
for 0 < x < 1 and 0 < x < 1/ν, respectively, where B(b, a) = Γ(a)Γ(b)/Γ(a + b) denotes the beta function and Φ1 is the degenerate hypergeometric function of two variables [10]. Letting ζ = φ − 1, r = a + b and noting that 2F1(a + b, b; a + b; 1 − φ) = φ−b, (5) becomes a TPB density. Also note that (6) becomes (5) for s = 1, ν = 1 and ζ = (1 − θ)/θ [10].
[20] considered an alternative special case of the CCH distribution for the shrinkage coefficients, ρj, by letting ν = r = 1 in (6). [20] refer to this special case as the hypergeometric-beta (HB) distribution. TPB and HB generalize the beta distribution in two distinct directions, with one practical advantage of the TPB being that it allows for a straightforward conjugate hierarchy leading to potentially substantial analytical and computational gains.
Now we move onto the hierarchical modeling of a flexible class of shrinkage priors for the estimation of a potentially sparse p-vector. Suppose a p-dimensional vector y|θ ~
(θ, I) is observed where θ = (θ1, …, θp)′ is of interest. Now we define a shrinkage prior that is obtained by mixing a normal distribution over its scale parameter with the TPB distribution.
Definition 2
The TPB normal scale mixture representation for the distribution of random variable θj is given by
| (7) |
where a > 0, b > 0 and φ > 0. The resulting marginal distribution on θj is denoted by
(a, b, φ).
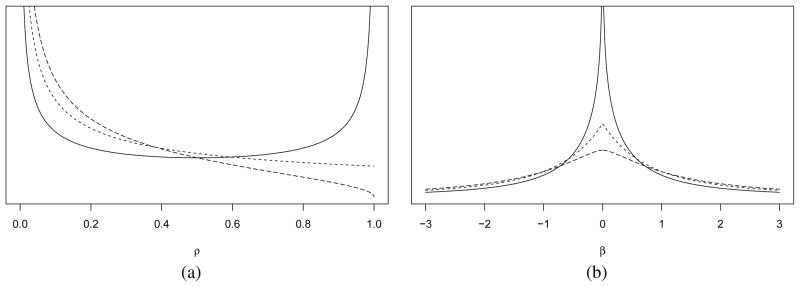
Figure 1 illustrates the density on ρj for varying values of a, b and φ. Note that the special case for a = b = 1/2 in Figure 1(a) gives the horseshoe prior. Also when a = φ = 1 and b = 1/2, this representation yields the Strawderman-Berger prior. For a fixed value of φ, smaller a values yield a density on θj that is more peaked at zero, while smaller values of b yield a density on θj that is heavier tailed. For fixed values of a and b, decreasing φ shifts the mass of the density on ρj from left to right, suggesting more support for stronger shrinkage. That said, the density assigned in the neighborhood of θj = 0 increases while making the overall density lighter-tailed. We next propose the equivalence of three hierarchical representations revealing a wide class of priors encompassing many of those mentioned earlier.
Figure 1.

(a, b) = {(1/2, 1/2), (1, 1/2), (1, 1), (1/2, 2), (2, 2), (5, 2)} for (a)–(f) respectively. φ = {1/10, 1/9, 1/8, 1/7, 1/6, 1/5, 1/4, 1/3, 1/2, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10} considered for all pairs of a and b. The line corresponding to the lowest value of φ is drawn with a dashed line.
Proposition 1
If θj ~
(a, b, φ), then
θj ~
(0, τj), τj ~
(a, λj) and λj ~
(b, φ).θj ~
(0, τj),
which implies that τj /φ ~ β′(a, b), the inverted beta distribution with parameters a and b.
The equivalence given in Proposition 1 is significant as it makes the work in Section 4 possible under the TPB normal scale mixtures as well as further revealing connections among previously proposed shrinkage priors. It provides a rich class of priors leading to great flexibility in terms of the induced shrinkage and makes it clear that this new class of priors can be considered simultaneous extensions to the work by [11, 12] and [6, 7]. It is worth mentioning that the hierarchical prior(s) given in Proposition 1 are different than the approach taken by [12] in how we handle the mixing. In particular, the first hierarchy presented in Proposition 1 is identical to the NG prior up to the first stage mixing. While fixing the values of a and b, we further mix over λj (rather than a global λ) and further over φ if desired as will be discussed later. φ acts as a global shrinkage parameter in the hierarchy. On the other hand, [12] choose to further mix over a and a global λ while fixing the values of b and φ. By doing so, they forfeit a complete conjugate structure and an explicit control over the tail behavior of π(θj).
As a direct corollary to Proposition 1, we observe a possible equivalence between the SB and the NEG priors.
Corollary 1
If a = 1 in Proposition 1, then TPBN = NEG. If (a, b, φ) = (1, 1/2, 1) in Proposition 1, then TPBN ≡ SB ≡ NEG.
An interesting, yet expected, observation on Proposition 1 is that a half-Cauchy prior can be represented as a scale mixture of gamma distributions, i.e. if τj ~
(1/2, λj) and λj ~
(1/2, φ), then
. This makes sense as τ1/2|λj has a half-Normal distribution and the mixing distribution on the precision parameter is gamma with shape parameter 1/2.
[7] further place a half-Cauchy prior on φ1/2 to complete the hierarchy. The aforementioned observation helps us formulate the complete hierarchy proposed in [7] in a conjugate manner. This should bring analytical and computational advantages as well as making the application of the procedure much easier for the average user without the need for a relatively more complex sampling scheme.
Corollary 2
If θj ~
(0, τj),
and φ1/2 ~
(0, 1), then θj ~
(1/2, 1/2, φ), φ ~
(1/2, ω) and ω ~
(1/2, 1).
Hence disregarding the different treatments of the higher-level hyper-parameters, we have shown that the class of priors given in Definition 2 unites the priors in [16, 11, 6, 7] under one family and reveals their close connections through the equivalence of hierarchies given in Proposition 1. The first hierarchy in Proposition 1 makes much of the work possible in the following sections.
4 Estimation and Posterior Inference in Regression Models
4.1 Fully Bayes and Approximate Inference
Consider the linear regression model, y = Xβ+ε, where y is an n-dimensional vector of responses, X is the n × p design matrix and ε is an n-dimensional vector of independent residuals which are normally distributed,
(0, σ2In) with variance σ2.
We place the hierarchical prior given in Proposition 1 on each βj, i.e. βj ~
(0, σ2τj), τj ~
(a, λj), λj ~
(b, φ). φ is used as a global shrinkage parameter common to all βj, and may be inferred using the data. Thus we follow the hierarchy by letting φ ~
(1/2, ω), ω ~
(1/2, 1) which implies φ1/2
~
(0, 1) that is identical to what was used in [7] at this level of the hierarchy. However, we do not believe at this level in the hierarchy the choice of the prior will have a huge impact on the results. Although treating φ as unknown may be reasonable, when there exists some prior knowledge, it is appropriate to fix a φ value to reflect our prior belief in terms of underlying sparsity of the coefficient vector. This sounds rather natural as soon as one starts seeing φ as a parameter that governs the multiplicity adjustment as discussed in [7]. Note also that here we form the dependence on the error variance at a lower level of hierarchy rather than forming it in the prior of φ as done in [7]. If we let a = b = 1/2, we will have formulated the hierarchical prior given in [7] in a completely conjugate manner. We also let σ−2
~
(c0/2, d0/2). Under a normal likelihood, an efficient Gibbs sampler may be obtained as the fully conditional posteriors can be extracted: β|y,
X, σ2, τ1, …, τp ~
(μβ,
Vβ), σ−2|y,
X,
β, τ1, …, τp ~
(c*, d*),
, λj |τj, φ ~
(a+b, τj +φ),
, where μβ = (X′X + T−1)−1X′y, Vβ = σ2(X′X + T−1)−1, c* = (n + p + c0)/2, d* = {(y − Xβ) ′(y − Xβ) + β′T−1β + d0}/2, T = diag(τ1, …, τp).
As an alternative to MCMC and Laplace approximations [23], a lower-bound on marginal likelihoods may be obtained via variational methods [17] yielding approximate posterior distributions on the model parameters. Using a similar approach to [5, 1], the approximate marginal posterior distributions of the parameters are given by β ~
(μβ, Vβ), σ−2 ~
(c*, d*),
, λj ~
(a+b, 〈τ〉 +〈φ〉), φ ~
(pb+1/2,
, ω ~ G(1, 〈φ〉 + 1), where μβ = 〈β 〉 = (X′X + T−1)−1X′y, Vβ = 〈σ−2〉−1(X′ X + T−1)−1,
, c* = (n + p + c0)/2,
, 〈ββ′〉 = Vβ + 〈β〉 〈β′〉, 〈σ−2〉 = c*/d*, 〈λj〉 = (a + b)/(〈τj〉 + 〈φ〉),
and
This procedure consists of initializing the moments and iterating through them until some convergence criterion is reached. The deterministic nature of these approximations make them attractive as a quick alternative to MCMC.
This conjugate modeling approach we have taken allows for a very straightforward implementation of Strawderman-Berger and horseshoe priors or, more generally, TPB normal scale mixture priors in regression models without the need for a more sophisticated sampling scheme which may ultimately attract more audiences towards the use of these more flexible and carefully defined normal scale mixture priors.
4.2 Sparse Maximum a Posteriori Estimation
Although not our main focus, many readers are interested in sparse solutions, hence we give the following brief discussion. Given a, b and φ, maximum a posteriori (MAP) estimation is rather straightforward via a simple expectation-maximization (EM) procedure. This is accomplished in a similar manner to [8] by obtaining the joint MAP estimates of the error variance and the regression coefficients having taken the expectation with respect to the conditional posterior distribution of using the second hierarchy given in Proposition 1. The kth expectation step then would consist of calculating
| (8) |
where and denote the modal estimates of the jth component of β and the error variance σ2 at iteration (k − 1). The solution to (8) may be expressed in terms of some special function(s) for changing values of a, b and φ. b < 1 is a good choice as it will keep the tails of the marginal density on βj heavy. A careful choice of a, on the other hand, is essential to sparse estimation. Admissible values of a for sparse estimation is apparent by the representation in Definition 2, noting that for any a > 1, π(ρj = 1) = 0, i.e. βj may never be shrunk exactly to zero. Hence for sparse estimation, it is essential that 0 < a ≤ 1. Figure 2 (a) and (b) give the prior densities on ρj for b = 1/2, φ = 1 and a = {1/2, 1, 3/2} and the resulting marginal prior densities on βj. These marginal densities are given by
Figure 2.
Prior densities of (a) ρj and (b) βj for a = 1/2 (solid), a = 1 (dashed) and a = 3/2 (long dash).
where Erf(.) denotes the error function and is the incomplete gamma function. Figure 2 clearly illustrates that while all three cases have very similar tail behavior, their behavior around the origin differ drastically.
5 Experiments
Throughout this section we use the Jeffreys’ prior on the error precision by setting c0 = d0 = 0. We generate data for two cases, (n, p) = {(50, 20), (250, 100)}, from
, for i = 1, …, n where β* is a p-vector that on average contains 20q non-zero elements which are indexed by the set
for some random q ∈ (0, 1). We randomize the procedure in the following manner: (i) C ~
(p, Ip×p), (ii) xi ~
(0, C), (iii) q ~
(1, 1) for the first and q ~
(1, 4) for the second cases, (iv) I(j ∈
 ) ~ Bernoulli(q) for j = 1, …, p where I(.) denotes the indicator function, (v) for j ∈
, βj ~
(0, 6) and for j ∉
, βj = 0 and finally (vi) εi ~
(0, σ2) where σ ~
(0, 6). We generated 1000 data sets for each case resulting in a median signal-to-noise ratio of approximately 3.3 and 4.5. We obtain the estimate of the regression coefficients, β̂, using the variational Bayes procedure and measure the performance by model error which is calculated as (β* − β̂)′C(β* − β̂). Figure 3(a) and (b) display the median relative model error (RME) values (with their distributions obtained via bootstrapping) which is obtained by dividing the model error observed from our procedures by that of ℓ1 regularization (lasso) tuned by 10-fold cross-validation. The boxplots in Figure 3(a) and (b) correspond to different (a, b, φ) values where C+ signifies that φ is treated as unknown with a half-Cauchy prior as given earlier in Section 4.1. It is worth mentioning that we attain a clearly superior performance compared to the lasso, particularly in the second case, despite the fact that the estimator resulting from the variational Bayes procedure is not a thresholding rule. Note that b = 1 choice leads to much better performance under Case 2 than Case 1. This is due to the fact that Case 2 involves a much sparser underlying setup on average than Case 1 and that the lighter tails attained by setting b = 1 leads to stronger shrinkage.
) ~ Bernoulli(q) for j = 1, …, p where I(.) denotes the indicator function, (v) for j ∈
, βj ~
(0, 6) and for j ∉
, βj = 0 and finally (vi) εi ~
(0, σ2) where σ ~
(0, 6). We generated 1000 data sets for each case resulting in a median signal-to-noise ratio of approximately 3.3 and 4.5. We obtain the estimate of the regression coefficients, β̂, using the variational Bayes procedure and measure the performance by model error which is calculated as (β* − β̂)′C(β* − β̂). Figure 3(a) and (b) display the median relative model error (RME) values (with their distributions obtained via bootstrapping) which is obtained by dividing the model error observed from our procedures by that of ℓ1 regularization (lasso) tuned by 10-fold cross-validation. The boxplots in Figure 3(a) and (b) correspond to different (a, b, φ) values where C+ signifies that φ is treated as unknown with a half-Cauchy prior as given earlier in Section 4.1. It is worth mentioning that we attain a clearly superior performance compared to the lasso, particularly in the second case, despite the fact that the estimator resulting from the variational Bayes procedure is not a thresholding rule. Note that b = 1 choice leads to much better performance under Case 2 than Case 1. This is due to the fact that Case 2 involves a much sparser underlying setup on average than Case 1 and that the lighter tails attained by setting b = 1 leads to stronger shrinkage.
Figure 3.
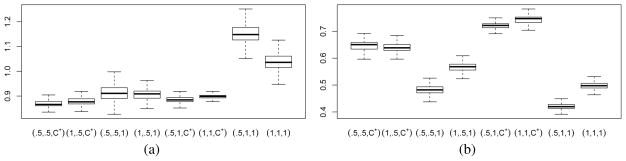
Relative ME at different (a, b, φ) values for (a) Case 1 and (b) Case 2.
To give a high dimensional example, we also generate a data set from the model
, for i = 1, …, 100, where β* is a 10000-dimensional very sparse vector with 10 randomly chosen components set to be 3, εi ~
(0, 32) and xij ~
(0, 1) for j = 1, …, p. This β* choice leads to a signal-to-noise ratios of 3.16. For the particular data set we generated, the randomly chosen components of β* to be non-zero were indexed by 1263, 2199, 2421, 4809, 5530, 7483, 7638, 7741, 7891 and 8187. We set (a, b, φ) = (1, 1/2, 10−4) which implies that a priori ℙ(ρj > 0.5) = 0.99 placing much more density in the neighborhood of ρj = 1 (total shrinkage). This choice is due to the fact that n/p = 0.01 and to roughly reflect that we do not want any more than 100 predictors in the resulting model. Hence φ is used, a priori, to limit the number of predictors in the model in relation to the sample size. Also note that with a = 1, the conditional posterior distribution of
is reduced to an inverse Gaussian. Since we are adjusting the global shrinkage parameter, φ, a priori, and it is chosen such that ℙ (ρj > 0.5) = 0.99, whether a = 1/2 or a = 1 should not matter. We first run the Gibbs sampler for 100000 iterations (2.4 hours on a computer with a 2.8 GHz CPU and 12 Gb of RAM using Matlab), discard the first 20000, thin the rest by picking every 5th sample to obtain the posteriors of the parameters. We observed that the chain converged by the 10000th iteration. For comparison purposes, we also ran the variational Bayes procedure using the values from the converged chain as the initial points (80 seconds). Figure 4 gives the posterior means attained by sampling and the variational approximation. The estimates corresponding to the zero elements of β* are plotted with smaller shapes to prevent clutter. We see that in both cases the procedure is able to pick up the larger signals and shrink a significantly large portion of the rest towards zero. The approximate inference results are in accordance with the results from the Gibbs sampler. It should be noted that using a good informed guess on φ, rather than treating it as an unknown in this high dimensional setting, improves the performance drastically.
Figure 4.
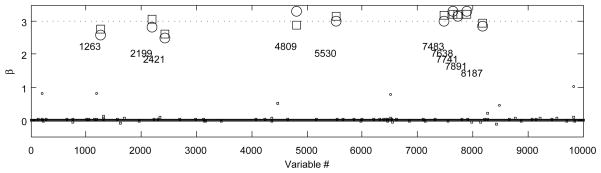
Posterior mean of β by sampling (square) and by approximate inference (circle).
6 Discussion
We conclude that the proposed hierarchical prior formulation constitutes a useful encompassing framework in understanding the behavior of different scale mixtures of normals and connecting them under a broader family of hierarchical priors. While ℓ1 regularization, or namely lasso, arising from a double exponential prior in the Bayesian framework yields certain computational advantages, it demonstrates much inferior estimation performance relative to the more carefully formulated scale mixtures of normals. The proposed equivalence of the hierarchies in Proposition 1 makes computation much easier for the TPB scale mixtures of normals. As per different choices of hyper-parameters, we recommend that a ∈ (0, 1] and b ∈ (0, 1); in particular (a, b) = {(1/2, 1/2), (1, 1/2)}. These choices guarantee that the resulting prior has a kink at zero, which is essential for sparse estimation, and leads to heavy tails to avoid unnecessary bias in large signals (recall that a choice of b = 1/2 will yield Cauchy-like tails). In problems where oracle knowledge on sparsity exists or when p ≫ n, we recommend that φ is fixed at a reasonable quantity to reflect an appropriate sparsity constraint as mentioned in Section 5.
Acknowledgments
This work was supported by Award Number R01ES017436 from the National Institute of Environmental Health Sciences. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institute of Environmental Health Sciences or the National Institutes of Health.
Contributor Information
Artin Armagan, Email: artin@stat.duke.edu, Dept. of Statistical Science, Duke University, Durham, NC 27708.
David B. Dunson, Email: dunson@stat.duke.edu, Dept. of Statistical Science, Duke University, Durham, NC 27708
Merlise Clyde, Email: clyde@stat.duke.edu, Dept. of Statistical Science, Duke University, Durham, NC 27708.
References
- 1.Armagan A. Variational bridge regression. JMLR: W&CP. 2009;5:17–24. [Google Scholar]
- 2.Armagan A, Dunson DB, Lee J. Generalized double Pareto shrinkage. 2011 arXiv:1104.0861v2. [PMC free article] [PubMed] [Google Scholar]
- 3.Armero C, Bayarri MJ. Prior assessments for prediction in queues. The Statistician. 1994;43(1):139–153. [Google Scholar]
- 4.Berger J. A robust generalized Bayes estimator and confidence region for a multivariate normal mean. The Annals of Statistics. 1980;8(4):716–761. [Google Scholar]
- 5.Bishop CM, Tipping ME. Variational relevance vector machines. UAI ’00: Proceedings of the 16th Conference on Uncertainty in Artificial Intelligence; San Francisco, CA, USA. Morgan Kaufmann Publishers Inc; 2000. pp. 46–53. [Google Scholar]
- 6.Carvalho CM, Polson NG, Scott JG. Handling sparsity via the horseshoe. JMLR: W&CP. 2009;5 [Google Scholar]
- 7.Carvalho CM, Polson NG, Scott JG. The horseshoe estimator for sparse signals. Biometrika. 2010;97(2):465–480. [Google Scholar]
- 8.Figueiredo MAT. Adaptive sparseness for supervised learning. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2003;25:1150–1159. [Google Scholar]
- 9.George EI, McCulloch RE. Variable selection via Gibbs sampling. Journal of the American Statistical Association. 1993;88 [Google Scholar]
- 10.Gordy M. Finance and Economics Discussion Series 1998-18. Board of Governors of the Federal Reserve System (U.S.); 1998. A generalization of generalized beta distributions. [Google Scholar]
- 11.Griffin JE, Brown PJ. Technical Report. 2007. Bayesian adaptive lassos with non-convex penalization. [Google Scholar]
- 12.Griffin JE, Brown PJ. Inference with normal-gamma prior distributions in regression problems. Bayesian Analysis. 2010;5(1):171–188. [Google Scholar]
- 13.Hans C. Bayesian lasso regression. Biometrika. 2009;96:835–845. [Google Scholar]
- 14.Hoggart CJ, Whittaker JC, Balding David J, De Iorio M. Simultaneous analysis of all SNPs in genome-wide and re-sequencing association studies. PLoS Genetics. 2008;4(7) doi: 10.1371/journal.pgen.1000130. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ishwaran H, Rao JS. Spike and slab variable selection: Frequentist and Bayesian strategies. The Annals of Statistics. 2005;33(2):730–773. [Google Scholar]
- 16.Johnstone IM, Silverman BW. Needles and straw in haystacks: Empirical Bayes estimates of possibly sparse sequences. Annals of Statistics. 2004;32(4):1594–1649. [Google Scholar]
- 17.Jordan MI, Ghahramani Z, Jaakkola TS, Saul LK. An introduction to variational methods for graphical models. MIT Press; Cambridge, MA, USA: 1999. [Google Scholar]
- 18.Mitchell TJ, Beauchamp JJ. Bayesian variable selection in linear regression. Journal of the American Statistical Association. 1988;83(404):1023–1032. [Google Scholar]
- 19.Park T, Casella G. The Bayesian lasso. Journal of the American Statistical Association. 2008;103(6):681–686. [Google Scholar]
- 20.Polson NG, Scott JG. Discussion Paper 2009-14. Department of Statistical Science, Duke University; 2009. Alternative global-local shrinkage rules using hypergeometric-beta mixtures. [Google Scholar]
- 21.Strawderman WE. Proper Bayes minimax estimators of the multivariate normal mean. The Annals of Mathematical Statistics. 1971;42(1):385–388. [Google Scholar]
- 22.Tibshirani R. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society Series B (Methodological) 1996;58(1):267–288. [Google Scholar]
- 23.Tierney L, Kadane JB. Accurate approximations for posterior moments and marginal densities. Journal of the American Statistical Association. 1986;81(393):82–86. [Google Scholar]
- 24.Tipping ME. Sparse Bayesian learning and the relevance vector machine. Journal of Machine Learning Research. 2001;1 [Google Scholar]