

Abstract
We consider the problem of estimating the density of a random variable when precise measurements on the variable are not available, but replicated proxies contaminated with measurement error are available for sufficiently many subjects. Under the assumption of additive measurement errors this reduces to a problem of deconvolution of densities. Deconvolution methods often make restrictive and unrealistic assumptions about the density of interest and the distribution of measurement errors, e.g., normality and homoscedasticity and thus independence from the variable of interest. This article relaxes these assumptions and introduces novel Bayesian semiparametric methodology based on Dirichlet process mixture models for robust deconvolution of densities in the presence of conditionally heteroscedastic measurement errors. In particular, the models can adapt to asymmetry, heavy tails and multimodality. In simulation experiments, we show that our methods vastly outperform a recent Bayesian approach based on estimating the densities via mixtures of splines. We apply our methods to data from nutritional epidemiology. Even in the special case when the measurement errors are homoscedastic, our methodology is novel and dominates other methods that have been proposed previously. Additional simulation results, instructions on getting access to the data set and R programs implementing our methods are included as part of online supplemental materials.
Some Key Words: B-spline, Conditional heteroscedasticity, Density deconvolution, Dirichlet process mixture models, Measurement errors, Skew-normal distribution, Variance function
1 Introduction
Many problems of practical importance require estimation of the unknown density of a random variable. The variable, however, may not be observed precisely, observations being subject to measurement errors. Under the assumption of additive measurement errors, the observations are generated from a convolution of the density of interest and the density of the measurement errors. The problem of estimating the density of interest from available contaminated measurements then becomes a problem of deconvolution of densities.
This article proposes novel Bayesian semiparametric approaches for robust estimation of the density of interest when the variability of the measurement errors depends on the associated unobserved value of the variable of interest through an unknown relationship. The proposed methodology is fundamentally different from existing deconvolution methods, relaxes many restrictive assumptions of existing approaches by allowing both the density of interest and the distribution of measurement errors to deviate from standard parametric laws, and significantly outperforms previous methodology.
The literature on the problem of density deconvolution is vast. Most of the early literature on density deconvolution considers scenarios when a single contaminated measurement is available for each subject and assumes that the measurement errors are independently and identically distributed according to some known probability law (often normal) with constant variance. See, for example, Carroll and Hall (1988), Liu and Taylor (1989), Devroye (1989), Fan (1991a, 1991b, 1992) and Hesse (1998) among others. Of course, in reality the distribution of measurement errors is rarely known, and the assumption of constant variance measurement errors is also often unrealistic. The difficulty of a deconvolution problem depends directly on the shape (more specifically the smoothness) of the measurement error distribution (Fan 1991a, 1991b, 1992). Misspecification of the distribution of measurement errors may therefore lead to biased and inefficient estimates of the density of interest. The focus of recent deconvolution literature has thus been on robust deconvolution methods that relax the restrictive assumptions on the error distribution, assuming the availability of replicated proxies for each unknown value of the variable of interest. See, for example, Li and Vuong (1998) and Carroll and Hall (2004) among others.
All the above mentioned papers still assume that the measurement errors are independent of the variable of interest. Staudenmayer, et al. (2008) further relaxed this often unrealistic assumption and considered the problem of density deconvolution in the presence of conditionally heteroscedastic measurement errors. They took a Bayesian route and modeled the density of interest by a penalized positive mixture of normalized quadratic B-splines. Measurement errors were assumed to be normally distributed but the measurement error variance was modeled as a function of the associated unknown value of the variable of interest using a penalized positive mixture of quadratic B-splines.
The focus of this article is also on deconvolution in the presence of conditionally heteroscedastic measurement errors, but the proposed Bayesian semiparametric methods are vastly different from the approach of Staudenmayer, et al. (2008), as well as from other existing methods. The density of interest is modeled by a flexible location-scale mixture of normals induced by a Dirichlet process (Ferguson, 1973; Lo, 1984). For modeling conditionally heteroscedastic measurement errors, it is assumed that the measurement errors can be factored into ‘scaled errors’ that are independent of the variable of interest and have zero mean and unit variance, and a ‘variance function’ component that explains the conditional heteroscedasticity. This multiplicative structural assumption on the measurement errors was implicit in Staudenmayer, et al. (2008), where the scaled errors were assumed to come from a standard normal distribution.
Our approach is based on a more flexible representation of the scaled errors. The density of the scaled measurement errors is modeled using an infinite mixture model induced by a Dirichlet process, each component of the mixture being itself a two-component normal mixture with mean zero. This gives us the flexibility to model other aspects of the distribution of scaled errors. This deconvolution approach, therefore, uses flexible Dirichlet process mixture models twice, first to model the density of interest and second to model the density of the scaled errors, freeing them both from restrictive parametric assumptions, while at the same time accommodating conditional heteroscedasticity through the variance function.
It is important to see that even when the measurement errors are homoscedastic, our methodology is novel and dominates other methods that have been proposed previously. Our methods apply to this problem, allowing flexibility in the density of the variable of interest, flexible representations of the density of the measurement errors, and, if desired, at the same time build modeling robustness lest there be any remaining heteroscedasticity.
The article is organized as follows. Section 2 details the models. Sections 3 discusses some model diagnostic tools. Section 4 presents extensive simulation studies comparing the proposed semiparametric methods with the method of Staudenmayer, et al. (2008) and a possible nonparametric alternative. Section 5 presents an application of the proposed methodology in estimation of the distributions of daily dietary intakes from contaminated 24 hour recalls in a nutritional epidemiologic study. Section 6 contains concluding remarks. Appendices discuss model identifiability (Appendix A), the choice of hyper-parameters (Appendix B) and details of posterior computations (Appendix C). The supplementary materials provide results of additional simulation experiments and R programs implementing our methods.
2 Density Deconvolution Models
2.1 Background
The goal is to estimate the unknown density of a random variable X. There are i = 1, 2, …, n subjects. Precise measurements of X are not available. Instead, for j = 1, 2, …, mi, replicated proxies Wij contaminated with heteroscedastic measurement errors Uij are available for each subject. The replicates are assumed to be generated by the model
| (1) |
| (2) |
where Xi is the unobserved true value of X; εij are independently and identically distributed with zero mean and unit variance and are independent of the Xi, and v is an unknown smooth variance function. Identifiability of model (1)–(2) is discussed in Appendix A, where we show that 3 replicates more than suffices. Some simple diagnostic tools that may be employed in practical applications to assess the validity of the structural assumption (2) on the measurement errors are discussed in Section 3.
Of course, a special case of our work is when the measurement errors are homoscedastic, so that v(x) is constant. Even in this case, the use of Dirichlet process mixtures for both the target density and error distribution has not been considered previously.
The density of X is denoted by fX. The density of εij is denoted by fε. The implied conditional distributions of Wij and Uij, given Xi, is denoted by the generic notation fW|X and fU|X, respectively. The marginal density of Wij is denoted by fW.
Model (2), along with the moment restrictions imposed on the scaled errors εij, implies that the conditional heteroscedasticity of the measurement errors is explained completely through the variance function v, while other features of fU|X are derived from fε. In a Bayesian hierarchical framework, model (1)–(2) reduces the problem of deconvolution to three separate problems: (a) modeling the density of interest fX; (b) modeling the variance function v, and (c) modeling the density of the scaled errors fε.
2.2 Modeling the Distribution of X
We use Dirichlet process mixture models (DPMMs) (Ferguson, 1973, Escobar and West, 1995) for modeling fX. For modeling a density f, a DPMM with concentration parameter α, base measure P0, and mixture components coming from a parametric family {fc(· | ϕ): ϕ ~ P0}, can be specified as
In the literature, this construction of random mixture weights (Sethuraman, 1994), is often represented as π ~ Stick(α). DPMMs are, therefore, mixture models with a potentially infinite number of mixture components or ‘clusters’. For a given data set of finite size, however, the number of active clusters exhibited by the data is finite and can be inferred from the data.
Choice of the parametric family {fc(· | ϕ): ϕ ~ P0} is important. Mixtures of normal kernels are, in particular, very popular for their flexibility and computational tractability (Escobar and West, 1995; West, et al. 1994). In this article also, fX is specified as a mixture of normal kernels, with a conjugate normal-inverse-gamma (NIG) prior on the location and scale parameters
| (3) |
| (4) |
Here Normal(· | μ, σ2) denotes a normal distribution with mean μ and standard deviation σ. In what follows, the generic notation p0 will sometimes be used for specifying priors and hyper-priors.
2.3 Modeling the Variance Function
Examples of modeling log-transformed variance functions using flexible mixtures of splines are abundant in the literature when there is no measurement error. Yau and Kohn (2003), for example, modeled log{v(X)} using flexible mixtures of polynomial and thin-plate splines. Liu, et al. (2006) proposed a penalized mixture of smoothing splines, whereas Chan, et al. (2006) considered mixtures of locally adaptive radial basis functions.
In this article we model the variance function as a positive mixture of B-spline basis functions with smoothness inducing priors on the coefficients. For a given positive integer K, partition an interval [A, B] of interest into K subintervals using knot points t1 = ··· = tq+1 = A < tq+2 < tq+3 < ··· < tq+K < tq+K+1 = ··· = t2q+K+1 = B. For j = (q +1), …, (q + K), define Δj = (tj+1 − tj) and Δmax = maxj Δj. It is assumed that Δmax → 0 as K → ∞. Using these knot points, (q + K) = J B-spline bases of degree q, denoted by Bq,J = {bq,1, bq,2, …, bq,J}, can be defined through the recursion relation given on page 90 of de Boor (2000), see Figure S.1 in the supplementary materials. A flexible model for the variance function is
| (5) |
| (6) |
Here ξ = {ξ1, ξ2, …, ξJ}T; exp(ξ) = {exp(xi;1), exp(xi;2), …, exp(xi;J)}T, MVNJ(μ, Σ) denotes a J-variate normal distribution with mean μ and positive semidefinite covariance matrix Σ, and IG(a, b) denotes an inverse-Gamma distribution with shape parameter a and scale parameter b. We choose P = DTD, where D is a J × (J + 2) matrix such that Dξ computes the second differences in ξ. The prior induces smoothness in the coefficients because it penalizes , the sum of squares of the second order differences in ξ (Eilers and Marx, 1996). The variance parameter plays the role of smoothing parameter - the smaller the value of , the stronger the penalty and the smoother the variance function. The inverse-Gamma hyper-prior on allows the data to have strong influence on the posterior smoothness and makes the approach data adaptive.
2.4 Modeling the Distribution of the Scaled Errors
Three different approaches of modeling the density of the scaled errors fε are considered here, successively relaxing the model assumptions as we progress.
2.4.1 Model-I: Normal Distribution
We first consider the case where the scaled errors are assumed to follow a standard normal distribution
| (7) |
This implies that the conditional density of measurement errors is given by fU|X(U | X) = Normal{U | 0, v(X)}. Such an assumption was made by Staudenmayer, et al. (2008).
2.4.2 Model-II: Skew-Normal Distribution
The strong parametric assumption of normality of measurement errors may be restrictive and inappropriate for many practical applications. As a first step towards modeling departures from normality, we propose a novel use of skew-normal distributions (Azzalini, 1985) to model the distribution of scaled errors. A random variable Z following a skew-normal distribution with location ξ, scale ω and shape parameter λ has the density f(Z) = (2/ω)ϕ{(Z − xi;)/ω}Φ{λ(Z − ξ)/ω}. Here ϕ and Φ denote the probability density function and cumulative density function of a standard normal distribution, respectively. Positive and negative values of λ result in right and left skewed distributions, respectively. The Normal(· | μ, σ2) distribution is obtained as special cases with λ = 0, whereas the folded normal or half-normal distributions are obtained as limiting cases with λ → ±∞, see Figure S.2 in the supplementary materials. With δ = λ/(1 + λ2)1/2, the mean and the variance of this density are given by μ = ξ + ωδ(2/π)1/2 and σ2 = ω2(1 − 2δ2/π), respectively. Although the above parametrization is more constructive and intuitive in revealing the relationship with the normal family, we consider a different parametrization in terms of μ, σ2 and λ, denoted by SN(· | μ, σ2, λ), that is more useful for specifying distributions with moment constraints, namely f(Z) = (2ζ2/σ)ϕ{ζ1 + ζ2(Z − μ)/σ}Φ[λ{ζ1 + ζ2(Z − μ)/σ}], where ζ1 = δ(2/π)1/2 and ζ2 = (1 − 2δ2/π)1/2. For specifying the distribution of the scaled errors we now let
| (8) |
| (9) |
The implied conditionally heteroscedastic, unimodal and possibly asymmetric distribution for the measurement errors is given by fU|X(U | X) = SN{U | 0, v(X), λ}.
2.4.3 Model-III: Infinite Mixture Models
While skew-normal distributions can capture moderate skewness, they are still quite limited in their capacity to model more severe departures from normality. They can not, for example, model multimodality or heavy tails. In the context of regression analysis when there is no measurement error, moment constrained infinite mixture models have recently been used by Pelenis (2014) (see also the references therein) for flexible modeling of error distributions that can capture multimodality and heavy tails. They considered the mixture , with the moment constraint pkμk1 +(1−pk)μk2 = 0 for all k. Use of a two-component mixture of normals as components with each component constrained to have mean zero restricts the mean of the mixture to be zero while allowing the mixture to model other unconstrained aspects of the error distribution. Incorporating covariate information X in modeling the mixture probabilities, this model allows all aspects of the error distribution, other than the mean, to vary nonparametrically with the covariates, not just the conditional variance. Designed for regression problems, these nonparametric models, however, assume that this covariate information is precise. If X is measured with error, as is the case with deconvolution problems, the subject specific residuals may not be informative enough, particularly when the number of replicates per subject is small and the measurement errors have high conditional variability, making simultaneous learning of X and other parameters of the model difficult.
In this article, we take a different semiparametric middle path. The multiplicative structural assumption (2) on the measurement errors that reduces the problem of modeling fU|X to the two separate problems of modeling (a) a variance function and (b) modeling an error distribution independent of the variable of interest is retained. The difficult problem of flexible modeling of an error distribution with zero mean and unit variance moment restrictions is avoided through a simple reformulation of model (2) that replaces the unit variance identifiability restriction on the scaled errors by a similar constraint on the variance function. Model (2) is rewritten as
| (10) |
where X0 is arbitrary but fixed point, ṽ(Xi) = v(Xi)/v(X0), and ε̃ij = v1/2(X0)εij. With this specification, ṽ(X0) = 1, var(ε̃ij) = v(X0) and var(U | X) = v(X0)ṽ(X). The problem of modeling the unrestricted variance function v has now been replaced by the problem of modeling ṽ restricted to have value 1 at X0. The problem of modeling the density of ε with zero mean and unit variance moment constraints has also been replaced by the easier problem of modeling the density of ε̃ij with only a single moment constraint of zero mean.
The conditional variance of the measurement errors is now a scalar multiple of ṽ. So ṽ can still be referred to as the ‘variance function’. The variance of ε̃ij, however, does not equal unity, but is, in fact, unrestricted. With some abuse of nomenclature, ε̃ij is still referred to as the ‘scaled errors’. For notational convenience ε̃ij is denoted simply by εij.
The problem of flexibly modeling ṽ is now addressed. For any X, (i) bq,j(X) ≥ 0 ∀j, (ii) , (iii) bq,j is positive only inside the interval [tj, tj+q+1], (iv) for j ∈ {(q + 1), (q+2), …, (q+K)}, for any X ∈ (tj, tj+1), only (q+1) B-splines bq,j−q(X), bq,j−q+1(X), …, bq,j(X) are positive, and (v) when X = tj, bq,j(X) = 0. We let ṽ(X) = Bq,J (X) exp(ξ), as before, and we use the above mentioned local support properties of the B-spline bases to propose a flexible model for ṽ subject to ṽ(X0) = 1. When X0 ∈ (tj, tj+1), properties (ii) and (iv) cause the constraint to be simply . This is a restriction on only (q + 1) of the ξj’s, and the coefficients of the remaining B-splines remain unrestricted which makes the model for ṽ very flexible. In a Bayesian framework, the restriction ṽ(X0) = 1 can be imposed by restricting the support of the prior on ξ to the set { }. Choosing X0 = tj0 for some j0 ∈ {(q + 1), …, (q + K)}, we further have bj0(tj0) = 0, and the complete model for ṽ is given by
| (11) |
| (12) |
| (13) |
where I(·) denotes the indicator function.
Now that the variance of εij has become unrestricted and only a single moment constraint of zero mean is required, a DPMM with mixture components as specified in Pelenis (2014) can be used to model fε. That is, we let , πε ~ Stick(αε), where , subject to the moment constraint pμ1 + (1 − p)μ2 = 0. The moment constraint of zero mean implies that each component density can be described by four parameters. One such parametrization that facilitates prior specification is in terms of parameters (p, μ̃, ), where (μ1, μ2) can be retrieved from μ̃ as μ1 = c1μ̃, μ2 = c2μ̃, where c1 = (1 − p)/{p2 + (1 − p)2}1/2 and c2 = −p/{p2 + (1 − p)2}1/2. Clearly the zero mean constraint is satisfied, since pμ1 + (1 − p) μ2 = {pc1 + (1 − p)c2}μ̃ = 0. The family includes normal densities as special cases with (p, μ̃) = (0.5, 0) or (0, 0) or (1, 0). Symmetric component densities are obtained as special cases when p = 0.5 or μ̃ = 0. The mixture is symmetric when the all components are as well. Specification of the prior for fε is completed assuming non-informative priors for (p, μ̃, ). Letting Unif(ℓ, u) denote a uniform distribution on the interval (ℓ, u), the complete DPMM prior on fε can then be specified as
| (14) |
| (15) |
2.5 Choice of Hyper-parameters and Posterior Calculations
Appendix B describes the choice of hyper-parameters, while Appendix C gives the details of posterior computations.
3 Model Diagnostics
In practical deconvolution problems, the basic structural assumptions on the measurement errors may be dictated by prominent features of the data extracted by simple diagnostic tools and expert knowledge of the data generating process. Conditional heteroscedasticity, in particular, is easy to identify from the scatterplot of on W̄, where W̄ and denote the subject specific sample mean and variance, respectively (Eckert, et al., 1997). The multiplicative structural assumption (2) on the measurement errors provides one particular way of accommodating conditional heteroscedasticity in the model. When at least 4 replicates are available for sufficiently many subjects, one can define the pairs (Wij1, Cij2j3j4) for all i and for all j1 ≠ j2 ≠ j3 ≠ j4, where Cij2j3j4 = {(Wij2 − Wij3)/(Wij2 − Wij4)}. When (2) is true, Cj2j3j4= {(εj2 − εj3)/(εj2 − εj4)} is independent of Wj1. Therefore, the absence of non-random patterns in the plots of Wj1 against Cj2j3j4 and nonsignificant p-values in nonparametric tests of association between Wj1 and Cj2j3j4 for various j1 ≠ j2 ≠ j3 ≠ j4 may be taken as indications that (2) is valid or that the departures from (2) are not severe. For those cases with m (≥ 4) replicates per subject, the total number of possible such tests is m!/(m−4)! = L, say, where, for any positive integer r, r! = r ·(r −1) … 2·1. The p-values of these tests can be combined using the truncated product method of Zaykin, et al. (2002). The test statistic of this combined left-sided test is given by , where pℓ denotes the p-value of the ℓth test and ς is a prespecified truncation limit. If minℓ{pℓ} ≥ ς, the p-value of the combined test is trivially 1. Otherwise, the bootstrap procedure described in Zaykin, et al. (2002) may be used to estimate it.
4 Simulation Experiments
4.1 Background
The mean integrated squared error (MISE) of estimation of fX by f̂X is defined as MISE = ∫ E{fX(x) − f̂X(x)}2dx. A Markov chain Monte Carlo (MCMC) algorithm, implemented for drawing samples from the posterior to calculate estimates of fX and other functions of secondary interest, is detailed in Appendix C. Based on B simulated data sets, a Monte Carlo estimate of MISE is given by , where are a set of grid points on the range of X and for all i.
The simulation experiments are designed to evaluate the MISE performance of the proposed models for a wide range of possibilities. The Bayesian deconvolution models proposed in this article all take semiparametric routes to model conditional heteroscedasticity assuming a multiplicative structural assumption on the measurement errors. Performance of the proposed models is first evaluated for ‘semiparametric truth scenarios’ when the truth conforms to the assumed multiplicative structure. Efficiency of the proposed models will also be illustrated for ‘nonparametric truth’ scenarios when the truth departs from the assumed multiplicative structure.
The reported estimated MISE are all based on B = 400 simulated data sets. For the proposed methods 5,000 MCMC iterations were run in each case with the initial 3,000 iterations discarded as burn-in. In our R code, with n = 500 subjects and mi = 3 proxies for each subject, on an ordinary desktop, 5,000 MCMC iterations for models I, II and III required approximately 5 minutes, 10 minutes and 25 minutes, respectively. In comparison, the method of Staudenmayer, et al. (2008) and the nonparametric alternative described below in Section 4.3 took approximately 100 minutes.
4.2 Semiparametric Truth
This subsection presents the results of simulation experiments comparing our methods with the method of Staudenmayer, et al. (2008), referred to as the SRB method. The methods are compared over a factorial combination of three sample sizes (n = 250,500,1000), two densities for and , nine different types of distributions for the scaled errors (six light-tailed and three heavy-tailed, see Table 1 and Figure 1), and one variance function v(X) = (1 + X/4)2. For each subject, mi = 3 replicates were simulated. The MISE are presented in Table 2. Additional simulation results, where the true fX is a normalized mixture of B-splines, are presented in the supplementary materials.
Table 1.
The distributions used to generate the scaled errors in the simulation experiment. Let MRTCN(K, πε, p, μ̃ ) denote a K component mixture of moment restricted two-component normals: . Then SMRTN denotes a scaled version of MRTCN, scaled to have variance one. Laplace(μ, b) denotes a Laplace distribution with location μ and scale b. SMLaplace(K, πε, 0, b) denotes a K component mixture of Laplace densities: , scaled to have variance one. With μk denoting the kth order central moments of the scaled errors, the skewness and excess kurtosis of the distribution of scaled errors are measured by the coeficients γ1 = μ3 and γ2 = μ4 − 3, respectively. The densities (a)–(f) are light-tailed, whereas the densities (g)–(i) are heavy-tailed. The shapes of these distributions are illustrated in Figure 1.
| Distribution of scaled errors | Skewness (γ1) | Excess Kurtosis (γ2) |
|---|---|---|
|
| ||
| (a) Normal(0,1) | 0 | 0 |
| (b) Skew-normal(0,1,7) | 0.917 | 0.779 |
| (c) SMRTCN(1,1,0.4,2,2,1) | 0.499 | −0.966 |
| (d) SMRTCN(1,1,0.5,2,1,1) | 0 | −1.760 |
| (e) SMRTCN{2,(0.3,0.7),(0.6,0.5),(5,0),(1,4),(2,1)} | −0.567 | −1.714 |
| (f) SMRTCN{2,(0.3,0.7),(0.6,0.5),(0,4),(0.5,4),(0.5,4)} | 0 | −1.152 |
|
| ||
| (g) SMRTCN{2,(0.8,0.2),(0.5,0.5),(0,0),(0.25,5),(0.25,5)} | 0 | 7.524 |
| (h) Laplace(0,2−1/2) | 0 | 3 |
| (i) SMLaplace{2,(0.5,0.5),(0,0),(1,4)} | 0 | 7.671 |
Figure 1.

The distributions used to generate the scaled errors in the simulation experiment, superimposed over a standard normal density. The difierent choices cover a wide range of possibilities - (a) standard normal (not shown separately), (b) asymmetric skew-normal, (c) asymmetric bimodal, (d) symmetric bimodal, (e) asymmetric trimodal, (f) symmetric trimodal, (g) symmetric heavy-tailed, (h) symmetric heavy-tailed with a sharp peak at zero and (i) symmetric heavy-tailed with even a sharper peak at zero. The last six cases demonstrate the flexibility of mixtures of moment restricted two-component normals in capturing widely varying shapes.
Table 2.
Mean integrated squared error (MISE) performance of density deconvolution models described in Section 2 of this article (Models I, II and III) compared with the model of Staudenmayer, et al. (2008) (Model SRB) for different scaled error distributions. The true variance function was v(X) = (1 + X/4)2. See Section 4.2 for additional details. The minimum value in each row is highlighted.
| True Error Distribution | True X Distribution | Sample Size | MISE × 1000 | |||
|---|---|---|---|---|---|---|
| SRB | Model1 | Model2 | Model3 | |||
| (a) | 50–50 mixture of normals | 250 500 1000 |
10.15 6.64 4.50 |
5.31 3.15 1.96 |
5.61 3.16 2.08 |
5.55 3.34 2.21 |
| 80–20 mixture of normals | 250 500 1000 |
9.60 5.30 4.39 |
4.41 2.34 1.31 |
4.47 2.39 1.37 |
4.52 2.62 1.39 |
|
| (b) | 50–50 mixture of normals | 250 500 1000 |
11.79 11.85 8.66 |
7.80 5.79 4.58 |
4.41 3.11 1.91 |
4.55 3.33 2.21 |
| 80–20 mixture of normals | 250 500 1000 |
10.74 7.94 6.16 |
6.97 4.17 3.08 |
4.52 2.27 1.26 |
4.54 2.60 1.39 |
|
| (c) | 50–50 mixture of normals | 250 500 1000 |
12.61 9.27 9.15 |
8.74 4.91 4.13 |
5.31 3.57 2.53 |
4.60 3.39 1.91 |
| 80–20 mixture of normals | 250 500 1000 |
9.27 6.67 5.04 |
6.46 3.18 2.26 |
4.65 2.77 1.40 |
4.03 2.37 1.26 |
|
| (d) | 50–50 mixture of normals | 250 500 1000 |
10.10 6.54 6.02 |
7.71 4.26 3.41 |
9.94 7.01 5.58 |
4.40 2.70 1.40 |
| 80–20 mixture of normals | 250 500 1000 |
8.18 4.45 4.40 |
5.32 2.67 1.74 |
5.92 4.30 3.31 |
3.43 2.21 1.60 |
|
| (e) | 50–50 mixture of normals | 250 500 1000 |
10.03 9.38 8.39 |
6.01 3.87 2.42 |
5.92 3.57 2.25 |
4.03 2.99 1.75 |
| 80–20 mixture of normals | 250 500 1000 |
7.82 7.62 6.82 |
3.97 3.00 1.74 |
4.44 2.40 1.45 |
3.38 2.01 1.17 |
|
| (f) | 50–50 mixture of normals | 250 500 1000 |
9.35 7.18 4.63 |
5.82 3.47 2.46 |
6.52 3.67 2.62 |
5.37 3.62 2.10 |
| 80–20 mixture of normals | 250 500 1000 |
9.17 7.35 3.86 |
4.75 2.58 1.53 |
4.80 2.65 1.60 |
4.10 2.52 1.45 |
|
| (g) | 50–50 mixture of normals | 250 500 1000 |
15.68 23.27 49.77 |
11.78 15.57 18.91 |
10.38 14.85 21.00 |
3.30 2.07 1.12 |
| 80–20 mixture of normals | 250 500 1000 |
20.05 36.46 48.70 |
8.18 10.83 18.53 |
15.99 17.23 17.77 |
3.10 1.63 0.92 |
|
| (h) | 50–50 mixture of normals | 250 500 1000 |
11.29 15.07 18.79 |
6.62 8.07 12.04 |
7.01 7.24 8.41 |
5.18 3.29 1.99 |
| 80–20 mixture of normals | 250 500 1000 |
11.34 13.23 22.03 |
7.18 7.43 8.64 |
7.05 7.53 7.56 |
2.91 1.67 1.03 |
|
| (i) | 50–50 mixture of normals | 250 500 1000 |
19.34 28.79 54.03 |
7.69 17.32 26.78 |
9.90 11.02 11.64 |
3.10 2.14 0.94 |
| 80–20 mixture of normals | 250 500 1000 |
29.81 48.41 57.87 |
16.45 20.94 23.80 |
14.76 14.99 16.59 |
2.74 1.60 0.83 |
|
4.2.1 Results for Light-tailed Error Distributions
This section discusses MISE performances of the models for the 36 (3×2×6) cases where the scaled errors were light-tailed, distributions (a)–(f), see Table 1 and Figure 1. Results of the simulation experiments show that all three models proposed in this article significantly out-performed the SRB model in all 36 cases considered. When measurement errors are normally distributed, the reductions in MISE over the SRB method for all three models and for all six possible combination of sample sizes and true X distributions are more than 50%. This is particularly interesting, since the SRB method was originally proposed for normally distributed errors, even more so because our Model-II and Model-III relax the normality assumption on the measurement errors.
4.2.2 Results for Heavy-tailed Error Distributions
This section discusses MISE performances of the models for the 18 (3 × 2 × 3) cases where the distribution of scaled errors were heavy-tailed, distributions (g), (h) and (i), see Table 1 and Figure 1. Results for the error distribution (g) are summarized in Figure 2. The SRB model and Model-I assume normally distributed errors; Model-II assumes skew-normal errors whose tail behavior is similar to that of normal distributions. The results show the MISE performances of these three models to be very poor for heavy-tailed error distributions and the MISE increased with an increase in sample size due to the presence of an increasing number of outliers. Model-III, on the other hand, can accommodate heavy-tails in the error distributions and is, therefore, very robust to the presence of outliers. MISE patterns produced by Model-III for heavy-tailed errors were similar to that for light-tailed errors, and improvements in MISE over the other models were huge. For example, when the density for the scaled was (i), a mixture of Laplace densities with a very sharp peak at zero, for n = 1000, the improvements in MISEs over the SRB model were 54.03/0.94 ≈ 57 times for the 50–50 mixture of normals and 57.87/0.83 ≈ 70 times for the 80–20 mixture of normals.
Figure 2.

Results for heavy-tailed error distribution (g) with sample size n=1000 corresponding to 25th percentile MISE. The top panel shows the estimated densities under different models. The bottom left panel shows estimated densities of scaled errors under Model-II (dashed line) and Model-III (solid bold line) superimposed over a standard Normal density (solid line). The bottom right panel shows estimated variance functions under different models. For the top panel and the bottom right panel, the solid thin line is for Model-I; the dashed line is for Model-II; the solid bold line is for Model-III; and the dot-dashed line is for the Model of Staudenmayer, et al. (2008). In all three panels the bold gray lines represent the truth.
In simpler settings, when the measurement errors are independent of the variable of interest and have a known density, Fan (1991a, 1991b, 1992) showed that the dificulty of a deconvolution problem depends directly on the shape (more specifically the smoothness) of the measurement error distribution. The results of our simulation experiments provide empirical evidence in favor of a similar conclusion in more complicated and realistic deconvolution scenarios, where the measurement errors show strong patterns of conditional heteroscedasticity, and illustrate the importance of modeling the shape of the error distribution when it is unknown.
4.3 Nonparametric Truth
This subsection is aimed at providing some empirical support to the claim made in Section 2.4.3, where it was argued that for deconvolution problems the proposed semiparametric route to model the distribution of conditionally heteroscedastic measurement errors will often be more efficient than possible nonparametric alternatives, even when the truth departs from the assumed multiplicative structural assumption (2) on the measurement errors. This is done by comparing our Model III with a method that also models the density of interest by a DPMM like ours but employs the formulation of Pelenis (2014) to model the density of the measurement errors. This possible nonparametric alternative was reviewed in Section 2.4.3 and will be referred to as the NPM method. Recall that by modeling the mixture probabilities as functions of X the NPM model allows all aspects of the distribution of errors to vary with X, not just the conditional variance. In theory, the NPM model is, therefore, more flexible than Model-III as it can also accommodate departures from (2). However, in practice, for reasons described in Section 2.4.3, Model-III will often be more efficient than the NPM model, as is shown here.
In the simulation experiments the true conditional distributions that generate the measurement errors are designed to be of the form , where each component density has mean zero, the kth component has variance , and θUk denotes additional parameters. For the true and the fitted mixture probabilities we used the formulation of Chung and Dunson (2009) that allows easy posterior computation through data augmentation techniques. That is, we took with for k = 1; 2;…; (K − 1) and . The truth closely resembles the NPM model and clearly departs from the assumptions of Model III. The conditional variance is now given by . The two competing models are then compared over a factorial combination of three sample sizes (n = 250, 500, 1000), two densities for and , as defined in Section 4.2, and three different choices for the component densities and (l) . In each case, K = 8 and the parameters specifying the true mixture probabilities are set at αk = 2, βk = 1/2 for all k with taking values in {−1.9, −1, 0, 1, 2.5, 4, 5.5} in that order. We chose the priors for αk; βk and as in Chung and Dunson (2009). The component specific variance parameters are set by minimizing the sum of squares of on a grid. For the density (k) we set λU = 7. For the density (l) λUk take values in {7, 3, 1, 0, −1, −3, −7}, with λUk decreasing as X increases. For each subject, mi = 3 replicates were simulated.
The estimated MISE are presented in Table 3. The results show that Model III vastly outperforms the NPM model in all 18 (3 × 2 × 3) cases even though the truth actually conforms to the NPM model closely. The reductions in MISE are particularly significant when the true density of interest is a 50–50 mixture of normals. The results further emphasize the need for flexible and efficient semiparametric deconvolution models such as the ones proposed in this article.
Table 3.
Mean integrated squared error (MISE) performance of Models III compared with the NPM model for different measurement error distributions. See Section 4.3 for additional details. The minimum value in each row is highlighted.
| True Error Distribution | True X Distribution | Sample Size | MISE × 1000 | |
|---|---|---|---|---|
| NPM | Model3 | |||
| (j) | 50–50 mixture of normals | 250 500 1000 |
29.25 23.83 20.11 |
5.25 3.61 2.45 |
| 80–20 mixture of normals | 250 500 1000 |
8.09 6.71 7.34 |
4.62 3.12 2.05 |
|
| (k) | 50–50 mixture of normals | 250 500 1000 |
23.18 20.45 20.37 |
4.81 3.18 2.13 |
| 80–20 mixture of normals | 250 500 1000 |
11.62 8.26 8.01 |
4.42 2.77 1.43 |
|
| (l) | 50–50 mixture of normals | 250 500 1000 |
21.69 17.72 16.43 |
5.65 3.86 2.67 |
| 80–20 mixture of normals | 250 500 1000 |
5.67 3.67 3.37 |
4.71 2.98 2.01 |
|
5 Application in Nutritional Epidemiology
5.1 Data Description and Model Validation
Dietary habits are known to be leading causes of many chronic diseases. Accurate estimation of the distributions of dietary intakes is important in nutritional epidemiologic surveillance and epidemiology. One large scale epidemiologic study conducted by the National Cancer Institute, the Eating at America’s Table (EATS) study (Suber, et al., 2001), serves as the motivation for this paper. In this study n = 965 participants were interviewed mi = 4 times over the course of a year and their 24 hour dietary recalls (Wij’s) were recorded. The goal is to estimate the distribution of true daily intakes (Xi’s).
Figure 3 shows diagnostic plots (as described in Section 3) for daily intakes of folate. Conditional heteroscedasticity of measurements errors is one salient feature of the data, clearly identifiable from the plot of subject-specific means versus subject-specific variances. We did not see any non-random pattern in the scatterplots of Wj1 vs Cj2j3j4 for various j1 ≠ j2 ≠ j3 ≠ j4. A combined p-value of 1 given by nonparametric tests of association combined by the truncated product method of Zaykin, et al. (2002) with truncation limit as high as 0.50 is also strong evidence in favor of independence of Wj1 and Cj2j3j4 for all j1 ≠ j2 ≠ j3 ≠ j4. By the arguments presented in Section 3, model (1)–(2) may therefore be assumed to be valid for reported daily intakes of folate. Data on many more dietary components were recorded in the EATS study. Due to space constraints, it is not possible to present diagnostic plots for other dietary components. However, it should be noted that the combined p-values for nonparametric tests of association between Wj1 and Cj2j3j4 for various j1 ≠ j2 ≠ j3 ≠ j4 for all 25 dietary components, for which daily dietary intakes were recorded in the EATS study, are greater than 0.50 even for a truncation limit as high as 0.50, see Table S.1 of the supplementary materials.
Figure 3.
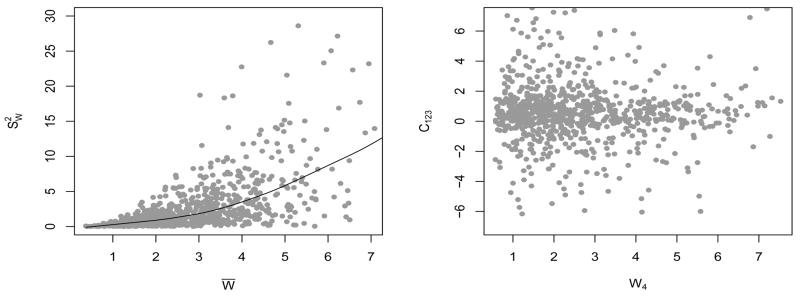
Diagnostic plots for reported daily intakes of folate. The left panel shows the plot of W̄ vs with a simple lowess fit superimposed. The right panel shows the plot of W4 vs C123.
5.2 Results for Daily Intakes of Folate
Estimates of the density of daily intakes of folate and other nuisance functions of secondary importance produced by different deconvolution models are summarized in Figure 4. When the density of scaled errors is allowed to be flexible, as in Model-III, the estimated density of daily folate intakes is visibly very different from the estimates when the measurement errors are assumed to be normally or skew-normally distributed, as in Model-I, Model-II or the SRB model, particularly in the interval of 3–6 mcg. Estimated 90% credible intervals for fX(3.7) for Model-I is (0.167, 0.283), for Model-II is (0.237, 0.375), and for Model-III is (0.092, 0.163). Since the credible interval for Model-III is disjoint from the credible intervals for the other models, the differences in the estimated densities at 3.7 may be considered to be significant.
Figure 4.

Results for data on daily folate intakes from EATS example. The top panel shows the estimated densities of daily folate intake under different models. The bottom left panel shows estimated densities of scaled errors under Model-II (dashed line) and Model-III (solid bold line) superimposed over a standard Normal density (solid line). The bottom right panel shows estimated variance functions under different models. The gray dots represent subject-specific sample means (x-axis) and variances (y-axis). For the top panel and the bottom right panel, the solid thin line is for Model-I; the dashed line is for Model-II; the solid bold line is for Model-III; and the dot-dashed line is for the Model of Staudenmayer, et al. (2008).
Our analysis also showed that the measurement error distributions of all dietary components included in the EATS study deviate from normality and exhibit strong conditional heteroscedasticity. These findings emphasize the importance of flexible conditionally heteroscedastic error distribution models in nutritional epidemiologic studies.
6 Summary and Discussion
6.1 Summary
We have considered the problem of Bayesian density deconvolution in the presence of conditionally heteroscedastic measurement errors. Attending to the specific needs of deconvolution problems, three different approaches were considered for modeling the distribution of measurement errors. The first model made the conventional normality assumption about the measurement errors. The next two models allowed, with varying degrees of flexibility, the distribution of measurement errors to deviate from normality. In all these models conditional heteroscedasticity was also modeled nonparametrically. The proposed methodology, therefore, makes important contributions to the density deconvolution literature, allowing both the distribution of interest and the distribution of measurement errors to deviate from standard parametric laws, while at the same time accommodating conditional heteroscedasticity. Efficiency of the models in recovering the true density of interest was illustrated through simulation experiments, and in particular we showed that our method vastly dominates that of Staudenmayer, et al. (2008). Results of the simulation experiments suggested that all the models introduced in this article out-perform previously existing methods, even while relaxing some of the restrictive assumptions of previous approaches. Simulation experiments also showed that our Bayesian semiparametric deconvolution approaches proposed in this article will often be more efficient than possible nonparametric alternatives, even when the true data generating process deviates from the assumed semiparametric framework.
6.2 Data Transformation and Homoscedasticity
In our application area of nutrition, many researchers assume that W is unbiased for X in the original scale that the nutrient is measured, i.e., E(WjX) = X as in our model, see Willett (1998), Spiegelman, et al. (1997, 2001, 2005) and Kipnis, et al. (2009). It is this original scale of X then that is of scientific interest in this instance. An alternative technique is a transform-retransform method: attempt to transform the Wij data to make it additive and with homoscedastic measurement error, fit in the transformed scale, and then back-transform the density. For example, if where , then , the classical homoscedastic deconvolution problem with target . One could then use any homoscedastic deconvolution method to estimate the density of X*, and then from that estimate the density of X. Our methods obviously apply to such a problem. We have used the kernel deconvolution R package “decon” (Wang and Wang, 2011), the only available set of programs, and compared it to our method both using transform-retransform with homoscedasticity and by working in the original scale, using Model III. In a variety of target distributions for X and a variety of sample sizes, our methods consistently have substantially lower MISE.
It is also the case though that transformations to a model such as h(W) = h(X) + U with do not satisfy the unbiasedness condition in the original scale. In the log-transformation case, there is a multiplicative bias, but in the cube-root case, , a model that many in nutrition would find uncomfortable and, indeed, objectionable.
Of course, other fields would be amenable to unbiasedness on a transformed scale, and hope that the measurement error is homoscedastic on that scale. Even in this problem, our methodology is novel and dominates other methods that have been proposed previously. Our methods apply to this problem, allowing flexible Bayesian semiparametric models for the density of X in the transformed scale, flexible Bayesian semiparametric models for the density of the measurement errors, and, if desired, at the same time build modeling robustness lest there be any remaining heteroscedasticity. We have experimented with this ideal case, and even here our methods substantially dominate those currently in the literature. It also must be remembered too that it is often not possible to transform to additivity with homoscedasticity: one example in the EATS data of Section 5, where this occurs with vitamin B for the Box-Cox family. Details are available from the first author.
6.3 Extensions
Application of the Bayesian semiparametric methodology, introduced in this article for modeling conditionally heteroscedastic errors with unknown distribution where the conditioning variable is not precisely measured, is not limited to deconvolution problems. An important extension of this work and the subject of an ongoing research project is an application of the proposed methodology to errors-in-variables regression problems.
Supplementary Material
Acknowledgments
Carroll’s research was supported by grant R37-CA05730 from the National Cancer Institute. Mallick’s research was supported in part by National Science Foundation grant DMS0914951. Staudenmayer’s work was supported in part by NIH grants CA121005 and R01-HL099557. The authors thank Jeff Hart, John P. Buonaccorsi and Susanne M. Schennach for their helpful suggestions. The authors also acknowledge the Texas A&M University Brazos HPC cluster that contributed to the research reported here. This publication is based in part on work supported by Award Number KUS-CI-016-04, made by King Abdullah University of Science and Technology (KAUST).
Appendix A Model Identifiability
Hu and Schennach (2008) showed that models such as ours are identified under very weak conditions. They show that when four variables, (Y, W, Z, X), where X is the only unobserved variate, are continuously distributed, their joint distribution is identified under the following conditions; their conditions are even weaker, but these suffice for our case.
Conditions 1
1. fY|W,Z,X = fY|X. 2. fW|Z,X = fW|X. 3.
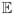 (W | X) = X. 4. The set {Y: fY|X(Y | X1) ≠ fY|X(Y | X2)} has positive probability under the marginal of Y for all X1 ≠ X2. 5. The marginal, joint and conditional densities of (Y, W, Z, X) are bounded.
(W | X) = X. 4. The set {Y: fY|X(Y | X1) ≠ fY|X(Y | X2)} has positive probability under the marginal of Y for all X1 ≠ X2. 5. The marginal, joint and conditional densities of (Y, W, Z, X) are bounded.
They also have a highly technical assumption about injectivity of operators, which is satisfied if the distributions of W given X and Z given X are complete. This means, for example, that if ∫ g(W)fW|X(W | X)dW = 0 for all X, then g ≡ 0. This is a weak assumption and we comment upon it no further.
When mi ≥ 3, identifiability of our model (1)–(2) is assured as it falls within the general framework of Hu and Schennach (2008). To see this, replace their Yi by our Wi1, their Wi by our Wi2, their Zi by our Wi3 and their Xi by our Xi. Conditions 3.1–3.4 then follow from the fact that (εi1, εi2, εi3, Xi) have a continuous distribution and are mutually independent with E(εij) = 0. Condition 3.5 follows assuming the variance function v is continuous.
We conjecture that model (1)–(2) is identifiable even with mi ≥ 2 under very weak assumptions. We have numerical evidence to support the claim.
Appendix B Choice of Hyper-Parameters
For the DPMM prior for fX, the prior variance of each is , whereas the prior variance of each μk, given is . Small values of γ0 and ν0 imply large prior variance and hence non-informativeness. We chose γ0 = 3 and ν0 = 1/5. The prior marginal mean and variance of X, obtained by integrating out all but the hyper-parameters, are given by μ0 and respectively. Taking an empirical Bayes type approach, we set μ0 = W̄ and , where W̄ is the mean of the subject-specific sample means W̄1:n, and is an estimate of the across subject variance from a one way random effects model. To ensure noninformativeness, hyper-parameters appearing in the prior for fε are chosen as σμ̃ = 3, aε = 1 and bε = 1. For real world applications, the values of A and B may not be known. We set [A, B] = [min(W̄1:n) − 0.1 range(W̄1:n), max(W̄1:n) + 0.1 range(W̄1:n)]. The DP concentration parameters αX and αε could have been assigned gamma hyper-priors (Escobar and West, 1995), but in this article we kept them fixed at αX = 0.1 and αε = 1, respectively. The prior mean and standard deviation of λ were set at μ0λ= 0 and σ0λ = 4. For modeling the variance functions v and ṽ, quadratic (q=2) B-splines based are used. See the supplementary materials for detailed expressions. The B-splines are based on (2 × 2 + 10 + 1) = 15 knot points that divide the interval [A, B] into K = 10 subintervals of equal length. We take X0 = t5. The identifiability restriction on the variance function for Model III now becomes {exp(ξ3) + exp(ξ4)} = 2. The inverse-gamma hyper-prior on the smoothing parameter is non-informative if bξ is small relative to ξTPξ. We chose aξ = bξ = 0.1.
Appendix C Posterior Inference
Define cluster labels C1:n, where Ci = k if Xi is associated with the kth component of the DPMM. Similarly for Model-III, define cluster labels , where Zij = k if εij comes from the kth component of (14). Let denote the total number of observations. With a slight abuse of notation, define and . Then for Model-I, fW|X(Wij | Xi, ξ) = Normal {Wij | Xi, v(Xi, ξ)}; for Model-II, fW|X(Wij | Xi, ξ, λ) = SN{Wij | Xi, v(Xi, ξ), λ}; and for Model-III, given Zij = k, . In what follows ζ denotes a generic variable that collects all other parameters of a model, including X1:n, that are not explicitly mentioned.
It is possible to integrate out the random mixture probabilities from the prior and posterior full conditionals of the cluster labels. Classical algorithms for fitting DPMMs make use of this and work with the resulting Polya urn scheme. Neal (2000) provided an excellent review of this type of algorithm for both conjugate and non-conjugate cases. In this article, the parameters specific to DPMMs are updated using algorithms specific to those models and other parameters are updated using the Metropolis-Hastings algorithm. In what follows, the generic notation q(current → proposed) denotes the proposal distributions of the Metropolis-Hastings steps proposing a move from the current value to the proposed value.
The starting values of the MCMC chain are determined as follows. Subject-specific sample means W̄1:n are used as starting values for X1:n. Each Ci is initialized at i with each Xi coming from its own cluster with mean μi = Xi and variance . In addition, is initialized at 0.1. The initial value of ξ is obtained by maximizing ℓ(ξ | 0.1, W̄1:n) with respect to ξ, where denotes the conditional log-posterior of ξ. The parameters of the distribution of scaled errors are initialized at values that correspond to the special standard normal case. For example, for Model-II, λ is initialized at zero. For Model-III, Zij’s are all initialized at 1 with . The MCMC iterations comprise the following steps.
-
Updating the parameters of the distribution of X: Conditionally given X1:n, the parameters specifying the DPMM for fX can be updated using a Gibbs sampler (Neal, 2000, Algorithm 2). The full conditional of Ci is given by
where b denotes the appropriate normalizing constant; for each i, C−i = C1:n −{Ci}; n−i,k =Σ{l:l≠i}1{cl=k} is the number of cl’s that equal k in C−i; and . tm denotes the density of a t-distribution with m degrees of freedom.
For all k ∈ C1:n, we update (μk, ) using the closed-form joint full conditional given by , where is the number of Xi’s associated with the kth cluster; νnk = (ν0 + nk); γnk = (γ0 + nk/2); μnk = (ν0μ0 + nkΣ{i:Ci=k} Xi)/(ν0 + nk) and .
Updating X1:n: Because the Xi’s are conditionally independent, the full conditional of Xi is given by . We use a Metropolis-Hastings sampler to update the Xi’s with proposal , where σX = (the range of W̄1:n)/6 and TN(· | m, s2, [ℓ,u]) denotes a truncated normal distribution with location m and scale s restricted to the interval [ℓ, u].
-
Updating the parameters of the distribution of scaled errors: For Model-II and Model-III, the parameters involved in the distribution of scaled errors have to be updated.
For Model-II, the distribution of scaled error is SN(0, 1, λ), involving only the parameter λ. The full conditional of λ is given by . We use Metropolis-Hastings sampler to update λ with random walk proposal .
For Model-III, we use Metropolis-Hastings samplers to update the latent parameters Z1:N as well as the component specific parameters (pk, μ̃k, )’s (Neal, 2000, Algorithm 5). We propose a new value of Zij, say Zij,new, according to its marginalized conditional priorwhere, for each (i, j) pair, Z−ij = Z1:N − {Zij}; N−ij,k = Σ[rs:rs≠ij} 1{Zrs=k}, the number of Zrs’s in Z−ij that equal k. If Zij,new ∉ Z−ij, we draw (pZij,new, μ̃Zij,new, ) from the prior p0(p, μ̃, . We update Zij to its proposed value with probabilityFor all k ∈ Z1:N, we propose a new value for (pk, μ̃k, ) with the proposal . We update θk to the proposed value θk,new with probability -
Updating the parameters of the variance function: The full conditional for ξ is given by . We use Metropolis-Hastings sampler to update ξ with random walk proposal q(ξ → ξnew) = MVN(ξnew | ξ, Σξ). For Model III, the identifiability restriction is imposed by replacing ξnew,3 = log{2 − exp(ξnew,4)}.
Finally, we update the hyper-parameter using its closed-form full conditional .
The covariance matrix Σξ of the proposal distribution for ξ is taken to be the inverse of the negative Hessian matrix of l(ξ | 0.1, W̄1:n) evaluated at the chosen initial value of ξ. See Appendix D for more details. Other variance parameters appearing in the proposal distributions are tuned to get good acceptance rates for the Metropolis-Hastings samplers, the values σλ = 1, σp = 0.01 and σσ = 0.1 working well in the examples considered. In simulation experiments, 5,000 MCMC iterations with the initial 3,000 discarded as burn-in produced very stable estimates of the density and the variance function.
The posterior estimate of fX is given by the unconditional predictive density fX(· | W1:N). A Monte Carlo estimate of fX(· | W1:N), based on M samples from the posterior, is given by
where is the sampled value of (μk, ) in the mth sample, is the number of Xi’s associated with the kth cluster, and k(m) is the total number of active clusters. With and defined in a similar fashion, the posterior Monte Carlo estimate of fε for Model-III is
The integral above can not be exactly evaluated. Monte Carlo approximation may be used. If N ≫ αε, the term may simply be neglected. For Model II, fε can be estimated by . For Models I and II, an estimate of the variance function v can similarly be obtained as . An estimate of the restricted variance function ṽ for Model III can be obtained using a similar formula. For Model III, v̂ and a scaled version of , scaled to have unit variance, can be obtained using the estimate of ṽ(X0).
Appendix D Initial Values and Proposals for ξ
The conditional posterior log-likelihood of ξ for Model-I is given by
The initial values for the M-H sampler for ξ is obtained as ξ (0) = arg max ℓ(ξ | 0.1, W̄1:n). Numerical optimization is performed using the optim routine in R with the analytical gradient supplied.
The covariance matrix of the random walk proposal for ξ is taken to be the inverse of the negative of the matrix of second partial derivatives of ℓ(ξ | 0.1, W̄1:n) evaluated at ξ (0). Expressions for the gradient and the second derivatives are given below.
Footnotes
Results on Model Flexibility, R programs, Data: The supplementary materials, available in a single zip file (supplements.zip), contain some figures and tables referenced in the main paper, results of additional simulation experiments, and R programs for implementing our methods with default hyper-prior choices. The EATS data set analyzed in this paper reside at the National Cancer Institute (NCI, http://www.cancer.gov/) and may be obtained from NCI arranging a Material Transfer Agreement. A simulated data set representative of the actual data (i.e., generated from the fitted model) is included in the supplementary materials. A readme file (ReadMe.txt) that provides further details of the contents is also included.
Contributor Information
Abhra Sarkar, Email: abhra@stat.tamu.edu, Department of Statistics, Texas A&M University, 3143 TAMU, College Station, TX 77843-3143 USA.
Bani K. Mallick, Email: bmallick@stat.tamu.edu, Department of Statistics, Texas A&M University, 3143 TAMU, College Station, TX 77843-3143 USA
John Staudenmayer, Email: jstauden@math.umass.edu, Department of Mathematics and Statistics, University of Massachusetts, Amherst, MA 01003-9305 USA.
Debdeep Pati, Email: debdeep@stat.fsu.edu, Department of Statistics, Florida State University, Tallahassee, FL 32306-4330 USA.
Raymond J. Carroll, Email: carroll@stat.tamu.edu, Department of Statistics, Texas A&M University, 3143 TAMU, College Station, TX 77843-3143 USA
References
- Azzalini A. A class of distributions which includes the Normal ones. Scandinavian Journal of Statistics. 1985;12:171–178. [Google Scholar]
- Carroll RJ, Hall P. Optimal rates of convergence for deconvolving a density. Journal of the American Statistical Association. 1988;83:1184–1186. [Google Scholar]
- Carroll RJ, Hall P. Low order approximations in deconvolution and regression with errors in variables. Journal of the Royal Statistical Society, Series B. 2004;66:31–46. [Google Scholar]
- Carroll RJ, Roeder K, Wasserman L. Flexible parametric measurement error models. Biometrics. 1999;55:44–54. doi: 10.1111/j.0006-341x.1999.00044.x. [DOI] [PubMed] [Google Scholar]
- Chan D, Kohn R, Nott D, Kirby C. Locally adaptive semiparametric estimation of the mean and variance functions in regression models. Journal of Computational and Graphical Statistics. 2006;15:915–936. [Google Scholar]
- Chung Y, Dunson DB. Nonparametric Bayes conditional distribution modeling with variable selection. Journal of the American Statistical Association. 2009;104:1646–1660. doi: 10.1198/jasa.2009.tm08302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Boor C. A Practical Guide to Splines. New York: Springer; 2000. [Google Scholar]
- Devroye L. Consistent deconvolution in density estimation. Canadian Journal of Statistics. 1989;17:235–239. [Google Scholar]
- Eckert RS, Carroll RJ, Wang N. Transformations to additivity in measurement error models. Biometrics. 1997;53:262–272. [PubMed] [Google Scholar]
- Eilers PHC, Marx BD. Flexible smoothing with B-splines and penalties. Statistical Science. 1996;11:89–121. [Google Scholar]
- Escobar MD, West M. Bayesian density estimation and inference using mixtures. Journal of the American Statistical Association. 1995;90:577–588. [Google Scholar]
- Fan J. On the optimal rates of convergence for nonparametric deconvolution problems. Annals of Statistics. 1991a;19:1257–1272. [Google Scholar]
- Fan J. Global behavior of deconvolution kernel estimators. Statistica Sinica. 1991b;1:541–551. [Google Scholar]
- Fan J. Deconvolution with supersmooth distributions. Canadian Journal of Statistics. 1992;20:155–169. [Google Scholar]
- Ferguson TF. A Bayesian analysis of some nonparametric problems. Annals of Statistics. 1973;1:209–230. [Google Scholar]
- Hesse CH. Data driven deconvolution. Journal of Nonparametric Statistics. 1998;10:343–373. [Google Scholar]
- Hu Y, Schennach SM. Instrumental variable treatment of nonclassical measurement error models. Econometrica. 2008;76:195–216. [Google Scholar]
- Kipnis V, Midthune D, Buckman DW, Dodd KW, Guenther PM, Krebs-Smith SM, Subar AF, Tooze JA, Carroll RJ, Freedman LS. Modeling data with excess zeros and measurement error: application to evaluating relationships between episodically consumed foods and health outcomes. Biometrics. 2009;65:1003–1010. doi: 10.1111/j.1541-0420.2009.01223.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li T, Vuong Q. Nonparametric estimation of the measurement error model using multiple indicators. Journal of Multivariate Analysis. 1998;65:139–165. [Google Scholar]
- Liu A, Tong T, Wang Y. Smoothing spline estimation of variance functions. Journal of Computational and Graphical Statistics. 2006;16:312–329. [Google Scholar]
- Liu MC, Taylor RL. A consistent nonparametric density estimator for the decon-volution problem. Canadian Journal of Statistics. 1989;17:427–438. [Google Scholar]
- Lo AY. On a class of Bayesian nonparametric estimates. I: Density estimates. Annals of Statistics. 1984;12:351–357. [Google Scholar]
- Neal RM. Markov chain sampling methods for Dirichlet process mixture models. Journal of Computational and Graphical Statistics. 2000;9:249–265. [Google Scholar]
- Pelenis J. Semiparametric Bayesian regression. Journal of Econometrics. 2014;178:624–638. [Google Scholar]
- Sethuraman J. A constructive definition of Dirichlet priors. Statistica Sinica. 1994;4:639–650. [Google Scholar]
- Spiegelman D, McDermott A, Rosner B. The regression calibration method for correcting measurement error bias in nutritional epidemiology. American Journal of Clinical Nutrition. 1997;65 (supplement):1179S–1186S. doi: 10.1093/ajcn/65.4.1179S. [DOI] [PubMed] [Google Scholar]
- Spiegelman D, Carroll RJ, Kipnis V. Efficient regression calibration for logistic regression in main study/internal validation study designs with an imperfect reference instrument. Statistics in Medicine. 2001;20:139–160. doi: 10.1002/1097-0258(20010115)20:1<139::aid-sim644>3.0.co;2-k. [DOI] [PubMed] [Google Scholar]
- Spiegelman D, Zhao B, Kim J. Correlated errors in biased surrogates: study designs and methods for measurement error correction. Statistics in Medicine. 2005;24:1657–1682. doi: 10.1002/sim.2055. [DOI] [PubMed] [Google Scholar]
- Staudenmayer J, Ruppert D, Buonaccorsi JP. Density estimation in the presence of heteroscedastic measurement error. Journal of the American Statistical Association. 2008;103:726–736. [Google Scholar]
- Suber AF, Thompson FE, Kipnis V, Midthune D, Hurwitz P, McNutt S, McIntosh A, Rosenfeld S. Comparative validation of the block, Willet, and National Cancer Institute food frequency questionnaires. American Journal of Epidemiology. 1990;154:1089–1099. doi: 10.1093/aje/154.12.1089. [DOI] [PubMed] [Google Scholar]
- Wang X, Wang B. Deconvolution estimation in measurement error models: the R package decon. Journal of Statistical Software. 2011;39:1–24. [PMC free article] [PubMed] [Google Scholar]
- West M, Müller P, Escobar MD. Hierarchical priors and mixture models, with application in regression and density estimation. In: Smith AFM, Freeman P, editors. Aspects of uncertainty: a tribute to D. V. Lindley. New York: Wiley; 1994. pp. 363–386. [Google Scholar]
- Willett W. Nutritional Epidemiology. 2. Oxford University Press; 1998. [Google Scholar]
- Yau P, Kohn R. Estimation and variable selection in nonparametric heteroscedastic regression. Statistics and Computing. 2003;13:191–208. [Google Scholar]
- Zaykin DV, Zhivotovsky LA, Westfall PH, Weir BS. Truncated product method for combining p-values. Genetic Epidemiology. 2002;22:170–185. doi: 10.1002/gepi.0042. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.