

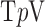
Abstract
Exploiting sparsity in the image gradient magnitude has proved to be an effective means for reducing the sampling rate in the projection view angle in computed tomography (CT). Most of the image reconstruction algorithms, developed for this purpose, solve a nonsmooth convex optimization problem involving the image total variation (TV). The TV seminorm is the 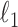 norm of the image gradient magnitude, and reducing the
norm of the image gradient magnitude, and reducing the 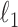 norm is known to encourage sparsity in its argument. Recently, there has been interest in employing nonconvex
norm is known to encourage sparsity in its argument. Recently, there has been interest in employing nonconvex 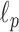 quasinorms with
quasinorms with 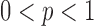 for sparsity exploiting image reconstruction, which is potentially more effective than
for sparsity exploiting image reconstruction, which is potentially more effective than 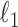 because nonconvex
because nonconvex 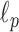 is closer to
is closer to 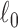 —a direct measure of sparsity. This paper develops algorithms for constrained minimization of the total
—a direct measure of sparsity. This paper develops algorithms for constrained minimization of the total 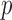 -variation
-variation 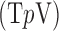 ,
, 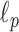 of the image gradient. Use of the algorithms is illustrated in the context of breast CT—an imaging modality that is still in the research phase and for which constraints on X-ray dose are extremely tight. The
of the image gradient. Use of the algorithms is illustrated in the context of breast CT—an imaging modality that is still in the research phase and for which constraints on X-ray dose are extremely tight. The 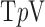 -based image reconstruction algorithms are demonstrated on computer simulated data for exploiting gradient magnitude sparsity to reduce the projection view angle sampling. The proposed algorithms are applied to projection data from a realistic breast CT simulation, where the total X-ray dose is equivalent to two-view digital mammography. Following the simulation survey, the algorithms are then demonstrated on a clinical breast CT data set.
-based image reconstruction algorithms are demonstrated on computer simulated data for exploiting gradient magnitude sparsity to reduce the projection view angle sampling. The proposed algorithms are applied to projection data from a realistic breast CT simulation, where the total X-ray dose is equivalent to two-view digital mammography. Following the simulation survey, the algorithms are then demonstrated on a clinical breast CT data set.
Keywords: Computed tomography, X-ray tomography, image reconstruction, iterative algorithms, optimization
I. Introduction
Much research for iterative image reconstruction (IIR) in computed tomography (CT) has focused on exploiting gradient magnitude image (GMI) sparsity. Several theoretical investigations have demonstrated accurate CT image reconstruction from reduced data sampling employing various convex optimization problems involving total variation (TV) minimization [1]–[6]. Many of these algorithms have been adapted to use on actual scanner data for sparse-view CT [7]–[12] or gated/dynamic CT [7], [13]–[17]. While the volume of work on this topic speaks to the success of the idea of exploiting GMI sparsity, TV minimization is not the most direct method for taking advantage of this prior.
The most direct measure of sparsity is totaling the number of nonzero pixels in an image. Mathematically, the number of nonzero components of a vector can be expressed as the 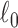 norm, which is understood to be the limit as
norm, which is understood to be the limit as 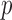 goes to zero of the
goes to zero of the 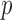 th power of the
th power of the 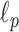 norm:
norm:
 |
As of yet, no algorithms have been developed for CT IIR that minimize 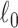 of the GMI, and sparsity exploiting IIR has focused on minimizing
of the GMI, and sparsity exploiting IIR has focused on minimizing 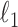 of the GMI—also known as TV. Logically,
of the GMI—also known as TV. Logically, 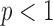 should improve on exploitation of GMI sparsity for sampling reduction, but optimization problems involving
should improve on exploitation of GMI sparsity for sampling reduction, but optimization problems involving 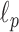 for
for 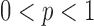 are nonconvex and may have multiple local minima. Recent theoretical results, however, do show that values of
are nonconvex and may have multiple local minima. Recent theoretical results, however, do show that values of 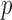 leading to nonconvex optimization problems may be practical for compressive sensing applications [18]–[20]. For exploiting GMI sparsity in particular accurate solvers have been developed for minimization of the total
leading to nonconvex optimization problems may be practical for compressive sensing applications [18]–[20]. For exploiting GMI sparsity in particular accurate solvers have been developed for minimization of the total 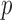 -variation
-variation 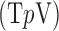 using reweighting techniques [21].
using reweighting techniques [21].
For tomographic X-ray imaging, the idea of exploiting nonconvex 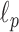 norms has been applied to perfusion imaging [22] and metal artifact reduction [23]. We have investigated the use of
norms has been applied to perfusion imaging [22] and metal artifact reduction [23]. We have investigated the use of 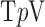 minimization in the context of IIR for digital breast tomosynthesis [24]. While these works show potential applications, they do not characterize quantitatively how much more sampling reduction is made possible by exploiting nonconvex
minimization in the context of IIR for digital breast tomosynthesis [24]. While these works show potential applications, they do not characterize quantitatively how much more sampling reduction is made possible by exploiting nonconvex 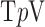 minimization as compared with convex TV minimization.
minimization as compared with convex TV minimization.
Despite the interest in TV-based IIR for CT over the past few years, the undersampling allowed for CT by TV minimization has only recently been quantified [5]. The aim of this article is to develop accurate solvers for nonconvex 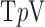 minimization and to quantify further reduction of the number of projections needed. Although the primary interest here is in ideal theoretical image recovery, we also apply the same algorithms to a realistic simulation of a breast CT in order to demonstrate that the presented algorithms are robust against noise and may prove useful for actual use with CT scanner data. Section II provides theoretical motivation for nonconvex optimization; Section III presents the IIR algorithms for
minimization and to quantify further reduction of the number of projections needed. Although the primary interest here is in ideal theoretical image recovery, we also apply the same algorithms to a realistic simulation of a breast CT in order to demonstrate that the presented algorithms are robust against noise and may prove useful for actual use with CT scanner data. Section II provides theoretical motivation for nonconvex optimization; Section III presents the IIR algorithms for 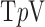 minimization; Section IV discusses algorithm parameter choices; Section V surveys image reconstruction on ideal CT simulated data to test phantom recovery as a function of number of views and value of
minimization; Section IV discusses algorithm parameter choices; Section V surveys image reconstruction on ideal CT simulated data to test phantom recovery as a function of number of views and value of 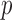 ; Section VI presents image reconstruction by nonconvex
; Section VI presents image reconstruction by nonconvex 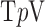 minimization on a realistic breast CT simulation; and finally, Section VII applies one of the proposed algorithms to clinical breast CT data.
minimization on a realistic breast CT simulation; and finally, Section VII applies one of the proposed algorithms to clinical breast CT data.
II. Motivation for Nonconvex Optimization for Exploiting Sparsity in IIR
We write the CT data model generically as a linear system
 |
where 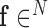 is the image vector comprised of voxel coefficients,
is the image vector comprised of voxel coefficients, 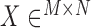 is the system matrix generated by projection of the voxels, and
is the system matrix generated by projection of the voxels, and 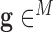 is the data vector containing the estimated projection samples. The model can be applied equally to 2D and 3D geometries, and we note that there are many specific forms to this linear system depending on sampling, image expansion elements, and approximation of continuous fan- or cone-beam projection.
is the data vector containing the estimated projection samples. The model can be applied equally to 2D and 3D geometries, and we note that there are many specific forms to this linear system depending on sampling, image expansion elements, and approximation of continuous fan- or cone-beam projection.
We focus on CT configurations with sparse angular sampling, where the sampling rate is too low for (2) to have a unique solution. In this situation, there has been much interest in exploiting GMI sparsity of the object to narrow the solution space and potentially obtain an accurate reconstruction from under-sampled data. The formulation of this idea results in a nonconvex constrained optimization:
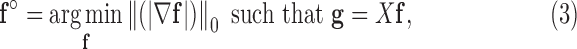 |
where the argument of the 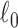 -norm is the voxel-wise magnitude of the image spatial gradient, and
-norm is the voxel-wise magnitude of the image spatial gradient, and 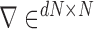 represents a discrete gradient operator with spatial dimension
represents a discrete gradient operator with spatial dimension 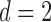 or 3. In order to make clear the distinction between a spatial-vector valued image, such as an image gradient, and a scalar valued image, we employ a vector symbol for the former case. For example, let
or 3. In order to make clear the distinction between a spatial-vector valued image, such as an image gradient, and a scalar valued image, we employ a vector symbol for the former case. For example, let 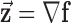 be the gradient of an image, where we stack the partial-derivative image vectors, so that
be the gradient of an image, where we stack the partial-derivative image vectors, so that 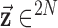 or
or 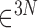 depending on whether we are working on 2 or 3 dimensions, respectively. Also, we use the absolute value symbol to convert a vector-valued image to a scalar image by taking the magnitude of the spatial-vector at each pixel/voxel. For example,
depending on whether we are working on 2 or 3 dimensions, respectively. Also, we use the absolute value symbol to convert a vector-valued image to a scalar image by taking the magnitude of the spatial-vector at each pixel/voxel. For example,  is a scalar image indicating the spatial-vector magnitude of
is a scalar image indicating the spatial-vector magnitude of 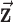 . We define multiplication, division, and other operations on vectors (other than matrix multiplication) by performing the operation separately for each component. Finally, we define multiplication between a scalar image
. We define multiplication, division, and other operations on vectors (other than matrix multiplication) by performing the operation separately for each component. Finally, we define multiplication between a scalar image 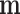 and spatial-vector image
and spatial-vector image 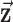 ;
; 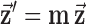 by scaling the spatial-vector pixelwise/voxelwise, i.e.,
by scaling the spatial-vector pixelwise/voxelwise, i.e., 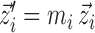 for
for 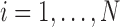 . The
. The 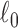 -norm in (3) counts the number of non-zero components in the argument vector; and
-norm in (3) counts the number of non-zero components in the argument vector; and 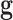 is the available projection data. In words, this optimization seeks the image
is the available projection data. In words, this optimization seeks the image 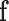 with the lowest GMI sparsity while agreeing exactly with the data.
with the lowest GMI sparsity while agreeing exactly with the data.
The optimization problem in (3) does not lead directly to a practical image reconstruction algorithm, because, as of yet, no large scale solver is available for this problem. Also, the equality constraint, requiring perfect agreement between the available and estimated data, makes no allowance for noise or imperfect physical modeling of X-ray projection. In working toward developing a practical image reconstruction algorithm, different relaxations of (3) have been considered. One such relaxation is
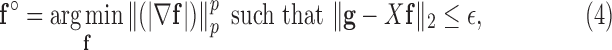 |
where the 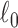 -norm is replaced by the
-norm is replaced by the 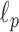 -norm, and the data equality constraint is relaxed to an inequality constraint with data-error tolerance parameter
-norm, and the data equality constraint is relaxed to an inequality constraint with data-error tolerance parameter 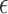 . An important strategy, which has been studied extensively in compressive sensing [25], [26], is to set
. An important strategy, which has been studied extensively in compressive sensing [25], [26], is to set  , which corresponds to TV minimization. This, on the one hand, maintains some of the sparsity seeking features of (3) and, on the other hand, leads to a convex problem, which has convenient properties for algorithm development. For example, a local minimizer is a global minimizer in convex optimization.
, which corresponds to TV minimization. This, on the one hand, maintains some of the sparsity seeking features of (3) and, on the other hand, leads to a convex problem, which has convenient properties for algorithm development. For example, a local minimizer is a global minimizer in convex optimization.
Another interesting option for GMI sparsity-exploiting image reconstruction is to consider (4) for 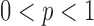 . Such a choice for
. Such a choice for 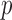 leads to nonconvex optimization, which can allow for greater sampling reduction than the
leads to nonconvex optimization, which can allow for greater sampling reduction than the  case while maintaining highly accurate image reconstruction. These gains intuitively stem from the fact
case while maintaining highly accurate image reconstruction. These gains intuitively stem from the fact  is closer to the ideal sparsity-exploiting case of
is closer to the ideal sparsity-exploiting case of  ; the catch, however, is on the algorithmic side where one has to deal with potential local minima, which are not part of the global solution set. Despite this potential difficulty, practical algorithms based on this nonconvex principle are available [20], [27], and gains in sampling reduction for various imaging systems have been reported for both simulated and real data cases. For X-ray tomography, use of this nonconvex strategy has shown promising results [24], [28], but the algorithms proposed in those works for CT are only motivated by the optimization problem in (4) and are not accurate solvers of this problem. An accurate solver is important for theoretical studies of CT image reconstruction with under-sampled data and may also aid in developing algorithms for limited-data tomographic devices.
; the catch, however, is on the algorithmic side where one has to deal with potential local minima, which are not part of the global solution set. Despite this potential difficulty, practical algorithms based on this nonconvex principle are available [20], [27], and gains in sampling reduction for various imaging systems have been reported for both simulated and real data cases. For X-ray tomography, use of this nonconvex strategy has shown promising results [24], [28], but the algorithms proposed in those works for CT are only motivated by the optimization problem in (4) and are not accurate solvers of this problem. An accurate solver is important for theoretical studies of CT image reconstruction with under-sampled data and may also aid in developing algorithms for limited-data tomographic devices.
III. Algorithm for Constrained 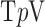 Minimization
Minimization
In order to address constrained minimization problems such as the one in (4), the optimization problem is frequently converted to unconstrained minimization essentially by considering the Lagrangian of (4):
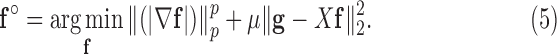 |
This approach is employed often even for the convex case of 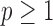 . Here, we derive an algorithm for solving (4) directly by employing the Chambolle-Pock (CP) framework [29], [30]. The strategy, illustrated in a simple one dimensional example in Appendix VIII-A, is to convert
. Here, we derive an algorithm for solving (4) directly by employing the Chambolle-Pock (CP) framework [29], [30]. The strategy, illustrated in a simple one dimensional example in Appendix VIII-A, is to convert 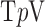 minimization to a convex weighted TV minimization problem, and write down the CP algorithm which solves the convex weighted problem. Once we have this algorithm, reweighting [31], [32] is employed to address the original
minimization to a convex weighted TV minimization problem, and write down the CP algorithm which solves the convex weighted problem. Once we have this algorithm, reweighting [31], [32] is employed to address the original 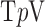 minimization problem. Maintaining the constrained form of the nonconvex minimization problem in (4) has two physically-motivated advantages: (1) the data-error tolerance
minimization problem. Maintaining the constrained form of the nonconvex minimization problem in (4) has two physically-motivated advantages: (1) the data-error tolerance 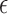 has more physical meaning than the regularization parameter
has more physical meaning than the regularization parameter 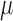 of the corresponding unconstrained problem of (5)
[2], [33], and (2) this form is more convenient for assessing
of the corresponding unconstrained problem of (5)
[2], [33], and (2) this form is more convenient for assessing 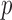 -dependence of the reconstructed images because changing
-dependence of the reconstructed images because changing 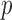 does not alter the data fidelity of the solution.
does not alter the data fidelity of the solution.
We start by rewriting (4), using an indicator function to encode the constraint:
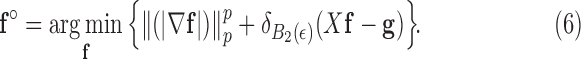 |
The indicator function is defined by
 |
and the ball 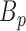 is defined as the following set:
is defined as the following set:
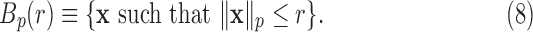 |
We also define an “ellipsoidal” set 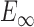 :
:
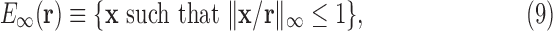 |
where 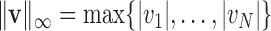 denotes the maximum norm. For
denotes the maximum norm. For 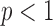 , (6) is not a convex problem, and as a result the CP algorithm cannot be applied directly to it. Following the reweighting strategy, we alter the objective function and introduce a weighted convex term to replace the nonconvex one:
, (6) is not a convex problem, and as a result the CP algorithm cannot be applied directly to it. Following the reweighting strategy, we alter the objective function and introduce a weighted convex term to replace the nonconvex one:
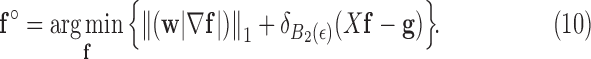 |
A CP algorithm for this convex problem is straightforward to derive, which will be done in Section III-A. To obtain an algorithm for the nonconvex problem in (6), we use the same algorithm solving (10) except that we alter the weights at each iteration by
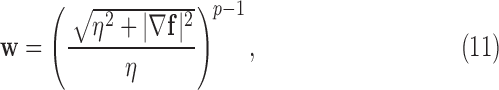 |
where 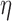 is a smoothing parameter introduced to avoid the singularity for
is a smoothing parameter introduced to avoid the singularity for 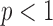 . The additional
. The additional 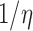 factor in the definition of
factor in the definition of 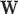 sets the maximum value possible for
sets the maximum value possible for 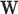 to unity. Note also that
to unity. Note also that 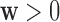 for
for 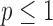 .
.
Before going on to deriving the reweighted CP algorithm, we introduce two parameters 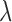 and
and 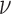 , which are convenient for algorithm efficiency and avoiding algorithm instability due to the reweighting. Both of these parameters are introduced into the weighted TV term of (10):
, which are convenient for algorithm efficiency and avoiding algorithm instability due to the reweighting. Both of these parameters are introduced into the weighted TV term of (10):
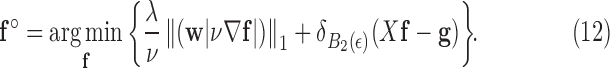 |
It is clear that 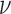 does not alter this optimization problem in any way, because the
does not alter this optimization problem in any way, because the 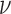 in the denominator cancels the one in front of
in the denominator cancels the one in front of 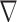 . The parameter
. The parameter 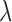 does affect the objective function, but for fixed weights
does affect the objective function, but for fixed weights 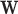 the solution of (12) does not depend on
the solution of (12) does not depend on 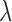 because of the hard constraint enforced by the indicator function. The effect of both of these parameters will be discussed in detail in Section IV-A.
because of the hard constraint enforced by the indicator function. The effect of both of these parameters will be discussed in detail in Section IV-A.
A. Algorithm Derivation and Pseudocode
The CP algorithm is designed to solve the following primal-dual pair of optimization problems:
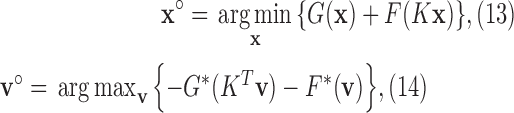 |
where 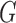 and
and 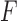 are convex functions and
are convex functions and 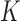 is a matrix, and where ∗ indicates convex conjugation by the Legendre transform
is a matrix, and where ∗ indicates convex conjugation by the Legendre transform
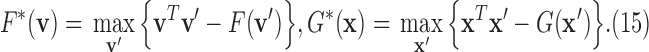 |
As described in [30], many optimization problems of interest for CT image reconstruction can be mapped onto the generic minimization problem of (13). Deriving a CP algorithm involves the following steps:
-
(1)
Make identifications between an optimization problem of interest, in our case (10), and (13).
-
(2)
Derive convex conjugates
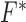 and
and 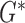 .
. -
(3)Compute the proximal mappings
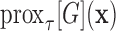 and
and 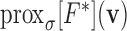 , defined by
, defined by 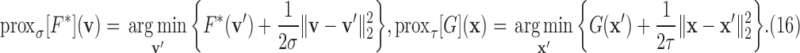
-
(4)
Substitute necessary components into Algorithm 1.
Algorithm 1 Pseudocode for  Steps of the Generic CP Algorithm
Steps of the Generic CP Algorithm
1:
 ;
;  ;
; 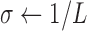 ;
; 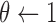 ;
; 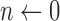
2: initialize
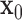 and
and 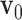 to zero vectors
to zero vectors3:
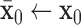
4: repeat
5:
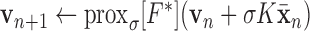
6:
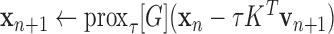
7:
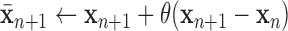
8:
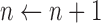
9: until
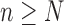
Because both terms in (12) contain linear transforms, the whole objective function is identified with 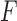 and the linear transform
and the linear transform 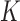 combines both X-ray projection
combines both X-ray projection 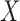 and the discrete gradient
and the discrete gradient 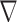 . The necessary assignments are
. The necessary assignments are
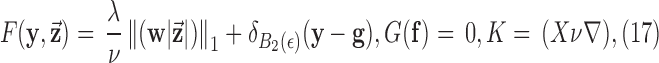 |
where the dual space contains vectors which are a concatenation of a data vector of size 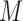 and an image gradient vector of size image dimension
and an image gradient vector of size image dimension 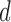 times
times 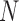 ,
, 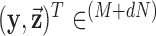 and
and 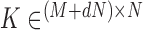 . Note that in making the assignments, the parameter
. Note that in making the assignments, the parameter 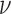 appears in the objective function
appears in the objective function 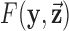 and the linear transform
and the linear transform 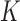 . Even though this parameter plays no role in the optimization problem in (12), it affects algorithm performance because it enters into the linear transform affecting
. Even though this parameter plays no role in the optimization problem in (12), it affects algorithm performance because it enters into the linear transform affecting 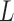 ,
, 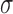 and
and 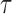 at line 1 in Algorithm 1.
at line 1 in Algorithm 1.
The detailed derivations for the necessary components 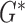 ,
, 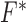 ,
, 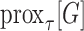 ,
, 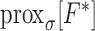 are presented in Appendices B, C, and D. Using the substitutions for the
are presented in Appendices B, C, and D. Using the substitutions for the  mappings generates the pseudocode in Algorithm 2 aside from the reweighting step in line 9. Note that the
mappings generates the pseudocode in Algorithm 2 aside from the reweighting step in line 9. Note that the 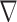 operator in this line does not have a factor of
operator in this line does not have a factor of 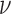 in front. This omission is by design, so that level of smoothing does not change with
in front. This omission is by design, so that level of smoothing does not change with 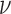 . This algorithm nominally solves (6), but there is no proof of convergence. We are only guaranteed that Algorithm 2 solves (12) if the weights
. This algorithm nominally solves (6), but there is no proof of convergence. We are only guaranteed that Algorithm 2 solves (12) if the weights 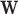 are fixed. As
are fixed. As 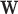 is in fact changing at line 9, convergence metrics take on an extra role; they not only tell when the solution is being approached but also if the particular choice of algorithm parameters yields stable or unstable updates. In particular, the convergence criteria play an important role in determining
is in fact changing at line 9, convergence metrics take on an extra role; they not only tell when the solution is being approached but also if the particular choice of algorithm parameters yields stable or unstable updates. In particular, the convergence criteria play an important role in determining 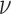 and
and 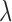 in Section IV-A.
in Section IV-A.
Algorithm 2 Pseudocode for 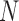 Steps of the CP Algorithm Instance for Reweighted Constrained
Steps of the CP Algorithm Instance for Reweighted Constrained 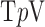 Minimization
Minimization
1: INPUT: data
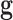 , data-error tolerance
, data-error tolerance 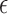 , exponent
, exponent 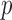 , and smoothing parameter
, and smoothing parameter 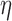
2: INPUT: algorithm parameters
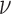 ,
, 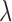
3:
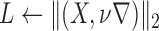 ;
; 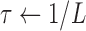 ;
; 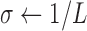 ;
; 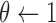 ;
; 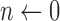
4: initialize
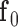 ,
, 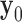 , and
, and 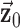 to zero vectors
to zero vectors5:
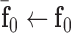
6: repeat
7:
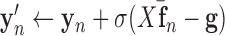
8:
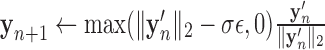
9:
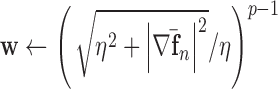
10:
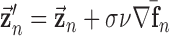
11:
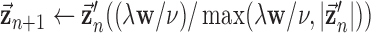
12:
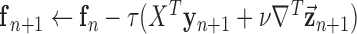
13:
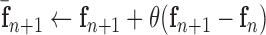
14:
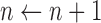
15: until
16: OUTPUT:
17: OUTPUT:
 ,
,  , and
, and 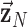 for evaluating cPD and conditions 3.
for evaluating cPD and conditions 3.
To check convergence, we derive the conditional primal-dual (cPD) gap and auxiliary conditions [30]. From the expressions for 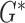 and
and 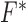 the dual maximization problem to (12) becomes
the dual maximization problem to (12) becomes
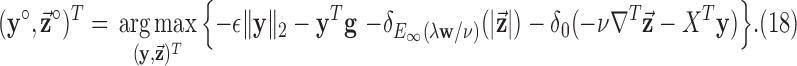 |
To form cPD, the primal-dual gap is written down without the indicator functions:
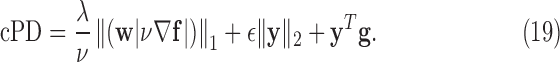 |
Auxiliary conditions are generated by each of the indicator functions in both the primal and dual objective functions. From the primal problem in (12) there is one constraint and from the dual maximization there are two additional constraints:
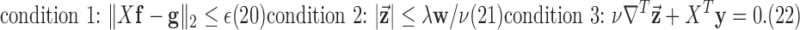 |
Condition 1 is the designed constraint on the data-error. Condition 2 does not provide a useful check because it is directly enforced at line 11 of Algorithm 2. Condition 3 is non-trivial and provides a useful part of the convergence check. Before demonstrating this nonconvex algorithm for GMI sparsity-exploiting image reconstruction, we present another variant that uses “anisotropic”  . It will be seen that this variant may allow for even greater reduction in sampling requirements.
. It will be seen that this variant may allow for even greater reduction in sampling requirements.
B. Constrained, Anisotropic  Minimization
Minimization
To this point we have been considering the isotropic form of 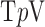 , which in two dimensions has the particular numerical implementation
, which in two dimensions has the particular numerical implementation
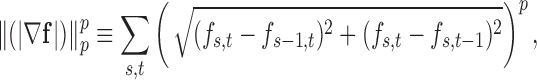 |
where 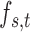 labels the scalar pixel value at image pixel location
labels the scalar pixel value at image pixel location 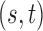 . Now we consider constrained minimization using anisotropic
. Now we consider constrained minimization using anisotropic 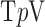 , the
, the 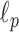 quasinorm of the gradient-vector image rather than of the GMI:
quasinorm of the gradient-vector image rather than of the GMI:
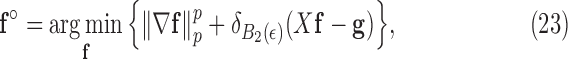 |
where in two dimensions the numerical implementation of anisotropic 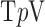 is
is
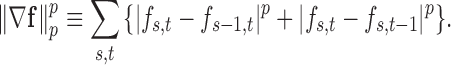 |
The consequence of this change is that for reweighting, the weights are computed separately for each partial-derivative image, allowing for finer control. Note that the expressions for isotropic and anisotropic 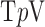 are the same when
are the same when  .
.
The reweighting program for solving (23) is listed in Algorithm 3, where the only differences in the listing appear at lines 10 and 12. For clarity, the component scalar images of the vector-valued weight images are written out at line 10, assuming a 2D gradient operator. Extension to 3D is straightforward. For convergence checking, we have
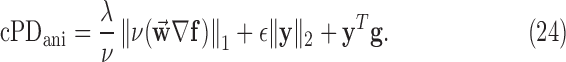 |
The auxiliary conditions 1 and 3 remain the same.
Algorithm 3 Pseudocode for  Steps of the CP Algorithm Instance for Reweighted Constrained Anisotropic
Steps of the CP Algorithm Instance for Reweighted Constrained Anisotropic 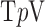 Minimization
Minimization
1: INPUT: data
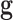 , data-error tolerance
, data-error tolerance 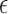 , exponent
, exponent 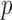 , and smoothing parameter
, and smoothing parameter 
2: INPUT: algorithm parameters
 ,
, 
3:
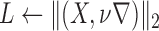 ;
; 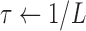 ;
; 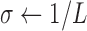 ;
; 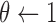 ;
; 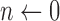
4: initialize
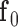 ,
, 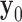 , and
, and 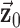 to zero vectors
to zero vectors5:
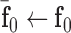
6: repeat
7:
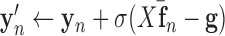
8:
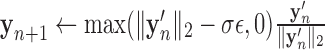
9:
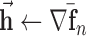
10:
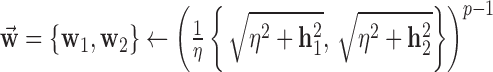
11:
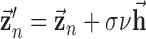
12:
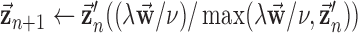
13:
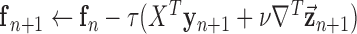
14:
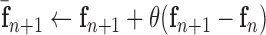
15:
16: until
17: OUTPUT:
18: OUTPUT:
 ,
, 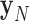 , and
, and 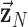 for evaluating
for evaluating 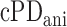 and conditions 3.
and conditions 3.
IV. System Specification and Parameter Tuning
Two linear transforms are important for the present theoretical studies on CT image reconstruction from limited projection data: the system matrix 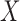 modeling X-ray projection, and the matrix
modeling X-ray projection, and the matrix  representing the finite differencing approximation of the image gradient. For computing the gradient
representing the finite differencing approximation of the image gradient. For computing the gradient  , 2 point forward differencing in each dimension is used, as described in [30].
, 2 point forward differencing in each dimension is used, as described in [30].
For specifying  , we simulate a configuration similar to that of breast CT except that we only consider here 2D fan-beam CT. The X-ray source to detector midpoint distance is taken to be 72 cm and the source to rotation center is 36 cm. The detector is modeled as a linear array with 256 detector bins. The source scanning arc is a full 360° circular trajectory. The angular sampling interval is equispaced along the trajectory, but the number of views is varied for the sparse sampling investigation. The pixel array consists of a 128×128 grid 18 cm on a side. Only the pixels in the inscribed circle of radius 18 cm are allowed to vary, accordingly the total number of active image pixels in the field-of-view (FOV) is 12,892 out of the 16,384 of the full square array.1 The matrix elements of
, we simulate a configuration similar to that of breast CT except that we only consider here 2D fan-beam CT. The X-ray source to detector midpoint distance is taken to be 72 cm and the source to rotation center is 36 cm. The detector is modeled as a linear array with 256 detector bins. The source scanning arc is a full 360° circular trajectory. The angular sampling interval is equispaced along the trajectory, but the number of views is varied for the sparse sampling investigation. The pixel array consists of a 128×128 grid 18 cm on a side. Only the pixels in the inscribed circle of radius 18 cm are allowed to vary, accordingly the total number of active image pixels in the field-of-view (FOV) is 12,892 out of the 16,384 of the full square array.1 The matrix elements of  are computed by the line-intersection method.
are computed by the line-intersection method.
The test phantom, shown in Fig. 1, models fat, fibroglandular tissue, and microcalcifications with linear attenuation coefficients of 0.194 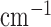 , 0.233
, 0.233 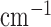 , and 1.6
, and 1.6 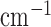 , respectively, for a monochromatic X-ray beam at 50 keV. The phantom is a realization of a probabilistic model described in [34]. For this phantom, the image is discretized on a 128×128 pixel array, and the gray values are thresholded and set to the values corresponding to one of the three tissue types. Constructing the phantom this way leads to a GMI which is somewhat sparse, as seen in Fig. 1. The total number of pixel values in the phantom is about three times larger than the number of nonzeros in the GMI, and we can expect that exploiting GMI sparsity will allow for accurate image reconstruction from reduced data sampling, using GMI sparsity exploiting algorithms. The described data and system model will be used in Section V to demonstrate the theoretical reduction in sampling enabled by constrained
, respectively, for a monochromatic X-ray beam at 50 keV. The phantom is a realization of a probabilistic model described in [34]. For this phantom, the image is discretized on a 128×128 pixel array, and the gray values are thresholded and set to the values corresponding to one of the three tissue types. Constructing the phantom this way leads to a GMI which is somewhat sparse, as seen in Fig. 1. The total number of pixel values in the phantom is about three times larger than the number of nonzeros in the GMI, and we can expect that exploiting GMI sparsity will allow for accurate image reconstruction from reduced data sampling, using GMI sparsity exploiting algorithms. The described data and system model will be used in Section V to demonstrate the theoretical reduction in sampling enabled by constrained 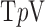 minimization. But first, having specified the CT system and test object, we address the choice of
minimization. But first, having specified the CT system and test object, we address the choice of 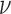 and
and 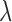 and illustrate single runs of Algorithm 2 in detail.
and illustrate single runs of Algorithm 2 in detail.
Fig. 1.
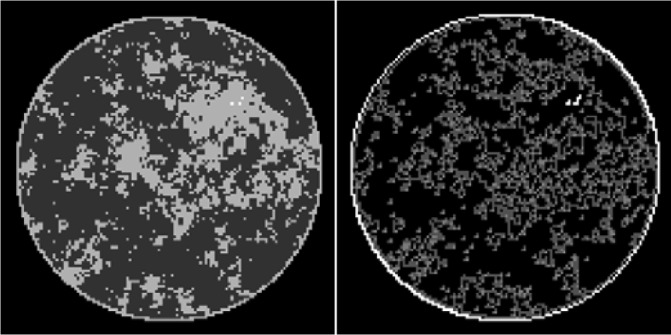
(Left) Discrete phantom modeled after a breast CT application shown in the gray-scale window 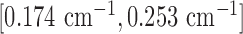 . (Right) Gradient magnitude image (GMI) of the phantom shown in the gray scale window
. (Right) Gradient magnitude image (GMI) of the phantom shown in the gray scale window 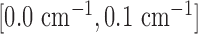 . The units of the GMI are also
. The units of the GMI are also 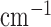 , because the numerical implementation of
, because the numerical implementation of 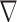 involves only the differences between neighboring pixels without dividing by the physical pixel dimension. The phantom array is composed of 12,892 pixel values, and there are 4,053 non-zero values in the GMI.
involves only the differences between neighboring pixels without dividing by the physical pixel dimension. The phantom array is composed of 12,892 pixel values, and there are 4,053 non-zero values in the GMI.
A. Determining 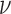 and
and 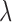
As shown in (17), the two linear transforms 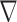 and
and 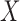 are combined into the transform
are combined into the transform 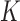 with the combination parameter
with the combination parameter 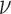 . Different values of
. Different values of 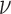 do not affect the solution of the optimization problems considered here, but it can affect the value of
do not affect the solution of the optimization problems considered here, but it can affect the value of 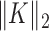 and consequently the step length and convergence rate of the CP algorithms. If the system configuration is fixed, then it is worthwhile to perform a parameter sweep over
and consequently the step length and convergence rate of the CP algorithms. If the system configuration is fixed, then it is worthwhile to perform a parameter sweep over 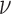 to find the value which leads to the fastest convergence rate. But for our purpose, where we are varying the configuration, such a parameter study is not beneficial. It is important, however, to standardize this parameter, because altering properties of the system model can implicitly yield quite different effective values of
to find the value which leads to the fastest convergence rate. But for our purpose, where we are varying the configuration, such a parameter study is not beneficial. It is important, however, to standardize this parameter, because altering properties of the system model can implicitly yield quite different effective values of 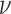 . The reason for this is that the spectrum of
. The reason for this is that the spectrum of 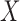 varies substantially depending on the size of the data vector and image array, and the physical units of projection and image gradient values are different. To standardize
varies substantially depending on the size of the data vector and image array, and the physical units of projection and image gradient values are different. To standardize 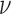 , we define:
, we define:
 |
The critical value of 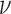 ,
, 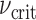 , is chosen so that
, is chosen so that 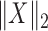 is equal to
is equal to  . Note that altering units on one of the transforms is automatically compensated with a different value of
. Note that altering units on one of the transforms is automatically compensated with a different value of 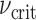 . For the present investigations
. For the present investigations 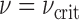 unless stated otherwise.
unless stated otherwise.
The role of 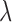 is more important than that of
is more important than that of 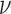 for the reweighting algorithms, because adjusting
for the reweighting algorithms, because adjusting 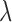 both affects convergence speed and enables control over the stability of the reweighted constrained
both affects convergence speed and enables control over the stability of the reweighted constrained 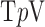 minimization. In order to separate these two roles of
minimization. In order to separate these two roles of 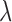 , we illustrate its effect on the convex case
, we illustrate its effect on the convex case  , and a nonconvex example with
, and a nonconvex example with 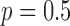 . In the convex
. In the convex  case stability of the algorithm is not an issue because there is no reweighting as the weights in Algorithm 2 evaluate to unity.
case stability of the algorithm is not an issue because there is no reweighting as the weights in Algorithm 2 evaluate to unity.
For this illustration, an ideal data simulation is specified where the number of views are too few for 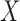 to have a left inverse. The number of views is set to 25, a value which will turn out to be too few for convex TV minimization, but sufficient for nonconvex
to have a left inverse. The number of views is set to 25, a value which will turn out to be too few for convex TV minimization, but sufficient for nonconvex 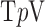 minimization. The simulation data are consistent in that no noise is included and the projector for the data matches that of the algorithm. Accordingly, we select
minimization. The simulation data are consistent in that no noise is included and the projector for the data matches that of the algorithm. Accordingly, we select 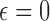 for the test runs.
for the test runs.
1. A Run of Constrained TV Minimization, the  Case
Case
Fig. 2 plots the various convergence metrics and the image RMSE for 1,000 iterations of Algorithm 2 with  and
and 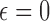 . Note that the value of
. Note that the value of 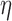 plays no role for
plays no role for  , because the exponent in the expression of the weights is
, because the exponent in the expression of the weights is  and accordingly the weights will all be unity in this case regardless of the value of
and accordingly the weights will all be unity in this case regardless of the value of 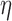 . Individual runs for
. Individual runs for 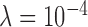 ,
, 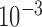 , and
, and 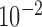 are shown. We discuss the convergence criteria from top to bottom.
are shown. We discuss the convergence criteria from top to bottom.
Fig. 2.

Convergence plots for image reconstruction from noiseless data containing 25 projections using Algorithm 2 with three different values of 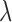 . For these results, we set
. For these results, we set 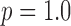 which yields convex constrained TV minimization and set
which yields convex constrained TV minimization and set 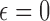 . The top three plots are used to evaluate convergence of the algorithm, and the middle value
. The top three plots are used to evaluate convergence of the algorithm, and the middle value 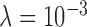 shows the fastest convergence rate. Note that for this convex case Algorithm 2 is proved to converge for any value of
shows the fastest convergence rate. Note that for this convex case Algorithm 2 is proved to converge for any value of 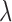 . The bottom plot indicates the discrepancy from the test phantom. The image RMSE is normalized by dividing the actual RMSE values in
. The bottom plot indicates the discrepancy from the test phantom. The image RMSE is normalized by dividing the actual RMSE values in  by 0.194
by 0.194  , the linear attenuation coefficient of the background fat tissue. That this image RMSE does not tend to zero while the convergence criteria do results from the fact that too few projections are available for accurate reconstruction by constrained TV minimization. Another indication for having too few views is that the solution TV is less than the test phantom TV.
, the linear attenuation coefficient of the background fat tissue. That this image RMSE does not tend to zero while the convergence criteria do results from the fact that too few projections are available for accurate reconstruction by constrained TV minimization. Another indication for having too few views is that the solution TV is less than the test phantom TV.
The top panel of Fig. 2 indicates the value of cPD multiplied by the iteration number. This plot is shown this way because cPD can be either negative or positive as it approaches zero, and multiplication by the iteration number helps to indicate the empirical convergence rate of this metric for different values of  . From this sub-figure we see that the values of
. From this sub-figure we see that the values of  , and
, and 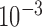 show empirical convergence faster than the reciprocal of the iteration number while cPD corresponding to
show empirical convergence faster than the reciprocal of the iteration number while cPD corresponding to 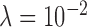 shows a convergence rate near the reciprocal of the iteration number. The second panel of Fig. 2 indicates the data RMSE, which tends to zero because the data are ideal. The third panel shows the constraint on the dual variables from (22) by plotting the left hand side of this equation, and this quantity also tends to zero. In each of these convergence plots we obtain the fastest rate with
shows a convergence rate near the reciprocal of the iteration number. The second panel of Fig. 2 indicates the data RMSE, which tends to zero because the data are ideal. The third panel shows the constraint on the dual variables from (22) by plotting the left hand side of this equation, and this quantity also tends to zero. In each of these convergence plots we obtain the fastest rate with 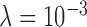 , among the three values shown. The image RMSE shown in the bottom panel is not a convergence metric because it says nothing about whether or not the image estimate is a solution to (4), but this metric is clearly of theoretical interest because it is an indicator of the success of the image reconstruction. For 25 views and
, among the three values shown. The image RMSE shown in the bottom panel is not a convergence metric because it says nothing about whether or not the image estimate is a solution to (4), but this metric is clearly of theoretical interest because it is an indicator of the success of the image reconstruction. For 25 views and  , we see that the image RMSE is tending to a non-zero value and that the number of views is insufficient for exact image recovery.
, we see that the image RMSE is tending to a non-zero value and that the number of views is insufficient for exact image recovery.
2. A Run of Constrained 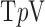 Minimization, the
Minimization, the 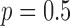 Case
Case
For this 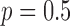 case all conditions are kept the same as the previous
case all conditions are kept the same as the previous 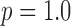 case except for the
case except for the 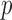 value, and we point out that the value of
value, and we point out that the value of 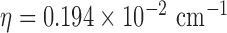 now plays a role,
now plays a role, 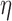 here is selected to be 1% of the background fat attenuation coefficient. The corresponding convergence plots are shown in Fig. 3, and similar convergence rates to the
here is selected to be 1% of the background fat attenuation coefficient. The corresponding convergence plots are shown in Fig. 3, and similar convergence rates to the 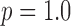 case are seen with a couple of notable exceptions. First, the
case are seen with a couple of notable exceptions. First, the 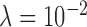 case yields unstable iteration as indicated by a steady, if slow, increase in cPD and a level dependence of the data RMSE and dual constraint. Second, the convergence rates, according to the convergence criteria, seem to be similar between
case yields unstable iteration as indicated by a steady, if slow, increase in cPD and a level dependence of the data RMSE and dual constraint. Second, the convergence rates, according to the convergence criteria, seem to be similar between 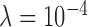 and
and 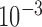 , yet the image RMSE for
, yet the image RMSE for 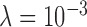 shows much lower values and a rapid drop at 500 iterations.
shows much lower values and a rapid drop at 500 iterations.
Fig. 3.

Same as Fig. 2 except 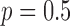 yielding a nonconvex constrained
yielding a nonconvex constrained 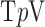 minimization problem. For
minimization problem. For 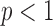 , selecting
, selecting 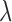 too large can lead to unstable behavior seen in the
too large can lead to unstable behavior seen in the 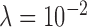 case as convergence metrics do not decay with iteration number. The fat normalized image RMSE plot is interesting in that the curve corresponding to
case as convergence metrics do not decay with iteration number. The fat normalized image RMSE plot is interesting in that the curve corresponding to 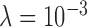 shows a rapid drop at 500 iterations and correspondingly we see in Fig. 4 that this run accurately recovers the phantom within the 1,000 iterations.
shows a rapid drop at 500 iterations and correspondingly we see in Fig. 4 that this run accurately recovers the phantom within the 1,000 iterations.
The corresponding images at iteration 1,000 along with the TV weights are shown in Fig. 4. The image estimates corroborate the image RMSE plot from Fig. 3 showing accurate recovery for 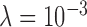 alone at 1,000 iterations. We reiterate that the reason for image estimate inaccuracy is different for
alone at 1,000 iterations. We reiterate that the reason for image estimate inaccuracy is different for 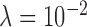 and
and 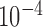 . For the former case, the reweighting is unstable and the test phantom will not be recovered at any iteration number, while for the latter case, the reweighting is stable but more iterations are needed. Indeed, for this particular case, we have continued the iteration and find that the test phantom is accurately recovered at 2,500 iterations for
. For the former case, the reweighting is unstable and the test phantom will not be recovered at any iteration number, while for the latter case, the reweighting is stable but more iterations are needed. Indeed, for this particular case, we have continued the iteration and find that the test phantom is accurately recovered at 2,500 iterations for 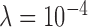 .
.
Fig. 4.
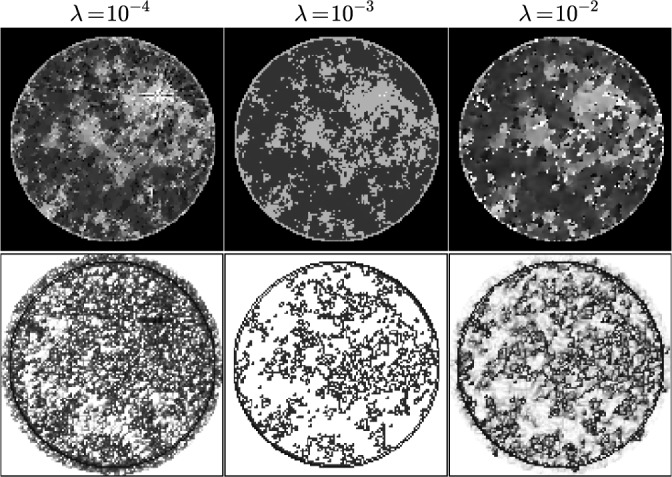
Top row shows images at iteration 1,000 obtained for various values of  using Algorithm 2 for
using Algorithm 2 for  . It is clear that the phantom is recovered visually at this iteration number for
. It is clear that the phantom is recovered visually at this iteration number for 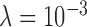 . Shown in the bottom row are the computed weighting images at iteration 1,000. For the recovered case of
. Shown in the bottom row are the computed weighting images at iteration 1,000. For the recovered case of 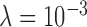 the weight image is 1.0 at all pixels where the GMI is zero.
the weight image is 1.0 at all pixels where the GMI is zero.
As an aid to determining optimal values of  , we have found it useful to monitor the change in the weighting function:
, we have found it useful to monitor the change in the weighting function:
 |
and partial step lengths:
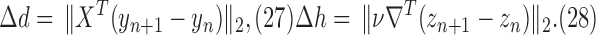 |
The use of 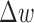 is straightforward as it is reasonable to expect that the weighting function should converge to a fixed weight if the reweighting procedure is stable. As seen in the top panel of Fig. 5,
is straightforward as it is reasonable to expect that the weighting function should converge to a fixed weight if the reweighting procedure is stable. As seen in the top panel of Fig. 5, 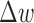 decreases to the lowest value for
decreases to the lowest value for 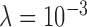 . For
. For 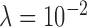 ,
, 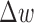 does not decay, which is consistent with instability of the reweighting, and for
does not decay, which is consistent with instability of the reweighting, and for 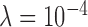 ,
, 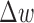 does show steady decay but just not as rapid as that of
does show steady decay but just not as rapid as that of 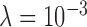 . It is also useful to examine the magnitude of the separate terms in the image update at line 12 of Algorithm 2. The quantity
. It is also useful to examine the magnitude of the separate terms in the image update at line 12 of Algorithm 2. The quantity 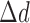 indicates the change in the image estimate due to data fidelity, and
indicates the change in the image estimate due to data fidelity, and 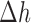 represents the change in the image due to the weighted TV minimization. Empirically, we find the best convergence behavior when
represents the change in the image due to the weighted TV minimization. Empirically, we find the best convergence behavior when 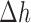 is of similar magnitude to
is of similar magnitude to 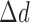 and
and 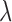 is an effective control parameter for controlling the relative sizes of these step lengths. For the convex case of
is an effective control parameter for controlling the relative sizes of these step lengths. For the convex case of 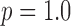 , we find that
, we find that 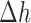 and
and 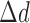 are still useful for selecting
are still useful for selecting 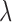 , but clearly
, but clearly 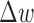 is not because there is no reweighting involved.
is not because there is no reweighting involved.
Fig. 5.

As an aid to selecting 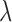 it is useful to plot the step lengths
it is useful to plot the step lengths 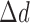 and
and 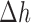 , defined in the text, as a function of iteration number. If
, defined in the text, as a function of iteration number. If 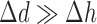 ,
, 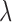 is too low yielding slow convergence. If
is too low yielding slow convergence. If 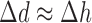 ,
, 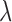 is near the optimal value for algorithm convergence rate. If
is near the optimal value for algorithm convergence rate. If 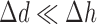 ,
, 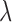 is too large and the algorithm behavior is likely unstable for
is too large and the algorithm behavior is likely unstable for 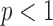 . The change in the weighting image,
. The change in the weighting image, 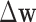 shown at top, is also a useful indicator for convergence of the reweighting algorithm.
shown at top, is also a useful indicator for convergence of the reweighting algorithm.
V. Phantom Recovery With Sparse-View Sampling
The isolated algorithm tests for 25 view projection data indicate the possibility for accurate image reconstruction from fewer views for nonconvex 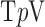 minimization, at
minimization, at 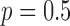 , than convex TV minimization. In this section, we explore this possibility more thoroughly, varying the number of views and value of
, than convex TV minimization. In this section, we explore this possibility more thoroughly, varying the number of views and value of 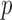 . In order to perform this parameter survey there are three technical issues to address: (1) the study design and stopping rule, (2) how to obtain results for
. In order to perform this parameter survey there are three technical issues to address: (1) the study design and stopping rule, (2) how to obtain results for 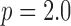 , and (3) how to handle the algorithm parameter
, and (3) how to handle the algorithm parameter 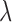 .
.
1. Study Design
The phantom recovery study employs ideal projection data so that only the issue of sampling sufficiency comes into question. In principle, the data error parameter 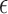 could be set to zero and image RMSE computed as a function of number of views and value of
could be set to zero and image RMSE computed as a function of number of views and value of 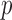 . Doing so, however, causes problems in comparing results between different parameter values, because we cannot hope to solve the optimization problem with
. Doing so, however, causes problems in comparing results between different parameter values, because we cannot hope to solve the optimization problem with 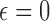 accurately. Instead, we employ the study design from [5] and choose a small but nonzero
accurately. Instead, we employ the study design from [5] and choose a small but nonzero 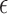 . We select
. We select 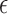 so that the relative data RMSE
so that the relative data RMSE 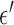 defined
defined
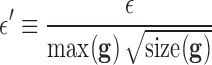 |
is 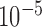 . During the iteration we use a stringent stopping rule and require that
. During the iteration we use a stringent stopping rule and require that
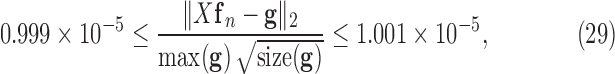 |
for 100 consecutive iterations.
1. Algorithm for 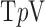 Minimization With
Minimization With 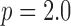
When 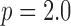 ,
, 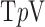 becomes the standard quadratic roughness metric, and the corresponding optimization problem is
becomes the standard quadratic roughness metric, and the corresponding optimization problem is
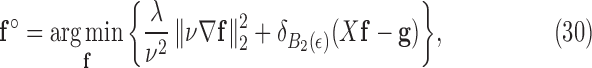 |
where the denominator in the first term is 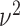 in order to make the optimization problem independent of
in order to make the optimization problem independent of 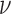 . Note that both isotropic and anisotropic
. Note that both isotropic and anisotropic 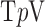 are the same when
are the same when 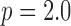 . Because the objective function is quadratic, reweighting is not necessary, and there are many algorithm choices available. In [5], the Lagrangian form of (30) is solved using the conjugate gradients algorithm adjusting the Lagrange multiplier so that the desired
. Because the objective function is quadratic, reweighting is not necessary, and there are many algorithm choices available. In [5], the Lagrangian form of (30) is solved using the conjugate gradients algorithm adjusting the Lagrange multiplier so that the desired 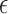 is obtained. For this work, we derive a different instance of the CP algorithm to handle the quadratic penalty. To obtain the pseudocode, we modify Algorithm 2 by removing the reweighting, i.e.,
is obtained. For this work, we derive a different instance of the CP algorithm to handle the quadratic penalty. To obtain the pseudocode, we modify Algorithm 2 by removing the reweighting, i.e., 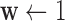 , and replacing line 11 with
, and replacing line 11 with
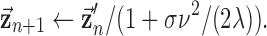 |
This modification directly solves the constrained quadratic roughness problem.
2. Automatic Setting of the Algorithm Parameter 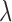
As noted in Section IV-A, there is trial and error involved in selecting the optimal value of 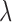 for fastest algorithm convergence. While this issue is manageable for a fixed configuration, it complicates surveys over configuration parameters, such as the number of views, because the optimal
for fastest algorithm convergence. While this issue is manageable for a fixed configuration, it complicates surveys over configuration parameters, such as the number of views, because the optimal 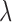 is likely different for each configuration. Furthermore, a bad choice of
is likely different for each configuration. Furthermore, a bad choice of 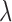 leading to instability of the reweighting causes the algorithm to never terminate by the specified stopping rule. In order to complete the parameter survey without intervention, we allow
leading to instability of the reweighting causes the algorithm to never terminate by the specified stopping rule. In order to complete the parameter survey without intervention, we allow 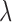 to vary with iteration number according to the following formula:
to vary with iteration number according to the following formula:
 |
yielding the sequence
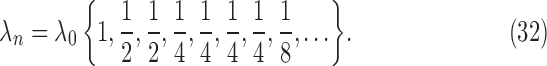 |
By having a decaying schedule for 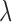 , we are assured that at some finite iteration number the reweighting algorithm becomes stable and dwelling on fixed values yields behavior similar to the basic algorithm within the plateaus of
, we are assured that at some finite iteration number the reweighting algorithm becomes stable and dwelling on fixed values yields behavior similar to the basic algorithm within the plateaus of 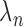 . Opening this possibility of variable
. Opening this possibility of variable 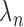 raises the question of other decay schedules or adaptive control, but such studies are beyond the scope of this article.
raises the question of other decay schedules or adaptive control, but such studies are beyond the scope of this article.
For the present results where 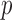 is varied in
is varied in 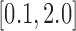 and the number of views range from 18 to 80, we find the sequence of
and the number of views range from 18 to 80, we find the sequence of 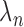 in (31) sufficient. Furthermore, with
in (31) sufficient. Furthermore, with 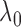 set to 1, the algorithm automatically converges to a solution satisfying the stopping rule specified in (29) for all numbers of views and values of
set to 1, the algorithm automatically converges to a solution satisfying the stopping rule specified in (29) for all numbers of views and values of 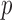 in the scope of the study. The smallest and largest number of iterations required are 4,331 and 33,920, respectively. Even though we found it sufficient to set
in the scope of the study. The smallest and largest number of iterations required are 4,331 and 33,920, respectively. Even though we found it sufficient to set 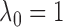 , we introduce this parameter in case there are other conceivable tomographic system configurations that call for larger
, we introduce this parameter in case there are other conceivable tomographic system configurations that call for larger 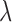 .
.
A. Test Phantom Recovery Results
The phantom recovery results for both isotropic and anisotropic 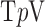 minimization are summarized in Fig. 6. For reference, we include the
minimization are summarized in Fig. 6. For reference, we include the 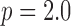 case, which does not exploit GMI sparsity. The image RMSE is reported as a fraction of the background fat attenuation. In the plots the image RMSE can be small, but it cannot be numerically zero because the data error tolerance parameter
case, which does not exploit GMI sparsity. The image RMSE is reported as a fraction of the background fat attenuation. In the plots the image RMSE can be small, but it cannot be numerically zero because the data error tolerance parameter 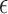 is not zero. Nevertheless some parameter choices lead to small image RMSE values, and for this work we say that the image is accurately recovered if the image RMSE is less than
is not zero. Nevertheless some parameter choices lead to small image RMSE values, and for this work we say that the image is accurately recovered if the image RMSE is less than 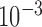 , or in other words 0.1% of fat attenuation. By comparison, the contrast between fibroglandular and fat is 20%. Because image reconstruction by constrained
, or in other words 0.1% of fat attenuation. By comparison, the contrast between fibroglandular and fat is 20%. Because image reconstruction by constrained 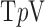 minimization exploits GMI sparsity, it is interesting to compare number of samples
minimization exploits GMI sparsity, it is interesting to compare number of samples 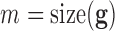 for accurate image recovery to the number of GMI nonzeros.
for accurate image recovery to the number of GMI nonzeros.
Fig. 6.

Image recovery plots for both isotropic and anisotropic 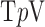 minimization subject to the data error constraint
minimization subject to the data error constraint 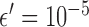 . The constraint parameter on the data RMSE is related to the
. The constraint parameter on the data RMSE is related to the 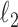 data error tolerance by:
data error tolerance by: 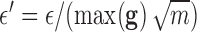 , where
, where 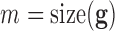 is the total number of measurements.
is the total number of measurements.
Accurate recovery for the 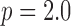 case, which is the same for both isotropic and anisotropic
case, which is the same for both isotropic and anisotropic 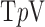 , occurs at 80 views—a number which can be interpreted as full sampling for the problem. At this number of views, the number of samples is
, occurs at 80 views—a number which can be interpreted as full sampling for the problem. At this number of views, the number of samples is 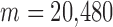 which is about 67% more than the number of pixels in the image array. That such an overdetermined configuration is needed for accurate image reconstruction for
which is about 67% more than the number of pixels in the image array. That such an overdetermined configuration is needed for accurate image reconstruction for  is a consequence of the condition number of
is a consequence of the condition number of 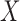 [5].
[5].
For 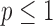 , both isotropic and anisotropic
, both isotropic and anisotropic 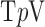 minimization are exploiting GMI sparsity for accurate image reconstruction and it is clear from both graphs that substantial reduction in the number of samples is permitted by this strategy. Starting with isotropic
minimization are exploiting GMI sparsity for accurate image reconstruction and it is clear from both graphs that substantial reduction in the number of samples is permitted by this strategy. Starting with isotropic 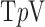 , we observe that for the convex case,
, we observe that for the convex case,  , accurate image reconstruction occurs at 35 views where
, accurate image reconstruction occurs at 35 views where 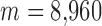 which is less than the number of image pixels
which is less than the number of image pixels 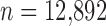 and is a little more than twice the phantom GMI sparsity 4,053. Reducing
and is a little more than twice the phantom GMI sparsity 4,053. Reducing 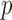 to
to 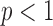 , leads to nonconvex
, leads to nonconvex 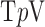 minimization but also to more effective exploitation of GMI sparsity. As seen in the top graph of Fig. 6, even introducing a little nonconvexity as in the
minimization but also to more effective exploitation of GMI sparsity. As seen in the top graph of Fig. 6, even introducing a little nonconvexity as in the 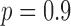 case yields a dramatic drop in the number of views as we obtain accurate image reconstruction at 30 views, where
case yields a dramatic drop in the number of views as we obtain accurate image reconstruction at 30 views, where 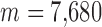 . For the present simulation, it appears that this strategy saturates at
. For the present simulation, it appears that this strategy saturates at 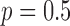 , where accurate image reconstruction occurs at 22 views and even going to
, where accurate image reconstruction occurs at 22 views and even going to 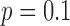 does not alter the necessary number of projections. Although, we do note that
does not alter the necessary number of projections. Although, we do note that 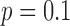 does yield slightly smaller image RMSE than
does yield slightly smaller image RMSE than 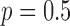 , indicating a possible increased robustness to some forms of data inconsistency. At 22 views, the number of samples is quite low as
, indicating a possible increased robustness to some forms of data inconsistency. At 22 views, the number of samples is quite low as 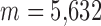 , which is only 39% greater than the number of GMI nonzeros.
, which is only 39% greater than the number of GMI nonzeros.
Comparing anisotropic 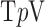 with the isotropic case, we observe that even greater sampling reduction is seen as accurate image reconstruction is observed at lower numbers of views for
with the isotropic case, we observe that even greater sampling reduction is seen as accurate image reconstruction is observed at lower numbers of views for 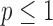 . For
. For 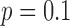 and 0.5, accurate image reconstruction is obtained at 20 views, corresponding to
and 0.5, accurate image reconstruction is obtained at 20 views, corresponding to 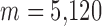 —only 26% greater than the number of GMI nonzeros. One might argue that the GMI sparsity might not provide the correct reference for anisotropic
—only 26% greater than the number of GMI nonzeros. One might argue that the GMI sparsity might not provide the correct reference for anisotropic 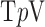 and instead sparsity in the phantom gradient itself should be the correct quantity of comparison. But we point out that the components of the phantom gradient are not independent, and the GMI sparsity provides a better estimate of the number of underlying independent parameters for the phantom gradient.
and instead sparsity in the phantom gradient itself should be the correct quantity of comparison. But we point out that the components of the phantom gradient are not independent, and the GMI sparsity provides a better estimate of the number of underlying independent parameters for the phantom gradient.
VI. Image Reconstruction With Noisy Projection Data
The previous sets of results demonstrate the theoretical motivation of constrained 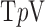 minimization for image reconstruction in CT. To consider use of the above algorithms on clinical data, it is important to understand the algorithms' response to inconsistency with the employed data model in (2). Response to data inconsistency is important to assess, because it provides a sense of algorithm robustness and because algorithm implementation choices, equivalent under ideal data conditions, may not be equivalent in the presence of data inconsistency. The data model used in the present formulation of constrained
minimization for image reconstruction in CT. To consider use of the above algorithms on clinical data, it is important to understand the algorithms' response to inconsistency with the employed data model in (2). Response to data inconsistency is important to assess, because it provides a sense of algorithm robustness and because algorithm implementation choices, equivalent under ideal data conditions, may not be equivalent in the presence of data inconsistency. The data model used in the present formulation of constrained 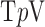 minimization is simplistic in that it ignores important physical factors such as the polychromaticity of the X-ray beam, X-ray scatter, partial volume averaging, and noise. While it may be possible to include some of these physical factors into the constrained
minimization is simplistic in that it ignores important physical factors such as the polychromaticity of the X-ray beam, X-ray scatter, partial volume averaging, and noise. While it may be possible to include some of these physical factors into the constrained 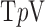 minimization for the purpose of potential image quality gain, such an effort is beyond the scope of this article. Instead, in this section we present reconstructed images from simulated data including one of the most important sources of data inconsistency for the breast CT application, namely noise. Later, in Section VII, we present reconstructed images from an actual breast CT scan data set, which naturally includes all the physical factors implicitly.
minimization for the purpose of potential image quality gain, such an effort is beyond the scope of this article. Instead, in this section we present reconstructed images from simulated data including one of the most important sources of data inconsistency for the breast CT application, namely noise. Later, in Section VII, we present reconstructed images from an actual breast CT scan data set, which naturally includes all the physical factors implicitly.
In this section, the simulated projection data are generated from a data model where the system size is scaled up and noise is included at a level typical of breast CT. The breast CT model is challenging because the prototype systems are designed to function at very low X-ray intensities so that the exposure to the subject is equivalent to two-view full-field digital mammography [35].
The image array is taken here to be the inscribed circle of a 512×512 pixel array with the square pixels having width 0.35 mm. The scan configuration is again circular fan-beam with the same geometry as described in Section IV, but the number of projections is 200 and the detector now consists of 1024 bins of width 0.36 mm. Noise is generated using a Poisson model with mean equal to the computed mean of the number of transmitted photons at each detector bin, where the integrated incident flux at each bin, per projection, is 66,000 photons. For the present simulations, the breast phantom is also modified in order to avoid isolated pixels of fibroglandular tissue. The phantom is generated, as before, with a power law noise distribution, but this image is smoothed by a Gaussian with 4 pixel full-width-half-maximum (FWHM) prior to binning into fat and fibroglandular tissues. No microcalcifications are modeled in the phantom. The new phantom and fan-beam FBP reconstructed images are shown in Fig. 7.
Fig. 7.
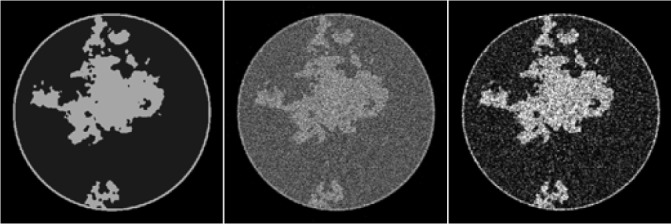
A breast CT simulation using linear attenuation coefficients for a 50 keV mono-energetic X-ray beam. The noise level is typical for prototype breast CT scanners. Shown are FBP reconstructions with a ramp filter and the same image after smoothing by a Gaussian of FWHM of 0.8 pixels. The FBP images serve to indicate visually the noise level inherent in the data.
The purpose of the present simulations is to illustrate in detail how realistic and challenging levels of data inconsistency impact the  motivated reweighting algorithm. The number of projections, being selected as 200, is fewer than the 500 views acquired in typical breast CT prototypes. For 200 projections the total number of samples is
motivated reweighting algorithm. The number of projections, being selected as 200, is fewer than the 500 views acquired in typical breast CT prototypes. For 200 projections the total number of samples is 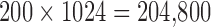 , and the number of pixels is 205,892. While this system is undersampled, it is more than the number required by constrained
, and the number of pixels is 205,892. While this system is undersampled, it is more than the number required by constrained 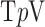 minimization for accurate image reconstruction from noiseless data at any value of
minimization for accurate image reconstruction from noiseless data at any value of 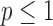 . In this way we isolate the issue of noise response, separating it from projection angular undersampling.
. In this way we isolate the issue of noise response, separating it from projection angular undersampling.
The results for image reconstruction by constrained 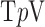 minimization for nonconvex
minimization for nonconvex 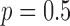 and 0.8 are compared with convex
and 0.8 are compared with convex 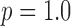 and 2.0 in Fig. 8. One of the convenient features of employing a hard data-error constraint is that the rows of the image array have identical data fidelity, allowing us to focus only on the impact of
and 2.0 in Fig. 8. One of the convenient features of employing a hard data-error constraint is that the rows of the image array have identical data fidelity, allowing us to focus only on the impact of 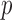 . We point out that the
. We point out that the 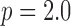 case is not GMI sparsity-exploiting, and as a consequence the corresponding images potentially suffer from both noise and undersampling artifacts.
case is not GMI sparsity-exploiting, and as a consequence the corresponding images potentially suffer from both noise and undersampling artifacts.
Fig. 8.

Reconstructed ROIs for 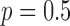 , 0.8, 1.0, and 2.0 for columns 1, 2, 3, and 4, respectively. The data error constraint parameter
, 0.8, 1.0, and 2.0 for columns 1, 2, 3, and 4, respectively. The data error constraint parameter 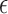 is set so as to correspond to a data RMSE of 0.015, 0.0145, 0.014, 0.012, and 0.01 for rows 1, 2, 3, 4, and 5, respectively. Shown in the array of images are a blow up ROI of the upper left side of the image so that small details can be seen clearly.
is set so as to correspond to a data RMSE of 0.015, 0.0145, 0.014, 0.012, and 0.01 for rows 1, 2, 3, 4, and 5, respectively. Shown in the array of images are a blow up ROI of the upper left side of the image so that small details can be seen clearly.
The array of images illustrates an important feature of the use of nonconvex 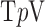 . With the underlying object model being complex, yet piecewise constant, the
. With the underlying object model being complex, yet piecewise constant, the 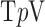 quasinorm reduces the speckle noise in regions of uniform attenuation coefficient relative to
quasinorm reduces the speckle noise in regions of uniform attenuation coefficient relative to 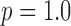 and 2.0. In terms of image RMSE relative to the truth, the panel with the lowest error appears in the second row and second column, corresponding to
and 2.0. In terms of image RMSE relative to the truth, the panel with the lowest error appears in the second row and second column, corresponding to 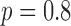 and
and 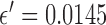 ; we point out, however, that image RMSE is not always the most appropriate measure of image quality and that image quality evaluation should take into account the imaging task [36]. Nevertheless the noise suppressing properties of
; we point out, however, that image RMSE is not always the most appropriate measure of image quality and that image quality evaluation should take into account the imaging task [36]. Nevertheless the noise suppressing properties of 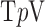 shows promise and may prove useful to image analysis algorithms such as those for segmentation.
shows promise and may prove useful to image analysis algorithms such as those for segmentation.
Scrutinizing the nonconvex images in Fig. 8, there is a potential difficulty for the breast CT application. As 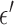 increases, the speckle noise is reduced but there also appear isolated pixels with high gray values which could potentially be mistaken for microcalcifications. In practice, these isolated peaks can be differentiated from actual structure because the latter generally involve groups of pixels. Nevertheless these specks can be distracting, and we discuss their origin and how to avoid these artifacts.
increases, the speckle noise is reduced but there also appear isolated pixels with high gray values which could potentially be mistaken for microcalcifications. In practice, these isolated peaks can be differentiated from actual structure because the latter generally involve groups of pixels. Nevertheless these specks can be distracting, and we discuss their origin and how to avoid these artifacts.
In Fig. 9, we focus on the panel that corresponds to 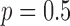 and
and 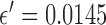 . On the left most column the same ROI shown in Fig. 8 is shown again along with the converged weight image
. On the left most column the same ROI shown in Fig. 8 is shown again along with the converged weight image 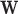 . The weight image is unity in uniform regions and small at pixels belonging to the edges of tissue structures; in this way noise in the uniform regions can be heavily smoothed away without blurring the edges. In the ROI there are a few residual specks due to data noise and we can see that these specks correspond to specks of low weighting in
. The weight image is unity in uniform regions and small at pixels belonging to the edges of tissue structures; in this way noise in the uniform regions can be heavily smoothed away without blurring the edges. In the ROI there are a few residual specks due to data noise and we can see that these specks correspond to specks of low weighting in 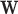 and these pixels are being mistaken for edge pixels of true structure. If such specks interfere with the function of the imaging system as they would, for example, in the breast CT application, there are measures which can be taken to avoid them.
and these pixels are being mistaken for edge pixels of true structure. If such specks interfere with the function of the imaging system as they would, for example, in the breast CT application, there are measures which can be taken to avoid them.
Fig. 9.
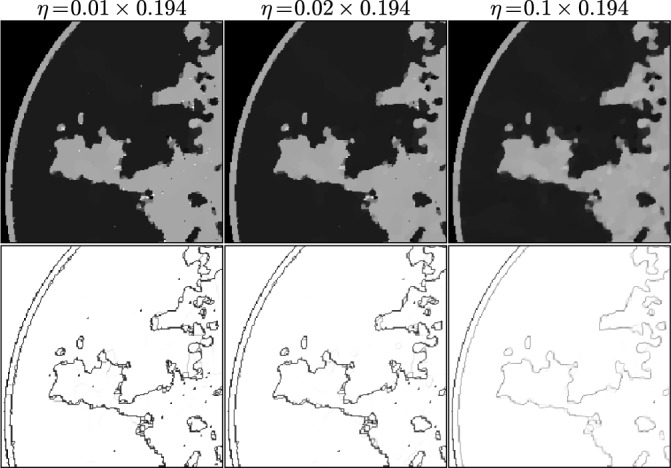
Focusing on the case of  and
and  set so that the data RMSE is 0.0145, we illustrate the reconstructed ROI dependence on the parameter
set so that the data RMSE is 0.0145, we illustrate the reconstructed ROI dependence on the parameter  in the top row. Shown in the bottom row is the corresponding impact on the weighting image.
in the top row. Shown in the bottom row is the corresponding impact on the weighting image.
Within the framework of the 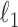 reweighting algorithm, one important option is to vary
reweighting algorithm, one important option is to vary 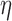 . The value of
. The value of 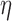 used here is 1% of the background fat attenuation value, and it is much smaller than the contrast between fat and fibroglandular tissue. By increasing
used here is 1% of the background fat attenuation value, and it is much smaller than the contrast between fat and fibroglandular tissue. By increasing 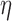 , the speck artifacts can be removed while still maintaining some of the enhanced edge-preserving feature of the
, the speck artifacts can be removed while still maintaining some of the enhanced edge-preserving feature of the 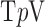 reweighting scheme. The effect of increasing
reweighting scheme. The effect of increasing 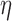 is shown in the middle and right columns of Fig. 9. As
is shown in the middle and right columns of Fig. 9. As 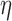 increases specks are removed but the weighting at edge pixels also increases.
increases specks are removed but the weighting at edge pixels also increases.
Another approach is to realize that the purpose of the 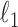 reweighting algorithm is to study image recovery under ideal data conditions, where it is important to be able to recover the phantom to arbitrarily high accuracy. For noisy data it may be advantageous to employ quadratic reweighting, which provides a different response in the image to data noise.
reweighting algorithm is to study image recovery under ideal data conditions, where it is important to be able to recover the phantom to arbitrarily high accuracy. For noisy data it may be advantageous to employ quadratic reweighting, which provides a different response in the image to data noise.
A.  Minimization by Quadratic Reweighting
Minimization by Quadratic Reweighting
The original nonconvex 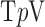 minimization problem from (4) can also be addressed by use of quadratic reweighting as illustrated in Appendix VIII-A. To implement quadratic reweighting, the convex weighted
minimization problem from (4) can also be addressed by use of quadratic reweighting as illustrated in Appendix VIII-A. To implement quadratic reweighting, the convex weighted  -based optimization problem in (10) is replaced by the following convex weighted quadratic optimization problem
-based optimization problem in (10) is replaced by the following convex weighted quadratic optimization problem
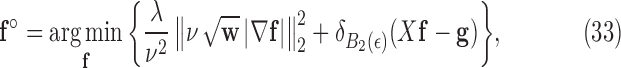 |
which modifies (30) by including a weighting factor in the quadratic roughness penalty. The corresponding dual maximization problem is
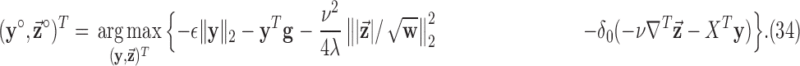 |
and accordingly
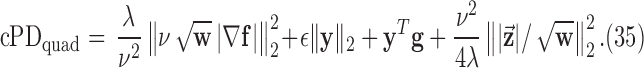 |
The pseudocode for  minimization by quadratic reweighting is given in Algorithm 4. The difference between this algorithm and Algorithm 2 appears in line 9, where the exponent of the weights expression is changed from
minimization by quadratic reweighting is given in Algorithm 4. The difference between this algorithm and Algorithm 2 appears in line 9, where the exponent of the weights expression is changed from  to
to  , and line 11, where the form of the update step for the dual gradient variable is altered.
, and line 11, where the form of the update step for the dual gradient variable is altered.
Algorithm 4 Pseudocode for  Steps of the CP Algorithm Instance for Quadratic Reweighted Constrained
Steps of the CP Algorithm Instance for Quadratic Reweighted Constrained 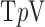 Minimization
Minimization
1: INPUT: data
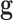 , data-error tolerance
, data-error tolerance 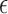 , exponent
, exponent 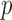 , and smoothing parameter
, and smoothing parameter 
2: INPUT: algorithm parameters
 ,
, 
3:
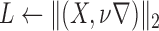 ;
; 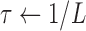 ;
; 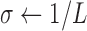 ;
; 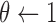 ;
; 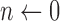
4: initialize
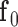 ,
, 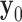 , and
, and 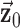 to zero vectors
to zero vectors5:
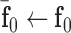
6: repeat
7:
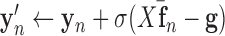
8:
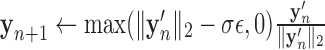
9:
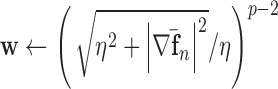
10:
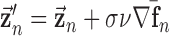
11:
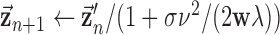
12:
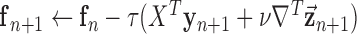
13:
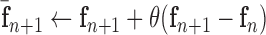
14:
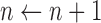
15: until
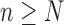
16: OUTPUT:
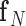
17: OUTPUT:
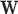 ,
, 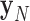 , and
, and 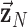 for evaluating
for evaluating 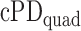 and conditions 3.
and conditions 3.
The quadratic reweighting algorithm has a different response to noise and other inconsistency mainly because of the parameter 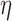 . The weighted image roughness term with finite
. The weighted image roughness term with finite  is smooth, whereas the same term for
is smooth, whereas the same term for 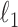 -reweighting is nonsmooth even when
-reweighting is nonsmooth even when 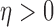 . To see the qualitative difference between these algorithms, Fig. 10 shows ROIs for these algorithms and the same parameters
. To see the qualitative difference between these algorithms, Fig. 10 shows ROIs for these algorithms and the same parameters 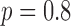 and
and 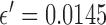 . For both ROIs
. For both ROIs 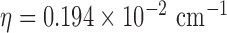 , which is 1% of the fat attenuation. The quality of the noise is markedly different with the quadratic reweighting exchanging the sparse specks with more blobby variations which would not be mistaken for microcalcifications.
, which is 1% of the fat attenuation. The quality of the noise is markedly different with the quadratic reweighting exchanging the sparse specks with more blobby variations which would not be mistaken for microcalcifications.
Fig. 10.
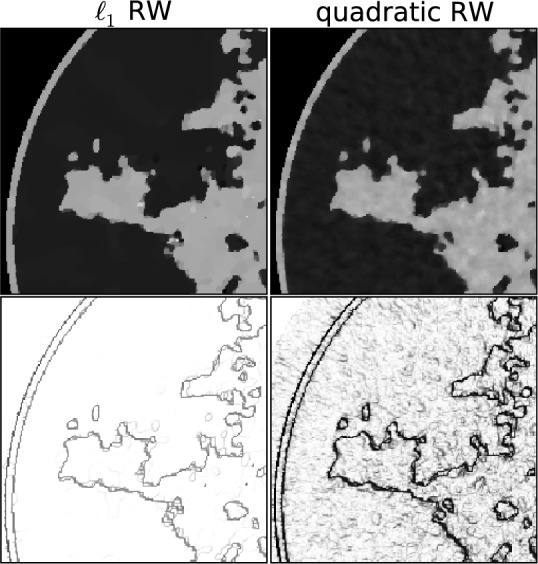
Focusing on the case of 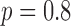 and
and 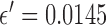 , we illustrate the reconstructed ROI for (left)
, we illustrate the reconstructed ROI for (left) 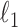 reweighting compared with (right) quadratic reweighting. The parameter
reweighting compared with (right) quadratic reweighting. The parameter 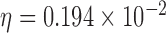 or 1% of the fat attenuation. Shown in the bottom row is the corresponding weighting image.
or 1% of the fat attenuation. Shown in the bottom row is the corresponding weighting image.
VII. Application to Clinical Breast CT Data
While the simulations of Section VI illustrate the properties of the proposed IIR algorithm on a realistic simulation of breast CT, the data model used does not contain all the inconsistencies present in an actual scanner. Thus, we apply the algorithm to a clinical breast CT data set. The purpose of doing so is to first demonstrate that use of nonconvex  minimization can yield useful images under actual clinical conditions, and that the nonconvexity of the problem formulation does not lead to strange image artifacts. The second goal is to survey image properties for different values of
minimization can yield useful images under actual clinical conditions, and that the nonconvexity of the problem formulation does not lead to strange image artifacts. The second goal is to survey image properties for different values of  and data-error fidelity parameter
and data-error fidelity parameter  . To this end we perform reconstructions on a single data set, displaying the same slice. We make no attempt to find optimal
. To this end we perform reconstructions on a single data set, displaying the same slice. We make no attempt to find optimal  and
and  , nor to claim that the present algorithm is better than other image reconstruction algorithms. Ultimately, evaluation of the algorithm needs to be tied together with acquisition optimization. As the present algorithm appears to be robust against angular under-sampling, it is possible that the breast CT acquisition could be altered to include fewer projections in a step-and-shoot mode, allowing for greater X-ray intensity for each projection, while maintaining the total dose of 2 mammographic projections.
, nor to claim that the present algorithm is better than other image reconstruction algorithms. Ultimately, evaluation of the algorithm needs to be tied together with acquisition optimization. As the present algorithm appears to be robust against angular under-sampling, it is possible that the breast CT acquisition could be altered to include fewer projections in a step-and-shoot mode, allowing for greater X-ray intensity for each projection, while maintaining the total dose of 2 mammographic projections.
The prototype breast CT scanner at UC Davis is described in [37] and [38]. The data set consists of 500 projection views acquired on a 768×1024 flat-panel detector with pixel size of 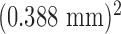 . The volume reconstruction is performed on a
. The volume reconstruction is performed on a 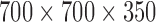 image array with cubic voxels of dimension
image array with cubic voxels of dimension 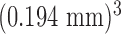 .
.
The particular version of 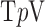 minimization is quadratic reweighting, shown in Algorithm 4, with
minimization is quadratic reweighting, shown in Algorithm 4, with 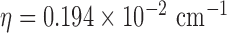 , the same value as the simulation. For quadratic reweighting, the
, the same value as the simulation. For quadratic reweighting, the  case does not need to be dealt with separately as is the case for
case does not need to be dealt with separately as is the case for 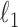 reweighting. Setting
reweighting. Setting  in Algorithm 4 sets the weights
in Algorithm 4 sets the weights 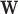 to one. For each reconstruction, the
to one. For each reconstruction, the 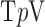 minimization algorithm is run for 1000 iterations in order to obtain converged volumes, but we note that in practice this may be too high a computational burden and that it is likely not necessary to obtain accurate convergence for
minimization algorithm is run for 1000 iterations in order to obtain converged volumes, but we note that in practice this may be too high a computational burden and that it is likely not necessary to obtain accurate convergence for 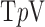 minimization to yield clinically useful volumes [24].
minimization to yield clinically useful volumes [24].
Breast CT volumes are reconstructed for a range of parameters: 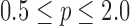 , and relative data-error RMSE
, and relative data-error RMSE 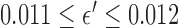 . For reference to the standard image reconstruction algorithm, we show one of the
. For reference to the standard image reconstruction algorithm, we show one of the 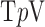 minimization images in comparison with image reconstruction by the Feldkamp-Davis-Kress (FDK) algorithm in Fig. 11. The selected
minimization images in comparison with image reconstruction by the Feldkamp-Davis-Kress (FDK) algorithm in Fig. 11. The selected 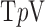 minimization image for the comparison is obtained for
minimization image for the comparison is obtained for 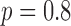 and
and 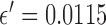 . Given that the number of projections is 500, we do not expect large differences between FDK and IIR algorithms, and we observe in Fig. 11 that the two images show similar structures with the
. Given that the number of projections is 500, we do not expect large differences between FDK and IIR algorithms, and we observe in Fig. 11 that the two images show similar structures with the 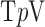 minimization image showing, visually, a lower noise level. That the two images have similar structure content provides a challenging check on the
minimization image showing, visually, a lower noise level. That the two images have similar structure content provides a challenging check on the 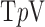 minimization IIR algorithm.
minimization IIR algorithm.
Fig. 11.

(Left) A slice from a volume reconstructed from breast CT data by 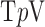 minimization, using quadratic reweighting. The parameters yielding this image are
minimization, using quadratic reweighting. The parameters yielding this image are 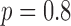 and relative data RMSE
and relative data RMSE 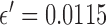 . (Right) The corresponding slice image generated by the Feldkamp-Davis-Kress (FDK) algorithm. The display gray scale window is
. (Right) The corresponding slice image generated by the Feldkamp-Davis-Kress (FDK) algorithm. The display gray scale window is 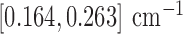 .
.
To appreciate the impact of varying 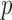 and
and 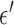 , we show arrays of images of the same full slice in Figs. 12 and 13, and ROIs in Fig. 14. In the full slice images we observe little difference for the tight data-error constraint of
, we show arrays of images of the same full slice in Figs. 12 and 13, and ROIs in Fig. 14. In the full slice images we observe little difference for the tight data-error constraint of 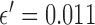 , which is understandable because the view sampling rate is high and the set of feasible images satisfying the data-error constraint is relatively small. There is, however, a small but visually noticeable change in the quality of the noise as
, which is understandable because the view sampling rate is high and the set of feasible images satisfying the data-error constraint is relatively small. There is, however, a small but visually noticeable change in the quality of the noise as 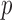 varies. As the data-error constraint is relaxed, we observe that the smaller values of
varies. As the data-error constraint is relaxed, we observe that the smaller values of 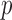 become regularized more rapidly than larger
become regularized more rapidly than larger 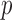 . The regularization for nonconvex
. The regularization for nonconvex 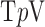 is not uniform. As
is not uniform. As 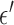 increases, noise on the soft tissue is reduced substantially while the high contrast microcalcifications are preserved with little blurring.
increases, noise on the soft tissue is reduced substantially while the high contrast microcalcifications are preserved with little blurring.
Fig. 12.
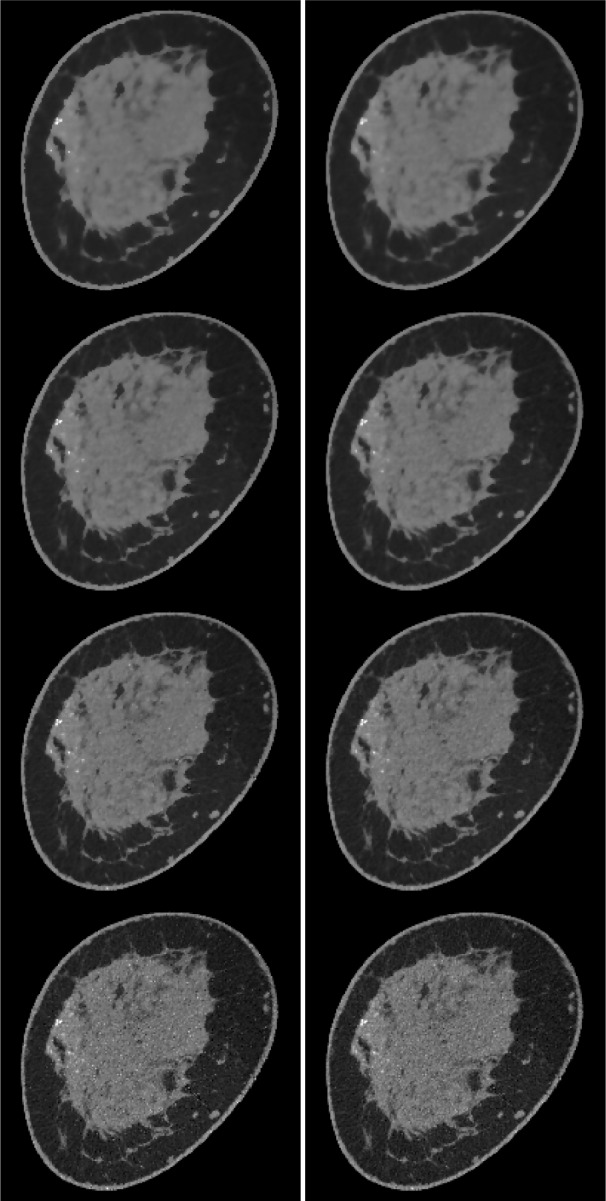
Slice images obtained with 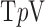 minimization from breast CT data for (left column)
minimization from breast CT data for (left column) 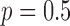 and (right column)
and (right column) 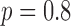 . The relative data-error RMSE increases from the bottom row to top row with values
. The relative data-error RMSE increases from the bottom row to top row with values 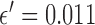 , 0.0115, 0.01175, and 0.012. The display gray scale window is
, 0.0115, 0.01175, and 0.012. The display gray scale window is 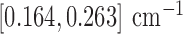 .
.
Fig. 13.
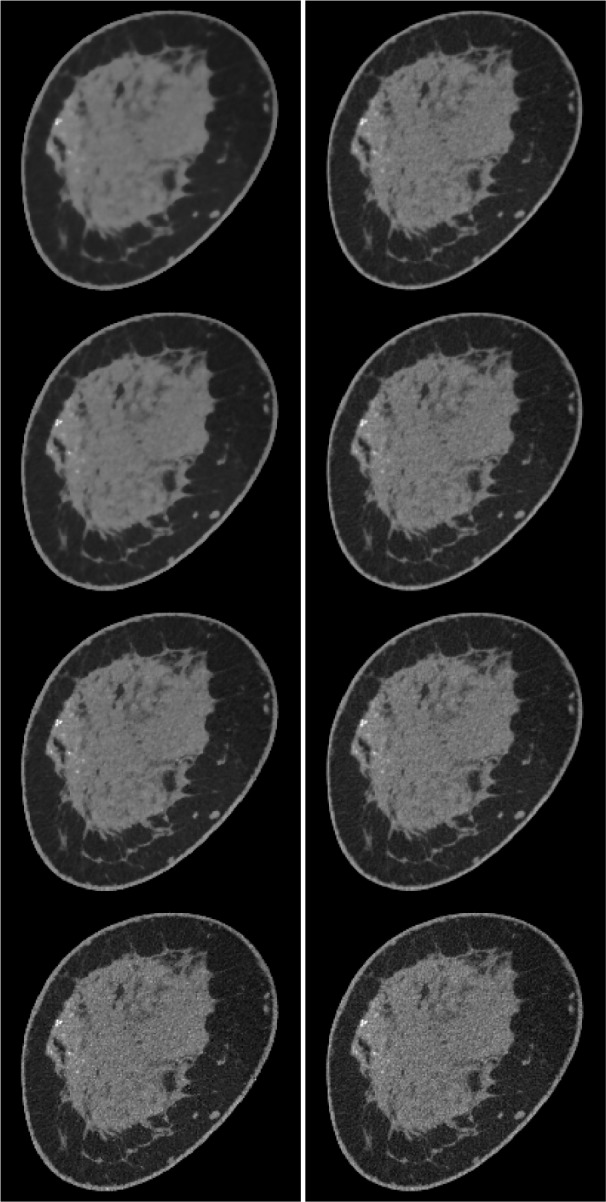
Same as Fig. 12 except that the left and right columns show images for 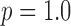 and
and 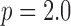 , respectively.
, respectively.
Fig. 14.

Expanded ROIs of the images shown in Figs. 12 and 13. The ROI corresponds to the left-center part of the image containing the microcalcifications. The gray scale window is expanded to 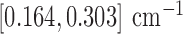 in order to accommodate the higher attenuation values of the microcalcifications. The columns correspond to
in order to accommodate the higher attenuation values of the microcalcifications. The columns correspond to 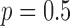 , 0.8, 1.0, and 2.0 from left to right. And the rows correspond to
, 0.8, 1.0, and 2.0 from left to right. And the rows correspond to 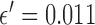 , 0.0115, 0.01175, and 0.012 from bottom to top.
, 0.0115, 0.01175, and 0.012 from bottom to top.
To better visualize the impact of the 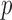 and
and 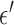 on the microcalcifications and to observe more local texture changes in the soft tissue, we show an ROI array in Fig. 14. The GMI sparsity promoting values of
on the microcalcifications and to observe more local texture changes in the soft tissue, we show an ROI array in Fig. 14. The GMI sparsity promoting values of 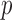 ,
, 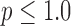 all show rapid regularization of the soft tissue with increasing
all show rapid regularization of the soft tissue with increasing 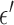 , while the texture change for
, while the texture change for 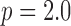 , is much more gradual. For the higher contrast microcalcifications, the visual dependence with increasing
, is much more gradual. For the higher contrast microcalcifications, the visual dependence with increasing 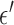 is quite different, depending on
is quite different, depending on 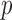 . For
. For 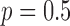 , we note little change in the sharpness of the microcalcifications. Rather, the calcifications disappear as
, we note little change in the sharpness of the microcalcifications. Rather, the calcifications disappear as 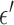 increases with smaller calcifications disappearing at lower
increases with smaller calcifications disappearing at lower 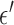 . At the other extreme,
. At the other extreme, 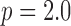 , the microcalcifications exhibit the more traditional trend of becoming more blurry, albeit that this trend is not very strong over the shown range of
, the microcalcifications exhibit the more traditional trend of becoming more blurry, albeit that this trend is not very strong over the shown range of 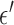 . The intermediate values of
. The intermediate values of 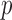 show trends which are a combination of the rapid reduction in contrast and standard blurring.
show trends which are a combination of the rapid reduction in contrast and standard blurring.
With these preliminary results, we cannot yet make a recommendation for an optimal image reconstruction algorithm for the breast CT system. The results instead are intended to demonstrate the effect of the parameters 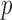 and
and 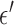 . Moreover the proper choice of algorithm depends on the scanner configuration, visual task, and type of observer (human or machine). We do expect, however, that use of nonconvex
. Moreover the proper choice of algorithm depends on the scanner configuration, visual task, and type of observer (human or machine). We do expect, however, that use of nonconvex 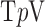 minimization will facilitate scanning configurations with a lower view angle sampling rate, which could impact the optimal balance between number of views and X-ray beam intensity.
minimization will facilitate scanning configurations with a lower view angle sampling rate, which could impact the optimal balance between number of views and X-ray beam intensity.
VIII. Conclusion
This work develops accurate reweighting IIR algorithms for application to CT that are used to investigate sparse data image reconstruction with nonconvex 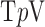 minimization. The algorithms are efficient enough for research purposes in that accurate solution is obtained within hundreds to thousands of iterations.
minimization. The algorithms are efficient enough for research purposes in that accurate solution is obtained within hundreds to thousands of iterations.
Employing 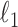 -reweighting for both isotropic and anisotropic
-reweighting for both isotropic and anisotropic 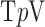 minimization, we observe substantial reduction in the necessary number of projections for accurate recovery of the test phantom. In fact, the number of measurements needed for
minimization, we observe substantial reduction in the necessary number of projections for accurate recovery of the test phantom. In fact, the number of measurements needed for 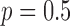 is a small fraction larger than the number of nonzero elements of the test phantom's GMI. These experiments do not necessarily generalize to a rule relating number of samples to GMI sparsity, but the results are nonetheless striking especially considering that the phantom has no particular symmetry and has the complexity similar to what might be found for fibroglandular tissue in breast CT. It may not be practical to reduce the number of views to the limit of ideal image recovery, but it is important to identify this limit. With this knowledge there is the option to operate at a number of views slightly greater than the recovery limit, where there are still fewer projections than what would be needed for convex TV minimization or algorithms that do not exploit GMI sparsity.
is a small fraction larger than the number of nonzero elements of the test phantom's GMI. These experiments do not necessarily generalize to a rule relating number of samples to GMI sparsity, but the results are nonetheless striking especially considering that the phantom has no particular symmetry and has the complexity similar to what might be found for fibroglandular tissue in breast CT. It may not be practical to reduce the number of views to the limit of ideal image recovery, but it is important to identify this limit. With this knowledge there is the option to operate at a number of views slightly greater than the recovery limit, where there are still fewer projections than what would be needed for convex TV minimization or algorithms that do not exploit GMI sparsity.
The response to noise present in a realistic breast CT simulation is also tested along with application to an actual clinical breast CT data set. The results show that the reweighting algorithms provide images that may be clinically useful. The fact that the IIR algorithms employing nonconvex 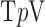 allows for accurate image recovery with very sparse projection data could prove interesting for fixed dose trade off studies. Namely, the operating point in the balance between number of projections and exposure per projection may be shifted toward fewer projections with the use of nonconvex
allows for accurate image recovery with very sparse projection data could prove interesting for fixed dose trade off studies. Namely, the operating point in the balance between number of projections and exposure per projection may be shifted toward fewer projections with the use of nonconvex 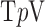 minimization.
minimization.
Acknowledgement
The authors are grateful to Zheng Zhang for careful checking of the equations and pseudocodes. The contents of this article are solely the responsibility of the authors and do not necessarily represent the official views of the National Institutes of Health.
Biographies

Emil Y. Sidky (M'11) received the B.S. degree in physics, astronomy-physics, and mathematics from the University of Wisconsin—Madison in 1987 and the Ph.D. in physics from The University of Chicago in 1993. He held academic positions in physics at the University of Copenhagen and Kansas State University. He joined the University of Chicago in 2001, where he is currently a Research Associate Professor. His current interests are in CT image reconstruction, large-scale optimization, and objective assessment of image quality.

Rick Chartrand (M'06–SM'12) received the B.Sc. (Hons.) degree in mathematics from the University of Manitoba in 1993 and the Ph.D. degree in mathematics from the University of California, Berkeley, in 1999. He held academic positions at Middlebury College and the University of Illinois at Chicago before coming to Los Alamos National Laboratory in 2003, where he is currently a Technical Staff Member with the Applied Mathematics and Plasma Physics Group. His research interests include compressive sensing, nonconvex continuous optimization, image processing, dictionary learning, computing on accelerated platforms, and geometric modeling of high-dimensional data.

John M. Boone was born in Los Angeles, CA, USA. He received the B.A. degree in biophysics from University of California, Berkeley, in 1979 and the M.S. and Ph.D. degrees in radiological sciences from University of California Irvine in 1981 and 1985, respectively. He held faculty positions at the University of Missouri Columbia and Thomas Jefferson University, Philadelphia, PA, USA, before joining the faculty at University of California, Davis, Sacramento, CA, USA, in 1992, where he is currently a Professor and Vice Chair (Research) of radiology and Professor of biomedical engineering. His interests are in the development of dedicated breast computed tomography (CT) systems, radiation dosimetry in CT, and image quality assessment in breast imaging and body CT. He is a fellow of the American Association of Physicists in Medicine, the Society of Breast Imaging, and the American College of Radiology.

Xiaochuan Pan received the bachelor's degree from Beijing University, Beijing, China, in 1982, the master's degree from the Institute of Physics, Chinese Academy of Sciences, Beijing, in 1986, and the master's and Ph.D. degrees from the University of Chicago, Chicago, USA, in 1988 and 1991, respectively, all in physics. He is currently a Professor with the Departments of Radiology and Radiation and Cellular Oncology and the Committee on Medical Physics, University of Chicago. His research interests include physics, algorithms, and applications of tomographic imaging. He is a recipient of awards, such as the IEEE NPSS Early Achievement Award and the IEEE EMBS Technical Award, and a fellow of AAPM, AIMBE, IAMBE, OSA, and SPIE. He has served as a chair and/or a reviewer of study sections/review panels for funding agencies, including NIH, NSF, and NSERC, as an Associate Editor (or editorial board member) for journals in the field such as the IEEE Transactions on Medical Imaging, IEEE Transactions on Biomedical Engineering, IEEE Journal of Translational Engineering in Health and Medicine, Physics in Medicine and Biology, and Medical Physics, as a Chair/Member of technical committees of professional organizations, such as IEEE and RSNA, and as a chair/member of programs, themes, and technical/scientific committees for conferences, such as IEEE EMBC, IEEE MIC, RSNA, AAPM, and MICCIA.
Appendix
A. Illustration of Reweighting for Nonconvex Optimization
For the purpose of this article being self-contained, we illustrate here a simple one dimensional example of the use of reweighting to solve a nonconvex optimization. So that there is some resemblance to the optimization problems discussed in the text, we select a constrained 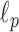 -minimization problem as an example
-minimization problem as an example
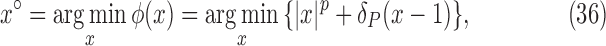 |
where the set  stands for all nonnegative real numbers and the corresponding indicator function encodes the constraint
stands for all nonnegative real numbers and the corresponding indicator function encodes the constraint  . The objective function of this nonconvex minimization problem is represented by the solid black curves of Figs. 15 and 16.
. The objective function of this nonconvex minimization problem is represented by the solid black curves of Figs. 15 and 16.
Fig. 15.
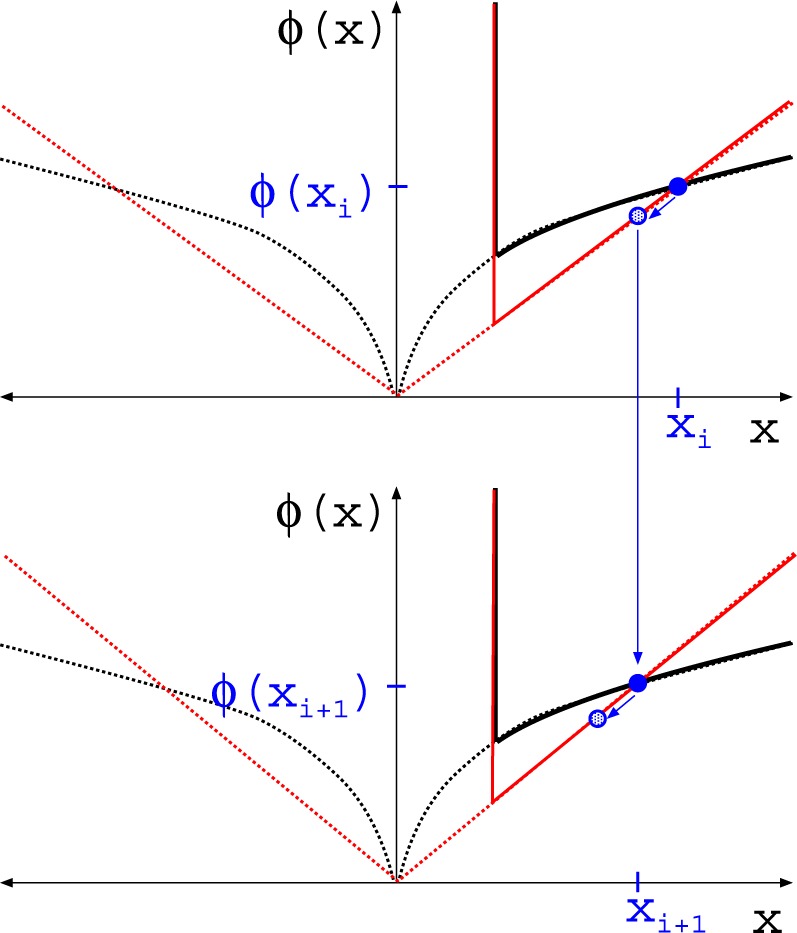
Illustration of one iteration of 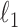 -reweighting for solving the nonconvex optimization (36). The dashed black curve is the
-reweighting for solving the nonconvex optimization (36). The dashed black curve is the 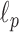 quasinorm for some
quasinorm for some 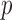 with
with 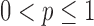 . The solid black curve is the complete objective of (36). The solution estimate
. The solid black curve is the complete objective of (36). The solution estimate 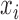 is indicated by the solid blue circle in the top graph. The intermediate convex weighted
is indicated by the solid blue circle in the top graph. The intermediate convex weighted 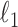 minimization is indicated by the solid red curve, where the weight is selected so that the red curve intersects the solid blue circle. The estimate
minimization is indicated by the solid red curve, where the weight is selected so that the red curve intersects the solid blue circle. The estimate 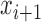 , indicated by the shaded blue circle in the top graph and the solid circle in the bottom graph, is generated by a single iteration of the Chambolle-Pock algorithm, which takes a step toward the solution. The bottom graph illustrates how the weight is adjusted so that the surrogate weighted
, indicated by the shaded blue circle in the top graph and the solid circle in the bottom graph, is generated by a single iteration of the Chambolle-Pock algorithm, which takes a step toward the solution. The bottom graph illustrates how the weight is adjusted so that the surrogate weighted 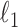 term intersects the solid blue circle corresponding
term intersects the solid blue circle corresponding 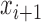 .
.
Fig. 16.
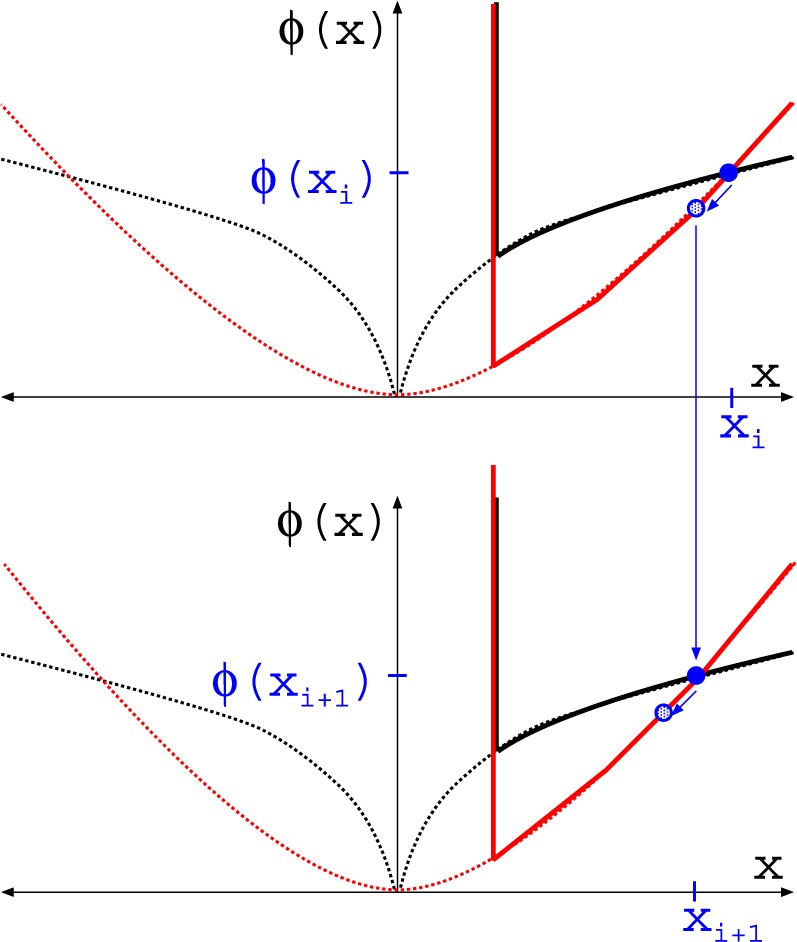
Same as Fig. 15 accept that the figure illustrates quadratic reweighting.
The use of reweighting here involves making an initial estimate 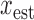 for
for 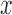 . This estimate is then used to replace the nonconvex objective function with a convex function taking on the same value at
. This estimate is then used to replace the nonconvex objective function with a convex function taking on the same value at 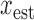 . In the context of
. In the context of 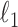 -reweighting a weighted
-reweighting a weighted 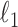 -norm replaces the
-norm replaces the 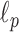 term and the weighting factor is used to match the convex and nonconvex objectives at
term and the weighting factor is used to match the convex and nonconvex objectives at 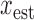 . In this case, the weighting factor is
. In this case, the weighting factor is
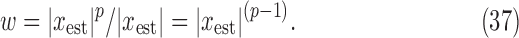 |
The intermediate convex optimization acting as a surrogate for (36) is
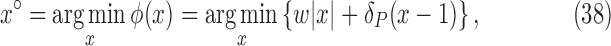 |
which can be solved by a host of convex optimization algorithms such as the Chambolle-Pock algorithm used in the text. There is some freedom in designing the reweighting algorithm, reflecting how accurate the intermediate optimization (38) is solved. For the algorithms in the text only one iteration of the solver for the intermediate problem is taken. The result is then assigned to 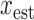 , which is in turn used to compute new weights. An illustration of this one-intermediate-step
, which is in turn used to compute new weights. An illustration of this one-intermediate-step 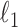 -reweighting algorithm is shown in Fig. 15.
-reweighting algorithm is shown in Fig. 15.
For quadratic reweighting the weights and intermediate convex optimization problem are
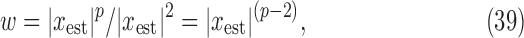 |
and
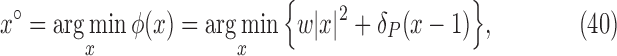 |
respectively. The corresponding one-intermediate-step quadratic reweighting algorithm is shown in Fig. 16.
The 1D nonconvex problem, (36), discussed here is used for illustration purposes. But there are peculiarities of this low dimensional example. For example, it is clear from both Figs. 15 and 16 that the solution of (36) coincides with the solutions of both the weighted 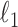 and quadratic surrogate convex optimization problems. This will not be the case for the multidimensional optimization problems considered in the text. Also, for the multidimensional case it is important to guard against potential division by zero in computing the weights. For the present one dimensional problem this danger seems remote. Nevertheless a possible corresponding weight for
and quadratic surrogate convex optimization problems. This will not be the case for the multidimensional optimization problems considered in the text. Also, for the multidimensional case it is important to guard against potential division by zero in computing the weights. For the present one dimensional problem this danger seems remote. Nevertheless a possible corresponding weight for 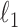 -reweighting is
-reweighting is
 |
where 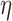 is a small nonnegative real number. And similarly for quadratic reweighting
is a small nonnegative real number. And similarly for quadratic reweighting
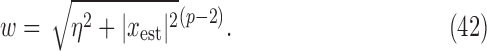 |
The following sections show derivations for 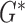 ,
, 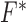 ,
, 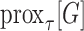 , and
, and 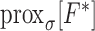 from Section III-A.
from Section III-A.
B. Derivation of 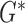 and
and 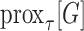
As 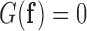 , it is easy to show that
, it is easy to show that
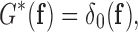 |
(see for example (18) of [30] and subsequent discussion). It is also easy to show that
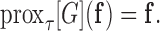 |
C. Derivation of 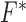
This computation is more involved, and we split this up into two, defining
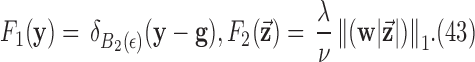 |
Starting with 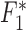 ,
,
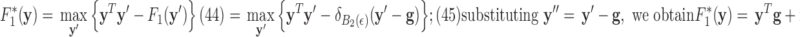 |
The maximizer, 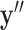 , at (47) is derived by noting that the objective in (46) is maximized when
, at (47) is derived by noting that the objective in (46) is maximized when 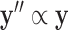 and the magnitude of
and the magnitude of 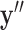 is limited to
is limited to 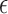 by the indicator function. The next term
by the indicator function. The next term 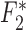 is
is
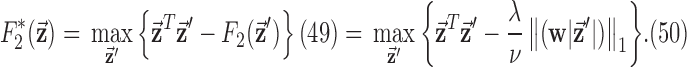 |
Now we substitute the polar decompositions 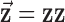 and
and 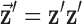 , where
, where 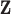 ,
, 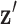 are non-negative scalar images and
are non-negative scalar images and 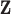 ,
, 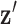 are spatial unit-vector images. Since
are spatial unit-vector images. Since 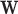 and
and 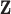 are non-negative, we obtain
are non-negative, we obtain
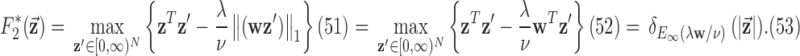 |
In going from (50)–(51), we note that the second term in the objective does not depend on 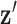 and, fixing
and, fixing 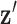 and allowing
and allowing 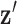 to vary, the objective function is maximized when the spatial-unit-vectors in
to vary, the objective function is maximized when the spatial-unit-vectors in 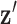 point in the same direction as
point in the same direction as 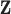 , i.e.,
, i.e., 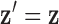 . The indicator function at the last line comes about from considering two cases regarding the coefficient of
. The indicator function at the last line comes about from considering two cases regarding the coefficient of 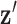 in (52): if all components of
in (52): if all components of 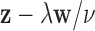 are non-positive the objective function is maximized at
are non-positive the objective function is maximized at 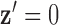 where its value is zero; otherwise if one component of
where its value is zero; otherwise if one component of 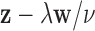 is positive the objective function can be made arbitrarily large. Equivalently, the coefficients of
is positive the objective function can be made arbitrarily large. Equivalently, the coefficients of 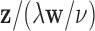 can be compared to 1: if the maximum coefficient, i.e.,
can be compared to 1: if the maximum coefficient, i.e., 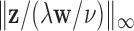 , is less than 1 then the maximization problem yields 0; otherwise, it yields
, is less than 1 then the maximization problem yields 0; otherwise, it yields  .
.
Combining the terms,
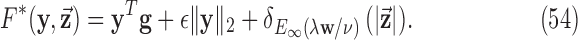 |
D. Derivation of 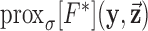
Next we compute 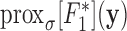 :
:
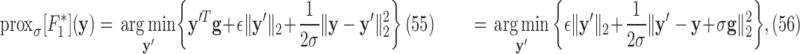 |
by completing the square and ignoring terms independent of  . From the symmetry of the objective function in (56), the minimizer lies on the segment between
. From the symmetry of the objective function in (56), the minimizer lies on the segment between  and
and  , so we can convert to a scalar minimization problem over non-negative
, so we can convert to a scalar minimization problem over non-negative 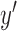 as follows:
as follows:
 |
Now we compute  :
:
 |
by making the same polar decomposition substitutions as in (51), because the indicator term does not depend on 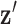 and the quadratic term is minimized when
and the quadratic term is minimized when 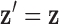 for fixed
for fixed 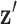 . The objective function of (61) is separable and the result of the minimization is a component-wise thresholding of
. The objective function of (61) is separable and the result of the minimization is a component-wise thresholding of 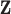 by the maximum value of the corresponding component of
by the maximum value of the corresponding component of 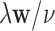 :
:
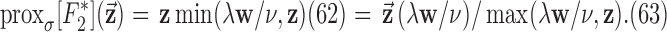 |
The form of the  in (63) is equivalent to that of (62), but it is computationally more convenient because the computation of
in (63) is equivalent to that of (62), but it is computationally more convenient because the computation of  in (62) needs to avoid potential division by zero. The denominator of (63), on the other hand, is strictly positive.
in (62) needs to avoid potential division by zero. The denominator of (63), on the other hand, is strictly positive.
Funding Statement
The work of R. Chartrand was supported by the UC Laboratory Fees Research Program, and the U.S. Department of Energy through the LANL/LDRD Program. This work was supported by NIH R01 under Grants CA158446 (EYS), CA120540 (XP), EB000225 (XP), and EB002138 (JMB).
Footnotes
Two ways to implement the use of only FOV pixels are: (1) redefine the projection and gradient matrices as 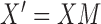 ,
, 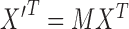 ,
,  , and
, and  , where
, where  is a diagonal matrix that masks the rectangular pixel array to zero outside the FOV, or (2) mask the image iterates
is a diagonal matrix that masks the rectangular pixel array to zero outside the FOV, or (2) mask the image iterates 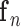 directly with
directly with  in which case condition 3 is slightly modified:
in which case condition 3 is slightly modified: 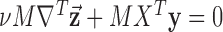 .
.
References
- [1].Sidky E. Y., Kao C.-M., and Pan X., “Accurate image reconstruction from few-views and limited-angle data in divergent-beam CT, ” J. X-Ray Sci. Technol., vol. 14, no. 2, pp. 119–139, Jun. 2006. [Google Scholar]
- [2].Sidky E. Y. and Pan X., “Image reconstruction in circular cone-beam computed tomography by constrained, total-variation minimization, ” Phys. Med. Biol., vol. 53, no. 17, pp. 4777–4807, Sep. 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Defrise M., Vanhove C., and Liu X., “An algorithm for total variation regularization in high-dimensional linear problems, ” Inverse Problems, vol. 27, no. 6, pp. 065002-1–065002-16, 2011. [Google Scholar]
- [4].Jensen T. L., Jørgensen J. H., Hansen P. C., and Jensen S. H., “Implementation of an optimal first-order method for strongly convex total variation regularization, ” BIT Numer. Math., vol. 52, no. 2, pp. 329–356, 2012. [Google Scholar]
- [5].Jørgensen J. S., Sidky E. Y., and Pan X., “Quantifying admissible undersampling for sparsity-exploiting iterative image reconstruction in X-ray CT, ” IEEE Trans. Med. Imag., vol. 32, pp. 460–473, Feb. 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Ramani S. and Fessler J., “A splitting-based iterative algorithm for accelerated statistical X-ray CT reconstruction, ” IEEE Trans. Med. Imag., vol. 31, pp. 677–688, Mar. 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Chen G. H., Tang J., and Leng S., “Prior image constrained compressed sensing (PICCS): A method to accurately reconstruct dynamic CT images from highly undersampled projection data sets, ” Med. Phys., vol. 35, no. 2, pp. 660–663, Feb. 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Bian J., et al. , “Evaluation of sparse-view reconstruction from flat-panel-detector cone-beam CT, ” Phys. Med. Biol., vol. 55, no. 22, pp. 6575–6599, Nov. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [9].Sidky E. Y., Anastasio M. A., and Pan X., “Image reconstruction exploiting object sparsity in boundary-enhanced X-ray phase-contrast tomography, ” Opt. Exp., vol. 18, no. 10, pp. 10404–10422, May 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Ritschl L., Bergner F., Fleischmann C., and Kachelrieß M., “Improved total variation-based CT image reconstruction applied to clinical data, ” Phys. Med. Biol., vol. 56, no. 6, pp. 1545–1562, Mar. 2011. [DOI] [PubMed] [Google Scholar]
- [11].Han X., et al. , “Algorithm-enabled low-dose micro-CT imaging, ” IEEE Trans. Med. Imag., vol. 30, pp. 606–620, Mar. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Han X., Bian J., Ritman E. L., Sidky E. Y., and Pan X., “Optimization-based reconstruction of sparse images from few-view projections, ” Phys. Med. Biol., vol. 57, no. 16, pp. 5245–5274, Aug. 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Song J., Liu Q. H., Johnson G. A., and Badea C. T., “Sparseness prior based iterative image reconstruction for retrospectively gated cardiac micro-CT, ” Med. Phys., vol. 34, pp. 4476–4483, Oct. 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Chen G.-H., Tang J., and Hsieh J., “Temporal resolution improvement using PICCS in MDCT cardiac imaging, ” Med. Phys., vol. 36, no. 6, pp. 2130–2135, Jun. 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Bergner F., et al. , “An investigation of 4D cone-beam CT algorithms for slowly rotating scanners, ” Med. Phys., vol. 37, no. 9, pp. 5044–5054, Sep. 2010. [DOI] [PubMed] [Google Scholar]
- [16].Ritschl L., Sawall S., Knaup M., Hess A., and Kachelrieß M., “Iterative 4D cardiac micro-CT image reconstruction using an adaptive spatio-temporal sparsity prior, ” Phys. Med. Biol., vol. 57, no. 6, pp. 1517–1526, Mar. 2012. [DOI] [PubMed] [Google Scholar]
- [17].Kuntz J., Flach B., Kueres R., Semmler W., Kachelrieß M., and Bartling S., “Constrained reconstructions for 4D intervention guidance, ” Phys. Med. Biol., vol. 58, no. 10, pp. 3283–3300, May 2013. [DOI] [PubMed] [Google Scholar]
- [18].Chartrand R. and Staneva V., “Restricted isometry properties and nonconvex compressive sensing, ” Inverse Problems, vol. 24, no. 3, pp. 035020-1–035020-14, Jun. 2008. [Google Scholar]
- [19].Daubechies I., DeVore R., Fornasier M., and Güntürk C. S., “Iteratively reweighted least squares minimization for sparse recovery, ” Commun. Pure Appl. Math., vol. 63, no. 1, pp. 1–38, Jan. 2010. [Google Scholar]
- [20].Chartrand R., “Nonconvex splitting for regularized low-rank + sparse decomposition, ” IEEE Trans. Signal Process., vol. 60, no. 11, pp. 5810–5819, Nov. 2012. [Google Scholar]
- [21].Chartrand R., “Nonconvex compressive sensing and reconstruction of gradient-sparse images: Random vs. tomographic Fourier sampling, ” in Proc. IEEE ICIP, Oct. 2008, pp. 2624–2627. [Google Scholar]
- [22].Ramirez-Giraldo J. C., Trzasko J., Leng S., Yu L., Manduca A., and McCollough C. H., “Nonconvex prior image constrained compressed sensing (NCPICCS): Theory and simulations on perfusion CT, ” Med. Phys., vol. 38, no. 4, pp. 2157–2167, Apr. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Zhang X. and Xing L., “Sequentially reweighted TV minimization for CT metal artifact reduction, ” Med. Phys., vol. 40, no. 7, pp. 071907-1–071907-12, Jul. 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Sidky E. Y., Pan X., Reiser I. S., Nishikawa R. M., Moore R. H., and Kopans D. B., “Enhanced imaging of microcalcifications in digital breast tomosynthesis through improved image-reconstruction algorithms, ” Med. Phys., vol. 36, no. 11, pp. 4920–4932, Nov. 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Candès E. J., Romberg J., and Tao T., “Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information, ” IEEE Trans. Inf. Theory, vol. 52, no. 2, pp. 489–509, Feb. 2006. [Google Scholar]
- [26].Candès E. J. and Wakin M. B., “An introduction to compressive sampling, ” IEEE Signal Process. Mag., vol. 25, no. 2, pp. 21–30, Mar. 2008. [Google Scholar]
- [27].Chartrand R., “Exact reconstructions of sparse signals via nonconvex minimization, ” IEEE Signal Process. Lett., vol. 14, no. 10, pp. 707–710, Oct. 2007. [Google Scholar]
- [28].Sidky E. Y., Chartrand R., and Pan X., “Image reconstruction from few views by non-convex optimization, ” in Proc. IEEE NSS Conf. Rec., Nov. 2007, pp. 3526–3530. [Google Scholar]
- [29].Chambolle A. and Pock T., “A first-order primal-dual algorithm for convex problems with applications to imaging, ” J. Math. Imag. Vis., vol. 40, no. 1, pp. 120–145, May 2011. [Google Scholar]
- [30].Sidky E. Y., Jørgensen J. H., and Pan X., “Convex optimization problem prototyping for image reconstruction in computed tomography with the Chambolle–Pock algorithm, ” Phys. Med. Biol., vol. 57, no. 10, pp. 3065–3091, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
-
[31].Candès E. J., Wakin M. B., and Boyd S. P., “Enhancing sparsity by reweighted
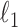 minimization, ” J. Fourier Anal. Appl., vol. 14, no. 5, pp. 877–905, Dec.
2008. [Google Scholar]
minimization, ” J. Fourier Anal. Appl., vol. 14, no. 5, pp. 877–905, Dec.
2008. [Google Scholar] - [32].Chartrand R. and Yin W., “Iteratively reweighted algorithms for compressive sensing, ” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., Apr. 2008, pp. 3869–3872. [Google Scholar]
- [33].Niu T. and Zhu L., “Accelerated barrier optimization compressed sensing (ABOCS) reconstruction for cone-beam CT: Phantom studies, ” Med. Phys., vol. 39, no. 7, pp. 4588–4598, Jul. 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Reiser I. and Nishikawa R. M., “Task-based assessment of breast tomosynthesis: Effect of acquisition parameters and quantum noise, ” Med. Phys., vol. 37, no. 4, pp. 1591–1600, Apr. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Boone J. M., Kwan A. L. C., Seibert J. A., Shah N., Lindfors K. K., and Nelson T. R., “Technique factors and their relationship to radiation dose in pendant geometry breast CT, ” Med. Phys., vol. 32, no. 12, pp. 3767–3776, Dec. 2005. [DOI] [PubMed] [Google Scholar]
- [36].Barrett H. H. and Myers K. J., Foundations of Image Science, Hoboken, NJ USA: Wiley, 2004. [Google Scholar]
- [37].Kwan A. L. C., Boone J. M., Yang K., and Huang S.-Y., “Evaluation of the spatial resolution characteristics of a cone-beam breast CT scanner, ” Med. Phys., vol. 34, no. 1, pp. 275–281, Jan. 2007. [DOI] [PubMed] [Google Scholar]
- [38].Prionas N. D., et al. , “Contrast-enhanced dedicated breast CT: Initial clinical experience, ” Radiology, vol. 256, no. 3, pp. 714–723, Sep. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]