

Abstract
The last years have witnessed tremendous technical advances in the field of transcriptomics that enable the simultaneous assessment of nearly all transcripts expressed in a tissue at a given time. These advances harbor the potential to gain a better understanding of the complex biological systems and for the identification and development of novel biomarkers. This article will review the current knowledge of transcriptomics biomarkers in the cardiovascular field and will provide an overview about the promises and challenges of the transcriptomics approach for biomarker identification.
Keywords: Transcriptomics, Biomarker, Gene expression, RNA, Risk prediction, Coronary artery disease
Introduction
While cardiovascular disease (CVD) has traditionally been considered a disease of Western society, its global incidence is on the rise and it is currently more prevalent in low- and middle income countries in Asia and Africa [1]. To prevent CVD, accurate personal risk-assessment is paramount. The 2012 European Society of Cardiology (ESC) guidelines recommend risk-assessment using the updated SCORE charts based on age, gender, smoking, blood pressure, and total cholesterol [2]. The recent joint guidelines by the American College of Cardiology and the American Heart Association (ACC/AHA) recommend a model based on the Framingham Risk Score using generally similar parameters [3]. However, these current risk prediction models only provide a rough estimate of individual risk. Therefore, great value is posited in the identification and development of new biomarkers for CVD risk prediction.
Decades of research have shown that improvement of risk prediction requires comprehensive understanding of the disease mechanism. The tremendous progress achieved in the ‘omics’ field has successfully improved the understanding of CVD pathophysiology by comprehensively interrogating disease states at the molecular level. This molecular phenotyping has become feasible by novel, robust, and fast high-throughput analytic platforms providing novel opportunities for molecular biomarker identification [4]. Transcriptomics, the study of ribonucleic acid (RNA) transcripts and their expression patterns at a genome-wide level, is particularly promising for biomarker identification.
This article will review current knowledge of transcriptomics biomarkers in the cardiovascular field and provide an overview about the promises and challenges of the transcriptomics approach for biomarker identification.
RNA
RNA has long been considered as the messenger molecule between genes and proteins, where RNA is transcribed from DNA to messenger RNA (mRNA) and subsequently translated into protein [5, 6]. In recent years, non-coding RNA species have been characterized including microRNAs (miRNAs) and long non-coding RNAs (lncRNAs) [7, 8].
miRNAs are endogenous, non-coding small RNAs of about 22 nucleotides regulating gene expression at a post-transcriptional level [9, 10]. They are involved in a broad range of biological processes and their dysregulation impacts disease development [11]. Of great interest is that miRNAs are stable in biological fluids such as blood and urine [12, 13], are actively secreted in microparticles and show tissue-specificity, attractive features of potential biomarkers [14].
lncRNAs cover RNA molecules over 200 nucleotides and are observed in a wide range of tissues. They exert a broad repertoire of functions and have been linked to differentiation and developmental processes and disease [8, 15]. Compared to miRNAs, the widespread attention on lncRNAs is a rather recent phenomenon, nonetheless some promising evidence of using lncRNAs as biomarkers exist [16].
Technology Platforms
Historically, investigation of RNA expression was performed using northern blotting or RT-PCR approaches, at best investigating several RNA targets at once. For several years, the use of expression microarrays has allowed rapid unbiased screening of nearly the entire transcriptome for discovery of the most promising targets. In microarray-based methods tens of thousands of transcripts are simultaneously analyzed by chemically labeling RNA molecules and subsequent hybridization to probes on the microarray. The strength of microarrays lies in the extensive coverage, the high-throughput applicability and the relative inexpensiveness of the microarray approach. However, microarray technology is limited by the amount of RNA required, the limited dynamic range for quantification and can only detect predefined transcripts. Furthermore, questions are raised about the reproducibility and reliability of microarray experiments.
Currently, we are on the brink of a new revolution, brought about by the advent of next-generation RNA-sequencing (RNA-seq). Although still prohibitively expensive, advances in RNA-seq will allow for superior scrutiny of the transcriptome, providing absolute quantification of transcripts while including splice variants, non-coding RNA and yet unknown transcripts [17]. RNA-seq uses deep-sequencing technologies whereby a population of RNA (e.g., mRNA or miRNA) is converted to a cDNA library which is subsequently sequenced in a high-throughput base-by-base manner to obtain short sequences. The reads, typically 30–400 bp depending on the DNA-sequencing technology used, are used to reconstruct the original RNA-sequence in silico [18]. The use of this so called next generation sequencing technology for the analysis of RNA has pioneered work with small regulatory RNAs, possibly because this field has benefited less from microarrays as the usual size of small RNAs is too short to be captured adequately with the limited resolution of microarrays [19]. Detailed descriptions of microarray and RNA-seq approaches are out of the scope of this work, but many excellent reviews provide a comprehensive overview, e.g., [19–21].
As the technological capabilities for measuring transcript expression have vastly improved, the importance of expression data for the development of new biomarkers has soared. The opportunity for transcriptome-wide screening of biomarkers allows for unbiased investigation of their potential as an individual biomarker for disease.
Transcriptomics-based Biomarkers in Cardiovascular Disease
Recent advances in the cardiovascular biomarker field have identified novel and emerging transcriptomics-based biomarkers (Table 1). Here, we highlight examples that have started to emerge in clinical practice.
Table 1.
Studies evaluating gene expression data for the use of biomarker identification for coronary artery disease
| Study scheme | Selected references | |
|---|---|---|
| Gene expression (single genes) | ||
| sST2 | HF, Ischemic heart disease | [22, 25, 26] |
| GDF15 | acute coronary syndromes, Angina pectoris, HF | [30, 32] |
| FSTL1 | ACS, HF | [35, 37] |
| Gene expression signatures | ||
| 23-gene score (Corus CAD) | Obstructive CAD | [43–45] |
| Circulating microRNAs | ||
| miR-126, miR-223, miR-197 | CHD | [53] |
| miR-1, miR-122, miR-133, miR-208a/b, miR-375, miR-499 | AMI | [49, 90–94] |
| miR-21, mir-29a, miR-208a | Post-MI | [95] |
| miR-1, miR-133a, miR-499, miR-208 | CAD | [96, 97] |
| microRNA signatures | ||
| 20-miRNA signature | AMI, single time point | [56•] |
| 6-miRNA signature | AMI, serial time points | [98] |
| 4-miRNA signature | AMI vs Takotsubo Cardiomyopathy | [99] |
ST2 (IL-1RL-1, Interleukin 1 receptor-like 1)
ST2 represents a promising biomarker identified by a transcriptomics approach. Weinberg and colleagues [22] identified the ST2 gene as upregulated in cardiac myocytes subjected to mechanical strain by microarray analysis. Soluble ST2 is a secreted receptor belonging to the IL-1 receptor family that regulates inflammation and immunity [23]. The soluble form of the protein can be measured in peripheral blood and a test kit for measurements of soluble ST2 is already commercially available (Critical Diagnostics Presage ST2 Assay). It has been shown that ST2 levels rise above normal in the context of various cardiac diseases [24] such as heart failure [25] and ischemic heart disease [26]. In the Framingham Heart Study, measurements of soluble ST2 showed clear gender differences, an increase with age and increased levels in association with diabetes and hypertension [27] and soluble ST2 added prognostic value to standard risk factors [28]. Novel findings, however, indicate that genetic factors account for up to 40 % of the inter-individual variability of soluble ST2 levels, which must be taken into account in future studies of ST2 as a biomarker [29]. ST2 is a clear example how the initial microarray analyses identified a target as cardiac biomarker and led to the development of a suitable assay.
Growth Differentiation Factor-15 (GDF-15)
GDF-15, a distant member of the TGF-β cytokine superfamily, has been identified by gene expression microarray analyses as being massively upregulated in nitric oxide (NO)-treated cardiomyocytes [30], under oxidative stress, in pressure overloaded left ventricles of mice with aortic stenosis, and a mouse model of dilated cardiomyopathy [31]. Levels of GDF15 can be measured in serum and plasma and evidence are accumulating that GDF15 is a strong and independent predictor of mortality and disease progression in patients with established disease, such as acute coronary syndromes, angina pectoris, heart failure [32]. Moreover, circulating GDF-15 levels are independently related to intermediate cardiovascular phenotypes, including endothelial dysfunction, intima media thickness, plaque burden, and left ventricular hypertrophy and dilatation [33, 34]. Thus, measurement of GDF-15 may contribute to a refined risk assessment on top of traditional risk factors and biomarkers.
The same group that reported on GDF15 as cardiac biomarker identified follistatin-like 1 (FSTL1) as an inducer of GDF15 production and an independent biomarker in acute coronary syndrome by using an expression screen for cDNAs encoding activators of the GDF15 promoter [35]. FSTL1 had previously been indicated as a putative biomarker in chronic systolic heart failure [36] and has been discussed as a novel therapeutic target for post-myocardial infarction and acute coronary syndrome [37].
Expression Signatures
A precise gene expression signature, i.e., an RNA expression pattern, has the promise to diagnose and classify diseases and potentially guide personalized treatment decisions for patients [4]. Gene expression signatures have already been shown to accurately predict cardiomyopathy etiology in heart failure [38, 39] and to be useful in monitoring clinically significant allograft rejection [40, 41]. These data support ongoing efforts to incorporate biomarkers based on expression profiling to determine prognosis and response to therapy [38, 42].
In the Personalized Risk Evaluation and Diagnosis in the Coronary Tree (PREDICT) study, a whole blood gene expression score was developed and validated for the assessment of obstructive CAD in non-diabetic patients [43, 44]. This score is a function of the expression levels of 23 genes grouped into highly correlated terms reflecting biological processes or cell types [44] and is associated with the probability of obstructive CAD [45]. Subsequently, a multiplex assay for expression levels of the 23 gene transcripts became commercially available (Corus CAD, CardioDx, Palo Alto, CA) [45]. Multiplex tests are often complex, containing multiple sample processing steps, operators, machines and types of reagents which can affect assay variability. Assessment of the laboratory process variability showed that the Corus CAD intra-batch PCR variability contributed most to the overall variability while the reagent lot contributed most to inter-batch variability [45]. Thomas et al. [46] evaluated the diagnostic accuracy of the gene expression score to determine obstructive CAD in symptomatic patients referred for myocardial perfusion in the multicenter COMPASS study. The investigators found that the gene expression score was a significant predictor of obstructive CAD and resulted, at a predefined threshold, in a high sensitivity and high negative predictive value. Although the added value of a transcriptomics profile such as Corus CAD must be rigorously tested against current standard-of-care risk prediction and explored in different populations to define its clinical utility, the Corus CAD assay is extremely promising and one of the best examples of the value of transcriptomics-based biomarkers in the cardiovascular field today.
Circulating microRNAs
Changes in the circulating miRNA levels have been associated with cardiovascular disease [47, 48]. As PCR-based techniques for quantifying circulating miRNAs improved, studies began to explore whether miRNAs could serve as clinical biomarkers, e.g., as biomarkers of the acute coronary syndrome [49, 50], acute myocardial infarction [51], heart failure [52].
In the Bruneck study, one of the largest studies measuring miRNAs, Zampetaki et al. [53] screened levels of 19 circulating miRNAs by quantitative RT-PCR. Three miRNAs formed a signature for myocardial infarction: miR-126, miR-223 and miR-197. Those miRNAs added information to the Framingham Risk Score for the endpoint coronary heart disease and led to better patient stratification to risk categories, indicating the potential value of these miRNAs as biomarkers for cardiovascular risk prediction.
However, most published miRNAs studies were small case-control studies and should be interpreted with caution and further work in larger populations is required. Detailed overviews of the current miRNA biomarker literature are given in, e.g., [9, 54, 55].
MicroRNA Signatures
Similar to specific gene expression signatures, signatures of miRNAs may reflect a given disease state and have potential as a biomarker. Meder et al. [56•] assessed whole-genome miRNA expression in whole blood samples of patients with acute myocardial infarction (AMI); 121 miRNAs were identified to be significantly dysregulated in AMI. The predictive power of these miRNAs were evaluated by receiver operator characteristic curves, and area under the curve (AUC) values of up to 0.94 were observed for the most predictive single miRNAs, miR-1291, and miR-663b. Using an algorithm for self-learning pattern recognition, a unique 20-miRNA signature was identified that predicts AMI with higher power and better AUC compared to individual miRNAs, even at stages when troponin T was still negative. These study results implicate that miRNA signatures, derived from peripheral blood, can serve as a valuable biomarker and may improve biomarker-based diagnosis of AMI. However, it needs to be mentioned that the sample size was rather small and larger patient cohorts are needed for validation.
In a subsequent miRNA study the same group investigated the kinetics of miRNA dysregulation in serial measurements in AMI patients and confirmed a 6-miRNA signature, including five out of the 20 miRNAs identified in the previous study [57]. These serial measurements identified distinct miRNA patterns in the very early phase of AMI that resolved within the first days of successful therapy. Significant differences were seen mainly at the two earliest time points, indicating those miRNAs to be early markers of AMI. The authors hypothesize that, although the release of molecules from injured myocardium may be similar for miRNA and proteins, a whole-blood approach may provide further information because it would reflect the disease processes involved in the pathogenesis of rather than solely detecting myocardial necrosis.
Clearly, future studies are needed to examine the value of miRNA signatures as potential robust biomarkers; nevertheless, miRNAs and miRNA signatures are emerging promising new players in cardiovascular biomarker research.
Long Non-coding RNAs
Recently another class of non-coding RNAs, lncRNAs, has aroused interest in cardiovascular function and disease. Growing evidence suggest that lncRNAs are key regulatory molecules at every level of cellular physiology, and their alterations are associated with multiple human diseases [58, 59] and may provide promising new targets for biomarker identification. Despite the progress made in oncology studies that tested lncRNAs as biomarkers for, e.g., breast cancer [60], endometrial carcinoma [61] and lung cancer [62••], data on lncRNA biomarkers in the cardiovascular field is still poor and further work is essential to improve the overall understanding and value of lncRNAs as biomarkers.
Challenges in Biomarker Development
Multiple stages are required for the “pipeline” of transcriptomics biomarker discovery and development. These stages include among others i) discovery of putative biomarkers for the target disease phenotype, ii) (technical) validation of those biomarkers in various disease and population cohorts to characterize biomarker performance, and iii) subsequent testing in large prospective clinical trials before translation into clinical routine. In addition, the impact of a new biomarker on clinical outcomes in terms of efficacy and cost effectiveness is a further step that should be taken. Novel technologies have contributed to a massive increase in biomarker discovery projects and reports, however, only few have been validated for routine clinical practice [63].
Numerous excellent reports are published providing a comprehensive overview of pitfalls and challenges for biomarker discovery and translation, e.g., [55, 63–67]. Here, we briefly review the key challenging points (summarized in Fig. 1).
Fig. 1.
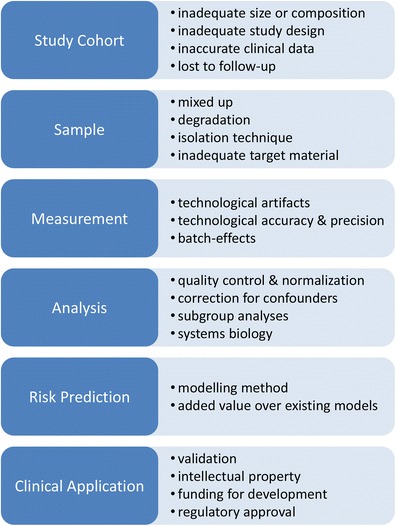
Challenges in transcriptomic biomarker development. Figure depicts main steps in Biomarker discovery and development and associated challenges to overcome
Study Design
An appropriate study design is a foremost requirement for reliable transcriptomics-based biomarker identification, ensuring adequate sample size for analysis and accounting for possible confounders. We recently showed that age, gender, body mass index, inflammatory status, and smoking influence gene expression [68]. Likewise, consideration should be given to the influence of cardiovascular risk factors, ethnicity, and medication on gene expression [4]. In addition, common gene variants (i.e., single-nucleotide polymorphisms) and epigenetic patterns can influence gene expression [4]. To achieve adequate statistical power, large sample sizes, accurate clinical phenotyping and well-characterized populations are mandatory [64, 69]. Another primary consideration in study design is the choice of tissue or cell type to investigate. Due to the ease of access, circulating blood is often used as surrogate source of diseased tissue. However, it is unclear whether the blood transcriptome is suitable as a surrogate for tissues like, e.g., heart tissue. One needs to consider that whole blood contains a mixture of cell types whose proportions show inter variability and may alter depending on disease state [70].
Animal models and in vitro experiments are still important methods employed for biomarker research. However, the translation of these studies toward clinical application is difficult and could lead to false targets. Comparison of transcriptomics data from ex-vivo monocytes and the in vitro monocytic THP-1 cell-line showed important differences [71]. Likewise, recently Seok et al. showed that human inflammatory expression profiles where highly similar between various causes of inflammation, yet very different from mice inflammatory expression profiles [72••]. This indicates that great care must be taken when translating such results into the clinical setting.
Analytical Considerations and Standardization
In contrast to genomic data, a subject’s gene expression data will vary spatially and temporally. To reduce confounding factors influencing gene expression data, such as different sample preparations and differences in the PCR runs, gene expression data have to be normalized. This is a critical issue and a major concern in transcriptomics studies. Especially for circulating miRNA measurements normalization is a “hot topic” in the current discussion, and several normalization approaches are used such as quantile-quantile normalization or spike-in of artificial RNA material [20]. However, normalization is currently applied in a non-standardized fashion and application of universal reference material is required. Furthermore, variation caused by preanalytical and analytical factors can substantially influence gene expression data [4]. Schurmann et al. [73] showed that factors such as RNA quality, storage time of blood, and batches of RNA processing and amplification have strong influence on gene expression data. Other studies provide evidence for the variability inherent to the PCR process and about batch effects in high-throughput technologies [45, 74]. In addition, numerous variables have been shown to influence the detection of miRNAs in the preanalytical phase such as heparin [75••] and can lead to erroneous results [76]. This can be particularly challenging in the clinical setting, as differences in sample collection, sample processing, and assay performance in different clinical centers are to be expected. Therefore, to eliminate technical and analytical variability and avoid artifactual data generation, consensus on standard methods for all steps is imperative.
Validation
Validation of initial discovery results in independent, large-scale studies are required in the field of biomarker research. Ideally, results of transcriptomics analyses will be validated in multi-center real-world studies, even comprising decentralized processing of RNA and PCR analysis and optimization of (decentralized) clinical laboratory testing procedures [4]. After validation of the initial expression results, the putative biomarker must be rigorously tested against the existing standard of care and explored in a wider population to define its clinical utility.
Another aspect that will become increasingly important is the validation of biomarkers for specific subgroups. It has been common practice for clinical laboratories to use specific reference values for several important subgroups like men and women or children and adults, when evaluating diagnostic markers. However, it is uncommon to determine the predictive value of a biomarker for specific subgroups. This is about to change, as it is clear from the recent recommendations on cardiovascular risk-assessment by the ACC/AHA, stating that race- and sex- specific risk-assessment is highly recommended [3].
Multidisciplinary Approaches
Getting candidate biomarkers into large-scale validation studies requires the integration of diverse skills. Most biomarker discovery is conducted in labs lacking the resources and multidisciplinary expertise needed [63]. Therefore, biomarker discovery should be a component of large research networks, involving industry and experts in distinct fields such as molecular biology, analytical chemistry, bioinformatics, clinical-trial design, epidemiology, statistics, and health-care economics [63]. Several collaborative initiatives have emerged in recent years to orchestrate biomarker research efforts (including transcriptomics-based biomarkers). These include, among others, the Innovative Medicines Initiative (IMI) (www.imi.europa.eu/) and the BiomarCaRE Consortium (www.biomarcare.eu), both funded by the European Union.
Transcriptomics, Genomics, and Epigenomics
The current trend in biomarker research is increasingly focused on the discovery of causal biomarkers indicative of changes in pathophysiologic processes that are the basis of the complex disease and a potential target for drug development. GWAS provide an important tool to reveal causality through the principle of “Mendelian randomization”. Zacho et al. is a case in point, showing that genetically raised CRP levels did not influence risk of myocardial ischemia [77]. Another clear example is the recent landmark paper by Voight et al. which showed that genetic predispositions that raised HDL-cholesterol levels had no influence on disease outcome, as opposed to genetic alterations in LDL-cholesterol levels [78]. The method of ‘Mendelian randomization’ is also well-suited to indicate causality of transcriptomics-derived biomarkers.
GWAS has found many single nucleotide polymorphisms (SNPs) affecting disease, yet the complex mechanisms through which they exert their effect, is still largely unknown, as many appear in non-coding regions of the genome. SNPs which influence mRNA expression are known as expression Quantitative Trait Loci (eQTL).
SNPs associated with complex diseases are more likely to be eQTLs compared to other SNPs and 45 % of genes associated with CVD contain eQTLs [79, 80]. SNPs also influence known risk factors of cardiovascular disease, for example lipoproteins, for which 96 eQTLs have been found in 157 known loci [81, 82]. This shows that eQTLs may be an important mechanism for cardiovascular risk SNPs, and emphasizes the importance of transcriptomics for the interpretation of GWAS results.
In addition to genetic biomarkers, epigenetic DNA modifications like DNA methylation and histone modifications could serve as biomarkers of disease. Most interest has recently been directed at DNA-methylation biomarkers, enabled by development of ‘epigenome-wide’ DNA-methylation arrays. To elucidate the tissue specific down-regulation of gene expression by DNA-methylation in a high-throughput fashion, transcriptomics are indispensable. In a recent study, Grundberg et al. compared DNA-methylation to GWAS and transcriptomics data and found that 28 % of methylation quantitative trait loci (meQTL’s) are associated with nearby SNPs, and 6 % of SNPs played a role in both DNA-methylation and adipose tissue gene expression [83], showing the complex interplay between genetic variants, methylation, and expression.
In addition, SNPs may also influence the expression of mRNA through interference with non-coding RNA (ncRNA) regulatory activity. For example, Gamazon et al. analyzed the effects of SNP’s on expression (mRNA-eQTL) and microRNA expression (miRNA-eQTL) and showed significant enrichment of miRNA-eQTLs in known mRNA-eQTLs, thereby providing important evidence for specific miRNA-mRNA interactions. Furthermore, many of the found SNPs were associated with traits of complex diseases [84•]. In an identical fashion, Kumar et al. identified SNPs that influence lincRNA expression, and showed associations of these SNPs with complex diseases [85]. This indicates that dysregulation of transcriptome interactions could be an important disease mechanism, and may thus form interesting biomarker targets.
Future Perspectives
Despite a tremendous increase of interest in the transcriptome, we are only just scratching the surface of its complexity. To fully elucidate the transcriptome requires robust sample processing as well as advances in technology and analysis methods.
Whole transcriptome RNA sequencing is still in its infancy yet new developments seem very promising. Meanwhile, several companies acknowledge the trend for multimarker diagnostics, and have developed custom expression arrays and multiplex PCR solutions suited for clinical application. Improvements in microfluidics lead to reduced sample volume requirements, smaller machines and laboratory set-ups and will soon culminate in lab-on-chip solutions.
Advances in analysis methods require standardization of data normalization and optimal modeling [86]. An increasingly important strategy of in silico modeling is the systems biology approach [87]. It combines data at various biological levels (e.g., genomic, epigenomic, transcriptomic, and proteomic) to identify targets of interest (Fig. 2). In addition, it sheds light on the relation of the target biomarker to other markers, paving the way for in silico pathway analysis and enabling the identification of pathological pathways [88].
Fig. 2.
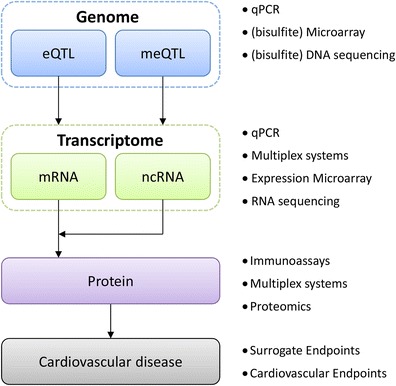
Transcriptomics for biomarker discovery. Simplified schematic of relevant transcriptome interactions for current biomarker development. Large studies are required to elucidate the complex interactions of the genome and epigenome with the transcriptome and subsequently the proteome. Bullets denote contemporary techniques. eQTL, expression quantitative trait loci; meQTL, methylation quantitative trait loci; mRNA, messenger RNA; ncRNA, non-coding RNA
As new biomarkers emerge on the horizon, improved risk prediction will have to be translated into increased health benefits from therapeutic intervention. This is especially interesting for causal biomarkers, which can themselves act as a target for novel drug development. Furthermore, companion diagnostics indicating individual drug efficacy, will likely take a more prominent role, as we progress toward personalized medicine.
Conclusion
Over the last years, gene expression analyses strongly influenced the area of biomarker identification and development in the cardiovascular field. Several potential biomarkers have been identified including gene expression signatures and non-coding RNAs, and a few have been translated into clinical utility. However, several aspects in the “transcriptomics pipeline” of biomarker development deserve consideration, ranging from appropriate study design and material to analytical methods, standardizations, most importantly, and validation. Finally, to reach clinical application of the biomarker, fundamental questions about the clinical potential need to be evaluated as outlined by Morrow and deLemos [89]: i) can the clinician measure the biomarker?, ii) does the biomarker add new information?, and iii) does the biomarker help the clinician to manage patients?.
Acknowledgments
Tanja Zeller acknowledges funding by the European Union (BiomarCaRE, grant number: HEALTH-2011-278913) and the Deutsche Stiftung für Herzforschung. Marten Antoon Siemelink acknowledges funding by the European Union (BiomarCaRE, grant number: HEALTH-2011-278913).
Compliance with Ethics Guidelines
ᅟ
Conflict of Interest
Marten Antoon Siemelink and Tanja Zeller declare that they have no conflict of interest.
Human and Animal Rights and Informed Consent
This article does not contain any studies with human or animal subjects performed by any of the authors.
Footnotes
This article is part of the Topical Collection on Cardiovascular Genomics
Contributor Information
Marten Antoon Siemelink, Email: M.A.Siemelink@umcutrecht.nl.
Tanja Zeller, Email: t.zeller@uke.de.
References
Papers of particular interest, published recently, have been highlighted as: • Of importance •• Of major importance
- 1.Shanthi Mendis PP, Bo Norrving. World Health Organization, World Heart Federation, World Stroke Organization. Global atlas on cardiovascular disease prevention and control: policies, strategies, and interventions.2011. 164 p.
- 2.Perk J, De Backer G, Gohlke H, Graham I, Reiner Z, Verschuren WM, et al. [European Guidelines on Cardiovascular Disease Prevention in Clinical Practice (version 2012). The Fifth Joint Task Force of the European Society of Cardiology and other societies on cardiovascular disease prevention in clinical practice (constituted by representatives of nine societies and by invited experts)]. Giornale italiano di cardiologia. 2013 May;14(5):328-92. Linee guida europee sulla prevenzione delle malattie cardiovascolari nella pratica clinica (versione 2012). Quinta Task Force congiunta della Societa Europea di cardiologia e di altre societa sulla prevenzione delle malattie cardiovascolari nella pratica clinica (costituita da rappresentanti di nove societa e da esperti invitati). [DOI] [PubMed]
- 3.Goff DC, Jr., Lloyd-Jones DM, Bennett G, Coady S, D'Agostino RB, Sr., Gibbons R, et al. 2013 ACC/AHA Guideline on the Assessment of Cardiovascular Risk: A Report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. Circulation. 2013 Nov 12.
- 4.Zeller T, Blankenberg S. Blood-based gene expression tests: promises and limitations. Circ Cardiovasc Genet. 2013;6(2):139–40. doi: 10.1161/CIRCGENETICS.113.000149. [DOI] [PubMed] [Google Scholar]
- 5.Crick FH. On protein synthesis. Symp Soc Exp Biol. 1958;12:138–63. [PubMed] [Google Scholar]
- 6.Mattick JS. The genetic signatures of noncoding RNAs. PLoS Genet. 2009;5(4):e1000459. doi: 10.1371/journal.pgen.1000459. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Eddy SR. Non-coding RNA, genes and the modern RNA world. Nat Rev Genet. 2001;2(12):919–29. doi: 10.1038/35103511. [DOI] [PubMed] [Google Scholar]
- 8.Mercer TR, Dinger ME, Mattick JS. Long non-coding RNAs: insights into functions. Nat Rev Genet. 2009;10(3):155–9. doi: 10.1038/nrg2521. [DOI] [PubMed] [Google Scholar]
- 9.Fichtlscherer S, Zeiher AM, Dimmeler S. Circulating microRNAs: biomarkers or mediators of cardiovascular diseases? Arterioscler, Thromb, Vasc Biol. 2011;31(11):2383–90. doi: 10.1161/ATVBAHA.111.226696. [DOI] [PubMed] [Google Scholar]
- 10.Bartel DP. MicroRNAs: genomics, biogenesis, mechanism, and function. Cell. 2004;116(2):281–97. doi: 10.1016/S0092-8674(04)00045-5. [DOI] [PubMed] [Google Scholar]
- 11.Small EM, Olson EN. Pervasive roles of microRNAs in cardiovascular biology. Nature. 2011;469(7330):336–42. doi: 10.1038/nature09783. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Mitchell PS, Parkin RK, Kroh EM, Fritz BR, Wyman SK, Pogosova-Agadjanyan EL, et al. Circulating microRNAs as stable blood-based markers for cancer detection. Proc Natl Acad Sci U S A. 2008;105(30):10513–8. doi: 10.1073/pnas.0804549105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Kinet V, Halkein J, Dirkx E, Windt LJ. Cardiovascular extracellular microRNAs: emerging diagnostic markers and mechanisms of cell-to-cell RNA communication. Front Genet. 2013;4:214. doi: 10.3389/fgene.2013.00214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Saikumar J, Ramachandran K, Vaidya VS. Noninvasive Micromarkers. Clinical chemistry. 2014 Jan 9. PubMed PMID: 24407912. [DOI] [PMC free article] [PubMed]
- 15.Ponting CP, Oliver PL, Reik W. Evolution and functions of long noncoding RNAs. Cell. 2009;136(4):629–41. doi: 10.1016/j.cell.2009.02.006. [DOI] [PubMed] [Google Scholar]
- 16.Hauptman N, Glavac D. MicroRNAs and long non-coding RNAs: prospects in diagnostics and therapy of cancer. Radiol Oncol. 2013;47(4):311–8. doi: 10.2478/raon-2013-0062. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Churko JM, Mantalas GL, Snyder MP, Wu JC. Overview of high throughput sequencing technologies to elucidate molecular pathways in cardiovascular diseases. Circ Res. 2013;112(12):1613–23. doi: 10.1161/CIRCRESAHA.113.300939. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Wang Z, Gerstein M, Snyder M. RNA-Seq: a revolutionary tool for transcriptomics. Nat Rev Genet. 2009;10(1):57–63. doi: 10.1038/nrg2484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Marguerat S, Bahler J. RNA-seq: from technology to biology. Cell Mol Life Sci: CMLS. 2010;67(4):569–79. doi: 10.1007/s00018-009-0180-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Devonshire AS, Sanders R, Wilkes TM, Taylor MS, Foy CA, Huggett JF. Application of next generation qPCR and sequencing platforms to mRNA biomarker analysis. Methods. 2013;59(1):89–100. doi: 10.1016/j.ymeth.2012.07.021. [DOI] [PubMed] [Google Scholar]
- 21.Grant SF, Hakonarson H. Microarray technology and applications in the arena of genome-wide association. Clin Chem. 2008;54(7):1116–24. doi: 10.1373/clinchem.2008.105395. [DOI] [PubMed] [Google Scholar]
- 22.Weinberg EO, Shimpo M, De Keulenaer GW, MacGillivray C, Tominaga S, Solomon SD, et al. Expression and regulation of ST2, an interleukin-1 receptor family member, in cardiomyocytes and myocardial infarction. Circulation. 2002;106(23):2961–6. doi: 10.1161/01.CIR.0000038705.69871.D9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Weinberg EO. ST2 protein in heart disease: from discovery to mechanisms and prognostic value. Biomark Med. 2009;3(5):495–511. doi: 10.2217/bmm.09.56. [DOI] [PubMed] [Google Scholar]
- 24.Ciccone MM, Cortese F, Gesualdo M, Riccardi R, Di Nunzio D, Moncelli M, et al. A Novel Cardiac Bio-Marker: ST2: A Review. Molecules. 2013;18(12):15314–28. doi: 10.3390/molecules181215314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Weinberg EO, Shimpo M, Hurwitz S, Tominaga S, Rouleau JL, Lee RT. Identification of serum soluble ST2 receptor as a novel heart failure biomarker. Circulation. 2003;107(5):721–6. doi: 10.1161/01.CIR.0000047274.66749.FE. [DOI] [PubMed] [Google Scholar]
- 26.Manzano-Fernandez S, Mueller T, Pascual-Figal D, Truong QA, Januzzi JL. Usefulness of soluble concentrations of interleukin family member ST2 as predictor of mortality in patients with acutely decompensated heart failure relative to left ventricular ejection fraction. Am J Cardiol. 2011;107(2):259–67. doi: 10.1016/j.amjcard.2010.09.011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Coglianese EE, Larson MG, Vasan RS, Ho JE, Ghorbani A, McCabe EL, et al. Distribution and clinical correlates of the interleukin receptor family member soluble ST2 in the Framingham Heart Study. Clin Chem. 2012;58(12):1673–81. doi: 10.1373/clinchem.2012.192153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Wang TJ, Wollert KC, Larson MG, Coglianese E, McCabe EL, Cheng S, et al. Prognostic utility of novel biomarkers of cardiovascular stress: the Framingham Heart Study. Circulation. 2012;126(13):1596–604. doi: 10.1161/CIRCULATIONAHA.112.129437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Ho JE, Chen WY, Chen MH, Larson MG, McCabe EL, Cheng S, et al. Common genetic variation at the IL1RL1 locus regulates IL-33/ST2 signaling. J Clin Inv. 2013;123(10):4208–18. doi: 10.1172/JCI67119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Kempf T, Eden M, Strelau J, Naguib M, Willenbockel C, Tongers J, et al. The transforming growth factor-beta superfamily member growth-differentiation factor-15 protects the heart from ischemia/reperfusion injury. Circ Res. 2006;98(3):351–60. doi: 10.1161/01.RES.0000202805.73038.48. [DOI] [PubMed] [Google Scholar]
- 31.Wollert KC. Growth-differentiation factor-15 in cardiovascular disease: from bench to bedside, and back. Basic Res Cardiol. 2007;102(5):412–5. doi: 10.1007/s00395-007-0662-3. [DOI] [PubMed] [Google Scholar]
- 32.Lindahl B. The story of growth differentiation factor 15: another piece of the puzzle. Clin Chem. 2013;59(11):1550–2. doi: 10.1373/clinchem.2013.212811. [DOI] [PubMed] [Google Scholar]
- 33.Lind L, Wallentin L, Kempf T, Tapken H, Quint A, Lindahl B, et al. Growth-differentiation factor-15 is an independent marker of cardiovascular dysfunction and disease in the elderly: results from the Prospective Investigation of the Vasculature in Uppsala Seniors (PIVUS) Study. Eur Heart J. 2009;30(19):2346–53. doi: 10.1093/eurheartj/ehp261. [DOI] [PubMed] [Google Scholar]
- 34.Rohatgi A, Patel P, Das SR, Ayers CR, Khera A, Martinez-Rumayor A, et al. Association of growth differentiation factor-15 with coronary atherosclerosis and mortality in a young, multiethnic population: observations from the Dallas Heart Study. Clin Chem. 2012;58(1):172–82. doi: 10.1373/clinchem.2011.171926. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Widera C, Giannitsis E, Kempf T, Korf-Klingebiel M, Fiedler B, Sharma S, et al. Identification of follistatin-like 1 by expression cloning as an activator of the growth differentiation factor 15 gene and a prognostic biomarker in acute coronary syndrome. Clin Chem. 2012;58(8):1233–41. doi: 10.1373/clinchem.2012.182816. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.El-Armouche A, Ouchi N, Tanaka K, Doros G, Wittkopper K, Schulze T, et al. Follistatin-like 1 in chronic systolic heart failure: a marker of left ventricular remodeling. Circ Heart Fail. 2011;4(5):621–7. doi: 10.1161/CIRCHEARTFAILURE.110.960625. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Ogura Y, Ouchi N, Ohashi K, Shibata R, Kataoka Y, Kambara T, et al. Therapeutic impact of follistatin-like 1 on myocardial ischemic injury in preclinical models. Circulation. 2012;126(14):1728–38. doi: 10.1161/CIRCULATIONAHA.112.115089. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Kittleson MM, Ye SQ, Irizarry RA, Minhas KM, Edness G, Conte JV, et al. Identification of a gene expression profile that differentiates between ischemic and nonischemic cardiomyopathy. Circulation. 2004;110(22):3444–51. doi: 10.1161/01.CIR.0000148178.19465.11. [DOI] [PubMed] [Google Scholar]
- 39.Kittleson MM, Minhas KM, Irizarry RA, Ye SQ, Edness G, Breton E, et al. Gene expression analysis of ischemic and nonischemic cardiomyopathy: shared and distinct genes in the development of heart failure. Physiol Genomics. 2005;21(3):299–307. doi: 10.1152/physiolgenomics.00255.2004. [DOI] [PubMed] [Google Scholar]
- 40.Horwitz PA, Tsai EJ, Putt ME, Gilmore JM, Lepore JJ, Parmacek MS, et al. Detection of cardiac allograft rejection and response to immunosuppressive therapy with peripheral blood gene expression. Circulation. 2004;110(25):3815–21. doi: 10.1161/01.CIR.0000150539.72783.BF. [DOI] [PubMed] [Google Scholar]
- 41.Deng MC, Eisen HJ, Mehra MR, Billingham M, Marboe CC, Berry G, et al. Noninvasive discrimination of rejection in cardiac allograft recipients using gene expression profiling. Am J Transplant: Off J Am Soc Transplant Am Soc Transplant Surg. 2006;6(1):150–60. doi: 10.1111/j.1600-6143.2005.01175.x. [DOI] [PubMed] [Google Scholar]
- 42.Pedrotty DM, Morley MP, Cappola TP. Transcriptomic biomarkers of cardiovascular disease. Prog Cardiovasc Dis. 2012;55(1):64–9. doi: 10.1016/j.pcad.2012.06.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Elashoff MR, Wingrove JA, Beineke P, Daniels SE, Tingley WG, Rosenberg S, et al. Development of a blood-based gene expression algorithm for assessment of obstructive coronary artery disease in non-diabetic patients. BMC Med Genet. 2011;4:26. doi: 10.1186/1755-8794-4-26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Rosenberg S, Elashoff MR, Beineke P, Daniels SE, Wingrove JA, Tingley WG, et al. Multicenter validation of the diagnostic accuracy of a blood-based gene expression test for assessing obstructive coronary artery disease in nondiabetic patients. Ann Intern Med. 2010;153(7):425–34. doi: 10.7326/0003-4819-153-7-201010050-00005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Elashoff MR, Nuttall R, Beineke P, Doctolero MH, Dickson M, Johnson AM, et al. Identification of factors contributing to variability in a blood-based gene expression test. PLoS One. 2012;7(7):e40068. doi: 10.1371/journal.pone.0040068. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Thomas GS, Voros S, McPherson JA, Lansky AJ, Winn ME, Bateman TM, et al. A blood-based gene expression test for obstructive coronary artery disease tested in symptomatic nondiabetic patients referred for myocardial perfusion imaging the COMPASS study. Circ Cardiovasc Genet. 2013;6(2):154–62. doi: 10.1161/CIRCGENETICS.112.964015. [DOI] [PubMed] [Google Scholar]
- 47.Tijsen AJ, Pinto YM, Creemers EE. Circulating microRNAs as diagnostic biomarkers for cardiovascular diseases. Am J Physiol Heart Circ Physiol. 2012;303(9):H1085–95. doi: 10.1152/ajpheart.00191.2012. [DOI] [PubMed] [Google Scholar]
- 48.Deddens JC, Colijn JM, Oerlemans MI, Pasterkamp G, Chamuleau SA, Doevendans PA, et al. Circulating microRNAs as novel biomarkers for the early diagnosis of acute coronary syndrome. J Cardiovasc Transl Res. 2013;6(6):884–98. doi: 10.1007/s12265-013-9493-9. [DOI] [PubMed] [Google Scholar]
- 49.Kuwabara Y, Ono K, Horie T, Nishi H, Nagao K, Kinoshita M, et al. Increased microRNA-1 and microRNA-133a levels in serum of patients with cardiovascular disease indicate myocardial damage. Circ Cardiovasc Genet. 2011;4(4):446–54. doi: 10.1161/CIRCGENETICS.110.958975. [DOI] [PubMed] [Google Scholar]
- 50.Oerlemans MI, Mosterd A, Dekker MS, de Vrey EA, van Mil A, Pasterkamp G, et al. Early assessment of acute coronary syndromes in the emergency department: the potential diagnostic value of circulating microRNAs. EMBO Mol Med. 2012;4(11):1176–85. doi: 10.1002/emmm.201201749. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.D’Alessandra Y, Pompilio G, Capogrossi MC. MicroRNAs and myocardial infarction. Curr Opin Cardiol. 2012;27(3):228–35. doi: 10.1097/HCO.0b013e3283522052. [DOI] [PubMed] [Google Scholar]
- 52.Tijsen AJ, Creemers EE, Moerland PD, de Windt LJ, van der Wal AC, Kok WE, et al. MiR423-5p as a circulating biomarker for heart failure. Circ Res. 2010;106(6):1035–9. doi: 10.1161/CIRCRESAHA.110.218297. [DOI] [PubMed] [Google Scholar]
- 53.Zampetaki A, Willeit P, Tilling L, Drozdov I, Prokopi M, Renard JM, et al. Prospective study on circulating MicroRNAs and risk of myocardial infarction. J Am Coll Cardiol. 2012;60(4):290–9. doi: 10.1016/j.jacc.2012.03.056. [DOI] [PubMed] [Google Scholar]
- 54.Mayr M, Zampetaki A, Willeit P, Willeit J, Kiechl S. MicroRNAs within the continuum of postgenomics biomarker discovery. Arterioscler, Thromb, Vasc Biol. 2013;33(2):206–14. doi: 10.1161/ATVBAHA.112.300141. [DOI] [PubMed] [Google Scholar]
- 55.De Guire V, Robitaille R, Tetreault N, Guerin R, Menard C, Bambace N, et al. Circulating miRNAs as sensitive and specific biomarkers for the diagnosis and monitoring of human diseases: promises and challenges. Clin Biochem. 2013;46(10–11):846–60. doi: 10.1016/j.clinbiochem.2013.03.015. [DOI] [PubMed] [Google Scholar]
- 56.•.Meder B, Keller A, Vogel B, Haas J, Sedaghat-Hamedani F, Kayvanpour E, et al. MicroRNA signatures in total peripheral blood as novel biomarkers for acute myocardial infarction. Basic Res Cardiol. 2011;106(1):13–23. doi: 10.1007/s00395-010-0123-2. [DOI] [PubMed] [Google Scholar]
- 57.Vogel B, Keller A, Frese KS, Kloos W, Kayvanpour E, Sedaghat-Hamedani F, et al. Refining diagnostic microRNA signatures by whole-miRNome kinetic analysis in acute myocardial infarction. Clin Chem. 2013;59(2):410–8. doi: 10.1373/clinchem.2011.181370. [DOI] [PubMed] [Google Scholar]
- 58.Scheuermann JC, Boyer LA. Getting to the heart of the matter: long non-coding RNAs in cardiac development and disease. EMBO J. 2013;32(13):1805–16. doi: 10.1038/emboj.2013.134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Batista PJ, Chang HY. Long noncoding RNAs: cellular address codes in development and disease. Cell. 2013;152(6):1298–307. doi: 10.1016/j.cell.2013.02.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Sorensen KP, Thomassen M, Tan Q, Bak M, Cold S, Burton M, et al. Long non-coding RNA HOTAIR is an independent prognostic marker of metastasis in estrogen receptor-positive primary breast cancer. Breast Cancer Res Treat. 2013;142(3):529–36. doi: 10.1007/s10549-013-2776-7. [DOI] [PubMed] [Google Scholar]
- 61.He X, Bao W, Li X, Chen Z, Che Q, Wang H, et al. The long non-coding RNA HOTAIR is upregulated in endometrial carcinoma and correlates with poor prognosis. Int J Mol Med. 2014;33(2):325–32. doi: 10.3892/ijmm.2013.1570. [DOI] [PubMed] [Google Scholar]
- 62.••.Weber DG, Johnen G, Casjens S, Bryk O, Pesch B, Jockel KH, et al. Evaluation of long noncoding RNA MALAT1 as a candidate blood-based biomarker for the diagnosis of non-small cell lung cancer. BMC Res Notes. 2013;6:518. doi: 10.1186/1756-0500-6-518. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Poste G. Bring on the biomarkers. Nature. 2011;469(7329):156–7. doi: 10.1038/469156a. [DOI] [PubMed] [Google Scholar]
- 64.Drucker E, Krapfenbauer K. Pitfalls and limitations in translation from biomarker discovery to clinical utility in predictive and personalised medicine. EPMA J. 2013;4(1):7. doi: 10.1186/1878-5085-4-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Tang WH. Contemporary challenges in translating biomarker evidence into clinical practice. J Am Coll Cardiol. 2010;55(19):2077–9. doi: 10.1016/j.jacc.2010.03.008. [DOI] [PubMed] [Google Scholar]
- 66.Perlis RH. Translating biomarkers to clinical practice. Mol Psychiatry. 2011;16(11):1076–87. doi: 10.1038/mp.2011.63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Zampetaki A, Mayr M. Analytical challenges and technical limitations in assessing circulating miRNAs. Thromb Haemostasis. 2012;108(4):592–8. doi: 10.1160/TH12-02-0097. [DOI] [PubMed] [Google Scholar]
- 68.Zeller T, Wild P, Szymczak S, Rotival M, Schillert A, Castagne R, et al. Genetics and beyond–the transcriptome of human monocytes and disease susceptibility. PLoS One. 2010;5(5):e10693. doi: 10.1371/journal.pone.0010693. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Filiou MD, Turck CW. General overview: biomarkers in neuroscience research. Int Rev Neurobiol. 2011;101:1–17. doi: 10.1016/B978-0-12-387718-5.00001-8. [DOI] [PubMed] [Google Scholar]
- 70.McHale CM, Zhang L, Thomas R, Smith MT. Analysis of the transcriptome in molecular epidemiology studies. Environ Mol Mutagen. 2013;54(7):500–17. doi: 10.1002/em.21798. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Kohro T, Tanaka T, Murakami T, Wada Y, Aburatani H, Hamakubo T, et al. A comparison of differences in the gene expression profiles of phorbol 12-myristate 13-acetate differentiated THP-1 cells and human monocyte-derived macrophage. J Atheroscler Thromb. 2004;11(2):88–97. doi: 10.5551/jat.11.88. [DOI] [PubMed] [Google Scholar]
- 72.••.Seok J, Warren HS, Cuenca AG, Mindrinos MN, Baker HV, Xu W, et al. Genomic responses in mouse models poorly mimic human inflammatory diseases. Proc Natl Acad Sci U S A. 2013;110(9):3507–12. doi: 10.1073/pnas.1222878110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Schurmann C, Heim K, Schillert A, Blankenberg S, Carstensen M, Dorr M, et al. Analyzing illumina gene expression microarray data from different tissues: methodological aspects of data analysis in the metaxpress consortium. PLoS One. 2012;7(12):e50938. doi: 10.1371/journal.pone.0050938. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Leek JT, Scharpf RB, Bravo HC, Simcha D, Langmead B, Johnson WE, et al. Tackling the widespread and critical impact of batch effects in high-throughput data. Nat Rev Genet. 2010;11(10):733–9. doi: 10.1038/nrg2825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.••.Boeckel JN, Thome CE, Leistner D, Zeiher AM, Fichtlscherer S, Dimmeler S. Heparin selectively affects the quantification of microRNAs in human blood samples. Clin Chem. 2013;59(7):1125–7. doi: 10.1373/clinchem.2012.199505. [DOI] [PubMed] [Google Scholar]
- 76.Becker N, Lockwood CM. Pre-analytical variables in miRNA analysis. Clin Biochem. 2013;46(10–11):861–8. doi: 10.1016/j.clinbiochem.2013.02.015. [DOI] [PubMed] [Google Scholar]
- 77.Zacho J, Tybjaerg-Hansen A, Jensen JS, Grande P, Sillesen H, Nordestgaard BG. Genetically elevated C-reactive protein and ischemic vascular disease. N Engl J Med. 2008;359(18):1897–908. doi: 10.1056/NEJMoa0707402. [DOI] [PubMed] [Google Scholar]
- 78.Voight BF, Peloso GM, Orho-Melander M, Frikke-Schmidt R, Barbalic M, Jensen MK, et al. Plasma HDL cholesterol and risk of myocardial infarction: a mendelian randomisation study. Lancet. 2012;380(9841):572–80. doi: 10.1016/S0140-6736(12)60312-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79.Nicolae DL, Gamazon E, Zhang W, Duan S, Dolan ME, Cox NJ. Trait-associated SNPs are more likely to be eQTLs: annotation to enhance discovery from GWAS. PLoS Genet. 2010;6(4):e1000888. doi: 10.1371/journal.pgen.1000888. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80.Zhang X, Johnson AD, Hendricks AE, Hwang SJ, Tanriverdi K, Ganesh SK, et al. Genetic associations with expression for genes implicated in GWAS studies for atherosclerotic cardiovascular disease and blood phenotypes. Hum Mol Genet. 2014;23(3):782–95. doi: 10.1093/hmg/ddt461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Teslovich TM, Musunuru K, Smith AV, Edmondson AC, Stylianou IM, Koseki M, et al. Biological, clinical and population relevance of 95 loci for blood lipids. Nature. 2010;466(7307):707–13. doi: 10.1038/nature09270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Global Lipids Genetics C. Willer CJ, Schmidt EM, Sengupta S, Peloso GM, Gustafsson S, et al. Discovery and refinement of loci associated with lipid levels. Nat Genet. 2013;45(11):1274–83. doi: 10.1038/ng.2797. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Grundberg E, Meduri E, Sandling JK, Hedman AK, Keildson S, Buil A, et al. Global analysis of DNA methylation variation in adipose tissue from twins reveals links to disease-associated variants in distal regulatory elements. Am J Hum Genet. 2013;93(5):876–90. doi: 10.1016/j.ajhg.2013.10.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.•.Gamazon ER, Ziliak D, Im HK, LaCroix B, Park DS, Cox NJ, et al. Genetic architecture of microRNA expression: implications for the transcriptome and complex traits. Am J Hum Genet. 2012;90(6):1046–63. doi: 10.1016/j.ajhg.2012.04.023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.Kumar V, Westra HJ, Karjalainen J, Zhernakova DV, Esko T, Hrdlickova B, et al. Human disease-associated genetic variation impacts large intergenic non-coding RNA expression. PLoS Genet. 2013;9(1):e1003201. doi: 10.1371/journal.pgen.1003201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Shi L, Campbell G, Jones WD, Campagne F, Wen Z, Walker SJ, et al. The MicroArray Quality Control (MAQC)-II study of common practices for the development and validation of microarray-based predictive models. Nat Biotechnol. 2010;28(8):827–38. doi: 10.1038/nbt.1665. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87.Shalhoub J, Sikkel MB, Davies KJ, Vorkas PA, Want EJ, Davies AH. Systems biology of human atherosclerosis. Vasc Endovasc Surg. 2014;48(1):5–17. doi: 10.1177/1538574413510628. [DOI] [PubMed] [Google Scholar]
- 88.Diez D, Wheelock AM, Goto S, Haeggstrom JZ, Paulsson-Berne G, Hansson GK, et al. The use of network analyses for elucidating mechanisms in cardiovascular disease. Mol BioSyst. 2010;6(2):289–304. doi: 10.1039/b912078e. [DOI] [PubMed] [Google Scholar]
- 89.Morrow DA, de Lemos JA. Benchmarks for the assessment of novel cardiovascular biomarkers. Circulation. 2007;115(8):949–52. doi: 10.1161/CIRCULATIONAHA.106.683110. [DOI] [PubMed] [Google Scholar]
- 90.Creemers EE, Tijsen AJ, Pinto YM. Circulating microRNAs: novel biomarkers and extracellular communicators in cardiovascular disease? Circ Res. 2012;110(3):483–95. doi: 10.1161/CIRCRESAHA.111.247452. [DOI] [PubMed] [Google Scholar]
- 91.D‘Alessandra Y, Devanna P, Limana F, Straino S, Di Carlo A, Brambilla PG, et al. Circulating microRNAs are new and sensitive biomarkers of myocardial infarction. Eur Heart J. 2010;31(22):2765–73. doi: 10.1093/eurheartj/ehq167. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Corsten MF, Dennert R, Jochems S, Kuznetsova T, Devaux Y, Hofstra L, et al. Circulating MicroRNA-208b and MicroRNA-499 reflect myocardial damage in cardiovascular disease. Circ Cardiovasc Genet. 2010;3(6):499–506. doi: 10.1161/CIRCGENETICS.110.957415. [DOI] [PubMed] [Google Scholar]
- 93.Gidlof O, Andersson P, van der Pals J, Gotberg M, Erlinge D. Cardiospecific microRNA plasma levels correlate with troponin and cardiac function in patients with ST elevation myocardial infarction, are selectively dependent on renal elimination, and can be detected in urine samples. Cardiology. 2011;118(4):217–26. doi: 10.1159/000328869. [DOI] [PubMed] [Google Scholar]
- 94.Cheng Y, Zhang C. MicroRNA-21 in cardiovascular disease. J Cardiovasc Transl Res. 2010;3(3):251–5. doi: 10.1007/s12265-010-9169-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Zile MR, Mehurg SM, Arroyo JE, Stroud RE, DeSantis SM, Spinale FG. Relationship between the temporal profile of plasma microRNA and left ventricular remodeling in patients after myocardial infarction. Circ Cardiovasc Genet. 2011;4(6):614–9. doi: 10.1161/CIRCGENETICS.111.959841. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96.Widera C, Gupta SK, Lorenzen JM, Bang C, Bauersachs J, Bethmann K, et al. Diagnostic and prognostic impact of six circulating microRNAs in acute coronary syndrome. Journal of molecular and cellular cardiology. 2011;51(5):872–5. doi: 10.1016/j.yjmcc.2011.07.011. [DOI] [PubMed] [Google Scholar]
- 97.De Rosa S, Fichtlscherer S, Lehmann R, Assmus B, Dimmeler S, Zeiher AM. Transcoronary concentration gradients of circulating microRNAs. Circulation. 2011;124(18):1936–44. doi: 10.1161/CIRCULATIONAHA.111.037572. [DOI] [PubMed] [Google Scholar]
- 98.Vogel B, Keller A, Frese KS, Leidinger P, Sedaghat-Hamedani F, Kayvanpour E, et al. Multivariate miRNA signatures as biomarkers for non-ischaemic systolic heart failure. Eur Heart J. 2013;34(36):2812–22. doi: 10.1093/eurheartj/eht256. [DOI] [PubMed] [Google Scholar]
- 99.Jaguszewski M, Osipova J, Ghadri JR, Napp LC, Widera C, Franke J, et al. A signature of circulating microRNAs differentiates takotsubo cardiomyopathy from acute myocardial infarction. European heart journal. doi: 10.1093/eurheartj/eht392 [DOI] [PMC free article] [PubMed]