

Abstract
To convey their ideas successfully, writers must envision how readers will interpret their texts. In our previous research (Traxler & Gernsbacher, 1992), we discovered that writers who received feedback from their readers successfully revised descriptions of geometric figures, whereas writers who did not receive feedback did not. We also discovered that writers who received feedback from their readers on one set of descriptions wrote better descriptions of a new set of geometric figures. We concluded that feedback—even a minimal form of feedback—helps writers learn to envision how readers will interpret their texts. In the present research, we investigated another way that writers can learn to envision how readers will interpret their texts. Our treatment placed writers “in their readers’ shoes”. In three experiments, half the writers performed a task that their readers would subsequently perform, and the other half of the writers performed a control task. In our first and second experiments, the writers who gained their readers’ perspective by performing their readers’ task successfully revised their descriptions of geometric figures, whereas writers who performed the control task did not. In our third experiment, we discovered that writers who performed their readers’ task did not improve their descriptions merely because they were exposed to examples of other writers’ descriptions. We concluded that gaining their readers’ perspective helps writers communicate more clearly because perspective-taking helps writers form a mental representation of how readers interpret their texts.
INTRODUCTION
Consider the following three scenarios. One: While grading an undergraduate’s term paper, we write comments at several places that boil down to the following, “This point isn’t clear”. The student arrives in our office frustrated; he claims he knew what he wanted to say. Two: A colleague asks us to comment on one of his recent manuscripts. Too embarrassed to admit to our colleague that we couldn’t grasp the meaning of his new theory, we tell him we were “unconvinced by his theoretical arguments”. Three: We receive reviews on a grant proposal. We become angered by a reviewer’s comment, “The motivation for Experiment 6 is unclear”. In all of these situations, all of us—our undergraduate student, our colleague who sought our feedback, ourselves—presumably knew what we wanted to say. Why was it so difficult to communicate those ideas in writing?
Recently, we suggested that successful written communication requires that writers build and compare three mental representations (Traxler & Gernsbacher, 1992). One representation is of the ideas the writers want to convey. Another representation is of the text as it is written. We joined Sommers (1980) in proposing that writers revise their texts when they perceive a mismatch between these two representations (i.e. a mismatch between what they wanted to convey and what they think their texts did convey).
However, we further proposed that building and comparing only these two representations is insufficient for writers to convey their ideas successfully. Writers must also build and compare a third mental representation: a representation of how their readers will interpret their text. Writers have difficulty building this third representation, because it requires them to take a naive perspective. If writers already know what they want to convey, they have already formed the interpretation that they want their readers to form. Forming it again—from their readers’ perspective—is difficult.
In our previous research (Traxler & Gernsbacher, 1992), we performed a laboratory manipulation that was intended to improve writers’ ability to envision how their readers had or would interpret their texts. We shall describe our previous experiments in some detail because the procedure we followed in those experiments parallels the procedure we followed in the present experiments.
IMPROVING WRITERS’ MENTAL REPRESENTATIONS THROUGH FEEDBACK
In our first experiment (Traxler & Gernsbacher, 1992), we asked one group of university students, whom we called writers, to write descriptions of several Tangram figures. The Tangram figures (similar to those used by Clark & Wilkes-Gibbs, 1986, and Schober & Clark, 1989) were solid black, geometric shapes, as shown in Fig. 1. Each writer wrote descriptions of one set of eight figures (set A or set B). After the writers wrote their descriptions, another group of university students, whom we called readers, read each description and tried to select each “target“ figure from among distractor figures. An example figure and distractors are shown in Fig. 2. Each reader read two sets of descriptions: one set was written by a writer who would subsequently receive feedback; the other set was written by a writer who would not receive feedback. Therefore, each reader contributed data to both the feedback and the no-feedback conditions.
FIG. 1.

Experimental stimuli: Eight target figures in sets A (left) and B (right).
FIG. 2.
Example target figure and its three distractors.
The next week, the writers and readers attended a second session. At the beginning of the second writing session, a random half of the writers received feedback on how well their readers had selected the figures (using those writers’ descriptions). The feedback was simply a number for each of the eight figures that represented how many readers (none, one or both) were able successfully to select that figure from its distractors. During the same time that the writers who received feedback were evaluating their feedback, the rest of the writers (who did not receive feedback) estimated how many of their readers had selected the correct figure. So, both groups of writers spent the same amount of time reviewing the figures and their previous descriptions. Then, both groups of writers revised their descriptions. Later that week, the same readers read the revised descriptions and again tried to select each target figure.
Following this second writing and reading session, the writers attended a third writing session. At the beginning of the third writing session, the writers who had previously received feedback again received feedback on how well their readers had selected the figures during the second reading session (using the revised descriptions). The other half of the writers did not receive feedback (but they again performed the estimation task). Then, both groups of writers again revised their descriptions. In a final reading session, the readers read these revised descriptions.
Our dependent measure was how many figures the readers correctly selected during each of the three reading sessions. Performance during the first reading session provided a baseline against which we could compare performance during the subsequent two sessions because, during the first sessions, none of the writers had received any feedback and none of the readers had seen any figures. To determine how much the writers’ descriptions improved over the course of the experiment, we computed an improvement score for each writer by subtracting readers’ percent correct from the first session from readers’ percent correct from the subsequent sessions.
We predicted that feedback would improve the writers’ ability to revise their descriptions because feedback should help writers envision how readers interpret their texts. If writers have difficulty envisioning how readers interpret their texts, and if feedback helps writers envision how readers interpret their texts, then writers who receive feedback from their readers should improve their texts.
As Fig. 3 illustrates, descriptions written by the writers who received feedback led to a reliable improvement in the readers’ identification performance from the baseline session to the second reading session. Descriptions written by the writers who did not receive feedback did not lead to a reliable improvement. The beneficial effects of feedback were even more pronounced at the third reading session. Thus, the results of this experiment demonstrated that feedback—even minimal feedback provided by a single number that represented the readers’ identification performance—improved the writers’ descriptions.
FIG. 3.
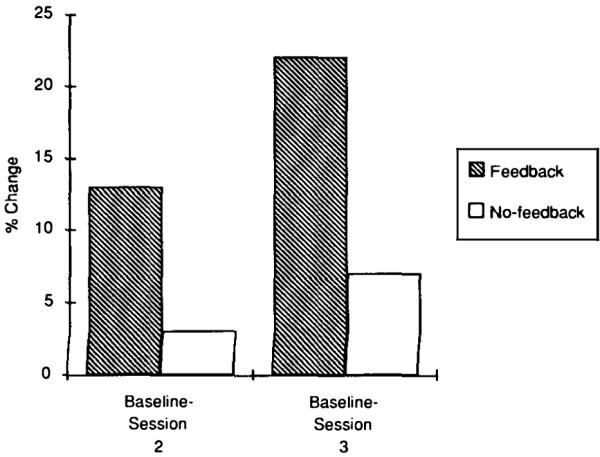
Subjects’ mean improvement in selection during Experiment 1 (from Traxler & Gernsbacher, 1992).
Our second experiment investigated whether feedback would improve adults’ written communication during a new writing task. If feedback gives writers a better sense of how their texts are interpreted, then this ablity to build a more accurate mental representation should transfer to descriptions of novel stimuli. In contrast, if feedback merely causes writers to detect specific problems in previously written descriptions, then we should not have observed any benefit of feedback when writers described novel stimuli.
The first two writing and reading sessions of our second experiment were identical to the first two writing and reading sessions of our first experiment. During the third writing session, however, all the writers were given a new set of figures to describe. If a writer had previously described the figures in set A, he or she described the figures in set B, and vice versa. Thus, the writers in the feedback condition had received feedback on their descriptions of only one set of figures; now they were describing a new set. We predicted that the writers who received feedback would write better descriptions of the new set of figures because feedback would have given them a better sense of how readers interpreted their previous descriptions.
Our results, shown in Fig. 4, supported our predictions. The two left-most bars in Fig. 4 show that descriptions revised by writers who received feedback led to a statistically reliable improvement in readers’ identification performance, whereas descriptions revised by writers who did not receive feedback did not lead to a reliable improvement. This result replicates our first experiment. The two right-most bars in Fig. 4 show that descriptions of the new stimuli that were written by the writers who had previously received feedback also led to an improvement in readers’ identification performance. Note, however, that these are new descriptions—descriptions that the writers had neither revised nor received feedback on. In contrast, consider the descriptions of the new stimuli written by the writers who had not received feedback; those descriptions led to a decrement in readers’ performance.
FIG. 4.
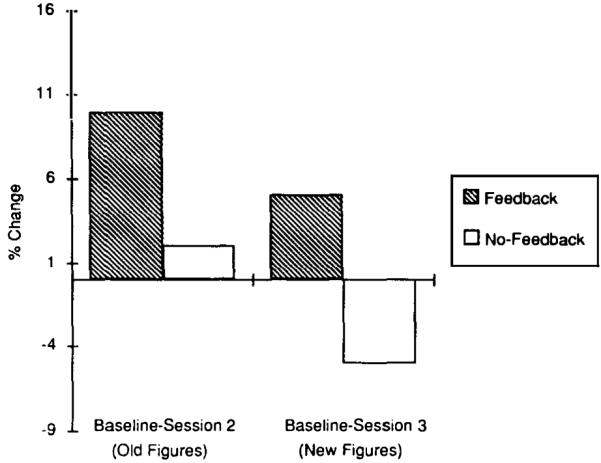
Subjects’ mean improvement in selection during Experiment 2 (from Traxler & Gernsbacher, 1992).
Thus, the results of both experiments demonstrated that feedback improves written communication. Furthermore, the results of our second experiment demonstrate that feedback—even minimal feedbackimproves subsequent written communication. We proposed that feedback helped writers develop a better sense of how readers interpreted their texts. In the experiments we report here, we performed another laboratory manipulation that we hypothesised would more directly help writers build a more accurate representation of how their readers interpret their texts; we (metaphorically speaking) put writers in their readers’ shoes.
IMPROVING WRITERS’ REPRESENTATIONS THROUGH PERSPECTIVE-TAKING
Since ancient times, philosophers of rhetoric (Aristotle, c. 330 B.C./1963; Plato, c. 386 B.C./1952) have argued that writers must adapt their texts to the particular needs and characteristics of their audiences to communicate effectively. Contemporary communication theorists continue to argue that writers must consider their audiences to communicate effectively (Berkenkotter, 1981; Booth, 1970; Ede, 1984; Gage, 1986; 1987; Hayes & Flower, 1986; Kroll, 1978; Pfister & Petrik, 1980; Sommers, 1980). In fact, the ability to consider one’s audience when forming an utterance marks a milestone in cognitive and linguistic development. Piaget (1956), Flavell, Botkin, Fry and Wright (1968), Glucksberg and Danks (1975) and others argue that children often communicate effectively because they suffer from cognitive egocentrism: They fail to recognise that other persons’ perspectives differ from their own. Instead, children “often act as if everyone can see and know everything that they see and know” (Glucksberg & Danks, 1975, p. 201).
Surely adult writers realise that others do not see or know everything that they see and know. Still, adults consistently fail to communicate effectively in writing (Bartlett, 1981; Bridwell, 1980; Hayes et al. , 1987; Stallard, 1974). Even professional writers, with years of experience, often produce texts that their intended audience cannot easily understand (Duffy, Curran & Sass, 1983; Swaney, Janik, Bond & Hayes, 1981). Even though these writers recognise that their audiences’ perspectives differ from their own, perhaps they still cannot accurately envision how their texts will affect their audiences. Indeed, if writers seek to communicate effectively, and if writers accurately envision how their texts affect their readers, then they should not write texts that their readers cannot understand.
If, as we have proposed, successful written communication requires that writers build accurate mental representations of how their readers will interpret their texts, and if writers’ inability to take their readers’ perspective decreases the likelihood that writers can build accurate mental representations of how readers will interpret their texts, then a treatment that forces writers to take their readers’ perspective should lead to more effective communication. Thus, we hypothesised that writers who performed an activity that provided them with their readers’ perspective would improve their texts when they revised them. We tested this hypothesis in the experiments we report here.
These experiments began as the two experiments we reported in Traxler and Gernsbacher (1992): During a first writing session one group of subjects (writers) described one set of geometric figures, and during a first reading session another group of subjects (readers) read descriptions and tried to select the figures that had been described by the writers from similar-looking distractors. However, the beginning of the second writing session differed from our previous experiments: At the beginning of the second writing session, half the writers performed the selection task; in other words, they performed a task that gave them their readers’ perspective. They performed the selection task on a set of figures that they had not seen before. While half the writers were performing the selection task, the other half of the writers performed a “control” task which familiarized them with the other set of figures and their distractors as much as the selection task did. The control task involved ranking each target figure and its three distractors along several dimensions (e.g. “Which figure has the largest area?” or “Which figure is more angular?”). Thus, all of the writers were exposed to one of two treatments: They were either placed in their readers’ shoes (i.e. they performed the selection task) or they performed a ranking task that familiarized them with the figures and the distractors but did not give them as thorough a sense of the task faced by their readers.
Then, both groups of writers revised their descriptions of the original set of figures (the figures they originally described, not the figures they selected or ranked). If gaining a better perspective of the readers’ task helps writers to convey their ideas more clearly, then the writers who performed the selection task should have improved their descriptions on revision. Likewise, the writers who did not take their readers’ perspective should have shown little or no improvement on revision.
EXPERIMENT 1
Methods
Subjects
Sixty-eight undergraduates from introductory psychology courses at the University of Oregon participated as one means of fulfilling a course requirement. Most of them were in their first or second year at the university. Thirty-four students were randomly assigned to be writers and 34 were randomly assigned to be readers.
Materials
The experimental materials comprised the two sets of eight target Tangram figures used previously by Traxler and Gernsbacher (1992). As illustrated in Fig. 1, no two target figures within a set were identical, and no target figure appeared in more than one set. Half the writers described set A and half described set B. Pilot data suggested that the target figures in the two sets were equivalently difficult to describe. Each target figure was mounted on a 4 × 6 inch card, and the eight target figures in each set were placed in a three-ring binder.
The experimental materials also included distractor figures. Three distractor figures were created for each target figure by making slight alterations to each target figure, as illustrated in Fig. 2. Pilot data suggested that across the two sets of target figures (A and B), the distractor figures were roughly equal in discriminability from their target figures. The target figures and their distractor figures were each mounted on a 4 × 6 inch card and placed in a three-ring binder. Within each binder, the figures were arranged so that each group of four figures contained a random arrangement of one target figure and its three distractors. The groups of four (a target figure and its three distractors) appeared in a different order than the order in which the writers viewed the target figures (and the order in which the writers’ descriptions were presented to the readers). Each binder also included two additional groups of four figures; in these two groups, all four figures were distractors. These two additional groups of four distractors prevented readers from using the process of elimination to determine which group of four contained the target figure described last. Thus, the binders used for the readers’ selection task contained 40 figures, arranged in ten groups of four; eight groups of four contained a target figure and its three distractors, and two groups of four contained only distractors.
Design
The experiment comprised two sessions separated by a 1-week interval. During the entire experiment, each writer was yoked with two readers; similarly, each reader was yoked with two writers. As a result, we measured two readers’ selection performance for each writer, and each reader read descriptions written by two different writers (one who performed the selection task and one who performed the ranking task). We assigned two readers to each writer to increase the reliability of our dependent measure.
Procedure: Writing Session 1
The writers read instructions telling them to “describe each of the eight geometric figures so thoroughly that another person reading your descriptions would be able to select each target figure from a group of very similar-looking distractor figures“. The writers were told that two other subjects would actually read the descriptions they wrote, and that these two “readers” would have the task of selecting the figures from distractors using only the writers’ descriptions. The writers were shown an example target figure and its three matching distractors (e.g. Fig. 2).
The writers received a binder containing the eight figures that they were to describe, a packet of eight blank 81 × 11 inch ruled pages, and their choice of pen or pencil. Although the eight figures and eight blank pages were numbered “Figure 1” through “Figure 8”, the writers were allowed to describe the figures in any order and return to previously written descriptions. The writers were not given a time limit or a minimum or maximum length requirement. They were told, however, that they were required to stay in the experiment room until everyone in the session had finished.
The writers’ handwritten descriptions were typed into a computer. The typists corrected only spelling errors; errors of grammar, punctuation, capitalisation and so forth were left uncorrected. Although all the writers were treated identically during writing session 1, we randomly assigned each writer to one of two treatment groups: those who would subsequently perform the selection task and those who would subsequently perform the ranking task.
Procedure: Reading Session 1
The readers read instructions telling them that their task was “to read descriptions of geometric figures and to select each geometric figure from a set of very similar looking distractors”. The readers were told that each target figure would be accompanied by three very similar-looking distractors, and that they should examine all the figures before making their selection.
Each reader read two sets of eight descriptions; each set was written by a different writer. Half the readers read descriptions written by a selectiontask writer first, and the other half read descriptions written by a rankingtask writer first. Furthermore, of the two sets of descriptions that each reader read, one described figures in set A and the other described figures in set B. Thus, no reader read more than one description of each figure. Half the readers read descriptions of set A figures first and half read descriptions of set B first.
The readers read typewritten copies of the first set of descriptions and selected the figures from a binder containing 40 figures. As described before, the 40 figures included eight groups that consisted of a target figure and three distractors, and two groups of four distractors. Each figure was labelled with a random number.
The readers read each description and searched through the binder for the figure that they judged fitted the description best. The readers were told that the figures were arranged in the binders in groups of four. They were also told that eight of the four-figure groups contained a target figure and three distractors and that two groups contained only distractors. Thus, the readers were faced with a two-tiered task. On a first pass, they needed to select a group of four figures, all of which could possibly fit the description. On a second (and more time-consuming) pass, they needed to select from the group of four the one figure that best fitted the description.
After reading and selecting figures for the first set of descriptions, the readers took a short break, after which they were given another three-ring binder containing the other set of 40 figures. The readers were also given the typed descriptions written by the second writer to whom they were assigned. Again, they read each description, selected a figure and recorded their response by writing down the number of the figure. The readers were told there was no time limit for selecting each figure, but that they would have 1 hour to read and select the figures for two sets of eight descriptions. They were also told that they were required to remain in the experiment room until everyone in the session had finished.
Procedure: Writing Session 2
At the beginning of writing session 2, half the writers performed the selection task and half performed the ranking task. Those who performed the selection task were treated the same way that the readers were treated during reading session 1. They were given a three-ring binder containing 40 geometric figures (8 targets and 32 distractors), a standard set of eight descriptions, and lined paper on which to record their selections. The figures were not the figures the writers had described in writing session 1; that is, those writers who themselves had described set A figures performed the selection task on set B figures, whereas those writers who themselves had described set B figures performed the selection task on set A figures. The standard set of descriptions was created from descriptions written by the subjects in a previous experiment. These selection-task writers were given the same instructions as the actual readers. The only difference between the writers performing the selection task and the readers performing the selection task was that the writers read 8 descriptions (rather than 16).
The writers who performed the ranking task were given a three-ring binder containing 40 geometric figures (which included the 8 target figures and 32 distractors from the set they had not described during writing session 1). They were also given a packet containing a list of questions about the geometric figures and space to write down their answers. The writers were asked to compare the members of each set of four figures and rank the four members (on a scale of 1–4) according to the questions in the packet. The writers who performed the ranking task evaluated each group of four figures, wrote their answers in the packet, and proceeded to the next set of four.
After all of the writers had performed the selection or ranking task at the beginning of writing session 2, they revised the descriptions that they had written during writing session 1. They were given the three-ring binder that contained the eight figures they had described during writing session 1. They were also given packets containing typed versions of the descriptions they had written during writing session 1. Then, all of the writers revised their descriptions. They were told to make changes by crossing out entire sentences in their old descriptions and rewriting the sentences. They were also told to add sentences to their descriptions by writing them on the paper below the original description and indicating where in the original description the additional sentences should be inserted.
The writers who performed the selection task were told:
Your experience in selecting figures should help you detect problems in your own texts. You have seen many examples of geometric figures and distractors, and you have read several descriptions written by someone else. This may have helped you get a better idea of what information is helpful to readers. You should make use of whatever knowledge or insight you picked up while trying to identify the geometric figures when you revise your descriptions.
The writers who performed the ranking task were told:
Your experience in comparing figures to one another may help you detect problems in your own texts. You have seen many examples of geometric figures. This may have helped you get a better idea of what information is helpful to readers. You should make use of whatever knowledge or insight you picked up while comparing the geometric figures when you revise your descriptions.
Procedure: Reading Session 2
The readers were told that they would again be reading descriptions of figures, and their task was again to select the described figures. They were told that the descriptions were written by the same writers who wrote the descriptions they read during reading session 1. The descriptions were presented in the same order as they were presented during reading session 1. The readers read and selected figures for the eight descriptions written by one writer; they took a short break and then they read and selected figures for the eight descriptions written by the other writer.
Results
If gaining a better perspective of the readers’ task helps writers to convey their ideas more clearly, then writers who performed the selection task should have improved their descriptions when they revised them. This improvement should be manifested in the readers’ selection performance. The writers who performed the ranking task should not have improved their descriptions. Our results, shown in the two left-most bars of Fig. 5, supported our prediciton.
FIG. 5.
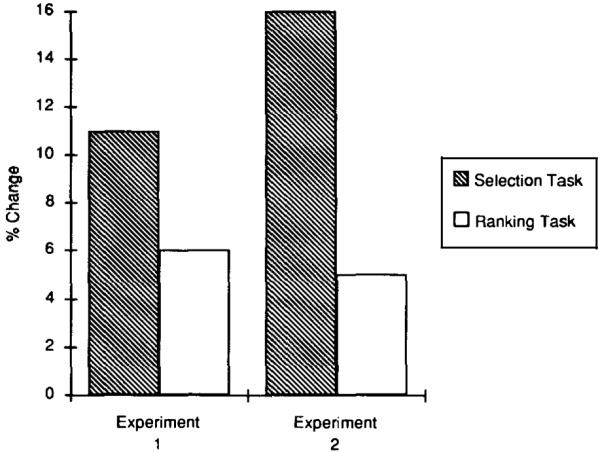
Subjects’ mean improvement in selection during Experiments 1 and 2.
The two left-most bars of Fig. 5 present the readers’ mean improvement scores. We computed each reader's improvement score by subtracting performance during reading session 2 from performance during reading session 1. (The data from which we computed the improvement scores are presented in Table 1.) The hatched bars in Fig. 5 represent the readers’ improvement when they selected figures using descriptions revised by writers who performed the selection task; the unfilled bars represent the readers’ improvement when they selected figures using descriptions revised by writers who performed the ranking task. Repeated-measures analyses of variance (ANOVAs) of these improvement scores documented that descriptions revised by writers who performed the selection task led to a reliable amount of improvement [F(1,33) = 10.99, P < 0. 001]. In contrast, the descriptions revised by writers who performed the ranking task did not lead to a reliable amount of improvement [F(1,33) = 2.75, P > 0.10].
TABLE 1.
Subjects′ Mean Percent Correct in Selection During Experiments 1, 2 and 3
| Experiment | Condition | Session 1 | Session 2 | Session 3 |
|---|---|---|---|---|
| 1a | Readers Rankers |
56 62 |
67 68 |
— — |
| 2a | Readers Rankers |
44 55 |
60 60 |
— — |
| 3 | Readers Raters |
61 62 |
67 65 |
72 63 |
These two experiments comprised only two sessions.
EXPERIMENT 2
The results of our first experiment demonstrated that writers improve their descriptions when they perform a task that puts them in their readers’ shoes. We have proposed that writers must build and compare three mental representations to communicate effectively: a representation of their ideas (what they want to convey), a representation of their texts (what they think they conveyed) and a representation of how their readers will interpret their texts (what their readers think the writers conveyed). We have also proposed that building this third mental representation is difficult because writers have already built the first two representations. We suggest that the perspective-taking treatment improved writers’ texts because it enabled them to build this third mental representation more accurately.
In our second experiment, we modified the perspective-taking treatment to give writers an even better idea of the difficulty their readers faced. In our first experiment, the writers who performed the readers’ (selection) task were not told how well they performed that selection task. We know from previous research (Traxler & Gernsbacher, 1992) that writers are overly optimistic when they predict how many target figures their readers will select correctly. Thus, we suspected that the writers who performed the selection task in Experiment 1 were overly optimistic about their success at that task (i.e. they believed the selection task was easier than it actually was).
Therefore, in Experiment 2, we gave the writers who performed the selection task feedback about how accurately they performed the selection task. We predicted that this feedback would further improve the writers’ ability to envision their readers’ task and, therefore, the writers who performed the selection task would further improve their descriptions when they revised them.
Methods
Subjects
Eighty undergraduates drawn from the same population as the subjects in Experiment 1 participated as one means of fulfilling a course requirement. Forty subjects were randomly assigned to be writers and 40 were randomly assigned to be readers. No subject who participated in Experiment 1 participated in Experiment 2.
Materials, Design and Procedure
Experiment 2 was identical to Experiment 1 except that after the writers performed the selection task, they were told the correct answers. Specifically, the writers notified the experimenter when they had finished making their selections. Then, the experimenter gave the writers a list of the correct answers and asked them to make a tick-mark next to their incorrect answers. In this way, the selection-task writers assessed their own performance on the selection task.
Results
If gaining a better perspective of the readers’ task helps writers more clearly convey their ideas, then the writers who performed the selection task should have improved their descriptions when they revised them. The writers who performed the ranking task should not have improved their descriptions when they revised them. Furthermore, giving writers feedback about their accuracy in the selection task should help them more fully gain their readers’ perspective. Our results, shown in the two right-most bars of Fig. 5, supported our prediction.
The two right-most bars of Fig. 5 present the readers’ mean improvement scores in Experiment 2. As in Experiment 1, we computed each improvement score by subtracting performance during reading session 2 from performance during reading session 1. (The data from which we computed these improvement scores are shown in Table 1.) The hatched bars in Fig. 5 represent the readers’ improvement when they selected figures using descriptions revised by the writers who performed the selection task; the unfilled bars represent the readers’ improvement when they selected figures using descriptions revised by the writers who performed the ranking task. The descriptions revised by the writers in Experiment 2 who performed the selection task led to a reliable amount of improvement [F(1,39) = 19.72, P < 0.0001]; in contrast, the descriptions revised by the writers who performed the ranking task did not lead to a reliable amount of improvement [F(1,39) = 2.12, P > 0. 15].
EXPERIMENT 3
Experiment 2 replicated Experiment 1. In both experiments, the writers who performed the selection task improved their descriptions, whereas those who performed the ranking task did not. However, in both experiments, the writers who performed the selection task read example descriptions, whereas the writers who performed the ranking task did not. Perhaps the writers who performed the selection task improved merely because they were exposed to a set of example descriptions.
We tested this alternative explanation in Experiment 3. In this experiment, both groups of writers were exposed to example descriptions. One group read the example descriptions and performed the selection task, and the other group read the example descriptions and rated them on a 10-point scale according to different qualities (e.g. “How much information did the description contain?”, “How clear was the description?”, “How graphic was the description?”, “How well were you able to form a mental picture of what the author was describing?”, “Overall, what was the quality of the description?”). The writers who performed the rating task were also asked to evaluate the example descriptions by answering the following question: “What could this writer do to improve the quality of his or her descriptions?” If the improvement we observed in Experiments 1 and 2 was due merely to the selection-task writers being exposed to a set of example descriptions, then the writers who performed the rating task in Experiment 3 should also have improved their descriptions.
Methods
Subjects
Forty-six undergraduates drawn from the same population as the subjects in Experiments 1 and 2 participated as one means of fulfilling a course requirement. Twenty-three of the subjects were randomly assigned to be writers and 23 were randomly assigned to be readers. No subject who participated in Experiments 1 or 2 participated in Experiment 3.
Design
Experiment 3 differed from Experiments 1 and 2 in two ways: The experiment comprised three sessions (instead of two) and the writers who performed the rating task rated descriptions of geometric figures (not the geometric figures themselves). The three sessions were separated by 1-week intervals, as summarised in Fig. 6. As in Experiments 1 and 2, each writer was yoked with two readers, and each reader was yoked with two writers.
FIG. 6.

Summary of events during Experiment 3.
Procedure: Writing Session 1 and Reading Session 1
The procedure followed during writing and reading sessions 1 was identical to the procedure followed during writing and reading sessions 1 of Experiments 1 and 2.
Procedure: Writing Session 2
At the beginning of writing session 2, half of the writers performed the selection task (as did half of the writers in Experiments 1 and 2) and the other half performed a new version of the control task. The latter writers were given a packet containing eight descriptions, questions about each description and spaces to record their ratings. The descriptions read by these writers were the same descriptions read by the writers who performed the selection task. Thus, they were descriptions of the set of figures that the writers had not described during writing session 1.
After all the writers performed either the selection task or the rating task, they received the three-ring binder that contained the eight figures that they had described during writing session 1. All of the writers also received packets containing typed versions of the descriptions they wrote during writing session 1. The writers then revised their descriptions. Those writers who performed the selection task were given the same instructions as the writers who performed the selection task in the previous experiments; those writers who performed the rating task were told:
Your experience in evaluating descriptions may help you detect problems in your own texts. You may be able to analyse your own descriptions in the same way that you analysed the descriptions written by someone else. This analysis may help you determine what information is most helpful to readers. You should make use of whatever knowledge or insight you picked up while making your evaluations when you revise your own descriptions.
Procedure: Reading Session 2
The procedure followed in reading session 2 was identical to the procedure followed during reading session 2 of Experiments 1 and 2.
Procedure: Writing Session 3
At the beginning of writing session 3, half the writers performed the selection task and the other half performed the new rating task. Both groups of writers used the same sets of descriptions to perform their respective tasks as they had used during writing session 1. After the writers performed their respective tasks, they received typed copies of the descriptions as they had revised them in writing session 2. Then, they (re)revised their descriptions, following the same instructions they were given in writing session 2.
Procedure: Reading Session 3
The procedure followed in reading session 3 was identical to the procedure followed in reading session 2. However, the descriptions given to the readers were the descriptions produced by the writers during writing session 3.
Results
If the writers who performed the selection task in the previous two experiments improved their descriptions because they were exposed to example descriptions, then the writers who performed the rating task in this experiment should have improved their descriptions. However, our results, shown in Fig. 7, did not support this alternative explanation. Rather, our results supported the hypothesis that to improve their descriptions, writers must perform a task that encourages them to take their readers’ perspective.
FIG. 7.
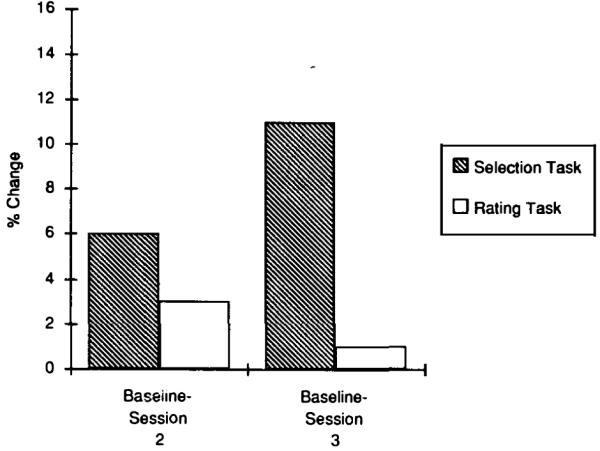
Subjects’ mean improvement in selection during Experiment 3.
Figure 7 presents the readers’ mean improvement scores in Experiment 3. As in Experiments 1 and 2, we computed the first improvement score by subtracting performance during reading session 2 from performance during reading session 1. We computed a second improvement score by subtracting performance during reading session 3 from performance during reading session 1. (The data from which we computed the improvement scores are shown in Table 1.) The hatched bars in Fig. 7 represent the readers’ improvement when they selected figures using descriptions revised by writers who performed the selection task; the unfilled bars represent the readers’ improvement when they selected figures using descriptions revised by writers who performed the rating task.
As in Experiments 1 and 2, descriptions revised by writers who performed the selection task led to a reliable amount of improvement. This improvement was most apparent when comparing the baseline session with the third reading session, as illustrated by the two right-most bars. The descriptions revised by the writers who performed the selection task led to a reliable amount of improvement [F(1,22) = 6.02, P < 0.02]; in contrast, the descriptions revised by the writers who performed the new ranking task did not lead to a reliable amount of improvement (F < 1).
CONCLUSIONS
Our data suggest that writers communicate more effectively when they take their readers’ perspective. In all three experiments, the writers who performed a task similar to their readers’ task improved their texts when they revised them (as indicated by the readers’ improved selection-task performance). What accounts for this improvement?
We propose that writers fail to communicate effectively whenever they fail to envision accurately how readers will interpret their texts. Thus, to communicate effectively, writers must detect instances when their intended meaning differs from their readers’ interpretation of their text. To detect instances when their intended meaning differs from their readers’ interpretations, we propose that writers must build accurate representations of how readers will interpret their texts and writers must compare those representations with their intended meaning. Writers should revise whenever they detect a difference between their representations of what they intended to convey and their accurate representations of how readers will interpret their texts.
We propose that perspective-taking causes writers to improve their texts because it helps them build more accurate representations of how readers interpret their texts. Before writers experience their readers’ task, they might have difficulty “de-centring” (Flower, 1979) or viewing their texts from an outsider’s perspective. After writers take their readers’ perspective (by becoming readers themselves, in our experiments), they “decentre” and build more accurate representations of how readers interpret their texts. Writers who take their readers’ perspective make better choices when they revise their texts, because they have a better idea of how particular choices will affect their readers’ interpretations.
In our experiments, the writers had few bases on which to choose a general strategy for their composing efforts, to decide what information to include in their descriptions and to determine how much detail to include in their descriptions before they performed a task that compelled them to take their readers’ perspective. After they experienced their readers’ task, the writers were able to assess more accurately how their revision choices would ultimately affect their readers, because their representations of how readers interpreted their texts more closely resembled the readers’ actual interpretations.
How Does Motivation Affect Writing Quality?
Did the writers in our experiments improve their descriptions simply because their experience in doing their readers’ task motivated them to work harder than the writers who performed the control task? We believe not, for several reasons. First, we have no reason to assume that the selection task was intrinsically more motivating than either of the control tasks. Secondly, we know from previous experiments that increased motivation, by itself, does not lead to improved texts (Beach, 1979; Duffy et al., 1983; Hayes, 1988; Swaney et al., 1981). And, finally, we know from daily experience that many highly motivated writers (e.g. scholars writing journal articles, researchers writing grant proposals, academics writing textbooks) fail to produce comprehensible text. We propose that even highly motivated and hard-working writers can still fail to build accurate representations of how readers will interpret their texts.
How Does Our Model Compare with Other Theories of the Composing Process?
Hayes and Flower’s (1986) “goal-directed” process model and Scardamalia and Bereiter’s (1987) “knowledge telling vs knowledge transforming” model constitute the broadest and most compelling theoretical descriptions of writers’ composing processes. Clark and Wilkes-Gibbs’ (1986) collaborative communication model constitutes one of the broadest and most compelling theoretical descriptions of general communication processes. Our model extends these models.
Hayes and Flower’s (1986) goal-directed model proposes that writers compose and revise texts according to a hierarchical structure of goals and plans. For example, a writer’s superordinate goal might be to convince readers to support a particular candidate for political office. Once writers have determined a superordinate goal, they then generate, evaluate and implement plans to accomplish that superordinate goal. Often, this planning process compels writers to establish subordinate goals. Writers then generate, evaluate and implement subordinate plans, and so on. For example, if the writer’s superordinate goal is to convince readers to support a particular candidate, the writer might instantiate a subordinate goal of describing the candidate’s qualifications and the actions that candidate has taken to promote the public good. Hayes and Flower propose that writers seek to satisfy each of the goals they set, monitoring their progress as they compose; expert writers differ from novice writers in that experts monitor their progress more successfully.
Our model adds to Hayes and Flower’s (1986) model by providing a mechanism through which writers detect problems in their texts and decide on revisions. We propose that writers revise when they detect differences between what they intended to convey and their representations of what their readers will think their texts convey. This mechanism empowers the goal-setting and planning processes proposed by Hayes and Flower in the following way: If writers intend merely to express their feelings, they will probably be satisfied with whatever they write, because they do not care whether a reader will interpret their texts the same way they do. However, writers who intend their readers to understand a complicated process (like writing) or writers who want to persuade their readers to vote for a particular political candidate—that is, writers who establish higher-order goals and monitor their progress towards achieving those goals—will monitor their progress more assiduously. We propose that expert writers build more accurate representations of how readers interpret their texts, and they frequently monitor their progress by comparing those representations with their intentions.
Scardamalia and Bereiter’s (1987; Bereiter, Burtis & Scardamalia, 1988) model describes the process by which novices and experts generate and structure information in texts. They propose that “knowledge telling” characterises novices’ composing efforts. When writers do “knowledge telling”, they use their topic as a memory retrieval cue and merely write down whatever information the retrieval cue evokes, in whatever order the information becomes active. However, serial memory searches do not always produce knowledge structures that readers can readily comprehend-partly because serial memory searches can activate a high proportion of irrelevant information. When writers do “knowledge transforming”, they may begin with a serial memory search (as in “knowledge telling”), but they execute further cognitive processes that select and restructure the information activated by the serial search.
Our model adds to Scardamalia and Bereiter’s model (1987; Bereiter et al., 1988) by providing a mechanism through which “knowledge transforming” writers select and restructure the information that is activated by their serial search. We propose that writers will continue to search for, select and structure information as long as their representations of their intended meaning differ from their representations of their readers’ interpretation. Furthermore, the more accurately writers envision their readers’ interpretations, the more effectively and efficiently they will execute “knowledge-transforming processes”.
In Clark and Wilkes-Gibbs’ (1986) model, participants in communication collaborate to establish and maintain a mutual referential framework. Although Clark and Wilkes-Gibbs’ model has been validated primarily by experiments involving speakers and listeners, we believe that their theoretical framework also describes some aspects of written communication. In particular, we believe that the cognitive processes that guide writers’ composing decisions resemble the cognitive processes that guide speakers’ and listeners’ production decisions.
Clark and Wilkes-Gibbs (1986) propose that, in spoken discourse, speakers have a fairly easy time assessing whether their listeners understand what they say because they continually receive feedback from listeners. Writers suffer a great communicative disadvantage because they (most often) do not receive feedback from readers that tells them where or when readers do or do not understand what they have written. Instead, writers must rely on internally generated assessments. Writers need feedback just as much as speakers do, but because they cannot rely on readers for feedback, they must generate their own.
So, what happens when writers build inaccurate representations of how readers interpret their texts? Those writers might still try to monitor their progress, and give themselves feedback, but the feedback they give themselves might not resemble the feedback an actual reader would give them. On the other hand, writers who build accurate representations of how readers interpret texts give themselves feedback that closely resembles the feedback an actual reader would give them.
If Perspective-taking Improves Writing, Why do “Audience Analysis Techniques” Fail to Improve Writing Quality?
Despite theorists’ and practitioners’ widespread emphasis on audience analysis, empirical data show that formal audience analysis treatments are mostly ineffective (Hayes, 1988). Given the results of the current study-that writers can take their readers’ perspective and that by doing so helps them to communicate more effectively-why do audience analysis treatments fail? Perhaps formal audience analysis treatments do not succeed in getting writers to take their readers’ perspective because information about general audience characteristics does not put writers in their readers’ shoes. Knowing that the “typical” audience member is 40 years old, male, college-educated and a member of the middle-class might not help a college sophomore see things from the “typical” audience member’s perspective. But if the writer identified a “typical” audience member and attended the audience member’s classes for a week, talked to the audience member’s friends, or worked at the audience member’s job, then the writer might more accurately envision how the “typical” audience member would interpret the writer’s text.
How Applicable are Perspective-taking Techniques Across Writing Genres?
Regardless of task or genre, writers want to affect their audiences. In our experiments, the writers wanted their readers to select the correct figures. In persuasive text, writers want readers to believe something they believe. In humorous text, writers want readers to laugh. In research reports, writers want readers to understand the results of their studies and how those results answer their empirical questions. We propose that, in all of these cases, writers will communicate effectively only to the extent that they accurately envision how their texts will affect their readers. That is, when a humour writer incorrectly concludes that a line will “get a laugh” when it will not, the writer will fail to achieve the desired effect. When a researcher incorrectly concludes that a reviewer will comprehend the motivation for Experiment 6 when the reviewer will not, the researcher will fail to achieve the desired effect. But if all these writers accurately envision how their readers will interpret their texts, and if they continue to revise until their readers’ interpretations coincide with their intentions, then the writers will communicate effectively.
Acknowledgments
This research was supported by NIH Research Career Development Award K04 NS-01376 (awarded to the second author), Air Force Office of Sponsored Research Grants 89-0258 and 89-0305 (also awarded to the second author) and a grant from the Keck Foundation (awarded to the Institute of Cognitive and Decision Sciences at the University of Oregon). We thank Caroline Bolliger, Sara Glover, Estee Langpre, Maureen Marron, Rachel R.W. Robertson, Mike Stickler and Marlaina Watkins for help in testing our subjects and Tari Hugo for help in transcribing the written descriptions. We also thank Dick Hayes and an anonymous reviewer for their helpful comments on an earlier draft of the manuscript.
REFERENCES
- Aristotle . In: The philosophy of Aristotle. Bambrough R, editor. Mentor; New York: 1963. c. 330 b.c. translated by A.E. Wardman & J.L. Creed. [Google Scholar]
- Bartlett EJ. Learning to write: Some cognitive and linguistic components. Center for Applied Linguistics; Washington, DC: 1981. [Google Scholar]
- Beach R. The effects of between-draft teacher evaluation versus student self-evaluation on high-school students’ revising of rough drafts. Research in the Teaching of English. 1979;13:111–119. [Google Scholar]
- Bereiter C, Burtis PJ, Scardamalia M. Cognitive operations in constructing main points in written composition. Journal of Memory and Language. 1988;27:261–278. [Google Scholar]
- Berkenkotter C. Understanding a writer’s awareness of audience. College Composition and Communication. 1981;31:213–220. [Google Scholar]
- Booth WC. Now don’t try to reson with me: Essays and ironies for a credulous age. University of Chicago Press; Chicago, IL: 1970. [Google Scholar]
- Birdwell LS. Revising strategies in twelfth grade students: Transactional writing. Research in the Teaching of English. 1980;14:107–122. [Google Scholar]
- Clark HH, Wilkes-Gibbs D. Referring as a collaborative process. Cognition. 1986;22:1–39. doi: 10.1016/0010-0277(86)90010-7. [DOI] [PubMed] [Google Scholar]
- Duffy T, Curran T, Sass D. Document design for technical job tasks: An evaluation. Human Factors. 1983;25:143–160. [Google Scholar]
- Ede L. Audience: An introduction to research. College Composition and Communication. 1984;35:140–154. [Google Scholar]
- Flavell JH, Botkin PJ, Fry CL, Jr, Wright JW. The development of roletaking and communication skills in children. John Wiley; New York: 1968. [Google Scholar]
- Flower LS. Writer-based prose: A cognitive basis for problems in writing. College English. 1979;41:19–37. [Google Scholar]
- Gage JT. The teaching of writing: Theory and practice. In: Petrosky AR, Bartholomae D, editors. The teaching of writing: Eighty-fifth yearbook of the National Society for the Study of Education. University of Chicago Press; Chicago, IL: 1986. pp. 8–29. [Google Scholar]
- Gage JT. The shape of reason: Argumentative writing in college. Macmillan; New York: 1987. [Google Scholar]
- Glucksberg S, Danks J. Experimental psycholinguistics: An introduction. Lawrence Erlbaum Associates Inc; Hillsdale, NJ: 1975. [Google Scholar]
- Hayes JR. Writing research: The analysis of a very complex task. In: Klahr D, Kotovsky K, editors. Complex information processing: The impact of Herbert A. Simon. Lawrence Eribaum Associates Inc; Hillsdale, NJ: 1988. pp. 209–234. [Google Scholar]
- Hayes JR, Flower LS. Writing research and the writer. American Psychologist. 1986;41:1106–1113. [Google Scholar]
- Hayes JR, Flower LS, Schriver KA, Stratman J, Carey L. Cognitive processes in revision. In: Rosenberg S, editor. Advances in psycholinguistics, Vol. II: Reading, writing, and language processing. Cambridge University Press; Cambridge: 1987. pp. 176–240. [Google Scholar]
- Kroll BM. Cognitive egocentrism and the problem of audience awareness in written discourse. Research in the Teaching of English. 1978;12:269–281. [Google Scholar]
- Pfister FR, Petrik JF. A heuristic model for creating a writer’s audience. College Composition and Communication. 1980;31:213–220. [Google Scholar]
- Piaget J. The language and thought of the child. New American Library; New York: 1956. (translated by M. Gabian) [Google Scholar]
- Plato . Gorgias. Hobbs-Merrill; Indianapolis, IN: 1952. c. 386 b.c. (trans. by W.C. Helmbold) [Google Scholar]
- Scardamalia M, Bereiter C. Knowledge telling and knowledge transforming in written composition. In: Rosenberg S, editor. Advances in applied psycholinguistics. Vol. 2. Cambridge University Press; Cambridge: 1987. pp. 142–175. [Google Scholar]
- Schober MF, Clark HH. Understanding by addressees and overhearers. Cognitive Psychology. 1989;21:211–232. [Google Scholar]
- Sommers N. Revision strategies of student writers and experienced adult writers. College Composition and Communication. 1980;31:378–387. [Google Scholar]
- Stallard C. An analysis of the writing behavior of good student writers. Research in the Teaching of English. 1974;8:206–218. [Google Scholar]
- Swaney JH, Janik CJ, Bond SJ, Hayes JR. Editing for comprehension: Improving the process through reading protocols. Carnegie Mellon University, Document Design Project; Pittsburgh, PA: 1981. (Tech. Rep. No. 14) [Google Scholar]
- Traxler MJ, Gernsbacher MA. Improving written communication through minimal feedback. Language and Cognitive Processes. 1992;7:1–22. doi: 10.1080/01690969208409378. [DOI] [PMC free article] [PubMed] [Google Scholar]