

Abstract
Visual search (e.g., finding a specific object in an array of other objects) is performed most effectively when people are able to ignore distracting nontargets. In repeated search, however, incidental learning of object identities may facilitate performance. In three experiments, with over 1,100 participants, we examined the extent to which search could be facilitated by object memory and by memory for spatial layouts. Participants searched for new targets (real-world, nameable objects) embedded among repeated distractors. To make the task more challenging, some participants performed search for multiple targets, increasing demands on visual working memory (WM). Following search, memory for search distractors was assessed using a surprise two-alternative forced choice recognition memory test with semantically matched foils. Search performance was facilitated by distractor object learning and by spatial memory; it was most robust when object identity was consistently tied to spatial locations and weakest (or absent) when object identities were inconsistent across trials. Incidental memory for distractors was better among participants who searched under high WM load, relative to low WM load. These results were observed when visual search included exhaustive-search trials (Experiment 1) or when all trials were self-terminating (Experiment 2). In Experiment 3, stimulus exposure was equated across WM load groups by presenting objects in a single-object stream; recognition accuracy was similar to that in Experiments 1 and 2. Together, the results suggest that people incidentally generate memory for nontarget objects encountered during search and that such memory can facilitate search performance.
Consider a task in which you search for real-world objects. For example, imagine that you are asked to determine whether some target object (e.g., a hammer) is present among a set of distractor objects (e.g., a phone, a computer, a shoe). As you search for the hammer, what might you learn about the nontargets? Although the task is most efficiently completed by ignoring the distractors, people must process them to some degree and may incidentally learn their identities (Williams, Henderson, & Zacks, 2005). Indeed, if the same set of distractors was used repeatedly, such learning might facilitate search performance (Chun & Jiang, 1999; Endo & Takeda, 2004; Mruczek & Sheinberg, 2005). For instance, knowledge of the appearance or locations of the phone, computer, and shoe may increase your speed in locating a new target or determining its absence.
In the present investigation, we assessed whether visual search could be facilitated through incidental learning of repeated distractors and whether such learning involved information about both object identities and spatial layouts. In all the experiments, the stimuli were real-world, nameable objects. On each trial in the first experiment, participants searched for new target objects embedded within sets of repeated distractors, indicating whether the target(s) was present in or absent from the display. The location and identity of the target(s) were unpredictable. Search was conducted among fixed spatial locations with fixed object-to-location mapping (Experiment 1A), fixed spatial locations with random object-to-location mapping (Experiment 1B), random locations with fixed object identities (Experiment 1C), and fixed locations with random object identities (Experiment 1D). In Experiment 2, each of these conditions was examined again, but search targets were present on all trials. In both experiments, we also assessed whether a visual working memory (WM) load interacted with the learning of search arrays. Search facilitation was measured, and incidental recognition memory was later assessed using surprise two-alternative forced choice (2AFC) token discrimination tests. Finally, in Experiment 3, participants were given a passive search task in which the search items were presented centrally in rapid succession; incidental memory for distractors was again tested following all search trials.
Incidental Acquisition of Visual Information
It is clear that substantial information is incidentally acquired during visual search. For example, Castelhano and Henderson (2005; see also Hollingworth & Henderson, 2002) had participants view photographs of real-world scenes in two different tasks: intentional memorization and visual search. In both conditions, the participants performed reliably above chance for basic-level token discrimination (i.e., “which of these two different objects did you see previously?”) and for mirror image discrimination (i.e., “which manifestation of this image did you see previously?”), suggesting that detailed long-term visual representations were incidentally generated during scene perception.
Williams et al. (2005) investigated incidental retention of visual details for real-world objects encountered during a search task. Participants counted the number of targets present in an array of 12 photographs, consisting of four image types: targets, distractors matched for category but not for color (category distractors), distractors matched for color but not for category (color distractors), and unrelated distractors. Search arrays were presented twice, once per block of trials. Results showed that all classes of objects were viewed less frequently upon second presentation of the search arrays, suggesting that memory for their visual details was acquired during the first presentation. Incidental recognition memory for search objects was tested with foils matching the semantic labels of the presented objects (e.g., if the presented object was a black phone, the foil was a new black phone). Memory performance was above chance for each class of objects and was best for search targets (83%) and distractors related to the target (≈60%); both types of related distractors were remembered better than unrelated distractors. Williams et al. concluded that detailed visual information for objects is incidentally encoded during visual search.
Search Efficiency and Facilitation
If visual information is acquired during search, it would be reasonable to expect such learning to enhance search efficiency (as indexed by the slope of the line relating response time [RT] to set size). However, this does not seem to be the case. The long-term benefits of repeated visual search were investigated by Wolfe and colleagues in several experiments. Wolfe, Klempen, and Dahlen (2000) found that repeated presentations of an unchanged display elicited shorter RTs as a function of trial number but did not increase search efficiency; stimuli included letters, shapes, simple conjunctions (e.g., a horizontal black bar), and compound conjunctions (e.g., a red circle topped with a yellow vertical line). If search was inefficient on the first presentation, it remained inefficient even after 350 presentations, suggesting that the perceptual effects of attention vanish once attention has been redeployed elsewhere. Wolfe, Oliva, Butcher, and Arsenio (2002) presented participants with more complex stimuli: realistically colored, computer-generated real-world objects (e.g., a coffee machine, a laptop, a fruit bowl). The participants were first shown a number of search objects. At the start of the trial, each of the objects was rotated slightly, with 50% of the trials also replacing one object with a scrambled version of itself. The participants indicated the presence or absence of a scrambled object. In the repeated search condition, the same objects were continuously present on the screen for an entire block of 288 trials; the unrepeated condition consisted of a random selection of objects on each trial. The repeated and unrepeated conditions were not reliably different in mean RTs or search slopes. In another experiment, Wolfe et al. (2002) found that repeated visual search was no more efficient than unrepeated search when participants looked for a scrambled object among normal objects in a realistic scene. Wolfe and colleagues argued that repeated search may lead an observer to acquire visual information but does not enable the observer to perceive the display more efficiently; objects appear to be recognized one at a time. They suggested that when attention is moved away from an object, it no longer affects visual perception and that the attentional guidance used to find a target in a repeated scene is therefore quite similar to the guidance used in a novel scene.
Although Wolfe and colleagues have consistently shown that search efficiency is not enhanced as a scene is repeated, it seems that memory for search displays may nevertheless affect performance. Numerous studies have complemented Wolfe et al.’s (2002) finding that, as search is conducted within a repeated scene, search decisions may be reached more quickly, reducing RTs as a function of experience with the display. In the contextual cuing paradigm (Chun & Jiang, 2003; Jiang & Leung, 2005; Jiang & Song, 2005), repeated presentations of spatial configurations allow participants to more quickly locate targets after only a few repetitions. Chun and Jiang (1998) had participants search for a rotated T among a set of rotated Ls. Half of the search configurations were repeated, and targets appeared in consistent locations within these displays. Targets in repeated configurations were located more quickly than were randomly configured displays, presumably due to learned associations between spatial configurations and target locations. Chun and Jiang (1999) investigated the extent to which search could be facilitated when target identities were cued by the presence of consistent distractor identities. They presented people with novel objects: Search targets were symmetrical around the vertical axis (0°); distractor objects were symmetrical around other orientations (30°, 60°, 90°, 120°, 150°). On consistent-mapping trials, a given target shape was paired with the same distractor identities. On varied-mapping trials, random assortments of distractors were paired with targets. Unlike the prior experiments (in which spatial configurations predicted target location), the locations of targets and distractors were randomized on each trial. RTs were nevertheless shorter in the consistent-mapping condition, suggesting that sensitivity to the distractor context facilitated search performance by cuing the identity of the target.
The contextual-cuing experiments suggest that visual search is improved when people can learn associations between distractor configurations and target locations or between distractor identities and target identities. Taking this further, Endo and Takeda (2004) reported that people can also learn associations between distractor identities and target locations. Using a closed contour search task (i.e., the targets were abstract shapes with closed contours, shown among nonclosed distractors), they investigated each of the possible correlations between target information and distractor regularity. In their fourth experiment, distractor configurations were correlated with consistent target identities (configuration repetition condition), and distractor identities were correlated with consistent target locations (identity repetition condition), in a mixed-block design. Thus, in the configuration repetition condition, the spatial layout cued what the target was but not its location; in the identity repetition condition, distractor identities cued where the target was but not its identity. The results showed a contextual-cuing effect in the identity repetition condition, but not in the configuration repetition condition: Participants could use distractor identities to locate targets but did not learn associations between distractor configurations and target identities.
Considerations of spatial layouts aside, familiarity with targets and distractors also influences search performance. For instance, Frith (1974) reported that it is more difficult to visually scan for a letter among mirrored letters than the converse (see also Reicher, Snyder, & Richards, 1976; Richards & Reicher, 1978). More recently, Mruczek and Sheinberg (2005) examined the effect of target and distractor familiarity on visual search for heterogeneous stimuli. They manipulated levels of familiarity to large sets of targets and distractors by engaging participants in prolonged search for photographs of real-world objects. As the participants gained more experience with the images, RTs and search slopes decreased. Familiarity effects were indicated by faster search among familiar distractors, relative to unfamiliar distractors, and by faster location of familiar targets. They argued that incidental encoding of the images allowed people to more efficiently analyze and dismiss objects, supporting a role for item memory in visual search.
The Present Investigation
In the present investigation, we tested the extent to which visual search performance would benefit from incidental learning of spatial information and object identities. We employed an unpredictable search task for complex visual stimuli; the location and identity of targets was randomized on every trial, and potential targets were seen only once. Thus, the participants were given a difficult serial search task that required careful attentional scanning. Our fundamental question was, to what extent can incidental learning of background information aid in the location (or absence determination) of a previously unseen object?
We sought to answer four specific questions. First, when search is unpredictable, can incidental learning of complex distractor objects facilitate performance over a short period of time? Second, if such learning occurs, does it rely on a correlation between distractor identities and spatial locations, or can performance be improved entirely by memory for the objects? Third, how well are distractors remembered when participants are given no reason to encode them? And fourth, will a concurrent visual WM load interact with distractor learning? We examined search performance and incidental memory (indicated by search times and recognition performance, respectively) as a function of WM load, which was manipulated by requiring people to search for varying numbers of potential targets. Previous work by Menneer, Barrett, Phillips, Donnelly, and Cave (2007; Menneer, Cave, & Donnelly, 2009) indicated that multiple-target search is less accurate than single-target search. We varied the number of search targets such that WM load would be germane to the task at hand. As WM load increased, the participants were required to maintain more potential target images in memory, any (or none) of which might appear in the search array. Task demands not only required the maintenance of visual information in memory, but also tapped executive functions by tacitly requiring the participants to compare each viewed object with the visual objects held in memory.
In all the experiments, the participants repeatedly searched for new targets embedded within sets of repeated distractors. In Experiment 1, they indicated whether targets were present or absent, and in Experiment 2 (in which targets were always present), they indicated which of several potential targets was located. In both experiments, we examined the contributions of spatial consistency and object repetition by systematically decoupling these sources of information. Our first condition (Experiments 1A and 2A) consisted of fixed spatial locations with fixed object-to-location mapping. That is, the same distractor objects appeared in the same places across trials, with targets replacing one distractor per trial (on target-present trials). It was expected, and found, that these highly stable displays would promote the strongest learning across search trials.
The second condition (Experiments 1B and 2B) employed fixed spatial locations with random object-to-location mapping. In this case, the spatial layout was constant, but the distractors randomly traded positions on every trial. The participants could potentially benefit from repeated objects or repeated layouts but could not use any correlations between objects and positions. The third condition (Experiments 1C and 2C) used the same repeated objects, now in random spatial locations across trials. The participants could benefit from seeing repeated distractors but could not use spatial information. Finally, the fourth condition (Experiments 1D and 2D) consisted of fixed spatial locations (as in Condition 1), but object identities were less predictable. Specifically, in the first three conditions, one set of objects was used repeatedly in one block of trials, and a second set of objects was used repeatedly in a second block. In the fourth condition, we spread the use of all objects across both blocks, in randomly generated sets, with the restriction that all the objects must be repeated as often as in the previous three conditions. In this manner, we reduced the likelihood of repeated objects by 50%, while holding spatial layouts constant, making these conditions most naturally comparable to the “A” and “B” conditions in each experiment. Figure 1 provides examples of all these conditions.
Figure 1.

Examples of each level of spatial and object consistency employed across experiments. Note that actual search displays consisted of 20 items.
In Experiment 3, visual search was passive; the participants viewed a centrally presented stream of images, one at a time, and indicated their search decisions after all the items had been shown. This experiment was conducted to allow assessment of the effects of WM load on object encoding, while controlling the viewing time for each object.
We made three main predictions. First, we expected that the participants would benefit from repeated exposure to distractor stimuli, with shorter search RTs being elicited in each of the first three conditions and with diminished (or eliminated) learning in the final condition. In Experiments 1A/2A, learning should be robust, due to the consistency of both object identities and spatial layouts. If object memory and spatial memory are independent of each other, we should find similar improvement in Experiments 1B/2B, despite the imperfect correlation of objects and layouts. Conversely, if object and spatial memory are interdependent, we should observe an interference effect, since familiar spatial layouts would be repeatedly populated by rearranged objects. In Experiments 1C/2C, no valid spatial information was available, since object locations were randomized on each trial. Thus, if RTs improved across trials, it would provide compelling evidence that object memory alone can facilitate search performance. Critically, in Experiments 1D/2D, spatial information was consistent, but the coherence of the distractor sets was reduced across trials. If performance is driven largely by incidental learning of distractor identities, we should find diminished (or eliminated) learning in this condition, relative to the others.
Second, we expected participants (in all the experiments) to incidentally generate memory for the distractor objects and, therefore, to discriminate between search distractors and foils at levels exceeding chance. (Note that, in all the conditions [even Experiments 1D and 2D], every object was shown equally often, making all the recognition tests comparable to each other.) Third, our manipulation of WM load motivated an interesting prediction. The load manipulation was mainly intended to challenge the participants, requiring them to search more slowly and carefully, thus providing a greater opportunity to encode distractor objects across trials. We also predicted, however, that despite holding more visual information in memory, high-load participants would generate stronger incidental memory for the distractors. We expected this because high-load participants would have to analyze all distractors more carefully, allowing “deeper” encoding (Craik & Lockhart, 1972). We return to this prediction in Experiment 3.
EXPERIMENT 1
In Experiment 1, participants indicated the presence or absence of a new target object(s) embedded among repeated distractors. When present, the target replaced a single distractor object (occupying its same spatial location in Experiments 1A/1B/1D). No target object appeared more than one time in any condition. In Experiment 1A, spatial layouts and object identities were held constant; each distractor was placed in the same location throughout a block of 40 trials. In Experiment 1B, we held the set of object locations fixed throughout each block but varied the object-to-location mapping of distractors. In this way, the participants could benefit from the consistent layout of objects across the screen but could not predict which image would appear in any given location. In Experiment 1C, we removed the ability to guide search by spatial memory by randomizing the layout on each trial; the participants could use experience with the distractors to improve search but could not use spatial information. In Experiment 1D, we held spatial layout constant within a block of trials, but distractors were not coherently grouped within sets and could appear in either search block. The participants could therefore use experience with the spatial layout to improve search but could not as easily learn object identities. In each condition, following all search trials, we administered a surprise 2AFC recognition memory test. The participants were shown previously seen distractor images, each with a semantically matched foil (e.g., if the old image was a coffee pot, the matched foil would be a new, visually distinct coffee pot), and they indicated which one was old.
Method
Participants
Three hundred seventy students from Arizona State University participated in Experiment 1 in partial fulfillment of a course requirement. Approximately 45 students participated in each of eight between-subjects conditions. All the participants had normal or corrected-to-normal vision.
Design
Four levels of spatial and object consistency (see Figure 1) and two levels of WM load (low, high) were manipulated between subjects. Presence of the target during search (absent, present) was a within-subjects variable in equal proportions.
Stimuli
The stimuli were real-world objects of various image types, including line drawings, detailed sketches, small-scale photographs, and clip art. Images were selected to avoid any obvious categorical relationships among the stimuli, and approximately equal proportions of each image type were used. Most categories were represented by a single image (e.g, the category computer represented by a single laptop). Categories with multiple representations consisted of images that were visually distinct (e.g., the category animals represented by a sitting cat and a standing dog). Images were resized (while maintaining original proportions) to a maximum of 2.5° in visual angle (horizontal or vertical) from a viewing distance of 55 cm. Images were no smaller than 2.0° in visual angle along either dimension, were converted to grayscale, and contained little or no background. A single object or entity was present in each image (e.g., an ice cream cone or a pair of shoes). Although stimulus characteristics such as luminance or contrast were not directly manipulated, the variation across image types and categories would have made it extremely difficult for the participants to select targets on the basis of any such feature.
Apparatus
Data were collected on up to eight computers simultaneously; each was equipped with identical software and hardware (Gateway E4610 PC, 1.8 GHz, 2 GB RAM). Dividing walls separated participant stations on either side to reduce distraction. Each display was a 17-in. NEC (16.0 in. viewable) CRT monitor, with resolution set to 1,280 × 1,024 pixels and a refresh rate of 60 Hz. Display was controlled by an NVIDIA GE Force 7300 GS video card (527 MB). E-Prime v1.2 software (Schneider, Eschman, & Zuccolotto, 2002) was used to control stimulus presentation and collect responses.
Procedure
In visual search, the participants completed two 40-trial blocks, each with 20 target-absent and 20 target-present trials, randomly dispersed, for a total of 80 trials. Each block entailed repeated presentation of the same distractor images for all 40 trials (except in Experiment 1D). A 1-min break was placed between blocks to allow the participants to rest their eyes. A new distractor set was introduced in the second block of trials and was again used for all 40 trials. Order of presentation of distractor sets was counterbalanced across participants. In Experiment 1D, distractor sets were randomly composed on each trial, with the constraint that each image be presented equally often, again with 40 repetitions per object.
The participants were instructed that, at the beginning of each trial, they would see either one or three different potential targets (low and high WM load conditions, respectively) that should be kept in mind. Low-load participants tried to determine whether the target was present in the display. High-load participants tried to determine whether any of the three potential targets were present in the display or whether all were absent; they were informed that only one target would appear on any trial. Given this procedure, we used the same search targets across load conditions, making them directly comparable. Target images were randomized and were not repeated. The participants were also informed that the target image, if present in the display, would be mirrored along its vertical axis, and sample stimuli were shown to demonstrate this point. Gray-scaling of all stimuli and mirroring of the targets were performed to minimize pop-out effects (Treisman & Gelade, 1980) and to avoid potential template-matching strategies that would circumvent visual search. Instructions emphasized accuracy over speed. Two practice trials were administered. None of the practice stimuli were used in the rest of the experiment.
Search trials (see Figure 2) began by showing the target image(s). When the participant was ready, he/she pressed the space bar to clear the screen and initiate an array of 20 images (either 20 distractors or 19 distractors and 1 target), all shown on a blank white background. On target-present trials, a single distractor was replaced by the target; different distractors were replaced across trials (the participants were not informed of this regularity). Spacing and size of the images minimized parafoveal identification of the objects.
Figure 2.

Timeline showing the progression of events for a single visual search trial. Participants were shown a target image(s) and progressed to the next screen upon a keypress. The visual search array was then presented and was terminated upon a space bar key-press. Target presence was then queried, followed by 1-sec accuracy feedback and a 1-sec delay prior to the start of the next trial.
The participants rested their fingers on the space bar during search. Once a target was found or it was determined that no target was present in the display, the participants pressed the space bar to terminate search. The search array was then immediately cleared from the screen, and the participants were prompted to press “f “ or “j” (for present and absent, respectively), which were labeled on the query screen. Using the space bar to terminate the display (instead of requiring an immediate presence decision) allowed measures of search time to reflect termination of the search process, without additional time for response selection. Brief accuracy feedback was given, followed by a 1-sec delay screen before the next trial.
After visual search, the participants were given a surprise 2AFC recognition test for the distractor images encountered during search. Two images were shown per trial on a white background: one prior distractor and one semantically matched foil, equally mapped to each side of the screen. The participants indicated their selection on the keyboard, and feedback was provided. All 40 distractor images were tested; the images were pooled and presented in random order to minimize any effect of time elapsed since learning.
Results
Seventeen of the 370 participants (5%) in Experiment 1 were excluded from analysis, for several reasons. Three were lost because of data corruption. One was removed because visual search accuracy was >2.5 standard deviations below the group mean. Five were removed because their mean visual search times were >2.5 standard deviations above their group means, and 8 were removed because recognition accuracy was >2.5 standard deviations below their group means (all were below chance). Overall, error rates for visual search were very low (7%). For the sake of brevity, we do not discuss the analysis of search accuracy, but the results are shown in Table A1.1
Visual search RTs
For visual search, RTs were divided into epochs, with each epoch comprising 25% of the block’s trials. Following Endo and Takeda (2004), we examined RTs as a function of experience with the search display; main effects of epoch would indicate that RTs reliably decreased as the trials progressed. Although Experiment 1 had many conditions, the key results are easily summarized: Figures 3 and 4 present mean search times (for target-present and target-absent search, respectively); RTs are plotted across epochs, as a function of experiment and load. As is shown, search times were consistently longer for the participants under high WM load and were longer in target-absent trials. Of greater interest, reliable learning (effects of epoch) were observed in every condition, although not to equivalent degrees.
Figure 3.

Time series analysis showing mean visual search response times (rTs) on target-present trials, as a function of epoch, in Experiment 1. The results are plotted separately for each working memory load group.
Figure 4.

Time series analysis showing mean visual search response times (rTs) on target-absent trials, as a function of epoch, in Experiment 1. The results are plotted separately for each working memory load group.
RTs for accurate search trials were entered into a five-way repeated measures ANOVA, with experiment (1A, 1B, 1C, and 1D), WM load (low, high), trial type (target present, target absent), block (1 or 2), and epoch (1–4) as factors. We found an effect of experiment [F(3,345) = 5.42, p = .001, ], with the shortest overall RTs in Experiment 1A (3,203 msec), followed by Experiment 1C (3,465 msec), Experiment 1D (3,473 msec), and Experiment 1B (3,756 msec). There was an effect of load [F(1,345) = 590.41, p < .001, ], with faster search among low-load groups (2,344 msec) than among high-load groups (4,605 msec).
There was an effect of trial type [F(1,345) = 1,790.19, p < .001, ], with participants responding more quickly to target presence (2,297 msec) than to target absence (4,652 msec). We found an effect of block [F(1,345) = 39.06, p < .001, ], with slower search in Block 1 (3,584 msec) than in Block 2 (3,364 msec). Of key interest, there was a main effect of epoch [F(3,343) = 45.12, p < .001, ], indicating that search RTs decreased significantly within blocks of trials (3,726, 3,507, 3,378, and 3,285 msec for Epochs 1–4, respectively).
There were several two-way interactions. Of particular interest, we found an experiment × block interaction [F(3,345) = 5.16, p = .002, ]. The greatest decrease in RTs across blocks was elicited in Experiment 1D (435 msec), followed by Experiment 1A (219 msec), Experiment 1C (160 msec), and Experiment 1B (66 msec). The largest benefit in Experiment 1D reflects the fact that distractor objects were shared across blocks. We found an experiment × trial type interaction [F(3,345) = 4.85, p = .003, ]; the disparity between trial types (target present, absent) was greatest in Experiment 1B (2,683 msec), followed by Experiment 1C (2,380 msec), Experiment 1D (2,285 msec), and Experiment 1A (2,093 msec). There was a load × trial type interaction [F(1,345) = 211.90, p < .001, ], indicating a larger disparity between trial types among the high-load groups (3,166 msec) than among the low-load groups (1,545 msec).
A load × block interaction [F(1,345) = 14.09, p < .001, ] indicated a larger decrease in RTs across blocks for the high-load groups (352 msec) than for the low-load groups (88 msec). Importantly, a load × epoch interaction [F(3,343) = 11.53, p < .001, ] indicated steeper learning slopes for the high-load groups (−216 msec/epoch) than for the low-load groups (−74 msec/epoch).2 Lastly, we found a block × epoch interaction [F(3,343) = 4.32, p = .005, ]. Learning slopes were steeper in Block 1 (−156 msec/epoch) than in Block 2 (−134 msec/epoch). We also found four higher order interactions: experiment × trial type × block, F(3,345) = 7.46, p < .001, ; trial type × block × epoch, F(3,343) = 7.79, p < .001, ; experiment × load × trial type × block, F(3,345) = 5.46, p = .001, ; and load × trial type × block × epoch, F(3,343) = 3.03, p < .03, .
Because the effects of epoch were of particular interest, we tested for simple effects, finding significant epoch effects in each experiment: Experiment 1A, F(3,68) = 15.39, p < .001, (with mean RTs of 3,557, 3,196, 3,078, and 2,979 msec for Epochs 1–4, respectively); Experiment 1B, F(3,84) = 14.39, p < .001, (mean RTs of 4,055, 3,792, 3,636, and 3,541 msec); Experiment 1C, F(3,97) = 11.11, p < .001, (mean RTs of 3,681, 3,496, 3,373, and 3,309 msec); Experiment 1D, F(3,88) = 8.78, p < .001, (mean RTs of 3,612, 3,544, 3,425, and 3,312 msec).
As was noted earlier, Experiment 1A employed complete consistency in both spatial and object identity information within a block of trials; Experiments 1B, 1C, and 1D degraded these information sources in unique manners. Accordingly, we performed three final analyses, comparing Experiment 1A with each of the other experiments. We were specifically interested in potential experiment × epoch interactions, which would indicate different learning slopes across experiments. Neither Experiment 1B nor Experiment 1C exhibited different learning slopes, relative to Experiment 1A [Experiment 1A vs. 1B, F(3,154) = 0.49, p = .123; Experiment 1A vs. 1C, F(3,167) = 1.65, p = .18]. However, the learning slope in Experiment 1A (−185 msec/epoch) was steeper than the slope in Experiment 1D (−102 msec/epoch) [F(3,158) = 3.94, p = .01, ]. Figure 5 presents search RTs as a function of experiment and epoch, collapsed across all other factors. In Figure 5, RTs are scaled, shown as proportions of Epoch 1 means for each experiment.
Figure 5.
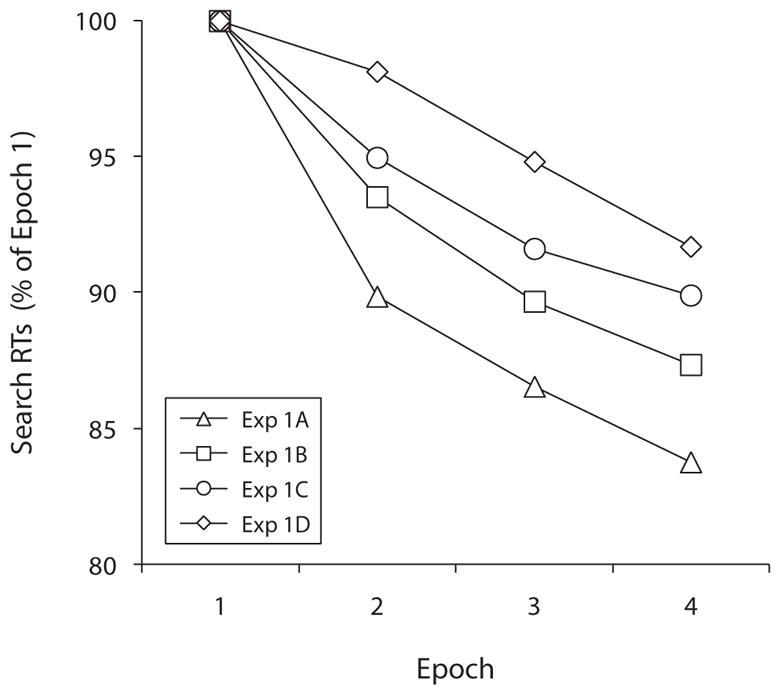
Time series analysis showing mean visual search response times (rTs) as a function of experiment and epoch in Experiment 1. The results are scaled to the proportion of mean search rTs in Epoch 1 per group.
Recognition
Although chance performance on 2AFC tests should be 50%, we were concerned that our materials may have contained selection biases. That is, some characteristics of the true distractors may have increased the likelihood that we would have originally chosen them for the search trials, rather than the foils used in the recognition tests. If so, the participants could potentially have guessed which images were old on the basis of visual characteristics, irrespective of memory (e.g., “this coffee cup looks more like it would have been used in this task”). We therefore established an empirical baseline: Forty-five naive participants saw the same 2AFC pairs with no prior exposure. The search experiment was described, and these participants were asked to guess which image (per pair) was more likely to be chosen by an experimenter for use in such a task. Mean guessing accuracy was 59% (SD = 0.08), which reliably exceeded 50% [t(44) = 7.46, p < .01], verifying a potential selection bias. To be conservative, we therefore evaluated recognition performance relative to this empirical baseline of 59%, rather than 50%. As we describe next, all the groups produced recognition well in excess of this baseline, with superior performance among high-load groups.
Recognition accuracy was entered into a two-way ANOVA with experiment and WM load as factors. We found an effect of experiment [F(3,345) = 3.98, p = .008, ], with the best performance in Experiment 1B (80%), followed by Experiment 1D (78%), Experiment 1C (77%), and Experiment 1A (75%). There was also an effect of load [F(1,345) = 89.25, p < .001, ], with better memory among the high-load groups (83%) than among the low-load groups (72%). The interaction was not significant (F < 1). Figure 6 presents mean recognition accuracy as a function of experiment and load.
Figure 6.
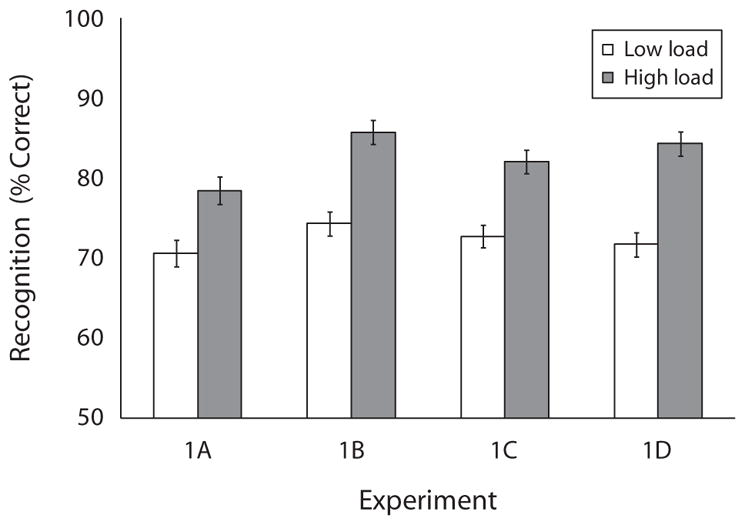
Recognition memory performance in Experiment 1. The results are plotted as a function of experiment and Wm load.
Discussion
The participants in Experiment 1 demonstrated incidental learning of repeated search arrays, with steadily decreasing search RTs over trials. In Experiment 1A, two sources of information could have been used by the participants to improve search performance: distractor identities and their consistent locations. In Experiment 1B, the participants could benefit from the consistent layout of objects across the screen but could not predict which image would appear in any given location. In both experiments, significant learning effects occurred, indicating that people could benefit from spatial and object memory, even when these information sources were imperfectly correlated. In Experiment 1C, spatial consistency was eliminated, but familiarity with the distractors still allowed the participants to improve performance across trials. Conversely, the search displays in Experiment 1D were spatially consistent but were inconsistent with respect to the identities of distractor items: The participants once more improved performance over trials, but the benefit was reduced, relative to the complementary condition in which distractor sets were consistent within blocks of trials (Experiment 1A). Given the results, it appears that the contribution of object learning to search performance outweighed that of spatial learning. When object information was inconsistent, performance was more disrupted, relative to conditions wherein spatial information was disrupted.
It is important to note that we observed reliable practice effects; RTs in Block 2 were consistently shorter than those in Block 1. However, it is unlikely that practice can fully account for our learning effects. The main effect of block accounted for only 10% of the variance in RTs, in contrast with 28% explained by the main effect of epoch. Moreover, in the first three conditions, mean RTs decreased by 148 msec across blocks; but the effect was much larger across epochs. In Experiments 1A, 1B, and 1C, mean RTs dropped by 487 msec across Epochs 1–4, more than triple the change across blocks. Experiment 1D was the only condition in which certain information could be useful in both blocks (i.e., individual distractors could appear in Blocks 1 and 2), and only in this condition was the pattern of results different: The decrease in RTs across blocks (435 msec) was larger than that across epochs (300 msec). That some performance enhancement was produced is not altogether surprising, since the distractors were repeated often across the experiment; they were merely unpredictable on any given trial. In sum, a general practice effect improved the participants’ performance with experience, but this effect was overshadowed by the benefit provided from repeating distractor identities within blocks.
Given the residual learning that occurred in Experiment 1D, we should note that such improvements in search RTs do not appear to reflect a general practice effect. In a separate experiment (N = 38), we replicated the experiments reported above, with one key difference. Participants again searched for targets under low or high WM load, with the same numbers of objects per display. In this case, however, every trial presented all new objects and random spatial layouts. We again observed a robust effect of WM load on search times, with slower search among high-load participants. However, we observed no evidence of learning across epochs. Although this is not surprising (since there was little information for people to learn), it does suggest that general practice has little impact in our procedure.
Although search would have been performed most efficiently by ignoring distracting nontarget objects, people nevertheless benefited from their repetition and retained detailed information about them, without instruction to do so. Consistent with Williams et al. (2005), our participants discriminated previously seen distractors from semantically matched foils at levels greater than chance. Paradoxically, the high-load groups outperformed the low-load groups. Clearly, loaded participants had a more difficult search task, performing more slowly and producing more errors. One might presume that people experiencing greater difficulty during search would evince less memory for the displays. Indeed, our load manipulation forced people to maintain extra images in visual WM, which might be expected to interfere with distractor encoding. However, our method required people to make more frequent and careful mental comparisons, pitting each distractor against three potential targets with distinct visual details. It is possible that such careful, repeated mental comparisons resulted in deeper encoding of distractor identities, akin to verbal depth of processing (Craik & Lockhart, 1972). Similarly, Conway, Cowan, and Bunting (2001) reported that decreased WM resources are associated with difficulty in inhibiting distracting information. Accordingly, loaded participants may have been less able to block distractor identities during search, driving up RTs and, concurrently, increasing retention for their visual details. Experiment 1 could not fully resolve this issue, since visual search RTs were confounded with WM load. That is, the high-load groups also had greater viewing opportunities than did the low-load groups, because of their slower search process. We later address this issue in Experiment 3 by equating stimulus exposure across WM load groups in an altered search procedure.
EXPERIMENT 2
In Experiment 2, we sought to complement the previous findings by answering two questions. First, does distractor learning require frequent exhaustive searches, or will it occur when search targets are always present? Second, are differences in learning among WM load groups graded? That is, is there a qualitative difference between holding one object in memory, relative to numerous objects? Or is the phenomenon continuous, so that the number of objects held in memory is directly related to subsequent search and memory performance? The participants in Experiment 2 performed search with targets present on every trial. Now, rather than an absence versus presence decision, the participants’ task was to search for several targets and (upon finding one) indicate which potential target was found. In Experiments 2A–2D, we varied spatial and object consistency in a fashion analogous to that in Experiments 1A–1D. We also introduced a medium-load group to examine graded differences in visual search behavior and incidental recognition. Finding that RTs decrease across trials would suggest that learning occurs not only during exhaustive search, but also during more variable, self-terminating search. Conversely, if RTs are stable across trials, it would suggest that learning is driven by exhaustive searches, wherein every item is examined on every trial. With respect to WM load, we expected the intermediate-load group to exhibit learning that would fall between the performance levels of the low- and high-load groups. If, however, performance for the medium-load group fell in line with that for the high-load group, it would suggest a qualitative difference between holding one object in memory and holding several objects in memory. The stimuli and apparatus were identical to those in Experiment 1.
Method
Participants
Six hundred two students from Arizona State University participated in Experiment 2 in partial fulfillment of a course requirement. Approximately 50 students participated in each of 12 between-subjects conditions. All the participants had normal or corrected-to-normal vision.
Design
Four levels of spatial and object consistency were manipulated between subjects (see Figure 1). Three levels of WM load (low, medium, high) were manipulated between subjects.
Procedure
The participants completed two 20-trial blocks of visual search, for a total of 40 trials. Each block entailed repeated presentations of the same distractor images for all 20 trials (except in Experiment 2D). A 1-min break was placed between blocks to allow the participants to rest. A new distractor set was introduced in the second block of trials and was again used for all 20 trials. Order of presentation of distractor sets was counterbalanced across participants. In Experiment 2D, distractor sets were randomly composed on each trial, with the constraint that each image be presented equally often across the entire experiment.
The participants were instructed that at the beginning of each trial, they would see two, three, or four different potential targets (low, medium, and high WM conditions, respectively) that should be kept in mind. Search was concluded by pressing the space bar once any target was located (only one target was present). Afterward, the participants were shown the target images once more and indicated which target had appeared in the search array, using the keyboard. Target images were randomized and were not repeated. Two practice trials were administered, and none of the practice stimuli were used in the rest of the experiment. After visual search, the participants were given a surprise 2AFC recognition memory test for distractor images encountered during search (all 40 distractors were tested). The procedure was identical to that in Experiment 1.
Results
The exclusion criteria from Experiment 1 were used in Experiment 2. Thirty-three participants (5%) were excluded from analysis, 7 for poor search accuracy, 10 for below-chance 2AFC performance, and 16 for excessive visual search times. Overall, search errors were again infrequent (7%; see Table A2 for the results).3
Visual search RTs
As in Experiment 1, although Experiment 2 had many conditions, the results are easily summarized: The key learning results of Experiment 1 were replicated, but learning was eliminated in Experiment 2D. Search times from accurate trials were entered into a four-way repeated measures ANOVA with experiment (2A, 2B, 2C, and 2D), WM load (low, medium, high), block (1 or 2), and epoch (1–4) as factors. The main effect of experiment was not significant [F(3,558) = 1.51, p = .21]. As before, we found an effect of load [F(2,558) = 292.79, p < .001, ], with faster search among lower load groups (2,609, 3,621, and 4,318 msec, for low, medium, and high load, respectively). There was a small effect of block [F(1,558) = 4.49, p = .034, ], with slower search in Block 1 (3,559 msec) than in Block 2 (3,473 msec). Of key interest, we again found an effect of epoch [F(3,556) = 15.24, p < .001, ], since search RTs decreased within blocks of trials (with mean RTs of 3,751, 3,517, 3,411, and 3,385 msec for Epochs 1–4, respectively). Figure 7 shows mean search times, plotted across epochs, as a function of experiment and load.
Figure 7.

Time series analysis showing mean visual search response times (rTs) as a function of epoch in Experiment 2. The results are plotted separately for each working memory load group.
We found two interactions. Of primary importance, there was an experiment × epoch interaction [F(9,1353) = 2.57, p = .006, ]. Learning slopes were steepest in Experiment 2A (−237 msec/epoch), followed by Experiment 2C (−126 msec/epoch), Experiment 2B (−75 msec/epoch), and Experiment 2D (−43 msec/epoch). We also found a load × block interaction [F(2,558) = 3.14, p = .044, ]: The low-load and high-load groups showed decreased mean search RTs from Block 1 to Block 2 (by 164 and 153 msec for low and high load, respectively), but the medium-load group showed increased RTs across blocks (by 58 msec).
As in Experiment 1, we assessed simple effects of epoch in each experiment. We found significant effects of epoch in the first three experiments: Experiment 2A, F(3,140) = 13.69, p < .001, (mean RTs of 3,905, 3,444, 3,326, and 3,154 msec for Epochs 1–4, respectively); Experiment 2B, F(3,138) = 4.38, p = .006, (mean RTs of 3,776, 3,583, 3,367, and 3,598 msec); Experiment 2C, F(3,139) = 3.56, p = .016, (mean RTs of 3,702, 3,421, 3,386, and 3,295 msec). The effect of epoch was not significant in Experiment 2D [F(3,133) = 0.74, p = .528] (with mean RTs of 3,619, 3,619, 3,564, and 3,494 msec).
As in Experiment 1, we performed three ANOVAs, separately comparing Experiment 2A with each of the other experiments. We were again interested in potential experiment × epoch interactions. Experiment 2C did not exhibit a significantly different learning slope, relative to Experiment 2A [F(3,281) = 1.38, p = .249]. However, the learning slope in Experiment 2A was significantly steeper than those in both Experiments 2B and 2D [F(3,280) = 3.84, p = .01, ; and F(3,275) = 5.55, p = .001, ]. Figure 8 presents search RTs as a function of experiment and epoch, collapsed across load and block; RTs are again scaled to the proportions of Epoch 1 means, per group.
Figure 8.
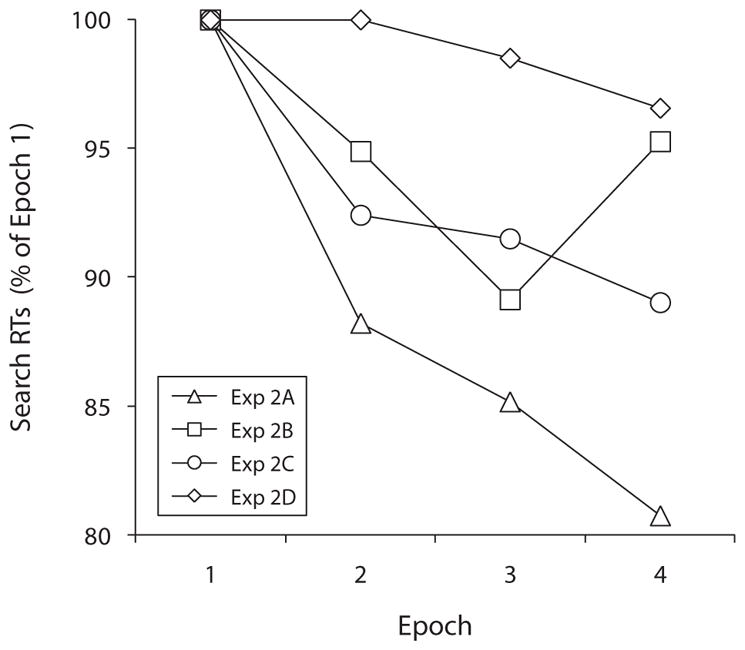
Time series analysis showing mean visual search response times (rTs) as a function of experiment and epoch in Experiment 2. The results are scaled to the proportion of mean search rTs in Epoch 1, per group.
Recognition
Figure 9 shows mean recognition accuracy as a function of experiment and load. All the groups again performed well above the empirically established baseline of 59%. Recognition accuracy was entered into a two-way ANOVA, with experiment and WM load as factors. We found an effect of experiment [F(3,558) = 6.14, p < .001, ], with the best performance in Experiments 2B and 2D (both 74%), followed by Experiment 2A (73%) and Experiment 2C (70%). There was also an effect of load [F(2,558) = 67.46, p < .001, ], with better memory among the higher load groups (66%, 74%, and 78% for low-, medium-, and high-load groups, respectively). The interaction was not significant (F < 1).
Figure 9.
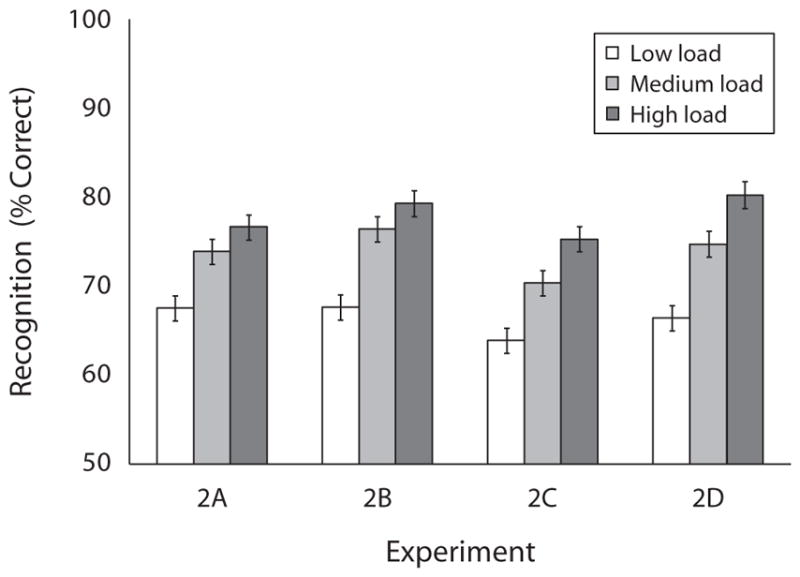
Recognition memory performance in Experiment 2. The results are plotted as a function of experiment and working memory load.
Discussion
Experiment 2 supported the findings of Experiment 1, corroborating the prior results in a different search task. In Experiment 2, exhaustive searching was not required unless the target was the last possible item to be viewed. Lower load groups continued to perform more quickly and more accurately, relative to higher load groups. With the addition of the medium-load group, we found that this is a graded phenomenon, rather than a qualitative difference between single- and multiple-target search. Search RTs and recognition performance varied as a direct function of WM load. Although this is not particularly surprising, it is nevertheless important and lends credence to the notion that the more targets a person searches for, the more his or her WM resources are taxed (Menneer et al., 2007; Menneer et al., 2009).
Search times were analogous to those in our prior findings. In each of the first three subexperiments, RTs decreased within blocks of trials (although the effect was diminished in Experiment 2B). However, in Experiment 2D, RTs did not decrease, remaining essentially flat across epochs. Learning slopes were steeper in Experiment 2A than in Experiment 2D, suggesting that learning was driven largely by the repetition of distractor objects within blocks. It would be reasonable to assume that, in Experiment 1, the bulk of distractor learning occurred on target-absent trials, wherein all items and locations were viewed at least once per trial. Target-absent trials would have provided greater encoding opportunity, relative to the shorter target-present trials. Regardless, Experiment 2 showed that even nonexhaustive search can support incidental learning of displays.
Although we found a practice effect, it was again much smaller in magnitude than the decrease in RTs within blocks: The main effect of block accounted for 1% of the variance in RTs, with an 86-msec drop from Block 1 to Block 2. By contrast, the main effect of epoch accounted for 8% of the variance, with a 366-msec drop in RTs from the first to last epochs. It appears that object memory facilitates search performance, even in target-present search. Lastly, we replicated our prior recognition findings. People remembered distractor items at levels exceeding chance, despite having fewer exposures to the stimuli, relative to Experiment 1. Higher load groups once more outperformed the lower load groups.
EXPERIMENT 3
In both Experiments 1 and 2, we identified a nonintuitive finding wherein an increased WM load during visual search resulted in greater incidental retention of distractor objects. However, because high-load groups also performed search more slowly, it is possible that they exhibited better memory simply because they were afforded greater viewing opportunities. To assess this finding more directly, in Experiment 3, we equated stimulus exposure across WM load groups. Following Williams (2009), we employed a rapid serial visual presentation (RSVP) task: Participants saw each member of the search set, presented centrally in rapid succession. People no longer self-terminated their own search process: They viewed each image for 250 msec, making search decisions after all the items had been shown. The participants in Experiment 3A indicated target presence versus absence, and the participants in Experiment 3B (in which targets were always present) indicated which of several targets had been shown in the stream. WM load was now a blocked within-subjects variable. In this way, stimulus exposure was identical across WM load conditions. Following search trials, we tested recognition memory for distractors, as before.
If increased viewing time was solely responsible for the previous load effect on recognition, we should no longer find such an effect in Experiment 3, or we might find a reversal. Alternatively, if higher WM loads still increased retention of visual information, it would suggest that load has an independent influence on incidental memory, perhaps due to the increased mental comparisons necessary for multiple target search or an inability to inhibit task-irrelevant information in the presence of load.
Method
Participants
One hundred twenty-eight students from Arizona State University participated in Experiment 3 in partial fulfillment of a course requirement. Fifty-nine students participated in Experiment 3A, and 69 students participated in Experiment 3B. All the participants had normal or corrected-to-normal vision.
Design
Two levels of WM load (low, high) were manipulated within subjects. In Experiment 3A, presence of the target during search (absent, present) was a within-subjects variable in equal proportions. In Experiment 3B, targets were present on every trial.
Procedure
In Experiment 3A, the participants completed two 40-trial blocks of visual search, for a total of 80 trials. Each block entailed repeated presentations of the same distractor images for all 40 trials. A 1-min break separated blocks, and a new distractor set was introduced in the second block of trials. Distractor sets were randomly generated for each participant, although the stimuli were identical to those in Experiments 1 and 2.
The participants were instructed that, at the beginning of each trial, they would see either one or three different potential targets (low- and high-WM conditions, respectively) that should be kept in mind. After a space bar press, the participants were shown a central fixation cross for 250 msec, followed by a stream of 20 images in rapid succession. On target-absent trials, each of the 20 distractors was shown centrally for 250 msec, followed by a 50-msec blank screen and then the next distractor. Order of presentation of distractors within the stream was randomized. On target-present trials, a single target object replaced a distractor, and placement of the target within the stream was randomized. Following the search stream, the participants indicated target presence or absence, using the keyboard. Target images were randomized and were not repeated. Six practice trials were administered (three per WM load condition), and none of the practice stimuli were used in the rest of the experiment. WM load was blocked; each participant performed one block of single-target search and one block of three-target search, with a counterbalanced order of presentation. After the visual search blocks, the participants were given a surprise 2AFC recognition memory test for distractor images encountered during search; the procedure was identical to that in Experiments 1 and 2.
In Experiment 3B, the participants completed two 20-trial blocks of visual search, for a total of 40 trials. The participants searched for either two or four different potential targets (low- and high-WM conditions, respectively). A single target was always present in the stream of objects. Following the search stream, the participants were again shown the target images and indicated which target had appeared, using the keyboard. In all other respects, the procedure and stimuli were identical to those in Experiment 3A.
Results
Three participants (2%) were excluded from analysis, 2 for poor search accuracy and 1 for below-chance recognition performance. Overall, search errors were very low (3% and 5% for Experiments 3A and 3B, respectively; see Table A3 for the results).4
Experiment 3A
Recognition accuracy was entered into a one-way ANOVA, analyzed as a function of WM load (low, high) at the time of encoding. The main effect of load was significant [F(1,56) = 10.23, p = .002, ], with better memory for distractors encoded during high-load trials (94%) than for those encoded during low-load trials (89%).
Experiment 3B
Recognition accuracy was analyzed as in Experiment 3A. We found a main effect of load [F(1,67) = 10.19, p = .002, ], with better memory for distractors encoded during high-load trials (89%) than for those encoded during low-load trials (83%). Figure 10 shows mean recognition accuracy as a function of load for both experiments.
Figure 10.
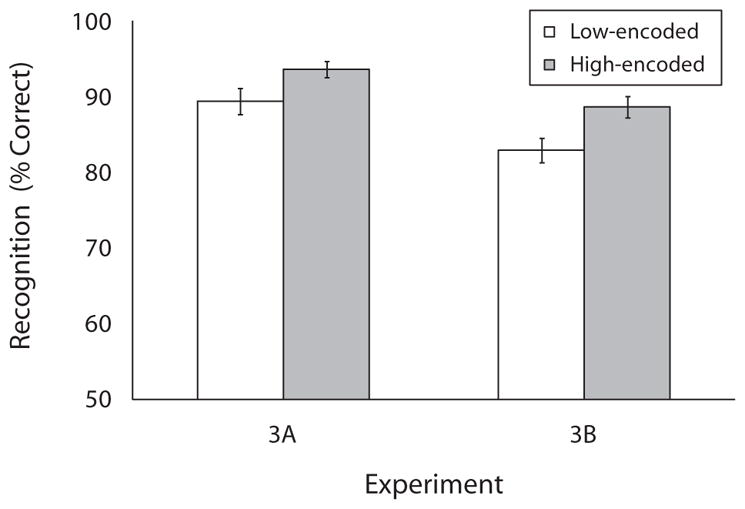
Recognition memory performance in Experiment 3. The results are plotted as a function of working memory load for both Experiments 3A and 3B.
Discussion
In line with the previous two experiments, loaded search was accompanied by an accuracy cost; multiple-target search, even in a passive task, is more difficult than single-target search. Importantly, Experiment 3 solidified the finding that increased WM load during search results in greater incidental memory. Although the low- and high-load conditions entailed equal exposure to the distractors, the high-load condition still produced higher recognition scores. Notably, the effect was diminished, relative to Experiments 1 and 2 (the average effect was 11.5% in Experiments 1 and 2 and 5.5% in Experiment 3), suggesting that exposure duration affected incidental memory in the first two experiments. Nevertheless, Experiment 3 suggests that WM load has an independent, substantial role in determining the amount of information acquired incidentally.5
GENERAL DISCUSSION
The present investigation focused on the extent to which people can learn from repeated visual search and how memory for repeated distractors can improve performance. The notion that people learn from repeatedly searching through a consistent environment is familiar (Chun & Jiang, 1999; Endo & Takeda, 2004; Mruczek & Sheinberg, 2005; Wolfe et al., 2000). Our findings built upon previous work by elucidating the relationship between object and spatial learning in a complex search task with real-world stimuli. Furthermore, we examined the effect of varying WM load on both search performance and incidental learning. In Experiment 1A, wherein objects were consistently mapped to fixed locations, search performance could be improved via learning of both spatial layouts and distractor identities. There was an imperfect correlation between object locations and identities in Experiment 1B; people could learn from both spatial and item memory, but not their conjunction. No valid spatial information was available in Experiment 1C, since objects were located randomly on each trial. If the participants in the first two conditions had benefitted only from repeated spatial layouts, we should have observed no improvement over trials in the third condition. However, we found shorter search RTs over trials in all these conditions, suggesting that people can improve performance by learning distractor identities alone, without stable locations in space. Critically, when distractor identities were less predictable in Experiment 1D, performance was significantly diminished, despite the consistency of spatial layouts across trials. Experiment 2 replicated each of these effects, showing that such learning does not require exhaustive search. Moreover, during target-present search, learning in the absence of object consistency (Experiment 2D) was diminished to nonsignificance, further suggesting that object learning was critical to search performance.
An argument could be made that it was not visual (i.e., perceptual) memory that was used to facilitate search but, rather, memory for the semantic labels of distractor items. Unlike prior work that showed better search performance through learning of abstract shapes (Chun & Jiang, 1999; Endo & Takeda, 2004), our objects were real-world, nameable items. Therefore, the participants in our study may not have learned their visual patterns but, rather, their semantic labels. Although this possibility cannot be ruled out entirely, we find it unlikely for two reasons: (1) Visual identification of an object necessarily precedes semantic retrieval, making it a likely candidate for search facilitation; and (2) recognition performance indicated substantial visual memory. Because our recognition tests entailed 2AFC with matched foils, the participants were required to discriminate between two semantically identical visual icons. These tests elicited above-chance performance, demonstrating visual memory. Our findings are consistent with those in Mruczek and Sheinberg (2005) and suggest that incidental encoding of distractor identities allows people to more efficiently analyze and dismiss nontargets, facilitating performance as the items are learned.
By looking at RTs across experiments, it becomes clear that repeated spatial layouts also affect performance in visual search. If spatial information was not important, we would expect equivalent RTs across the various levels of spatial consistency (i.e., Experiments 1A, 1B, and 1C), and learning would thus be attributed to object memory alone. This, however, was not the case: When spatial layouts were held constant, RTs were shorter, relative to when spatial information was degraded or eliminated. That spatial memory may facilitate search performance is, of course, consistent with the contextual-cuing paradigm (Chun & Jiang, 1998, 2003; Jiang & Leung, 2005; Jiang & Song, 2005), wherein repeated spatial configurations engender faster target location. Moreover, Kunar, Flusberg, and Wolfe (2008) found that, when only a subset of the search items are relevant, people can learn to restrict their attention to the pertinent locations in space. In a search task using letters, participants indicated the presence or absence of a target letter presented among distractors; only a subset of letters were used as potential targets. In the repeated condition, the search array was fixed across trials (in the unrepeated condition, search items changed on each trial). The participants in this condition learned to restrict their attention to relevant locations, those in which targets consistently appeared. Search RTs varied as a function of the probed set size (i.e., the number of letters/locations used as targets), but not the screen set size (i.e., the total number of letters on the screen), suggesting that the participants used memory for spatial locations to guide visual search.
Our results also include a curious finding, in which the complete absence of spatial information (Experiment 1C) resulted in shorter search times, relative to a condition in which spatial layouts were repeated but were not consistently mapped to object identities (Experiment 1B). It would be reasonable to expect the opposite effect, wherein any repeated spatial layout is conducive to faster search, relative to randomized configurations. Hollingworth (2007) provided some insight. He used a change detection task to investigate whether object position representations are defined according to relative or absolute spatial locations. Participants studied natural scenes or object arrays for brief durations (400–4,000 msec, depending on the task), followed by a blank screen or masked interstimulus interval. The test image was then presented, and the participants were cued to indicate whether a single target object was the same as or different from that in study. In the change condition, the target was left–right mirrored. Additionally, the target either appeared in the same position within the display or was placed in a different location (the participants were instructed that target location had no bearing on the task and simply to respond on the basis of the image). Performance was higher when the target position remained constant, but this same-position advantage (see also Hollingworth, 2006) was reduced when contextual changes in the test display disrupted the relative spatial relationships among objects. When contextual changes preserved the relative spatial relationships, the same-position advantage remained stable. Hollingworth (2007) concluded that object positions are defined relative to the overall spatial arrangement, rather than absolute spatial locations. It is therefore not surprising that search times were shortest in Experiment 1A, wherein the relative (and absolute) spatial locations of objects were preserved across trials. We suggest that, in Experiment 1B, the repeated spatial configurations encouraged incidental learning for the overall layout but that interference was caused by the random object-to-location changes, since these would have disrupted the relative spatial relationships among the distractors. Complete randomization of search arrays (Experiment 1C) would preclude memory for spatial configurations, thereby removing this potential interference.
Alternatively, our findings may be explained by a fixation recency effect. Körner and Gilchrist (2007) found that the time necessary to locate a target letter in repeated visual search depended on when that letter had last been fixated in the previous search. The more recently an item had been fixated on the previous trial, the faster it could be found when it became a target on the next trial. Memory for the identity and location of an object on trial n may, therefore, have created interference whereby the object was expected to appear in the same location on trial n+1. Again, complete randomization of the search arrays in Experiment 1C would eliminate any potential fixation recency effects, reducing interference, relative to Experiment 1B. With regard to Experiment 2, although the main effect of Experiment was not significant (p = .21), the trend for longest RTs in Condition 2B was consistent with the results in Experiment 1. We recently replicated this finding in a similar study using eyetracking (Hout & Goldinger, 2009). Further work is necessary to resolve this curious effect.
Finally, the recognition data suggest that incidental memory for distractors was generated during search, consistent with the findings of Williams et al. (2005). Although the participants were not instructed to encode the distractor images, people in all the experiments consistently performed above the empirically established chance level of 59%. Moreover, despite experiencing greater difficulty with the search task, our higher load groups consistently outperformed the lower load groups in recognition memory. In Experiments 1 and 2, loaded participants searched longer and remembered distractors better, relative to lower load groups. It was therefore possible that the higher load groups learned more simply because they were afforded greater opportunity to encode the material. Indeed, prior work has shown that visual memory tends to increase as objects are viewed more often (Hollingworth, 2005; Hollingworth & Henderson, 2002; Melcher, 2006; Tatler, Gilchrist, & Land, 2005). Specifically, Williams (2010) monitored eye movements in a visual search task for pictures of real-world objects. Regression analyses indicated that distractor memory was best predicted by the amount of viewing (total fixation time, fixation count) that an object received, rather than by the number of times an item was presented. Although the present results do not rule out the possibility that increased viewing behavior affected recognition memory in favor of higher load groups, in Experiments 1 and 2, the results of Experiment 3 indicated that WM load has an effect independently of increasing exposure to the distractors.
The participants in Experiment 3 performed visual search in an RSVP task that equated distractor exposure across levels of WM load (each distractor was shown for 250 msec per trial, except when replaced by the target). Once again, distractors encoded during high-load search trials were remembered better than those encoded during low-load search. We posit two potential (nonexclusive) explanations for this effect. First, when more careful discriminations are required to reject distractors, it results in deeper encoding. Holding several targets in mind requires people to make multiple mental comparisons (e.g., Sternberg, 1966). Therefore, processing of the distractors may occur to a fuller extent, relative to single-target comparisons, enabling higher load groups to better differentiate between old distractors and foils.
Second, when WM capacity is decreased by a cognitive load, it reduces participants’ ability to block out distracting information. Previous work has shown that people under cognitive load are more distracted by task-irrelevant information (de Fockert, Rees, Frith, & Lavie, 2001; Lavie & de Fockert, 2005; Lavie, Hirst, de Fockert, & Viding, 2004). Conway et al. (2001) examined the cocktail party phenomenon (Moray, 1959; Wood & Cowan, 1995), comparing people with low and high WM capacities (see Conway, Tuholski, Shisler, & Engle, 1999; Engle, Conway, Tuholski, & Shisler, 1995; Gazzaley, Cooney, Rissman, & D’Esposito, 2005). In a dichotic listening task, people attended to speech in noise; participants’ names were occasionally interjected into the unattended stream. People with low WM capacity (analogous to our high-load groups) were more likely to be distracted by their names, relative to those with high WM capacity. It is possible that our load manipulation decreased WM resources, enabling distractor identities to permeate memory to a greater extent.
Taken together, our findings suggest that memory for distractors is incidentally generated during visual search when target and distractors are depictions of real-world objects. Although such learning does not increase the efficiency of visual search (Wolfe et al., 2000), it nevertheless reduces search time. Given repeated distractors, participants improved search performance despite having no indication of target identity, location, or presence. Moreover, repeated objects generate incidental learning, as reflected in later visual memory, especially when people operate under a visual WM load.
Acknowledgments
Support was provided by NIH Grant R01-DC04535-10 to the second author. We thank Kiera Kunkel and Matt Fickett for assistance in data collection. We also thank Yuhong Jiang, Carrick Williams, Zhe Chen, and Thomas Geyer for helpful comments on previous versions of the manuscript.
APPENDIX
Table A1.
Visual Search Error rates (in Percentages) As a Function of Working memory (Wm) Load, Trial Type, and Epoch, From Experiment 1
| WM Load Group | Trial Type
|
||||||||
|---|---|---|---|---|---|---|---|---|---|
| Target Absent
|
Target Present
|
||||||||
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | ||
| Experiment 1A | Low | 1 | 1 | 1 | 1 | 5 | 5 | 5 | 4 |
| High | 5 | 3 | 4 | 7 | 16 | 18 | 16 | 18 | |
| Experiment 1B | Low | 1 | 1 | 1 | 1 | 6 | 6 | 6 | 6 |
| High | 6 | 3 | 3 | 4 | 18 | 14 | 12 | 13 | |
| Experiment 1C | Low | 2 | 2 | 1 | 2 | 9 | 6 | 6 | 6 |
| High | 4 | 5 | 5 | 4 | 17 | 16 | 15 | 16 | |
| Experiment 1D | Low | 2 | 1 | 2 | 2 | 6 | 4 | 6 | 6 |
| High | 3 | 3 | 4 | 5 | 16 | 18 | 17 | 17 | |
Note—Data are presented collapsed across blocks, since there were no significant differences between the first and second blocks.
Table A2.
Visual Search Error rates (in Percentages) As a Function of Working memory (Wm) Load and Epoch, From Experiment 2
| WM Load Group | Epoch
|
||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||
| Experiment 2A | Low | 1 | 2 | 1 | 3 |
| Medium | 3 | 3 | 4 | 3 | |
| High | 6 | 5 | 3 | 5 | |
| Experiment 2B | Low | 0 | 1 | 2 | 1 |
| Medium | 3 | 2 | 5 | 2 | |
| High | 5 | 4 | 5 | 4 | |
| Experiment 2C | Low | 1 | 0 | 1 | 2 |
| Medium | 5 | 4 | 4 | 3 | |
| High | 5 | 5 | 4 | 4 | |
| Experiment 2D | Low | 2 | 1 | 2 | 2 |
| Medium | 3 | 2 | 4 | 4 | |
| High | 5 | 5 | 5 | 4 | |
Note—Data are presented collapsed across blocks, since there were no significant differences between the first and second blocks.
Table A3.
Visual Search Error rates (in Percentages) As a Function of Working memory (Wm) Load and Trial Type, From Experiment 3
| WM Load Group | Trial Type
|
||
|---|---|---|---|
| Target Absent | Target Present | ||
| Experiment 3A | Low | 1 | 2 |
| High | 3 | 6 | |
| Experiment 3B | Low | – | 2 |
| High | – | 8 | |
Footnotes
We examined visual search error rates in a five-way, repeated measures ANOVA (see Experiment 1, visual search RTs). We found main effects of load and trial type (both Fs > 200, ps < .001). Error rates were higher among the high-load groups than among the low-load groups, and the participants committed more misses than false alarms. The main effects of experiment, block, and epoch were not significant (all Fs < 2). We found three interactions: load × trial type, block × epoch, and trial type × block × epoch (all Fs > 3, ps < .05).
Learning slope refers to the slope of the best-fitting line for RT as a function of epoch.
We examined visual search error rates in a four-way repeated measures ANOVA (see Experiment 2, visual search RTs). We found a main effect of load (F > 36, p < .001), with fewer errors among lower load groups. The main effects of experiment, block, and epoch were not significant (all Fs < 2). We also found a load × epoch interaction (F > 2, p < .05).
For Experiment 3A, we examined visual search error rates in a two-way repeated measures ANOVA. We found main effects of load and trial type (both Fs > 16, ps < .001), with fewer errors on low-load trials than on high-load trials and more misses than false alarms. The interaction was not significant (F < 4). For Experiment 3B, we examined visual search error rates as a function of load. The participants committed fewer errors on low-load trials than on high-load trials (F > 43, p < .001).
We also investigated this issue in an active search task, wherein participants searched for targets in randomly generated four-item arrays. Search trials were 1 sec in duration, and each distractor was shown 21 times throughout the experiment (WM load was blocked within subjects). Distractors seen during high-load blocks (79%) were remembered significantly better than were those seen during low-load blocks (67%) [F(1,22) = 19.27, p < .001, ].
References
- Castelhano MS, Henderson JM. Incidental visual memory for objects in scenes. Visual Cognition. 2005;12:1017–1040. doi: 10.1080/13506280444000634. [DOI] [Google Scholar]
- Chun MM, Jiang Y. Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology. 1998;36:28–71. doi: 10.1006/cogp.1998.0681. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Top-down attentional guidance based on implicit learning of visual covariation. Psychological Science. 1999;10:360–365. doi: 10.1111/1467-9280.00168. [DOI] [Google Scholar]
- Chun MM, Jiang Y. Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2003;29:224–234. doi: 10.1037/0278-7393.29.2.224. [DOI] [PubMed] [Google Scholar]
- Conway ARA, Cowan N, Bunting MF. The cocktail party phenomenon revisited: The importance of working memory capacity. Psychonomic Bulletin & Review. 2001;8:331–335. doi: 10.3758/bf03196169. [DOI] [PubMed] [Google Scholar]
- Conway ARA, Tuholski SW, Shisler RJ, Engle RW. The effect of memory load on negative priming: An individual differences investigation. Memory & Cognition. 1999;27:1042–1050. doi: 10.3758/bf03201233. [DOI] [PubMed] [Google Scholar]
- Craik FIM, Lockhart RS. Levels of processing: A framework for memory research. Journal of Verbal Learning & Verbal Behavior. 1972;11:671–684. doi: 10.1016/S0022-5371(72)80001-X. [DOI] [Google Scholar]
- de Fockert JW, Rees G, Frith CD, Lavie N. The role of working memory in visual selective attention. Science. 2001;291:1803–1806. doi: 10.1126/science.1056496. [DOI] [PubMed] [Google Scholar]
- Endo N, Takeda Y. Selective learning of spatial configuration and object identity in visual search. Perception & Psychophysics. 2004;66:293–302. doi: 10.3758/bf03194880. [DOI] [PubMed] [Google Scholar]
- Engle RW, Conway ARA, Tuholski SW, Shisler RJ. A resource account of inhibition. Psychological Science. 1995;6:122–125. doi: 10.1111/j.1467-9280.1995.tb00318.x. [DOI] [Google Scholar]
- Frith U. A curious effect with reversed letters explained by a theory of schema. Perception & Psychophysics. 1974;16:113–116. [Google Scholar]
- Gazzaley A, Cooney JW, Rissman J, D’Esposito M. Top-down suppression deficit underlies working memory impairment in normal aging. Nature Neuroscience. 2005;8:1298–1300. doi: 10.1038/nn1543. [DOI] [PubMed] [Google Scholar]
- Hollingworth A. The relationship between online visual representation of a scene and long-term scene memory. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2005;31:396–411. doi: 10.1037/0278-7393.31.3.396. [DOI] [PubMed] [Google Scholar]
- Hollingworth A. Scene and position specificity in visual memory for objects. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2006;32:58–69. doi: 10.1037/0278-7393.32.1.58. [DOI] [PubMed] [Google Scholar]
- Hollingworth A. Object–position binding in visual memory for natural scenes and object arrays. Journal of Experimental Psychology: Human Perception & Performance. 2007;33:31–47. doi: 10.1037/0096-1523.33.1.31. [DOI] [PubMed] [Google Scholar]
- Hollingworth A, Henderson JM. Accurate visual memory for previously attended objects in natural scenes. Journal of Experimental Psychology: Human Perception & Performance. 2002;28:113–136. doi: 10.1037/0096-1523.28.1.113. [DOI] [Google Scholar]
- Hout MC, Goldinger SD. Incidental learning speeds visual search by lowering response thresholds, not by improving oculomotor behaviors: Evidence from eye movements. 2009 doi: 10.1037/a0023894. Manuscript submitted for publication. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jiang Y, Leung AW. Implicit learning of ignored visual context. Psychonomic Bulletin & Review. 2005;12:100–106. doi: 10.3758/bf03196353. [DOI] [PubMed] [Google Scholar]
- Jiang Y, Song JH. Hyperspecificity in visual implicit learning: Learning of spatial layout is contingent on item identity. Journal of Experimental Psychology: Human Perception & Performance. 2005;31:1439–1448. doi: 10.1037/0096-1523.31.6.1439. [DOI] [PubMed] [Google Scholar]
- Körner C, Gilchrist ID. Finding a new target in an old display: Evidence for a memory recency effect in visual search. Psychonomic Bulletin & Review. 2007;14:846–851. doi: 10.3758/bf03194110. [DOI] [PubMed] [Google Scholar]
- Kunar MA, Flusberg S, Wolfe JM. The role of memory and restricted context in repeated visual search. Perception & Psychophysics. 2008;70:314–328. doi: 10.3758/PP.70.2.314. [DOI] [PubMed] [Google Scholar]
- Lavie N, de Fockert JW. The role of working memory in attentional capture. Psychonomic Bulletin & Review. 2005;12:669–674. doi: 10.3758/bf03196756. [DOI] [PubMed] [Google Scholar]
- Lavie N, Hirst A, de Fockert JW, Viding E. Load theory of selective attention and cognitive control. Journal of Experimental Psychology: General. 2004;133:339–354. doi: 10.1037/0096-3445.133.3.339. [DOI] [PubMed] [Google Scholar]
- Melcher D. Accumulation and persistence of memory for natural scenes. Journal of Vision. 2006;6:8–17. doi: 10.1167/6.1.2. [DOI] [PubMed] [Google Scholar]
- Menneer T, Barrett DJK, Phillips L, Donnelly N, Cave KR. Costs in searching for two targets: Dividing search across target types could improve airport security screening. Applied Cognitive Psychology. 2007;21:915–932. doi: 10.1002/acp.1305. [DOI] [Google Scholar]
- Menneer T, Cave KR, Donnelly N. The cost of search for multiple targets: Effects of practice and target similarity. Journal of Experimental Psychology: Applied. 2009;15:125–139. doi: 10.1037/a0015331. [DOI] [PubMed] [Google Scholar]
- Moray N. Attention in dichotic listening: Affective cues and the influence of instructions. Quarterly Journal of Experimental Psychology. 1959;11:56–60. [Google Scholar]
- Mruczek REB, Sheinberg DL. Distractor familiarity leads to more efficient visual search for complex stimuli. Perception & Psychophysics. 2005;67:1016–1031. doi: 10.3758/bf03193628. [DOI] [PubMed] [Google Scholar]
- Reicher GM, Snyder CRR, Richards JT. Familiarity of background characters in visual scanning. Journal of Experimental Psychology: Human Perception & Performance. 1976;2:522–530. doi: 10.1037/0096-1523.2.4.522. [DOI] [PubMed] [Google Scholar]
- Richards JT, Reicher GM. The effects of background familiarity in visual search: An analysis of underlying factors. Perception & Psychophysics. 1978;23:499–505. [Google Scholar]
- Schneider W, Eschman A, Zuccolotto A. E-Prime user’s guide. Pittsburgh, PA: Psychology Software Tools; 2002. [Google Scholar]
- Sternberg S. High-speed scanning in human memory. Science. 1966;153:652–654. doi: 10.1126/science.153.3736.652. [DOI] [PubMed] [Google Scholar]
- Tatler BW, Gilchrist ID, Land MF. Visual memory for objects in natural scenes: From fixations to object files. Quarterly Journal of Experimental Psychology. 2005;58A:931–960. doi: 10.1080/02724980443000430. [DOI] [PubMed] [Google Scholar]
- Treisman AM, Gelade G. A feature-integration theory of attention. Cognitive Psychology. 1980;12:97–136. doi: 10.1016/0010-0285(80)90005-5. [DOI] [PubMed] [Google Scholar]
- Williams CC. Encoding and visual memory: Is task always irrelevant?. Paper presented at the 50th Annual Meeting of the Psychonomic Society; Boston. 2009. Nov, [Google Scholar]
- Williams CC. Not all visual memories are created equal. Visual Cognition. 2010;18:201–228. [Google Scholar]
- Williams CC, Henderson JM, Zacks RT. Incidental visual memory for targets and distractors in visual search. Perception & Psychophysics. 2005;67:816–827. doi: 10.3758/bf03193535. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wolfe JM, Klempen N, Dahlen K. Postattentive vision. Journal of Experimental Psychology: Human Perception & Performance. 2000;26:693–716. doi: 10.1037/0096-1523.26.2.693. [DOI] [PubMed] [Google Scholar]
- Wolfe JM, Oliva A, Butcher SJ, Arsenio HC. An unbinding problem? The disintegration of visible, previously attended objects does not attract attention. Journal of Vision. 2002;2(3):256–271. doi: 10.1167/2.3.5. [DOI] [PubMed] [Google Scholar]
- Wood NL, Cowan N. The cocktail party phenomenon revisited: Attention and memory in the classic selective listening procedure of Cherry (1953) Journal of Experimental Psychology: General. 1995;124:243–262. doi: 10.1037/0096-3445.124.3.243. [DOI] [PubMed] [Google Scholar]