

Abstract
We compare methods for estimating optimal dynamic decision rules from observational data, with particular focus on estimating the regret functions defined by Murphy (in J. R. Stat. Soc., Ser. B, Stat. Methodol. 65:331–355, 2003). We formulate a doubly robust version of the regret-regression approach of Almirall et al. (in Biometrics 66:131–139, 2010) and Henderson et al. (in Biometrics 66:1192–1201, 2010) and demonstrate that it is equivalent to a reduced form of Robins’ efficient g-estimation procedure (Robins, in Proceedings of the Second Symposium on Biostatistics. Springer, New York, pp. 189–326, 2004). Simulation studies suggest that while the regret-regression approach is most efficient when there is no model misspecification, in the presence of misspecification the efficient g-estimation procedure is more robust. The g-estimation method can be difficult to apply in complex circumstances, however. We illustrate the ideas and methods through an application on control of blood clotting time for patients on long term anticoagulation.
Keywords: Causal inference, Dynamic treatment regimes, G-estimation, Regret-regression
Introduction
A dynamic treatment regime is a decision rule, or set of decision rules, which determines how a treatment should be assigned to a patient over time. Typically a patient is observed at regular intervals, and at each visit a treatment decision or action A is made in response to measurements of state S taken at that visit together with the history of previous decisions and measurements. An optimal dynamic treatment regime is one which maximises an overall outcome Y measured at the end of a sequence of visits.
Since the seminal work of Murphy [15] there has been growing interest in biostatistical applications of decision rule methodology. Recent work includes Arjas and Saarela [1], Dawid and Didelez [6], Moodie et al. [13], Zhao et al. [21, 22]. The focus of most work has been on testing for treatment effects, typically for binary A and with rather few measurement times. Even in very simple circumstances there can be severe statistical challenges in this area (Chakraborty et al. [3]; Hernan et al. [10]; Moodie and Richardson [14]; Zhang et al. [20]).
Motivated by an application on anticoagulation, we suppose the treatment decision A is essentially continuous rather than categorical, and our interest is in estimation of optimal decisions rather than testing. We concentrate on the regret functions proposed by Murphy [15], which are defined in Sect. 2 and form a particular case of the so-called advantage learning class of approaches. A variety of methods have been proposed for estimation from observational or trial data (e.g. Moodie et al. [12]; Almirall et al. [2]; Henderson et al. [8]; Zhang et al. [20]; Zhao et al. [21, 22]). Some of these rely on knowledge or assumptions on the process by which decisions on treatment A are reached, which is straightforward for a randomised trial, and some of which rely on modelling the evolution of the states S as time proceeds. A particular case of the former is the g-estimation procedure proposed by Robins [17], and beautifully summarised by Moodie et al. [12]. A special case of the latter is the so-called regret-regression approach that was proposed independently by Almirall et al. [2] and Henderson et al. [8]. These methods all formulate the problem in terms of the structural nested mean models (SNMMs) described by Robins [17]. An alternative approach based on marginal structural models has been proposed by Orellana et al. [16], which allows the estimation of simple dynamic treatment rules. For example, the decision when to start a treatment may be based on state measurements progressing beyond a threshold, which must be determined. We will focus on the SNMM approaches in this paper.
An estimation method is doubly robust if it gives consistent parameter estimates whenever either the state mechanism S or the action process A has been modelled correctly. The g-estimation method is founded, as stated, on knowledge of the decision or action process A. If there is also assumed knowledge of the state S mechanism then a doubly robust form can be constructed (Robins [17]). It is of interest therefore to ask whether a doubly robust form of the regret-regression approach can be found. In Sect. 3 below we propose such a modification and we show how it is closely linked to doubly robust g-estimation. In Sect. 4 we use simulation to compare performance of various methods in terms of efficiency and robustness, and in Sect. 5 we illustrate use in treatment of patients on long term anticoagulation therapy.
Modelling Dynamic Treatment Regimes
We assume that we have data from n independent individuals, each observed according to the same visit schedule consisting of K visits. At visit j, measurements are taken which define the current state S j of the patient and a treatment decision A j is made. After K visits an outcome Y is measured. Our aim is to use the observed data to determine the optimal dynamic treatment regime to maximise the outcome Y. As an illustration we will use data from a study investigating patients taking the anticoagulation treatment warfarin to avoid abnormal blood clotting. Here measurements of blood-clotting potential are taken at each visit, defining S j, and a dose of warfarin is prescribed, defining the action A j. The final outcome Y is the time spent with blood-clotting time within a target range over the entire course of follow-up.
Taking a potential outcomes (or counterfactual) approach (see for example Greenland et al. [7]), let  be the set of all possible actions that could be taken at visit j, and let
be the set of all possible actions that could be taken at visit j, and let 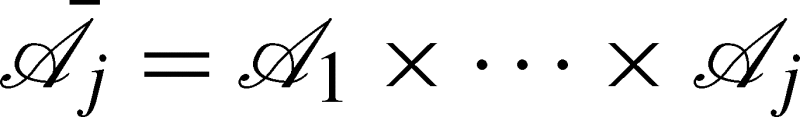 be the set of all possible treatment regimes up to visit j. For
be the set of all possible treatment regimes up to visit j. For 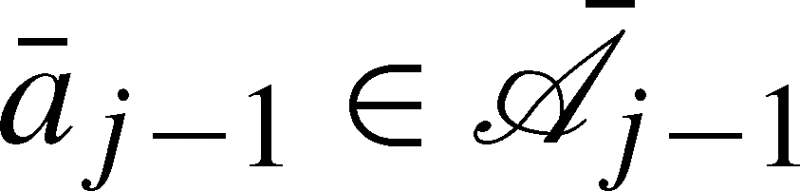 ,
, 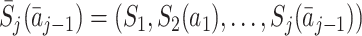 denotes the potential state history under the treatment regime
denotes the potential state history under the treatment regime  . Similarly,
. Similarly, 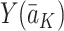 denotes the potential outcome under the treatment regime
denotes the potential outcome under the treatment regime 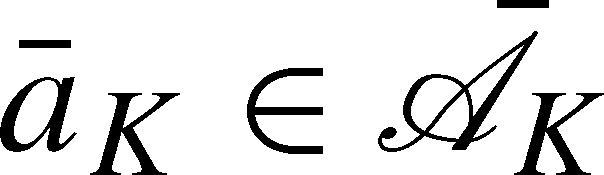 .
.
We make the consistency assumption that the observed state history  is equal to the potential state history
is equal to the potential state history  under the observed treatment regime
under the observed treatment regime 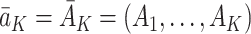 and that the observed outcome Y is equal to the potential outcome
and that the observed outcome Y is equal to the potential outcome 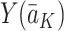 under the observed treatment regime
under the observed treatment regime 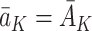 . In short, this means that the method by which treatments are assigned does not affect the values of the future states or the outcome (see Cole and Frangakis [5], for a thorough discussion of the consistency assumption). Throughout this paper we will therefore replace potential outcomes notation, e.g.
. In short, this means that the method by which treatments are assigned does not affect the values of the future states or the outcome (see Cole and Frangakis [5], for a thorough discussion of the consistency assumption). Throughout this paper we will therefore replace potential outcomes notation, e.g. 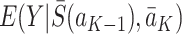 for the expected value of the potential outcome
for the expected value of the potential outcome 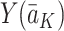 conditional on the treatment regime
conditional on the treatment regime 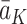 and potential state history
and potential state history 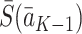 , with the observed outcomes notation
, with the observed outcomes notation 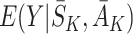 .
.
We also make the assumption of no unmeasured confounders, which means that the choice of treatment to be received does not depend on potential future states or the potential outcome except through observed state and treatment history. When no drop-out occurs this assumption is equivalent to exchangeability. It enables us to estimate causal effects from observational data (see Hernán and Robins [11], for a discussion of the exchangeability assumption). We make a third assumption of positivity, that the optimal treatment regime has a positive probability of being observed in the data or, in the case of a continuous treatment, that it is identifiable from the observed data (see Cole and Hernán [4], for a discussion of positivity and Henderson et al. [8], for the extension in the continuous case). All three assumptions are standard in causal inference.
Let 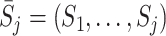 be the observed measurement history up to and including visit j, and
be the observed measurement history up to and including visit j, and 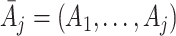 be the history of actions taken up to visit j. A dynamic treatment regime d is defined by a set of decision rules,
be the history of actions taken up to visit j. A dynamic treatment regime d is defined by a set of decision rules, 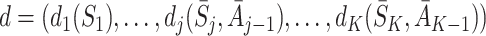 , which prescribe an action to be taken at each visit given all information available at the time of the visit, including the current state S
j. The optimal dynamic treatment regime
, which prescribe an action to be taken at each visit given all information available at the time of the visit, including the current state S
j. The optimal dynamic treatment regime 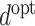 is the one which optimises the expected value of the outcome Y.
is the one which optimises the expected value of the outcome Y.
A naive approach to modelling the outcome would be to regress Y on state history 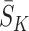 and action history
and action history 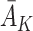 . However, this ignores the potential effect of previous actions
. However, this ignores the potential effect of previous actions 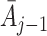 and states
and states 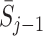 on the current state
on the current state 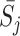 . Including the state S
j in the analysis may introduce bias because action history
. Including the state S
j in the analysis may introduce bias because action history 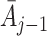 and state history
and state history 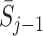 may influence both the current state S
j and the outcome Y.
may influence both the current state S
j and the outcome Y.
This problem can be solved by modelling quantities which isolate the causal effect of treatment A j on Y (see Hernán [9], for a discussion of the use of causal effects in causal inference). Murphy [15] proposed the use of regret functions which measure the expected decrease in Y due to an action a j taken at time j compared to the optimal action, given that optimal actions are used in the future. The regret at time j is defined by
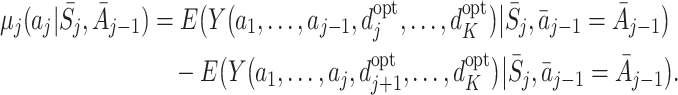 |
1 |
As an alternative Robins [17] suggested using a blip function which compares actions to a reference action a 0. The blip measures the expected change in Y when action a j is taken at time j compared to a 0, assuming future actions are a 0,
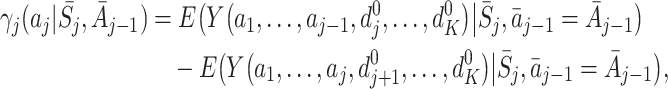 |
2 |
where the reference regime d 0 specifies that all actions are set to a 0.
It has been argued by Robins [17] that correct models can be specified more easily for blip functions because a comparison to a reference regime can be envisaged more readily by clinicians than a comparison to an unspecified optimal regime. However, determining the optimal regime from models for the blip functions can be computationally challenging, whereas the optimal action 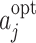 immediately follows from the form of the regret function because by construction
immediately follows from the form of the regret function because by construction 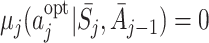 . Also, because the form of the optimal treatment immediately follows from the form of the regret function, the use of regrets enables us to restrict our attention to decision rules with simple forms (see also Rosthøj et al. [19]). For these reasons we will use regret functions in the rest of this paper.
. Also, because the form of the optimal treatment immediately follows from the form of the regret function, the use of regrets enables us to restrict our attention to decision rules with simple forms (see also Rosthøj et al. [19]). For these reasons we will use regret functions in the rest of this paper.
Estimating Optimal Dynamic Treatment Regimes
Two methods which can be used to estimate the optimal dynamic treatment regime are g-estimation (Robins [17], see also Moodie et al. [12]) and regret-regression, which was proposed independently by Henderson et al. [8] and Almirall et al. [2].
G-estimation
In order to estimate an optimal dynamic treatment regime using g-estimation, we must first specify models for the regret functions 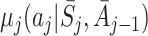 . The form of the regret functions determines the form of the optimal treatment rules. Hereafter, when we refer to an optimal decision rule we therefore mean the decision rule of the specified form which optimises the expected outcome. Models for μ
j may depend on parameters ψ, which may be shared across time-points. See Moodie et al. [12] and Moodie et al. [13] for examples of models with different parameters at different time-points. We then define
. The form of the regret functions determines the form of the optimal treatment rules. Hereafter, when we refer to an optimal decision rule we therefore mean the decision rule of the specified form which optimises the expected outcome. Models for μ
j may depend on parameters ψ, which may be shared across time-points. See Moodie et al. [12] and Moodie et al. [13] for examples of models with different parameters at different time-points. We then define
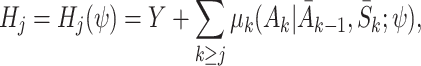 |
which provides an estimate of the expected outcome in the counterfactual event that optimal decisions are followed from time j onwards (Robins [17]; Moodie et al. [12]). For conciseness we shorten 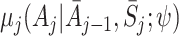 to μ
j for the remainder of this paper.
to μ
j for the remainder of this paper.
We also specify models for the probability density 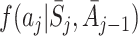 for the assigned value of the action A
j, conditional on state and action history, and for
for the assigned value of the action A
j, conditional on state and action history, and for 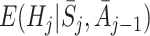 . We can then form the g-estimation equations
. We can then form the g-estimation equations
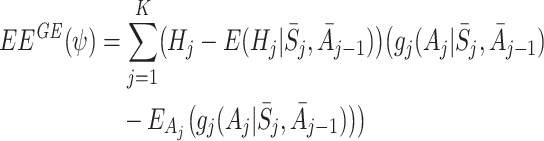 |
3 |
for some functions 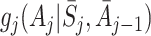 of the same dimension as ψ. It has been shown that solutions
of the same dimension as ψ. It has been shown that solutions 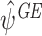 to E(EE
GE(ψ))=0 provide consistent estimates of ψ if the regret functions are correctly modelled and either the model specified for
to E(EE
GE(ψ))=0 provide consistent estimates of ψ if the regret functions are correctly modelled and either the model specified for 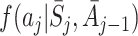 or the model specified for
or the model specified for 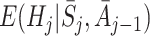 is correct (Robins [17]). We give a simpler proof in Appendix A.1. G-estimation is therefore doubly robust in the sense discussed in the Introduction.
is correct (Robins [17]). We give a simpler proof in Appendix A.1. G-estimation is therefore doubly robust in the sense discussed in the Introduction.
A simple choice for the functions g j(A j) is (Moodie et al. [12]):
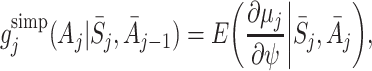 |
which can be calculated easily from the μ j(ψ). The alternative
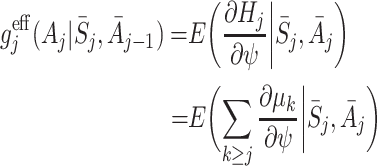 |
4 |
gives Robins’ [17] locally efficient semiparametric estimator of ψ. While 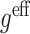 has been shown to be more efficient than
has been shown to be more efficient than 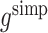 (Robins [17]), it can be more complicated to calculate because it requires expected values of μ
k conditional on
(Robins [17]), it can be more complicated to calculate because it requires expected values of μ
k conditional on 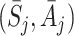 for k>j. In turn these require conditional expectations of (functions of) all S
k and A
k for k>j and hence detailed knowledge of both state and action evolution processes.
for k>j. In turn these require conditional expectations of (functions of) all S
k and A
k for k>j and hence detailed knowledge of both state and action evolution processes.
Regret-regression
Murphy [15] showed that 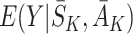 can be decomposed into a sum of regret functions μ
j and nuisance functions
can be decomposed into a sum of regret functions μ
j and nuisance functions 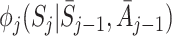 as follows:
as follows:
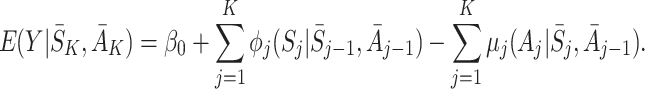 |
5 |
The nuisance function 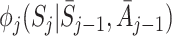 for j≥2 is defined to be
for j≥2 is defined to be
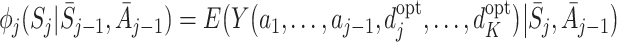 |
6 |
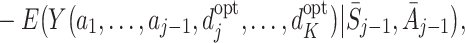 |
7 |
with 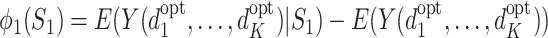 . The function
. The function 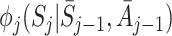 expresses the change in the expected value of Y due to the measurement of S
j when optimal decision rules are used in the future. Note that
expresses the change in the expected value of Y due to the measurement of S
j when optimal decision rules are used in the future. Note that 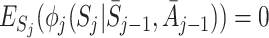 follows from the definition of
follows from the definition of 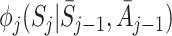 . Note also that the decomposition (5) requires the nuisance and regret functions to be defined as differences of expectations under the assumption that optimal policies are followed at future time-points. There is no similar decomposition with non-negative {μ
j} based on a comparison with non-optimal policies, such as the blip functions suggested by Robins [17] (see Appendix B).
. Note also that the decomposition (5) requires the nuisance and regret functions to be defined as differences of expectations under the assumption that optimal policies are followed at future time-points. There is no similar decomposition with non-negative {μ
j} based on a comparison with non-optimal policies, such as the blip functions suggested by Robins [17] (see Appendix B).
The decomposition (5) can be used to estimate regret parameters ψ if models are specified for the 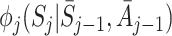 (Henderson et al. [8]; Almirall et al. [2]). To satisfy the condition
(Henderson et al. [8]; Almirall et al. [2]). To satisfy the condition 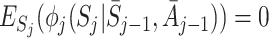 , Henderson et al. [8] suggested the form
, Henderson et al. [8] suggested the form
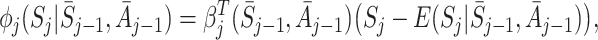 |
where 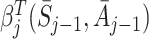 is a coefficient which may depend on the state and action history before time j. Under this approach a model must be specified for
is a coefficient which may depend on the state and action history before time j. Under this approach a model must be specified for 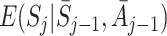 . Parameters can be estimated using least squares, which is equivalent to solving E(EE
RR(ψ))=0, where EE
RR(ψ) are the regret-regression estimating equations
. Parameters can be estimated using least squares, which is equivalent to solving E(EE
RR(ψ))=0, where EE
RR(ψ) are the regret-regression estimating equations
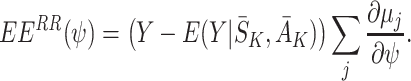 |
8 |
A proof is given in Appendix A.2 that the resulting estimates 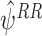 are consistent estimates for ψ provided the regret functions
are consistent estimates for ψ provided the regret functions 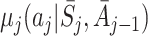 and the nuisance functions
and the nuisance functions 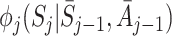 have been modelled correctly.
have been modelled correctly.
A natural question to ask is whether we can formulate a doubly robust version of regret-regression, which is robust to misspecification of either 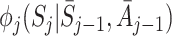 or the probability density
or the probability density 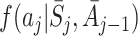 of assigning action A
j. A naive extension of the estimating equations (8) would be
of assigning action A
j. A naive extension of the estimating equations (8) would be
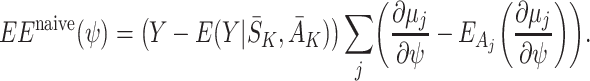 |
9 |
However, the resulting estimates 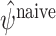 are not consistent if the
are not consistent if the 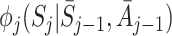 are misspecified because when we take the expectation over Y the left bracket of (9) retains some dependence on A
j for j=1,…,K−1 (see Appendix A). However, we obtain consistent estimates with the double-robustness property if we replace the sum in (9) with the contribution just from the final term:
are misspecified because when we take the expectation over Y the left bracket of (9) retains some dependence on A
j for j=1,…,K−1 (see Appendix A). However, we obtain consistent estimates with the double-robustness property if we replace the sum in (9) with the contribution just from the final term:
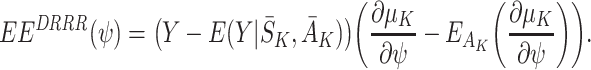 |
10 |
The estimators 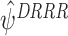 derived from (10) will be consistent because E(EE
DRRR)=0.
derived from (10) will be consistent because E(EE
DRRR)=0.
Note that
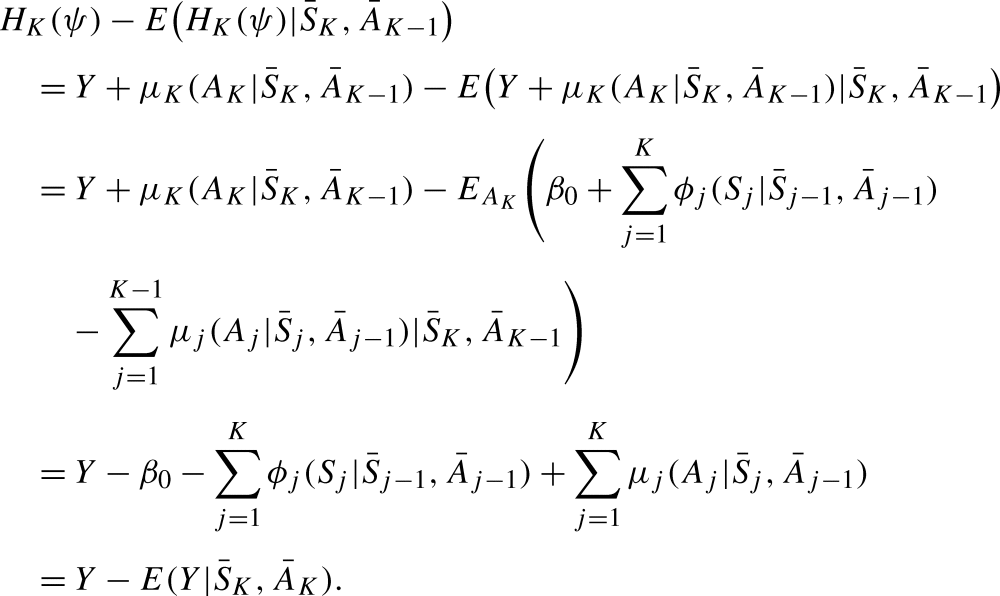 |
So the doubly robust regret-regression estimating equations (10) are identical to the final (j=K) term of the g-estimating equations (3) with 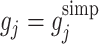 when
when 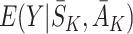 is modelled in the same way. Specification of
is modelled in the same way. Specification of 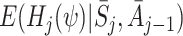 is equivalent to specification of the nuisance functions
is equivalent to specification of the nuisance functions 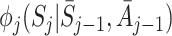 for regret-regression because
for regret-regression because
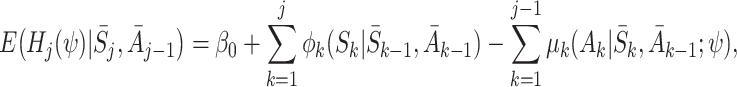 |
(see Appendix A.1). It may be difficult to identify an appropriate model for either 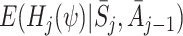 or
or 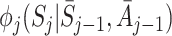 , and the choice of which to specify is likely to depend on the context. See Henderson et al. [8] and Rosthøj et al. [19] for further discussion about modelling
, and the choice of which to specify is likely to depend on the context. See Henderson et al. [8] and Rosthøj et al. [19] for further discussion about modelling 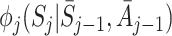 . We recommend taking the models to be as general as possible, see Sect. 5 for an example. Since these models are not of direct interest, it is safer to err on the side of overfitting (Henderson et al. [8]). We will show via simulation studies in Sect. 4 that restricting to the final term in this way results in a loss of precision for
. We recommend taking the models to be as general as possible, see Sect. 5 for an example. Since these models are not of direct interest, it is safer to err on the side of overfitting (Henderson et al. [8]). We will show via simulation studies in Sect. 4 that restricting to the final term in this way results in a loss of precision for 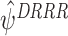 compared to
compared to 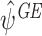 .
.
Simulation
We demonstrate the behaviour of 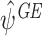 with
with 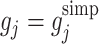 ,
, 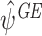 with
with 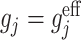 ,
, 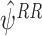 and
and 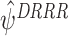 using a simulation study. We generated data from 1000 patients, followed-up over 5 time-points. States were normally distributed with E(S
1)=0.5, E(S
j|A
j−1)=(0.5−A
j−1) for j>1 and residual variance
using a simulation study. We generated data from 1000 patients, followed-up over 5 time-points. States were normally distributed with E(S
1)=0.5, E(S
j|A
j−1)=(0.5−A
j−1) for j>1 and residual variance 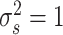 . Actions were generated as A
j∼U(1.25,3) when S
1>0.5 and A
j∼U(0,1.75) when S
1≤0.5. By definition μ
j is non-negative, so regret functions were taken to be quadratic with
. Actions were generated as A
j∼U(1.25,3) when S
1>0.5 and A
j∼U(0,1.75) when S
1≤0.5. By definition μ
j is non-negative, so regret functions were taken to be quadratic with 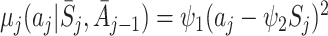 , with ψ
1=6 and ψ
2=2. The optimal action at visit j,
, with ψ
1=6 and ψ
2=2. The optimal action at visit j, 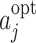 , is the action satisfying
, is the action satisfying 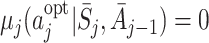 , giving
, giving 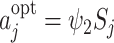 . Note that the optimal action may be negative, even though the observed actions are always positive. In practice this would mean that estimated optimal actions had been extrapolated to a region of
. Note that the optimal action may be negative, even though the observed actions are always positive. In practice this would mean that estimated optimal actions had been extrapolated to a region of  that had not been observed in the data. Such an extrapolation would only be appropriate if regret functions had been modelled correctly. Outcomes Y were normally distributed with
that had not been observed in the data. Such an extrapolation would only be appropriate if regret functions had been modelled correctly. Outcomes Y were normally distributed with
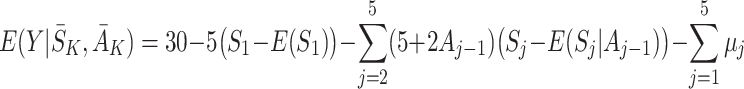 |
and variance 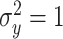 .
.
For both g-estimation and regret-regression, parameters were estimated using a two-stage process. In the first stage the model for the state distribution was fitted to the observed states and, if required, the model for assigning actions was fitted to the observed actions. For regret-regression these models were then used to estimate the residuals 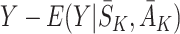 using the decomposition (5), and parameters estimated using least squares. For all other methods the models were used to determine the corresponding estimating equations, which were solved numerically. Standard errors were calculated using bootstrapping with 100 bootstrap samples.
using the decomposition (5), and parameters estimated using least squares. For all other methods the models were used to determine the corresponding estimating equations, which were solved numerically. Standard errors were calculated using bootstrapping with 100 bootstrap samples.
Parameter estimates 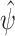 were obtained using correctly and incorrectly specified models for S
j and A
j. The misspecified model for S
j assumed S
j∼N(0.5,1), and so ignored the dependence of the states on the previous action. In the misspecified action model the actions were assumed to be uniformly distributed between 0 and 3.
were obtained using correctly and incorrectly specified models for S
j and A
j. The misspecified model for S
j assumed S
j∼N(0.5,1), and so ignored the dependence of the states on the previous action. In the misspecified action model the actions were assumed to be uniformly distributed between 0 and 3.
Table 1 shows results for ψ 2, which is the parameter of most interest since it determines the optimal dose. Results for other parameters are not reported, but lead to similar conclusions. Coverage probability is estimated by the proportion of simulations for which the estimated confidence interval contains the true parameter value. Parameter estimates were discarded when convergence was not achieved.
Table 1.
Simulation results for ψ
2 using regret-regression (RR), doubly-robust regret-regression (DRRR), g-estimation with 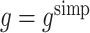 (GE SIMP) and g-estimation with
(GE SIMP) and g-estimation with 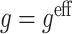 (GE EFF). Reported are means of parameter estimates with standard deviation of parameter estimates in brackets, means of estimated standard errors, coverage probability, root-mean-square error and the number of simulated data sets for which convergence was achieved. Results are based on 1000 samples of size n=1000
(GE EFF). Reported are means of parameter estimates with standard deviation of parameter estimates in brackets, means of estimated standard errors, coverage probability, root-mean-square error and the number of simulated data sets for which convergence was achieved. Results are based on 1000 samples of size n=1000
| Misspecification | Method | Mean (SD) | Mean of SE estimates | Coverage | RMSE | Number converged |
|---|---|---|---|---|---|---|
| No misspecification | RR | 2.000 (0.001) | 0.001 | 0.938 | 0.001 | 975 |
| DRRR | 2.000 (0.038) | 0.042 | 0.972 | 0.038 | 1000 | |
| GE SIMP | 2.000 (0.027) | 0.040 | 0.998 | 0.027 | 1000 | |
| GE EFF | 2.000 (0.008) | 0.008 | 0.973 | 0.008 | 988 | |
| Misspecified P(S j) | RR | 1.957 (0.003) | 0.003 | 0 | 0.043 | 994 |
| DRRR | 1.994 (0.128) | 0.145 | 0.991 | 0.128 | 999 | |
| GE SIMP | 1.987 (0.072) | 0.090 | 0.993 | 0.073 | 1000 | |
| GE EFF | 1.987 (0.072) | 0.091 | 0.994 | 0.073 | 1000 | |
| Misspecified P(A j) | RR | 2.000 (0.001) | 0.001 | 0.933 | 0.001 | 972 |
| DRRR | 2.007 (0.058) | 0.065 | 0.986 | 0.059 | 970 | |
| GE SIMP | 1.999 (0.028) | 0.034 | 0.993 | 0.028 | 989 | |
| GE EFF | 2.000 (0.008) | 0.008 | 0.958 | 0.008 | 942 | |
| Misspecified P(S j) and P(A j) | RR | 1.957 (0.003) | 0.003 | 0 | 0.043 | 797 |
| DRRR | 1.840 (0.233) | 0.220 | 0.814 | 0.283 | 800 | |
| GE SIMP | 1.960 (0.044) | 0.057 | 0.990 | 0.059 | 799 | |
| GE EFF | 1.960 (0.044) | 0.057 | 0.980 | 0.059 | 799 |
When models for both S j and A j were specified correctly, parameter estimates were consistent using all estimation methods. The most efficient method was RR. For GE SIMP estimated standard errors tended to be too high, leading to over-coverage of confidence intervals.
When the model for S
j is misspecified, RR results are slightly biased, with none of the estimated confidence intervals containing the true parameter value ψ
2=2. All other methods are robust to misspecification of the state model, and gave consistent parameter estimates. The GE EFF estimating equations for this scenario are identical to the GE SIMP estimating equations because the incorrect model for S
j has been used when calculating expressions for the 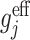 ; because the misspecified model for S
j is independent of A
j−1, only the term involving μ
j in (4) depends on A
j, and all other terms therefore cancel when subtracting
; because the misspecified model for S
j is independent of A
j−1, only the term involving μ
j in (4) depends on A
j, and all other terms therefore cancel when subtracting 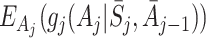 from
from 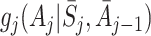 . The DRRR method was less efficient than GE SIMP and GE EFF. For all the methods overestimation of standard errors gave over-coverage of confidence intervals.
. The DRRR method was less efficient than GE SIMP and GE EFF. For all the methods overestimation of standard errors gave over-coverage of confidence intervals.
When the model for A j is misspecified, all methods give consistent parameter estimates. For RR this is because the method does not depend on the model for A j, and all other methods are robust to misspecification of the action model. Again, the most efficient method is RR.
When models for both S j and A j are misspecified, none of the methods would be expected to give consistent parameter estimates. Here all methods gave biased results, with DRRR parameter estimates being the most biased. RR has the smallest root mean squared error, with similar bias but smaller standard errors compared to GE SIMP. Parameter estimates from misspecified models took longer to converge, as indicated by the low convergence rates.
The bias caused by misspecification of state and action models in our simulation study was smaller than might be expected from a previous simulation study (Almirall et al. [2]). This could be because we have focussed on a continuous treatment decision, whereas Almirall et al. considered only binary actions. Model misspecification in the Almirall et al. study was generated by multiplying estimated state values by random noise of varying amplitudes. In contrast, our simulation study aimed to explore model misspecifications that might occur in practice, such as omitting variables from the state and action models.
Example: Blood-Clotting
We illustrate the methods with data taken from 303 patients at risk of thrombosis who were receiving long-term anticoagulation therapy for abnormal blood-clotting. These data have been analysed previously by Rosthøj et al. [18] and by Henderson et al. [8]. The ability of the blood to clot was measured using the International Normalised Ratio (INR), with high values indicating that the blood clots too slowly, increasing the risk of haemorrhage, and low values indicating fast clotting-times with an increased risk of thrombosis. Each patient attended 14 clinic visits at which their INR was measured and their dose of anticoagulant was adjusted accordingly. The aim of therapy is to maintain a patient’s INR within a target range, which is pre-specified for each patient.
As an outcome for analysis we used the proportion of time over follow-up that was spent with the INR within target range. The final dose adjustment did not contribute to the outcome, and we treated the first four clinic visits as a stabilisation period, giving K=9. States S j are defined to be the standardised difference between the INR at the jth visit and the target range. Actions A j are defined to be the change in anticoagulant dose at the jth visit. With these definitions S j=0 for 50 % of state observations and A j=0 for 60 % of actions taken.
We modelled the regrets as quadratic functions, depending on the previous two states and the previous action:
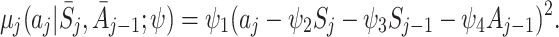 |
To model the states we used a mixture model with logistic and normal components to account for the high number of zero states. Linear predictors for both models were allowed to depend on the previous four states and actions, as well as a number of interactions between them. The model for the actions was defined in the same way.
Parameters were estimated using RR, DRRR and GE SIMP, with standard errors by bootstrap with 1000 resamplings. We were unable to implement the more efficient method GE EFF because of the extra complexity introduced by the dependence of the regret functions on the previous state and the previous action. In this case no terms in 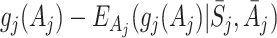 automatically cancelled, as was the case for the simulation study. So, for example, it would be necessary to calculate E(∂μ
9/∂ψ|S
1,A
1) by integrating out all other S
j and A
j. In this complicated scenario we found such calculations to be algebraically intractable.
automatically cancelled, as was the case for the simulation study. So, for example, it would be necessary to calculate E(∂μ
9/∂ψ|S
1,A
1) by integrating out all other S
j and A
j. In this complicated scenario we found such calculations to be algebraically intractable.
Results are given in Table 2. Parameter estimates from RR, DRRR and GE SIMP are similar, although the RR results tend to favour slightly more extreme changes of dose than the GE SIMP results. The difference between RR and GE SIMP results could indicate some model misspecification, but standard errors are too large to draw any firm conclusions. The DRRR standard errors were substantially larger than the GE SIMP standard errors. We can therefore place most confidence in the GE SIMP parameter estimates because GE SIMP is the most efficient estimation method with the double-robustness property. Some bootstrap samples (3 out of 1000) did not converge using RR, and for others there was a tendency for ψ 1 to be estimated close to 0. This could explain the larger standard errors estimated for RR compared to GE SIMP.
Table 2.
Results for the blood-clotting example using regret-regression (RR), doubly robust regret-regression (DRRR) and g-estimation with 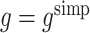 (GE SIMP). Reported are estimated parameter values with standard errors in brackets
(GE SIMP). Reported are estimated parameter values with standard errors in brackets
| Parameter | RR | DRRR | GE SIMP |
|---|---|---|---|
| ψ 1 | 0.093 (0.065) | 0.099 (0.059) | 0.113 (0.046) |
| ψ 2 | −2.477 (1.594) | −2.264 (1.856) | −2.267 (0.435) |
| ψ 3 | −1.729 (0.976) | −1.817 (0.966) | −1.535 (0.683) |
| ψ 4 | −0.993 (0.517) | −1.058 (0.608) | −0.822 (0.339) |
The estimates for ψ 2 indicate that the dose should be increased if the current state is too low and should be decreased if it is too high, as would be expected. Negative values of ψ 3 indicate that if the previous state is below range then the current dose should be adjusted upwards, and if it is above range then the current dose should be adjusted down. Similarly, estimates for ψ 4 indicate that if the previous dose was increased then the current dose should be reduced and vice versa. So, for example, a patient whose current INR measurement is S j=0.5, and who previously also had high INR, S j−1=0.5, and whose dose was reduced, A j−1=−0.5, would be recommended to reduce their dose by 1.44 according to the GE SIMP estimates. By comparison, a patient who also had S j=0.5, but whose INR was previously too low, S j−1=−0.5, resulting in an increase of dose A j−1=0.5, would be recommended to reduce their dose by a smaller amount of 0.80.
In summary, both methods give plausible parameter estimates, but RR standard errors seem large in comparison with GE SIMP standard errors. The simulation results suggest that standard errors estimated using GE SIMP could also be overly conservative.
Discussion
We have demonstrated that two methods which have been proposed for estimating optimal dynamic treatment regimes, regret-regression and g-estimation, are closely related. Formulating a doubly robust version of regret-regression led to a truncated version of the g-estimation equations.
The regret-regression approach is efficient when the model for states S j is correctly specified. No model for actions A j is required. G-estimation, on the other hand, can be applied when the action model is known, without the need to model states correctly. This is perhaps the best approach for trial data, where actions are randomised and hence fully understood. For observational data it may be the case that the natural process of state evolution is easier to model than the subjective actions chosen by health personnel. G-estimation is doubly robust in the sense that parameter estimates are consistent provided that either the states or the actions are modelled correctly. An assumption of no unmeasured confounders is necessary for inference in both cases.
Regret-regression outperforms efficient g-estimation even when the latter makes use of correct specification of both action and state models. However, it performs poorly when the state model is misspecified, whereas efficient g-estimation is robust. Given that the states are fully observed one can argue that careful attention to modelling and diagnostics should reduce or remove the risk of major misspecification. Nonetheless our recommendation is to attempt efficient g-estimation whenever possible. Unfortunately, as in the blood clotting application, when the regret and state models are fairly complex it can be difficult or in practice impossible to obtain the functions H j(ψ) defined at (1) that are required for implementation.
Biases resulting from model misspecification were smaller than might have been expected from a previous simulation study (Almirall et al. [2]). One difference here is that we have focussed on continuous rather than binary treatment decisions. It would be interesting to see if such small biases persist for other forms of regret functions and more complicated models. We have assumed throughout that regret functions have been specified correctly. We leave investigation of the effects of regret misspecification for future work.
Acknowledgements
JB was supported by the Medical Research Council Grant number G0902100. SR was supported by Public Health Services Grant 5 R01 CA 54706-11 from the National Cancer Institute.
Appendix A: Consistency of Estimating Equations
A.1 Consistency of 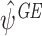
We assume throughout that regret functions have been modelled correctly. We will show that E(EE GE(ψ))=0 providing that either the states or the treatment probabilities have also been modelled correctly, where
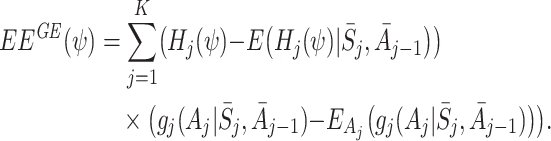 |
Consider
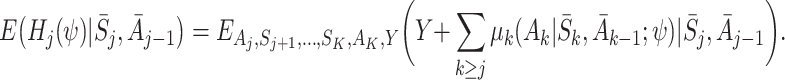 |
Taking the expectation over Y, and using the decomposition (5), we get
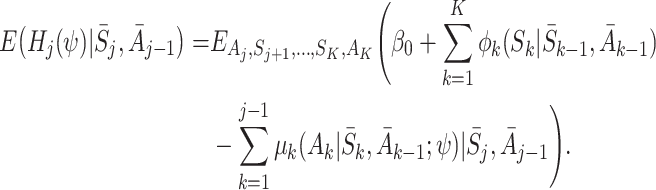 |
None of the terms on the right-hand side depend on A K, so
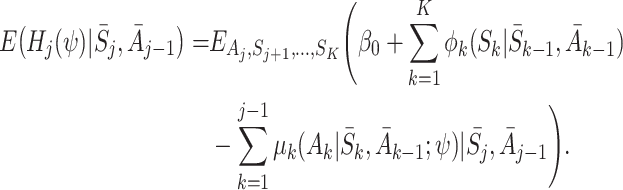 |
Now the only term depending on S
K is 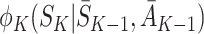 , which has expectation zero, so
, which has expectation zero, so
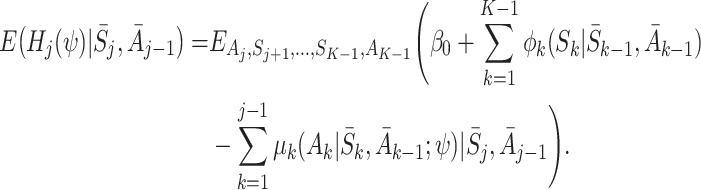 |
Repeating these steps to take expectations of A K−1, S K−1, …, A j, we get
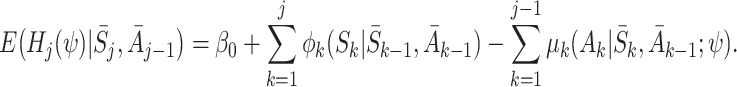 |
Let 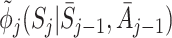 be the postulated model for
be the postulated model for 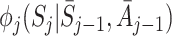 , so
, so 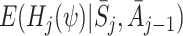 is modelled as
is modelled as 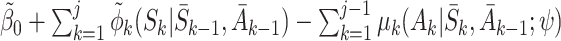 . Then
. Then
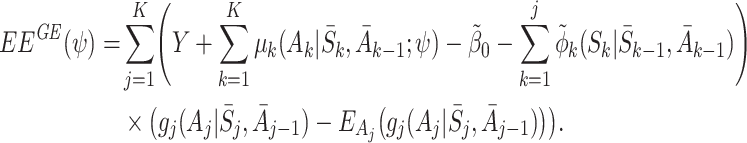 |
The expectation of the estimating equations over all random variables is then
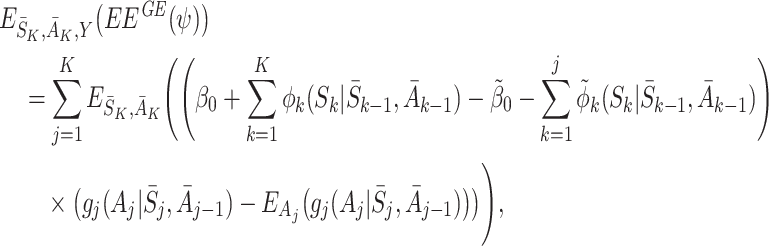 |
where we have again used the decomposition (5) to take the expectation over Y. The only terms involving S
j+1,…,S
K are the 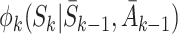 which have expectation zero, so
which have expectation zero, so
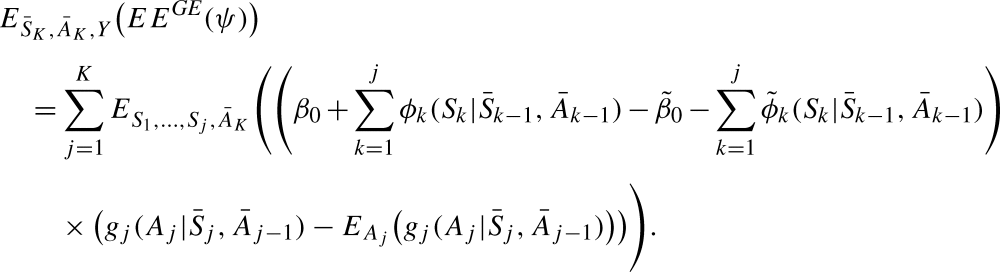 |
This expression is equal to zero if the states are modelled correctly, i.e. if 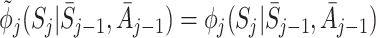 and
and 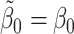 . Otherwise, if the treatment probabilities are modelled correctly then the expectation with respect to A
j gives zero because the first bracket does not depend on A
j, and the expectation of the second bracket is zero.
. Otherwise, if the treatment probabilities are modelled correctly then the expectation with respect to A
j gives zero because the first bracket does not depend on A
j, and the expectation of the second bracket is zero.
A.2 Consistency of 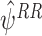
We will show that E(EE RR(ψ))=0 when the regret functions and the states have been modelled correctly, where
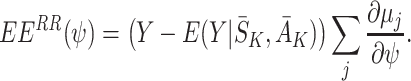 |
Let 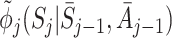 and
and 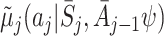 be the postulated models for
be the postulated models for 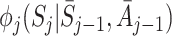 and
and 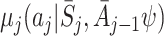 , respectively. Then the model for
, respectively. Then the model for 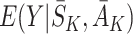 is
is
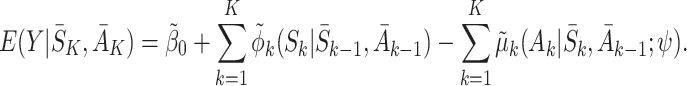 |
The expectation of the estimating equations over all random variables is then
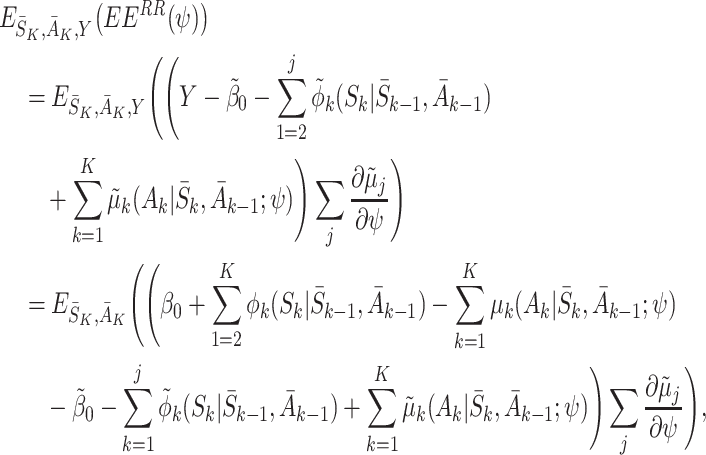 |
where we have used the decomposition (5) to take the expectation over Y. This expression is equal to zero if the regret functions and the states are modelled correctly, i.e. if 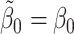 ,
, 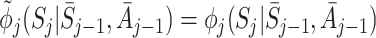 and
and 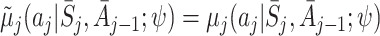 .
.
Appendix B: Uniqueness of the Regret-Regression Decomposition
The regret function is defined as
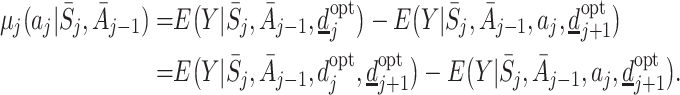 |
Suppose we wish to contrast the effect of action A j with the best that can be achieved at time j on the assumption that rules d ∗ are followed in the future, not necessarily optimal. We might define
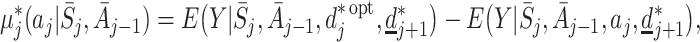 |
where 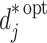 has the obvious interpretation. Suppose there is a corresponding nuisance function
has the obvious interpretation. Suppose there is a corresponding nuisance function 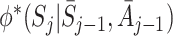 and an equivalent decomposition to (5):
and an equivalent decomposition to (5):
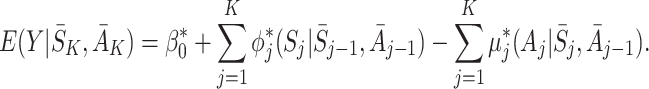 |
It must follow that
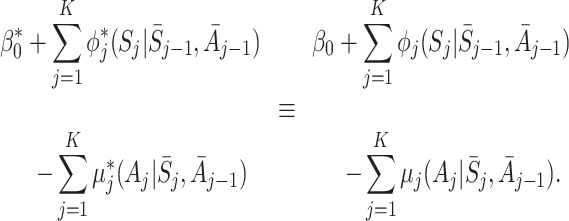 |
At time K there are no future actions. Hence 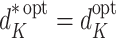 and
and 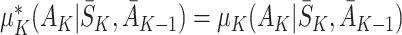 . Consequently
. Consequently
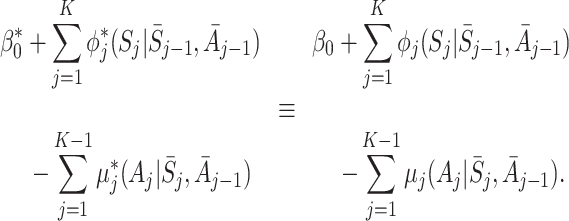 |
State S
K appears only in 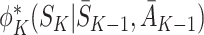 on the left-hand side and only in
on the left-hand side and only in 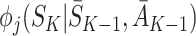 on the right-hand side. Since the equality holds for all S
K, these terms must be identically equal. However, by definition
on the right-hand side. Since the equality holds for all S
K, these terms must be identically equal. However, by definition 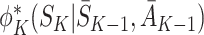 depends on following decision rule
depends on following decision rule 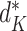 at time K whereas
at time K whereas 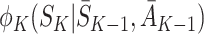 assumes rule
assumes rule 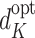 is followed. Thus, except in the special case of decisions having no effect, the decomposition can hold only if
is followed. Thus, except in the special case of decisions having no effect, the decomposition can hold only if 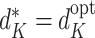 .
.
We can continue in this way, successively cancelling terms, to show that a decomposition equivalent to (5) can hold only if 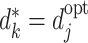 for j=1,2,…,K.
for j=1,2,…,K.
References
- 1.Arjas E, Saarela O. Optimal dynamic regimes: presenting a case for predictive inference. Int J Biostat. 2010 doi: 10.2202/1557-4679.1204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Almirall D, Ten Have T, Murphy SA. Structural nested mean models for assessing time-varying effect moderation. Biometrics. 2010;66:131–139. doi: 10.1111/j.1541-0420.2009.01238.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Chakraborty B, Murphy SA, Strecher V. Inference for non-regular parameters in optimal dynamic treatment regimes. Stat Methods Med Res. 2010;19:317–343. doi: 10.1177/0962280209105013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Cole SR, Hernán MA. Constructing inverse probability weights for marginal structural models. Am J Epidemiol. 2008;168:656–664. doi: 10.1093/aje/kwn164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Cole SR, Frangakis CE. The consistency statement in causal inference: a definition or an assumption? Epidemiology. 2009;20:3–5. doi: 10.1097/EDE.0b013e31818ef366. [DOI] [PubMed] [Google Scholar]
- 6.Dawid AP, Didelez V. Identifying the consequences of dynamic treatment strategies: a decision-theoretic overview. Stat Surv. 2010;4:184–231. doi: 10.1214/10-SS081. [DOI] [Google Scholar]
- 7.Greenland S, Robins JM, Pearl J. Confounding and collapsibility in causal inference. Stat Sci. 1999;14:29–46. doi: 10.1214/ss/1009211805. [DOI] [Google Scholar]
- 8.Henderson R, Ansell P, Alshibani D. Regret-regression for optimal dynamic treatment regimes. Biometrics. 2010;66:1192–1201. doi: 10.1111/j.1541-0420.2009.01368.x. [DOI] [PubMed] [Google Scholar]
- 9.Hernán MA. A definition of causal effect for epidemiological research. J Epidemiol Community Health. 2004;58:265–271. doi: 10.1136/jech.2002.006361. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Hernan MA, Lanoy E, Costagliola D, Robins JM. Comparison of dynamic treatment regimes via inverse probability weighting. Basic Clin Pharmacol Toxicol. 2006;98:237–242. doi: 10.1111/j.1742-7843.2006.pto_329.x. [DOI] [PubMed] [Google Scholar]
- 11.Hernán MA, Robins JM. Estimating causal effects from epidemiological data. J Epidemiol Community Health. 2006;60:578–586. doi: 10.1136/jech.2004.029496. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Moodie EMM, Richardson TS, Stephens DA. Demystifying optimal dynamic treatment regimes. Biometrics. 2007;63:447–455. doi: 10.1111/j.1541-0420.2006.00686.x. [DOI] [PubMed] [Google Scholar]
- 13.Moodie EM, Platt RW, Kramer MS. Estimating response-maximized decision rules with applications to breastfeeding. J Am Stat Assoc. 2009;485:155–165. doi: 10.1198/jasa.2009.0011. [DOI] [Google Scholar]
- 14.Moodie EM, Richardson TS. Estimating optimal dynamic regimes: correcting bias under the null. Scand J Stat. 2010;37:126–146. doi: 10.1111/j.1467-9469.2009.00661.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Murphy SA. Optimal dynamic treatment regimes. J R Stat Soc, Ser B, Stat Methodol. 2003;65:331–355. doi: 10.1111/1467-9868.00389. [DOI] [Google Scholar]
- 16.Orellana L, Rotnitzky A, Robins JM. Dynamic regime marginal structural mean models for estimation of optimal dynamic treatment regimes, part I: main content. Int J Biostat. 2010 [PubMed] [Google Scholar]
- 17.Robins JM. Optimal structural nested models for optimal sequential decisions. In: Lin DY, Heagerty P, editors. Proceedings of the second symposium on biostatistics. New York: Springer; 2004. pp. 189–326. [Google Scholar]
- 18.Rosthøj S, Fullwood C, Henderson R, Stewart S. Estimation of optimal dynamic anticoagulation regimes from observational data: a regret-based approach. Stat Med. 2006;25:4197–4215. doi: 10.1002/sim.2694. [DOI] [PubMed] [Google Scholar]
- 19. Rosthoj S, Henderson R, Barrett JK (2013) Determination of optimal dynamic treatment strategies from incomplete data structures. Stat Biosci (submitted for publication)
- 20.Zhang B, Tsiatis AA, Laber EB, Davidian M. A robust method for estimating optimal treatment regimes. Biometrics. 2012 doi: 10.1111/j.1541-0420.2012.01763.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Zhao YQ, Zeng D, Socinski MA, Kosorok MR. Reinforcement learning strategies for clinical trials in nonsmall cell lung cancer. Biometrics. 2011;67:1422–1433. doi: 10.1111/j.1541-0420.2011.01572.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Zhao YQ, Zeng D, Rush AJ, Kosorok MR. Estimating individualized treatment rules using outcome weighted learning. J Am Stat Assoc. 2012;107:1106–1118. doi: 10.1080/01621459.2012.695674. [DOI] [PMC free article] [PubMed] [Google Scholar]