

Abstract
Repeated pairings of a particular visual context with a specific location of a target stimulus facilitate target search in humans. We explored an animal model of such contextual cueing. Pigeons had to peck a target which could appear in one of four locations on color photographs of real-world scenes. On half of the trials, each of four scenes was consistently paired with one of four possible target locations; on the other half of the trials, each of four different scenes was randomly paired with the same four possible target locations. In Experiments 1 and 2, pigeons exhibited robust contextual cueing when the context preceded the target by 1 s to 8 s, with reaction times to the target being shorter on predictive-scene trials than on random-scene trials. Pigeons also responded more frequently during the delay on predictive-scene trials than on random-scene trials; indeed, during the delay on predictive-scene trials, pigeons predominately pecked toward the location of the upcoming target, suggesting that attentional guidance contributes to contextual cueing. In Experiment 3, involving left-right and top-bottom scene reversals, pigeons exhibited stronger control by global than by local scene cues. These results attest to the robustness and associative basis of contextual cueing in pigeons.
Keywords: contextual cueing, attentional guidance, associative learning, animal model
The environment is replete with visual information. At any given time, people must attend to relevant stimuli and ignore irrelevant stimuli in order to engage in adaptive behavior. For example, to safely cross the street, we attend to the color of the traffic lights as well as to the motion of nearby cars and pedestrians, while we simultaneously ignore the buildings and trees along the roadway.
Salient visual objects can unconditionally command our attention (Awh, Belopolsky, & Theeuwes, 2012). Yet, such “bottom-up” control may not tell the full story of how we navigate the complex visual contexts that we confront in everyday life; experience-dependent “top-down” control may also play a key part in behavioral adaptation (Chun, 2000). For instance, should we be looking for a pharmacy in France, we would do well to peer above the doorways where a green cross is most likely to be displayed; but, should we be seeking a street sign, we would best be advised to gaze toward corner buildings where road placards are most likely to be affixed.
The significance of context to visual object identification has long been appreciated (e.g., Biederman, 1972). Still more recent research by Chun and Jiang (1998) initiated a new chapter on the importance of contextual stimuli to adaptive visual behavior. These investigators discovered that the spatial configuration of objects in a visual scene can serve as a powerful contextual cue, facilitating an individual's search for a target item.
Specifically, Chun and Jiang found that, when the specific location of a target was consistently associated with a particular spatial arrangement of distractor items in the display, reaction times (RTs) to identify the target became reliably shorter than when the target appeared in newly generated spatial arrangements of the same distractor items. Chun and Jiang called this RT benefit the contextual cueing effect and proposed that contextual cueing is due to attention being guided toward the location of the target, owing to learned associations between the context and the location of the target.
Subsequent research has sought to elucidate the perceptual and cognitive mechanisms underlying contextual cueing in humans. Possible animal models of contextual cueing have only recently been developed (for pigeons: Brooks, Rasmussen, Hollingworth, & Wasserman, 2008; for rhesus monkeys: Brooks, Dai, & Sheinberg, 2011), with the recent paper by Goujon and Fagot (2013: for baboons) being the first published demonstration. Here, we report the results of a new pigeon analog of the human contextual cueing task in the hope of shedding fresh light on the comparative and associative mechanisms underlying contextual cueing.
Chun (2000) offered two compelling justifications for the comparative study of contextual cueing. First, most research in visual processing gives little consideration to the history of the observer; being endowed with the capacity to see also requires that organisms learn to interpret their visual world based on their experience in it. Second, more needs to be understood concerning the neural mechanisms and evolutionary origins of attentional guidance. For these reasons, animal models are critical for controlling and isolating the role of learning in contextual cueing as well as for elucidating its physiological and phylogenetic foundations (Lazareva, Shimizu, & Wasserman, 2012).
A critical feature of our present project was that it used photographs of real scenes as experimental contexts. Although contextual cueing has been demonstrated in humans using both naturalistic scenes and arrays of abstract distractors (e.g., Brockmole & Henderson, 2006a; Brockmole & Henderson, 2006b; Rosenbaum & Jiang, 2013), experiments have consistently shown that lifelike scene-target associations are learned faster and more strongly contribute to search time benefits than do distractor array-target associations. Thus, we used color photographs of real-world scenes in order to maximize the effect of contextual cueing on pigeons' visually guided behavior.
We also investigated the time between context and target presentation (Stimulus Onset Asynchrony, SOA) from 0 s to 8 s to see if different SOAs differentially affect contextual cueing. In most human studies of contextual cueing, the context and target are simultaneously presented. Only a few studies have programmed a nonzero SOA between context and target presentation, ranging from 250 ms to 1,500 ms (Geyer, Zehetleitner, & Müller, 2010; Goujon, 2011; Jiang, Sigstad, & Swallow, 2013; Kunar, Flusberg, & Wolfe, 2006, 2008; Ogawa & Kumada, 2008; Peterson, & Kramer, 2001). Even fewer studies have parametrically investigated the effect of the SOA on contextual cueing. Kunar et al. (2006) found a slight weakening of contextual cueing with increasing SOAs and Kunar et al. (2008) observed a more robust SOA effect when placeholders demarcated the possible target locations. More recently, Jiang et al. (2012) reported that contextual cueing was similar across SOAs from 0 ms to 1,000 ms.
This manipulation of SOA also afforded us the ability to explore the possible role of attentional guidance by closely monitoring the pigeons' behavior during the 1 s to 8 s prior to the presentation of the target. Here, we leveraged the fact that pigeons will make unsolicited anticipatory reports in the location of impending stimuli that predict reward (Brooks, 2010), which can be used as an on-line measure of attentional guidance similar to the use of eye and hand movements in human subjects (see Peterson & Kramer, 2001; Spivey 2008).
In overview, the present project used photographs of real-world scenes to explore contextual cueing and its possible mechanisms in pigeons. In Experiments 1 and 2, we gave the same experimental procedures to two different sets of birds in different orders. On half of the daily trials, each of four scenes perfectly predicted the target's location (Predictive condition); on the other half of the trials, none of four other scenes predicted the target's location, with the target randomly appearing in one of the same four possible locations (Random condition). Evidence of contextual cueing would come from shorter RTs in the Predictive condition than in the Random condition. Furthermore, we manipulated the temporal delay between presentations of the contextual stimuli and the target stimuli to see what effect this delay would have on contextual cueing. We also monitored pecking during the delay to see if such anticipatory responding provided any clues as to the associative nature of contextual cueing.
Finally, in Experiment 3, we vertically and horizontally reversed the Predictive photographic scenes to see whether the global scene contexts and/or the local cues in the immediate vicinity of the upcoming target exerted greater control over pigeons' visually directed responding. Assessing the contributions of global and local cues has been a topic of considerable interest to researchers studying animal spatial cognition (Brown & Cook, 2006).
General Method
Animals
We kept eight feral pigeons at 85% of their free-feeding weights. The four birds in Experiment 1 and the four other birds in Experiment 2 had participated in unrelated studies before beginning this project; none had seen photographs of real-world scenes. Both groups of pigeons were combined to serve in Experiment 3.
Apparatus
We used four 36- × 36- × 41-cm conditioning chambers (detailed by Castro, Kennedy & Wasserman, 2010) located in a dark room supplied with continuous white noise. Each chamber was equipped with a 15-in LCD monitor behind a resistive touchscreen. The viewable portion of the screen was 28.5 cm × 17.0 cm. Pecks to the touchscreen were processed by a serial controller outside the chamber. A rotary dispenser delivered 45-mg food pellets through a vinyl tube into a plastic cup just above the wire floor in the center of the rear wall opposite the touchscreen. Illumination during experimental sessions was provided by a houselight on the upper rear wall of the chamber. The pellet dispenser and houselight were controlled by a digital I/O interface. Each chamber was controlled by an iMac computer. Programs were developed in MatLab with Psychtoolbox-3 extensions (Brainard, 1997; Pelli, 1997; http://psychtoolbox.org/).
Stimulus Materials
In Pretraining, the context was a single photograph (snow and ice). In Training, the contexts were eight different photographs. Four of the Training photographs (desert, cornfield, mountain, lake) depicted nature scenes; the other four Training photographs (street, highway, house, cemetery) also included humanmade items. The 16.5- × 16.5-cm scenes were displayed in full color at a resolution of 555 × 555 pixels.
The same target was used in Pretraining and Training—an abstract shape consisting of nine white concentric circles superimposed on a dark gray square (3 × 3 cm). The target could appear in the top-left, top-right, bottom-left, and bottom-right corners of the contexts, 1.4 cm from the borders of the contextual image.
Pretraining
To familiarize the pigeons with the basic task before beginning Experiments 1 and 2, the birds had to peck the target, which randomly appeared in one of four possible locations on the Pretraining photograph. The context was always the same photograph, so that it could not predict the location of the target. Pretraining comprised 240 trials (60 randomly scheduled presentations of the target in each corner of the Pretraining image) and continued for 3 days prior to Training.
Design
On half of the trials (Predictive condition) in Experiments 1, 2, and 3, the identity of one of the four scenes (house, mountain, lake, and cemetery) was consistently paired with one of four possible locations (top-left, top-right, bottom-left, and bottom-right corners) in which the target could appear (Figure 1). The scene-location pairings were counterbalanced across birds in each experiment. On the other half of the trials (Random condition), the other four scenes (street, desert, cornfield, and highway) were randomly paired with the target's four possible locations (not shown in Figure 1).
Figure 1.
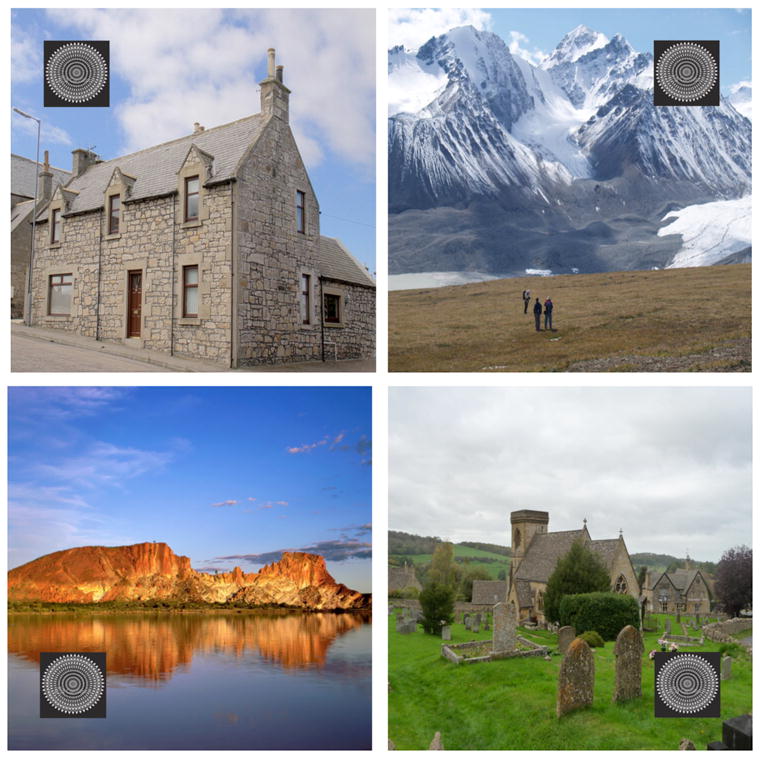
Examples of the predictive scene stimuli shown with the target stimulus superimposed in the four possible target locations. Each pigeon was shown uniquely counterbalanced context-target location pairings.
To explore the effect of differing SOAs between the context and the target, we created two separate training regimes and taught them to two different sets of four pigeons. These training regimes have been separated into Experiments 1 and 2. In Experiment 1, we first trained with a 2-s SOA (Experiment 1a), tested with variable SOAs (Experiment 1b), and finally ran an extended 0-s SOA phase (Experiment 1c). In Experiment 2, we first trained with a 0-s SOA (Experiment 2a), tested with variable SOAs (Experiment 2b), and finally ran an extended 2-s SOA phase (Experiment 2c). In each experiment, pigeons received sets of both Predictive and Random contexts; the between-subject manipulation involved the order SOA training.
RT Analysis
We excluded from our RT analyses any “outlier” trials on which the RT to the target equaled or exceeded 20 s; fewer than 0.20% of the trials were excluded across all three experiments. Furthermore, before any inferential statistical analyses were conducted, pigeons' RTs were subjected to logarithmic transformation in order to bring these RT distributions into closer accord with normality. In addition to reporting and depicting the outcomes of the statistical analyses of these log-transformed scores, we also report the main non-transformed RTs in ms to provide a clearer idea of the speed of pigeons' responses to the target stimuli; these non-transformed RTs appear in parentheses in the Results section of our experiments.
Experiment 1
In our first investigation into scene-based contextual cueing in pigeons, we consistently paired each of four scenes in the Predictive condition with each of four locations where the target was about to appear; we randomly paired each of four different scenes in the Random condition with the same four target locations. We initially set the SOA to 2 s (Experiment 1a). Then, to see whether different SOAs would affect the strength of contextual cueing, we randomly varied the SOA across days among 0-, 1-, 2-, 4-, and 8-s values (Experiment 1b). Finally, we explored whether contextual cueing could be sustained when there was no delay between onset of the contextual stimuli and the target (Experiment 1c).
Experiment 1a
Training
Daily training sessions comprised 256 trials. Each trial began with a start stimulus—a black plus sign in the center of a small white square (3 × 3 cm)—in the center of the screen. After one peck anywhere on the start stimulus, the context involving one of the eight possible scenes appeared in the center of the black screen. The context was presented for 2 s, during which we recorded the number and location of any pecks that occurred; no SOA pecks were ever required. After 2 s, the target was superimposed on the scene in one of four possible locations. The pigeons had to peck the target once, after which food was delivered (one 45-mg pellet) and a 10-s intertrial interval (ITI) ensued, during which the screen went black. The time between target onset and pigeons' pecking it was recorded. Training lasted 20 days.
Results
Across multiple training days, a predictive relationship between the background context and the target location clearly speeded the pigeons' responses when compared to a random relationship. The disparity between RTs at the start of training (213 ms) grew to a much larger disparity (437 ms) by the end of training. Learning curves that depict the growth of this disparity can be found in the top portion of Figure 2. The generally falling scores indicate that RTs were much briefer in the Predictive condition than in the Random condition and that the disparity in RT grew larger as training progressed. These scores were submitted to a repeated-measures analysis of variance (ANOVA) with condition (Predictive vs. Random) and day (1 to 20) as within-subjects factors. The significant main effect of day, F(19, 57) = 19.91, p < .001, , 95% CIs = .74, .87, indicates that RTs progressively fell over training. The main effect of condition was also significant, F(1, 3) 193.82, p < .001, , 95% CIs = .27, .99, with the Predictive condition (M = 956 ms, SE = 81.37) supporting briefer RTs than the Random condition (M = 1,330 ms, SE = 91.99); this RT disparity documents contextual cueing. The Condition × Day interaction was also significant, F(19, 57) = 7.45, p < .001, , 95% CIs = .45, .72, indicating that the Predictive-Random disparity grew greater throughout training although beginning at nearly the same RT value on Day 1; Tukey post hoc analyses revealed that the Predictive-Random disparity was significant from Day 2 onward.
Figure 2.
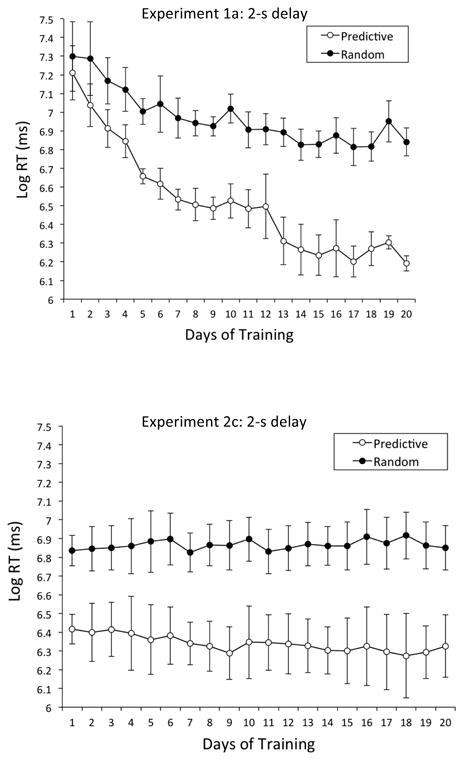
Mean RTs in Experiments 1a and 2c: 2-s delay. Top Panel: Mean Log RTs (ms) for the Predictive and Random conditions as a function of days of training in Experiment 1a: 2-s delay. Bottom Panel: Mean Log RTs (ms) for the Predictive and Random conditions as a function of days of training in Experiment 2c: 2-s delay. Error bars represent the standard error of the mean. As a guide to calibrating Log RTs to RTs (ms): Log RT of 6 = 403 ms, Log RT of 6.5 = 665 ms, Log RT of 7 = 1,097 ms, and Log RT of 7.5 = 1,808 ms.
We next compared the rate of pigeons' anticipatory responding to the Predictive vs. Random contexts. The top of Figure 3 depicts the mean rate of anticipatory responding (in pecks per s) in the Predictive and Random conditions as a function of days of training. These generally rising scores indicate that the pigeons exhibited a higher rate of anticipatory pecking in the Predictive condition than in the Random condition and that the disparity in anticipatory pecking grew larger from 0.03 pecks per s on Day 1 to 0.44 pecks per s on Day 20. These scores were submitted to a repeated-measures ANOVA with condition (Predictive vs. Random) and day (1 to 20) as within-subjects factors. The main effect of day was significant, F(19, 57) = 3.25, p < .001, , 95% CIs = .15, .53, indicating that anticipatory pecking rose as training progressed. The Predictive contexts tended to support a higher rate of anticipatory responding (M = 0.64 pecks per s, SE = 0.05) than the Random contexts (M = 0.41 pecks per s, SE = 0.03), but this disparity was not significant. The interaction between condition and day was significant, F(19, 57) = 2.32, p < .01, , 95% CIs = .04, .44, indicating that the Predictive-Random disparity in anticipatory pecking grew larger with training although beginning at virtually the same value; Tukey post hoc analyses divulged that the disparity first became significant on Day 17.
Figure 3.
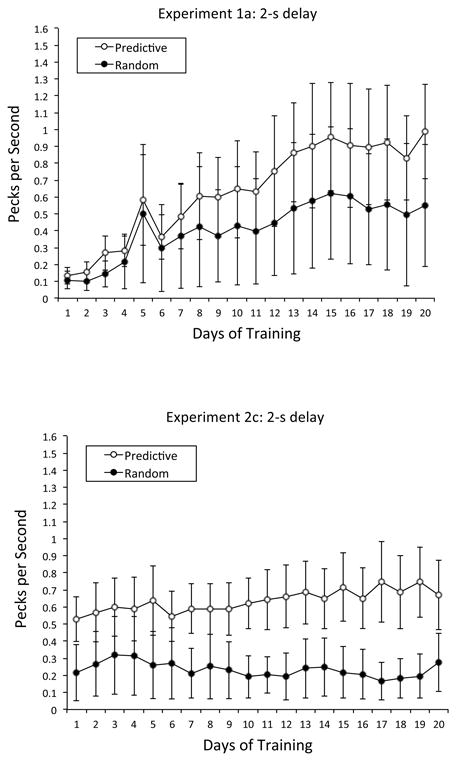
Mean rate of anticipatory responding in Experiments 1a and 2c: 2-s delay. Top Panel: Mean pecks per s in the Predictive and Random conditions as a function of days of training in Experiment 1a: 2-s delay. Bottom Panel: Mean pecks per s in the Predictive and Random conditions as a function of days of training in Experiment 2c: 2-s delay. Error bars represent the standard error of the mean.
Next, the location of anticipatory responding to the photographic contexts was analyzed. Preliminary analyses found no discriminative anticipatory responding in the Random condition, because these contexts were randomly paired with the target's location; so, only trials in the Predictive condition were formally analyzed. In addition, because we were concerned with where any recorded anticipatory pecks were directed, only trials with pecks were considered.
For this analysis, the entire area in which anticipatory pecks could be made was divided into equal-sized quadrants. If a peck was made in the quadrant where the target was next to appear, then it was deemed to be a correct anticipatory response; if the peck was made outside that quadrant, then it was deemed to be an incorrect anticipatory response. Because an incorrect anticipatory response was three times more likely to occur by chance than was a correct anticipatory response, incorrect anticipatory pecks were divided by 3 to equate their a priori probability of occurrence.
The top of Figure 4 illustrates the mean rate of correct and incorrect anticipatory responding as a function of days of training. Correct anticipatory pecking increased throughout training from 0.20 pecks per s on Day 1 to 1.18 pecks per s on Day 20, compared to incorrect anticipatory pecking which remained constant. The adjusted rate of anticipatory responding to the contexts was analyzed using a repeated-measures ANOVA with response type (correct vs. incorrect anticipatory responding) and day (1 to 20) as within-subjects factors. The main effect of response type was significant, F(1, 3) = 11.68, p < .05, , 95% CIs = .00, .90, with correct anticipatory responding (M = 0.80 pecks per s, SE = 0.08) exceeding incorrect anticipatory responding (M = 0.08 pecks per s, SE = 0.02). Also significant was the main effect of day, F(19, 57) = 2.84, p < .001, , 95% CIs = .10, .49, indicating an overall increase in anticipatory responding as training progressed. Most importantly, the Response Type × Day interaction was significant, F(19, 57) = 2.71, p < .001, , 95% CIs = .09, .48, indicating that the Correct-Incorrect disparity grew greater throughout training although beginning at virtually the same value on Day 1; Tukey post hoc analyses revealed that the Correct-Incorrect disparity first became significant on Day 11.
Figure 4.
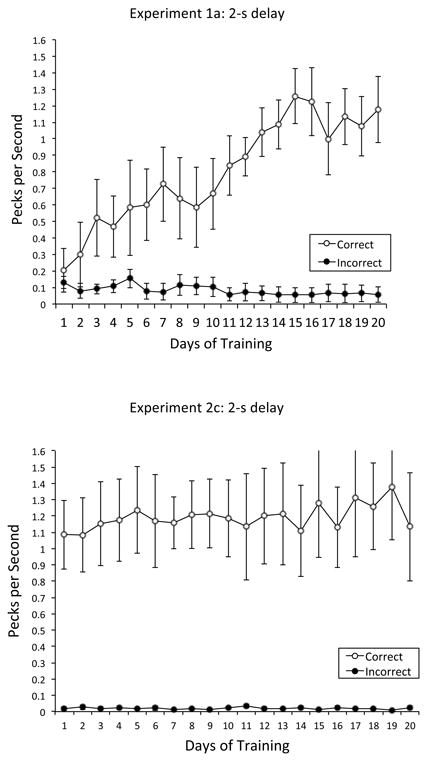
Mean rate of correct vs. incorrect anticipatory responding in Experiments 1a and 2c: 2-s delay. Top Panel: Mean rate of correct vs. incorrect anticipatory responding in pecks per s as a function of days of training in Experiment 1a: 2-s delay. Bottom Panel: Mean rate of correct vs. incorrect anticipatory responding in pecks per s as a function of days of training in Experiment 2c: 2-s delay. Error bars represent the standard error of the mean.
Comparing the top of Figure 2 with the top of Figure 4 suggests that both the disparity in RTs between the Predictive and Random contexts as well as the disparity between correct and incorrect anticipatory contextual pecking in the Predictive condition grew larger throughout training. We calculated the daily mean disparity scores for the RTs (Predictive vs. Random) and the anticipatory contextual responses (correct vs. incorrect location) and correlated them with one another. The resulting correlation coefficient was 0.87, p < .001, suggesting that the increasing preponderance of correct anticipatory responses made to the Predictive contexts may have contributed to the RT benefit in the Predictive condition.
Experiment 1b
Training
The training procedure in Experiment 1b was the same as in Experiment 1a, except that the delay between onset of the context and onset of the target varied randomly among 0-, 1-, 2-, 4-, and 8-s values across days within each block of 5 days. On 0-s SOA days, the context and target were simultaneously presented; on 1-, 2-, 4-, and 8-s SOA days, the context was presented 1, 2, 4, and 8 s, respectively, before the target. Training lasted 30 days.
Results
The top of Figure 5 displays mean Log RTs (ms) for each condition and each SOA. Overall RTs tended to decline with increases in the SOA, with the decrease being greater for Predictive contexts than for Random contexts. These scores were submitted to a repeated-measures ANOVA with condition (Predictive vs. Random), SOA (0, 1, 2, 4, and 8 s), and block (six 5-day blocks) as within-subjects factors. The main effect of condition, F(1, 3) = 464.22, p < .001, , 95% CIs = .52, 1.00, was significant, with RTs in the Predictive condition (M = 919 ms, SE = 61.49) generally shorter than those in the Random condition (M = 1,175 ms, SE = 70.57), confirming contextual cueing. A significant main effect of SOA was also obtained, F(4, 12) = 10.64, p < .001, , 95% CIs = .30, .84; Tukey post hoc analyses revealed that RTs at the 0-s SOA were significantly longer than those at the 1-, 2-, 4-, and 8-s SOAs, p < .05, but RTs at the 1-, 2-, 4-, and 8-s SOAs were not significantly different from one another. The Condition × SOA interaction too was significant, F(4, 12) = 7.76, p < .01, , 95% CIs = .18, .80. Tukey post hoc analyses revealed that contextual cueing was observed at each SOA, p < .05, except 0 s; in addition, the RT disparity tended to be the greatest at 2 s. Finally, there was a significant Block × Condition × SOA interaction, F(20, 60) = 1.74, p = .05, , 95% CIs = .00, .35. To further explicate the three-way interaction, we calculated the RT disparity between the Predictive and Random conditions for each block of training; we found that the contextual cueing effect was greatest in the first block and then fell slightly in later training blocks.
Figure 5.
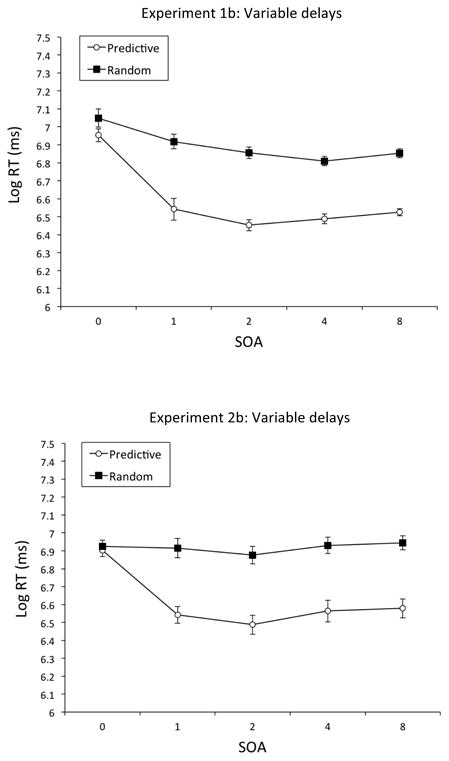
Mean RTs for the 5 SOA conditions in Experiments 1b and 2b: Variable delays. Top Panel: Mean Log RTs (ms) for the Predictive and Random conditions for each SOA in Experiment 1b: Variable delays. Bottom Panel: Mean Log RTs (ms) for the Predictive and Random conditions for each SOA in Experiment 2b: Variable delays. Error bars represent the standard error of the mean. As a guide to calibrating Log RTs to RTs (ms): Log RT of 6 = 403 ms, Log RT of 6.5 = 665 ms, Log RT of 7 = 1,097 ms, and Log RT of 7.5 = 1,808 ms.
We next compared the rate of pigeons' anticipatory responses to the Predictive vs. Random contexts. Because no anticipatory responding was possible in the 0-s SOA condition, only pecks in the 1-, 2-, 4-, and 8-s SOA conditions were analyzed. The top of Figure 6 depicts the mean rate of anticipatory responding for each condition and each SOA. Pigeons tended to exhibit a higher rate of anticipatory responding in the Predictive condition (M = 0.74 pecks per s, SE = 0.06) than in the Random condition (M = 0.49 pecks per s, SE = 0.06), with the disparity in anticipatory pecking in the Predictive and Random conditions remaining relatively constant across the different SOAs. However, a repeated-measures ANOVA with condition (Predictive vs. Random), SOA (1, 2, 4, and 8 s), and block (six 5-day blocks) as within-subjects factors revealed no reliable main effects or interactions.
Figure 6.
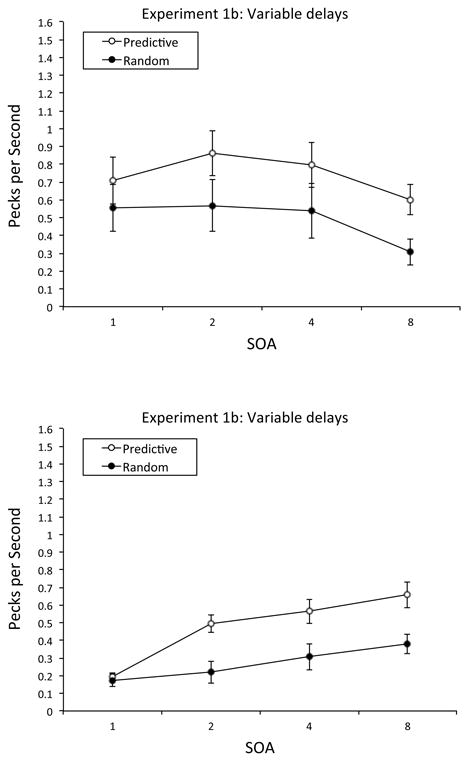
Mean rate of anticipatory responding in Experiments 1b and 2b: Variable delays. Top Panel: Mean pecks per s in the Predictive and Random conditions for each SOA in Experiment 1b: Variable delays. Bottom Panel: Mean pecks per s in the Predictive and Random conditions for each SOA in Experiment 2b: Variable delays. Error bars represent the standard error of the mean.
We also analyzed the location of anticipatory responses to the Predictive contexts. The top of Figure 7 depicts the mean rate of correct and incorrect anticipatory responding at each SOA. The birds exhibited a higher rate of correct anticipatory pecking (M = 0.79 pecks per s, SE = 0.08) than incorrect anticipatory pecking (M = 0.10 pecks per s, SE = 0.02) at each SOA, with the disparity tending to be greatest at 2 s. Anticipatory responding to the contexts was analyzed using a repeated-measures ANOVA with response type (correct vs. incorrect anticipatory response), SOA (1, 2, 4, and 8 s), and block (six 5-day blocks) as within-subjects factors. A significant main effect of SOA was obtained, F(3, 9) = 26.64, p < .001, , 95% CIs = .54, .93; Tukey post hoc analyses revealed that the overall rate of anticipatory pecking was generally ordered 2 s > 1 s > 4 s > 8 s, p < .05. The response type × SOA interaction was also significant, F(3, 9) = 6.21, p < .01, , 95% CIs = .04, .78; Tukey post hoc analyses revealed that the disparity between correct and incorrect anticipatory responding was significant at every SOA, with the Correct-Incorrect disparity again ordered 2 s > 1 s > 4 s > 8 s, p < .05.
Figure 7.
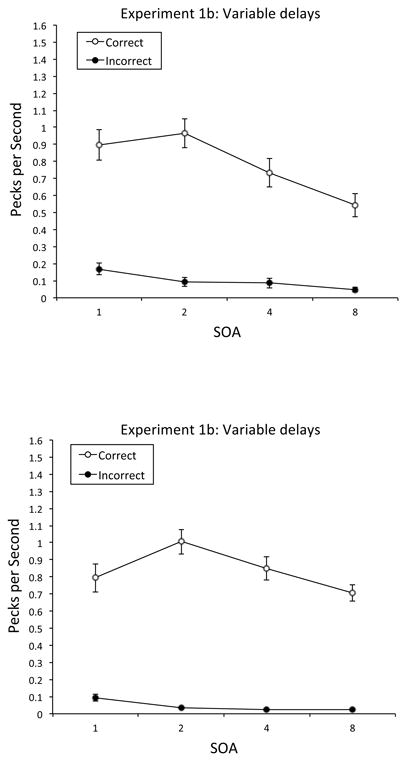
Mean rate of correct vs. incorrect anticipatory responding in Experiments 1b and 2b: Variable delays. Top Panel: Mean rate of correct vs. incorrect anticipatory responding in pecks per s for each SOA in Experiment 1b: Variable delays. Bottom Panel: Mean rate of correct vs. incorrect anticipatory responding in pecks per s for each SOA in Experiment 2b: Variable delays. Error bars represent the standard error of the mean.
Experiment 1c
Training
The training procedure was the same as in Experiment 1a, except that the context and target were simultaneously presented. Training lasted 20 days.
Results
The top of Figure 8 shows that mean Log RTs (ms) exhibited no strong discrepancy between the Predictive and Random conditions, although RTs were a bit briefer in the Predictive condition (M = 1,155 ms, SE = 40.23) than in the Random condition (M = 1,232 ms, SE = 41.30); overall RTs fell slightly over the course of training. A repeated-measures ANOVA with condition (Predictive vs. Random) and day (1 to 20) as within-subjects factors revealed a significant main effect of day, F(19, 57) = 2.30, p < .01, , 95% CIs = .04, .43, but no significant main effect of condition or interaction between the two variables.
Figure 8.
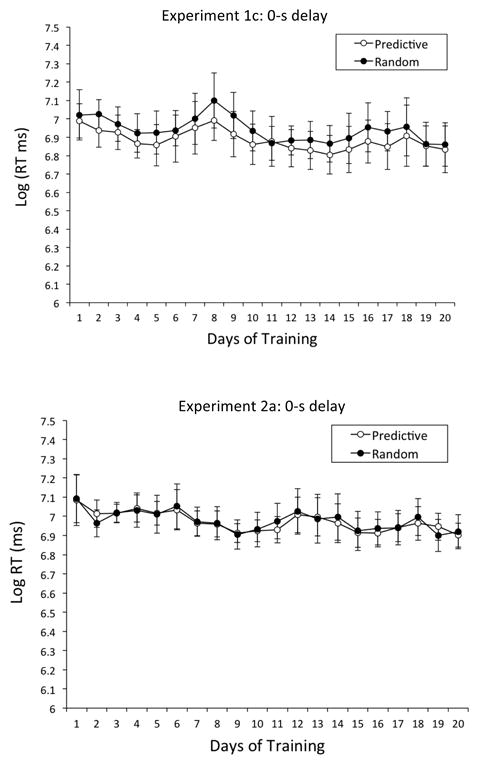
Mean Log RTs (ms) in Experiments 1c and 2a: 0-s delay. Top Panel: Mean Log RTs (ms) for the Predictive and Random conditions as a function of days of training in Experiment 1c: 0-s delay. Bottom Panel: Mean Log RTs (ms) for the Predictive and Random conditions as a function of days of training in Experiment 2a: 0-s delay. Error bars represent the standard error of the mean. As a guide to calibrating Log RTs to RTs (ms): Log RT of 6 = 403 ms, Log RT of 6.5 = 665 ms, Log RT of 7 = 1,097 ms, and Log RT of 7.5 = 1,808 ms.
Experiment 2
In Experiment 2, we gave a different set of pigeons the same procedures as in Experiment 1, but we reversed their order of administration. Doing so allowed us to assess the robustness of our initial results as well as to determine if there were measurable sequence effects. First, as in Experiment 1c, we simultaneously presented the context and the target to see whether a delay between context and target was necessary for contextual cueing to occur (Experiment 2a). Second, we randomly varied the SOAs among the same five values as in Experiment 1b (Experiment 2b). Finally, we trained the birds with the 2-s SOA alone as in Experiment 1a (Experiment 2c).
Experiment 2a
Training
The training procedure was the same as in Experiment 1c.
Results
The bottom of Figure 8 shows that we observed no difference in mean Log RTs (ms) between the Predictive and Random conditions, with RTs remaining relatively constant over the 20 days of initial training. A repeated-measures ANOVA with condition (Predictive vs. Random) and day (1 to 20) as within-subjects factors revealed no significant main effect of day, condition, or interaction. So, just as in Experiment 1c (Figure 8, top), we did not obtain a reliable contextual cueing effect at a 0-s SOA, even though the Predictive contexts (M = 1,178 ms, SE = 23.52) supported slightly shorter RTs than the Random contexts (M = 1,206 ms, SE = 26.84).
Experiment 2b
Training
The training procedure was the same as in Experiment 1b.
Results
The bottom of Figure 5 displays mean Log RTs (ms) for each condition and each SOA. As in Experiment 1b (Figure 5, top), overall RTs tended to decline with increases in the SOA, with the decrease being greater to the Predictive contexts. A repeated-measures ANOVA with condition (Predictive vs. Random), SOA (0, 1, 2, 4, and 8 s), and block (six 5-day blocks) as within-subjects factors revealed a significant main effect of condition, F(1, 3) = 42.13, p < .01, , 95% CIs = .00, .97, with RTs in the Predictive condition (M = 900 ms, SE = 52.85) being reliably briefer than those in the Random condition (M = 1,189 ms, SE = 69.89), confirming contextual cueing. A significant main effect of block was also observed, F(5, 15) = 6.05, p < .01, , 95% CIs = .16, .75, indicating that the pigeons exhibited briefer RTs over the course of training; RTs in the first block were significantly longer those in the third, fourth, fifth, and sixth blocks. The main effect of SOA was also significant, F(4, 12) = 11.04, p < .001, , 95% CIs = .31, .85; Tukey post hoc analyses revealed that RTs at the 0-s SOA were significantly longer than those at the 1-, 2-, 4-, and 8-s SOAs, p < .05, but RTs at the 1-, 2-, 4-, and 8-s SOAs were not significantly different from one another. Beyond these main effects, there were three significant interactions: Block × SOA, F(20, 60) = 1.77, p < .05, , 95% CIs = .00, .96; Condition × SOA, F(4, 12) = 36.26, p < .001, , 95% CIs = .70, .94; and, Block × Condition × SOA, F(20, 60) = 2.10, p < .05, , 95% CIs = .02, .40.
The main effect of blocks and its participation in two interactions suggest that contextual cueing emerged at different rates at different SOAs over training. To capture the speed of emergence of contextual cueing at the different SOAs, we narrowed our RT analysis to the initial training block. These RTs were submitted to a repeated-measures ANOVA with condition (Predictive vs. Random) and SOA (0, 1, 2, 4, and 8 s) as within-subjects factors. A significant main effect of condition was obtained, F(1, 3) = 13.11, p < .05, , 95% CIs = .00, .91, with the Predictive condition (M = 981 ms, SE = 53.25) supporting briefer RTs than the Random condition (M = 1,261 ms, SE = 82.46); this RT advantage indicates that contextual cueing was present in the very first block of training. The rapid emergence of contextual cueing suggests that the birds may have already learned the associations between the contexts and the target locations during the immediately preceding 20 days of training at the 0-s SOA, even though they did not earlier show any sign of having acquired these associations. The Condition × SOA interaction was also significant, F(4, 12) = 5.16, p < .05, , 95% CIs = .06, .74; Tukey post hoc analyses indicated that contextual cueing effect was reliable at each SOA, p < .05, except 0 s. And, as in Experiment 1b, the RT disparity was greatest at 2 s. The main effect of SOA was not significant. To further illuminate the three-way interaction, we calculated the disparity in RT between the Predictive and Random conditions for each block of training. These scores confirmed that the contextual cueing effect was present in the very first block and that it generally grew in strength in subsequent blocks of training.
Next, we compared the rate of pigeons' anticipatory responding to the Predictive vs. Random contexts in the 1-, 2-, 4-, and 8-s SOA conditions. The bottom of Figure 6 depicts the mean rate of anticipatory pecking for each condition and each SOA. Pigeons generally exhibited a higher rate of anticipatory responding in the Predictive condition (M = 0.48 pecks per s, SE = 0.03) than in the Random condition (M = 0.27 pecks per s, SE = 0.03) at each SOA; responding also rose at longer SOAs, with the rise being greater to Predictive than to Random contexts. A repeated-measures ANOVA with condition (Predictive vs. Random), SOA (1, 2, 4, and 8 s), and block (six 5-day blocks) as within-subjects factors revealed a significant main effect of SOA, F(1, 3) = 4.95, p < .05, , 95% CIs = .00, .82, and a significant condition × SOA interaction, F(3, 15) = 5.10, p < .05, , 95% CIs = .04, .66; Tukey post hoc analyses revealed that the Predictive-Random disparity in anticipatory responding was significant at each SOA, p < .05, except 1 s. No other main effect or interaction was significant. We also examined the Predictive-Random disparity in the rate of anticipatory responding in each of the six blocks of training; we found that the disparity was evident even in the first block and that it generally increased as training progressed.
Comparing the top and bottom portions of Figure 6 suggests a disparity in pigeons' rate of anticipatory responding to the Predictive and Random contexts in our two experiments; that disparity may have resulted from the immediately prior phase of training. Birds in Experiment 1b may have become accustomed to a 2-s SOA because of the previous 20 days of 2-s SOA training; thus, they pecked most rapidly at the 2-s SOA, with their rate falling at both shorter and longer SOAs. By comparison, birds in Experiment 2b may have become accustomed to a 0-s SOA, where anticipatory pecking was impossible. When these birds were given the full set of nonzero SOAs, they pecked at higher rates as the available time to respond was increased.
Finally, we analyzed the location of anticipatory pecks to the Predictive scene contexts. The bottom of Figure 7 shows the mean rate of correct and incorrect anticipatory responding at each SOA. Just as in Experiment 1b, the birds exhibited a higher rate of correct anticipatory pecking than incorrect anticipatory pecking at each SOA, with the disparity tending to be greatest at 2 s. These scores were submitted to a repeated-measures ANOVA with response type (correct vs. incorrect anticipatory response), SOA (1, 2, 4, and 8 s), and block (six 5-day blocks) as within-subjects factors. The main effect of response type was significant, F(1, 3) = 119.00, p < .01, , 95% CIs = .15, .99, with correct anticipatory responding (M = 0.84 pecks per s, SE = 0.10) exceeding incorrect anticipatory responding (M = 0.04 pecks per s, SE = 0.01). The response type × block interaction was also significant, F(5, 15) = 3.37, p < .05, , 95% CIs = .00, .64; Tukey post hoc analyses revealed that the disparity between correct and incorrect anticipatory responding was significant in each block of training, with the disparity increasing as training progressed, p < .05. No other main effect or interaction was significant, although the Correct-Incorrect disparity was greatest at the 2-s SOA.
Experiment 2c
Training
The training procedure was the same as in Experiment 1a.
Results
The bottom of Figure 2 shows that mean Log RTs (ms) were much briefer in the Predictive than in the Random condition. A repeated-measures ANOVA with condition (Predictive vs. Random) and day (1 to 20) as within-subjects factors disclosed a significant main effect of condition, F(1, 3) = 45.87, p < .01, , 95% CIs = .00, .97, with the Predictive condition (M = 717 ms, SE = 23.57) supporting briefer RTs than the Random condition (M = 1,114 ms, SE = 30.18), although there was no main effect of day or interaction between these variables.
The bottom of Figure 3 shows that the mean rate of anticipatory pecking in the Predictive condition (M = 0.64 pecks per s, SE = 0.04) tended to be greater than in the Random condition (M = 0.23 pecks per s, SE = 0.03), with this disparity increasing over the 20 days of training. A repeated-measures ANOVA with condition (Predictive vs. Random) and day (1 to 20) as within-subjects factors revealed a significant Condition × Day interaction, F(19, 57) = 2.77, p < .01, , 95% CIs = .10, .48; Tukey post hoc analyses indicated that the Predictive-Random disparity was reliable as early as Day 1, p < .05.
The mean rate of correct and incorrect anticipatory pecking during the 20 days of training is shown in the bottom of Figure 4. Correct anticipatory pecking greatly exceeded incorrect anticipatory pecking, with the disparity remaining constant throughout training. A repeated-measures ANOVA with response type (correct vs. incorrect anticipatory response) and day (1 to 20) as within-subjects factors revealed a significant main effect of response type, F(1, 3) = 19.79, p < .05, , 95% CIs = .00, .93, with correct anticipatory responding (M = 1.19 pecks per s, SE = 0.10) surpassing incorrect anticipatory responding (M = 0.02 pecks per s, SE = 0.01). No other main effect or interaction was significant.
Discussion of Experiments 1 and 2
The present pair of experiments clearly document contextual cueing in pigeons using real-world photographic scenes. As training progressed in Experiment 1a (Figure 2, top), target search became faster in the Predictive condition (in which the locations of the target were consistently associated with specific contexts) than in the Random condition (in which such consistent context-target associations were precluded). In addition, the rise in anticipatory responses during the context-target delay that were discriminatively directed toward the location of the upcoming target in the Predictive condition (Figure 4, top) was reliably correlated with the RT advantage in the Predictive condition (Figure 2, top). Actively attending to and pecking toward the location of the upcoming target might well have contributed to lower RTs in the Predictive condition, because pigeons would have been positioned closer to the target in that condition than in the Random condition. This strong correlation between the emergence of contextual cueing and the increase in anticipatory responses directed toward the upcoming target in the Predictive condition supports the attentional guidance hypothesis advanced by Chun and Jiang (1998).
Our results are also consistent with those of a related human study in which the contextual stimuli were shown 1,000 ms before search onset (Peterson & Kramer, 2001). There, eye movements disclosed that greater proportions of initial fixations were placed on the target when the contextual configurations were repeated than when they were novel; indeed, on average the first saccade was closer to the target for repeated configurations than for novel configurations (see Kunar et al., 2008 for additional results).
Although the aforementioned investigations, along with electrophysiological studies (Olson, Chun, & Allison, 2001; Schankin & Schubö, 2009), suggest that contextual cueing may be due to attentional guidance toward the location of the target, Kunar and colleagues (2006) have reported contradictory findings. These authors varied the number of distractors and calculated search slope as a measure of attentional guidance. No changes in search slope were observed across nine separate experiments, suggesting that the RT benefits were not facilitated by attention being guided by contextual cueing.
Instead, Kunar, Flusberg, Horowitz, and Wolfe (2007) proposed that late-stage, facilitated response production might contribute to contextual cueing. According to this account, contextual cueing may decrease the threshold to make a response after the target is detected, resulting in faster RTs in a repeated context than in a novel one. These authors reported that, when interference was added to the response production process, no RT benefit of predictive contexts over random ones was observed (Kunar et al., 2007, Experiment 3). In addition, changing from a discrimination task to a detection task and introducing target-absent trials eliminated contextual cueing (Kunar & Wolfe, 2011, Experiment 5).
It is, of course, entirely possible that both attentional guidance and facilitated response production contribute to contextual cueing. Event-related potential (ERP) studies suggest that response-related processes, in addition to visual-spatial guidance, may contribute to contextual cueing (Schankin & Schubö, 2009). Also, a recent eye-movement study suggests that, although attentional guidance accounts for most of the contextual cueing effect, facilitated response production also plays a measurable part (Zhao, Liu, Jiao, Zhou, Li, & Sun, 2012).
In the present study, the robust correlation between the decrease in RTs and the increase in discriminative anticipatory pecks throughout training suggests that our photographic contexts were effectively guiding the pigeons' attention and pecking toward the location of the target before it was even presented, rather than facilitating response production after the target was detected, thereby shortening the RTs for the Predictive displays compared to the Random displays (also see Jiang et al., 2012).
In addition, we found that an SOA of 0 s did not promote the expression of contextual cueing in Experiment 2a (Figure 8, bottom) or the maintenance of contextual cueing in Experiment 1c (Figure 8, top), perhaps because anticipatory responses were precluded with a 0-s SOA. Nevertheless, pigeons in Experiment 2b did appear to have learned the context-target associations with a 0-s SOA, as evidenced by their rapid expression of faster RTs at all nonzero SOAs (Figure 5, bottom).
Taking all of this work into account, it would appear that the results of our experiments more strongly support the attentional guidance interpretation. However, we do concede that it is possible that both early-stage attentional guidance and late-stage response generation may have contributed to our contextual cueing effect at nonzero SOAs. Future research would do well to devise new paradigms to differentiate these two plausible processes in contextual cueing.
Experiment 3
Experiments 1 and 2 thus provide compelling evidence that real-world scenes can readily serve as effective contextual cues to guide pigeons' attention and responding to the location of an upcoming target. Having established this fact, we next asked: just what information in the scenes did the pigeons use to locate the target? Is this information conveyed by global properties of the scenes or is it conveyed by local features immediately adjacent to the upcoming target or do both global and local scene cues participate in the contextual cueing effect that we observed?
Questions concerning the hierarchical nature of stimulus control have previously been investigated by researchers studying contextual cueing. In contrast with studies using arrays of distractors (Brady & Chun, 2007; Jiang & Wagner, 2004), studies using naturalistic scenes have consistently found that attentional guidance is based on the global perception of scenes rather than on the local stimuli immediately adjacent to the target.
Brockmole, Castelhano, and Henderson (2006) found no decrement in contextual cueing when the local cues surrounding the target were altered while the global cues were preserved; yet, when global scene information was changed while local cues were held constant, the RT benefits from contextual cueing were eradicated. Later experiments have directly compared array-based and scene-based contextual cueing. Using arrays of three-dimensional objects displayed on a large table within a global scene, Brooks, Rasmussen, and Hollingworth (2010) found that array-based learning was nested within scene-based learning; using arrays of two-dimensional objects superimposed on a scene, Rosenbaum and Jiang (2014) found that scene learning completely overshadowed any array learning.
Eye movement research has found that participants have quicker access to global information, although local visual information surrounding the target may also exert behavioral control. For example, Brockmole and Henderson (2006b) showed participants photographic scenes paired with letter targets in predictable locations. Then, the scenes and the associated target locations were both horizontally reversed. This concerted reversal spatially disturbed the left-right relationship of the local scene cues immediately surrounding the target while preserving the global identity of the scene. For example, if the target was located on a particular building on the left of an image, the building (and the target) would now be located on the right, while the global structure of the skyline could remain intact. The results showed that participants' eyes first moved toward the target's original location, indicating that the preserved global contexts exerted initial attentional control; however, when that first search failed to find the target, participants' eyes subsequently moved to the target's new location. These findings suggest that, when global recognition of the context provides insufficient spatial information to find the target in its new location, local information comes into play.
Elaborating on the Brockmole and Henderson study (2006b), we designed Experiment 3 to see whether global scene information or detailed local information guides pigeons' attention and behavior toward the location of an upcoming target. Rather than only jointly changing the target's location along with left-right mirror reversals (as had Brockmole & Henderson, 2006b), we presented the target in both the reversed location (Local Cue Condition) and in its original location (Global Cue Condition). Also, we varied the Predictive contexts with both left-right and top-bottom mirror reversals (Horizontal Reversal vs. Vertical Reversal conditions, respectively) to better assess the robustness of contextual cueing to large-scale contextual changes. In addition to recording RTs, we also measured the location of any anticipatory pecks to the horizontally and vertically reversed contexts to see whether the pigeons' attention was more globally or more locally controlled. If attention were more globally controlled by the scenes, then the pigeons' anticipatory pecks should be directed toward the original location of the target, thereby encouraging the pigeons' RTs to be fastest when the target is actually presented in the “original” location on the reversed scene. However, if attention were more locally controlled by specific features in the scenes, then the pigeons' anticipatory pecks should be directed toward the changed location of the target, thereby encouraging the pigeons' RTs to be fastest when the target is presented in that “changed” location on the reversed scene.
Method
Design
Daily sessions contained original Training trials (Predictive and Random trials) randomly intermixed with four different kinds of Testing trials. Training trials followed the same design as in Experiment 1a. Testing trials included four new conditions created from each pigeon's four original Predictive contexts: Horizontal Global, Horizontal Local, Vertical Global, and Vertical Local. As shown in Figure 9, the Testing contexts were either horizontally or vertically reversed (Horizontal Reversal vs. Vertical Reversal conditions). In addition, on Testing trials, the target was either presented in the same location where it had previously appeared on Training trials (Global Cue Condition) or in a new location that was horizontally or vertically reversed in concert with the now reversed scenes (Local Cue Condition).
Figure 9.
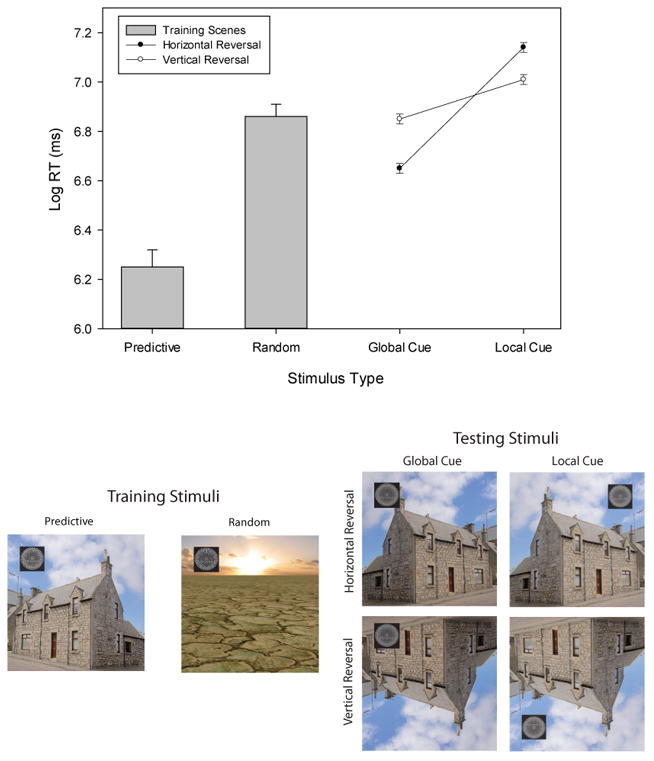
Top Panel: The mean Log RT (ms) and the standard error of the mean for each Training and Testing condition in Experiment 3. Bottom Panel: Examples of the Training (left) and Testing (right) contextual stimuli paired with the target stimulus superimposed in the designated locations in the Horizontal Local (top-left), Horizontal Global (top-right), Vertical Local (bottom-left), and Vertical Global (bottom-right) conditions in Experiment 3. As a guide to calibrating Log RTs to RTs (ms): Log RT of 6 = 403 ms, Log RT of 6.5 = 665 ms, and Log RT of 7 = 1,097 ms.
Training and Testing
The experimental procedure was the same as in Experiment 1a, except that 16 daily sessions comprised 192 Training trials (Predictive and Random trials) randomly intermixed with 48 Testing trials. The Testing stimuli were 16 different scene-target arrangements, each presented three times. Half of the Testing stimuli were created by horizontally reversing each of the four Predictive contexts (house, mountain, lake, and cemetery); the other half of the Testing stimuli were created by vertically reversing the same four Predictive contexts. In both horizontal and vertical reversal conditions, on half of the trials, the target was presented in the same location where it had been presented on Training trials; on the other half of the trials, the target was presented in the location that was horizontally reversed (in the Horizontal Reversal Condition) or vertically reversed (in the Vertical Reversal Condition).
Results and Discussion
First, we analyzed RTs to the target stimulus on all Training and Testing trials to confirm that the Predictive and Random Training contexts again differed from one another as well as that the Training and Testing contexts differed from one another. These RTs (Figure 9) were submitted to a repeated-measures ANOVA with condition (Predictive vs. Random vs. Horizontal Global vs. Horizontal Local vs. Vertical Global vs. Vertical Local) and day (1 to 16) as within-subjects factors. The significant main effect of day, F(15, 105) = 2.21, p < .01, , 95% CIs = .02, .27, indicated that RTs decreased over sessions, perhaps because of the pigeons' increasing familiarity with the reversed backgrounds. The main effect of condition was also significant, F(5, 35) = 106.46, p < .001, , 95% CIs = .88, .95. The Predictive condition (M = 693 ms, SE = 18.43) supported significantly briefer RTs than the Random condition (M = 1,140 ms, SE = 24.59) and all four Testing conditions. Because the Predictive condition supported faster RTs than all four Testing conditions, it appears that global and local cues each controlled pigeons' visual search behavior as both were changed in our experimental design; subsequent analyses more precisely examined the respective contributions of these cues. The Random condition also supported significantly longer RTs than the Horizontal Global condition and significantly shorter RTs than the Horizontal Local condition, but it did not support significantly different RTs from the Vertical Global or Vertical Local conditions. Thus, our manipulation of local and global scene cues, as in the Horizontal Local condition, was strong enough to yield RTs with predictive scene backgrounds that were even slower than with random scene backgrounds. The Condition × Day interaction was also significant, F(75, 525) = 2.37, p < .001, , 95% CIs = .09, .15. Nevertheless, in both the first and second half of the experiment, the pigeons' pattern of responding in all six conditions remained the same; the RT disparities among the four Testing conditions became slightly smaller, with RTs in the Predictive and Random conditions remaining unchanged.
Second, we focused our main RT analyses on the Testing trials alone, in order to factorially assess how global vs. local cues affected RTs to horizontally vs. vertically reversed contexts. These RTs were submitted to a repeated-measures ANOVA with reversal type (horizontal vs. vertical reversal), cueing type (global vs. local cue), and day (1 to 16) as within-subjects factors. A significant main effect of day, F(15, 105) = 2.31, p < .01, , 95% CIs = .02, .28, again indicated that RTs decreased over sessions. The main effect of cueing type was also significant, F(1, 7) = 32.84, p < .001, , 95% CIs = .30, .90, with Global Cue contexts (M = 1,065 ms, SE = 26.16) supporting shorter RTs than Local Cue contexts (M = 1,524 ms, SE = 38.07). The Cueing Type × Day interaction was significant, F(15, 105) = 5.21, p < .001, , 95% CIs = .20, .47, with the RT disparities among the four testing conditions becoming slightly smaller from the first to the second half of the experiment.
In both the Horizontal and Vertical Reversal conditions, RTs were faster in the Global than in the Local Cue conditions (Figure 9). However, the interaction between cueing type and reversal type was significant, F(1, 7) = 27.13, p < .001, , 95% CIs = .24, .89, indicating a greater global-local disparity for Horizontal than for Vertical reversals.
Tukey post hoc analyses indicated that the Horizontal Global condition (M = 953 ms, SE = 31.66) supported significantly shorter RTs than the other three conditions (Figure 9), p < .05; in addition, RTs in the Vertical Global condition (M = 1,179 ms, SE = 39.31) were significantly shorter than those in the two Local conditions, p < .05; RTs in the Horizontal Local condition (M = 1,609 ms, SE = 56.83) and in the Vertical Local condition (M = 1,441 ms, SE = 49.79) did not differ significantly. The Cueing Type × Reversal Type × Day interaction was also significant, F(15, 105) = 1.80, p < .05, , 95% CIs = .00, .23. In both the first and second half of the experiment, the RT pattern captured by the Cueing Type × Reversal Type interaction remained the same, with the disparities among the four conditions becoming slightly smaller in the second half. No other main effect or interaction was significant.
How can these reliable differences best be understood? The Horizontal Global trials and the Horizontal Local trials displayed the same visual scene; in the former case the target appeared in the correct absolute position on the screen but in the incorrect position relative to the local scene cues, whereas in the latter condition the target appeared in the correct position relative to the local scene cues but in the incorrect absolute position on the screen. The faster RTs on Horizontal Global trials than on Horizontal Local trials clearly document stronger global than local cue control. The same trend was obtained on Vertical Global and Vertical Local trials, but with the disparity between the vertical reversal conditions being smaller than between the horizontal reversal conditions. The smaller disparity in the vertical reversal conditions suggests that horizontal reversals better supported the recognition of visual scenes than did vertical reversals. Categorization studies using naturalistic stimuli with intact backgrounds have also found that horizontal and vertical reversals of the same images differentially affected pigeons' discriminative performance. When category-trained birds were later tested with reversed stimuli, their accuracy dropped significantly when the images were vertically reversed; however, no drop in accuracy was observed when the training stimuli were horizontally reversed (Wasserman, Kiedinger, & Bhatt, 1988, Experiment 3).
Finally, consider the Horizontal Local and Vertical Global contexts. In the former case, when overall performance indicated that the scene was less disruptively reversed, the target appeared in the correct position relative to local scene cues, but it was put into the incorrect absolute position on the screen; in the latter case, when overall performance indicated that the scene was more disruptively reversed, the target appeared in the incorrect position relative to local scene cues, but it was put into the correct absolute position on the screen. Nevertheless, the Vertical Global contexts supported faster RTs than the Horizontal Local contexts. This disparity again documents stronger global than local cue control.
We then analyzed our pigeons' anticipatory responses during the SOA to see how the Training and Testing scenes may have guided the birds' attention and facilitated their target search. For anticipatory responses on Training trials, our analyses replicated the results in Experiments 1a and 2c. The rate of anticipatory responding was submitted to a repeated-measures ANOVA with condition (Predictive vs. Random) and day (1 to 16) as within-subjects factors. The main effect of condition was marginally significant, F(1, 7) = 5.14, p = .06, , 95% CIs = .00, .69, with the Predictive contexts again supporting generally higher rates of anticipatory responding (M = 0.88 pecks per s, SE = 0.05) than the Random contexts (M = 0.46 pecks per s, SE = 0.06). The main effect of day was significant, F(15,105) = 2.28, p < .01, , 95% CIs = .02, .28, indicating an increasing rate of anticipatory responding as training progressed. The interaction between condition and days was not significant, F < 1.
We also examined the location of anticipatory pecks to the Predictive contexts on Training trials. The corrected rate of anticipatory responding was submitted to a repeated-measures ANOVA with response type (correct vs. incorrect anticipatory response) and day (1 to 16) as within-subjects factors. The main effect of response type was significant, F(1, 7) = 33.51, p < .001, , 95% CIs = .31, .91, with the rate of correct anticipatory responding (M = 1.16 pecks per s, SE = 0.08) exceeding the rate of incorrect anticipatory responding (M = 0.08 pecks per s, SE = 0.02). Also significant were the main effect of day, F(15, 105) = 2.14, p < .05, , 95% CIs = .01, .27, and the interaction between response type and day, F(15, 105) = 1.91, p < .05, , 95% CIs = .00, .24; from the first half to the second half of the experiment, the Correct-Incorrect disparity in pecking became smaller.
To determine how global or local cues may have directed the pigeons' attention and responding, we analyzed the rate of anticipatory pecking to the contexts on Testing trials. For this analysis, we divided the entire scene area into four equal-sized quadrants. We denoted the quadrants as follows: Global Cue (GC), Local Cue (LC), Possible Location (PO), and Impossible Location (IM) (Figure 10). The Global Cue location refers to the quadrant to which the pigeons should have directed their pecks based on the entire composition of the scene, despite the fact that the scene was now reversed either horizontally or vertically; this quadrant continued to contain the target on Predictive Training trials. The Local Cue location refers to the quadrant to which the pigeons should have directed their pecks based on the cues that were closest to the target on Predictive Training trials, despite the fact that those local cues were now either horizontally or vertically reversed. The Possible Location and the Impossible Location refer to the pair of quadrants to which the pigeons should never direct their pecks because these regions never contained the target stimulus on Predictive training trials. We counted pecking in those quadrants as a control for pigeons' indiscriminate pecking. We separated these quadrants into those that, in our factorial design, could contain the target on Testing trials (Possible Location) and those that could not (Impossible Location); in neither case, did we expect the pigeons to peck very much.
Figure 10.
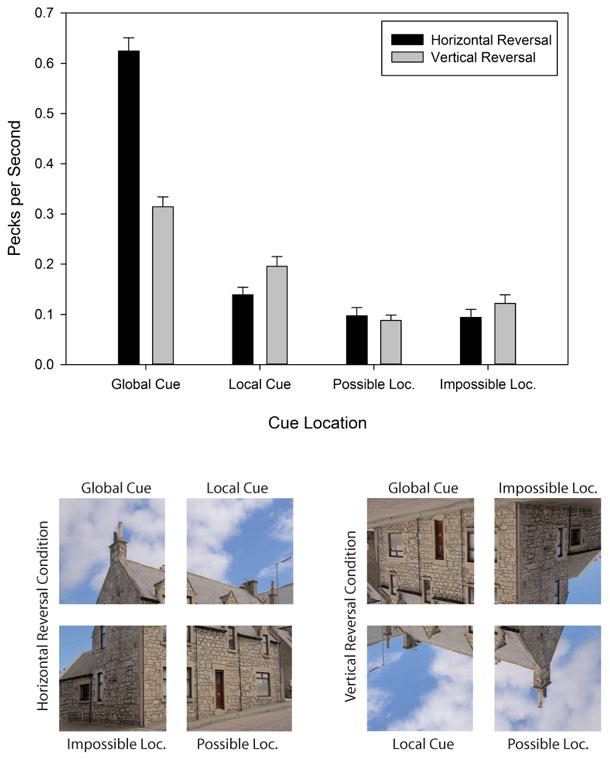
Top Panel: Mean anticipatory pecks per s to GC, LC, PO, and IM locations for the Horizontal vs. Vertical Cue conditions in Experiment 3. Bottom Panel: Examples of the GC, LC, PO, and IM locations for the Horizontal vs. Vertical Cue conditions in Experiment 3.
Recall that our RT analyses clearly indicated that global cues exerted stronger control over pigeons' RTs than local cues. Thus, we expected more anticipatory pecks to be made to the GC locations than to the LC locations. Additionally, because the RT disparity between the global and local conditions was greater in the horizontal reversal conditions than in the vertical reversal conditions, we expected the disparity between anticipatory pecks to the GC locations and those to the LC locations to be greater in the horizontal reversal conditions than in the vertical reversal conditions. Because anticipatory responses were made prior to the presentations of the target, the Global Cue vs. Local Cue conditions arranged in the experiment were irrelevant to the present analysis; we only examined in which of the four types of quadrants greater anticipatory responding occurred to the Horizontally vs. Vertically reversed contexts.
The rate of anticipatory responding was analyzed using a repeated-measures ANOVA with day (1 to 16), reversal type (horizontal vs. vertical reversal), and response type (global cue vs. local cue vs. possible location vs. impossible location) as within-subjects factors. The main effect of response type was significant, F(3, 21) = 184.84, p < .001, , 95% CIs = .91, .97, indicating that different parts of the Testing scenes differentially controlled anticipatory responding. Tukey post hoc analyses indicated that, compared to pecking in the other three locations, the rate of anticipatory responding in the GC location (M = 0.47 pecks per s, SE = 0.03) was reliably greatest, p < .05, as evidence that the global information in the visual contexts directed the pigeons' anticipatory responding. The rate of pecking in the LC location (M = 0.17 pecks per s, SE = 0.01) also differed reliably from pecking in both the PO location (M = 0.09 pecks per s, SE = 0.01) and the IM location (M = 0.11 pecks per s, SE = 0.01), suggesting that local cues too exerted weaker, but nevertheless reliable control over anticipatory responding. Pecking to the PO and IM locations did not reliably differ. The main effect of reversal type was also significant, F(1, 7) = 20.47, p < .001, , 95% CIs = .78, .98, with the rate of anticipatory responding being higher in the Horizontal Reversal location (M = 0.24 pecks per s, SE = 0.03) than in the Vertical Reversal location (M = 0.18 pecks per s, SE = 0.01).
Moreover, the interaction between response type and reversal type was significant, F(3, 21) = 42.85, p < .001, , 95% CIs = .68, .90. Tukey post hoc analyses revealed that, in the Horizontal Reversal condition, the rate of anticipatory responding in the GC location was significantly higher than in the other three locations, p < .05, whereas the rate of anticipatory responding in the LC, PO, and IM locations did not differ from each other (Figure 10, top). This result suggests that, when the contexts were horizontally reversed, the pigeons' attention was predominantly controlled by global cues.
In the Vertical Reversal Condition, the rate of anticipatory responding in the GC location was again significantly higher than in the other three locations; in addition, the rate of anticipatory responding in the LC location differed reliably from the PO location, but not from the IM location; the rate of anticipatory responding in the PO and IM locations did not reliably differ (Figure 10, bottom). No other main effect or interaction was reliable. This pattern of results suggests that, when the contexts were vertically reversed, both global and local contexts exerted attentional control. Perhaps because global cues were more strongly disrupted when the scenes were vertically reversed, local information surrounding the target was more effective for pigeons' anticipating the location of the upcoming target. Indeed, Tukey post hoc analyses indicate that significantly more anticipatory pecks were directed to the LC location in the Vertical Reversal Condition than in the Horizontal Reversal Condition.
Finally, we explored whether anticipatory responding to the quadrant where the target was about to appear (correct responding vs. adjusted incorrect responding) in the Predictive Condition and in each of the four Testing conditions could have contributed to our overall pattern of RT results. We calculated the five mean RTs (Predictive vs. Horizontal Global vs. Horizontal Local vs. Vertical Global vs. Vertical Local) as well as the five mean disparity scores for anticipatory contextual responses (correct location vs. incorrect location) across all 16 days and then correlated them with one another (Table 1). The resulting correlation was -0.99, p < .001. This extremely high correlation suggests that pigeons' specific pattern of anticipatory responding to the various scene contexts reliably contributed to their overall pattern of RT performance, with increases in correctly directed anticipatory responding supporting progressively briefer RTs.
Table 1. Latency and Rate of Anticipatory Responses for all Five Predictive Context Conditions in Experiment 3.
| Condition | Latency (LogMs) | Correct Anticipatory Response (pecks per s) | Incorrect Anticipatory Response (pecks per s) | Anticipatory Response Disparity (pecks per s) |
|---|---|---|---|---|
| Predictive | 6.25 | 2.32 | 0.17 | 2.15 |
| Horizontal Global | 6.65 | 1.28 | 0.30 | 0.97 |
| Vertical Global | 6.85 | 0.90 | 0.40 | 0.50 |
| Vertical Local | 7.01 | 0.74 | 0.41 | 0.32 |
| Horizontal Local | 7.14 | 0.42 | 0.60 | -0.18 |
The results of Experiment 3 thus indicate that global scene properties more effectively controlled pigeons' visual search behavior than did local scene details; nevertheless, local details did promote target detection when global scene processing was made less accessible for target search by mirror-image reversal. These results are broadly consistent with the earlier discussed eye movement studies of Brockmole and Henderson (2006), which suggested that detailed local cues could be used for target localization when global cues were sufficiently disrupted. These results do not agree with the findings of Brooks, Rasmussen, and Hollingworth (2010), which suggested that disrupting the global context should interfere with access to local information or the results of Rosenbaum and Jiang (2014), which suggested that local information should be poorly learned because of the overwhelming salience of global cues.
Although our pigeons exhibited exceptionally strong global control, it may be possible to reconcile the birds' also evidencing reliable local control with the fact that pigeons are often deemed to be adept processors of particulate visual information (see Wasserman & Biederman, 2012). For example, although vertical scene reversals are much more disruptive to categorization behavior than are horizontal scene reversals (Wasserman, Kiedinger, & Bhatt, 1988), pigeons still respond well above chance with vertically reversed stimuli, suggesting that the local cues that were learned in training are still sufficient to support correct categorization behavior.
One issue with the use of naturalistic stimuli in both human and animal research is that they may constrain the results of certain stimulus transformations. Whereas artificial stimuli can be designed so that horizontal or vertical reversals equally disrupt stimulus identity, the superstructure of a “naturalistic scene” may impart a kind of regularity that systematically affects such transformations. For example, common features of naturalistic scenes, such as “sky” and “ground,” each extend horizontally, but not vertically; this factor ought to make vertical reversals more unlike the original scenes than horizontal reversals.
To assess the similarity of the context across horizontal and vertical reversals in our study, we utilized the Gist Descriptor, which analyzes the energy spectra of images in various regions (Oliva & Torralba, 2001), and has earlier been used to assess scene similarity. We computed the Gist Descriptors for each image and for each of the reversed versions. To compare the similarity of those images, we then took the sum of the squared differences between the Gist Descriptor of each original context and the Gist Descriptor its two reversed versions. These similarity scores were then compared using a paired t-test. Across the four predictive contexts alone (t(3) = 3.93, Cohen's d = 2.46, p < .05) and across all eight contexts (t(7) = 3.09, Cohen's d = 1.59, p < .05), horizontal reversals were more similar to the original contexts than were the vertical reversals.
Notwithstanding this disparity in stimulus similarity associated with horizontal and vertical reversals of naturalistic scene backgrounds, our overall finding that global image properties dominated the local cues that immediately surrounded the target expands our understanding of the stimulus control of spatially-directed behavior.
The role of global vs. local cues in spatial cognition has been extensively examined using the familiar landmark-based spatial search paradigm (Spetch, Cheng, & Mondloch, 1992). In such studies, pigeons must use a visual landmark to find a hidden target and then peck the area containing the hidden target to receive food. Results show that, when the landmark is shifted, the peak place of pigeons' pecking moves along with the shifted landmark, indicating that the birds use the landmark, which conveys detailed spatial information for target localization.
Cheng and Spetch (1995) subsequently investigated whether, in addition to the landmark, pigeons can use a global cue—the square outline (frame) of the search array—to find a hidden goal. Although search was primarily controlled by the landmark for some pigeons, for other pigeons search was primarily controlled by the frame; indeed, still other birds used the relation between the frame and the landmark. Evidently, the control of visual search by global or local information may differ from individual to individual.
Overshadowing among competing landmarks further underscores the importance of local cues for target localization. Both pigeons and humans show stronger control by closer landmarks than by farther landmarks when both are simultaneously presented and signal target location (Spetch, 1995; Leising, Garlick, & Blaisdell, 2011).
Our study, by contrast, yielded stronger evidence for global than for local control of spatially-directed responding. This empirical disparity between our study and many earlier landmark search studies may stem from several sharp differences in the experimental paradigms. We always made the target visible to the pigeons after nonzero SOAs; during the SOAs, the birds were free to peck at the (target-absent) contexts, but they were never required do so. In the landmark search paradigm, the birds had to discover where the (never-visible) target was located and to peck within its unmarked boundaries to receive food (Spetch et al., 1992; Cheng & Spetch, 1995). Moreover, our study entailed photographic scenes which were rich with visual information that could be associated with the location of the target; the traditional landmark search paradigm entails only a small number of local landmarks in the immediate vicinity of the hidden target. Even though the earlier overshadowing studies involving multiple local cues were more similar to our global scene study, the small number of landmarks that were presented in those studies does not approximate the richness of real-world scenes (Spetch, 1995; Leising, Garlick, & Blaisdell, 2011).
Our study also suggests that global and local cueing effects may be interdependent in pigeons as well as humans. Although the associations between the global contexts and the locations of the upcoming target more strongly contributed to the contextual cueing effect, local features associated with the placement of the upcoming target also influenced spatially controlled attention and responding. When both global and local information were intact (in the Predictive condition), the pigeons most quickly pecked the target; when either global or local cues misdirected the pigeons away from the current target location, pecking the target was slowed.
Landmark-based studies too have found that the strength of local control can depend on the configuration of global cues (Legge, Spetch, & Batty, 2009). Local versus global control turned out to depend on the horizontal, vertical, and diagonal patterns of 2-, 3-, 4-, or 5-element linear strings of items (as well as on the individual pigeons being studied). When linear arrays were horizontally arranged, pigeons attended more to local cues; when linear arrays were vertically or diagonally arranged, pigeons attended more to global cues.
General Discussion
Our study documents, for the first time, reliable contextual cueing in animals using real-world scenes as cueing contexts, and comparing visual search behavior with predictive and random contexts. Our study thus joins that of Goujon and Fagot (2013) in documenting the species and situational generality of contextual cueing.
The baboons in Goujon and Fagot (2013) responded more quickly to repeated patterns of distractors that were uniquely paired with particular target locations than to other patterns of distractors that were randomly associated with target locations; our pigeons responded more quickly to repeated photographic scenes that were uniquely paired with particular target locations than to other photographic scenes that were randomly associated with target locations. The learning of context-target associations was remarkably fast in each species; reliable contextual cueing was seen after only 24 training trials for baboons and after only 256 training trials for pigeons. Baboons exhibited reliable contextual cueing at a 0-s SOA; pigeons did not do so, but they did exhibit rapid and reliable contextual cueing when later exposed to nonzero SOAs.
Goujon and Fagot (2013) did not investigate the effect of the SOA on contextual cueing. We saw little difference in contextual cueing when we varied SOAs from 1 s to 8 s. Although pigeons were not required to do so, they did peck during the SOAs. Examining those pecks, we found: (1) that pigeons pecked at a higher rate on Predictive trials (when they could anticipate the location of the upcoming target) than on Random trials (when they could not anticipate the location of the upcoming target) and (2) that, on Predictive trials, pigeons were more likely to peck the quadrant in the scene where the target was about to appear than to peck in the three other quadrants. These spatially appropriate anticipatory responses appear to have contributed to the shorter RTs on Predictive than on Random trials.
Such rapid and robust learning strongly recommends itself for researchers seeking new and efficient paradigms to study associative learning processes. It also suggests that, even though all that the pigeons had to do to procure food reinforcement in this task was to peck the target when it appeared, the birds visually processed and remembered the preceding context, and associated it with the location of the upcoming target stimulus. Such unrequired S-S learning is reminiscent of anticipatory spatial learning in autoshaping (Wasserman, Carr, & Deich, 1978).
Indeed, if one were to analyze the contextual cueing paradigm from the perspective of S-S and R-S contingencies, then one would have to concede that S-S learning plays a surprisingly large part. Still, one could argue that our pigeons' moving toward and pecking at regions of the Predictive scenes that uniquely signalled the imminent presentation of the target stimulus may convey a small, but measurable advantage: the briefer RTs that empirically define contextual cueing are associated with shorter delays to food reinforcement. Future research might well pursue the implications of this delay of reinforcement analysis.
Finally, it should be noted that much of what made human contextual cueing interesting to the vision science community was that Chun and Jiang (1998) deemed the phenomenon to be a form of implicit, incidental learning, with humans being unable to recognize the predictive contextual cues in later explicit recognition tests. There are two parts to this claim.
First, participants can ably perform the target identification task without engaging in learning at all: they must merely locate and respond to the target. So, it can safely be assumed that learning the predictive contexts in the contextual cueing task represents incidental learning.
Second, learning proceeds implicitly: that is to say, without awareness. This claim has not gone unchallenged. Recent tests of awareness using possibly more sensitive recognition measures has yielded evidence of explicit learning in contextual cueing (Smyth & Shanks, 2008). Indeed, unlike cueing with arrays of distractor objects, scene-based contextual cueing has often resulted in participants expressing explicit awareness of the link between background context and target location (Brockmole & Henderson, 2006).
Given the thorny problems associated with objective measures of awareness in humans, it is unlikely that animal research will make much headway on the role of awareness in contextual conditioning. Nevertheless, animal research into contextual cueing offers considerable potential for elucidating the evolutionary and biological bases of this important phenomenon.
Acknowledgments
This research was supported by National Eye Institute Grant EY019781.
The authors thank Leyre Castro and Yasuo Nagasaka for their help with data analysis.
Contributor Information
Edward A. Wasserman, Department of Psychology, The University of Iowa
Yuejia Teng, Department of Psychology, The University of Iowa.
Daniel I. Brooks, Department of Neuroscience, Brown University
References
- Awh E, Belopolsky AV, Theeuwes J. Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in Cognitive Sciences. 2012;16:437–443. doi: 10.1016/j.tics.2012.06.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Biederman I. Perceiving real-world scenes. Science. 1972;177:77–80. doi: 10.1126/science.177.4043.77. [DOI] [PubMed] [Google Scholar]
- Brady TF, Chun MM. Spatial constraints on learning in visual search: Modeling contextual cuing. Journal of Experimental Psychology: Human Perception and Performance. 2007;33:798–815. doi: 10.1037/0096-1523.33.4.798. [DOI] [PubMed] [Google Scholar]
- Brainard DH. The psychophysics toolbox. Spatial Vision. 1997;10:433–436. doi: 10.1163/156856897X00357. [DOI] [PubMed] [Google Scholar]
- Brockmole JR, Henderson JM. Using real-world scenes as contextual cues for search. Visual Cognition. 2006a;13:99–108. doi: 10.1080/13506280500165188. [DOI] [Google Scholar]
- Brockmole JR, Henderson JM. Recognition and attention guidance during contextual cueing in real-world scenes: Evidence from eye movements. The Quarterly Journal of Experimental Psychology. 2006b;59:1177–1187. doi: 10.1080/17470210600665996. [DOI] [PubMed] [Google Scholar]
- Brockmole JR, Castelhano MS, Henderson JM. Contextual cueing in naturalistic scenes: Global and local contexts. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2006;32:699–706. doi: 10.1037/0278-7393.32.4.699. [DOI] [PubMed] [Google Scholar]
- Brooks DI. The dynamics of spatial anticipation in pigeons and rats Doctoral dissertation. The University of Iowa; 2010. [Google Scholar]
- Brooks DI, Dai J, Sheinberg D. Scene-based contextual cueing in the rhesus macaque. Journal of Vision. 2011;11:1329–1329. doi: 10.1167/11.11.1329. [DOI] [Google Scholar]
- Brooks DI, Rasmussen IP, Hollingworth A, Wasserman EA. Contextual cueing in the pigeon; Paper presented at the International Conference on Comparative Cognition; Melbourne Beach, FL. 2008. Mar, [Google Scholar]
- Brooks DI, Rasmussen IP, Hollingworth A. The nesting of search contexts within natural scenes: Evidence from contextual cuing. Journal of Experimental Psychology: Human Perception and Performance. 2010;36:1406–1418. doi: 10.1037/a0019257. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown MF, Cook RG, editors. Animal spatial cognition: Comparative, neural, and computational approaches. 2006 [On-line]. Available: www.pigeon.psy.tufts.edu/asc/
- Castro L, Kennedy PL, Wasserman EA. Conditional same-different discrimination by pigeons: Acquisition and generalization to novel and few-item displays. Journal of Experimental Psychology: Animal Behavior Processes. 2010;36:23–38. doi: 10.1037/a0016326. [DOI] [PubMed] [Google Scholar]
- Cheng K, Spetch ML. Stimulus control in the use of landmarks by pigeons in a touch-screen task. Journal of the Experimental Analysis of Behavior. 1995;63:187–201. doi: 10.1901/jeab.1995.63-187. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chun MM. Contextual cueing of visual attention. Trends in Cognitive Sciences. 2000;4:170–178. doi: 10.1016/S1364-6613(00)01476-5. [DOI] [PubMed] [Google Scholar]
- Chun MM, Jiang Y. Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology. 1998;36:28–71. doi: 10.1006/cogp.1998.0681. [DOI] [PubMed] [Google Scholar]
- Geyer T, Zehetleitner M, Müller HJ. Contextual cueing of pop-out visual search: When context guides the deployment of attention. Journal of Vision. 2010;10:1–11. doi: 10.1167/10.5.20. [DOI] [PubMed] [Google Scholar]
- Goujon A. Categorical implicit learning in real-world scenes: Evidence from contextual cueing. Quarterly Journal of Experimental Psychology. 2011;64:920–941. doi: 10.1080/17470218.2010.526231. [DOI] [PubMed] [Google Scholar]
- Goujon A, Fagot J. Learning of spatial statistics in nonhuman primates: Contextual cueing in baboons (Papio papio) Behavioural Brain Research. 2013;247:101–109. doi: 10.1016/j.bbr.2013.03.004. [DOI] [PubMed] [Google Scholar]
- Jiang YV, Sigstad HM, Swallow KM. The time course of attentional deployment in contextual cueing. Psychonomic Bulletin & Review. 2013;20:282–288. doi: 10.3758/s13423-012-0338-3. [DOI] [PubMed] [Google Scholar]
- Jiang Y, Wagner LC. What is learned in spatial contextual cuing-configuration or individual locations? Perception and Psychophysics. 2004;66:454–463. doi: 10.3758/bf03194893. [DOI] [PubMed] [Google Scholar]
- Kunar MA, Flusberg S, Horowitz TS, Wolfe JM. Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology: Human Perception and Performance. 2007;33:816–828. doi: 10.1037/0096-1523.33.4.816. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kunar MA, Flusberg SJ, Wolfe JM. Contextual cuing by global features. Perception & Psychophysics. 2006;68:1204–1216. doi: 10.3758/bf03193721. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kunar MA, Flusberg SJ, Wolfe JM. Time to guide: Evidence for delayed attentional guidance in contextual cueing. Visual Cognition. 2008;16:804–825. doi: 10.1080/13506280701751224. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kunar MA, Wolfe JM. Target absent trials in configural contextual cueing. Attention, Perception, & Psychophysics. 2011;73:2077–2091. doi: 10.3758/s13414-011-0164-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lazareva OF, Shimizu T, Wasserman EA. How animals see the world. New York: Oxford University Press; 2012. [Google Scholar]
- Legge ELG, Spetch ML, Batty ER. Pigeons' (Columba livia) hierarchical organization of local and global cues in touch screen tasks. Behavioural Processes. 2009;80:128–139. doi: 10.1016/j.beproc.2008.10.011. [DOI] [PubMed] [Google Scholar]
- Leising KJ, Garlick D, Blaisdell AP. Overshadowing between landmarks on the touchscreen and in ARENA with pigeons. Journal of Experimental Psychology: Animal Behavior Processes. 2011;37:488–494. doi: 10.1037/a0023914. [DOI] [PubMed] [Google Scholar]
- Ogawa H, Kumada T. The encoding process of nonconfigural information in contextual cuing. Attention, Perception, & Psychophysics. 2008;70:329–336. doi: 10.3758/PP.70.2.329. [DOI] [PubMed] [Google Scholar]
- Olson IR, Chun MM, Allison T. Contextual guidance of attention: Human intracranial event-related potential evidence for feedback modulation in anatomically early, temporally late stages of visual processing. Brain. 2001;124:1417–1425. doi: 10.1093/brain/124.7.1417. [DOI] [PubMed] [Google Scholar]
- Pelli DG. The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision. 1997;10:437–442. doi: 10.1163/156856897X00366. [DOI] [PubMed] [Google Scholar]
- Peterson MS, Kramer AF. Attentional guidance of the eyes by contextual information and abrupt onsets. Perception & Psychophysics. 2001;63(7):1239–1249. doi: 10.3758/bf03194537. [DOI] [PubMed] [Google Scholar]
- Rosenbaum GM, Jiang YV. Interaction between scene-based and array-based contextual cueing. Attention, Perception, & Psychophysics. 2013;75:888–899. doi: 10.3758/s13414-013-0446-9. [DOI] [PubMed] [Google Scholar]
- Schankin A, Schubö A. Cognitive processes facilitated by contextual cueing: Evidence from event-related brain potentials. Psychophysiology. 2009;46:668–679. doi: 10.1111/j.1469-8986.2009.00807.x. [DOI] [PubMed] [Google Scholar]
- Smyth AC, Shanks DR. Awareness in contextual cuing with extended and concurrent explicit tests. Memory & Cognition. 2008;36:403–415. doi: 10.3758/mc.36.2.403. [DOI] [PubMed] [Google Scholar]
- Spetch ML. Overshadowing in landmark learning: Touch-screen studies with pigeons and humans. Journal of Experimental Psychology: Animal Behavior Processes. 1995;21:166–181. doi: 10.1037//0097-7403.21.2.166. org/10.1037/0097-7403.21.2.166. [DOI] [PubMed] [Google Scholar]
- Spetch ML, Cheng K, Mondloch MV. Landmark use by pigeons in a touch-screen spatial search task. Animal Learning & Behavior. 1992;20:281–292. [Google Scholar]
- Spivey M. The continuity of mind. New York: Oxford University Press; 2008. [Google Scholar]
- Wasserman EA, Biederman I. Recognition by components: A bird's eye view. In: Lazareva OF, Shimizu T, Wasserman EA, editors. How animals see the world. New York: Oxford University Press; 2012. [Google Scholar]
- Wasserman EA, Carr DL, Deich JD. Association of conditioned stimuli during serial conditioning by pigeons. Animal Learning & Behavior. 1978;6:52–56. doi: 10.3758/BF03212002. [DOI] [Google Scholar]
- Wasserman EA, Kiedinger RE, Bhatt RS. Conceptual behavior in pigeons: Categories, subcategories, and pseudocategories. Journal of Experimental Psychology: Animal Behavior Processes. 1988;14:235–246. doi: 10.1037/0097-7403.14.3.235. [DOI] [Google Scholar]
- Zhao G, Liu Q, Jiao J, Zhou PL, Li H, Sun HJ. Dual-state modulation of the contextual cueing effect: Evidence from eye movements recordings. Journal of Vision. 2012;12:1–13. doi: 10.1167/12.6.11. [DOI] [PubMed] [Google Scholar]