

Abstract
Purpose
Career advancement in academic medicine often hinges on the ability to garner research funds, and the National Institutes of Health’s (NIH’s) R01 award is the “gold standard” of an independent research program. Studies show inconsistencies in R01 reviewers’ scoring and in award outcomes for certain applicant groups. Consistent with the NIH recommendation to examine potential bias in R01 peer review, the authors performed a text analysis of R01 reviewers’ critiques.
Method
The authors collected 454 critiques (262 from 91 unfunded and 192 from 67 funded applications) from 67 of 76 (88%) R01 investigators at the University of Wisconsin-Madison with initially unfunded applications subsequently funded between December 2007 and May 2009. To analyze critiques the authors developed positive and negative grant application evaluation word categories and selected 5 existing categories relevant to grant review. The authors analyzed results with linear mixed effects models for differences due to applicant and application characteristics.
Results
Critiques of funded applications contained more positive descriptors and superlatives and fewer negative evaluation words than critiques of unfunded applications. Experienced investigators’ critiques contained more references to competence. Critiques showed differences due to applicant sex despite similar application scores or funding outcomes: more praise for applications from female investigators; greater reference to competence/ability for funded applications from female experienced investigators; and more negative evaluation words for applications from male investigators (Ps < .05).
Conclusions
Results suggest that text analysis is a promising tool for assessing consistency in R01 reviewers’ judgments and gender stereotypes may operate in R01 review.
An important determinant of career advancement in academic medicine is the ability to compete for research support.1 The National Institutes of Health (NIH) is the largest funder of research at U.S. academic medical centers, and its R01 award is considered the “gold standard” of an independent research program.1 The NIH’s two-stage system of peer review determines R01 funding.2 In the first phase, ~3 peer reviewers assign preliminary scores and write critiques based on the proposed work’s overall impact/priority, significance, innovation, approach, investigators, and environment.2,3 Applications with the top ~50% of preliminary impact/priority scores are discussed at review-group meetings where all members contribute a final score.3 Applicants receive a Summary Statement with individual reviewers’ critiques, a summary paragraph, and the average final impact/priority score for discussed applications. In the second stage, NIH staff and the Advisory Council of each NIH Institute and Center (IC) weigh peer review outcomes and IC priorities to make final funding recommendations to IC directors.2,3 The NIH continually evaluates its review process. Although NIH peer review is considered one of the best systems in the world, studies have identified inconsistencies among R01 reviewers’ scores,4–6 and unexplained differences in award outcomes for some groups of R01 applicants.3,7–13 If bias unrelated to the quality of the proposed science negatively impacts the outcome of a grant review, it runs counter to the NIH’s goal to fund the best science, threatens scientific workforce diversity, and undermines the competitiveness of the U.S. scientific enterprise.7,14–16
An Advisory Committee to the NIH Director,17 followed by a plan for action by the NIH’s Deputy Director,18 made recommendations to examine the NIH’s grant review process for bias. Recommendations included the need for “text-based analysis of the commentary on individual grant reviews.”17 Prior studies of R01 peer review outcomes have analyzed application success rates or applicant funding rates,8–12,19 award probabilities,7,13 or reviewer-assigned scores.4,5,8,12 These methods can effectively identify award or scoring disparities between certain groups of applicants or proposal types, but provide little insight into reviewers’ reasoning for scoring or award recommendations. Text analysis of reviewers’ critiques would be novel to the study of scientific review because it can provide a window into reviewers’ decision-making processes.20–26 When used in combination with traditional comparisons, text analysis would permit testing whether reviewers’ judgments are congruent with scores and funding outcomes.21 Our research aligns with the NIH’s call for action and, to our knowledge, is the first text analysis of the written critiques of R01 applications. In this study we empirically link the contents of critiques to funding outcomes and scores to test for consistency in reviewers’ judgments across different categories of R01 investigators.
Method
The institutional review board at the University of Wisconsin-Madison (UW-Madison) approved all aspects of this study. In June 2009, we searched the NIH’s Computer Retrieval of Information on Scientific Projects (CRISP) database for all principal investigators (PIs) at UW-Madison with R01 awards funded with amended status (i.e., initially unfunded and subsequently revised applications) in the NIH’s 2008–09 fiscal years (FY). Award dates spanned December 2007 through May 2009. We invited PIs, via 3 rounds of email letters, to send us electronic PDF copies of all Summary Statements from unfunded and funded award cycles. R01 recipients provided consent by emailing PDF copies of their Summary Statements and could request withdrawal of their materials from the study.
We assigned identifiers (IDs) to applicants, Summary Statements, and critiques (as surrogate for the anonymous reviewer). We recorded (if present): application funding outcome, application type (Type 1/new R01 or Type 2/renewal), impact/priority score, the NIH IC, and use of human subjects. To ascertain applicant sex, we searched the Internet using a strategy similar to that employed by Jagsi and colleagues.19 We also examined home institution websites to ascertain each applicant’s training background. We searched CRISP for all grants held by investigators prior to the study award period, and classified investigators as “experienced” according to NIH criteria.27 We electronically formatted and de-identified each critique prior to text analysis.
We analyzed critiques with the Linguistic Inquiry Word Count text analysis software program (LIWC 2007, Austin TX), which calculates the percentage of words from predefined linguistic categories in written documents.28 We examined words in the LIWC’s 80 default word categories and 7 others developed for use with LIWC,23–25 and identified five categories relevant to scientific grant review (Table 1). These word categories are “ability” (e.g., skilled, expert, talented), “achievement” (e.g., honors, awards, prize), “agentic” (e.g., accomplish, leader, competent), “research” (e.g., scholarship, publications, grants), and “standout adjectives” (e.g., exceptional, outstanding, excellent). We developed two categories that reflect “positive evaluation” (e.g., groundbreaking, solid, comprehensive) and “negative evaluation” (e.g., illogical, unsubstantiated, diffuse) of a grant application.
Table 1.
Words in Linguistic Categories Used With the LIWC Software Program, From a Text Analysis Study of 454 Critiques of R01 Applications From Male and Female Investigators, University of Wisconsin-Madison, Fiscal Year 2008–2009
| Category | Word or root worda |
|---|---|
| Ability words24,25 | abilit*, able, adept*, adroit*, analy*, aptitude, brain*, bright*, brillian*, capab*, capacit*, clever*, compet*, creati*, expert*, flair, genius, gift*, inherent*, innate, insight*, instinct*, intell*, knack, natural*, proficien*, propensity, skill*, smart*, talent* |
| Achievement words28,b | abilit*, able*, accomplish*, ace, achiev*, acquir*, acquisition*, adequa*, advanc*, advantag*, ahead, ambiti*, approv*, attain*, attempt*, authorit*, award*, beat*, best, better, bonus*, burnout*, capab*, celebrat*, challeng*, champ*, climb*, closure, compet*, conclud*, conclus*, confidence, confident*, conquer*, conscientious*, control*, creat*, crown*, defeat*, determin*, diligen*, domina*, demote*, driven, dropout*, earn*, effect*, efficien*, effort*, elit*, enabl*, endeav*, excel*, fail*, finaliz*, first, firsts, found*, fulfill*, gain*, goal*, hero*, hon*, ideal*, importan*, improv*, inadequa*, incapab*, incentive*, incompeten*, ineffect*, initiat*, irresponsible*, king*, lazie*, lazy, lead*, lesson*, limit*, los*, master*, medal*, mediocr*, motiv*, obtain*, opportun*, organiz*, originat*, outcome*, overcome, overconfiden*, overtak*, perfect*, perform*, persever*, persist*, plan*, potential*, power*, practice, prais*, presiden*, pride, prize*, produc*, proficien*, progress, promot*, proud*, purpose*, queen, queenly, quit*, rank*, recover*, requir*, resolv*, resourceful*, responsib*, reward*, skill*, solution*, solv*, strateg*, strength*, striv*, strong*, succeed*, success*, super, superb*, surviv*, team*, top, tried, tries, triumph*, try, trying, unable, unbeat*, unproduc*, unsuccessful*, victor*, win*, won, work* |
| Agentic words23 | accomplish*, achiev*, active*, agentic, agress*, ambiti*, analy*, assert*, assiduous*, assurance, blunt*, bold*, candid*, compete*, competi*, confident*, conscientious*, daring, decisive*, defend*, direct*, domina*, driv*, dynamic*, forc*, forthright*, frank*, hardwork*, hostil*, independen*, individualistic, influence*, initiat*, intellectual, lead*, manage*, masculine, master*, mechanic*, mechanistic*, noetic, organiz*, originat*, outspoken, perform*, perserver*, power, produc*, rational*, reliabl*, risk, solid, start*, strength, strong*, success*, suggest*, superior, sure, worldly |
| Negative evaluative words | bias*, concern*, deficient, dependent, detract*, diffuse*, diminish*, fail*, ill*, inaccura*, inadequate*, inappropriate*, incomplete*, insignificant, insufficient, lack*, limit*, missing, narrow*, need*, not, omission, omit*, overambitious, overly, overstat*, poor*, question*, quo, shaky, simplistic, tentative*, unacceptabl*, unclear, underdevelop*, unproductive*, unproven, unsubstantiated, unsupported, weak* |
| Positive evaluative words | accept*, accomplish*, advanc*, ambitio*, appropriat*, art, believabl*, best, breadth, clear*, commit*, competitive*, complet*, comprehensive, convinc*, creat*, detail*, didactic, efficac*, energ*, enthus*, exceptional*, expan*, expla*, fascinat*, feasib*, focus*, groundbreaking, high*, impact*, impress*, includ*, indisputabl*, innovat*, interest*, logic*, mechanistic, meticulous*, new*, nice*, novel, obvious*, original, outstanding, pioneer*, productiv*, provocative*, quality, reasonabl*, reliab*, rigor*, significan*, solid*, sophistic*, sound*, specif*, stellar, strength, strong*, success*, superior*, support*, tailor*, target*, thought*, transform*, unimpeachable, unique*, valid*, valu*, well* |
| Research words24,25 | contribution*, data, discover*, experiment*, finding*, fund*, grant*, journal*, manuscript*, method*, project*, publication*, publish*, research*, result*, scholarship*, scien*, studies, study*, test, tested, testing, tests, theor*, vita, vitas |
| Standout adjectives24,25 | amazing, *excellen*, exceptional*, extraordinar*, fabulous*, magnificent, most, outstanding, remarkable, suberb*, suprem*, terrific*, unique, unmatched, unparalleled, wonderf* |
Abbreviation: LIWC indicates Linguistic Inquiry Word Count text analysis software program.
An asterisk (*) indicates root words counted with any ending; some words appear in more than one category.
Category condensed to accommodate space; full category available from authors on request.
Employing a modified Delphi technique29,30 we solicited lists of positive and negative evaluation words relevant to NIH grant applications from four local experienced NIH grant reviewers. We collated and resent lists for feedback, and gathered experts for a final vote.29,31 To further validate these categories we recruited two students to rate on Likert scales the levels of negative or positive evaluation words in critiques. Students’ ratings and LIWC output were correlated for both positive (r =.22) and negative (r = .24) evaluation words (Ps < .01).
We imported LIWC results and priority scores into IBM SPSS statistical software, Version 20.0 (Armonk, NY; IBM Corp., 2011), and matched these data to applicant IDs, and Summary Statement and applicant information. We analyzed all data with linear mixed-effects models and deemed P-values ≤ .05 as statistically significant.
Results
Out of 76 eligible PIs identified from the NIH’s CRISP database, 67 (88%) participated. Of these 67, 44 participants were male (66%) and 23 (34%) were female; 59 (88%) held PhDs; 17 (25%) proposed clinical research, 12 (27% of 44) male, 5 (22% of 23) female; and 54 (80%) were experienced investigators. Our final sample included 454 critiques (262 from 91 unfunded and 192 from 67 funded applications). Investigators were from 45 different departments, and 15 of the NIH’s 27 ICs funded their applications. There were between 2–5 critiques from each unfunded and 2–4 critiques from each funded application; 28 investigators (42%) had two unfunded applications.
We computed the intraclass correlation coefficient (ICC) for each linguistic variable32,33 and identified significant between-subject variation in each word category (word count = 11.3%; achievement = 14%; ability = 18.3%; agentic words = 22.3%; negative evaluation = 22.8%; positive evaluation words = 11%; research = 37%; and standout = 41%). We modeled each linguistic word category as a dependent variable with application funding outcome (unfunded vs. funded), applicant experience level (new vs. experienced investigator), and applicant sex (M vs. F) as fixed effects. Models included applicant IDs as a random effect and used restricted maximum likelihood (REML) estimation. Initial models assessed main effects and subsequent models included interaction terms.
Models showed a main effect for funding outcome for five word categories. Critiques of funded applications contained significantly more ability, agentic, standout, and positive evaluation words; and significantly fewer negative evaluation words than critiques of unfunded applications (Table 2) (Ps < .05). There were also main effects for experience level and applicant sex for four word categories. Critiques of experienced investigators’ applications contained significantly more ability, agentic, standout, and positive evaluation words than critiques of new investigators’ applications (Ps < .05). Critiques of female investigators’ applications contained significantly more words from the ability, agentic, and standout categories and significantly fewer negative evaluation words than those of male investigators (Ps < .05).
Table 2.
The Average Percentage of Words in Unfunded vs. Funded, New vs. Experienced Investigators’, and Male vs. Female Investigators’ R01 Application Critiques, from a Text Analysis Study of 454 Critiques, University of Wisconsin-Madison, Fiscal Year 2008–2009a
| Linguistic category | Funding outcome
|
Experience level
|
Applicant sex
|
|||
|---|---|---|---|---|---|---|
| Unfunded (n = 262) | Funded (n = 192) | New (n = 86) | Experienced (n = 368) | Male (n = 292) | Female (n = 162) | |
| Ability | .49 (.03) | .63 (.03)b | .49 (.05) | .63 (.03)c | .48 (.03) | .64 (.04)d |
|
| ||||||
| Achievement | 2.83 (.08) | 2.95 (.08) | 2.81 (.13) | 2.98 (.07) | 2.82 (.09) | 2.70 (.11) |
|
| ||||||
| Agentic | 1.04 (.05) | 1.35 (.06)b | 1.04 (.09) | 1.34 (.04)c | .92 (.06) | 1.46 (.07)d |
|
| ||||||
| Negative | 1.78 (.04) | 1.61 (.04)b | 1.72 (.05) | 1.67 (.03) | 1.97 (.04) | 1.42 (.04)d |
|
| ||||||
| Positive | 2.24 (.07) | 2.60 (.07)b | 2.24 (.11) | 2.61 (.06)c | 2.41 (.07) | 2.44 (.09) |
|
| ||||||
| Research | 2.67 (.12) | 2.66 (.12) | 2.58 (.20) | 2.75 (.10) | 2.62 (.13) | 2.71 (.16) |
|
| ||||||
| Standout | .14 (.01) | .20 (.01)b | .15 (.02) | .19 (.01)c | .09 (.01) | .24 (.01)d |
Numbers in table reflect estimated marginal means (and standard errors) of words by linguistic category in critiques of applications from 67 investigators. N = 454 total critiques; n in table = number of critiques per category.
Difference in means of unfunded vs. funded grant critiques is significant at P < .05.
Difference in means of new vs. experienced investigators grant critiques is significant at P < .05.
Difference in means of male vs. female investigators’ grant critiques is significant at P < .05.
Main effects were qualified by significant three-way interactions between funding outcome, investigator experience level, and applicant sex for ability [β = .40, t(397) = 2.76, P = .006], agentic [β = .70, t(402) = 2.62, P = .009], positive evaluation [β = −.97, t(397) = −2.67, P = .008], and standout words [β = .11, t(391) = 2.64, P = .009]; and two-way interactions between funding outcome and applicant sex [β = −.55, t(412) = −2.73, P = .007] and experience level and applicant sex [β = −.32, t(166) = −2.17, P = .032] for negative evaluation words. To probe these results we performed pairwise comparisons, based on estimated marginal means (Table 3), on three-way interaction terms. We used the Bonferroni correction to adjust P values.
Table 3.
The Average Percentage of Words from Linguistic Categories in Critiques of Unfunded and Funded R01 Applications from Male and Female Investigators by Experience Level and Application Type, from a Text Analysis Study of 454 Critiques, University of Wisconsin-Madison, Fiscal Year 2008–2009a
| Linguistic category | New investigators
|
Experienced investigators
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Type 1
|
Type 2
|
|||||||||||
| Male
|
Female
|
Male
|
Female
|
Male
|
Female
|
|||||||
| Unfd n = 27 |
Fd n = 18 |
Unfd n = 22 |
Fd n = 19 |
Unfd n = 70 |
Fd n = 56 |
Unfd n = 28 |
Fd n = 17 |
Unfd n = 70 |
Fd n = 51 |
Unfd n = 45 |
Fd n = 31 |
|
| Word count | 1,031 (134) | 1,096 (154) | 767 (145) | 828 (153) | 1,107 (88) | 915 (93) | 1,024 (143) | 837 (168) | 1,211 (88) | 1,026 (97) | 993 (111) | 777 (124) |
|
| ||||||||||||
| Ability | .41 (.08) | .49 (.09) | .46 (.08) | .57 (.09) | .60 (.48) | .56 (.05) | .57 (.08) | .70 (.09) | .45 (.05) | .53 (.05) | .50 (.06) | 1.14c (.07) |
|
| ||||||||||||
| Achievement | 2.60 (.22) | 2.87 (.24) | 2.97 (.23) | 2.83 (.24) | 2.68 (.97) | 3.04 (.97) | 2.94 (.98) | 3.55 (.99) | 3.03 (.97) | 2.85 (.97) | 3.00 (.97) | 2.96 (.98) |
|
| ||||||||||||
| Agentic | .96 (.13) | .90 (.15) | .96 (.14) | 1.26 (.15) | 1.02 (.07) | 1.04 (.08) | 1.19 (.11) | 1.52c (.15) | 1.00 (.07) | 1.01 (.08) | 1.24 (.09) | 2.72c (.10) |
|
| ||||||||||||
| Negative | 1.96 (.09) | 1.87 (.11) | 1.85 (.10) | 1.21c (.11) | 1.98 (.05) | 1.95 (.06) | 1.60b (.09) | 1.13c (.11) | 1.97 (.05) | 1.97 (.06) | 1.50b (.07) | 1.16c (.08) |
|
| ||||||||||||
| Positive | 1.76 (.17) | 2.25 (.20) | 1.82 (.20) | 3.26c (.20) | 2.46 (.11) | 2.73 (.11) | 2.26 (.70) | 2.41 (.21) | 2.58 (.11) | 2.74 (.12) | 2.53 (.13) | 2.74 (.15) |
|
| ||||||||||||
| Research | 2.54 (.30) | 2.22 (.31) | 2.74 (.32) | 2.81 (.32) | 2.61 (.20) | 2.78 (.20) | 2.67 (.25) | 2.23 (.30) | 2.80 (.20) | 2.86 (.21) | 2.96 (.21) | 2.92 (.24) |
|
| ||||||||||||
| Standout | .11 (.03) | .11 (.03) | .15 (.03) | .21c (.03) | .12 (.01) | .11 (.01) | .12 (.02) | .36c (.03) | .11 (.01) | .11 (.01) | .24b (.02) | .39c (.02) |
Abbreviations: Unfd = unfunded; Fd = funded.
Numbers in table reflect estimated marginal means (and standard errors) of words by linguistic category in critiques of unfunded (Unfd) and funded (Fd) applications from New (n = 13) and Experienced Type 1 (n = 24) and Type 2 (n = 30) Investigators. N = 454 total critiques; n in table = number of critiques.
male vs. female investigators’ unfunded grant critiques, P < .01.
male vs. female investigators’ funded grant critiques, P < .01.
There were no significant linguistic category differences between male and female new investigators’ unfunded application critiques (Table 3). However, critiques of funded applications from female new investigators contained significantly more positive evaluation [F(1, 175) = 13.1, P < .001] and standout words [F(1, 126) = 7.74, P = .006], and significantly fewer negative evaluation words than those from male new investigators [F(1, 272) = 19, P < .001] (Figure 1).
Figure 1.
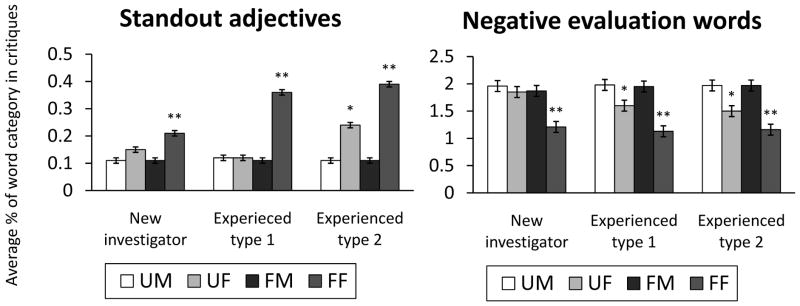
Average percentage of standout adjectives and negative evaluation words in National Institutes of Health R01 grant application critiques, from a text analysis study of 454 critiques, University of Wisconsin-Madison, 2008–2009. Figure reflects estimated marginal means (and standard error bars) of standout and negative words in critiques of unfunded and funded applications submitted by male and female applicants as new or experienced investigators of Type 1 or Type 2 R01s. UM = unfunded male; UF = unfunded female; FM = funded male; FF = funded female.
*UM vs. UF, P < .01.
**FM vs. FF, P < .01.
Pairwise comparisons showed significantly more standout and significantly fewer negative evaluation words in female than male experienced investigators’ critiques from both unfunded and funded applications. Female experienced investigators’ critiques from funded applications also contained significantly more ability and agentic words (Ps < .01). Experienced investigators can submit either Type 1 (new R01) or Type 2 (renewal) applications, so we segregated their text analysis results and computed another set of linear mixed-effects models using REML estimators for each linguistic category with funding outcome (unfunded vs. funded), applicant sex (M vs. F), and application type (Type 1 vs. Type 2) as fixed effects; we included interaction terms. Models used applicant IDs as a random effect. Models showed a significant three-way interaction effect between funding outcome, applicant sex, and application type for ability [β = .39, t(320) = 2.91, P = .004], agentic [β = 1.16, t(329) = 4.76, P < .001], and standout words [β = −.10, t(319) = −2.67, P = .008]; and a significant two-way interaction effect between funding outcome and applicant sex for negative evaluation words [β = −0.44, t(360) = −2.77, P = .006]. Pairwise comparisons showed that compared with critiques of applications from equivalent male investigators, only critiques of funded Type 2 applications from female experienced investigators contained significantly more ability words [F(1, 114) = 50.61, P < .001], and only critiques of unfunded Type 2 applications from female experienced investigators contained significantly more standout words [F(1, 80) = 41, P < .001] (Figure 1). Critiques of both Type 1 and Type 2 funded applications from female experienced investigators contained significantly more standout and agentic words (Ps < .01). Negative evaluation words occurred significantly more often in male than female experienced investigators’ Type 1 and Type 2 critiques from both unfunded and funded applications (Ps < .01). Models showed no significant differences in word counts or in research or achievement words.
We found no significant correlation between study variables and an LIWC category called “negate” (e.g., not, never). This suggests that words from each linguistic category do not co-occur in critiques with words that would reverse their meaning (e.g., “not” enthusiastic).
Priority scores assigned to 118 applications from 53 (98%) experienced investigators were available for analysis [54 scores from Type 1 (30 unfunded, 24 funded) and 64 from Type 2 (35 unfunded, 29 funded) applications]. We computed a linear mixed-effects model with priority score as the dependent variable; and funding outcome, applicant sex, and application type as fixed effects—we included interaction terms. Models used applicant IDs as a random effect to account for repeated measures per applicant. Results showed a significant main effect only for funding outcome (i.e., funded applications had better scores), [β = −51, t(68) = −7.65, P < .01]. Priority scores and linguistic word categories showed significant correlations indicating that lower (i.e., more competitive) scores were associated with critiques containing more words in the ability, agentic, positive evaluation, and standout categories, but fewer negative evaluation words (Ps < .05). Separate correlations of female and male experienced investigators’ data showed that correlations were significant only for female investigators (Table 4).
Table 4.
Correlations Between Priority Scores and Words in LIWC Categories in Critiques of R01 Applications from Experienced Male and Female Investigators, from a Text Analysis Study of 454 Critiques, University of Wisconsin-Madison, Fiscal Year 2008–2009a
| Variable | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 1 Priority scores | -- | −.417b | .008 | −.406b | .290 b | −.199c | −.071 | −.425b |
| 2 Ability | −.061 | -- | .073 | .575b | −.336b | .072 | −.041 | .395b |
| 3 Achievement | −.070 | .075 | -- | .161 | −.005 | .300b | −.066 | .078 |
| 4 Agentic | −.089 | .430b | .293b | -- | −.130 | .275b | −.063 | .386b |
| 5 Negative | .020 | .052 | .083 | .074 | -- | −.087 | .171 | −.346b |
| 6 Positive | −.112 | −.007 | .204b | −.014 | −.003 | -- | .024 | .176 |
| 7 Research | .101 | .076 | .173b | .167b | −.013 | .101 | -- | .022 |
| 8 Standout | −.110 | −.017 | .030 | .051 | .330b | −.119 | −.038 | -- |
Abbreviations: LIWC = Linguistic Inquiry Word Count text analysis software program.
Correlations between experienced female investigators’ scores and word categories in critiques are above the diagonal; experienced male investigators’ are shown below.
Correlation is significant, P < .01.
Correlation is significant, P < .05.
To test whether high or low levels of words from each category in critiques predicted priority scores and whether this differed by applicant sex, we split each LIWC word category at its median to create dichotomous indicators of “high” vs. “low” levels of words. We then analyzed experienced investigators’ priority scores using a set of linear mixed-effects models with each word category indicator variable (high vs. low), and applicant sex (M vs. F) as fixed-effects; we included interactions terms. Models used applicant IDs as a random effect; and REML estimators. Models showed significant two-way interactions between applicant sex and the high/low-indicators of ability [β = 20, t(327) = 2.60, P = .010], agentic [β = 20, t(326) = 2.45, P = .015], standout [β = 23, t(317) = 2.57, P = .011], and negative evaluation words [β = −19, t(318) = −1.89, P = .05]. Pairwise comparisons, performed on the interaction terms showed that when critiques of female experienced investigators’ applications contained high levels of words from the standout [F(1, 317) = 7.58, P = .006], ability [F(1, 323) = 8.36, P = .004], and agentic categories [F(1, 322) = 8.17, P = .05], and low levels of negative evaluation words [F(1, 319) = 4.69, P = .031], their proposals were assigned significantly lower (i.e., more competitive) scores. By comparison, male experienced investigators’ priority scores did not differ significantly by the levels of linguistic category words in their critiques.
Discussion
Our findings suggest that text analysis of application critiques is a promising tool for evaluating potential bias in peer review of NIH R01 grant applications. Text analysis appropriately sorted R01 applications that were unfunded from those that were funded as well as those from new investigators from experienced investigators. Overall, critiques of funded R01s contained more positive evaluation and standout words, more references to ability and competence (e.g., agentic words), and fewer negative evaluation words than critiques of unfunded applications. Critiques of experienced investigators’ applications contained more words from the ability, agentic, standout adjective, and positive evaluation categories than critiques of new investigators’ applications. However, these patterns were not consistent across critiques of applications from male and female investigators, suggesting that text analysis may be able to uncover discrepancies in reviewers’ judgments that are masked when only scores or funding outcomes are compared. We identified three patterns of differences in R01 critiques by applicant sex that occurred despite similar scores or funding outcomes: more positive descriptors, praise, and acclamation for funded applications from all types of female investigators; greater reference to competence and ability for funded applications from female experienced investigators, particularly for renewals; and more negative evaluation words for applications from all types of male investigators. Sub-analyses of experienced investigators’ data again confirmed the potential of text analysis to uncover discrepancies in reviewers’ judgments masked by comparing scores and funding outcomes alone. High levels of standout, ability, and agentic words and low levels of negative evaluation words in critiques predicted more competitive priority scores—as one would expect—but only for female experienced investigators.
When taken together, our findings suggest that subtle gender bias may operate in R01 peer review. Such gender bias may be unconscious and derives from pervasive cultural stereotypes that women have lower competence than men in fields like academic medicine and science where men have historically predominated.14,34,35 A large body of experimental research concludes that in such male-typed domains, gender stereotypes lead evaluators to give a woman greater praise than a man for the same performance.21,36–38 By comparison, the assumption of men’s competence in male-typed domains leads evaluators to more often notice and document negative performance from men because it is not expected.37,39 This could be one interpretation of the comparable scores and funding outcomes for male and female investigators despite the greater occurrence of negative evaluation words in critiques of men’s proposals and the apparent stronger critiques of women’s proposals. Male and female evaluators are equally prone to such gender biased judgments.40,41
Paradoxically, gender stereotypes also lead reviewers to require more proof of ability from a woman than a man prior to confirming her competence,37,42 and greater proof to confirm men’s incompetence in male-typed domains.37,39 This may also explain why men’s vs. women’s proposals were funded despite more negative critiques (i.e., higher standards for incompetence), and why there were more references to ability and competence in critiques of applications from female vs. male experienced investigators. Being an experienced investigator, particularly one renewing an R01, conflates two male-typed domains: science and leadership.43,44 Therefore, women scientific leaders would be held to the highest ability standards to confirm competence.21,37
Despite the more laudatory critiques of women’s applications, particularly for renewals, we cannot conclude from our study that women needed to outperform men to receive an R01. If this were the case, we would expect to find that women had to earn more competitive scores than men to have their applications funded, which we did not. We think it is more likely that the same level of performance was interpreted in gender-stereotypic ways, leading to more positive commentary about women’s applications. This does not fully rule out the possibility that gender stereotypes may also inadvertently influence reviewers to hold female investigators to a higher standard of competence. Such gender bias could help explain results from prior studies showing lower success rates for female vs. male R01 applicants, particularly for renewals.9,10,45
A potential limitation of our text analysis is that although we selected word categories relevant to grant review we did not include all possible categories. Another limitation is that the LIWC software program does not account for the context in which words are used, but word categories showed no correlation with “negate” words (i.e., that would reverse their meaning), and positive and negative ratings of critiques from our sample correlated with LIWC output for our positive and negative evaluation categories. Our study is limited to a single site, but UW-Madison is similar to other large public research institutions, and proposals represented 45 departments and were reviewed across 15 NIH ICs. Participant selection bias is possible, although we had an 88% response rate from all eligible PIs. We studied no critiques from initially funded or from unfunded unresubmitted applications. We cannot rule out the possibility that observed differences in critiques occurred because of differences in background qualifications or because men and women are engaged in different research areas, but ~90% of our sample held PhDs and similar proportions of male and female PIs performed clinical research.
We studied R01 critiques before the NIH implemented its streamlined review process. Priority scores and commentary based on the 5-criteria areas continue to be used to evaluate R01 applications; however, changes include a broader range for impact/priority scores, scoring for the 5-criteria, use of a bullet-point format instead of narrative format for critiques, and limit of a single resubmission for unfunded applications. These changes might reduce the amount of text available for analysis, but we have no reason to believe that they would change the impact of cultural stereotypes on judgment. Findings from our study may provide a useful comparison point for future studies of the impact of streamlining on R01 peer review. Our results should encourage future experimental studies. If stereotype-based bias is confirmed, promising interventions that foster behavioral change could be studied in the context of R01 peer review.46,47
The NIH R01 is critical for launching the scientific careers of new investigators and in maintaining the research programs of experienced investigators. Promoting an equitable peer review process will ensure that the best and most innovative research will advance. Our text analysis of R01 critiques suggests that gender stereotypes may infuse subtle bias in the R01 peer review process.
Acknowledgments
Funding: This work was supported by National Institutes of Health (NIH) grants R01 GM111002, R01 GM088477, DP4 GM096822, and R25 GM083252.
Footnotes
Other disclosures: None.
Ethical approval: The institutional review board at the University of Wisconsin-Madison approved all aspects of this study.
Disclaimers: None.
Previous presentations: Data were presented in part at the NIH workshop on Brainstorming Ideas for Conducting Studies with the Peer Review System: Strategies for Enhancing the Diversity of the Biomedical Research Workforce, March 28, 2012, Bethesda, MD.
Contributor Information
Dr. Anna Kaatz, Assistant scientist, Center for Women’s Health Research, University of Wisconsin-Madison, Madison, Wisconsin.
Ms. Wairimu Magua, Doctoral candidate, Department of Industrial & Systems Engineering, University of Wisconsin-Madison, Madison, Wisconsin.
Dr. David R. Zimmerman, Professor, Department of Industrial & Systems Engineering, University of Wisconsin-Madison, Madison, Wisconsin.
Dr. Molly Carnes, Director, Center for Women’s Health Research; professor, Departments of Medicine, Psychiatry, and Industrial & Systems Engineering, University of Wisconsin-Madison, Madison, Wisconsin; and a part-time physician, William S. Middleton Memorial Veterans Hospital Geriatric Research Education and Clinical Center, Madison, Wisconsin.
References
- 1.National Research Council of the National Academies. Bridges to Independence: Fostering the Independence of New Investigators in Biomedical Research. Washington, DC: The National Academies Press; 2005. [PubMed] [Google Scholar]
- 2.Grants and Funding: Peer Review Process. Office of Extramural Research, National Institutes of Health; [Accessed June 9, 2014.]. ( http://grants.nih.gov/grants/peer_review_process.htm) [Google Scholar]
- 3.Grants and Funding: NIH Research Project Grant Program (R01) Office of Extramural Research, National Institutes of Health; [Accessed June 9, 2014.]. ( http://grants.nih.gov/grants/funding/r01.htm) [Google Scholar]
- 4.Johnson VE. Statistical analysis of the National Institutes of Health peer review system. P Natl Acad Sci USA. 2008;105:11076–11080. doi: 10.1073/pnas.0804538105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Kaplan D, Lacetera N, Kaplan C. Sample size and precision in NIH peer review. PLoS ONE. 2008;3:e2761. doi: 10.1371/journal.pone.0002761. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Martin MR, Kopstein A, Janice JM. An analysis of preliminary and post-discussion priority scores for grant applications peer reviewed by the Center for Scientific Review at the NIH. PLoS ONE. 2010;5:e13526. doi: 10.1371/journal.pone.0013526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ginther DK, Schaffer WT, Schnell J, et al. Race, ethnicity, and NIH research awards. Science. 2011 Aug 19;333:1015–1019. doi: 10.1126/science.1196783. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Kotchen TA, Lindquist T, Miller Sostek A, Hoffmann R, Malik K, Stanfield B. Outcomes of National Institutes of Health peer review of clinical grant applications. J Invest Med. 2006;54:13–19. doi: 10.2310/6650.2005.05026. [DOI] [PubMed] [Google Scholar]
- 9.Ley TJ, Hamilton BH. The gender gap in NIH grant applications. Science. 2008;322:1472–1474. doi: 10.1126/science.1165878. [DOI] [PubMed] [Google Scholar]
- 10.Pohlhaus JR, Jiang H, Wagner RM, Schaffer WT, Pinn VW. Sex differences in application, success, and funding rates for NIH extramural programs. Acad Med. 2011;86:759–767. doi: 10.1097/ACM.0b013e31821836ff. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Dickler HB, Fang D, Heinig SJ, Johnson E, Korn D. New physician-investigators receiving National Institutes of Health research project grants. J Amer Med Assoc. 2007;297:2496–2501. doi: 10.1001/jama.297.22.2496. [DOI] [PubMed] [Google Scholar]
- 12.Kotchen TA, Lindquist T, Malik K, Ehrenfeld E. NIH peer review of grant applications for clinical research. J Amer Med Assoc. 2004;291:836–843. doi: 10.1001/jama.291.7.836. [DOI] [PubMed] [Google Scholar]
- 13.Ginther DK, Haak LL, Schaffer WT, Kington R. Are race, ethnicity, and medical school affiliation associated with NIH R01 type 1 award probability for physician investigators? Acad Med. 2012;87:1516–1524. doi: 10.1097/ACM.0b013e31826d726b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.National Academy of Sciences National Academy of Engineering Institute of Medicine of the National Academies. Beyond Bias and Barriers: Fulfilling the Potential of Women in Academic Science and Engineering. Washington, D.C: National Academies Press; 2007. [PubMed] [Google Scholar]
- 15.Chubin DE, Hackett EJ. Peerless science: Peer review and US science policy. Albany: SUNY Press; 1990. [Google Scholar]
- 16.National Academies of Sciences. Rising Above the Gathering Storm: Energizing and Employing America for a Brighter Economic Future. Washington, DC: The National Academies Press; 2007. [Google Scholar]
- 17.Working Group on Diversity in the Biomedical Research Workforce (WGDBRW), The Advisory Committee to the Director (ACD), National Institutes of Health. [Accessed June 9, 2014.];Draft Report of the Adivsory Committee to the Director Working Group on Diversity in the Biomedical Research Workforce. ( http://acd.od.nih.gov/Diversity%20in%20the%20Biomedical%20Research%20Workforce%20Report.pdf)
- 18.Tabak LA. [Accessed June 9, 2014.];An Initiative to Increase the Diversity of the NIH-funded Workforce. ( http://acd.od.nih.gov/Diversity-in-the-Biomedical-Workforce-Implementation-Plan.pdf)
- 19.Jagsi R, Motomura AR, Griffith KA, Rangarajan S, Ubel PA. Sex differences in attainment of independent funding by career development awardees. Ann Intern Med. 2009;151:804–811. doi: 10.7326/0003-4819-151-11-200912010-00009. [DOI] [PubMed] [Google Scholar]
- 20.Biernat M, Eidelman S. Translating subjective language in letters of recommendation: The case of the sexist professor. Eur J Soc Psychol. 2007;37:1149–1175. [Google Scholar]
- 21.Biernat M, Tocci MJ, Williams JC. The language of performance evaluations: Gender-based shifts in content and consistency of judgment. Soc PsycholPers Sci. 2012;3:186–192. [Google Scholar]
- 22.Axelson RD, Solow CM, Ferguson KJ, Cohen MB. Assessing implicit gender bias in Medical Student Performance Evaluations. Eval Health Prof. 2010;33:365–385. doi: 10.1177/0163278710375097. [DOI] [PubMed] [Google Scholar]
- 23.Isaac C, Chertoff J, Lee B, Carnes M. Do students’ and authors’ genders affect evaluations? A linguistic analysis of Medical Student Performance Evaluations. Acad Med. 2011;86:59–66. doi: 10.1097/ACM.0b013e318200561d. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Madera JM, Hebl MR, Martin RC. Gender and letters of recommendation for academia: Agentic and communal differences. J Appl Psychol. 2009;94:1591–1599. doi: 10.1037/a0016539. [DOI] [PubMed] [Google Scholar]
- 25.Schmader T, Whitehead J, Wysocki V. A linguistic comparison of letters of recommendation for male and female chemistry and biochemistry job applicants. Sex Roles. 2007;57:509–514. doi: 10.1007/s11199-007-9291-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Trix F, Psenka C. Exploring the color of glass: Letters of recommendation for female and male medical faculty. Discourse Soc. 2003;14:191–220. [Google Scholar]
- 27.Grants and Funding: New and Early Stage Investigator Policies. Office of Extramural Research, National Institutes of Health; [Accessed June 9, 2014.]. ( http://grants.nih.gov/grants/new_investigators/) [Google Scholar]
- 28.Pennebaker J, Chung C, Ireland M, Gonzales A, Booth R. The development and psychometric properties of LIWC2007. Austin, TX: LIWC. Net; 2007. [Google Scholar]
- 29.Cluster RL, Scarcella JA, Stewart JA. The modified Delphi technique - A rotational modification. J Vocat Technol Ed. 1999;15(2):50–58. [Google Scholar]
- 30.de Villiers MR, de Villiers PJT, Kent AP. The Delphi technique in health sciences education research. Med Teach. 2005;27:639–643. doi: 10.1080/13611260500069947. [DOI] [PubMed] [Google Scholar]
- 31.Landeta J, Barrutia J, Lertxundi A. Hybrid Delphi: A methodology to facilitate contribution from experts in professional contexts. Technol Forecast Soc Change. 2011;78:1629–1641. [Google Scholar]
- 32.Hox JJ. Multilevel Modeling: When and Why. In: Balderjahn I, Mathar R, Schader M, editors. Classification, Data Analysis and Data Highways. New York: Springer; 1998. pp. 147–154. [Google Scholar]
- 33.West BT, Welch KB, Galecki AT. Linear Mixed Models: A Practical Guide Using Statistical Software. Chapman & Hall/CRC; Boca Raton, FL: 2007. [Google Scholar]
- 34.Handelsman J, Cantor N, Carnes M, et al. Careers in science. More women in science. Science. 2005;309:1190–1191. doi: 10.1126/science.1113252. [DOI] [PubMed] [Google Scholar]
- 35.Moss-Racusin CA, Dovidio JF, Brescoll VL, Graham MJ, Handelsman J. Science faculty’s subtle gender biases favor male students. P Natl Acad Sci USA. 2012;109(41):16474–16479. doi: 10.1073/pnas.1211286109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Biernat M. Stereotypes and shifting standards: Forming, communicating and translating person impressions. In: Devine PGP, Plant A, editors. Advances in Experimental Social Psychology. Vol. 45. San Diego, CA: Academic Press; 2012. pp. 1–50. [Google Scholar]
- 37.Biernat M, Kobrynowicz D. Gender- and race-based standards of competence: Lower minimum standards but higher ability standards for devalued groups. J Pers Soc Psychol. 1997;72:544–557. doi: 10.1037//0022-3514.72.3.544. [DOI] [PubMed] [Google Scholar]
- 38.Biernat M, Vescio TK. She swings, she hits, she’s great, she’s benched: Implications of gender-based shifting standards for judgment and behavior. Pers Soc Psychol Bulletin. 2002;28:66–77. [Google Scholar]
- 39.Biernat M, Fuegen K, Kobrynowicz D. Shifting standards and the inference of incompetence: Effects of formal and informal evaluation tools. Pers Soc Psychol Bulletin. 2010;36:855–868. doi: 10.1177/0146167210369483. [DOI] [PubMed] [Google Scholar]
- 40.Devine PG. Stereotypes and prejudice: Their automatic and controlled components. J Pers Soc Psychol. 1989;56:5–18. [Google Scholar]
- 41.Nosek BA, Smyth FL, Hansen JJ, et al. Pervasiveness and correlates of implicit attitudes and stereotypes. Eur Rev Soc Psychol. 2007;18:36–88. [Google Scholar]
- 42.Foschi M. Double standards in the evaluation of men and women. Soc Psychol Quart. 1996:237–254. [Google Scholar]
- 43.Marchant A, Bhattacharya A, Carnes M. Can the language of tenure criteria influence women’s academic advancement? J Womens Health (Larchmt) 2007;16:998–1003. doi: 10.1089/jwh.2007.0348. [DOI] [PubMed] [Google Scholar]
- 44.Carnes M, Bland C. A challenge to academic health centers and the National Institutes of Health to prevent unintended gender bias in the selection of clinical and translational science award leaders. Acad Med. 2007;82:202–206. doi: 10.1097/ACM.0b013e31802d939f. [DOI] [PubMed] [Google Scholar]
- 45.National Institutes of Health Research Portfolio Online Reporting Tools. R01-Equivalent Grants: Success Rates, By Gender and Type of Application. National Institutes of Health; [Accessed June 9, 2014.]. NIH IMPAC, Success Rate File. ( http://report.nih.gov/NIHDatabook/Charts/Default.aspx?showm=Y&chartId=178&catId=15) [Google Scholar]
- 46.Carnes M, Devine PG, Isaac C, et al. Promoting institutional change through bias literacy. J Divers Higher Ed. 2012;5:63–77. doi: 10.1037/a0028128. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Devine PG, Forscher PS, Austin AJ, Cox WTL. Long-term reduction in implicit race prejudice: A prejudice habit-breaking intervention. J Exp Soc Psychol. 2012;48:1267–1278. doi: 10.1016/j.jesp.2012.06.003. [DOI] [PMC free article] [PubMed] [Google Scholar]