

Abstract
Statistical X-ray computed tomography (CT) reconstruction can improve image quality from reduced dose scans, but requires very long computation time. Ordered subsets (OS) methods have been widely used for research in X-ray CT statistical image reconstruction (and are used in clinical PET and SPECT reconstruction). In particular, OS methods based on separable quadratic surrogates (OS-SQS) are massively parallelizable and are well suited to modern computing architectures, but the number of iterations required for convergence should be reduced for better practical use. This paper introduces OS-SQS-momentum algorithms that combine Nesterov's momentum techniques with OS-SQS methods, greatly improving convergence speed in early iterations. If the number of subsets is too large, the OS-SQS-momentum methods can be unstable, so we propose diminishing step sizes that stabilize the method while preserving the very fast convergence behavior. Experiments with simulated and real 3D CT scan data illustrate the performance of the proposed algorithms.
Index Terms: Statistical image reconstruction, computed tomography, parallelizable iterative algorithms, ordered subsets, separable quadratic surrogates, momentum, stochastic gradient, relaxation
I. Introduction
Statistical X-ray CT image reconstruction methods can provide images with improved resolution, reduced noise and reduced artifacts from lower dose scans, by minimizing regularized cost-functions [1]–[4]. However, current iterative methods require too much computation time to be used for every clinical scan. Many general iterative algorithms have been applied to statistical CT reconstruction including coordinate descent [5], [6], preconditioned conjugate gradient [7], and ordered subsets [8], [9], but these algorithms all converge slower to the minimizer than is desired for clinical CT. This paper describes new image reconstruction algorithms that require less computation time.
Recent advances on iterative algorithms in X-ray CT minimize the cost function by using splitting techniques [10]–[12] accompanied with the method-of-multipliers framework [13]. The Chambolle-Pock primal-dual algorithm [14] has been applied to tomography [15], [16]. Momentum techniques [17]-[19] that use previous update directions have been applied to X-ray CT [20]-[22], accelerating a gradient descent update using the Lipschitz constant of the gradient of the cost function.
This paper focuses on momentum techniques that have received wide attention in the optimization community. Nesterov [17], [18] developed two momentum techniques that use previous descent directions to decrease the cost function at the fast convergence rate O (1/n2), where n counts the number of iterations. The rate O (1/n2) is known to be optimal1 for first-order2 optimization methods [23], while ordinary gradient descent has the rate O (1/n). Nesterov's momentum algorithms have been extended to handle nonsmooth convex functions [19], [24], and have been applied to image restoration problems [19], [25].
Momentum techniques in X-ray CT [20]–[22] have been used to accelerate gradient descent methods. However, these “traditional” momentum algorithms do not show significant improvement in convergence speed compared with other existing algorithms, due to the large Lipschitz constant of the gradient of the cost function [11]. Here, we propose to combine momentum techniques with ordered subsets (OS) methods [8], [9] that provide fast initial acceleration. (Preliminary results based on this idea were discussed in [26], [27].) OS methods, an instance of incremental gradient methods [28], approximate a gradient of a cost function using only a subset of the data to reduce computational cost per image-update. Even though the approximation in the method may prevent the algorithm from converging to the optimum, OS methods are widely used in tomography problems for their M-times initial acceleration in run time, where M is the number of subsets, leading to rate O (1/(nM)) in early iterations. Remarkably, our proposed OS-momentum algorithms should have the rate O (1/(nM)2) in early iterations providing a promising M2 acceleration compared to the standard Nesterov method.
Conventional momentum methods use either the (smallest) Lipschitz constant or a backtracking scheme to ensure monotonic descent in the gradient step [19]. Here, to reduce computation, we instead use diagonal preconditioning (or majorizing) based on the separable quadratic surrogate (SQS) [9] that is used widely for designing monotonic descent algorithms for X-ray CT. Another advantage of using SQS is that we can further accelerate the algorithm using the nonuniform approach in SQS methods that provides larger updates for the voxels that are far from their respective optima [29].
Combining OS methods with Nesterov's momentum techniques directly is a practical approach for acceleration but lacks convergence theory.3 Indeed, we observed unstable behavior in some cases. To stabilize the algorithm, we adapt the diminishing step size rule developed for stochastic gradient method with Nesterov's momentum in [33]. We view the OS-SQS methods in a stochastic sense and study the relaxation scheme of momentum approach [33]. We investigate various relaxation schemes to achieve both fast initial acceleration and stability (or convergence) in a stochastic sense. (Note that this relaxation (or diminishing step size) is not necessary if OS is not used in the proposed algorithms.)
This paper is organized as follows. Section II explains the problem of X-ray CT image reconstruction and Section III summarizes the OS-SQS algorithms. Section IV reviews momentum techniques and combines them with OS-SQS. Section V suggests a step size relaxation scheme that stabilizes the proposed algorithms. Section VI shows experimental results on simulated and real CT scans. Section VII offers conclusion and discussion.
II. Problem
We consider a (simplified) linear model for X-ray CT transmission tomography:
| (1) |
where y ∈ ℝNd is (post-log) measurement data, is a forward projection operator [34], [35] (aij ≥ 0 for all i, j), is an unknown (nonnegative) image (of attenuation coefficients) to be reconstructed and ε ∈ ℝNd is noise.
A penalized weighted least squares (PWLS) [3], [4] criterion is widely used for reconstructing an image x with a roughness penalty and a nonnegativity constraint:4
| (2) |
where the diagonal matrix W ⪰ 0 provides statistical weighting that accounts for the ray-dependent variance of the noise ε. Here, we focus on smooth5 convex regularization functions:
| (3) |
where ψr(t) ≜ βrψ(t), the function ψ(·) is an edge-preserving potential function such as a Fair potential function in [36], the parameter βr provides spatial weighting [37], and C ≜ {crj} ∈ ℝNr × Np is a finite-differencing matrix considering 26 neighboring voxels in 3D image space. The regularizer (3) makes the PWLS cost function Ψ(x) in (2) to be smooth and strictly convex with a unique global minimizer x̂ [38]. Throughout this manuscript, we assume that the objective Ψ(x) is smooth and (strictly) convex.
This nonquadratic PWLS cost function cannot be optimized analytically and requires an iterative algorithm. We propose algorithms combining OS and (relaxed) momentum approaches that minimize a smooth convex objective function Ψ(x) for CT rapidly and efficiently. Although we focus on PWLS for simplicity, the methods may also apply to penalized-likelihood formulations and to cost functions with nonsmooth regularizers, which we leave as future extensions.
III. OS-SQS Algorithms
A. Optimization transfer method
When a cost function Ψ(x) is difficult to minimize, we can replace it by a (simple) surrogate ϕ(x; x(n)) at the nth iteration, and generate a sequence {x(n)} by minimizing the surrogate as
| (4) |
This optimization transfer method [39] is also known as a majorization-minimization approach [40, Section 8.3].
To monotonically decrease Ψ(x) using an optimization transfer method, a surrogate function ϕ(x; x(n)) at nth iteration should satisfy the following majorization conditions:
| (5) |
Surrogates satisfying the conditions in (5) can be constructed using a Lipschitz constant [19], quadratic surrogates [41], and SQS methods [9], [29].
B. SQS algorithms
An optimization transfer method used widely in tomography problems is a SQS method [9] yielding the following surrogate function ϕ(x; x(n)) with a diagonal Hessian (second-order derivatives) matrix D ≜ diag{dj}, at nth iteration:
| (6) |
for all x, x(n) ∈ χ, which satisfies (5). The standard SQS algorithm [9] uses the following diagonal majorizing matrix
| (7) |
using the maximum curvature ψ¨r(0) = maxt ψ¨r(t) [41], where , and the vector 1 ∈ ℝNp consists of Np ones. (This D is positive definite because its diagonal entries are all positive.)
Table I gives the outline of the computationally efficient (and massively parallelizable) SQS algorithm, where the operation
 χ [x] projects x onto a constraint set
by a (simple) element-wise clipping that replaces negative element values to zero. The sequence {x(n)} generated from the SQS algorithm in Table I has the following convergence rate [29]:
χ [x] projects x onto a constraint set
by a (simple) element-wise clipping that replaces negative element values to zero. The sequence {x(n)} generated from the SQS algorithm in Table I has the following convergence rate [29]:
Table I. SQS Methods.
| (8) |
for any diagonal majorizing matrix D satisfying the conditions (5) and (6), including the choice (7), by a simple generalization of [19, Theorem 3.1]. Based on (8), the nonuniform approach [29] (see Section V-E) accelerates SQS methods by providing larger updates for the voxels that are far from their respective optima, which we use in our experiments (in Section VI).
SQS algorithms require many iterations to converge, both due to the O (1/n) rate in (8) and large values in D needed for satisfying the conditions (5) and (6) in 3D X-ray CT problem. Thus we usually combine SQS algorithms with OS algorithms for faster convergence in early iterations [9], [29].
C. OS algorithms
Iterative reconstruction requires both forward and back projection operations Ax and A⊤y on the fly [34], [35] due to their large-scale in 3D, and thus computation of the gradient ∇Ψ(x) = A ⊤ W(Ax − y) + ∇R(x) is very expensive. OS methods [8] accelerate gradient-based algorithms such as in Table I by grouping the projection views into M subsets evenly and using only the subset of measured data to approximate the exact gradient of the cost function.
OS methods define the subset-based cost function:
| (9) |
for m = 0,1, …, M − 1, where and the matrices ym, Am, Wm are sub-matrices of y, A, W for the mth subset, and rely on the following “subset balance” approximation [8], [9]:
| (10) |
Using (10), OS methods provide initial acceleration of about the factor of the number of subsets M in run time, by replacing ∇Ψ(x) in Table I with the approximation M∇Ψm(x) that requires about -times less computation, as described in Table II.
Table II. OS-SQS Methods.
| 1: Initialize x(0) and compute D. |
| 2: for n = 0, 1, … |
| 3: for m = 0, 1, …, M − 1 |
| 4: k = nM + m |
| 5: |
We count one iteration after all M sub-iterations are performed, considering the use of projection operators A and A⊤ per iteration, and in practice the initial convergence rate is O (1/(nM)). (Using large M can slow down the algorithm in run time due to the regularizer computation [42].) OS algorithms approach a limit-cycle because the assumption (10) breaks near the optimum [43]. OS algorithms can be modified to converge to the optimum with some loss of acceleration in early iterations [28], [44].
IV. OS-SQS Methods with Nesterov's Momentum
To further accelerate OS-SQS methods, we propose to adapt two of Nesterov's momentum techniques [17], [18] that reuse previous descent directions as momentum towards the minimizer for acceleration. (One could also consider another Nesterov momentum approach [45] achieving same rate as other two [17], [18].) This section reviews both momentum approaches and combines them with OS methods.
The first momentum method [17] uses two previous iterates, while the second [18] accumulates all gradients. Without using OS methods, both Nesterov methods provide O (1/n2) convergence rate. We heuristically expect that combining momentum with OS methods will provide roughly O (1/(nM)2) rates in early iterations, by replacing n by nM. The main benefit of combining OS and Nesterov's momentum is that we have approximately M2 times acceleration in early iterations with M subsets, yet the extra computation and memory needed (in using Nesterov's momentum approaches) are almost negligible. We discuss both proposed algorithms in more detail.
A. Proposed OS-SQS methods with momentum 1 (OS-mom1)
Table III illustrates the proposed combination of an OS-SQS algorithm with the momentum technique that is described in [17], where the algorithm generates two sequences and , and line 7 of the algorithm corresponds to a momentum step with Nesterov's optimal parameter sequence tk. Table III reduces to the ordinary OS-SQS algorithm in Table II when tk = 1 for all k ≥ 0.
Table III. Proposed OS-SQS methods with momentum in [17] (OS-mom1).
| 1: Initialize x(0) = z(0), t0 = 1 and compute D. |
| 2: for n = 0, 1, … |
| 3: for m = 0, 1, …, M − 1 |
| 4: k = nM + m |
| 5: |
| 6: |
| 7: |
The non-OS version of Table III satisfies the following convergence rate:
Lemma 1: For n ≥ 0, the sequence {x(n)} generated by the non-OS version (M = 1) of Table III satisfies
| (11) |
where D is a diagonal majorizing matrix satisfying the conditions (5) and (6), such as (7).
The inequality (11) is a simple generalization of [19, Theorem 4.4]. In practice, we expect the initial rate of OS-mom1 for M > 1 to be O (1/(nM)2) with the approximation (10), which is the main benefit of this approach, while the computation cost remains almost the same as that of OS-SQS algorithm in Table II. The only slight drawback of Table III over Table II is the extra memory needed to store the image .
B. Proposed OS-SQS methods with momentum 2 (OS-mom2)
Table IV summarizes the second proposed OS-SQS algorithm with momentum. This second method, OS-mom2, is based on [18] and uses accumulation of the past (subset) gradients in line 7. Rather than using the original choice of coefficient
from [18], Table IV uses the tk from [46], [47] that gives faster convergence. Both
and
in Table IV lie in the set χ (e.g., are nonnegative) because of the projection operation
χ[·]. Furthermore,
is a convex combination of
and
and thus also lies in χ. This may improve the stability of OS-mom2 over OS-mom1 that lacks this property.
Table IV.
Proposed OS-SQS Methods with Momentum in [18] (OS-mom2), The Notation (l)M Denotes l mod M.
| 1: Initialize x(0) = υ(0) = z(0), t0 = 1 and compute D. |
| 2: for n = 0, 1, … |
| 3: for m = 0, 1, …, M − 1 |
| 4: k = nM + m |
| 5: |
| 6: |
| 7: |
| 8: |
The sequence {x(n)} generated by Table IV with M = 1 can be proven to satisfy the inequality (11), by generalizing [18, Theorem 2]. While the one-subset (M = 1) version of Table IV provides O(1/n2), we heuristically expect from (10) for the OS version to have the rate O (1/(nM)2) in early iterations. (The convergence analysis of this algorithm in Table IV is discussed stochastically in the next section.) Compared with Table III, one additional
χ [·] operation per iteration and extra arithmetic operations are required in Table IV, but those are negligible.
Overall, the two proposed algorithms in Tables III and IV are expected to provide fast convergence rate O (1/(nM)2) in early iterations, which we confirm empirically in Section VI. However, the type of momentum affects the overall convergence when combined with OS. Also, the convergence behavior of two algorithms is affected by the number and ordering of subsets, as discussed in Section VI.
The proposed OS-momentum algorithms in Tables III and IV become unstable in some cases when M is too large, as predicted by the convergence analysis in [33]. To stabilize the algorithms, the next section proposes to adapt a recent relaxation scheme [33] developed for stochastic gradient methods with momentum.
V. Relaxation of Momentum
This section relates the OS-SQS algorithm to diagonally preconditioned stochastic gradient methods and adapts a relaxation scheme designed for stochastic gradient algorithms with momentum. Then we investigate various choices of relaxation6 to achieve overall fast convergence.
A. Stochastic gradient method
If one uses random subset orders, then one can view OS methods as stochastic gradient methods by defining M∇ΨSk(x) as a stochastic estimate of ∇Ψ(x), where a random variable Sk at kth iteration is uniformly chosen from {0, 1, …, M − 1}. In this stochastic setting, OS-SQS methods satisfy:
| (12) |
for all x ∈
 , for some finite constants {σj}, where
, for some finite constants {σj}, where
 is the expectation operator over the random selection of Sk, ∇j ≜ ∂/∂xj, and
is a bounded feasible set that includes x̂. The feasible set
can be derived based on the measurement data y [44, Section A.2], and we assume that the sequences generated by the algorithms are within the set
. The last inequality in (12) is a generalized version of [33, eqn. (2.5)] for (diagonally preconditioned) OS-SQS-type algorithms. The vector σ ≜ {σj} has smaller values if we use smaller M or the subsets are balanced as (10). However, estimating the value of σ:
is the expectation operator over the random selection of Sk, ∇j ≜ ∂/∂xj, and
is a bounded feasible set that includes x̂. The feasible set
can be derived based on the measurement data y [44, Section A.2], and we assume that the sequences generated by the algorithms are within the set
. The last inequality in (12) is a generalized version of [33, eqn. (2.5)] for (diagonally preconditioned) OS-SQS-type algorithms. The vector σ ≜ {σj} has smaller values if we use smaller M or the subsets are balanced as (10). However, estimating the value of σ:
| (13) |
where
| (14) |
appears to be impractical, so Section V-F provides a practical approach for approximating σ.
B. Proposed OS-SQS methods with relaxed momentum (OS-mom3)
Inspired by [33], Table V describes a generalized version of OS-SQS-momentum methods that reduces to OS-mom2 if one uses a deterministic subset ordering Sk = (k mod M) and a fixed majorizing diagonal matrix
Table V.
Proposed Stochastic OS-SQS Algorithms with Momentum (OS-mom3). ξk is a Realization of a Random Variable Sk.
| 1: Initialize x(0) = v(0) = z(0), t0 ∈ (0, 1] and compute D. |
| 2: for n = 0, 1, … |
| 3: for m = 0, 1, …, M − 1 |
| 4: k = nM + m |
| 5: Choose |
| 6: Choose |
| 7: |
| 8: |
| 9: |
| (15) |
For M = 1, the algorithm with these choices satisfies (11) with n = k. However, for M > 1, the analysis in [33] illustrates that using the choice (15) leads to the following inequality
| (16) |
for k ≥ 0, where p ≜ {pj ≜ maxx,x̅∈
|xj − x̅j|} measures the diameter of the feasible set
. This expression reveals that OS methods (M > 1) with momentum may suffer from error accumulation due to the last term in (16) that depends on the error bounds (σ) in (12). To improve stability for the case M > 1, we would like to find a way to decrease this last term. Using a larger constant denominator, i.e., Γ(k) = qD for q > 1, would slow the accumulation of error but would not prevent eventual accumulation of error [33].
To stabilize the algorithm for M > 1, we adapt the relaxed momentum approach in [33] as described in Table V with appropriately selected Γ(k) and tk satisfying the conditions in lines 5 and 6 in Table V. Then, the algorithm in Table V satisfies the following convergence rate:
Lemma 2: For k = nM + m ≥ 0, the sequence generated by Table V satisfies
| (17) |
Proof: See Appendix A.
Lemma 2 shows that increasing Γ(k) can help prevent accumulation of error σ. Next we discuss the selection of parameters Γ(k) and tk.
C. The choice of Γ(k) and tk
For any given , we use t0 = 1 and the following rule:
| (18) |
for all k ≥ 0, where and α0 = 1. The choice (18) increases the fastest among all possible choices satisfying the condition in line 6 of Table V (see the proof in Appendix B).7
In this paper, we focus on the choice
| (19) |
for a nondecreasing ck ≥ 0 and a fixed diagonal matrix Γ ≜ diag{γj} ≻ 0. The choice (19) generalizes [33], enabling more flexibility in the choice of ck. We leave other formulations of Γ(k) that may provide better convergence as future work.
For Γ(k) in (19), computing αk in (18) becomes
| (20) |
Overall, the computational cost of Table V with the choices (18) and (19) remains similar to that of Table IV. Using (18) and (19), the proposed algorithm in Table V achieves the following inequality:
Corollary 1: For k = nM+m ≥ 0, the sequence generated by Table V with the coefficients (18) and (19) satisfies
| (21) |
Proof: Use Lemma 2 and the inequality conditions of the sequence {tk} in (18):
for k ≥ 0, which can be easily proven by induction.
There are two parameters ck and Γ to be tuned in (19). Based on Corollary 1, the next two subsections explore how these parameters affect convergence rate. (We made a preliminary investigation of these two parameters in [48].)
D. The choice of ck
In Corollary 1, the choice of ck controls the overall convergence rate. We first consider a constant ck = c.
Corollary 2: For k = nM + m ≥ 0 and a fixed constant ck = c ∈ [0, 2], the sequence generated by Table V with the coefficients (18) and (19) satisfies
| (22) |
Proof: Use the derivation in [33, Section 6.3] using
In Corollary 2, the choice ck = 1.5 provides the rate
| (23) |
achieving, on average, the optimal rate in the presence of stochastic noise8. Corollary 2 shows that using c ≤ 1 will suffer from error accumulation, using 1 < c < 1.5 might provide faster initial convergence than c = 1.5 but does not achieve the optimal rate, and c > 1.5 will cause slower overall convergence rate than c = 1.5. So, we prefer 1 < c ≤ 1.5, for which we expect to eventually reach smaller cost function values than the choice Γ(k) = D (or Γ = 0) in (15), since we prevent the accumulation of error from OS methods by increasing the denominator Γ(k) as (19). In other words, the algorithm with M > 1 and (19) is slower than the choice of (15) initially, but eventually becomes faster and reaches the optimum on average.
In light of these trade-offs, we further consider using an increasing sequence ck that is upper-bounded by 1.5, hoping to provide fast overall convergence rate. We investigated the following choice:
| (24) |
for k ≥ 0 with a parameter η > 0. This choice of ck balances between fast initial acceleration and prevention of error accumulation. In other words, this increasing ck can provide faster initial convergence than a constant ck = 1.5 (or η = 0), yet guarantees the optimal (asymptotic) rate as the case ck = 1.5, based on Corollary 1. We leave further optimization of ck as future work.
E. The choice of D and Γ
To optimize the choice of Γ(k) in (19), we would like to minimize the upper bound on the right hand side of (22) with respect to both D and Γ, where we consider a fixed ck = c for simplicity. In nonuniform SQS [29], to accelerate algorithms in Tables I and II, we suggested to use D that minimizes the right hand side of (8) among all possible choices of D generated by a (general) SQS technique [9], [29] (details are omitted) and thus satisfies (5) and (6). Similarly in our proposed methods, we use the following diagonal majorizing matrix D̂ that minimizes the right hand side of (22):
| (25) |
instead of (7), where the vector û is defined as
| (26) |
To choose Γ, we also minimize the upper bound on the right hand side of (22) with respect to Γ. For simplicity in designing Γ, we ignore the term, and we ignore the “+1” and “+2” factors added to k. The optimal Γ for k (sub)iterations is
| (27) |
It is usually undesirable to have to select the (sub)iteration k before iterating. The choice c = 1.5 cancels out the parameter k in (27) leading to the k-independent choice:
| (28) |
Since we prefer the choice of ck that eventually becomes 1.5 for the optimal rate, we focus on the choice Γ̂1.5 in (28).
F. The choice of σ and û
The optimized D̂ (25) and Γ̂1.5 (28) rely on unavailable parameters {σj} (13) and {ûj} (26), so we provide a practical approach to estimate them, which we used in Section VI. In practice, the sequences in Table V visit only a part of the feasible set
, so it would be preferable to compute σ̃j(x) in (14) within such part of
for estimating σj, but even that is impractical. Instead, we use σ̃j(x(0)) as a practical approximation of σj, which is computationally efficient. This quantity measures the variance of the stochastic estimate of the gradient at the initial image x(0), and depends on the grouping and number of subsets. This estimate of σj may be sensitive to the choice of x(0), and we leave further investigation as future work.
To save computation, we evaluate σ̃j(x(0)) simultaneously with the computation of D in (7) or (25) using modified projectors A and A⊤ (see [29, Section III.F]) that handle two inputs.
We further approximate ûj (26) by
| (29) |
for Γ̂1.5 in (28), where ζ > 0 is an (unknown) constant, and a vector is a (normalized) approximation of ûj, which is computed by applying an edge-detector to the filtered back-projection (FBP) image that is used for the initial x(0) as described in [29, Section III.E].9 In low-dose clinical CT, the root mean squared difference (RMSD10) within the region -of-interest (ROI) between the initial FBP image x(0) and the optimal image x̂ is about 30 [HU], i.e., , so we let ζ = 30 [HU] in (29) as a reasonable choice in practice11 where . Then, our final practical choice of Γ becomes
| (30) |
VI. Results
We investigate the convergence rate of the three proposed OS-momentum algorithms in Tables III, IV and V, namely OS-mom1, OS-mom2 and OS-mom3 in this section, for PWLS reconstruction of simulated and real 3D CT scans. We implemented12 the proposed algorithm in C and ran on a machine with two 2.27GHz 10-core Intel Xeon E7-8860 processors using 40 threads.13
We use an edge-preserving potential function ψr(·) in [29, eqn. (45)] with a = 0.0558, b = 1.6395, and δ = 10:
For simulation data, the spatial weighting βr was chosen empirically to be
| (31) |
for uniform resolution properties [37], where and κmax ≜ maxj κj. We emulated βr of the GE product “Veo” for the patient 3D CT scans. We use a diagonal majorizing matrix D̂ in (25) using the nonuniform approach [29] with (29) for SQS methods. We investigated 12, 24 and 48 subsets for OS algorithms.
We first use simulated data to analyze the factors that affect the stability of the proposed OS-momentum algorithms, and further study the relaxation scheme for the algorithms. Then we verify the convergence speed of the proposed algorithm using real 3D CT scans. We computed the RMSD between the current and converged14 image within the ROI versus computation time for 30 iterations (n) to measure the convergence rate.15
A. Simulation data
We simulated a 888 × 64 × 2934 sinogram (number of detector columns × detector rows × projection views) from a 1024 × 1024 × 154 XCAT phantom [51] scanned in a helical geometry with pitch 1.0 (see Fig. 1). We reconstructed 512 × 512 × 154 images with an initial FBP image x(0) in Fig. 1(a) using a (simple) single-slice rebinning method [52]. Fig. 2 shows that SQS-Nesterov's momentum methods without OS algorithms do not accelerate SQS much. OS algorithm itself can accelerate the SQS algorithm better than Nesterov's momentum. Our proposed OS-momentum algorithms rapidly decrease RMSD in early iterations (disregarding the diverging curves that we address shortly). However, the convergence behavior of OS-momentum algorithm depends on several factors such as the number of subsets, the order of subsets, and the type of momentum techniques. Thus, we discuss these in more detail based on the results in Fig. 2, and suggest ways to improve the stability of the algorithm while preserving the fast convergence rate.
Fig. 1.
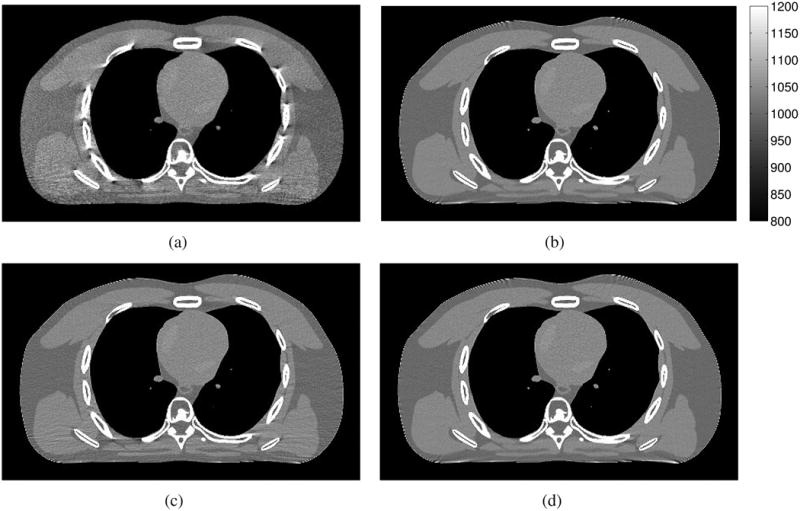
Simulation data: a transaxial plane of (a) an initial FBP image x(0), (b) a converged image x̂, and two reconstructed images x(15) after 15 iterations (about 680 seconds) of (c) OSb(24) and (d) OSb(24)-mom2. (Images are cropped for better visualization.)
Fig. 2.

Simulation data: convergence rate of OS algorithms (1, 12, 24, and 48 subsets) for 30 iterations with and without momentum for (a) sequential order and (b) bit-reversal order in Table VI. (The first iteration counts the precomputation of the denominator D in (7), and thus there are no changes during the first iteration.)
The number of subsets: Intuitively, using more subsets will provide faster initial convergence but will increase instability due to errors between the full gradient and subset gradient. Also, performing many sub-iterations (m) can increase error accumulation per outer iteration (n). Fig. 2 confirms this behavior.
The ordering of subsets: Interestingly, the results of the proposed algorithms depend greatly on the subset ordering. Fig. 2 focuses on two deterministic orders: a sequential (OSs) order, and a bit-reversal (OSb) order [53] that selects each order-adjacent subsets to have their projection views to be far apart as described in Table VI. The ordering greatly affects the build-up of momentum in OS-momentum algorithms, whereas ordering is less important for ordinary OS methods as seen in Fig. 2. The bit-reversal order provided much better stability in Fig. 2(b) compared to the results in Fig. 2(a). Apparently, the bit-reversal order can cancel out some gradient errors, because successive updates are likely to have opposite directions due to its subset ordering rule. In contrast, the sequential ordering has high correlation between the updates from two adjacent subsets, increasing error accumulation through momentum. Therefore, we recommend using the bit-reversal order. (Fig. 3(d) shows that random ordering (OSr) performed worse than the bit-reversal order.)
-
Type of momentum: Fig. 2 shows that combining OS with two of Nesterov's momentum techniques in Tables III and IV (OS-mom1 and OS-mom2) resulted in different behaviors, whereas the one-subset versions of them behaved almost the same. Fig. 2 shows that the OS-mom2 algorithm is more stable than the OS-mom1 algorithm perhaps due to the different formulation of momentum or the fact that the momentum term in Table III is not guaranteed to stay within the set χ unlike that in Table IV. Therefore, we recommend using the OS-mom2 algorithm in Table IV for better stability.
Fig. 1 shows the initial image and the converged image and reconstructed images after 15 iterations (about 680 seconds) of conventional OS and our proposed OS-momentum algorithm with 24 subsets and the bit-reversal ordering. The OSb(24)-mom2 reconstructed image is very similar to the converged image after 15 iterations while that of conventional OS is still noticeably different. However, even the more stable OS-mom2 algorithm becomes unstable eventually for many subsets (M > 24) as seen in Fig. 2; the next subsection shows how relaxation improves stability.
-
The choice of Γ: Section V-E gives an optimized Γ in (19) that minimizes the right term of (22), i.e., the gradient error term, on average. However, since the right term in (22) is a worst-case loose upper-bound, we can afford to use smaller Γ than Γ̂1.5 in (28) (or (30)). In addition, we may use even smaller Γ depending on the order of subsets. Specifically, the bit-reversal ordering (OSb) appears to accumulate less gradient error than other orderings, including random subset orders (OSr), so the choice (28) (or (30)) may be too conservative. Therefore, we investigated decreasing the matrix Γ̂1.5 (28) (or (30)) by a factor λ ∈ (0, 1] as
(32) Fig. 3 shows the effect of the parameter λ for various choices of the number and ordering of subsets. In all cases, λ = 1 is too conservative and yields very slow convergence. Smaller λ ≤ 0.1 values lead to faster convergence, but it failed to stabilize the case of sequential ordering for M > 24. However, λ = 0.01 worked well for the bit-reversal orderings in the simulation data, while the choice λ = 0.001 was too small to suppress the accumulation of error within 30 iterations for 48 subsets. Any value of λ > 0 here will eventually lead to stability as Γ(k) increases with ck = 1.5, based on the convergence analysis (22). Particularly, OSs-mom3 algorithm with λ = 0.1 in Figs. 3(b) and 3(c) illustrates this stability property, where the RMSD curve recovers from the initial diverging behavior as the algorithm proceeds.
Table VI.
Examples of Subset Orderings: Two Deterministic Subset Ordering (OSs, OSb) and One Instance of Random Ordering (OSr) for OS Methods with M = 8 Subsets in a Simple Geometry with 24 Projection Views Denoted as (p0, p1, …, p23), where those are Reasonably Grouped into the Following 8 Subsets: S0 = (p0, p8, p16), S1 = (p1, p9, p17), …, S7 = (p7, p15, p23).
| Sequential (OSs): (S0, S1, S2, S3, S4, S5, S6, S7), (S0, S1, … |
| Bit-reversal (OSb): (S0, S4, S2, S6, S1, S5, S3, S7), (S0, S4, … |
| Random (OSr): S6, S7, S1, S7, S5, S0, S2, S4, S7, S3, … |
Fig. 3.

Simulation data: convergence rate for various choices of the parameter λ in relaxation scheme of OS-momentum algorithms (c, ζ, λ) for (a) 12, (b) 24, (c) 48 subsets with both sequential (OSs) and bit-reversal (OSb) subset orderings in Table VI for 30 iterations. (The plot (b) and (c) share the legend of (a).) The averaged plot of five realizations of random subset ordering (OSr) is illustrated in (d) for 24 subsets.
For Fig. 3(d), we executed five realizations of the random ordering and show the average of them for each curve. Here, we found that λ = 0.01 was too small to suppress the error within 30 iterations, and λ = 0.1 worked the best. Based on Fig. 3, we recommend using the bit-reversal order with λ = 0.01 rather than random ordering.
Figs. 2 and 3 are plotted with respect to the run time of each algorithm. Using larger subsets slightly increased the run time due to extra regularizer computation, but those increases were minor compared to the acceleration given by OS methods. The additional computation required for momentum methods was almost negligible, confirming that introducing momentum approach accelerates OS algorithm significantly in run time.
Overall, the simulation study demonstrated dramatic acceleration from combining OS algorithm and momentum approach. Next, we study the proposed OS-momentum algorithms on patient data, and verify that the parameters tuned with the simulation data work well for real CT scans.16
B. Patient CT scan data
From a 888 × 32 × 7146 sinogram measured in a helical geometry with pitch 0.5, we reconstructed a 512 × 512 × 109 shoulder region image in Fig. 4. Fig. 5 shows the RMSD convergence curves for the bit-reversal subset ordering, where the results are similar to those for the simulation in Fig. 3 in terms of parameter selection. In Fig. 5(a), the parameter λ = 0.01 for both 24 and 48 subsets worked well providing overall fast convergence. Particularly for M = 48, the choice λ = 0.01 greatly reduced the gradient approximation error and converged faster than the un-relaxed OS-momentum algorithm.
Fig. 4.
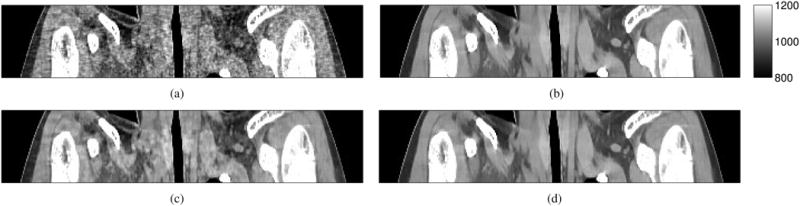
Patient CT scan data: a sagittal plane of (a) an initial FBP image x(0), (b) a converged image x̂, and two reconstructed images x(15) after 15 iterations (about 865 seconds) from (c) OSb(24) and (d) OSb(24)-mom3 where (c, ζ, λ) = (1.5, 30, 0.01).
Fig. 5.

Patient CT scan data: convergence rate of OSb methods (24, 48 subsets) for 30 iterations with and without momentum for (a) several choices of (c, ζ, λ) with a fixed ck = c = 1.5 and (b) the choices of (λ, η) for an increasing ck in (24) with 24 subsets and ζ = 30 [HU].
In Fig. 5(b), we further investigate the increasing ck (24) in (19) that starts from 1 and eventually becomes 1.5 with a tuning parameter η in (24). Larger η in (24) leads to a slowly increasing ck, i.e. smaller ck values in early sub-iterations (k), and thus, the results in Fig. 5(b) show better initial acceleration from using large η. Particularly, using large η for the choice λ = 0.1 showed a big acceleration, while that was less effective in the case λ = 0.01 due to small values of Γ (32) in (19).
Fig. 4 shows the initial FBP image, converged, and reconstructed images from conventional OS and the proposed OS-momentum with relaxation. Visually, the reconstructed image from the proposed algorithm is almost identical to the converged image after 15 iterations.
VII. Conclusion and Discussion
We introduced the combination of OS-SQS and Nesterov's momentum techniques in tomography problems. We quantified the accelerated convergence of the proposed algorithms using simulated and patient 3D CT scans. The initial combination could lack stability for large numbers of subsets, depending on the subset ordering and type of momentum. So, we adapted a diminishing step size approach to stabilize the proposed algorithm while preserving fast convergence.
We have focused on PWLS cost function in this paper, but the proposed algorithms can be applied to any convex cost function for tomography problems, including penalized-likelihood methods based on Poisson models for pre-log sinogram data. The ideas also generalize to parallel MRI problems [54], [55]. We are further interested in studying the proof of convergence of the OS-momentum algorithm for a (bit-reversal) “deterministic” order.
The accumulating error of the proposed algorithms in Section V is hard to measure due to the computational complexity, and thus optimizing the relaxation parameters for an increasing Γ(k) in (19) remains an open issue. In our experiments, we observed that simply averaging all of the sub-iterations at the final iteration [29] greatly reduces RMSD, particularly when the proposed algorithm becomes unstable (depending on the relaxation parameters). One could consider this averaging technique to improve stability, or alternatively one could discard the current momentum and restart the build-up of the momentum as in [30], [56]. Such refinements could make OS-momentum a practical approach for low-dose CT.
Supplementary Material
Acknowledgments
Date of current version August 19, 2014. This work was supported in part by GE Healthcare, the National Institutes of Health under Grant R01-HL-098686, and equipment donations from Intel Corporation.
Appendix A: Proof of Lemma 2
We extend the proof of [33, Theorem 7] for diagonally preconditioned stochastic OS-SQS-type algorithms for the proof of Lemma 2. We first use the following lemma:
Lemma 3: For k = nM + m ≥ 0, the sequence generated by Table V satisfies
where
that satisfies ,
and
Proof: Simply generalize the proof of [33, Lemma 2] using the proof of [18, Lemma 1].
Using Lemma 3 with the fact minυ⪰0 Φ(k)(υ) ≤ Φ(k)(x̂) leads to the following:
Finally, the expectation on the above equation provides Lemma 2, as in [33, Theorem 7].
Appendix B: Choice of coefficients tk
Lemma 4: For any given satisfying its constraint in line 5 of Table V, the {tk} generated by t0 = 1
where and α1 = 1, tightly satisfies the following conditions:
which are equivalent to the conditions in line 6 of Table V.
Proof: Let t0 have the largest possible value 1.
For k = 0,
| (33) |
For k > 0, we get
| (34) |
This rule for tk (34) reduces to those used in Tables III and IV when for all k ≥ 0 and j.
Footnotes
This paper has supplementary downloadable materials.
Nesterov [23] showed that there exists at least one convex function that cannot be minimized faster than the rate O (1/n2) by any first-order optimization methods. Therefore, the rate O (1/n2) is optimal for first-order methods in convex problems.
First-order optimization methods refer to a class of iterative algorithms that use only first-order information of a cost function such as its value and its gradient.
Some previous works combine incremental gradient methods [28] and relatively small momentum with convergence analysis [30]–[32], but our focus is to use larger momentum like Nesterov's methods with os methods in tomography problem for fast initial convergence rate.
For two vectors x and z of the same size, the expression x ⪰ z (or x ≻ z) means that x − z is element-wise nonnegative (or element-wise positive). For two symmetric matrices X and Z of the same size, the notation X ⪰ Z (or X ≻ Z) means that X − Z is positive semidefinite (or positive definite). A weighted Euclidean seminorm is defined as for a vector y ≜ {yi} and a positive semidefinite diagonal matrix W ≜ diag{wi}.
A smooth function refers to a function that is differentiable with a Lipschitz continuous gradient [19].
The relaxation scheme involves couple of parameters and we provide a table of notations in the supplementary material to improve readability.
The coefficient (18) increases faster than the choice for a constant ck = c ≥ 1 used in [33], so we use the choice (18) that leads to faster convergence based on Lemma 2.
Stochastic gradient algorithms (using only first-order information) cannot decrease the stochastic noise faster than the rate [49], and the proposed relaxation scheme achieves this optimal rate [33].
We provide convergence results from using the oracle û, compared to its approximate ζū, in the supplementary material.
, where Np, ROI is the number of voxels within the ROI.
This choice worked well in our experiments, but may depend on the initial image, the cost function and the measurements, so improving the choice of ζ is future work.
The matlab code of the proposed OS-momentum methods will be available through the last author's toolbox [50].
Our implementation and choice of platform are likely to be suboptimal, and further exploiting the massively parallelizable nature of the proposed algorithms will provide additional speedup in run time, which we leave as future work.
We ran thousands of iterations of (convergent) SQS algorithm to generate (almost) converged images x̂.
Even though the convergence analysis in Section V is based on the cost function, we plot RMSD rather than the cost function because RMSD is more informative (see [29, Supplementary material]).
We provide results from one patient data here, and present additional results from another real CT scan in the supplementary material.
Contributor Information
Donghwan Kim, Email: kimdongh@umich.edu, Department of Electrical Engineering and Computer Science, University of Michigan, Ann Arbor, MI 48105 USA.
Sathish Ramani, Email: umrsat@gmail.com, GE Global Research Center, Niskayuna, NY 12309 USA.
Jeffrey A. Fessler, Email: fessler@umich.edu, Department of Electrical Engineering and Computer Science, University of Michigan, Ann Arbor, MI 48105 USA.
References
- 1.Fessler JA. Statistical image reconstruction methods for transmission tomography. In: Sonka M, Michael Fitzpatrick J, editors. Handbook of Medical Imaging, Volume 2. Medical Image Processing and Analysis. SPIE; Bellingham: 2000. pp. 1–70. [Google Scholar]
- 2.Elbakri IA, Fessler JA. Statistical image reconstruction for polyenergetic X-ray computed tomography. IEEE Trans Med Imag. 2002 Feb;21(2):89–99. doi: 10.1109/42.993128. [DOI] [PubMed] [Google Scholar]
- 3.Sauer K, Bouman C. A local update strategy for iterative reconstruction from projections. IEEE Trans Sig Proc. 1993 Feb;41(2):534–48. [Google Scholar]
- 4.Thibault JB, Sauer K, Bouman C, Hsieh J. A three-dimensional statistical approach to improved image quality for multi-slice helical CT. Med Phys. 2007 Nov;34(11):4526–44. doi: 10.1118/1.2789499. [DOI] [PubMed] [Google Scholar]
- 5.Fessler JA, Ficaro EP, Clinthorne NH, Lange K. Grouped-coordinate ascent algorithms for penalized-likelihood transmission image reconstruction. IEEE Trans Med Imag. 1997 Apr;16(2):166–75. doi: 10.1109/42.563662. [DOI] [PubMed] [Google Scholar]
- 6.Yu Z, Thibault JB, Bouman CA, Sauer KD, Hsieh J. Fast model-based X-ray CT reconstruction using spatially non-homogeneous ICD optimization. IEEE Trans Im Proc. 2011 Jan;20(1):161–75. doi: 10.1109/TIP.2010.2058811. [DOI] [PubMed] [Google Scholar]
- 7.Fessler JA, Booth SD. Conjugate-gradient preconditioning methods for shift-variant PET image reconstruction. IEEE Trans Im Proc. 1999 May;8(5):688–99. doi: 10.1109/83.760336. [DOI] [PubMed] [Google Scholar]
- 8.Hudson HM, Larkin RS. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans Med Imag. 1994 Dec;13(4):601–9. doi: 10.1109/42.363108. [DOI] [PubMed] [Google Scholar]
- 9.Erdoğan H, Fessler JA. Ordered subsets algorithms for transmission tomography. Phys Med Biol. 1999 Nov;44(11):2835–51. doi: 10.1088/0031-9155/44/11/311. [DOI] [PubMed] [Google Scholar]
- 10.Goldstein T, Osher S. The split Bregman method for L1-regularized problems. SIAM J Imaging Sci. 2009;2(2):323–43. [Google Scholar]
- 11.Ramani S, Fessler JA. A splitting-based iterative algorithm for accelerated statistical X-ray CT reconstruction. IEEE Trans Med Imag. 2012 Mar;31(3):677–88. doi: 10.1109/TMI.2011.2175233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.McGaffin MG, Ramani S, Fessler JA. Reduced memory augmented Lagrangian algorithm for 3D iterative X-ray CT image reconstruction. Proc SPIE 8313 Medical Imaging 2012: Phys Med Im. 2012:831327. [Google Scholar]
- 13.Bertsekas DP. Multiplier methods: A survey. Automatica. 1976 Mar;12(2):133–45. [Google Scholar]
- 14.Chambolle A, Pock T. A first-order primal-dual algorithm for convex problems with applications to imaging. J Math Im Vision. 2011;40(1):120–145. [Google Scholar]
- 15.Sidky EY, Jorgensen JH, Pan X. Convex optimization problem prototyping for image reconstruction in computed tomography with the Chambolle-Pock algorithm. Phys Med Biol. 2012 May;57(10):3065–92. doi: 10.1088/0031-9155/57/10/3065. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Sidky EY, Jrgensen JS, Pan X. First-order convex feasibility algorithms for X-ray CT. Med Phys. 2013;40(3):031115. doi: 10.1118/1.4790698. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Nesterov Y. A method for unconstrained convex minimization problem with the rate of convergence O(1/k2) Dokl Akad Nauk USSR. 1983;269(3):543–7. [Google Scholar]
- 18.Nesterov Y. Smooth minimization of non-smooth functions. Mathematical Programming. 2005 May;103(1):127–52. [Google Scholar]
- 19.Beck A, Teboulle M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J Imaging Sci. 2009;2(1):183–202. [Google Scholar]
- 20.Choi K, Wang J, Zhu L, Suh TS, Boyd S, Xing L. Compressed sensing based cone-beam computed tomography reconstruction with a first-order method. Med Phys. 2010 Nov;37(9):5113–25. doi: 10.1118/1.3481510. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Jensen TL, Jrgensen JH, Hansen PC, Jense SH. Implementation of an optimal first-order method for strongly convex total variation regularization. BIT Numerical Mathematics. 2012 Jun;52(2):329–56. [Google Scholar]
- 22.Anthoine S, Aujol JF, Boursier Y, Mélot C. Some proximal methods for Poisson intensity CBCT and PET. Inverse Prob and Imaging. 2012 Nov;6(4):565–98. [Google Scholar]
- 23.Nesterov Y. Introductory lectures on convex optimization: A basic course. Kluwer; 2004. [Google Scholar]
- 24.Nesterov Y. Gradient methods for minimizing composite functions. Mathematical Programming. 2013 Aug;140(1):125–61. [Google Scholar]
- 25.Beck A, Teboulle M. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Trans Im Proc. 2009 Nov;18(11):2419–34. doi: 10.1109/TIP.2009.2028250. [DOI] [PubMed] [Google Scholar]
- 26.Kim D, Ramani S, Fessler JA. Ordered subsets with momentum for accelerated X-ray CT image reconstruction. Proc IEEE Conf Acoust Speech Sig Proc. 2013:920–3. [Google Scholar]
- 27.Kim D, Ramani S, Fessler JA. Accelerating X-ray CT ordered subsets image reconstruction with Nesterov's first-order methods. Proc Intl Mtg on Fully 3D Image Recon in Rad and Nuc Med. 2013:22–5. [Google Scholar]
- 28.Ahn S, Fessler JA, Blatt D, Hero AO. Convergent incremental optimization transfer algorithms: Application to tomography. IEEE Trans Med Imag. 2006 Mar;25(3):283–96. doi: 10.1109/TMI.2005.862740. [DOI] [PubMed] [Google Scholar]
- 29.Kim D, Pal D, Thibault JB, Fessler JA. Accelerating ordered subsets image reconstruction for X-ray CT using spatially non-uniform optimization transfer. IEEE Trans Med Imag. 2013 Nov;32(11):1965–78. doi: 10.1109/TMI.2013.2266898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Mangasarian OL, Solodov MV. Serial and parallel back-propagation convergence via nonmonotone perturbed minimization. Optimization Methods and Software. 1994;4(2):103–16. [Google Scholar]
- 31.Tseng P. An incremental gradient(-projection) method with momentum term and adaptive stepsize rule. SIAM J Optim. 1998;8(2):506–31. [Google Scholar]
- 32.Blatt D, Hero AO, Gauchman H. A convergent incremental gradient method with a constant step size. SIAM J Optim. 2007;18(1):29–51. [Google Scholar]
- 33.Devolder O. Tech Rep, CORE. Catholic University of Louvain; Louvain-la-Neuve, Belgium: 2011. Stochastic first order methods in smooth convex optimization. [Google Scholar]
- 34.De Man B, Basu S. Distance-driven projection and backprojection in three dimensions. Phys Med Biol. 2004 Jun;49(11):2463–75. doi: 10.1088/0031-9155/49/11/024. [DOI] [PubMed] [Google Scholar]
- 35.Long Y, Fessler JA, Balter JM. 3D forward and back-projection for X-ray CT using separable footprints. IEEE Trans Med Imag. 2010 Nov;29(11):1839–50. doi: 10.1109/TMI.2010.2050898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Fair RC. On the robust estimation of econometric models. Ann Econ Social Measurement. 1974 Oct;2:667–77. [Google Scholar]
- 37.Fessler JA, Rogers WL. Spatial resolution properties of penalized-likelihood image reconstruction methods: Space-invariant tomographs. IEEE Trans Im Proc. 1996 Sep;5(9):1346–58. doi: 10.1109/83.535846. [DOI] [PubMed] [Google Scholar]
- 38.Delaney AH, Bresler Y. Globally convergent edge-preserving regularized reconstruction: an application to limited-angle tomography. IEEE Trans Im Proc. 1998 Feb;7(2):204–21. doi: 10.1109/83.660997. [DOI] [PubMed] [Google Scholar]
- 39.Lange K, Hunter DR, Yang I. Optimization transfer using surrogate objective functions. J Computational and Graphical Stat. 2000 Mar;9(1):1–20. [Google Scholar]
- 40.Ortega JM, Rheinboldt WC. Iterative solution of nonlinear equations in several variables. Academic; New York: 1970. [Google Scholar]
- 41.Erdog¢an H, Fessler JA. Monotonic algorithms for transmission tomography. IEEE Trans Med Imag. 1999 Sep;18(9):801–14. doi: 10.1109/42.802758. [DOI] [PubMed] [Google Scholar]
- 42.Cho JH, Fessler JA. Accelerating ordered-subsets image reconstruction for X-ray CT using double surrogates. Proc SPIE 8313 Medical Imaging 2012: Phys Med Im. 2012:83131X. doi: 10.1109/TMI.2013.2266898. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Luo ZQ. On the convergence of the LMS algorithm with adaptive learning rate for linear feedforward networks. Neural Computation. 1991 Jun;32(2):226–45. doi: 10.1162/neco.1991.3.2.226. [DOI] [PubMed] [Google Scholar]
- 44.Ahn S, Fessler JA. Globally convergent image reconstruction for emission tomography using relaxed ordered subsets algorithms. IEEE Trans Med Imag. 2003 May;22(5):613–26. doi: 10.1109/TMI.2003.812251. [DOI] [PubMed] [Google Scholar]
- 45.Nesterov Y. On an approach to the construction of optimal methods of minimization of smooth convex functions. Èkonom i Mat Metody. 1988;24:509–17. [Google Scholar]
- 46.Tseng P. On accelerated proximal gradient methods for convex-concave optimization. 2008 Available from http://pages.cs.wisc.edu/∼brecht/cs726docs/Tseng.APG.pdf.
- 47.Devolder O, Glineur François, Nesterov Y. Intermediate gradient methods for smooth convex problems with inexact oracle. 2013 CORE discussion paper 2013/17.
- 48.Kim D, Fessler JA. Ordered subsets acceleration using relaxed momentum for X-ray CT image reconstruction. Proc IEEE Nuc Sci Symp Med Im Conf. 2013:1–5. [Google Scholar]
- 49.Nemirovski A, Yudin D. Problem complexity and method efficiency in optimization. John Wiley; 1983. [Google Scholar]
- 50.Fessler JA. Matlab tomography toolbox. 2004 Available from web.eecs.umich.edu/∼fessler.
- 51.Segars WP, Mahesh M, Beck TJ, Frey EC, Tsui BMW. Realistic CT simulation using the 4D XCAT phantom. Med Phys. 2008 Aug;35(8):3800–8. doi: 10.1118/1.2955743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Noo F, Defrise M, Clackdoyle R. Single-slice rebinning method for helical cone-beam CT. Phys Med Biol. 1999 Feb;44(2):561–70. doi: 10.1088/0031-9155/44/2/019. [DOI] [PubMed] [Google Scholar]
- 53.Herman GT, Meyer LB. Algebraic reconstruction techniques can be made computationally efficient. IEEE Trans Med Imag. 1993 Sep;12(3):600–9. doi: 10.1109/42.241889. [DOI] [PubMed] [Google Scholar]
- 54.Ramani S, Fessler JA. Accelerated nonCartesian SENSE reconstruction using a majorize-minimize algorithm combining variable-splitting. Proc IEEE Intl Symp Biomed Imag. 2013:704–7. [Google Scholar]
- 55.Muckley M, Noll DC, Fessler JA. Accelerating SENSE-type MR image reconstruction algorithms with incremental gradients. Proc Intl Soc Mag Res Med. 2014:4400. [Google Scholar]
- 56.O'Donoghue B, Candès E. Adaptive restart for accelerated gradient schemes. Found Computational Math. 2014 [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.