

Abstract
The metaSEM package provides functions to conduct univariate, multivariate, and three-level meta-analyses using a structural equation modeling (SEM) approach via the OpenMx package in the R statistical platform. It also implements the two-stage SEM approach to conducting fixed- and random-effects meta-analytic SEM on correlation or covariance matrices. This paper briefly outlines the theories and their implementations. It provides a summary on how meta-analyses can be formulated as structural equation models. The paper closes with a conclusion on several relevant topics to this SEM-based meta-analysis. Several examples are used to illustrate the procedures in the supplementary material.
Keywords: meta-analysis, structural equation modeling, meta-analytic structural equation modeling, metaSEM, R
1. Introduction
Meta-analysis is a popular technique for synthesizing research findings in the social, behavioral, educational, and medical sciences (e.g., Hedges and Olkin, 1985; Whitehead, 2002; Borenstein et al., 2009; Schmidt and Hunter, 2015). There are several standalone programs for conducting meta-analyses, e.g., Comprehensive Meta-Analysis (Borenstein et al., 2005). There are also macros or packages to fit some meta-analytic models in standard statistical packages such as SPSS (Lipsey and Wilson, 2000), and SAS (Arthur et al., 2001). R (R Development Core Team, 2014) is a popular open source statistical platform for computations and data analysis. There are also several R packages available for meta-analysis (e.g., Viechtbauer, 2010; Lumley, 2012; Schwarzer, 2014).
The metaSEM package (Cheung, 2014b) is another R package for conducting meta-analyses. It formulates univariate, multivariate, and three-level meta-analytic models as structural equation models (Cheung, 2008, 2013b, 2014c, in press) via the OpenMx package (Boker et al., 2011). It also implements the two-stage structural equation modeling (TSSEM) approach (Cheung and Chan, 2005, 2009; Cheung, 2014a) to fit fixed- and random-effects meta-analytic structural equation modeling (MASEM) on correlation or covariance matrices. This paper outlines the meta-analytic models implemented in the metaSEM package (Cheung, in press). There are two main objectives of this paper. First, it provides an succinct summary on how various meta-analytic models can be formulated as structural equation models. Readers may refer to the references for more details and advantages of formulating meta-analytic models as structural equation models. Second, it illustrates how to conduct these analyses using the metaSEM package. Complete R code, output, and remarks are included in the supplementary material. Users may refer to http://courses.nus.edu.sg/course/psycwlm/Internet/metaSEM/ on how to install the metaSEM package.
2. Structural equation modeling based meta-analysis
SEM is a multivariate technique to fit and test hypothesized models. Let y be a p × 1 vector of a sample of continuous data from a multivariate normal distribution where p is the number of observed variables. It is hypothesized that the model for the first and the second moments are functions of θ, where θ is a vector of parameters that can be regression coefficients, error variances, factor loadings, and factor variances. The model is:
| (1) |
where μ and Σ are the population mean vector and covariance matrix, respectively. Maximum likelihood (ML) estimation method is the most common estimation method in SEM. The −2*log-likelihood (−2LL) for the ith case is,
| (2) |
where pi is the number of filtered variables with complete data in the ith case, μi(θ) and Σi(θ) are the model implied mean vector and the model implied covariance matrix for the ith case, respectively. Since there is a subscript i in Equation 2, the model implied mean vector and covariance matrix may vary across cases. Thus, it automatically handles incomplete data by selecting the complete data in the log-likelihood function with the full information maximum likelihood (ML or FIML) estimation method (Enders, 2010).
To obtain the parameter estimates, we may take the sum of the −2LLi over all cases and minimize it. Iterative methods are used to obtain the parameter estimates. When it is convergent, the asymptotic sampling covariance matrix of the parameter estimates may be obtained from the inverse of the Hessian matrix. The standard errors (SEs) of the parameter estimates are calculated by taking the square root of the diagonal elements of the asymptotic sampling covariance matrix. The parameter estimates divided by their SEs follow a z distribution under the null hypothesis. A likelihood ratio (LR) statistic may also be used to compare nested models. The model fit and the significance of individual parameters can be tested (e.g., Kline, 2011).
2.1. Univariate fixed-effects model
The following subsections briefly introduce how various meta-analytic models can be formulated as structural equation models. Let us begin with the meta-analytic model with only one effect size yi in the ith study (Cheung, 2008). yi can be any effect size, such as the odds ratio, raw mean difference, standardized mean difference, correlation coefficient, or its Fisher's z transformed score. When the sample sizes in the primary studies are reasonably large, yi can be assumed to be normally distributed with a variance of vi (e.g., see Borenstein et al., 2009, for the formulas of common effect sizes. The univariate fixed-effects model for the ith study is:
| (3) |
where βF is the common effect under the fixed-effects model, and Var(ei) = vi is the known sampling variance. To conduct a univariate fixed-effects meta-analysis in SEM, we may fit the following model implied moments:
| (4) |
Since vi is known, the only parameter in the model is βF. Figure 1 shows the graphical model of the fixed-effects meta-analysis.
Figure 1.
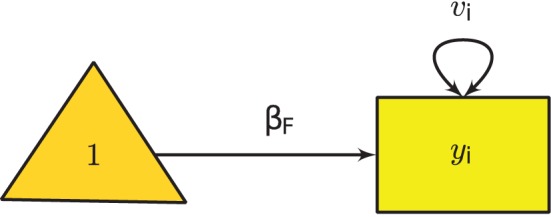
Univariate fixed-effects meta-analysis.
2.2. Univariate random-effects model
Since the primary studies are conducted by different researchers in different settings, these studies are unlikely not direct replicates of each other. It is reasonable to expect that the population effect sizes may not be the same. A random-effects model allows studies to have their own study-specific effect. The model for the ith study is:
| (5) |
where βR is the average population effect under the random-effects model, and Var(ui) = τ2 is the heterogeneity variance that has to be estimated. To fit the model in SEM, we may consider the following model implied moments:
| (6) |
In the literature of meta-analysis, vi and τ2 + vi are known as the conditional and the unconditional variances, respectively. Under this model we have to estimate both βR and τ2. Figure 2 shows the graphical model of the random-effects meta-analysis. Various estimation methods, such as methods of moments, ML estimation and restricted maximum likelihood (REML) estimation may be used to estimate τ2 (e.g., Borenstein et al., 2009). The default estimation method in the SEM-based meta-analysis is ML estimation, while the REML estimation method may also be used to minimize the slight negative bias on the estimated variance component using the ML estimation method (Cheung, 2013a).
Figure 2.
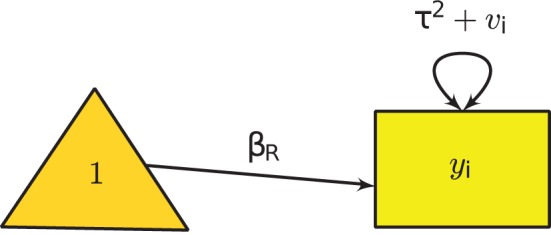
Univariate random-effects meta-analysis.
2.2.1. Quantifying heterogeneity
To test the homogeneity of the population effect sizes, we may compute the Q statistic (Cochran, 1954),
| (7) |
where wi = 1/vi. Under the null hypothesis of the homogeneity of effect sizes, the Q statistic has an approximate chi-square distribution with (k − 1) degrees of freedom (dfs). The Q statistic may be significant simply because of the large number of studies. Conversely, a large Q statistic may be non-significant because of the small number of studies. Therefore, the significance of the Q statistic should not be used to determine whether a fixed- or a random-effects model is used in the analysis.
One popular index quantifying the degree of heterogeneity of effect sizes is the I2 (Higgins and Thompson, 2002). The general formula is
| (8) |
where is a typical within-study sampling variance. I2 can be interpreted as the proportion of the total variation of the effect size that is due to the between study heterogeneity. Higgins and Thompson (2002) defined the typical within-study sampling variance using the Q statistic:
| (9) |
One advantage of using Q as the typical within-study sampling variance is that I2 can be simplified to I2Q = Q − (k − 1)/Q.
Two more definitions of have also been proposed in the literature. Takkouche et al. (1999) suggested that the harmonic mean of vi can be used as the typical within-study sampling variance,
| (10) |
Xiong et al. (2010) also discussed an estimator of I2 that is based on the arithmetic mean:
| (11) |
All of the above definitions are available in the metaSEM package. Users may choose among them by specifying the argument I2 = “I2q” based on the Q statistic (the default), I2 = “I2hm” based on the harmonic mean, and I2 = “I2am” based on the arithmetic mean.
2.3. Univariate mixed-effects model
The mixed-effects meta-analysis extends the random-effects meta-analysis by using study characteristics as predictors. Assuming that xi is an (m + 1) × 1 vector of predictors including a constant of 1 where m is the number predictors in the ith study, the mixed-effects model is:
| (12) |
where β is a a (m + 1) × 1 vector of regression coefficients including the intercept. To fit the model in SEM, we may use the following model implied conditional mean and variance:
| (13) |
Figure 3 shows the graphical model of the mixed-effects meta-analysis with one predictor. A phantom variable P is introduced to specify the predictor xi. Since xi is specified via definition variables (see Cheung, 2010), xi is treated as a design matrix rather than as variables.
Figure 3.
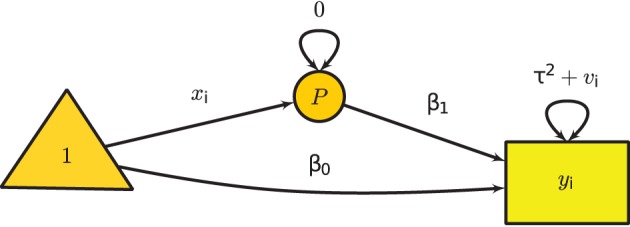
Univariate mixed-effects meta-analysis with one predictor.
Mathematically, it is clear that the random-effects meta-analysis is a special case of the mixed-effects meta-analysis by fixing x = 1 as a constant of ones, while the fixed-effects meta-analysis is a special case of the random-effects meta-analysis by fixing τ2 = 0. It should be noted that the assumptions and interpretations on the fixed- and random-effects models are different.
2.3.1. Explained variance
Besides testing whether the predictors are significant, researchers may want to quantify the degree of prediction. The percentage of variance explained by the inclusion of predictors,
| (14) |
can be calculated by comparing the 20 without a predictor and the 21 with predictors (Raudenbush, 2009). When the calculated R2 is negative, it is usually truncated to zero.
2.4. Multivariate meta-analysis
When the research questions become more complicated, a single effect size may not be sufficient to summarize the effect in the primary studies. Multiple effect sizes are required to quantify the effect of the studies. Let us assume that there are a total of p effect sizes with m predictors in k studies. Since it is likely that different numbers of effect sizes are reported in the primary studies, we assume that there are pi effect sizes in the ith study. The model for the multivariate mixed-effects meta-analysis in the ith study is:
| (15) |
where yi is a pi × 1 vector of effect sizes, Bi is a pi × (m + 1) matrix of regression coefficients including the intercepts, xi is a (m + 1) × 1 matrix of predictors including 1 in the first column, Zi is a pi × p filter matrix selecting the effect sizes that are present, ui is a p × 1 study-specific random effects, and ei is a pi × 1 sampling error.
We assume that Var(ei) = Vi is known in the ith study and that Var(ui) = T2 is the variance component of the between-study heterogeneity that has to be estimated. The model handles missing effect sizes by selecting the complete effect sizes only in the above equation. Since xi is a design matrix, missing value is not allowed in xi. When there are missing values in xi, the whole study will be deleted before the analysis is conducted.
The −2LL of the above model is:
| (16) |
To fit the multivariate mixed-effects meta-analysis in SEM, we use the following model implied conditional mean vector and covariance matrix (Cheung, 2013b):
| (17) |
Figure 4 shows the graphical model of the multivariate mixed-effects meta-analysis with two effect sizes per study and one predictor. A phantom variable P is introduced to specify the predictor xi.
Figure 4.
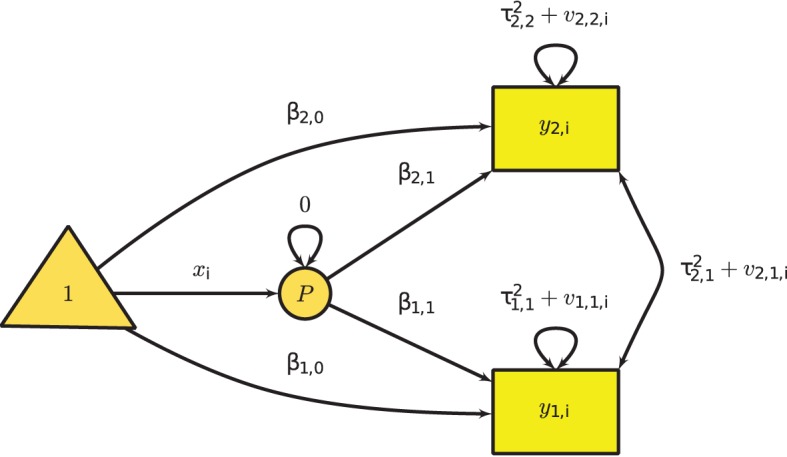
Multivariate mixed-effects meta-analysis with two effect sizes per study and one predictor.
The multivariate random-effects meta-analysis is a special case of the multivariate mixed-effects meta-analysis by using Xi = 1 as the design matrix; the random-effects meta-analysis is a special case of the fixed-effects meta-analysis by fixing T2 = 0. Moreover, the univariate meta-analysis is also a special case of the multivariate meta-analysis with only one effect size. The I2 and R2 in a univariate meta-analysis may also be calculated for each effect size in a multivariate meta-analysis.
2.5. Three-level meta-analysis
Effect sizes are assumed to be independent in most meta-analytic models. However, the effect sizes can be non-independent for various reasons. For example, the effect sizes reported in the same study may be more similar than the effect sizes reported in other studies. When the degree of dependence is known, the multivariate meta-analysis introduced in the Section 2.4 can be used to model the dependence. When the degree of dependence is not known, a three-level meta-analytic model may be used to address the dependence among the effect sizes (e.g., Konstantopoulos, 2011; Cheung, 2014c; Van den Noortgate et al., 2013). The model is:
| (18) |
where yij is the effect size for the ith effect size in the jth cluster, β is an (m + 1) × 1 vector of regression coefficients including the intercept, xij is the (m + 1) × 1 predictors including 1 in the first element for the ith study at the jth cluster, u(2)ij and u(3)j are the random effects at level 2 and level 3, respectively, and Var(eij) = vij is the known sampling variance of the effect size.
To fit the three-level meta-analytic model in SEM, we may use the following model implied moments for the conditional mean and variance:
| (19) |
where Var(u(2)ij) = τ2(2) and Var(u(3)j) = τ2(3) are the heterogeneity at level 2 and level 3, respectively (Cheung, 2014c).
2.5.1. Quantifying heterogeneity and explained variance
Similar to the I2 defined in a random-effects meta-analysis, we may define the degree of heterogeneity for a three-level meta-analysis in level 2 and level 3 as,
| (20) |
where is the typical within-study sampling variance defined in a random-effects meta-analysis. I2(2) and I2(3) can be interpreted as the proportion of the total variation of the effect size that is due to the level 2 and level 3, respectively. Since is sample specific, one limitation of I2(2) and I2(3) is that they are not estimating any population quantities. Cheung (2014c) introduced two intra-class correlations (ICCs),
| (21) |
Both ICC(2) and ICC(3) are estimating their population counterparts τ2(2)/(τ2(2) + τ2(3)) and τ2(3)/(τ2(2) + τ2(3)), respectively. ICC(2) and ICC(3) can be interpreted as the percentage of the population heterogeneity due to level 2 and level 3, respectively.
When there are predictors, we may calculate the R2 for level 2 and level 3 in a similar manner to that defined before,
| (22) |
When the estimates are negative, they are usually truncated to zero.
3. Meta-analytic structural equation modeling
SEM is a popular modeling techniques in the social and behavioral sciences. When there are more and more studies addressing similar research questions using similar variables, there is a need to compare and synthesize these findings. MASEM combines ideas of meta-analysis and SEM by pooling correlation (or covariance) matrices and testing structural equation models on the pooled correlation (or covariance) matrix (e.g., Viswesvaran and Ones, 1995; Cheung and Chan, 2005; Becker, 2009). There are two stages in conducting the analysis. In the first stage of the analysis, the correlation (or covariance) matrices are pooled together. In the second stage of the analysis, the pooled correlation (or covariance) matrix is used to fit structural equation models.
Cheung and Chan (2005, 2009) proposed a fixed-effects TSSEM. The fixed-effects TSSEM approach has been extended to the random-effects TSSEM by Cheung (2014a). Regardless of whether a fixed- or a random-effects model is used, the metaSEM package handles this automatically. In other words, parameter estimates, SEs, and goodness-of-fit indices in the stage 2 analysis have already taken the stage 1 model into account.
3.1. Stage 1 analysis
The main objective of the stage 1 analysis is to pool the correlation (or covariance) matrices together. There are two classes of models in meta-analysis—fixed-effects models and random-effects models (see Hedges and Vevea, 1998; Schmidt et al., 2009). Fixed-effects models are used for conditional inferences based on the selected studies. They are intended to draw conclusions on the studies included in the meta-analysis. Researchers are mainly interested in the studies used in the analysis. The assumption in fixed-effects models is usually, but not always, that all studies share common effect sizes. The stage one analysis in both the fixed- and the random-effects TSSEM is based on the ML estimation method. Thus, the parameter estimates are unbiased and efficient when the missing correlation coefficients are missing completely at random (MCAR) or missing at random (MAR) (e.g., Enders, 2010).
3.1.1. Fixed-effects model
Under the fixed-effects (or more correctly the common effects) model, it is assumed that the population correlation (or covariance) matrices are the same while there are study-specific correlation (or covariance matrices) under the random-effects model. To simplify the presentation, I will mainly focus on the analysis of correlation matrices. Generalizing to analysis of covariance matrices is a straight-forward process (see Cheung and Chan, 2009). A covariance matrix in the ith study can be decomposed into a product of the matrices of correlations and standard deviations:
| (23) |
where Σi(θ) is the model implied covariance matrix, Di is the diagonal matrix of standard deviations, and Pi is the correlation matrix. Under the assumption of the homogeneity of correlation matrices, we may obtain a common correlation matrix by imposing the constraint P = P1 = P2 = … = Pk, where Di may vary across studies. When there are missing correlations, the missing data are filtered out. If we want to obtain a common covariance matrix under the assumption of the homogeneity of covariance matrices, we may also add the constraint D = D1 = D2 = … = Dk.
An LR statistic can be used to test the null hypothesis of homogeneity of correlation matrices P1 = P2 = … = Pk. Moreover, various goodness-of-fit indices may also be used to evaluate the appropriateness of the “close” fit of the homogeneity of correlation matrices.
3.1.2. Random-effects model
Since the primary studies are independently conducted by different researchers, the samples, measures, and research focuses are likely different. The assumption of homogeneity of correlation matrices may not be reasonable. A random-effects TSSEM is usually more appropriate to analyze the data (Cheung, 2014a). When a random-effects model is used, the correlation matrices are treated as vectors of multivariate effect sizes. Let ri = vechs(Ri) be the p(p − 1)/2 × 1 vector of a sample correlation for p variables by taking the column-wise non-redundant elements from Ri. If an analysis of the covariance matrices is conducted, the p(p + 1)/2 × 1 vectorized multivariate effect sizes become si = vech(Si).
The model for the sample correlation vector ri is:
| (24) |
where ρR is the p(p − 1)/2 × 1 vector of average population correlation vector under a random-effects model, Var(ui) = T2 is the variance components of the random effects, and Var(ei) = Vi is the known conditional sampling covariance matrix. The multivariate random-effects meta-analysis introduced in Section 2.4 may be used to conduct the stage 1 analysis with a random-effects model.
When there are many variables or not enough data (studies) in the analysis, 2 can be non-positive definite. The results cannot be trusted. One workaround is to fix T2 to a diagonal matrix rather than as a symmetric matrix. This can be done easily by specifying the argument RE.type = “Diag” when calling the tssem1() function.
3.2. Stage 2 analysis
After the stage 1 analysis with either a fixed- or a random-effects model, a vector of pooled correlations r and its asymptotic covariance matrix V are available after the analysis. It should be noted that 2 is not directly involved in fitting the correlation structure in the stage 2 analysis. However, the presence of T2 is required so that the heterogeneity of the random effects has been properly taken in the stage 1 analysis.
Most applications of MASEM use the pooled correlation matrix as if it was an observed correlation matrix to fit structural equation models. Cheung and Chan (2005) discussed some of these problems. For example, the elements of the pooled correlation matrix are usually based on different studies. Researchers usually use an ad-hoc sample size, such as the harmonic or arithmetic means of the individual sample sizes, as the sample size in fitting structural equation models. Unless all the correlation coefficients are based on the same number of studies, the precision of some correlation coefficients are over-estimated while others are under-estimated. Another issue is that the pooled correlation matrix is analyzed as it was a covariance matrix. It is generally incorrect to analyze the correlation matrix in SEM, although most published articles using MASEM have treated the pooled correlation matrix as a covariance matrix. Many SEM experts (e.g., Cudeck, 1989) have warned about the problems of analyzing the correlation matrix instead of the covariance matrix in primary-research applications of SEM. Specifically, the chi-square statistics and (or) the SEs of parameter estimates may be incorrect.
The TSSEM approach addresses these issues. The weighted least square (WLS) estimation is used to fit the proposed models in the stage 2 analysis. A correlation structural model ρ() is fitted with the WLS estimation method by minimizing the following fit function,
| (25) |
An LR statistic and various goodness-of-fit indices may be used to judge whether the proposed structural model is appropriate, while SEs may be used to test the significance of individual parameter estimates.
4. Conclusion
This paper introduced various meta-analytic models using a SEM approach. More importantly, these models have all been implemented in the metaSEM package which is freely available as an R package. Due to space constraint, I did not include topics, such as using REML as the estimation method (see Cheung, 2013a), constructing likelihood-based confidence interval (LBCI) (see Cheung, 2009), and using alternative random-effects MASEM (see Cheung and Cheung, under review). Readers may refer to the relevant papers and the metaSEM package for details. Some of these models can be implemented in standard SEM software such as Mplus (Muthén and Muthén, 2012). Since SEM software was not designed for meta-analysis, transformations on the effect sizes are required to meet the distribution assumptions (see e.g., Cheung, 2008, 2013b). To conclude, SEM provides a flexible framework to develop meta-analytic techniques. Many of the techniques available in SEM can be easily extended to meta-analysis. The supplementary material include some examples on how to analyze these models using the metaSEM package.
Funding
Preparation of this paper was supported by the Academic Research Fund Tier 1 (FY2013-FRC5-002; R-581-000-158-112) from the Ministry of Education, Singapore.
Conflict of interest statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary material
The Supplementary Material for this article can be found online at: http://www.frontiersin.org/journal/10.3389/fpsyg.2014.01521/abstract
References
- Arthur W., Bennett W., Huffcutt A. I. (2001). Conducting Meta-Analysis using SAS. Mahwah, NJ: Lawrence Erlbaum Associates. [Google Scholar]
- Becker B. J. (2009). Model-based meta-analysis, in The Handbook of Research Synthesis and Meta-Analysis, 2nd Edn., eds Cooper H., Hedges L. V., Valentine J. C. (New York, NY: Russell Sage Foundation; ), 377–395. [Google Scholar]
- Boker S., Neale M., Maes H., Wilde M., Spiegel M., Brick T., et al. (2011). OpenMx: an open source extended structural equation modeling framework. Psychometrika, 76, 306–317. 10.1007/s11336-010-9200-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Borenstein M., Hedges L. V., Rothstein H. R. (2005). Comprehensive Meta-Analysis, Version 2. Englewood, NJ: Biostat, Inc. [Google Scholar]
- Borenstein M., Hedges L. V., Higgins J. P., Rothstein H. R. (2009). Introduction to Meta-Analysis. Chichester; Hoboken: John Wiley & Sons; 10.1002/9780470743386 [DOI] [Google Scholar]
- Cheung M. W.-L., Chan W. (2005). Meta-analytic structural equation modeling: a two-stage approach. Psychol. Methods 10, 40–64. 10.1037/1082-989X.10.1.40 [DOI] [PubMed] [Google Scholar]
- Cheung M. W.-L., Chan W. (2009). A two-stage approach to synthesizing covariance matrices in meta-analytic structural equation modeling. Struct. Equ. Modeling 16, 28–53. 10.1080/1070551080256129523807765 [DOI] [Google Scholar]
- Cheung M. W.-L. (2008). A model for integrating fixed-, random-, and mixed-effects meta-analyses into structural equation modeling. Psychol. Methods 13, 182–202. 10.1037/a0013163 [DOI] [PubMed] [Google Scholar]
- Cheung M. W.-L. (2009). Constructing approximate confidence intervals for parameters with structural equation models. Struct. Equ. Modeling 16, 267–294 10.1080/10705510902751291 [DOI] [Google Scholar]
- Cheung M. W.-L. (2010). Fixed-effects meta-analyses as multiple-group structural equation models. Struct. Equ. Modeling 17, 481–509 10.1080/10705511.2010.489367 [DOI] [Google Scholar]
- Cheung M. W.-L. (2013a). Implementing restricted maximum likelihood (REML) estimation in structural equation models. Struct. Equ. Modeling 20, 157–167 10.1080/10705511.2013.742404 [DOI] [Google Scholar]
- Cheung M. W.-L. (2013b). Multivariate meta-analysis as structural equation models. Struct. Equ. Modeling 20, 429–454 10.1080/10705511.2013.797827 [DOI] [Google Scholar]
- Cheung M. W.-L. (2014a). Fixed- and random-effects meta-analytic structural equation modeling: examples and analyses in R. Behav. Res. Methods 46, 29–40. 10.3758/s13428-013-0361-y [DOI] [PubMed] [Google Scholar]
- Cheung M. W.-L. (in press). Meta-Analysis: A Structural Equation Modeling Approach. Wiley; Available online at: http://as.wiley.com/WileyCDA/WileyTitle/productCd-1119993431.html [Google Scholar]
- Cheung M. W.-L. (2014b). metaSEM: Meta-Analysis using Structural Equation Modeling, Version 0.9. Singapore: R package. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cheung M. W.-L. (2014c). Modeling dependent effect sizes with three-level meta-analyses: a structural equation modeling approach. Psychol. Methods 19, 211–229. 10.1037/a0032968 [DOI] [PubMed] [Google Scholar]
- Cochran W. (1954). The combination of estimates from different experiments. Biometrics 10, 101–129 10.2307/3001666 [DOI] [Google Scholar]
- Cudeck R. (1989). Analysis of correlation-matrices using covariance structure models. Psychol. Bull. 105, 317–327 10.1037/0033-2909.105.2.317 [DOI] [Google Scholar]
- Enders C. K. (2010). Applied Missing Data Analysis. New York, NY: Guilford Press. [Google Scholar]
- Hedges L. V., Olkin I. (1985). Statistical Methods for Meta-Analysis. Orlando, FL: Academic Press. [Google Scholar]
- Hedges L. V., Vevea J. L. (1998). Fixed- and random-effects models in meta-analysis. Psychol. Methods 3, 486–504 10.1037/1082-989X.3.4.486 [DOI] [Google Scholar]
- Higgins J. P. T., Thompson S. G. (2002). Quantifying heterogeneity in a meta-analysis. Stat. Med. 21, 1539–1558. 10.1002/sim.1186 [DOI] [PubMed] [Google Scholar]
- Kline R. B. (2011). Principles and practice of structural equation modeling, 3rd Edn. New York, NY: Guilford Press. [Google Scholar]
- Konstantopoulos S. (2011). Fixed effects and variance components estimation in three-level meta-analysis. Res. Synth. Methods 2, 61–76 10.1002/jrsm.35 [DOI] [PubMed] [Google Scholar]
- Lipsey M. W., Wilson D. (2000). Practical Meta-Analysis. Thousand Oaks, CA: Sage Publications, Inc. [Google Scholar]
- Lumley T. (2012). rmeta: Meta-Analysis, Version 2.16. Vienna: R package [Google Scholar]
- Muthén B. O., Muthén L. K. (2012). Mplus Users Guide, 7th Edn. Los Angeles, CA: Muthé & Muthén. [Google Scholar]
- Raudenbush S. W. (2009). Analyzing effect sizes: random effects models, in The Handbook of Research Synthesis and Meta-Analysis, 2nd Edn., eds Cooper H. M., Hedges L. V., Valentine J. C. (New York, NY: Russell Sage Foundation; ), 295–315. [Google Scholar]
- R Development Core Team (2014). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. [Google Scholar]
- Schmidt F. L., Hunter J. E. (2015). Methods of Meta-Analysis: Correcting Error and Bias in Research Findings, 3rd Edn. Thousand Oaks, CA: Sage. [Google Scholar]
- Schmidt F. L., Oh I.-S., Hayes T. L. (2009). Fixed- versus random-effects models in meta-analysis: model properties and an empirical comparison of differences in results. Br. J. Math. Stat. Psychol. 62, 97–128. 10.1348/000711007X255327 [DOI] [PubMed] [Google Scholar]
- Schwarzer G. (2014). meta: Meta-Analysis with R, Version 4.0-1. Vienna: R package [Google Scholar]
- Takkouche B., Cadarso-Suárez C., Spiegelman D. (1999). Evaluation of old and new tests of heterogeneity in epidemiologic meta-analysis. Am. J. Epidemiol. 150, 206–215. 10.1093/oxfordjournals.aje.a009981 [DOI] [PubMed] [Google Scholar]
- Van den Noortgate W., López-López J. A., Marín-Martínez F., Sánchez-Meca J. (2013). Three-level meta-analysis of dependent effect sizes. Behav. Res. Methods 45, 576–594. 10.3758/s13428-012-0261-6 [DOI] [PubMed] [Google Scholar]
- Viechtbauer W. (2010). Conducting meta-analyses in R with the metafor package. J. Stat. Softw. 36, 1–48. [Google Scholar]
- Viswesvaran C., Ones D. S. (1995). Theory testing: combining psychometric meta-analysis and structural equations modeling. Pers. Psychol. 48, 865–885 10.1111/j.1744-6570.1995.tb01784.x [DOI] [Google Scholar]
- Whitehead A. (2002). Meta-Analysis of Controlled Clinical Trials. Chichester, UK: John Wiley & Sons; 10.1002/0470854200 [DOI] [Google Scholar]
- Xiong C., Miller J. P., Morris J. C. (2010). Measuring study-specific heterogeneity in meta-analysis: application to an antecedent biomarker study of alzheimer's disease. Stat. Biopharm. Res. 2, 300–309. 10.1198/sbr.2009.0067 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.