

The American Heart Association has established the Cardiovascular Genome-Phenome Study (CV-GPS) as a means by which to achieve the goal of using modern genomics and phenotyping optimally to combat cardiovascular disease (CVD). CVD remains the leading cause of death in the United States and has become a major cause of morbidity and mortality worldwide. The course of CVD begins at an early age and evolves throughout life. Typically, risk factor precursors (eg, prehypertension, borderline abnormal lipids) are first observed in adolescence or young adulthood. By middle age, they develop into full-fledged cardiometabolic risk factors and subclinical disease, which usually become clinically apparent in older age. Importantly, risk factors for CVD reflect the complex interplay between genetic and environmental factors and demonstrate the complexity of the multiple determinants of disease.
Editorial see p 17
Many of the genetic and environmental determinants of CVD have been identified over the past 50 years, and successful preventive and therapeutic strategies have been developed as a result. However, many potential genetic or acquired disease drivers remain unaccounted for, as illustrated by the observation that the major CVD risk factors combined account for only a fraction of the population-attributable risk.1 In addition, variations in CVD risk exist among individuals with similar risk profiles. Part of these differences may reflect differences in profiles of known risk factors that have not yet been fully refined but also individual differences in underlying genetic modifiers of such risk factors. Modern genomics, with its ability to provide ideally unbiased analysis of the entire genome, offers an approach to the ascertainment of all genetic determinants of CVD. Furthermore, the increasingly broad range of “omics” methods, including RNA-Seq, modern proteomics, metabolomics, and metabonomics, provide deeper and more refined molecular detail by which to define an individual’s genome and its relationship to (patho)phenotype. Armed with these increasingly powerful molecular methods, modern genomics has yielded some new genetic targets that may account, in part, for the missing population-attributable risk and unexplained variation in risk among individuals, population subgroups, and aggregate populations.2 However, the conventional strategy of seeking simple associations between genomic loci or individual gene products and disease phenotype is limited (with rare exception) by the typically small effect sizes of given variants in a population and by a failure to take into consideration the networked complexity of protein-protein interactions and their modification by environmental (epigenetic and posttranslational) modulators.3
These limitations of modern genomics are compounded by limitations of conventional phenotyping. Specific cardiovascular phenotypes have been defined on the basis of their mechanistic relevance to clinical atherothrombotic vascular disease (eg, hypertension and hypercholesterolemia), their ease of measurement in individuals and in populations, and their epidemiological tractability. This approach to phenotyping grew in parallel with the evolution of clinical trials that, by their contemporary nature, tend to be diagnostically overinclusive, downplaying (except by predefined subgroup analyses when feasible) differences in phenotype that may better predict outcomes or response to therapy (eg, subpopulation differences in response to specific antihypertensive therapies). In addition, with some important exceptions (vide infra), many major epidemiological studies and clinical trials do not collect data over time, which further limits the strength of association between genotype and phenotype, the ability to evaluate the intrasubject and intersubject variations in risk factors over time, and the potential dynamic effects of such variations on genetic susceptibility and the ability to infer causality.
In light of the dramatic expansion of genomic data, it has become clear that traditional phenotyping as conducted in conventional epidemiological cohort studies may limit the ability to elucidate optimally genome-phenome relationships. There is, therefore, a clear need to develop deep phenotyping (ie, traits that are not typically measured or traits that are “orthogonal” to or not directly associated with the clinical phenotype under consideration) and dynamic phenotyping (including responses to perturbations) to capture fully the complexity of human disease. Furthermore, this approach to phenotyping coupled to modern genomics will be essential for achieving a truly individualized approach to the diagnosis, prognosis, and therapy of CVD.
With this background, there are 3 elements of note in CV-GPS. First, CV-GPS aims to provide a platform with which to integrate (virtually) existing and future CVD population studies. Beginning with the Framingham Heart Study (FHS) and the Jackson Heart Study (JHS), CV-GPS will consolidate available phenotypic and diverse omic data sets (genomic, transcriptomic, proteomic, metabolomic, epigenomic), expanding these data sets with the recruitment of other population data sets with information on CVD. This universe of data sets will define the big data platform that will be used to explore testable hypotheses about CVD. Second, CV-GPS will facilitate the development of the information technology infrastructure necessary for handling these big data and for classifying deep phenotypes. Third, CV-GPS will provide core support for methodological analyses (novel omics platforms) and a biorepository (real or virtual) for biological specimens from existing or future population study participants. Through these mechanisms, CV-GPS aspires to establish a national standard for all genome-phenome studies, applying the most cutting-edge approaches to the acquisition, storage, and analysis of information contained within this biophenorepository to deepen our understanding of the determinants of CVD.
The FHS as a Component of CV-GPS
Design and Component Cohorts
The FHS consists of ≈15 000 extensively phenotyped women and men (Figure 1). Details of the constituent cohorts, sample size, DNA availability, ethnic/racial composition, recruitment year and ages, and follow-up are given in the Table. The design and sampling criteria of the FHS cohorts have been published previously.4–7 The cohorts span a wide range of ages throughout the adult life course, between 20 and 100 years of age. The FHS is funded by the National Heart, Lung, and Blood Institute (NHLBI).
Figure 1.

Design of the Framingham Heart Study, including its constituent cohorts.
Table.
The Framingham Heart Study and Its Constituent Cohorts: Cohort Characteristics

Suitability of FHS for CV-GPS
Several features of the FHS make it a valuable asset to CV-GPS. These resources are briefly detailed below.
Extensive Longitudinal Phenotypic Data
The FHS has routinely collected longitudinal data over the adult life span of each participant in its 6 constituent cohorts, with extensive information on serial measures of risk factors, subclinical disease, and clinical outcomes, including CVD; lung, blood, and neurological conditions (stroke and dementia); and cause-specific mortality. At each FHS examination cycle, data are collected on blood pressure, anthropometry, lipids, smoking, glycemic traits and diabetes mellitus, ECG, and lung function. Across select serial examinations, the FHS has compiled multiple measures of cardiovascular structure and function as measured by echocardiography, cardiac computed tomography (CT), cardiac and brain magnetic resonance imaging (MRI), carotid ultrasound, conduit artery stiffness, and flow-mediated dilation. Further details on the traits available are detailed in Appendix I, Item 1 and summarized in Figure 2.
Figure 2.

Extensive phenotypic characterization of the Framingham Heart Study (FHS) participants. CMS indicates Centers for Medicare and Medicaid Services data.
Extensive Genotypic Data
In the 1990s and early 2000s, DNA samples were collected in the Original, Offspring, Third Generation, and Offspring Spouse cohorts of the FHS to establish an invaluable resource for genetic research. Most of the FHS participants with available genomic and cell line—based DNA are Offspring, Third Generation, and Offspring Spouses. Additionally, FHS collected DNA on ≈1000 participants from the Original Cohort who were alive at the time of DNA collection; DNA was also extracted on an additional ≈500 deceased Original Cohort participants from available whole blood as part of the SNP Health Association Resource (SHARe)8 project (see below). At FHS, ≈9300 participants across the constituent cohorts underwent genome-wide genotyping of 550 000 single-nucleotide polymorphisms (SNPs) using the Affymetrix platform for the SHARe project, and >7500 individuals underwent genotyping of 50 000 SNPs using the Illumina Cardiochip in the Candidate Gene Association Resource (CARe) project.9 With the use of extant genotypes, imputation has been completed of all participants to 40 million SNPs using the 1000G Imputation. Additionally, participants in the Offspring and Third Generation cohorts have undergone genotyping of ≈200 000 functional exonic variants via Illumina V1.0 Exome Chip. FHS has completed whole-exome sequencing in ≈2975 participants from several projects (including the NHLBI GO Exome Sequence Project10 and the CHARGE targeted Sequencing project)11 and low-pass whole-genome sequencing (WGS) in ≈850 participants.12 Of note, the genotyping (including whole-exome sequencing and WGS) that has been conducted to date with the FHS samples in numerous NHLBI-funded genotyping and sequencing programs has produced extremely high-quality sequence data with high call rates and low error rates. Most recently, a subsample of FHS participants has been selected to undergo WGS in a subset of its participants as part of the NHLBI-WGS project.13 Appendix I, Item 2 tabulates genotypic data available at FHS.
Available Omics Data
In addition to genotype data and multiple measures of heart, lung, blood, and sleep phenotypes, the FHS has been actively collecting various omics data, including DNA methylation, transcriptomics (mRNA and microRNA expression in whole blood), metabolomic markers, and protein biomarkers, over the past 5 to 10 years. The rich FHS resources with multiple measures of CVD risk factors, key subclinical disease traits and numerous clinical CVD outcomes, extensive genotype data, and a variety of omics data provide an excellent basis for genome-phenome analysis and integrative genomics.
Family Data
With the recruitment of the Offspring and Third Generation cohorts, the FHS is a full-fledged family study, with 3 generations of participants. DNA is available in 1037 extended families consisting of 5673 individuals who are genetically informative for imputation to a total of 7917 family members across all 3 cohorts. These families will provide a rich resource for CV-GPS that will greatly facilitate the examination of genome-phenome associations across the full spectrum of CVD phenotypes (including risk factors and subclinical and clinical CVD); a wide range of other lung, blood, sleep, and neurological traits; and a comprehensive battery of omics traits (as noted above). In addition, family data will provide an opportunity to track cosegregation of genetic and trait variation within families, strengthening the attribution of genetic causation.
FHS Biorepositories
The FHS maintains both a genetic and a nongenetic biorepository. FHS maintains in its genetic biorepository whole-blood aliquots, buffy coats, and PAXgene tubes on its cohorts at select examination cycles. There are 8444 unique Epstein-Barr virus—transformed cell lines on FHS participants, and 5823 participants have aliquots of lymphocytes in cryogenic storage. The repository has >25 000 stock DNA samples extracted from either a cell line or a blood source. From those stock DNA samples, FHS has formulated stock distribution plate sets. Stock DNA sample concentrations are normalized, checked by electrophoresis on an agarose gel for visual confirmation of DNA quality and concentration, and then forensically genotyped and compared with archival forensic data, or known family structures, to validate the identity of each DNA sample.
Currently, the FHS nongenetic biorepository contains ≈1.3 million biospecimens of various sample types, including serum, plasma, buffy coat, red blood cells, and urine. Access to FHS biosamples from its genetic or nongenetic biorepository requires appropriate approvals (institutional review board, laboratory, DNA committee, etc) and a signed data and material distribution agreement and is consistent with the informed consent of its participants.
FHS Public Databases That Can Be Accessed as Part of CV-GPS
FHS has contributed high quality and high volume to data repository programs such as the Database of Genotypes and Phenotypes (dbGaP), maintained by the National Center for Biotechnology Information, and the Biological Specimen and Data Repositories Information Coordinating Center (BioLINCC) of the NHLBI. FHS data can also be accessed via the parent study. All access to FHS data requires approval by the recipient institutional review board and the relevant FHS committees and must be consistent with the participant informed consent. All FHS data stored at the recipient institution must have appropriate safeguards to protect participant confidentiality.
FHS dbGaP Phenotypic Data Sets for Genetic Research
Framingham data sets and documentation are formatted according to dbGaP standards before submission. Each data set submission includes a dbGaP-formatted data set, a coding manual, a data collection protocol, related informed consents, an annotated data collection form, and a funding source reference. Both ancillary study data sets and NHLBI FHS-contracted data sets are posted on dbGaP. Well over 365 data sets were submitted by FHS by the first quarter of 2014.
FHS BioLINCC Data Sets for Nongenetic Research
Since 2000, the BioLINCC data repository has been updated approximately every 2 years with FHS contract—supported and ancillary grant—supported data and documentation. Data sets and documentation are formatted according to BioLINCC standards, including data sets, protocols for collection, and coding manuals. We propose to continue these deposits using past experience and expertise. Since 2000, 137 data sets and 442 corresponding documentation files have been submitted to BioLINCC.
FHS Summary
In conclusion, the large community-based cohorts with a 3-generational family structure, accompanying minority cohorts with a parallel examination structure, an extensive catalog of available traits, and the availability of substantial omics resources and biosamples establish the FHS as uniquely suited for the American Heart Association CV-GPS initiative.
The JHS as a Component of CV-GPS
Background
The JHS is a single-site, prospective, cohort study of risk factors of CVD among 5301 blacks living in the Jackson, MS, metropolitan area. The JHS is a collaborative effort among 3 Jackson-area academic institutions, the University of Mississippi Medical Center, Jackson State University, and Tougaloo College. Primary goals of the JHS are to broaden the research on CVD risk factors in a black population, to increase access and participation of black populations and scientists in biomedical research and professions, and to implement outreach activities to increase awareness and to promote healthy lifestyles in the community.14 Three clinical examinations have been completed, including the baseline examination, examination 1 (2000–2004), examination 2 (2005–2008), and examination 3 (2009–2013), allowing comprehensive assessment of cardiovascular health and disease of the cohort at ≈4-year intervals. Ongoing monitoring of cardiovascular events and deaths among cohort participants was achieved by annual telephone follow-up interviews and surveillance of hospital discharge records and vital records. At present, the JHS is not conducting clinical examinations, but annual telephone follow-up and surveillance of the cohort for CVD events and deaths continue. The JHS is funded by the NHLBI and the National Institute on Minority Health and Health Disparities.
Design
The JHS is a cohort study of extensively phenotyped black women and men. The details of the cohort, including design, sampling, recruitment, examinations, and follow-up, are described elsewhere.15–17 The JHS cohort spans a wide range of ages throughout the adult life course, between 21 and 101 years of age.
Suitability of JHS for CV-GPS
Several features of the JHS make it a valuable asset to CV-GPS. Among these resources are included extensive phenotypic and genotypic data, which are briefly detailed below.
Longitudinal Phenotypic Data
The JHS has collected longitudinal data among its study participants, with extensive information on measures of risk factors, subclinical disease, and clinical outcomes, including CVD, kidney disease, and neurological conditions (stroke and transient ischemic attack), as well as mortality. At each JHS examination cycle, data were collected on blood pressure, anthropometry, lipids, smoking, glycemic status, and diabetes mellitus. Across select serial examinations, the JHS has compiled multiple measures of cardiovascular structure and function as determined by echocardiography, ECG, cardiac CT, cardiac MRI, carotid ultrasound, and conduit artery stiffness. Further details on the phenotypic data available are provided in the Appendix II, Item 1 and are summarized in Figure 3.
Figure 3.

Extensive phenotypic characterization of the Jackson Heart Study (JHS) participants. DM indicates diabetes mellitus.
Genotypic Data
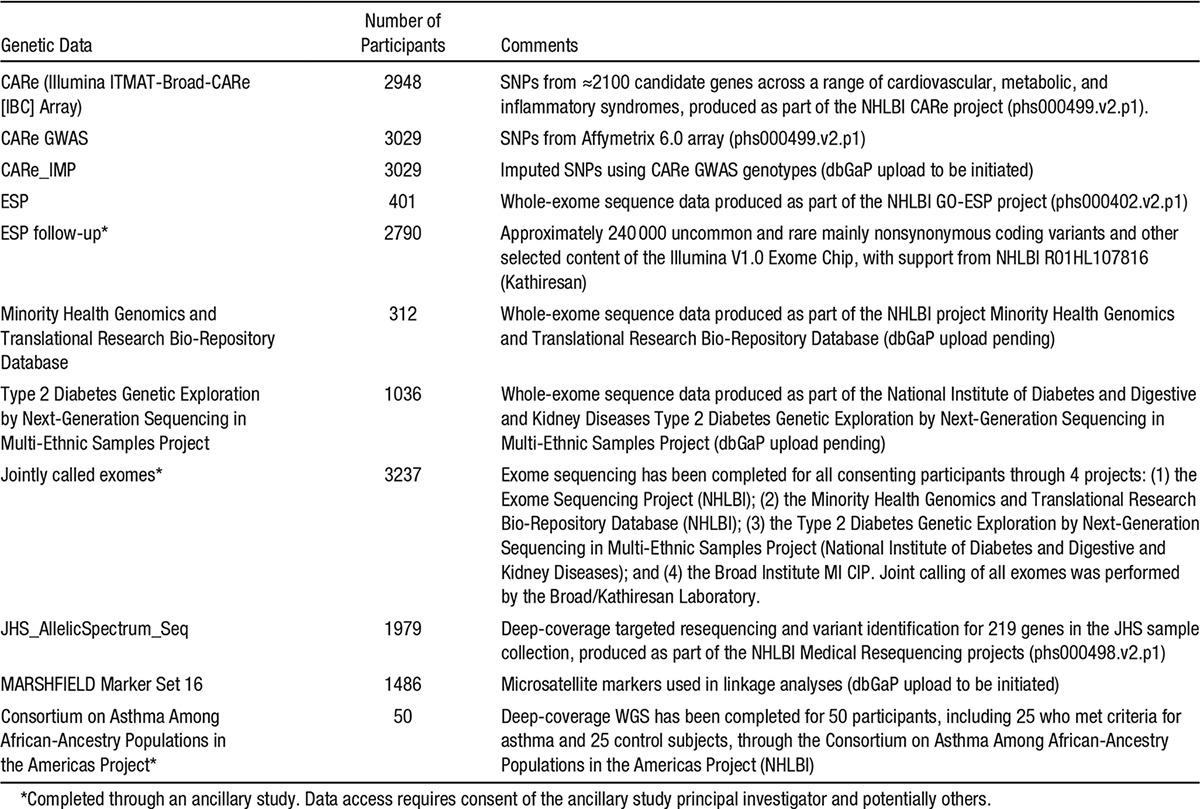
At examinations 1 and 2, DNA samples were collected from consenting study participants to establish an invaluable resource for genetic research. A Family Cohort (see below) includes >1500 participants, including cryptically related individuals identified by genetic analysis, in nearly 300 pedigrees, which vary in structure from sibships to cousin pairs to extended 3-generation families. Through the CARe project and after extensive quality control procedures, 3029 participants have genome-wide genotyping on the Affymetrix 6.0 platform, which interrogates >900 000 SNPs and has >900 000 probes for copy number variation. These data have been imputed to ≈37 million SNPs using the 1000 Genomes project reference panel (version 3, March 2012 release). In addition, through the CARe project, 2948 individuals have genotyping data for ≈50 000 SNPs on the gene-centric Illumina Cardiochip (IBC Array), which provides dense tagging of ≈2100 candidate genes for CVD.9 Genotyping has been completed in 2790 participants for ≈240 000 uncommon and rare, mainly nonsynonymous coding variants and other selected content of the Illumina V1.0 Exome Chip, with support from NHLBI R01HL107816 (principal investigator, S. Kathiresan). Exome sequencing has been completed for all consenting participants through 4 projects: the Exome Sequencing Project (NHLBI), the Minority Health Genomics and Translational Research Bio-Repository Database (NHLBI), the Type 2 Diabetes Genetic Exploration by Next-Generation Sequencing in Multi-Ethnic Samples Project (National Institute of Diabetes and Digestive and Kidney Diseases), and the Broad Institute MI CIP. Joint calling of all exomes was performed by the Broad/Kathiresan laboratory, providing, after extensive quality control measures, a single jointly-called exome data set representing 3237 JHS participants. Prior deep-coverage WGS has been completed for 50 participants, including 25 who met criteria for asthma and 25 control subjects, through the Consortium on Asthma Among African-Ancestry Populations in the Americas Project (NHLBI). Of note, the genotyping and sequencing that have been completed to date using JHS samples have produced extremely high-quality data with high call rates and low error rates. Appendix II, Item 2, also tabulates genotyping and sequence data available at JHS.
Available Biomarker Data
In addition to genotype data and multiple measures of heart, lung, blood, and sleep phenotypes, the JHS has been actively collecting various biomarkers data, including protein biomarkers, over the past 5 to 10 years. The rich JHS data set, with multiple measures of CVD risk factors, key subclinical disease traits, several clinical CVD outcomes, and extensive genotype data, provides an excellent basis for genome-phenome analysis and integrative genomics.
Family Data
With the intentional recruitment of family members of participants selected on the basis of family size and availability, the JHS includes a well-developed, nested family study, with DNA available for 1486 genetically informative individuals in >270 pedigrees (primarily sibships and extended families). These families will support the examination of genome-phenome associations across the full spectrum of CVD phenotypes and a wide range of other lung, blood, sleep, and neurological traits by allowing segregation and other family-based analyses, particularly of uncommon and rare variants.
JHS Biorepository
The JHS maintains both a genetic and a nongenetic biorepository, including serum, plasma, and urine aliquots, and purified DNA. There are ≈1500 participants with aliquots of mononuclear leukocytes in cryogenic storage. The repository has DNA samples from blood cells of >4700 participants, including ≈3400 whose consent allows sharing of genetic data through controlled-access repositories such as the dbGaP. Currently, the JHS nongenetic biorepository contains biospecimens of various sample types, including serum, plasma, and urine. Access to JHS biosamples from its genetic or nongenetic biorepository requires appropriate approvals (institutional review board, laboratory, genetics committee, etc) and a signed data and material distribution agreement and is subject to stipulations in the informed consent of each participant.
JHS Public Databases That Can Be Accessed as Part of CV-GPS
JHS has contributed high-quality and high-volume data to repositories such as dbGaP, maintained by the National Center for Biotechnology Information, and BioLINCC of the NHLBI. JHS data can also be accessed via the parent study. All access to JHS data requires approval by the recipient institutional review board and relevant JHS committees and must be consistent with the participant informed consent. All JHS data stored at the recipient institution must have appropriate safeguards to protect participant confidentiality.
JHS dbGaP Phenotypic Data Sets for Genetic Research
JHS data sets and documentation are formatted according to dbGaP standards before submission. Each data set submission includes a dbGaP-formatted data set, a coding manual, a data collection protocol, related informed consents, an annotated data collection form, and a funding source reference. NHLBI JHS-contracted data sets are posted on dbGaP.
JHS BioLINCC Data Sets for Nongenetic Research
Since 2000, the BioLINCC data repository has been updated ≈3 years after completion of the examination with JHS contract—supported and ancillary grant—supported data and documentation. Data sets and documentation are formatted according to BioLINCC standards, including data sets, protocols for collection, and coding manuals. We propose to continue these deposits using past experience and expertise.
JHS Summary
In conclusion, a large community-based cohort of blacks, the extensive catalog of available traits, and the availability of substantial resources and biosamples establish the JHS as uniquely suited for the American Heart Association CV-GPS initiative.
Population and Cohort Studies in CVD
Cohort Studies as Population Laboratories
As illustrated by the FHS and JHS, large, observational, clinical studies provide an exceptional opportunity to understand better the cause of CVD. They have collected a wealth of information on large numbers of participants using rigorous standardized protocols. These and many other cohort and existing databases should be considered population laboratories that provide an opportunity for basic, clinical, and population science colleagues to propose new, cutting-edge science. The advantages of population laboratories for potential CV-GPS (and other) investigators include the following: (1) cost-effectiveness: research infrastructure is in place with cohort recruitment completed; (2) time efficiency: multiple predictor variables and outcome data are immediately available to be leveraged by CV-GPS ancillary study proposals; (3) temporality: cohort studies allow the evaluation of predictors of cardiovascular outcomes because exposures (health behaviors, risk factors, stored specimens, imaging, etc) were evaluated before the development of outcomes; (4) availability of events: validated CVD events are available in many cohorts (eg, myocardial infarction, heart failure, atrial fibrillation, cardiovascular procedures, stroke, and death); (5) large stored specimen repositories: most cohorts have plasma, serum, and DNA available for use; (6) dense genotypes: genetic information has been collected in most cohorts (eg, genome-wide association study [GWAS] data, epigenetic data); (7) community-based sampling: given that cohorts are recruited from the community, risk factors and disease outcomes are more representative of the population at large; and (8) excellent collaborative investigators: an existing cadre of scientists familiar with the study are available to assist with both operational and scientific issues.
Overview of Current Established Studies
The CV-GPS initiative is fortunate to be able to leverage the excellent research infrastructure resulting from the strategic vision and research funding over many decades by National Institutes of Health/NHLBI colleagues, the hard work of cohort study investigators/staff, and the selfless dedication of study participants. It should be noted that although the CV-GPS initiative has initially focused on the FHS and JHS, these studies represent only a subset of available cohorts. The larger set of cohort studies provide access to an even broader spectrum of characteristics such as age (ranging from childhood to the oldest old), US race/ethnic group (ie, black, Hispanic, Chinese, Japanese, white, Native American, Alaska Native), phenotypic characteristics (health behaviors, risk factors, subclinical disease, laboratory measures, environmental factors, etc), and CVD states (eg, free of clinical CVD, prevalent CVD, incident CVD).
Some examples of major NHLBI cohorts include the Atherosclerosis Risk in Communities Study18 (n=15 792; age, 45–64 years at baseline examination [1987–1989]; white and black participants); the Coronary Artery Risk Development in Young Adults Study19 (n=5115; age, 18–30 years at the baseline examination [1985–1986]; white and black participants); the Cardiovascular Health Study20 (n=5888; age, ≥65 years at baseline examination [1990–1991]; white and black participants); the FHS (described in detail above); the Hispanic Community Health Study/Study of Latinos21 (n=16 400; age, 18–74 years at baseline examination [2008–2011]; participants are Hispanics/Latinos representing different groups of origin [Central Americans, Cubans, Dominicans, Mexicans, Puerto Ricans, and South Americans]); JHS (described in detail above); the Multi-Ethnic Study of Atherosclerosis22 (n=6814; age, 45–84 years at baseline examination [2000–2002]; participants from multiple race/ethnic groups [black, white, Hispanic, Chinese]); the Strong Heart Study23 (n=4500 Native American tribal members; age, 45–74 years at baseline examination [1984–1988]); and the Women’s Health Initiative Observational Study24 (n=93 676 postmenopausal women; age, 50–79 years at baseline examination [1991–1994]). Given that these cohorts differ in the populations studied (ie, age, race/ethnicity), phenotypic characteristics evaluated, amount/types of stored specimens, and events observed, CV-GPS investigators should consider the suitability of different cohort studies for the proposed hypotheses they plan to explore.
Cohort Studies: A Legacy of Discovery
The CV-GPS program builds on an exceptional legacy of discovery in population studies. Although it is clearly beyond the scope of this article to report all significant scientific findings from these studies, some noteworthy findings include the following: (1) identification of major risk factors for CVD in middle-aged and older adults25,26; (2) documentation of the ability to measure accurately risk factors in children and of the persistence (tracking) of risk factors from childhood into middle age27,28; (3) description of race/ethnic disparities in CVD and identification of some mechanisms for those disparities29–32; (4) identification of a number of dietary factors that affect CVD risk (ie, saturated fat, trans fats)33,34; (5) documentation of associations of active and passive cigarette exposure on CVD risk35,36; (6) identification of subclinical disease markers as intermediate markers of CVD risk and predictors of CVD events37–39; (7) assessment of the importance of the neighborhood characteristics on CVD risk40,41; (8) identification of the importance of inflammatory markers on CVD risk42–44; (9) documentation of the importance of the diabetes and obesity epidemic on CVD risk factors and outcomes45–47; (10) monitoring of time trends in medical care, including medication use in the United States48,49; (11) identification of genetic markers for outcomes by the integration of dense genotyping50,51; and (12) introduction and refinement of risk prediction equations to allow appropriate risk stratification for use in clinical practice.25,52,53 Although these and many other discoveries have resulted from prior evaluation of cohort study data, it should be noted that tremendous opportunities remain for future innovation using these population resources to advance science through CV-GPS and other research initiatives.
Power of Large Numbers and Value of Data Set Integration
Often, scientific discovery is inhibited by the lack of an appropriate sample size, an unsuitable study design, or a nonrepresentative population. The next generation of studies will seek to evaluate the importance of technological advances such as genetics, epigenetics, and metabolomics on cardiovascular risk. It is important to note that GWASs have generally observed relatively small associations with risk factors and disease outcomes. Thus, it is reasonable to anticipate that future research efforts will require the evaluation of a vast array of variables that may have small to modest effects on outcomes. This differs substantially from past work that was powered to seek associations with larger effect sizes such as traditional CVD risk factors. Pooling multiple cohort studies provides an opportunity to further increase sample size and study power, which is especially crucial for the investigation of both small effect sizes and CVD outcomes in informative subgroups. A prime example of this pooling is currently being explored in the genetic consortium evaluating GWAS data. Given the relatively small effect size of single genes, it is imperative both to pool cohort data for primary analyses and validation of observed associations and to examine their interactions in the complex molecular networks through which they exert their effects on phenotype. Ensuring standardization of variables across studies is a challenge when data are pooled. However, a major advantage of pooling NHLBI-funded cohort data is that, although not perfectly harmonized, similar methods have been used across studies to evaluate risk factors, survey instruments, physical measurements, and events.
Integration of Omics and New Technologies Into Population Studies
Recent advances have made large-scale integration of new predictor variables, such as genomics/epigenetics, metabolomics, and the microbiome, more economically and technologically feasible for large-scale implementation. Population studies provide an excellent opportunity for the rapid evaluation of these new technologies as a result of the availability of stored specimens, existing phenotypes, and outcome data. Substantial economies of scale are gained when omics ancillary studies/variables are added to an existing cohort study. Incorporation of new technology not only leverages the wealth of existing data from the parent population study for use by the initiating investigators but also allows the new data to be used as variables or covariates for further discovery by all research colleagues. For example, a novel proposed biomarker for coronary atherosclerosis may also be evaluated as a predictor of heart failure or stroke outcomes. The result of these efforts will be the creation of an enhanced data set available to a broad community of scientific colleagues that facilitates the efficient evaluation of additional scientific questions. Extramural funding of new science (ie, CV-GPS and other funding sources) that leverage existing cohorts preserves resources and time for omics-based discovery efforts.
Conclusions
The next generation of scientific discovery certainty requires the creation of large data repositories to ensure adequate sample size to detect small but important effects, computational platforms that seek complex interactions through analysis of interactive genomic and phenomic networks, multiple samples to allow validation of initial study findings, study diversity to allow the findings to be applicable to a larger universe of the public (age, race/ethnicity, sex, socioeconomic status, etc), and a user-friendly interface that makes these data more accessible to the larger community of researchers. Existing cohorts provide much of the initial data that can be approached as the overall infrastructure of CV-GPS is built; importantly, new prospective study populations and cohorts are encouraged to participate in CV-GPS to ensure that all possible population-based genomic and phenomic data are available in one integrated site for optimal analytic benefit. These data requirements and aspirations for comprehensive participant populations are essential as CV-GPS seeks to identify new determinants of the origin of CVD and, more important, factors that can be translated into new and improved diagnostic and treatment pathways for CVD.
Acknowledgments
We would like to acknowledge the FHS investigators and personnel who contributed to the data displayed in Appendix I, Items 1 and 2, and the JHS investigators and personnel who contributed to data displayed in Appendix II, Items 1 and 2.
Disclosures
None.
Appendix I
1. FHS Phenotypic Data

2. Available FHS Genetic Data

Appendix II
1. JHS Phenotypic Data

2. Available JHS Genetic Data
Consent for genetic analysis: JHS participants completed a “layered” consent document that allowed them to stipulate whether their data and samples could be used for genetic research, to limit research to certain diseases (eg, CVDs and related diseases and risk factors), to specify whether all qualifying investigators or only those collaborating with JHS investigators could analyze their genotype and phenotype data, and to indicate whether for-profit entities could access their data.
References
- 1.Cheng S, Claggett B, Correia AW, Shah AM, Gupta DK, Skali H, Ni H, Rosamond WD, Heiss G, Folsom AR, Coresh J, Solomon SD. Temporal trends in the population attributable risk for cardiovascular disease: the Atherosclerosis Risk in Communities Study. Circulation. 2014;130:820–828. doi: 10.1161/CIRCULATIONAHA.113.008506. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Peloso GM, Auer PL, Bis JC, Voorman A, Morrison AC, Stitziel NO, Brody JA, Khetarpal SA, Crosby JR, Fornage M, Isaacs A, Jakobsdottir J, Feitosa MF, Davies G, Huffman JE, Manichaikul A, Davis B, Lohman K, Joon AY, Smith AV, Grove ML, Zanoni P, Redon V, Demissie S, Lawson K, Peters U, Carlson C, Jackson RD, Ryckman KK, Mackey RH, Robinson JG, Siscovick DS, Schreiner PJ, Mychaleckyj JC, Pankow JS, Hofman A, Uitterlinden AG, Harris TB, Taylor KD, Stafford JM, Reynolds LM, Marioni RE, Dehghan A, Franco OH, Patel AP, Lu Y, Hindy G, Gottesman O, Bottinger EP, Melander O, Orho-Melander M, Loos RJ, Duga S, Merlini PA, Farrall M, Goel A, Asselta R, Girelli D, Martinelli N, Shah SH, Kraus WE, Li M, Rader DJ, Reilly MP, McPherson R, Watkins H, Ardissino D, Zhang Q, Wang J, Tsai MY, Taylor HA, Correa A, Griswold ME, Lange LA, Starr JM, Rudan I, Eiriksdottir G, Launer LJ, Ordovas JM, Levy D, Chen YD, Reiner AP, Hayward C, Polasek O, Deary IJ, Borecki IB, Liu Y, Gudnason V, Wilson JG, van Duijn CM, Kooperberg C, Rich SS, Psaty BM, Rotter JI, O’Donnell CJ, Rice K, Boerwinkle E, Kathiresan S, Cupples LA NHLBI GO Exome Sequencing Project. Association of low-frequency and rare coding-sequence variants with blood lipids and coronary heart disease in 56,000 whites and blacks. Am J Hum Genet. 2014;94:223–232. doi: 10.1016/j.ajhg.2014.01.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Barabási AL, Gulbahce N, Loscalzo J. Network medicine: a network-based approach to human disease. Nat Rev Genet. 2011;12:56–68. doi: 10.1038/nrg2918. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Dawber TR, Meadors GF, Moore FE. Epidemiologic approaches to heart disease: the Framingham Study. Am J Public Health. 1951;41:279–286. doi: 10.2105/ajph.41.3.279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Kannel WB, Feinleib M, McNamara PM, Garrison RJ, Castelli WP. An investigation of coronary heart disease in families: the Framingham Offspring Study. Am J Epidemiol. 1979;110:281–290. doi: 10.1093/oxfordjournals.aje.a112813. [DOI] [PubMed] [Google Scholar]
- 6.Quan SF, Howard BV, Iber C, Kiley JP, Nieto FJ, O’Connor GT, Rapoport DM, Redline S, Robbins J, Samet JM, Wahl PW. The Sleep Heart Health Study: design, rationale, and methods. Sleep. 1997;20:1077–1085. [PubMed] [Google Scholar]
- 7.Splansky GL, Corey D, Yang Q, Atwood LD, Cupples LA, Benjamin EJ, D’Agostino RB, Sr, Fox CS, Larson MG, Murabito JM, O’Donnell CJ, Vasan RS, Wolf PA, Levy D. The Third Generation Cohort of the National Heart, Lung, and Blood Institute’s Framingham Heart Study: design, recruitment, and initial examination. Am J Epidemiol. 2007;165:1328–1335. doi: 10.1093/aje/kwm021. [DOI] [PubMed] [Google Scholar]
- 8.National Heart, Lung, and Blood Institute. SHARe: SNP Health Association Resource. http://www.nhlbi.nih.gov/research/resources/genetics-genomics/share.htm. Accessed October 19, 2014.
- 9.Musunuru K, Lettre G, Young T, Farlow DN, Pirruccello JP, Ejebe KG, Keating BJ, Yang Q, Chen MH, Lapchyk N, Crenshaw A, Ziaugra L, Rachupka A, Benjamin EJ, Cupples LA, Fornage M, Fox ER, Heckbert SR, Hirschhorn JN, Newton-Cheh C, Nizzari MM, Paltoo DN, Papanicolaou GJ, Patel SR, Psaty BM, Rader DJ, Redline S, Rich SS, Rotter JI, Taylor HA, Jr, Tracy RP, Vasan RS, Wilson JG, Kathiresan S, Fabsitz RR, Boerwinkle E, Gabriel SB NHLBI Candidate Gene Association Resource. Candidate gene association resource (CARe): design, methods, and proof of concept. Circ Cardiovasc Genet. 2010;3:267–275. doi: 10.1161/CIRCGENETICS.109.882696. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.National Heart, Lung, and Blood Institute. NHLBI Grand Opportunity Exome Sequencing Project (ESP). https://esp.gs.washington.edu/drupal/. Accessed October 19, 2014.
- 11.Boerwinkle E, Heckbert SR. Following-up genome-wide association study signals: lessons learned from Cohorts for Heart and Aging Research in Genomic Epidemiology (CHARGE) Consortium Targeted Sequencing Study. Circ Cardiovasc Genet. 2014;7:332–334. doi: 10.1161/CIRCGENETICS.113.000078. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Morrison AC, Voorman A, Johnson AD, Liu X, Yu J, Li A, Muzny D, Yu F, Rice K, Zhu C, Bis J, Heiss G, O’Donnell CJ, Psaty BM, Cupples LA, Gibbs R, Boerwinkle E Cohorts for Heart and Aging Research in Genetic Epidemiology (CHARGE) Consortium. Whole-genome sequence-based analysis of high-density lipoprotein cholesterol. Nat Genet. 2013;45:899–901. doi: 10.1038/ng.2671. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.National Heart, Lung, and Blood Institute. NHLBI Whole Genome Sequencing Project. http://grants.nih.gov/grants/guide/notice-files/NOT-HL-14–030.html. Accessed October 19, 2014.
- 14.Taylor HA., Jr. The Jackson Heart Study: an overview. Ethn Dis. 2005;15:S6-1–S6-3. [PubMed] [Google Scholar]
- 15.Fuqua SR, Wyatt SB, Andrew ME, Sarpong DF, Henderson FR, Cunningham MF, Taylor HA., Jr. Recruiting African-American research participation in the Jackson Heart Study: methods, response rates, and sample description. Ethn Dis. 2005;15(suppl 6):S6–S18. [PubMed] [Google Scholar]
- 16.Wilson JG, Rotimi CN, Ekunwe L, Royal CD, Crump ME, Wyatt SB, Steffes MW, Adeyemo A, Zhou J, Taylor HA, Jr, Jaquish C. Study design for genetic analysis in the Jackson Heart Study. Ethn Dis. 2005;15(suppl 6):S6–S30. [PubMed] [Google Scholar]
- 17.Keku E, Rosamond W, Taylor HA, Jr, Garrison R, Wyatt SB, Richard M, Jenkins B, Reeves L, Sarpong D. Cardiovascular disease event classification in the Jackson Heart Study: methods and procedures. Ethn Dis. 2005;15(suppl 6):S6–S62. [PubMed] [Google Scholar]
- 18.The Atherosclerosis Risk in Communities (ARIC) Study: design and objectives: the ARIC Investigators. Am J Epidemiol. 1989;129:687–702. [PubMed] [Google Scholar]
- 19.Friedman GD, Cutter GR, Donahue RP, Hughes GH, Hulley SB, Jacobs DR, Jr, Liu K, Savage PJ. CARDIA: study design, recruitment, and some characteristics of the examined subjects. J Clin Epidemiol. 1988;41:1105–1116. doi: 10.1016/0895-4356(88)90080-7. [DOI] [PubMed] [Google Scholar]
- 20.Fried LP, Borhani NO, Enright P, Furberg CD, Gardin JM, Kronmal RA, Kuller LH, Manolio TA, Mittelmark MB, Newman A. The Cardiovascular Health Study: design and rationale. Ann Epidemiol. 1991;1:263–276. doi: 10.1016/1047-2797(91)90005-w. [DOI] [PubMed] [Google Scholar]
- 21.Sorlie PD, Avilés-Santa LM, Wassertheil-Smoller S, Kaplan RC, Daviglus ML, Giachello AL, Schneiderman N, Raij L, Talavera G, Allison M, Lavange L, Chambless LE, Heiss G. Design and implementation of the Hispanic Community Health Study/Study of Latinos. Ann Epidemiol. 2010;20:629–641. doi: 10.1016/j.annepidem.2010.03.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Bild DE, Bluemke DA, Burke GL, Detrano R, Diez Roux AV, Folsom AR, Greenland P, Jacob DR, Jr, Kronmal R, Liu K, Nelson JC, O’Leary D, Saad MF, Shea S, Szklo M, Tracy RP. Multi-Ethnic Study of Atherosclerosis: objectives and design. Am J Epidemiol. 2002;156:871–881. doi: 10.1093/aje/kwf113. [DOI] [PubMed] [Google Scholar]
- 23.Lee ET, Welty TK, Fabsitz R, Cowan LD, Le N-A, Oopik AJ, Cucchiara AJ, Savage PJ, Howard BV. The Strong Heart Study: a study of cardiovascular disease in American Indians: design and methods. Am J Epidemiol. 1990;132:1141–1155. doi: 10.1093/oxfordjournals.aje.a115757. [DOI] [PubMed] [Google Scholar]
- 24.Women’s Health Initiative Study Group. Design of the Women’s Health Initiative clinical trial and observational study. Control Clin Trials. 1998;19:61–109. doi: 10.1016/s0197-2456(97)00078-0. [DOI] [PubMed] [Google Scholar]
- 25.Wilson PW, D’Agostino RB, Levy D, Belanger AM, Silbershatz H, Kannel WB. Prediction of coronary heart disease using risk factor categories. Circulation. 1998;97:1837–1847. doi: 10.1161/01.cir.97.18.1837. [DOI] [PubMed] [Google Scholar]
- 26.Odden MC, Shlipak MG, Whitson HE, Katz R, Kearney PM, Defilippi C, Shastri S, Sarnak MJ, Siscovick DS, Cushman M, Psaty BM, Newman AB. Risk factors for cardiovascular disease across the spectrum of older age: the Cardiovascular Health Study. Atherosclerosis. 2014;237:336–342. doi: 10.1016/j.atherosclerosis.2014.09.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Webber LS, Cresanta JL, Voors AW, Berenson GS. Tracking of cardiovascular disease risk factor variables in school-age children. J Chronic Dis. 1983;36:647–660. doi: 10.1016/0021-9681(83)90081-4. [DOI] [PubMed] [Google Scholar]
- 28.Lauer RM, Connor WE, Leaverton PE, Reiter MA, Clarke WR. Coronary heart disease risk factors in school children: the Muscatine study. J Pediatr. 1975;86:697–706. doi: 10.1016/s0022-3476(75)80353-2. [DOI] [PubMed] [Google Scholar]
- 29.Kuller L, Fisher L, McClelland R, Fried L, Cushman M, Jackson S, Manolio T. Differences in prevalence of and risk factors for subclinical vascular disease among black and white participants in the Cardiovascular Health Study. Arterioscler Thromb Vasc Biol. 1998;18:283–293. doi: 10.1161/01.atv.18.2.283. [DOI] [PubMed] [Google Scholar]
- 30.Paramsothy P, Knopp R, Bertoni AG, Tsai MY, Rue T, Heckbert SR. Combined hyperlipidemia in relation to race/ethnicity, obesity, and insulin resistance in the Multi-Ethnic Study of Atherosclerosis. Metabolism. 2009;58:212–219. doi: 10.1016/j.metabol.2008.09.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Daviglus ML, Talavera GA, Avilés-Santa ML, Allison M, Cai J, Criqui MH, Gellman M, Giachello AL, Gouskova N, Kaplan RC, LaVange L, Penedo F, Perreira K, Pirzada A, Schneiderman N, Wassertheil-Smoller S, Sorlie PD, Stamler J. Prevalence of major cardiovascular risk factors and cardiovascular diseases among Hispanic/Latino individuals of diverse backgrounds in the United States. JAMA. 2012;308:1775–1784. doi: 10.1001/jama.2012.14517. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Wyatt SB, Akylbekova EL, Wofford MR, Coady SA, Walker ER, Andrew ME, Keahey WJ, Taylor HA, Jones DW. Prevalence, awareness, treatment, and control of hypertension in the Jackson Heart Study. Hypertension. 2008;51:650–656. doi: 10.1161/HYPERTENSIONAHA.107.100081. [DOI] [PubMed] [Google Scholar]
- 33.Mann GV, Pearson G, Gordon T, Dawber TR. Diet and cardiovascular disease in the Framingham study, I: measurement of dietary intake. Am J Clin Nutr. 1962;11:200–225. doi: 10.1093/ajcn/11.3.200. [DOI] [PubMed] [Google Scholar]
- 34.Van Horn LV, Ballew C, Liu K, Ruth K, McDonald A, Hilner JE, Burke GL, Savage PJ, Bragg C, Caan B. Diet, body size, and plasma lipids-lipoproteins in young adults: differences by race and sex: the Coronary Artery Risk Development in Young Adults (CARDIA) study. Am J Epidemiol. 1991;133:9–23. doi: 10.1093/oxfordjournals.aje.a115807. [DOI] [PubMed] [Google Scholar]
- 35.Howard G, Burke GL, Szklo M, Tell GS, Eckfeldt J, Evans G, Heiss G. Active and passive smoking are associated with increased carotid wall thickness: the Atherosclerosis Risk in Communities Study. Arch Intern Med. 1994;154:1277–1282. [PubMed] [Google Scholar]
- 36.Kannel WB, Castelli WP, McNamara PM. Cigarette smoking and risk of coronary heart disease: epidemiologic clues to pathogenesis: the Framingham study. Natl Cancer Inst Monogr. 1968;28:9–20. [PubMed] [Google Scholar]
- 37.Kuller LH, Shemanski L, Psaty BM, Borhani NO, Gardin J, Haan MN, O’Leary DH, Savage PJ, Tell GS, Tracy R. Subclinical disease as an independent risk factor for cardiovascular disease. Circulation. 1995;92:720–726. doi: 10.1161/01.cir.92.4.720. [DOI] [PubMed] [Google Scholar]
- 38.Detrano R, Guerci AD, Carr JJ, Bild DE, Burke G, Folsom AR, Liu K, Shea S, Szklo M, Bluemke DA, O’Leary DH, Tracy R, Watson K, Wong ND, Kronmal RA. Coronary calcium as a predictor of coronary events in four racial or ethnic groups. N Engl J Med. 2008;358:1336–1345. doi: 10.1056/NEJMoa072100. [DOI] [PubMed] [Google Scholar]
- 39.Chambless LE, Folsom AR, Clegg LX, Sharrett AR, Shahar E, Nieto FJ, Rosamond WD, Evans G. Carotid wall thickness is predictive of incident clinical stroke: the Atherosclerosis Risk in Communities (ARIC) study. Am J Epidemiol. 2000;151:478–487. doi: 10.1093/oxfordjournals.aje.a010233. [DOI] [PubMed] [Google Scholar]
- 40.Auchincloss AH, Diez Roux AV, Mujahid MS, Shen M, Bertoni AG, Carnethon MR. Neighborhood resources for physical activity and healthy foods and incidence of type 2 diabetes mellitus: the Multi-Ethnic Study of Atherosclerosis. Arch Intern Med. 2009;169:1698–1704. doi: 10.1001/archinternmed.2009.302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Henderson C, Diez-Roux AV, Kiefe CI, West DE, Jacobs DR, Williams DR. Neighborhood characteristics, individual-level socioeconomic factors, and depressive symptoms in young adults: the CARDIA Study. J Epidemiol Community Health. 2005;59:322–328. doi: 10.1136/jech.2003.018846. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Olson NC, Cushman M, Lutsey PL, McClure LA, Judd S, Tracy RP, Folsom AR, Zakai NA. Inflammation markers and incident venous thromboembolism: the REasons for Geographic And Racial Differences in Stroke (REGARDS) Cohort [published online ahead of print October 7, 2014]. J Thromb Haemost. doi: 10.1111/jth.12742. doi: 10.1111/jth.12742. http://onlinelibrary.wiley.com/doi/10.1111/jth.12742/abstract;jsessionid=ECC98E260A87C4B10C3A6CA07977B031.f02t01. Accessed October 19, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Zakai NA, Katz R, Jenny NS, Psaty BM, Reiner AP, Schwartz SM, Cushman M. Inflammation and hemostasis biomarkers and cardiovascular risk in the elderly: the Cardiovascular Health Study. J Thromb Haemost. 2007;5:1128–1135. doi: 10.1111/j.1538-7836.2007.02528.x. [DOI] [PubMed] [Google Scholar]
- 44.Fontes JD, Yamamoto JF, Larson MG, Wang N, Dallmeier D, Rienstra M, Schnabel RB, Vasan RS, Keaney JF, Jr, Benjamin EJ. Clinical correlates of change in inflammatory biomarkers: the Framingham Heart Study. Atherosclerosis. 2013;228:217–223. doi: 10.1016/j.atherosclerosis.2013.01.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Truesdale K, Lewis CE, Loria C, Cai J, Stevens J, Schreiner PJ. Changes in risk factors for cardiovascular disease by baseline weight status in young adults who maintain or gain weight over 15 years: the CARDIA Study. Int J Obesity. 2006;30:1397–1407. doi: 10.1038/sj.ijo.0803307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Wong ND, Nelson JC, Granston T, Bertoni AG, Blumenthal RS, Carr JJ, Guerci A, Jacobs DR, Jr, Kronmal R, Liu K, Saad M, Selvin E, Tracy R, Detrano R. Metabolic syndrome, diabetes, and incidence and progression of coronary calcium: the Multiethnic Study of Atherosclerosis study. JACC Cardiovasc Imaging. 2012;5:358–366. doi: 10.1016/j.jcmg.2011.12.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Sims M, Diez Roux AV, Boykin S, Sarpong D, Gebreab SY, Wyatt SB, Hickson D, Payton M, Ekunwe L, Taylor HA. The socioeconomic gradient of diabetes prevalence, awareness, treatment, and control among African Americans in the Jackson Heart Study. Ann Epidemiol. 2011;21:892–898. doi: 10.1016/j.annepidem.2011.05.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Lemaitre RN, Furberg CD, Newman AB, Hulley SB, Gordon DJ, Gottdiener JS, McDonald RH, Jr, Psaty BM. Time trends in the use of cholesterol-lowering agents in older adults: the Cardiovascular Health Study. Arch Intern Med. 1998;158:1761–1768. doi: 10.1001/archinte.158.16.1761. [DOI] [PubMed] [Google Scholar]
- 49.Adams NB, Lutsey PL, Folsom AR, Herrington DH, Sibley CT, Zakai NA, Ades S, Burke GL, Cushman M. Statin therapy and levels of hemostatic factors in a healthy population: the Multi-Ethnic Study of Atherosclerosis. J Thromb Haemost. 2013;11:1078–1084. doi: 10.1111/jth.12223. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Alonso A, Krijthe BP, Aspelund T, Stepas KA, Pencina MJ, Moser CB, Sinner MF, Sotoodehnia N, Fontes JD, Janssens AC, Kronmal RA, Magnani JW, Witteman JC, Chamberlain AM, Lubitz SA, Schnabel RB, Agarwal SK, McManus DD, Ellinor PT, Larson MG, Burke GL, Launer LJ, Hofman A, Levy D, Gottdiener JS, Kääb S, Couper D, Harris TB, Soliman EZ, Stricker BH, Gudnason V, Heckbert SR, Benjamin EJ. Simple risk model predicts incidence of atrial fibrillation in a racially and geographically diverse population: the CHARGE-AF consortium. J Am Heart Assoc. 2013;2:e000102. doi: 10.1161/JAHA.112.000102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Li J, Lange LA, Duan Q, Lu Y, Singleton AB, Zonderman AB, Evans MK, Li Y, Taylor HA, Willis MS, Nalls M, Wilson JG, Lange EM. Genome-wide admixture and association study of serum iron, ferritin, transferrin saturation and total iron binding capacity in African Americans [published online ahead of print September 15, 2014]. Hum Mol Genet. doi: 10.1093/hmg/ddu454. doi: 10.1093/hmg/ddu454. http://hmg.oxfordjournals.org/content/early/2014/09/29/hmg.ddu454.long. Accessed October 19, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Matsushita K, Mahmoodi BK, Woodward M, Emberson JR, Jafar TH, Jee SH, Polkinghorne KR, Shankar A, Smith DH, Tonelli M, Warnock DG, Wen CP, Coresh J, Gansevoort RT, Hemmelgarn BR, Levey AS Chronic Kidney Disease Prognosis Consortium. Comparison of risk prediction using the CKD-EPI equation and the MDRD study equation for estimated glomerular filtration rate. JAMA. 2012;307:1941–1951. doi: 10.1001/jama.2012.3954. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Miedema MD, Duprez DA, Misialek JR, Blaha MJ, Nasir K, Silverman MG, Blankstein R, Budoff MJ, Greenland P, Folsom AR. Use of coronary artery calcium testing to guide aspirin utilization for primary prevention: estimates from the Multi-Ethnic Study of Atherosclerosis. Circ Cardiovasc Qual Outcomes. 2014;7:453–460. doi: 10.1161/CIRCOUTCOMES.113.000690. [DOI] [PMC free article] [PubMed] [Google Scholar]