

Abstract
We study the variability of predictions made by bagged learners and random forests, and show how to estimate standard errors for these methods. Our work builds on variance estimates for bagging proposed by Efron (1992, 2013) that are based on the jackknife and the infinitesimal jackknife (IJ). In practice, bagged predictors are computed using a finite number B of bootstrap replicates, and working with a large B can be computationally expensive. Direct applications of jackknife and IJ estimators to bagging require B = Θ(n1.5) bootstrap replicates to converge, where n is the size of the training set. We propose improved versions that only require B = Θ(n) replicates. Moreover, we show that the IJ estimator requires 1.7 times less bootstrap replicates than the jackknife to achieve a given accuracy. Finally, we study the sampling distributions of the jackknife and IJ variance estimates themselves. We illustrate our findings with multiple experiments and simulation studies.
Keywords: bagging, jackknife methods, Monte Carlo noise, variance estimation
1. Introduction
Bagging (Breiman, 1996) is a popular technique for stabilizing statistical learners. Bagging is often conceptualized as a variance reduction technique, and so it is important to understand how the sampling variance of a bagged learner compares to the variance of the original learner. In this paper, we develop and study methods for estimating the variance of bagged predictors and random forests (Breiman, 2001), a popular extension of bagged trees. These variance estimates only require the bootstrap replicates that were used to form the bagged prediction itself, and so can be obtained with moderate computational overhead. The results presented here build on the jackknife-after-bootstrap methodology introduced by Efron (1992) and on the infinitesimal jackknife for bagging (IJ) (Efron, 2013).
Figure 1 shows the results from applying our method to a random forest trained on the “Auto MPG” data set, a regression task where we aim to predict the miles-per-gallon (MPG) gas consumption of an automobile based on 7 features including weight and horsepower. The error bars shown in Figure 1 give an estimate of the sampling variance of the random forest; in other words, they tell us how much the random forest’s predictions might change if we trained it on a new training set. The fact that the error bars do not in general cross the prediction-equals-observation diagonal suggests that there is some residual noise in the MPG of a car that cannot be explained by a random forest model based on the available predictor variables.1
Figure 1.
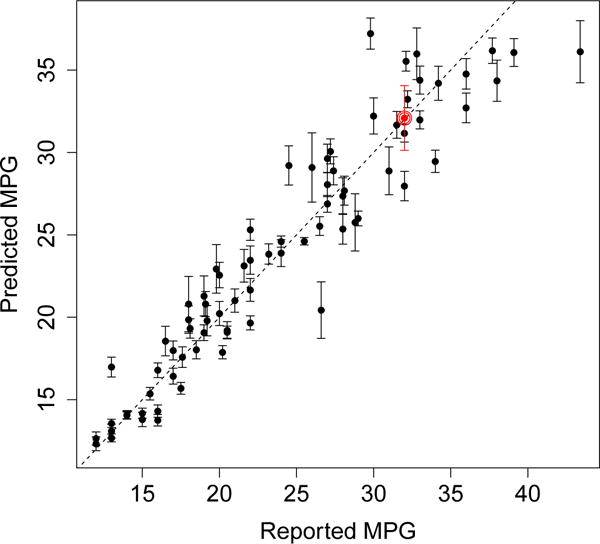
Random forest predictions on the “Auto MPG” data set. The random forest was trained using 314 examples; the graph shows results on a test set of size 78. The error bars are 1 standard error in each direction. Because this is a fairly small data set, we estimated standard errors for the random forest using the averaged estimator from Section 5.2. A more detailed description of the experiment is provided in Appendix C.
Figure 1 tells us that the random forest was more confident about some predictions than others. Rather reassuringly, we observe that the random forest was in general less confident about the predictions for which the reported MPG and predicted MPG were very different. There is not a perfect correlation, however, between the error level and the size of the error bars. One of the points, circled in red near (32, 32), appears particularly surprising: the random forest got the prediction almost exactly right, but gave the prediction large error bars of ±2. This curious datapoint corresponds to the 1982 Dodge Rampage, a two-door Coupe Utility that is a mix between a passenger car and a truck with a cargo tray. Perhaps our random forest had a hard time confidently estimating the mileage of the Rampage because it could not quite decide whether to cluster it with cars or with trucks. We present experiments on larger data sets in Section 3.
Estimating the variance of bagged learners based on the preexisting bootstrap replicates can be challenging, as there are two distinct sources of noise. In addition to the sampling noise (i.e., the noise arising from randomness during data collection), we also need to control the Monte Carlo noise arising from the use of a finite number of bootstrap replicates. We study the effects of both sampling noise and Monte Carlo noise.
In our experience, the errors of the jackknife and IJ estimates of variance are often dominated by Monte Carlo effects. Monte Carlo bias can be particularly troublesome: if we are not careful, the jackknife and IJ estimators can conflate Monte Carlo noise with the underlying sampling noise and badly overestimate the sampling variance. We show how to estimate the magnitude of this Monte Carlo bias and develop bias-corrected versions of the jackknife and IJ estimators that outperform the original ones. We also show that the IJ estimate of variance is able to use the preexisting bootstrap replicates more efficiently than the jackknife estimator by having a lower Monte Carlo variance, and needs 1.7 times less bootstrap replicates than the jackknife to achieve a given accuracy.
If we take the number of bootstrap replicates to infinity, Monte Carlo effects disappear and only sampling errors remain. We compare the sampling biases of both the jackknife and IJ rules and present some evidence that, while the jackknife rule has an upward sampling bias and the IJ estimator can have a downward bias, the arithmetic mean of the two variance estimates can be close to unbiased. We also propose a simple method for estimating the sampling variance of the IJ estimator itself.
Our paper is structured as follows. We first present an overview of our main results in Section 2, and apply them to random forest examples in Section 3. We then take a closer look at Monte Carlo effects in Section 4 and analyze the sampling distribution of the limiting IJ and jackknife rules with B → ∞ in Section 5. We spread simulation experiments throughout Sections 4 and 5 to validate our theoretical analysis.
1.1 Related Work
In this paper, we focus on methods based on the jackknife and the infinitesimal jackknife for bagging (Efron, 1992, 2013) that let us estimate standard errors based on the pre-existing bootstrap replicates. Other approaches that rely on forming second-order bootstrap replicates have been studied by Duan (2011) and Sexton and Laake (2009). Directly bootstrapping a random forest is usually not a good idea, as it requires forming a large number of base learners. Sexton and Laake (2009), however, propose a clever work-around to this problem. Their approach, which could have been called a bootstrap of little bags, involves bootstrapping small random forests with around B = 10 trees and then applying a bias correction to remove the extra Monte Carlo noise.
There has been considerable interest in studying classes of models for which bagging can achieve meaningful variance reduction, and also in outlining situations where bagging can fail completely (e.g., Skurichina and Duin, 1998; Bühlmann and Yu, 2002; Chen and Hall, 2003; Buja and Stuetzle, 2006; Friedman and Hall, 2007). The problem of producing practical estimates of the sampling variance of bagged predictors, however, appears to have received somewhat less attention in the literature so far.
2. Estimating the Variance of Bagged Predictors
This section presents our main result: estimates of variance for bagged predictors that can be computed from the same bootstrap replicates that give the predictors. Section 3 then applies the result to random forests, which can be analyzed as a special class of bagged predictors.
Suppose that we have training examples Z1 = (x1, y1), …, Zn = (xn, yn), an input x to a prediction problem, and a base learner . To make things concrete, the Zi could be a list of e-mails xi paired with labels yi that catalog the e-mails as either spam or non-spam, t(x; Zi) could be a decision tree trained on these labeled e-mails, and x could be a new e-mail that we seek to classify. The quantity would then be the output of the tree predictor on input x.
With bagging, we aim to stabilize the base learner t by resampling the training data. In our case, the bagged version of is defined as
| (1) |
where the are drawn independently with replacement from the original data (i.e., they form a bootstrap sample). The expectation is taken with respect to the bootstrap measure.
The expectation in (1) cannot in general be evaluated exactly, and so we form the bagged estimator by Monte Carlo
| (2) |
and the are elements in the bth bootstrap sample. As B → ∞, we recover the perfectly bagged estimator .
2.1 Basic Variance Estimates
The goal of our paper is to study the sampling variance of bagged learners
In other words, we ask how much variance would have once we make B large enough to eliminate the bootstrap effects. We consider two basic estimates of V: The Infinitesimal Jackknife estimate (Efron, 2013), which results in the simple expression
| (3) |
where is the covariance between t*(x) and the number of times the ith training example appears in a bootstrap sample; and the Jackknife-after-Bootstrap estimate (Efron, 1992)
| (4) |
where is the average of t*(x) over all the bootstrap samples not containing the ith example and is the mean of all the t*(x).
The jackknife-after-bootstrap estimate arises directly by applying the jackknife to the bootstrap distribution. The infinitesimal jackknife (Jaeckel, 1972), also called the non-parametric delta method, is an alternative to the jackknife where, instead of studying the behavior of a statistic when we remove one observation at a time, we look at what happens to the statistic when we individually down-weight each observation by an infinitesimal amount. When the infinitesimal jackknife is available, it sometimes gives more stable predictions than the regular jackknife. Efron (2013) shows how an application of the infinitesimal jackknife principle to the bootstrap distribution leads to the simple estimate .
2.2 Finite-B Bias
In practice, we can only ever work with a finite number B of bootstrap replicates. The natural Monte Carlo approximations to the estimators introduced above are
| (5) |
and
| (6) |
Here, indicates the number of times the ith observation appears in the bootstrap sample b.
In our experience, these finite-B estimates of variance are often badly biased upwards if the number of bootstrap samples B is too small. Fortunately, bias-corrected versions are available:
| (7) |
| (8) |
These bias corrections are derived in Section 4. In many applications, the simple estimators (5) and (6) require B = Θ(n1.5) bootstrap replicates to reduce Monte Carlo noise down to the level of the inherent sampling noise, whereas our bias-corrected versions only require B = Θ(n) replicates. The bias-corrected jackknife (8) was also discussed by Sexton and Laake (2009).
In Figure 2, we show how can be used to accurately estimate the variance of a bagged tree. We compare the true sampling variance of a bagged regression tree with our variance estimate. The underlying signal is a step function with four jumps that are reflected as spikes in the variance of the bagged tree. On average, our variance estimator accurately identifies the location and magnitude of these spikes.
Figure 2.
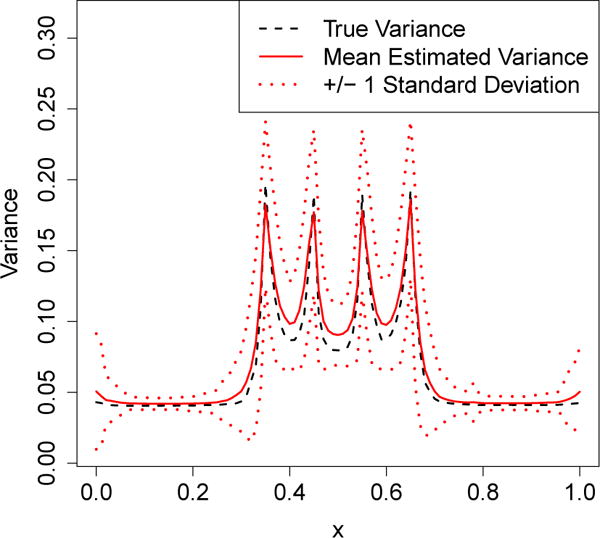
Testing the performance of the bias-corrected infinitesimal jackknife estimate of variance for bagged predictors, as defined in (15), on a bagged regression tree. We compare the true sampling error with the average standard error estimate produced by our method across multiple runs; the dotted lines indicate one-standard-error-wide confidence bands for our standard error estimate.
Figure 3 compares the performance of the four considered variance estimates on a bagged adaptive polynomial regression example described in detail in Section 4.4. We see that the uncorrected estimators and are badly biased: the lower whiskers of their boxplots do not even touch the limiting estimate with B → ∞. We also see that that has about half the variance of . This example highlights the importance of using estimators that use available bootstrap replicates efficiently: with B = 500 bootstrap replicates, can give us a reasonable estimate of V, whereas is quite unstable and biased upwards by a factor 2.
Figure 3.

Performance, as a function of B, of the jackknife and IJ estimators and their bias-corrected modifications on the cholesterol data set of Efron and Feldman (1991). The boxplots depict bootstrap realizations of each estimator. The dotted line indicates the mean of all the realizations of the IJ-U and J-U estimators (weighted by B).
The figure also suggests that the Monte Carlo noise of decays faster (as a function of B) than that of . This is no accident: as we show in Section 4.2, the infinitesimal jackknife requires 1.7 times less bootstrap replicates than the jackknife to achieve a given level of level of Monte Carlo error.
2.3 Limiting Sampling Distributions
The performance of and depends on both sampling noise and Monte Carlo noise. In order for (and analogously ) to be accurate, we need both the sampling error of , namely , and the Monte Carlo error to be small.
It is well known that jackknife estimates of variance are in general biased upwards (Efron and Stein, 1981). This phenomenon also holds for bagging: is somewhat biased upwards for V. We present some evidence suggesting that is biased downwards by a similar amount, and that the arithmetic mean of and is closer to being unbiased for V than either of the two estimators alone.
We also develop a simple estimator for the variance of itself:
where and is the mean of the .
3. Random Forest Experiments
Random forests (Breiman, 2001) are a widely used extension of bagged trees. Suppose that we have a tree-structured predictor t and training data Z1, …, Zn. Using notation from (2), the bagged version of this tree predictor is
Random forests extend bagged trees by allowing the individual trees to depend on an auxiliary noise source ξb. The main idea is that the auxiliary noise ξb encourages more diversity among the individual trees, and allows for more variance reduction than bagging. Several variants of random forests have been analyzed theoretically by, e.g., Biau et al. (2008), Biau (2012), Lin and Jeon (2006), and Meinshausen (2006).
Standard implementations of random forests use the auxiliary noise ξb to randomly restrict the number of variables on which the bootstrapped trees can split at any given training step. At each step, m features are randomly selected from the pool of all p possible features and the tree predictor must then split on one of these m features. If m = p the tree can always split on any feature and the random forest becomes a bagged tree; if m = 1, then the tree has no freedom in choosing which feature to split on.
Following Breiman (2001), random forests are usually defined more abstractly for theoretical analysis: any predictor of the form
| (9) |
is called a random forest. Various choices of noise distribution Ξ lead to different random forest predictors. In particular, trivial noise sources are allowed and so the class of random forests includes bagged trees as a special case. In this paper, we only consider random forests of type (9) where individual trees are all trained on bootstrap samples of the training data. We note, however, that that variants of random forests that do not use bootstrap noise have also been found to work well (e.g., Dietterich, 2000; Geurts et al., 2006).
All our results about bagged predictors apply directly to random forests. The reason for this is that random forests can also be defined as bagged predictors with different base learners. Suppose that, on each bootstrap replicate, we drew K times from the auxiliary noise distribution Ξ instead of just once. This would give us a predictor of the form
Adding the extra draws from Ξ to the random forest does not change the B → ∞ limit of the random forest. If we take K → ∞, we effectively marginalize over the noise from Ξ, and get a predictor
In other words, the random forest as defined in (9) is just a noisy estimate of a bagged predictor with base learner .
It is straight-forward to check that our results about and also hold for bagged predictors with randomized base learners. The extra noise from using t(·; ξ) instead of does not affect the limiting correlations in (3) and (4); meanwhile, the bias corrections from (7) and (8) do not depend on how we produced the t* and remain valid with random forests. Thus, we can estimate confidence intervals for random forests from N* and t* using exactly the same formulas as for bagging.
In the rest of this section, we show how the variance estimates studied in this paper can be used to gain valuable insights in applications of random forests. We use the variance estimate (7) to minimize the required computational resources. We implemented the IJ-U estimator for random forests on top of the R package randomForest (Liaw and Wiener, 2002).
3.1 E-mail Spam Example
The e-mail spam data set (spambase) is part of a standard classification task, the goal of which is to distinguish spam e-mail (1) from non-spam (0) using p = 57 features. Here, we investigate the performance of random forests on this data set.
We fit the spam data using random forests with m = 5, 19 and 57 splitting variables. With m = 5, the trees were highly constrained in their choice of splitting variables, while m = 57 is just a bagged tree. The three random forests obtained test-set accuracies of 95.1%, 95.2% and 94.7% respectively, and it appears that the m = 5 or 19 forests are best. We can use the IJ-U variance formula to gain deeper insight into these numbers, and get a better understanding about what is constraining the accuracy of each predictor.
In Figure 4, we plot test-set predictions against IJ-U estimates of standard error for all three random forests. The m = 57 random forest appears to be quite unstable, in that the estimated errors are high. Because many of its predictions have large standard errors, it is plausible that the predictions made by the random forest could change drastically if we got more training data. Thus, the m = 57 forest appears to suffer from overfitting, and the quality of its predictions could improve substantially with more data.
Figure 4.
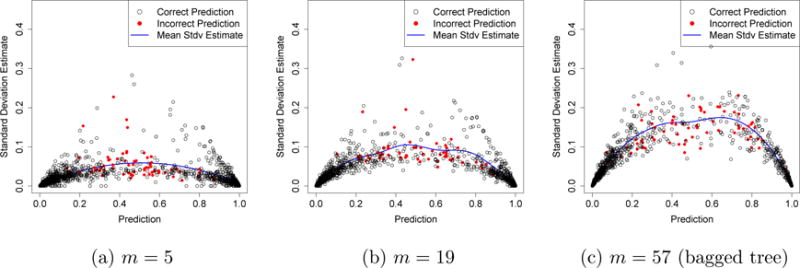
Standard errors of random forest predictions on the e-mail spam data. The random forests with m = 5, 19, and 57 splitting variables were all trained on a train set of size n = 3,065; the panels above show class predictions and IJ-U estimates for standard errors on a test set of size 1,536. The solid curves are smoothing splines (df = 4) fit through the data (including both correct and incorrect predictions).
Conversely, predictions made by the m = 5 random forest appear to be remarkably stable, and almost all predictions have standard errors that lie below 0.1. This suggests that the m = 5 forest may be mostly constrained by bias: if the predictor reports that a certain e-mail is spam with probability 0.5 ± 0.1, then the predictor has effectively abandoned any hope of unambiguously classifying the e-mail. Even if we managed to acquire much more training data, the class prediction for that e-mail would probably not converge to a strong vote for spam or non-spam.
The m = 19 forest appears to have balanced the bias-variance trade-off well. We can further corroborate our intuition about the bias problem faced by the m = 5 forest by comparing its predictions with those of the m = 19 forest. As shown in Figure 5, whenever the m = 5 forest made a cautious prediction that an e-mail might be spam (e.g., a prediction of around 0.8), the m = 19 forest made the same classification decision but with more confidence (i.e., with a more extreme class probability estimate ). Similarly, the m = 19 forest tended to lower cautious non-spam predictions made by the m = 5 forest. In other words, the m = 5 forest appears to have often made lukewarm predictions with mid-range values of on e-mails for which there was sufficient information in the data to make confident predictions. This analysis again suggests that the m = 5 forest was constrained by bias and was not able to efficiently use all the information present in the data set.
Figure 5.
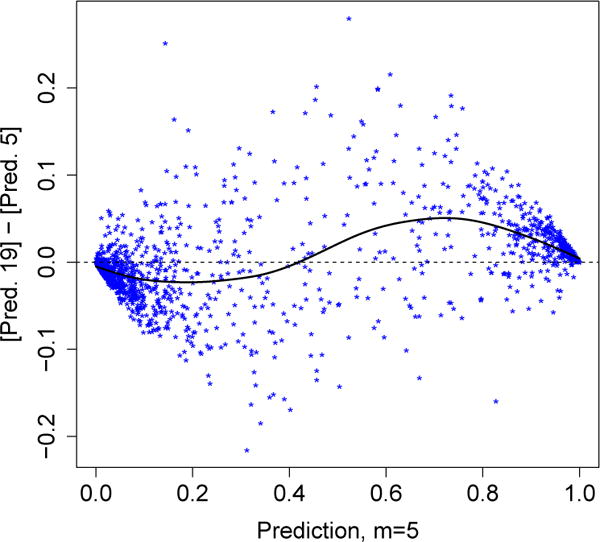
Comparison of the predictions made by the m = 5 and m = 19 random forests. The stars indicate pairs of test set predictions; the solid line is a smoothing spline (df = 6) fit through the data.
3.2 California Housing Example
In the previous example, we saw that the varying accuracy of random forests with different numbers m of splitting variables primarily reflected a bias-variance trade-off. Random forests with small m had high bias, while those with large m had high variance. This bias-variance trade-off does not, however, underlie all random forests. The California housing data set—a regression task with n = 20, 460 and p = 8—provides a contrasting example.
In Figure 6a, we plot the random forest out-of-bag MSE and IJ-U estimate of average sampling variance across all training examples, with m between 1 and 8. We immediately notice that the sampling variance is not monotone increasing in m. Rather, the sampling variance is high if m is too big or too small, and attains a minimum at m = 4. Meanwhile, in terms of MSE, the optimal choice is m = 5. Thus, there is no bias-variance trade-off here: picking a value of m around 4 or 5 is optimal both from the MSE minimization and the variance minimization points of view.
Figure 6.
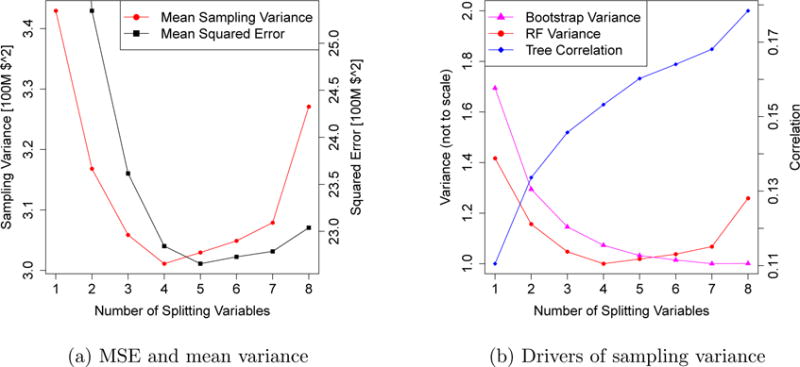
Performance of random forests on the California housing data. The left panel plots MSE and mean sampling variance as a function of the number m of splitting variables. The MSE estimate is the out-of bag error, while the mean sampling variance is the average estimate of variance computed over all training examples. The right panel displays the drivers of sampling variance, namely the variance of the individual bootstrapped trees (bootstrap variance v) and their correlation (tree correlation ρ).
We can gain more insight into this phenomenon using ideas going back to Breiman (2001), who showed that the sampling variance of a random forest is governed by two factors: the variance v of the individual bootstrapped trees and their correlation ρ. The variance of the ensemble is then ρv. In Figure 6b, we show how both v and ρ react when we vary m. Trees with large m are fairly correlated, and so the random forest does not get as substantial a variance reduction over the base learner as with a smaller m. With a very small m, however, the variance v of the individual trees shoots up, and so the decrease in ρ is no longer sufficient to bring down the variance of the whole forest. The increasing ρ-curve and the decreasing v-curve thus jointly produce a U-shaped relationship between m and the variance of the random forest. The m = 4 forest achieves a low variance by matching fairly stable base learners with a small correlation ρ.
4. Controlling Monte Carlo Error
In this section, we analyze the behavior of both the IJ and jackknife estimators under Monte Carlo noise. We begin by discussing the Monte Carlo distribution of the infinitesimal jackknife estimate of variance with a finite B; the case of the jackknife-after-bootstrap estimate of variance is similar but more technical and is presented in Appendix A. We show that the jackknife estimator needs 1.7 times more bootstrap replicates than the IJ estimator to control Monte Carlo noise at a given level. We also highlight a bias problem for both estimators, and recommend a bias correction. When there is no risk of ambiguity, we use the short-hand t* for t*(x).
4.1 Monte Carlo Error for the IJ Estimator
We first consider the Monte Carlo bias of the infinitesimal jackknife for bagging. Let
| (10) |
be the perfect IJ estimator with B = ∞ (Efron, 2013). Then, the Monte Carlo bias of is
is the Monte Carlo estimate of the bootstrap covariance. Since depends on all n observations, and can in practice be treated as independent for computing Var*[Ci], especially when n is large (see remark below). Thus, as , we see that
| (11) |
Notice that is the standard bootstrap estimate for the variance of the base learner . Thus, the bias of grows linearly in the variance of the original estimator that is being bagged.
Meanwhile, by the central limit theorem, Ci converges to a Gaussian random variable as B gets large. Thus, the Monte Carlo asymptotic variance of is approximately . The Ci can be treated as roughly independent, and so the limiting distribution of the IJ estimate of variance has approximate moments
| (12) |
Interestingly, the Monte Carlo mean squared error (MSE) of mostly depends on the problem through , where is the bootstrap estimate of the variance of the base learner. In other words, the computational difficulty of obtaining confidence intervals for bagged learners depends on the variance of the base learner.
4.1.1 Remark: The IJ Estimator for Sub-bagging
We have focused on the case where each bootstrap replicate contains exactly n samples. However, in some applications, bagging with subsamples of size m ≠ n has been found to work well (e.g., Bühlmann and Yu, 2002; Buja and Stuetzle, 2006; Friedman, 2002; Strobl et al., 2007). Our results directly extend to the case where m ≠ n samples are drawn with replacement from the original sample. We can check that (10) still holds, but now . Carrying out the same analysis as above, we can establish an analogue to (12):
| (13) |
For simplicity of exposition, we will restrict our analysis to the case m = n for the rest of this paper.
4.1.2 Remark: Approximate Independence
In the above derivation, we used the approximation
We can evaluate the accuracy of this approximation using the formula
In the case of the sample mean paired with the Poisson bootstrap, this term reduces to
and the correction to (11) would be .
4.2 Comparison of Monte Carlo Errors
As shown in Appendix A, the Monte Carlo error for the jackknife-after-bootstrap estimate of variance has approximate moments
| (14) |
where is the jackknife estimate computed with B = ∞ bootstrap replicates. The Monte Carlo stability of again primarily depends on .
By comparing (12) with (14), we notice that the IJ estimator makes better use of a finite number B of bootstrap replicates than the jackknife estimator. For a fixed value of B, the Monte Carlo bias of is about e − 1 or 1.7 times as large as that of ; the ratio of Monte Carlo variance starts off at 3 for small values of B and decays down to 1.7 as B gets much larger than n. Alternatively, we see that the IJ estimate with B bootstrap replicates has errors on the same scale as the jackknife estimate with 1.7 · B replicates.
This suggests that if computational considerations matter and there is a desire to perform as few bootstrap replicates B as possible while controlling Monte Carlo error, the infinitesimal jackknife method may be preferable to the jackknife-after-bootstrap.
4.3 Correcting for Monte Carlo Bias
The Monte Carlo MSEs of and are in practice dominated by bias, especially for large n. Typically, we would like to pick B large enough to keep the Monte Carlo MSE on the order of 1/n. For both (12) and (14), we see that performing B = Θ(n) bootstrap iterations is enough to control the variance. To reduce the bias to the desired level, namely , we would need to take B = Θ(n1.5) bootstrap samples.
Although the Monte Carlo bias for both and is large, this bias only depends on and so is highly predictable. This suggests a bias-corrected modification of the IJ and jackknife estimators respectively:
| (15) |
| (16) |
Here and are as defined in (5), and is the bootstrap estimate of variance from (11). The letter U stands for unbiased. This transformation effectively removes the Monte Carlo bias in our experiments without noticeably increasing variance. The bias corrected estimates only need B = Θ(n) bootstrap replicates to control Monte Carlo MSE at level 1/n.
4.4 A Numerical Example
To validate the observations made in this section, we re-visit the cholesterol data set used by Efron (2013) as a central example in developing the IJ estimate of variance. The data set (introduced by Efron and Feldman, 1991) contains records for n = 164 participants in a clinical study, all of whom received a proposed cholesterol-lowering drug. The data contains a measure d of the cholesterol level decrease observed for each subject, as well as a measure c of compliance (i.e. how faithful the subject was in taking the medication). Efron and Feldman originally fit d as a polynomial function of c; the degree of the polynomial was adaptively selected by minimizing Mallows’ Cp criterion (1973).
We here follow Efron (2013) and study the bagged adaptive polynomial fit of d against c for predicting the cholesterol decrease of a new subject with a specific compliance level. The degree of the polynomial is selected among integers between 1 and 6 by Cp minimization. Efron (2013) gives a more detailed description of the experiment. We restrict our attention to predicting the cholesterol decrease of a new patient with compliance level c = −2.25; this corresponds to the patient with the lowest observed compliance level.
In Figure 3, we compare the performance of the variance estimates for bagged predictors studied in this paper. The boxplots depict repeated realizations of the variance estimates with a finite B. We can immediately verify the qualitative insights presented in this section. Both the jackknife and IJ rules are badly biased for small B, and this bias goes away more slowly than the Monte Carlo variance. Moreover, at any given B, the jackknife estimator is noticeably less stable than the IJ estimator.
The J-U and IJ-U estimators appear to fix the bias problem without introducing instability. The J-U estimator has a slightly higher mean than the IJ-U one. As discussed in Section 5.2, this is not surprising, as the limiting (B → ∞) jackknife estimator has an upward sampling bias while the limiting IJ estimator can have a downward sampling bias. The fact that the J-U and IJ-U estimators are so close suggests that both methods work well for this problem.
The insights developed here also appear to hold quantitatively. In Figure 7, we compare the ratios of Monte Carlo bias and variance for the jackknife and IJ estimators with theoretical approximations implied by (12) and (14). The theoretical formulas appear to present a credible picture of the relative merits of the jackknife and IJ rules.
Figure 7.
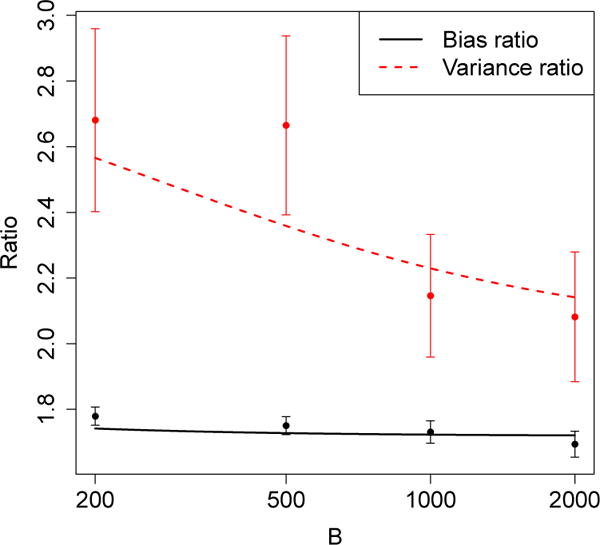
Predicted and actual performance ratios for the uncorrected and estimators in the cholesterol compliance example. The plot shows both and . The observations are derived from the data presented in Figure 3; the error bars are one standard deviation in each direction. The solid lines are theoretical predictions obtained from (12) and (14).
5. Sampling Distribution of Variance Estimates
In practice, the and estimates are computed with a finite number B of bootstrap replicates. In this section, however, we let B go to infinity, and study the sampling properties of the IJ and jackknife variance estimates in the absence of Monte Carlo errors. In other words, we study the impact of noise in the data itself. Recall that we write and for the limiting estimators with B = ∞ bootstrap replicates.
We begin by developing a simple formula for the sampling variance of itself. In the process of developing this variance formula, we obtain an ANOVA expansion of that we then use in Section 5.2 to compare the sampling biases of the jackknife and infinitesimal jackknife estimators.
5.1 Sampling Variance of the IJ Estimate of Variance
If the data Zi are independently drawn from a distribution F, then the variance of the IJ estimator is very nearly given by
| (17) |
| (18) |
This expression suggests a natural plug-in estimator
| (19) |
where is a bootstrap estimate for hF(Zi) and is the mean of the . The rest of the notation is as in Section 2.
The relation (17) arises from a general connection between the infinitesimal jackknife and the theory of Hájek projections. The Hájek projection of an estimator is the best approximation to that estimator that only considers first-order effects. In our case, the Hájek projection of is
| (20) |
where hF(Zi) is as in (18). The variance of the Hájek projection is .
The key insight behind (17) is that the IJ estimator is effectively trying to estimate the variance of the Hájek projection of , and that
| (21) |
The approximation (17) then follows immediately, as the right-hand side of the above expression is a sum of independent random variables. Note that we cannot apply this right-hand side expression directly, as h depends on the unknown underlying distribution F.
The connections between Hájek projections and the infinitesimal jackknife have been understood for a long time. Jaeckel (1972) originally introduced the infinitesimal jackknife as a practical approximation to the first-order variance of an estimator (in our case, the right-hand side of (21)). More recently, Efron (2013) showed that is equal to the variance of a “bootstrap Hájek projection.” In Appendix B, we build on these ideas and show that, in cases where a plug-in approximation is valid, (21) holds very nearly for bagged estimators.
We apply our variance formula to the cholesterol data set of Efron (2013), following the methodology described in Section 4.4. In Figure 8, we use the formula (19) to study the sampling variance of as a function of the compliance level c. The main message here is rather reassuring: as seen in Figure 8b, the coefficient of variation of appears to be fairly low, suggesting that the IJ variance estimates can be trusted in this example. Note that, the formula from (19) can require many bootstrap replicates to stabilize and suffers from an upward Monte Carlo bias just like . We used B = 100,000 bootstrap replicates to generate Figure 8.
Figure 8.
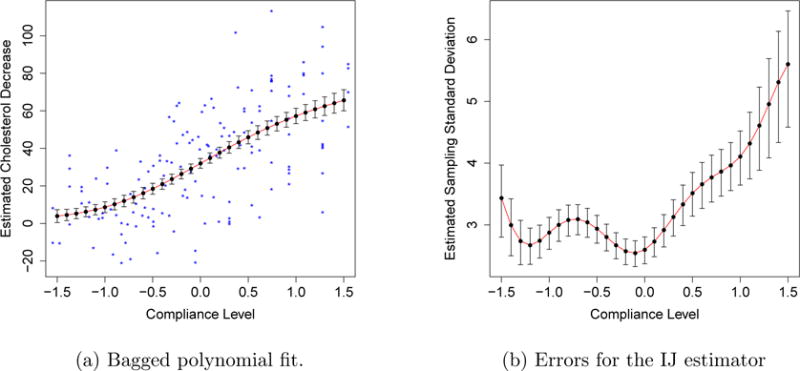
Stability of the IJ estimate of variance on the cholesterol data. The left panel shows the bagged fit to the data, along with error bars generated by the IJ method; the stars denote the data (some data points have x-values that exceed the range of the plot). In the right panel, we use (19) to estimate error bars for the error bars in the first panel. All error bars are one standard deviation in each direction.
5.2 Sampling Bias of the Jackknife and IJ Estimators
We can understand the sampling biases of both the jackknife and IJ estimators in the context of the ANOVA decomposition of Efron and Stein (1981). Suppose that we have data Z1, …, Zn drawn independently from a distribution F, and compute our estimate based on this data. Then, we can decompose its variance as
| (22) |
where
is the variance due to first-order effects, V2 is the variance due to second-order effects of the form
and so on. Note that all the terms Vk are non-negative.
Efron and Stein (1981) showed that, under general conditions, the jackknife estimate of variance is biased upwards. In our case, their result implies that the jackknife estimator computed on n + 1 data points has variance
| (23) |
Meanwhile, (21) suggests that
| (24) |
In other words, on average, both the jackknife and IJ estimators get the first-order variance term right. The jackknife estimator then proceeds to double the second-order term, triple the third-order term etc, while the IJ estimator just drops the higher order terms.
By comparing (23) and (24), we see that the upward bias of and the downward bias of partially cancel out. In fact,
| (25) |
and so the arithmetic mean of and has an upward bias that depends only on third-and higher-order effects. Thus, we might expect that in small-sample situations where and exhibit some bias, the mean of the two estimates may work better than either of them taken individually.
To test this idea, we used both the jackknife and IJ methods to estimate the variance of a bagged tree trained on a sample of size n = 25. (See Appendix C for details.) Since the sample size is so small, both the jackknife and IJ estimators exhibit some bias as seen in Figure 9a. However, the mean of the two estimators is nearly unbiased for the true variance of the bagged tree. (It appears that this mean has a very slight upward bias, just as we would expect from (25).)
Figure 9.
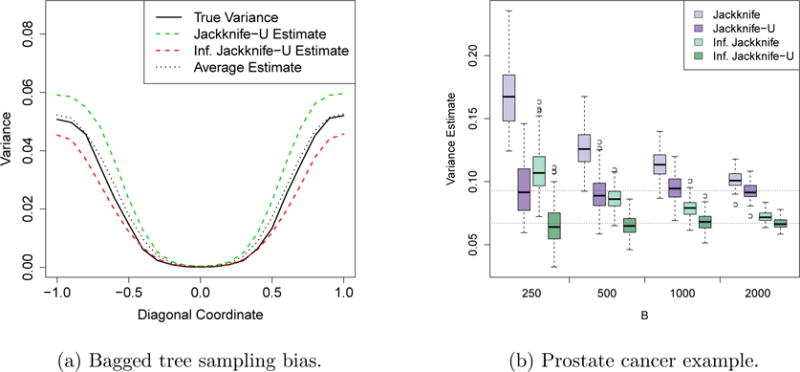
Sampling bias of the jackknife and IJ rules. In the left panel, we compare the expected values of the jackknife and IJ estimators as well as their mean with the true variance of a bagged tree. In this example, the features take values in (x1, x2) ∈ [−1, 1]2; we depict variance estimates along the diagonal x1 = x2. The prostate cancer plot can be interpreted in the same way as Figure 3, except that the we now indicate the weighted means of the J-U and IJ-U estimators separately.
This issue can arise in real data sets too. When training bagged forward stepwise regression on a prostate cancer data set discussed by Hastie et al. (2009), the jackknife and IJ methods give fairly different estimates of variance: the jackknife estimator converged to 0.093, while the IJ estimator stabilized at 0.067 (Figure 9b). Based on the discussion in this section, it appears that (0.093 + 0.067)/2 = 0.08 should be considered a more unbiased estimate of variance than either of the two numbers on their own.
In the more extensive simulations presented in Table 1, averaging and is in general less biased than either of the original estimators (although the “AND” experiment seems to provide an exception to this rule, suggesting that most of the bias of for this function is due to higher-order interactions). However, has systematically lower variance, which allows it to win in terms of overall mean squared error. Thus, if unbiasedness is important, averaging and seems like a promising idea, but appears to be the better rule in terms of raw MSE minimization.
Table 1.
Simulation study. We evaluate the mean bias, variance, and MSE of different variance estimates for random forests. Here, n is the number of test examples used, p is the number of features, and B is the number of trees grown; the numbers in parentheses are 95% confidence errors from sampling. The best methods for each evaluation metric are highlighted in bold. The data-generating functions are described in Appendix C.
| Function | n | p | B | ERR |
|
|
|
|||
|---|---|---|---|---|---|---|---|---|---|---|
| Cosine | 50 | 2 | 200 | Bias | −0.15 (±0.03) | 0.14 (±0.02) | −0.01 (±0.02) | |||
| Var | 0.08 (±0.02) | 0.41 (±0.13) | 0.2 (±0.06) | |||||||
| MSE | 0.11 (±0.03) | 0.43 (±0.13) | 0.2 (±0.06) | |||||||
|
| ||||||||||
| Cosine | 200 | 2 | 500 | Bias | −0.05 (±0.01) | 0.07 (±0.01) | 0.01 (±0.01) | |||
| Var | 0.02 (±0) | 0.07 (±0.01) | 0.04 (±0.01) | |||||||
| MSE | 0.02 (±0) | 0.07 (±0.01) | 0.04 (±0.01) | |||||||
|
| ||||||||||
| XOR | 50 | 50 | 200 | Bias | −0.3 (±0.03) | 0.37 (±0.04) | 0.03 (±0.03) | |||
| Var | 0.48 (±0.03) | 1.82 (±0.12) | 0.89 (±0.05) | |||||||
| MSE | 0.58 (±0.03) | 1.96 (±0.13) | 0.89 (±0.05) | |||||||
|
| ||||||||||
| XOR | 200 | 50 | 500 | Bias | −0.08 (±0.02) | 0.24 (±0.03) | 0.08 (±0.02) | |||
| Var | 0.26 (±0.02) | 0.77 (±0.04) | 0.4 (±0.02) | |||||||
| MSE | 0.27 (±0.01) | 0.83 (±0.04) | 0.41 (±0.02) | |||||||
|
| ||||||||||
| AND | 50 | 500 | 200 | Bias | −0.23 (±0.04) | 0.65 (±0.05) | 0.21 (±0.04) | |||
| Var | 1.15 (±0.05) | 4.23 (±0.18) | 2.05 (±0.09) | |||||||
| MSE | 1.21 (±0.06) | 4.64 (±0.21) | 2.09 (±0.09) | |||||||
|
| ||||||||||
| AND | 200 | 500 | 500 | Bias | −0.04 (±0.04) | 0.32 (±0.04) | 0.14 (±0.03) | |||
| Var | 0.55 (±0.07) | 1.71 (±0.22) | 0.85 (±0.11) | |||||||
| MSE | 0.57 (±0.08) | 1.82 (±0.24) | 0.88 (±0.11) | |||||||
|
| ||||||||||
| Auto | 314 | 7 | 1000 | Bias | −0.11 (±0.02) | 0.23 (±0.05) | 0.06 (±0.03) | |||
| Var | 0.13 (±0.04) | 0.49 (±0.19) | 0.27 (±0.1) | |||||||
| MSE | 0.15 (±0.04) | 0.58 (±0.24) | 0.29 (±0.11) | |||||||
|
| ||||||||||
Finally, we emphasize that this relative bias result relies on the heuristic relationship (24). While this approximation does not seem problematic for the first-order analysis presented in Section 5.1, we may be concerned that the plug-in argument from Appendix B used to justify it may not give us correct second- and higher-order terms. Thus, although our simulation results seem promising, developing a formal and general understanding of the relative biases of and remains an open topic for follow-up research.
6. Conclusion
In this paper, we studied the jackknife-after-bootstrap and infinitesimal jackknife (IJ) methods (Efron, 1992, 2013) for estimating the variance of bagged predictors. We demonstrated that both estimators suffer from considerable Monte Carlo bias, and we proposed bias-corrected versions of the methods that appear to work well in practice. We also provided a simple formula for the sampling variance of the IJ estimator, and showed that from a sampling bias point of view the arithmetic mean of the jackknife and IJ estimators is often preferable to either of the original methods. Finally, we applied these methods in numerous experiments, including some random forest examples, and showed how they can be used to gain valuable insights in realistic problems.
Acknowledgments
The authors are grateful for helpful suggestions from the action editor and three anonymous referees. S.W. is supported by a B.C. and E.J. Eaves Stanford Graduate Fellowship.
Appendix A. The Effect of Monte Carlo Noise on the Jackknife Estimator
In this section, we derive expressions for the finite-B Monte Carlo bias and variance of the jackknife-after-bootstrap estimate of variance. Recall from (6) that
and indicates the number of times the ith observation appears in the bootstrap sample b. If is not defined because for either all or none of the b = 1, …, B, then just set .
Now is the sum of squares of noisy quantities, and so will be biased upwards. Specifically,
where is the jackknife estimate computed with B = ∞ bootstrap replicates. For convenience, let
and recall that
For all Bi ≠ 0 or B, the conditional expectation is
in the degenerate cases with Bi ∈ {0, B}. Thus,
and so
Meanwhile, for Bi ∉ {0, B},
where
Thus,
where 1i = 1({Bi ∉ {0, B}}).
As n and B get large, Bi converges in law to a Gaussian random variable
and the above expressions are uniformly integrable. We can verify that
and
Finally, this lets us conclude that
where the error term depends on , , and .
We now address Monte Carlo variance. By the central limit theorem, converges to a Gaussian random variable as B gets large. Thus, the asymptotic Monte Carlo variance of is approximately , and so
In practice, the terms and can be well approximated by , namely the bootstrap estimate of variance for the base learner. (Note that , , and can always be inspected on a random forest, so this assumption can be checked in applications.) This lets us considerably simplify our expressions for Monte Carlo bias and variance:
Appendix B. The IJ estimator and Hájek projections
Up to (27), the derivation below is an alternate presentation of the argument made by Efron (2013) in the proof of his Theorem 1. To establish a connection between the IJ estimate of variance for bagged estimators and the theory of Hájek projections, it is useful to consider as a functional over distributions. Let G be a probability distribution, and let T be a functional over distributions with the following property:
| (26) |
where the Y1, …, Yn are drawn independently from G. We call functionals T satisfying (26) averaging. Clearly, can be expressed as an averaging functional applied to the empirical distribution defined by the observations Z1, …, Zn.
Suppose that we have an averaging functional T, a sample Z1, …, Zn forming an empirical distribution , and want to study the variance of . The infinitesimal jackknife estimate for the variance of is given by
where is the discrete distribution that places weight 1/n + (n − 1)/n · ε at Zi and weight 1/n − ε/n at all the other Zj.
We can transform samples from into samples from by the following method. Let be a sample from . Go through the whole sample and, independently for each j, take and with probability ε replace it with Zi. The sample can now be considered a sample from .
When ε → 0, the probability of replacing two of the with this procedure becomes negligible, and we can equivalently transform our sample into a sample from by transforming a single random element from into Zi with probability n ε. Without loss of generality this element is the first one, and so we conclude that
where τ defines T through (26). Thus,
and so
| (27) |
| (28) |
where on the last line we only replaced the empirical approximation with its true value F. In the case of bagging, this last expression is equivalent to (21).
A crucial step in the above argument is the plug-in approximation (28). If T is just a sum, then the error of (28) is within ; presumably, similar statements hold whenever T is sufficiently well-behaved. That being said, it is possible to construct counter-examples where (28) fails; a simple such example is when T counts the number of times is matched in the rest of the training data. Establishing general conditions under which (28) holds is an interesting topic for further research.
Appendix C. Description of Experiments
This section provides a more detailed description of the experiments reported in this paper.
C.1 Auto MPG Example (Figure 1)
The Auto MPG data set, available from the UCI Machine Learning Repository (Bache and Lichman, 2013), is a regression task with 7 features. After discarding examples with missing entries, the data set had 392 rows, which we divided into a test set of size 78 and a train set of size 314. We estimated the variance of the random forest predictions using the estimator advocated in Section 5.2, with B = 10,000 bootstrap replicates.
C.2 Bagged Tree Simulation (Figure 2)
The data for this simulation was drawn from a model yi = f(xi) + εi, where xi ~ U([0, 1]), , and f(x) is the step function shown in Figure 10. We modeled the data using 5-leaf regression trees generated using the R package tree (Venables and Ripley, 2002); for bagging, we used B = 10,000 bootstrap replicates. The reported data is compiled over 1,000 simulation runs with n = 500 data points each.
Figure 10.
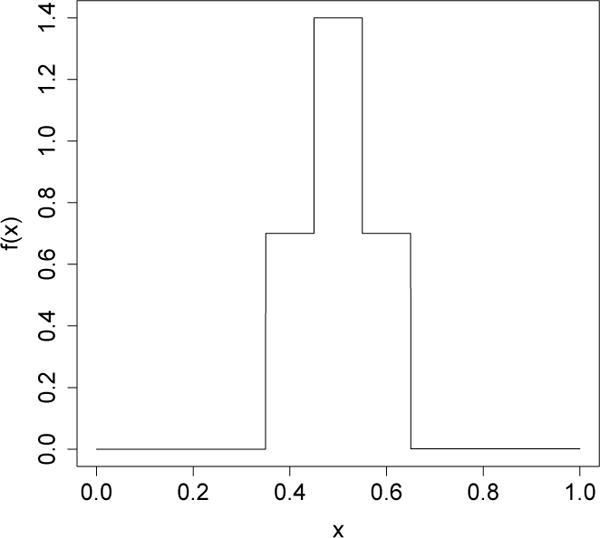
Underlying model for the bagged tree example from Figure 2.
C.3 Cholesterol Example (Figures 3, 7, and 8)
For the cholesterol data set (Efron and Feldman, 1991), we closely follow the methodology of Efron (2013); see his paper for details. The data set has n = 164 subjects and only one predictor.
C.4 E-mail Spam Example (Figures 4 and 5)
The e-mail spam data set (spambase, Bache and Lichman, 2013) is a classification problem with n = 4,601 e-mails and p = 57 features; the goal is to discern spam from non-spam. We divided the data into train and test sets of size 3,065 and 1,536 respectively. Each of the random forests described in Section 3.1 was fit on the train set using the R package randomForest (Liaw and Wiener, 2002) with B = 40,000 bootstrap replicates.
C.5 California Housing Example (Figure 6)
The California housing data set (described in Hastie et al., 2009, and available from StatLib) contains aggregated data from n = 20,460 neighborhoods. There are p = 8 features; the response is the median house value. We fit random forests on this data using the R package randomForest (Liaw and Wiener, 2002) with B = 1,000 bootstrap replicates.
C.6 Bagged Tree Simulation #2 (Figure 9a)
We drew n = 25 points from a model where the xi are uniformly distributed over a square, i.e., xi ~ U([−1, 1]2); the yi are deterministically given by yi = 1({‖xi‖2 ≥ 1}). We fit this data using the R package tree (Venables and Ripley, 2002). The bagged predictors were generated using B = 1,000 bootstrap replicates. The reported results are based on 2,000 simulation runs.
C.7 Prostate Cancer Example (Figure 9b)
The prostate cancer data (published by Stamey et al., 1989) is described in Section 1 of Hastie et al. (2009). We used forward stepwise regression as implemented by the R function step as our base learner. This data set has n = 97 subjects and 8 available predictor variables. In figure 9b, we display standard errors for the predicted response of a patient whose features match those of patient #41 in the data set.
C.8 Simulations for Table 1
The data generation functions used in Table 1 are defined as follows. The Xi for i = 1, …, p are all generated as independent U([0, 1[) random variables, and .
Cosine: Y = 3 · cos (π · (X1 + X2)), with p = 2.
- XOR: Treating XOR as a function with a 0/1 return-value,
and p = 50. - AND: With analogous notation,
and p = 500. Auto: This example is based on a parametric bootstrap built on the same data set as used in Figure 1. We first fit a random forest to the training set, and evaluated the MSE on the test set. We then generated new training sets by replacing the labels Yi from the original training set with , where is the original random forest prediction at the ith training example and ε is fresh residual noise.
During the simulation, we first generated a random test set of size 50 (except for the auto example, where we just used the original test set of size 78). Then, while keeping the test set fixed, we generated 100 training sets and produced variance estimates at each test point. Table 1 reports average performance over the test set.
Footnotes
Editor: Nicolai Meinshausen
Our method produces standard error estimates for random forest predictions. We then represent these standard error estimates as Gaussian confidence intervals , where zα is a quantile of the normal distribution.
Contributor Information
Stefan Wager, Email: swager@stanford.edu.
Trevor Hastie, Email: hastie@stanford.edu.
Bradley Efron, Email: brad@stat.stanford.edu.
References
- Bache Kevin, Lichman Moshe. UCI machine learning repository. 2013 URL http://archive.ics.uci.edu/ml.
- Biau Gérard. Analysis of a random forests model. The Journal of Machine Learning Research. 2012;13(4):1063–1095. [Google Scholar]
- Biau Gérard, Devroye Luc, Lugosi Gábor. Consistency of random forests and other averaging classifiers. The Journal of Machine Learning Research. 2008;9:2015–2033. [Google Scholar]
- Breiman Leo. Bagging predictors. Machine Learning. 1996;24(2):123–140. [Google Scholar]
- Breiman Leo. Random forests. Machine Learning. 2001;45(1):5–32. [Google Scholar]
- Bühlmann Peter, Yu Bin. Analyzing bagging. The Annals of Statistics. 2002;30(4):927–961. [Google Scholar]
- Buja Andreas, Stuetzle Werner. Observations on bagging. Statistica Sinica. 2006;16(2):323. [Google Scholar]
- Chen Song Xi, Hall Peter. Effects of bagging and bias correction on estimators defined by estimating equations. Statistica Sinica. 2003;13(1):97–110. [Google Scholar]
- Dietterich Thomas G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Machine Learning. 2000;40(2):139–157. [Google Scholar]
- Duan Jiangtao. PhD thesis. North Carolina State University; 2011. Bootstrap-Based Variance Estimators for a Bagging Predictor. [Google Scholar]
- Efron Bradley. Jackknife-after-bootstrap standard errors and influence functions. Journal of the Royal Statistical Society. Series B (Methodological) 1992:83–127. [Google Scholar]
- Efron Bradley. Estimation and accuracy after model selection. Journal of the American Statistical Association. 2013 doi: 10.1080/01621459.2013.823775. (just-accepted) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Efron Bradley, Feldman David. Compliance as an explanatory variable in clinical trials. Journal of the American Statistical Association. 1991;86(413):9–17. [Google Scholar]
- Efron Bradley, Stein Charles. The jackknife estimate of variance. The Annals of Statistics. 1981:586–596. [Google Scholar]
- Friedman Jerome H. Stochastic gradient boosting. Computational Statistics & Data Analysis. 2002;38(4):367–378. [Google Scholar]
- Friedman Jerome H, Hall Peter. On bagging and nonlinear estimation. Journal of Statistical Planning and Inference. 2007;137(3):669–683. [Google Scholar]
- Geurts Pierre, Ernst Damien, Wehenkel Louis. Extremely randomized trees. Machine Learning. 2006;63(1):3–42. [Google Scholar]
- Hastie Trevor, Tibshirani Robert, Friedman Jerome. The Elements of Statistical Learning. New York: Springer; 2009. [Google Scholar]
- Jaeckel Louis A. The Infinitesimal Jackknife. 1972. [Google Scholar]
- Liaw Andy, Wiener Matthew. Classification and regression by randomForest. R News. 2002;2(3):18–22. URL http://CRAN.R-project.org/doc/Rnews/ [Google Scholar]
- Lin Yi, Jeon Yongho. Random forests and adaptive nearest neighbors. Journal of the American Statistical Association. 2006;101(474):578–590. [Google Scholar]
- Mallows Colin L. Some comments on Cp. Technometrics. 1973;15(4):661–675. [Google Scholar]
- Meinshausen Nicolai. Quantile regression forests. The Journal of Machine Learning Research. 2006;7:983–999. [Google Scholar]
- Sexton Joseph, Laake Petter. Standard errors for bagged and random forest estimators. Computational Statistics & Data Analysis. 2009;53(3):801–811. [Google Scholar]
- Skurichina Marina, Duin Robert PW. Bagging for linear classifiers. Pattern Recognition. 1998;31(7):909–930. [Google Scholar]
- Stamey Thomas A, Kabalin John N, McNeal John E, Johnstone Iain M, Freiha Fuad, Redwine EA, Yang N. Prostate specific antigen in the diagnosis and treatment of adenocarcinoma of the prostate. II. radical prostatectomy treated patients. The Journal of Urology. 1989;141(5):1076–1083. doi: 10.1016/s0022-5347(17)41175-x. [DOI] [PubMed] [Google Scholar]
- Strobl Carolin, Boulesteix Anne-Laure, Zeileis Achim, Hothorn Torsten. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinformatics. 2007;8(1):25. doi: 10.1186/1471-2105-8-25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venables William N, Ripley Brian D. Modern Applied Statistics with S. fourth. Springer; New York: 2002. URL http://www.stats.ox.ac.uk/pub/MASS4. [Google Scholar]