

Abstract
Genome-wide association studies (GWASs) have identified many genetic variants underlying complex traits. Many detected genetic loci harbor variants that associate with multiple—even distinct—traits. Most current analysis approaches focus on single traits, even though the final results from multiple traits are evaluated together. Such approaches miss the opportunity to systemically integrate the phenome-wide data available for genetic association analysis. In this study, we propose a general approach that can integrate association evidence from summary statistics of multiple traits, either correlated, independent, continuous, or binary traits, which might come from the same or different studies. We allow for trait heterogeneity effects. Population structure and cryptic relatedness can also be controlled. Our simulations suggest that the proposed method has improved statistical power over single-trait analysis in most of the cases we studied. We applied our method to the Continental Origins and Genetic Epidemiology Network (COGENT) African ancestry samples for three blood pressure traits and identified four loci (CHIC2, HOXA-EVX1, IGFBP1/IGFBP3, and CDH17; p < 5.0 × 10−8) associated with hypertension-related traits that were missed by a single-trait analysis in the original report. Six additional loci with suggestive association evidence (p < 5.0 × 10−7) were also observed, including CACNA1D and WNT3. Our study strongly suggests that analyzing multiple phenotypes can improve statistical power and that such analysis can be executed with the summary statistics from GWASs. Our method also provides a way to study a cross phenotype (CP) association by using summary statistics from GWASs of multiple phenotypes.
Introduction
Genome-wide association studies (GWASs) have been a major design to discover the genetic determinants of complex traits, with thousands of common genetic variants thus uncovered. The identification of genetic variants reveals important biological insights into the genetic architecture of complex traits such as hypertension (MIM 145500), human height (MIM 606255), and blood lipids.1–3 It is well known that the effect sizes of identified common variants are often small and that a large sample size is necessary to ensure sufficient power to detect such variants. A common strategy is to perform a meta-analysis, combining the effect and variance estimates from as many independent studies as possible with the same or similar phenotypes, which does not require one to pool the individual-level data, thereby reducing the logistical and regulatory burden associated with transferring individual data across centers,4 as well as avoiding the need to explicitly model study design differences or manage confounding by genotyping batch effects and trait ascertainment that differentially affect allele frequency estimates across studies. Notably, GWASs are generally performed with single traits (at a univariate level), although multiple related phenotypes are often collected and studied and are expected to reflect common physiological processes. For example, a hypertension study often measures systolic blood pressure (SBP), diastolic blood pressure (DBP), and hypertension status (HTN), and these phenotypes are analyzed separately.1,5 It has been suggested that univariate analysis could suffer low statistical power compared with multivariate analysis.4 Systematic simultaneous analysis of multiple traits could improve the quality of inferences from analysis of outcomes that all relate to the biological construct of interest.
The joint analysis of multiple phenotypes within a cohort has recently become popular for improving statistical power to detect genetic linkage and association. Solovieff et al. provided a detailed summary of such kinds of approaches.4 Most multivariate methods are based on a multivariate regression framework and require both genotypes and phenotypes at the individual level, with an assumption of approximately normally distributed phenotypes. Extensions to allow for nonnormally distributed phenotypes and categorical phenotypes have also been developed based on generalized estimating equations (GEEs), ordinal regression, and a Bayesian framework.6–10 On the other hand, approaches have been developed based on a dimension reduction technique on the phenotypes, such as principal-components (PCs) analysis and canonical correlation analysis.11,12 However, it has been reported that testing only the top PCs has lower power than the combined-PC approach.13
In contrast to multivariate analysis, a method for integrating the results from standard univariate analyses across various phenotypes in GWASs has recently been developed. The Fisher’s combined p value method can be applied to independent studies but is not straightforward when aggregating p values of different but correlated phenotypes within the same cohort, which will result in inflated type I error. The cross-phenotype meta-analysis (CPMA) was developed for testing whether there is association of a SNP to multiple phenotypes, rather than directly evaluating the aggregated association evidence between a SNP and multiple phenotypes.14 Although the method can be applied to multiple independent studies, it does not allow overlapping or correlated samples among studies. Standard fixed and random effects meta-analysis methods are also used to combine association across multiple phenotypes but are not well suited to situations where a genetic variant has opposite effects on different phenotypes. As an example, psoriasis (MIM 309480) and Crohn disease (CD) have been reported to be positively correlated, with the prevalence of CD in individuals with psoriasis significantly higher than in controls.15 However, the G allele of SNP rs12720356 in TYK2 (MIM 176941) increases risk for Crohn disease and decreases risk for psoriasis.16,17 For HTN-related traits, SBP rises linearly with age, in the absence of treatment, whereas DBP has an inverted “U” pattern with a zenith around age 50. Although SBP and DBP are positively correlated, a genetic variant might have opposite effect for the two traits. An extension of fixed effects meta-analysis is the subset-based meta-analysis,18 which allows opposite effects and is able to test association to a subset of phenotypes. This method exhaustively searches all possible phenotype subsets and identifies the subset of traits with the strongest association, but with the cost of exponentially increased multiple tests. In addition, the method does not allow for heterogeneity across cohorts for the same phenotype. Several methods have also been developed based on a linear combination of the univariate test statistics.19,20 These methods have been further used to test for association between correlated traits and genetic markers.21,22 However, the authors focus on only a single study with multiple traits measured in the same individuals. In addition, individual-level genotype and phenotype data are also required for the method by Yang et al.22 The trait-based association test that uses an extended simes (TATES) procedure combines p values obtained in univariate analysis of traits measured in the same individuals while correcting for correlations among phenotypes.23 This approach can be challenging when combining association evidence across multiple independent studies because the phenotype correlation matrix can change from cohort to cohort. Another approach, the pleiotropy regional identification method (PRIMe),24 evaluates pleiotropic loci in a genomic region with multiple phenotypes based on results of GWASs. This method calculates a pleiotropic index defined by the number of traits with low association p values in a genomic region. The flipping sign test uses p values obtained from individual trait analysis to combine association from multiple correlated traits but requires computationally intensive simulations to obtain combined p values at the genome-wide significance level.5
In this study, we propose a general approach that can integrate association evidence from multiple correlated continuous and binary traits from one or multiple studies. We allow for heterogeneity of effects for the same trait in different studies that might result from different populations, environmental exposures, or designs. We also allow heterogeneity effects for different phenotypes, which is not unexpected in practice. In addition, population structure and cryptic relatedness can be controlled. For cryptic relatedness, we also allow for overlapping or related subjects between the different cohorts studied. Although the proposed method is not specifically designed for identifying subsets of associated traits, we will offer insight into how to detect such subsets of traits.
Material and Methods
Assume we have summary statistical results of GWASs from J cohorts with K phenotypic traits. In each cohort, single SNP-trait association was analyzed for each trait separately. Let Tijk be a summary statistic for the ith SNP, jth cohort, and kth trait. Let Ti = (Ti11,...,TiJ1,...,Ti1K,...,TiJK)T. For simplification, we omit the SNP index. Thus, T = (T11,...,TJ1,...,T1K,...,TJK)T represents a vector of test statistics for testing the association of a SNP with K traits. Let β = (β11,..., βJ1,..., β1K,..., βJK)T be the effect sizes of the SNP. The null hypothesis is H0: β = 0 and the alternative hypothesis H1 is that at least one of the elements of β is not equal to zero. We use a Wald test statistic , where are the estimated coefficient and corresponding standard error for the kth trait in the jth cohort. It is reasonable to assume that T follows a multivariate normal distribution with mean 0 and correlation matrix R under the null hypothesis. In practice, R needs to be estimated and we will address that later. A standard method to test β = 0 is the test statistic SJK = TTR−1T, which has asymptotically a χ2 distribution with J × K degrees of freedom. This test is omnibus with respect to the alternative hypothesis. When heterogeneous effects exist, in particular if a variant contributes to only a subset of traits, this test is less powerful because of the large number of degrees of freedom. When the effect is homogeneous, i.e., the effect sizes are all the same regardless of traits or cohorts, the most powerful test statistic is
| (Equation 1) |
which follows a χ2 distribution with one degree of freedom, where eT = (1,...,1) has length J × K and W is a diagonal matrix of weights for the individual test statistics.19,20 When the statistics in T are mutually independent and W is diagonal with inverses of variances as elements, SHom is equivalent to an inverse variance weighted meta-analysis. A similar method to SHom has previously been proposed but it is not specifically for combining the effects across multiple traits.24 Equivalently, we can take the sample sizes for the weights, i.e., for the sample size nj of the jth cohort. Here we assigned more weight to a large study because a large study carries more information than a small study. The advantage of using sample size over inverse variance is that then we do not need to worry about the traits being on different scales, because a variance is dependent on the scale of measurement. In this study we take .
The homogeneous effect size assumption is unlikely to be true, especially when multiple phenotypes are analyzed together. We introduce a test statistic based on SHom, which is more powerful than SJK for homogenous data, because it has one degree of freedom. Ideally, we would like to have a test statistic that includes only the cohorts and traits with a true contribution to the association of a genetic variant under the alternative hypothesis H1. The truncated statistic methods for combining statistical evidence have been suggested for such an analysis.25,26 We adopt a similar idea here. For a given τ > 0, we let T(τ) be the subvector of T satisfying |Tjk| > τ. That is, only the statistics in the vector T with an absolute value larger than τ will be kept. Similarly, we let R(τ) be a submatrix of R representing the correlation matrix and W(τ) to be the diagonal submatrix of W, corresponding to T(τ). To further allow for different effect directions of a variant for different traits in different cohorts, we let . Thus, the signed weights will lead to adding evidence to the association, whether or not the effects of a variant are in the same or different directions. Define
| (Equation 2) |
When τ is large, S(τ) can be undefined if |Tjk| ≤ τ for all j and k. In this case we define S(τ) = 0. Our test statistic is then
| (Equation 3) |
The asymptotic distribution of SHet does not follow a standard distribution but can be evaluated by simulation (see the section Evaluating the Distribution of SHet under the Null Hypothesis). We can rank the statistics |Tjk| for all j and k and evaluate S(τ) at these values to obtain . Because SHet gives more weight to the large trait-cohort specific statistics, it can maintain statistical power when heterogeneity exists.
Estimation of the Correlation Matrix R among Test Statistics
We assume that the traits are quantitative but we can apply the same argument for qualitative traits. Let Y1 and Y2 be two trait vectors and G1 and G2 be two genotype vectors. Without loss of generality, we assume no covariates. If Y1 and Y2 come from the same study cohort, G1 and G2 are the same. We assume that linear regressions were applied to evaluate the association evidence between Y1 and G1 and between Y2 and G2. That is, we have Y1 = G1 β1 + ε1 and Y2 = G2 β2 + ε2, where and . Assume least-squares estimates were obtained and let T1 and T2 be the corresponding Wald test statistics for testing β1 = 0 and β2 = 0, respectively. Then and . The correlation between T1 and T2 is
| (Equation 4) |
If Y1 and Y2 are two traits from the same cohort, then we have G1 = G2 and cov(Y1,Y2) = r12Iσ1σ2, where r12 is the correlation between trait 1 and trait 2. We then have
| (Equation 5) |
If Y1 and Y2 are from different cohorts, then a correlation can be induced only by either overlapping samples or related subjects in the two cohorts. In either case, Equation 5 can capture the correlation. We note that Equation 5 does not depend on individual genotypes but only on the correlation between the two traits. Thus, corr(T1,T2) can be estimated from the summary statistics for all the independent SNPs in a genome-wide association study. That is,
| (Equation 6) |
where T1,T2 are the test statistics for the SNP for traits 1 and 2 in their corresponding cohorts, and μ1 and μ2 are their corresponding means. We suggest using independent SNPs across the genome in Equation 6 rather than all the SNPs regardless of the LD among them, which will lead to inflated correlation estimation.27
Evaluating the Distribution of SHet under the Null Hypothesis
Although SHom follows a χ2 distribution with one degree of freedom, SHet does not have a closed form under the null hypothesis because of the data-adaptive approach we are using. However, SHet can be viewed as the maximum of weighted sum of trait-specific test statistics satisfying different thresholds, which is closely related to a gamma distribution.28 We assume under the null hypothesis that SHet follows a gamma distribution with a mean shift and we use simulations to estimate this gamma distribution. Under the null, a correlation between two test statistics T1,T2 is determined by the trait correlation in Equation 2 and is independent of the SNP. Instead of generating genotype and phenotype data, we can directly simulate the test statistic T from a multivariate normal distribution , where is the estimated correlation matrix given by Equation 6. We use the following steps to evaluate the distribution under the null hypothesis:
-
(1)
Estimate the correlation matrix by Equation 6 with the observed test statistics across the common genome-wide SNPs for all cohorts and traits.
-
(2)
Generate L random vectors from the multivariate normal distribution .
-
(3)
For the lth realization in step 2, calculate the test statistic SHet,l as in Equation 3. The weight matrix in Equation 2 is calculated with the cohort sample sizes.
-
(4)
Fit SHet,1, SHet,2, ...SHet,L to a gamma distribution gamma(α, β) + c, where α, β are the shape and scale parameters and c is a constant, and we estimate parameters α, β, and c by matching the first three moments to the data. The estimated parameters are represented by , , and , respectively.
-
(5)
For any observed statistic SHet,o, the p value is calculated by , where S0 is the fractile corresponding a significance level α0 of the distribution .
The above procedure is not dependent on the particular SNP and this null distribution can be used for testing any SNP association, which drastically reduces the computation time. Notably, we can also directly use simulated SHet,1, SHet,2, ...SHet,L as the distribution under the null hypothesis. However, the computation is still intensive for GWASs because of the need to evaluate test statistics at a significance level of 5 × 10−8. We therefore suggest the use of the estimated gamma distribution.
Simulations
We conducted simulations to evaluate the type I error and power of the proposed method. Five cohorts with 3,000 individuals each and three blood pressure traits were generated. We allowed a portion of the samples to overlap among the cohorts, which simulated cryptic relatedness between samples from different cohorts. The simulated data mimicked the blood pressure data from the COGENT BP consortium,5 which included SBP, DBP, and HTN. The correlations between SBP and DBP was obtained from the CARe data. We first simulated a genotype gi for the ith individual with a minor allele frequency being sampled from a uniform distribution between 0.01 and 0.5, with the assumption of Hardy-Weinberg equilibrium.
To simulate the phenotype data, we first generated latent phenotypes by using a linear additive model
| (Equation 7) |
where , μ, β, and εi are column vectors of length 2, representing traits, intercepts, trait-specific effect sizes of a genotype, and random errors. We used parameters estimated from actual African American data. In our simulation, we simulated consisting of SBP and DBP, with population means 127 and 78, respectively, and , where we let , and ρ is the correlation between SBP and DBP, which we varied. To simulate HTN, we assumed that individuals with either > 140 or > 90 have antihypertensive medications. The effects of antihypertensive medications for SBP and DBP followed the normal distributions and , respectively. These effects of medications mimic the current GWASs for which ten and five units are often added to SBP and DBP when an individual is on antihypertensive medications.5,29 The observed phenotype values for SBP and DBP are
| (Equation 8) |
where . The hypertensive case is defined as either observed SBP > 140 (equivalently Yi1 > 140), observed DBP > 90 (equivalently Yi2 > 90), or on antihypertensive medication. Otherwise, a control is defined. The above simulation process was used to generate the data under both the null and alternative hypotheses for five cohorts. For data under the null hypothesis, we simply let β = 0 in Equation 7. For data under the alternative hypothesis, we set the phenotypic variance explained by a variant as 0.3% of total variance and calculated the β value according to the simulated causal variant allele frequency assuming an additive model of inheritance. In the case of heterogeneity across cohorts, we set β with the calculated value in one cohort and 0 in the rest of the cohorts.
Results
We first examined whether the correlation among phenotypes can be well estimated by the corresponding genome-wide test statistics, as represented in Equations 5 and 6. We simulated three correlated traits (SBP, DBP, and HTN) via the method above but with genetic effects β = 0 and ρ = 0.7 for 3,000 subjects. We also simulated 100,000 independent SNPs for each individual with minor allele frequencies being sampled from a uniform distribution between 0.01 and 0.5, with the assumption of Hardy-Weinberg equilibrium. We performed association tests for all the SNPs with the software Plink.30 Table 1 shows the estimated correlation among the three traits using trait values and the estimated correlation matrix based on the test statistics of 100,000 SNPs. We observed that the trait correlations can be approximated through the calculation of correlations of test statistics of SNPs corresponding to traits (Table 1).
Table 1.
Comparison of Trait Correlations Used for Simulation and Estimated by Test Statistics from SNPs of GWASs
| SBP | DBP | HTN | |
|---|---|---|---|
| SBP | – | 0.76 | 0.73 |
| DBP | 0.69 | – | 0.70 |
| HTN | 0.66 | 0.60 | – |
Values above diagonal are generating correlation coefficients, and under diagonal are estimated based on the test statistics of 100,000 SNPs.
We next examined the type I error of statistics SHom and SHet under three scenarios: (1) ρ = 0, (2) ρ = 0.25, and (3) ρ = 0.5. For each scenario, we simulated 5 independent cohorts each with 3,000 subjects, 100,000 SNPs, and three traits (SBP, DBP, and HTN) under the null hypothesis of no genetic contribution to any of the three traits. We performed the association tests for all the SNPs with the software Plink30 to obtain the test statistics in each cohort separately. We next calculated SHet for all the 100,000 SNPs and estimated the parameters α, β, and c for the shifted gamma distribution by matching the first three moments. Figure 1 depicts the empirical distributions of under the three scenarios when no overlapping subjects were generated between the five cohorts. We observed that the estimated fits the empirical distribution of well (Figure 1). In particular, we did not observe a departure in the tail of the gamma distribution. We observed similar results when there were 500 overlapping subjects among the five simulated cohorts (Figure 2). We next used these estimated gamma distribution parameters to evaluate the type I error rates correspondingly.
Figure 1.
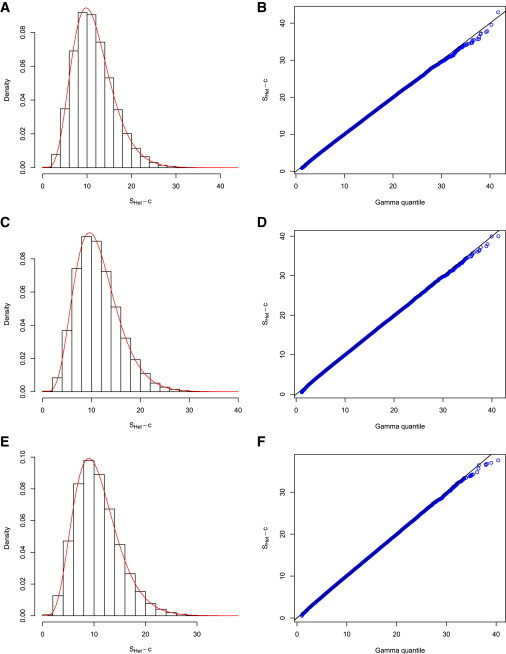
SHet Distribution
Distribution of the test statistic SHet under three scenarios: trait correlation is 0 (A and B), trait correlation is 0.25 (C and D), and trait correlation is 0.5 (E and F). We generated 5 cohorts, each with sample size 3,000, with no overlapping samples between cohorts. Left panel is the histogram of SHet based on 100,000 replications and the red curve represents the theoretical distribution gamma(α,β), where α,β are the shape and scale parameters that were estimated by matching the first two moments. Right panel is a QQ plot of SHet.
Figure 2.
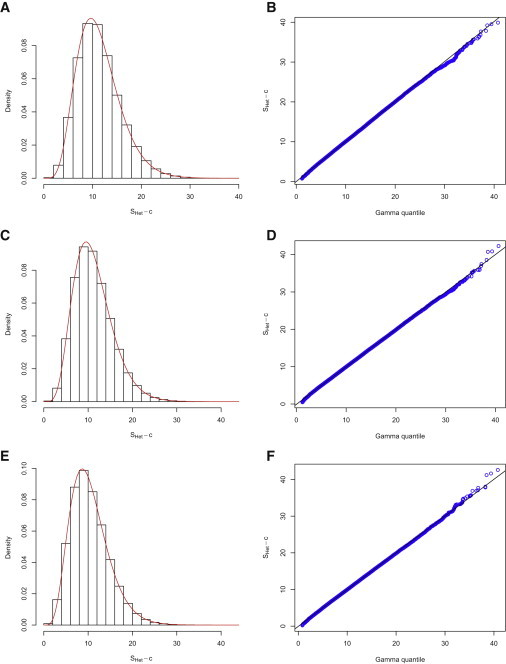
SHet Distribution when Cohorts Have Overlapping Subjects
Distribution of the test statistic SHet under three scenarios as in Figure 1. We generated 5 cohorts, each with sample size 3,000; 500 subjects were overlapping between cohorts. Left and right panels are as in Figure 1.
Under each of six scenarios (ρ = (0, 0.25, 0.5) × (nonoverlapping, overlapping sample)), we repeated the above process 100 times, which led to 107 SHom and SHet statistics. We calculated p values of SHom statistics by and SHet statistics by using the shift gamma distribution with previous estimated corresponding parameters, respectively. We then calculated the type I error rates by evaluating the proportion of the p values less than a significance level. Table 2 presents the type I error rates at different significance levels. We observed that the type I error rates were well controlled for SHom. For SHet, type I error rates were slightly inflated when significance levels were less than 10−5. Thus, the proposed SHet test statistics can be fitted reasonably well by an estimated shift gamma distribution under the null hypothesis. Because the distribution of SHet under the null hypothesis depends only on the correlation matrix among traits and number of cohorts and does not depend on a SNP, we can estimate the gamma (α, β) + c that can be used for testing any SNP. This method is computationally feasible. We also observed that the type I error can be well controlled for SHom, which follows under the null hypothesis. The well-controlled type I error rates for both SHom and SHet regardless of nonoverlapping or overlapping samples among cohorts indicates that correlations estimated by Equation 6 are well enough for approximating the induced correlations among the summary statistics by overlapped samples.
Table 2.
Type I Error Rates for SHom and SHet
| ρ | No. of Overlapped Samples |
Significance Level |
||||||
|---|---|---|---|---|---|---|---|---|
| 0.05 | 10−2 | 10−3 | 10−4 | 10−5 | 10−6 | 10−7 | ||
| SHom | ||||||||
| 0.00 | 0 | 5.03 × 10−2 | 9.99 × 10−3 | 9.96 × 10−4 | 9.74 × 10−5 | 1.00 × 10−5 | 8.00 × 10−7 | 3.00 × 10−7 |
| 500 | 4.76 × 10−2 | 9.18 × 10−3 | 9.02 × 10−4 | 9.05 × 10−5 | 6.50 × 10−6 | 8.00 × 10−7 | 2.00 × 10−7 | |
| 0.25 | 0 | 5.04 × 10−2 | 1.02 × 10−2 | 1.03 × 10−3 | 1.07 × 10−4 | 1.12 × 10−5 | 7.00 × 10−7 | 0.00 × 100 |
| 500 | 4.94 × 10−2 | 9.81 × 10−3 | 9.52 × 10−4 | 9.57 × 10−5 | 9.50 × 10−6 | 7.00 × 10−7 | 1.00 × 10−7 | |
| 0.50 | 0 | 5.06 × 10−2 | 1.02 × 10−2 | 1.03 × 10−3 | 1.06 × 10−4 | 1.23 × 10−5 | 1.10 × 10−6 | 0.00 × 100 |
| 500 | 4.74 × 10−2 | 9.21 × 10−3 | 8.65 × 10−4 | 7.97 × 10−5 | 7.30 × 10−6 | 7.00 × 10−7 | 2.00 × 10−7 | |
| SHet | ||||||||
| 0.00 | 0 | 4.99 × 10−2 | 1.00 × 10−2 | 1.03 × 10−3 | 1.10 × 10−4 | 1.17 × 10−5 | 2.00 × 10−6 | 1.00 × 10−7 |
| 500 | 4.99 × 10−2 | 1.00 × 10−2 | 1.01 × 10−3 | 1.06 × 10−4 | 1.30 × 10−5 | 1.70 × 10−6 | 1.00 × 10−7 | |
| 0.25 | 0 | 4.98 × 10−2 | 9.98 × 10−3 | 1.04 × 10−3 | 1.11 × 10−4 | 1.25 × 10−5 | 1.10 × 10−6 | 2.00 × 10−7 |
| 500 | 4.98 × 10−2 | 1.00 × 10−2 | 1.02 × 10−3 | 1.11 × 10−4 | 1.28 × 10−5 | 8.00 × 10−7 | 0.00 × 100 | |
| 0.50 | 0 | 4.99 × 10−2 | 1.01 × 10−2 | 1.05 × 10−3 | 1.10 × 10−4 | 1.23 × 10−5 | 1.30 × 10−6 | 1.00 × 10−7 |
| 500 | 4.99 × 10−2 | 1.01 × 10−2 | 1.05 × 10−3 | 1.15 × 10−4 | 1.26 × 10−5 | 1.30 × 10−6 | 2.00 × 10−7 | |
Type I error rate was calculated from the asymptotic χ2 distribution with 1 d.f. for SHom, and the shift gamma distribution parameters were estimated by matching the first three moments for SHet. We simulated ten million replications for each scenario.
Power
We evaluated the power of the statistics SHom and SHet by simulating three traits, SBP, DBP, and HTN. To simulate the three traits, a SNP was simulated and its genetic effect was added correspondingly. For illustration, we simulated two scenarios: ρ = 0 and ρ = 0.5. In both scenarios, HTN is always correlated with SBP and DBP because of the way the data were simulated. In each scenario, we generated 5 cohorts, each with a sample size of 3,000 subjects. We allowed different genetic contributions to the traits: a genetic variant contributes to a trait in only one of five cohorts (heterogeneity across cohorts within the same trait) or in all five cohorts (no heterogeneity within a trait), and a genetic variant affects SBP only (heterogeneity between traits) or affects both SBP and DBP. After both genotypes and phenotypes were simulated, we perform association tests for all SNPs with the software Plink and calculated SHom and SHet. We calculated the p values for SHom by a and with the previous estimated shift gamma distribution for SHet, respectively. Power was defined as the proportion of test statistics with p values less than a corresponding significance level. We also examined the power when there were 500 overlapping subjects between cohorts. We analyzed the power of SHom for SBP, DBP, and HTN, separately as well as combined, and this is denoted as SHom−SBP, SHom−DBP, SHom−HT, and SHom, respectively. Power analysis was calculated based on 1,000 replications.
We first examined the power when SBP and DBP were simulated independently. Figure 3 shows the power when a genetic variant contributes to only one of the five cohorts, which represents heterogeneity across cohorts for the same trait. When a genetic variant contributes only to SBP, SHet has the best power, followed by SHom−SBP, SHom, and SHom−HT (Figure 3A). SHom−DBP did not have power because there was no genetic contribution to DBP. This result suggests that the proposed statistic SHet is able to capture association evidence even when the data include noise because of heterogeneity among traits and cohorts. SHom−SBP has more power than SHom, which is not surprising because SHom included DBP, which had no genetic contribution. The overlap of subjects across the five cohorts is equivalent to reducing the number of subjects who did not have a genetic contribution from SBP. It is thus not surprising that SHom−SBP had the most power in this situation (Figure 3B). When a genetic variant contributes to both SBP and DBP in one cohort with the effect sizes in the same direction, the combined trait analyses by SHom and SHet had much improved power although SHet still had the greatest power (Figure 3C). The power for SHom was further improved when there were overlapping samples between studies (Figure 3D), which could be attributed to reduced heterogeneity across cohorts. When a genetic variant contributed to both SBP and DBP in one cohort but with the effects in opposite directions, SHet still maintained power, whereas SHom had almost no power because of the cancellation of the SBP and DBP contributions whether or not there were overlapping samples among cohorts (Figures 3E and 3F).
Figure 3.
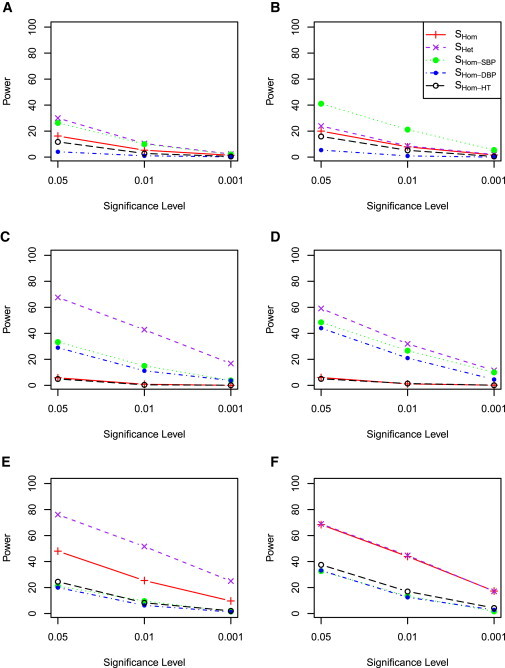
Power Comparison of SHom and SHet when One Cohort Has Genetic Contribution
SBP and DBP were simulated independently. HTN was simulated according to SBP and DBP and simulated medication status. Five cohorts were simulated, but only one of the five cohorts has a genetic contribution. Left: No overlapping samples among the five cohorts. Right: 500 samples were the same in each cohort and a genetic variant contributes phenotypic variation for the same samples.
(A and B) A genetic variant affects only SBP.
(C and D) A genetic variant affects both SBP and DBP but with opposite effect directions.
(E and F) A genetic variant affects both SBP and DBP with the same effect direction.
Figure 4 shows the power when a genetic variant contributes to all five cohorts, which represents no heterogeneity across cohorts for the same trait. When a genetic variant contributed only to SBP, SHom−SBP had the most power, regardless of whether there were overlapping samples or not between cohorts (Figures 4A and 4B). The power of SHom and SHet were comparable, with SHet outperforming SHom for no overlapping samples between cohorts. When a genetic variant contributed to both SBP and DBP and the effects were in the same direction (no trait or cohort heterogeneity), SHet performed similarly to SHom (Figures 4C and 4D). However, SHom had no power although SHet maintained power when the genetic effects were in opposite directions (Figures 4E and 4F).
Figure 4.
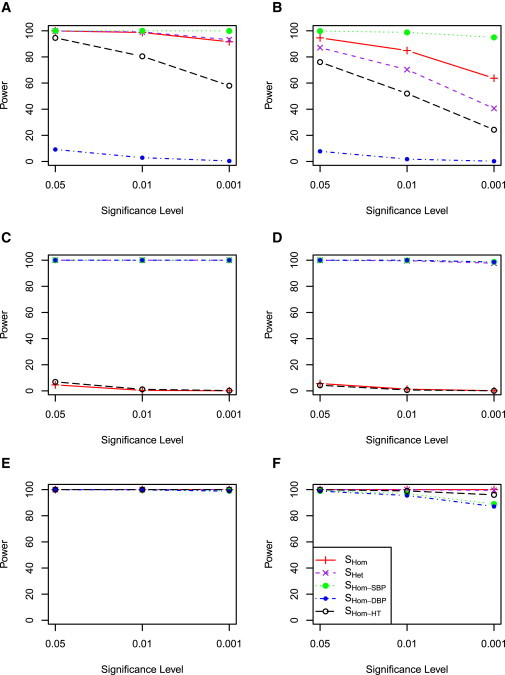
Power Comparison of SHom and SHet when Five Cohorts Have Genetic Contribution
Five cohorts were simulated and the genetic variant has contribution in all five cohorts. Details as in Figure 3.
The results were similar when SBP and DBP were highly correlated (correlation coefficient = 0.5). That is, SHet usually outperformed or performed equivalently well as the other test statistics when heterogeneity due to cohorts or traits were present in our simulated data (Figures 5 and 6). Interestingly, SHet improved power substantially when a genetic variant contributed to SBP and DBP in opposite directions but SBP and DBP were positively correlated, compared with no correlation (Figures 3E and 3F versus Figures 5E and 5F). Intuitively, if two traits are highly positively correlated, we are less likely to observe the estimated effects for a variant in opposite directions under the null hypothesis. The same is true if two traits are highly negatively correlated, wherein we will less likely observe the estimated effects for a variant in the same directions under the null hypothesis. The test statistic SHet apparently captures this information whereas SHom does not.
Figure 5.
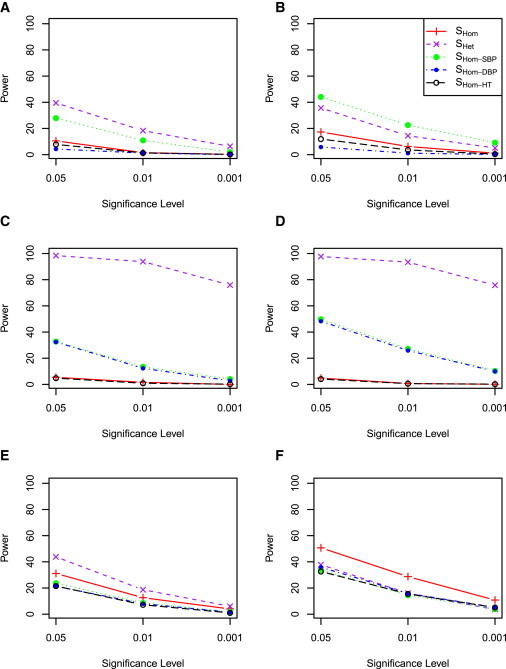
Power Comparison of SHom and SHet with Correlation 0.5 when One Cohort Has Genetic Contribution
SBP and DBP were simulated with correlation 0.5. Five cohorts were simulated but only one of the five cohorts has a genetic contribution. Details as in Figure 3.
Figure 6.
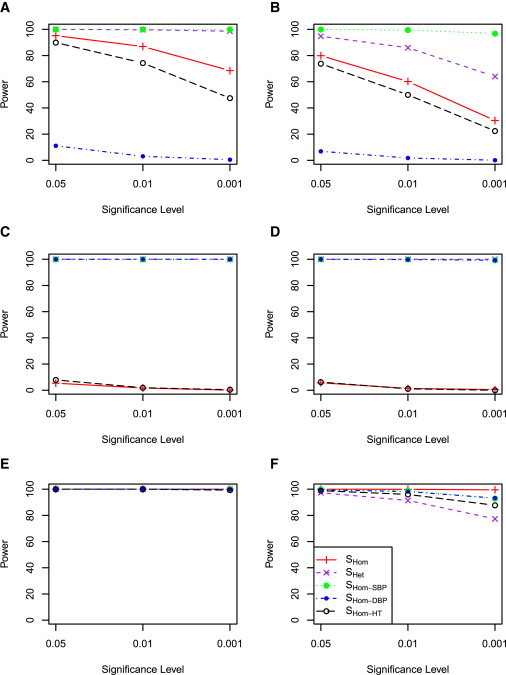
Power Comparison of SHom and SHet with Correlation 0.5 when Five Cohorts Have Genetic Contribution
SBP and DBP were simulated with correlation 0.5. Five cohorts were simulated and the genetic variant has a contribution in all five cohorts. Details as in Figure 3.
Application to the BP GWAS Data from the Continental Origins and Genetic Epidemiology Network
We applied SHet and SHom to the BP data from COGENT BP, which consists of 19 African ancestry cohorts, as detailed in Franceschini et al.5 In brief, the COGENT study includes 29,378 subjects, 20 years or older, from 18 U.S. African American cohorts and one cohort from Yoruba, Nigeria. The African American cohorts include Biological bank of Vanderbilt University (BioVU), Atherosclerosis Risk In Communities (ARIC), Coronary Artery Risk Development in Young Adults (CARDIA), Cleveland Family Study (CFS), Jackson Heart Study (JHS), Multi-Ethnic Study of Atherosclerosis (MESA), Cardiovascular Health Study (CHS), Genetic Study of Atherosclerosis Risk (GeneSTAR), Genetic Epidemiology Network of Arteriopathy (GENOA), Healthy Aging in Neighborhoods of Diversity Across the Life Span Study (HANDLS), Health, Aging, and Body Composition (Health ABC) Study, the Hypertension Genetic Epidemiology Network (HyperGEN), the Mount Sinai study (New York City, NY, USA), the Women’s Health Initiative SNP Health Association Resource (WHI-SHARe), the Howard University Family Study (HUFS), the Bogalusa Heart Study (Bogalusa), the Sea Islands Genetic NETwork (SIGNET) and REGARDs, and the Loyola Maywood study (Maywood). Each study received IRB approval of its consent procedures, examination and surveillance components, data security measures, and DNA collection and its use for genetic research. All participants in each study gave written informed consent for participation in the study and to conduct genetic research. Genotyping for the 19 cohorts was performed with either Affymetrix or the Illumina whole-genome SNP genotyping arrays. Quality control of genotyping data and imputation were performed in each cohort separately. Uniform protocols for analysis were conducted by each study. The summary statistics from the GWASs, including the SNP estimated effect sizes and their corresponding standard errors for SBP, DBP, and HTN, were collected for meta-analysis.5 In this analysis, we applied SHet and SHom to these summary statistics. Because we observed many unexpected large estimated effect sizes for the HTN analysis in SIGNET, we excluded the HTN results of SIGNET. Thus, our analysis included 56 trait-specific results from GWASs.
We obtained the inverse variance weighted meta-analysis results with the software METAL31 for SBP, DBP, and HTN from the original report,5 where SNP rs11041530 at CYB5R2 (MIM 608342) is the only variant reaching genome-wide significance (SBP, p = 4.0 × 10−8). We calculated the proposed statistics SHet and SHom for each SNP and the corresponding p values with a gamma distribution for combining SBP, DBP, and HTN. Figure 7 presents the QQ plots and Manhattan plots of SHet and SHom. The genomic control (GC) inflation factors are 1.08 and 1.05 for SHet and SHom, respectively. A possible reason for the slightly inflated GC factors could be that the hypertension traits are polygenic with a large number of genetic variants of small effect sizes contributing to the phenotypic variation. Combining SBP, DBP, and HTN would further aggregate these variants. SHom detected the HOXA-EVX1 (MIM 142996) locus on chromosome 7 at a genome-wide significance level (Table 3 and Figure 7, p = 2.35 × 10−9). This locus was also reported in the original study and was replicated in Asian and European populations, although SBP, DBP, or HTN trait-specific meta-analyses did not reach genome-wide significance in the discovery phase.5 In comparison, SHet was able to detect four loci at genome-wide significance level (p < 5.0 × 10−8), including HOXA-EVX1 on chromosome 7, CHIC2 (MIM 604332) on chromosome 4, IGFBP1-IGFBP3 (MIM 146730, 146732) on chromosome 7, and CDH17 (MIM 603017) on chromosome 8 (Table 3 and Figure 7). The regional plots for these four loci are presented in Figure 8. Figure S1 (available online) shows forest plots of the cohort-specific effect sizes of SBP, DBP, and HTN for these four loci. Note that these loci have opposite directions in SBP and DBP meta-analysis except HOXA-EVX1 (Table 3), suggesting that the same genetic variant increases SBP but decreases DBP level (i.e., increases pulse pressure) or vice versa. Interestingly, CHIC2 has been reported to be associated with pulse pressure by large GWASs in a European population.32 The most significant variant, rs11725861 in CHIC2, is located 3 kb away from the sentinel SNP rs871606 reported in Wain et al.,32 and these two SNPs are in strong linkage disequilibrium in HapMap CEU data (r2 = 0.35, D’ = 1). Because pulse pressure is defined as the difference between SBP and DBP, the opposite effect sizes of SBP and DBP in this study are thus consistent with the reported association evidence with pulse pressure in European population. The IGF system is implicated in the development of cardiovascular disease. Low circulating levels of IGFBP1 have been reported to be associated with the presence of macrovascular disease and hypertension in type 2 diabetes,33,34 although there is no direct report of association evidence between the variants at IGFBP1 and blood pressure. However, a recent meta-analysis of European cohorts identified IGFBP3 as being associated with long-term averaging of pulse blood pressure.35 The most significant variant, rs11977526 near IGFBP3, is located 43 kb away from the sentinel SNP rs2949837 reported in Ganesh et al.35 and these two SNPs are in strong linkage disequilibrium in HapMap CEU data (r2 = 0.66, D’ = 0.94). There has been no association reported between CDH17 on chromosome 8q21 and blood pressure, although linkage evidence was reported for this locus to essential hypertension in European population.36
Figure 7.
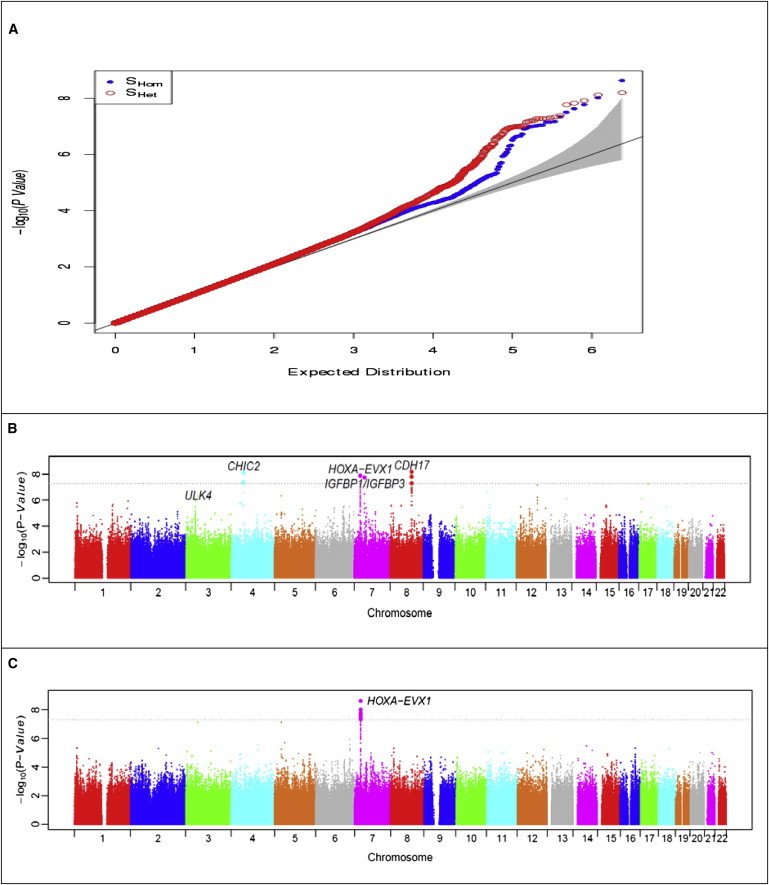
QQ Plots and Manhattan Plots after Combining SBP, DBP, and HTN via SHom and SHet for the COGENT BP GWAS Data
Shown are QQ plots (A), Manhattan plot of SHet (B), and Manhattan plot of SHom (C).
Table 3.
The Top Genetic Variants Identified by SHet and SHom in the COGENT BP Consortium by First Performing Meta-analysis and then SHet and SHom
| Chr | SNP | POS | Genes | Effect Allele | Freq |
Meta-analysis HTN |
Meta-analysis SBP |
Meta-analysis DBP |
SHom |
SHet |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| beta | SE | p | beta | SE | p | beta | SE | p | p | p | ||||||
| Loci Reaching Genome-wide Significance | ||||||||||||||||
| 4 | rs11725861 | 54497062 | CHIC2 | A | 0.84 | 0.04 | 0.03 | 2.16 × 10−1 | 0.79 | 0.22 | 2.89 × 10−4 | −0.18 | 0.13 | 1.63 × 10−1 | 2.56 × 10−1 | 8.45 × 10−9 |
| 7 | rs11564022 | 27303571 | HOXA-EVX1 | T | 0.23 | −0.12 | 0.02 | 2.16 × 10−6 | −0.89 | 0.19 | 1.83 × 10−6 | −0.60 | 0.11 | 7.66 × 10−8 | 2.35 × 10−9 | 1.34 × 10−8 |
| 7 | rs11977526 | 45974635 | IGFBP1, IGFBP3 | A | 0.32 | −0.01 | 0.02 | 5.30 × 10−1 | −0.37 | 0.18 | 3.73 × 10−2 | 0.30 | 0.11 | 4.62 × 10−3 | 8.21 × 10−1 | 1.87 × 10−8 |
| 8 | rs2446849 | 95172673 | CDH17 | T | 0.80 | −0.06 | 0.03 | 3.00 × 10−2 | −0.63 | 0.20 | 2.00 × 10−3 | 0.22 | 0.12 | 6.75 × 10−2 | 2.11 × 10−1 | 7.01 × 10−9 |
| Loci Reaching Suggestive Significance | ||||||||||||||||
| 3 | rs10049492 | 53571572 | CACNA1D | A | 0.74 | 0.12 | 0.03 | 1.42 × 10−5 | 0.85 | 0.19 | 1.74 × 10−5 | 0.57 | 0.12 | 1.77 × 10−6 | 7.11 × 10−8 | 4.60 × 10−7 |
| 5 | rs6886515 | 30702383 | none | A | 0.61 | 0.11 | 0.02 | 4.61 × 10−7 | 0.71 | 0.17 | 2.46 × 10−5 | 0.40 | 0.10 | 6.02 × 10−5 | 7.15 × 10−8 | 4.63 × 10−7 |
| 6 | rs9401512 | 122707473 | HSF2/PKIB | T | 0.30 | 0.00 | 0.02 | 9.17 × 10−1 | 0.44 | 0.17 | 1.04 × 10−2 | −0.23 | 0.10 | 2.75 × 10−2 | 9.43 × 10−1 | 5.75 × 10−8 |
| 11 | rs11041530 | 7658079 | CYB5R2 | C | 0.12 | −0.09 | 0.03 | 9.83 × 10−3 | −1.35 | 0.25 | 4.04 × 10−8 | −0.54 | 0.15 | 2.65 × 10−4 | 9.08 × 10−6 | 2.55 × 10−7 |
| 12 | rs11837544 | 93192534 | PLXNC1 | A | 0.20 | −0.01 | 0.03 | 5.89 × 10−1 | −0.50 | 0.20 | 1.36 × 10−2 | 0.27 | 0.12 | 2.28 × 10−2 | 9.37 × 10−1 | 6.89 × 10−8 |
| 17 | rs430685 | 42214309 | GOSR2/WNT3 | T | 0.02 | −0.42 | 0.14 | 2.65 × 10−3 | 1.26 | 0.84 | 1.33 × 10−1 | 1.51 | 0.50 | 2.64 × 10−3 | 8.07 × 10−1 | 5.77 × 10−8 |
Figure 8.
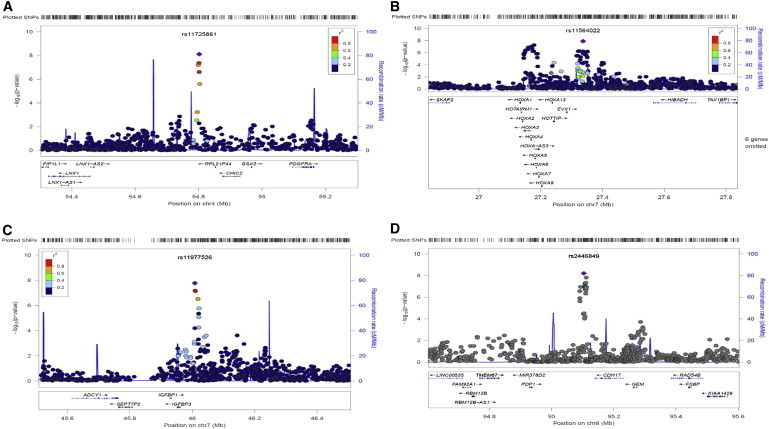
Regional Association Plots
Regional association plots of the four SNPs reaching genome-wide significance (p < 5 × 10−8) by SHet for the COGENT BP GWAS data. The most significant SNP at each locus is shown in purple. The fine-scale recombination rate is shown as a blue vertical line. Gene positions are shown at the bottom.
Six additional loci were also identified by SHet with suggestive evidence (p < 5 × 10−7, Table 3). The mutations in CACNA1D (MIM 114206), encoding Cav1.3, were reported to regulate Na+, K+, and Ca2+ and to underlie a common subtype of adrenal hypertension.37 The SNP rs6886515 on chromosome 5 is located in an intergenic region. SNP rs9401512 is in HSF2/PKIB (MIM 140581, 606914) on chromosome 6 and has not been reported to be associated with hypertension-related traits. However, this region has been reported to harbor BP variants in admixture mapping analyses.38,39 SNP rs11041530 in CYB5R2 was reported in the original study but was not significant in a replication analysis.5 We have not seen any report of PLXNC1 (MIM 604259) and hypertension. SNP rs430685 locates in WNT3 (MIM 165330) on chromosome 17 and this locus is close to the locus GOSR2 (MIM 604027) reported in Ehret et al.1 SNP rs430685 is 153 kb away from the sentinel SNP rs17608766 reported in Ehret et al.1 with D’ of 1.0 but r2 value of 0.003 between these two SNPs in HapMap CEU data, indicating that these two signals might be different. WNT3 belongs to the Wnt/frizzled receptor signaling pathway, which has been suggested to have an important functional role in cardiovascular and renal disorders.40
Discussion
The observations from GWASs suggest that many genetic variants are associated with multiple correlated or even distinct traits, and such associations have been termed cross-phenotype (CP) associations,4 which is relevant to pleiotropy in complex disease. We proposed a statistic SHet and compared it with SHom, and both methods can integrate association evidence of multiple continuous and binary traits from multiple GWASs and thus detect CP associations. Both methods need only the summary statistics obtained from GWASs. SHom is an extension of the linear combination of the univariate test statistics19,20 but allows for sample size as weights. SHet is a further extension of SHom allowing for heterogeneous effects of a trait from different studies, which could be due to different designs, environmental factors, or populations, as well as heterogeneity effects for different phenotypes, which are not unexpected in practice. Under the null hypothesis, SHom is asymptotically distributed as chi-square with 1 degree of freedom, although the asymptotical distribution of SHet is less clear but related to a gamma distribution.28 Our simulations indeed suggest that SHet can be well approximated by a shift gamma distribution with parameters that can be estimated from the data.
The simulations indicated that the type I error rate is reasonably controlled for both methods (Table 2 and Figures 1 and 2). The estimated gamma distributions well fitted the corresponding empirical distributions as observed from both histograms and the Q-Q plots of SHet (Figures 1 and 2). When we applied both methods to the data from COGENT BP African ancestry GWASs for blood pressure traits, we did not observe any substantial inflation of the type I error rate (Figure 7), further indicating that both methods are valid.
Our simulations suggest that when heterogeneity is of less concern, SHom is more powerful than SHet. In contrast, when heterogeneity is present, SHet is more powerful than SHom. This property can also be observed from the application of both statistics to the data from COGENT BP African ancestry GWASs for blood pressure traits. SHom was able to detect the HOXA-EVX1 locus (p = 2.35 × 10−9) whereas SHet identified four loci (CHIC2, HOXA-EVX1, IGFBP1/IGFBP3, and CDH17; p < 5.0 × 10−8) at a genome-wide significance level. All four loci were missed by single-trait analysis at genome-wide significance level (p < 5.0 × 10−8) and only the HOXA-EVX1 locus was identified by the flipping sign test in the original report,5 suggesting that SHet is more powerful than combined p values methods when heterogeneity is present. The flipping sign test is similar to Fisher’s method for combining the p values for different traits but requires a large number of simulations to estimate the null distribution to account for the trait correlations. Thus the flipping sign test is similar to SHom but SHom is more flexible and requires substantially less computational time because of using the estimated asymptotic distribution. The HTN-, SBP-, and DBP-specific meta-analysis of the HOXA-EVX1 locus did not show any heterogeneity (Table 3), which is the reason that this locus was detected by SHom. As suggested by our simulations, SHet is more applicable to heterogeneous data and was able to identify three additional loci, CHIC2, IGFBP1/IGFBP3, and CDH17. This is also consistent with the fact that the effect sizes estimated in the SBP- and DBP-specific meta-analyses were in opposite directions for all three of these loci (Table 3). In addition, SHet was able to identify six loci with suggestive association evidence for hypertension-related traits. Among the identified loci, CHIC2, HOXA-EVX1, IGFBP1/IGFBP3, CACNA1D, and GOSR2/WNT3 have been confirmed to be associated with hypertension-related traits,5,32–35 suggesting that our methods powerfully identify true signals.
Compared with existing methods, SHom and SHet have multiple advantages for identifying cross-phenotype (CP) associations. Both methods are able to combine traits measured on different scales, including continuous and binary traits. Further, SHet allows for heterogeneous effects. Both methods are able to accommodate overlapping or related subjects within and among different studies or cohorts, as our simulations suggested. We assumed that the trait-specific summary statistics have already well accounted for the confounding effect caused by either population structure or cryptic relatedness within a cohort. Since our approach accounts for correlations of test statistics among traits or cohorts, SHom and SHet are able to control the effect of cryptic relatedness occurring among cohorts, as observed in the simulations when overlapping samples were simulated among cohorts (Figures 3, 4, 5, and 6). SHom and SHet are in principal able to control the effect of population structure occurring between cohorts, although this property of the methods has not been formally evaluated in our simulation studies.
In contrast, a fixed or random effect meta-analysis is able to combine results from multiple studies but is limited to the same traits and no overlapping or related subjects across studies. The cross-phenotype meta-analysis14 is able to test CP association but cannot be applied when there are overlapping subjects. The linear combination of univariate test statistics applies only to a single study with multiple traits and requires individual-level genotype and phenotype data.17,18 The TATES requires only p values, not the individual-level genotype and phenotype data, but cannot be applied to multiple studies.23 The scaled marginal model proposed by Schifano et al.41 requires individual-level genotype and phenotype data. Thus, SHom and SHet are quite general and can be applied to a wide range of data and study designs, and they require only that estimates exist for a given SNP.
In contrast to the subset-based meta-analysis,18 SHom and SHet do not specifically identify a subset of associated traits. However, trait-specific meta-analysis results can be examined after a SNP is identified by SHet, which will allow one to see whether the association evidence from SHet is contributed by only a subset of the traits. When maximizing the statistic in Equation 3, we can record which trait or cohort contributed to the final statistic. The current SHom and SHet test CP associations for only one SNP. Huang et al.24 developed an interesting method, PRIMe, which can test a pleiotropic effect for multiple variants in a genomic region. It should not be difficult to extend SHom and SHet to test for multiple variants in a genomic region by using a similar idea as the PRIMe uses, although further studies are warranted to investigate this.
Our proposed statistics SHom and SHet use the summary statistics to estimate the correlation coefficients among traits and cohorts. If trait correlations are known, SHom and SHet can also be applied by supplying the correlation matrix in Equation 3 without using genome-wide summary statistics. There are advantages to using summary statistics instead of individual-level data. First, as pointed out by Lin and Zeng,42 there is no asymptotic efficiency gain by analyzing individual-level data compared with meta-analysis when the parameter of interest has a common value across studies, although this aspect of performance is less clear when heterogeneity is present. Second, in practice it is easier and more feasible to obtain summary statistics than individual-level data. Finally, study-specific analysis is better to control the confounding within different study designs by environmental factors and between study designs by batch effects across experiments than pooling all data.
In summary, the proposed general statistics SHom and SHet are useful for detecting CP associations. In particular, SHet is better for analyzing multiple different phenotypes because heterogeneity occurs frequently. These methods could easily be deployed in existing consortia collections of association study metadata to improve the chances of novel discoveries and provide more return from those investments, as we have demonstrated in the COGENT consortium. The software of SHom and SHet can be freely downloaded from the author’s website.
Consortia
The members of the COGENT BP Consortium are Nora Franceschini, Ervin Fox, Zhaogong Zhang, Todd L. Edwards, Michael A. Nalls, Yun Ju Sung, Bamidele O. Tayo, Yan V. Sun, Omri Gottesman, Adebawole Adeyemo, Andrew D. Johnson, J. Hunter Young, Ken Rice, Qing Duan, Fang Chen, Yun Li, Hua Tang, Myriam Fornage, Keith L. Keene, Jeanette S. Andrews, Jennifer A. Smith, Jessica D. Faul, Zhang Guangfa, Wei Guo, Yu Liu, Sarah S. Murray, Solomon K. Musani, Sathanur Srinivasan, Digna R. Velez Edwards, Heming Wang, Lewis C. Becker, Pascal Bovet, Murielle Bochud, Ulrich Broeckel, Michel Burnier, Cara Carty, Wei-Min Chen, Guanjie Chen, Wei Chen, Jingzhong Ding, Albert W. Dreisbach, Michele K. Evans, Xiuqing Guo, Melissa E. Garcia, Rich Jensen, Margaux F. Keller, Guillaume Lettre, Vaneet Lotay, Lisa W. Martin, Alanna C. Morrison, Thomas H. Mosley, Adesola Ogunniyi, Walter Palmas, George Papanicolaou, Alan Penman, Joseph F. Polak, Paul M. Ridker, Babatunde Salako, Andrew B. Singleton, Daniel Shriner, Kent D. Taylor, Ramachandran Vasan, Kerri Wiggins, Scott M. Williams, Lisa R. Yanek, Wei Zhao, Alan B. Zonderman, Diane M. Becker, Gerald Berenson, Eric Boerwinkle, Erwin Bottinger, Mary Cushman, Charles Eaton, Gerardo Heiss, Joel N. Hirschhron, Virginia J. Howard, Matthew B. Lanktree, Kiang Liu, Yongmei Liu, Ruth Loos, Karen Margolis, Bruce M. Psaty, Nicholas J. Schork, David R. Weir, Charles N. Rotimi, Michele M. Sale, Tamara Harris, Sharon L.R. Kardia, Steven C. Hunt, Donna Arnett, Susan Redline, Richard S. Cooper, Neil Risch, D.C. Rao, Jerome I. Rotter, Aravinda Chakravarti, Alex P. Reiner, Daniel Levy, Brendan J. Keating, and Xiaofeng Zhu.
Acknowledgments
We are gratefully indebted to Robert C. Elston for his valuable discussions and suggestions that greatly improved the manuscript. The work was supported by the NIH grants HG003054 from the National Human Genome Research Institute and HL086718, HL053353, HL113338, and HL123677 from the National Heart, Lung, and Blood Institute. Funding information for the COGENT BP Consortium is provided in the Supplemental Data.
Supplemental Data
Web Resources
The URLs for data presented herein are as follows:
CPASSOC software, http://hal.case.edu/zhu-web/
GWAS Catalog, http://www.genome.gov/gwastudies/
Online Mendelian Inheritance in Man (OMIM), http://www.omim.org/
References
- 1.Ehret G.B., Munroe P.B., Rice K.M., Bochud M., Johnson A.D., Chasman D.I., Smith A.V., Tobin M.D., Verwoert G.C., Hwang S.J., International Consortium for Blood Pressure Genome-Wide Association Studies. CARDIoGRAM consortium. CKDGen Consortium. KidneyGen Consortium. EchoGen consortium. CHARGE-HF consortium Genetic variants in novel pathways influence blood pressure and cardiovascular disease risk. Nature. 2011;478:103–109. doi: 10.1038/nature10405. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Teslovich T.M., Musunuru K., Smith A.V., Edmondson A.C., Stylianou I.M., Koseki M., Pirruccello J.P., Ripatti S., Chasman D.I., Willer C.J. Biological, clinical and population relevance of 95 loci for blood lipids. Nature. 2010;466:707–713. doi: 10.1038/nature09270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Lango Allen H., Estrada K., Lettre G., Berndt S.I., Weedon M.N., Rivadeneira F., Willer C.J., Jackson A.U., Vedantam S., Raychaudhuri S. Hundreds of variants clustered in genomic loci and biological pathways affect human height. Nature. 2010;467:832–838. doi: 10.1038/nature09410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Solovieff N., Cotsapas C., Lee P.H., Purcell S.M., Smoller J.W. Pleiotropy in complex traits: challenges and strategies. Nat. Rev. Genet. 2013;14:483–495. doi: 10.1038/nrg3461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Franceschini N., Fox E., Zhang Z., Edwards T.L., Nalls M.A., Sung Y.J., Tayo B.O., Sun Y.V., Gottesman O., Adeyemo A., Asian Genetic Epidemiology Network Consortium Genome-wide association analysis of blood-pressure traits in African-ancestry individuals reveals common associated genes in African and non-African populations. Am. J. Hum. Genet. 2013;93:545–554. doi: 10.1016/j.ajhg.2013.07.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Zeger S.L., Liang K.Y. Longitudinal data analysis for discrete and continuous outcomes. Biometrics. 1986;42:121–130. [PubMed] [Google Scholar]
- 7.Lange C., Silverman E.K., Xu X., Weiss S.T., Laird N.M. A multivariate family-based association test using generalized estimating equations: FBAT-GEE. Biostatistics. 2003;4:195–206. doi: 10.1093/biostatistics/4.2.195. [DOI] [PubMed] [Google Scholar]
- 8.Zhou X., Stephens M. Efficient multivariate linear mixed model algorithms for genome-wide association studies. Nat. Methods. 2014;11:407–409. doi: 10.1038/nmeth.2848. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Zhang H., Liu C.T., Wang X. An association test for multiple traits based on the generalized Kendall’s tau. J. Am. Stat. Assoc. 2010;105:473–481. doi: 10.1198/jasa.2009.ap08387. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.O’Reilly P.F., Hoggart C.J., Pomyen Y., Calboli F.C., Elliott P., Jarvelin M.R., Coin L.J. MultiPhen: joint model of multiple phenotypes can increase discovery in GWAS. PLoS ONE. 2012;7:e34861. doi: 10.1371/journal.pone.0034861. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ott J., Rabinowitz D. A principal-components approach based on heritability for combining phenotype information. Hum. Hered. 1999;49:106–111. doi: 10.1159/000022854. [DOI] [PubMed] [Google Scholar]
- 12.Klei L., Luca D., Devlin B., Roeder K. Pleiotropy and principal components of heritability combine to increase power for association analysis. Genet. Epidemiol. 2008;32:9–19. doi: 10.1002/gepi.20257. [DOI] [PubMed] [Google Scholar]
- 13.Aschard H., Vilhjálmsson B.J., Greliche N., Morange P.E., Trégouët D.A., Kraft P. Maximizing the power of principal-component analysis of correlated phenotypes in genome-wide association studies. Am. J. Hum. Genet. 2014;94:662–676. doi: 10.1016/j.ajhg.2014.03.016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Cotsapas C., Voight B.F., Rossin E., Lage K., Neale B.M., Wallace C., Abecasis G.R., Barrett J.C., Behrens T., Cho J., FOCiS Network of Consortia Pervasive sharing of genetic effects in autoimmune disease. PLoS Genet. 2011;7:e1002254. doi: 10.1371/journal.pgen.1002254. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Skroza N., Proietti I., Pampena R., La Viola G., Bernardini N., Nicolucci F., Tolino E., Zuber S., Soccodato V., Potenza C. Correlations between psoriasis and inflammatory bowel diseases. Biomed Res Int. 2013;2013:983902. doi: 10.1155/2013/983902. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Franke A., McGovern D.P., Barrett J.C., Wang K., Radford-Smith G.L., Ahmad T., Lees C.W., Balschun T., Lee J., Roberts R. Genome-wide meta-analysis increases to 71 the number of confirmed Crohn’s disease susceptibility loci. Nat. Genet. 2010;42:1118–1125. doi: 10.1038/ng.717. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Strange A., Capon F., Spencer C.C., Knight J., Weale M.E., Allen M.H., Barton A., Band G., Bellenguez C., Bergboer J.G., Genetic Analysis of Psoriasis Consortium & the Wellcome Trust Case Control Consortium 2 A genome-wide association study identifies new psoriasis susceptibility loci and an interaction between HLA-C and ERAP1. Nat. Genet. 2010;42:985–990. doi: 10.1038/ng.694. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Bhattacharjee S., Rajaraman P., Jacobs K.B., Wheeler W.A., Melin B.S., Hartge P., Yeager M., Chung C.C., Chanock S.J., Chatterjee N., GliomaScan Consortium A subset-based approach improves power and interpretation for the combined analysis of genetic association studies of heterogeneous traits. Am. J. Hum. Genet. 2012;90:821–835. doi: 10.1016/j.ajhg.2012.03.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Wei L.J., Johnson W.E. Combining dependent tests with incomplete repeated measurements. Biometrika. 1985;72:359–364. [Google Scholar]
- 20.O’Brien P.C. Procedures for comparing samples with multiple endpoints. Biometrics. 1984;40:1079–1087. [PubMed] [Google Scholar]
- 21.Xu X., Tian L., Wei L.J. Combining dependent tests for linkage or association across multiple phenotypic traits. Biostatistics. 2003;4:223–229. doi: 10.1093/biostatistics/4.2.223. [DOI] [PubMed] [Google Scholar]
- 22.Yang Q., Wu H., Guo C.Y., Fox C.S. Analyze multivariate phenotypes in genetic association studies by combining univariate association tests. Genet. Epidemiol. 2010;34:444–454. doi: 10.1002/gepi.20497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.van der Sluis S., Posthuma D., Dolan C.V. TATES: efficient multivariate genotype-phenotype analysis for genome-wide association studies. PLoS Genet. 2013;9:e1003235. doi: 10.1371/journal.pgen.1003235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Huang J., Johnson A.D., O’Donnell C.J. PRIMe: a method for characterization and evaluation of pleiotropic regions from multiple genome-wide association studies. Bioinformatics. 2011;27:1201–1206. doi: 10.1093/bioinformatics/btr116. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Li Y., Feng T., Zhu X. Detecting association with rare variants for common diseases using haplotype-based methods. Stat. Interface. 2011;4:273–284. [Google Scholar]
- 26.Zaykin D.V., Zhivotovsky L.A., Westfall P.H., Weir B.S. Truncated product method for combining P-values. Genet. Epidemiol. 2002;22:170–185. doi: 10.1002/gepi.0042. [DOI] [PubMed] [Google Scholar]
- 27.Zhu X., Feng T., Elston R.C. Linkage-disequilibrium-based binning misleads the interpretation of genome-wide association studies. Am. J. Hum. Genet. 2012;91:965–968. doi: 10.1016/j.ajhg.2012.05.029. author reply 969–970. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Alam K., Wallenius K.T. Distribution of a sum of order statistics. Scand. J. Stat. 1979;6:123–126. [Google Scholar]
- 29.Levy D., Ehret G.B., Rice K., Verwoert G.C., Launer L.J., Dehghan A., Glazer N.L., Morrison A.C., Johnson A.D., Aspelund T. Genome-wide association study of blood pressure and hypertension. Nat. Genet. 2009;41:677–687. doi: 10.1038/ng.384. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Purcell S., Neale B., Todd-Brown K., Thomas L., Ferreira M.A., Bender D., Maller J., Sklar P., de Bakker P.I., Daly M.J., Sham P.C. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 2007;81:559–575. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Willer C.J., Li Y., Abecasis G.R. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics. 2010;26:2190–2191. doi: 10.1093/bioinformatics/btq340. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Wain L.V., Verwoert G.C., O’Reilly P.F., Shi G., Johnson T., Johnson A.D., Bochud M., Rice K.M., Henneman P., Smith A.V., LifeLines Cohort Study. EchoGen consortium. AortaGen Consortium. CHARGE Consortium Heart Failure Working Group. KidneyGen consortium. CKDGen consortium. Cardiogenics consortium. CardioGram Genome-wide association study identifies six new loci influencing pulse pressure and mean arterial pressure. Nat. Genet. 2011;43:1005–1011. doi: 10.1038/ng.922. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Heald A.H., Siddals K.W., Fraser W., Taylor W., Kaushal K., Morris J., Young R.J., White A., Gibson J.M. Low circulating levels of insulin-like growth factor binding protein-1 (IGFBP-1) are closely associated with the presence of macrovascular disease and hypertension in type 2 diabetes. Diabetes. 2002;51:2629–2636. doi: 10.2337/diabetes.51.8.2629. [DOI] [PubMed] [Google Scholar]
- 34.Rajwani A., Ezzat V., Smith J., Yuldasheva N.Y., Duncan E.R., Gage M., Cubbon R.M., Kahn M.B., Imrie H., Abbas A. Increasing circulating IGFBP1 levels improves insulin sensitivity, promotes nitric oxide production, lowers blood pressure, and protects against atherosclerosis. Diabetes. 2012;61:915–924. doi: 10.2337/db11-0963. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Ganesh S.K., Chasman D.I., Larson M.G., Guo X., Verwoert G., Bis J.C., Gu X., Smith A.V., Yang M.L., Zhang Y., Global Blood Pressure Genetics Consortium Effects of long-term averaging of quantitative blood pressure traits on the detection of genetic associations. Am. J. Hum. Genet. 2014;95:49–65. doi: 10.1016/j.ajhg.2014.06.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Ciullo M., Bellenguez C., Colonna V., Nutile T., Calabria A., Pacente R., Iovino G., Trimarco B., Bourgain C., Persico M.G. New susceptibility locus for hypertension on chromosome 8q by efficient pedigree-breaking in an Italian isolate. Hum. Mol. Genet. 2006;15:1735–1743. doi: 10.1093/hmg/ddl097. [DOI] [PubMed] [Google Scholar]
- 37.Azizan E.A., Poulsen H., Tuluc P., Zhou J., Clausen M.V., Lieb A., Maniero C., Garg S., Bochukova E.G., Zhao W. Somatic mutations in ATP1A1 and CACNA1D underlie a common subtype of adrenal hypertension. Nat. Genet. 2013;45:1055–1060. doi: 10.1038/ng.2716. [DOI] [PubMed] [Google Scholar]
- 38.Zhu X., Luke A., Cooper R.S., Quertermous T., Hanis C., Mosley T., Gu C.C., Tang H., Rao D.C., Risch N., Weder A. Admixture mapping for hypertension loci with genome-scan markers. Nat. Genet. 2005;37:177–181. doi: 10.1038/ng1510. [DOI] [PubMed] [Google Scholar]
- 39.Zhu X., Cooper R.S. Admixture mapping provides evidence of association of the VNN1 gene with hypertension. PLoS ONE. 2007;2:e1244. doi: 10.1371/journal.pone.0001244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Balakumar P., Jagadeesh G. Potential cross-talk between (pro)renin receptors and Wnt/frizzled receptors in cardiovascular and renal disorders. Hypertens. Res. 2011;34:1161–1170. doi: 10.1038/hr.2011.113. [DOI] [PubMed] [Google Scholar]
- 41.Schifano E.D., Li L., Christiani D.C., Lin X. Genome-wide association analysis for multiple continuous secondary phenotypes. Am. J. Hum. Genet. 2013;92:744–759. doi: 10.1016/j.ajhg.2013.04.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Lin D.Y., Zeng D. On the relative efficiency of using summary statistics versus individual-level data in meta-analysis. Biometrika. 2010;97:321–332. doi: 10.1093/biomet/asq006. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.