

Abstract
Background
The aim of this study was to create a new meta-analysis method for cost-effectiveness studies using comparative efficiency research (COMER).
Methods
We built a new score named total incremental net benefit (TINB), with inverse variance weighting of incremental net benefits (INB). This permits determination of whether an alternative is cost-effective, given a specific threshold (TINB > 0 test). Before validation of the model, the structure of dependence between costs and quality-adjusted life years (QoL) was analysed using copula distributions. The goodness-of-fit of a Spanish prospective observational study (n = 498) was analysed using the Independent, Gaussian, T, Gumbel, Clayton, Frank and Placket copulas. Validation was carried out by simulating a copula distribution with log-normal distribution for costs and gamma distribution for disutilities. Hypothetical cohorts were created by varying the sample size (n: 15–500) and assuming three scenarios (1-cost-effective; 2-non-cost-effective; 3-dominant). The COMER result was compared to the theoretical result according to the incremental cost-effectiveness ratio (ICER) and the INB, assuming a margin of error of 2,000 and 500 monetary units, respectively.
Results
The Frank copula with positive dependence (−0.4279) showed a goodness-of-fit sufficient to represent costs and QoL (p-values 0.524 and 0.808). The theoretical INB was within the 95% confidence interval of the TINB, based on 15 individuals with a probability > 80% for scenarios 1 and 2, and > 90% for scenario 3. The TINB > 0 test with 15 individuals showed p-values of 0.0105 (SD: 0.0411) for scenario 1, 0.613 (SD: 0.265) for scenario 2 and < 0.0001 for scenario 3.
Conclusions
COMER is a valid tool for combining cost-effectiveness studies and may be of use to health decision makers.
Electronic supplementary material
The online version of this article (doi:10.1186/1471-2288-14-139) contains supplementary material, which is available to authorized users.
Keywords: Cost-effectiveness analysis, Meta-analysis, Incremental net benefit, Copula distribution
Background
Economic evaluation of health technologies (EEHT) has become a first-order health policy decision making tool at the European level. EEHT allows both the economic and clinical value of technologies (drugs, devices, health programs, etc.) to be evaluated [1] and, when used for the allocation of health resources, allows decision-makers to make informed decisions on specific problems by combining the probabilities of all possible outcomes and the health benefits assigned to each of them [2, 3].
In the last decade, there has been a rise in EEHT, as reflected by the large amount of cost-effectiveness studies [4, 5] and the interest in the technological advances generated by their results. Although cost-effectiveness analyses (CEA) have improved due to the development of methods of synthesizing evidence, systematic revisions and direct, indirect and mixed meta-analyses [6, 7], there is still no consensual method for carrying out meta-analyses of CEA. Proposed methods range from mere qualitative review of CEA [8, 9] to the categorization of CEA according to whether the costs are higher, the same or lower and whether the effects are better, the same or poorer, in order to assess how many CEA there are in each category [10]. We suggest that the method for meta-analyses of CEA proposed here, which is known as COMparative Efficiency Research (COMER), and which groups together studies on a specific topic, may represent reality more closely and allow more evidence-based decision making. As for any meta-analysis, the validity of the COMER method will depend on systematic review of the types of studies supporting the data, the populations assessed and the variability or levels of consistency between centres and/or studies.
Although meta-analyses usually use aggregate study data, recent research has shown that the use of individual-level data or individual- and aggregate-level data, allows for a better estimate of variability [11, 12]. Therefore, the COMER method should be able to use both individual and aggregate data, although it remains difficult to obtain original data from clinical studies for use by researchers other than the original authors [13].
The aim of this study was to create a method of CEA meta-analysis based on either individual or aggregate data through the generation of a multivariate distribution function which allows the dependence between costs and effects to be modelled. This mathematical dependence is called copula.
Methods
Cost-effectiveness studies compare the efficiency of therapies evaluated using the incremental cost-effectiveness ratio (ICER), where the numerator is the difference between the estimated cost of the new treatment and that of the reference treatment and the denominator estimates the effectiveness gained by the new treatment compared with the reference treatment [1].
| 1 |
where 1 and 2 correspond to the new treatment and the reference treatment, respectively.
Thus, when the therapy being assessed is more expensive than the reference treatment, and is also less effective, the new treatment is dominated. When the treatment is more effective than the reference treatment, and also less expensive, the new treatment is dominant over the reference treatment. In the remaining cases, the ICER must be compared with the willingness to pay (k) to assess whether the new treatment is cost-effective (ICER < = k) or not cost-effective (ICER > k) [1, 2]. The choice of the threshold of efficiency remains an unresolved issue in many health systems. Theoretically, the threshold of efficiency should be related to the value that society accords to a health outcome in, for example, life years gained, depending on the available resources [1, 2].
One limitation of the ICER is that, as it is a ratio, the expected value of the ICER represents the difference in the expected cost divided by the difference in the expected effectiveness. Therefore, the main difficulty in making inferences from cost-effectiveness studies is that the random variable obtained is not necessarily normal or symmetric [14]. However, even when cost and effectiveness data are distributed normally, there is no guarantee that the ratio between them will also behave normally and, ultimately, it is not possible to calculate the confidence intervals (CI). Thus, there is a need to use alternative methods, such as bootstrapping or incremental net benefits (INB) for this purpose [15].
Therefore, the COMER methodology, both for individual and aggregate data, consists of estimating the total incremental net benefit (TINB) according to the INB of the studies included weighted by the inverse of the variance of each INB.
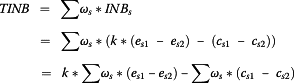 |
2 |
Where s is the number of the study and 1 and 2 the new treatment and reference treatment, respectively:
and
| 3 |
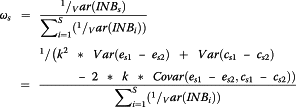 |
and the variance is:
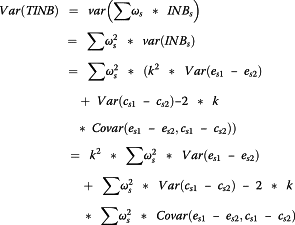 |
4 |
According to the central limit theorem, the INB is asymptotically normal [15] and the TINB is also asymptotically normal when the mean and variance is known, and the probability of the TINB being < 0 can be calculated. Therefore, the decision criterion will be that the new treatment is cost-effective for the established threshold if the probability is lower than 5% (Table 1).
Table 1.
Summary of COMER outcomes
| Study | Alternative 1 | Alternative 2 | ICER | INB (variance) | INB <0 (%)* | Weight (%) | ||
|---|---|---|---|---|---|---|---|---|
| Costs | Effects | Costs | Effects | |||||
| 1 | c11 | e11 | c12 | e12 | ICER1 | INB1 (Var(INB1)) | P(x1<0) | ω1 |
| 2 | c21 | e21 | c22 | e22 | ICER2 | INB2 (Var(INB2)) | P(x2<0) | ω2 |
| 3 | c31 | e31 | c32 | e32 | ICER3 | INB3 (Var(INB3)) | P(x3<0) | ω3 |
| Σ ωs *cs1 | Σ ωs *es1 | Σ ωs *cs2 | Σ ωs *es2 | ICERS | TINB =Σ ωs *INBs, (Var(TINB)) | P(TINB<0) | Σ ωs=1 | |
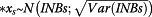
ICER: Incremental Cost-effectiveness Ratio; INB: Incremental Net Benefit.
TINB: Total Incremental Net Benefit.
Equivalently,
with
 |
Validation of the method
The costs and effects of individual patients were modelled for marginal distributions to illustrate the COMER method. The use of the copula distribution, which permits the joint distribution of costs and effects to be obtained, has been suggested [16], since the dependence between costs and effects does not have to be linear. In this way, a cost and effect dependence structure is obtained through the copula and their univariate behaviour.
The process carried out consisted of:
Identifying the copula: the joint distribution that best fits the costs and effects.
Creating a simulated cohort under the marginal and joint distribution for each alternative compared.
COMER estimation.
Method validation.
Identification of marginal distributions and copula
Copulas are bivariate distributions that provide dependent structures for two statistical variables, with any type of univariate distribution [17–19]. In its construction, a C(u,v) copula is a multivariate distribution function defined from U and V random variables with uniform distribution in the interval [0,1], which verifies the following properties:
C(u, 0) = 0 = C(0, v)
C(u, 1) = u and C(1, v) = v
For u1, u2, v1, v2 in [0, 1] so that u1 ≤ u2 and v1 ≤ v2, C(u2, v2) − C(u2, v1) − C(u1, v2) + C(u1, v1) ≥ 0.
Since the relationship between random variables is not based on the distribution, but rather constructed from mathematical structures between random variables, dependence can be evaluated using non-parametric correlation statistics (Spearman’s ρs and Kendall’s τ), which are independent on marginal distributions.
Copula distributions are little used in health economics, and are mainly applied to specify the distribution of regression models with more than one dependent variable [20–23]. We used copulas to describe the dependence structure of cost-effect random variables, allowing random generation of a patient cohort under such a distribution in order to make different simulations. By applying copulas to EEHT, the joint distribution of each treatment can be simulated, since Cj(cij,eij) is a copula for treatment j, where costs (c) and effects (e) are known for each patient i. In addition, Sklar’s theorem [24] shows that, given a copula (the joint distribution), the copula can be reconstructed through the marginal theoretical or empirical inverse distribution function, according to the specific case. However, recent studies show that there is no justification for the claim that a specific copula may be the most appropriate for the combination of costs and effects, not even when costs are broken down into direct and indirect costs, or if effects are represented by the following measurements: therapeutic success, life years, or quality-adjusted life years (QALY) [25].
To create a hypothetical population to test the validity of the COMER methodology, we used data from a Spanish prospective observational study of patients with allergic rhinitis (n = 498) with direct costs (c) and mean utilities from the SF-12v1 (e) [26]. The study served to obtain a copula structure which, by adding some theoretical marginal distributions, allowed the generation of a hypothetical population on which to apply the COMER methodology. The empirical copula was compared to the parametric estimate of the potential copula (Additional file 1) to evaluate the goodness of fit of the data with the theoretical copulas [27]. The copula bound to evaluate the goodness of fit was developed using the inversion of Kendall’s τ. The p-value of the test was calculated by simulation of size-100 bootstrap, due to the lack of an analytical construction.
The following copulas were evaluated [19, 25, 28]:
Independent copula: this can be generated automatically since, given U and V random variables, the joint distribution function is C0(u, v) = u * v. Thus, the association between this copula and some data indicates the stochastic independence of U and V; equivalently, the absence of structure.
Gaussian copula: this is defined as G∅(u, v) = Nρ(Φ− 1(u), Φ− 1(v)) where Nρ(x, y) is the normal distribution function of parameters x: mean and y: the standard deviation, Φ− 1(x) is the marginal distribution function N(0,1) and ρ is Pearson’s correlation coefficient. The Gaussian copula is still a multivariate normal distribution.
T copula: this is derived from the Student’s t multivariate distribution and is defined as  where |ρ| < 1, θ > 0. This copula shows a similar structure to the Gaussian copula, but presents tail dependence, points (0,1) and (1,0). One of its qualities is that it includes the Gaussian copula when θ → ∞.
where |ρ| < 1, θ > 0. This copula shows a similar structure to the Gaussian copula, but presents tail dependence, points (0,1) and (1,0). One of its qualities is that it includes the Gaussian copula when θ → ∞.
Gumbel copula: this allows a positive dependence structure to be modelled, region (1,1), and is defined as  where θ ∈ [1, ∞]. When θ = 1 it is equivalent to the independent copula and when θ → ∞ it behaves as a comonotonic copula (min(u,v)). Thus, the behaviour of the Gumbel copula is an interpolation between the independent copula and the copula of perfect positive dependence.
where θ ∈ [1, ∞]. When θ = 1 it is equivalent to the independent copula and when θ → ∞ it behaves as a comonotonic copula (min(u,v)). Thus, the behaviour of the Gumbel copula is an interpolation between the independent copula and the copula of perfect positive dependence.
Clayton copula: this is defined as  where θ > 0. Like the Gumbel copula, this copula is an interpolation but lies between the independent copula and the perfect negative dependence (point (0,0)).
where θ > 0. Like the Gumbel copula, this copula is an interpolation but lies between the independent copula and the perfect negative dependence (point (0,0)).
Frank Copula: this has the quality of showing symmetric dependencies and not showing dependence at points (0,0) and (1,1). It is defined as 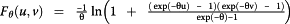 where θ ∈ ℝ \{0}.
where θ ∈ ℝ \{0}.
Plackett copula: this is defined as 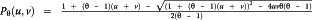 where θ ≥ 0. This structure shows both positive and negative maximum dependence in function of parameter θ.
where θ ≥ 0. This structure shows both positive and negative maximum dependence in function of parameter θ.
Creation of cohorts
Once the joint distribution was known, some theoretical marginal distributions were associated. To simulate costs, a lognormal distribution was associated, and to simulate life quality, a gamma distribution was associated (disutilities), with respect to a baseline quality of life (0.9 utility) [14] (Table 2). For the two alternatives, the same copula and the same randomization (bivariate uniforms [0,1]) were used. This ensured covariance and correlation between the values generated for the costs and effects. Different random samples per cohort were created with sample sizes between 15 and 500 individuals for each alternative. Individuals in the simulated cohort were randomly assigned to the studies. To ensure that there was a minimum variability per study, the random assignation was conditioned to ensure that, for each study, there were at least 3 individuals.
Table 2.
Simulated scenarios
| Scenario 1: Cost-effective | ||
| CONTROL | ACTIVE | |
| Cost | Lognormal (6.214608, 0.75) | Lognormal (6.907755, 0.75) |
| Effect | 0.9-Gamma (6.25, 0.024) | 0.9-Gamma (2, 0.05) |
| ICER | 13,247.85 = (1,324.78 - 662.39)/(0.8-0.75) | |
| INB* | 837.61 | |
| Scenario 2: Non-cost-effective | ||
| CONTROL | ACTIVE | |
| Cost | Lognormal (6.214608, 0.75) | Lognormal(6.214608, 0.75) |
| Effect | 0.9-Gamma (6.25, 0.024) | 0.9-Gamma (4.5, 0.03) |
| ICER | 44,159.49 = (1,324.78 - 662.39)/(0.765-0.75) | |
| INB* | −212.39 | |
| Scenario 3: Dominant | ||
| CONTROL | ACTIVE | |
| Cost | Lognormal (6.907755, 0.75) | Lognormal (6.214608, 0.75) |
| Effect | 0.9-Gamma (6.25, 0.024) | 0.9-Gamma (2, 0.05) |
| ICER | −13,247.85 = (662.39 – 1,324.78)/(0.8-0.75) | |
| INB* | 2,162.39 | |
ICER: Incremental Cost-effectiveness Ratio; INB: Incremental Net Benefit.
*k=30,000.
The COMER methodology was applied to the simulated data for each alternative. For each alternative the mean costs, mean effectiveness, differential variance in costs, differential variance in effects and covariance between the differences in costs and effects, and the INB were estimated, setting an efficiency threshold (k = 30,000 monetary units per QALY gained). For example, of a sample of 15 individuals, the seven first could be assigned to study 1, the following five to study 2, and the remaining three to study 3, and the COMER methodology applied (Additional file 2).
For each sample size generated, 500 replications were made, entailing 25,000 meta-analyses for each scenario, thus allowing the number of the times the methodology agreed with reality to be validated. A 2,000-monetary-unit/QALY-tolerance was assumed to calculate the ICER, and a 500-monetary-unit-tolerance was assumed for the TINB. Additionally, we estimated the minimum sample size required to obtain an adjusted estimate with a probability >70% and when simulations converged to the original Kendall’s τ.
The following are the scenarios evaluated by modifying the marginal distribution parameters (Table 2):
The second alternative is cost-effective.
The second alternative is more costly and more effective, although the ICER is above the willingness to pay threshold.
The second alternative is dominant.
All the possibilities are covered by these scenarios since the remaining potential outcomes derived from an EEHT which have not explicitly been evaluated are obtained assuming that the current alternative is the second alternative instead of the first.
The analysis was made using the R 3.0.1 statistical package (Additional file 3). In addition, the COMER method is included as an Excel file in the supplementary materials (Additional file 4).
Results
Comparison of the copulas used with the real costs and effects data showed p-values between 0.075 and 0.191 for the independent distribution, 0.443 and 0.769 for the Gaussian copula, 0.309 and 0.633 for the T copula, 0.004 and 0.034 for the Gumbel copula, 0.242 and 0.526 for the Clayton copula, 0.524 and 0.808 for the Frank copula and 0.531 and 0.808 for the Plackett copula (Table 3).
Table 3.
Goodness-of-fit of p values (100 times)
| Minimum | 1st quartile | Median | Mean | 3rd quartile | Maximum | |
|---|---|---|---|---|---|---|
| Independent | 0.075 | 0.105 | 0.121 | 0.119 | 0.129 | 0.191 |
| Gaussian | 0.443 | 0.558 | 0.61 | 0.599 | 0.637 | 0.769 |
| T | 0.309 | 0.457 | 0.49 | 0.489 | 0.532 | 0.633 |
| Gumbel | 0.004 | 0.011 | 0.014 | 0.015 | 0.018 | 0.034 |
| Clayton | 0.242 | 0.355 | 0.398 | 0.395 | 0.435 | 0.526 |
| Frank | 0.524 | 0.663 | 0.695 | 0.696 | 0.738 | 0.808 |
| Plackett | 0.531 | 0.668 | 0.71 | 0.703 | 0.739 | 0.808 |
Therefore, both the Frank and Plackett copulas were candidates to be the copula for the distribution of the simulated cohort. We opted for the Frank copula, which showed a value of −0.4279 (p-value: 0.128), indicating a positive dependence between costs and effects (Figure 1).
Figure 1.
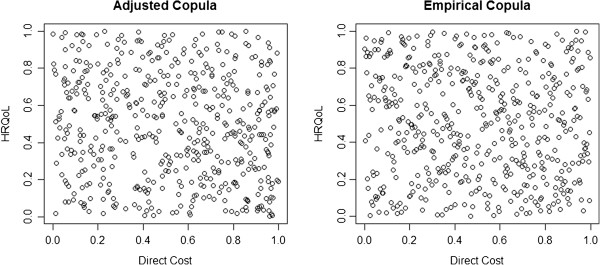
Adjusted Copula (Frank Copula) vs. Empirical Copula.
Evaluation of the convergence from the empirical to the theoretical Kendall’s τ showed a range between −0.505 and 0.543 for 15 simulated individuals (mean: 0.029; SD: 0.192), between −0.135 and 0.228 for 115 individuals (mean: 0.046; SD: 0.062) and between −0.059 and 0.130 for 415 individuals (mean: 0.049; SD: 0.029).
-
Cost-effective scenario
In the cost-effectiveness scenario it was observed that, starting from a sample size of 75 individuals per cohort, both the ICER and the INB were within the tolerance. It was also observed that, when the number of simulated individuals was increased, the adjustment increased with probabilities > 90%.
Comparison of the INB with the individual data and the TINB showed a minimum of 175, 115 and 75 individuals were necessary to obtain a probability greater than 70%, when tolerances of 6%, 9% and 12%, respectively, were assumed. However, the INB was within the CI of the TINB with a probability > 85% for samples of > 15 individuals and > 90% for samples > 25 individuals. The same happened when the CI of the TINB for each meta-analysis was compared with the theoretical value of the INB. (+80% for 15+ individuals and +90% for 25+ individuals) (Figure 2A).
With respect to the probability of alternative 2 being cost-effective, for the sample size of 15 individuals, the p-value was 0.0105 (SD: 0.0411), for 115 individuals it was 0.015 (SD: 0.0214) and for 415 individuals it was 0.0165 (SD: 0.0128). Thus, for the meta-analyses obtained, alternative 2 was cost-effective.
-
Non-cost-effective scenario
The ICER reached values > 70% within the tolerance, from 400 individuals upwards. Because the denominator of the ICER had a mean difference of 0.01 QALYs, the ICER showed values between 19,840 and 103,436 for n: 15. This meant that, in 7% of the simulations with n: 15 and in 1% of those with n:35,the ICER was inferior to the willingness-to-pay, and was thus cost-effective. However, the probability of the INB being within the tolerance (500 monetary units) was > 95% for any sample size.
Comparison of the INB with the individual data with respect to the 95% CI of the TINB showed a probability of 85% for samples > 15 individuals. The same occurred when the 95% CI of the TINB for each meta-analysis was compared with the theoretical value of the INB (+80% for 15+ individuals and +90% for 25+ individuals) (Figure 2B). The mean difference between the mean TINB and the theoretical value showed a range of 15 to 121 monetary units.
With respect to the probability of alternative 2 being cost-effective, for the sample size of 15 individuals, the p-value was 0.613 (SD: 0.265), for 115 individuals it was 0.709 (SD: 0.123) and for 415 individuals it was 0.729 (SD: 0.072). Thus, for the meta-analyses obtained, the outcome showed that alternative 2 was not cost-effective.
-
Dominant scenario
The ICER reached values > 70% within the tolerance, from 35 individuals upwards, while the INB reached these values from 15 individuals upwards. Furthermore, when comparing the INB with the individual data and the theoretical INB with a 6% tolerance, a probability > 70% was obtained from 35 individuals upwards.
When the INB of the individual data or the theoretical INB was within the CI, probabilities > 90% were observed for any sample size (Figure 2C). Regarding the probability of alternative 2 being cost-effective, scenario 3 showed p-values < 0.0001 for any sample size.
Figure 2.
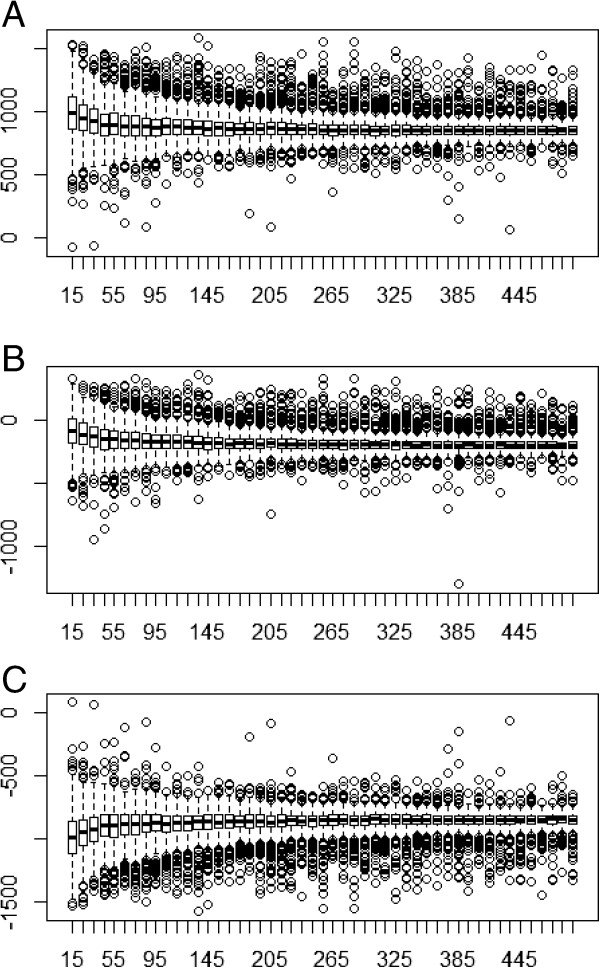
Boxplot of TINB convergence. A: Cost-effective scenario; B: Non-cost-effective scenario; C: Dominant scenario.
Discussion
EEHT are a set of tools which aim to examine the short and long-term consequences of using health technologies on individuals and on society. Since there are numerous alternatives for allocating those resources, EEHT tries to make relevant information from the efficiency perspective available to health decision makers, understanding efficiency as the maximization of health gains obtained from the limited resources available. The application of COMER in decision-making may allow decision-makers to move from evidence-based medicine to economic evaluation based on evidence, understanding evidence within a comprehensive framework where both clinical and economic evidence are compatible. COMER may be applied both in studies where individual level data or aggregate level data are available, always provided the covariance matrix of the difference between costs and effects, the mean cost and the mean effects of each alternative are available. When there is access to individual data from clinical studies, these measurement can be obtained through bootstrapping [29–31], and in the case of economic evaluation models, they can be obtained from the Monte Carlo simulation [14]. The advantage of bootstrapping is that it is a non- parametric method which does not presuppose any distribution and is based on studying the sample as if it were the population, through resampling [30].
We believe that the fact that the simulated individuals were only assigned to 3 studies did not influence the results. Although many meta-analyses agglutinate more than 3 studies, the number of studies used was the minimum required to enable evaluation of the generalization of the results. In addition, in the assignation of individuals per study we forced the assignation of three or more individuals to avoid studies with minimum or null variability. Although, in reality it is unusual to find studies with 3 cases, analysis of very-small samples allows a small number of individuals to be assigned, thus generating greater heterogeneity between studies, as occurs in reality. However, the analysis with small simple sizes showed, as expected, greater divergence in the results obtained using the ICER and the TINB. Likewise, using two theoretical distributions such as the lognormal for costs and the gamma for disutilities is sufficient to validate the method. Furthermore, since approximation by copulas is independent of marginal distributions, and because typical theoretical distributions were selected to simulate the uncertainty of the costs and disutilities, we believe that the outcome is not biased by this decision. However, any interpretation of the COMER methodology must take into consideration the field in which it has been implemented and validated. In addition, the meta-analysis constructed has fixed effects (inverse variance weighting), which means it must be assumed that the studies are homogenous. This assumption does not necessarily occur in reality, and even though, to validate the method, different sample sizes and high levels of variance (e.g., a coefficient of variation for the costs >1) were used to generate greater heterogeneity in the study data, this should be taken into account when interpreting the results. Future studies should use the COMER methodology to develop a method to adjust the divergences in the homogeneity of the populations evaluated, similar to that carried out for meta-regressions.
A potential limitation to applying the COMER method is that health systems in different countries can generate different resource uses and, hence, different total costs. For this reason, the transfer of economic evaluations must be assessed and costs must be homogenized before using this method [32–34]. When using studies from different countries with potentially-similar cost structures, the currencies must be homogenized to US dollar equivalents and costs must be updated to the same year, as is done in comparisons made by the World Health Organization [35], the OECD [36] or the IMF [37].
Some authors suggest that a separate cost and effectiveness meta-analysis is sufficient to make an appropriate value judgment [38], while other suggest assessment of the results of the costs and marginal effects of CEA in order to evaluate the worth of a new treatment [10]. However, we believe that the COMER method has potential applications, even for teams with limited resources. Mere systematic review and meta-analysis, separate from economic evaluation studies, are not an EEHT per se, as they could lead decision makers to draw the wrong conclusion due to the impossibility of balancing global costs and effects and measuring additional value. EEHT should be accompanied by a fuller meta-analysis such as the proposed COMER method, although a full, new EEHT might be necessary if sufficient information were not obtained by the COMER method.
Conclusions
Systematic review of economic analyses requires methods to synthesize and interpret the results of multiple analyses. The COMER methodology is a valid option for the analysis of both individual and aggregate data and may allow decision-makers to better understand the added value of new therapeutic alternatives by synthesizing all available evidence. The COMER methodology opens the way to further research of this type of meta-analysis with two variables having a known dependence structure [16], both from a frequentist and from a Bayesian perspective [39].
Electronic supplementary material
Additional file 1: Copula distributions and associated correlation. (DOC 276 KB)
Additional file 2: Example of the COMER with a sample size of 15 (scenario cost-effective). (DOC 66 KB)
Additional file 3: Script COMER function in R. (DOC 31 KB)
Additional file 4: Comparative efficiency research (COMER) template. (XLSX 17 KB)
Acknowledgments
We wish to thank Prof. Carles Cuadras for his invaluable help in providing more information on copula distributions in one of his seminars.
Abbreviations
- CEA
Cost-effectiveness analyses
- CI
Confidence interval
- COMER
Comparative efficiency research
- EEHT
Economic evaluation of health technologies
- ICER
Incremental cost-effectiveness ratio
- INB
Incremental net benefits
- QALY
Quality adjusted life years
- SD
Standard deviation
- TINB
Total incremental net benefit.
Footnotes
Competing interest
The authors declare that they have no competing interests.
Authors’ contributions
CC developed the idea for the study, conducted the research and data analysis, wrote the COMER program, and drafted the report. WD provided background information based on experience with copula distributions. All investigators contributed to the final version of the report and they agree to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved. All authors read and approved the final manuscript.
Contributor Information
Carlos Crespo, Email: ccrespo@ub.edu.
Antonio Monleon, Email: amonleong@ub.edu.
Walter Díaz, Email: waldiaz@live.com.
Martín Ríos, Email: mrios@ub.edu.
References
- 1.Drummond MF, Sculpher MJ, Torrance GW, O’Brien BJ, Stoddart GL. Methods for the economic evaluation of health care programmes. 3. Oxford: Oxford University Press; 2005. [Google Scholar]
- 2.Gisbert R. Economía y Salud. Economía, gestión económica y evaluación en el ámbito sanitario. Barcelona: Masson; 2002. [Google Scholar]
- 3.Oliva J, Antoñanzas F, Rivero-Arias O. Evaluación económica y la toma de decisiones en salud. El papel de la evaluación económica en la adopción y difusión de tecnologías sanitarias. Informe SESPAS 2008. Gac Sanit. 2008;22(Suppl 1):137–42. doi: 10.1016/S0213-9111(08)76085-0. [DOI] [PubMed] [Google Scholar]
- 4.Neumann PJ, Fang CH, Cohen JT. 30 years of pharmaceutical cost-utility analyses: growth, diversity and methodological improvement. Pharmacoeconomics. 2009;27(10):861–72. doi: 10.2165/11312720-000000000-00000. [DOI] [PubMed] [Google Scholar]
- 5.Rodríguez Barrios JM, Pérez Alcántara F, Crespo Palomo C, González García P, Antón De Las Heras E, Brosa Riestra M. The use of cost per life year gained as a measurement of cost-effectiveness in Spain: a systematic review of recent publications. Eur J Health Econ. 2012;13(6):723–40. doi: 10.1007/s10198-011-0326-y. [DOI] [PubMed] [Google Scholar]
- 6.Sutton A, Ades AE, Cooper N, Abrams K. Use of indirect and mixed treatment comparisons for technology assessment. Pharmacoeconomics. 2008;26(9):753–67. doi: 10.2165/00019053-200826090-00006. [DOI] [PubMed] [Google Scholar]
- 7.Hoaglin DC, Hawkins N, Jansen JP, Scott DA, Itzler R, Cappelleri JC, Barrett A. Conducting indirect-treatment-comparison and network-meta-analysis studies: report of the ISPOR Task Force on Indirect Treatment Comparisons Good Research Practices: part 2. Value Health. 2011;14(4):429–37. doi: 10.1016/j.jval.2011.01.011. [DOI] [PubMed] [Google Scholar]
- 8.Luce BR, Simpson K. Methods of cost-effectiveness analysis: areas of consensus and debate. Clin Ther. 1995;17(1):109–25. doi: 10.1016/0149-2918(95)80012-3. [DOI] [PubMed] [Google Scholar]
- 9.Drummond MF, Shemilt I, Vale L, On behalf of the Campbell and Cochrane Economic Methods group . Should The Cochrane Collaboration be Producing Reviews of Efficiency? York, UK: The Cochrane Collaboration; 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Nixon J, Khan KS, Kleijnen J. Summarising economic evaluations in systematic reviews: a new approach. BMJ. 2001;322(7302):1596–8. doi: 10.1136/bmj.322.7302.1596. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Saramago P, Manca A, Sutton AJ. Deriving input parameters for cost-effectiveness modeling: taxonomy of data types and approaches to their statistical synthesis. Value Health. 2012;15(5):639–49. doi: 10.1016/j.jval.2012.02.009. [DOI] [PubMed] [Google Scholar]
- 12.Signorovitch JE, Sikirica V, Erder MH, Xie J, Lu M, Hodgkins PS, Wu EQ. Matching-adjusted indirect comparisons: a new tool for timely comparative effectiveness research. Value Health. 2012;15(6):940–7. doi: 10.1016/j.jval.2012.05.004. [DOI] [PubMed] [Google Scholar]
- 13.Van Walraven C. Individual patient meta-analysis: rewards and challenges. J Clin Epidemiol. 2010;63(3):235–7. doi: 10.1016/j.jclinepi.2009.04.001. [DOI] [PubMed] [Google Scholar]
- 14.Briggs A, Sculpher M, Claxton K. Decision Modelling for Health Economic Evaluation. Oxford UK: Oxford University Press; 2006. Handbooks in Health Economic Evaluation. [Google Scholar]
- 15.Stinnett AA, Mullahy J. Net health benefits: a new framework for the analysis of uncertainty in cost–effectiveness analysis. Med Decis Making. 1998;18:S68–80. doi: 10.1177/0272989X9801800209. [DOI] [PubMed] [Google Scholar]
- 16.Naveršnik K, Rojnik K. Handling input correlations in pharmacoeconomic models. Value Health. 2012;15(3):540–9. doi: 10.1016/j.jval.2011.12.008. [DOI] [PubMed] [Google Scholar]
- 17.Cuadras CM. Probability distributions with given multivariate marginals and given dependence structure. J Multivar Anal. 1992;42:51–66. doi: 10.1016/0047-259X(92)90078-T. [DOI] [Google Scholar]
- 18.Genest C, MacKay J. The joy of copulas: bivariate distributions with uniform marginals. Am Stat. 1986;40:280–283. [Google Scholar]
- 19.Nelsen RB. An Introduction to Copulas. 2. New York: Springer; 2006. [Google Scholar]
- 20.Smith M. Modelling sample selection using Archimedean copulas. Econometrics J. 2003;6:99–123. doi: 10.1111/1368-423X.00101. [DOI] [Google Scholar]
- 21.Quinn C: Generalisable Regression Methods for Cost-Effectiveness using Copulas. HEDG Working Paper 05/13. http://www.york.ac.uk/economics/postgrad/herc/hedg/wps/wp2005/
- 22.Quinn C: Improving Precision in Cost-Effectiveness Analysis using Copulas. HEDG Working Paper 07/23. http://www.york.ac.uk/media/economics/documents/herc/wp/07_23.pdf
- 23.Murteira JMR, Lourenço OD: Health Care Utilization and Self-Assessed Health: Specification of Bivariate Models Using Copulas. HEDG Working Paper 07/27. http://www.york.ac.uk/media/economics/documents/herc/wp/07_27.pdf
- 24.Sklar A. Fonctions de Répartition à n Dimensions et Leurs Marges. 1959. pp. 229–231. [Google Scholar]
- 25.Diaz W. Contribution to Dependence and Dimensionality in Copulas. Barcelona, Spain: University of Barcelona, Statistical Department; 2012. PhD Thesis. [Google Scholar]
- 26.Colas C, Valero A: Direct and Indirect Cost of Allergic Rhinitis in Spain. Reunión Anual de la Asociación Aragonesa de Alergia 2012 Plenary session; http://www.alergoaragon.org/2012/inaugural1.html
- 27.Fermanian JD. Goodness-of-fit tests for copulas. J Multivar Anal. 2005;95(1):119–152. doi: 10.1016/j.jmva.2004.07.004. [DOI] [Google Scholar]
- 28.Yan J. Enjoy the joy of copulas: with a package copula. J Stat Softw. 2007;21(4):1–21. [Google Scholar]
- 29.Briggs AH, Wonderling DE, Mooney CZ. Pulling cost-effectiveness analysis up by its bootstraps: a non- parametric approach to confidence interval estimation. Health Econ. 1997;6(4):327–40. doi: 10.1002/(SICI)1099-1050(199707)6:4<327::AID-HEC282>3.0.CO;2-W. [DOI] [PubMed] [Google Scholar]
- 30.Campbell MK, Torgerson DJ. Bootstrapping: estimating confidence intervals for cost-effectiveness ratios. QJM. 1999;92(3):177–82. doi: 10.1093/qjmed/92.3.177. [DOI] [PubMed] [Google Scholar]
- 31.Hunink MG, Bult JR, de Vries J, Weinstein MC. Uncertainty in decision models analyzing cost-effectiveness: the joint distribution of incremental costs and effectiveness evaluated with a nonparametric bootstrap method. Med Decis Making. 1998;18(3):337–46. doi: 10.1177/0272989X9801800312. [DOI] [PubMed] [Google Scholar]
- 32.Drummond M, Pang F. Transferability of economic evaluation results. In: Drummond M, McGuire A, editors. Economic Evaluation in Health Care: Merging Theory with Practice. New York (NY): Oxford University Press; 2001. [Google Scholar]
- 33.Sculpher MJ, Pang FS, Manca A, Drummond MF, Golder S, Urdahl H, Eastwood A. Generalisability in economic evaluation studies in healthcare: a review and case studies. Health Technol Assess. 2004;8(49):1–192. doi: 10.3310/hta8490. [DOI] [PubMed] [Google Scholar]
- 34.Antonanzas F, Rodríguez-Ibeas R, Juárez C, Hutter F, Lorente R, Pinillos M. Transferability indices for health economic evaluations: methods and applications. Health Econ. 2009;18(6):629–43. doi: 10.1002/hec.1397. [DOI] [PubMed] [Google Scholar]
- 35.Tan-Torres Edejer T, Baltussen R, Adam T, Hutubessy R, Acharya A, Evans DB, Murray CJL. Making Choices in Health: WHO Guide to Cost-Effectiveness Analysis. Geneva: World Health Organization; 2003. [Google Scholar]
- 36.Organisation for Economic Co-operation and Development: Purchasing Power Parities for GDP dataset (1960–2012). http://stats.oecd.org/Index.aspx?datasetcode=SNA_TABLE4#
- 37.International Monetary Fund . World Economic Outlook Database. 2013. [Google Scholar]
- 38.Shemilt I, McDaid D, Marsh K, Henderson C, Bertranou E, Mallander J, Vale L. Issues in the incorporation of economic perspectives and evidence into Cochrane reviews. Syst Rev. 2013;2(1):83. doi: 10.1186/2046-4053-2-83. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Moreno E, Girón FJ, Vázquez-Polo FJ, Negrín MA. Complementing information from incremental net benefit: a Bayesian perspective. Health Serv Outcomes Res Met. 2010;10:86–99. doi: 10.1007/s10742-010-0059-x. [DOI] [Google Scholar]
Pre-publication history
- The pre-publication history for this paper can be accessed here: http://www.biomedcentral.com/1471-2288/14/139/prepub
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Additional file 1: Copula distributions and associated correlation. (DOC 276 KB)
Additional file 2: Example of the COMER with a sample size of 15 (scenario cost-effective). (DOC 66 KB)
Additional file 3: Script COMER function in R. (DOC 31 KB)
Additional file 4: Comparative efficiency research (COMER) template. (XLSX 17 KB)