

Abstract
Formulation of speech separation as a supervised learning problem has shown considerable promise. In its simplest form, a supervised learning algorithm, typically a deep neural network, is trained to learn a mapping from noisy features to a time-frequency representation of the target of interest. Traditionally, the ideal binary mask (IBM) is used as the target because of its simplicity and large speech intelligibility gains. The supervised learning framework, however, is not restricted to the use of binary targets. In this study, we evaluate and compare separation results by using different training targets, including the IBM, the target binary mask, the ideal ratio mask (IRM), the short-time Fourier transform spectral magnitude and its corresponding mask (FFT-MASK), and the Gammatone frequency power spectrum. Our results in various test conditions reveal that the two ratio mask targets, the IRM and the FFT-MASK, outperform the other targets in terms of objective intelligibility and quality metrics. In addition, we find that masking based targets, in general, are significantly better than spectral envelope based targets. We also present comparisons with recent methods in non-negative matrix factorization and speech enhancement, which show clear performance advantages of supervised speech separation.
Index Terms: Deep neural networks, speech separation, supervised learning, training targets
I. Introduction
SPEECH separation, which is the task of separating speech from a noisy mixture, has major applications, such as robust automatic speech recognition (ASR), hearing aids design, and mobile speech communication. Monaural speech separation (i.e., speech separation from single-microphone recordings) is perhaps most desirable from the application standpoint. Compared to multi-microphone solutions, a monaural system is less sensitive to room reverberation and spatial source configuration [38]. On the other hand, monaural separation is a severely underdetermined figure-ground separation problem. This study focuses on monaural separation.
Monaural speech separation has been widely studied in the speech and signal processing community for decades. From the signal processing viewpoint, many methods have been proposed to estimate the ideal Wiener filter, which is the optimal filter to recover clean speech in the minimum mean squared error (MMSE) sense [21]. A popular alternative to Wiener filtering is statistical model-based methods [13], [21], which infer speech spectral coefficients given noisy observations under prior distribution assumptions for speech and noise. Signal processing based methods usually work reasonably well in relatively high signal-to-noise ratio (SNR) conditions. However, they are generally less effective in low SNR and non-stationary noise conditions [21].
In contrast to signal processing based methods, model-based methods build models of speech and/or noise using premixed signals and show promising results in challenging conditions. For example, techniques in [14], [26] build probabilistic interaction models between different sources based on learned priors, and show significant performance gain in low SNR conditions. Another line of work is non-negative matrix factorization (NMF) [22], [31], where noisy observations are modeled as weighted sums of non-negative source bases. These model-based methods work well if underlying assumptions are met. However, in our experience (see e.g. [37]), these methods do not generalize well to unseen noisy conditions and are mostly effective for structured interference, e.g. music or a competing speaker. Moreover, these methods often require expensive inference, making them hard to use in real-world speech applications.
Recently, we have formulated monaural speech separation as a supervised learning problem, which is a data driven approach. In the simplest form, acoustic features are extracted from noisy mixtures to train a supervised learning algorithm, e.g. a deep neural network (DNN) [36]. In many previous studies (e.g. [10], [16], [17]), the training target (or the learning signal) is set to the ideal binary mask (IBM), which is a binary mask constructed from premixed speech and noise signals (see Section III-A for definition). This simplifies speech separation to a binary classification problem, a well studied machine learning task. Furthermore, IBM processing has been shown to yield large speech intelligibility improvements even in extremely low SNR conditions [1], [2], [19], [33]. Supervised speech separation aiming to estimate the IBM has shown a lot of promise. Notably, this approach has provided the first demonstration of improved speech intelligibility in noise for both normal hearing [17] and hearing impaired listeners [12]. Supervised speech separation has also been shown to generalize well given sufficient training data [36], [39]. In addition, the system operates in a frame-by-frame fashion and inference is fast, making it amenable to real-time implementation.
A suitable training target is important for supervised learning. On the one hand, one should use a target that can substantially improve speech perception in noise. On the other hand, the mapping from features to the target of interest should be amenable for training, say in terms of optimization difficulty [9]. Although the IBM is the optimal binary mask, it may not necessarily be the best target for training and prediction. Separation using binary masking typically produces residual musical noise. Other ideal targets are possible and can potentially improve speech intelligibility and/or quality, such as the target binary mask (TBM) [1], [18], the ideal ratio mask (IRM), the short-time Fourier transform (STFT) spectral magnitude, and the Gammatone frequency power spectrum. We note that some of them have been used in our preliminary work [11], [23], [37]. However, what training targets are appropriate for supervised speech separation remains unclear. This is clearly an important question with potentially important implications for separation performance. This paper addresses this question systematically, including a study of new training targets. In addition, we compare supervised separation with NMF and speech enhancement methods.
The rest of the paper is organized as follows. We first describe the DNN based supervised speech separation framework and the various training targets that we evaluate in the next two sections. Experimental settings and evaluation and comparison results are presented in Section IV and V, respectively. Discussions and conclusions are provided in Section VI.
II. Supervised Speech Separation
Speech separation can be interpreted as the process that maps a noisy signal to a separated signal with improved intelligibility and/or perceptual quality1. Without considering the impact of phase, this is often treated as the estimation of clean speech magnitude or some ideal mask. Supervised speech separation formulates this as a supervised learning problem such that the mapping is explicitly learned from data. Acoustic features are extracted from a mixture, which, along with the corresponding desired outputs are fed into a learning machine for training. New noisy mixtures are separated by passing estimated outputs and mixture phase into a resynthesizer.
To focus our study on learning targets, we use a fixed set of complementary features [34] throughout the experiments. The feature set includes amplitude modulation spectrogram (AMS), relative spectral transformed perceptual linear prediction coefficients (RASTA-PLP), mel-frequency cepstral coefficients (MFCC), and 64-channel Gammatone filterbank power spectra (GF). All these features are extracted at the frame level and are concatenated with the corresponding delta features. We also employ an auto-regressive moving average (ARMA) filter [3], [4] to smooth temporal trajectories of all features:
| (1) |
Here C(t) is the feature vector at frame t, is the filtered feature vector, and m is the order of the filter. We use a second order ARMA filter (m = 2), which we found consistently improves separation performance in low SNR conditions [4].
We use DNNs (multilayer perceptrons) as the discriminative learning machine, which has been shown to work well for speech separation [35], [36]. All DNNs use three hidden layers, each having 1024 rectified linear hidden units (ReLU) [8]. The standard backpropagation algorithm coupled with dropout regularization [15] (dropout rate 0.2) are used to train the networks. No unsupervised pretraining is used. We use the adaptive gradient descent [5] along with a momentum term as the optimization technique. A momentum rate of 0.5 is used for the first 5 epochs, after which the rate increases to and is kept as 0.9. The DNNs are trained to predict the desired outputs across all frequency bands, and the mean squared error (MSE) is used as the cost (loss) function. The dimensionality of the output layer depends on the target of interest, which is described in the next section. For targets in the range [0,1], we use sigmoid activation functions in the output layer; for the rest we use linear activation functions.
To further incorporate temporal context, we splice a 5-frame window of features as input to the DNNs. The output of the network is composed of the corresponding 5-frame window of targets. In other words, the DNNs predict the neighboring frames’ targets together. The multiple estimates for each frame are then averaged to produce the final estimate. Doing so yields small but consistent improvements over predicting single-frame targets.
III. TRAINING TARGETS
We introduce six training targets evaluated in this study below. We assume that the input signal is sampled at 16 kHz, and use a 20-ms analysis window with 10-ms overlap. An illustration of different training targets is shown in Fig. 1.
Fig. 1.
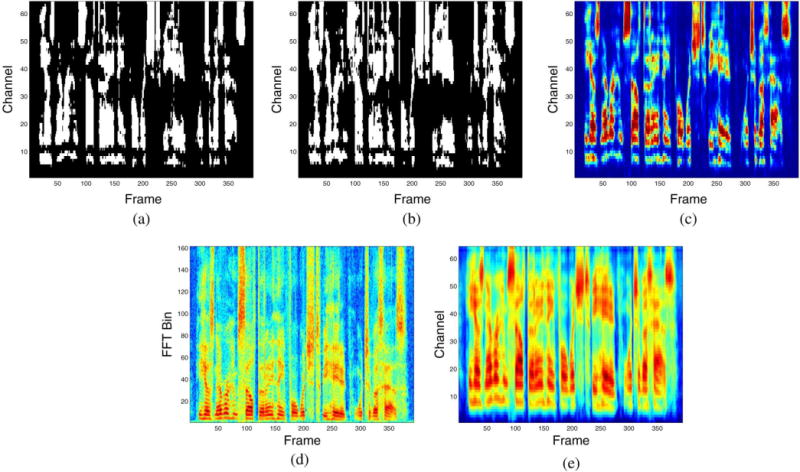
Various training targets for a TIMIT utterance mixed with a factory noise at −5 dB SNR.
A. Ideal Binary Mask (IBM)
The ideal binary mask is a main computational goal for computational auditory scene analysis (CASA) [32]. The IBM is a time-frequency (T-F) mask constructed from premixed signals. For each T-F unit, we set the corresponding mask value to 1 if the local SNR is greater than a local criterion (denoted as LC), otherwise it is set to 0. Quantitatively, the IBM is defined as:
| (2) |
where SNR(t, f) denotes the local SNR within the T-F unit at time and frequency f. As mentioned earlier, it is well established that IBM processing of sound mixtures yields large speech intelligibility gains for both normal hearing and hearing impaired listeners. In addition, the effectiveness of IBM estimation has been exemplified by the recent success in improving human speech intelligibility [17], [12].
Following common practice, we use a 64-channel Gammatone filterbank to derive the IBM; hence the DNN has 64×5 =320 sigmoidal output units with a 5-frame window of targets. Note that although we train on binary targets, in testing we use the posterior probabilities from the DNN, representing the probability of speech dominance, as a soft mask for resynthesis which is found to produce better quality. The choice of LC has a significant impact on speech intelligibility [18]; we set LC to be 5 dB smaller than the SNR of the mixture to preserve enough speech information. For example, if the mixture SNR is −5 dB, the corresponding LC is set to −10 dB.
B. Target Binary Mask (TBM)
Unlike the IBM, the TBM [18] is a binary mask that is obtained by comparing the target speech energy in each T-F unit with a reference speech-shaped noise (SSN). That is, the SNR(t, f) term in Eq. (2) is calculated using the reference SSN, regardless of the actual interference. Although the TBM is obtained in a noise-independent way, subject tests have shown that the TBM achieves similar intelligibility improvements as the IBM [18]. The reason the TBM works is that it preserves the spectrotemporal modulation patterns essential to speech perception, i.e. where the target speech energy occurs in the time-frequency domain. Since the TBM can be interpreted as a cartoon of target speech patterns, it may be easier to learn the TBM than the IBM. We use the same frontend to generate the TBM, i.e. a 64-channel Gammatone filterbank, and the same LC values.
C. Ideal Ratio Mask (IRM)
The ideal ratio mask is defined as follows:
| (3) |
where S2(t, f) and N2(t, f) denote the speech and noise energy, respectively, in a particular T-F unit. β is a tunable parameter to scale the mask. Although technically different, one can see that the IRM is closely related to the frequency-domain Wiener filter assuming speech and noise are uncorrelated [28], [21]. We experimented with different β values and found β = 0.5 to be the best choice. Interestingly, with β = 0.5, Eq. (3) becomes similar to the square-root Wiener filter, which is the optimal estimator of the power spectrum [21].
Like the IBM and TBM, the IRM is also obtained by using a 64-channel Gammatone filterbank and is in the range of [0,1].
D. Gammatone Frequency Power Spectrum (GF-POW)
We also evaluate performance by directly predicting the 64-channel Gammatone frequency power spectrum (GF-POW) of clean speech. The Gammatone filterbank has a finer resolution in lower frequency regions compared to STFT. Since there is no direct inverse transformation for Gammatone filtering, we convert the estimated power spectrum to a mask, , for resynthesis. Here, and denote the speech and mixture energy in the Gammatone frequency domain, respectively. Predicting GF-POW has been shown to be useful in our recent supervised dereverberation work [11]. Note that the construction of the IBM and the IRM also involves GF-POW.
E. Short-Time Fourier Transform Spectral Magnitude (FFT-MAG) and Mask (FFT-MASK)
If the goal is to recover clean speech, then predicting the STFT magnitude of clean speech seems to be a very natural choice. We use a 320-point FFT analysis; thus the spectral magnitude in each frame is a 161-D vector. We call this target FFT-MAG. The estimated magnitude combined with the mixture phase is passed through an inverse FFT to generate the estimated clean speech. Raw spectral magnitudes usually have a very large dynamic range, hence proper compression or normalization are needed to make them amenable to the backpropagation training. We will show in Section V-A that different normalizations can lead to significantly different results. We note that a very recent study [39] predicts the log compressed spectral magnitude under a supervised speech separation framework.
For a comparison with masking, we straightforwardly rewrite the clean spectral magnitude, SFFT(t, f), as
| (4) |
where YFFT is the (uncompressed) noisy STFT spectral magnitude. Apart from directly predicting SFFT, we also predict SFFT(t, f)/YFFT(t, f), which can be interpreted as a mask.
The clean magnitude is reconstructed by multiplying the predicted mask with the noisy magnitude. We call this target FFT-MASK, which is an intermediate target to recover clean magnitude. Note that unlike the IRM, the FFT-MASK is not upper-bounded by 1, and therefore we use linear output activation functions in the DNNs. For better numerical stability in backpropagation training, we clip values greater than 10 in the FFT-MASK to 10, where 10 is an arbitrarily chosen value. The motivation of introducing FFT-MASK is to enable a direct comparison with FFT-MAG, as the perfect estimation of these two targets produces the same underlying objective–the clean speech magnitude.
IV. EXPERIMENTAL SETTINGS
We use 2000 randomly chosen utterances from the TIMIT [7] training set as our training utterances. The TIMIT core test set, which consists of 192 utterances from unseen speakers of both genders, is used as the test set. We use SSN and 4 other noises from the NOISEX dataset [30] as our training and test noises. These include a babble noise, a factory noise (called “factory1”), a destroyer engine room noise, and an operation room noise (called “oproom”). Except SSN, all other noises are non-stationary. All noises are around 4 minutes long. To create the training sets, we use random cuts from the first 2 minutes of each noise to mix with the training utterances at −5 and 0 dB SNR. The test mixtures are constructed by mixing random cuts from the last 2 minutes of each noise with the test utterances at −5, 0 and 5 dB SNR, where 5 dB is an unseen SNR condition. Dividing the noises into two halves ensures that the new noise segments are used during testing. Aside from the aforementioned noises, we also use an unseen factory noise (called “factory2”) and a tank noise from NOISEX to evaluate generalization performance. Note that separation of these broadband noises at low SNRs is a very challenging task. For example, even for the stationary SSN, the human intelligibility score at −5 dB is only around 65% and 35% for normal hearing and hearing impaired listeners, respectively [12].
To put our results in perspective, we compare with model-based speech enhancement and NMF based separation. For speech enhancement, we compare with a recent system by Hendriks et al. [13], which uses an MMSE estimator of speech DFT coefficients assuming a generalized gamma distribution for speech magnitude [6]. For noise tracking, a state-of-the-art MMSE noise power spectral density estimator is used [13]. For a fair comparison with NMF, we use the supervised NMF method where the speech bases and noise bases are trained separately (for each type of noise) using the same training data used by the DNNs. We made an effort to yield the best performance of supervised NMF; we have tried different variants and found that a recent version using an active-set Newton algorithm (ASNA) [31] produces the best results. The final system, denoted as ASNA-NMF, models a sliding window of 5 frames of magnitude spectra and uses 160 speech bases and 80 noise bases. Using larger numbers of bases (e.g., 1000) does not seem to improve the performance significantly on our test set.
For evaluation metrics, we use the Short-Time Objective Intelligibility score (STOI) [29] to measure the objective intelligibility. STOI denotes a correlation of short-time temporal envelopes between clean and separated speech, and has been shown to be highly correlated to human speech intelligibility score. We also evaluate objective speech quality using the Perceptual Evaluation of Speech Quality (PESQ) score [27]. Like STOI, PESQ is obtained by comparing the separated speech with the corresponding clean speech. The STOI score ranges from 0 to 1, and PESQ score −0.5 to 4.5.
To supplement the above perceptually oriented metrics, we also give SNR results, which take into account the underlying signal energy of each T-F unit. We should point out that the traditional SNR metric comparing the separated speech with clean speech is not appropriate here. First, different targets aim to reconstruct different underlying signals. For example, the ground truth signal of IBM prediction differs from that of FFT-MASK prediction, therefore the use of the traditional SNR is problematic. Second, the traditional SNR does not take account of perceptual effects and it is well documented that SNR may not correlate with speech intelligibility. For example, LC = 0 dB maximizes the SNR gain of the IBM [20]. However, the choice of LC = 0 dB is clearly worse than negative LC values (e.g. −6 dB) for both human speech intelligibility [18] and automatic speech recognition performance [24]. In other words, lower output SNRs lead to higher speech intelligibility (see also [17], [12]). As our study focuses on different training targets, it makes sense to use the target-based SNR that compares the separated speech with the target signal resynthesized from the corresponding ideal target. That is, the output SNRs of IBM, TBM and IRM predictions are obtained using the signals resynthesized from the IBM, TBM and IRM, respectively, as the ground truth (see also [32]). For FFT-MAG, FFT-MASK, ASNA-NMF and Hendriks et al.’s system, the ground truth signal is resynthesized using the clean speech magnitude combined with the mixture phase, as the computational objective of these targets/methods is to obtain STFT clean speech magnitude and the separated speech is reconstructed using the mixture phase. Using the target-based SNR facilitates comparisons between these two groups of targets/methods.
V. RESULTS
A. Comparison Between Targets
Before presenting comprehensive evaluations, we compare various compression/normalization techniques for predicting FFT-MAG. If one wants to predict the clean magnitude, proper normalizations or compressions are needed because the magnitudes typically have a very broad dynamic range, causing difficulty for gradient descent based training algorithms. We show that different ways of normalization impact performance significantly. In Table I, we compare STOI and PESQ performance on the factory 1 noise using different kinds of normalization/compression methods. We first use the log compression, which is perhaps the most widely used compression technique (e.g. [39]). Since log magnitude is not bounded, we use linear output units in the DNNs. Next, we use percent normalization, which linearly scales the data to the range of [0,1]. This is done by first subtracting the minimum value, and then dividing by the difference between the maximum and minimum value. We use sigmoidal output units in this case. Finally, we normalize the magnitudes by first performing a log compression followed by percent normalization, and use sigmoidal output units. From Table I we can see that the performance of these normalization methods does not differ too much at −5 dB. However, at 0 and 5 dB, the traditional log compression performs significantly worse in terms of STOI (e.g., 4% worse at 5 dB) than the log compression followed by percent normalization. Using only percent normalization gives closer, but still worse, STOI results; but its PESQ results are the worst among the three. We believe log + percent normalization performs better because it preserves spectral details while simultaneously making the target bounded. Therefore, we use this normalization scheme when predicting spectral magnitude/energy based targets in the remaining experiments.
TABLE I.
Performance on Factory1 when the Clean Magnitudes are Normalized/Compressed in Different Ways
| Methods | −5 dB | 0 dB | 5 dB | |||
|---|---|---|---|---|---|---|
| STOI | PESQ | STOI | PESQ | STOI | PESQ | |
| Log Compression | 0.65 | 1.82 | 0.72 | 2.11 | 0.75 | 2.23 |
| Percent Normalization | 0.65 | 1.60 | 0.73 | 1.76 | 0.77 | 1.83 |
| Log + Percent Norm. | 0.66 | 1.73 | 0.75 | 2.06 | 0.79 | 2.25 |
The comparisons between different targets in various test conditions are shown in Tables II, III, and IV at different mixture SNRs, where best score is highlighted by boldface. In these tables, “SNR” denotes the target-based SNR mentioned in Section IV. We first discuss the results in the most challenging scenario, the −5 dB SNR case, as shown in Table II. Generally, regardless of the target of choice, the supervised speech separation framework provides substantial improvements compared to unprocessed mixtures. For the two binary masking targets, the IBM and the TBM, large improvements are obtained in STOI and SNR. Although we use the posterior probabilities from the DNNs as soft masks for resynthesis, the PESQ improvements are still limited over unprocessed mixtures, except in the case of the operation room noise. This is consistent with the common point of view that binary masking tends to improve speech intelligibility but not speech quality. Compared to the IBM, using the TBM as the target results in similar STOI scores but significantly worse PESQ scores and SNRs. For supervised techniques like the one used here, the IBM seems to be a better choice than the TBM, probably because the TBM is defined by completely ignoring the noise characteristics in the mixture.
TABLE II.
Performance Comparisons Between Various Targets and Systems on −5 dB Mixtures. “MC-IRM” stands for Multi-Condition Training (on all five noises) and uses IRM as the Training Target
| Target/System | Factory1 | Babble | SSN | Engine | Oproom | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | |
| Mixture | 0.54 | 1.29 | −5.00 | 0.55 | 1.42 | −5.00 | 0.57 | 1.48 | −5.00 | 0.57 | 1.41 | −5.00 | 0.59 | 1.40 | −5.00 |
| IBM | 0.66 | 1.49 | 6.63 | 0.63 | 1.50 | 3.98 | 0.72 | 1.45 | 8.71 | 0.78 | 1.53 | 13.24 | 0.77 | 1.81 | 12.24 |
| TBM | 0.65 | 1.33 | 5.19 | 0.62 | 1.32 | 3.08 | 0.72 | 1.45 | 8.71 | 0.77 | 1.52 | 6.16 | 0.76 | 1.60 | 6.38 |
| IRM | 0.67 | 1.75 | 8.27 | 0.63 | 1.64 | 4.39 | 0.73 | 1.87 | 10.81 | 0.80 | 2.17 | 15.66 | 0.79 | 2.19 | 15.33 |
| FFT-MAG | 0.66 | 1.73 | 5.45 | 0.62 | 1.50 | 3.80 | 0.72 | 1.76 | 5.18 | 0.76 | 2.02 | 6.09 | 0.74 | 2.01 | 5.84 |
| FFT-MASK | 0.68 | 1.77 | 7.59 | 0.65 | 1.65 | 5.52 | 0.74 | 1.87 | 7.58 | 0.78 | 2.16 | 9.73 | 0.77 | 2.15 | 9.89 |
| GF-POW | 0.67 | 1.80 | 8.23 | 0.62 | 1.63 | 5.98 | 0.72 | 1.85 | 8.62 | 0.76 | 2.06 | 9.83 | 0.74 | 2.14 | 9.31 |
| MC-IRM | 0.69 | 1.80 | 9.52 | 0.64 | 1.65 | 5.08 | 0.74 | 1.88 | 11.40 | 0.78 | 2.12 | 14.97 | 0.77 | 2.16 | 14.79 |
| ASNA-NMF | 0.60 | 1.55 | 5.62 | 0.57 | 1.53 | 4.21 | 0.64 | 1.61 | 5.69 | 0.70 | 1.84 | 7.04 | 0.68 | 1.81 | 7.08 |
| SPEH | 0.51 | 1.56 | 4.13 | 0.50 | 1.38 | 3.07 | 0.57 | 1.68 | 4.34 | 0.62 | 1.85 | 5.73 | 0.58 | 1.88 | 5.98 |
TABLE III.
Performance Comparisons Between Various Targets and Systems on 0 dB Mixtures
| Target/System | Factory1 | Babble | SSN | Engine | Oproom | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | |
| Mixture | 0.65 | 1.62 | 0.00 | 0.66 | 1.73 | 0.00 | 0.69 | 1.75 | 0.00 | 0.68 | 1.66 | 0.00 | 0.70 | 1.78 | 0.00 |
| IBM | 0.78 | 1.85 | 12.17 | 0.76 | 1.89 | 8.91 | 0.82 | 1.75 | 14.48 | 0.85 | 1.79 | 17.13 | 0.83 | 2.11 | 16.13 |
| TBM | 0.77 | 1.67 | 10.43 | 0.75 | 1.65 | 8.20 | 0.82 | 1.75 | 14.48 | 0.84 | 1.75 | 9.76 | 0.82 | 1.83 | 10.08 |
| IRM | 0.78 | 2.17 | 14.03 | 0.76 | 2.05 | 10.54 | 0.83 | 2.26 | 16.39 | 0.86 | 2.48 | 19.23 | 0.84 | 2.47 | 18.62 |
| FFT-MAG | 0.75 | 2.06 | 6.09 | 0.72 | 1.89 | 4.92 | 0.78 | 2.09 | 5.71 | 0.80 | 2.28 | 6.36 | 0.78 | 2.23 | 6.21 |
| FFT-MASK | 0.79 | 2.22 | 11.07 | 0.77 | 2.10 | 9.44 | 0.83 | 1.87 | 10.59 | 0.85 | 2.51 | 12.14 | 0.83 | 2.47 | 12.43 |
| GF-POW | 0.76 | 2.19 | 9.68 | 0.73 | 2.05 | 8.09 | 0.80 | 2.23 | 9.64 | 0.81 | 2.38 | 10.40 | 0.80 | 2.42 | 10.19 |
| MC-IRM | 0.79 | 2.20 | 15.19 | 0.77 | 2.07 | 11.18 | 0.83 | 2.26 | 16.45 | 0.85 | 2.43 | 18.84 | 0.83 | 2.45 | 18.54 |
| ASNA-NMF | 0.72 | 1.93 | 9.15 | 0.71 | 1.91 | 7.64 | 0.76 | 1.97 | 8.86 | 0.80 | 2.19 | 9.81 | 0.77 | 2.15 | 10.14 |
| SPEH | 0.64 | 2.00 | 7.52 | 0.64 | 1.82 | 6.85 | 0.71 | 2.09 | 7.07 | 0.75 | 2.24 | 8.57 | 0.70 | 2.25 | 8.89 |
TABLE IV.
Performance Comparisons Between Various Targets and Systems on 5 dB Mixtures
| Target/System | Factory1 | Babble | SSN | Engine | Oproom | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | STOI | PESQ | SNR | |
| Mixture | 0.77 | 1.99 | 5.00 | 0.77 | 2.08 | 5.00 | 0.81 | 2.05 | 5.00 | 0.80 | 1.97 | 5.00 | 0.79 | 2.16 | 5.00 |
| IBM | 0.86 | 2.13 | 16.73 | 0.86 | 2.28 | 13.93 | 0.87 | 1.81 | 18.05 | 0.89 | 2.02 | 19.66 | 0.86 | 2.26 | 19.12 |
| TBM | 0.85 | 1.92 | 15.45 | 0.85 | 1.95 | 13.80 | 0.87 | 1.81 | 18.05 | 0.88 | 1.89 | 13.52 | 0.86 | 2.00 | 13.69 |
| IRM | 0.86 | 2.51 | 19.84 | 0.86 | 2.47 | 17.27 | 0.88 | 2.17 | 18.56 | 0.90 | 2.75 | 23.29 | 0.88 | 2.77 | 22.57 |
| FFT-MAG | 0.79 | 2.25 | 6.02 | 0.77 | 2.11 | 5.27 | 0.79 | 1.92 | 5.40 | 0.83 | 2.42 | 6.30 | 0.81 | 2.34 | 6.08 |
| FFT-MASK | 0.86 | 2.59 | 13.60 | 0.85 | 2.23 | 12.63 | 0.85 | 2.23 | 11.11 | 0.90 | 2.80 | 14.04 | 0.87 | 2.76 | 14.24 |
| GF-POW | 0.81 | 2.48 | 9.95 | 0.80 | 2.41 | 9.01 | 0.82 | 2.17 | 9.21 | 0.85 | 2.61 | 10.43 | 0.83 | 2.63 | 10.27 |
| MC-IRM | 0.87 | 2.52 | 20.65 | 0.86 | 2.48 | 17.87 | 0.88 | 2.33 | 19.98 | 0.90 | 2.70 | 22.92 | 0.88 | 2.72 | 21.98 |
| ASNA-NMF | 0.82 | 2.28 | 12.53 | 0.81 | 2.28 | 11.34 | 0.85 | 2.30 | 12.32 | 0.87 | 2.51 | 12.76 | 0.84 | 2.48 | 13.11 |
| SPEH | 0.77 | 2.39 | 10.84 | 0.76 | 2.25 | 10.66 | 0.82 | 2.47 | 10.25 | 0.85 | 2.59 | 11.55 | 0.80 | 2.62 | 11.51 |
Going from binary masking to ratio masking improves all objective metrics, as exemplified by the performance of the IRM. On factory1, babble and SSN, predicting the IRM achieves slightly better or equal STOI results than predicting the IBM. On the engine and operation room noises, predicting the IRM yields more than two percent STOI improvements. Predicting the IRM seems to be especially beneficial for improving objective speech quality. For example, the PESQ score improves by 0.65 and 0.76 in the engine noise compared to the IBM and unprocessed mixtures, respectively. On average, predicting the IRM provides a 2 dB SNR improvements over predicting the IBM.
On the two challenging noises, factory1 and babble, and the relatively easier noise, SSN, predicting FFT-MAG achieves similar STOI and better PESQ results compared to predicting the IBM. However, predicting FFT-MAG achieves the worst performance on the other noises in terms of STOI. For example, on the operation room noise, the STOI is 3% worse than predicting the IBM. Similarly, FFT-MAG is consistently worse than the IRM, especially in the case of engine noise and operation room noise.
Interestingly, FFT-MASK produces comparable and sometimes even slightly better STOI and PESQ results than the IRM. Also, FFT-MASK produces significantly better SNR results than FFT-MAG on all noises. This contrast with FFT-MAG appears surprising at first, considering that the DNNs in both cases are essentially trained to estimate the same underlying target, the clean magnitude. We will provide some analysis in the next subsection as to why FFT-MASK performs better.
Predicting GF-POW, which is also a spectral envelope based target, has a similar performance trend as FFT-MAG. In general, it produces worse STOI results than either binary or ratio masking. Nevertheless, GF-POW seems to be consistently better than FFT-MAG.
The performance trend at 0 dB is similar to that at −5 dB, as shown in Table III. That is to say, all targets improve objective metrics over unprocessed mixtures. Binary masking significantly improves objective intelligibility scores but the improvement in objective quality is minor. Predicting the IRM instead of the IBM significantly improves both objective quality and intelligibility metrics. FFT-MAG fails to compete with the other targets, whereas FFT-MASK is on par with the IRM. One noticeable difference at 0 dB is that the performance degradation of FFT-MAG becomes noticeably larger. For example, in the −5 dB factory1 noise condition, FFT-MAG produces the same STOI results as the IBM, whereas at 0 dB FFT-MAG is 3% points worse.
Separation at 5 dB is relatively easier, hence we can see in Table IV that the STOI difference between various masking based targets becomes smaller. In contrast, FFT-MAG performs much worse than all the masking based targets. For example, the STOI and PESQ results obtained on SSN are even worse than those of unprocessed mixtures. In general, the IRM and FFT-MASK perform comparably; with the former slightly better on average.
In Fig. 2, we illustrate the STFT magnitudes of a separated speech utterance resynthesized using the estimated IBM, IRM, FFT-MAG and FFT-MASK. The mixture here is a TIMIT male utterance with factory1 at 5 dB. We can see that predicting the IBM preserves spectrotemporal modulation patterns of the clean speech, which are essential for speech intelligibility [25]. Also, the separated speech tends to have clearer onsets/offsets and sharper spectral transitions. Predicting FFT-MAG works reasonably well for low frequency regions where most of the speech energy resides. However, it misses a lot of details in the mid- to high-frequency regions, which are important for both intelligibility and quality. Visually speaking, the results are similar between IRM prediction and FFT-MASK prediction in the sense that they both preserve important modulation patterns as well as fine structures.
Fig. 2.
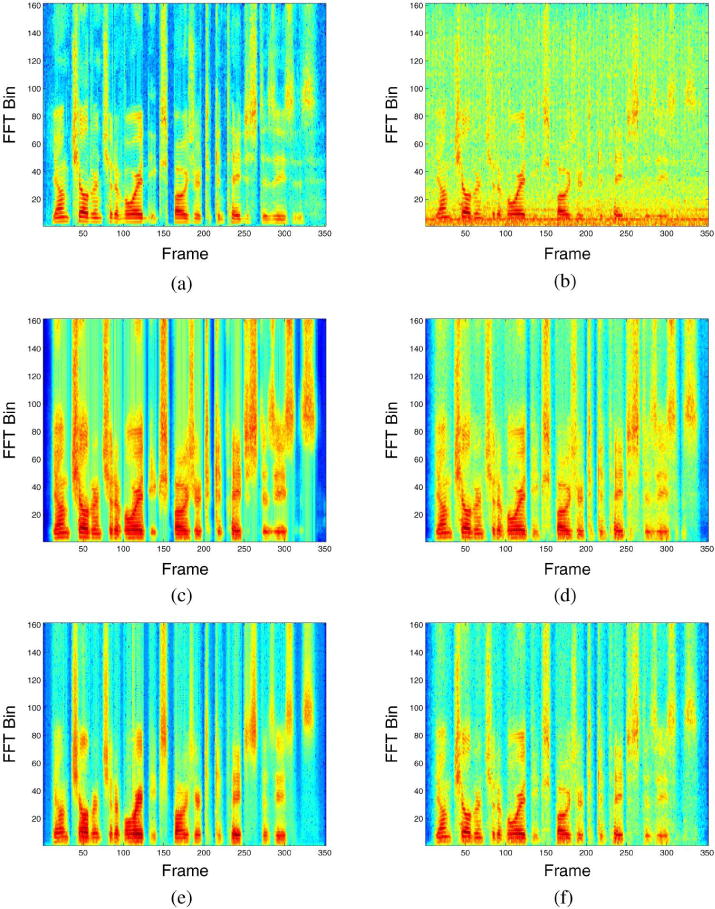
STFT magnitudes of a separated speech using different training targets. The mixture here is a TIMIT male utterance mixed with the factory1 noise at 5 dB.
B. Issues with FFT-MAG Prediction
We are interested in why predicting FFT-MAG produces the worst results, and in particular, why there is a substantial performance gap between FFT-MAG and FFT-MASK. We start our analysis with two hypotheses. First, since FFT-MAG is the same across different noises and SNRs, the DNN has to learn a many-to-one mapping (recall that we train on −5 and 0 dB mixtures), which may be a more difficult task compared to learning a one-to-one mapping as in FFT-MASK. Second, masking may be inherently better. To verify these hypotheses, we designed two experiments. In the first experiment, we train a DNN to predict FFT-MAG only for 0 dB factory1 to reduce many-to-one mapping, and in the second experiment we train a DNN to predict log S/log Y (LOGMASK), where S and Y denote the clean and noisy magnitude (with time and frequency index omitted), for −5 and 0 dB factory1. The STOI results are shown in Fig. 3. From the figure we can see that learning a many-to-one mapping does not seem to be the cause as the performance in the matched SNR condition is only marginally better. Interestingly, the new mask log S/log Y does improve performance over FFT-MAG, but is still significantly worse than FFT-MASK. This seems to indicate that, although masking is helpful, the use of log compression is likely one of the causes of the performance difference. We further analyze why log compression affects performance below.
Fig. 3.
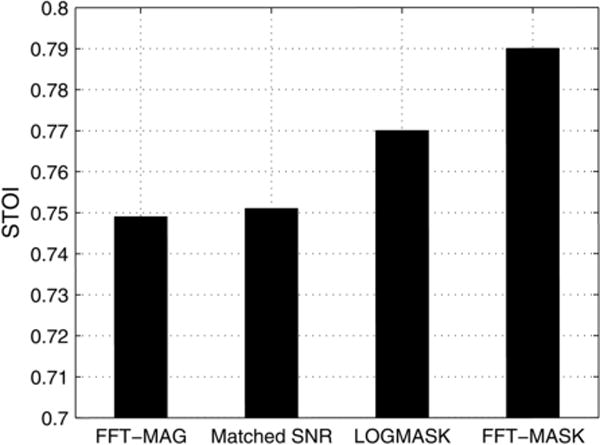
STOI results for 0 dB factory1. “Matched SNR” denotes training FFT-MAG also for 0 dB factory1. “LOGMASK” is a new mask (log S/log Y).
Let η denote the ratio between the network’s output and the desired output. Here η ∈ [0, +∞], and when η >1 or η < 1 the neural network overestimates or underestimates the target, respectively. We assume that the network learns equally well for both targets, meaning that η is in the same range. In Fig. 4, we plot the average η values obtained on the training set across frequency for both targets, and we can see that this is basically the case. Since the goal is to estimate the clean magnitude, we evaluate the estimation error in terms of the absolute deviation from the clean magnitude S. Recall that for FFT-MASK, we predict a mask S/Y, whereas for log magnitude we predict log S. Therefore for FFT-MASK, the network output is ηS/Y, and the estimation error EMASK is:
| (5) |
For FFT-MAG, the network output is η log S, and we have the estimation error EMAG as:
| (6) |
In practice, S ≫ 1 when speech is present, hence we assume S > 1. When η > 1 (overestimation), EMAG = (Sη−1 − 1)S, which is exponential with respect to η. In this case, EMAG clearly grows much faster than EMASK, which is linear with respect to η. For the case when η < 1, EMASK = (1 − η)S and EMAG = (1 – Sη−1)S. To see which error is greater, we plot in Fig. 5(a) the contour of the ratio between EMAG and EMASK by varying S and η. We can see that EMASK is consistently smaller than EMAG except only when both S and η are very small (the region where the ratio is less than 1). This can also be seen in Fig. 5(b), where we plot normalized error curves (EMASK/S and EMAG/S) when S = 50.
Fig. 4.
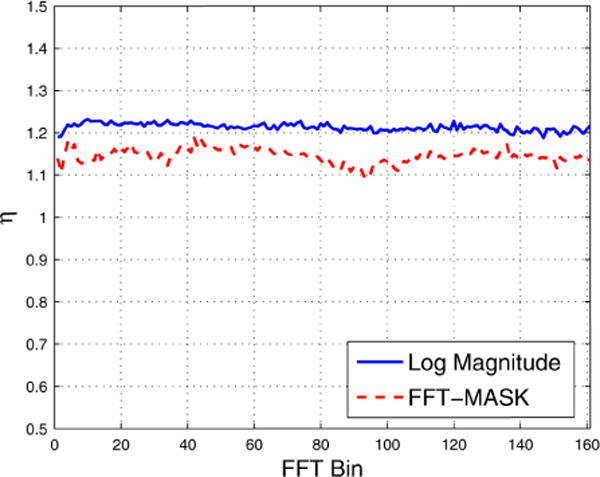
Average η values across frequency obtained on the training set.
Fig. 5.
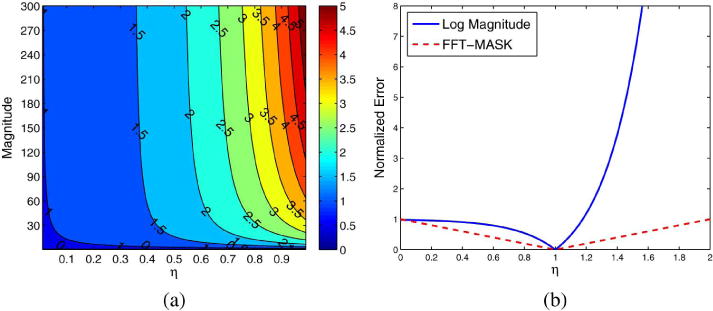
Comparison of EMAG and EMASK. Left: contour plot of the ratio EMAG/EMASK. Right: normalized error curves (EMASK/S and EMAG/S) when S = 50.
The analysis implies that, when using supervised techniques for estimating the clean magnitude, which is the underlying goal, one is likely more accurate by predicting the masking function FFT-MASK rather than the log magnitude. Roughly speaking, this is because the errors are magnified by the exponential expansion when converting to the magnitude domain before resynthesis. This analysis does not depend on the frequency scale, hence it also applies to the Gammatone frequency scale, partly explaining why predicting GF-POW is worse than predicting the IRM. In addition, we can show that similar analysis applies to other types of nonlinear compression, such as the cubic root compression S1/3, and even to masks involving nonlinear compression, such as the LOGMASK mentioned above. The above analysis assumes that the network learns equally well for both FFT-MAG and FFT-MASK, i.e. assuming the same η. Actually, training on FFT-MAG seems harder than on FFT-MASK, as indicated by the consistently larger η values across frequency, shown in Fig. 4. This is perhaps due to the speaker-independence setting, where the patterns in FFT-MAG are more sensitive to speaker variations.
The log or root compression is often used for reducing the dynamic range. If one wants to predict the clean magnitude, such a compression is also needed in neural networks to avoid numerical issues so that gradients can flow well. Nevertheless, we argue that regardless of the frequency scale, such a compression is better achieved via masking, which can be thought as a form of normalization, instead of a nonlinear compression.
C. Comparison with Other Systems
We now compare with a very recent supervised NMF system [31], i.e. ASNA-NMF, and a recent speech enhancement system [13], which we call SPEH. The results of these two systems are shown in the bottom of Tables II, III, and IV. ASNA-NMF is also a data driven method, trained on the same data as used by the DNNs. Its performance, however, is significantly worse than supervised speech separation. The performance difference in terms of STOI is particularly large compared to our DNN that predicts the IRM, e.g. 10% worse for the −5 dB engine noise. In challenging cases, e.g. −5 dB babble, ASNA-NMF improves upon unprocessed mixtures by only 2 percentage points in STOI. ASNA-NMF on average achieves significantly worse STOI but better PESQ results compared to binary masking (IBM and TBM). However, its PESQ results are consistently worse than ratio masking (IRM and FFT-MASK). Informal listening indicates that the output from ASNA-NMF has noticeable speech distortions and residual noise even at 5 dB. Speech enhancement, which does not rely on training, seems to have difficulty in challenging test conditions. SPEH fails to improve STOI for 4 out of 5 noises at −5 dB, and 3 out of 5 noises at 0 dB. Even at 5 dB where spectral patterns of speech are prominent, SPEH is outperformed by both DNN and ASNA-NMF. This is to be expected as the latter techniques are data-driven. With the same ground truth signal, FFT-MASK significantly outperforms ASNA-NMF and SPEH in terms of SNR. For example, at −5 dB, the average output SNR of FFT-MASK is 2.13 dB and 3.41 dB better than ASNA-NMF and SPEH, respectively.
In practice, supervised speech separation is often trained on multiple noises (i.e., multi-condition training) for good generalization (e.g. [36]). We train such a system on all 5 noises to predict the IRM. This system is called MC-IRM and its performance is also shown in Table II to IV. We can see that on average the performance does not degrade thanks to the representational power of DNNs. In fact, the performance of multi-condition training even improves over individually trained models sometimes (e.g., for −5 dB factory1), and the performance advantage over ASNA-NMF and SPEH remains.
We further compare the generalization performance on two unseen noises–a different factory noise (factory2) and a tank noise, both from NOISEX. We compare MC-IRM with ASNA-NMF and SPEH. The two data driven systems MC-IRM and ASNA-NMF are both trained on the previously used 5 noises at −5 and 0 dB. Note that the main purpose of this set of experiments is to compare relative performance. As we are training on only 5 noises, the presented results by no means represent the best obtainable ones for either MC-IRM or ASNA-NMF. It is expected that the performance will be significantly improved using more noises for training, at least for MC-IRM as indicated by the results in [36], [39]. The generalization results at −5, 0, and 5 dB are shown in Tables V, Tables VI, and Tables VII, respectively. Note that at 5 dB, the SNR, speakers and noises are all new. We can see that MC-IRM again outperforms the other two systems on both noises across all SNR conditions, especially in terms of STOI. The STOI and PESQ improvements of MC-IRM over unprocessed mixtures are large, while the STOI improvements of the other two systems are limited or marginal. We should also point out that with more training data, separation in the test phase takes significantly more time for ASNA-NMF. In contrast, this does not affect supervised speech separation systems, where the additional computational burden occurs only in the training phase.
TABLE V.
Generalization Performance on Two Unseen Noises at −5 dB
| Target | Factory2 | Tank | ||
|---|---|---|---|---|
| STOI | PESQ | STOI | PESQ | |
| Mixture | 0.65 | 1.57 | 0.68 | 1.70 |
| MC-IRM | 0.76 | 2.02 | 0.75 | 2.16 |
| ASNA-NMF | 0.70 | 1.96 | 0.69 | 2.03 |
| SPEH | 0.65 | 1.95 | 0.68 | 2.04 |
TABLE VI.
Generalization Performance on Two Unseen Noises at 0 dB
| Target | Factory2 | Tank | ||
|---|---|---|---|---|
| STOI | PESQ | STOI | PESQ | |
| Mixture | 0.76 | 1.93 | 0.77 | 2.06 |
| MC-IRM | 0.85 | 2.44 | 0.83 | 2.52 |
| ASNA-NMF | 0.80 | 2.33 | 0.79 | 2.38 |
| SPEH | 0.76 | 2.40 | 0.78 | 2.43 |
TABLE VII.
Generalization Performance on Two Unseen Noises at 5 dB
| Target | Factory2 | Tank | ||
|---|---|---|---|---|
| STOI | PESQ | STOI | PESQ | |
| Mixture | 0.84 | 2.29 | 0.85 | 2.41 |
| MC-IRM | 0.90 | 2.80 | 0.89 | 2.88 |
| ASNA-NMF | 0.86 | 2.64 | 0.86 | 2.70 |
| SPEH | 0.85 | 2.74 | 0.86 | 2.82 |
VI. CONCLUDING REMARKS
Choosing a suitable training target is critical for supervised learning, as it is directly related to the underlying computational goal. In the context of speech separation, the speech resynthesized (either directly or indirectly) using any ideal target restores intelligibility and quality. In practice, however, since the targets have to be estimated, the choice should be made by considering how well it can be estimated and how the errors in estimation affect performance.
Traditionally, the IBM is used as the training target for supervised speech separation. Despite the simplicity of the IBM and the recent success of classification based speech separation it has inspired, it is unclear whether the IBM is the best target in terms of estimation. In this study, we have systematically investigated the relative performance between various training targets, some new and others not, using both objective intelligibility and quality metrics. The compared targets can be categorized into binary masking based (IBM and TBM), ratio masking based (IRM and FFT-MASK), and spectral envelope based (FFT-MAG and GF-POW) targets. In general, we have found that binary masking produces worse objective quality results compared to ratio masking. We also found that binary masking leads to slightly worse objective intelligibility results than ratio masking. This is likely because predicting ratio targets is less sensitive to estimation errors than predicting binary targets. An unexpected finding of this study is that the direct prediction of spectral envelopes produces the worst results, as best illustrated by the substantial performance gap between FFT-MAG and FFT-MASK, where the two targets are essentially two alternative views of the same underlying goal, the clean speech magnitude. Aside from the analysis presented in Section V-B, which points to the issue of nonlinear compression, we believe that masking has several advantages over spectral envelope estimation. Perhaps most importantly, masks make direct contact with the observed mixtures in the sense that they are used to modulate the mixtures in the time-frequency domain. In contrast, direct estimation of speech magnitude ignores the mixture which contains the true underlying signal. This can be problematic when there is a significant amount of erroneous estimation. Furthermore, ideal masks are inherently normalized and usually bounded, potentially making training easier and prediction more accurate compared to unbounded spectral envelope based targets. Finally, ideal masks are likely easier to learn than spectral envelopes, as their spectrotemporal patterns are more stable with respect to speaker variations.
We have also compared a supervised IRM estimation algorithm with recent algorithms in supervised NMF and statistical model-based speech enhancement. The comparisons across various test conditions clearly indicate significant performance advantage of our system.
To conclude, we hope efforts will be devoted to the design of new training targets in the future, which has the potential to further improve performance without adding significant computational burden. For example, predicting intermediate targets that encode more structure [37] or are easier to learn [9] has been shown to be useful.
Acknowledgments
This work was supported in part by the Air force Office of Scientific Research (AFOSR) under Grant FA9550-12-1-0130, the National Institute on Deafness and Other Communication (NIDCD) under Grant R01 DC012048, a Small Business Technology Transfer (STTR) subcontract from Kuzer, and the Ohio Supercomputer Center. The associate editor coordinating the review of this manuscript and approving it for publication was Prof. Thomas Fang Zheng.
Biographies

Yuxuan Wang received his B.E. degree in network engineering from Nanjing University of Posts and Telecommunications, Nanjing, China, in 2009. He is currently pursuing his Ph.D. degree at The Ohio State University. He is interested in speech separation, robust automatic speech recognition, and machine learning.
Arun Narayanan, photograph and biography not provide at the time of publication.
DeLiang Wang, photograph and biography not provide at the time of publication.
Footnotes
Depending on the application, the desired output of the mapping does not have to be clean speech.
Color versions of one or more of the figures in this paper are available online at http://ieeexplore.ieee.org.
Contributor Information
Yuxuan Wang, Email: wangyuxu@cse.ohio-state.edu, Department of Computer Science and Engineering, The Ohio State University, Columbus, OH 43210 USA.
Arun Narayanan, Email: narayaar@cse.ohio-state.edu, Department of Computer Science and Engineering, The Ohio State University, Columbus, OH 43210 USA.
DeLiang Wang, Email: dwang@cse.ohio-state.edu, Department of Computer Science and Engineering and the Center for Cognitive and Brain Sciences, The Ohio State University, Columbus, OH 43210 USA.
References
- 1.Anzalone M, Calandruccio L, Doherty K, Carney L. Determination of the potential benefit of time-frequency gain manipulation. Ear Hear. 2006;27(5):480–492. doi: 10.1097/01.aud.0000233891.86809.df. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Brungart D, Chang P, Simpson B, Wang D. Isolating the energetic component of speech-on-speech masking with ideal time-frequency segregation. J Acoust Soc Amer. 2006;120:4007–4018. doi: 10.1121/1.2363929. [DOI] [PubMed] [Google Scholar]
- 3.Chen C, Bilmes J. MVA processing of speech features. IEEE Trans Audio, Speech, Lang Process. 2007 Jan;15(1):257–270. [Google Scholar]
- 4.Chen J, Wang Y, Wang D. A feature study for classification-based speech separation at very low signal-to-noise ratio. Proc ICASSP. 2014:7059–7063. [Google Scholar]
- 5.Duchi J, Hazan E, Singer Y. Adaptive subgradient methods for online learning and stochastic optimization. J Mach Learn Res. 2011:2121–2159. [Google Scholar]
- 6.Erkelens J, Hendriks R, Heusdens R, Jensen J. Minimum mean-square error estimation of discrete fourier coefficients with generalized gamma priors. IEEE Trans Audio, Speech, Lang Process. 2007 Aug;15(6):1741–1752. [Google Scholar]
- 7.Garofolo J. DARPA TIMIT acoustic-phonetic continuous speech corpus. Gaithersburg, MD, USA: Nat Inst of Standards Technol; 1993. [Google Scholar]
- 8.Glorot X, Bordes A, Bengio Y. Deep sparse rectifier networks. Proc 14th Int Conf Artif Intell Statist JMLR W&CP Volume. 2011;15:315–323. [Google Scholar]
- 9.Gulcehre C, Bengio Y. Knowledge matters: Importance of prior information for optimization. Proc Int Conf Learn Representat (ICLR) 2013 [Google Scholar]
- 10.Han K, Wang D. A classification based approach to speech segregation. J Acoust Soc Amer. 2012;132:3475–3483. doi: 10.1121/1.4754541. [DOI] [PubMed] [Google Scholar]
- 11.Han K, Wang Y, Wang D. Learning spectral mapping for speech dereverberation. Proc ICASSP. 2014:4648–4652. [Google Scholar]
- 12.Healy E, Yoho S, Wang Y, Wang D. An algorithm to improve speech recognition in noise for hearing-impaired listeners. J Acous Soc Amer. 2013:3029–3038. doi: 10.1121/1.4820893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hendriks R, Heusdens R, Jensen J. MMSE based noise PSD tracking with low complexity. Proc ICASSP. 2010:4266–4269. [Google Scholar]
- 14.Hershey JR, Rennie SJ, Olsen PA, Kristjansson TT. Super-human multi-talker speech recognition: A graphical modeling approach. Comput Speech Lang. 2010:45–66. [Google Scholar]
- 15.Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580. 2012 [Google Scholar]
- 16.Jin Z, Wang D. A supervised learning approach to monaural segregation of reverberant speech. IEEE Trans Audio Speech Lang Process. 2009 May;17(4):625–638. [Google Scholar]
- 17.Kim G, Lu Y, Hu Y, Loizou P. An algorithm that improves speech intelligibility in noise for normal-hearing listeners. J Acoust Soc Amer. 2009:1486–1494. doi: 10.1121/1.3184603. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Kjems U, Boldt J, Pedersen M, Lunner T, Wang D. Role of mask pattern in intelligibility of ideal binary-masked noisy speech. J Acoust Soc Amer. 2009;126:1415–1426. doi: 10.1121/1.3179673. [DOI] [PubMed] [Google Scholar]
- 19.Li N, Loizou P. Factors influencing intelligibility of ideal binary-masked speech: Implications for noise reduction. J Acoust Soc Amer. 2008;123(3):1673–1682. doi: 10.1121/1.2832617. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Li Y, Wang D. On the optimality of ideal binary time–frequency masks. Speech Commun. 2009:230–239. [Google Scholar]
- 21.Loizou PC. Speech Enhancement: Theory and Practice. Boca Raton, FL, USA: CRC; 2007. [Google Scholar]
- 22.Mohammadiha N, Smaragdis P, Leijon A. Supervised and unsupervised speech enhancement approaches using nonnegative matrix factorization. IEEE Trans Audio Speech Lang Process. 2013 Oct;21(10):2140–2151. [Google Scholar]
- 23.Narayanan A, Wang D. Ideal ratio mask estimation using deep neural networks for robust speech recognition. Proc ICASSP. 2013:7092–7096. [Google Scholar]
- 24.Narayanan A, Wang D. The role of binary mask patterns in automatic speech recognition in background noise. J Acoust Soc Amer. 2013:3083–3093. doi: 10.1121/1.4798661. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Plomp R. The Intelligent Ear: On the Nature of Sound Perception. Mahwah, NJ, USA: Lawrence Erlbaum Associates; 2002. [Google Scholar]
- 26.Reddy AM, Raj B. Soft mask methods for single-channel speaker separation. IEEE Trans Audio, Speech, Lang Process. 2007 Aug;15(6):1766–1776. [Google Scholar]
- 27.Rix A, Beerends J, Hollier M, Hekstra A. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. Proc ICASSP. 2001:749–752. [Google Scholar]
- 28.Srinivasan S, Roman N, Wang D. Binary and ratio time-frequency masks for robust speech recognition. Speech Commun. 2006;48(11):1486–1501. [Google Scholar]
- 29.Taal C, Hendriks R, Heusdens R, Jensen J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans Audio, Speech, Lang Process. 2011 Sep;19(7):2125–2136. doi: 10.1121/1.3641373. [DOI] [PubMed] [Google Scholar]
- 30.Varga A, Steeneken H. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993;12:247–251. [Google Scholar]
- 31.Virtanen T, Gemmeke J, Raj B. Active-set Newton algorithm for overcomplete non-negative representations of audio. IEEE Trans Audio, Speech, Lang Process. 2013 Nov;21(11):2277–2289. [Google Scholar]
- 32.Wang D. On ideal binary mask as the computational goal of auditory scene analysis. In: Divenyi P, editor. Speech Separation by Humans and Machines. Norwell, MA, USA: Kluwer; 2005. pp. 181–197. [Google Scholar]
- 33.Wang D, Kjems U, Pedersen M, Boldt J, Lunner T. Speech intelligibility in background noise with ideal binary time-frequency masking. J Acoust Soc Amer. 2009;125:2336–2347. doi: 10.1121/1.3083233. [DOI] [PubMed] [Google Scholar]
- 34.Wang Y, Han K, Wang D. Exploring monaural features for classification-based speech segregation. IEEE Trans Audio, Speech, Lang Process. 2013 Feb;21(2):270–279. [Google Scholar]
- 35.Wang Y, Wang D. Cocktail party processing via structured prediction. Proc NIPS. 2012:224–232. [Google Scholar]
- 36.Wang Y, Wang D. Towards scaling up classification-based speech separation. IEEE Trans Audio, Speech, Lang Process. 2013 Jul;21(7):1381–1390. [Google Scholar]
- 37.Wang Y, Wang D. A structure-preserving training target for supervised speech separation. Proc ICASSP. 2014:6127–6131. [Google Scholar]
- 38.Woodruff J. Ph D dissertation. The Ohio State Univ; Columbus, OH, USA: 2012. Integrating monaural and binaural cues for sound localization and segregation in reverberant environments. [Google Scholar]
- 39.Xu Y, Du J, Dai L, Lee C. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Processing Lett. 2014 Jan;21(1):66–68. [Google Scholar]